 第4章 使用数组、切片和映射
第4章 使用数组、切片和映射
# 第4章 使用数组、切片和映射
数组(Arrays)、切片(Slices)和映射(Maps)是Go语言定义的内置容器类型。它们几乎是每个程序的重要组成部分,通常也是其他数据结构的构建块。本节将介绍使用这些基本数据结构的一些常见模式,因为其中的细微差别对于新手来说可能并不明显。
在本章中,我们将讨论以下内容:
- 使用数组
- 使用切片
- 使用切片实现栈
- 使用映射
- 实现集合
- 使用映射进行线程安全的缓存
# 使用数组
数组是固定大小的数据结构。无法调整数组的大小,也不能用变量作为数组的大小来创建数组(换句话说,只有当n是常量整数时,[n]int才有效)。因此,数组可用于表示具有固定数量元素的对象,比如SHA256哈希值,它是32字节。
数组的零值是数组中每个元素的零值。例如,[5]int会初始化为包含五个整数,且值均为0。字符串数组的零值则是包含空字符串。
# 创建数组并传递数组
本方法展示了如何创建数组,以及将数组值传递给函数和方法。我们还将讨论按值传递数组的影响。
# 如何操作...
- 使用固定大小创建数组:
var arr [2]int // 包含2个整数的数组
也可以使用数组字面量声明数组,而无需指定其大小:
x := [...]int{1,2} // 包含2个整数的数组
还可以像定义映射那样指定数组索引:
y := [...]int{1, 4: 10} // 包含5个整数的数组,
// y[0]=1, y[4]=10,其他所有元素为0
// [1 0 0 0 10]
2
3
- 使用数组定义新的固定大小数据类型:
// SHA256哈希值是256位 - 32字节
type SHA256 [32]byte
2
- 数组是按值传递的:
func main() {
var h SHA256
h = getHash()
// f函数会得到一个32字节的数组,是h的副本
f(h)
...
}
func f(hash SHA256) {
hash[0] = 0 // 这会改变传递给f函数的hash副本。
// 不会影响main函数中声明的h的值
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 警告 按值传递数组意味着每次将数组作为参数传递给函数时,数组都会被复制。如果你将 [1000]int64类型的数组传递给函数,运行时会分配并复制8000字节(int64是64位,即8字节,1000个int64值就是8000字节)。这种复制是浅拷贝,也就是说,如果你传递的数组包含指针,或者传递的数组包含含有指针的结构体,那么被复制的是指针,而不是指针指向的内容。 |
|---|
请参考以下示例:
func f(m [2]map[string]int) {
m[0]["x"]=1
}
func main() {
array := [2]map[string]int{}
// array的一个副本被传递给f函数
// 但array[0]和array[1]是映射
// 这些映射的内容不会被复制。
f(array)
// 这将输出[x:1]
fmt.Println(array[0])
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 使用切片
切片是对数组的一种视图。你可能会处理多个操作相同底层数据的切片。
切片的零值是nil。读取或写入nil切片会导致程序崩溃;不过,可以向nil切片追加元素,这会创建一个新的切片。
# 创建切片
创建切片有多种方法。
# 如何操作...
使用make(sliceType,length[,capacity]):
slice1 := make([]int,0)
// len(slice1)=0, cap(slice1)=0
slice2 := make([]int,0,10)
// len(slice2)=0, cap(slice2)=10
slice3 := make([]int,10)
// len(slice3)=10, cap(slice3)=10
2
3
4
5
6
在前面的代码片段中,你看到了使用make创建切片的三种不同方式:
slice1 := make([]int,0)创建了一个空切片,0是该切片的长度。slice1变量被初始化为一个非nil、长度为0的切片。slice2 := make([]int,0,10)创建了一个容量为10的空切片。如果你知道这个切片可能的最大大小,这种方式是更好的选择。这种切片分配方式在追加第11个元素之前,都能避免分配/复制操作。slice3 := make([]int,10)创建了一个大小和容量均为10的切片。切片元素被初始化为0。一般来说,使用这种形式分配的切片,其元素会被初始化为元素类型的零值。 | 提示
在分配非零长度的切片时要小心。我个人就曾遇到过非常隐蔽的错误,因为我把make([]int,0,10)错写成了make([]int,10),然后继续向分配的切片追加10个元素,最终得到了20个元素。 | | ------------------------------------------------------------ |
请参考以下示例:
values: = make([]string,10)
for _,s: = range results {
if someFunc(s) {
values=append(values,s)
}
}
2
3
4
5
6
前面的代码片段创建了一个包含10个空字符串的字符串切片,然后通过for循环追加字符串。
也可以使用字面量初始化切片:
slice := []int{1,2,3,4,5}
// len(slice)=5 cap(slice)=5
2
或者,你可以将切片变量保留为nil,然后向其追加元素。内置的append函数会接受nil切片并创建一个新切片:
// values切片声明后为nil
var values []string
for _,x: = range results {
if someFunc(s) {
values=appennd(values, s)
}
}
2
3
4
5
6
7
# 从数组创建切片
许多函数接受切片而不是数组。如果你有一个数组,需要将其传递给一个期望接收切片的函数,那就需要从数组创建切片。这既简单又高效。从数组创建切片是一个常数时间操作。
# 如何操作...
使用[:]符号从数组创建切片。该切片将以数组作为其底层存储:
arr := [...]int{0, 1, 2, 3, 4, 5}
slice := arr[:] // slice包含arr的所有元素
slice[2] = 10
// 这里,arr = [...]int{0,1,10,3, 4,5}
// len(slice) = 6
// cap(slice) = 6
2
3
4
5
6
可以创建一个指向数组某一部分的切片:
slice2 := arr[1:3]
// 这里,slice2 = {1,10}
// len(slice2) = 2
// cap(slice2) = 5
2
3
4
还可以对现有切片进行切片操作。切片操作的边界由原始切片的容量决定:
slice3 := slice2[0:4]
// len(slice3)=4
// cap(slice3)=5
// slice3 = {1,10,3,4}
2
3
4
# 它的工作原理...
切片是一种数据结构,包含三个值:切片长度、容量和指向底层数组的指针。对数组进行切片操作,只是创建了这个数据结构,并将指针初始化为指向数组。这是一个常数时间操作。
![图4.1 数组arr和切片arr[:]的区别](/assets/img/Figure4.1.f68c7608.png)
图4.1 数组arr和切片arr[:]的区别
# 追加/插入/删除切片元素
切片以数组作为底层存储,但当数组空间不足时无法扩展。因此,如果追加操作超出了切片的容量,就会分配一个新的、更大的数组,并将切片内容复制到这个新数组中。
# 如何操作...
要在切片末尾添加新值,使用内置的append函数:
// 创建一个空整数切片
islice := make([]int, 0)
// 向islice追加值1、2、3,并将结果赋给newSlice
newSlice := append(islice, 1, 2, 3)
// islice: []
// newSlice: [1 2 3]
// 创建一个空整数切片
islice = make([]int, 0)
// 另一个包含3个元素的整数切片
otherSlice := []int{1, 2, 3}
// 将'otherSlice'追加到'islice'
newSlice = append(islice, otherSlice...)
newSlice = append(newSlice, otherSlice...)
// islice: []
// otherSlice: [1 2 3]
// newSlice: [1 2 3 1 2 3]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
要从切片(slice)的开头或结尾删除元素,可以使用切片操作:
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 从索引1开始切片
suffix := slice[1:]
// suffix: [1 2 3 4 5 6 7 8 9]
// 从索引3开始切片
suffix2 := slice[3:]
// suffix2: [3 4 5 6 7 8 9]
// 切片到索引5(不包括5)
prefix := slice[:5]
// prefix: [0 1 2 3 4]
// 从索引3切片到索引6(不包括6)
mid := slice[3:6]
// [3 4 5]
2
3
4
5
6
7
8
9
10
11
12
13
使用slices包可以在切片的任意位置插入或删除元素:
slices.Delete(slice, i, j)从切片中删除slice[i:j]的元素,并返回修改后的切片。slices.Insert(slice, i, value...)从索引i开始插入值,将从i开始的所有元素向后移动以腾出空间。
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 删除切片中slice[3:7]部分
edges := slices.Delete(slice, 3, 7)
// edges: [0 1 2 7 8 9]
// slice: [0 1 2 7 8 9 0 0 0 0]
inserted := slices.Insert(slice, 3, 3, 4)
// inserted: [0 1 2 3 4 7 8 9 0 0 0 0]
// edges: [0 1 2 7 8 9]
// slices: [0 1 2 7 8 9 0 0 0 0]
2
3
4
5
6
7
8
9
或者,你可以使用for循环从切片中删除元素并对其进行截断,如下所示:
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 保留一个用于写入的索引
write := 0
for _, elem := range slice {
if elem % 2 == 0 {
slice[write] = elem
write++
}
}
// 截断切片
slice = slice[:write]
2
3
4
5
6
7
8
9
10
11
# 工作原理……
切片是对数组的一种视图。它包含三部分信息:
ptr:指向数组中某个元素的指针,它是切片的起始位置。len:切片中的元素数量。cap:该切片底层数组中剩余的容量。
如果向切片中追加元素超出了其容量,运行时会分配一个更大的数组,并将切片的内容复制到新数组中。之后,新的切片会指向这个新数组。
这让很多人感到困惑。一个切片可能会与其他切片共享元素。因此,修改一个切片也可能会修改其他切片。
图4.2展示了四个不同的切片使用相同底层数组的情况:
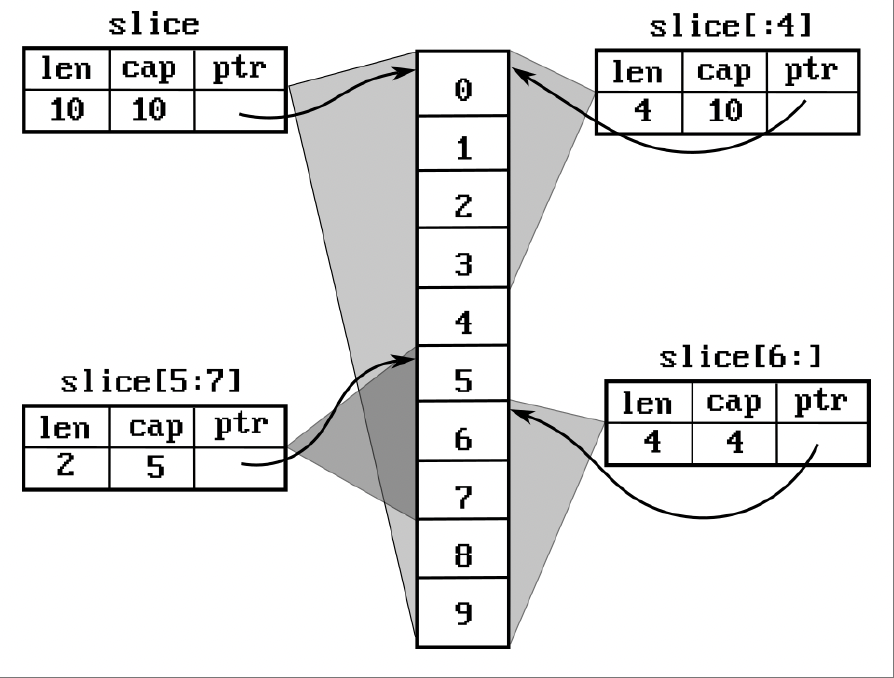
图4.2 - 共享相同底层数组的切片
请看下面的示例:
// 向切片中追加1,并返回新的切片
func Append1(input []int) []int {
return append(input, 1)
}
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
shortSlice := slice[:4]
// shortSlice: []int{0, 1, 2, 3}
newSlice := Append1(slice[:4])
// newSlice:= []int{0, 1, 2, 3, 1}
// slice: []int{0, 1, 2, 3, 1, 5, 6, 7, 8, 9}
}
2
3
4
5
6
7
8
9
10
11
12
13
请注意,向newSlice追加元素也会修改slice中的一个元素,因为newSlice有足够的容量容纳多一个元素,这个新元素会覆盖slice[4]。
截断一个切片就是简单地创建一个比原始切片更短的新切片。底层数组不会改变。如下所示:
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
newSlice := slice[:5]
// newSlice: []int{0, 1, 2, 3, 4}
2
3
记住,newSlice只是一个数据结构,它包含与slice相同的ptr和cap,但len更短。因此,从现有切片或数组创建新切片是一个常数时间操作(O(1))。
# 使用切片实现栈(stack)
切片一个常见的用法是实现栈。下面是实现方法。
# 如何实现……
栈的入栈操作(push)就是简单地使用append:
// 泛型栈,类型为T
type Stack[T any] []T
func (s *Stack[T]) Push(val T) {
*s = append(*s, val)
}
2
3
4
5
实现出栈操作(pop),则是截断切片:
func (s *Stack[T]) Pop() (val T) {
val = (*s)[len(*s)-1]
*s = (*s)[:len(*s)-1]
return
}
2
3
4
5
再次注意括号和间接引用的使用。我们不能写成*s[len(*s)-1],因为这会被解释为*(s[len(*s)-1]。为了避免这种情况,我们使用(*s)。
# 处理映射(map)
你可以使用整数索引访问数组或切片的元素。映射提供了类似的语法,但索引键不仅可以是整数,还可以是任何“可比较”(comparable)的类型(意味着可以使用==或!=进行比较)。映射是一种关联数据类型,也就是说,它存储键值对。每个键在映射中只出现一次。Go语言中的映射提供了均摊常数时间(amortized constant-time)的元素访问方式(也就是说,从时间维度衡量,映射元素的访问看起来像常数时间操作)。
Go语言的映射类型为访问底层复杂的数据结构提供了便利。它是“引用”类型(reference types)之一,也就是说,将一个映射变量赋值给另一个映射,只是将指向底层结构的指针进行了赋值,并不会复制映射中的元素。
| 警告 映射是无序集合。不要依赖映射中元素的顺序。在同一程序的不同时间,相同的插入顺序可能会导致不同的迭代顺序。 |
|---|
# 定义、初始化和使用映射
与切片类似,映射的零值是nil。从nil映射中读取数据与从没有元素的非nil映射中读取数据的结果相同。向nil映射中写入数据会导致程序崩溃。本节展示映射的不同初始化和使用方式。
# 如何实现……
使用make创建新映射,或者使用字面量。你不能向nil映射中写入数据(但可以读取!),所以必须使用make或字面量对所有映射进行初始化:
func main() {
// 创建一个新的空映射
m1 := make(map[int]string)
// 使用空映射字面量初始化映射
m2 := map[int]string{}
// 使用映射字面量初始化映射
m3 := map[int]string {
1: "a",
2: "b",
}
}
2
3
4
5
6
7
8
9
10
11
与切片不同,映射的值是不可寻址的:
type User struct {
Name string
}
func main() {
usersByID := make(map[int]User)
usersByID[1] = User{Name: "John Doe"}
fmt.Println(usersByID[1].Name)
// 输出: John Doe
// 以下代码会导致编译错误
usersByID[1].Name = "James"
}
2
3
4
5
6
7
8
9
10
11
12
13
在前面的示例中,你无法设置存储在映射中的结构体的成员变量。当你使用usersByID[1]访问该映射元素时,返回的是存储在映射中的User的副本,将其Name设置为其他值的操作不会生效,因为这个副本并没有被存储到任何地方。
因此,你可以将映射值读取并赋值给一个可寻址的变量,对其进行修改,然后再将其设置回映射:
user := usersByID[1]
user.Name = "James"
usersByID[1] = user
2
3
或者,你可以在映射中存储指针:
userPtrsByID := make(map[int]*User)
userPtrsByID[1] = &User {
Name: "John Doe"
}
userPtrsByID[1].Name = "James" // 这是可行的。
2
3
4
5
6
如果映射中没有给定键对应的元素,它将返回映射值类型的零值:
user := usersByID[2] // user被设置为User{}
userPtr := userPtrsByID[2] // userPtr被设置为nil
2
要区分返回零值是因为映射中没有该元素,还是因为映射中存储的就是零值,可以使用映射查找的双返回值形式:
user, exists := usersByID[1] // exists = true
userPtr, exists := userPtrsByID[2] // exists = false
2
使用delete从映射中删除一个元素:
delete(usersByID, 1)
# 使用映射实现集合(set)
集合对于从一组值中去除重复项很有用。通过使用零大小的值结构,映射可以高效地用作集合。
# 如何实现……
使用键类型为集合元素类型,值类型为struct{}的映射:
stringSet := make(map[string]struct{})
使用struct{}{}值向集合中添加值:
stringSet[value] = struct{}{}
使用映射查找的双值形式检查值是否存在:
if _, exists := stringSet[str]; exists {
// 字符串str存在于集合中
}
2
3
映射是无序的。如果元素的顺序很重要,可以结合映射使用一个切片:
// 从输入中删除重复项,并保留顺序
func DedupOrdered(input []string) []string {
set := make(map[string]struct{})
output := make([]string, 0, len(input))
for _, in := range input {
if _, exists := set[in]; exists {
continue
}
output = append(output, in)
set[in] = struct{}{}
}
return output
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 工作原理……
struct{}结构是一个零大小的对象。编译器和运行时会单独处理这类对象。当它用作映射中的值时,映射只会为其键分配存储空间。因此,这是一种实现集合的高效方式。
| 警告 永远不要依赖零大小结构的指针相等性。编译器可能会将两个零大小的独立变量放置在相同的内存位置。 以下比较的结果是未定义的: |
|---|
x:=&struct{}{}
y:=&struct{}{}
if x==y { //x==y的结果可能返回true或false。
// Do something
}
2
3
4
5
6
7
# 复合键(Composite keys)
当有多个值用于标识一个特定对象时,就需要使用复合键。例如,假设你正在处理一个系统,其中用户可能有多个会话。你可以将这些信息存储在一个映射的映射中,或者创建一个包含用户ID和会话ID的复合键。
# 如何实现……
使用可比较的结构体或数组作为映射键。一般来说,可比较的结构体不包含以下内容:
- 切片
- 通道(Channels)
- 函数
- 映射
- 其他不可比较的结构体
因此,要使用复合键,请执行以下步骤:
- 定义一个可比较的结构体:
type Key struct {
UserID string
SessionID string
}
type User struct {
Name string
}
var compositeKeyMap = map[Key]User{}
2
3
4
5
6
7
8
9
10
- 使用映射键的实例来访问元素:
compositeKeyMap[Key{
UserID: "123",
SessionID: "1",
}] = User {
Name: "John Doe",
}
2
3
4
5
6
- 你可以使用字面量映射对其进行初始化:
var compositeKeyMap = map[Key]User {
Key {
UserID: "123",
SessionID: "1",
}: User {
Name: "John Doe",
},
}
2
3
4
5
6
7
8
# 工作原理……
映射实现会从其键生成哈希值,然后使用比较运算符检查是否相等。因此,任何可比较的数据结构都可以用作键值。
要注意指针比较。包含指针字段的结构体在比较时会检查指针的相等性。考虑以下键:
type KeyWithPointer struct {
UserID string
SessionID *int
}
var sessionMap = map[KeyWithPointer]{}
func main() {
session := 1
key := KeyWithPointer{
UserID: "John",
SessionID: &session,
}
sessionMap[key] = User{ Name: "John Doe"}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在前面的代码片段中,复合映射键包含一个指向整数session的指针。在向映射中添加一个元素后,更改session的值不会影响指向该变量的映射键。映射键仍将指向同一个变量。只有当另一个KeyWithPointer实例也指向同一个session变量时,才能使用它来定位User对象,如下所示:
fmt.Println( sessionMap[KeyWithPointer{
UserID: "John",
SessionID: &session,
}].Name) // "John Doe"
2
3
4
但是:
i := 1
fmt.Println( sessionMap[KeyWithPointer{
UserID: "John",
SessionID: &i,
}].Name) // ""
2
3
4
5
# 使用映射(map)实现线程安全的缓存
有时,为了获得可接受的性能,缓存是很有必要的。其核心思想是复用之前已经计算或获取过的值。映射(map)是缓存这类值的自然选择,但是由于缓存的特性,它们通常会在多个协程(goroutine)之间共享,所以在使用时必须格外小心。
# 简单缓存
这是一个带有获取(get)/存入(put)方法的简单缓存,用于从缓存中检索对象并将元素放入其中。
# 实现步骤……
要缓存可以通过键访问的值,可以使用一个包含映射(map)和互斥锁(mutex)的结构体:
type ObjectCache struct {
mutex sync.RWMutex
values map[string]*Object
}
// 初始化并返回一个新的缓存实例
func NewObjectCache() *ObjectCache {
return &ObjectCache{
values: make(map[string]*Object),
}
}
2
3
4
5
6
7
8
9
10
11
为确保在使用缓存时遵循正确的协议,应防止直接访问缓存的内部:
// 从缓存中获取一个对象
func (cache *ObjectCache) Get(key string) (*Object, bool) {
cache.mutex.RLock()
obj, exists := cache.values[key]
cache.mutex.RUnlock()
return obj, exists
}
// 使用给定的键将一个对象放入缓存
func (cache *ObjectCache) Put(key string, value *Object) {
cache.mutex.Lock()
cache.values[key] = value
cache.mutex.Unlock()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 具有阻塞行为的缓存
在上一个示例的简单缓存中,如果多个协程(goroutine)请求同一个键,它们可能都会决定去检索对象并将其放回缓存,这是低效的。通常情况下,你会希望其中一个协程(goroutine)去检索对象,而其他协程等待。这可以使用sync.Once来实现。
# 实现步骤……
缓存元素是包含sync.Once的结构体,以确保一个协程(goroutine)获取对象时,其他协程等待。此外,缓存包含一个Get方法,该方法使用getObjectFunc回调函数在对象不在缓存中时检索对象:
type cacheItem struct {
sync.Once
object *Object
}
type ObjectCache struct {
mutex sync.RWMutex
values map[string]*cacheItem
getObjectFunc func(string) (*Object, error)
}
func NewObjectCache(getObjectFunc func(string) (*Object, error)) *ObjectCache {
return &ObjectCache{
values: make(map[string]*cacheItem),
getObjectFunc: getObjectFunc,
}
}
func (item *cacheItem) get(key string, cache *ObjectCache) (err error) {
// 调用item.Once.Do
item.Do(func() {
item.object, err = cache.getObjectFunc(key)
})
return
}
func (cache *ObjectCache) Get(key string) (*Object, error) {
cache.mutex.RLock()
object, exists := cache.values[key]
cache.mutex.RUnlock()
if exists {
return object.object, nil
}
cache.mutex.Lock()
object, exists = cache.values[key]
if!exists {
object = &cacheItem{}
cache.values[key] = object
}
cache.mutex.Unlock()
err := object.get(key, cache)
return object.object, err
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 工作原理……
Get方法首先对缓存进行读锁定,然后检查键是否存在于缓存中并解锁。如果值已缓存,则返回该值。
如果值不在缓存中,则对缓存进行写锁定,因为这将是对values映射(map)的并发修改。再次检查values映射(map),以确保没有其他协程(goroutine)已经在那里放入了值。如果没有,则此协程(goroutine)将一个未初始化的cacheItem放入缓存并解锁。
cacheItem包含一个sync.Once,它只允许一个协程(goroutine)调用Once.Do,而其他协程(goroutine)则被阻塞,等待获胜的调用完成。此时,会从cacheItem.get方法中调用getObjectFunc回调函数。在这一点上,不会出现内存竞争,因为只有一个协程(goroutine)可以执行item.Do函数。该函数的结果将存储在cacheItem中,所以不会给values映射(map)的使用者带来任何问题。实际上,请注意,在getObjectFunc运行时,缓存并未锁定,可能有许多其他协程(goroutine)在对缓存进行读取和 / 或写入操作。