 3.12 线程池与队列系统的设计
3.12 线程池与队列系统的设计
# 3.12.1 线程池的设计原理
在很多新手的认知中,线程池和队列系统 是一项非常高深的技术,其实也不然,当你熟练掌握了多线程编程技术后,这一切将会变的很容易,你需要克服的是内心的恐惧而已。
所谓线程池不过是一组线程而已,一般情况下,我们需要异步执行一些任务,这些任务的产生和执行是存在于我们程序的整个生命周期的,与其让操作系统频繁地为我们创建和销毁线程,我们通常需要创建一组在我们程序生命周期内不会退出的线程,为了不浪费系统资源,我们的基本要求是当有任务需要执行时,这些线程可以自动拿到任务去执行,没有任务时这些线程处于阻塞或者睡眠状态。这里就涉及到这些处理任务的工作线程的唤醒与睡眠,如果你理解了上文中介绍的各种线程同步技术,相信你现在对如何唤醒和睡眠线程已经很熟悉了。
既然在程序生命周期内会产生很多任务,那么这些任务必须有一个存放的地方,而这个地方就是队列,所以不要一提到队列就认为是一个具体的 list,它可以是一个全局变量、链表等等。而线程池中的线程从队列中如何取任务,则也可以设计得非常灵活,如从尾部放入任务,从头部取出,或者从头部放入,从尾部取出等等。而队列也可以根据实际应用设计得”丰富多彩“,例如,可以根据任务的优先级设计多个队列(例如分为高、中、低三个级别或者分为关键、普通两个级别)。
这本质上就是生产者消费者模式,产生任务的线程是生产者,线程池中的线程是消费者。当然,这不是绝对的,线程池中的线程处理一个任务以后可能会产生一个新的关联任务,那么此时这个工作线程又是生产者的角色。
既然会有多个线程同时操作这个队列,根据多线程程序的原则,这个队列我们一般需要对其加锁,以避免多线程竞争产生非预期的结果。
当然,技术上除了要解决线程池的创建、往队列中投递任务、从队列中取任务处理,我们还需要做一些善后工作,如线程池的清理,即如何退出线程池中的工作线程和清理任务队列。
这就是线程池和任务队列的核心原理,希望读者能认真体会。
说了这么多,结合前文介绍的,具体的实现也变得很容易,我们来看一个具体的例子:
/**
* 任务池模型,TaskPool.h
* zhangyl 2019.02.14
*/
#include <thread>
#include <mutex>
#include <condition_variable>
#include <list>
#include <vector>
#include <memory>
#include <iostream>
class Task
{
public:
virtual void doIt()
{
std::cout << "handle a task..." << std::endl;
}
virtual ~Task()
{
//为了看到一个task的销毁,这里刻意补上其析构函数
std::cout << "a task destructed..." << std::endl;
}
};
class TaskPool final
{
public:
TaskPool();
~TaskPool();
TaskPool(const TaskPool& rhs) = delete;
TaskPool& operator=(const TaskPool& rhs) = delete;
public:
void init(int threadNum = 5);
void stop();
void addTask(Task* task);
void removeAllTasks();
private:
void threadFunc();
private:
std::list<std::shared_ptr<Task>> m_taskList;
std::mutex m_mutexList;
std::condition_variable m_cv;
bool m_bRunning;
std::vector<std::shared_ptr<std::thread>> m_threads;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
/**
* 任务池模型,TaskPool.cpp
* zhangyl 2019.02.14
*/
#include "TaskPool.h"
TaskPool::TaskPool() : m_bRunning(false)
{
}
TaskPool::~TaskPool()
{
removeAllTasks();
}
void TaskPool::init(int threadNum/* = 5*/)
{
if (threadNum <= 0)
threadNum = 5;
m_bRunning = true;
for (int i = 0; i < threadNum; ++i)
{
std::shared_ptr<std::thread> spThread;
spThread.reset(new std::thread(std::bind(&TaskPool::threadFunc, this)));
m_threads.push_back(spThread);
}
}
void TaskPool::threadFunc()
{
std::shared_ptr<Task> spTask;
while (true)
{
std::unique_lock<std::mutex> guard(m_mutexList);
while (m_taskList.empty())
{
if (!m_bRunning)
break;
//如果获得了互斥锁,但是条件不满足的话,m_cv.wait()调用会释放锁,且挂起当前
//线程,因此不往下执行。
//当发生变化后,条件满足,m_cv.wait() 将唤醒挂起的线程,且获得锁。
m_cv.wait(guard);
}
if (!m_bRunning)
break;
spTask = m_taskList.front();
m_taskList.pop_front();
if (spTask == NULL)
continue;
spTask->doIt();
spTask.reset();
}
std::cout << "exit thread, threadID: " << std::this_thread::get_id() << std::endl;
}
void TaskPool::stop()
{
m_bRunning = false;
m_cv.notify_all();
//等待所有线程退出
for (auto& iter : m_threads)
{
if (iter->joinable())
iter->join();
}
}
void TaskPool::addTask(Task* task)
{
std::shared_ptr<Task> spTask;
spTask.reset(task);
{
std::lock_guard<std::mutex> guard(m_mutexList);
m_taskList.push_back(spTask);
std::cout << "add a Task." << std::endl;
}
m_cv.notify_one();
}
void TaskPool::removeAllTasks()
{
{
std::lock_guard<std::mutex> guard(m_mutexList);
for (auto& iter : m_taskList)
{
iter.reset();
}
m_taskList.clear();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
上述代码封装了一个简单的任务队列模型,我们可以这么使用这个 TaskPool 对象:
#include "TaskPool.h"
#include <chrono>
int main()
{
TaskPool threadPool;
threadPool.init();
Task* task = NULL;
for (int i = 0; i < 10; ++i)
{
task = new Task();
threadPool.addTask(task);
}
std::this_thread::sleep_for(std::chrono::seconds(5));
threadPool.stop();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
程序执行结果如下:
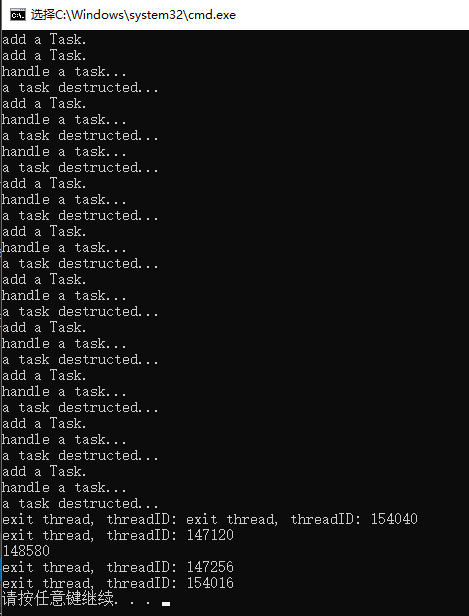
由于退出线程的输出提示不是原子的,多个线程并行执行,因此上图中这部分的输出出现了”错乱“。
上述代码演示了一个基本的多线程队列模型,虽然简单,但是比较典型,可以应付实际生产中的一部分需求,你可以基于这个基础模型进行扩展,不管怎么扩展其基本原理都是一样的。
# 3.12.2 环形队列
例如,如果生产者和消费者(即产生任务者和处理任务者)的速度差不多,可以将队列改成环形队列,以节省内存空间。另外,很多应用为了追求效率,利用一些技巧将队列无锁化。这些都是仁者见仁智者见智的扩展了,本文不再介绍。不管如何,希望读者一定要理解线程池和任务队列的基本设计原理,只有这样你才能做更多高级的扩展和设计。
# 3.12.3 消息中间件
基于生产者消费者理论模型的队列系统在实际开发中实在是太常用了,以至于在一组服务中可能每个进程都需要一个这样的队列系统。既然如此,出于复用和解耦的目的,业界产生了许多独立的队列系统,这些队列系统或以一个独立的进程运行或以支持分布式的一组服务运行。我们把这种独立的队列系统称之为消息中间件。这些消息中间件在功能上做了丰富的扩展,如消费的方式、主备切换、容灾容错,数据自动备份和过期数据自动清理等等,比较典型的有 Kafka、ActiveMQ、RabbitMQ、RocketMQ 等。下图是 Kafka 官网提供的一张介绍 Kafka 作用的图片:
下图是笔者开发过的一个金融交易系统后台服务拓扑图,其大量使用消息中间件 kafka:
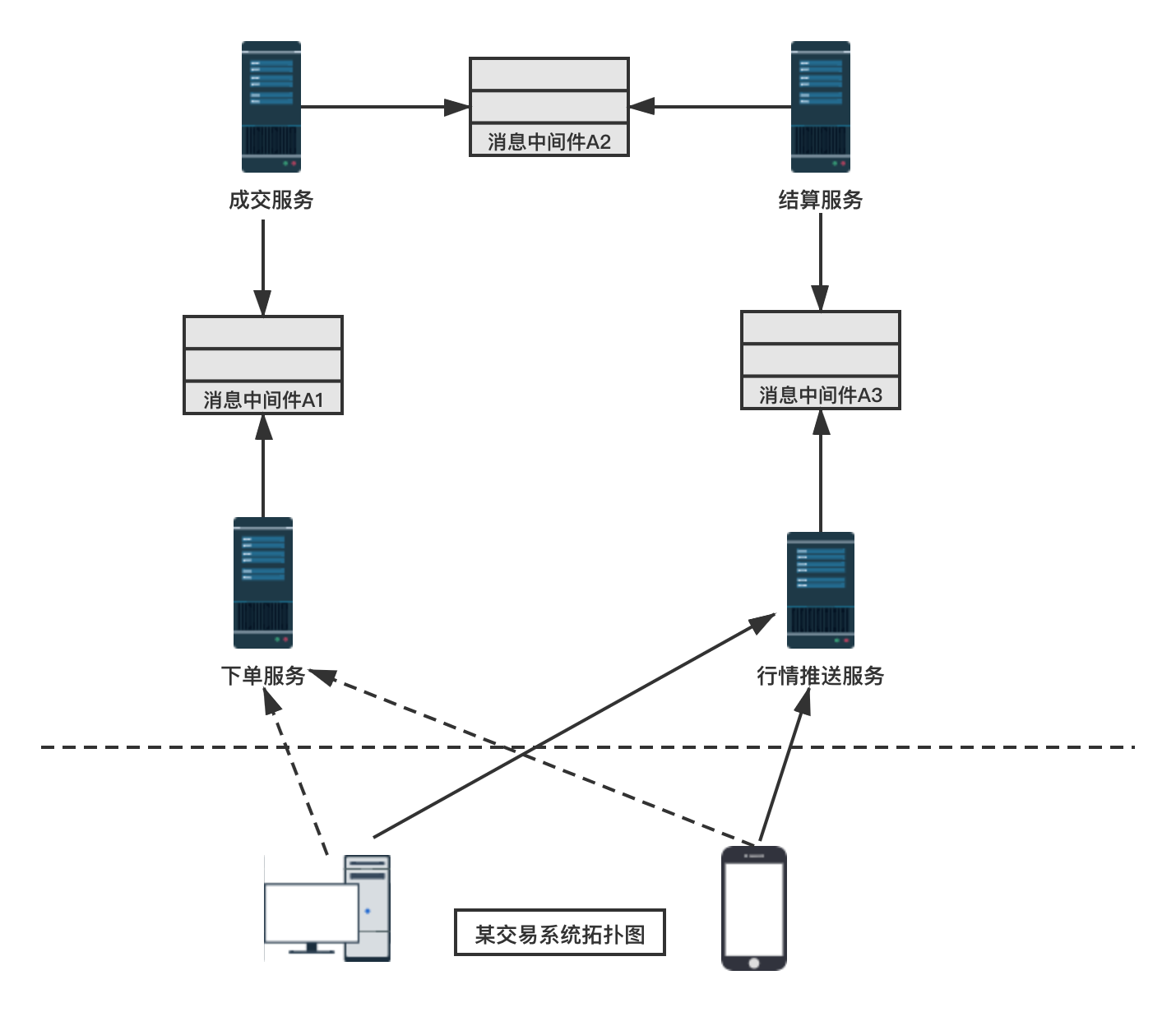
整个交易的流程如下:
- 前端通过 HTTP 请求向下单服务请求下单,下单服务在校验完数据后,会向**消息中间件 A1 **投递一条下单请求;
- 成交服务订阅了消息中间件 A1的消息,取出下单请求,结合自己的成交规则,如果可以成交,向**消息中间件 A2 **投递一条成交后的消息;
- 结算服务订阅了消息中间件A2,从其中拿到成交消息后,对用户资金账户进行结算,结算完成后,用户的下单就算正式完成了,然后产生一条行情消息投递给消息中间件 A3;
- 行情推送服务器从消息中间件 A3 中拿到行情消息后推送给所有已经连接的客户端。
上述过程中,每个消息中间件(kafka)都有一个生产者和消费者,虚线箭头表示短连接,实线箭头表示长连接。当然,实际的金融交易系统要比这里的模型复杂许多,这里为了演示方便做了大量简化。
有了这种专门的队列系统,生产者和消费者将最大化解耦,利用消息中间件提供的对外消息接口,生产者只需要负责生产消息,它不必关心谁是消费者,消费者也不用关心生产者是谁、何时有数据,而队列系统本身也不关心自己有多少生产者和消费者。当然,这种消息中间件还有其他一些非常优秀的功能,如对数据的备份、负载和容灾容错措施。笔者建议学有余力的读者适当地去了解一两种开源的队列系统的使用方法,如果掌握其设计思路那就善莫大焉了。