 2 Go并发原语
2 Go并发原语
# 2 Go并发原语
本章将介绍Go语言的基本并发工具。我们首先会探讨goroutine和通道(channel),它们是Go语言定义的两个并发构建模块。接着,我们还会研究标准库中包含的一些并发实用工具。我们将涵盖以下主题:
- goroutine
- 通道和select语句
- 互斥锁(Mutexes)
- 等待组(Wait groups)
- 条件变量(Condition variables)
在本章结束时,你将具备足够的知识,能够使用Go语言特性和标准库对象来解决基本的并发问题。
# 技术要求
无。
# 协程(Goroutines)
首先,介绍一些基础知识。
进程(process)是程序的一个实例,它拥有特定的专用资源,如内存空间、处理器时间、文件句柄(例如,Linux中的大多数进程都有标准输入(stdin)、标准输出(stdout)和标准错误输出(stderr)),并且至少包含一个线程。我们称它为实例,是因为同一程序可用于创建多个进程。在大多数通用操作系统中,每个进程都是相互隔离的,所以任何两个想要通信的进程都必须通过定义明确的进程间通信工具来实现。当一个进程终止时,为该进程分配的所有内存都会被释放,所有打开的文件都会被关闭,并且所有线程都会终止。
线程(thread)是一个执行上下文,它包含运行一系列指令所需的所有资源。通常,这包括一个栈(stack)和处理器寄存器的值。栈对于在该线程内保持嵌套函数调用的顺序,以及存储在该线程中执行的函数里声明的值来说是必要的。一个给定的函数可能在许多不同的线程中执行,所以当该函数在某个线程中运行时使用的局部变量会存储在该线程的栈中。调度器(scheduler)为线程分配处理器时间。有些调度器是抢占式的(preemptive),可以随时停止一个线程以切换到另一个线程;有些调度器是协作式的(collaborative),必须等待线程主动让出资源才能切换到另一个线程。线程通常由操作系统管理。
goroutine是由Go运行时(Go runtime)管理的执行上下文(与由操作系统管理的线程不同)。与操作系统线程相比,goroutine的启动开销通常要小得多。goroutine启动时的栈很小,并会根据需要增长。创建新的goroutine比创建操作系统线程更快、成本更低。Go调度器会分配操作系统线程来运行goroutine。
在Go程序中,使用go关键字后跟一个函数调用来创建goroutine:
go f()
go g(i,j)
go func() {
...
}()
go func(i,j int) {
...
}(1,2)
2
3
4
5
6
7
8
go关键字会在一个新的goroutine中启动给定的函数。现有的goroutine会与新创建的goroutine并发继续运行。作为goroutine运行的函数可以接受参数,但不能返回值。goroutine函数的参数会在goroutine启动前求值,并在goroutine开始运行时传递给该函数。
你可能会问,为什么需要开发一个全新的线程系统呢?仅仅是为了获得轻量级线程吗?goroutine不仅仅是轻量级线程。它们是通过在准备运行的goroutine之间高效共享处理能力来提高吞吐量的关键。下面是其核心思想。
Go运行时使用的操作系统线程数量等于平台上的处理器/核心数量(除非你通过设置GOMAXPROCS环境变量或调用runtime.GOMAXPROCS函数来更改这一数量)。这是平台能够并行处理的任务数量。超过这个数量,操作系统就不得不采用时间共享的方式。在有GOMAXPROCS个线程并行运行的情况下,在操作系统层面不会有上下文切换开销。Go调度器将goroutine分配给操作系统线程,以便在每个线程上完成更多工作,而不是在多个线程上做较少的工作。较小的上下文切换并不是Go调度器性能优于操作系统调度器的唯一原因。Go调度器性能更好是因为它知道唤醒哪些goroutine能让它们发挥更大作用。操作系统并不了解通道操作或互斥锁,而这些在用户空间中都是由Go运行时管理的。
线程和goroutine之间还有一些更细微的差别。线程通常有优先级。当一个低优先级线程与一个高优先级线程竞争共享资源时,高优先级线程获得资源的机会更大。goroutine没有预先分配的优先级。不过,Go语言规范允许调度器对某些goroutine给予优先处理。例如,Go运行时的较新版本包含了会选择处于饥饿状态的goroutine的调度算法。但一般来说,一个正确的并发Go程序不应依赖调度行为。许多语言都有诸如具有可配置调度算法的线程池之类的工具。这些工具是基于线程创建是一项昂贵操作的假设开发的,而在Go语言中并非如此。另一个区别在于goroutine栈的管理方式。一个goroutine启动时的栈很小(Go 1.19及之后的运行时使用历史平均大小,早期版本使用2K),并且每次函数调用都会检查剩余栈空间是否足够。如果不够,栈会进行扩容。而操作系统线程通常以大得多的栈(以兆字节为单位)启动,并且通常不会增长。
Go程序启动时,Go运行时会启动几个goroutine。具体数量取决于实现,并且可能在不同版本之间有所变化。不过,至少会有一个用于垃圾回收器(garbage collector),另一个用于主goroutine(main goroutine)。主goroutine只是调用main函数,并在该函数返回时终止程序。当main函数返回且程序退出时,所有正在运行的goroutine都会突然终止,即使函数还未执行完毕,也没有机会进行任何清理操作。
让我们看看创建一个goroutine时会发生什么:
func f() {
fmt.Println("Hello from goroutine")
}
func main() {
go f()
fmt.Println("Hello from main")
time.Sleep(100)
}
2
3
4
5
6
7
8
9
这个程序从主goroutine开始。当运行go f()语句时,会创建一个新的goroutine。请记住,goroutine是一个执行上下文,这意味着go关键字会使运行时分配一个新的栈,并将其设置为运行f()函数。然后这个goroutine会被标记为准备运行。主goroutine会继续运行,而不会等待f()被调用,并将“Hello from main”打印到控制台。然后它会等待100毫秒。在此期间,新创建的goroutine可能会开始运行,调用f(),并打印“Hello from goroutine”。fmt.Println内置了互斥机制,以确保两个goroutine不会破坏彼此的输出。
这个程序可能会输出以下几种情况之一:
- 先输出“Hello from main”,然后输出“Hello from goroutine”:这种情况是主goroutine先打印输出,然后新创建的goroutine再打印。
- 先输出“Hello from goroutine”,然后输出“Hello from main”:这种情况是在main()函数中创建的goroutine先运行,然后主goroutine再打印输出。
- 只输出“Hello from main”:这种情况是主goroutine继续运行,但新创建的goroutine在给定的100毫秒内一直没有机会运行,导致main函数返回。一旦main函数返回,程序就会终止,而这个goroutine始终没有机会运行。虽然这种情况不太可能观察到,但确实是有可能的。
带参数的函数也可以作为goroutine运行:
func f(s string) {
fmt.Printf("Goroutine %s\n", s)
}
func main() {
for _, s := range []string{"a", "b", "c"} {
go f(s)
}
time.Sleep(100)
}
2
3
4
5
6
7
8
9
10
每次运行这个程序,输出“a”“b”“c”的顺序都可能是随机的。这是因为for循环创建了三个goroutine,每个goroutine都使用当前的s值调用f函数,而调度器可以按任意顺序选择它们运行。当然,如果所有goroutine在给定的100毫秒内没有全部完成,输出中可能会缺少一些字符串。
自然地,这也可以使用匿名函数来实现。但现在,情况变得有趣起来:
func main() {
for _, s := range []string{"a", "b", "c"} {
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
}
time.Sleep(100)
}
2
3
4
5
6
7
8
输出结果如下:
Goroutine c
Goroutine c
Goroutine c
2
3
那么,这里发生了什么呢?
首先,这是一个数据竞争(data race)问题,因为存在一个共享变量,它被一个goroutine写入,同时被另外三个goroutine读取,且没有任何同步机制。如果我们展开for循环,这个问题会更加明显,如下所示:
func main() {
var s string
s = "a"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
s = "b"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
s = "c"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
time.Sleep(100)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在这个例子中,每个匿名函数都是一个闭包(closure)。我们运行了三个goroutine,每个goroutine都有一个闭包,这些闭包从外部作用域捕获了s变量。因此,我们有三个goroutine读取共享的s变量,而一个goroutine(主goroutine)同时向它写入数据。这就是数据竞争。在上述运行结果中,三个goroutine都是在s的最后一次赋值之后运行的。实际上还有其他可能的运行情况。事实上,这个程序甚至可能正确运行并打印出预期的输出。
这就是数据竞争的危险之处。像这样的程序很少能正确运行,所以在代码部署到生产环境之前很容易诊断和修复。而那些很少产生错误输出的数据竞争问题通常会进入生产环境,从而引发很多麻烦。
让我们更详细地了解闭包的工作原理。闭包在Go开发中常常引发误解,因为仅仅将一个声明的函数重构为匿名函数可能会产生意想不到的后果。
闭包是一个带有上下文的函数,其上下文包括它外部作用域中的一些变量。在前面的例子中,有三个闭包,每个闭包都从其作用域中捕获了s变量。作用域定义了程序中某个给定点可访问的所有符号名称。在Go语言中,作用域是由语法决定的,所以在我们声明匿名函数的地方,作用域包括所有导出函数、变量、类型名称、main函数以及s变量。Go编译器会分析源代码,以确定一个在函数中定义的变量在该函数返回后是否可能被引用。例如,当你将一个指向某个函数中定义的变量的指针传递给另一个函数时,或者当你将一个全局指针变量赋值为指向某个函数中定义的变量时,就会出现这种情况。一旦声明该变量的函数返回,全局变量将指向一个无效的内存位置。随着函数的进入和返回,栈上的位置会不断变化。当检测到这种情况(或者甚至只是检测到有这种情况的可能性,比如创建一个goroutine或调用另一个函数)时,该变量会被分配到堆(heap)上。也就是说,编译器不是在栈上分配该变量,而是在堆上动态分配它,这样即使该变量离开了作用域,其内容仍然可以访问。这正是我们例子中发生的情况。s变量被分配到堆上,因为即使main函数返回后,仍有goroutine可以继续运行并访问该变量。这种情况如图2.1所示:
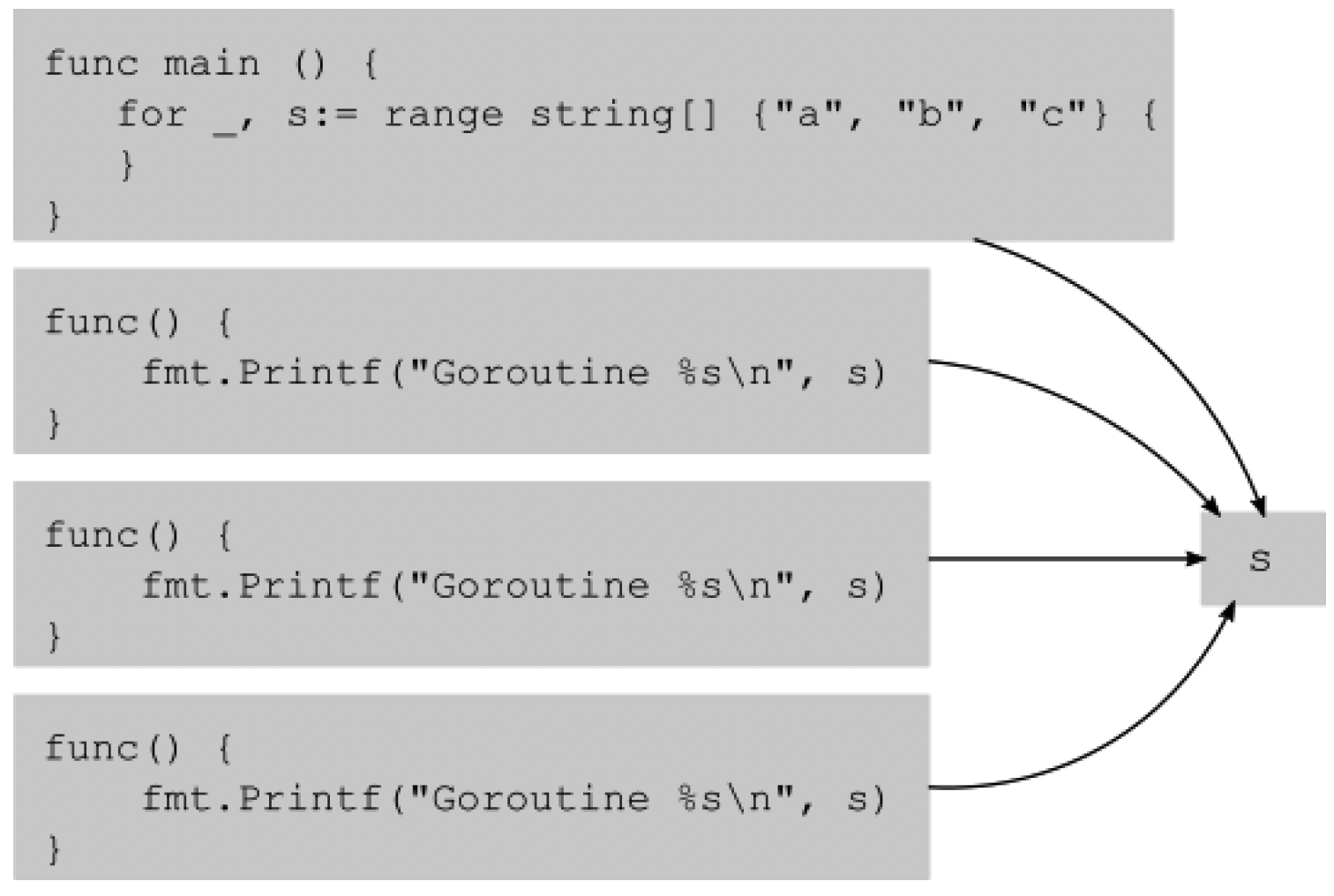 Figure 2.1 – Closures
Figure 2.1 – Closures
作为goroutine的闭包可以是一个非常强大的工具,但使用时必须小心。大多数作为goroutine运行的闭包会共享内存,所以它们很容易出现竞态条件(race condition)。
我们可以通过在每次迭代时创建s变量的副本来修复我们的程序。第一次迭代将s设置为“a”,我们创建它的一个副本,并在闭包中捕获这个副本。然后下一次迭代将s设置为“b”,这没问题,因为第一次迭代创建的闭包仍然使用“a”。我们创建一个新的s副本,这次其值为“b”,依此类推。下面的代码展示了这种做法:
for _, s := range []string{"a", "b", "c"} {
s := s // 重新声明s,创建一个副本
// 这里,重新声明的s遮蔽了循环变量s
go func() {…}
}
2
3
4
5
另一种方法是将其作为参数传递:
for _, s := range []string{"a", "b", "c"} {
go func(s string) {
fmt.Printf("Goroutine %s\n", s)
}(s) // 这会将s的一个副本传递给函数
}
2
3
4
5
在这两种解决方案中,循环变量s不再被分配到堆上,因为捕获的是它的副本。在第一种使用重新声明变量的解决方案中,副本被分配到堆上,但循环变量s不会。
关于goroutine,一个常见的问题是:我们如何停止一个正在运行的goroutine呢?并没有一个神奇的函数可以终止或暂停一个goroutine。如果你想停止一个goroutine,你必须向它发送一些消息,或者设置一个与该goroutine共享的标志,然后goroutine必须对消息做出响应,或者读取共享变量并返回。如果你想暂停它,你必须使用一种同步机制来阻塞它。这个事实让一些开发者感到焦虑,因为他们找不到有效的方法来终止他们的goroutine。然而,这是并发编程的现实之一。能够创建并发执行块只是问题的一部分。一旦创建了它们,你必须注意如何以负责任的方式终止它们。
一个恐慌(panic)可以终止一个goroutine。如果在一个goroutine中发生恐慌,它会在调用栈中向上传播,直到找到一个recover语句,或者直到该goroutine返回。这被称为栈展开(stack unwinding)。如果恐慌没有被处理,将会打印一条恐慌消息,并且程序会崩溃。
在结束这个话题之前,讨论一下Go运行时如何管理goroutine可能会有所帮助。Go使用M:N调度器,它在N个操作系统线程上运行M个goroutine。在内部,Go运行时会跟踪操作系统线程和goroutine。当一个操作系统线程准备好执行一个goroutine时,调度器会选择一个准备运行的goroutine并将其分配给该线程。操作系统线程会运行这个goroutine,直到它阻塞、让出资源或被抢占。一个goroutine有几种可能被阻塞的方式。通过通道操作或互斥锁导致的阻塞由Go运行时管理。如果goroutine因为同步I/O操作而被阻塞,那么运行该goroutine的线程也会被阻塞(这由操作系统管理)。在这种情况下,Go运行时会启动一个新线程,或者使用一个已有的线程并继续操作。当操作系统线程解除阻塞(即I/O操作结束)时,该线程会被重新投入使用或返回线程池。Go运行时使用GOMAXPROCS变量来限制运行用户goroutine的活动操作系统线程数量。不过,等待I/O操作的操作系统线程数量没有限制。所以,一个Go程序实际使用的操作系统线程数量可能比GOMAXPROCS高得多。然而,只有GOMAXPROCS个这样的线程会执行用户goroutine。
图2.2展示了这种情况。假设GOMAXPROCS = 2。线程1和线程2是正在执行goroutine的操作系统线程。在线程1上运行的goroutine G1执行一个同步I/O操作,阻塞了线程1。由于线程1不再可用,Go运行时会分配线程3并继续运行goroutine。请注意,即使有三个操作系统线程,但只有两个是活动线程,一个是阻塞线程。当在线程1上运行的系统调用完成后,goroutine G1再次变为可运行状态,但现在多了一个线程。Go运行时会继续使用线程3运行,不再使用线程1。
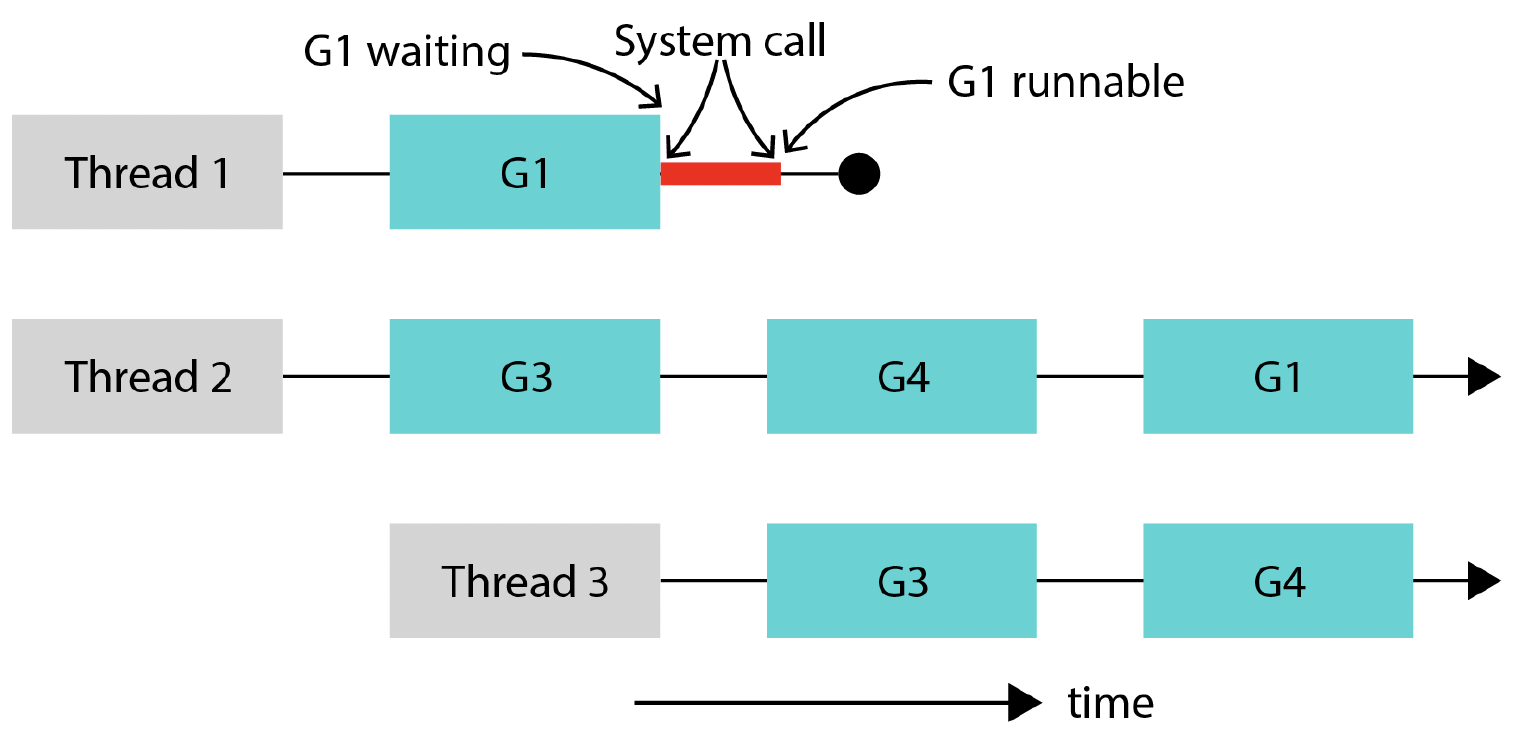 Figure 2.2 – System calls block OS threads)
Figure 2.2 – System calls block OS threads)
对于异步I/O操作(如网络操作以及某些平台上的一些文件操作),也会发生类似的过程。不过,不是让线程为系统调用而阻塞,而是goroutine被阻塞,并且使用一个网络轮询器线程(netpoller thread)来等待异步事件。当网络轮询器接收到事件时,它会唤醒相关的goroutine。
# 通道(Channels)
通道(Channels)允许协程(goroutines)通过通信来共享内存,这与通过共享内存来通信的方式截然不同。在使用通道时,你要牢记通道实际上是两种功能的结合:它既是同步工具,也是数据传输的管道。
你可以通过指定通道的类型和容量来声明一个通道:
ch:=make(chan int,2)
上述声明创建并初始化了一个可以传输整数值的通道,其容量为2。通道是一种先进先出(FIFO,First-In-First-Out)的管道。也就是说,如果你向通道发送一些值,接收方将按照写入的顺序接收这些值。使用以下语法向通道发送数据或从通道接收数据:
ch <- 1 // 向通道发送1
<- ch // 从通道接收一个值
x= <- ch // 从通道接收值并将其赋给x
x:= <- ch // 从通道接收值,声明与读取值类型相同(这里是int)的变量x,并将值赋给x
2
3
4
len()和cap()函数对通道的作用符合预期。len()函数将返回通道中等待处理的元素数量,cap()函数将返回通道缓冲区的容量。不过,这些函数的存在并不意味着下面的代码是正确的:
// 不要这样做!
if len(ch) > 0 {
x := <-ch
}
2
3
4
这段代码检查通道中是否有数据,如果有则进行读取。但这段代码存在竞争条件(race condition)。即使在检查通道长度时通道中可能有数据,但当该协程尝试读取时,另一个协程可能已经将数据接收了。换句话说,如果len(ch)返回非零值,这仅意味着在检查长度时通道中有值,但并不意味着在len函数返回后通道中仍然有值。
图2.3展示了使用两个协程对该通道进行操作的一种可能顺序。第一个协程向通道发送值1和2,这些值存储在通道缓冲区中(此时len(ch)=2,cap(ch)=2)。然后另一个协程接收1。此时,2是通道中下一个要读取的值,通道缓冲区中只有一个值。第一个协程发送3。通道已满,因此向通道发送4的操作会阻塞。当第二个协程从通道接收2时,第一个协程的发送操作成功,第一个协程被唤醒。
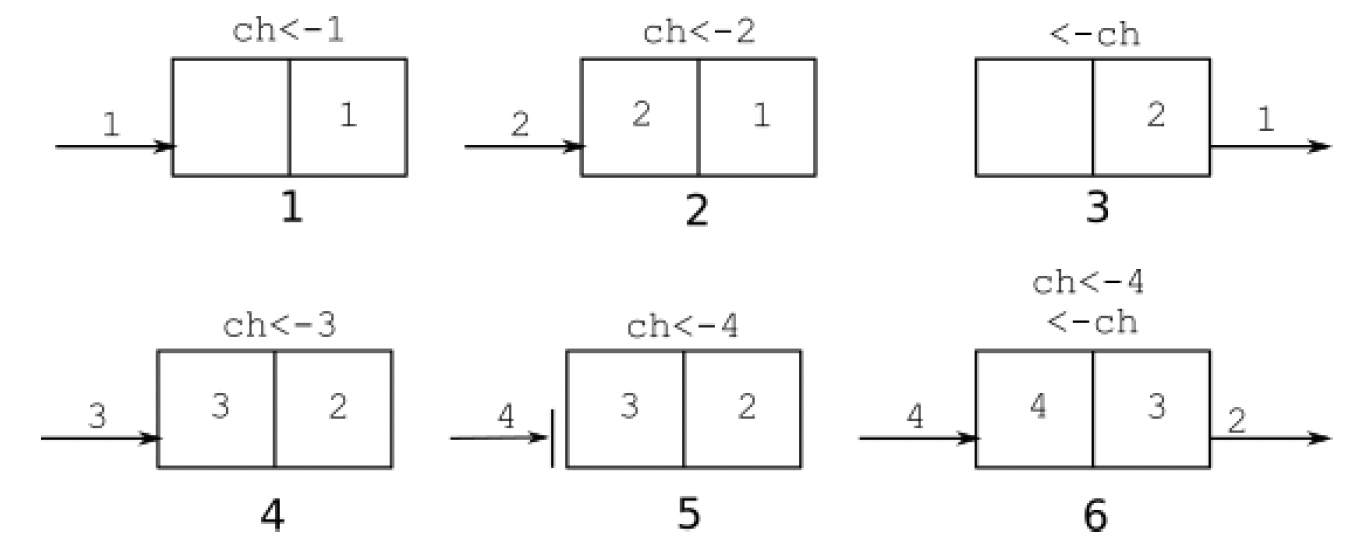
图2.3 - 容量为2的带缓冲通道的可能操作顺序
这个例子表明,向通道发送数据的操作会阻塞,直到通道准备好接收值。如果通道尚未准备好接收值,发送操作就会阻塞。
类似地,图2.4展示了一个阻塞的接收操作。第一个协程发送1,第二个协程接收它。此时len(ch)=0,所以第二个协程的下一次接收操作会阻塞。当第一个协程向通道发送值2时,第二个协程接收该值并被唤醒。
 图2.4 - 阻塞的接收操作
图2.4 - 阻塞的接收操作
所以,从通道接收数据的操作会阻塞,直到通道准备好提供值。
通道实际上是一个指向包含其内部状态的数据结构的指针,因此通道变量的零值是nil。正因如此,必须使用make关键字初始化通道。如果你忘记初始化通道,它将永远不会准备好接收或提供值,因此从空通道读取或向空通道写入数据会无限期阻塞。
Go语言的垃圾回收器(garbage collector)会回收不再使用的通道。如果没有协程直接或间接引用一个通道,即使其缓冲区中还有元素,该通道也会被垃圾回收。你无需关闭通道来使其符合垃圾回收的条件。实际上,关闭通道的意义不止于清理资源。
你可能已经注意到,使用通道发送和接收数据是一对一的操作:一个协程发送,另一个协程接收数据。无法通过一个通道发送能被多个协程接收的数据。然而,关闭通道是向所有接收协程的一次性广播。事实上,这是一次性通知多个协程的唯一方法。这是一个非常有用的特性,在开发服务器时尤为如此。例如,net/http包实现了一个Server类型,它在单独的协程中处理每个请求。context.Context的实例会传递给每个请求处理程序,其中包含一个Done()通道。例如,如果在请求处理程序准备好响应之前客户端关闭了连接,处理程序可以检查Done()通道是否已关闭,并提前终止处理。如果请求处理程序创建协程来准备响应,它应该将相同的上下文传递给这些协程,一旦Done()通道关闭,它们都将收到取消通知。我们将在本书后面讨论如何使用context.Context。
从已关闭的通道接收数据是有效的操作。实际上,从已关闭的通道接收数据总是会成功,并返回通道类型的零值。向已关闭的通道写入数据则是一个错误:向已关闭的通道写入数据总是会导致程序崩溃(panic)。
图2.5描述了关闭通道的工作原理。这个例子从一个协程向通道发送1和2,然后关闭通道开始。通道关闭后,再向其发送更多数据会导致程序崩溃。通道将通道已关闭的信息作为其缓冲区中的一个值保存,因此接收操作仍然可以继续。协程接收1和2,然后每次读取都会返回通道类型的零值,在这个例子中是整数0。
 图2.5 - 关闭通道
图2.5 - 关闭通道
对于接收方来说,通常需要知道读取数据时通道是否已关闭。可以使用以下形式来测试通道状态:
y, ok := <-ch
这种形式的通道接收操作将返回接收到的值,以及该值是真实接收的还是因为通道关闭而返回的。如果ok=true,表示值已成功接收。如果ok=false,表示通道已关闭,此时接收到的值只是零值。由于向已关闭的通道发送数据会导致程序崩溃,所以不存在类似的发送语法。
如果创建的通道没有缓冲区会怎样呢?这样的通道被称为无缓冲通道(unbuffered channel),它的行为与带缓冲通道类似,但len(ch)=0且cap(ch)=0。因此,发送操作会阻塞,直到另一个协程从通道接收数据。接收操作也会阻塞,直到另一个协程向通道发送数据。换句话说,无缓冲通道是在协程之间原子性地传输数据的一种方式。让我们通过以下代码片段来看看无缓冲通道是如何用于发送消息和同步协程的:
1: chn := make(chan bool) // 创建一个无缓冲通道
2: go func() {
3: chn <- true // 向通道发送数据
4: }()
5: go func() {
6: var y bool
7: y <-chn // 从通道接收数据
8: fmt.Println(y)
9: }()
2
3
4
5
6
7
8
9
第1行创建了一个无缓冲的布尔型通道。
第2行创建了协程G1,第5行创建了协程G2。
此时有两种可能的执行情况:G1在G2准备好接收(第7行)之前尝试发送(第3行),或者G2在G1准备好发送(第3行)之前尝试接收(第7行)。图2.6中的第一个图展示了G1先运行的情况。在第3行,G1尝试向通道发送数据。然而,此时G2还未准备好接收。由于通道是无缓冲的且没有可用的接收方,G1会阻塞。
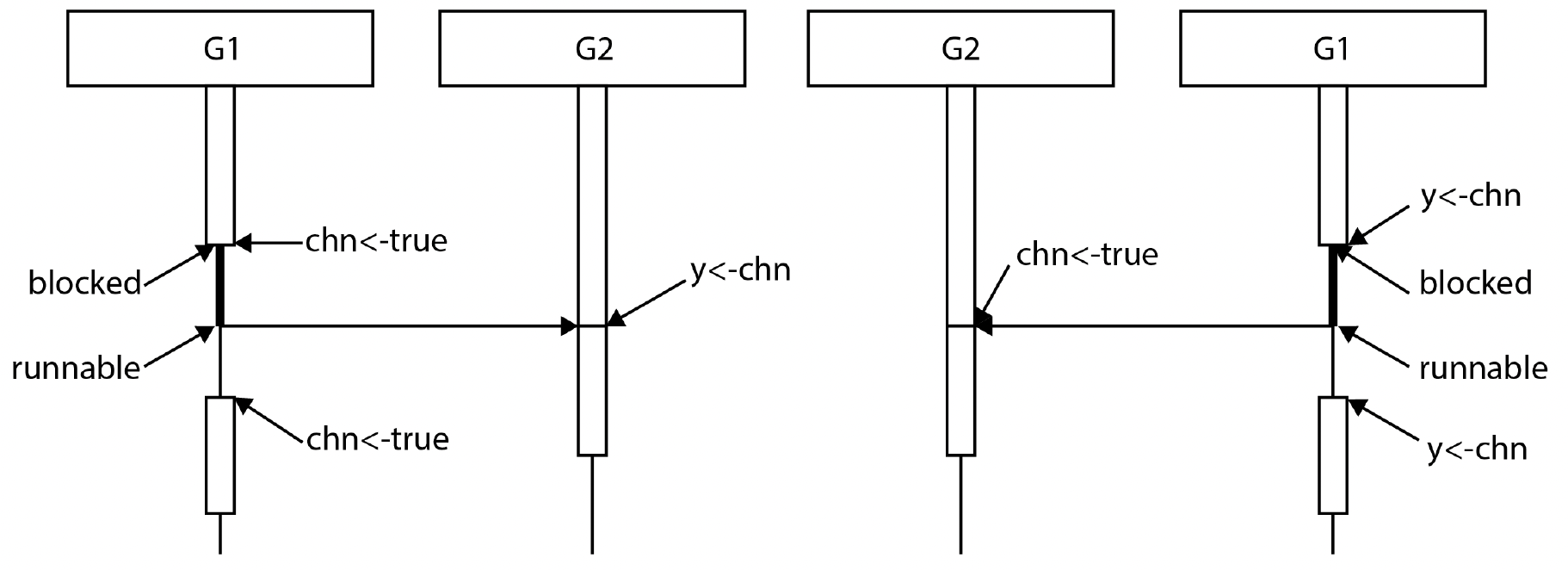 图2.6 - 使用无缓冲通道的两种可能执行情况
图2.6 - 使用无缓冲通道的两种可能执行情况
过了一会儿,G2执行第7行。这是一个通道接收操作,并且有一个协程(G1)正在等待向该通道发送数据。因此,G1被解除阻塞并向通道发送值,G2无需阻塞即可接收该值。现在由调度器决定G1何时可以继续运行。
图2.6右侧展示了第二种可能的场景,即G2先运行的情况。由于G1尚未向通道发送数据,G2会阻塞。当G1准备好发送时,G2已经在等待接收,所以G1无需阻塞即可发送值,G2被解除阻塞并接收该值。调度器决定G2何时可以再次运行。
请注意,无缓冲通道在两个协程之间充当同步点。两个协程必须协调一致,消息传输才能发生。
这里需要提醒一点。从一个协程向另一个协程传输值时,传输的是值的副本。所以,如果一个协程执行ch<-x发送x的值,另一个协程通过y<-ch接收,这就相当于y=x,并且还额外提供了同步保证。关键在于,这并不会转移值的所有权。如果传输的值是一个指针,那么最终会形成一个共享内存系统。考虑以下程序:
type Data struct {
Values map[string]interface{}
}
func processData(data Data,pipeline chan Data) {
data.Values = getInitialValues() // 初始化映射
pipeline <- data // 将数据发送到另一个协程进行处理
data.Values["status"] = "sent" // 可能存在数据竞争!
}
2
3
4
5
6
7
8
9
processData函数初始化Values映射,然后将数据发送到另一个协程进行处理。但映射实际上是一个指向复杂映射结构的指针。当数据通过通道发送时,接收方接收到的是指向同一映射结构的指针副本。如果接收协程对Values映射进行读取或写入操作,该操作将与前面代码片段中的写入操作并发执行,这就产生了数据竞争。
因此,按照惯例,最好假设如果一个值通过通道发送,该值的所有权也随之转移,并且在通过通道发送变量后不应再使用它。你可以重新声明它或丢弃它。如果确实需要,可以包含额外的机制,如互斥锁(mutex),以便在值共享后协调协程。
通道可以声明方向。这种通道在作为函数参数或函数返回值时很有用:
var receiveOnly <-chan int // 只能接收,不能写入或关闭
var sendOnly chan<- int // 只能发送,不能读取或关闭
2
这种声明的好处在于类型安全:将只写通道作为参数的函数不能从该通道接收数据或关闭它。从函数返回的只读通道,调用方只能从该通道接收数据,而不能发送数据或关闭它。例如:
func streamResults() <-chan Data {
resultCh := make(chan Data)
go func() {
defer close(resultCh)
results := getResults()
for _, result := range results {
resultCh <- result
}
}()
return resultCh
}
2
3
4
5
6
7
8
9
10
11
这是一种将查询结果流式传输给调用方的典型方式。该函数首先声明一个双向通道,但将其作为单向通道返回。这告知调用方只能从该通道读取数据。流式传输函数会向该通道写入数据,并在完成所有操作后关闭它。
到目前为止,我们都是在两个协程的场景下讨论通道。但通道可用于与多个协程进行通信。当多个协程尝试向一个通道发送数据,或者多个协程尝试从一个通道读取数据时,它们的调度是随机的。这条简单规则有许多影响。
你可以创建多个工作协程,它们都从一个通道接收数据。另一个协程向该通道发送工作项,每个工作项将被一个可用的工作协程获取并处理。这在工作池模式(worker pool patterns)中很有用,多个协程可以并发处理一系列任务。然后,你可以让一个协程从由许多工作协程写入的通道读取数据。这个读取协程将收集这些协程执行计算的结果。以下程序说明了这一思路:
1: workCh := make(chan Work)
2: resultCh := make(chan Result)
3: done := make(chan bool)
4:
5: // 创建10个工作协程
6: for i := 0; i < 10; i++ {
7: go func() {
8: for {
9: // 从工作通道获取工作
10: work := <- workCh
11: // 计算结果
12: // 通过结果通道发送结果
13: resultCh <- result
14: }
15: }()
16: }
17: results := make([]Result, 0)
18: go func() {
19: // 收集所有结果
20: for _, i := 0; i < len(workQueue); i++ {
21: results = append(results, <-resultCh)
22: }
23: // 当所有结果都收集完毕,通知done通道
24: done <- true
25: }()
26: // 将所有工作发送给工作协程
27: for _, work := range workQueue {
28: workCh <- work
29: }
30: // 等待所有操作完成
31: <- done
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这是一个示例程序,用于说明如何使用多个通道来协调工作。有两个用于传递数据的通道,workCh用于向协程发送工作,resultCh用于收集计算结果。还有一个通道done,用于控制程序流程。这是必要的,因为我们希望在继续执行之前等待所有结果都被计算并存储在切片中。程序首先创建工作协程,然后创建一个单独的协程来收集结果。所有这些协程都会阻塞,等待接收数据(第10行和第21行)。主程序体中的for循环将遍历工作队列,并将工作项发送给等待的工作协程(第28行)。每个工作协程将接收工作(第10行),计算结果,并将结果发送给收集协程(第13行),收集协程会将结果放入切片中。主协程将发送所有工作项,然后阻塞,直到从done通道接收到一个值(第31行),这个值会在所有结果都被收集后(第24行)到来。如你所见,这个程序中通道操作存在顺序:28 < 10 < 13 < 21 < 24 < 31。在分析程序的并发执行时,这些类型的顺序至关重要。
你可能已经注意到,在这个程序中,所有工作协程都泄漏了,即它们从未停止。一个很好的停止方法是在完成对workCh通道的写入后关闭它。然后我们可以在工作协程中检查通道是否已关闭:
for _, work := range workQueue {
workCh <- work
}
close(workCh)
2
3
4
这将通知工作协程工作队列已耗尽,并且工作通道已关闭。我们修改工作协程来检查这一点,如下所示:
work, ok := <- workCh
if !ok { // 通道是否已关闭?
return // 是,终止
}
2
3
4
还有一种更地道的做法。你可以在for循环中遍历通道,当通道关闭时循环会自动退出:
go func() {
for work := range workCh { // 接收数据直到通道关闭
// 计算结果
// 通过结果通道发送结果
resultCh <- result
}
}()
2
3
4
5
6
7
通过这种修改,一旦工作通道关闭,所有正在运行的工作协程都将终止。我们将在本书后面更详细地探讨这些模式。不过,目前这些模式引出了另一个问题:如何处理多个通道呢?为了回答这个问题,我们必须引入select语句。以下是Go语言规范中的定义:select语句用于选择一组可能的发送或接收操作中的一个继续执行。
select语句看起来类似于switch-case语句:
select {
case x := <-ch1:
// 从ch1接收x
case y := <-ch2:
// 从ch2接收y
case ch3 <- z:
// 向ch3发送z
default:
// 可选的默认分支,如果其他操作都无法继续执行
}
2
3
4
5
6
7
8
9
10
从高层次来看,select语句会选择一个可以继续执行的发送或接收操作,然后运行与所选操作对应的代码块。注意前面注释中的过去时态。只有在从ch1接收到x之后,从ch1接收x的代码块才会运行。如果有多个可以继续执行的发送或接收操作,select语句会随机选择一个。如果没有任何操作可以继续执行,select语句会选择默认选项。如果没有默认选项,select语句会阻塞,直到有一个通道操作可用。
根据前面的定义,以下代码会无限阻塞:
select {}
在select语句中使用default选项,对非阻塞的发送和接收操作很有用。只有在所有其他选项都未准备好时,才会选择default选项。下面是一个非阻塞发送操作的示例:
select {
case ch <- x:
sent = true
default:
}
2
3
4
5
上述select语句会测试ch通道是否准备好发送数据。如果准备好,就会发送x的值;如果没准备好,就会继续执行default选项中的代码。注意,这仅仅表示在测试时ch通道没有准备好发送数据。当default选项开始执行时,向ch通道发送数据的操作可能就变得可行了。
类似地,下面是一个非阻塞接收操作:
select {
case x = <-ch:
received = true
default:
}
2
3
4
5
关于协程(goroutines),一个常见的问题是如何停止它们。如前所述,不存在能在协程运行过程中停止它的神奇函数。不过,通过使用非阻塞接收操作和一个用于发出停止请求信号的通道,你可以优雅地终止一个长时间运行的协程:
stopCh := make(chan struct{})
requestCh := make(chan Request)
resultCh := make(chan Result)
go func() {
for { // 无限循环
var req Request
select {
case req = <-requestCh:
// 接收到一个要处理的请求
case <-stopCh:
// 收到停止请求,进行清理并返回
cleanup()
return
}
// 进行一些处理
someLongProcessing(req)
// 在执行另一个长时间任务前检查是否收到停止请求
select {
case <-stopCh:
// 收到停止请求,进行清理并返回
cleanup()
return
default:
}
// 进行更多处理
result := otherLongProcessing(req)
select {
// 等待直到resultCh可以发送数据,或者收到停止请求
case resultCh <- result:
// 结果已发送
case <-stopCh:
// 收到停止请求
cleanup()
return
}
}
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
上述函数使用了三个通道:一个用于从requestCh接收请求,一个用于向resultCh发送结果,还有一个stopCh用于通知协程有停止请求。要发送停止请求,主协程只需关闭stop通道,这会向所有工作协程广播停止请求。
第7行的select语句会阻塞,直到请求通道或停止通道中有数据可接收。如果从停止通道接收到数据,协程就会进行清理并返回。如果接收到一个请求,协程就会处理它。第18行的select语句是对停止通道的非阻塞读取。如果在处理过程中收到停止请求,就会在这里检测到,协程可以进行清理并返回。否则,处理继续进行并计算结果。第27行的select语句会检查监听协程是否准备好接收结果,或者是否收到停止请求。如果监听协程已准备好,就发送结果,然后循环重新开始。如果监听协程未准备好但收到了停止请求,协程就会进行清理并返回。这个select是阻塞式的,所以它会等待,直到能够发送结果或接收到停止请求并返回。注意,对于第27行的select语句,如果结果通道和停止通道都处于可用状态,选择是随机的。即使收到了停止请求,协程也可能会发送结果通道的数据并继续循环。第7行的select语句也存在同样的情况。如果请求通道和停止通道都可用,select语句可能会选择读取请求,而不是停止。
这个例子引出了一个要点:在select语句中,所有可用的通道被选中的可能性是相同的,也就是说,不存在通道优先级。在高负载情况下,前面的协程即使在收到停止请求后,也可能会处理很多请求。处理这种情况的一种方法是再次检查优先级更高的通道:
select {
case req = <-requestCh:
// 接收到一个要处理的请求
// 检查是否也收到了停止请求
select {
case <-stopCh:
cleanup()
return
default:
}
case <-stopCh:
// 收到停止请求,进行清理并返回
cleanup()
return
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这样在从请求通道接收到请求后,会再次检查停止请求,如果收到停止请求就返回。
另外,注意上述实现如果停止,会丢失已接收的请求。如果不希望出现这种副作用,清理过程应该将请求放回队列中。
通道可用于根据信号优雅地终止程序。在容器化环境中,这一点很重要,因为编排平台可能会使用信号终止正在运行的容器。下面的代码片段说明了这种场景:
var term chan struct{}
func main() {
term = make(chan struct{})
sig := make(chan os.Signal, 1)
go func() {
<-sig
close(term)
}()
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)
go func() {
for {
select {
case <-term:
return
default:
}
// 执行工作
}
}()
//...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这个程序会通过关闭全局的term通道来处理来自操作系统的中断和终止信号。所有工作协程都会检查term通道,以判断程序是否正在终止并返回。这让应用程序有机会在程序终止前执行清理操作。监听信号的通道必须是带缓冲的,因为运行时使用非阻塞写入来发送信号消息。
最后,让我们仔细看看select语句的一些有趣特性,这些特性可能会引起一些误解。例如,下面是一个有效的select语句。当通道准备好接收数据时,select语句会随机选择其中一个case:
select {
case <-ch:
case <-ch:
}
2
3
4
case块中的第一个操作不一定是通道发送或接收操作,例如:
func main() {
var i int
f := func() int {
i++
return i
}
ch1 := make(chan int)
ch2 := make(chan int)
select {
case ch1 <- f():
case ch2 <- f():
default:
}
fmt.Println(i)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上述程序使用了非阻塞发送操作。由于没有其他协程,通道发送操作无法被选中,但f()函数在两个case中都会被调用。这个程序会输出2。更复杂一点的select语句如下:
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
ch2 <- 1
}()
go func() {
fmt.Println(<-ch1)
}()
select {
case ch1 <- <-ch2:
time.Sleep(time.Second)
default:
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在这个程序中,有一个协程向ch2通道发送数据,还有一个协程从ch1通道接收数据。两个通道都是无缓冲的,所以两个协程都会在通道操作处阻塞。但是select语句中有一个case是从ch2接收值并将其发送到ch1。到底会发生什么呢?select语句会根据ch1还是ch2的就绪状态来做出决定吗?
select语句会立即计算通道发送操作的参数。这意味着<-ch2会执行,而不会先检查它是否准备好接收数据。如果ch2没有准备好接收数据,即使有default情况,select语句也会阻塞,直到它准备好。一旦从ch2接收到消息,select语句就会做出选择:如果ch1准备好发送这个值,就会发送;如果没有准备好,就会选择default情况。
# 互斥锁(Mutex)
Mutex是“mutual exclusion”(互斥)的缩写。它是一种同步机制,用于确保在其他协程等待时,只有一个协程可以进入临界区。
声明的互斥锁可以直接使用。声明后,互斥锁提供两种基本操作:锁定(lock)和解锁(unlock)。互斥锁只能被锁定一次,所以如果一个协程锁定了互斥锁,所有其他试图锁定它的协程都会阻塞,直到该互斥锁被解锁。这就确保了只有一个协程能进入临界区。
互斥锁的典型用法如下:
var m sync.Mutex
func f() {
m.Lock()
// 临界区
m.Unlock()
}
func g() {
m.Lock()
defer m.Unlock()
// 临界区
}
2
3
4
5
6
7
8
9
10
11
为确保临界区的互斥性,互斥锁必须是一个共享对象。也就是说,为特定临界区定义的互斥锁必须由所有相关协程共享,才能实现互斥。
我们用一个实际的例子来说明互斥锁的使用。缓存问题是一个经常需要解决的常见问题:某些操作,比如复杂的计算、I/O操作或数据库操作,速度比较慢,所以一旦获得结果,将其缓存是很有意义的。但根据定义,缓存会被多个协程共享,所以它必须是线程安全的。下面的示例是一个缓存实现,它从数据库加载对象并将其放入映射(map)中。如果对象在数据库中不存在,缓存也会记录这一情况:
type Cache struct {
mu sync.Mutex
m map[string]*Data
}
func (c *Cache) Get(ID string) (Data, bool) {
c.mu.Lock()
data, exists := c.m[ID]
c.mu.Unlock()
if exists {
if data == nil {
return Data{}, false
}
return *data, true
}
data, loaded := retrieveData(ID)
c.mu.Lock()
defer c.mu.Unlock()
d, exists := c.m[data.ID]
if exists {
return *d, true
}
if!loaded {
c.m[ID] = nil
return Data{}, false
}
c.m[data.ID] = data
return *data, true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Cache结构体包含一个互斥锁。Get方法首先锁定缓存,这是因为Cache.m在协程之间共享,所有涉及Cache.m的读或写操作都只能由一个协程执行。如果此时有其他缓存请求正在进行,这个调用会阻塞,直到其他协程完成操作。
第一个临界区只是读取映射,查看请求的对象是否已经在缓存中。注意,临界区一完成,就会解锁缓存,以便其他协程可以进入它们的临界区。如果请求的对象在缓存中,或者缓存中记录了该对象不存在,方法就会返回。否则,方法会从数据库中检索对象。由于在这个操作过程中没有持有锁,其他协程可以继续使用缓存,这可能会导致其他协程也加载相同的对象。一旦对象被加载,再次锁定缓存,因为必须将加载的对象放入缓存中。这次,我们可以使用defer c.mu.Unlock()来确保方法返回时缓存被解锁。再次检查对象是否已被另一个协程放入缓存中,这是有可能的,因为多个协程可能会同时使用相同的ID请求对象,并且许多协程可能会继续从数据库加载该对象。在获取锁之后再次检查,可以确保如果另一个协程已经将对象放入缓存中,就不会用新的副本覆盖它。
这里需要注意一个重要的点:互斥锁不应该被复制。当你复制一个互斥锁时,最终会得到两个互斥锁,即原始的和复制的,锁定原始互斥锁并不能阻止复制的互斥锁被锁定。go vet工具可以检测到这类问题。例如,使用值接收者而不是指针来声明缓存的Get方法,会复制缓存结构体和互斥锁:
func (c Cache) Get(ID string) (Data, bool) {…}
这会在每次调用时复制互斥锁,因此所有并发的Get调用都可以进入临界区,而不会实现互斥。
互斥锁不会跟踪是哪个协程锁定了它,这会带来一些影响。首先,同一个协程两次锁定互斥锁会导致该协程死锁。在多个函数相互调用且都锁定同一个互斥锁时,这是一个常见的问题:
var m sync.Mutex
func f() {
m.Lock()
defer m.Unlock()
// 处理过程
}
func g() {
m.Lock()
defer m.Unlock()
f() // 死锁
}
2
3
4
5
6
7
8
9
10
11
在这里,g()函数调用f()函数,但m互斥锁已经被锁定,所以f()函数会发生死锁。修正这个问题的一种方法是声明两个版本的f函数,一个有锁操作,一个没有:
func f() {
m.Lock()
defer m.Unlock()
fUnlocked()
}
func fUnlocked() {
// 处理过程
}
func g() {
m.Lock()
defer m.Unlock()
fUnlocked()
}
2
3
4
5
6
7
8
9
10
11
12
13
其次,没有什么能阻止一个不相关的协程解锁另一个协程锁定的互斥锁。在重构算法后,并且在这个过程中忘记更改互斥锁的名称时,就容易发生这种情况,它们会产生非常隐蔽的错误。
互斥锁的功能可以使用一个缓冲区大小为1的通道来实现:
var mutexCh = make(chan struct{}, 1)
func Lock() {
mutexCh <- struct{}{}
}
func Unlock() {
select {
case <-mutexCh:
default:
}
}
2
3
4
5
6
7
8
9
10
很多时候,比如在前面的缓存示例中,存在两种类型的临界区:一种用于读操作,一种用于写操作。读操作的临界区允许多个读操作协程进入,但在所有读操作完成之前,不允许写操作协程进入。写操作的临界区会排除所有其他写操作协程和读操作协程。这意味着一个结构体可以有多个并发的读操作,但只能有一个写操作。为此,可以使用读写互斥锁(RWMutex)。这种互斥锁允许多个读操作协程或单个写操作协程持有锁。修改后的缓存实现如下:
type Cache struct {
mu sync.RWMutex // 使用读写互斥锁
cache map[string]*Data
}
func (c *Cache) Get(ID string) (Data, bool) {
c.mu.RLock()
data, exists := c.m[data.ID]
c.mu.RUnlock()
if exists {
if data == nil {
return Data{}, false
}
return *data, true
}
data, loaded := retrieveData(ID)
c.mu.Lock()
defer c.mu.Unlock()
d, exists := c.m[data.ID]
if exists {
return *d, true
}
if!loaded {
c.m[ID] = nil
return Data{}, false
}
c.m[data.ID] = data
return *data, true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
注意,第一个锁是读锁,它允许多个读操作协程并发执行。一旦确定需要更新缓存,就会使用写锁。
# 等待组(Wait groups)
等待组用于等待一组任务完成,通常是等待一组goroutine执行结束。它本质上是一个线程安全的计数器,能让你一直等待,直到计数器归零。常见的使用模式如下:
// 创建一个等待组
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
// 在创建goroutine **之前** 向等待组添加计数
wg.Add(1)
go func() {
// 确保等待组知晓goroutine已完成
defer wg.Done()
// 执行任务
}()
}
// 等待所有goroutine完成
wg.Wait()
2
3
4
5
6
7
8
9
10
11
12
13
创建等待组时,其初始值为零,所以调用Wait方法时不会等待任何任务。因此,在调用Wait之前,你必须添加需要等待的任务数量。为此,我们调用Add(n),其中n是要添加等待的任务数量。在创建需要等待的任务(这里指goroutine)之前调用Add(1),这样更便于阅读代码。然后,主goroutine调用Wait方法,它会一直等待,直到等待组的计数器归零。为了实现这一点,我们必须确保每个返回的goroutine都调用了Done方法。使用defer语句是确保这一点的最简单方式。
等待组的一个常见用途是在编排服务(orchestrator service)中,该服务调用多个其他服务并收集结果。编排服务必须等待所有被调用的服务返回,才能继续后续的计算。
看下面这个示例:
func orchestratorService() (Result1, Result2) {
wg := sync.WaitGroup{} // 创建一个等待组
wg.Add(1) // 添加第一个goroutine
var result1 Result1
go func() {
defer wg.Done() // 确保等待组知晓任务完成
result1 = callService1() // 调用服务1
}()
wg.Add(1) // 添加第二个goroutine
var result2 Result2
go func() {
defer wg.Done() // 确保等待组知晓任务完成
result2 = callService2() // 调用服务2
}()
wg.Wait() // 等待两个服务都返回
return result1, result2 // 返回结果
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在使用等待组时,常见的错误是在错误的位置调用Add或Done方法。有两点需要牢记:
- 必须在程序调用
Wait方法之前调用Add。这意味着你不能在使用等待组等待的goroutine内部调用Add。因为无法保证在调用Wait之前,该goroutine就会开始执行。 - 最终必须调用
Done方法。最安全的做法是在goroutine内部使用defer语句,这样即使goroutine的逻辑发生变化,或者它以意外的方式(比如发生恐慌(panic))返回,Done也会被调用。
有时,同时使用等待组和通道(channels)会引发类似“先有鸡还是先有蛋”的问题:你必须在Wait之后关闭通道,但除非关闭通道,否则Wait不会结束。看下面这个程序:
func main() {
ch := make(chan int)
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
ch <- i
}(i)
}
// 没有goroutine从ch读取数据
// 所有goroutine都不会返回
// 所以下面的Wait会发生死锁
wg.Wait()
close(ch)
for i := range ch {
fmt.Println(i)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
一种可能的解决方案是在调用Wait之前,将16 - 18行的for循环放到一个单独的goroutine中,这样就会有一个goroutine从通道中读取数据。由于通道会被读取,所有goroutine都会结束,这将使wg.Wait解除阻塞,然后关闭通道,终止读取数据的for循环:
go func() {
for i := range ch {
fmt.Println(i)
}
}()
wg.Wait()
close(ch)
2
3
4
5
6
7
另一种解决方案如下:
go func() {
wg.Wait()
close(ch)
}()
for i := range ch {
fmt.Println(i)
}
2
3
4
5
6
7
8
此时,等待组在另一个goroutine中等待,在所有被等待的goroutine返回后,它会关闭通道。
# 条件变量(Condition variables)
条件变量与之前介绍的并发原语有所不同,对于Go语言来说,它并非必不可少的并发工具,因为在大多数情况下,条件变量可以用通道替代。不过,在共享内存系统中,条件变量是重要的同步工具。例如,Java语言就利用条件变量构建了其核心同步功能之一。
并发计算中一个著名的问题是生产者 - 消费者问题。有一个或多个生产者线程生成数据值,这些值由一个或多个消费者线程消费。由于所有生产者和消费者都是并发运行的,有时会出现生产者生成的值不足以满足所有消费者的情况,有时又会出现消费者数量不足,无法消费生产者生成的值的情况。通常会有一个有限容量的队列,生产者将数据放入队列,消费者从队列中取出数据。这个问题已经有一个优雅的解决方案:使用通道。所有生产者向通道写入数据,所有消费者从通道读取数据,问题就解决了。但在共享内存系统中,通常会使用条件变量来处理这种情况。条件变量是一种同步机制,多个goroutine可以等待某个条件发生,而另一个goroutine则可以向等待的goroutine宣告该条件已发生。
条件变量支持以下三种操作:
Wait:阻塞当前goroutine,直到某个条件发生。Signal:当条件发生时,唤醒一个等待的goroutine。Broadcast:当条件发生时,唤醒所有等待的goroutine。
与其他并发原语不同,条件变量需要一个互斥锁(mutex)。互斥锁用于锁定修改条件的goroutine中的临界区。条件的具体内容并不重要,关键在于条件只能在临界区中修改,并且必须通过锁定用于创建条件变量的互斥锁才能进入该临界区,如下代码所示:
lock := sync.Mutex{}
cond := sync.NewCond(&lock)
2
现在,我们使用这个条件变量来实现生产者 - 消费者问题。我们的生产者将生成整数并放入一个循环队列中。队列容量有限,所以如果队列已满,生产者必须等待消费者从队列中取出数据。这意味着我们需要一个条件变量,让生产者等待,直到有消费者消费了一个值。当消费者消费了一个值后,队列就有了更多空间,生产者就可以使用这些空间,但此时消费了该值的消费者必须向等待的生产者发出信号,告知有可用空间。类似地,如果消费者在生产者生成新值之前就消费完了所有值,消费者就必须等待新值可用。所以,我们还需要另一个条件变量,让消费者等待,直到生产者生成一个值。当生产者生成了一个新值后,它必须向等待的消费者发出信号,告知有新值可用。
我们先从一个简单的循环队列实现开始:
type Queue struct {
elements []int
front, rear int
len int
}
// NewQueue初始化一个具有给定容量的空循环队列
func NewQueue(capacity int) *Queue {
return &Queue{
elements: make([]int, capacity),
front: 0, // 从elements[front]读取数据
rear: -1, // 向elements[rear]写入数据
len: 0,
}
}
// Enqueue向队列中添加一个值。如果队列已满,返回false
func (q *Queue) Enqueue(value int) bool {
if q.len == len(q.elements) {
return false
}
// 推进写入指针,循环移动
q.rear = (q.rear + 1) % len(q.elements)
// 写入值
q.elements[q.rear] = value
q.len++
return true
}
// Dequeue从队列中移除一个值。如果队列已空,返回0和false
func (q *Queue) Dequeue() (int, bool) {
if q.len == 0 {
return 0, false
}
// 读取读取指针处的值
data := q.elements[q.front]
// 推进读取指针,循环移动
q.front = (q.front + 1) % len(q.elements)
q.len--
return data, true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
我们需要一个锁、两个条件变量和一个循环队列:
func main() {
lock := sync.Mutex{}
fullCond := sync.NewCond(&lock)
emptyCond := sync.NewCond(&lock)
queue := NewQueue(10)
2
3
4
5
下面是生产者函数,它在一个无限循环中运行,生成随机整数值:
producer := func() {
for {
// 生成值
value := rand.Int()
lock.Lock()
for !queue.Enqueue(value) {
fmt.Println("Queue is full")
fullCond.Wait()
}
lock.Unlock()
emptyCond.Signal()
time.Sleep(time.Millisecond *
time.Duration(rand.Intn(1000)))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
生产者生成一个随机整数,进入其临界区,并尝试将该值入队。如果入队成功,它会解锁互斥锁,并向一个消费者发出信号,告知有新值生成。如果此时没有消费者在emptyCond变量上等待,该信号将丢失。然而,如果队列已满,生产者就会开始在fullCond变量上等待。注意,Wait是在临界区中调用的,此时互斥锁是锁定的。调用Wait时,它会自动解锁互斥锁并暂停goroutine的执行。在等待期间,生产者不再处于其临界区,从而允许消费者进入他们自己的临界区。当一个消费者消费了一个值后,它会向fullCond发出信号,这将唤醒一个等待的生产者。当生产者被唤醒时,它会再次锁定互斥锁。唤醒和锁定互斥锁不是原子操作,这意味着当Wait返回时,唤醒goroutine的条件可能不再成立,所以必须在循环中调用Wait来重新检查条件。当重新检查条件时,goroutine会再次处于其临界区,这样就不会出现竞态条件。消费者函数如下:
consumer := func() {
for {
lock.Lock()
var v int
for {
var ok bool
if v, ok = queue.Dequeue(); !ok {
fmt.Println("Queue is empty")
emptyCond.Wait()
continue
}
break
}
lock.Unlock()
fullCond.Signal()
time.Sleep(time.Millisecond *
time.Duration(rand.Intn(1000)))
fmt.Println(v)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
注意生产者和消费者之间的对称性。消费者进入其临界区,并在一个for循环中尝试从队列中取出一个值。如果队列中有值,就会读取该值,for循环终止,然后解锁互斥锁。接着,该goroutine通知任何可能的生产者,队列中有一个值已被读取,所以队列很可能不再满了。当消费者离开其临界区并向生产者发出信号时,有可能另一个生产者已经生成了值,使队列再次满了。这就是为什么生产者被唤醒后必须再次检查条件。同样的逻辑也适用于消费者:如果消费者无法读取值,它就开始等待,当被唤醒时,它必须检查队列中是否有可消费的元素。程序的其余部分如下:
for i := 0; i < 10; i++ {
go producer()
}
for i := 0; i < 10; i++ {
go consumer()
}
select {} // 无限期等待
2
3
4
5
6
7
你可以用不同数量的生产者和消费者运行这个程序,观察其行为。当生产者数量多于消费者时,你应该会看到更多关于队列已满的消息;当消费者数量多于生产者时,你应该会看到更多关于队列已空的消息。
# 总结
在本章中,我们介绍了Go语言支持的两个并发原语:goroutine和通道,以及Go标准库中的一些基本同步原语。下一章将使用这些原语来解决一些常见的并发问题。
# 问题
- 你能用通道实现一个互斥锁(mutex)吗?读写互斥锁(RWMutex mutex)呢?
- 大多数条件变量都可以用通道替代。你如何用通道实现
Broadcast操作?