 6.11 http 协议
6.11 http 协议
http 协议是用途最广泛的协议之一,相信绝大多数开发者都知道 http 协议和 http 请求,但是很多人只停留在“会用”的阶段。我面试过很多求职者,一说到 http 协议,他们能滔滔不绝,然后我问 http 协议的具体格式是啥样子的?很多人说不清楚,说不清楚就不清楚吧,有人甚至能将 html 文档页面的头部 <head> 标签当作 http 协议的头。大多数开发者都知道 http GET 和 POST 请求,也可以利用一些库或者框架发送 http GET 或者 POST 请求。但是 GET/POST 请求的数据放在协议包的哪里,服务器如何识别并解析这些数据,很多人又说不清楚。
当说到 http 服务器时,很多人离开了 Apache、nginx 这样现成的 http web server 之外,自己实现一个 http 服务器不知道如何下手,如果实际应用场景有需要使用到一些简单 http 请求时,例如需要某个服务提供一个支持 http 请求的健康检查接口,此时使用 Apache、nginx 这样的 http 服务器程序实在太劳师动众,此时我们最好可以自己实现一个简单的 http 服务。
# 6.11.1 http 格式协议介绍
http 协议是建立在 TCP 协议之上的应用层协议,HTTP 的全写是 Hypertext Transfer Protocol,超级文本传输协议。
http 协议的格式如下:
GET或POST 请求的url路径(一般是去掉域名的路径) HTTP协议版本号\r\n
字段1名: 字段1值\r\n
字段2名: 字段2值\r\n
...
字段n名 : 字段n值\r\n
\r\n
http协议包体内容
2
3
4
5
6
7
如上图所示, http 协议由包头(1 ~ 6 行)和包体(7 行以后)两部分组成,包头与包体之间使用一个 \r\n 分割,其中包头每一行均以 \r\n 结束,最后包头结束时再添加一个\r\n(空行)表示包头结束。也就是说 http 协议大多数情况下是文本形式的明文格式,这也是 Hypertext Transfer Protocol 中的 **text(文本)**的名称含义。
由于 http 协议包头的每一行都是以 \r\n 结束,所以 http 协议包头以 \r\n\r\n 结束,我们在用程序解析 http 格式的数据时可以通过 \r\n\r\n 来界定包头的结束位置和包体的起始位置。
也就是说,http 协议也分为 head(包头) 和 body(包体) 两部分,注意这里的 head 和 body 不是指 html 文档中的 <head> 和 <body> 标签,实际上,html 文档中内容(当然也包括其中的 <head> 和 <body> 标签)仅是 http 协议包的 body 的一部分。
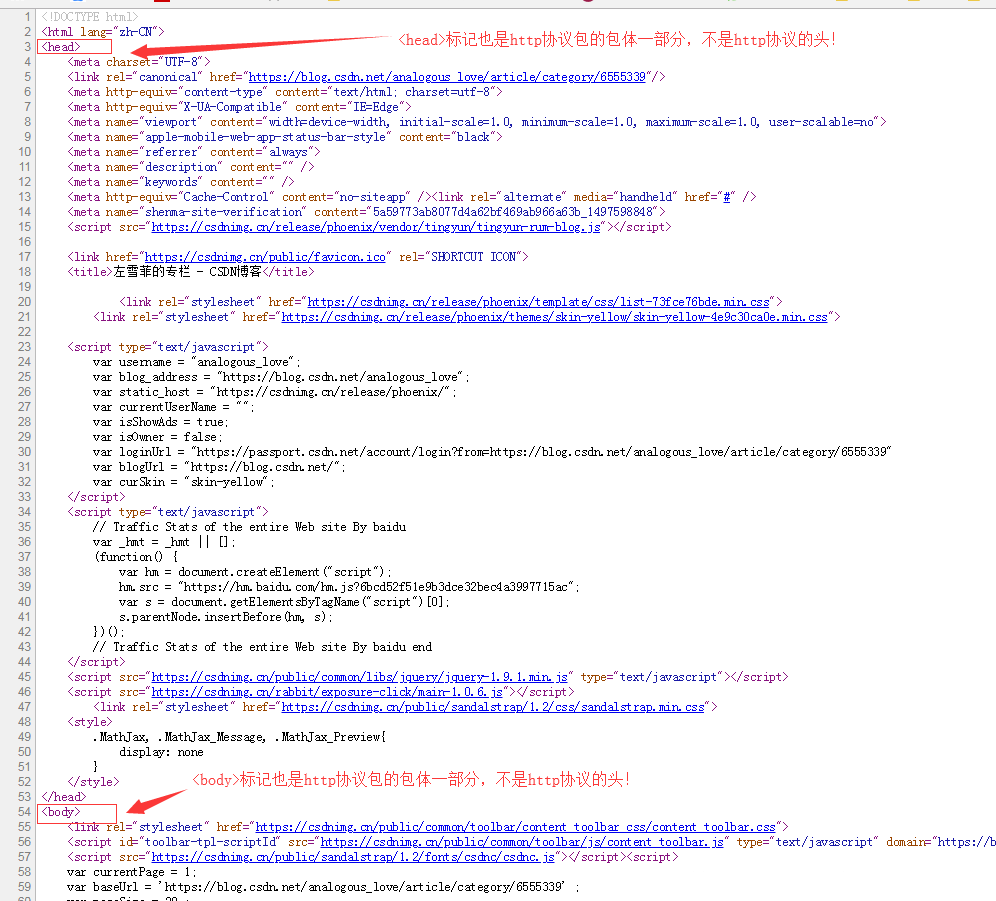
# 6.11.2 GET 与 POST 方法
HTTP 请求的方法有 GET、POST、HEAD、PUT、DELETE 等,其中 GET 和 POST 是我们用的最多的两个方法。我们来以一个具体的例子说明使用 GET 方法时 HTTP 协议包格式。
假设,我们在浏览器中请求 http://www.hootina.org/index_2013.php 这个网址,这是一个典型的 GET 方法,浏览器为我们组装的 http 数据包格式如下:
GET /index_2013.php HTTP/1.1\r\n
Host: www.hootina.org\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
\r\n
2
3
4
5
6
7
8
9
读者可以通过打开浏览器的调试窗口查看得到上面的信息,例如,对于 Chrome 浏览器,在页面上右键选择【检查】菜单即可,快捷键 F12:
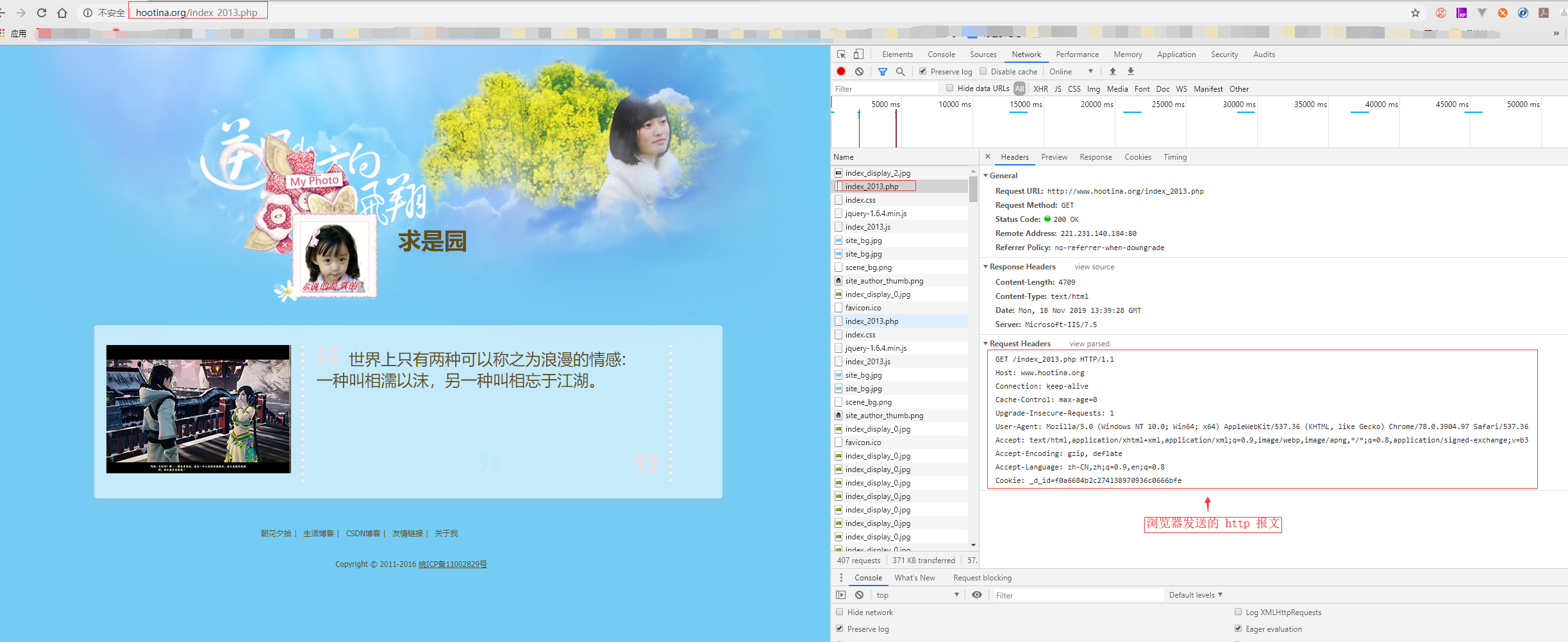
上面这个请求只有包头没有包体,http 协议的包体部分不是必需的,也就是说 GET 请求一般没有包体部分。
如果 GET 请求带参数,那么一般是附加在请求的 URL 后面,参数与参数之间使用 & 分割,例如请求 http://www.hootina.org/index_2013.php?param1=value1¶m2=value2¶m3=value3,这个请求有三个参数 param1、param2 和 param3,其对应的参数值分别是 value1、value2、value3。
我们看下这个请求组装的 http 协议报文格式:
GET /index_2013.php?param1=value1¶m2=value2¶m3=value3 HTTP/1.1\r\n
Host: www.hootina.org\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
\r\n
2
3
4
5
6
7
8
9
由于浏览器对 URL 的长度最大值有限制,因此放在 URL 后面的 GET 参数数量和长度也是有限制的,不同的浏览器最大长度限制值不一样。
再来看下 POST 方法。
POST 方法请求的数据放在 HTTP 协议包的什么位置呢?我们再来看一个例子,以 12306 网站(https://kyfw.12306.cn/otn/login/init)中登录输入用户名、密码和选择正确的图片验证码后点击登录按钮为例,这是一个典型的 http post 请求。
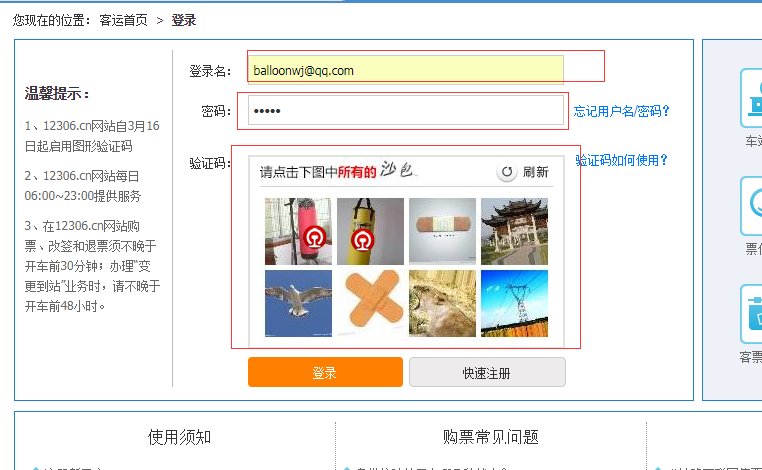
浏览器以 POST 方式组装了 http 协议包发送了我们的用户名、密码和图片验证码等信息,组装的 HTTP 包内容格式如下:
POST /passport/web/login HTTP/1.1\r\n
Host: kyfw.12306.cn\r\n
Connection: keep-alive\r\n
Content-Length: 55\r\n
Accept: application/json, text/javascript, */*; q=0.01\r\n
Origin: https://kyfw.12306.cn\r\n
X-Requested-With: XMLHttpRequest\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n
Content-Type: application/x-www-form-urlencoded; charset=UTF-8\r\n
Referer: https://kyfw.12306.cn/otn/login/init\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
Cookie: _passport_session=0b2cc5b86eb74bcc976bfa9dfef3e8a20712; _passport_ct=18d19b0930954d76b8057c732ce4cdcat8137; route=6f50b51faa11b987e576cdb301e545c4; RAIL_EXPIRATION=1526718782244; RAIL_DEVICEID=QuRAhOyIWv9lwWEhkq03x5Yl_livKZxx7gW6_-52oTZQda1c4zmVWxdw5Zk79xSDFHe9LJ57F8luYOFp_yahxDXQAOmEV8U1VgXavacuM2UPCFy3knfn42yTsJM3EYOy-hwpsP-jTb2OXevJj5acf40XsvsPDcM7; BIGipServerpool_passport=300745226.50215.0000; BIGipServerotn=1257243146.38945.0000; BIGipServerpassport=1005060362.50215.0000\r\n
\r\n
username=balloonwj%40qq.com&password=iloveyou&appid=otn
2
3
4
5
6
7
8
9
10
11
12
13
14
15
其中 username=balloonwj%40qq.com&password=iloveyou&appid=otn 就是我们的 POST 请求携带的数据,但是读者需要注意以下几个事项:
我的用户名是 balloonwj@qq.com,在包体里面变成 balloonwj%40qq.com,其中 %40 是 @ 符号的 16 进制转码形式。浏览器会对部分 URL 或者包体部分的部分字符做一下 16 进制转码,这个码表可以参考这里:http://www.w3school.com.cn/tags/html_ref_urlencode.html。
这里有三个变量,分别是 username、password 和 appid,它们之间使用 & 符号分割,但是请注意,这不意味着 POST 请求传递多个数据时必须使用 & 符号分割。只不过这里是浏览器 html 表单(浏览器中输入用户名和密码的文本框是 html 表单的一种)分割多个变量采用的默认方式而已。读者可以根据自己的需求,灵活组织 POST 方法携带的数据格式,只要收发端协商好格式就可以。例如分割多个变量也可以使用如下几种形式:
方法一:
username=balloonwj%40qq.com|password=iloveyou|appid=otn
方法二:
username:balloonwj%40qq.com\r\n
password:iloveyou\r\n
appid:otn\r\n
方法三
username,password,appid=balloonwj%40qq.com,iloveyou,otn
2
3
4
5
6
7
8
9
10
- POST 方法请求的数据是放在 http 包体中的(\r\n\r\n 标志之后)。
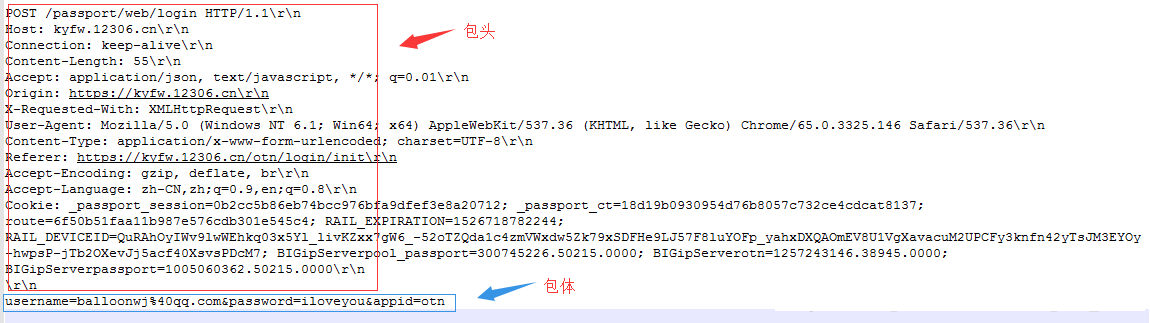
如上图所示,由于 http 协议是基于 TCP 协议的,TCP 协议是流式协议,包头部分可以通过多出的 \r\n 来分界,但对端如何知道包体部分有多长呢?这是协议本身要解决的问题。目前一般有两种方式,第一种方式就是在包头中设置一个 Content-Length 字段(字段名不区分大小写),这个字段的值标识了包体的长度。这种在包头中通过字段设置包体长度的方法我们在前面章节中已经介绍过了,这里不再赘述。
上图中 Content-Length 值为 55,这是数据 username=balloonwj%40qq.com&password=iloveyou&appid=otn 字符串的长度,服务器收到一个数据包后,先从包头解析出这个字段的值,再根据这个值去读取相应长度的数据作为 http 协议的包体数据。
GET 与 POST 请求的安全性比较
在了解了 http 的 GET 和 POST 方法之后,有的开发者可能会有这样一种认识,即 POST 请求比 GET 请求要安全,其理由是:GET 请求的数据直接暴露在 URL 后面,而 POST 请求的数据在 http 协议包的包体里面。这种认识其实是偏颇的,就算是 POST 请求,仍然可以通过打开浏览器的调试窗口查看,或者进行抓包分析,所以理论上说这两种类型的请求方式数据被破解的难度是相同的,因此在实际开发中,无论是 POST 还是 GET 请求,我们会对一些关键性的信息进行一些混淆和加密。
在对安全要求更高的应用中,如交易支付,会将 SSL 与 HTTP 结合起来,即所谓的 HTTPS。 HTTPS 是在 HTTP 的基础上通过传输加密和身份认证保证了传输过程的安全性,SSL 全称是 Secure Socket Layer(安全套接字层),即在 TCP 层与 HTTP 层再加入一个 SSL 层。HTTPS 使用一个不同于 HTTP 的默认端口及一个加密/身份验证层,HTTPS 默认端口为 443。HTTPS 现在被广泛用于互联网上对安全敏感的通讯。有兴趣的读者可以自行搜索更多关于 HTTPS 的内容进一步学习。
# 6.11.3 HTTP chunk 编码
HTTP 协议在传输的过程中,如果包体过大,例如使用 http 上传一个大文件,或者传输内容给对端时,内容是动态产生的,例如一个动态 php 页面,传输方无法预先知道传输的内容有多大,这个时候就可以使用 http chunk 编码技术了。
HTTP chunked 技术原理是将整个 HTTP 包体分成多个小块,每一块都有自己的字段说明自身的长度,对端收到这些块后,去除说明部分,将多个小块合并在一起得到完整的包体内容。传输方在 http 包头中设置 Transfer-Encoding:chunked 来告诉对端这个数据是分块传输的(代替 Content-Length 字段)。
分块传输的编码格式:
[chunkSize][\r\n][chunkData][\r\n][chunkSize][\r\n][chunkData][\r\n][chunkSize=0][\r\n][\r\n]
编码格式中使用若干个 chunk 组成,每一个 chunk 为 [chunkSize][\r\n][chunkData][\r\n],最后以一个 chunkSize 为 0 且没有 chunkData 的 chunk 结束。每个 chunk 有两部分组成,第一部分是该 chunk 的长度(chunkSize),第二部分是指定长度的内容,每个部分用 \r\n 隔开。需要注意的是最后一个长度为 0 的 chunk 只有 chunkSize 没有 chunkData,因此其格式变成了 [chunkSize=0][\r\n][\r\n]。
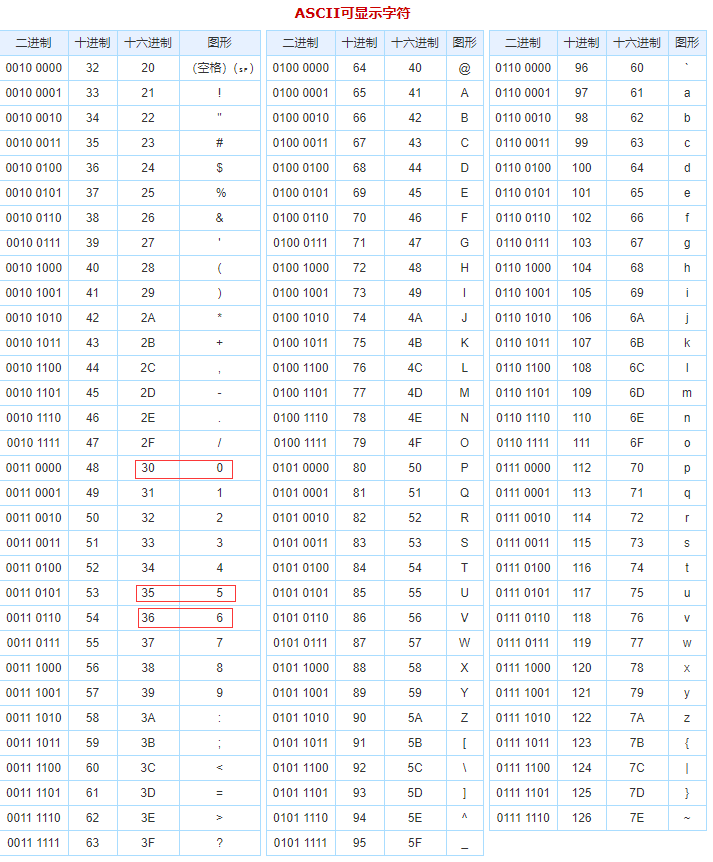
chunkSize 是以十六进制的 ASCII 码表示每个字节,例如某个 chunkSize 部分一共两个字节,第一个字节值是 35(十六进制),第二个字节值是 36(十六进制),十六进制的 35 和十六进制 36 在 ASCII 码表中分别表示阿拉伯数字 5 和 6,因此被 http 协议解释为十六进制数 56,十六进制 56 对应十进制的 86,后面紧跟 \r\n(0d 0a),再接着是连续的 86 个字节的 chunkData。chunk 数据以 0 长度的 chunk 块结束,也就是 30 0d 0a 0d 0a,十六进制 30 对应阿拉伯数字 0。这个 chunk 的结构如下图所示:

在介绍了 chunked 技术的编码格式后,对端对 chunked 格式的解压也很容易了。首先对端要在收到的 http 头部找到 Transfer-Encoding 字段,并且其值是 chunked,说明这个 HTTP 数据包使用 chunked 技术编码的。接下来按格式对分块进行解析就可以了:
找到 HTTP 包体开始的地方(HTTP 头部 \r\n\r\n 下一个位置)和接下来一个 \r\n 中间的部分,这是第一个 chunkSize 内容;
假设第一个 chunkSize 的长度是 n 个字节,对照 ASCII 码表将这 n 个字节依次转换成数字,然后将这些数字拼凑起来当成十六进制数值,再转换成十进制,这就是接下来的 chunkData 的长度。
接下就跳过 \r\n 去获取下一个数据块的 chunkSize 和 chunkData,直到遇到一个 chunkSize 为 0 的数据块。
然后将各个数据块的 chunkData 按顺序拼接在一起得到这个 http 数据包的完整包体。
理顺上面的逻辑后,用代码实现起来就比较简单了,这里就不展示具体的例子了。
# 6.11.4 http 客户端的编码实现
如果读者能理解上文说的 http 协议格式,就可以自己通过代码组装 http 协议报文来发送 http 请求了,这也是各种 http 工具和库模拟 HTTP 请求的基本原理。这个过程大致如下:
举个例子,我们要请求 http://www.hootina.org/index_2013.php 这个 URL,我们先取出 URL 中的域名部分,即 hootina.org,然后通过 socket API gethostbyname() 函数得到 hootina.org 这个域名对应的 ip 地址,因为这个 URL 中没有显式指定请求的端口号,所以使用 HTTP 协议的默认端口号 80。有了 ip 和端口号之后,我们使用 socket API connect() 函数 去连接服务器,然后根据上面介绍的格式组装成 http 协议包,并利用 socket API send() 函数将组装的协议包发出去,如果服务器有应答,我们可以使用 socket API recv() 去接收数据,然后再按 http 协议格式进行解包(分为解析包头和包体两个步骤)就可以了。
# 6.11.5 http 服务端的实现
我们这里简化一些问题,假设客户端发送的请求都是 GET 请求,当客户端发来 http 请求之后,我们拿到 http 包后就可以做相应的处理,这里用 Flamingo 服务器实现一个支持 http 协议格式的注册请求为例。假设用户在浏览器里面输入以下网址,就可以实现一个注册功能:
http://120.55.94.78:12345/register.do?p={"username": "13917043329", "nickname": "balloon", "password": "123"}
这里我们的 http 协议使用的是 12345 端口号而不是默认的 80 端口,如何侦听 12345 端口是网络编程基础知识,这里就不介绍了。当我们收到数据以后:
void HttpSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receiveTime)
{
string inbuf;
//先把所有数据都取出来
inbuf.append(pBuffer->peek(), pBuffer->readableBytes());
//因为一个http包头的数据至少\r\n\r\n,所以大于4个字符
//小于等于4个字符,说明数据未收完,退出,等待网络底层接着收取
if (inbuf.length() <= 4)
return;
//我们收到的GET请求数据包一般格式如下:
/*
GET /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} HTTP/1.1\r\n
Host: 120.55.94.78:12345\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN, zh; q=0.9, en; q=0.8\r\n
\r\n
*/
//检查是否以\r\n\r\n结束,如果不是说明包头不完整,退出
string end = inbuf.substr(inbuf.length() - 4);
if (end != "\r\n\r\n")
return;
//以\r\n分割每一行
std::vector<string> lines;
StringUtil::Split(inbuf, lines, "\r\n");
if (lines.size() < 1 || lines[0].empty())
{
conn->forceClose();
return;
}
std::vector<string> chunk;
StringUtil::Split(lines[0], chunk, " ");
//chunk中至少有三个字符串:GET url HTTP版本号
if (chunk.size() < 3)
{
conn->forceClose();
return;
}
LOG_INFO << "url: " << chunk[1] << " from " << conn->peerAddress().toIpPort();
//inbuf = /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22}
std::vector<string> part;
//通过?分割成前后两端,前面是url,后面是参数
StringUtil::Split(chunk[1], part, "?");
//chunk中至少有三个字符串:GET、url和HTTP版本号
if (part.size() < 2)
{
conn->forceClose();
return;
}
string url = part[0];
string param = part[1].substr(2);
if (!Process(conn, url, param))
{
LOG_ERROR << "handle http request error, from:" << conn->peerAddress().toIpPort() << ", request: " << pBuffer->retrieveAllAsString();
}
//短连接,处理完关闭连接
conn->forceClose();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
上述代码中,在接收到的字节流中必须存在 \r\n\r\n 标志(即至少有一个 http 包头部分),然后利用 \r\n 分割得到每一行,其中第一行的数据是:
GET /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} HTTP/1.1
注意:这里为了方便说明问题,并没有处理对端是 http chunked 传输的 http 包。
其中 %22 是 "(双引号)的 URL 转码形式,%20 是空格的 URL 转码形式,然后我们根据空格分成三段,其中第二段就是我们的网址 URL和参数:
/register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22}
然后我们根据网址与参数之间的问号将这个分成两段,第一段是 URL,第二段是 GET 参数内容,然后我们根据 URL 匹配网址。
bool HttpSession::Process(const std::shared_ptr<TcpConnection>& conn, const std::string& url, const std::string& param)
{
if (url.empty())
return false;
if (url == "/register.do")
OnRegisterResponse(param, conn);
else if (url == "/login.do")
OnLoginResponse(param, conn);
else
return false;
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果是注册请求,会走注册处理逻辑:
void HttpSession::OnRegisterResponse(const std::string& data, const std::shared_ptr<TcpConnection>& conn)
{
string retData;
string decodeData;
URLEncodeUtil::Decode(data, decodeData);
BussinessLogic::RegisterUser(decodeData, conn, false, retData);
if (!retData.empty())
{
std::string response;
URLEncodeUtil::Encode(retData, response);
MakeupResponse(retData, response);
conn->send(response);
LOG_INFO << "Response to client: cmd=msg_type_register" << ", data=" << retData << conn->peerAddress().toIpPort();;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注册结果放在 retData 中,为了发给客户端,我们对应答结果中的特殊字符(如双引号)进行转码,如返回结果是:
{"code":0, "msg":"ok"}
会被转码成:
{%22code%22:0,%20%22msg%22:%22ok%22}
然后,将数据组装成 http 协议发给客户端,给客户端的应答协议与 http 请求协议有一点点差别,就是将请求的 URL 路径换成 http 响应码,如 200 表示应答正常返回、404 表示页面不存在。应答协议格式如下:
GET或POST 响应码 HTTP协议版本号\r\n
字段1名: 字段1值\r\n
字段2名: 字段2值\r\n
...
字段n名 : 字段n值\r\n
\r\n
http协议包体内容
2
3
4
5
6
7
举个例子如:
HTTP/1.1 200 OK\r\n
Content-Type: text/html\r\n
Content-Length:42\r\n
\r\n
{%22code%22:%200,%20%22msg%22:%20%22ok%22}
2
3
4
5
注意,包头中的 Content-Length 字段值必须设置成包体(即字符串 {%22code%22:%200,%20%22msg%22:%20%22ok%22} )的长度,这里是 42。
浏览器会得到如下应答结果,如下图所示:

需要注意的是, http 请求一般是短连接,即一次请求完数据后连接就会断开,这里我们也实现了这个功能,在上述代码第 68 行:
conn->forceClose();
我们这里的实现是无论一个 http 请求是否成功,服务器处理完后会立即关闭连接。
当然,上述实现代码中还存在一些没处理好的地方,例如,如果你仔细观察上面的代码就会发现,上述代码在处理收到的数据时,没有考虑到如下情形:即对不满足一个 http 包头时的处理,如果某个客户端(不是使用浏览器)通过程序模拟了一个连接请求,但是迟迟不发含有 \r\n\r\n 的数据,这路连接将会一直占用。因此,我们可以判断收到的数据长度,防止别有用心的客户端给我们的服务器乱发数据。我们假定每个 http 请求最大数据包长度是 2048,如果用户发送的数据累积不含 \r\n\r\n 且超过 2048 个,我们认为连接非法,将其断开。代码修改成如下形式:
void HttpSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime)
{
//LOG_INFO << "Recv a http request from " << conn->peerAddress().toIpPort();
string inbuf;
//先把所有数据都取出来
inbuf.append(pBuffer->peek(), pBuffer->readableBytes());
//因为一个http包头的数据至少\r\n\r\n,所以大于4个字符
//小于等于4个字符,说明数据未收完,退出,等待网络底层接着收取
if (inbuf.length() <= 4)
return;
//我们收到的GET请求数据包一般格式如下:
/*
GET /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} HTTP/1.1\r\n
Host: 120.55.94.78:12345\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: zh-CN, zh; q=0.9, en; q=0.8\r\n
\r\n
*/
string end = inbuf.substr(inbuf.length() - 4);
if (end != "\r\n\r\n")
{
if (inbuf.length() >= MAX_URL_LENGTH)
{
//超过2048个字符,且不含\r\n\r\n,我们认为是非法请求
conn->forceClose();
}
//检查是否以\r\n\r\n结束,如果不是且长度不超过2048个字符说明包头不完整,退出
return;
}
//找到完整的包头
//以\r\n分割每一行
std::vector<string> lines;
StringUtil::Split(inbuf, lines, "\r\n");
if (lines.size() < 1 || lines[0].empty())
{
conn->forceClose();
return;
}
std::vector<string> chunk;
StringUtil::Split(lines[0], chunk, " ");
//chunk中至少有三个字符串:GET+url+HTTP版本号
if (chunk.size() < 3)
{
conn->forceClose();
return;
}
LOG_INFO << "url: " << chunk[1] << " from " << conn->peerAddress().toIpPort();
//inbuf = /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22}
std::vector<string> part;
//通过?分割成前后两端,前面是url,后面是参数
StringUtil::Split(chunk[1], part, "?");
//chunk中至少有三个字符串:GET+url+HTTP版本号
if (part.size() < 2)
{
conn->forceClose();
return;
}
string url = part[0];
string param = part[1].substr(2);
if (!Process(conn, url, param))
{
LOG_ERROR << "handle http request error, from:" << conn->peerAddress().toIpPort() << ", request: " << pBuffer->retrieveAllAsString();
}
//短连接,处理完关闭连接
conn->forceClose();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
上述代码逻辑只能解决客户端发送非法数据的情况,如果一个客户端连上来不给我们发任何数据,这段逻辑就无能为力了。如果不断有客户端这么做,会浪费我们大量的连接资源,所以我们还需要一个定时器去定时检测哪些 http 连接超过一定时间内没给我们发数据,找到后将连接断开。这又涉及到服务器定时器如何设计了,关于这部分请参考定时器相关的章节。
实际开发中,在设计通用 web 服务器时,需要对对端发过来的 http 数据做的校验远比这个例子考虑的情形要多。这里只是为了说明问题方便,仅列举了少数几种情形。大多数 Web 服务器在接收到请求时可能会从磁盘加载某个文件内容返回给客户端,其基本原理也是利用文件内容组装成 http 应答包。
# 6.11.6 http 协议与长连接
在大多数开发者的认知中,一提到 http 协议和 http 请求,那么必然要和短连接关联起来,这种认识是不正确的。尽管目前大多数的 Web 服务器,其实现的 http 连接基本上都是短连接,但可以在 http 协议头中设置 keepalive 字段,该字段建议连接的双方使用长连接进行通信,而不是每次请求都建立新的连接,但这只是一个建议选项,不少 Web 服务器并不遵循 keepalive 字段的建议。
相反,在实际商业项目中,有这样一种场景会使用长连接的 http 协议:在一些业务需要对外保密的企业,一般禁止内部员工通过除浏览器以外任何客户端访问外网,企业内部会安装一些安全软件,这类软件会过滤掉除 http 协议格式以外的所有数据包。为了应对这种网络场景,可以使用 http 长连接访问外网,这是很多客户端支持 http 代理的原因。
# 6.11.7 libcurl
libcurl 是一个被广泛使用、跨平台用于发送 http 请求的第三方 C/C++ 库,其下载地址是: https://curl.haxx.se/libcurl/ 。其基本用法如下:
使用 curl_easy_init() 函数初始化一个 CURL 对象;
CURL* curl = curl_easy_init();1调用 curl_easy_setopt() 函数给 CURL 对象设置相关选项,如请求的 URL 地址、请求的方法、请求最大超时时间、是否需要在请求结果中保留 HTTP 协议头信息、请求结果放在哪里等。
//设置请求的URL curl_easy_setopt(curl, CURLOPT_URL, url); //设置CURLOPT_POST这个选项值,则使用POST方法进行请求,否则为GET方法 curl_easy_setopt(curl, CURLOPT_POST, 1L); //将请求结果放到response中,response的类型是std::string curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void*)&response); //设置连接超时时间 curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, connTimeout); //设置读取数据的超时时间 curl_easy_setopt(curl, CURLOPT_TIMEOUT, readTimeout); //请求结果中保留应答的http协议头信息 curl_easy_setopt(curl, CURLOPT_HEADER, 1L);1
2
3
4
5
6
7
8
9
10
11
12调用 curl_easy_perform() 函数发送实际的 http 请求,并得到一个类型为 CURLcode 的返回值,如果返回值为 CURLE_OK 说明请求成功。
CURLcode res = curl_easy_perform(curl);1无论调用成功与否,调用 curl_easy_cleanup() 函数释放 curl_easy_init() 函数分配的 CURL 对象。
curl_easy_cleanup(curl);1
我基于 libcurl 做了一个简单的封装,实现如下:
CurlClient.h
/**
* 封装curl的http库, CurlClient.h
* zhangyl 2019.08.27
*/
#ifndef __CURL_CLIENT_H__
#define __CURL_CLIENT_H__
#include <string>
#include "curl.h"
class CCurlClient final
{
public:
CCurlClient();
~CCurlClient();
CCurlClient(const CCurlClient& rhs) = delete;
CCurlClient& operator=(const CCurlClient& rhs) = delete;
/**
* 初始化libcurl
* 非线程安全函数,建议在程序初始化时调用一次,以免出现多线程调用curl_easy_init出现崩溃问题
*/
static void init();
/**
* 反初始化libcurl
* 非线程安全函数,建议在程序退出时调用一次
*/
static void uninit();
/** 发送http get请求
* @param url 请求的网址
* @param headers 随请求发送的自定义http头信息,多个自定义头之间使用\r\n分割,最后一个以\r\n结束,无自定义http头信息则设置为nullptr
* @param response 如果请求成功则存储http请求结果(注意:response在函数调用中是追加模式,也就是说如果上一次response的值不清空,调用这个函数时会追加,而不是覆盖)
* @param autoRedirect 请求得到http 3xx的状态码是否自动重定向至新的url
* @param bReserveHeaders 请求的结果中(存储于response),是否保留http头部信息
* @param connTimeout 连接超时时间,单位为秒(对于某些http URI资源不好的,总是返回超时可以将该参数设置大一点)
* @param readTimeout 读取数据超时时间,单位为秒(对于某些http URI资源不好的,总是返回超时可以将该参数设置大一点)
*/
bool get(const char* url, const char* headers, std::string& response, bool autoRedirect = false, bool bReserveHeaders = false, int64_t connTimeout = 1L, int64_t readTimeout = 5L);
/** 发送http post请求
* @param url 请求的网址
* @param headers 随请求发送的自定义http头信息,多个自定义头之间使用\r\n分割,最后一个以\r\n结束,无自定义http头信息则设置为nullptr
* @param postParams post参数内容
* @param response 如果请求成功则存储http请求结果(注意:response在函数调用中是追加模式,也就是说如果上一次response的值不清空,调用这个函数时会追加,而不是覆盖)
* @param autoRedirect 请求得到http 3xx的状态码是否自动重定向至新的url
* @param bReserveHeaders 请求的结果中(存储于response),是否保留http头部信息
* @param connTimeout 连接超时时间,单位为秒(对于某些http URI资源不好的,总是返回超时可以将该参数设置大一点)
* @param readTimeout 读取数据超时时间,单位为秒(对于某些http URI资源不好的,总是返回超时可以将该参数设置大一点)
*/
bool post(const char* url, const char* headers, const char* postParams, std::string& response, bool autoRedirect = false, bool bReserveHeaders = false, int64_t connTimeout = 1L, int64_t readTimeout = 5L);
private:
static bool m_bGlobalInit;
};
#endif //!__CURL_CLIENT_H__
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/**
* 封装curl的http库, CurlClient.cpp
* zhangyl 2019.08.27
*/
#include "CurlClient.h"
#include <iostream>
void* returnback = NULL;
// reply of the requery
size_t req_reply(void* ptr, size_t size, size_t nmemb, void* stream)
{
std::string* str = (std::string*)stream;
(*str).append((char*)ptr, size * nmemb);
return size * nmemb;
}
bool CCurlClient::m_bGlobalInit = false;
CCurlClient::CCurlClient()
{
}
CCurlClient::~CCurlClient()
{
}
void CCurlClient::init()
{
if (!m_bGlobalInit)
{
curl_global_init(CURL_GLOBAL_ALL);
m_bGlobalInit = true;
}
}
void CCurlClient::uninit()
{
if (m_bGlobalInit)
{
curl_global_cleanup();
m_bGlobalInit = false;
}
}
// http GET
bool CCurlClient::get(const char* url, const char* headers, std::string& response,
bool autoRedirect/* = false*/, bool bReserveHeaders/* = false*/, int64_t connTimeout/* = 1L*/, int64_t readTimeout/* = 5L*/)
{
// init curl
CURL* curl = curl_easy_init();
if (curl == nullptr)
return false;
// set params
curl_easy_setopt(curl, CURLOPT_URL, url); // url
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, false); // if want to use https
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYHOST, false); // set peer and host verify false
curl_easy_setopt(curl, CURLOPT_VERBOSE, 0L);
curl_easy_setopt(curl, CURLOPT_READFUNCTION, NULL);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, req_reply);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void*)&response);
//禁用SIGALRM+sigsetjmp/siglongjmp的超时机制,
//采用其他超时机制,因为该机制修改了一个全局变量,在多线程下可能会出现问题
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, connTimeout); // set transport and time out time
curl_easy_setopt(curl, CURLOPT_TIMEOUT, readTimeout);
//遇到 http 3xx 状态码是否自定重定位
if (autoRedirect)
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);
else
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 0L);
if (bReserveHeaders)
curl_easy_setopt(curl, CURLOPT_HEADER, 1L);
else
curl_easy_setopt(curl, CURLOPT_HEADER, 0L);
//添加自定义头信息
if (headers != nullptr)
{
struct curl_slist* chunk = NULL;
chunk = curl_slist_append(chunk, headers);
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, chunk);
}
// start req
CURLcode res = curl_easy_perform(curl);
// release curl
curl_easy_cleanup(curl);
return res == CURLcode::CURLE_OK;
}
// http POST
bool CCurlClient::post(const char* url, const char* headers, const char* postParams, std::string& response,
bool autoRedirect/* = false*/, bool bReserveHeaders/* = false*/, int64_t connTimeout/* = 1L*/, int64_t readTimeout/* = 5L*/)
{
// init curl
CURL* curl = curl_easy_init();
if (curl == nullptr)
return false;
// set params
curl_easy_setopt(curl, CURLOPT_POST, 1L); // post req
curl_easy_setopt(curl, CURLOPT_URL, url); // url
curl_easy_setopt(curl, CURLOPT_POSTFIELDS, postParams); // params
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, false); // if want to use https
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYHOST, false); // set peer and host verify false
curl_easy_setopt(curl, CURLOPT_VERBOSE, 0L);
curl_easy_setopt(curl, CURLOPT_READFUNCTION, NULL);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, req_reply);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void*)& response);
//禁用SIGALRM+sigsetjmp/siglongjmp的超时机制,
//采用其他超时机制,因为该机制修改了一个全局变量,在多线程下可能会出现问题
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, connTimeout);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, readTimeout);
//遇到 http 3xx 状态码是否自定重定位
if (autoRedirect)
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);
else
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 0L);
if (bReserveHeaders)
curl_easy_setopt(curl, CURLOPT_HEADER, 1L);
else
curl_easy_setopt(curl, CURLOPT_HEADER, 0L);
//添加自定义头信息
if (headers != nullptr)
{
struct curl_slist* chunk = NULL;
chunk = curl_slist_append(chunk, headers);
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, chunk);
}
// start req
CURLcode res = curl_easy_perform(curl);
// release curl
curl_easy_cleanup(curl);
return res == CURLcode::CURLE_OK;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
上述代码实现中,有以下几个需要注意的事项:
函数 curl_easy_init() 第一次调用时其内部会调用 curl_global_init(CURL_GLOBAL_ALL),**curl_global_init() **函数会初始化 libcurl 的一些内部全局状态,这个步骤是非线程安全的,也就是说如果多个线程同时首次调用 curl_easy_init() 函数可能会出现线程安全问题,笔者在实际开发中遇到的现象就是程序莫名其妙的在 curl_easy_init() 函数中崩溃,因此我将 curl_global_init() 函数调用单独提取出来封装成一个 init() 方法,你的程序调用这个库的 CCurlClient::get/post() 方法之前应该调用且只调用一个 CCurlClient::init() 方法。
以下两行代码分别设置了 http 请求的连接超时时间和读取数据的超时时间,对于一些 URL 资源地址网络不是很畅通的 web 服务器,应该将这两个超时值稍微设置长一点,而不是使用我这里给的默认值,否则可能会因为超时时间太短而无法得到期望的结果。
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, connTimeout); curl_easy_setopt(curl, CURLOPT_TIMEOUT, readTimeout);1
2有些 http 请求的结果,资源所在的 web 服务器会返回一个 3xx 开头的重定向 HTTP 状态码,服务器是想告诉你资源已经被挪到其他地址去了,可以使用重定向提示的地址去访问你要的资源。对于这种情况,我们需要将 CCurlClient::get/post() 方法的 autoRedirect 参数值设置为 true 以告诉 libcurl 自动重定向至新的 URL 获取数据。
CCurlClient 类用法示例:
std::string httpResponse;
CCurlClient curlClient;
std::ostringstream headers;
headers << "CLIENT-ID: " << m_strClientID << "\r\n" << "ACCOUNT-ID: " << m_strAccountID << "\r\n";
if (!curlClient.get(someURL, headers.str().c_str(), httpResponse))
{
//TODO:请求失败的操作
return;
}
//请求成功后,应答结果就存储在httpResponse中
//TODO:对httpResponse进一步操作
2
3
4
5
6
7
8
9
10
11
12
# 6.11.8 Restful 接口与 Java SpringMVC
时下最流行的对于提供 http 接口的 web 服务都建议遵循 Restful 设计风格,这是一种建议将 http URL 的路径定义为可对资源类型和特性进行描述的规范。
从事 Java 开发的读者应该对 SpringMVC 框架很熟悉,该框架提供的 Controller 很容易提供一个对外访问的 http 接口(当然,实际提供此功能的是框架自带的 Tomcat 服务器),一个 Controller 可以按如下方式提供一个 http 接口:
@GetMapping(value = "/symbol")
public String fixKlineItem(@RequestParam(value = "symbol") String symbol,
@RequestParam(value = "type") String type) {
//TODO:对http请求的一些处理工作
return "{\"symbol\": \"600053\"}";
}
2
3
4
5
6
上述 rest 接口提供了一个对外访问的 http 接口,可以通过如下 URL 去访问:
http://somehost.com/symbo?symbol=600053&type=1
这个接口需要提供两个参数,分别是 symbol 和 type。
这种方式开发对外的 http 接口很方便,不需要手动处理接收过来的 http 请求协议包,但并不意味着这些工作不存在,这些工作已经由 tomcat 和 SpringMVC 框架替开发者做掉了,开发者可以专注于业务逻辑的开发。
但需要提醒一下一些做 Java 开发的读者,虽然你不再需要手动解析 http 协议包,但是框架是如何做的这些工作,建议读者还是在业余时间认真学习一下,这样才能知其然也知其所以然,提高自己的开发水平。
关于 http 协议的内容其实非常多,本节只介绍了实际开发中较常用的部分内容,关于 http 协议有许多专业的资料,HTTP 协议的 RFC 文档可以参考这里: https://www.ietf.org/rfc/rfc2616 (opens new window)。