 第10章 处理大量数据
第10章 处理大量数据
# 第10章 处理大量数据
利用Go语言的并发原语,有多种方法可以高效地处理大量数据。与线程不同,创建goroutine的开销很小。在一个程序中拥有数千个goroutine是很常见的。基于此,我们将探讨一些并发处理大量数据的常见模式。
本章包含以下方法:
- 工作池(Worker pools)
- 连接池(Connection pools)
- 管道(Pipelines)
- 处理大型结果集
# 工作池
假设你有大量的数据元素(例如图像文件),并且想要对每个元素应用相同的逻辑。你可以编写一个处理单个输入实例的函数,然后在for循环中调用这个函数。这样的程序会按顺序处理输入元素,如果处理每个元素需要t秒,那么处理完所有输入最终将耗时n×t秒,其中n是输入的数量。
如果你想通过使用并发编程来提高吞吐量,可以创建一个由工作goroutine组成的池。你可以将下一个输入提供给工作池中的空闲成员,在该成员处理输入时,你可以将后续输入分配给另一个成员。如果有p个逻辑处理器(可以是物理处理器的内核)并行运行,理论上最快可以在n×t/p秒内得到结果(这是理论上限,因为并行进程之间的负载分配并不总是完美的,而且还存在同步和通信开销)。接下来,我们将研究两种不同的实现工作池的方式。
# 有上限的工作池
如果每个工作单元的初始化成本不高(例如,加载文件或建立网络连接的成本可能很高,这里假设没有这类情况 ),最好根据需要创建工作单元,并对工作单元的数量设置一个给定的限制。
# 操作方法……
为每个输入创建一个新的goroutine。使用一个通道作为同步计数器来限制最大工作单元数(这里,通道用作信号量)。如果有结果,使用一个输出通道来收集结果:
// 设定最大工作池大小
const maxPoolSize = 100
func main() {
// 1. 初始化
// 通过outputCh接收工作池的输出
outputCh := make(chan Output)
// 用于限制工作池大小的信号量
sem := make(chan struct{}, maxPoolSize)
// 2. 读取输出
// 读取器goroutine读取结果,直到outputCh关闭
readerWg := sync.WaitGroup{}
readerWg.Add(1)
go func() {
defer readerWg.Done()
for result := range outputCh {
// 处理结果
fmt.Println(result)
}
}()
// 3. 处理循环
// 根据需要创建工作单元,但活动工作单元的数量受sem容量的限制
wg := sync.WaitGroup{}
// 此循环将输入发送给工作单元,并根据需要创建它们
for {
nextInput, done := getNextInput()
if done {
break
}
wg.Add(1)
// 如果goroutine数量过多,此操作将阻塞
sem <- struct{}{}
go func(inp Input) {
defer wg.Done()
defer func() {
<-sem
}()
outputCh <- doWork(inp)
}(nextInput)
}
// 4. 等待处理完成
// 此goroutine等待所有工作池goroutine完成,然后关闭输出通道
go func() {
// 等待处理完成
wg.Wait()
// 关闭输出通道,以便读取器goroutine可以终止
close(outputCh)
}()
// 等待输出通道关闭
readerWg.Wait()
// 如果程序执行到这里,所有goroutine都已完成
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 工作原理……
- 首先是初始化。我们创建两个通道:
outputCh:工作池的输出通道。每个工作单元会将结果写入此通道。sem:信号量通道,用于限制活动工作单元的数量。它的容量被设置为maxPoolSize。当我们启动一个新的工作goroutine时,向这个通道发送一个元素。只要sem通道中的元素数量少于maxPoolSize,发送操作就不会阻塞。当一个工作goroutine完成时,它从通道中接收一个元素,释放容量。由于这个通道的容量是maxPoolSize,如果有maxPoolSize个工作单元正在运行,发送操作将阻塞,直到有一个goroutine结束并从通道中接收元素。
- 读取输出:在开始处理之前,我们启动一个goroutine从
outputCh读取数据,这样可以在所有输入被发送到工作单元之前读取结果。由于工作单元的数量是有限的,创建了maxPoolSize个工作单元后,后续创建操作将阻塞,所以我们必须在创建工作池之前开始监听输出。 - 处理循环:我们读取下一个输入并创建一个新的工作单元来处理它。活动工作单元由
wg这个WaitGroup跟踪,稍后将用它来等待工作单元完成。在创建新的工作单元之前,我们向信号量通道发送一个元素。如果已经有maxPoolSize个工作单元在运行,这个操作将阻塞,直到其中一个工作单元终止。工作单元处理输入,将输出写入outputCh,然后终止,并从信号量通道接收一个元素。 - 这个goroutine等待跟踪工作单元的
WaitGroup。当所有工作单元完成后,输出通道被关闭。这也会向在步骤2中创建的读取器WaitGroup发送信号。 - 等待输出处理完成。程序必须等待所有输出生成。这只有在
outputCh关闭(在步骤4中发生),然后readerWg被释放之后才会发生。
# 固定大小的工作池
如果创建一个工作单元的操作成本很高,那么固定大小的工作池是有意义的。只需创建最大数量的工作单元,让它们从一个公共输入通道读取数据。这个输入通道负责在可用的工作单元之间分配工作。
# 操作方法……
有几种方法可以实现这一点。我们将研究两种方法。
在下面的函数中,创建了一个大小为poolSize的固定大小工作池。所有工作单元都从同一个输入通道读取数据,并将输出写入同一个输出通道。这个程序使用一个读取器goroutine从工作池中收集结果,同时在调用者所在的同一个goroutine中提供输入:
const poolSize = 50
func workerPoolWithConcurrentReader() {
// 1. 初始化
// 通过inputCh向工作池发送输入
inputCh := make(chan Input)
// 通过outputCh接收工作池的输出
outputCh := make(chan Output)
// 2. 创建工作池
wg := sync.WaitGroup{}
for i := 0; i < poolSize; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for work := range inputCh {
outputCh <- doWork(work)
}
}()
}
// 3.a 读取器goroutine
// 读取器goroutine读取结果,直到outputCh关闭
readerWg := sync.WaitGroup{}
readerWg.Add(1)
go func() {
defer readerWg.Done()
for result := range outputCh {
// 处理结果
fmt.Println(result)
}
}()
// 4. 等待工作单元
// 此goroutine等待所有工作池goroutine完成,然后关闭输出通道
go func() {
// 等待处理完成
wg.Wait()
// 关闭输出通道,以便读取器goroutine可以终止
close(outputCh)
}()
// 5.a 发送输入
// 此循环将输入发送到工作池
for {
nextInput, done := getNextInput()
if done {
break
}
inputCh <- nextInput
}
// 关闭输入通道,以便工作池goroutine终止
close(inputCh)
// 等待输出通道关闭
readerWg.Wait()
// 如果程序执行到这里,所有goroutine都已完成
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
以下版本使用一个goroutine将工作提交到工作池,同时在调用者所在的同一个goroutine中读取结果:
func workerPoolWithConcurrentWriter() {
// 1. 初始化
// 通过inputCh向工作池发送输入
inputCh := make(chan Input)
// 通过outputCh接收工作池的输出
outputCh := make(chan Output)
// 2. 创建工作池
wg := sync.WaitGroup{}
for i := 0; i < poolSize; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for work := range inputCh {
outputCh <- doWork(work)
}
}()
}
// 3.b 写入器goroutine
// 写入器goroutine将工作提交到工作池
go func() {
for {
nextInput, done := getNextInput()
if done {
break
}
inputCh <- nextInput
}
// 关闭输入通道,以便工作池goroutine终止
close(inputCh)
}()
// 4. 等待工作单元
// 此goroutine等待所有工作池goroutine完成,然后关闭输出通道
go func() {
// 等待处理完成
wg.Wait()
// 关闭输出通道,以便读取器goroutine可以终止
close(outputCh)
}()
// 5.b 读取结果
// 读取结果,直到outputCh关闭
for result := range outputCh {
// 处理结果
fmt.Println(result)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 工作原理……
- 首先是初始化。我们创建两个通道:
inputCh:这是工作池的输入通道。工作池中的每个工作单元在for-range循环中从同一个inputCh读取数据,所以当一个工作单元接收到一个输入时,它会停止监听通道,让另一个工作单元获取下一个输入。outputCh:这是工作池的输出通道。所有工作单元完成工作后,都会将输出写入此通道。
- 创建工作池:由于这是一个固定大小的工作池,我们可以在一个简单的for循环中创建工作单元。需要一个
WaitGroup,以便我们可以等待处理完成。每个工作单元从inputCh读取数据,直到它关闭,处理输入,并写入outputCh。
其余算法在两个示例中有所不同。我们先来看第一个示例:
- 读取器goroutine:在这个单独的goroutine中读取工作池的输出,直到
outputCh关闭。当outputCh关闭时,向readerWg发送信号。 - 等待工作单元:这是一个单独的goroutine,等待所有工作单元完成。当所有工作单元终止(这是因为
inputCh关闭)时,它关闭outputCh。 - 这个for循环将输入发送到
inputCh,然后关闭inputCh。这会导致所有工作单元在完成工作后终止。当所有工作单元终止时,在步骤4中创建的goroutine会关闭outputCh。当输出处理完成时,向readerWg发送信号,终止计算。
接下来,我们看第二个示例:
- 写入器goroutine:这个goroutine生成工作池的输入。它将所有输入逐个发送到
inputCh,当所有输入都发送完毕后,它关闭inputCh,导致工作池终止。 - 等待工作单元:这部分与前面的示例相同。
- 读取结果:这个for循环从
outputCh读取结果,直到它关闭。当所有工作单元完成时,outputCh将被关闭。
# 连接池
当处理多个用户对稀缺资源的使用时,连接池(Connection pools)非常有用,因为创建该资源的实例成本可能很高,比如网络连接或数据库连接。通过一对通道,你可以实现一个高效的线程安全连接池。
# 如何操作...
创建一个连接池类型,它包含两个容量为PoolSize的通道:
available通道用于存放已建立但归还到连接池的连接。total通道用于记录连接的总数,即可用连接数加上正在使用的连接数。
要从连接池中获取连接,先检查available通道。如果有可用连接,就返回该连接;否则,检查total连接池,如果未超过限制,则创建一个新连接。
连接池的使用者在使用完连接后,应将连接发送到available通道,以归还连接。
下面的代码片段展示了这样一个连接池:
type ConnectionPool struct {
// 这个通道存放归还到连接池的连接
available chan net.Conn
// 这个通道统计当前活动连接的总数
total chan struct{}
}
func NewConnectionPool(poolSize int) *ConnectionPool {
return &ConnectionPool {
available: make(chan net.Conn,poolSize),
total: make(chan struct{}, poolSize),
}
}
func (pool *ConnectionPool) GetConnection() (net.Conn, error) {
select {
// 如果连接池中有可用连接,返回一个
case conn := <-pool.available:
fmt.Printf("Returning an idle connection.\n")
return conn, nil
default:
// 没有可用连接
select {
case conn := <-pool.available:
fmt.Printf("Returning an idle connection.\n")
return conn, nil
case pool.total <- struct{}{}: // 等待直到连接池未满
fmt.Println("Creating a new connection")
// 创建一个新连接
conn, err := net.Dial("tcp", "localhost:2000")
if err != nil {
return nil, err
}
return conn, nil
}// end-inner-select
}// end-outer-select
}
func (pool *ConnectionPool) Release(conn net.Conn) {
pool.available <- conn
fmt.Printf("Releasing a connection. \n")
}
func (pool *ConnectionPool) Close(conn net.Conn) {
fmt.Println("Closing connection")
conn.Close()
<-pool.total
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 它的工作原理...
- 使用
PoolSize初始化连接池:
pool := NewConnectionPool(PoolSize)
- 这将创建两个容量均为
PoolSize的通道。available通道将保存所有归还到连接池的连接,而total通道将记录已建立的连接数。 - 要获取一个新连接,使用以下代码:
conn, err := pool.GetConnection()
GetConnection的这个实现展示了如何设置通道优先级。如果available通道中有空闲连接,GetConnection将返回该连接;否则,它将进入default分支,在该分支中,它要么创建一个新连接,要么使用返回到available通道的连接。
注意GetConnection中嵌套select语句的模式。这是在通道间实现优先级的常见模式。如果有可用连接,那么case conn := <-pool.available将被选中,连接将从可用连接通道中移除。然而,如果在第一个select语句执行时没有可用连接,default分支将被执行,它将在conn:=<-pool.available和pool.total<-struct{}{}这两个case之间进行选择。如果第一个case可用(即其他某个goroutine将连接归还到连接池时),该连接将被返回给调用者;如果第二个case可用(即某个连接关闭,从而从pool.total中移除一个元素时),则创建一个新连接并返回给调用者。
4. 当连接池的客户端使用完连接后,应调用以下代码:
pool.Release(conn)
- 这将把连接添加到
available通道。
如果某个连接无响应,客户端可以关闭它。此时,应通知连接池,并且total通道的计数应减1,但该连接不应添加到available通道中。这可以通过以下代码实现:
pool.Close(conn)
# 管道
每当你需要对输入数据进行多个阶段的操作时,都可以构建一个管道(Pipelines)。goroutine和通道可用于构建具有不同结构的高吞吐量处理管道。
# 无扇出/扇入的简单管道
通过使用通道连接每个在各自goroutine中运行的阶段,就可以构建一个简单的管道。该管道的结构如图10.1所示。

图10.1 简单异步管道
# 如何操作...
这个管道使用一个单独的错误通道来报告处理错误。我们使用自定义错误类型来捕获诊断信息:
type PipelineError struct {
// 发生错误的阶段
Stage int
// 负载数据
Payload any
// 实际错误
Err error
}
2
3
4
5
6
7
8
每个阶段都实现为一个函数,该函数创建一个新的goroutine。goroutine从输入通道读取输入数据,并将输出写入输出通道:
func Stage1(input <-chan InputPayload, errCh chan<- error) <-chan
Stage2Payload {
// 1. 创建本阶段的输出通道。这将作为下一阶段的输入通道
output := make(chan Stage2Payload)
// 2. 创建处理goroutine
go func() {
// 3. 处理完成后关闭输出通道
defer close(output)
// 4. 处理所有输入,直到输入通道关闭
for in := range input {
// 5. 处理数据
err := processData(in.Id)
// 6. 将错误发送到错误通道
if err != nil {
errCh <- PipelineError{
Stage: 1,
Payload: in,
Err: err,
}
continue
}
// 7. 将输出发送到下一阶段
output <- Stage2Payload{
Id: in.Id,
}
}
}()
return output
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
阶段2和阶段3使用相同的模式实现。管道的构建如下:
func main() {
// 1. 创建输入通道和错误通道
errCh := make(chan error)
inputCh := make(chan InputPayload)
// 2. 通过连接各个阶段来构建管道
outputCh := Stage3(Stage2(Stage1(inputCh, errCh), errCh), errCh)
// 3. 异步输入数据
go func() {
defer close(inputCh)
for i := 0; i < 1000; i++ {
inputCh <- InputPayload{
Id: i,
}
}
}()
// 4. 异步监听错误通道
go func() {
for err := range errCh {
fmt.Println(err)
}
}()
// 5. 读取输出
for out := range outputCh {
fmt.Println(out)
}
// 6. 关闭错误通道
close(errCh)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
对于每个阶段,遵循以下步骤:
- 创建该阶段的输出通道,它将作为下一阶段的输入通道。
- 阶段函数返回后,处理goroutine会继续运行。
- 确保处理goroutine终止时关闭本阶段的输出通道。
- 从上个阶段读取输入,直到输入通道关闭。
- 处理输入。
- 如果发生错误,将错误发送到错误通道,不再生成输出。
- 将输出发送到下一阶段。
| 警告
每个阶段都在各自的goroutine中运行。这意味着一旦将负载数据传递到下一阶段,就不应在当前阶段访问该负载数据。如果负载数据包含指针,或者负载数据本身就是指针,则可能会发生数据竞争。 | | ------------------------------------------------------------ |
管道的设置如下:
- 创建输入通道和错误通道。连接各个阶段以形成管道。阶段n的输出成为阶段n + 1的输入。最后一个阶段的输出成为输出通道。
- 异步将输入发送到输入通道。所有输入发送完毕后,关闭输入通道。这将终止第一个阶段,关闭其输出通道,而该输出通道也是阶段2的输入通道。依此类推,直到所有阶段退出。
- 启动一个goroutine来监听并记录错误。
- 收集输出。
- 关闭错误通道,以便错误收集goroutine终止。
# 以工作池为阶段的管道
前面的示例在每个阶段都使用单个工作线程。你可以通过用工作池(worker pools)替换每个阶段来提高管道的吞吐量。最终的管道如图10.2所示。

图10.2 以工作池为阶段的管道
# 如何操作...
现在每个阶段会创建多个goroutine,它们都从同一个输入通道读取数据(扇出)。每个工作线程的输出都写入一个公共的输出通道(扇入),该通道成为下一阶段的输入通道。由于现在有多个goroutine向输出通道写入数据,所以不能在输入通道关闭时就关闭阶段输出通道。相反,我们使用一个等待组(wait group)和另一个goroutine,以便在所有处理goroutine终止时关闭输出通道:
func Stage1(input <-chan InputPayload, errCh chan<- error, nInstances
int) <-chan Stage2Payload {
// 1. 创建公共输出通道
output := make(chan Stage2Payload)
// 2. 所有处理完成后关闭输出通道
wg := sync.WaitGroup{}
// 3. 创建nInstances个goroutine
for i := 0; i < nInstances; i++ {
wg.Add(1)
go func() {
defer wg.Done()
// 处理所有输入
for in := range input {
// 处理数据
err := processData(in.Id)
if err != nil {
errCh <- PipelineError{
Stage: 1,
Payload: in,
Err: err,
}
continue
}
// 将输出发送到公共输出通道
output <- Stage2Payload{
Id: in.Id,
}
}
}()
}
// 4. 另一个goroutine等待所有工作线程完成,然后关闭输出通道
go func() {
wg.Wait()
close(output)
}()
return output
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
管道的构建方式与前面的示例相同:
func main() {
errCh := make(chan error)
inputCh := make(chan InputPayload)
nInstances := 5
// 通过连接各个阶段来构建管道
outputCh := Stage3(Stage2(Stage1(inputCh, errCh, nInstances),
errCh, nInstances), errCh, nInstances)
// 异步输入数据
go func() {
defer close(inputCh)
for i := 0; i < 1000; i++ {
inputCh <- InputPayload{
Id: i,
}
}
}()
// 异步监听错误通道
go func() {
for err := range errCh {
fmt.Println(err)
}
}()
// 读取输出
for out := range outputCh {
fmt.Println(out)
}
// 关闭错误通道
close(errCh)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 它的工作原理...
对于每个阶段,遵循以下步骤:
- 创建输出通道,它将成为下一阶段的输入通道。
有多个goroutine在for-range循环中从同一个输入通道读取数据,因此当输入通道关闭时,所有这些goroutine都将终止。但是,我们不能使用defer来关闭输出通道,因为这会导致多次关闭输出通道(从而引发恐慌)。所以,我们使用一个WaitGroup来跟踪工作goroutine。一个单独的goroutine等待该等待组,当所有goroutine终止时,它会关闭输出通道。
2. 创建nInstances个goroutine,它们都从同一个输入通道读取数据,并写入输出通道。如果发生错误,工作线程将错误发送到错误通道。
3. 这个goroutine等待工作goroutine完成。当它们完成时,它会关闭输出通道。
管道的设置与上一节相同,只是在初始化时还会将工作池大小发送到阶段函数。
# 带有扇出(fan-out)和扇入(fan-in)的管道
在这种设置中,各个阶段通过专用通道依次连接,如图10.3所示:
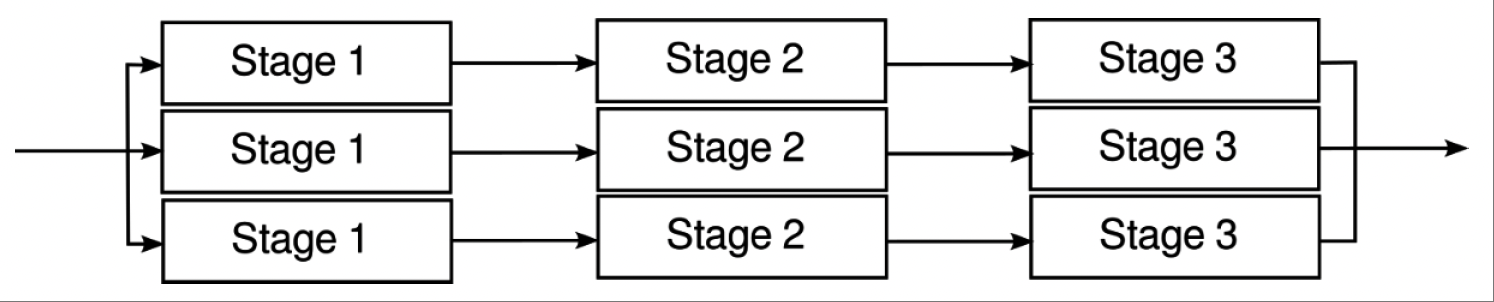 图10.3:带有扇出和扇入的管道
图10.3:带有扇出和扇入的管道
# 如何实现……
每个管道阶段从给定的输入通道读取数据,并写入输出通道,如下所示:
func Stage1(input <-chan InputPayload, errCh chan<- error) <-chan Stage2Payload {
output := make(chan Stage2Payload)
go func() {
defer close(output)
// 处理所有输入
for in := range input {
// 处理数据
err := processData(in.Id)
if err != nil {
errCh <- PipelineError{
Stage: 1,
Payload: in,
Err: err,
}
continue
}
output <- Stage2Payload{
Id: in.Id,
}
}
}()
return output
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
一个单独的fanIn函数接受一个输出通道列表,并使用一个监听每个通道的goroutine来合并它们:
func fanIn(inputs []<-chan OutputPayload) <-chan OutputPayload {
result := make(chan OutputPayload)
// 在单独的goroutine中监听输入通道
inputWg := sync.WaitGroup{}
for inputIndex := range inputs {
inputWg.Add(1)
go func(index int) {
defer inputWg.Done()
for data := range inputs[index] {
// 将数据发送到输出通道
result <- data
}
}(inputIndex)
}
// 当所有输入通道都关闭时,关闭扇入通道
go func() {
inputWg.Wait()
close(result)
}()
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
通过将每个阶段的输出连接到下一个阶段的输入,在for循环中设置管道。最终的输出通道都被导向fanIn函数:
func main() {
errCh := make(chan error)
inputCh := make(chan InputPayload)
poolSize := 5
outputs := make([]<-chan OutputPayload, 0)
// 所有Stage1的goroutine监听同一个输入通道
for i := 0; i < poolSize; i++ {
outputCh1 := Stage1(inputCh, errCh)
outputCh2 := Stage2(outputCh1, errCh)
outputCh3 := Stage3(outputCh2, errCh)
outputs = append(outputs, outputCh3)
}
outputCh := fanIn(outputs)
// 异步输入数据
go func() {
defer close(inputCh)
for i := 0; i < 1000; i++ {
inputCh <- InputPayload{
Id: i,
}
}
}()
// 异步监听错误通道
go func() {
for err := range errCh {
fmt.Println(err)
}
}()
// 读取输出
for out := range outputCh {
fmt.Println(out)
}
// 关闭错误通道
close(errCh)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 工作原理……
工作阶段与简单管道的情况相同。扇入阶段的工作原理如下。
对于每个输出通道,扇入函数创建一个goroutine,从该输出通道读取数据并写入一个公共通道。这个公共通道成为管道的合并输出通道。扇入函数创建另一个goroutine,它等待一个用于跟踪所有goroutine的等待组(wait group)。当所有goroutine都完成时,这个goroutine关闭输出通道。
主函数通过将每个阶段的输出连接到下一个阶段的输入来构建管道。最后一个阶段的输出通道存储在一个切片中,并传递给扇入函数。扇入函数的输出通道成为管道的合并输出。
请注意,所有这些管道变体都使用一个单独的错误通道。另一种方法是将任何错误存储在负载(payload)中,并传递到下一个阶段。如果传入的负载有一个非空的错误,所有阶段都会将其传递到下一个阶段,这样负载可以在管道末尾被记录为错误:
type Stage2Paylaod struct {
// 负载数据
Err error
}
func Stage2(input <-chan Stage2Payload) <-chan Stage3Payload {
output := make(chan Stage2Payload)
go func() {
defer close(output)
// 处理所有输入
for in := range input {
// 如果有错误,传递它
if in.Err!= nil {
output <- StagerPayload {
Err: in.Err,
}
continue
}
...
}
}()
return output
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
还要注意,除了简单管道的情况,它们返回的结果也是无序的,因为在任何给定时刻都有多个输入通过管道,并且无法保证它们到达输出端的顺序。
# 处理大型结果集
在处理可能很大的结果集时,将所有数据加载到内存中并进行处理并不总是可行的。你可能需要以一种可控的方式流式传输数据元素。本节展示如何使用并发原语(concurrency primitives)来处理这种情况。
# 使用goroutine流式传输结果
在这个用例中,一个goroutine通过通道发送查询结果。可以使用上下文(context)来取消流式传输的goroutine。
# 如何实现……
创建一个保存数据元素和错误信息的数据结构:
type Result struct {
Err error
// 其他数据元素
}
2
3
4
StreamResults函数运行数据库查询,并创建一个迭代查询结果的goroutine。该goroutine通过通道发送每个结果:
func StreamResults(
ctx context.Context,
db *sql.DB,
query string,
args...any,
) (<-chan Result, error) {
rows, err := db.QueryContext(ctx, query, args...)
if err!= nil {
return nil, err
}
output := make(chan Result)
go func() {
defer rows.Close()
defer close(result)
if rows.Next() {
var result Result
// 检查上下文是否被取消
if result.Err = ctx.Err(); result.Err!= nil {
// 上下文被取消。返回
output <- result
return
}
// 设置结果字段
buildResult(rows, &result)
output <- result
}
// 如果有错误,返回它
if result.Err = rows.Err(); result.Err!= nil {
output <- result
}
}()
return output
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
按如下方式使用流式传输的结果:
// 设置一个可取消的上下文
cancelableCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 调用流式传输API
results, err := StreamResults(cancelableCtx, db, "SELECT EMAIL FROM USERS")
if err != nil {
return err
}
// 收集并处理结果
for result := range results {
if result.Err != nil {
// 处理结果中的错误
continue
}
// 处理结果
if err := ProcessResult(result); err!= nil {
// 处理错误。取消流式传输结果
cancel()
// 期望至少再从通道接收一条消息,
// 因为流式传输的goroutine会发送错误
for range results {}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 工作原理……
尽管我们看的是一个数据库查询示例,但这种模式在你处理可能生成大量数据的函数时都很有用。这种模式不是将所有数据加载到内存中,而是逐个加载和处理数据项。
StreamResults生成函数启动一个goroutine闭包,它捕获生成结果所需的上下文和其他信息(在这种情况下是一个sql.Rows实例)。生成函数创建一个通道并立即返回。goroutine收集结果并将它们发送到通道。当所有结果都被处理或检测到错误时,通道被关闭。
现在由调用者与goroutine进行通信。调用者从通道收集结果,直到通道关闭,并逐个处理它们。调用者还检查接收到的消息中的错误字段,以处理goroutine检测到的任何错误。
这个方案使用了一个可取消的上下文。当上下文被取消时,goroutine在关闭通道之前会通过通道再发送一条消息,因此如果上下文被取消,调用者必须清空通道。