 7.12 带有网络通信模块的服务器的经典结构
7.12 带有网络通信模块的服务器的经典结构
为了行文方便,以下将侦听 socket 称之为 listenfd,将由调用 accept 函数返回的 socket 称之为 clientfd。
# 7.12.1 为何要将 listenfd 设置成非阻塞的?
我们知道如果需要使用 IO 复用函数统一管理各个 fd,需要将 clientfd 设置成非阻塞的,那么 listenfd 一定要设置成非阻塞的吗?答案是不一定的——只要不用 IO 复用函数去管理 listenfd 就可以了,listenfd 如果不设置成非阻塞的,那么 accept 函数在没有新连接时就会阻塞。
# 1. 结构一:listenfd 设置为阻塞模式,为了 listenfd 独立分配一个接受连接线程
有很多服务器程序结构确实采用的是阻塞的 listenfd,为了不让 accept 函数在没有连接时因阻塞对程序其他逻辑执行流造成影响,我们通常将 accept 函数放在一个独立的线程中,这个线程的伪码如下:
//接受连接线程
void* accept_thread_func(void* param)
{
//可以在这里做一些初始化工作...
while (退出标志)
{
struct sockaddr_in clientaddr;
socklen_t clientaddrlen = sizeof(clientaddr);
//没有连接时,线程会阻塞在accept函数处
int clientfd = accept(listenfd, (struct sockaddr *)&clientaddr, &clientaddrlen);
if (clientfd == -1)
{
//出错了,可以在此做一些清理资源动作,如关闭listenfd
break;
}
//将clientfd交给其他IO线程的IO复用函数
//由于跨线程操作,需要使用锁对公共操作的资源进行保护
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
其他 IO 线程的结构依旧还是利用 IO 复用函数处理 clientfd 的 one thread one loop 结构,这里以 epoll_wait 为例,即:
//其他IO线程
void* io_thread_func(void* param)
{
//可以在这里做一些初始化工作
while (退出标志)
{
epoll_event epoll_events[1024];
//所有的clientfd都挂载到epollfd由epoll_wait统一检测读写事件
n = epoll_wait(epollfd, epoll_events, 1024, 1000);
//epoll_wait返回时处理对应clientfd上的读写事件
//其他一些操作
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
当然,这里的 IO 线程可以存在多个,这种结构示意图如下:
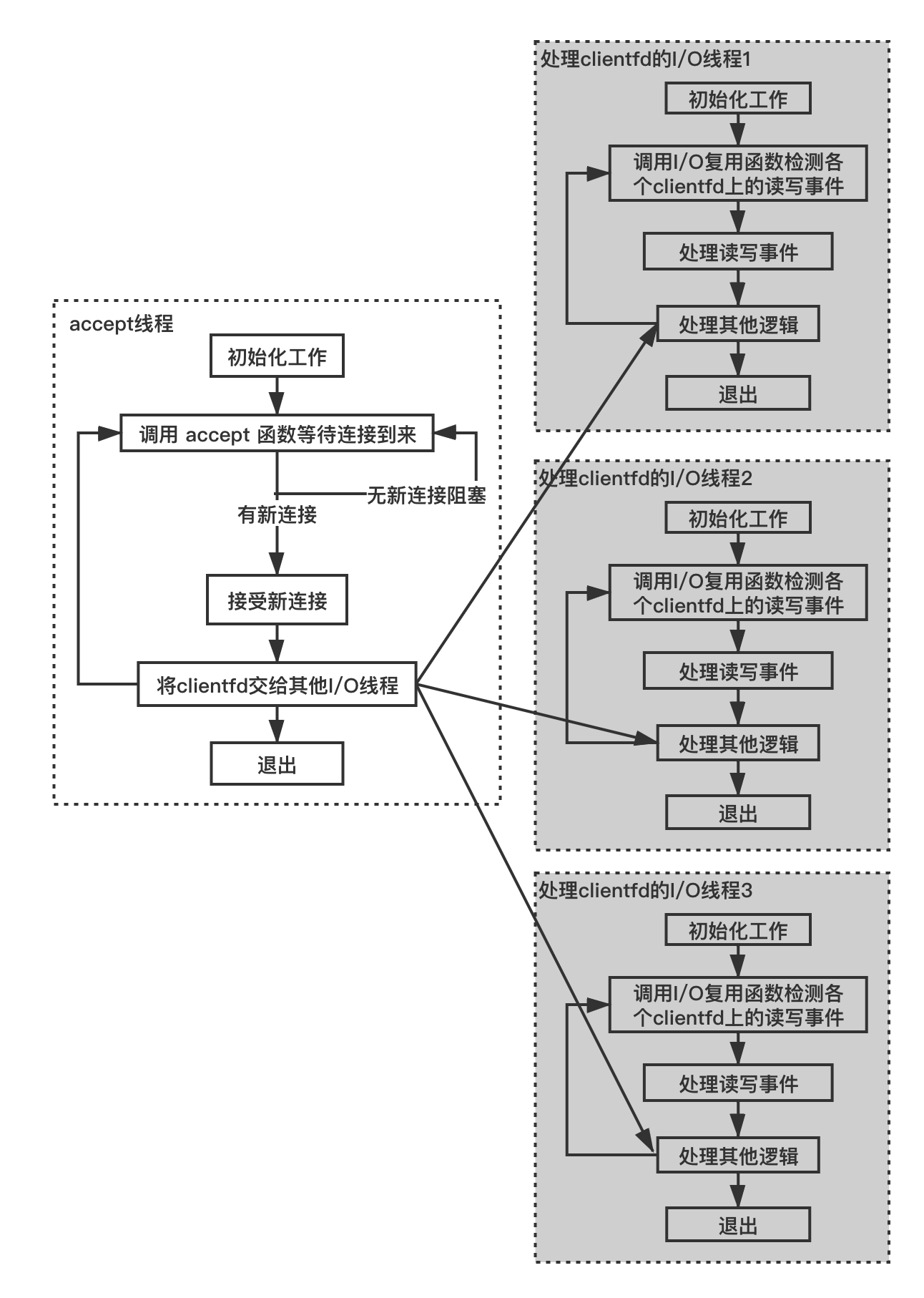
将 clientfd 从 accept_thread_func 交给 io_thread_func方法也很多,这里以使用一个互斥锁来实现为例:
//存储accept函数产生的clientfd的多线程共享变量
std::vector<int> g_vecClientfds;
//保护g_vecClientfds的互斥体
std::mutex g_clientfdMutex;
//接受连接线程
void* accept_thread_func(void* param)
{
//可以在这里做一些初始化工作...
while (退出标志)
{
struct sockaddr_in clientaddr;
socklen_t clientaddrlen = sizeof(clientaddr);
//没有连接时,线程会阻塞在accept函数处
int clientfd = accept(listenfd, (struct sockaddr *)&clientaddr, &clientaddrlen);
if (clientfd == -1)
{
//出错了,可以在此做一些清理资源动作,如关闭listenfd
break;
}
//将clientfd交给其他IO线程的IO复用函数
//由于跨线程操作,可以需要一些锁对公共操作的资源进行保护
std::lock_guard<std::mutex> scopedLock(g_clientfdMutex);
g_vecClientfds.push_back(clientfd);
}
}
//其他IO线程
void* io_thread_func(void* param)
{
//可以在这里做一些初始化工作
while (退出标志)
{
epoll_event epoll_events[1024];
//所有的clientfd都挂载到epollfd由epoll_wait统一检测读写事件
n = epoll_wait(epollfd, epoll_events, 1024, 1000);
//epoll_wait返回时处理对应clientfd上的读写事件
//其他一些操作
//从共享变量g_vecClientfds取出新的clientfd
retrieveNewClientfds(epollfd);
}
}
void retrieveNewClientfds(int epollfd)
{
std::lock_guard<std::mutex> scopedLock(g_clientfdMutex);
if (!g_vecClientfds.empty())
{
//遍历g_vecClientfds取出各个fd,然后将fd设置挂载到所在线程的epollfd上
//全部取出后,清空g_vecClientfds
g_vecClientfds.clear();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
注意上述代码中,由于要求 clientfd 是非阻塞的,设置 clientfd 为非阻塞的这段逻辑你可以放在 accept_thread_func 或 io_thread_func 中均可。
上述代码有点效率问题,某个时刻 accept_thread_func 往 g_vecClientfds 添加了一个 clientfd,但此时如果 io_thread_func 函数正阻塞在 epoll_wait 处,所以此时我们要唤醒 epoll_wait,我们已经在《7.5 one thread one loop 思想》中介绍了如何设计这个唤醒逻辑,这里就不再赘述了。
# 2. 结构二: listenfd 为阻塞模式,使用同一个 one thread one loop 结构去处理 listenfd 的事件
单独为 listenfd 分配一个线程毕竟是对资源的一种浪费,有读者可能说,listenfd 虽然设置成了阻塞模式,但我可以将 listenfd 挂载在到某个 loop 的 epollfd 上,当 epoll_wait 返回且 listenfd 上有读事件时调用 accept 函数时,此时 accept 就不会阻塞了。伪码如下:
void* io_thread_func(void* param)
{
//可以在这里做一些初始化工作
while (退出标志)
{
epoll_event epoll_events[1024];
//listenfd和clientfd都挂载到epollfd由epoll_wait统一检测读写事件
n = epoll_wait(epollfd, epoll_events, 1024, 1000);
if (listenfd上有事件)
{
//此时调用accept函数不会阻塞
int clientfd = accept(listenfd, ...);
//对clientfd作进一步处理
}
//其他一些操作
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
如上述代码所示,这种情况下确实可以将 listenfd 设置成阻塞模式,调用 accept 函数也不会造成流程阻塞。
但是这样的设计存在着严重的效率问题:这种设计在每一轮循环中只能一次接受一个连接(每次循环仅调用了一次 accept),如果连接数较多,这种处理速度可能跟不上,所以要在一个循环里面处理 accept,但是实际情形是我们没法确定下一轮调用 accept 时 backlog 队列中是否还有新连接呀,如果没有,由于 listenfd 是阻塞模式的, accept 会阻塞。

# 3. 结构三: listenfd 为非阻塞模式,使用同一个 one thread one loop 结构去处理 listenfd 的事件
当将 listenfd 设置成非阻塞模式,我们就不会存在这种窘境了。伪码如下:
void* io_thread_func(void* param)
{
//可以在这里做一些初始化工作
while (退出标志)
{
epoll_event epoll_events[1024];
//listenfd和clientfd都挂载到epollfd由epoll_wait统一检测读写事件
n = epoll_wait(epollfd, epoll_events, 1024, 1000);
if (listenfd上有事件)
{
while (true)
{
//此时调用accept函数不会阻塞
int clientfd = accept(listenfd, ...);
if (clientfd == -1)
{
//错误码是EWOULDBLOCK说明此时已经没有新连接了
//可以退出内层的while循环了
if (errno == EWOULDBLOCK)
break;
//被信号中断重新调用一次accept即可
else if (errno == EINTR)
continue;
else
{
//其他情况认为出错
//做一次错误处理逻辑
}
} else {
//正常接受连接
//对clientfd作进一步处理
}//end inner-if
}//end inner-while-loop
}//end outer-if
//其他一些操作
}//end outer-while-loop
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
将 listenfd 设置成非阻塞模式还有一个好处时,我们可以自己定义一次 listenfd 读事件时最大接受多少连接数,这个逻辑也很容易实现,只需要将上述代码的内层 while 循环的判断条件从 true 改成特定的次数就可以:
void* io_thread_func(void* param)
{
//可以在这里做一些初始化工作
//每次处理的最大连接数目
const int MAX_ACCEPTS_PER_CALL = 200;
//当前数量
int currentAccept;
while (退出标志)
{
epoll_event epoll_events[1024];
//listenfd和clientfd都挂载到epollfd由epoll_wait统一检测读写事件
n = epoll_wait(epollfd, epoll_events, 1024, 1000);
if (listenfd上有事件)
{
currentAccept = 0;
while (currentAccept <= MAX_ACCEPTS_PER_CALL)
{
//此时调用accept函数不会阻塞
int clientfd = accept(listenfd, ...);
if (clientfd == -1)
{
//错误码是EWOULDBLOCK说明此时已经没有新连接了
//可以退出内层的while循环了
if (errno == EWOULDBLOCK)
break;
//被信号中断重新调用一次accept即可
else if (errno == EINTR)
continue;
else
{
//其他情况认为出错
//做一次错误处理逻辑
}
} else {
//累加处理数量
++currentAccept;
//正常接受连接
//对clientfd作进一步处理
}//end inner-if
}//end inner-while-loop
}//end outer-if
//其他一些操作
}//end outer-while-loop
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
这是一段比较常用的逻辑,我们以 redis-server 的源码中的使用为例:
//https://github.com/balloonwj/redis-6.0.3/blob/master/src/networking.c
//networking.c 971行
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
//MAX_ACCEPTS_PER_CALL在redis中是1000
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
//每次最大处理max个连接数目
while(max--) {
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
//未达到每次处理新连接的最大数时已经无新连接待接收,直接while循环
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 7.12.2 one thread one loop 经典服务器结构
解决了 listenfd 为什么被建议设置成非阻塞的问题,现在我们将 listenfd 挂载到某个 loop 所属的 epollfd 上与 clientfd 统一处理就没疑问了。让我们来进一步讨论这一结构。
# 1. listenfd 单独使用一个 loop,clientfd 分配至其他 loop
这是在实际商业服务器中比较常用的一个结构,listenfd 单独挂载到一个线程的 Loop 的 epollfd 上(这个线程一般是主线程),为了表述方便,我们将这个线程称之为”主线程“,对应的 loop 称之为主 Loop;产生新的 clientfd 按一定的策略挂载到其他线程 Loop 的 epollfd 上,我们将这些线程称之为工作线程,对应的 Loop 称之为工作 Loop 。
例如使用轮询策略(round robin),clientfd 均匀的给其他的工作线程,如下图所示:
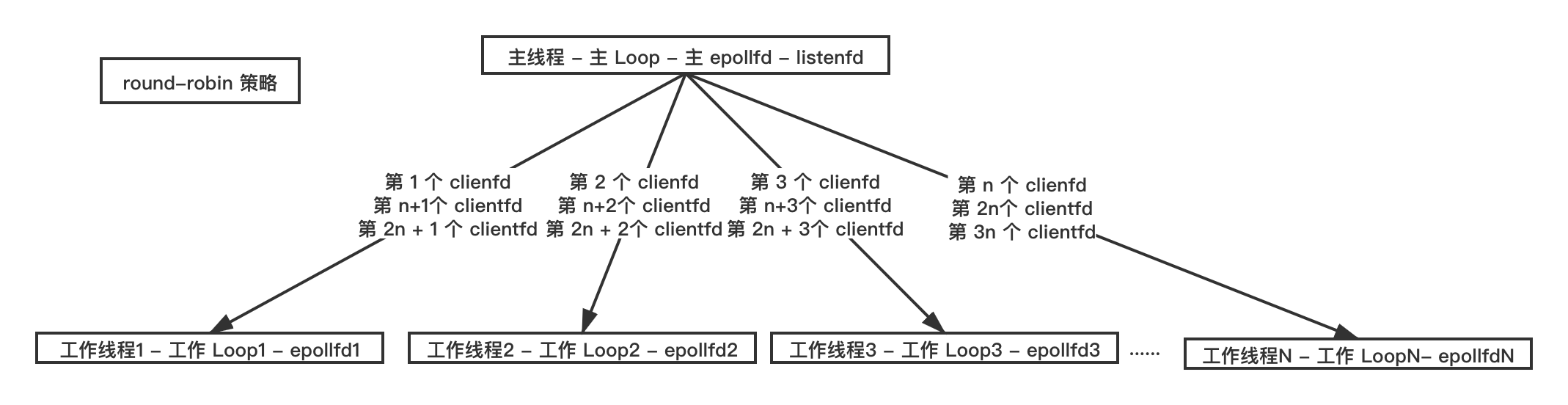
轮询策略可以做一些优化,clientfd 挂到各个工作 Loop 上之后,由于连接断开 clientfd 会从工作 Loop 上移除,所以一段时间后各个工作 Loop 上 clientfd 数量可能不一样,可能会出现数量差别很大的极端情况,因此主 Loop 在分配新产生的 clientfd 时可以先查询一下各个 Loop 上当前实际的 clientfd 数量,把当前新产生的 clientfd 分配给持有 clientfd 最少的 Loop。如下图所示:
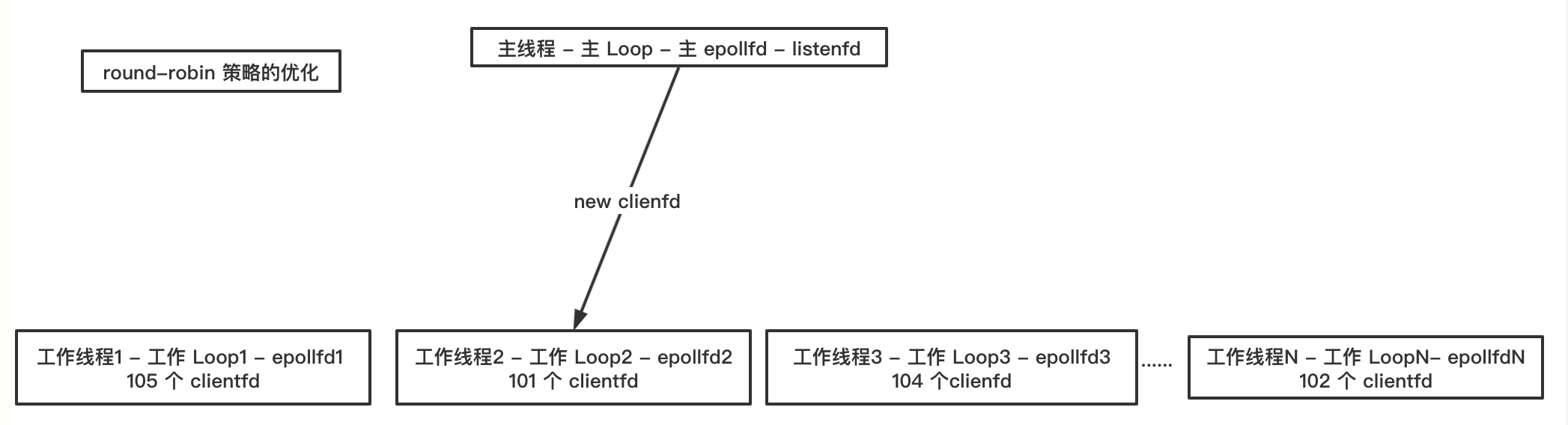
当然,你也可以根据一定的策略比重来分配 clientfd,例如假设现在有 4 个工作线程(对应 4 个工作 Loop),其分配比重为 1 : 4 : 4 : 1,程序运行一段时间后,在没有断开连接的情况,那么这四个工作 Loop 上的 clientfd 数量比例理论上应该也是 1 : 4 : 4 : 1。
# 2. listenfd 不单独使用一个 loop,所有 clientfd 按一定策略分配给各个 loop
对于一些建立和断开连接操作不是很频繁的场景,实际没必要让 listenfd 单独使用一个线程,因为在这种场景下如果让 listenfd 单独使用一个 Loop,这个线程大多数情况可能处于空闲状态,而负责的 clientfd 的其他线程可能比较忙碌,例如像用户较多的即时通讯服务器、实时对战类型的游戏服务器。这样不仅浪费资源,同时效率也不高,所以这种场景下应该让 listenfd 所在的线程也参与 clientfd 读写事件的处理。
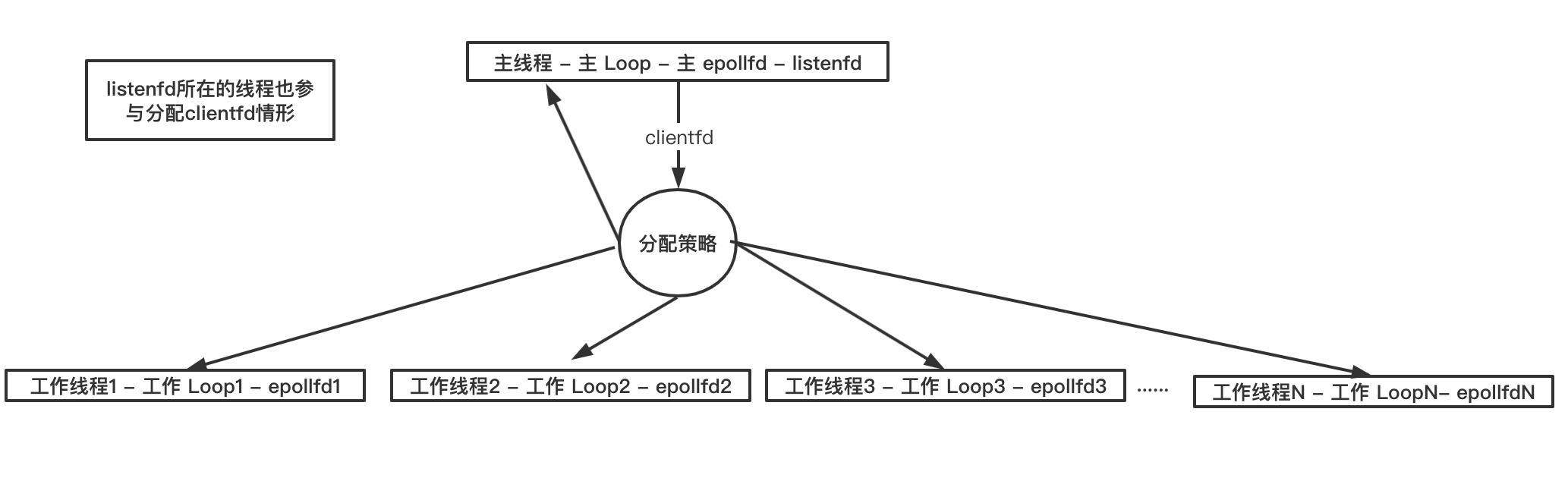
redis 6.0 引入了多线程 IO,在多线程启用状态下,主线程既参处理 listenfd 逻辑,也参与分配 clientfd 和处理 clientfd 的读写事件,这是 listenfd 不单独使用一个 loop、所有 clientfd 按一定策略分配给各个 loop 的典型案例。
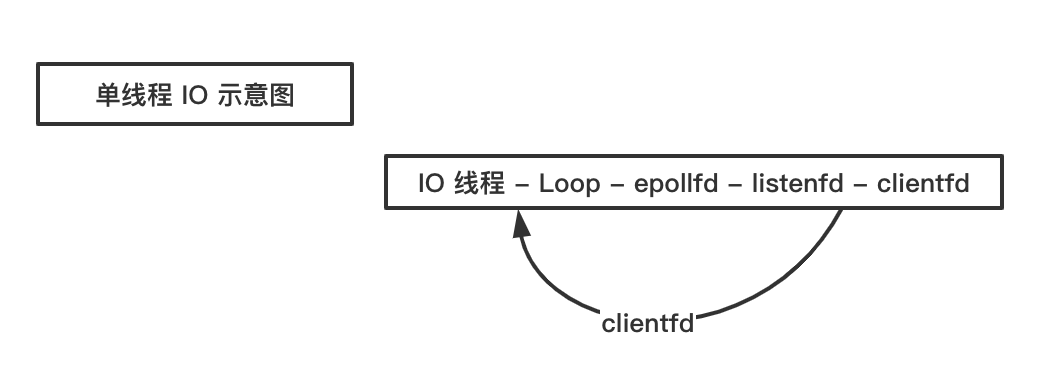
# 3. listenfd 和所有 clientfd 均使用一个 loop
这种是上述情形的特例,一般用于整个 Loop 都是高效的内存操作的情形,例如 redis-server 的 IO 线程,即所谓的单线程 IO。
# 7.12.3 服务器性能瓶颈在哪里?
在 7.11 《侵入式服务与非侵入式程序结构》这一节,我们讨论了一个服务器程序的基本结构,从线程的维度来看,可以分为网路线程和业务处理线程,其中网络线程执行的逻辑一般比较固定,而业务线程执行的逻辑则随着业务的不同而千差万别。
在机器物理资源有限的情况下,我们假定某个服务线程数目也是有限的。为了合理分配线程资源,让程序性能最大化,我们需要找到程序的性能瓶颈在哪里,一般按照业务类型的不同,我们将服务器程序归为两类:
- IO 密集型
- 计算密集型
所谓 IO密集型指的是程序业务上没有复杂的计算或者耗时的业务逻辑处理,大多数情况下是频繁的网络收发操作,这类业务如 IM、交易系统中的行情推送服务、实时对战游戏的服务等,所谓计算密集型指的是程序业务逻辑中存在耗时的计算,这类服务如数据处理服务、调度服务等。
如果服务是 IO 密集型,那么我们需要将线程数目向网络通信组件上倾斜,反过来如果是计算密集型的服务,我们应该将线程数目向业务模块倾斜。举个例子,假设现在总线程数目是 10 个,那么对于 IO 密集型服务,我们的网络线程数目可以设置为大于 5,而业务线程数目小于 5;反过来,对于计算密集型服务,我们可以将网络线程数目设置为小于 5,业务线程数目大于 5,具体数目根据网络通信逻辑与业务处理逻辑在整个服务中的资源占用比例,谁占用资源率大,倾斜的线程数应该越多。