 4.16 主机字节序和网络字节序
4.16 主机字节序和网络字节序
# 4.16.1 主机字节序
网络通信本质上是不同的机器进行数据交换,一般不同的机器有着不同的 CPU 型号,不同的 CPU 其字节序可能不一样。所谓字节序指的是对于存储需要多个字节(大于 1 字节)的整数来说,其每个字节在不同的机器内存中存储的顺序。这就是所谓的主机字节序,一般分为两类:
little-endian (LE,俗称小端编码或小头编码)
对于一个整数值,如果使用小端字节序,整数的高位存储在内存地址高的位置,整数的低位存储在内存地址低的位置上(所谓的高高低低),这种序列比较符合人的思维习惯。Intel x86 系列的系统使用的是小端编码方式。
big-endian(BE,俗称大端编码或大头编码)
对于一个整数值,如果使用大端字节序,整数的高位存储在内存地址低的位置,整数的低位存储在内存地址高的位置上(所谓的高低低高),这是最直观的字节序。Java 程序、Mac 机器上的程序一般是大端编码方式。
举个例子,对于内存中双字值 0x10203040 (4 字节)的存储方式,如果使用小端编码,其内存中存储方式如下:
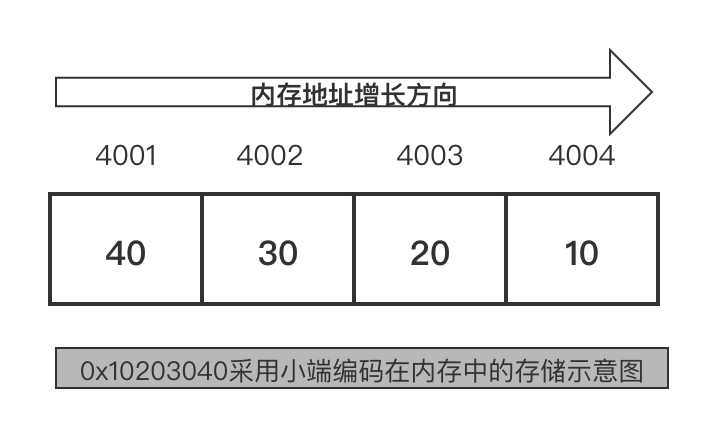
如果使用大端编码 来存储 0x10203040,在内存中存储示意图如下:

关于大端和小端一词来源于《格列佛游记》中的小人国故事,小人国中的两个国家因为吃鸡蛋应该先从鸡蛋的大端还是小端先磕破这一“宗教信仰”问题水火难容,频繁发生战争。
# 4.16.2 网络字节序
网络字节序是 TCP/IP 协议中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释,网络字节顺序采用 big-endian 排序方式。因此为了不同的机器和系统可以正常交换数据,一般建议将需要传输的整型值转换成网络字节序,我们前面代码中使用端口时即将端口号数值从本地字节序转换成网络字节序:
//2.初始化服务器地址
struct sockaddr_in bindaddr;
bindaddr.sin_family = AF_INET;
bindaddr.sin_addr.s_addr = htonl(INADDR_ANY);
//将端口号3000转换成网络字节序
bindaddr.sin_port = htons(3000);
if (bind(listenfd, (struct sockaddr *)&bindaddr, sizeof(bindaddr)) == -1)
{
std::cout << "bind listen socket error." << std::endl;
return -1;
}
2
3
4
5
6
7
8
9
10
11
htons 函数即将一个 short 类型从本机字节序转换成网络字节序(Big Endian),你可以这么记忆这个函数:host to net short => htons,与这个函数类似的还有一系列将整型转网络字节序的函数(以 Linux 系统为例):
#include <arpa/inet.h>
//host to net long
uint32_t htonl(uint32_t hostlong);
//host to net short
uint16_t htons(uint16_t hostshort);
2
3
4
5
6
与此相反,当从网络上收到数据以后,如果需要将整数从网络字节序转换成本地字节序,也有对应的系列函数:
#include <arpa/inet.h>
//net to host long
uint32_t ntohl(uint32_t netlong);
//net to host short
uint16_t ntohs(uint16_t netshort);
2
3
4
5
6
这类转换函数的实现原理也很简单,以本地字节序转网络字节序为例,如果发现本机字节序就是网络字节序(即本机字节序就是大端编码)则什么也不做,反之将字节顺序互换。
那如何判断本机字节序是不是网络字节序呢?可以随意找一个 2 字节的十六进制数值测试一下,例如 0x1234,如果本机字节序是小头编码,这值 12 存储在高地址字节中,34 存储在低地址字节中,这样当强行把 0x1234 转换成 1 字节的 char 时,高字节被丢弃,剩下低字节值,就是 34;反之,如果本机字节序是大端编码,则高地址字节中存储的是 34,低地址字节中存储的是 12,当强转成一个字节的 char 时,其值是 12,代码实现如下:
//判断本机是否是网络字节序
bool isNetByteOrder()
{
unsigned short mode = 0x1234;
char* pmode = (char*)&mode;
//低字节放低位 小端字节
if (*pmode == 0x34)
return false;
return true;
}
2
3
4
5
6
7
8
9
10
11
在上面的基础上,我们来实现一下 htons 函数:
uint16_t htons(uint16_t hostshort);
{
//如果已经本机字节序是网络字节序,则直接返回
if (isNetByteOrder())
return hostshort;
return ((uint16_t)(hostshort >> 8)) | ((uint16_t)((hostshort & 0x00ff) << 8));
}
2
3
4
5
6
7
8
其他的函数实现原理类似,读者可以自己实现一下,这里不再重复介绍。
# 4.16.3 操作系统提供的字节转换函数一览表
为了便于读者查阅,让我们对操作系统提供的这些函数进行一下汇总:
Windows 平台:
#include <winsock2.h>
/**
* 本机字节序转网络字节序
*/
htou_short htons(u_short hostshort);
u_long htonl(u_long hostlong);
unsigned __int64 htonll(unsigned __int64 Value);
/**
* 网络字节序转本机字节序
*/
u_short ntohs(u_short netshort);
u_long ntohl(u_long netlong);
unsigned __int64 ntohll(unsigned __int64 Value);
2
3
4
5
6
7
8
9
10
11
12
13
14
注意:我们知道在 Windows 上使用 socket 函数需要先调用 WSAStartup 来装在相关的系统 dll 库。在使用这个系列的函数时不用先调用 WSAStartup 函数也可以使用。
Linux 平台:
#include <arpa/inet.h>
/**
* 本机字节序转网络字节序
*/
uint16_t htons(uint16_t hostshort);
uint32_t htonl(uint32_t hostlong);
/**
* 网络字节序转本机字节序
*/
uint16_t ntohs(uint16_t netshort);
uint32_t ntohl(uint32_t netlong);
2
3
4
5
6
7
8
9
10
11
12
13
对于 2 字节(short) 和 4 字节(int),Linux 和 Windows 都提供了同名且函数签名形式一样的函数,我们在写跨平台代码时可直接调用。遗憾的是 Linux 下并没有提供与 Windows 相同函数名和签名的对 8 字节(long long)整数进行转换的函数。没关系,Linux 提供了另外一批显式从本节字节序与 Big Endian 或 Little Endian 互转的函数:
#include <endian.h>
uint16_t htobe16(uint16_t host_16bits);
uint16_t htole16(uint16_t host_16bits);
uint16_t be16toh(uint16_t big_endian_16bits);
uint16_t le16toh(uint16_t little_endian_16bits);
uint32_t htobe32(uint32_t host_32bits);
uint32_t htole32(uint32_t host_32bits);
uint32_t be32toh(uint32_t big_endian_32bits);
uint32_t le32toh(uint32_t little_endian_32bits);
uint64_t htobe64(uint64_t host_64bits);
uint64_t htole64(uint64_t host_64bits);
uint64_t be64toh(uint64_t big_endian_64bits);
uint64_t le64toh(uint64_t little_endian_64bits);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这一组函数也使用起来非常方便,对于 Windows 上的 htonll 函数则对应 htobe64 函数,对于 ntohll 函数则对应 be64toh 函数。因此,我们在写跨平台兼容代码时,可以这么写:
#ifdef WIN32
// Windows上存在ntohll和htonll,直接使用
#else
//Linux下没有这两个函数,定义之
#define ntohll(x) be64toh(x)
#define htonll(x) htobe64(x)
#endif
2
3
4
5
6
7