 2.4 gdb 调试准备
2.4 gdb 调试准备
调试是开发过程中一项不可或缺的工作,在Linux编程中,通常使用gdb来调试C/C++程序。一个合格的Linux C/C++开发人员,必须熟练使用gdb调试。互联网上有太多的关于gdb的教程,基本上是人云亦云。笔者从事Linux服务器开发多年,本文将介绍gdb调试内容是实际开发中最常用的知识和经验总结,当然也包括一些重难点内容。不过,初学者不用担心,这个系列是一个带读者从入门到高级的进阶课程。
选择哪个程序作为gdb调试教程的示例程序着实让笔者纠结了很久,很多gdb教程都是人为的“造”一些实例代码,个人感觉这样做有点脱离实际生产,实际项目中的代码与这种造出来的代码相差很大,而且比造出来的程序难调试许多;但实际项目代码因为企业单位有保密要求,也不方便外传。因此,经过综合考虑,本文将以带领读者调试redis代码为例。让我们先从调试的基础知识开始吧。
# 2.4.1 被调试的程序需要带调试信息
一般我们需要调试某个程序,为了能清晰地看到调试的每一行代码、调用的堆栈信息、变量名、函数名等信息,需要我们的调试程序带有调试符号信息。这就是在我们使用gcc编译程序时需要加上**-g**选项。举个例子,以下命令将生成一个带调试信息的程序hello_server(hello_server.c为任意cpp文件)。
gcc -g -o hello_server hello_server.c
那么如何判断hello_server带有调试信息呢?我们使用gdb来调试一下这个程序,gdb会显示正确读取到该程序的调试信息:
[root@localhost testclient]# gdb hello_server
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-100.el7_4.1
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/testclient/hello_server...done.
(gdb)
2
3
4
5
6
7
8
9
10
11
12
gdb加载成功以后,会显示一行“Reading symbols from /root/testclient/hello_server...done.”,即读取符号文件完毕的信息,说明该程序含有调试信息。我们不加**-g**选项再试试:
[root@localhost testclient]# gcc -o hello_server2 hello_server.c
[root@localhost testclient]# gdb hello_server2
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-100.el7_4.1
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/testclient/hello_server2...(no debugging symbols found)...done.
(gdb)
2
3
4
5
6
7
8
9
10
11
12
13
细心的读者应该看出差别了,我们这次不加**-g选项,用gdb调试生成的hello_server2**程序时,读取调试符号信息时提示:
“Reading symbols from /root/testclient/hello_server2...(no debugging symbols found)...done.”
当然,这里顺便提一下,除了不加**-g选项,也可以使用Linux的strip命令移除掉某个程序中的调试信息,我们这里对hello_server**使用strip命令试试:
[root@localhost testclient]# strip hello_server
##使用strip命令之前
-rwxr-xr-x. 1 root root 12416 Sep 8 09:45 hello_server
##使用strip命令之后
-rwxr-xr-x. 1 root root 6312 Sep 8 09:55 hello_server
2
3
4
5
可以发现,我们对hello_server使用strip命令之后,这个程序大小明显变小了(由12416个字节减小为6312个字节)。我们通常会在程序测试没问题后,需要发布到生产环境或者正式环境,会生成不带调试符号信息的程序,以减小程序体积或提高程序执行效率。
我们再用gdb验证一下这个程序的调试信息是否确实被移除了:
[root@localhost testclient]# gdb hello_server
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-100.el7_4.1
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /root/testclient/hello_server...(no debugging symbols found)...done.
(gdb)
2
3
4
5
6
7
8
9
10
11
12
这里需要在另外补充两点说明:
这里举得例子虽然以gcc为例,但**-g选项实际上同样也适用于使用makefile**、cmake等工具编译生成的Linux程序。
在实际生成调试程序时,我们一般不仅要加上**-g选项,也建议关闭编译器的程序的优化选项。编译器的程序的优化选项一般有五个级别,从O0**~O4(注意第一个O0,是字母O加上数字0),O0表示不优化(关闭优化),从O1~O4优化级别越来越高,O4级别最高。关闭优化的目的是为了调试的时候,符号文件显示的调试变量等能与源代码完全对应起来。举个例子,假设有以下代码:
int func() { int a = 1; int b = a + 1; int c = a + b; return a + b + c; } int main() { int a = func(); printf("%d\n", a); }1
2
3
4
5
6
7
8
9
10
11
12
13
以上代码中,由于在main函数中调用了func函数,由func函数值可以在编译期间直接算出来,如果开启了优化选项,可能你实际调试的时候,这个函数中的局部变量a,b,c可能已经被编译器优化掉,取而代之的是直接的值,甚至连函数func也可能被优化掉。如果出现这种情况,调试的时候,看到的代码和实际的代码可能就会有差异了,这会给排查和定位问题带来困难。当然,上面说的优化现象是否一定会出现,不同版本的编译器可能会有不同的行为。总之一句话,生成调试文件时建议关闭编译器优化选项(使用O0选项)。
# 2.4.2 启动gdb调试的方法
使用gdb调试一个程序一般有三种情方式:
- gdb filename
- gdb attach pid
- gdb filename corename
我们来逐一介绍。
# 1. 方法一 直接调试目标程序
gdb filename
其中filename是你需要启动的调试程序文件名,这种方式,是直接使用gdb启动一个程序进行调试,也就是说这个程序还没有启动。上文中使用gdb调试hello_server系列就是使用这种方式的。
# 2. 方法二 附加进程
某些情况下,一个程序已经启动了,我们想调试这个程序,但是又不想重启这个程序。假设有这样一个场景,我们的聊天测试服务器程序正在运行,我们运行一段时间之后,发现这个聊天服务器再也没法接受新的客户端连接了,这个时候我们肯定是不能重启程序的,如果重启,当前程序的各种状态信息就丢失了。这个时候,我们只需要使用gdb attach 程序进程ID来将gdb调试器附加到我们的聊天测试服务器程序上即可。假设,我们的聊天程序叫chatserver,我们可以使用ps命令获取该进程的PID,然后gdb attach上去,就可以调试了。
[zhangyl@localhost flamingoserver]$ ps -ef | grep chatserver
zhangyl 42921 1 17 11:18 ? 00:00:04 ./chatserver -d
zhangyl 42936 42898 0 11:18 pts/0 00:00:00 grep --color=auto chatserver
2
3
我们得到chatserver的PID为42921,然后我们使用gdb attach 42921把gdb附加到chatserver进程:
[zhangyl@localhost flamingoserver]$ gdb attach 42921
attach: No such file or directory.
Attaching to process 42921
Reading symbols from /home/zhangyl/flamingoserver/chatserver...done.
Reading symbols from /usr/lib64/mysql/libmysqlclient.so.18...Reading symbols from /usr/lib64/mysql/libmysqlclient.so.18...(no debugging symbols found)...done.
Reading symbols from /lib64/libpthread.so.0...(no debugging symbols found)...done.
[New LWP 42931]
[New LWP 42930]
[New LWP 42929]
[New LWP 42928]
[New LWP 42927]
[New LWP 42926]
[New LWP 42925]
[New LWP 42924]
[New LWP 42922]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Loaded symbols for /lib64/libpthread.so.0
Reading symbols from /lib64/libc.so.6...(no debugging symbols found)...done.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
为了节约篇幅,上述代码中我删掉了一些无关的信息。当提示“Attaching to process 42921”说明我们已经成功将gdb附加到目标进程了。需要注意的是,由于我们的程序使用了一些系统库(如libc.so),由于这是发行版本的Linux系统,这些库是没有调试符号的,所以gdb会提示找不到这些库的调试符号。我们的目的是调试chatserver,对系统API调用的内部实现并不关注,所以这些提示我们可以不关注。只要chatserver这个文件有调试信息即可。
当用gdb attach上目标进程后,调试器会暂停下来,此时我们可以使用continue命令让程序继续运行,或者加上相应的断点再继续运行程序。(这里提到的continue命令不熟悉也没有关系,下文会详细介绍这些命令的使用方法)
当您调试完程序想结束此次调试,且不对当前进程chatserver有任何影响,也就是说想让这个程序继续运行,可以在gdb的命令行界面输入detach命令让程序与 gdb 调试器分离,这样chatserver可以继续运行。
(gdb) detach
Detaching from program: /home/zhangyl/flamingoserver/chatserver, process 42921
2
然后再退出gdb就可以了。
(gdb) quit
[zhangyl@localhost flamingoserver]$
2
# 3. 方法三 调试core文件 —— 定位进程崩溃问题
有时候,我们的服务器程序运行一段时间后,会突然崩溃。这当然不是我们希望看到的,我们需要解决这个问题。只要程序在崩溃的时候,有core文件产生,我们就可以使用这个core文件来定位崩溃的原因。当然,Linux系统默认是不开启程序崩溃产生core文件的这一机制的,我们可以使用ulimit -c来查看系统是否开启了这一机制。(顺便提一句,ulimit命令不仅仅可以查看core文件生成是否开启,还可以查看其它的一些功能,如系统允许的最大文件描述符的数量等等,具体的可以使用ulimit -a命令来查看,由于这个与本章主题无关,这里不再介绍。)
[zhangyl@localhost flamingoserver]$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15045
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
如上所示, core file size那一行默认是0,表示关闭生成core文件,如果我们需要修改某个选项的值,可以使用ulimit 选项名 设置值来修改,例如我们可以将core文件生成改成具体某个值(最大允许的字节数)或不限制大小,这里我们直接改成不限制大小,执行命令ulimit -c unlimited:
[zhangyl@localhost flamingoserver]$ ulimit -c unlimited
[zhangyl@localhost flamingoserver]$ ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15045
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
注意,这个命令容易记错,第一个ulimit是Linux命令,-c选项后面的unlimited是选项的值,表示不限制大小,当然您也可以改成具体的数值大小。
还有一个问题就是,这样修改以后,当我们关闭这个Linux会话后,这个设置项的值就会被还原成0,而我们的服务器程序一般是以后台程序(守护进程)长周期运行,也就是说当前会话虽然被关闭,服务器程序仍然继续在后台运行,这样这个程序崩溃在某个时刻崩溃后,是无法产生core文件,这种情形不利于排查问题。所以,我们希望这个选项永久生效。设置永久生效的方式有两种:
在**/etc/security/limits.conf**中增加一行
#<domain> <type> <item> <value> * soft core unlimited1
2
这里设置的是不限制core文件的大小,也可以设置成具体的数值,如1024表示生成的core文件最大是1024k。
- 把“ulimit -c unlimited”这一行,加到**/etc/profile**文件中去,放到这个文件最后一行即可,修正成功以后执行“source /etc/profile”让配置立即生效。当然这只是对root用户,如果想仅仅作用于某一用户,可以把“ulimit -c unlimited”加到该用户对应的~/.bashrc或~/.bash_profile文件中去。
生成的core文件的默认命名方式是:core.pid,其位置是崩溃程序所在目录,举个例子,比如某个程序当时运行时其进程ID是16663,那么如果其崩溃产生的core文件的名称是core.16663。我们来看一个具体的例子吧,某次我发现的我的服务器上msg_server崩溃了,在当前目录下产生了一个如下的core文件:
-rw------- 1 root root 10092544 Sep 9 15:14 core.21985
那么我们就可以通过这个core.21985的文件来排查崩溃的原因,调试core文件的命令是:
gdb filename corename
- filename就是程序名,这里就是msg_server;
- corename 是core.21985。
我们输入gdb msg_server core.21985来启动调试:
[root@myaliyun msg_server]# gdb msg_server core.21985
Reading symbols from /root/teamtalkserver/src/msg_server/msg_server...done.
[New LWP 21985]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Core was generated by `./msg_server -d'.
Program terminated with signal 11, Segmentation fault.
#0 0x00000000004ceb1f in std::less<CMsgConn*>::operator() (this=0x2283878, __x=@0x7ffca83563a0: 0x2284430, __y=@0x51: <error reading variable>)
at /usr/include/c++/4.8.2/bits/stl_function.h:235
235 { return __x < __y; }
2
3
4
5
6
7
8
9
10
我们可以看到程序崩溃的地方是在stl_function.h的235行,然后通过bt命令(下文将详细介绍)查看崩溃时的调用堆栈,进一步分析就能找到崩溃的原因。
(gdb) bt
#0 0x00000000004ceb1f in std::less<CMsgConn*>::operator() (this=0x2283878, __x=@0x7ffca83563a0: 0x2284430, __y=@0x51: <error reading variable>)
at /usr/include/c++/4.8.2/bits/stl_function.h:235
#1 0x00000000004cdd70 in std::_Rb_tree<CMsgConn*, CMsgConn*, std::_Identity<CMsgConn*>, std::less<CMsgConn*>, std::allocator<CMsgConn*> >::_M_get_insert_unique_pos
(this=0x2283878, __k=@0x7ffca83563a0: 0x2284430) at /usr/include/c++/4.8.2/bits/stl_tree.h:1324
#2 0x00000000004cd18a in std::_Rb_tree<CMsgConn*, CMsgConn*, std::_Identity<CMsgConn*>, std::less<CMsgConn*>, std::allocator<CMsgConn*> >::_M_insert_unique<CMsgConn* const&> (this=0x2283878, __v=@0x7ffca83563a0: 0x2284430) at /usr/include/c++/4.8.2/bits/stl_tree.h:1377
#3 0x00000000004cc8bd in std::set<CMsgConn*, std::less<CMsgConn*>, std::allocator<CMsgConn*> >::insert (this=0x2283878, __x=@0x7ffca83563a0: 0x2284430)
at /usr/include/c++/4.8.2/bits/stl_set.h:463
#4 0x00000000004cb011 in CImUser::AddUnValidateMsgConn (this=0x2283820, pMsgConn=0x2284430) at /root/teamtalkserver/src/msg_server/ImUser.h:42
#5 0x00000000004c64ae in CDBServConn::_HandleValidateResponse (this=0x227f6a0, pPdu=0x22860d0) at /root/teamtalkserver/src/msg_server/DBServConn.cpp:319
#6 0x00000000004c5e3d in CDBServConn::HandlePdu (this=0x227f6a0, pPdu=0x22860d0) at /root/teamtalkserver/src/msg_server/DBServConn.cpp:203
#7 0x00000000005022b3 in CImConn::OnRead (this=0x227f6a0) at /root/teamtalkserver/src/base/imconn.cpp:148
#8 0x0000000000501db3 in imconn_callback (callback_data=0x7f4b20 <g_db_server_conn_map>, msg=3 '\003', handle=8, pParam=0x0)
at /root/teamtalkserver/src/base/imconn.cpp:47
#9 0x0000000000504025 in CBaseSocket::OnRead (this=0x227f820) at /root/teamtalkserver/src/base/BaseSocket.cpp:178
#10 0x0000000000502f8a in CEventDispatch::StartDispatch (this=0x2279990, wait_timeout=100) at /root/teamtalkserver/src/base/EventDispatch.cpp:386
#11 0x00000000004fddbe in netlib_eventloop (wait_timeout=100) at /root/teamtalkserver/src/base/netlib.cpp:160
#12 0x00000000004d18c2 in main (argc=2, argv=0x7ffca8359978) at /root/teamtalkserver/src/msg_server/msg_server.cpp:213
(gdb)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
堆栈#0~#3是系统库函数调用序列,都是经过反复测试过的,一般不存在问题;堆栈#4~#12是我们自己的业务逻辑调用序列,我们可以排查这部分代码进而定位到问题原因。
细心的读者会发现这样一个问题:一个正在程序运行时,其PID是可以获取到的,但是当程序崩溃后,产生了core文件,尤其是多个程序同时崩溃,我们无法通过core文件名中的PID来判断对应哪个服务。解决这个问题有两个方法:
程序启动时,记录一下PID;
void writePid() { uint32_t curPid = (uint32_t) getpid(); FILE* f = fopen("xxserver.pid", "w"); assert(f); char szPid[32]; snprintf(szPid, sizeof(szPid), "%d", curPid); fwrite(szPid, strlen(szPid), 1, f); fclose(f); }1
2
3
4
5
6
7
8
9
10我们在程序启动时调用上述writePID函数,将程序当时的PID记录到xxserver.pid文件中去,这样当程序崩溃时,我们可以从这个文件中得到进程当时运行的PID,这样就可以与默认的core文件名后面的PID做匹配了。
自定义core文件的名称和目录
/proc/sys/kernel/core_uses_pid可以控制产生的core文件的文件名中是否添加PID作为扩展,如果添加则文件内容为1,否则为0; /proc/sys/kernel/core_pattern可以设置格式化的core文件保存位置或文件名。修改方式如下:
echo "/corefile/core-%e-%p-%t" > /proc/sys/kernel/core_pattern1各个参数的说明如下:
参数名称 参数含义(英文) 参数含义(中文) %p insert pid into filename 添加pid到core文件名中 %u insert current uid into filename 添加当前uid到core文件名中 %g insert current gid into filename 添加当前gid到core文件名中 %s insert signal that caused the coredump into the filename 添加导致产生core的信号到core文件名中 %t insert UNIX time that the coredump occurred into filename 添加core文件生成时间(UNIX)到core文件名中 %h insert hostname where the coredump happened into filename 添加主机名到core文件名中 %e insert coredumping executable name into filename 添加程序名到core文件名中 假设我们现在的程序叫test,我们设置该程序崩溃时的core文件名如下:
echo "/root/testcore/core-%e-%p-%t" > /proc/sys/kernel/core_pattern1那么最终会在**/root/testcore/**目录下生成的 test 的 core 文件名格式如下:
-rw-------. 1 root root 409600 Jan 14 13:54 core-test-13154-15474452911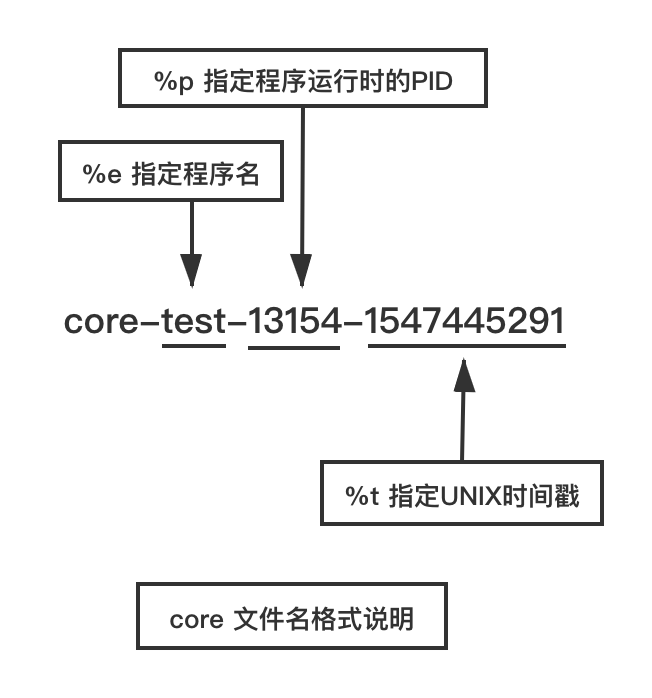
需要注意的是,使用的用户必须对指定core文件目录具有写权限,否则会因为权限不足而无法生成core文件。