 1. 并发——高级概述
1. 并发——高级概述
# 1. 并发——高级概述
对于许多不接触并发程序的人(甚至对一些接触过的人来说),并发和并行似乎是同一个概念。在日常用语中,人们通常不会对二者进行区分。但是,计算机科学家和软件工程师之所以特别强调区分并发和并行,是有充分理由的。本章将介绍并发的概念(以及它不是什么),还有一些并发的基础概念。
具体来说,本章将涵盖以下主要内容:
- 并发与并行
- 共享内存与消息传递
- 原子性、竞态条件、死锁和饥饿
在本章结束时,你将对并发和并行、基本的并发编程模型以及一些并发的基本概念有一个高层次的理解。
# 技术要求
阅读本章需要对Go语言有一定的了解。部分示例会用到协程(goroutines)、通道(channels)和互斥锁(mutexes)。
# 并发与并行
在计算机科学领域,并发和并行可能曾经含义相同,但那已经是很久以前的事了。很多人会告诉你并发不是什么:“并发不是并行”,但当要解释并发究竟是什么的时候,却很难给出一个简单的定义。由于并发与现实世界的运行方式不同,不同的并发定义强调了该概念的不同方面。现实世界遵循并行机制,我将尝试总结并发背后的一些核心思想,希望你能充分理解其抽象本质,以便将其应用于解决实际问题。
我们周围的许多事物都在同时独立运行。你身边可能有人在各自做着自己的事情,有时他们会与你或彼此之间产生互动。所有这些事情都是并行发生的,所以并行是理解多个相互独立的事物之间如何互动的自然思维方式。如果你观察一群人中某个人的行为,会发现事情更具顺序性:那个人会依次做不同的事情,并且可能会按顺序与群体中的其他人进行互动。这与分布式系统中多个程序之间的交互,或者多线程程序中一个程序的多个线程之间的交互非常相似。
在计算机科学领域,人们普遍认为并发研究始于Edsger Dijkstra的工作,特别是他1965年发表的一篇题为《并发编程控制中的一个问题的解决方案》的短文。这篇论文讨论了一个涉及N台共享内存的计算机的互斥问题。这是一个非常巧妙的描述,突出了并发和并行的区别:它提到了“并发编程”和“并行执行”。并发与程序的编写方式有关,而并行则与程序的运行方式相关。
尽管当时这在很大程度上只是一项学术研究,但随着时间的推移,并发领域不断发展,并衍生出许多不同但相关的主题,包括硬件设计、分布式系统、嵌入式系统、数据库、云计算等等。由于硬件技术的进步,如今并发编程已成为每位软件工程师必备的核心技能之一。现在,多核处理器已成为标准配置,本质上就是将多个处理器集成在一块芯片上,它们通常共享内存。这些多核处理器用于数据中心,支撑基于云的应用程序,在这些应用中,人们可以在几分钟内调配数百台通过网络连接的计算机,并在完成工作负载后将其销毁。同样的并发原理适用于在分布式系统中的多台机器上运行的应用程序、在笔记本电脑的多核处理器上运行的应用程序,以及在单核系统上运行的应用程序。因此,任何一位严谨的软件开发人员都必须熟悉这些原理,才能开发出正确、安全且可扩展的程序。
多年来,人们开发了多种数学模型来分析和验证并发系统的行为。通信顺序进程(Communicating Sequential Processes,CSP)就是这样一种影响了Go语言设计的模型。在CSP中,系统由多个并行运行的顺序进程组成。这些进程可以同步地相互通信,这意味着一个系统向另一个系统发送消息时,只有在另一个系统接收到消息后,发送方才能继续执行(这与Go语言中无缓冲通道的行为完全相同)。
这种形式化框架的验证方面非常引人关注,因为它们旨在证明复杂系统的某些属性。这些属性可能包括“系统会发生死锁吗?”等问题,这对于关键任务系统可能会产生危及生命的影响。你肯定不希望自动驾驶软件在飞行过程中停止工作。大多数验证活动归根结底是要证明程序状态的相关属性。这就是证明并发系统的属性如此困难的原因:当多个系统一起运行时,组合系统的可能状态会呈指数级增长。
顺序系统的状态反映了系统在某个时间点的历史情况。对于顺序程序,状态可以定义为内存中的值以及程序当前的执行位置。有了这两个要素,就可以确定下一个状态。随着程序的执行,它会修改变量的值并推进执行位置,从而使程序的状态发生变化。为了说明这个概念,请看下面用伪代码编写的简单程序:
- 增加x的值
- 如果x<3,跳转到步骤1
- 终止程序
程序从位置loc=1和x=0开始。当执行位置1的语句时,x变为1,位置变为2。当执行位置2的语句时,x保持不变,但位置回到1。这个过程会一直持续,每次执行位置1的语句时x都会增加,直到x达到3。一旦x等于3,程序就会终止。图1.1展示了程序的状态序列:
 图1.1——程序的状态序列
图1.1——程序的状态序列
当多个进程并行运行时,整个系统的状态是其各个组件状态的组合。例如,如果这个程序有两个实例在运行,那么就会有两个x变量实例,即x1和x2,以及两个位置loc1和loc2,分别指向要运行的下一行代码。在每个状态下,下一个可能的状态会根据系统的哪个副本先运行而产生分支。图1.2展示了这个系统的一些状态:
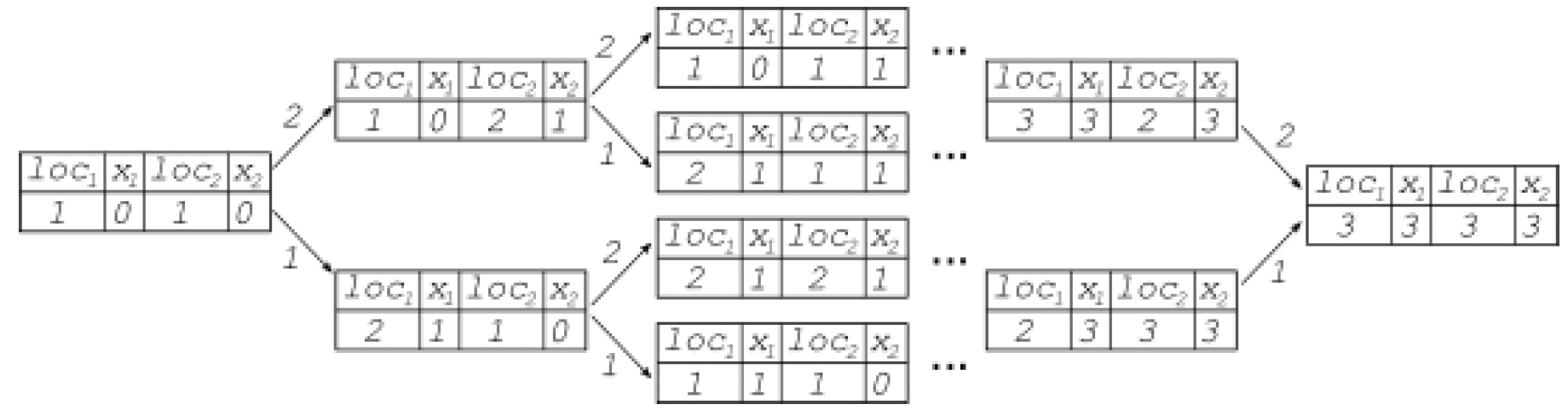 图1.2——并行程序的状态
图1.2——并行程序的状态
在这个图中,箭头用在该步骤中运行的进程的索引进行标注。复合程序的一次特定运行就是图中的一条路径。从这些图中可以观察到以下几点:
- 每个顺序进程有七个不同的状态。
- 每个顺序进程每次运行都会经历相同的状态序列,但程序的两个实例的状态在每条路径上以不同的方式交错。
- 在一次特定的运行中,复合系统可以经历14个不同的状态。也就是说,复合状态图中从起始状态到结束状态的任何一条路径的长度都是14(每个进程必须经历七个不同的状态,因此复合状态有14个)。
- 复合系统的每次运行都可以经过其中一条可能的路径。
- 复合系统中有128个不同的状态(对于系统1的每个状态,系统2可以处于7个不同的状态,所以2的7次方等于128)。
- 无论采取哪条路径,结束状态都是相同的。
一般来说,对于一个有n个状态的系统,m个该系统的副本并行运行将有n的m次方个不同的状态。这就是分析并发程序如此困难的原因之一:并发程序的独立组件可以以任何顺序运行,这使得进行状态分析几乎变得不可能。
现在是时候给出并发的定义了: “并发是指程序的不同部分能够以无序或部分有序的方式执行,而不影响结果。”
对于那些刚接触并发领域的人来说,这是一个很有趣的定义。一方面,它没有提及同时做多个事情,而是提到了“无序”执行算法。“同时做多个事情”描述的是并行的概念。并发与程序的编写方式有关,因此,按照Go语言的创造者之一Rob Pike的说法,并发是“同时处理多个事情”。
现在,来谈谈“排序”相关的内容。存在“全序关系”,比如整数的小于关系。对于任意两个整数,你可以使用小于关系对它们进行比较。对于顺序程序,我们可以定义一种“先行发生关系(happened-before relationship)”,这是一种全序关系:对于在一个顺序进程中发生的任意两个不同事件,一个事件必定在另一个事件之前发生。那么,如果两个事件发生在不同的进程中,如何定义先行发生关系呢?可以使用全局同步时钟对发生在不同进程中的事件进行排序。然而,在典型的分布式系统中,通常不存在精度足够的这种时钟。另一种可能是进程之间的因果关系:如果一个进程向另一个进程发送消息,当消息被接收时,发送消息之前发生的任何事情都发生在第二个进程接收消息之前。这在图1.3中进行了说明:
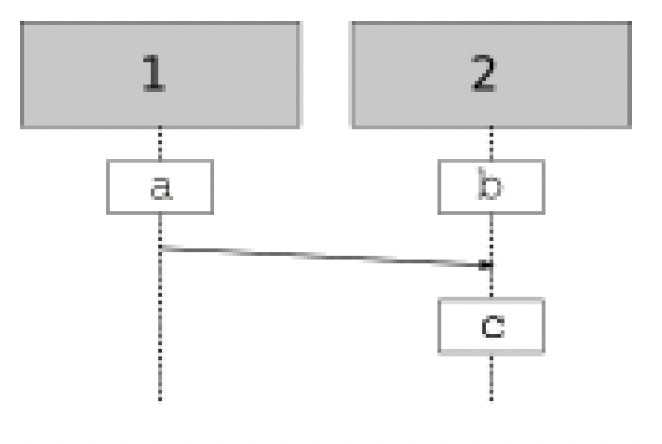 图1.3——a和b发生在c之前
图1.3——a和b发生在c之前
在这里,事件a发生在c之前,b发生在c之前,但无法确定a和b的先后顺序。它们是“并发”发生的。在并发程序中,并非每对事件都具有可比性,因此先行发生关系是一种偏序关系。
让我们重新审视著名的“哲学家就餐问题”,以探索并发、并行和无序执行的概念。这个问题最初由Dijkstra提出,后来由C.A.R. Hoare完善。问题描述如下:五位哲学家围坐在一张圆桌旁用餐。每位哲学家面前有一个盘子,每个盘子之间有一把叉子,总共五把叉子。他们吃的食物需要用到两把叉子,分别在盘子的左侧和右侧。每位哲学家会随机思考一段时间,然后进食一会儿。为了进食,哲学家必须拿起两把叉子——盘子左侧和右侧各一把:
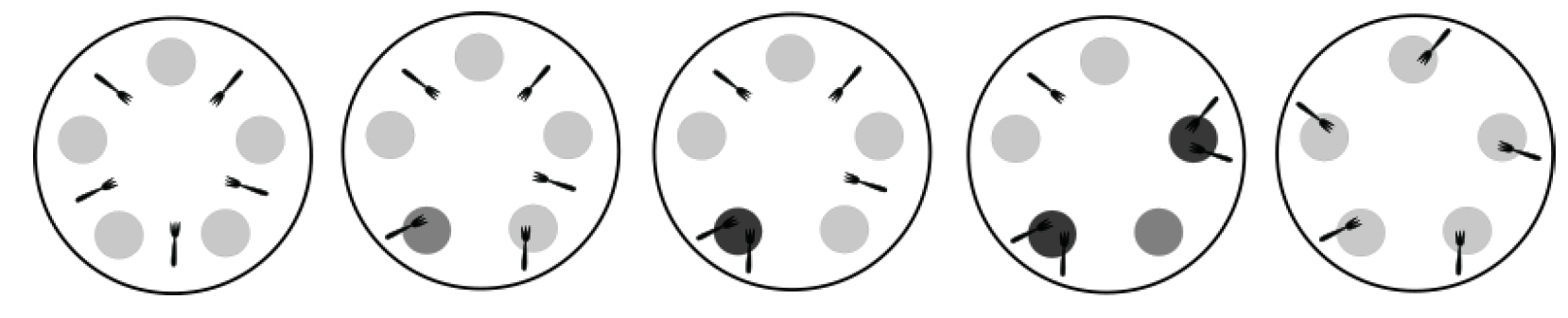 图1.4——哲学家就餐问题——一些可能的状态
图1.4——哲学家就餐问题——一些可能的状态
目标是设计一个并发框架,既能让哲学家们吃饱,又能让他们有时间思考。我们稍后还会详细探讨这个问题。在本章中,我们关注的是可能的状态,图1.4展示了其中一些状态。从左到右,第一张图显示所有哲学家都在思考。第二张图显示有两位哲学家拿起了左手边的叉子,所以其中一位哲学家在等待另一位吃完。第三张图显示有一位哲学家在进食,而其他哲学家在思考。正在进食的哲学家旁边的两位在等待轮到自己使用叉子。第四张图显示有两位哲学家同时在进食。可以看到,这是同时进食的哲学家的最大数量,因为没有足够的资源(叉子)让更多的哲学家同时进食。最后一张图显示每位哲学家都拿着一把叉子,所以他们都在等待拿起第二把叉子以便进食。只有至少有一位哲学家放弃并把叉子放回桌子上,让另一位哲学家能够拿起它,这种情况才能得到解决。
现在,让我们稍微改变一下问题的设定。假设不是五位哲学家坐在桌旁,而是只有一位哲学家,她在思考时喜欢踱步。当她感到饥饿时,会随机选择一个盘子,依次拿起该盘子旁边的两把叉子,然后开始进食。吃完后,她会依次把叉子放回桌子上,然后继续边踱步边思考。不过,在这个过程中她可能会分心,随时起身,可能不会把一把或两把叉子放回桌子上。
当这位哲学家选择一个盘子时,可能会出现以下情况:
- 两把叉子都在桌子上。然后,她拿起叉子开始进食。
- 一把叉子在桌子上,另一把在旁边的盘子上。她意识到不能只用一把叉子进食,于是起身选择另一个盘子。她可能会也可能不会把手里的叉子放回桌子上。
- 一把叉子在桌子上,另一把在所选的盘子上。她拿起第二把叉子开始进食。
- 两把叉子都不在桌子上,因为它们都在相邻的盘子上。她意识到没有叉子就无法进食,于是起身选择另一个盘子。
- 两把叉子都在所选的盘子上。她开始进食。
尽管修改后的问题只有一位哲学家,但它的可能状态与原始问题是相同的。前面图中所示的五种状态仍然是修改后问题的一些可能状态。原始问题中有五个处理器(哲学家)使用共享资源(叉子)进行计算(进食和思考),说明了并发程序的并行执行。在修改后的程序中,只有一个处理器(哲学家)通过分时(time sharing)来扮演缺失的哲学家的角色,使用共享资源执行相同的计算。底层算法(哲学家的行为)是相同的。因此,并发编程就是将一个问题组织成可以通过分时运行或并行运行的计算单元。从这个意义上说,并发是一种类似于面向对象编程或函数式编程的编程模型。面向对象编程将问题分解为相互交互的逻辑相关的结构组件,函数式编程将问题分解为相互调用的函数组件,而并发编程将问题分解为相互发送消息的时间组件,这些组件可以交错或并行运行。
分时是指多个用户或进程共享计算资源。在并发编程中,共享资源就是处理器本身。当一个程序创建多个执行线程时,处理器会在一段时间内运行一个线程,然后切换到另一个线程,依此类推。这称为上下文切换(context-switching)。执行线程的上下文包含其堆栈以及该线程停止时处理器寄存器的状态。通过这种方式,处理器可以快速在不同堆栈之间切换,在每次切换时保存和恢复处理器状态。处理器进行切换的具体代码位置取决于底层实现。在抢占式线程模型(preemptive threading)中,正在运行的线程可以在其执行过程中的任何时间被停止。在非抢占式线程模型(non-preemptive threading,或协作式线程模型cooperative threading)中,正在运行的线程通过执行阻塞操作、系统调用或其他操作自愿放弃执行权。
在很长一段时间里(直到Go 1.14版本之前),Go运行时使用的是协作式调度器。这意味着在下面这个程序中,一旦第一个协程开始运行,就没有办法停止它。如果你使用低于1.14版本的Go构建并在单个操作系统线程上多次运行这个程序,有些运行会打印“Hello”,而有些则不会。这是因为如果第一个协程在第二个协程之前开始工作,它将永远不会让第二个协程运行:
func main() {
ch := make(chan bool)
go func() {
for {}
}()
go func() {
fmt.Println("hello")
}()
<-ch
}
2
3
4
5
6
7
8
9
10
对于更新版本的Go,情况不再如此。现在,Go运行时使用抢占式调度器,即使有一个协程试图占用所有处理器周期,它也能运行其他协程。
作为并发系统的开发者,你必须了解线程/协程是如何调度的。这种理解是识别并发系统可能行为方式的关键。从高层次来看,线程/协程的状态可以用图1.5表示:
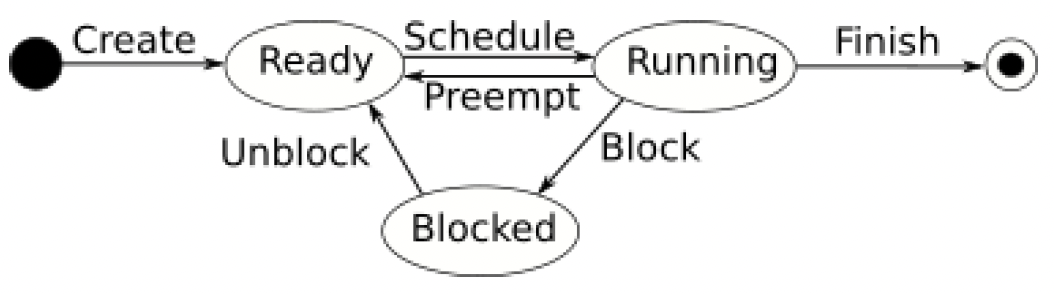 图1.5——线程状态图
图1.5——线程状态图
当创建一个线程时,它处于就绪(Ready)状态。当调度器将其分配给一个处理器时,它会进入运行(Running)状态并开始运行。正在运行的线程可以被抢占并回到就绪状态。当线程执行I/O操作、等待锁或通道操作而被阻塞时,它会进入阻塞(Blocked)状态。当I/O操作完成、锁被解锁或通道操作完成时,线程会回到就绪状态,等待被调度。
你首先应该注意到,处于阻塞状态等待某个事件发生的线程,在解除阻塞后可能不会立即开始运行。在设计和分析并发程序时,这个事实通常会被忽略。这对Go程序意味着什么呢?这意味着解锁一个互斥锁并不意味着等待该互斥锁的某个协程会立即开始运行。同样,向通道写入数据并不意味着接收数据的协程会立即开始运行。它们将准备好运行,但可能不会立即被调度。
你会看到这个线程状态图的不同变体。每个操作系统和每种语言运行时都有不同的方式来调度它们的执行线程。例如,一个线程系统可能会区分因I/O操作而被阻塞和因互斥锁而被阻塞的情况。这只是几乎所有线程实现都共有的一个高层次描述。
# 共享内存与消息传递
如果你使用Go语言进行开发有一段时间了,很可能听过这样一句话:“不要通过共享内存来通信,而要通过通信来共享内存”。在程序的并发块之间共享内存,会引发大量难以诊断的细微错误。这些问题会随机出现,通常是在负载情况下,而这种负载在受控的测试环境中又无法模拟,并且很难甚至无法重现。无法重现的问题就无法测试,所以发现这类问题往往靠运气。一旦发现,通常只需做很小的改动就能轻松修复,这更是雪上加霜。Go语言同时支持共享内存和消息传递模型,所以我们来花些时间了解一下共享内存和消息传递范式。
在共享内存系统中,可以有多个处理器或核心,以及多个使用相同内存的执行线程。在统一内存访问(Uniform Memory Access,UMA)系统中,所有处理器对内存的访问权限相同。这可能会降低吞吐量,因为多个处理器共享相同的内存访问总线。在非统一内存访问(Non-Uniform Memory Access,NUMA)系统中,处理器可能对某些内存块有专用访问权。在这样的系统中,操作系统可以将在某个处理器上运行的进程的内存分配到该处理器的专用内存区域,从而提高内存吞吐量。几乎所有系统还使用更快的高速缓存(cache memory)来缩短内存访问时间,并且采用缓存一致性协议(cache coherence protocols),以确保进程不会从主内存中读取陈旧值(即已在缓存中更新但未写入主内存的值) 。
在单个程序中,共享内存仅仅意味着多个执行线程访问内存的同一部分。在大多数情况下,使用共享内存编写程序是很自然的事。在像Go这样的大多数现代语言中,执行线程可以不受限制地访问整个进程的内存空间。因此,线程可以访问的任何变量,都能被该线程读取和修改。如果没有编译器或硬件优化,这本来不会有问题。在执行程序时,现代处理器通常不会等待内存读或写操作完成。它们采用流水线方式执行指令。所以,当一条指令等待读/写操作完成时,处理器可以开始运行程序的下一条指令。如果第二条指令在第一条指令之前完成,那么该指令的结果可能会“乱序”写入内存。
我们来看这个非常简单的程序示例:
var locked,y int
func f() {
locked=1
y=2
...
}
2
3
4
5
6
在这个程序中,假设f()函数开始时locked和y都初始化为0。然后,locked被设置为1,大概是为了实现某种锁定机制,接着y被设置为2。如果此时对内存进行快照,我们可能会看到以下情况之一:
locked=0, y=0:处理器运行了赋值操作,但更新尚未写入内存。locked=0, y=2:y变量已在内存中更新,但locked尚未在内存中更新。locked=1, y=0:locked变量已更新并写入内存,但y变量可能更新了也可能还未更新。locked=1, y=2:两个变量都已更新,且更新已写入内存。
指令重排序并不局限于处理器。编译器也可以在不影响顺序程序计算结果的前提下调整语句顺序。这通常在编译的优化阶段进行。在前面的程序中,没有什么能阻止编译器颠倒这两个赋值操作的顺序。根据代码的其他部分,编译器可能会判定在y=2之后执行locked=1更好。
简而言之,如果没有额外的机制,一个线程无法保证看到其他线程修改的变量的正确值。
为了使共享内存应用程序正确运行,我们需要一种方法来告诉编译器和处理器将所有更改提交到内存。用于此目的的底层工具是内存屏障(memory barrier)。内存屏障是一种指令,它对处理器和编译器施加特定的顺序约束。在内存屏障之后,保证在屏障之前发出的所有操作都在屏障之后的操作之前完成。在前面的程序中,在对y赋值之后添加一个内存屏障,可确保快照时locked=1且y=2。所以,内存屏障是确保共享内存应用程序正确运行的关键底层特性。
你可能想知道,这对我有什么用呢?当处理使用共享内存的并发程序时,只有在内存屏障之后,一个块中执行的操作的效果才会保证对其他并发块可见。在Go语言中有一些特定的操作:原子读/写(sync/atomic包中的函数)和通道读/写。其他同步操作(互斥锁(mutexes)、等待组(wait groups)和条件变量(condition variables))使用原子读/写和通道操作,因此也包含内存屏障。
| 注意 这里有必要快速说明一下调试并发程序的问题。调试并发程序的常见做法是在代码的关键点打印一些变量的值,以便在出现意外行为时获取程序状态信息。但这种做法通常会阻止意外行为的发生,因为向控制台打印内容或向文件写入日志消息通常涉及互斥锁和原子操作。所以,在生产环境中关闭日志记录时,比在开发过程中有大量日志记录时更容易出现错误。 |
|---|
现在,来谈谈消息传递模型。对于许多语言来说,并发是一个附加功能,通过库定义函数来创建和管理并发执行块(线程)。Go语言采用了不同的方法,将并发作为语言的核心特性。Go语言的并发特性受到通信顺序进程(Communicating Sequential Processes,CSP)的启发,在CSP中,多个独立的进程通过发送/接收消息进行通信。长期以来,这也是Unix/Linux系统的基本进程模型。Unix的理念是“让每个程序都把一件事做好”,然后组合这些程序,使它们能够完成更复杂的任务。大多数传统的Unix/Linux程序被编写为从终端读取/写入数据,这样它们就可以以管道的形式一个接一个地连接起来,每个程序使用前一个程序的输出作为输入,这借助了进程间通信机制。这个系统也类似于一个由多台互联计算机组成的分布式系统。每台计算机都有专用内存,在其中进行计算,将结果发送到网络上的其他计算机,并接收其他计算机的结果。
消息传递是在分布式系统中建立“发生在先”关系的核心思想之一。当一个系统从另一个系统接收到一条消息时,你可以确定在发送方系统发送该消息之前发生的任何事件,都发生在接收方系统接收到该消息之前。如果没有这种因果关系,在分布式系统中通常就无法确定某个事件何时发生。同样的理念也适用于并发系统。在消息传递系统中,“发生在先”关系是通过消息建立的。在共享内存系统中,这种“发生在先”关系是通过锁建立的。
同时拥有这两种模型有一些优点——例如,许多算法在共享内存系统上实现起来要容易得多,而消息传递系统则不存在某些类型的数据竞争(data races)。当然也有一些缺点。例如,在混合模型中,很容易意外地共享内存,从而产生数据竞争。防止这种意外共享的一个常用方法是注意数据所有权:当你通过通道将一个数据对象发送到另一个协程(goroutine)时,该数据对象的所有权就转移到了接收协程,发送协程在未确保互斥的情况下,不得再次访问该对象。但有时,这很难做到。
例如,尽管下面的代码片段使用通道在线程之间进行通信,但通过通道发送的对象是一个映射(map),它是一个指向复杂数据结构的指针。在通过通道发送操作之后继续使用同一个映射,可能会导致数据损坏和程序崩溃:
// Compute some result
data:=computeData()
m:=make(map[string]Data)
// Put the result in a map
m["result"]=data
// Send the map to another goroutine
c<-m
// Here, m is shared between the other goroutine and this one
2
3
4
5
6
7
8
# 原子性、竞争、死锁和饥饿
要成功编写和分析并发程序,你必须了解一些关键概念:原子性(atomicity)、竞争(race)、死锁(deadlocks)和饥饿(starvation)。原子性是一种特性,你必须谨慎利用它来确保操作的安全和正确。竞争是并发系统中与事件时间相关的自然现象,可能会产生难以重现的细微错误。你必须不惜一切代价避免死锁。饥饿通常与调度算法有关,但也可能由程序中的错误引起。
竞争条件(race condition)是指程序的结果取决于并发执行的顺序或时间的情况。当其中至少一个结果不理想时,竞争条件就是一个错误。考虑以下表示银行账户的数据类型:
type Account struct {
Balance int
}
func (acct *Account) Withdraw(amt int) error {
if acct.Balance < amt {
return ErrInsufficient
}
acct.Balance -= amt
return nil
}
2
3
4
5
6
7
8
9
10
11
Account类型有一个Withdraw方法,该方法会检查余额,看是否有足够的资金用于取款,然后要么因资金不足返回错误,要么减少余额。现在,我们从两个协程中调用这个方法:
acct:=Account{Balance:10}
go func() {acct.Withdraw(6)}() // Goroutine 1
go func() {acct.Withdraw(5)}() // Goroutine 2
2
3
逻辑上不应该允许账户余额变为负数。其中一个协程应该成功运行,而另一个协程应该因资金不足而失败。根据哪个协程先运行,账户的最终余额应该是5或4。然而,这些协程可能会交错执行,导致许多可能的运行情况,以下展示了其中一些:
可能的运行情况1acct.Balance=10 | 可能的运行情况1acct.Balance=10 | 可能的运行情况1acct.Balance=10 |
|---|---|---|
Goroutine 1 (amt=6) | Goroutine 2 (amt=5) | |
if acct.Balance < amt | ||
if acct.Balance < amt | ||
acct.Balance -= amt | ||
acct.Balance -= amt | ||
可能的运行情况2acct.Balance=10 | 可能的运行情况2acct.Balance=10 | 可能的运行情况2acct.Balance=10 |
| --- | --- | --- |
Goroutine 1 (amt=6) | Goroutine 2 (amt=5) | |
if acct.Balance < amt | ||
if acct.Balance < amt | ||
acct.Balance -= amt | ||
acct.Balance -= amt | ||
可能的运行情况3acct.Balance=10 | 可能的运行情况3acct.Balance=10 | 可能的运行情况3acct.Balance=10 |
| --- | --- | --- |
Goroutine 1 (amt=6) | Goroutine 2 (amt=5) | |
if acct.Balance < amt | ||
acct.Balance -= amt | ||
if acct.Balance < amt | ||
return ErrInsufficient | ||
可能的运行情况4acct.Balance=10 | 可能的运行情况4acct.Balance=10 | 可能的运行情况4acct.Balance=10 |
| --- | --- | --- |
Goroutine 1 (amt=6) | Goroutine 2 (amt=5) | |
if acct.Balance < amt | ||
acct.Balance -= amt | ||
if acct.Balance < amt | ||
return ErrInsufficient |
可能的运行情况1和2使账户余额为负数,尽管在单线程程序中逻辑上可以防止这种情况。可能的运行情况3和4也是竞争条件,但它们使系统处于一致状态。两个协程竞争资金,其中一个成功,另一个失败。这使得竞争条件很难诊断:它们很少发生,即使在检测到它们的条件下进行复制,也无法重现。
# 总结
本章的主题是并发(concurrency)不是并行(parallelism)。并行是人们熟悉的直观概念,因为现实世界是并行运作的。并发是一种计算模式,其中代码块可能并行运行,也可能不并行运行。关键在于,无论程序如何运行,我们都要确保得到正确的结果。
我们还讨论了两种主要的并发编程范式:消息传递(message passing)和共享内存(shared memory)。Go语言同时支持这两种方式,这使得编程变得容易,但也同样容易出错。本章的最后一部分介绍了并发编程的基本概念,即竞态条件(race conditions)、原子性(atomicity)、死锁和活锁概念。需要注意的重要一点是,这些并非理论概念,而是影响程序运行和失败方式的实际情况。
本章我们尽量避免涉及Go语言的特定内容。下一章将介绍Go语言的并发原语。
# 问题
我们研究了单个哲学家在思考时会走动的就餐哲学家问题。如果有两个哲学家,你能预见到哪些问题?
# 进一步阅读
关于并发的文献非常丰富。以下只是并发和分布式计算领域中与本章讨论主题相关的一些开创性著作。每一位严肃的软件从业者至少都应该对这些有基本的了解。
- 下面这篇论文通俗易懂且篇幅较短,它定义了互斥和临界区:E. W. Dijkstra. 1965. Solution of a problem in concurrent programming control. Commun. ACM 8, 9 (Sept. 1965), 569. https://doi.org/10.1145/365559.365617。
- 这是一本关于通信顺序进程(Communicating Sequential Processes,CSP)的书,它将CSP定义为一种形式语言:Hoare, C. A. R. (2004) [originally published in 1985 by Prentice Hall International]. “Communicating Sequential Processes” (PDF). Usingcsp.com。
- 下面这篇论文讨论了分布式系统中事件的顺序:Time, Clocks and the Ordering of Events in a Distributed System, Leslie Lamport, Communications of the ACM 21, 7 (July 1978), 558 - 565。该论文被重印于多个文集,包括Distributed Computing: Concepts and Implementations, McEntire et al., ed. IEEE Press, 1984. | July 1978,pp. 558 - 565。它在2000年获得了分布式计算领域的有影响力论文奖(后来更名为Edsger W. Dijkstra分布式计算奖),并在2007年获得了ACM SIGOPS名人堂奖。