 6.8 跨语言之间的网络通信协议识别与解析
6.8 跨语言之间的网络通信协议识别与解析
在实际开发中,由于不同平台开发工具和编程语言的差别,我们需要不同编程语言之间去解析通信协议,这里以 C++ 和 Java 语言为例,通过一个示例来分析如何跨语言之间解析通信协议,编写跨平台代码。
这里以在 Java 中解析 C++ 网络数据包为例。 通常,这对于很多人来说是一件很困难的事情,所以只能变着法子使用第三方的库。其实只要你掌握了一定的基础知识,利用一些现成的字节流抓包工具(如 tcpdump、wireshark)很容易解决这个问题。我们这里使用 tcpdump 工具来尝试分析和解决这个问题。
首先,在我们需要明确字节序列的概念后,我们知道 x86 和 x64 系列的 CPU 使用小端编码,而数据在网络上传输,以及 Java 语言中,使用的是大端编码。 举个例子,看一个 x64 机器上的 32 位数值在内存中的存储方式,代码如下:
int main()
{
int32_t i = 123456;
return 0;
}
2
3
4
5
6
变量 i 在内存中的地址序列是 0x003CF7C4 ~ 0x003CF7C8,值为 40 e2 01 00。
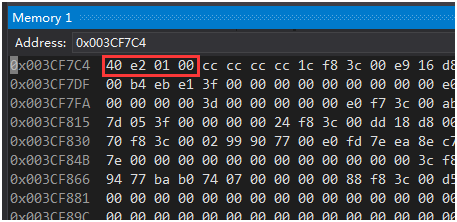
十六进制 0001e240 值等于 10 进制 123456,对于整数 123456,十万位的数字 1 是权重最高的位,个位的数字 6 是权重最低的位,小端编码中权重高的位存储在内存地址高(内存地址值大)的位置,权重值低的位存储在内存地址低(内存地址值小)的位置,这就是所谓的"高高低低原则"(高位高地址,低位低地址)。 大端编码的规则与小端编码的规则相反,大端编码使用的是"高低低高原则",即权重高的位存储在内存地址值低的位置,权重低的位存储在内存地址高的位置。
如果我们一个 C++ 程序的 int32 值 123456 不作转换地传给 Java 程序,那么 Java 按照大端编码的形式读出来的值是:十六进制 40E20100 = 十进制 1088553216。所以,为了表达同样的值,要么在发送方将数据转换成网络字节序(big endian),要么让接收端做转换。
下面看一下如果 C++ 端传送一个类型为 msg 数据结构,Java 端该如何解析(由于 Java 中是没有指针的,也无法操作内存地址,导致很多开发者无从下手),下面利用 tcpdump 来寻找解决这个问题的思路。
#pragma pack(push, 1)
struct msg
{
char compressflag;
int32_t originsize;
int32_t compresssize;
char reservered[16];
char buf[63];
}
#pragma pack(pop)
2
3
4
5
6
7
8
9
10
客户端发送的数据包:
利用 tcpdump 抓到的包如下:
放大一点:
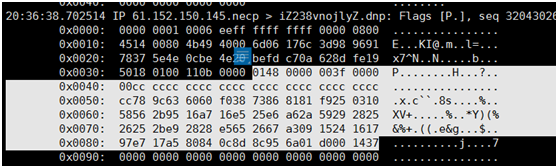
我们白色标识出来就是我们收到的数据包。这里我想说明两点:
- 如果我们知道发送端发送的字节流,再比对接收端收到的字节流,我们就能检测数据包的完整性,也可以利用这个来排查一些网络通信问题;
- 对于 Java 程序只要按照这个顺序,先利用 java.net.Socket 的输出流 java.io.DataOutputStream 对象的 readByte、readInt32、readInt32、readBytes、readBytes 方法依次读出一个 char、int32、int32、16 个字节的字节数组、63 个字节数组即可。当然,为了还原像 int32 这样的整型值,我们需要额外做一些从 little-endian 向 big-endian 的转换工作。