 3 Go内存模型
3 Go内存模型
# 3 Go内存模型
Go内存模型规定了内存写操作何时对其他goroutine可见,更重要的是,它也规定了这些可见性保证不存在的情况。作为开发者,在开发并发程序时,遵循一些准则就可以跳过内存模型的细节。即便如此,如前文所述,明显的错误在质量保证(QA)阶段很容易被发现,而在生产环境中出现的错误通常无法在开发环境中重现,这时你可能不得不通过阅读代码来分析程序行为。在这种情况下,对内存模型有深入了解会很有帮助。
在本章中,我们将讨论以下内容:
- 为什么需要内存模型
- 内存操作之间的先发生(happened-before)关系
- Go并发原语的同步特性
# 为什么需要内存模型
1965年,戈登·摩尔(Gordon Moore)观察到,密集集成电路中的晶体管数量每年都会翻倍。后来在1975年,这一周期调整为每两年翻倍。由于这些技术进步,很快就能将大量组件集成到一个微小的芯片中,从而制造出更快的处理器。
现代处理器采用了许多先进技术,如缓存、分支预测和流水线技术,以充分利用CPU上的电路。然而,在21世纪初,硬件工程师开始触及单芯片优化的极限。因此,他们制造出了包含多个核心的芯片。如今,大多数性能考量既涉及单个核心执行指令的速度,也关乎有多少核心能够同时运行这些指令。
在硬件不断改进的同时,编译器技术也在不断发展。现代编译器能够对程序进行深度优化,以至于编译后的代码与原始代码大相径庭。换句话说,程序的执行顺序和方式可能与编写的语句顺序有很大差异。这些重新排序不会影响顺序执行程序的行为,但在涉及多个线程时,可能会产生意外的结果。
一般来说,优化不应改变有效程序的行为 —— 但我们如何定义什么是有效程序呢?答案就是内存模型。内存模型定义了什么是有效程序、编译器构建者必须确保的内容,以及程序员可以期望的结果。
换句话说,内存模型是编译器构建者对硬件构建者的回应。作为开发者,我们必须理解这个回应,以便创建在不同平台上都能以相同方式运行的有效程序。
Go内存模型文档以一条有效程序的经验法则作为开篇:对于那些修改被多个goroutine同时访问的数据的程序,必须对这种访问进行序列化处理。就这么简单 —— 但为什么做起来这么难呢?主要原因在于要弄清楚程序语句的效果在运行时何时能被观察到,以及个人认知能力的局限:你根本无法分析并发程序所有可能的执行顺序。熟悉内存模型有助于根据观察到的行为找出并发程序中的问题。
Go内存模型中有一句很有名的话:
如果你必须阅读本文档的其余部分(即Go内存模型)才能理解你程序的行为,那你就太自作聪明了。
别耍小聪明。
我对这句话的理解是,不要编写依赖于Go内存模型复杂细节的程序。你应该阅读并理解Go内存模型。它会告诉你可以对运行时抱有哪些期望,以及哪些事情不能做。如果更多人阅读它,StackOverflow上与Go并发相关的问题就会减少。
# 内存操作之间的先行发生(happened-before)关系
这一切都归结于内存操作在运行时的顺序,以及运行时如何保证这些内存操作的效果何时可见。为了解释Go内存模型,我们需要定义三种关系,它们定义了内存操作的不同顺序。
在任何一个goroutine中,内存操作的顺序必须与该goroutine中由控制流语句和表达式求值顺序所确定的正确顺序执行相对应。这种顺序就是先序(sequenced-before)关系。然而,这并不意味着编译器必须按照编写的顺序执行程序。只要变量的内存读操作读取到的是最后写入该变量的值,编译器就可以重新安排语句的执行顺序。
参考以下程序:
x=1
y=2
z=x
y++
w=y
2
3
4
5
变量z的值始终会被设置为1,变量w的值始终会被设置为3。第1行和第2行是内存写操作。第3行读取x并写入z。第4行读取y并写入y。第5行读取y并写入w。这很明显。可能不那么明显的是,编译器可以按照所有内存读操作都读取到最新写入值的方式重新排列这段代码,如下所示:
x=1
z=x
y=2
y++
w=y
2
3
4
5
在这些程序中,每一行都先序于它后面的那一行。先序关系是关于语句在运行时的顺序,并且考虑了程序的控制流。例如,看下面这个程序:
y=0
for i:=0;i<2;i++ {
y++
}
2
3
4
在这个程序中,如果在第3行语句开始时y的值为1,那么当i=0时执行的i++语句就先序于第3行。
这些都是普通的内存操作。还有同步内存操作,其定义如下:
- 同步读操作:互斥锁(Mutex)锁定、通道接收、原子读,以及原子比较并交换操作。
- 同步写操作:互斥锁解锁、通道发送和通道关闭、原子写,以及原子比较并交换操作。
注意,原子比较并交换操作既是同步读操作,也是同步写操作。
普通内存操作用于定义单个goroutine内的先序关系。当涉及多个goroutine时,同步内存操作用来定义同步先序(synchronized-before)关系。也就是说:如果对一个变量的同步内存读操作观察到了对该变量的最后一次同步写操作,那么该同步写操作就同步先序于该同步读操作。
先发生关系是同步先序关系和先序关系的组合,如下所示:
- 如果内存写操作
w同步先序于内存读操作r,那么w先发生于r。 - 如果内存写操作
x先序于w,并且内存读操作y后序于r,那么x先发生于y。
对于以下程序,图3.1展示了这种关系:
go func() {
x = 1
ch <- 1
}()
go func() {
<-ch
fmt.Println(x)
}()
2
3
4
5
6
7
8
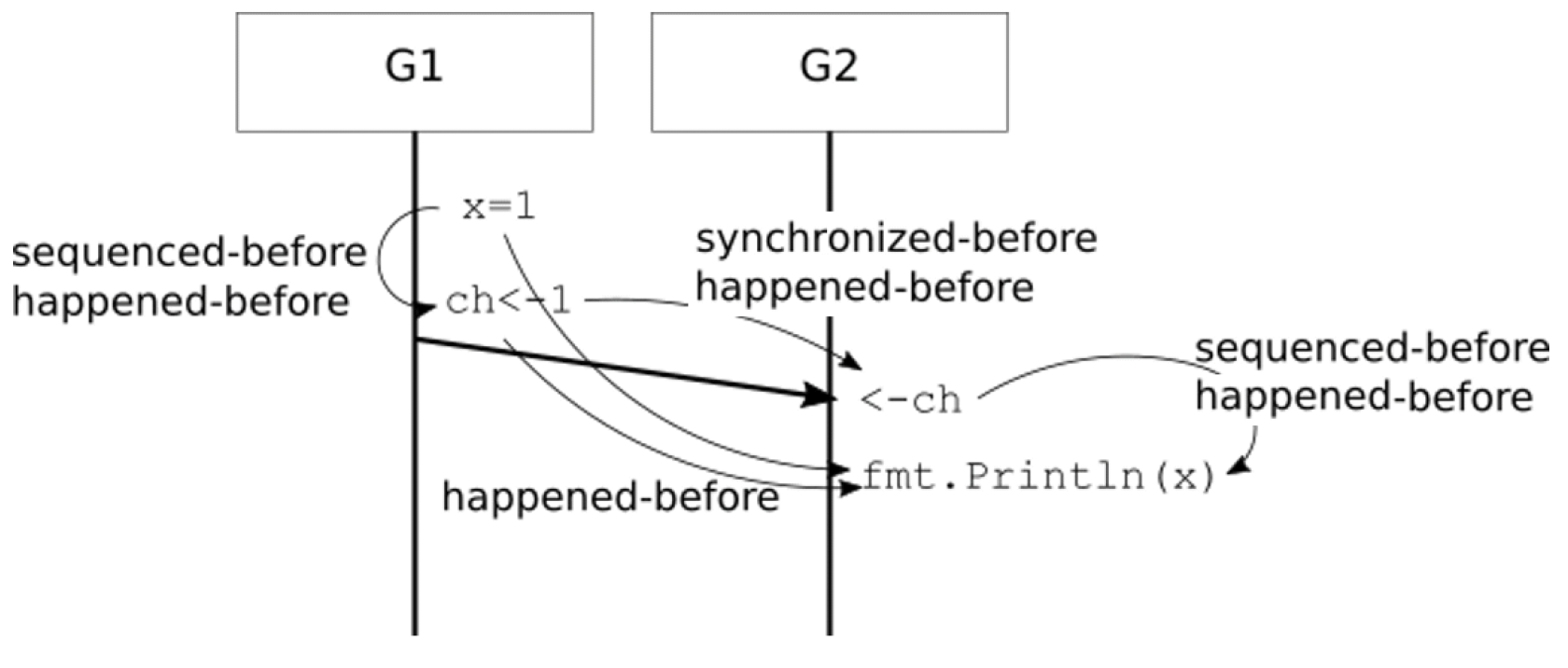 图3.1 先序、同步先序、先发生
图3.1 先序、同步先序、先发生
然而,以下修改会导致数据竞争。在第一个goroutine向通道发送1且第二个goroutine接收到之后,x++和fmt.Println(x)是并发执行的:
go func() {
for {
x ++
ch <- 1
}
}()
go func() {
for range ch {
fmt.Println(x)
}
}()
2
3
4
5
6
7
8
9
10
11
先发生关系很重要,因为内存读操作能够保证看到在它之前发生的内存写操作的效果。如果你怀疑存在竞态条件,确定哪些操作先于其他操作发生有助于找出问题所在。
经验法则是,如果内存写操作先发生于内存读操作,那么它们就不是并发的,也就不会导致数据竞争。如果你无法确定写操作和读操作之间的先发生关系,那么它们就是并发的。
# Go并发原语的同步特性
定义了先发生关系之后,就很容易为Go内存模型制定基本规则了。
# 包初始化
如果包A导入了另一个包B,那么包B中所有init()函数的完成先发生于包A中init()函数的开始。
以下程序总是会先打印“B initializing”,再打印“A initializing”:
package B
import "fmt"
func init() {
fmt.Println("B initializing")
}
2
3
4
5
package A
import (
"fmt"
"B"
)
func init() {
fmt.Println("A initializing")
}
2
3
4
5
6
7
8
这也适用于主包:程序的主包直接或间接导入的所有包,在main()函数开始之前,都会完成它们的init()函数。如果一个init()函数创建了一个goroutine,无法保证这个goroutine会在main()函数开始运行之前结束。这些goroutine是并发运行的。
# 协程(Goroutine)
如果一个程序启动了一个goroutine,那么go语句同步先序于(因此也先发生于)该goroutine执行的开始。以下程序总是会打印“Before goroutine”,因为对a的赋值先发生于goroutine开始运行:
a := "Before goroutine"
go func() { fmt.Println(a) }()
select {}
2
3
一个goroutine的终止与程序中的任何事件都不同步。以下程序可能会打印0或1,这里存在数据竞争:
var x int
go func() { x = 1 }()
fmt.Println(x)
select {}
2
3
4
换句话说,一个goroutine可以看到它开始之前的所有更新,并且一个goroutine无法确定另一个goroutine的终止情况,除非与它有明确的通信。
# 通道
对无缓冲通道的发送或关闭操作,会在从该通道接收操作完成之前进行同步(因此先行发生于接收操作)。对无缓冲通道的接收操作,会在该通道相应的发送操作完成之前进行同步(因此先行发生于发送操作)。换句话说,如果一个协程通过无缓冲通道发送一个值,接收该值的协程会先完成接收,然后发送协程才会完成发送。下面的程序总是输出1:
var x int
ch := make(chan int)
go func() {
<-ch
fmt.Println(x)
}()
x = 1
ch <- 0
select {}
2
3
4
5
6
7
8
9
在这个程序中,对x的写入操作在通道写入之前执行,通道写入在通道读取之前同步。打印操作在通道读取之后执行,所以对x的写入先行发生于对x的打印。
下面的程序也会输出1:
var x int
ch := make(chan int)
go func() {
ch <- 0
fmt.Println(x)
}()
x = 1
<-ch
select {}
2
3
4
5
6
7
8
9
这种保证如何扩展到有缓冲通道呢?如果一个通道的容量为C,那么在单个接收操作完成之前,多个协程可以发送C个数据项。实际上,第n次通道接收操作,在该通道的第n + C次发送操作完成之前进行同步。
对于容量为2的通道,图3.2展示了这种情况。
图3.2——有缓冲通道(容量 = 2)的先行发生保证
这个程序创建了10个工作协程,它们共享5个实例的资源。所有10个工作协程都处理队列中的任务,但在任何给定时间,最多只有5个协程可以使用该资源:
resources := make(chan struct{}, 5)
jobs := make(chan Work)
for worker := 0; worker < 10; worker++ {
go func() {
for work := range <-jobs {
// 执行工作
// 获取资源
resources <- struct{}{}
// 使用资源进行工作
<-resources
}
}()
}
2
3
4
5
6
7
8
9
10
11
12
13
简而言之,在通道接收操作之后,接收协程可以看到相应发送操作之前的所有更新;在通道发送操作之后,发送协程可以看到相应接收操作之前的所有操作。
# 互斥锁
假设两个协程G1和G2试图通过锁定一个共享互斥锁进入它们的临界区。再假设G1锁定了互斥锁(第一次调用Lock()),G2被阻塞。当G1解锁互斥锁(第一次调用Unlock())时,G2锁定了它(第二次调用Lock())。G1的解锁操作在G2锁定之前进行同步(因此先行发生于G2的锁定操作)。结果是,G2可以看到G1在其临界区内进行的内存写入操作的效果。
一般来说,对于互斥锁M,当i > 0时,M.Unlock()的第n次调用在M.Lock()的第(n + i)次返回之前进行同步(因此先行发生于该返回操作):
func main() {
var m sync.Mutex
var a int
// 在主协程中锁定互斥锁
m.Lock()
done := make(chan struct{})
// G1
go func() {
// 这将阻塞,直到G2解锁互斥锁
m.Lock()
// a=1先行发生,所以这里打印1
fmt.Println(a)
m.Unlock()
close(done)
}()
// G2
go func() {
a = 1
// G1将阻塞,直到这个操作运行
m.Unlock()
}()
<-done
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
即使第一个协程先运行,这个程序也总是打印1。
总结一下:如果互斥锁锁定成功,那么在相应解锁操作之前发生的所有事情都是可见的。
# 原子内存操作
sync/atomic包提供底层的原子内存读取和写入操作。如果一个原子读取操作观察到了一个原子写入操作的效果,那么该原子写入操作在这个原子读取操作之前进行同步。
下面的程序总是打印1。这是因为if块中的打印语句只有在原子存储操作完成后才会运行:
func main() {
var i int
var v atomic.Value
go func() {
// 这个协程最终会将1存储到v中
i = 1
v.Store(1)
}()
go func() {
// 忙等待
for {
// 这将一直检查,直到v的值为1
if val, _ := v.Load().(int); val == 1 {
fmt.Println(i)
return
}
}
}()
select {}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 映射(Map)、一次性初始化(Once)和等待组(WaitGroup)
这些是更高级的同步工具,可以通过前面解释的操作来建模。sync.Map提供了一个线程安全的映射实现,你可以直接使用,而无需额外的互斥锁。如果元素只写入一次但读取多次,或者多个协程处理不相交的键集,那么这个映射实现的性能可能优于内置映射加上互斥锁的方式。对于这些用例,sync.Map在并发使用方面表现更好,但它没有内置映射的类型安全性。缓存是sync.Map的一个很好的用例,这里展示一个简单的缓存示例。
对于sync.Map,写入操作先行发生于观察到该写入效果的读取操作。
sync.Once为在多个协程存在的情况下初始化某些内容提供了一种便捷方式。初始化由传递给sync.Once.Do()的函数执行。当多个协程调用sync.Once.Do()时,其中一个协程执行初始化,而其他协程被阻塞。初始化完成后,sync.Once.Do()不再调用初始化函数,并且不会产生任何显著的开销。
Go内存模型保证,如果其中一个协程导致初始化函数运行,那么该函数的完成先行发生于所有其他协程的sync.Once()返回。
下面是一个缓存实现,它使用sync.Map作为缓存,并使用sync.Once确保元素初始化。每个缓存的数据元素都包含一个sync.Once实例,用于在初始化完成之前,阻塞其他试图加载相同ID元素的协程:
type Cache struct {
values sync.Map
}
type cachedValue struct {
sync.Once
value *Data
}
func (c *Cache) Get(id string) *Data {
// 获取缓存的值,或者存储一个空值
v, _ := c.values.LoadOrStore(id, &cachedValue{})
cv := v.(*cachedValue)
// 如果未初始化,则在此处初始化
cv.Do(func() {
cv.value = loadData(id)
})
return cv.value
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
对于WaitGroup,调用Done()会在它所解锁的Wait()调用返回之前进行同步(因此先行发生于该返回操作)。下面的程序总是打印1:
func main() {
var i int
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
i = 1
wg.Done()
}()
wg.Wait()
// 如果执行到这里,说明wg.Done()已被调用,所以i=1
fmt.Println(i)
}
2
3
4
5
6
7
8
9
10
11
12
总结一下:
sync.Map的读取操作会返回最后写入的值。- 如果多个协程调用
sync.Once,只有一个协程会运行初始化,其他协程将等待。一旦初始化完成,其效果对所有等待的协程都是可见的。 - 对于
WaitGroup,当Wait()返回时,所有的Done()调用都已完成。
# 总结
如果你始终对多个协程之间共享的变量进行序列化访问,那么你不需要了解Go内存模型的所有细节。然而,当你阅读、编写、分析和优化并发代码时,Go内存模型可以为你提供指导,帮助你创建安全高效的程序。
接下来,我们将开始研究一些有趣的并发算法。
# 延伸阅读
- 《Go内存模型》:https://go.dev/ref/mem
- Russ Cox于2016年2月25日的演讲《Go的内存模型》:http://nil.csail.mit.edu/6.824/2016/notes/gomem.pdf