 shellcodisation在病毒学中的应用
shellcodisation在病毒学中的应用
# 1 shellcodisation在病毒学中的应用
# 1.1 背景定义
通常情况下,恶意代码(malicious code)会尝试完成多项操作:避开反病毒软件(antivirus)的检测、传播到其他主机或可执行文件(executable)、执行特定操作(例如捕获用户私人数据、在系统中开启后门(backdoor)等);它们可能会采用多种技术来实现这些目标。
本部分将选取几个特定目标,解释其实现方式,并尝试说明在实现过程中可能遇到的困难。
本文中,我们仅考虑针对Windows系统的恶意程序(malicious program),尽管文中介绍的部分技术可能适用于其他操作系统(operating system)。
# 1.2 恶意代码的选定目标
为了给出具体示例,我们假设要创建的恶意代码能够实现以下功能:
- 避开基于特征码识别(signature identification)的反病毒软件检测;
- 在受感染主机(infected host)上留下尽可能少的痕迹;
- 嵌入合法程序(legitimate program)以创建特洛伊木马(Trojan);
- 拦截使用受感染计算机的用户的私人数据(private data);
- 加密自身以防止(或复杂化)人工分析(manual analysis)。
我们将选择一些具体技术来实现这些目标。需要注意的是,当然还有许多其他解决方案,但这些技术是实际恶意软件(malware)中常用技术的良好代表。
# 1.2.1 避开基于特征码识别的反病毒软件检测
为了避开检测,恶意代码可以实现多态性(polymorphism)。需要说明的是,多态恶意程序由两部分组成:
- 真正的恶意负载(malicious payload),该部分经过加密;
- 解密部分(decryption part),位于病毒(virus)开头,负责解密恶意负载并将执行权转移给它。
每次感染时,用于加密恶意负载的密钥(key)都会更改,因此同一病毒的两个副本会具有完全不同的负载。
图1展示了未实现多态性的恶意代码。反病毒软件可以建立其识别特征码(identification signature),一旦该特征码被添加到反病毒数据库(antivirus database)中,该恶意代码就会被检测到。
图1:基于特征码检测恶意负载
图2展示了实现多态性的同一恶意代码的两个副本。由于存储在解密部分中的加密密钥不同,加密后的负载也完全不同。这使得针对恶意负载建立识别特征码变得非常困难。
图2:实现多态性的同一病毒的两个副本
这一机制可以防止针对恶意负载建立特征码识别,但反病毒软件仍可能针对解密部分建立特征码。为了避免这种情况,可以对解密部分使用变形性(metamorphism)技术。需要注意的是,这仅在自动传播(automated propagation)场景下是必需的。如果该恶意程序是为定向攻击(targeted attack)专门开发的,只需手动重写解密循环(decryption loop)即可。
实现变形性难度较大,且超出了本文的讨论范围。我们仅关注在恶意负载上实现多态性的能力。
需要注意的是,由于解密密钥可能存在于解密部分中,这种多态性无法保护恶意负载免受人工分析。加密过程可以依赖于简单的32位密钥异或(XOR)操作。
# 1.2.2 在受感染主机上留下尽可能少的痕迹
为了在受感染系统(infected system)上留下尽可能少的痕迹,我们选择为恶意代码添加仅在内存(memory)中执行的功能。以下是一个场景示例:
- 一段代码在目标系统(targeted system)上运行,例如在缓冲区溢出(buffer overflow)漏洞利用(exploitation)之后;
- 该代码连接回服务器(server),并将恶意负载直接下载到当前进程(process)的内存中;
- 该代码将执行权转移给恶意负载,恶意负载在未被复制到硬盘驱动器(hard drive)的情况下执行。
图3总结了这一原理。
# 图3:恶意负载不写入硬盘驱动器的执行过程
# 1.2.3 嵌入合法程序以创建特洛伊木马
其目的是将恶意负载嵌入合法程序中,使得当有人使用该程序时,恶意负载能够被执行。当然,程序的正常行为不能受到干扰,以免用户察觉感染。
这种嵌入可以通过多种方式实现。我们考虑将恶意负载添加到主可执行文件(main executable)中的情况。为了尽量减少对PE头(PE header)的修改,恶意负载将被添加到可执行文件的末尾,即最后一个节(section)之后。
执行流程(execution flow)的重定向可以通过以下方式实现:在PE头中,将可执行文件的入口点(entry point)替换为恶意负载的入口点;然后在恶意负载中添加一个跳转指令(jump),使其在执行完成后跳转到原始入口点(original entry point)。
然而,这种解决方案意味着恶意负载会首先执行。具有代码模拟(code emulation)功能的反病毒软件在扫描受感染的可执行文件时,将能够模拟并分析该恶意负载。更好的解决方案是修补(patch)一些在受感染程序使用过程中可能会执行的指令。例如,如果目标程序是文本编辑器(text editor),可以修补用于保存编辑文档(edited document)的函数(function)。这样一来,反病毒软件在扫描受感染的可执行文件时,既不会执行也不会分析该恶意代码。当然,这种解决方案需要对目标可执行文件进行人工分析,以找到合适的指令,因此无法用于自动感染(automatic infection)。
图4展示了这些不同情况。左侧是原始可执行文件(original executable);中间是感染后的可执行文件,其中PE头中的可执行文件入口点已被替换为恶意负载的入口点;右侧是感染后的可执行文件,其中通过修补指令实现了执行流程的重定向。
图4:可执行文件的感染过程
# 1.2.4 拦截使用受感染计算机的用户的私人数据
进程会处理一些可能有价值的数据,而我们的恶意代码可以尝试拦截这些数据。然而,从操作系统的角度来看,我们的恶意代码只是一个普通进程。与其他进程一样,它有自己的内存空间(memory space),其与其他进程交互的能力受到操作系统安全模型(security model)的限制。如果想要拦截私人数据,就必须突破这些限制。
这可以通过多种方式实现:
- 在内核层(kernel level)工作。Windows的安全模型设计如下:如果恶意代码能够将一些代码注入(inject)内核(kernel),它将能够分析所有输入输出(input and output),并捕获私人数据(如键盘敲击(keyboard stroke)、网络流量(network traffic)、文件系统访问(accesses to file system)等)。该解决方案的缺点是需要管理员权限(administrative privileges)。
- 针对特定应用程序(specific application)。例如,如果想要捕获用户在网站上的凭据(credentials),可以为浏览器(browser)开发一个恶意插件(malicious plugin),该插件将分析所有网络流量并提取目标数据。然而,这种技术与特定应用程序绑定。
- 使用代码注入(code injection)和应用程序编程接口挂钩(API hooking)。要拦截的数据存储在进程内存中的缓冲区(buffer)中,并作为函数调用(function call)的参数(argument)传递。例如,服务器有一个缓冲区,通过调用“recv”函数接收数据,还有一个缓冲区通过“send”函数发送数据。在这种解决方案中,恶意代码使用Windows应用程序编程接口(Windows API)的标准函数(standard function)将一些代码注入到其他进程中。注入的代码会在特定的导入函数(imported function)上安装挂钩(hook),以拦截对这些函数的每次调用。然后,它可以在调用前后分析参数(parameter),并查找有价值的数据。这种解决方案具有通用性,且不需要管理员权限。但需要注意的是,如果恶意代码在受限会话(limited session)中运行,它当然无法将代码注入到在另一个会话中运行的进程中。后续,我们将重点关注这种技术。
# 1.2.4.1 代码注入
代码注入可以通过多种方式实现:
- 将要注入的代码构建到动态链接库(dll)中,然后将该动态链接库加载(load)到目标进程(targeted process)中并“执行”。动态链接库注入机制(dll injection mechanism)可以依赖多种技术(修改注册表(registry)、使用全局钩子(wide-system Hooks)、使用远程线程创建函数(CreateRemoteThread)等)[1]。
- 通过使用Win32应用程序编程接口(Win32 API)的一些标准函数,将代码直接注入到远程进程(remote process)内存中:
- 打开进程函数(OpenProcess):通过进程标识符(PID)指定进程,并打开一个具有特定权限的句柄(handle);
- 远程内存分配函数(VirtualAllocEx):通过句柄指定进程,并在该进程中分配(allocate)内存;
- 进程内存写入函数(WriteProcessMemory):将本地内存(local memory)中的数据复制到通过句柄指定的另一个进程的内存中;
- 远程线程创建函数(CreateRemoteThread):通过句柄指定进程,并在该进程中创建一个线程(thread)。该函数特别需要传入所创建线程的执行地址(execution address)作为参数;
- 句柄关闭函数(CloseHandle):关闭已打开的句柄。
图5总结了这些操作。
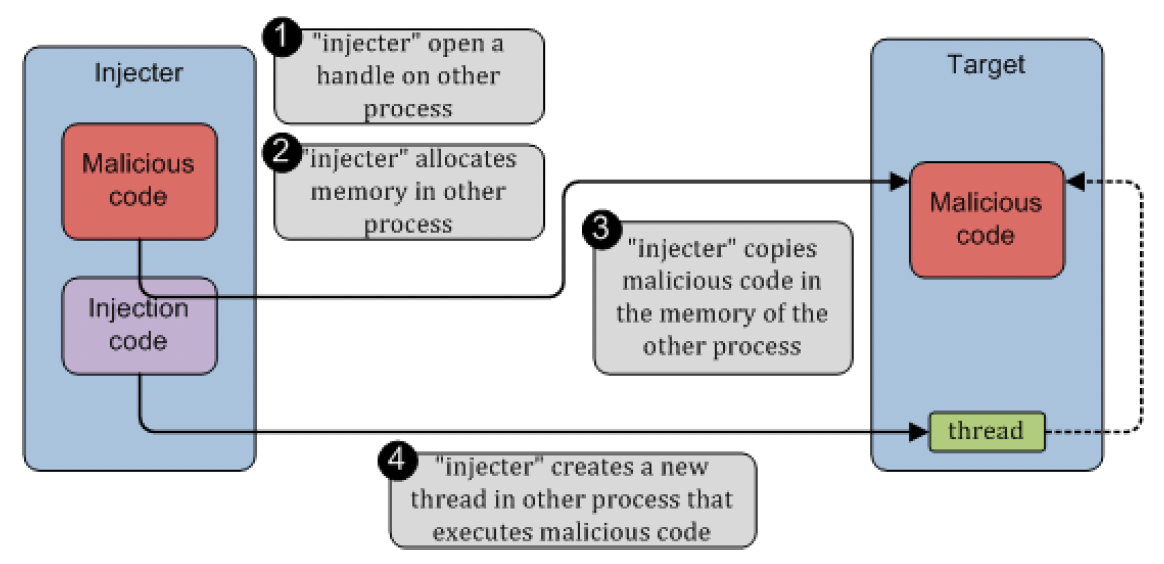
图5:使用VirtualAllocEx/WriteProcessMemory/CreateRemoteThread技术进行代码注入
这种技术允许在不将动态链接库写入硬盘驱动器的情况下执行代码。我们最终选择这种解决方案在恶意软件中实现代码注入。
需要注意的是,这种技术依赖于Windows内核提供的特定服务(specific services),而这些服务尤其受到个人防火墙(personal firewall)等防护程序(protection program)的监控。不过,有时可以通过一些小技巧绕过其中部分程序。这方面的内容超出了本文的讨论范围,后续将不再考虑。
# 1.2.4.2 API hooking
注入到目标进程中的代码随后可以修改内存,以拦截函数调用。这可以通过两种方式实现:
- 代码可以修补导入地址表(Import Address Table)。导入地址表是一个包含所有导入函数地址的表,由Windows加载器(Windows loader)在进程创建时填充。对导入函数(即导入表(import table)中的函数)的每次调用都是通过该表中的地址进行的。因此,通过修补其中一些值,我们可以拦截所需的函数调用。
- 第一种解决方案实施起来相当容易。但问题在于,Windows提供了另一种导入函数的方式。我们可以声明一个函数指针(function pointer),并在执行过程中通过调用加载库函数(LoadLibrary)和获取进程地址函数(GetProcAddress)来解析函数地址,而不是在代码中直接使用该函数(这会在导入表中创建相应的条目)。当然,在这种情况下,该函数在导入表或导入地址表中都没有对应的条目。
为了解决这个问题,我们可以直接用跳转到我们代码的指令修补函数的头部(header),而不是修补导入地址表。这种解决方案会带来许多问题:必须更改节的内存权限(memory rights)、必须计算指令对齐(instruction alignment)以保存被覆盖的指令(overwritten instructions)、必须重建栈(stack)等,但它的优点是无论解析机制(resolution mechanism)如何,都能始终正常工作。该解决方案的完整描述超出了本文的讨论范围。
# 1.2.5 加密自身以防止人工分析
其原理与多态性中使用的原理类似,但目标不同:多态性用于防范反病毒软件等执行的自动分析(automated analysis),而此处我们希望保护恶意负载免受人工分析。这带来了一些差异:
- 必须使用真正的加密算法(real encryption algorithm)。简单的32位密钥异或操作远远不够。例如,我们可以使用256位密钥的高级加密标准(AES)。
- 密钥不应与加密后的恶意代码存储在同一个文件中。例如,可以使用另一个可执行文件来解密恶意代码,或者从服务器获取密钥。
图6展示了这一场景。
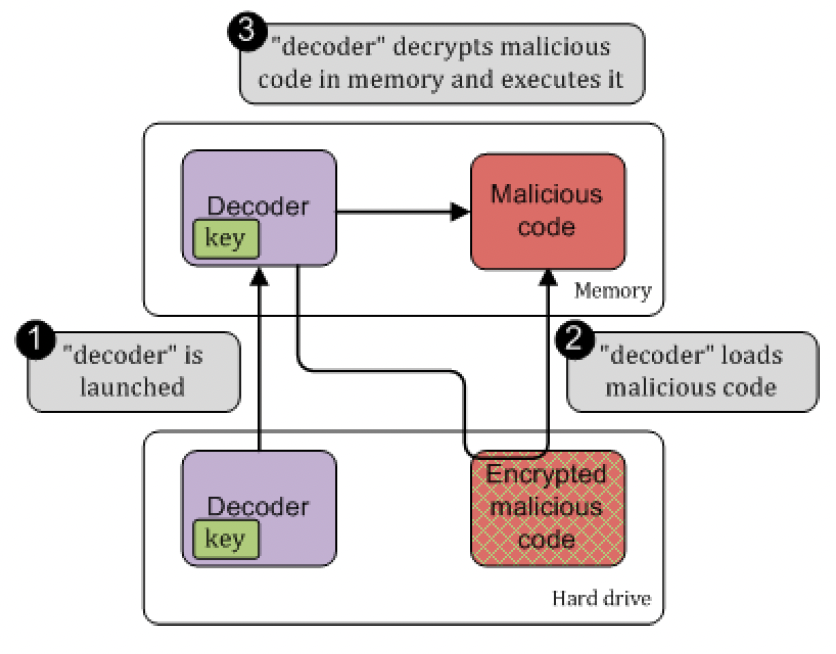
# 图6:加密恶意软件的执行过程
当然,如果从解码器(decoder)中提取密钥,解密恶意代码会很容易。然而,我们需要同时获取这两部分才能解密恶意代码,如果它们通过不同的方式被引入目标系统,这可能会变得困难。如果仅捕获了解码器,它不包含任何有价值的信息;如果仅捕获了恶意代码,则无法对其进行解密。
这一原理可以进一步扩展:将密钥分成多个部分,并存储在多个位置。可以使用沙米尔秘密共享(Shamir's secret sharing)算法[2]来实现这一点。
# 1.3 基于可执行文件的实现
在本部分中,我们假设恶意代码是一个通过正常编写的一组C源文件编译生成的可执行文件“malware.exe”。本节仅简要概述在实现前面列出的功能时可能遇到的问题。
# 1.3.1 实现多态性
其目的是加密“malware.exe”中所有表征恶意负载的二进制数据(binary data):所有函数、已初始化数据(initialized data)和字符串(string)。主要问题是这些数据分散在整个可执行文件中,解密部分必须找到并解密每个数据块。由于这可能会变得非常复杂,因此很难在解密部分实现变形性。此外,PE文件的元数据(metadata)不能被加密,否则Windows将无法加载该可执行文件。
更好的解决方案是使用一个能够加密整个可执行文件的工具,例如加壳工具(packer)。使用知名的UPX[3]等公共加壳工具不一定是一个好的解决方案,因为生成的可执行文件具有一些非常特定的属性,可能会被反病毒软件识别。我们必须开发自己的加壳工具,以实现真正的多态性,这是一项相当艰巨的工作。
# 1.3.2 仅在内存中执行
在远程服务器上运行的代码能够将“malware.exe”复制到其地址空间(address space)中。但此时我们在内存中得到的是PE文件的副本,而不是可直接执行的映射可执行文件(mapped executable)。在跳转到“malware.exe”的入口点之前,我们必须完成Windows加载器通常执行的所有初始化工作:
- 将节映射(map)到正确的地址,因为“malware.exe”可能包含硬编码地址(hardcoded address)。这可以通过使用内存分配函数(VirtualAlloc)来实现,该函数允许在参数中指定的地址分配内存。当然,如果该内存已经被分配,该函数将执行失败;
- 解析导入函数(resolved imported functions):加载所需的库(required libraries)、查找所需的函数并更新导入地址表。需要注意的是,通过使用动态地址解析(dynamic address resolution)可以避免这一步骤。
这并不复杂,但需要一定的工作量。此外,获取“malware.exe”的代码段大小会显著增加,因此它可能无法作为缓冲区溢出漏洞利用中的shellcode使用。
# 1.3.3 感染其他可执行文件
其目的是将从“malware.exe”中提取的恶意负载添加到目标可执行文件(以下称为“target.exe”)中。
要执行感染,可以简单地尝试将“malware.exe”的节添加到“target.exe”的最后一个节之后。然而,该操作并不简单:
必须修改受感染可执行文件的PE头的多个部分:节的数量、节表(section table)、镜像大小(size of image)等;
由于“malware.exe”的代码可能包含硬编码地址,必须精心选择其首选加载地址(preferred load address),以便表征恶意负载的节在“malware.exe”进程和受感染的“target.exe”进程中都加载到相同的地址;
添加代码中的导入表(importation table)不会被Windows加载器解析。因此,所需的库不会被加载,导入地址表也不会被填充。与上一节一样,解决方案可能是在“malware.exe”的编程过程中仅使用动态地址解析,但这很快会变得繁琐。
# 1.3.4 执行代码注入
我们总会遇到相同的问题:“malware.exe”必须映射到正确的地址,并且导入的函数必须被解析。
# 1.3.5 实现真正的加密
与多态性一样,最好的解决方案可能是使用特定的加壳工具,该工具将从服务器等位置获取密钥并解密恶意代码。同样,这是一项相当艰巨的工作。
# 1.3.6 小结
总而言之,当然可以为可执行文件添加这些功能,但这需要大量的工作。
这些困难源于可执行文件的几个特性:
- 代码和数据分散在可执行文件中;
- 在开始执行之前,进程需要一些初始化工作(通常由Windows加载器完成):将节映射到内存中的正确位置、加载所需的库、填充导入地址表等;
- 代码包含硬编码地址,因此节必须映射到正确的地址。否则,必须使用重定位表(relocation table)来修补每个硬编码地址。
因此,如果代码仅由一个代码块组成、能够初始化地址空间且不包含硬编码地址(即代码是shellcode),那么所有这些功能都可以更容易地实现。
# 1.4 基于shellcode的实现
现在,让我们假设我们的恶意代码是一个shellcode,即一个完全自主的代码块。如果我们将执行权转移到其第一个字节,该shellcode将执行与正常可执行文件完全相同的操作。
前面列出的功能的实现将变得非常简单。
# 1.4.1 实现多态性
解密部分将成为一个对shellcode执行解密操作的循环。如果加密算法是简单的32位密钥异或操作,那么解密循环将非常简单:
// 多态负载的解密循环(Decryption loop of the polymorphic payload)
UINT uiXorKey = 0xaabbccdd;
UINT i = 0;
UINT j = 0;
/* Decrypt shellcode */
for (i = 0, j = 0; i < sizeof(bShellcode) - 1; i++, j = (j + 1) & 0x3) {
bShellcode[i] = bShellcode[i] ^ ((CHAR *)&uiXorKey)[j];
}
/* Jump on shellcode */
((VOID (*)(VOID))&bShellcode)();
2
3
4
5
6
7
8
9
10
11
12
# 1.4.2 仅在内存中执行
根据定义,shellcode能够在任何进程的任何地址执行。在服务器上运行的外部代码只需将shellcode从远程位置获取到已分配的缓冲区中,并跳转到该缓冲区的开头即可。无需进行任何初始化,因为所有工作都由shellcode自身处理。此外,不需要将shellcode映射到特定地址。
# 1.4.3 感染其他可执行文件
执行简单的感染变得非常容易。例如,可以将shellcode复制到最后一个节中(该节的大小会相应增加)。
# 1.4.4 执行代码注入
在另一个进程中执行shellcode变得非常容易:只需在其他进程的地址空间中分配一些内存、复制shellcode,并创建一个新线程,将起始地址设置为已分配内存的第一个字节。
# 1.4.5 实现真正的加密
真正加密的实现基于与多态性相同的原理。唯一的区别是,加密将不再是简单的32位密钥异或操作,而是高级加密标准(AES)等“真正的”加密算法。
# 1.4.6 小结
我们可以看到,如果恶意代码是shellcode而不是可执行文件,这些功能的实现会大大简化。现在的问题是找到一种从一组C源文件生成shellcode的方法。