 5 工作池与管道
5 工作池与管道
# 5 工作池与管道
本章将介绍两种相互关联的并发结构:工作池(Worker Pools)和管道(Pipelines)。工作池主要处理将工作分配给多个执行相同计算的实例,而数据管道则是把工作分解为一系列不同的计算步骤,依次执行。
在本章中,你将看到几个工作池和数据管道的实际示例。这些模式是解决许多问题的常用方案,而且没有单一的最佳解决方案。我会尽量将并发相关的问题与计算逻辑分开。如果你在解决自己的问题时也能这样做,就能通过迭代找到最适合你具体情况的解决方案。
本章将涵盖以下主题:
- 使用文件扫描器示例讲解工作池
- 使用CSV文件处理器示例讲解数据管道
# 技术要求
无。
# 工作池
许多Go语言的并发程序都是工作池的各种变体组合。其中一个原因可能是通道为将任务分配给等待的协程提供了非常好的机制。工作池简单来说就是一组(一个或多个)协程,它们对多个输入实例执行相同的任务。与按需创建协程相比,工作池可能更实用,原因有以下几点。其一,在工作池中创建一个工作实例的成本可能较高(不是创建协程的成本高,创建协程成本很低,但初始化工作协程的成本可能较高),所以可以一次性创建固定数量的工作实例并重复使用。其二,你可能需要无限制数量的协程,所以一次性创建合理数量的协程更为可行。无论哪种情况,一旦确定需要工作池,就可以反复使用一些易于复用的模式来创建高性能的工作池。
我们在第2章中首次看到了一个简单的工作池实现。这里我们来看看同一模式的一些变体。我们将编写一个程序,它递归扫描目录并搜索正则表达式匹配项,类似于一个简单的grep工具。Work结构体定义为包含文件名和正则表达式:
type Work struct {
file string
pattern *regexp.Regexp
}
2
3
4
在大多数系统中,可打开的文件数量是有限的,所以我们使用固定大小的工作池:
func main() {
jobs := make(chan Work)
wg := sync.WaitGroup{}
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
defer wg.Done()
worker(jobs)
}()
}
...
2
3
4
5
6
7
8
9
10
11
注意,我们在这里创建了一个等待组(WaitGroup),这样就能在程序退出前等待所有工作协程完成处理。还要注意,通过使用匿名函数包装实际的工作函数,我们可以将工作函数本身与等待组的机制隔离开来。然后,我们编译所有协程都将使用的正则表达式:
rex, err := regexp.Compile(os.Args[2])
if err != nil {
panic(err)
}
2
3
4
main函数的其余部分遍历目录并将文件发送给工作协程:
filepath.Walk(os.Args[1], func(path string, d fs.FileInfo, err error) error {
if err != nil {
return err
}
if!d.IsDir() {
jobs <- Work{file: path, pattern: rex}
}
return nil
})
2
3
4
5
6
7
8
9
最后,我们终止所有工作协程并等待它们完成:
...
close(jobs)
wg.Wait()
}
2
3
4
实际的工作函数逐行读取文件,并检查是否有匹配正则表达式的内容。如果有,就打印文件名和匹配的行:
func worker(jobs chan Work) {
for work := range jobs {
f, err := os.Open(work.file)
if err != nil {
fmt.Println(err)
continue
}
scn := bufio.NewScanner(f)
lineNumber := 1
for scn.Scan() {
result := work.pattern.Find(scn.Bytes())
if len(result) > 0 {
fmt.Printf("%s#%d: %s\n", work.file, lineNumber, string(result))
}
lineNumber++
}
f.Close()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
注意,工作函数会一直运行,直到jobs通道关闭。程序运行时,每个文件都会被发送到工作函数,工作函数对文件进行处理。由于工作池中有三个工作协程,在任何时刻,最多会有三个文件被并发处理。还要注意,工作协程会并发打印结果,所以每个文件的匹配行是随机交错显示的。
这个工作池直接打印结果,而不是将结果返回给调用者。在许多情况下,提交工作后需要从工作池中获取结果。一个好的方法是在Work结构体中包含一个返回通道:
type Work struct {
file string
pattern *regexp.Regexp
result chan Result
}
2
3
4
5
我们修改工作函数,通过结果通道发送结果。并且,在文件处理完成后不要忘记关闭结果通道,这样接收端就知道该通道不会再有结果传来:
...
for scn.Scan() {
result := work.pattern.Find(scn.Bytes())
if len(result) > 0 {
work.result <- Result{
file: work.file,
lineNumber: lineNumber,
text: string(result),
}
}
lineNumber++
}
close(work.result)
2
3
4
5
6
7
8
9
10
11
12
13
这种设计解决了结果交错的问题。我们可以从一个结果通道读取数据,直到读取完毕,然后再处理下一个通道。但我们不能使用同一个协程提交任务并读取结果,否则会导致死锁。你知道为什么吗?因为我们会向工作池提交任务,但却没有协程监听结果,所以在提交足够多的任务分配给每个工作协程后,通道发送操作就会阻塞。所以,接收结果的协程必须与发送任务的协程不同。我选择将目录遍历操作放在一个单独的协程中,在主协程中读取结果。
还有一个问题需要解决:如何让接收结果的协程知道结果通道呢?每个提交的工作都包含一个新的结果通道,我们需要从这些通道读取数据。我们可以使用一个切片,将所有这些通道添加到切片中,但这个切片需要同步处理,因为多个协程会对其进行读写操作。
我们可以使用一个通道来发送这些结果通道:
allResults := make(chan chan Result)
我们会将每个新的结果通道发送到allResults通道。当主协程接收到这个通道时,会遍历它来打印结果,一旦工作协程关闭结果通道,就停止遍历。然后,主协程会从allResults通道接收下一个通道,并继续打印结果。现在目录遍历部分的代码如下:
go func() {
defer close(allResults)
filepath.Walk(os.Args[1], func(path string, d fs.FileInfo, err error) error {
if err != nil {
return err
}
if!d.IsDir() {
ch := make(chan Result)
jobs <- Work{file: path, pattern: rex, result: ch}
allResults <- ch
}
return nil
})
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
注意开头的defer语句。所有文件发送完毕后,我们关闭allResults通道,以表示处理完成。我们使用以下代码读取结果:
for resultCh := range allResults {
for result := range resultCh {
fmt.Printf("%s #%d: %s\n", result.file, result.lineNumber, result.text)
}
}
2
3
4
5
图5.1展示了我们如何分析这个算法。这里有三个协程,从左到右分别是路径遍历协程、工作协程和主协程。该图仅展示了这些协程的同步点。最初,路径遍历协程开始运行,找到一个文件,并尝试将Work结构体发送到jobs通道。工作协程等待从jobs通道接收数据,主协程等待从allResults通道接收数据:
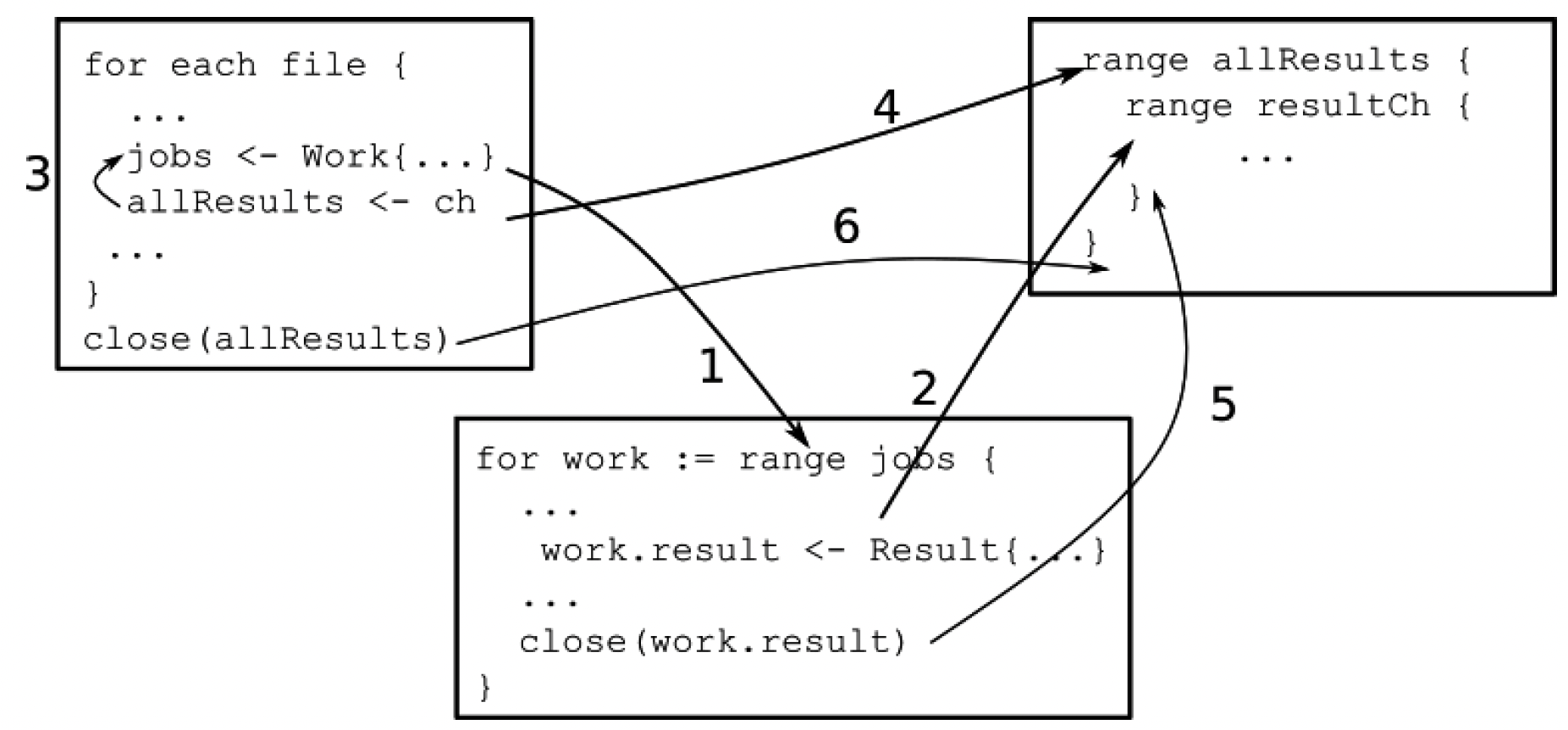 图5.1 工作池的“发生在先”关系
图5.1 工作池的“发生在先”关系
假设现在有一个工作协程可用,那么向jobs通道发送数据的操作就会成功,工作协程接收到工作(箭头1)。此时,路径遍历协程继续向allResults通道发送数据(箭头3),这依赖于主协程从该通道接收数据(箭头4),所以路径遍历协程继续运行,主协程开始等待从resultCh接收结果。在这期间,工作协程计算出结果并写入工作的结果通道,然后主协程接收这个结果(箭头2)。这个过程一直持续,直到工作协程完成任务,关闭结果通道,这会终止主协程中的循环(箭头5)。此时路径遍历协程准备发送下一个工作。当路径遍历协程完成工作时,它会关闭allResults通道,这会终止主协程中的for循环(箭头6)。
也可以使用工作池来执行计算,其结果稍后会被使用(类似于JavaScript中的Promise,或Java中的Future):
resultCh:=make(chan Result)
jobs<-Work{
file:"someFile",
pattern: compiledPattern,
ch:resultCh,
}
2
3
4
5
6
// 做其他事情...
for result := range <-resultCh {
...
}
2
3
4
这与直接调用工作函数有什么不同呢?假设你正在编写一个服务器程序,请求中包含要搜索的文件名和模式。如果同时有数千个请求到达,可能会打开数千个文件,这在你的平台上可能不可行。如果你使用工作池方法,无论同时有多少请求到达,最多只会有预定义数量的工作协程(因此,也只会打开预定义数量的文件)。所以,工作池是限制系统中并发数量的好方法。
最后,你有没有注意到这个工作池实现中没有使用互斥锁(mutexes)?并且唯一显式的等待操作是使用WaitGroup等待所有工作协程完成?
# 管道、扇出与扇入
很多时候,一项计算需要经过多个阶段,对结果进行转换和丰富。通常,会有一个初始阶段获取一系列数据项。这个阶段将这些数据项逐个传递给后续阶段,每个阶段对数据进行处理,生成结果,并传递给下一个阶段。图像处理管道就是一个很好的例子,图像在其中经过解码、变换、滤波、裁剪,然后编码成另一幅图像。许多数据处理应用程序处理的数据量巨大,因此,并发管道对于实现可接受的性能至关重要。
在本章中,我们将构建一个简单的数据处理管道,从逗号分隔值(CSV)文本文件中读取记录。每条记录包含一个人的身高和体重测量值,单位分别是英寸和磅。我们的管道将把这些测量值转换为厘米和千克,然后以JSON对象流的形式输出。我们将使用一些通用函数来抽象问题的阶段处理部分,这样实际的计算单元在不同的管道实现中就无需改变。
Record结构体定义如下:
type Record struct {
Row int `json:"row"`
Height float64 `json:"height"`
Weight float64 `json:"weight"`
}
2
3
4
5
这个管道有三个阶段:
- 解析(Parse):接受从文件中读取的一行数据。然后将行号解析为整数,将身高和体重值解析为浮点数,并返回一个
Record结构体:
func newRecord(in []string) (rec Record, err error) {
rec.Row, err = strconv.Atoi(in[0])
if err != nil {
return
}
rec.Height, err = strconv.ParseFloat(in[1], 64)
if err != nil {
return
}
rec.Weight, err = strconv.ParseFloat(in[2], 64)
return
}
func parse(input []string) Record {
rec, err := newRecord(input)
if err != nil {
panic(err)
}
return rec
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 转换(Convert):接受一个
Record结构体作为输入。然后将身高和体重转换为厘米和千克,并输出转换后的Record结构体:
func convert(input Record) Record {
input.Height = 2.54 * input.Height
input.Weight = 0.454 * input.Weight
return input
}
2
3
4
5
- 编码(Encode):接受一个
Record结构体作为输入。将该记录编码为一个JSON对象:
func encode(input Record) []byte {
data, err := json.Marshal(input)
if err != nil {
panic(err)
}
return data
}
2
3
4
5
6
7
构建管道的方式有很多种。最直接的方法是同步管道。同步管道只是将一个函数的输出传递给另一个函数。管道的输入从CSV文件读取:
func synchronousPipeline(input *csv.Reader) {
// 跳过标题行
input.Read()
for {
rec, err := input.Read()
if err == io.EOF {
return
}
if err != nil {
panic(err)
}
// 管道操作:解析、转换、编码
out := encode(convert(parse(rec)))
fmt.Println(string(out))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这个管道的执行过程如图5.2所示。管道只是处理完一条记录,再处理下一条,直到处理完所有记录。假设每个阶段耗时1微秒,那么它每3微秒产生一个输出。
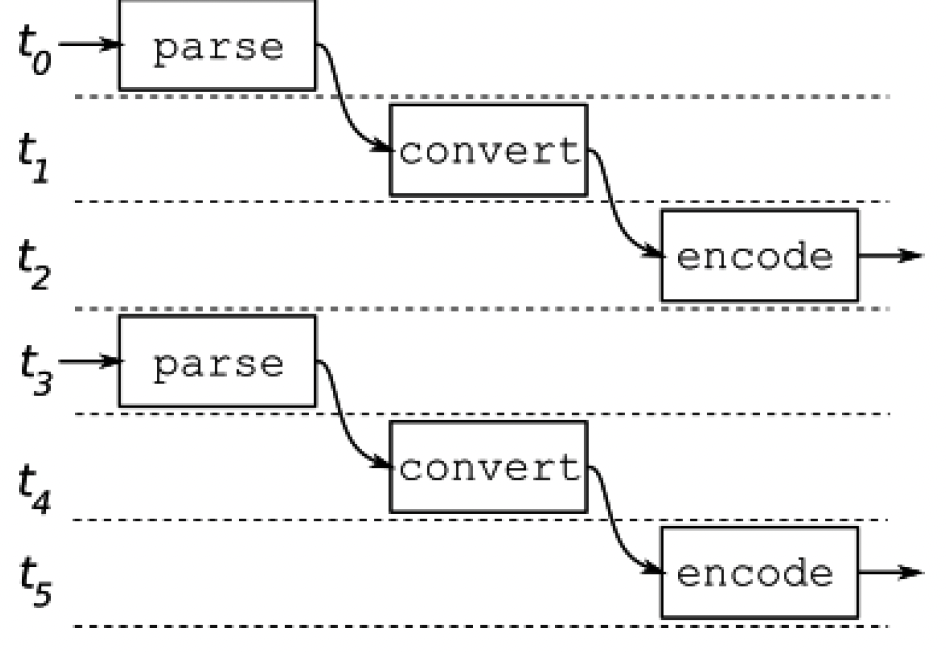 图5.2 同步管道
图5.2 同步管道
# 异步管道
异步管道在单独的goroutine中运行每个阶段。每个阶段从一个通道读取下一个输入,进行处理,并将结果写入输出通道。当输入通道关闭时,它会关闭输出通道,这会导致下一个阶段关闭其通道,依此类推,直到所有通道都关闭,管道终止。从图5.3中可以明显看出这种操作方式的好处:假设所有阶段并行运行,如果每个阶段耗时1微秒,那么在最初的3微秒之后,这个管道每1微秒就会产生一个输出。
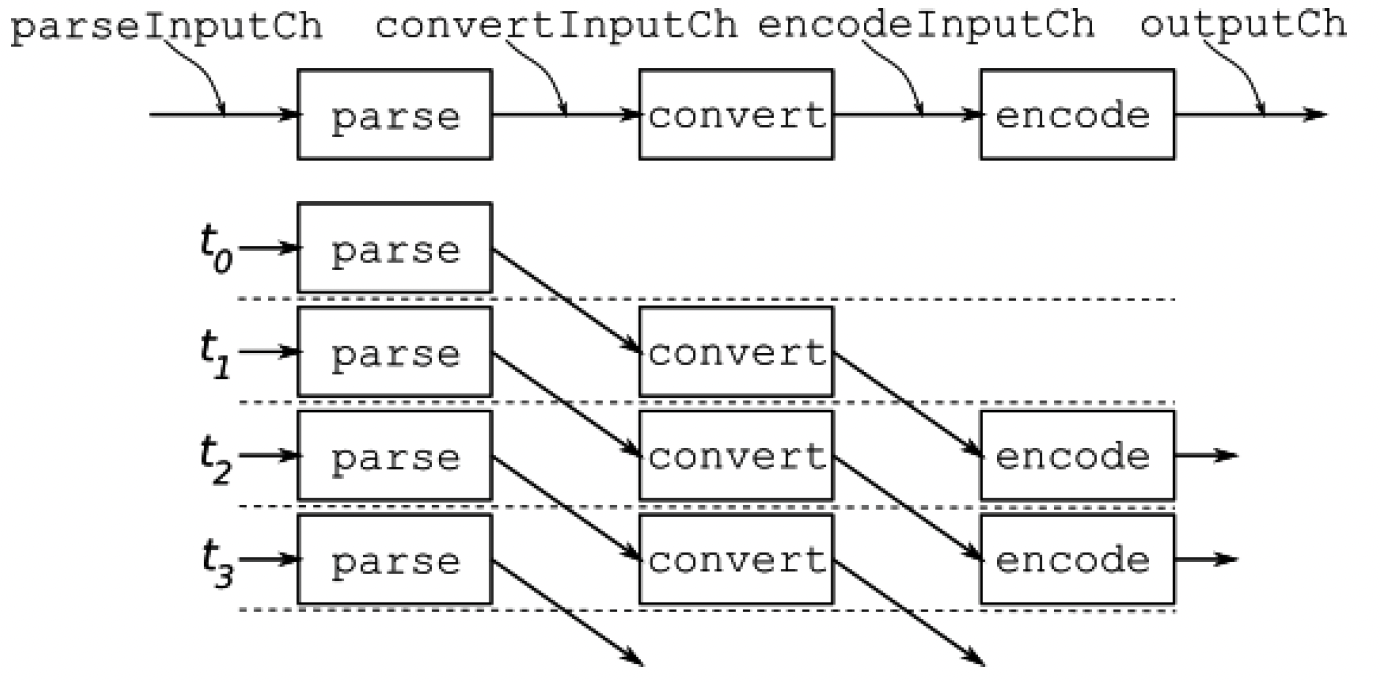 图5.3 异步管道
图5.3 异步管道
我们可以使用一些通用函数将这个管道的各个阶段连接起来。我们将每个阶段封装在一个函数中,该函数在for循环中从通道读取数据,调用一个函数处理输入,并将输出写入输出通道:
func pipelineStage[IN any, OUT any](input <-chan IN, output
chan<- OUT, process func(IN) OUT) {
defer close(output)
for data := range input {
output <- process(data)
}
}
2
3
4
5
6
7
这里,IN和OUT类型参数分别是process函数的输入和输出数据类型,同时也是输入和输出通道的通道类型。
异步管道的设置要复杂一些,因为我们必须为连接每个阶段定义单独的通道:
func asynchronousPipeline(input *csv.Reader) {
parseInputCh := make(chan []string)
convertInputCh := make(chan Record)
encodeInputCh := make(chan Record)
outputCh := make(chan []byte)
// 我们需要这个通道来等待最终结果的打印
done := make(chan struct{})
// 启动管道阶段并连接它们
go pipelineStage(parseInputCh, convertInputCh, parse)
go pipelineStage(convertInputCh, encodeInputCh, convert)
go pipelineStage(encodeInputCh, outputCh, encode)
// 启动一个goroutine来读取管道输出
go func() {
for data := range outputCh {
fmt.Println(string(data))
}
close(done)
}()
// 跳过标题行
input.Read()
for {
rec, err := input.Read()
if err == io.EOF {
close(parseInputCh)
break
}
if err != nil {
panic(err)
}
// 将输入发送到管道
parseInputCh <- rec
}
// 等待最后一个输出被打印
<-done
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
你可能已经注意到,这个管道看起来像是一个接一个连接起来的工作池。实际上,每个阶段都可以实现为一个工作池。如果某些阶段需要很长时间才能完成,这种设计可能会很有用,因为多个阶段并发运行可以提高吞吐量。
# 扇出/扇入
在理想情况下,所有工作线程并行运行,每个阶段有两个工作线程,管道操作如图5.4所示。如果每个阶段每1微秒能产生一个输出,那么在最初的3微秒之后,这个管道每1微秒将产生两个输出:
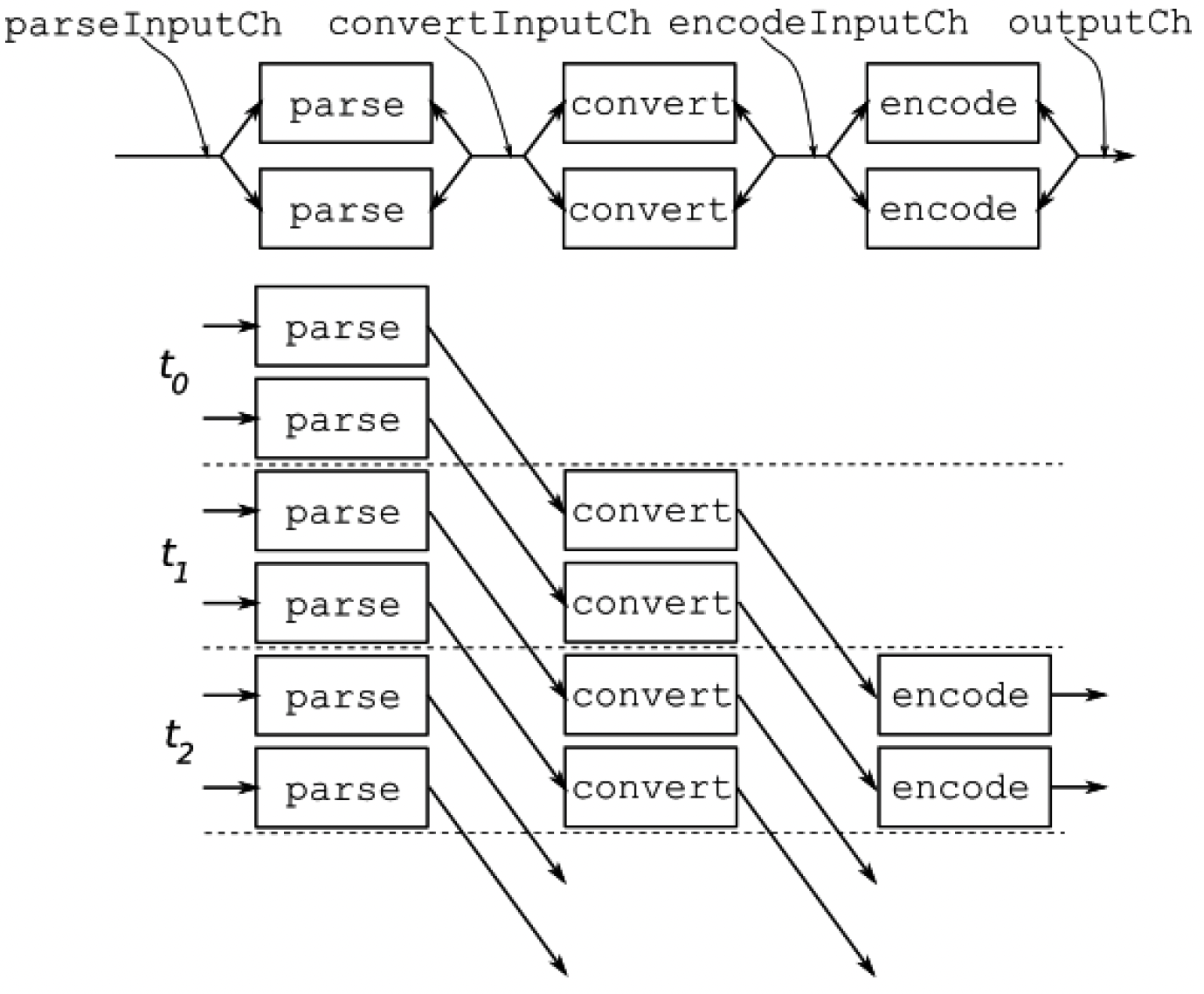 图5.4 每个阶段有两个工作线程的异步管道
图5.4 每个阶段有两个工作线程的异步管道
在这个设计中,管道的各个阶段使用共享通道进行通信,因此多个goroutine从同一个输入通道读取数据(扇出),并将数据写入共享的输出通道(扇入)。
这个管道需要对我们的通用函数进行一些修改。之前的通用函数依赖于输入通道的关闭来关闭自身的输出通道,这样各个阶段就能依次关闭。在每个阶段有多个工作线程实例运行的情况下,每个工作线程都会尝试关闭输出通道,这会导致程序崩溃。我们必须在所有工作线程终止后再关闭输出通道。所以,我们需要一个等待组(WaitGroup):
func workerPoolPipelineStage[IN any, OUT any](input <-chan IN,
output chan<- OUT, process func(IN) OUT, numWorkers int) {
// 所有工作线程完成后关闭输出通道
defer close(output)
// 启动工作池
wg := sync.WaitGroup{}
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for data := range input {
output <- process(data)
}
}()
}
// 等待所有工作线程完成
wg.Wait()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
当输入通道关闭时,管道阶段中的所有工作线程将逐个终止。等待组确保在所有goroutine完成之前函数不会返回,之后它会关闭输出通道,这会触发下一个阶段的相同事件序列。
现在管道设置使用这个通用函数:
numWorkers := 2
// 启动管道阶段并连接它们
go workerPoolPipelineStage(parseInputCh, convertInputCh, parse,
numWorkers)
go workerPoolPipelineStage(convertInputCh, encodeInputCh,
convert, numWorkers)
go workerPoolPipelineStage(encodeInputCh, outputCh, encode,
numWorkers)
2
3
4
5
6
7
8
如果你构建并运行这个管道,很快就会发现输出可能是这样的:
{"row":65,"height":172.72,"weight":97.61}
{"row":64,"height":195.58,"weight":81.266}
{"row":66,"height":142.24,"weight":101.242}
{"row":68,"height":152.4,"weight":80.358}
{"row":67,"height":162.56,"weight":104.87400000000001}
2
3
4
5
行的顺序乱了!因为有多个数据实例在管道中处理,最快处理完的会先出现在输出中,而它可能不是最先进入管道的。在很多情况下,从管道输出的记录顺序并不重要。但在某些情况下,你需要它们按顺序输出。这种管道构建方式并不适合解决这些问题。当然,你可以添加一个新阶段来对它们进行排序,但这可能需要一个无界缓冲区:如果每个阶段有多个工作线程,并且第一条记录处理时间很长,以至于其他所有记录都在它之前完成了管道处理,那么你就必须缓冲所有记录以便进行排序。这就违背了使用管道的初衷。
我们将研究另一种可以处理这个问题的管道设计。到目前为止,我们的管道在各个阶段之间使用共享通道,所有工作线程都从这个通道发送和接收数据。另一种选择是在每个阶段的goroutine之间使用专用通道。当管道的某些阶段计算成本较高时,这种设计尤其有益。有多个goroutine可用于并发计算这些高成本操作,可以提高整个管道的吞吐量。
以我们的示例来说,假设转换阶段执行的是高成本计算,所以我们希望在这个阶段有一个包含多个工作线程的工作池。因此,在管道解析输入后,它会将数据扇出到多个从共享通道读取数据的转换goroutine,但这些goroutine会通过各自的通道返回响应。所以,在对这个阶段的输出进行编码之前,我们必须进行扇入并对结果进行排序。如图5.5所示:
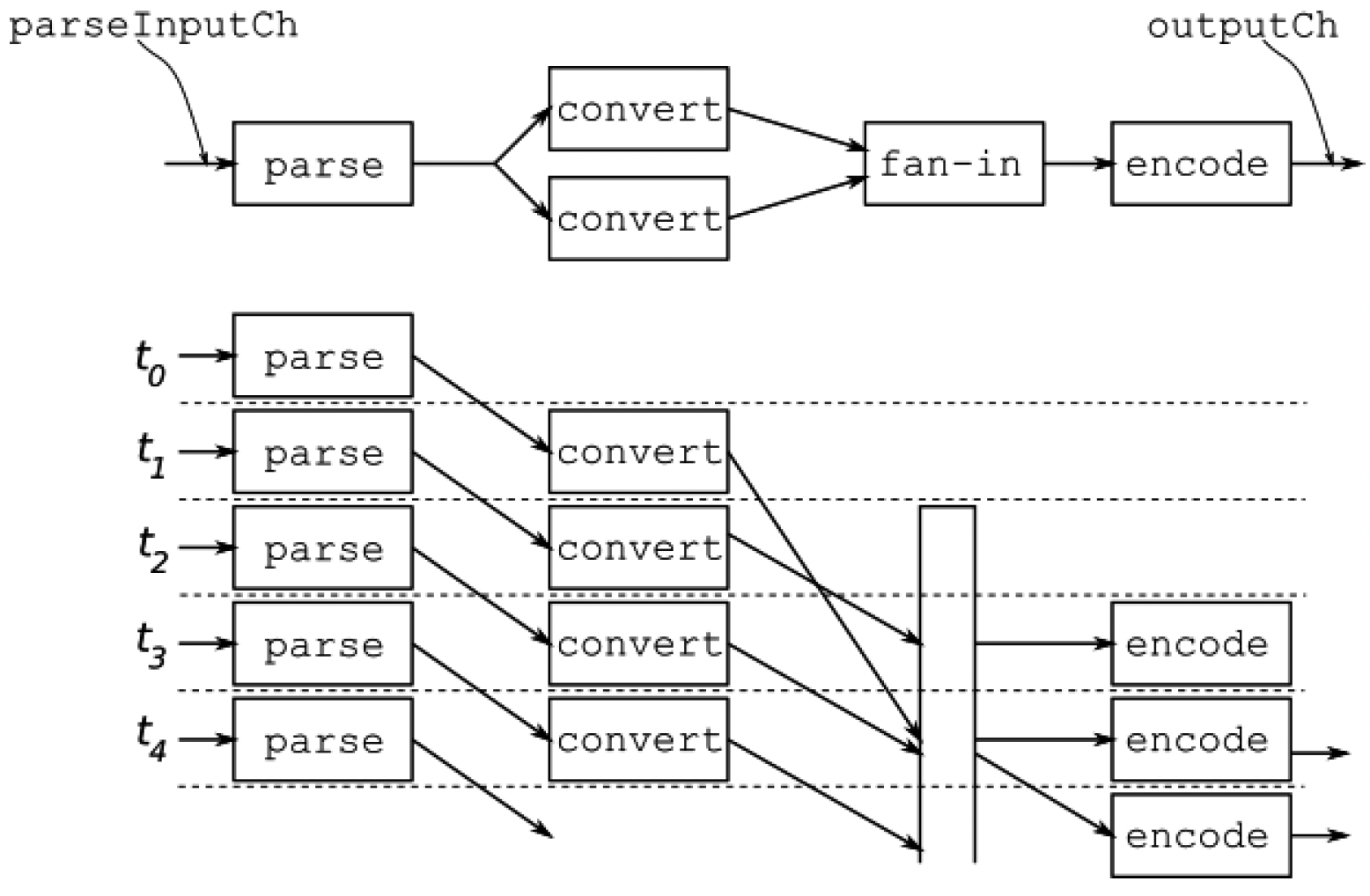 图5.5 无序的扇出/扇入
图5.5 无序的扇出/扇入
我们需要一个新的泛型函数,它接受一个输入通道和一个用于取消操作的done通道,并返回一个输出通道。这样,我们就可以将一个协程的输出连接到另一个阶段中另一个协程的输入:
func cancelablePipelineStage[IN any, OUT any](input <-chan IN,
done <-chan struct{}, process func(IN) OUT) <-chan OUT {
outputCh := make(chan OUT)
go func() {
for {
select {
case data, ok := <-input:
if!ok {
close(outputCh)
return
}
outputCh <- process(data)
case <-done:
return
}
}
}()
return outputCh
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
现在,我们可以编写一个通用的扇入(fan-in)函数:
func fanIn[T any](done <-chan struct{}, channels ...<-chan T)
<-chan T {
outputCh := make(chan T)
wg := sync.WaitGroup{}
for _, ch := range channels {
wg.Add(1)
go func(input <-chan T) {
defer wg.Done()
for {
select {
case data, ok := <-input:
if!ok {
return
}
outputCh <- data
case <-done:
return
}
}
}(ch)
}
go func() {
wg.Wait()
close(outputCh)
}()
return outputCh
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
fanIn函数接收多个通道,使用单独的协程并发地从每个通道读取数据,并写入到公共的输出通道。当所有输入通道都关闭时,接收数据的协程终止,输出通道也随之关闭。如你所见,输出的顺序不一定与输入的顺序相同。协程可能会根据它们的运行顺序打乱输入顺序。
| 这里需要补充一点…… 如果输入通道的数量是固定的,使用 select语句很容易实现扇入。但在这里,输入通道的数量可能是动态变化的,而且可能非常多。如果Go语言支持带有可变数量通道的select语句,那就非常适合这些情况。虽然Go语言的语法不支持,但标准库提供了相应的功能。reflect.Select函数允许你使用通道切片进行选择操作。 |
|---|
下面的代码片段使用2个工作协程连接管道的各个阶段,用于转换阶段:
// 解析阶段的单个输入通道
parseInputCh := make(chan []string)
convertInputCh := cancelablePipelineStage(parseInputCh, done,
parse)
numWorkers := 2
fanInChannels := make([]<-chan Record, 0)
for i := 0; i < numWorkers; i++ {
// 扇出
convertOutputCh :=
cancelablePipelineStage(convertInputCh,
done, convert)
fanInChannels = append(fanInChannels, convertOutputCh)
}
convertOutputCh := fanIn(done, fanInChannels...)
outputCh := cancelablePipelineStage(convertOutputCh, done,
encode)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 有序扇入
如何编写一个既能扇入又能对记录进行排序的函数呢?关键思路是存储乱序的记录,直到预期的记录到来。假设我们有两个输入通道,由两个协程监听,第一个协程接收到一个乱序的记录。我们知道第二个协程下次会接收到预期的记录,因为管道中的记录数量不能超过并发工作协程的数量,而且我们已经接收到了第二条记录,所以第一条记录肯定还在前序阶段。在等待该记录到来的过程中,我们必须阻止第一个协程返回其他记录。但是,如何暂停一个正在运行的协程呢?答案是:让它等待一个通道的信号。
让我们尝试用伪代码整理出一个算法。我发现编写代表协程的伪代码块,并在它们之间绘制箭头来表示消息交换很有帮助。对于每个输入通道,我们将使用一个协程从管道中接收数据元素,将其发送到排序协程正在接收的扇入通道,并等待从暂停通道接收信号。在第二阶段,我们有一个排序协程,它从扇入通道接收数据并判断记录是否顺序正确。如果不正确,它会将该记录存储在为其输入通道专门设置的缓冲区中。此时,该输入通道对应的协程正在等待从其暂停通道接收信号,所以它不能再接受任何输入。当正确的输入到来时,排序协程会输出所有排队的数据,并通过向暂停通道发送信号来释放所有等待的协程。如图5.6所示:
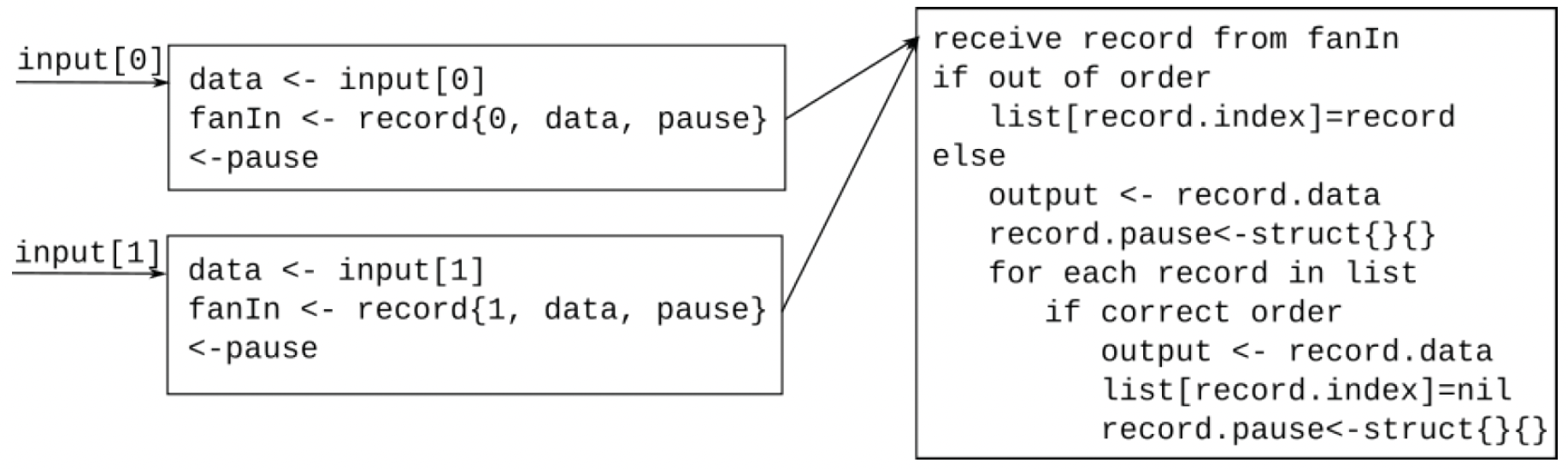 图5.6——有序扇入的伪代码
图5.6——有序扇入的伪代码
那么,让我们开始构建这个有序扇入算法。首先,我们需要一种获取记录序列号的方法:
type sequenced interface {
getSequence() int
}
func (r Record) getSequence() int { return r.Row }
2
3
4
对于每个通道,我们需要一个地方来存储乱序的记录,以及一个用于暂停协程的通道:
type fanInRecord[T sequenced] struct {
index int // 输入通道的索引
data T
pause chan struct{}
}
2
3
4
5
我们为每个输入通道创建一个协程。每个协程从其分配的通道读取数据,创建一个fanInRecord实例,并通过fanInCh通道发送出去。这可能是预期的记录,也可能是乱序的记录,但这由fanInCh通道的接收端来判断。此时,这个协程必须暂停,直到做出判断。所以,它会从相关的暂停通道接收信号。另一个协程通过向暂停通道发送信号来释放这个协程,之后这个协程会再次开始监听输入通道。当然,如果输入通道关闭,相应的协程会返回,当所有协程都返回时,fanInCh通道也会关闭:
func orderedFanIn[T indexable](done <-chan struct{}, channels
...<-chan T) <-chan T {
fanInCh := make(chan fanInRecord[T])
wg := sync.WaitGroup{}
for i := range channels {
pauseCh := make(chan struct{})
wg.Add(1)
go func(index int, pause chan struct{}) {
defer wg.Done()
for {
var ok bool
var data T
// 从通道接收输入
select {
case data, ok = <-channels[index]:
if!ok {
return
}
// 发送输入
fanInCh <- fanInRecord[T]{
index: index,
data: data,
pause: pause,
}
case <-done:
return
}
// 暂停协程
select {
case <-pause:
case <-done:
return
}
}
}(i, pauseCh)
}
go func() {
wg.Wait()
close(queue)
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
函数的第二部分包含排序逻辑。当从一个通道接收到乱序记录时,它会被存储在为该通道专门设置的缓冲区中,所以我们只需要一个容量为len(channels)的缓冲区。当接收到预期的记录时,算法会扫描存储的记录并按正确顺序输出:
outputCh := make(chan T)
go func() {
defer close(outputCh)
// 预期的下一条记录
expected := 1
queuedData := make([]*fanInRecord[T], len(channels))
for in := range fanInCh {
// 如果这个输入是预期的,将其发送到输出通道
if in.data.getSequence() == expected {
select {
case outputCh <- in.data:
in.pause <- struct{}{}
expected++
allDone := false
// 发送所有排队的数据
for!allDone {
allDone = true
for i, d := range queuedData {
if d != nil && d.data.getSequence() ==
expected {
select {
case outputCh <- d.data:
queuedData[i] = nil
d.pause <- struct{}{}
expected++
allDone = false
case <-done:
return
}
}
}
}
case <-done:
return
}
} else {
// 这是乱序的,将其排队
in := in
queuedData[in.index] = &in
}
}
}()
return outputCh
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
这个协程的作用是监听队列通道,如果接收到的记录是乱序的,就将其排队。发送记录的协程会被阻塞,直到这个协程释放它。如果接收到正确的记录,它会被直接发送到输出通道,发送该记录的协程会被解锁,然后扫描所有排队的记录,查看下一个预期的记录是否已经在队列中。如果是,就发送该记录,通过向暂停通道发送信号来解锁相应的协程,并将该记录出队。
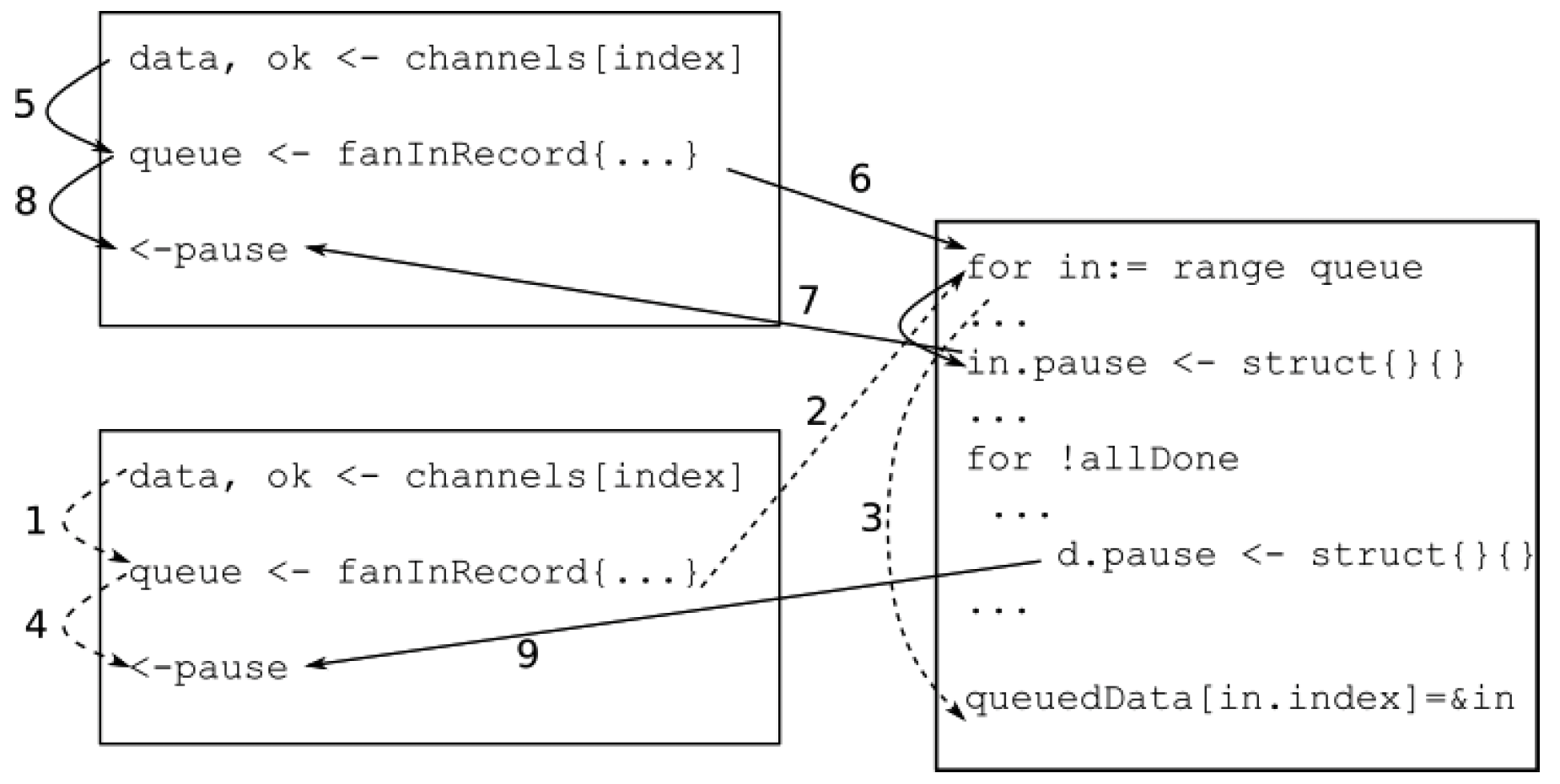 图5.7——有序扇入的先行发生关系
图5.7——有序扇入的先行发生关系
让我们看看这些协程是如何交互的,如图5.7所示。其中一个协程读取到一个乱序输入(箭头1),并通过fanInCh通道将其发送到扇入协程(箭头2)。扇入协程意识到这是一个乱序记录,将其排队(箭头3)。在此过程中,该协程开始等待从其暂停通道接收信号(箭头4)。与此同时,另一个协程接收到另一个输入(箭头5),并通过fanInCh通道将其发送到扇入协程(箭头6)。扇入协程意识到这是预期的数据包,释放正在等待(或即将等待)从其暂停通道接收信号的协程(箭头7)。扇入协程还会查看存储的请求,发现有一条记录在等待,这条记录现在成为了预期的数据包。所以,它也释放了那个协程(箭头9)。
如你所见,根据具体需求,管道可能会变得很复杂。解决这些问题没有单一的方法。这些示例展示了几种抽象构建和运行高性能数据管道底层复杂性的方法,以便实际的处理阶段可以只专注于数据处理。正如我在本章中试图说明的,使用并发组件和泛型函数可以构建和连接不同类型的管道,而无需更改处理逻辑。从简单的开始,分析你的程序,找出瓶颈,然后再决定是否需要扇出、何时扇出、如何扇入、如何确定工作池的大小,以及哪种类型的管道最适合你的用例。
最后,请注意这里所有的管道实现都使用了通道、协程和等待组(waitgroups)。没有临界区,没有互斥锁或条件变量,但也没有数据竞争。每个协程在新数据可用时就会立即处理。
# 总结
在本章中,我们研究了工作池和管道——这两种模式以不同的形式出现在几乎每一个重要项目中。这些模式有很多种实现方式,并且运行时行为也各不相同。你构建系统时应确保它们不依赖于管道或工作池的具体结构。我试图展示一些将并发相关问题与计算逻辑分离的方法。当你需要在不同设计之间进行迭代时,这些思路可能会让你的工作更轻松。
接下来,我们将讨论错误处理,以及如何将错误处理添加到这些模式中。
# 问题
- 你能修改工作协程的实现,使得调用者可以取消提交的任务吗?
- 许多语言提供了具有动态大小工作池的框架。你能想出在Go语言中如何实现吗?这种动态大小的工作池会比使用与动态大小工作池最大数量相同的协程的固定大小工作池性能更好吗?
- 尝试编写一个通用的(无序)扇入/扇出函数,它接受n个输入通道和m个输出通道。