 6.3 解包与处理
6.3 解包与处理
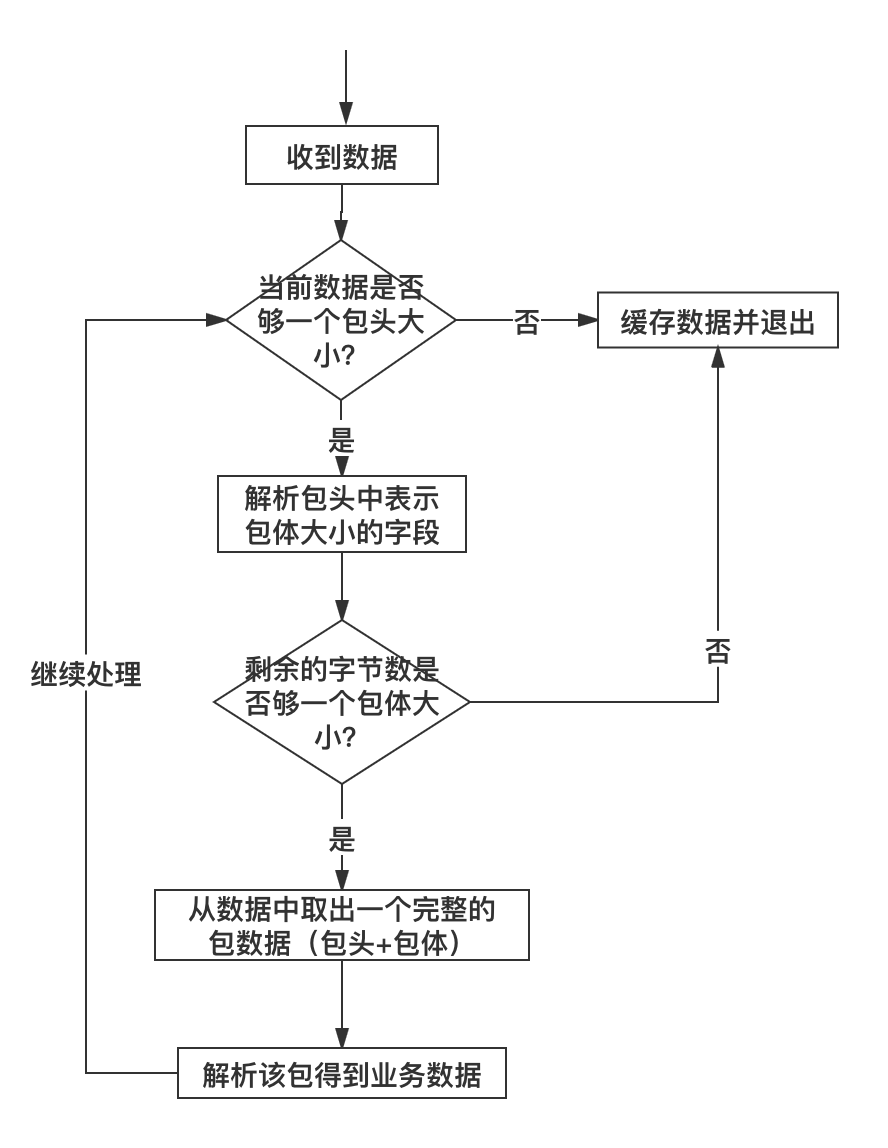
在理解了前面介绍的数据包的三种格式后,我们来介绍一下针对上述三种格式的数据包技术上应该如何处理。其处理流程都是一样的,这里我们以包头 + 包体 这种格式的数据包来说明。处理流程如下:
假设我们的包头格式如下:
//强制1字节对齐
#pragma pack(push, 1)
//协议头
struct msg_header
{
int32_t bodysize; //包体大小
};
#pragma pack(pop)
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
那么上面的流程实现代码如下:
//包最大字节数限制为10M
#define MAX_PACKAGE_SIZE 10 * 1024 * 1024
void ChatSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime)
{
while (true)
{
//不够一个包头大小
if (pBuffer->readableBytes() < (size_t)sizeof(msg_header))
{
//LOGI << "buffer is not enough for a package header, pBuffer->readableBytes()=" << pBuffer->readableBytes() << ", sizeof(msg_header)=" << sizeof(msg_header);
return;
}
//取包头信息
msg_header header;
memcpy(&header, pBuffer->peek(), sizeof(msg_header));
//包头有错误,立即关闭连接
if (header.bodysize <= 0 || header.bodysize > MAX_PACKAGE_SIZE)
{
//客户端发非法数据包,服务器主动关闭之
LOGE("Illegal package, bodysize: %lld, close TcpConnection, client: %s", header.bodysize, conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
//收到的数据不够一个完整的包
if (pBuffer->readableBytes() < (size_t)header.bodysize + sizeof(msg_header))
return;
pBuffer->retrieve(sizeof(msg_header));
//inbuf用来存放当前要处理的包
std::string inbuf;
inbuf.append(pBuffer->peek(), header.bodysize);
pBuffer->retrieve(header.bodysize);
//解包和业务处理
if (!Process(conn, inbuf.c_str(), inbuf.length()))
{
//客户端发非法数据包,服务器主动关闭之
LOGE("Process package error, close TcpConnection, client: %s", conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
}// end while-loop
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
上述流程代码的处理过程和流程图中是一致的,pBuffer 这里是一个自定义的接收缓冲区,这里的代码,已经将收到的数据放入了这个缓冲区,所以判断当前已收取的字节数目只需要使用这个对象的相应方法即可。上述代码有些细节我需要强调一下:
- 取包头时,你应该拷贝一份数据包头大小的数据出来,而不是从缓冲区 pBuffer 中直接将数据取出来(即取出来的数据从 pBuffer 中移除),这是因为倘若接下来根据包头中的字段得到包体大小时,如果剩余数据不够一个包体大小,你又得把这个包头数据放回缓冲区。为了避免这种不必要的操作,只有缓冲区数据大小够整个包的大小(代码中:header.bodysize + sizeof(msg))你才需要把整个包大小的数据从缓冲区移除,这也是这里的 pBuffer->peek() 方法 peek 单词的含义(中文可以翻译成”瞟一眼“或者”偷窥“)。
- 通过包头得到包体大小时,你一定要对 bodysize 的数值进行校验,我这里要求 bodysize 必须大于 0 且不大于 10 * 1024 * 1024(即 10 M)。当然,你可以根据实际情况决定 bodysize 的上下限(包体大小是 0 字节的包在某些业务场景下是允许的)。记住,一定要判断这个上下限,因为假设这是一个非法的客户端发来的数据,其 bodysize 设置了一个比较大的数值,例如 1 * 1024 * 1024 * 1024(即 1 G),你的逻辑会让你一直缓存该客户端发来的数据,那么很快你的服务器内存将会被耗尽,操作系统在检测到你的进程占用内存达到一定阈值时会杀死你的进程,导致服务不能再正常对外服务。如果你判断了 bodysize 字段是否满足你设置的上下限,对于非法的 bodysize,直接关闭这路连接即可。这也是服务的一种自我保护措施,避免因为非法数据包带来的损失。还有另外一种情况下 bodysize 也可能不是预期的合理值,即因为网络环境差或者某次数据解析逻辑错误,导致后续的数据错位,把不该当包头数据的数据当成了包头,这个时候解析出来的 bodysize 也可能不是合理值,同样,这种情形下也会被这段检验逻辑检测到,最终关闭连接。
- 不知道你有没有注意到整个判断包头、包体以及处理包的逻辑放在一个 while 循环里面,这是必要的。如果没有这个 while 循环,当你一次性收到多个包时,你只会处理一个,下次接着处理就需要等到新一批数据来临时再次触发这个逻辑。这样造成的结果就是,对端给你发送了多个请求,你最多只能应答一个,后面的应答得等到对端再次给你发送数据时。这就是对粘包逻辑的正确处理。
以上逻辑和代码是最基本的粘包和半包处理机制,也就是所谓的技术上的解包处理逻辑(业务上的解包处理逻辑后面章节再介绍)。希望读者能理解它,在理解它的基础之上,我们可以给解包拓展很多功能,例如,我们再给我们的协议包增加一个支持压缩的功能,我们的包头变成下面这个样子:
#pragma pack(push, 1)
//协议头
struct msg_header
{
char compressflag; //压缩标志,如果为1,则启用压缩,反之不启用压缩
int32_t originsize; //包体压缩前大小
int32_t compresssize; //包体压缩后大小
char reserved[16]; //保留字段,用于将来拓展
};
#pragma pack(pop)
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
修改后的代码如下:
//包最大字节数限制为10M
#define MAX_PACKAGE_SIZE 10 * 1024 * 1024
void ChatSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime)
{
while (true)
{
//不够一个包头大小
if (pBuffer->readableBytes() < (size_t)sizeof(msg_header))
{
//LOGI << "buffer is not enough for a package header, pBuffer->readableBytes()=" << pBuffer->readableBytes() << ", sizeof(msg_header)=" << sizeof(msg_header);
return;
}
//取包头信息
msg_header header;
memcpy(&header, pBuffer->peek(), sizeof(msg_header));
//数据包压缩过
if (header.compressflag == PACKAGE_COMPRESSED)
{
//包头有错误,立即关闭连接
if (header.compresssize <= 0 || header.compresssize > MAX_PACKAGE_SIZE ||
header.originsize <= 0 || header.originsize > MAX_PACKAGE_SIZE)
{
//客户端发非法数据包,服务器主动关闭之
LOGE("Illegal package, compresssize: %lld, originsize: %lld, close TcpConnection, client: %s", header.compresssize, header.originsize, conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
//收到的数据不够一个完整的包
if (pBuffer->readableBytes() < (size_t)header.compresssize + sizeof(msg_header))
return;
pBuffer->retrieve(sizeof(msg_header));
std::string inbuf;
inbuf.append(pBuffer->peek(), header.compresssize);
pBuffer->retrieve(header.compresssize);
std::string destbuf;
if (!ZlibUtil::UncompressBuf(inbuf, destbuf, header.originsize))
{
LOGE("uncompress error, client: %s", conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
//业务逻辑处理
if (!Process(conn, destbuf.c_str(), destbuf.length()))
{
//客户端发非法数据包,服务器主动关闭之
LOGE("Process error, close TcpConnection, client: %s", conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
}
//数据包未压缩
else
{
//包头有错误,立即关闭连接
if (header.originsize <= 0 || header.originsize > MAX_PACKAGE_SIZE)
{
//客户端发非法数据包,服务器主动关闭之
LOGE("Illegal package, compresssize: %lld, originsize: %lld, close TcpConnection, client: %s", header.compresssize, header.originsize, conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
//收到的数据不够一个完整的包
if (pBuffer->readableBytes() < (size_t)header.originsize + sizeof(msg_header))
return;
pBuffer->retrieve(sizeof(msg_header));
std::string inbuf;
inbuf.append(pBuffer->peek(), header.originsize);
pBuffer->retrieve(header.originsize);
//业务逻辑处理
if (!Process(conn, inbuf.c_str(), inbuf.length()))
{
//客户端发非法数据包,服务器主动关闭之
LOGE("Process error, close TcpConnection, client: %s", conn->peerAddress().toIpPort().c_str());
conn->forceClose();
return;
}
}// end else
}// end while-loop
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
这段代码先根据包头的压缩标志字段判断包体是否有压缩,如果有压缩,则取出包体大小去解压,解压后的数据才是真正的业务数据。整个程序执行流程图如下:
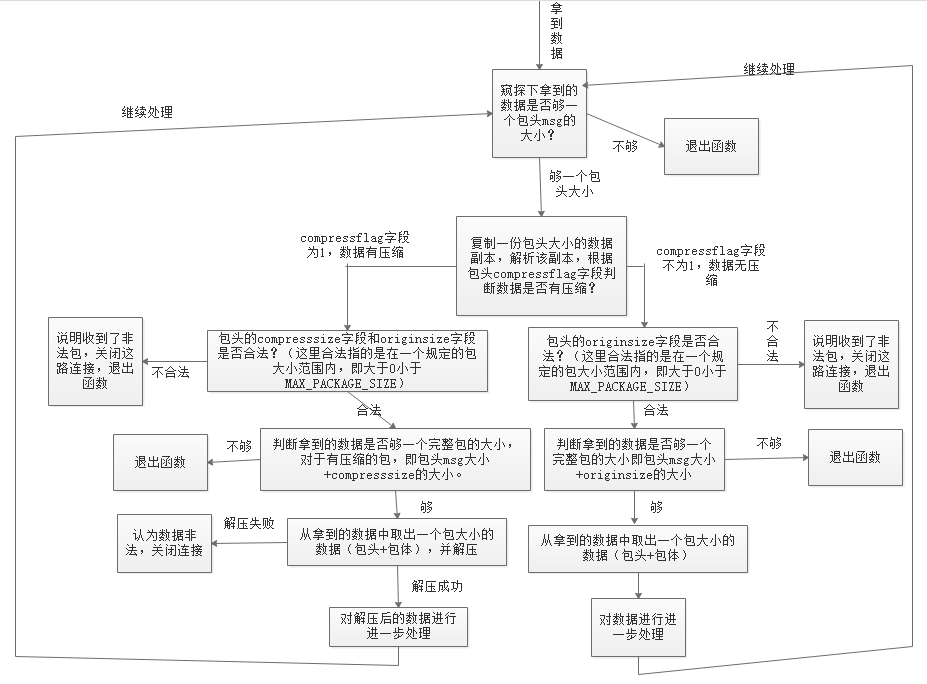
代码中有一个接收缓冲区变量 pBuffer,关于接收缓冲区如何设计,我们将在后面的章节中详细介绍。
上次更新: 2024/07/08, 00:14:14