 第14章 流式输入/输出
第14章 流式输入/输出
# 第14章 流式输入/输出
简单之中蕴含着灵活性与优雅。与其他一些选择实现功能丰富的流框架的语言不同,Go语言采用了一种基于能力的简单方法:读取器(reader)是用于读取字节的对象,写入器(writer)是用于写入字节的对象。内存缓冲区、文件、网络连接等都是读取器和写入器,它们由io.Reader和io.Writer接口定义。文件也是io.Seeker,因为你可以随机更改读写位置,但网络连接不是。文件和网络连接可以关闭,所以它们都是io.Closer,但内存缓冲区不是。这种简单而优雅的抽象是编写可在不同场景中使用的算法的关键。
在本章中,我们将介绍一些示例,展示如何以地道的方式使用这种基于能力的流框架。我们还将探讨如何处理文件和文件系统。本章涵盖的示例主要分为以下几个部分:
- 读取器/写入器
- 文件处理
- 二进制数据处理
- 数据复制
- 文件系统操作
- 管道操作
# 读取器/写入器
请记住,Go语言使用结构类型系统。这使得任何实现了Read([]byte) (int, error)方法的数据类型都是io.Reader,任何实现了Write([]byte) (int, error)方法的数据类型都是io.Writer。标准库中大量使用了这一特性。在本示例中,我们将介绍读取器和写入器的一些常见用法。
# 从读取器读取数据
io.Reader会填充你传递给它的字节切片。通过传递切片,实际上传递了两条信息:你想要读取多少数据(切片的长度)以及将读取的数据放在何处(切片的底层数组)。
# 操作方法……
- 创建一个足够大的字节切片,以容纳要读取的数据:
buffer := make([]byte, 1024)
- 将数据读取到字节切片中:
nRead, err := reader.Read(buffer)
- 检查读取了多少数据。实际读取的字节数可能小于缓冲区的大小:
buffer = buffer[:nRead]
- 检查错误。如果错误是
io.EOF,则表示读取器已到达流的末尾。如果是其他错误,则处理该错误或返回它:
if errors.Is(err, io.EOF) {
// 到达文件末尾。返回数据
return buffer, nil
}
if err != nil {
// 其他错误,处理它或返回
return nil, err
}
2
3
4
5
6
7
8
9
请注意步骤3和4的顺序。返回io.EOF不一定是错误,它仅仅意味着已到达文件末尾或网络连接已关闭,所以你应该停止读取。缓冲区中可能已经读取了一些数据,你应该处理这些数据。读取器会返回实际读取的数据量。
# 向写入器写入数据
- 将想要写入的数据编码为字节切片;例如,使用
json.Marshal将数据的JSON表示形式转换为[]byte:
buffer, err := json.Marshal(data)
if err != nil {
return err
}
2
3
4
- 写入数据:
_, err := writer.Write(buffer)
if err != nil {
return err
}
2
3
4
- 检查并处理错误。
| 警告
与读取器不同,写入器返回的所有错误都应视为错误。写入器不会返回io.EOF。即使发生错误,写入操作也可能已经写入了部分数据。 | | ------------------------------------------------------------ |
# 从字节切片读取数据和向字节切片写入数据
读取器或写入器不一定是文件或网络连接。本节展示如何将字节切片用作读取器和写入器。
# 操作方法……
- 要从
[]byte创建读取器,使用bytes.NewReader。以下示例将一个数据结构编码为JSON(返回一个[]byte),然后通过从该[]byte创建读取器,将其发送到HTTP POST请求中:
data, err := json.Marshal(myStruct)
if err != nil {
return err
}
rsp, err := http.Post(postUrl, "application/json", bytes.NewReader(data))
2
3
4
5
6
- 要将
[]byte用作写入器,使用bytes.Buffer。当你向其写入数据时,该缓冲区会将数据追加到底层的字节切片中。完成写入后,你可以获取缓冲区的内容:
buffer := &bytes.Buffer{}
encoder := json.NewEncoder(buffer)
if err := encoder.Encode(myStruct); err != nil {
return err
}
data := buffer.Bytes()
2
3
4
5
6
7
bytes.Buffer也是一个io.Reader,有独立的读取位置。向bytes.Buffer写入数据会将数据追加到底层切片的末尾。从bytes.Buffer读取数据则从底层切片的开头开始读取。因此,你可以读取之前写入的字节,如下所示:
buffer := &bytes.Buffer{}
encoder := json.NewEncoder(buffer)
if err := encoder.Encode(myStruct); err != nil {
return err
}
rsp, err := http.Post(postUrl, "application/json", buffer)
2
3
4
5
6
7
# 从字符串读取数据和向字符串写入数据
要从字符串创建读取器,使用strings.NewReader,如下所示:
rsp, err := http.Post(postUrl, "application/json", strings.NewReader(`{"key":"value"}`))
不要使用bytes.NewReader([]byte(stringValue))来替代strings.NewReader(stringValue)。前者会复制字符串的内容以创建字节切片,而后者则无需复制即可访问底层字节。
要将字符串用作io.Writer,使用strings.Builder。例如,作为io.Writer,strings.Builder可以传递给fmt.Fprint系列函数:
query := strings.Builder{}
args := make([]interface{}, 0)
query.WriteString("SELECT id,name FROM users ")
if !createdAt.IsZero() {
args = append(args, createdAt)
fmt.Fprintf(&query, "where createdAt < $%d", len(args))
}
rows, err := tx.Query(ctx, query.String(), args...)
2
3
4
5
6
7
8
9
# 文件处理
文件不过是存储系统上的字节序列。处理文件有两种方式:作为随机访问字节序列或作为字节流。在本节中,我们将介绍这两种类型的示例。
# 创建和打开文件
要处理文件的内容,首先必须打开或创建它。本示例展示如何做到这一点。
# 操作方法……
要打开一个现有文件进行读取,使用os.Open:
file, err := os.Open(fileName)
if err != nil {
// 处理错误
}
2
3
4
你可以从返回的文件对象中读取数据,完成操作后,应该使用file.Close()关闭它。因此,你可以将其用作io.Reader或io.ReadCloser(*os.File还实现了更多接口!)。
如果你尝试写入该文件,写入操作将报错。在我的Linux系统上,这个错误是一个*fs.PathError消息,提示“坏文件描述符”。
要创建一个新文件或覆盖现有文件,使用os.Create:
file, err := os.Create(fileName)
if err != nil {
// 处理错误
}
2
3
4
如果上述调用成功,返回的文件既可以读取也可以写入。文件以0o666 & ^umask的权限创建。如果在调用之前文件已存在,它将被截断为长度0。
| 提示 umask定义了应用程序无法在文件上设置的权限集。在前面的内容中, 0o666意味着所有者、所属组和其他用户都可以读取和写入该文件。例如,umask值为0o022时,文件模式将从0o666变为0o644,这意味着所有者可以读取和写入,而所属组和其他用户只能读取。 |
|---|
要打开一个现有文件进行读写,使用os.OpenFile。这是打开/创建系列函数中最通用的形式:
- 要打开一个现有文件进行读写,使用以下代码:
file, err := os.OpenFile(fileName, os.O_RDWR, 0)
最后一个参数是0。只有在创建文件是一种选项时才会使用这个参数。我们稍后会看到这种情况。
- 要打开一个现有文件仅用于读取,使用以下代码:
file, err := os.OpenFile(fileName, os.O_RDONLY, 0)
- 要打开一个现有文件仅用于写入,使用以下代码:
file, err := os.OpenFile(fileName, os.O_WRONLY, 0)
- 要打开一个现有文件仅用于追加内容,使用以下代码:
file, err := os.OpenFile(fileName, os.O_WRONLY|os.O_APPEND, 0)
尝试在文件末尾以外的位置写入将失败。
- 要打开一个现有文件,如果文件不存在则创建它,使用以下代码:
file, err := os.OpenFile(fileName, os.O_RDWR|os.O_CREATE, 0o644)
上述操作如果文件存在则会打开它进行读写。如果文件不存在,将使用0o644 & ^umask权限位创建文件。0o644意味着所有者可以读写(06),同一组的用户可以读取(04),其他用户也可以读取(04)。
以下代码等同于os.Create,即如果文件存在则截断并打开它,如果不存在则创建它:
file, err := os.Open(fileName, os.O_RDWR|os.O_CREATE|os.O_TRUNC, 0o644)
如果你只想在文件不存在时创建它,可以使用“排他”位:
file, err := os.Open(fileName, os.O_RDWR|os.O_CREATE|os.O_EXCL, 0o644)
如果文件已存在,此调用将失败。
| 提示 这是确保某个进程只有一个实例在运行,或者在资源未被锁定时锁定资源的常用方法。例如,如果你想锁定一个目录,可以使用此调用来创建一个锁文件。如果其他进程已经锁定了它(在你之前创建了文件),该调用将失败。 |
|---|
# 关闭文件
总是显式关闭打开的文件有两个原因:
- 关闭文件时,存储在缓冲区中的所有数据都会被刷新。
- 在任何给定时间,你可以打开的文件数量是有限制的。这些限制因平台而异。
以下步骤展示了如何始终如一地进行此操作。
# 操作方法……
当你完成对文件的操作后,要关闭文件。尽可能使用defer file.Close():
file, err := os.Open(fileName)
if err != nil {
// 处理错误
}
defer file.Close()
// 对文件进行操作
2
3
4
5
6
7
如果要处理多个文件,就不要依赖defer。不要这样做:
for _, fileName := range files {
file, err := os.Open(fileName)
if err != nil {
// 处理错误
}
defer file.Close()
// 对文件进行操作
}
2
3
4
5
6
7
8
9
延迟调用会在函数返回时执行,而不是在使用它们的代码块结束时执行。前面的代码会使所有文件保持打开状态,直到函数返回。如果文件数量很多,一旦超过特定平台的打开文件限制,os.Open就会开始失败。你可以采取以下两种方法之一。第一种是为所有的退出点显式关闭文件:
for _, fileName := range files {
file, err := os.Open(fileName)
if err != nil {
return err
}
// 对文件进行操作
err := useFile(file)
if err != nil {
file.Close()
return err
}
err := useFileAgain(file)
if err != nil {
file.Close()
return err
}
// 进行更多操作
file.Close()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
第二种方法是使用带defer的闭包:
for _, fileName := range files {
file, err := os.Open(fileName)
if err != nil {
return err
}
err = func() error {
defer file.Close()
// 对文件进行操作
err := useFile(file)
if err != nil {
return err
}
err := useFileAgain(file)
if err != nil {
return err
}
// 进行更多操作
return nil
}()
if err != nil {
return err
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
提示:文件会被垃圾回收(garbage collected)。如果你打开/创建文件,然后直接使用文件描述符(file descriptors)进行操作,垃圾回收器可能不会如你所愿。在通过文件描述符和/或系统调用(syscalls)处理文件时,使用runtime.KeepAlive(file)防止垃圾回收器关闭文件。避免依赖垃圾回收器来关闭文件,始终显式关闭文件。
# 读取/写入文件数据
当你打开一个文件进行读写操作时,操作系统会记录文件内的当前位置。读写操作在该当前位置执行,一旦读取或写入一些数据,当前位置就会向前移动,以适应读取或写入的数据量。例如,如果你打开一个文件进行读取,当前位置会被设置为偏移量0。然后,如果你从文件中读取10个字节,当前位置就会变为10(假设文件大小超过10字节)。下次你从文件中读取或写入数据时,将从偏移量10开始读取内容或写入数据。在对文件进行混合读写操作时,要牢记这种行为。
# 操作方法……
- 要从当前位置开始读取一些数据,使用
file.Read:
file, err := os.Open(fileName)
if err != nil {
return err
}
// 当前位置:0
buffer := make([]byte, 100)
// 读取100字节
n, err := file.Read(buffer)
// 当前位置:n
// n表示实际读取的字节数
data := buffer[:n]
if err != nil {
if errors.Is(err, io.EOF) {
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
检查读取的字节数n和检查是否有错误的顺序很重要。io.Reader可能会进行部分读取,并返回读取的字节数和一个错误。该错误可能是io.EOF,表示文件中的数据比你试图读取的数据少。例如,一个10字节的文件将返回n=10和err=io.EOF。还要注意,这种行为取决于文件的当前位置。下面的代码片段将文件读取为字节切片的切片:
slices := make([][]byte, 0)
for {
buffer := make([]byte, 1024)
n, err := file.Read(buffer)
if n > 0 {
slices = append(slices, buffer[:n])
buffer = make([]byte, 1024)
}
if err != nil {
if errors.Is(err, io.EOF) {
break
}
return err
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如果在上述代码开始时,文件中的当前位置是0,那么每次读取操作后,当前位置将前进n个字节。注意,除了最后一个字节切片,所有字节切片的大小都将是1024字节。最后一个切片的大小可能在1到1024字节之间,具体取决于文件大小。
- 向文件写入数据的操作类似:
buffer := []byte("Hello world!")
n, err := io.Write(buffer)
if err != nil {
return err
}
2
3
4
5
写入操作不会返回io.EOF。如果你写入的数据超出了文件末尾,文件会被扩大以容纳写入的字节。如果写入操作无法写入所有给定的字节,错误将始终不为空,你应该检查并处理该错误。如果开始时当前位置是0,写入操作后当前位置将变为n。
- 要从文件中读取所有内容,使用
os.ReadFile:
data, err := os.ReadFile("config.yaml")
if err != nil {
// 处理错误
}
2
3
4
提示:使用os.ReadFile时要小心。它会分配一个与文件大小相同的[]byte。只有在确定要读取的文件大小合理时,才使用此函数。
- 要以固定大小的块读取大文件,分配一个固定大小的缓冲区,并迭代读取,直到返回
io.EOF:
// 以10K块为单位读取文件
buf := make([]byte, 10240)
for {
n, err := file.Read(buf)
if n > 0 {
// 处理缓冲区内容:
processData(buf[:n])
}
// 检查错误。检查是否为io.EOF并进行处理
if err != nil {
if errors.Is(err, io.EOF) {
// 文件末尾。我们完成了
break
}
// 其他错误
return err
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 要将字节切片写入新文件,使用
os.WriteFile:
err := os.WriteFile("config.yaml", data, 0o644)
# 从/向特定位置读取/写入
我们之前讨论过当前位置的概念。本节介绍如何移动当前位置,以便从文件中的任意位置开始读取或写入。
# 操作方法……
你可以使用File.Seek更改当前位置。
- 要相对于文件开头设置当前位置,使用以下代码:
// 移动到文件中的偏移量100处
newLocation, err := file.Seek(100, io.SeekStart)
2
返回的newLocation是文件的新当前位置。后续的读取或写入操作将从该位置进行。
- 要相对于文件末尾设置当前位置,使用以下代码:
// 移动到文件末尾:
newLocation, err := file.Seek(0, io.SeekEnd)
2
上述代码也是快速确定当前文件大小的方法,因为newLocation是文件末尾之后的0字节位置。
- 你可以移动到文件末尾之后的位置。从这样的位置读取将读取到0字节。向这样的位置写入将扩展文件大小,以容纳在该位置写入的数据:
// 移动到文件末尾之后100字节处并写入1字节
newLocation, err := file.Seek(100, io.SeekEnd)
if err != nil {
panic(err)
}
// 写入1字节。
file.Write([]byte{0})
// 现在文件变大了101字节。
2
3
4
5
6
7
8
9
提示:像这样扩展文件时,文件末尾和新写入字节之间的区域会用0填充。底层平台可能会将此实现为空洞(hole);也就是说,未写入的区域可能实际上并未分配空间。
os.File支持用于随机访问的其他方法。File.WriteAt将数据写入给定位置(相对于文件开头),而不移动当前位置。File.ReadAt将从给定位置读取数据,而不移动当前位置:
// 移动到偏移量1000处
_, err := file.Seek(1000, io.SeekStart)
// 将"Hello world"写入偏移量10处。
n, err := file.WriteAt([]byte("Hello world!"), 10)
if err != nil {
panic(err)
}
// 写入偏移量1000处,因为WriteAt不会移动当前位置
_, err := file.WriteAt([]byte{"offset 1000"})
buffer := make([]byte, 5)
file.ReadAt(buffer, 10)
fmt.Println(string(buffer))
// 输出 "Hello"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 更改文件大小
扩展文件通常是通过在文件末尾写入更多数据来实现的,但如何缩小现有文件呢?本方法介绍了更改文件大小的不同方式。
# 操作方法……
- 要将文件截断为大小为0,可以使用截断标志打开文件:
file, err := os.OpenFile("test.txt", os.O_RDWR|os.O_TRUNC, 0o644)
// 文件已打开并被截断为0大小
2
- 如果文件已经打开,可以使用
File.Truncate设置文件大小。File.Truncate既可以扩展文件,也可以缩小文件:
// 将文件截断为0大小
err := file.Truncate(0)
if err != nil {
panic(err)
}
// 将文件扩展到100字节
err = file.Truncate(100)
if err != nil {
panic(err)
}
2
3
4
5
6
7
8
9
10
11
- 你还可以通过追加内容来扩展文件。有两种方法可以做到这一点。你可以以只追加模式打开文件:
file, err := os.OpenFile("test.txt", os.O_WRONLY|os.O_APPEND, 0)
// 文件已打开用于写入,当前位置设置为文件末尾
2
如果你以只追加模式打开文件,则无法从文件的其他位置进行读写,只能追加内容。
- 或者,你可以移动到文件末尾并在那里开始写入:
// 移动到文件末尾
_, err := file.Seek(0, io.SeekEnd)
if err != nil {
panic(err)
}
// 将新数据写入文件末尾
_, err := file.Write(data)
2
3
4
5
6
7
8
# 查找文件大小
如果文件已打开,可以按如下方式获取文件大小:
fileSize, err := file.Seek(0, io.SeekEnd)
这将返回当前文件大小,包括任何已追加但尚未刷新的数据。上述操作会将文件指针移动到文件末尾。要保留当前位置,可以使用以下代码:
// 获取当前位置
currentLocation, err := file.Seek(0, io.SeekCurrent)
if err != nil {
return err
}
// 查找文件大小
fileSize, err := file.Seek(0, io.SeekEnd)
if err != nil {
return err
}
// 移回保存的位置
_, err := file.Seek(currentLocation, io.SeekStart)
if err != nil {
return err
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
如果文件未打开,使用os.Stat:
fileInfo, err := os.Stat(fileName)
if err != nil {
return
}
fileSize := fileInfo.Size()
2
3
4
5
6
提示:如果你打开了文件并向其中追加了数据,os.Stat报告的文件大小可能与你通过File.Seek获得的文件大小不同。os.Stat函数从文件目录读取文件信息。File.Seek方法使用特定于进程的文件信息,这些信息可能尚未反映在目录条目中。
# 处理二进制数据
如果需要通过网络连接发送数据,或者将数据存储在文件中,首先必须对数据进行编码(也叫序列化或编组)。这是必要的,因为网络连接另一端的系统,或者读取你所写文件的应用程序,可能运行在不同的平台上。一种便于移植、易于调试,但不一定高效的方法是使用基于文本的编码方式,比如JSON。如果性能至关重要,或者使用场景有此需求,那就得用二进制编码。
有很多高级的二进制编码方案。Gob(https://pkg.go.dev/encoding/gob (opens new window))是一种特定于Go语言的编码方案,可用于网络应用程序。Protocol Buffers(https://protobuf.dev (opens new window))提供了一种语言无关、可扩展、基于模式驱动的结构化数据编码机制。类似的方案还有很多。所以,我们不具体选择某一种方案,而是来了解一下每个软件工程师都应该知道的二进制编码基础知识。
对数据进行编码,就是将数据元素转换为字节流。如果数据元素是单个字节,或者本身就是字节序列,那就可以直接编码。在处理多字节数据类型(如int16、int32、int64等)时,字节的排列顺序就很重要了。例如,有一个值为0xABCD的int16类型数据,该如何将这些字节编码为一个字节切片([]byte)呢?有两种选择:
- 小端序(Little-endian):0xABCD被编码为[]byte{0xCD, 0xAB}
- 大端序(Big-endian):0xABCD被编码为[]byte{0xAB, 0xCD}
同样,一个32位整数0x01234567,按小端序字节顺序编码得到[]byte{0x67, 0x45, 0x23, 0x01},按大端序字节顺序编码则得到[]byte{0x01, 0x23, 0x45, 0x67}。大多数现代硬件在内存中表示数值时使用小端序字节顺序,而网络协议(如IP协议)倾向于使用大端序。
# 如何操作……
二进制数据编码主要有两种方法:
- 第一种是使用固定结构。在这种方法中,数据字段的顺序和类型是固定的。例如,IPv4头部定义了每个头部字段的起止位置。这种方法无法省略某个字段,也不能添加扩展。图14.1展示了一个示例。
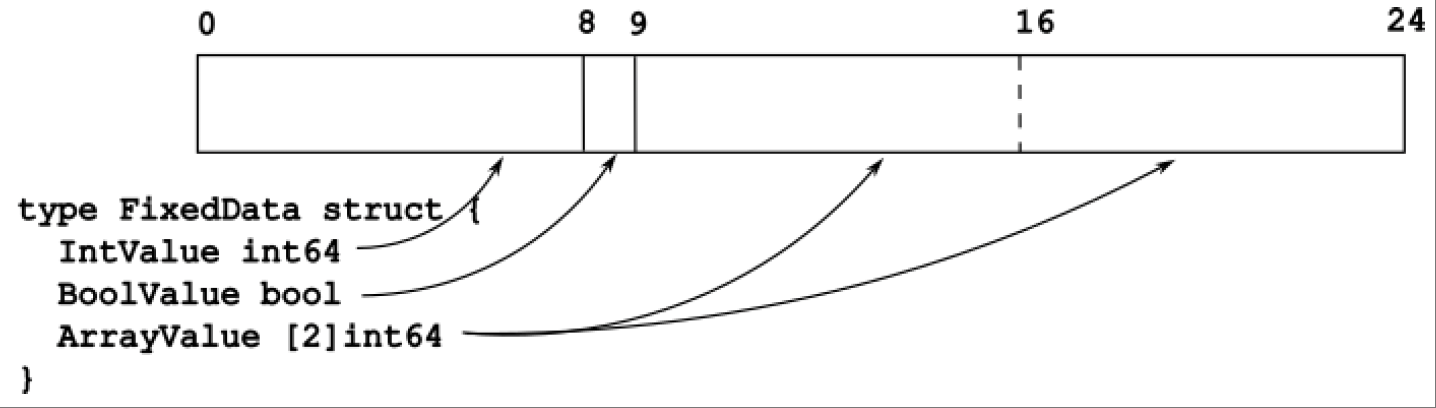
图14.1:固定长度编码示例
- 第二种是使用动态编码模式,如长度值(Length Value,LV)或标签长度值(Tag Length Value,TLV)。在这种模式下,编码后的数据长度不固定,但具有自描述性。标签定义数据类型和 / 或数据元素,可选的长度定义数据的长度,值就是数据元素的值。例如,一种常见的LV编码字符串的方法是,先对字符串的长度进行编码,然后再编码字符串本身的字节。使用TLV对字符串进行编码时,会先写入一个标签,表示该值是一个字符串字段,接着是长度,最后是字符串本身。图14.2展示了一个TLV编码模式示例。
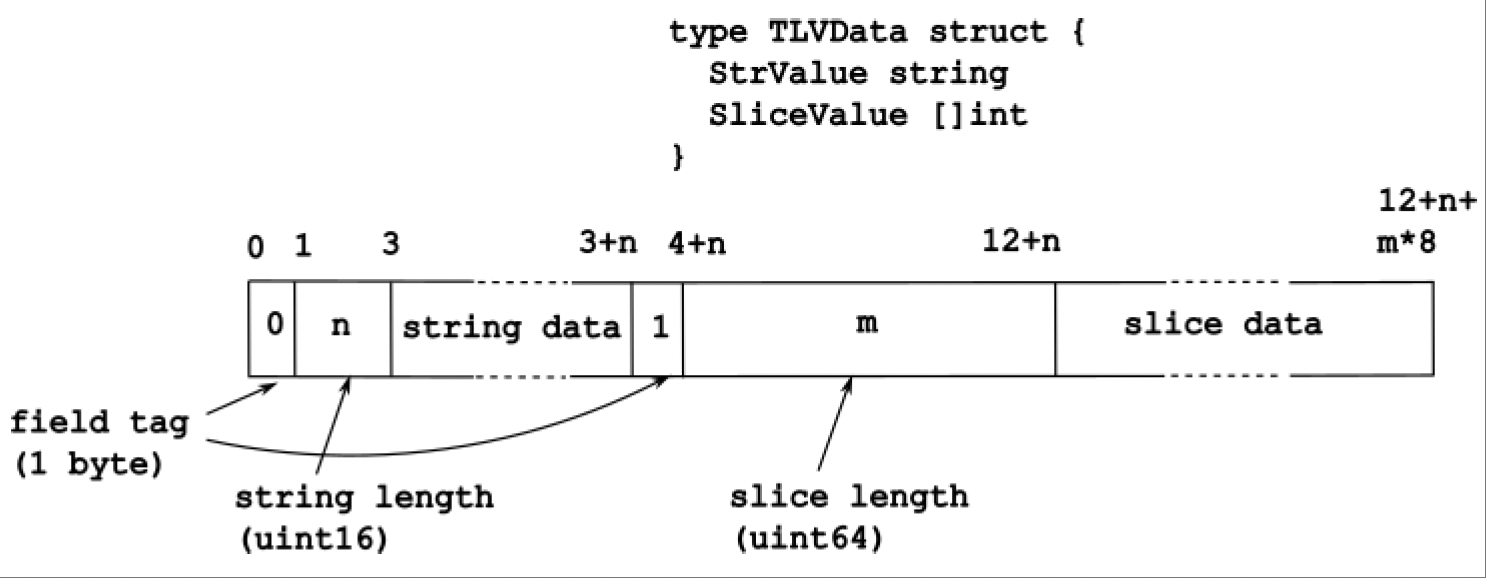
图14.2:TLV编码示例
这个示例使用16位编码字符串长度,64位编码切片长度。
使用encoding/binary包可以按大端序或小端序对数据进行编码。
对于固定长度编码,可以使用encoding.Write进行编码,使用encoding.Read进行解码:
type Data struct {
IntValue int64
BoolValue bool
ArrayValue [2]int64
}
func main() {
output := bytes.Buffer{}
data := Data{
IntValue: 1,
BoolValue: true,
ArrayValue: [2]int64{1, 2},
}
// 使用大端序字节顺序编码数据
binary.Write(&output, binary.BigEndian, data)
stream := output.Bytes()
fmt.Printf("Big endian encoded data : %v\n", stream)
// 解码数据
var value1 Data
binary.Read(bytes.NewReader(stream), binary.BigEndian, &value1)
fmt.Printf("Decoded data: %v\n", value1)
// 使用小端序字节顺序编码数据
output = bytes.Buffer{}
binary.Write(&output, binary.LittleEndian, data)
stream = output.Bytes()
fmt.Printf("Little endian encoded data: %v\n", stream)
// 解码数据
var value2 Data
binary.Read(bytes.NewReader(stream), binary.LittleEndian, &value2)
fmt.Printf("Decoded data: %v\n", value2)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
这个程序的输出如下:
Big endian encoded data : [0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 2]
Decoded data: {1 true [1 2]}
Little endian encoded data: [1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0]
Decoded data: {1 true [1 2]}
2
3
4
定义Data结构体时要特别注意。如果想使用encoding.Read或encoding.Write,就不能使用可变长度或特定于平台的类型:
- 不能用
int,因为int的大小是特定于平台的 - 不能用切片(slices)
- 不能用映射(maps)
- 不能用字符串(strings)
那么,如何对这些值进行编码呢?我们来看一种使用LV编码模式对字符串值进行编码的方法:
func EncodeString(s string) []byte {
// 为字符串长度(int16)和字符串内容分配输出缓冲区
buffer := make([]byte, 0, len(s)+2)
// 以小端序编码字符串长度 - 2字节
binary.LittleEndian.PutUint16(buffer, uint16(len(s)))
// 复制字符串字节
copy(buffer[2:], []byte(s))
return buffer
}
2
3
4
5
6
7
8
9
下面是解码字符串值的方法:
func DecodeString(input []byte) (string, error) {
// 读取字符串长度。长度至少为2字节
if len(input) < 2 {
return "", fmt.Errorf("invalid input")
}
n := binary.LittleEndian.Uint16(input)
if int(n)+2 > len(input) {
return "", fmt.Errorf("invalid input")
}
return string(input[2 : n+2]), nil
}
2
3
4
5
6
7
8
9
10
11
12
13
# 复制数据
io.Copy函数从一个读取器(reader)读取数据,并将其写入一个写入器(writer),直到其中一个操作失败,或者读取器返回io.EOF(文件结束标志)。在很多场景下,需要从读取器获取数据块,并将其发送到写入器,io.Copy在抽象层面上发挥作用,它允许将数据从文件复制到网络连接,或者从字符串复制到文件。它还会基于系统能力进行优化,以尽量减少数据复制。例如,如果平台支持splice系统调用,io.Copy就能使用它来避免使用缓冲区。在本节中,我们将了解io.Copy的一些用法。
# 复制文件
# 如何操作……
复制文件可按以下步骤进行:
- 打开源文件。
- 创建目标文件。
- 使用
io.Copy复制数据。 - 关闭两个文件。
下面展示了这些步骤:
sourceFile, err := os.Open(sourceFileName)
if err != nil {
panic(err)
}
defer sourceFile.Close()
targetFile, err := os.Create(targetFileName)
if err != nil {
panic(err)
}
defer targetFile.Close()
if err := io.Copy(targetFile, sourceFile); err != nil {
panic(err)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
由于io.Copy使用io.Reader和io.Writer接口,任何实现了这些接口的对象都可以用作源或目标。例如,下面的代码片段将文件内容作为HTTP请求的响应返回:
// Handle GET /path/{fileName}
func HandleGetImage(w http.ResponseWriter, req *http.Request) {
// 从请求中获取文件名
file, err := os.Open(req.PathValue("fileName"))
if err != nil {
http.Error(w, err.Error(), http.StatusNotFound)
return
}
defer file.Close()
// 将文件内容写入响应写入器
io.Copy(w, file)
}
2
3
4
5
6
7
8
9
10
11
12
13
# 操作文件系统
文件系统的很多方面都依赖于特定的平台。本节讨论以可移植的方式操作文件系统的方法。
# 操作文件名
使用path/filepath包以可移植的方式操作文件名。
# 如何操作……
- 要从多个路径段构建路径,使用
filepath.Join:
fmt.Println(filepath.Join("/a/b/", "/c/d"))
// 输出 /a/b/c
fmt.Println(filepath.Join("/a/b/c/d/", "../../x"))
// 输出 a/b/x
2
3
4
注意,filepath.Join不允许连续的分隔符,并且能正确解析..。
- 要将路径拆分为目录和文件名部分,使用
filepath.Split:
fmt.Println(filepath.Split("/home/bserdar/work.txt"))
// dir: "/home/bserdar" file: "work.txt"
fmt.Println(filepath.Split("/home/bserdar/projects/"))
// dir: "/home/bserdar/projects/" file: ""
2
3
4
- 避免在代码中使用路径分隔符(
/和\),使用filepath.Separator,这是一个特定于平台的符文(rune)值。
# 创建临时目录和文件
有时,需要创建唯一的目录名和文件名,主要用于存储临时数据。
# 如何操作……
- 要在特定平台的默认临时文件目录下创建临时目录,使用
os.MkdirTemp("", prefix):
dir, err := os.MkdirTemp("", "tempdir")
if err != nil {
// 处理错误
}
// 使用完后清理
defer os.RemoveAll(dir)
fmt.Println(dir)
// 输出 /tmp/example10287493
2
3
4
5
6
7
8
9
创建的名称是唯一的。如果多次调用创建临时目录的函数,每次都会生成一个唯一的名称。
- 要在特定目录下创建临时目录,使用
os.MkdirTemp(dir, prefix):
// 在当前目录下创建临时目录
dir, err := os.MkdirTemp(".", "tempdir")
if err != nil {
// 处理错误
}
// 使用完后清理
defer os.RemoveAll(dir)
2
3
4
5
6
7
8
- 要创建名称中的随机部分不是后缀的临时目录,使用
*。随机字符串会替换最后一个*字符:
dir, err := os.MkdirTemp(".", "myapp.*.txt")
if err != nil {
// 处理错误
}
defer os.RemoveAll(dir)
fmt.Println(dir)
// 输出 ./myapp.13984873.txt
2
3
4
5
6
7
8
- 要创建临时文件,使用
os.CreateTemp。会创建一个唯一的文件,并以读写模式打开。可以从返回的文件对象的Name字段获取创建的文件名:
file, err := os.CreateTemp("", "app.*.txt")
if err != nil {
// 处理错误
}
fmt.Println("Temp file", file.Name)
// 使用完后清理
defer os.Remove(file.Name)
defer file.Close()
2
3
4
5
6
7
8
9
与os.MkdirTemp类似,如果文件名中包含*,随机字符串会插入到最后一个*的位置。如果文件名中不包含*,随机字符串会追加到名称末尾。
# 读取目录
使用os.ReadDir列出或查找目录下的文件。
# 操作方法……
- 调用
os.ReadDir获取目录内容。这将按名称排序返回目录项:
entries, err := os.ReadDir(".")
if err != nil {
// handle error
}
for _, entry := range entries {
// Name contains the file name only, not the directory
name := entry.Name()
if entry.IsDir() {
// This is a directory
} else {
// This is not a directory. Does not mean it is a regular
// file Can be a named pipe, device, etc.
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果处理的可能是大目录,你可能会注意到os.ReadDir并非最佳选择。它会返回一个无界切片(unbounded slice),而且还会花时间对其进行排序。
- 对于注重性能和内存的应用程序,可以打开目录并使用
File.ReadDir读取:
// Open the directory
dir, err := os.Open("/tmp")
if err != nil {
panic(err)
}
defer dir.Close()
// Read directory entries unordered, 10 at a time
for {
entries, err := dir.ReadDir(10)
// Are we done reading
if errors.Is(err, io.EOF) {
break
}
if err != nil {
panic(err)
}
// There are at most 10 fileInfo entries
for _, entry := range entries {
// Process the entry
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- 要以可移植的方式递归遍历目录项,可以使用
io.fs.WalkDir。无论在哪个平台,这个函数都使用/作为路径分隔符。下面的示例打印/tmp下的所有文件,跳过目录:
err := fs.WalkDir(os.DirFS("/"), "/tmp", func(path string, d fs.DirEntry, err error) error {
if err != nil {
fmt.Println("Error during directory traversal", err)
return err
}
if !d.IsDir() {
// This is not a directory
fmt.Println(filepath.Join(path, d))
}
return nil
})
2
3
4
5
6
7
8
9
10
11
12
13
- 要递归遍历目录项,可以使用
filepath.WalkDir。这个函数使用特定于平台的路径分隔符。下面的示例递归打印/tmp下的所有目录:
err := filepath.WalkDir("/tmp", func(path string, d fs.DirEntry, err error) error {
if err != nil {
fmt.Println("Error during directory traversal", err)
return err
}
if d.IsDir() {
// This is a directory
fmt.Println(filepath.Join(path, d), " directory")
}
return nil
})
2
3
4
5
6
7
8
9
10
11
12
13
# 使用管道(pipe)
如果你有一段代码需要读取器(reader),而另一段代码需要写入器(writer),那么可以使用io.Pipe将二者连接起来。
# 连接需要读取器的代码和需要写入器的代码
这种用例的一个很好的例子是准备HTTP POST请求,它需要一个读取器。如果你拥有所有可用数据,或者已经有一个读取器(比如os.File),那么可以直接使用。然而,如果数据是由一个接受写入器的函数生成的,那就使用管道。
# 操作方法……
管道是一种同步连接的读取器和写入器。也就是说,如果你向管道写入数据,必须有一个读取器同时从管道读取数据。所以要确保将生成数据的一端(使用写入器的地方)放在与消费数据的一端(使用读取器的地方)不同的goroutine中。
- 使用
io.Pipe创建一个管道读取器和管道写入器:
pipeReader, pipeWriter := io.Pipe()
pipeReader将读取写入到pipeWriter中的所有数据。
- 在一个goroutine中使用
pipeWriter生成数据。当所有数据都写入后,关闭pipeWriter:
go func() {
// Close the writer side, so the reader knows when it is done
defer pipeWriter.Close()
encoder := json.NewEncoder(pipeWriter)
if err := encoder.Encode(payload); err != nil {
if errors.Is(err, io.ErrClosedPipe) {
// The reader side terminated with error
} else {
// Handle error
}
}
}()
2
3
4
5
6
7
8
9
10
11
12
- 在需要读取器的地方使用
pipeReader。如果函数执行失败且管道中的数据没有全部被消费,关闭pipeReader,以便写入器可以终止:
if _, err := http.Post(serverURL, "application/json", pipeReader); err != nil {
// Close the reader, so the writing goroutine terminates
pipeReader.Close()
// Handle error
}
2
3
4
5
在上述代码中,编码JSON数据的goroutine会阻塞,直到POST请求建立连接并传输数据。如果在此过程中出现错误,pipeReader.Close()可以确保编码JSON数据的goroutine不会泄漏。
# 使用TeeReader拦截读取器
在管道工程中,T形管(tee pipe)是一种T形管件,它将水流一分为二。TeeReader的名称就来源于此。io.TeeReader(r io.Reader, w io.Writer) io.Reader函数返回一个新的读取器,它在从r读取数据的同时,会将读取的数据写入到w。这对于拦截通过读取器的数据非常有用。
# 操作方法……
- 创建一个管道:
pipeReader, pipeWriter := io.Pipe()
- 使用
pipeWriter作为接收数据的写入器,从另一个读取器创建一个TeeReader:
file, err := os.Open(dataFile)
if err != nil {
// Handle error
}
defer file.Close()
tee := io.TeeReader(file, pipeWriter)
2
3
4
5
6
7
此时,从tee读取一些数据,会从file读取数据并将其写入到pipeWriter。
3. 在一个单独的goroutine中使用pipeReader处理从原始读取器读取的数据:
go func() {
// Copy the file to stdout
io.Copy(os.Stdout, pipeReader)
}()
2
3
4
- 使用
TeeReader读取数据:
_, err := http.Post(serverURL, "text/plain", tee)
if err != nil {
// Make sure pipe is closed
pipeReader.Close()
}
2
3
4
5
请注意,使用管道至少需要另一个goroutine来进行写入或读取操作。如果发生错误,要确保通过关闭管道的一端来终止所有使用管道的goroutine。