 3.13 纤程(Fiber)与协程(Coroutine)
3.13 纤程(Fiber)与协程(Coroutine)
# 3.13.1 纤程
纤程(Fiber)是 Windows 操作系统提供的概念。什么是纤程呢?
当我们需要异步执行一些任务时,常用的一种做法就是开启一个工作线程,在工作线程中执行我们的任务。但是这样存在两个问题:
- 由于线程的调度是操作系统内核控制的,我们没法准确地确定操作系统何时会运行或挂起该线程;
- 对于一些轻量级的任务,创建一个新的线程去做,消耗比较大,我们不希望有这种消耗。
那么有没有一种机制,既能起到新建线程执行任务,又没有新建线程消耗那么大呢?有,这就是纤程。
在 Windows 中一个线程中可以有多个纤程,用户可以根据需要自由在各个纤程之间切换。如果要在某个线程中使用纤程,必须先将该线程切换成纤程模式,可以调用如下 API 函数:
LPVOID ConvertThreadToFiber(LPVOID lpParameter);
这个函数不仅将当前线程切换成纤程模式,同时也得到线程中第一个纤程,我们可以通过这个函数的返回值来引用和操作纤程,这个纤程是线程中的“主纤程”,但是这个“主纤程”由于没法指定“纤程”函数,所以什么也做不了。可以通过参数 lpParameter 给主纤程传递数据,获取当前纤程的数据使用 API 函数:
PVOID GetFiberData();
当在不同纤程之间切换时,也会涉及到纤程上下文的切换,包括 CPU 寄存器数据的切换,在默认情况下,x86 系统的 CPU 浮点状态信息不属于 CPU 寄存器的一部分,不会为每个纤程都维护一份,因此如果读者的纤程中需要执行浮点操作,将会导致数据被破坏。为了禁用这种行为,我们需要 ConvertThreadToFiberEx 函数,该函数签名如下:
LPVOID ConvertThreadToFiberEx(LPVOID lpParameter, DWORD dwFlags);
将第二个参数 dwFlags 设置为 FIBER_FLAG_FLOAT_SWITCH 即可。
将线程从纤程模式切回至默认的线程模式,使用 API 函数:
BOOL ConvertFiberToThread();
上文我们说了默认的主纤程什么都做不了,所以我们在需要的时候要创建新的纤程,使用 API 函数:
LPVOID CreateFiber(SIZE_T dwStackSize,
LPFIBER_START_ROUTINE lpStartAddress,
LPVOID lpParameter);
2
3
和创建线程的函数很类似,参数 dwStackSize 指定纤程栈大小,如果使用默认的大小,将该值设置为 0 即可。我们可以通过 CreateFiber 函数返回值作为操作纤程的“句柄”。
纤程函数签名如下:
VOID WINAPI FIBER_START_ROUTINE(LPVOID lpFiberParameter);
当不需要使用纤程时,记得调用 DeleteFiber 删除纤程对象:
void DeleteFiber(LPVOID lpFiber);
在不同纤程之间切换,使用 API 函数:
void SwitchToFiber(LPVOID lpFiber);
参数 lpFiber 即上文说的纤程句柄。
和线程存在线程局部存储一样,纤程也可以有自己的局部存储——纤程局部存储,获取和设置纤程局部存储数据使用 API 函数:
DWORD WINAPI FlsAlloc(PFLS_CALLBACK_FUNCTION lpCallback);
BOOL WINAPI FlsFree(DWORD dwFlsIndex);
BOOL WINAPI FlsSetValue(DWORD dwFlsIndex, PVOID lpFlsData);
PVOID WINAPI FlsGetValue(DWORD dwFlsIndex);
2
3
4
5
这四个函数和《线程局部存储》小节中介绍的相对应的四个函数用法一样,这里就不再赘述了。
Windows 还提供了一个获取当前执行纤程的 API 函数:
PVOID GetCurrentFiber();
返回值也是纤程“句柄”。
我们来看一个具体的例子:
#include <Windows.h>
#include <string>
char g_szTime[64] = { "time not set..." };
LPVOID mainWorkerFiber = NULL;
LPVOID pWorkerFiber = NULL;
void WINAPI workerFiberProc(LPVOID lpFiberParameter)
{
while (true)
{
//假设这是一项很耗时的操作
SYSTEMTIME st;
GetLocalTime(&st);
wsprintfA(g_szTime, "%04d-%02d-%02d %02d:%02d:%02d", st.wYear, st.wMonth, st.wDay, st.wHour, st.wMinute, st.wSecond);
printf("%s\n", g_szTime);
//切换回主纤程
//SwitchToFiber(mainWorkerFiber);
}
}
int main()
{
mainWorkerFiber = ConvertThreadToFiber(NULL);
int index = 0;
while (index < 100)
{
++index;
pWorkerFiber = CreateFiber(0, workerFiberProc, NULL);
if (pWorkerFiber == NULL)
return -1;
//切换至新的纤程
SwitchToFiber(pWorkerFiber);
memset(g_szTime, 0, sizeof(g_szTime));
strncpy(g_szTime, "time not set...", strlen("time not set..."));
printf("%s\n", g_szTime);
Sleep(1000);
}
DeleteFiber(pWorkerFiber);
//切换回线程模式
ConvertFiberToThread();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
上述代码只有一个主线程,主线程在 36 行切换至新建的纤程 pWorkerFiber 中,由于新建的纤程函数中是一个 while 无限循环,这样 main 函数中 38 行及以后的代码永远不会执行。输出结果如下:

我们将纤程函数 workerFiberProc 19 行注释放开,这样 main 函数的 38 就有机会执行了,输出结果如下:
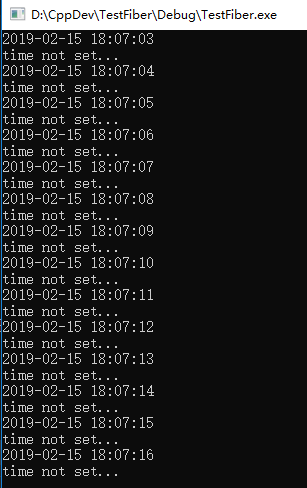
上述代码跳跃步骤是先从 main 函数 36 行跳到 workerFiberProc 函数执行,在 workerFiberProc 19 行跳回 main 函数 38 行执行,接着周而复始进行下一轮循环,直到 main 函数 while 条件不满足,退出程序。
纤程从本质上来说就是所谓的**协程(coroutine)**思想,Windows 纤程技术让单个线程能按用户的意愿像线程一样做自由切换,且没有线程切换那样的开销和不可控性。
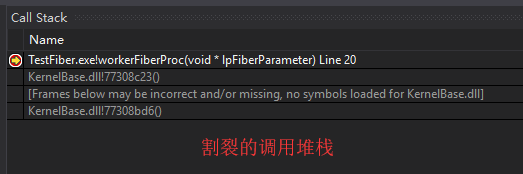
Windows 最早引入纤程是为了方便将 Unix 单线程程序迁移到 Windows 上来。当然也有人提出,调试时当程序执行点在纤程函数内部时,调用堆栈对用户是割裂的,对于习惯看连续性上下文堆栈的用户来说可能不太友好。
# 3.13.2 协程
如果读者理解了上文中介绍的纤程概念,那么协程(coroutine)应该也很好理解。
我们知道,线程是操作系统的内核对象,多线程编程时,如果线程数过多,就会导致频繁的上下文切换,这对性能是一种额外的损耗。例如,在一些高并发的网络服务器编程中,使用一个线程服务一个 socket 连接是很不明智的做法,因此现在的主流做法是利用操作系统提供的基于事件模式的异步编程模型,用少量的线程来服务大量的网络连接和 IO。但是采用异步和基于事件的编程模型,让程序代码变得复杂,非常容易出错,也提高排查错误的难度。
协程,是在应用层模拟的线程,它避免了线程上下文切换的部分额外损耗,同时又具有并发运行的优点,降低了编写并发程序的复杂度。还是以上面的高并发的网络服务器为例,可以为每一个 socket 连接使用一个协程来处理,在兼顾性能的情况下,代码也清晰。
协程是在 1963 年由 Melvin E. Conway USAF, Bedford, MA 等人提出的一个概念,且协程的概念是早于线程提出的。但是由于协程是非抢占式的调度,无法实现公平的任务调用,也无法直接利用多核 CPU 的优势,因此,我们不能武断地说协程是比线程更高级的技术。尽管协程的概念早于线程提出,但是目前主流的操作系统原生 API 并不支持协程技术,新兴的一些高级编程语言如 golang 都是在语言的运行时环境中自己利用线程技术模拟了一套协程。
在这些语言中,协程的内部实现上都是基于线程的,思路是维护了一组数据结构和 n 个线程,真正的执行还是线程,协程执行的代码被扔进一个待执行队列中,由这 n 个线程从队列中拉出来执行。这就解决了协程的执行问题。那么协程是怎么切换的呢?以 golang 为例,golang 对操作系统的各种 IO 函数(如 Linux 的 epoll、select, windows 的 IOCP 等)进行了封装,这些封装的函数提供给应用程序使用,而其内部调用了操作系统的异步 IO 函数,当这些异步函数返回 busy 或 blocking 时,golang 利用这个时机将现有的执行序列压栈,让线程去拉另外一个协程的代码来执行。由于 golang 是从编译器和语言基础库多个层面对协程做了实现,所以,golang 的协程是目前各类存在协程概念的语言中实现的最完整和成熟的,十万个协程同时运行也毫无压力。带来的优势就是,程序员在编写 golang 代码的时候,可以更多的关注业务逻辑的实现,尽量避免了在这些关键基础构件上耗费太多精力。
现今之所以协程技术这么流行是因为大多数设计喜欢使用异步编程以追求程序的性能,这就强行地将线性的程序逻辑打乱,程序逻辑变得非常混乱与复杂,对程序状态的管理也变得异常困难,例如 NodeJS 那恶心的层层Callback。在我们疯狂被 NodeJS 的层层回调恶心到的时候,golang 作为名门之后开始进入广大开发者的视野,并且迅速的在 Web 后端攻城略地。例如以 Docker 以及围绕 Docker 展开的整个容器生态圈为代表,其最大的卖点就是协程技术,至此协程技术开始真正的流行与被讨论起来。
腾讯公司开源了一套 C/C++ 版本的协程库 libco(参见链接13),有兴趣的读者可以研究一下其实现原理。
所以,协程技术从来不是什么新东西,只是人们为了从重复、复杂的底层技术中解脱出来,能够快速专注业务开发而带来的产物。万变不离其宗,只要我们掌握了多线程编程技术的核心原理,我们可以快速地学会协程技术。