 第2章 字符串处理
第2章 字符串处理
# 第2章 字符串处理
字符串是Go语言中的基本数据类型之一。
Go语言使用不可变的UTF - 8编码字符串。这可能会让新开发者感到困惑;毕竟,下面这样的代码是能正常运行的:
x := "Hello"
x += " World"
fmt.Println(x)
// Prints Hello World
2
3
4
我们不是刚刚修改了x吗?是的,我们修改了。这里不可变的是"Hello"和" World"这两个字符串。所以,字符串本身是不可变的,但字符串变量x是可变的。要修改字符串变量,你可以创建字节切片或符文(rune,可变的)切片,对它们进行处理,然后再将其转换回字符串。
UTF - 8是网络和互联网技术中最常用的编码方式。这意味着在Go程序中,任何时候处理文本,处理的都是UTF - 8编码的字符串。如果你必须处理其他编码的数据,需要先将其转换为UTF - 8编码,进行处理后,再转换回原来的编码。
UTF - 8是一种变长编码,每个码点(codepoint)使用1到4个字节表示。大多数码点代表一个字符,但也有一些代表其他信息,比如格式设置。这可能会带来一些意外情况。例如,字符串的长度(即它占用的字节数)与字符数是不同的。要确定字符串中的字符数,需要按顺序进行计数。在对字符串进行切片时,必须注意码点边界。
Go语言使用rune类型来表示码点。所以,一个字符串既可以看作是一个字节序列,也可以看作是一个符文序列。如图2.1所示。这里,x是一个字符串变量,它指向一个不可变的字符串,这个字符串是一个字节序列,也可以看作是一个符文序列。尽管UTF - 8是变长编码,但rune是固定长度的32位类型(uint32)。像字符H这样较小的码点,是32位十进制数72,而字节H是一个8位值。
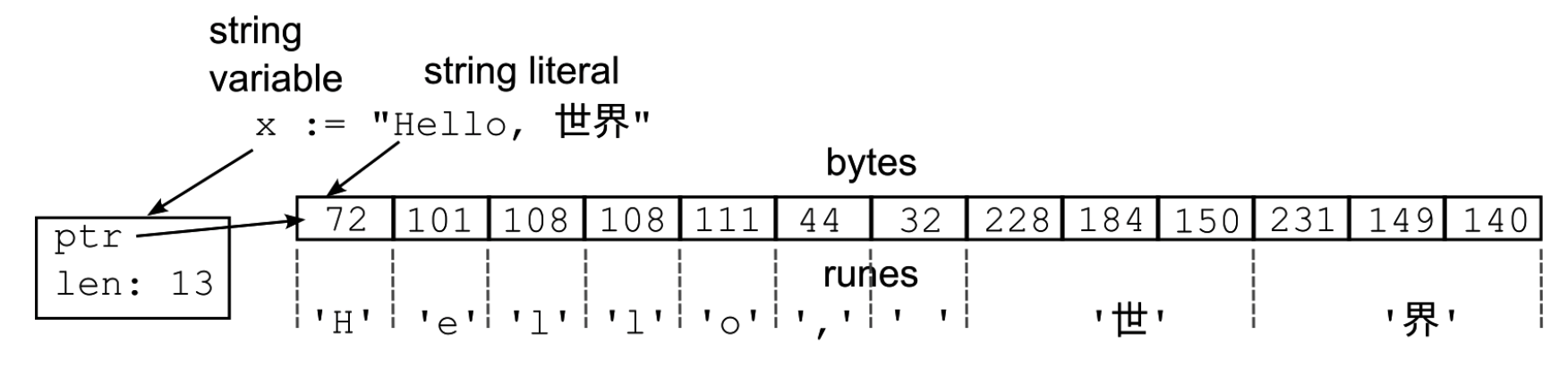 图2.1 字符串、字节和符文
图2.1 字符串、字节和符文
在本章中,我们将探讨一些涉及字符串和文本的常见操作。本章包含的方法如下:
- 创建字符串
- 格式化字符串
- 拼接字符串
- 大小写和标题格式比较
- 处理国际化字符串
- 编码处理
- 迭代字符串的字节和符文
- 分割字符串
- 正则表达式
- 逐行或逐词读取字符串
- 修剪字符串
- 模板(Templates)
# 创建字符串
在这个方法中,我们将探讨如何在程序中创建字符串。
# 操作方法……
- 使用字符串字面量。Go语言中有两种字符串字面量:
- 使用解释型字符串字面量,用双引号括起来:
x := "Hello world"
- 使用解释型字符串字面量时,必须转义某些字符:
x := "This is how you can include a \" in your string literal"
y := "You can also use a newline \n, tab \t"
2
- 可以包含Unicode码点或十六进制字节,用
\转义:
w := "\u65e5本\U00008a9e"
x := "\xff"
2
解释型字符串中不能包含换行符或未转义的双引号。
- 使用原始字符串字面量,用反引号括起来。原始字符串字面量可以包含除反引号之外的任何字符(包括换行符)。在原始字符串字面量中无法转义反引号。
x := `This is a
multiline raw string literal.
Backslash will print as backslash \`
2
3
如果你需要在原始字符串字面量中包含反引号,可以这样做:
x := `This is a raw string literal with ` + "`" + ` in it`
# 格式化字符串
Go标准库提供了多种在文本模板中替换值的方法。这里,我们将讨论fmt包中的文本格式化工具。它们为在文本模板中替换值提供了一种简单便捷的方式。
# 操作方法……
- 使用
fmt.Print系列函数来格式化值。fmt.Print将使用默认格式打印一个值。- 字符串值将按原样打印。
- 数值将首先转换为字符串,可以是整数、小数形式,对于大指数会使用科学计数法。
- 布尔值将打印为
true或false。 - 结构化值将打印为字段列表。
如果一个
Print函数以ln结尾(比如fmt.Println),在字符串输出后会输出一个换行符。 如果一个Print函数以f结尾,该函数将接受一个格式参数,这个参数将作为模板,用于替换值。
fmt.Sprintf将格式化一个字符串并返回它。
fmt.Fprintf将格式化一个字符串并写入io.Writer,io.Writer可以是文件、网络连接等。
fmt.Printf将格式化一个字符串并写入标准输出。
# 工作原理……
所有这些函数都使用%[选项]<动词>格式来从参数列表中获取参数。要在输出中生成一个%字符,使用%%:
func main() {
fmt.Printf("Print integers using %%d: %d| \n", 10)
// Print integers using %d: 10|
fmt.Printf("You can set the width of the printed number, left aligned: %5d| \n", 10)
// You can set the width of the printed number, left aligned: 10|
fmt.Printf("You can make numbers right-aligned with a given width: %-5d| \n", 10)
// You can make numbers right-aligned with a given width: 10 |
fmt.Printf("The width can be filled with 0s: %05d| \n", 10)
// The width can be filled with 0s: 00010|
fmt.Printf("You can use multiple arguments: %d %s %v\n", 10, "yes", true)
// You can use multiple arguments: 10 yes true
fmt.Printf("You can refer to the same argument multiple times : %d %s %[2]s %v\n", 10, "yes", true)
// You can refer to the same argument multiple times : 10 yes yes true
fmt.Printf("But if you use an index n, the next argument will be selected from n+1 : %d %s %[2]s %[1]v %v\n", 10, "yes", true)
// But if you use an index n, the next argument will be selected from n+1 : 10 yes yes 10 yes
fmt.Printf("Use %%v to use the default format for the type: %v %v %v\n", 10, "yes", true)
// Use %v to use the default format for the type: 10 yes true
fmt.Printf("For floating point, you can specify precision: %5.2f\n", 12.345657)
// For floating point, you can specify precision: 12.35
fmt.Printf("For floating point, you can specify precision: %5.2f\n", 12.0)
// For floating point, you can specify precision: 12.00
type S struct {
IntValue int
StringValue string
}
s := S{
IntValue: 1,
StringValue: `foo "bar"`,
}
// Print the field values of a structure, in the order they are declared
fmt.Printf("%v\n", s)
// {1 foo "bar"}
// Print the field names and values of a structure
fmt.Printf("%+v\n", s)
//{IntValue:1 StringValue:foo "bar"}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 拼接字符串
Go标准库提供了多种从组件构建字符串的方法。最佳方法取决于你处理的字符串类型以及字符串的长度。本节展示了几种构建字符串的方法。
# 操作方法……
- 要合并几个固定数量的字符串,或者向另一个字符串添加符文(rune),可以使用
+或+=运算符,或者string.Builder。 - 要通过算法构建字符串,使用
strings.Builder。 - 要合并字符串切片,使用
strings.Join。 - 要合并URL路径的各个部分,使用
path.Join。 - 要从路径段构建文件系统路径,使用
filepath.Join。
# 工作原理……
要构建常量值,或者进行简单的拼接,使用+或+=运算符:
var TwoLines = "这是第一行 \n" +
"这是第二行"
func ThreeLines(newLine string) string {
return TwoLines + "\n" + newLine
}
2
3
4
5
6
你可以用同样的方式向字符串添加符文:
func AddNewLine(line string) string {
return line + string('\n')
}
2
3
提示:
在注重性能的团队中,使用+运算符处理字符串可能会引发争议。确实,+运算符可能效率不高,因为多次相加可能会创建不必要的临时字符串来存储中间结果。同样正确的是,在某些用例中,编译器生成的代码可能比手动编写的代码更好。不过,除非在for循环中使用+运算符创建字符串,否则它很少会成为性能问题的根源。例如,x + y几乎总是比fmt.Sprintf("%s%s", x, y)性能更好。如果有疑问,可以编写基准测试并进行测量。在我的笔记本电脑上的测试结果如下:
BenchmarkXPlusY-12 98628536 11.31 ns/op
BenchmarkSprintf-12 12120278 97.70 ns/op
BenchmarkBuilder-12 33077902 34.89 ns/op
2
3
对于需要添加许多短字符串来构建一个长字符串的复杂情况,使用strings.Builder。尽管strings.Builder看起来像是字节切片(byte slice)的便捷前端,但它的功能不止于此。它可以从底层字节切片创建字符串而无需复制,因此它的性能几乎总是优于先使用字节切片然后再从其创建字符串的方式。
提示:这是一个示例,展示了为什么你应该优先使用标准库函数,而不是第三方库或手动优化。这些函数经过了大量优化,并且依赖于Go语言的内部机制,不会产生可移植性问题。
builder := strings.Builder{} // 零值即可使用
for i := 0; i < 10000; i++ {
builder.WriteString(getShortString(i))
}
fmt.Println(builder.String())
2
3
4
5
使用strings.Join合并字符串切片。如果你处理的是文件名,并且需要合并多个目录层级,使用filepath.Join以避免特定于平台的分隔符字符。filepath.Join在Windows平台上会使用\,在基于Linux的平台上会使用/。如果你处理的是URL并且需要合并多个部分,使用path.Join,它总是使用/来合并路径部分:
package main
import (
"fmt"
"path"
"path/filepath"
"strings"
)
func main() {
words := []string{"foo", "bar", "baz"}
fmt.Println(strings.Join(words, " "))
// foo bar baz
fmt.Println(strings.Join(words, ""))
// foobarbaz
fmt.Println(path.Join(words...))
// foo/bar/baz
fmt.Println(filepath.Join(words...))
// foo/bar/baz 或 foo\bar\baz,取决于主机系统
paths := []string{"/foo", "//bar", "baz"}
fmt.Println(strings.Join(paths, " "))
// /foo //bar baz
fmt.Println(path.Join(paths...))
// /foo/bar/baz
fmt.Println(filepath.Join(paths...))
// /foo/bar/baz 或 \foo\bar\baz,取决于主机系统
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 处理字符串大小写
在处理文本数据时,与字符串大小写相关的问题经常出现。文本搜索应该区分大小写还是不区分大小写?我们如何将字符串转换为小写或大写?在本节中,我们将探讨一些以可移植的方式处理这些常见问题的方法。
# 操作方法……
- 分别使用
strings.ToUpper和strings.ToLower函数将字符串转换为大写和小写。 - 当处理具有特殊大小写映射的语言文本时(例如在土耳其语中,“İ”是“I”的大写形式),使用
strings.ToUpperSpecial和strings.ToLowerSpecial函数。 - 要将文本转换为标题格式的大写形式,使用
strings.ToTitle函数。 - 要按字典顺序比较字符串,使用比较运算符。
- 要在忽略大小写的情况下测试字符串的等效性,使用
strings.EqualFold函数。
# 工作原理……
将字符串转换为大写或小写很简单:
greet := "Hello World!"
fmt.Println(strings.ToUpper(greet))
fmt.Println(strings.ToLower(greet))
2
3
这个程序的输出如下:
HELLO WORLD!
hello world!
2
但是不同语言的大小写形式可能有所不同。例如,一些突厥语有特殊情况:
word := "ilk"
fmt.Println(strings.ToUpper(word))
2
这将输出以下内容:
ILK
然而,这不是土耳其语中正确的大写形式。让我们试试下面的代码:
import (
"fmt"
"strings"
"unicode"
)
func main() {
word := "ilk"
fmt.Println(strings.ToUpperSpecial(unicode.TurkishCase, word))
}
2
3
4
5
6
7
8
9
10
上述程序将输出以下内容:
iLK
标题格式(title case)与大写或小写的主要区别在于处理连字和双字母组合(digraphs)时——也就是说,多个字符表示为单个字符,例如LJ(U+01C7):
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.ToTitle("LJ")) // U+01C7
fmt.Println(strings.ToUpper("LJ"))
fmt.Println(strings.ToLower("LJ"))
}
2
3
4
5
6
7
8
9
10
11
12
这个程序输出如下:
Lj LJ lj
大写、小写和标题格式定义了如何使用特定的大小写映射来打印字符串。这些是大小写映射。大小写折叠(Case folding)是为了比较目的将文本转换为相同大小写的过程。 对于区分大小写的字典顺序比较,使用关系运算符:
fmt.Println("a" < "b") // true
要以不区分大小写的方式比较两个Unicode字符串,使用strings.EqualFold函数:
fmt.Println(strings.EqualFold("here", "Here")) // true
fmt.Println(strings.EqualFold("here", "Here")) // true
fmt.Println(strings.EqualFold("GÖ", "gö")) // true
2
3
# 更多内容……
虽然标准库的strings包包含了大部分你需要的字符串比较函数,但在处理国际化字符串时,这些函数可能并不够。例如,在许多情况下,你可能希望“Montréal”和“montreal”被视为相等,但strings.EqualFold函数无法做到这一点。许多用于处理国际化文本的支持函数都在golang.org/x/text下的包中。
Unicode提供了多种表示给定字符串的方式。“Montréal”中的“é”可以表示为单个符文(rune)\u00e9,也可以表示为“e”后面跟着一个尖音符,即“e\u0301”。\u0301是“组合尖音符”(◌́ ),它会修改前面的码点。根据Unicode标准,“é”和“e + ◌́ ”是“规范等效”的。还有一种兼容等效,例如\ufb00表示将“ff”作为单个码点,以及“ff”序列。规范等效的序列也是兼容的,但并非所有兼容序列都是规范等效的。
因此,如果你需要从文本中删除变音符号(即非间距标记),可以按如下方式进行分解、删除变音符号,然后再组合:
// Based on the blog post https://go.dev/blog/normalization
package main
import (
"fmt"
"io"
"strings"
"unicode"
"golang.org/x/text/transform"
"golang.org/x/text/unicode/norm"
)
func main() {
isMn := func(r rune) bool {
return unicode.Is(unicode.Mn, r) // Mn: nonspacing marks
}
t := transform.Chain(norm.NFD, transform.RemoveFunc(isMn), norm.NFC)
rd := transform.NewReader(strings.NewReader("Montréal"), t)
str, _ := io.ReadAll(rd)
fmt.Println(string(str))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
上述程序将输出以下内容:
Montreal
# 处理编码
如果你的程序有可能需要处理不同系统生成的数据,那么你应该了解不同的文本编码。这是一个庞大的主题,但本节将提供一些入门指引。
# 如何操作……
- 使用
golang.org/x/text/encoding包来处理不同的编码。 - 要按名称查找编码,可以使用以下其中一个:
golang.org/x/text/encoding/ianaindexgolang.org/x/text/encoding/htmlindex
- 找到编码后,使用它将文本转换为UTF-8编码或从UTF-8编码转换回来。
# 工作原理……
使用其中一个索引查找编码。然后,使用该编码来读取/写入数据:
package main
import (
"fmt"
"os"
"golang.org/x/text/encoding/ianaindex"
)
func main() {
enc, err := ianaindex.MIME.Encoding("US-ASCII")
if err != nil {
panic(err)
}
b, err := os.ReadFile("ascii.txt")
if err != nil {
panic(err)
}
decoder := enc.NewDecoder()
encoded, err := decoder.Bytes(b)
if err != nil {
panic(err)
}
fmt.Println(string(encoded))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 迭代字符串的字节和符文
Go语言中的字符串可以看作是字节序列,也可以看作是符文序列。本节展示如何以这两种方式迭代字符串。
# 如何操作……
要迭代字符串的字节,可以使用索引:
for i := 0; i < len(str); i++ {
fmt.Print(str[i], " ")
}
2
3
要迭代字符串的符文,可以使用range:
for index, c := range str {
fmt.Print(c, " ")
}
2
3
# 工作原理……
Go语言的字符串是字节切片,所以你可能期望能够编写一个for循环来迭代字符串的字节和符文。你可能会认为可以这样做:
strBytes := []byte(str)
strRunes := []rune(str)
2
然而,将字符串转换为字节切片或符文切片是一个开销很大的操作。第一种方式会创建str字符串字节的可写副本,第二种方式会创建str字符串符文的可写副本。请记住,符文(rune)的类型是uint32。
有两种形式的for循环可以迭代字符串的元素。以下for循环将迭代字符串的字节:
str := "Hello 世界 "
for i := 0; i < len(str); i++ {
fmt.Print(str[i], " ")
}
2
3
4
输出如下:
72 101 108 108 111 32 228 184 150 231 149 140
还要注意,str[i]会返回第i个字节,而不是第i个符文。以下形式迭代字符串的符文:
for i, r := range str {
fmt.Printf("( %d %d %s)", i, r, string(r))
}
2
3
输出如下:
(0 72 H)(1 101 e)(2 108 l)(3 108 l)(4 111 o)(5 32 )(6 19990 世)(9 30028 界)
注意索引——它们的顺序是0、1、2、3、4、5、6、9。这是因为str[6]包含一个3字节的符文,str[9]也是如此。
当处理[]byte而不是字符串时,可以通过如下方式模拟符文迭代:
import (
"unicode/utf8"
"fmt"
)
str := []byte("Hello 世界")
for i := 0; i < len(str); {
r, n := utf8.DecodeRune(str[i:])
fmt.Print("(", i, r, " ", string(r), ")")
i += n
}
2
3
4
5
6
7
8
9
10
11
utf8.DecodeRune函数从字节切片中解码下一个符文,并返回该符文和消耗的字节数。通过这种方式,你可以在不先将字节切片转换为字符串的情况下解码其符文。
# 分割
strings包提供了方便的函数来分割字符串,以获得字符串切片。
# 如何操作……
- 要使用分隔符将字符串分割成多个部分,可以使用
strings.Split。 - 要分割字符串中以空格分隔的部分,可以使用
strings.Fields。
# 工作原理……
如果你需要解析由固定分隔符分隔的字符串,请使用strings.Split。如果你需要解析字符串中以空格分隔的部分,请使用strings.Fields:
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Split("a,b,c,d", ","))
// ["a", "b", "c", "d"]
fmt.Println(strings.Split("a, b, c, d", ","))
// ["a", " b", " c", " d"]
fmt.Println(strings.Fields("a b c d "))
// ["a", "b", "c", "d"]
fmt.Println(strings.Split("a---b---c--d--", "-"))
// ["a", "", "", "b", "", "", "c", "", "d", "", ""]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
请注意,当分隔符重复时,strings.Split可能会产生一些意外结果。例如,以“-”为分隔符时,“a---b”会被分割成“a”、“”、“”和“b”。这两个空字符串分别位于第一个和第二个“-”之间,以及第二个和第三个“-”之间。
# 逐行或逐词读取字符串
在处理大文本或用户输入等场景时,有很多按流处理字符串的用例。本方法展示了如何使用bufio.Scanner来实现这一目的。
# 如何操作……
- 使用
bufio.Scanner来读取行、单词或自定义块。 - 创建一个
bufio.Scanner实例。 - 设置分割方法。
- 在
for循环中读取扫描到的标记。
# 工作原理……
Scanner的工作方式类似于迭代器——每次调用Scan()方法,如果解析到下一个标记则返回true,如果没有更多标记则返回false。可以通过Text()方法获取标记:
package main
import (
"bufio"
"fmt"
"strings"
)
const input = `This is a string
that has 3
lines.`
func main() {
lineScanner := bufio.NewScanner(strings.NewReader(input))
line := 0
for lineScanner.Scan() {
text := lineScanner.Text()
line++
fmt.Printf("Line %d: %s\n", line, text)
}
if err := lineScanner.Err(); err != nil {
panic(err)
}
wordScanner := bufio.NewScanner(strings.NewReader(input))
wordScanner.Split(bufio.ScanWords)
word := 0
for wordScanner.Scan() {
text := wordScanner.Text()
word++
fmt.Printf("word %d: %s\n", word, text)
}
if err := wordScanner.Err(); err != nil {
panic(err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
输出如下:
Line 1: This is a string
Line 2: that has 3
Line 3: lines.
word 1: This
word 2: is
word 3: a
word 4: string
word 5: that
word 6: has
word 7: 3
word 8: lines.
2
3
4
5
6
7
8
9
10
11
# 修剪字符串两端
用户输入通常不规范,在重要文本的前后可能会包含额外的空格。本方法展示了如何使用字符串修剪函数来处理这种情况。
# 如何操作……
使用strings.Trim系列函数,如下所示:
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.TrimRight("Break-------", "-"))
// Break
fmt.Println(strings.TrimRight("Break with spaces-- -- --", "- "))
// Break with spaces
fmt.Println(strings.TrimSuffix("file.txt", ".txt"))
// file
fmt.Println(strings.TrimLeft(" \t Indented text", " \t"))
// Indented text
fmt.Println(strings.TrimSpace(" \t \n Indented text \n\t"))
// Indented text
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 正则表达式(Regular expressions)
正则表达式提供了高效的方法,用于确保文本数据与给定模式匹配、搜索模式、提取和替换文本的部分内容。通常,你只需编译一次正则表达式,然后多次使用编译后的正则表达式,就能高效地验证、搜索、提取或替换字符串的部分内容。
# 验证输入
格式验证(Format validation)是确保来自用户输入或其他来源的数据采用公认格式的过程。正则表达式可以成为进行这种验证的有效工具。
# 如何操作……
使用预编译的正则表达式来验证应符合特定模式的输入值。
package main
import (
"fmt"
"regexp"
)
var integerRegexp = regexp.MustCompile("^[0-9]+$")
func main() {
fmt.Println(integerRegexp.MatchString("123")) // true
fmt.Println(integerRegexp.MatchString(" 123 ")) // false
}
2
3
4
5
6
7
8
9
10
11
12
13
为确保完全匹配,请务必包含文本开头(^)和文本结尾标记($);否则,你最终可能会接受包含与正则表达式匹配的字符串的输入。
并非所有类型的输入都适合使用正则表达式进行验证。有些输入的正则表达式很复杂(比如电子邮件或密码策略的正则表达式),所以对于这些情况,自定义验证可能效果更好 。
# 搜索模式
你可以使用正则表达式在文本数据中进行搜索,以定位与某个模式匹配的字符串。
# 如何操作……
使用regexp.Find系列方法来搜索与某个模式匹配的子字符串。
package main
import (
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile(`[0-9]+`)
fmt.Println(re.FindAllString("This regular expression find numbers, like 1, 100, 500, etc.", -1))
}
2
3
4
5
6
7
8
9
10
11
输出如下:
[1 100 500]
# 从字符串中提取数据
你可以使用正则表达式来定位并提取符合某个模式的文本。
# 如何操作……
使用捕获组(capture groups)来提取与某个模式匹配的子字符串。
package main
import (
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile(`^(\w+)=(\w+)$`)
result := re.FindStringSubmatch(`property=12`)
fmt.Printf("Key: %s value: %s\n", result[1], result[2])
result = re.FindStringSubmatch(`x=y`)
fmt.Printf("Key: %s value: %s\n", result[1], result[2])
}
2
3
4
5
6
7
8
9
10
11
12
13
14
输出如下:
Key: property value: 12
Key: x value: y
2
让我们来看一下这个正则表达式:
^(\w+):行开头由一个或多个单词字符组成的字符串(捕获组1)=:一个“=”符号(\w+)$:由一个或多个单词字符组成的字符串(捕获组2),然后是行尾
请注意,捕获组是用括号括起来的。
FindStringSubmatch方法将匹配的字符串作为切片的第0个元素返回,然后是每个捕获组。使用捕获组,你可以像上面那样提取数据。
# 替换字符串的部分内容
你可以使用正则表达式在文本中进行搜索,将与某个模式匹配的部分替换为其他字符串。
# 如何操作……
使用Replace系列函数,将字符串中的模式替换为其他内容:
package main
import (
"fmt"
"regexp"
)
func main() {
// Find numbers, capture the first digit
re := regexp.MustCompile(`([0-9])[0-9]*`)
fmt.Println(re.ReplaceAllString("This example replaces numbers with 'x': 1, 100, 500.", "x"))
// This example replaces numbers with 'x': x, x, x.
fmt.Println(re.ReplaceAllString("This example replaces all numbers with their first digits: 1, 100, 500.", "${1}"))
// This example replaces all numbers with their first digits: 1,
// 1, 5.
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 模板(Templates)
!!!注意:由于{{ XYZ }}中 {{ 会导致页面解析失败无法展示,为了正常显示页面,下文中将 {{ 替换成 XXX,请读者注意甄别,实际编码时应该将 XXX 换回成 {{。
模板对于生成数据驱动的文本输出很有用。text/template包可用于以下场景:
- 配置文件:你可以在配置文件中使用模板,例如下面这个使用
env映射变量创建环境敏感型配置的示例:
logfile: {{.env.logDir}}/log.json
- 报告:使用模板为命令行应用程序生成输出和生成报告
- 网络应用程序(Web applications):
html/template包为基于模板的HTML生成提供了安全的HTML模板功能,用于构建网络应用程序
# 值替换
模板的主要用途是将数据元素插入到结构化文本中。本节介绍如何将程序中计算出的值插入到模板中。
# 如何操作……
使用 {{.name}} 语法在模板中替换值。
以下代码段使用不同的输入执行模板:
package main
import (
"os"
"text/template"
)
type Book struct {
Title string
Author string
PubYear int
}
const tp = `The book "{{.Title}}" by {{.Author}} was published in
{{.PubYear}}.
`
func main() {
book1 := Book{
Title: "Pride and Prejudice",
Author: "Jane Austen",
PubYear: 1813,
}
book2 := Book{
Title: "The Lord of the Rings",
Author: "J.R.R. Tolkien",
PubYear: 1954,
}
tmpl, err := template.New("book").Parse(tp)
if err != nil {
panic(err)
}
tmpl.Execute(os.Stdout, book1)
tmpl.Execute(os.Stdout, book2)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
上述程序输出如下:
The book "Pride and Prejudice" by Jane Austen was published in 1813. The book "The Lord of the Rings" by J.R.R. Tolkien was published in 1954.
template.New(name)调用会创建一个具有给定名称的空模板(后面会详细介绍)。返回的模板对象表示一个模板主体(在New()调用后为空)。Go模板引擎使用表示主体的模板,以及零个或多个与该主体关联的命名模板。tmpl.Parse(tp)调用将tp模板解析为给定命名模板的主体。如果tp中还有其他使用XXXdefine}}结构定义的模板定义,这些定义也会保留在tmpl中。
tmpl.Execute(os.Stdout,book1)执行模板,并将输出写入os.Stdout。第二个参数book1是用于计算模板的数据。你通过“.”来访问它。例如,当计算XXX.Author}}时,模板引擎会使用反射读取book1.Author,并输出其值。换句话说,在前面的示例中,对于第一个tmpl.Execute调用,“.”表示book1,对于第二个tmpl.Execute调用,“.”表示book2。
由于这是通过反射实现的,以下代码会产生相同的输出:
tmpl.Execute(os.Stdout,map[string]any { "Title":"Pride and Prejudice",
"Author": "Jane Austen", "PubYear": 1813,
})
2
3
# 迭代
模板(template)可以包含表格数据或列表,这些数据可通过程序中计算得到的切片(slice)或映射(map)来填充。模板提供了一种迭代机制来渲染此类内容。
# 操作方法……
- 对于切片/数组,操作如下:
{{ range <slice> }}
// 此处,{{.}} 指切片/数组的后续元素
{{ end }}
2
3
- 对于映射,操作如下:
{{ range <map> }}
// 此处,{{.}} 指映射的后续值(而非键)
// 映射的迭代顺序是不确定的
{{ end }}
2
3
4
或者,也可这样操作:
{{ range $key, $value := <map> }}
// 此处,{{$key}} 和 {{$value}} 是变量,分别设置为映射的后续键值对
{{ end }}
2
3
# 工作原理……
使用 range 遍历切片和映射。
使用以下内容修改前面的示例:
const tpIter = `{{range .}}
The book "{{.Title}}" by {{.Author}} was published in {{.PubYear}}.
{{end}}`
2
3
然后,再用以下内容修改:
...
tmpl, err = template.New("bookIter").Parse(tpIter)
if err != nil {
panic(err)
}
tmpl.Execute(os.Stdout, []Book{book1, book2})
2
3
4
5
6
输出结果如下:
The book "Pride and Prejudice" by Jane Austen was published in 1813.
The book "The Lord of the Rings" by J.R.R. Tolkien was published in 1954.
2
注意,. 是一个书籍切片,因此我们可以遍历它的元素。在计算 XXXrange .}} 内的部分时,. 会被设置为切片的连续元素——在第一次迭代时,. 是 book1,在第二次迭代时,. 是 book2。
我们稍后会处理空行问题。映射的情况也是如此:
tmpl.Execute(os.Stdout, map[int]Book{
1: book1, 2: book2,
})
2
3
# 变量和作用域
在模板中定义局部变量以保存计算值通常很有必要。模板中定义的变量遵循与函数中定义的变量类似的作用域规则——XXXrange}}、XXXif}}、XXXwith}}和 XXXdefine}} 块会创建新的作用域。
在一个作用域中定义的变量在该作用域包含的所有子作用域中都可访问,但在其外部则无法访问。
# 操作方法……
.(点号)指的是 “当前对象”,具体如下:
- 在顶级作用域中,
.指作为Execute方法的数据参数传入的对象。 - 在
XXXrange}}内部,.指当前切片/数组/映射元素。 - 在
XXXwith <expr>}}内部,.指<expr>的值。 - 在
XXXdefine}}块内部,.指传入XXXtemplate "name" <object>}}的对象的值。 .X指当前对象中名为X的成员:- 如果
.是一个映射,那么.X会计算为键为X的元素。 - 如果
.是一个结构体,那么.X会计算为导出的(exported)X成员变量。
- 如果
提示
注意这里强调的是导出的(exported)。模板引擎使用反射(reflection)来查找当前对象中 `X` 的值。如果当前对象是一个结构体,反射只能访问导出字段,因此无法访问未导出的变量。然而,如果当前对象是一个映射,这就变成了键查找,不存在这样的限制。换句话说,{{.name}} 只有在 . 是映射时才有效,而 {{.Name}} 对结构体和映射都有效。
2
使用以下方式定义一个在当前作用域中可见的新局部变量:
$name := value
# 工作原理……
使用 $name 符号将计算值赋给一个变量,而不是每次都重新计算:
{{ $disabled := false }}
{{ if eq .Selection "1"}}
{{ $disabled = true }}
{{ end }}
<input type="text" value="{{.Value1}}" {{if $disabled}}
disabled{{end}}>
<input type="text" value="{{.Value2}}" {{if $disabled}}
disabled{{end}}>
2
3
4
5
6
7
8
此模板的第一部分等同于以下内容:
disabled := false
if data.Selection == "1" {
disabled=true
}
2
3
4
$ 作为变量名的首字符是必需的。没有它,模板引擎会认为 name 是一个函数。
# 还有更多——嵌套循环和条件语句
在处理嵌套循环或条件语句时,作用域可能会带来挑战。每个 XXXrange}}、XXXif}} 和 XXXwith}} 都会创建一个新的作用域。在一个作用域中定义的变量仅在该作用域及其包含的所有子作用域中可访问。你可以利用这一点创建嵌套循环,同时仍能访问外部作用域中定义的变量:
type Book struct {
Title string
Author string
Editions []Edition
}
type Edition struct {
Edition int
PubYear int
}
const tp = `{{range $bookIndex, $book := .}}
{{$book.Author}}
{{range $book.Editions}}
{{$book.Title}} Edition: {{.Edition}} {{.PubYear}}
{{end}}
{{end}}`
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在这个模板中,第一个 range 定义了循环索引 $bookIndex 和循环变量 $book,这些变量可在嵌套作用域中使用。此时,. 指向 Book 字段的切片。下一个 range 遍历当前 $book.Editions——也就是说,此时 . 指向 Book.Editions 切片的连续元素。嵌套模板既可以访问 Edition 字段,也可以访问外部作用域中的 Book 字段。
# 处理空行
模板操作(即放置在模板中的代码元素)可能会导致产生不需要的空格和空行。Go 模板系统提供了一些机制来处理这些多余的空格。
# 操作方法……
在模板分隔符旁边使用 -:
XXX-会删除此模板元素之前输出的所有空格/制表符/换行符。-}}会删除此模板元素之后出现的所有空格/制表符/换行符。
如果一个模板指令(directive)产生输出,比如变量的值,它会被写入输出流。但如果一个模板指令不生成任何输出,比如 XXXrange}}或XXXif}}` 语句,那么它会被替换为空字符串。如果这些语句单独占一行,那么这些行也会被写入输出,如下所示:

此模板每四行产生一次输出。当没有内容输出时,它会打印三行空行。
通过在 XXX }} 结构中使用 - 来修复这个问题。XXX -}} 会删除后面的所有空白(包括空行),XXX- }} 会删除前面的所有空白,如下所示:
{{range . -}}
{{ if gt . 1 }}
{{- . }}
{{end -}}
{{end -}}
2
3
4
5
输出结果如下:
2
3
4
5
2
3
4
如何去除每行开头的空格呢?首先,我们必须找出它们存在的原因,如下所示:
{{- . }}
{{end -}}
2
第一个 - 会删除值前面的所有空格。我们不能在这一行中使用 -}} 或 XXX- end}},因为这些方法也会删除换行符。但我们可以这样做:
{{range . -}}
{{if gt .1}}
{{- . }}
{{end -}}
{{end -}}
2
3
4
5
这将产生以下输出:
2
3
4
5
2
3
4
# 模板组合
随着模板的增长,它们可能会变得重复。为了减少这种重复,Go 模板系统提供了命名块(组件),可以在模板中重复使用,就像程序中的函数一样。最终的模板可以由这些组件组合而成。
# 操作方法……
你可以创建可在多个上下文中重复使用的模板 “组件”。要定义一个命名模板,使用 {{define "name"}} 结构:
{{define "template1"}}
...
{{end}}
{{define "template2"}}
...
{{end}}
2
3
4
5
6
然后,使用 {{template "name" .}} 结构调用该模板,就好像它是一个只有一个参数的函数:
{{template "template1" .}}
{{range .List}}
{{template "template2" .}}
{{end}}
2
3
4
# 工作原理……
以下示例使用具名模板打印书籍列表:
package main
import (
"os"
"text/template"
)
const tp = `{{define "line"}}
{{.Title}} {{.Author}} {{.PubYear}}
{{end}}
Book list:
{{range . -}}
{{template "line" .}}
{{end -}}
`
type Book struct {
Title string
Author string
PubYear int
}
var books = []Book{
{
Title: "Pride and Prejudice",
Author: "Jane Austen",
PubYear: 1813,
},
{
Title: "To Kill a Mockingbird",
Author: "Harper Lee",
PubYear: 1960,
},
{
Title: "The Great Gatsby",
Author: "F. Scott Fitzgerald",
PubYear: 1925,
},
{
Title: "The Lord of the Rings",
Author: "J.R.R. Tolkien",
PubYear: 1954,
},
}
func main() {
tmpl, err := template.New("body").Parse(tp)
if err != nil {
panic(err)
}
tmpl.Execute(os.Stdout, books)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
在这个示例中,tmpl 模板包含两个模板——名为 body 的模板(因为它是使用 template.New("body") 创建的),以及名为 line 的模板(因为该模板包含 XXXdefine "line"}})。对于切片中的每个元素,body 模板会使用 books 切片中的连续元素实例化 line。
这等同于以下代码:
const lineTemplate = `{{.Title}} {{.Author}} {{.PubYear}}`
const bodyTemplate = `Book list:
{{range . -}}
{{template "line" .}}
{{end -}}`
func main() {
tmpl, err := template.New("body").Parse(bodyTemplate)
if err != nil {
panic(err)
}
_, err = tmpl.New("line").Parse(lineTemplate)
if err != nil {
panic(err)
}
tmpl.Execute(os.Stdout, books)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 模板组合——布局模板
在开发 Web 应用程序时,通常希望有几个模板来指定页面布局。完整的网页是通过组合页面组件构建而成的,这些组件作为独立的模板使用这种布局进行开发。不幸的是,Go 模板引擎迫使你考虑替代方案,因为 Go 模板引用是静态的。这意味着你需要为每个页面单独创建一个布局模板。
但也有其他选择。
我将向你展示一个基本思路,演示如何使用模板组合,以便你可以根据自己的用例进行扩展,或者如何使用现有的第三方库来实现这一点。使用布局模板进行组合的关键思想是,如果你使用已定义的模板名称定义一个新模板,新定义将覆盖旧定义。
# 操作方法……
- 创建一个布局模板。对于每次需要重新定义的部分,使用空模板或包含默认内容的模板。
- 创建一个配置系统,在其中定义每一种可能的组合。每种组合都包括布局模板,以及定义布局模板中各部分的模板。
- 将每种组合编译为单独的模板。
# 工作原理……
创建一个布局模板:
const layout=`
<!doctype html>
<html lang="en">
<head>
<title>{{template "pageTitle" .}}</title>
</head>
<body>
{{template "pageHeader" .}}
{{template "pageBody" .}}
{{template "pageFooter" .}}
</body>
</html>
{{define "pageTitle"}}{{end}}
{{define "pageHeader"}}{{end}}
{{define "pageBody"}}{{end}}
{{define "pageFooter"}}{{end}}`
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这个布局模板定义了四个没有内容的具名模板。对于每个新页面,我们可以重新创建这些组件:
const mainPage=`
{{define "pageTitle"}}Main Page{{end}}
{{define "pageHeader"}}
<h1>Main page</h1>
{{end}}
{{define "pageBody"}}
This is the page body.
{{end}}
{{define "pageFooter"}}
This is the page footer.
{{end}}`
2
3
4
5
6
7
8
9
10
11
我们可以定义第二个页面,与第一个页面类似:
const secondPage=`
{{define "pageTitle"}}Second page{{end}}
{{define "pageHeader"}}
<h1>Second page</h1>
{{end}}
{{define "pageBody"}}
This is the page body for the second page.
{{end}}`
2
3
4
5
6
7
8
现在,我们将 layout 与 mainPage 组合以获取主页面的模板,然后将 layout 与 secondPage 组合以获取第二个页面的模板:
import (
"html/template"
)
func main() {
mainPageTmpl := template.Must(template.New("body").Parse(layout))
template.Must(mainPageTmpl.Parse(mainPage))
secondPageTmpl := template.Must(template.New("body").Parse(layout))
template.Must(secondPageTmpl.Parse(secondPage))
mainPageTmpl.Execute(os.Stdout, nil)
secondPageTmpl.Execute(os.Stdout, nil)
}
2
3
4
5
6
7
8
9
10
11
12
你可以扩展这种模式,使用布局模板以及一个定义每个页面所有有效模板组合的配置文件来构建一个复杂的 Web 应用程序。这样的 YAML 文件如下所示:
mainPage:
- layouts/main.html
- mainPage.html
- fragments/status.html
detailPage:
- layouts/2col.html
- detailPage.html
- fragments/status.html
...
2
3
4
5
6
7
8
9
10
应用程序启动时,你可以按照给定顺序解析其组成模板,为 mainPage 和 detailPage 构建每个模板,并将每个模板放入一个映射中。然后,你可以查找想要生成的模板名称并使用已解析的模板。
# 更多内容……
Go 标准库文档始终是获取最新信息和优秀示例的最佳来源,例如以下链接:
- https://pkg.go.dev/strings
- https://pkg.go.dev/text/template
- https://pkg.go.dev/html/template
- https://pkg.go.dev/fmt
- https://pkg.go.dev/bufio
以下链接也很有用:
- 万维网字符模型:字符串匹配(Character Model for the World Wide Web: String Matching):https://www.w3.org/TR/charmod-norm/
- 字符属性、大小写映射和名称常见问题解答(Character Properties, Case Mappings & Names FAQ):https://unicode.org/faq/casemap_charprop.html
- RFC7564:PRECIS:https://www.rfc-editor.org/rfc/rfc7564
- 这是一篇关于 Unicode 规范化过程的精彩博客文章:https://go.dev/blog/normalization
- 对于标准库未处理的所有编码、国际化和与 Unicode 相关的问题,在搜索其他内容之前,可以先查看这里的软件包:https://pkg.go.dev/golang.org/x/text