 8 并发处理请求
8 并发处理请求
# 8 并发处理请求
服务器编程是一个相当广泛的话题。本章将主要聚焦于服务器编程中与并发相关的一些方面,从抽象意义上讲,就是通用的请求处理。归根结底,几乎所有程序都是为处理特定请求而编写的。对于服务器应用程序而言,定义和传播请求上下文非常重要,因此我们将从讨论context包开始本章内容。接下来,我们将研究一些简单的服务器,探索如何并发处理请求,并讨论处理服务器开发中一些基本问题的方法。本章的最后一部分是关于流式数据,这类数据是逐段生成的,这带来了独特的挑战,同时也展示了一些有趣的并发模式。
本章包含以下部分:
- 上下文(context)、取消和超时
- 后端服务
- 流式数据
在本章结束时,你应该能够很好地理解请求上下文,如何取消请求或设置请求超时,服务器编程的基本要素,限制并发的方法,以及如何处理逐段生成的数据。
# 技术要求
无。
# 上下文、取消和超时
在第2章中,我们展示了关闭多个goroutine之间共享的通道是发出取消信号的好方法。取消可能以不同方式发生:计算过程中某个部分的失败可能会使整个结果无效,计算可能持续时间过长导致超时,或者请求者通过关闭网络连接通知服务器应用程序,表明其不再需要结果。因此,将一个通道传递给处理请求的函数是合理的。但你必须小心:通道只能关闭一次,关闭已关闭的通道会导致程序恐慌(panic)。这里的 “请求” 一词应从抽象意义上理解:它可以是提交给服务器的API请求,也可以仅仅是处理较大计算中特定部分的函数调用。
让调用链中的函数了解与请求相关的某些数据也很有意义。例如,在一个有许多goroutine的并发系统中,将日志消息与请求关联起来很重要,这样就可以在不同的goroutine中追踪请求的处理过程。一个唯一的请求标识符是实现这一点的常用方法。为了实现这一点,那些服务调用的所有函数都应该知道这个请求标识符。
context.Context是一个用于处理这两个常见问题的对象。它包含我们提到的用于取消操作的Done通道,并且其行为类似于一个通用的键值存储。Context是专门设计用于作为请求作用域对象的,非常适合存储请求标识符、调用者身份和权限信息、请求特定的日志记录器等。
对于熟悉其他语言的人来说,一个常见的错误是将上下文视为线程局部存储(thread-local storage)。上下文并不能替代线程局部变量,它是用于在处理请求的goroutine之间共享的。上下文实例不能跨越进程边界;例如,当你调用一个HTTP API时,服务器请求处理程序会使用一个全新的上下文启动,这个上下文与用于发起调用的客户端上下文没有任何关系。应该将其作为需要它的函数的第一个参数进行传递。遵循这些约定将使代码更易于阅读,也能让静态代码分析器生成更合理的报告。
处理请求时,创建和准备上下文通常是首要任务。使用以下代码创建一个新的上下文:
ctx := context.Background()
这将创建一个没有取消或超时功能的空上下文。该上下文的Done通道将为nil,因此它是不可取消的。
你可以通过为上下文添加功能来使用它(听说过 “装饰器模式” 吗?)。当你为上下文添加取消或超时功能时,会得到一个新的上下文,它包装了你传入的原始上下文:
ctx1, cancel1 := context.WithCancel(ctx0)
这里,ctx1是一个引用原始上下文ctx0的新上下文,但添加了取消功能。你将ctx1传递给那些通过检查ctx1.Done()通道来支持取消操作的函数和goroutine。当你调用cancel1函数时,它将关闭ctx1.Done()通道,因此所有检查ctx1.Done()通道的goroutine和函数都会收到取消请求。你可以多次调用取消函数;底层通道只会在你第一次调用时关闭。如果原始上下文ctx0已经添加了取消功能,它不会受到ctx1取消操作的影响。但是,如果ctx0被取消,ctx1也会被取消。如果基于ctx1创建了其他可取消的上下文,那么每当ctx1被取消时,这些上下文也会被取消,但ctx1不会知道那些嵌套上下文的取消情况。取消功能的正确用法如下:
func someFunc(ctx context.Context) error {
ctx1, cancel1 := context.WithCancel(ctx)
defer cancel1()
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
defer wg.Done()
process2(ctx1)
}()
if err := process1(ctx1); err != nil {
cancel1()
return err
}
wg.Wait()
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这个函数调用两个独立的函数process1和process2来执行一些计算。process2函数在一个单独的goroutine中调用。如果process1失败,我们希望取消process2。为此,我们创建一个可取消的上下文(第2行),并确保在函数返回时取消这个新上下文(第3行)。这对于防止goroutine泄漏是必要的,因为正如你可能猜到的,实现这种级联取消需要额外的goroutine。调用取消函数可确保这些goroutine被终止。
这种情况如图8.1所示。ctx0是初始上下文,其Done通道为nil。ctx1是从ctx0创建的可取消上下文,因此cancel1是一个关闭ctx1的done通道的闭包。由于父上下文不可取消,所以不需要额外的goroutine。ctx2是另一个基于ctx1创建的可取消上下文,因此它有自己的done通道,以及一个关闭该done通道的闭包。它还有一个goroutine,等待父done通道或ctx2的done通道关闭。如果父done通道关闭,它将取消ctx2以及所有基于ctx2创建的上下文。如果ctx2被取消,该goroutine将直接终止。这就是必须调用取消函数的原因:如果上下文永远不被取消,就会导致goroutine泄漏。
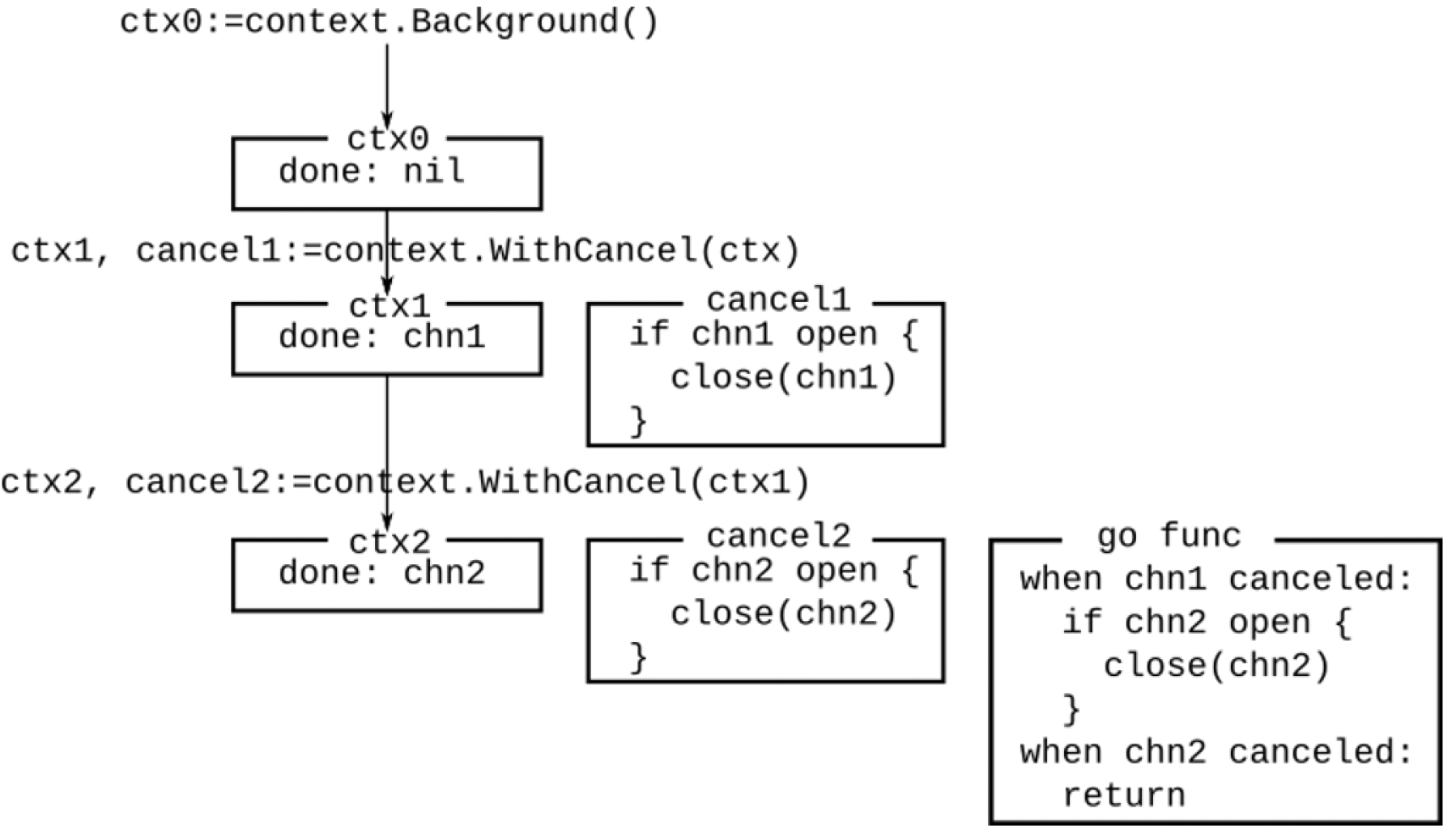 图8.1 嵌套上下文和取消
图8.1 嵌套上下文和取消
顺便提一下,图8.1给出了取消功能的概念概述。但是如何检查通道是否打开呢?标准库中的实际取消函数有相当复杂的实现,还包括取消子上下文的功能。一个可以多次调用的简单取消函数可以如下实现:
func GetCancelFunc() (cancel func(), done chan struct{}) {
var once sync.Once
done = make(chan struct{})
cancel = func() {
once.Do(func() { close(done) })
}
return
}
2
3
4
5
6
7
8
上下文的超时和截止时间的工作方式相同。与可取消上下文的唯一区别在于,带有截止时间或超时的上下文有一个定时器,一旦截止时间过去,定时器就会调用取消函数。超时是基于持续时间设置的:
ctx2, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
2
截止时间是基于某个时间点设置的:
d := time.Now().Add(2*time.Second)
ctx2, cancel := context.WithDeadline(ctx, d)
defer cancel()
2
3
当上下文被取消时,Err()方法将被设置为context.Canceled错误。当上下文超时时,Err()方法将返回context.DeadlineExceeded错误。
上下文还提供了一种存储请求特定值的机制。然而,你不应将此机制视为通用的map[any]any存储。如前所述,上下文是使用装饰器模式实现的。每次向上下文添加新内容时,都会创建一个包含该新内容的新上下文,而原上下文保持不变。存储在上下文中的值也是如此。如果你向上下文添加一个值,会得到一个包含该值的新上下文。当你在上下文中查询一个值(ctx.Value(key)),且键与ctx中存储的内容不匹配时,它会调用其父上下文来搜索该值,这个调用会递归进行,直到找到该键。这意味着两点:第一,你可以在新上下文中覆盖现有值。新上下文的使用者将看到新值,而旧上下文的使用者将看到未修改的值。第二,如果你向上下文中添加数百个值,就会得到一个包含数百个上下文的链。因此,要注意向上下文中放入什么内容以及放入多少内容。如果你需要添加很多值,可以添加一个包含多个值的单一结构体。
在一个简单的程序中,使用字符串作为上下文值的键并没有什么问题。然而,这容易被误用,如果多个包使用相同的名称来添加含义不同的值,可能会导致很难诊断的细微错误。因此,在上下文中处理值的惯用方式是使用Go类型系统来防止无意的键冲突 —— 也就是说,为每个键使用不同的类型。以下示例展示了如何向上下文中添加请求标识符:
type requestIDKeyType int
var requestIDKey requestIDKeyType
func WithRequestID(ctx context.Context) context.Context {
return context.WithValue(ctx, requestIDKey, uuid.New())
}
func GetRequestID(ctx context.Context) uuid.UUID {
id, _ := ctx.Value(requestIDKey).(uuid.UUID)
return id
}
2
3
4
5
6
7
8
9
10
11
第1行定义了一个未导出的数据类型,第2行使用该数据类型定义了一个上下文键。这种声明方式确保了在不同的包中,没有人会无意地创建相同的键。第4行定义了WithRequestID函数,该函数返回一个添加了请求标识符的新上下文。第8行定义了GetRequestID函数,用于从上下文中提取请求标识符。如果上下文没有请求标识符,它将返回UUID的零值(即一个由零组成的字节数组)。基于此,你能猜出下面的程序会打印什么吗?
ctx := context.Background()
ctx1 := WithRequestID(ctx)
ctx2 := WithRequestID(ctx1)
fmt.Println(GetRequestID(ctx), GetRequestID(ctx1), GetRequestID(ctx2))
2
3
4
实际上,每次运行该程序时,它都会打印不同的输出。不过,第一个输出始终是00000000-0000-0000-0000-000000000000(UUID的零值),第二个值将是ctx1中的请求标识符,第三个值将是ctx2中的请求标识符。注意,向上下文中添加另一个请求标识符不会覆盖ctx1中的请求标识符。
一个常见的问题是:应该在上下文中放入哪些值?指导原则是该值是否特定于请求,而不是值本身的性质。如果你有一个所有请求处理程序都共享的数据库连接,那么它不属于上下文。然而,如果你的系统可能根据调用者的凭据连接到不同的数据库,那么将该数据库连接放入上下文可能是有意义的。应用程序配置结构体不属于上下文。如果你根据请求从数据库加载一个配置项,那么将其放入上下文可能是合理的。
上下文对象旨在传递给多个goroutine,这意味着你必须注意涉及上下文值的竞态条件。考虑以下上下文:
newCtx := context.WithValue(ctx, mapKey, map[string]interface{}{"key": "value"})
如果newCtx被传递给多个goroutine,那么该上下文中的映射就变成了一个共享变量。多个goroutine向该映射中添加或删除值会导致竞态条件,可能会损坏内存。处理这个问题的正确方法是使用结构体:
type StructWithMap struct {
sync.Mutex
M map[string]interface{}
}
...
newCtx := context.WithValue(ctx, mapKey, &StructWithMap{
M: make(map[string]interface{}),
})
2
3
4
5
6
7
8
在这个例子中,一个指向包含互斥锁和映射的结构体的指针被放入了上下文。goroutine必须锁定互斥锁才能访问映射。还要注意,互斥锁不能被复制,所以放入上下文的是结构体的地址。
# 后端服务
如果你正在使用Go语言,很可能已经编写或即将编写某种后端服务。服务开发面临一系列独特的挑战。首先,请求处理的并发方面通常隐藏在服务框架之下,这可能会导致无意的内存共享和数据竞争。其次,并非所有服务的客户端都是善意的(存在攻击风险),也并非都没有漏洞。在本节中,我们将介绍一些使用HTTP和WebSocket服务的基本结构。但在此之前,了解一些TCP网络知识会很有帮助,因为许多更高级的协议,如HTTP和WebSocket,都是基于TCP的。接下来,我们将构建一个简单的TCP服务器,它可以并发处理请求并优雅地关闭。为此,我们需要一个监听器、一个请求处理器和一个等待组:
type TCPServer struct {
Listener net.Listener
HandlerFunc func(context.Context, net.Conn)
wg sync.WaitGroup
}
2
3
4
5
服务器提供了一个Listen方法来等待连接。它首先创建一个可取消的上下文(context)。当Listen方法返回时,这个上下文会被取消,从而通知所有活动的连接处理器进行取消操作。当建立一个连接时,该方法会创建一个新的协程来处理这个连接,然后继续监听:
func (srv *TCPServer) Listen() error {
baseContext, cancel := context.WithCancel(context.Background())
defer cancel()
for {
conn, err := srv.Listener.Accept()
if err != nil {
if errors.Is(err, net.ErrClosed) {
return nil
}
fmt.Println(err)
}
srv.wg.Add(1)
go func() {
defer srv.wg.Done()
srv.HandlerFunc(baseContext, conn)
}()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
你可能会注意到,Listen方法在Accept调用失败之前不会返回。一旦启动,服务器可以通过在另一个协程中关闭监听器来停止:
func (srv *TCPServer) StopListener() error {
return srv.Listener.Close()
}
2
3
关闭监听器会导致Accept调用失败,Listen方法将停止监听,取消上下文,并返回。取消上下文会通知所有活动连接服务器正在关闭,但期望它们立即停止处理是不合理的。我们必须给这些处理器一些时间来完成任务,这可以通过带有超时设置的WaitForConnections方法来实现:
func (srv *TCPServer) WaitForConnections(timeout time.Duration) {
toCh := time.After(timeout)
doneCh := make(chan struct{})
go func() {
srv.wg.Wait()
close(doneCh)
}()
select {
case <-toCh:
case <-doneCh:
}
}
2
3
4
5
6
7
8
9
10
11
12
这就是等待组(WaitGroup)发挥作用的地方。如果没有活动连接,srv.wg.Wait()会立即返回,关闭doneCh,这将导致WaitForConnections方法返回。如果有活动连接,我们会在一个单独的协程中等待它们,如果它们在超时之前全部完成,doneCh将被关闭,该方法也会返回。然而,如果在给定的超时时间内有连接没有响应停止请求,该方法仍然会返回,这些连接将保持活动状态。处理这种情况的一种选择是关闭这些活动连接,但这可能会导致意外行为。所以,在这种情况下,你需要自行决定最佳的处理方式。
容器化的后端服务可以处理终止信号以实现优雅关闭。这必须在任何服务器开始监听之前完成。以下代码片段将设置一个信号处理程序来监听终止信号,并给服务器5秒钟的时间进行关闭:
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGTERM, syscall.SIGINT)
go func() {
<-sig
srv.StopListener()
srv.WaitForConnections(5 * time.Second)
}()
2
3
4
5
6
7
以下是一个使用这些工具的简单回显服务器:
srv.Listener, err = net.Listen("tcp", "")
if err != nil {
panic(err)
}
srv.HandlerFunc = func(ctx context.Context, conn net.Conn) {
defer conn.Close()
// 回显服务器
io.Copy(conn, conn)
}
srv.Listen()
srv.WaitForConnections(5 * time.Second)
2
3
4
5
6
7
8
9
10
11
现在让我们来看一个使用标准库的简单HTTP服务。HTTP是一种基于文本的协议,建立在TCP之上,所以HTTP代码与TCP服务器的代码非常相似。一个HTTP请求包含一个头部,它会告知HTTP动词(GET、POST等)、路径(主机和端口之后的URL部分)以及HTTP头部信息。通常,HTTP服务器会为不同的请求类型使用不同的处理器,具体调用哪个处理器是根据请求头部信息(HTTP动词、路径和头部)来决定的。这被称为请求多路复用。Go标准库包含一个基本的多路复用器;市面上也有许多框架,它们提供不同的功能和性能特点。但在处理请求的应用层,你必须牢记一些关键假设:
- 请求处理器会被并发调用。
- 请求可能会无序接收。也就是说,客户端按特定顺序调用API并不意味着服务器会以相同的顺序接收这些调用。
- 你不能信任调用者。对于提供对特权资源访问的API,你必须对调用者进行身份验证,限制调用者可以发送或接收的数据大小,并验证API接收到的数据。
标准库提供了一个http.ServeMux类型,可以用作简单的请求多路复用器。你可以使用Handler和HandlerFunc方法将请求处理器注册到http.ServeMux的实例中。标准库还声明了一个默认的ServeMux实例,所以http.Handler和http.HandlerFunc函数可以用于将请求处理器注册到该特定实例中。因此,你可以这样做:
mux := http.NewServeMux()
svc := NewDashboardService()
mux.HandleFunc("/dashboard/", svc.DashboardHandler)
http.ListenAndServe("localhost:10001", mux)
2
3
4
这里发生的事情是,我们创建了一个多路复用器,创建了后端服务实现的一个实例(这里假设是一个仪表板服务),注册了/dashboard/路径的处理器,并启动了服务器。其余的请求处理在DashboardHandler方法中进行。Go语言的类型系统允许将方法传递给函数变量,所以在这种情况下,请求处理器是一个可以访问DashBoardService实现的方法,因此它可以包含所有的配置信息、数据库连接、远程服务的客户端等等。这里需要注意的一个重要点是,请求处理器方法会被并发调用,并且它们都会使用前面声明的svc实例。因此,如果你需要修改svc中的任何内容,必须使用互斥锁(mutex)来保护它。
许多多路复用器支持的一种常见模式是使用中间件函数构建调用链。在这种情况下,中间件是一个函数,它对请求执行一些操作,如身份验证或上下文准备,然后将请求传递给链中的下一个处理器。下一个处理器可以是实际的请求处理器,也可以是另一个中间件。例如,以下中间件使用一个有限的读取器替换请求体,以保护服务免受大请求的影响:
func Limit(maxSize int64, next http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
req.Body = http.MaxBytesReader(w, req.Body, maxSize)
next(w, req)
})
}
2
3
4
5
6
以下中间件使用给定的身份验证函数对调用者进行身份验证,并将用户标识符添加到上下文中。请注意,如果身份验证失败,甚至不会调用下一个处理器:
func Authenticate(authenticator func(*http.Request) (string, error), next http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
userId, err := authenticator(req)
if err != nil {
http.Error(w, err.Error(), http.StatusUnauthorized)
return
}
next(w, req.WithContext(WithUserID(req.Context(), userId)))
})
}
2
3
4
5
6
7
8
9
10
现在处理器注册变成了这样:
mux.HandleFunc("/dashboard/", Authenticate(authFunc, Limit(10240, svc.DashboardHandler)))
经过这样的设置,DashboardHandler保证会接收到经过身份验证且大小不超过10KB的请求。
接下来,让我们看看处理器本身。这个处理器通过计算并返回一些仪表板数据来响应GET请求,这些数据由多个后端服务的汇总信息组成。POST请求用于为用户设置仪表板参数。所以,处理器代码如下:
func (svc *DashboardService) DashboardHandler(w http.ResponseWriter, req *http.Request) {
switch req.Method {
case http.MethodGet:
dashboard := svc.GetDashboardData(req.Context(), GetUserID(req.Context()))
json.NewEncoder(w).Encode(dashboard)
case http.MethodPost:
var params DashboardParams
if err := json.NewDecoder(req.Body).Decode(¶ms); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
}
svc.SetDashboardConfig(req.Context(), GetUserID(req.Context()), params)
default:
http.Error(w, "Unhandled request type", http.StatusMethodNotAllowed)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如你所见,这段代码依赖中间件进行身份验证和限制请求大小。让我们看看GetDashboardData方法。
# 分配工作和收集结果
假设我们的服务器与两个后端服务进行通信以收集统计信息。第一个服务返回当前用户的信息,第二个服务返回账户信息,其中可能包含多个用户的信息。在这个例子中,我们将这些建模为一些不透明的后端服务,但在实际情况中,它们可以是其他Web服务、通过gRPC调用的微服务,或者数据库调用:
type DashboardService struct {
Users UserSvc
Accounts AccountSvc
}
type DashboardData struct {
UserData UserStats
AccountData AccountStats
LastTransactions[]Transaction
}
2
3
4
5
6
7
8
9
实际的处理器展示了几种将工作分配给多个协程并收集结果的方法:
func (svc *DashboardService) GetDashboardData(ctx context.Context, userID string) DashboardData {
result := DashboardData{}
wg := sync.WaitGroup{}
2
3
- 第一个协程调用
Users服务,为给定的用户标识符收集统计信息。它使用等待组来通知工作完成,并直接修改结果结构。只要没有其他协程访问result.UserData字段,这样做就是安全的。如果上下文被取消,Users.GetStats方法应尽快返回:
wg.Add(1)
go func() {
defer wg.Done()
var err error
// 这里设置result.UserData是安全的,因为这是唯一访问该字段的协程
result.UserData, err = svc.Users.GetStats(ctx, userID)
if err != nil {
log.Println(err)
}
}()
2
3
4
5
6
7
8
9
10
- 第二个协程通过通道获取账户级别的统计信息,但设置了100毫秒的超时时间。这意味着
Accounts.GetStats()方法会创建一个协程来计算统计信息并异步返回。当读取这个结果时,会在select语句中将其发送到acctCh通道。select语句还会检测上下文取消情况。如果在Accounts.GetStats方法运行时上下文被取消,它可能会在处理器返回后继续运行,但最终应该意识到上下文已被取消并返回。如果上下文因超时而被取消,将返回账户数据的零值:
acctCh := make(chan AccountStats)
go func() {
// 确保协程返回时acctCh被关闭,这样我们就不会无限期地等待它的结果
defer close(acctCh)
newCtx, cancel := context.WithTimeout(ctx, 100*time.Millisecond)
defer cancel()
resultCh := svc.Accounts.GetStats(newCtx, userID)
select {
case data := <-resultCh:
acctCh <- data
case <-newCtx.Done():
}
}()
2
3
4
5
6
7
8
9
10
11
12
13
- 第三部分创建两个协程(一个用于用户,另一个用于账户)来收集交易信息。这些协程将交易信息异步写入一个公共通道,另一个协程监听这个通道并填充
LastTransactions切片。有一个单独的等待组,在一个新的协程中等待,一旦接收到所有数据元素,就关闭交易通道:
transactionWg := sync.WaitGroup{}
transactionWg.Add(2)
transactionCh := make(chan Transaction)
go func() {
defer transactionWg.Done()
for t := range svc.Users.GetTransactions(ctx, userID) {
transactionCh <- t
}
}()
go func() {
defer transactionWg.Done()
for t := range svc.Accounts.GetTransactions(ctx, userID) {
transactionCh <- t
}
}()
go func() {
transactionWg.Wait()
close(transactionCh)
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 下一个协程从
transactionCh收集交易信息。请注意,这是一个扇入(fan-in)操作:
wg.Add(1)
go func() {
defer wg.Done()
for record := range transactionCh {
// 这里更新result.LastTransactions是安全的,因为这是唯一设置它的协程
result.LastTransactions = append(result.LastTransactions, record)
}
}()
2
3
4
5
6
7
8
- 最后一步,我们等待所有协程完成,从通道读取账户数据,然后返回。从
acctCh接收数据不会无限期阻塞,因为它要么返回一个值,要么被关闭,在这种情况下,我们返回AccountData的零值:
wg.Wait()
result.AccountData = <-acctCh
return result
2
3
这个例子展示了几种分配工作和收集结果的方法:一种是安全地使用共享内存,其他方法则是使用通道。如果你使用共享内存,要格外注意保护被多个协程访问的变量。如果你使用通道通信,要确保所有协程都能正确终止。
# 信号量——限制并发数
如果你想限制并发数会怎么样呢?仪表板处理器的开销可能很大,你可能希望限制对它的并发调用数量。信号量(Semaphores)可用于此目的。信号量是一种通用的并发原语。信号量维护一个计数器,代表可用资源的数量。这里的 “资源” 应从抽象意义上去理解:它可以指实际的计算资源,也可以仅仅表示进入临界区的权限。一个线程通过减少计数器的值来占用资源,并通过增加计数器的值来释放资源。如果计数器为零,则不允许占用资源,线程会阻塞,直到计数器再次变为非零。所以,信号量就像是带有计数器的互斥锁。换句话说,互斥锁是一种二元信号量。你可以使用容量为N的通道作为信号量,来控制对N个资源实例的访问:
semaphore := make(chan struct{}, N)
你可以通过发送操作来获取一个资源。如果信号量缓冲区已满,这个操作会阻塞:
semaphore <- struct{}{}
你可以通过接收操作来释放资源。这将唤醒其他等待获取资源的协程:
<-semaphore
我们这里使用的是struct{}类型的通道(其大小为0),所以通道缓冲区实际上不占用任何内存。
这是在可能创建数量不受限制的协程的程序中限制并发数的好方法。以下示例展示了一个限制对仪表板处理器并发调用的中间件:
func ConcurrencyLimiter(sem chan struct{}, next http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
sem <- struct{}{}
defer func() { <-sem }()
next(w, req)
})
}
2
3
4
5
6
7
可以使用以下方式定义一个有限制并发数的处理器:
mux.HandleFunc("/dashboard/", ConcurrencyLimiter(make(chan struct{}, limit), svc.DashboardHandler))
# 流数据处理
典型的软件工程师的工作围绕着数据的移动和转换。有时,正在移动或转换的数据没有预定义的大小限制,或者是以零碎的方式生成的,所以将所有数据加载并处理并不合理。这时,你可能就需要进行流数据处理。
我所说的流处理,指的是对持续生成的数据进行处理。这包括处理实际的字节流,比如传输大文件,也包括处理结构化对象列表,如从数据库中检索的记录,或者传感器生成的时间序列数据。所以,你通常需要一个“生成器”函数,它会根据特定规范收集数据,并将其传递给后续的处理层。
接下来,我们将构建一个(假设的)处理存储在数据库中的时间序列数据的应用程序。该应用程序将使用查询从数据库中选择一部分数据,计算移动平均值,并返回移动平均值超过特定阈值的实例。
首先是生成器:下面声明了一个Store数据类型,其中包含数据库信息。在程序启动时,会使用数据库连接初始化Store的实例:
type Store struct {
DB *sql.DB // 数据库连接
}
2
3
Entry结构体包含在特定时间进行的测量值:
type Entry struct {
At time.Time
Value float64
Error error
}
2
3
4
5
为什么Entry结构体中有一个Error字段呢?错误报告和处理是流处理结果时的重要考虑因素,因为错误可能发生在流处理的每个阶段:在准备阶段(例如运行查询时)、实际流处理期间(检索某些条目可能失败)以及所有元素处理完毕后(流是因为所有数据都已发送完毕而停止,还是因为发生了意外情况?)。与同步处理场景不同,同步处理要么产生数据,要么产生错误,而流处理可能同时包含多个错误和数据元素。所以,最好将这些错误与每个条目一起传递,以便下游的处理逻辑决定如何处理错误。
下面展示了这种生成器方法的一般结构。它被设计为Store的方法,因此可以访问数据库连接信息。该方法接收一个上下文以及一个描述请求结果的查询结构体。它返回一个Entry类型的通道,调用者可以从该通道接收查询结果,同时返回一个描述准备阶段发生的错误(例如查询错误):
func (svc Store) Stream(ctx context.Context, req Request) (<-chan Entry, error) {
// 通常你应该根据请求构建查询
rows, err := svc.DB.Query(`select at, value from measurements`)
if err != nil {
return nil, err
}
ret := make(chan Entry)
go func() {
// 关闭通道以通知接收者数据流已结束
defer close(ret)
// 关闭数据库结果集
defer rows.Close()
for {
var at int64
var entry Entry
// 检查是否被取消
select {
case <-ctx.Done():
return
default:
}
if!rows.Next() {
break
}
if err := rows.Scan(&at, &entry.Value); err != nil {
ret <- Entry{Error: err}
continue
}
entry.At = time.UnixMilli(at)
ret <- entry
}
if err := rows.Err(); err != nil {
ret <- Entry{Error: err}
}
}()
return ret, nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
该方法根据请求准备数据库查询并执行。此阶段的任何错误都会作为方法的错误值立即返回。如果查询成功运行,该方法会启动一个协程,从数据库中检索结果,并返回一个通道,调用者可以通过该通道逐个读取结果。在任何时候,调用者都可以通过取消上下文来取消生成器方法。协程首先延迟执行一些清理任务,即关闭数据库结果集和结果通道。协程会遍历结果集,并通过通道逐个发送结果。在遍历结果时捕获的任何错误都将在Entry结构体的实例中发送。当所有数据项都发送完毕后,协程将关闭通道,表明结果已耗尽。如果结果集出现故障,将发送一个额外的包含错误的Entry实例。
这里实际发生的是,Stream方法创建了一个通过通道发送数据的闭包。这意味着在Stream方法返回后,该闭包仍然存在。因此,任何需要进行的清理操作都在闭包中完成,而不是在Stream方法本身中。确保闭包通过消耗所有结果或取消上下文来终止也很重要;否则,协程(以及与之相关的数据库资源)将会泄漏。
流处理在结构上与数据管道类似。流处理组件可以依次连接,以高效地处理数据。例如,下面的函数读取输入流,并过滤掉低于特定值的条目,同时保留错误条目:
func MinFilter(min float64, in chan<- store.Entry) <-chan store.Entry {
outCh := make(chan store.Entry)
go func() {
defer close(outCh)
for entry := range in {
if entry.Err != nil || entry.Value >= min {
outCh <- entry
}
}
}()
return outCh
}
2
3
4
5
6
7
8
9
10
11
12
有时,你需要根据特定标准将流拆分为多个流。下面的函数返回一个闭包,该闭包将所有错误发送到一个单独的通道。返回的条目通道现在只包含没有错误的条目:
func ErrFilter(in <-chan store.Entry) (<-chan store.Entry, <-chan error) {
outCh := make(chan store.Entry)
errCh := make(chan error)
go func() {
defer close(outCh)
defer close(errCh)
for entry := range in {
if entry.Error != nil {
errCh <- entry.Error
} else {
outCh <- entry
}
}
}()
return outCh, errCh
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对流进行过滤并分离出错误后,我们可以计算测量值的移动平均值,并选择移动平均值高于阈值的条目。为此,我们定义了以下新结构体,其中包含条目和移动平均值:
type AboveThresholdEntry struct {
store.Entry
Avg float64
}
2
3
4
然后,下面的函数从输入通道读取条目,并计算测量值的移动平均值。移动平均值由流中最近windowSize个元素的平均值定义。当读取新的测量值时,从运行总和中移除第一个测量值,并将新的测量值添加进去。这需要一个具有给定大小的先进先出或循环缓冲区。通道可以充当这样的缓冲区:
func MovingAvg(threshold float64, windowSize int, in <-chan store.Entry) <-chan AboveThresholdEntry {
// 通道可以用作循环/先进先出缓冲区
window := make(chan float64, windowSize)
out := make(chan AboveThresholdEntry)
go func() {
defer close(out)
var runningTotal float64
for input := range in {
if len(window) == windowSize {
avg := runningTotal / float64(windowSize)
if avg > threshold {
out <- AboveThresholdEntry{
Entry: input,
Avg: avg,
}
}
// 丢弃窗口中最旧的值
runningTotal -= <-window
}
// 将值添加到窗口
window <- input
runningTotal += input
}
}()
return out
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
下面的代码片段将所有这些功能组合在一起。它从数据库中流式传输结果,过滤结果,计算移动平均值,并将选定的条目写入输出。如果在处理过程中出现任何错误,它会在所有输出写入后写入第一个错误:
// 流式传输结果
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
entries, err := st.Stream(ctx, store.Request{})
if err != nil {
panic(err)
}
2
3
4
5
6
7
// 移除所有小于0.001的条目
filteredEntries := filters.MinFilter(0.001, entries)
// 分离错误
entryCh, errCh := filters.ErrFilter(filteredEntries)
// 选择窗口大小为5且移动平均值>0.5的所有条目
resultCh := filters.MovingAvg(0.5, 5, entryCh)
// 我们将捕获第一个错误并取消
var streamErr error
go func() {
for err := range errCh {
// 捕获第一个错误
if streamErr == nil {
streamErr = err
cancel()
}
}
}()
for entry := range resultCh {
fmt.Printf("%+v\n", entry)
}
if streamErr != nil {
fmt.Println(streamErr)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这里有几点需要注意。首先,有一个单独的协程从错误通道接收数据。当捕获到第一个错误时,它会完全取消流处理。如果发生这种情况,Stream方法会收到取消信号并关闭entries通道。这将被管道中的下一个处理步骤(MinFilter)检测到,它会关闭自己的通道。这种情况会一直持续到resultCh关闭,当resultCh关闭时,从resultCh读取数据的for循环也会关闭。下一条语句读取streamErr变量,它是在错误处理协程中写入的,但这不是数据竞争。ErrFilter函数在关闭entryCh之前关闭errCh,而entryCh在resultCh之前关闭(你能明白为什么吗?),因此for循环的终止保证了errCh已关闭。其次,结果是在主协程中收集的。也可以使用一个单独的协程来收集结果,但那样你必须使用sync.WaitGroup来等待两个协程完成。你也可以选择在主协程中读取错误,同时在另一个协程中收集结果。在这种情况下,你又必须使用sync.WaitGroup,因为errCh的关闭发生在resultCh关闭之前,所以你必须等待resultCh关闭。
并非所有的数据流实现都能像这样使用Go语言的并发原语进行链式操作。例如,如果你采用的是微服务架构,使用HTTP请求、WebSocket,或者像gRPC这样的远程过程调用(Remote Procedure Call,RPC)方案,那么实际上你无法通过通道来链式连接各个组件。这些组件中的一部分可能位于网络中的不同节点上,因此它们之间的通信将通过网络连接进行。不过,借助简单的适配器,我们之前讨论的基本结构仍然可以使用。那么,我们来看看如何实现这样的适配器,以便有效地利用Go语言的并发原语。首先,我们需要确定在网络中不同组件之间交换数据时,我们的数据对象是什么样的。所以我们需要对这些数据对象进行序列化(或编组,marshal),并通过网络传输,在接收端再对其进行反序列化(或解组,unmarshal),以重建原始对象,或者尽可能接近原始对象的内容。在这种情况下,使用像gRPC这样的RPC实现会很有帮助,因为它会强制你仅使用可编组/可解组的对象来思考和建模你的数据对象。然而,情况并非总是如此。数据交换的一种常见格式是JSON,所以在这个例子中我们将使用JSON。你马上就能意识到这里存在的潜在问题:store.Entry结构可以很容易地进行编组,但在解组时,Entry.Error字段无法重建。如果你要通过网络连接发送错误信息,你应该实现包含错误类型和诊断信息的错误结构,这样在接收端就能正确地重建它们。为了简单起见,我们将错误简单地表示为字符串:
type Message struct {
At time.Time `json:"at"`
Value float64 `json:"value"`
Error string `json:"err"`
}
2
3
4
5
这里,Message结构是store.Entry类型的可序列化版本。当通过网络连接发送store.Entry类型的对象时,我们首先将每个条目转换为一个消息,将其编码为JSON格式,然后写入。由于我们处理的是多个store.Entry结构的流,我们有一个通道,从这个通道中读取数据流。一个实现此功能的简单通用适配器如下:
func EncodeFromChan[T any](input <-chan T, encode func(T) ([]byte, error), out io.Writer) <-chan error {
ret := make(chan error, 1)
go func() {
defer close(ret)
for entry := range input {
data, err := encode(entry)
if err != nil {
ret <- err
return
}
if _, err := out.Write(data); err != nil {
if !errors.Is(err, io.EOF) {
ret <- err
}
return
}
}
}()
return ret
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这个函数从给定的通道中读取条目,使用给定的encode函数对其进行序列化,并将结果写入给定的io.Writer。注意,它返回一个错误通道,该通道的容量为1。这个通道将错误信息传递给调用者,由于它的容量为1,即使调用者没有从该通道接收数据,错误信息也可以发送到通道中而不会阻塞。同一个通道也用作完成信号。使用这个适配器的HTTP处理器如下:
http.HandleFunc("/db", func(w http.ResponseWriter,req *http.Request) {
storeRequest := parseRequest(req)
data, err := st.Stream(req.Context(), storeRequest)
if err != nil {
http.Error(w,"Store error",http.StatusInternalServerError)
return
}
errCh := EncodeFromChan(data, func(entry store.Entry) ([]byte, error) {
msg := Message{
At: entry.At,
Value: entry.Value,
}
if entry.Error != nil {
msg.Error = entry.Error.Error()
}
return json.Marshal(msg)
}, w)
err = <-errCh
if err != nil {
fmt.Println("Encode error", err)
}
}))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这里有几点需要注意。处理器使用请求上下文调用store.Stream函数。因此,如果这个API的调用者停止监听数据流并关闭连接,上下文将被取消,处理器也将停止生成结果。其次,存储操作产生的错误可以作为HTTP错误返回,但编码器产生的错误不行。这是因为在检测到流中出现错误时,HTTP响应头已经写入了200 Ok的HTTP状态码,所以无法更改。此时最好的做法是停止处理并记录错误。请注意,这种情况不包括从存储中检索到的带有错误的条目。这些条目会被成功传输。只有在编组失败,或者写入网络连接失败(如果调用者终止连接,就可能发生这种情况)时,才会出现错误。
与编码函数类似,我们需要为连接的接收端编写一个解码器。下面这个通用函数读取并解码消息,并通过通道发送它们。从连接中实际读取数据的操作将在给定的decode函数中实现:
func DecodeToChan[T any](decode func(*T) error) (<-chan T, <-chan error) {
ret := make(chan T)
errch := make(chan error, 1)
go func() {
defer close(ret)
defer close(errch)
var entry T
for {
if err := decode(&entry); err != nil {
if !errors.Is(err, io.EOF) {
errch <- err
}
return
}
ret <- entry
}
}()
return ret, errch
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这次返回了两个通道:一个用于实际的数据流,另一个用于错误信息。同样,错误通道的容量为1,所以调用者不需要监听它。调用这个API并流式传输数据的HTTP客户端如下:
resp, err := http.Get(APIAddr+"/db")
if err != nil {
panic(err)
}
defer resp.Body.Close()
decoder := json.NewDecoder(resp.Body)
entries, rcvErr := DecodeToChan[store.Entry](
func(entry *store.Entry) error {
var msg Message
if err := decoder.Decode(&msg); err != nil {
return err
}
entry.At = msg.At
entry.Value = msg.Value
if msg.Error != "" {
entry.Error = fmt.Errorf(msg.Error)
}
return nil
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
如你所见,这是一个简单直接的HTTP调用,它使用JSON解码器从响应中解码Message对象的流,并将它们发送到entries通道。现在,这个通道可以作为流处理管道的输入。可以使用一个单独的goroutine来监听错误通道中的错误信息。
这个例子展示了在处理流时,如何在读取器/写入器和通道之间进行转换。像这样流式传输结果使用的内存非常少,能够快速返回结果,并且扩展性很好,因为数据会在到达时进行处理。下一个例子将使用WebSocket来说明如何并发处理多个流。
# 处理多个流
很多时候,你需要协调来自多个流的数据以及向多个流发送的数据,并且是并发地进行处理。一个简单的例子就是使用WebSocket的聊天室服务器。与由请求/响应对组成的标准HTTP不同,WebSocket通过HTTP进行双向通信,所以你可以在同一个连接上进行读取和写入操作。它们非常适合系统之间的长时间对话,在这种对话中双方都要发送和接收数据,比如这个聊天室的例子。我们将开发一个聊天室服务器,它可以接受来自多个客户端的WebSocket连接。服务器会将从一个客户端接收到的消息分发给当时所有连接的客户端。为此,我们定义以下消息结构:
type Message struct {
Timestamp time.Time
Message string
From string
}
2
3
4
5
我们先从客户端开始。每个客户端都将使用WebSocket连接到聊天服务器:
cli, err := websocket.Dial("ws://"+os.Args[1]+"/chat", "", "http://"+os.Args[1])
if err != nil {
panic(err)
}
defer cli.Close()
2
3
4
5
客户端将从终端读取文本输入,并通过WebSocket将其发送到聊天服务器。同时,所有客户端也会监听传入的消息。很明显,我们需要几个goroutine来并发完成这些操作。我们首先设置用于与服务器收发消息的通道。在下面的代码中,rcvCh将用于接收从服务器收到的消息,inputCh将用于向服务器发送消息:
decoder := json.NewDecoder(cli)
rcvCh, rcvErrCh := chat.DecodeToChan(func(msg *chat.Message) error {
return decoder.Decode(msg)
})
sendCh := make(chan chat.Message)
sendErrCh := chat.EncodeFromChan(sendCh, func(msg chat.Message) ([]byte, error) {
return json.Marshal(msg)
}, cli)
2
3
4
5
6
7
8
接下来,我们使用一个单独的goroutine从终端读取文本并发送到服务器:
done := make(chan struct{})
go func() {
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
text := scanner.Text()
select {
case <-done:
return
default:
}
sendCh <- chat.Message{
Message: text,
}
}
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
客户端代码的最后一部分用于处理从服务器接收的消息:
for {
select {
case msg, ok := <-rcvCh:
if!ok {
close(done)
return
}
fmt.Println(msg)
case <-sendErrCh:
return
case <-rcvErrCh:
return
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
服务器的实现稍微复杂一些,因为它必须将从客户端接收到的消息分发给所有连接的客户端。它还必须跟踪已连接的客户端,并确保恶意客户端不会破坏整个系统。服务器将有一个处理函数,其中包含解码器和编码器goroutine,类似于我们在客户端中使用的那些。然而,也有一些显著的区别。首先,服务器为每个连接的客户端创建一个单独的goroutine。这意味着如果我们需要跟踪所有活动连接,我们需要一个共享数据结构,因此还需要一个互斥锁来保护它。但有一种方法可以在不使用任何共享内存(从而避免内存竞态风险)的情况下实现这一点。我们不使用共享内存结构,而是创建一个控制器goroutine,它将跟踪所有活动连接,并将接收到的任何消息分发给它们。当建立一个新连接时,我们将使用一个通道connectCh来发送该连接的数据通道。当连接关闭时,我们将使用另一个通道disconnectCh来发送连接已断开的通知。我们还将使用一个数据通道来接收消息:
dispatch := make(chan chat.Message)
connectCh := make(chan chan chat.Message)
disconnectCh := make(chan chan chat.Message)
go func() {
clients := make(map[chan chat.Message]struct{})
for {
select {
case c := <-connectCh:
clients[c] = struct{}{}
case c := <-disconnectCh:
delete(clients, c)
case msg := <-dispatch:
for c := range clients {
select {
case c <- msg:
default:
delete(clients, c)
close(c)
}
}
}
}
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
连接处理函数负责实际的数据编码和解码:
http.Handle("/chat", websocket.Handler(func(conn *websocket.Conn) {
client := conn.RemoteAddr().String()
inputCh := make(chan chat.Message, 10)
connectCh <- inputCh
defer func() {
disconnectCh <- inputCh
}()
decoder := json.NewDecoder(conn)
data, decodeErrCh := chat.DecodeToChan(func(msg *chat.Message) error {
err := decoder.Decode(msg)
msg.From = client
msg.Timestamp = time.Now()
return err
})
encodeErrCh := chat.EncodeFromChan(inputCh, func(msg chat.Message) ([]byte, error) {
return json.Marshal(msg)
}, conn)
for {
select {
case msg, ok := <-data:
if!ok {
return
}
dispatch <- msg
case <-decodeErrCh:
return
case <-encodeErrCh:
return
}
}
}))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
如你所见,当一个新连接开始时,会构建一个输入通道来接收来自所有客户端的消息。这是一个带缓冲的通道,用于防止恶意客户端在不关闭WebSocket的情况下停止读取数据。输入通道将缓冲最后10条消息,如果这些消息无法发送,控制器将通过关闭数据通道来终止该客户端的连接。当数据通道关闭时,编码goroutine将终止,最终终止该客户端的处理函数。
这个简单的服务器展示了一种在多个客户端之间分发数据流,同时避免陷入内存竞态问题的方法。许多看似需要共享数据结构的算法,都可以转换为不需要共享数据结构的消息传递算法。但这并不总是可行的,所以在开发这类程序时,你应该对这两种方式进行评估。如果你在编写缓存,那么使用带有互斥锁的共享内存更合理。如果你在多个goroutine之间协调工作,那么使用多个通道的单独goroutine更合理。发挥你的判断力,试着编写代码,如果最终代码变得混乱不堪,那就抛弃它,换一种方法。
# 总结
本章介绍了用于处理请求(主要是通过网络传来的请求)的语言工具和并发模式。在不断演进的架构中,经常会出现这样的情况:为非网络系统开发的一些组件,在应用程序转向更面向服务的架构时,无法达到预期的性能。我希望了解这些工具和模式背后的基本原理和设计理念,能在你遇到这些问题时有所帮助。
接下来,我们将探讨原子操作(atomics),为什么在使用它们时要小心,以及如何有效地使用它们。