 第2章 原生API(Native API)基础
第2章 原生API(Native API)基础
# 第2章 原生API(Native API)基础
原生API(Native API)在整体设计中采用了通用的模式和类型。本章将重点介绍这些共性内容。
本章包含以下内容:
- 函数前缀
- 错误处理
- 字符串
- 链表
- 对象属性
- 客户端ID(Client ID)
- 时间与时间跨度
- 位图
- 示例:终止进程
# 2.1 函数前缀
浏览NtDll.Dll的导出函数时,你会遇到多个函数前缀。最常见的是Nt——这些是第1章中描述的系统调用(system calls)。
你还会遇到另一个前缀Zw。某些函数同时存在Nt前缀和Zw前缀的版本。实际上,如果一对函数除前缀(Nt与Zw)外名称完全相同,那么它们在实际使用中是同一个函数。你可以通过查看它们的相对虚拟地址(Relative Virtual Address,RVA)是否相同来验证这一点。图2-1展示了TotalPE中高亮显示的部分此类函数对。
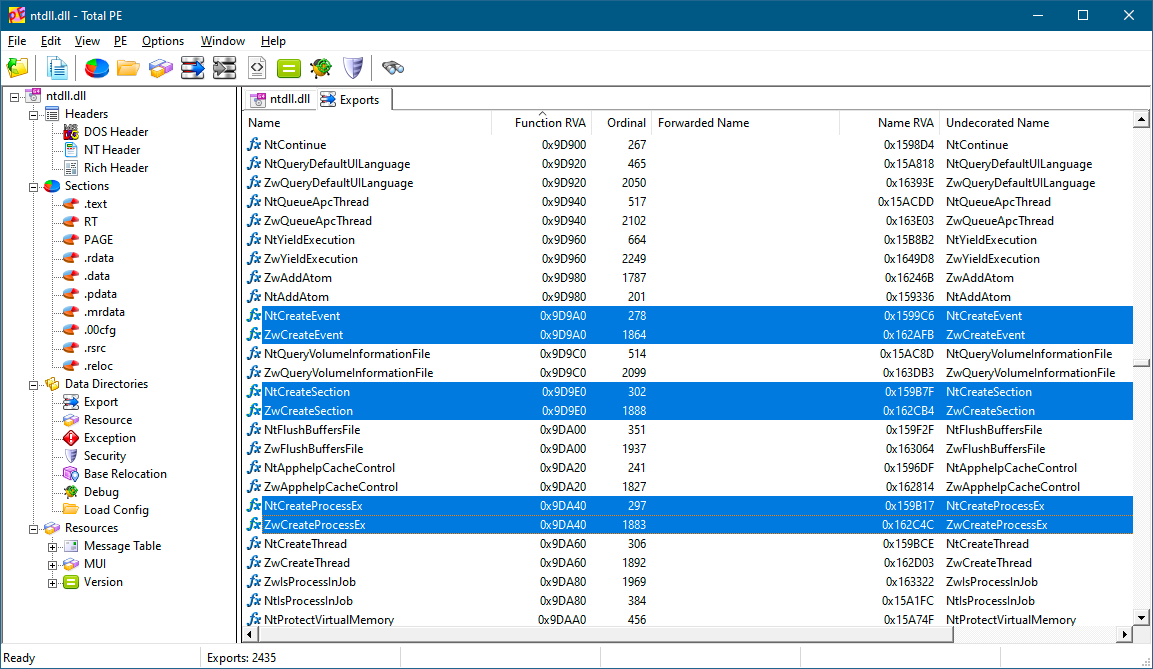
图2-1:Nt前缀和Zw前缀在NtDll.Dll导出函数中的示例
如果两个前缀的函数都存在,使用哪个前缀并无区别,但建议优先使用Nt前缀。
注:为什么会有两个前缀?实际上,在内核中,这些函数并非完全相同——
Zw前缀的函数在调用真正的系统调用(Nt前缀的函数)之前,会将线程的先前访问模式切换为内核模式(kernel-mode)。这使得内核代码可以直接调用系统调用,而不会被视为来自用户模式(user-mode)。在用户模式(user-mode)中,这对函数没有区别。
注:
Zw代表什么?微软官方文档称其没有任何实际含义,这也是选择该前缀的原因。民间传言这是微软某位开发人员姓名的首字母缩写。
NtDll.Dll的导出函数中还有另一个常见前缀Rtl,代表运行时库(Runtime Library)。这类函数分为两类:
- 辅助例程(Helper routines):不执行任何内核调用。例如,用于字符串操作、数值处理、内存操作、数据结构(位图、哈希表、树)处理的函数。示例包括
RtlClearBits、RtlCompareMemory、RtlComputeCrc32、RtlCreateHashTable等。 - 封装函数(Convenient wrappers):对
Nt函数进行封装,使其更易于调用某些系统调用。例如,RtlCreateUserProcessEx会先执行一些操作,然后将任务委托给系统调用本身NtCreateUserProcess。
此外,还有其他更具体的前缀,如下所示。其中一些是系统调用的封装函数,另一些提供更高级别的功能——具体取决于函数本身:
Tp:线程池(thread pool)相关函数。Rtlp:更多运行时库函数(“p”代表私有,private),出于某种原因被导出。Etw:Windows事件跟踪(Event Tracing for Windows)相关函数。Alpc:高级本地过程调用(Advanced Local Procedure Call)相关函数。Dbg、DbgUi:调试(debugging)相关函数。Csr:客户端/服务器运行时(Client Server Runtime)相关函数,用于与Windows子系统进程(Csrss.exe)通信。Ldr:加载器(loader)相关函数。
本书后续章节可能还会遇到其他一些专用前缀(如MD4、MD5、Sb、Ship、Rtlx、Ki、Exp、Nls、Etwp、Evt)。
# 2.2 错误处理
大多数原生API(Native API)函数直接返回NTSTATUS类型的结果。这是一个32位有符号整数,其中0表示成功(STATUS_SUCCESS),负值表示某种失败。
检查操作成功与否的常用方法是使用NT_SUCCESS宏,当给定的状态值为0(或正值)时,该宏返回true。
调试过程中,你可能会遇到错误,并且希望无需在头文件中查找特定错误码就能获取其文本描述。幸运的是,Visual Studio调试器支持在“监视”窗口中为错误码添加后缀(,hr),以获取对应的文本描述。图2-2展示了一些示例。
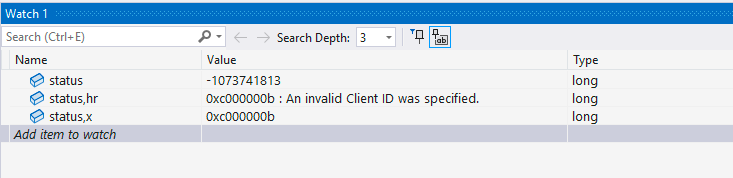
图2-2:Visual Studio的“监视”窗口
# 2.3 字符串
原生API(Native API)在许多场景中都会用到字符串。在某些情况下,这些字符串是简单的Unicode指针(wchar_t*或其类型定义,如WCHAR*),但大多数处理字符串的函数期望接收UNICODE_STRING类型的结构体。
“Unicode”一词在本书中的含义大致等同于UTF-16,即每个字符占2个字节。这是内核组件内部存储字符串的方式。通常来说,Unicode是一套与字符编码相关的标准。你可以访问 https://unicode.org (opens new window) 获取更多信息。
UNICODE_STRING结构体是一种字符串描述符——它描述一个字符串,但不一定拥有该字符串。以下是该结构体的简化定义:
typedef struct _UNICODE_STRING {
USHORT Length;
USHORT MaximumLength;
PWCH Buffer; // pointer to the characters
} UNICODE_STRING, *PUNICODE_STRING;
typedef const UNICODE_STRING *PCUNICODE_STRING;
2
3
4
5
6
Length成员存储字符串的长度(以字节为单位,而非字符数),且不包含可能存在的Unicode空终止符(NULL-terminator)——字符串不一定需要以空字符结尾。MaximumLength成员表示字符串在不需要重新分配内存的情况下可以扩展到的最大字节数。
UNICODE_STRING结构体的操作通常通过一组专门用于字符串处理的Rtl函数来完成。表2-1列出了Rtl函数中一些常见的字符串操作函数。
表2-1:常用的UNICODE_STRING操作函数
| 函数 | 描述 |
|---|---|
RtlInitUnicodeString | 基于现有的C风格字符串指针初始化UNICODE_STRING。设置Buffer成员,然后计算Length,并将MaximumLength设置为Length+2以容纳空终止符。注意:该函数不分配任何内存,仅初始化内部成员。 |
RtlCopyUnicodeString | 将一个UNICODE_STRING复制到另一个。目标字符串的Buffer指针必须在复制前已分配,且MaximumLength已正确设置。 |
RtlCompareUnicodeString | 比较两个UNICODE_STRING(相等、小于、大于),可指定是否区分大小写。 |
RtlCompareUnicodeStrings | 比较两个以空字符结尾的(C风格)Unicode字符串,可指定是否区分大小写。 |
RtlEqualUnicodeString | 比较两个UNICODE_STRING是否相等,可指定是否区分大小写。 |
RtlAppendUnicodeStringToString | 将一个UNICODE_STRING追加到另一个UNICODE_STRING的末尾。 |
RtlAppendUnicodeToString | 将一个C风格字符串追加到UNICODE_STRING的末尾。 |
RtlPrefixUnicodeString | 检查第一个字符串是否是第二个字符串的前缀,可指定是否区分大小写。 |
除上述函数外,还有一些用于操作C风格字符串指针的函数。此外,为方便使用,C运行时库(C Runtime Library)中的一些知名字符串函数在NtDll.Dll中也有实现,例如wcscpy_s、wcscat_s、wcslen、wcschr、strcpy、strcpy_s等。与使用Visual C++运行时库相比,这些函数在此处实现的原因将在第3章讨论原生应用程序(Native Applications)时阐明。
注:
wcs前缀的函数用于处理C风格Unicode字符串,str前缀的函数用于处理C风格ANSI字符串。部分函数中的后缀_s表示安全函数(safe function),使用这类函数时必须提供一个额外的参数,指定字符串的最大长度,以确保函数不会传输超过字符串缓冲区容量的数据。
不要使用非安全函数。如果在代码中使用了这些已弃用的函数,可以包含
<dontuse.h>头文件来触发错误提示。
初始化UNICODE_STRING是一项常见操作。RtlInitUnicodeString是一种简单的方式,可利用现有的C风格Unicode字符串对其进行初始化。常见场景是使用字符串常量进行初始化,示例如下:
UNICODE_STRING name;
RtlInitUnicodeString(&name, L"SomeString");
2
这种方法可行,但效率稍低——即使字符串长度可以在编译时计算,该函数仍会在运行时计算字符串长度。为解决这一轻微的效率问题,phnt提供了RTL_CONSTANT_STRING宏,使用方式如下:
UNICODE_STRING name = RTL_CONSTANT_STRING(L"SomeString");
然而,在撰写本书时,由于该宏未处理常量性(constness)问题,在C++编译中会失败。WDK头文件中该宏的定义更为复杂,能够正确处理常量性问题以及ANSI字符串的初始化。
以下是该宏的一个可能定义,通过强制类型转换移除常量性,用于Unicode字符串初始化:
#ifdef RTL_CONSTANT_STRING
#undef RTL_CONSTANT_STRING
#endif
#define RTL_CONSTANT_STRING(s) { sizeof(s) - sizeof((s)[0]), sizeof(s), (PWSTR)s }
2
3
4
我们可以为ANSI字符串常量初始化添加一个类似的宏(少数情况下会用到):
#define RTL_CONSTANT_ANSI_STRING(s) { sizeof(s) - sizeof((s)[0]), sizeof(s), (PSTR)s }
从技术上讲,你可以从WDK中复制该宏的定义,但上述定义已能满足需求,且易于理解和使用。
# 2.4 链表
原生API(Native API)的许多内部数据结构中都使用了双向循环链表(circular doubly linked lists)。例如,加载到进程中的所有模块都通过此类链表存储在PEB(进程环境块,Process Environment Block)结构中(详见第5章)。
所有这些链表的构建方式相同,均以LIST_ENTRY结构体为核心,其定义如下:
typedef struct _LIST_ENTRY {
struct _LIST_ENTRY *Flink;
struct _LIST_ENTRY *Blink;
} LIST_ENTRY, *PLIST_ENTRY;
2
3
4
图2-3展示了一个包含一个表头和三个节点的此类链表示例。

图2-3:双向循环链表
LIST_ENTRY结构体嵌入在目标数据结构内部。例如,在EPROCESS结构体中,ActiveProcessLinks成员的类型为LIST_ENTRY,指向其他EPROCESS结构体的LIST_ENTRY对象(前一个和后一个)。链表的表头单独存储;对于进程链表而言,表头是PsActiveProcessHead。已知LIST_ENTRY的地址时,可通过CONTAINING_RECORD宏获取其所属的目标数据结构的指针。
例如,假设你要管理一组MyDataItem类型的结构体,其定义如下:
struct MyDataItem {
// some data members
LIST_ENTRY Link;
// more data members
};
2
3
4
5
操作这类链表时,需要一个变量存储链表的表头。链表的自然遍历方式是通过LIST_ENTRY的Flink成员指向链表中的下一个LIST_ENTRY。已知LIST_ENTRY的指针时,我们真正需要的是包含该链表节点成员的MyDataItem结构体。这正是CONTAINING_RECORD宏的用途:
MyDataItem* GetItem(LIST_ENTRY* pEntry)
{
return CONTAINING_RECORD(pEntry, MyDataItem, Link);
}
2
3
4
该宏会进行正确的偏移量计算,并将结果强制转换为目标数据类型(示例中为MyDataItem)。
表2-2列出了用于操作这类链表的常见函数(在头文件中以 inline 方式实现)。所有操作均为常量时间复杂度。
表2-2:双向循环链表操作函数
| 函数 | 描述 |
|---|---|
InitializeListHead | 初始化链表表头,创建一个空链表。前驱指针(Flink)和后继指针(Blink)均指向自身。 |
InsertHeadList | 在链表头部插入一个节点。 |
AppendTailList | 将一个链表追加到另一个链表的末尾。 |
InsertTailList | 在链表尾部插入一个节点。 |
IsListEmpty | 检查链表是否为空。 |
RemoveHeadList | 移除链表头部的节点。 |
RemoveTailList | 移除链表尾部的节点。 |
RemoveEntryList | 从链表中移除指定的节点。 |
以下代码示例展示了当前进程中已加载的模块列表(详见第5章):
#include <phnt_windows.h>
#include <phnt.h>
#include <stdio.h>
int main()
{
PPEB peb = NtCurrentPeb();
auto& head = peb->Ldr->InLoadOrderModuleList;
for (auto next = head.Flink; next != &head; next = next->Flink)
{
auto mod = CONTAINING_RECORD(next, LDR_DATA_TABLE_ENTRY, InLoadOrderLinks);
printf("0x%p: %wZ\n", mod->DllBase, &mod->BaseDllName);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
NtCurrentPeb是一个宏,返回当前进程的PEB指针。已加载的模块存储在三个独立的链表中——示例使用的是按加载顺序存储模块的链表(我们将在第5章探讨其他链表)。按加载顺序排列的链表表头存储在Ldr成员(类型为PPEB_LDR_DATA)的InLoadOrderModuleList成员(LIST_ENTRY类型)中。
“%wZ”格式符可用于在
printf风格的格式化输出中打印UNICODE_STRING类型的字符串。
由于链表是循环的,通过查找空指针(NULL)来终止遍历是无效的——永远不会找到空指针。相反,next指针初始化为第一个节点,循环遍历直到next与peb->Ldr->InLoadOrderModuleList的地址相同,此时表示遍历结束。
每个next指针指向LDR_DATA_TABLE_ENTRY结构体(表示一个模块)中的InLoadOrderLinks成员(LIST_ENTRY类型)。这正是CONTAINING_RECORD宏的用武之地——它将指针偏移回结构体的起始位置,并强制转换为指定的类型。此处使用C++的auto关键字非常便捷,无需重复指定类型(LDR_DATA_TABLE_ENTRY*)。
在Debug x64构建模式下运行该示例,输出如下(本章源代码中的ModList项目):
0x00007FF6B0B40000: ModList.exe
0x00007FF937EF0000: ntdll.dll
0x00007FF937510000: KERNEL32.DLL
0x00007FF935C50000: KERNELBASE.dll
0x00007FF8D5D50000: VCRUNTIME140D.dll
0x00007FF847280000: ucrtbased.dll
2
3
4
5
6
# 2.5 对象属性(Object Attributes)
OBJECT_ATTRIBUTES 是许多原生API(Native API)中常见的结构体,其定义如下:
typedef struct _OBJECT_ATTRIBUTES {
ULONG Length;
HANDLE RootDirectory;
PUNICODE_STRING ObjectName;
ULONG Attributes;
PVOID SecurityDescriptor; // SECURITY_DESCRIPTOR
PVOID SecurityQualityOfService; // SECURITY_QUALITY_OF_SERVICE
} OBJECT_ATTRIBUTES;
typedef OBJECT_ATTRIBUTES *POBJECT_ATTRIBUTES;
typedef CONST OBJECT_ATTRIBUTES *PCOBJECT_ATTRIBUTES;
2
3
4
5
6
7
8
9
10
该结构体通常通过 InitializeObjectAttributes 宏进行初始化,该宏允许指定除 Length(由宏自动设置)和 SecurityQualityOfService(通常不需要)之外的所有结构体成员。以下是各成员的描述:
ObjectName:要创建或打开的对象名称,以UNICODE_STRING指针形式提供。对于没有名称的对象(如进程),有时可以将其设置为NULL。RootDirectory:如果对象名称是相对路径,此参数为对象管理器命名空间(object manager namespace)中的可选目录指针。如果ObjectName指定的是全限定名称,则RootDirectory应设置为NULL。Attributes:指定一组对相关操作有影响的标志。表2-3列出了已定义的标志及其含义。SecurityDescriptor:可选的安全描述符(SECURITY_DESCRIPTOR),用于设置新创建对象的安全属性。NULL表示新对象将获得基于调用者令牌(token)的默认安全描述符。SecurityQualityOfService:可选的属性集,与新对象的模拟级别(impersonation level)和上下文跟踪模式(context tracking mode)相关。对于大多数对象类型,此参数无意义。如需了解更多信息,请参考相关文档。
表2-3:对象属性标志
标志(OBJ_) | 描述 |
|---|---|
INHERIT(0x02) | 返回的句柄(handle)应标记为可继承。 |
PERMANENT(0x10) | 创建的对象应标记为永久性。永久性对象具有额外的引用计数,即使所有指向它的句柄都被关闭,也不会被销毁。 |
EXCLUSIVE(0x20) | 创建对象时,对象将以独占访问权限创建,不允许其他句柄打开该对象;打开对象时,请求独占访问权限,仅当对象最初以该标志创建时才会授予权限。 |
CASE_INSENSITIVE(0x40) | 打开对象时,对其名称执行不区分大小写的搜索。若无此标志,名称必须完全匹配(文件除外)。 |
OPENIF(0x80) | 如果对象存在,则打开它;否则,操作失败(不创建新对象)。 |
OPENLINK(0x100) | 如果要打开的对象是符号链接对象(symbolic link object),则直接打开该符号链接对象,而非跟随符号链接到其目标对象。 |
KERNEL_HANDLE(0x200) | 返回的句柄应为内核句柄(kernel handle)。此标志不能在用户模式(user-mode)中使用。 |
FORCE_ACCESS_CHECK(0x400) | 即使在 kernel-mode 访问模式下打开对象,也应执行访问检查(对用户模式无效)。 |
IGNORE_IMPERSONATED_DEVICEMAP(0x800) | 如果进程正在模拟用户,则使用进程的设备映射(device map)而非用户的设备映射(有关设备映射的更多信息,请参考相关文档)。 |
DONT_REPARSE(0x1000) | 遇到重解析点(reparse point)时不跟随,而是返回错误(STATUS_REPARSE_POINT_ENCOUNTERED)。重解析点超出本书讨论范围。 |
初始化 OBJECT_ATTRIBUTES 结构体的另一种方法是使用 RTL_CONSTANT_OBJECT_ATTRIBUTES 宏,该宏仅设置最常用的成员——对象名称(UNICODE_STRING 指针)和属性(Attributes)。
# 2.6 客户端ID(Client ID)
CLIENT_ID 结构体相对简单,但值得关注,因为它可能有些令人困惑:
typedef struct _CLIENT_ID {
HANDLE UniqueProcess;
HANDLE UniqueThread;
} CLIENT_ID, *PCLIENT_ID;
2
3
4
其用途是指定进程ID和/或线程ID。令人困惑的是,这些ID的类型是 HANDLE,而非简单的整数。原因是内核通过私有句柄表(private handle table)生成唯一的进程和线程ID,因此其内部类型为 HANDLE,但应将其视为ID来使用。
进程ID(和线程ID)的位数限制在约26位,因此无需使用64位值来表示它们。
如果需要将32位值放入 HANDLE 类型中,需要进行一些类型转换以满足编译器要求。以下是一种实现方式:
ULONG pid = ...;
CLIENT_ID cid;
cid.UniqueProcess = (HANDLE)(ULONG_PTR)pid;
2
3
对于64位进程,双重转换是必要的——首先将值扩展为64位,然后转换为 HANDLE(所有句柄的类型均为 void 指针)。
如果严格遵循“规范的C++用法”,可以使用更具体的类型转换:
cid.UniqueProcess = reinterpret_cast<HANDLE>(static_cast<ULONG_PTR>(pid));
你可以自由使用此类形式,为简洁起见,同时考虑到C开发人员和C++初学者的习惯,我将使用C风格的类型转换。
还有一种实现相同功能的方法——使用Windows头文件提供的简单函数/宏:
cid.UniqueProcess = ULongToHandle(pid);
注:你可能会注意到有一个宏 UlongToHandle(注意小写的 l),它仅调用内联函数(inline function)。两种方式均可使用。
建议使用内联函数/宏进行此类转换——更清晰且代码更简洁。
# 2.7 时间与时间跨度
原生API(Native API)提供日期/时间时,使用64位值,通常封装为 LARGE_INTEGER 类型:
typedef union _LARGE_INTEGER {
struct {
DWORD LowPart;
LONG HighPart;
};
LONGLONG QuadPart;
} LARGE_INTEGER;
2
3
4
5
6
7
它本质上是一个64位整数,通常通过 QuadPart 成员直接访问。日期和时间以100纳秒为单位,起始时间为格林威治标准时间(GMT)1601年1月1日午夜。例如,数值10000000(1000万)表示该日期午夜后的1秒。
使用100纳秒作为单位,并不意味着Windows目前能达到如此高的精度(尽管未来可能实现),但该测量单位始终适用。
对于时间跨度,使用相同的单位,但时间跨度是相对于调用时刻的。某些API允许指定绝对时间或相对时间:负值表示相对时间,正值表示绝对时间。
一个典型示例是 NtDelayExecution API(大致相当于Windows API中的 Sleep(Ex)),其中睡眠时间可以指定为相对时间或绝对时间。注意,Sleep(Ex) 仅支持以毫秒为单位的相对时间。
以下示例设置100毫秒的睡眠:
LARGE_INTEGER interval;
interval.QuadPart = -100 * 10000; // 100 msec
NtDelayExecution(FALSE, &interval);
2
3
以下示例设置睡眠到格林威治标准时间2026年3月12日中午:
TIME_FIELDS tf{};
tf.Year = 2026;
tf.Month = 3;
tf.Day = 12;
tf.Hour = 12;
LARGE_INTEGER interval;
RtlTimeFieldsToTime(&tf, &interval);
NtDelayExecution(FALSE, &interval);
2
3
4
5
6
7
8
该示例使用了辅助结构体 TIME_FIELDS,它更易于人类理解和使用:
typedef struct _TIME_FIELDS {
CSHORT Year; // 1601 ...
CSHORT Month; // 1 ... 12
CSHORT Day; // 1 ... 31
CSHORT Hour; // 0 ... 23
CSHORT Minute; // 0 ... 59
CSHORT Second; // 0 ... 59
CSHORT Milliseconds; // 0 ... 999
CSHORT Weekday; // 0 ... 6 = Sunday ... Saturday
} TIME_FIELDS, *PTIME_FIELDS;
2
3
4
5
6
7
8
9
10
要获取当前时间(以 LARGE_INTEGER 形式),可使用 NtQuerySystemTime:
NTSTATUS NtQuerySystemTime(_Out_ PLARGE_INTEGER SystemTime);
另一个可能提供更高精度的函数是 RtlGetSystemTimePrecise:
LARGE_INTEGER RtlGetSystemTimePrecise();
RtlGetSystemTimePrecise目前未包含在phnt头文件中。如果需要使用,请手动添加其声明。
还有其他用于时间操作的 Rtl 函数,例如 RtlCutoverTimeToSystemTime、RtlSystemTimeToLocalTime、RtlLocalTimeToSystemTime、RtlTimeToElapsedTimeFields 等。
# 2.8 位图(Bitmaps)
位图(由 RTL_BITMAP 类型表示)是一种高效的存储方式,用于表示某种事物的存在或不存在,每个状态仅占用1位。系统提供了用于设置、清除和其他操作位图的函数。以下是 RTL_BITMAP 的定义:
typedef struct _RTL_BITMAP {
ULONG SizeOfBitMap;
PULONG Buffer;
} RTL_BITMAP, *PRTL_BITMAP;
2
3
4
位图在 SizeOfBitMap 成员中存储其大小(以位为单位),并通过 Buffer 指针指向存储实际位的缓冲区(该缓冲区必须按4字节对齐)。位图的初始化通过 RtlInitializeBitMap 函数完成:
VOID RtlInitializeBitMap(
_Out_ PRTL_BITMAP BitMapHeader,
_In_ PULONG BitMapBuffer,
_In_ ULONG SizeOfBitMap
);
2
3
4
5
BitMapBuffer 是存储位的缓冲区指针(由调用者分配)。SizeOfBitMap 是要管理的位数。RtlInitializeBitMap 函数将缓冲区指针和位数复制到提供的结构体中,不会初始化位的状态(此工作由调用者完成)。
以下是用于位图操作的简单API:
VOID RtlClearBit( // 清除单个位
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(<, BitMapHeader->SizeOfBitMap) ULONG BitNumber);
VOID RtlSetBit( // 设置单个位
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(<, BitMapHeader->SizeOfBitMap) ULONG BitNumber);
BOOLEAN RtlTestBit( // 检查单个位的状态
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(<, BitMapHeader->SizeOfBitMap) ULONG BitNumber);
VOID RtlClearAllBits(_In_ PRTL_BITMAP BitMapHeader);
VOID RtlSetAllBits(_In_ PRTL_BITMAP BitMapHeader);
VOID RtlClearBits( // 清除一个范围内的位
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(0, BitMapHeader->SizeOfBitMap - NumberToClear) ULONG StartingIndex,
_In_range_(0, BitMapHeader->SizeOfBitMap - StartingIndex) ULONG NumberToClear);
VOID RtlSetBits( // 设置一个范围内的位
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(0, BitMapHeader->SizeOfBitMap - NumberToSet) ULONG StartingIndex,
_In_range_(0, BitMapHeader->SizeOfBitMap - StartingIndex) ULONG NumberToSet);
ULONG RtlNumberOfClearBits(_In_ PRTL_BITMAP BitMapHeader);
ULONG RtlNumberOfSetBits(_In_ PRTL_BITMAP BitMapHeader);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
这些API的功能一目了然。更有趣的API是查找一个或多个具有指定值(置位或清零)的位:
ULONG RtlFindClearBits(
_In_ PRTL_BITMAP BitMapHeader,
_In_ ULONG NumberToFind,
_In_ ULONG HintIndex);
ULONG RtlFindSetBits(
_In_ PRTL_BITMAP BitMapHeader,
_In_ ULONG NumberToFind,
_In_ ULONG HintIndex);
ULONG RtlFindClearBitsAndSet(
_In_ PRTL_BITMAP BitMapHeader,
_In_ ULONG NumberToFind,
_In_ ULONG HintIndex);
ULONG RtlFindSetBitsAndClear(
_In_ PRTL_BITMAP BitMapHeader,
_In_ ULONG NumberToFind,
_In_ ULONG HintIndex);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上述所有函数都从指定的提示索引(HintIndex)开始搜索一组连续的位,并返回该范围的起始位索引。如果未找到此类范围,这些函数返回-1(0xFFFFFFFF)。后两个函数还会翻转找到的位的状态。注意,提示索引仅作为参考,如果从该索引开始未找到目标范围,搜索将从索引0继续。
还有更多搜索API可供使用,包括 RtlFindFirstRunClear、RtlFindNextForwardRunClear、RtlFindLastBackwardRunClear 等。这些函数在Windows驱动程序开发工具包(WDK)中有相关文档说明。
上述所有函数都不是线程安全的。不过,有一些线程安全的函数,它们使用原子指令(Interlocked instructions)来保证线程和CPU安全:
VOID RtlInterlockedClearBitRun(
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(0, BitMapHeader->SizeOfBitMap - NumberToClear) ULONG StartingIndex,
_In_range_(0, BitMapHeader->SizeOfBitMap - StartingIndex) ULONG NumberToClear);
VOID RtlInterlockedSetBitRun(
_In_ PRTL_BITMAP BitMapHeader,
_In_range_(0, BitMapHeader->SizeOfBitMap - NumberToSet) ULONG StartingIndex,
_In_range_(0, BitMapHeader->SizeOfBitMap - StartingIndex) ULONG NumberToSet);
2
3
4
5
6
7
8
9
# 2.9 示例:终止进程
为演示 CLIENT_ID 和 OBJECT_ATTRIBUTES 的使用,我们将编写一个函数,根据进程ID终止进程。我们会将Windows API版本与原生API版本进行对比。首先是Windows API版本:
bool KillWin32(ULONG pid)
{
auto hProcess = OpenProcess(PROCESS_TERMINATE, FALSE, pid);
if (!hProcess)
return false;
auto success = TerminateProcess(hProcess, 1);
CloseHandle(hProcess);
return success;
}
2
3
4
5
6
7
8
9
10
调用 OpenProcess 以获取具有足够权限终止进程的句柄(PROCESS_TERMINATE 访问掩码)。如果成功,调用 TerminateProcess 终止进程,最后关闭句柄。
原生API版本使用上述示例底层的系统调用——NtOpenProcess(打开进程)和 NtTerminateProcess(终止进程)。NtOpenProcess 的函数原型如下(为简化,省略 NTAPI 宏):
NTSTATUS NtOpenProcess(
_Out_ PHANDLE ProcessHandle,
_In_ ACCESS_MASK DesiredAccess,
_In_ POBJECT_ATTRIBUTES ObjectAttributes,
_In_opt_ PCLIENT_ID ClientId);
2
3
4
5
该函数在第一个参数中返回进程句柄(如果调用成功)。DesiredAccess 是请求的访问掩码(本例中应为 PROCESS_TERMINATE)。我们必须提供 OBJECT_ATTRIBUTES 结构体,这可能看起来有些奇怪。
进程没有名称——它们有ID,而ID显然由最后一个参数提供。为什么需要 OBJECT_ATTRIBUTES?因为属性标志可能会影响操作结果,因此需要提供该结构体;名称可以设置为 NULL。
基于上述信息,我们可以实现终止进程的原生API版本:
NTSTATUS KillNative(ULONG pid)
{
OBJECT_ATTRIBUTES procAttr = RTL_CONSTANT_OBJECT_ATTRIBUTES(nullptr, 0);
CLIENT_ID cid{}; // 清零结构体
cid.UniqueProcess = ULongToHandle(pid);
HANDLE hProcess;
auto status = NtOpenProcess(&hProcess, PROCESS_TERMINATE, &procAttr, &cid);
if (!NT_SUCCESS(status))
return status;
status = NtTerminateProcess(hProcess, 1);
NtClose(hProcess);
return status;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意,必须清零 CLIENT_ID 结构体。否则,API将接收到无效的线程ID(垃圾值),导致操作失败——即使API本身对线程ID不感兴趣。以下是完整代码:
#include <phnt_windows.h>
#include <phnt.h>
#include <stdio.h>
#include <stdlib.h>
#pragma comment(lib, "ntdll")
int main(int argc, const char* argv[])
{
if (argc < 2)
{
printf("Usage: Kill <pid>\n");
return 0;
}
auto pid = strtoul(argv[1], nullptr, 0);
auto status = KillNative(pid);
if (NT_SUCCESS(status))
printf("Success!\n");
else
printf("Error: 0x%X\n", status);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
注意使用了C函数 strtoul(定义在 <stdlib.h> 中),该函数允许接收十六进制数值(前缀为 0x)。该函数的最后一个参数是基数(radix),若为0,函数将自动判断数值的基数。
其他整数大小和类型也有类似的函数:
strtol、strtoll等。
# 2.10 总结
本章重点介绍了原生API(Native API)的通用类型和模式。下一章中,我们将探讨什么是原生应用程序(Native Applications),以及如何(和为什么)编写原生应用程序。