 6.4 从 struct 到 TLV——协议的演化历史
6.4 从 struct 到 TLV——协议的演化历史
# 6.4.1 协议的演化
假设现在 A 与 B 之间要传输一个关于用户信息的数据包,可以将该数据包格式定义成如下形式:
#pragma pack(push, 1)
struct userinfo
{
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
};
#pragma pack(pop)
2
3
4
5
6
7
8
9
10
11
相信很多读者曾经都定义过这样的协议,这种数据结构简单明了,对端只要直接拷贝按字段解析就可以了。但是,需求总是不断变化的,某一天根据新的需求需要在这个结构中增加一个字段表示用户的年龄,于是修改协议结构成:
#pragma pack(push, 1)
struct userinfo
{
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
//用户年龄
int32_t age;
};
#pragma pack(pop)
2
3
4
5
6
7
8
9
10
11
12
13
问题并没有直接增加一个字段那么简单,新修改的协议格式导致旧的客户端无法兼容(旧的客户端已经分发出去),这个时候我们升级服务器端的协议格式成新的,会导致旧的客户端无法使用。所以我们在最初设计协议的时候,我们需要增加一个版本号字段,针对不同的版本来做不同的处理,即:
/**
* 旧的协议,版本号是 1
*/
#pragma pack(push, 1)
struct userinfo
{
//版本号
short version;
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
};
#pragma pack(pop)
/**
* 新的协议,版本号是 2
*/
#pragma pack(push, 1)
struct userinfo
{
//版本号
short version;
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
//用户年龄
int32_t age;
};
#pragma pack(pop)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
这样我们可以用以下伪码来兼容新旧协议:
//从包中读取一个 short 型字段
short version = <从包中读取一个 short 型字段>;
if (version == 1)
{
//当旧的协议格式进行处理
}
else if (version == 2)
{
//当新的协议格式进行处理
}
2
3
4
5
6
7
8
9
10
上述方法是一个兼容旧版协议的常见做法。但是这样也存在一个问题,如果我们的业务需求变化快,我们可能需要经常调整协议字段(增、删、改),这样我们的版本号数量会比较多,我们的代码会变成类似下面这种形式:
//从包中读取一个 short 型字段
short version = <从包中读取一个 short 型字段>;
if (version == 版本号1)
{
//对版本号1格式进行处理
}
else if (version == 版本号2)
{
//对版本号2格式进行处理
}
else if (version == 版本号3)
{
//对版本号3格式进行处理
}
else if (version == 版本号4)
{
//对版本号4格式进行处理
}
else if (version == 版本号5)
{
//对版本号5格式进行处理
}
...省略更多...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这只是考虑了协议顶层结构,还没有考虑更多复杂的嵌套结构,不管怎样,这样的代码会变得越来越难以维护。
这里只是为了说明问题,实际开发中,建议读者在设计协议时尽量考虑周全,避免反复修改协议结构。
上述协议格式还存在另外一个问题,对于 name 字段,其长度为 8 个字节,这种定长的字段,长度大小不具有伸缩性,太长很多情况都用不完则造成内存和网络带宽的浪费,太短则某些情况下不够用。那么有没有什么方法来解决呢?
方法是有的,对于字符串类型的字段,我们可以在该字段前面加一个表示字符串长度(length)的标志,那么上面的协议在内存中的状态可以表示成如下图示:
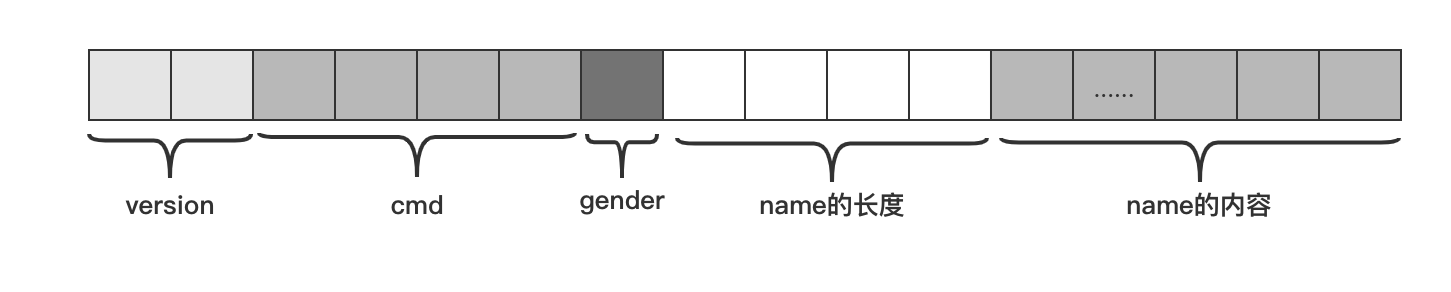
这种方法解决了定义字符串类型时太长浪费太短不够用的问题,但是没有解决修改协议(如新增字段)需要兼容众多旧版本的问题,对于这个问题,我们可以通过在每个字段前面加一个 type 类型来解决,我们可以使用一个 char 类型来表示常用的类型,规定如下:
| 类型 | Type值 | 类型描述 |
|---|---|---|
| bool | 0 | 布尔值 |
| char | 1 | char 型 |
| int16 | 2 | 16 位整型 |
| int32 | 3 | 32 位整型 |
| int64 | 4 | 64 位整型 |
| string | 5 | 字符串或二进制序列 |
| list | 6 | 列表 |
| map | 7 | map |
| 更多自定义类型省略...... |
那么对于上述协议,其内存格式变成:

这样,每个字段的类型就是自解释了。这就是所谓的 TLV(Type-Length-Value,有的资料也称 Tag-Length-Value,其设计思想来源于 ANS.1 规范中一种叫 BER(Basic Encoding Rules)的编码格式)。这种格式的协议,我们可以方便地增删和修改字段类型,程序解析时根据每个字段的 type 来得到字段的类型。
这里再根据笔者的经验多说几句,实际开发中 TLV 类型虽然易于扩展,但是也存在如下缺点:
TLV 格式因为每个字段增加了一个 type 类型,导致所占空间增大;
我们在解析字段时需要额外增加一些判断 type 的逻辑,去判断字段的类型,做相应的处理,即:
//读取第一个字节得到 type if (type == Type::BOOL) { //bool型处理 } else if (type == Type::CHAR) { //char型处理 } else if (type == Type::SHORT) { //short型处理 } ...更多类型省略...1
2
3
4
5
6
7
8
9
10
11
12
13
14如上代码所示,每个字段我们都需要有这样的逻辑判断,这样的编码方式是非常麻烦的。
即使我们知道了每个字段的技术类型(相对业务来说),每个字段的业务含义仍然需要我们制定文档格式,也就是说 TLV 格式只是做到了技术上自解释。
所以,在实际的开发中,完全遵循 TLV 格式的协议并不多,尤其是针对一些整型类型的字段,例如整型字段的大小一旦在知道类型后,其长度就是固定下来的,例如 short 类型占 2 个字节,int32 类型占 4 个字节,因此不必专门浪费一段空间去存储其长度信息。
TLV 格式还可以嵌套,如下图所示:

有的项目在 TLV 格式的基础上还扩展了一种叫 TTLV 格式的协议,即 Tag-Type-Length-Value,每个字段前面再增加一个 Tag 类型,这个时候 Type 表示数据类型,Tag 的含义由协议双方协定。
# 6.4.2 协议的分类
根据协议的内容是否是文本格式(即人为可读格式),我们将协议分为文本协议和二进制协议,像 http 协议的包头部分和 FTP 协议等都是典型的文本协议的例子。
# 6.4.3 协议设计工具
虽然 TLV 很简单,但是每搞一套新的协议都要从头编解码、调试,写编解码是一个毫无技术含量的枯燥体力活。在大量复制粘贴过程中,容易出错。
因此出现了一种叫 IDL(Interface Description Language)的语言规范,它是一种描述语言,也是一个中间语言,IDL 规范协议的使用类型,提供跨语言特性。可以定义一个描述协议格式的 IDL 文件,然后通过 IDL 工具分析 IDL 文件,就可以生成各种语言版本的协议代码。Google Protobuf 库自带的工具 protoc 就是这样一个工具。