 2 数据结构与算法
2 数据结构与算法
# 2 数据结构与算法
数据结构和算法是构建软件的基本单元,对于复杂的高性能软件而言尤为重要。理解它们有助于我们思考如何有效地组织和处理数据,从而编写出高效、高性能的软件。本章将解释不同的数据结构和算法,以及它们的大O符号(Big O notation)会受到哪些影响。
正如我们在第1章“Go语言性能入门”中提到的,设计层面的决策通常对性能有着最为显著的影响。最经济的计算是根本无需进行的计算——如果你在软件架构阶段就尽早朝着优化设计的方向努力,那么日后就能避免许多性能损失。
在本章中,我们将讨论以下主题:
- 利用大O符号进行基准测试
- 搜索和排序算法
- 树结构
- 队列
创建不包含多余信息的简单数据结构,有助于编写实用且高性能的代码。算法也将有助于提升现有数据结构的性能。
# 理解基准测试
指标和度量是优化的基础。“无法衡量,就无法改进”这句谚语在性能优化方面非常适用。为了能够在性能优化方面做出明智的决策,我们必须持续衡量试图优化的函数的性能。
正如我们在第1章“Go语言性能入门”中提到的,Go语言的创造者在设计语言时就充分考虑了性能因素。Go语言的测试包(https://golang.org/pkg/testing/ )用于系统地测试Go代码。测试包是Go语言的基础组成部分,它还包含一个很有用的内置基准测试功能。该功能通过go test -bench命令调用,用于运行你为函数定义的基准测试。测试结果也可以保存下来,供日后查看。有了函数之前的基准测试结果,你就可以跟踪函数长期以来的变化及其结果。基准测试与性能分析(profiling)和跟踪(tracing)配合得很好,可以获取系统状态的准确报告。我们将在第12章“分析Go代码性能”和第13章“跟踪Go代码”中进一步了解性能分析和跟踪。在进行基准测试时,需要注意应该禁用CPU频率缩放(见https://blog.golang.org/profiling-go-programs ),这将使每次基准测试的结果更加稳定。用于禁用频率缩放的bash脚本可以在https://github.com/bobstrecansky/HighPerformanceWithGo/blob/master/frequency_scaling_governor_diable.bash 找到。
# 基准测试执行
Go语言中的基准测试遵循一个规则,即函数名以“Benchmark”(首字母大写)开头,以此表明该函数是一个基准测试函数,应使用基准测试功能。要在测试包中执行你为代码定义的基准测试,可以在go test命令中使用-bench=.标志。这个测试标志会确保运行所有的基准测试。以下代码块展示了一个基准测试的示例:
package hello_test
import (
"fmt"
"testing"
)
func BenchmarkHello(b *testing.B) { // 基准测试定义
for i := 0; i < b.N; i++ {
fmt.Sprintf("Hello High Performance Go")
}
}
2
3
4
5
6
7
8
9
10
11
12
在这个(诚然很简单的)基准测试中,我们对fmt.Sprintf语句循环执行b.N次。基准测试包会执行并运行我们的Sprintf语句。在测试过程中,基准测试会调整b.N的值,直到能够可靠地对该函数进行计时。默认情况下,go benchmark测试会运行1秒钟,以获得具有统计意义的结果集。
在调用基准测试工具时,有许多可用的标志。以下表格列出了一些对基准测试有帮助的标志:
| 标志 | 用例 |
|---|---|
| -benchtime t | 运行测试足够的次数,使测试持续时间达到指定的t。增大这个值会增加b.N的循环次数。 |
| -count n | 每个测试运行n次。 |
| -benchmem | 开启测试的内存分析功能。 |
| -cpu x,y,z | 指定一个GOMAXPROCS值列表,基准测试将针对这些值执行。 |
以下是一个基准测试执行的示例。在这个示例中,我们对现有的Hello基准测试进行两次性能分析。我们还使用了四个GOMAXPROCS,查看测试的内存分析信息,并且将测试执行时间设定为2秒,而不是默认的1秒。我们可以像这样调用go test -bench功能:
$ go test -bench=. -benchtime 2s -count 2 -benchmem -cpu 4
基准测试会一直运行,直到函数返回、失败或跳过。测试完成后,基准测试的结果会作为标准错误输出返回。测试完成并整理好结果后,我们就可以对基准测试的结果进行合理的比较。以下结果展示了一个示例测试执行过程,以及前面BenchmarkHello函数的输出结果:
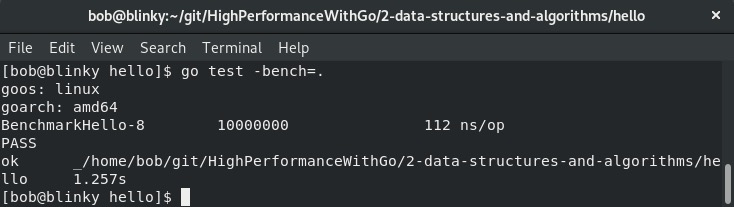
在输出结果中,我们可以看到返回了几个不同的数据:
GOOS和GOARCH(在第1章“Go语言性能入门”的“Go工具集”部分讨论过)。- 运行的基准测试名称,后面跟着:
-8:用于执行测试的GOMAXPROCS数量。10000000:为收集必要数据,循环运行的次数。112 ns/op:测试期间每次循环的速度。PASS:表示基准测试运行的最终状态。
- 测试的最后一行,包含测试运行的最终状态汇总(
ok)、运行测试的路径以及测试运行的总时间。
# 实际应用中的基准测试
在运行本书中的基准测试时,请务必记住,基准测试并不是衡量性能结果的唯一标准。基准测试有优点也有缺点:
- 基准测试的优点:
- 在潜在问题变得难以处理之前发现它们。
- 帮助开发者更深入地理解自己的代码。
- 能够在设计以及数据结构和算法阶段识别潜在的瓶颈。
- 基准测试的缺点:
- 需要按照一定的节奏进行,才能得到有意义的结果。
- 数据整理可能比较困难。
- 对于手头的问题,并不总是能得出有意义的结果。
基准测试适用于比较。在同一系统上对两个事物进行基准测试,能够得到相对一致的结果。如果你有能力运行更长时间的基准测试,可能会得到更能反映函数性能的结果。
Go语言的benchstat(https://godoc.org/golang.org/x/perf/cmd/benchstat )包是一个很有用的工具,它可以帮助你比较两个基准测试的结果。比较结果对于判断你对函数所做的更改对系统是产生积极影响还是消极影响非常重要。你可以使用go get工具安装benchstat:
go get golang.org/x/perf/cmd/benchstat
考虑以下比较测试。我们将测试包含三个元素的单个JSON结构的编组操作,与包含五个元素的两个JSON数组的编组操作进行对比。你可以在https://github.com/bobstrecansky/HighPerformanceWithGo/tree/master/2-data-structures-and-algorithms/Benchstat-comparison 找到这些测试的源代码。
为了得到一个比较示例,我们对测试执行基准测试,如下代码片段所示:
[bob@testhost single]$ go test -bench=. -count 5 -cpu 1,2,4 > ~/single.txt
[bob@testhost multi]$ go test -bench=. -count 5 -cpu 1,2,4 > ~/multi.txt
[bob@testhost ~]$ benchstat -html -sort -delta single.txt multi.txt > out.html
2
3
这会生成一个HTML表格,可用于验证执行时的最大差异。如下截图所示,即使在数据结构和处理的元素数量上增加少量复杂度,也会使函数的执行时间发生相当大的变化:

快速识别最终用户遇到的性能痛点,有助于你确定编写高性能软件的方向。
在下一节中,我们将了解什么是大O符号。
# 介绍大O符号(Big O notation)
大O符号是一种评估所选算法运行速度的有效方式,它能够反映算法运行速度如何随着输入数据规模的变化而变化。大O符号常用来描述函数的增长特性,确切地说是函数的上界。大O符号可分为不同的类别,最常见的类别包括O(1)、O(log n)、O(n)、O(nlog n)、O(n²) 和 O(2ⁿ)。下面我们快速了解一下这些算法,包括它们的定义以及在Go语言中的实际示例。
这些常见类别的图表如下。生成此图表的源代码可在 https://github.com/bobstrecansky/HighPerformanceWithGo/blob/master/2-data-structures-and-algorithms/plot/plot.go 找到:
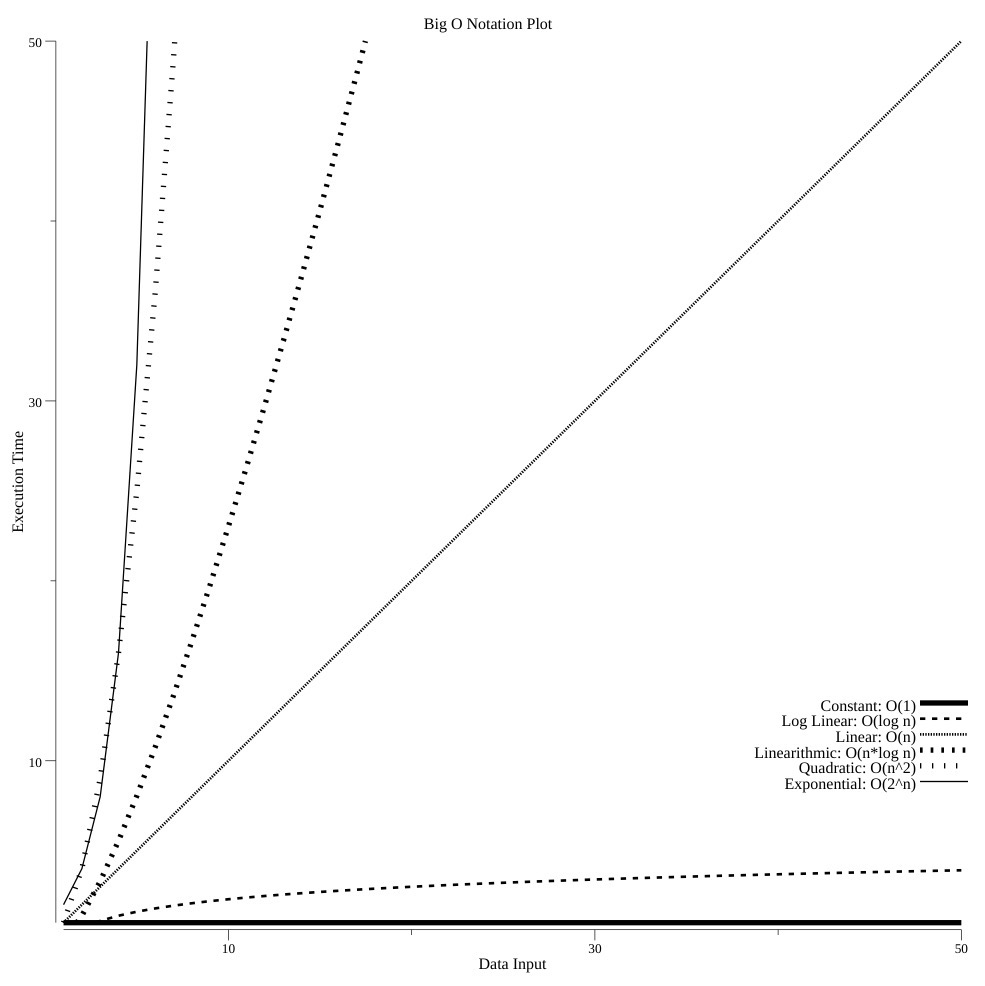
这个大O符号图表直观地展示了计算机软件中常用的不同算法。
# 大O符号的实际示例
如果我们选取一个包含32个输入值的示例数据集,就能快速计算出每个算法完成所需的时间。你会发现,下表中的单位完成时间增长得非常快。大O符号的实际值如下:
| 算法 | 单位完成时间 |
|---|---|
| O(1) | 1 |
| O(log n) | 5 |
| O(n) | 32 |
| O(nlog n) | 160 |
| O(n²) | 1024 |
| O(2ⁿ) | 4294967296 |
随着单位完成时间增加,代码的性能会降低。我们应尽量使用最简单的算法来处理手头的数据集。
# 数据结构操作和时间复杂度
下面的图表展示了一些常见的数据结构操作及其时间复杂度。正如前面提到的,数据结构是计算机科学性能的核心要素。在编写高性能代码时,理解不同数据结构之间的差异至关重要。随时查阅这张表格,有助于开发者在考虑操作对性能影响的同时,为手头的任务选择合适的数据结构操作:
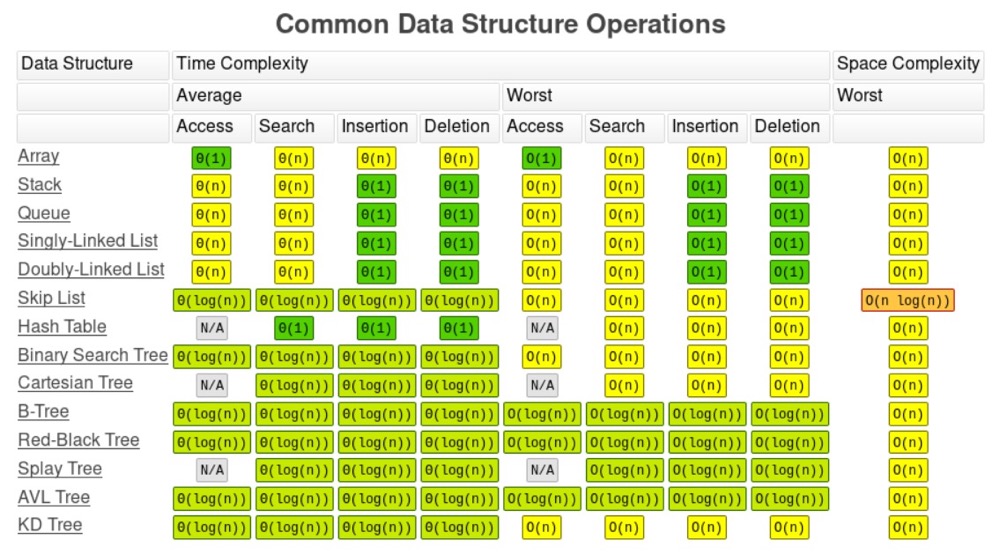
图2.4 常见数据结构操作
这张表格展示了特定数据结构的时间和空间复杂度,是很有价值的性能参考工具。
# O(1) - 常数时间
以常数时间编写的算法,其上界不依赖于算法的输入规模。常数时间是由一个常量值作为上界,因此执行时间不会超过数据集上界所需的时间。在实际应用中,这种类型的算法添加到函数中通常没问题,它不会给函数增加太多处理时间。要注意这里的常数。在数组中进行一次查找操作,对函数时间的影响微乎其微。但在数组中查找数千个单独的值,可能会增加一些开销。性能总是相对的,即便函数仅执行少量处理任务,也要留意其给函数带来的额外负载。
常数时间的示例如下:
- 在映射(map)或数组中访问单个元素
- 计算一个数的模
- 栈的入栈(Stack push)或出栈(stack pop)操作
- 判断一个整数是偶数还是奇数
在Go语言中,常数时间算法的一个示例是访问数组中的单个元素,代码如下:
package main
import "fmt"
func main() {
words := [3]string{"foo", "bar", "baz"}
fmt.Println(words[1])
}
2
3
4
5
6
7
8
这个函数的大O符号表示为O(1),因为我们只需查看words[1]这个特定值,就能找到想要的结果,即bar。在这个例子中,随着数组规模增大,访问数组中某个对象的时间保持不变。该算法的标准化时间应该都相同,如下表所示:
| 数据集中的项目数量 | 计算时间 |
|---|---|
| 10 | 1秒 |
| 100 | 1秒 |
| 1000 | 1秒 |
一些O(1)符号的示例代码如下:
package oone
func ThreeWords() string {
threewords := [3]string{"foo", "bar", "baz"}
return threewords[1]
}
func TenWords() string {
tenwords := [10]string{"foo", "bar", "baz", "qux", "grault", "waldo", "plugh", "xyzzy", "thud", "spam"}
return tenwords[6]
}
2
3
4
5
6
7
8
9
10
11
无论数组中有多少个元素,查找一个元素所需的时间都是相同的。在下面的示例输出中,我们分别有包含三个元素和十个元素的数组。它们执行所需的时间相同,并且在给定时间内完成的测试迭代次数也相同。从下面的截图中可以看出:
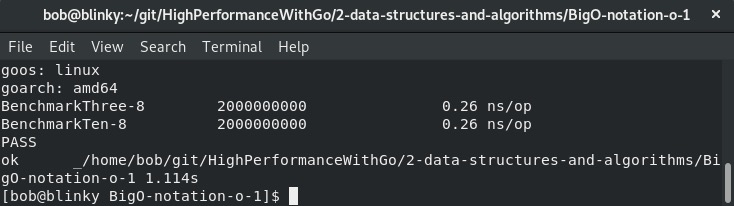
这个基准测试的结果符合预期。BenchmarkThree和BenchmarkTen基准测试的时间都是0.26纳秒/操作,这在数组查找操作中应该是一致的。
# O(log n) - 对数时间
对数增长通常表示为调和级数的部分和,可以表示为:

以对数时间编写的算法,其操作次数会随着输入规模的减小而趋于零。当必须访问数组中的所有元素时,不能使用O(log n)算法。单独使用O(log n)算法时,通常被认为是一种高效算法。在对数时间性能方面,一个重要的概念是搜索算法常与排序算法一起使用,这增加了求解的复杂性。根据数据集的规模和复杂性,在执行搜索算法之前对数据进行排序通常是有意义的。注意这个测试的输入和输出范围,添加了额外测试以展示数据集计算时间的对数增长情况。
对数时间算法的一些示例如下:
- 二分查找(Binary search)
- 字典查找(Dictionary search)
下表展示了对数时间的标准化时间:
| 数据集中的项目数量 | 计算时间 |
|---|---|
| 10 | 1秒 |
| 100 | 2秒 |
| 1000 | 3秒 |
Go语言的标准库中有一个名为sort.Search()的函数,以下代码片段将其列出以供参考:
func Search(n int, f func(int) bool) int {
// Define f(-1) == false and f(n) == true.
// Invariant: f(i-1) == false, f(j) == true.
i, j := 0, n
for i < j {
h := int(uint(i+j) >> 1)
// i ≤ h < j
if !f(h) {
i = h + 1
} else {
j = h
}
}
// i == j, f(i-1) == false, and f(j) (= f(i)) == true => answer is i.
return i
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段代码示例可在标准库的https://golang.org/src/sort/search.go中找到。O(log n)函数的代码和基准测试可在https://github.com/bobstrecansky/HighPerformanceWithGo/tree/master/2-data-structures-and-algorithms/BigO-notation-o-logn中找到。
下面的截图展示了对数时间的基准测试:
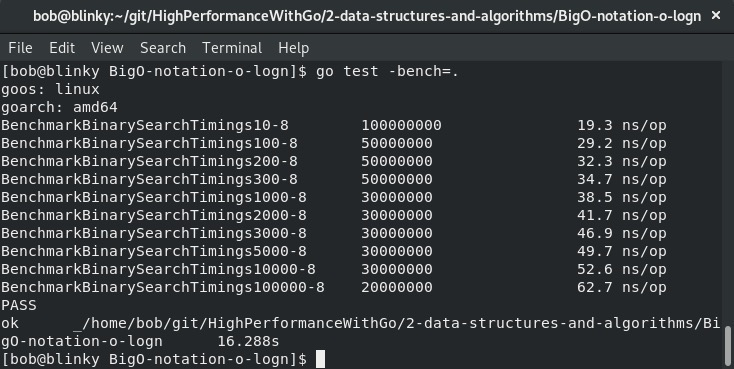
这个测试表明,随着我们设置的输入增加,时间呈对数增长。具有对数时间响应的算法对编写高性能代码非常有帮助。
# O(n)——线性时间
以线性时间编写的算法,其运行时间会随数据集大小线性变化。当需要按顺序读取整个数据集时,线性时间是最佳的时间复杂度。以线性时间运行的算法所花费的时间,与数据集中包含的元素数量呈1:1的关系。
线性时间的一些示例如下:
- 简单循环
- 线性搜索
线性时间的标准化计时可在下表中找到:
| 数据集中的元素数量 | 计算结果所需时间 |
|---|---|
| 10 | 10秒 |
| 100 | 100秒 |
| 1,000 | 1,000秒 |
请注意,计算结果所需时间呈线性增长,并且与数据集中的元素数量相关(请参考以下截图)。O(n)函数的代码和基准测试可在https://github.com/bobstrecansky/HighPerformanceWithGo/tree/master/2-data-structures-and-algorithms/BigO-notation-o-n找到:
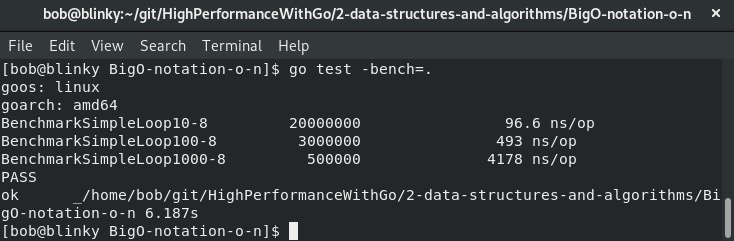
重要的是要记住,大O符号(Big O notation)不一定能完美地指示响应时间的增长情况;它只是表示一个上限。在查看这个基准测试时,要关注计算结果所需时间随数据集中元素数量线性增长这一事实。从性能角度来看,O(n)算法在计算机科学中通常不是严重影响性能的因素。计算机科学家经常在迭代器上执行循环,这是一种用于完成计算工作的常见模式。要始终留意数据集的大小!
# O(n log n)——准线性时间
以准线性(或对数线性)时间编写的算法,常用于在Go语言中对数组中的值进行排序。
准线性时间的一些示例如下:
- 快速排序(Quicksort)的平均时间复杂度
- 归并排序(Mergesort)的平均时间复杂度
- 堆排序(Heapsort)的平均时间复杂度
- Timsort排序的平均时间复杂度
准线性时间的标准化计时可在下表中找到:
| 数据集中的元素数量 | 计算结果所需时间 |
|---|---|
| 10 | 10秒 |
| 100 | 200秒 |
| 1,000 | 3,000秒 |
你会在这里看到一个熟悉的模式。这个算法遵循的模式与O(log n)算法类似。唯一的区别在于n这个乘数,所以我们可以看到带有比例因子的类似结果(请参考以下截图)。O(n log n)函数的代码和基准测试可在https://github.com/bobstrecansky/HighPerformanceWithGo/tree/master/2-data-structures-and-algorithms/BigO-notation-o-nlogn找到:
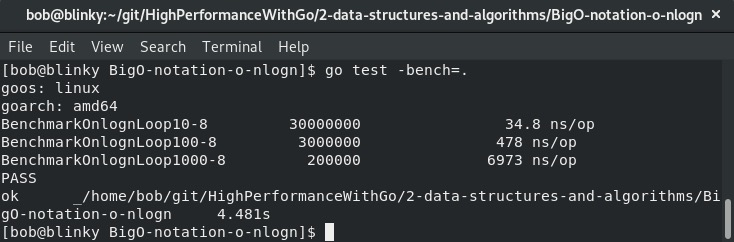
排序算法仍然相当快,并不是导致代码性能不佳的关键因素。通常,编程语言中使用的排序算法会根据数据规模混合使用多种排序算法。Go语言的快速排序算法(用于sort.Sort()函数),如果切片中的元素少于12个,会使用希尔排序(ShellSort)和插入排序(insertionSort)。这个快速排序的标准库算法如下:
func quickSort(data Interface, a, b, maxDepth int) {
for b-a > 12 { // 对于元素数量小于等于12的切片,使用ShellSort
if maxDepth == 0 {
heapSort(data, a, b)
return
}
maxDepth--
mlo, mhi := doPivot(data, a, b)
// 避免在较大的子问题上进行递归,保证栈深度最多为lg(b-a)
if mlo-a < b-mhi {
quickSort(data, a, mlo, maxDepth)
a = mhi // 即 quickSort(data, mhi, b)
} else {
quickSort(data, mhi, b, maxDepth)
b = mlo // 即 quickSort(data, a, mlo)
}
}
if b-a > 1 {
// 使用间隔为6进行ShellSort
// 因为b-a <= 12,所以可以写成这种简化形式
for i := a + 6; i < b; i++ {
if data.Less(i, i-6) {
data.Swap(i, i-6)
}
}
insertionSort(data, a, b)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
上述代码可在标准库的https://golang.org/src/sort/sort.go#L183找到。这个快速排序算法性能良好,在Go生态系统中被广泛使用。
# O(n²)——平方时间
以平方时间编写的算法,其执行时间与输入规模的平方直接相关。嵌套循环是常见的平方时间算法,一些排序算法也属于此类。
平方时间的一些示例如下:
- 冒泡排序(Bubble Sort)
- 插入排序(Insertion Sort)
- 选择排序(Selection Sort)
平方时间的标准化计时可在下表中找到:
| 数据集中的元素数量 | 计算结果所需时间 |
|---|---|
| 10 | 100秒 |
| 100 | 10,000秒 |
| 1,000 | 1,000,000秒 |
从这个表中可以看出,当输入规模增长10倍时,计算结果所需时间呈平方增长。
应尽可能避免使用平方时间算法。如果你需要使用嵌套循环或进行平方计算,一定要验证输入,并尝试限制输入规模。
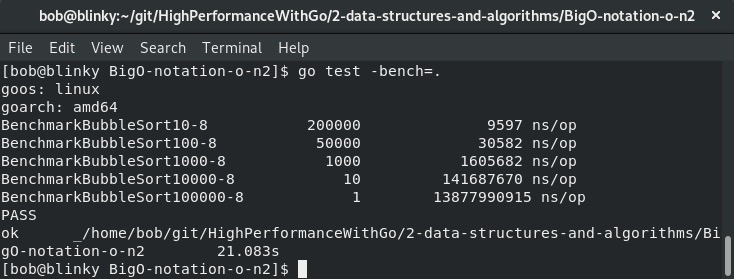
O(n²)函数的代码和基准测试可在https://github.com/bobstrecansky/HighPerformanceWithGo/tree/master/2-data-structures-and-algorithms/BigO-notation-o-n2找到。运行这个基准测试的输出如下:
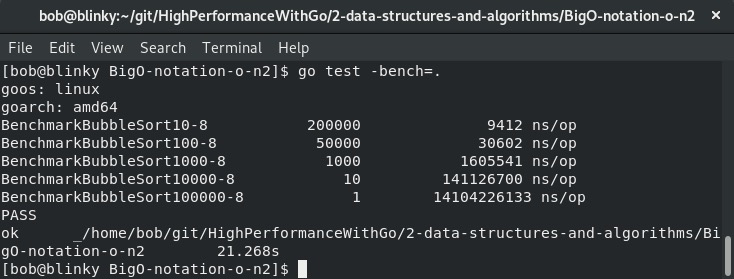
平方时间算法的成本会很快变得非常高。从我们自己的基准测试中就能看出这一点。
# O(2ⁿ)——指数时间
指数算法在向输入集添加数据时,运行时间会呈指数级增长。通常在对输入数据集没有先验了解,并且必须尝试输入集的每一种可能组合时使用这类算法。
指数时间的一些示例如下:
- 斐波那契数列(Fibonacci sequence)的糟糕递归实现
- 汉诺塔(Towers of Hanoi)问题
- 旅行商问题(Traveling salesman problem)
指数时间的标准化计时可在下表中找到:
| 数据集中的元素数量 | 计算结果所需时间 |
|---|---|
| 10 | 1,024秒 |
| 100 | 1.267×10³⁰秒 |
| 1,000 | 1.07×10³⁰¹秒 |
随着数据集中元素数量的增加,计算结果所需时间呈指数级增长。
指数时间算法只应在非常特殊的情况下,对范围非常有限的数据集使用。通常,进一步明确你所处理的问题或数据集,有助于避免使用指数时间算法。
O(n²)算法的代码可在https://github.com/bobstrecansky/HighPerformanceWithGo/tree/master/2-data-structures-and-algorithms/BigO-notation-o-n2找到。这个基准测试的一些示例输出可在以下截图中看到:
指数时间算法问题通常可以分解为更小、更易于处理的部分,这也有助于进行优化。
在下一节中,我们将介绍排序算法。
# 理解排序算法
排序算法用于将数据集中的各个元素按特定顺序排列。通常,排序算法会将数据集按字典序或数字顺序排列。能够高效地进行排序,对于编写高性能代码很重要,因为许多搜索算法都需要已排序的数据集。常见的数据结构操作如下图所示:
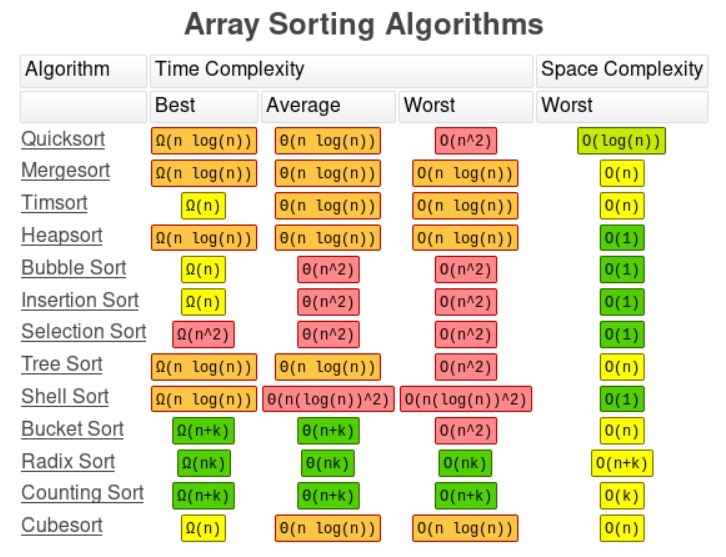
图2.12 来源于bigocheatsheet.com的常见数据结构操作
如你所见,数组排序算法的大O符号可能有很大差异。为未排序的列表选择正确的排序算法,对于提供优化解决方案至关重要。
# 插入排序
插入排序是一种排序算法,它逐个构建数组,直到得到一个已排序的数组。它的效率不是很高,但实现简单,对于非常小的数据集速度很快。该算法在原数组上进行排序,这也有助于减少函数调用的内存占用。
插入排序的标准库算法可在以下代码片段中找到。通过以下代码片段可以推断出,插入排序的平均时间复杂度为O(n²)。这是因为我们遍历了一个二维数组并对数据进行了操作:
func insertionSort(data Interface, a, b int) {
for i := a + 1; i < b; i++ {
for j := i; j > a && data.Less(j, j-1); j-- {
data.Swap(j, j-1)
}
}
}
2
3
4
5
6
7
这段代码可在标准库的https://golang.org/src/sort/sort.go#L183 (opens new window)找到。对于小数据集,简单的插入排序通常很有用,因为它非常易于阅读和理解。在编写高性能代码时,简单性往往比其他因素更重要。
# 堆排序(Heap sort)
Go语言的标准库中内置了堆排序算法,如下代码片段所示。这段代码帮助我们理解,堆排序是一种时间复杂度为O(nlog n)的排序算法。
这比我们之前的插入排序示例更好,因此对于较大的数据集,使用堆排序算法时,我们的代码性能会更高:
func heapSort(data Interface, a, b int) {
first := a
lo := 0
hi := b - a
// 构建堆,使最大元素位于堆顶
for i := (hi - 1) / 2; i >= 0; i-- {
siftDown(data, i, hi, first)
}
// 弹出元素,最大的元素先弹出,放到数据末尾
for i := hi - 1; i >= 0; i-- {
data.Swap(first, first+i)
siftDown(data, lo, i, first)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段代码可以在标准库中找到,路径为https://golang.org/src/sort/sort.go#L53 。当我们处理的数据集越来越大时,开始使用像堆排序这样高效的排序算法就变得很重要。
# 归并排序(Merge sort)
归并排序是一种平均时间复杂度为O(nlog n)的排序算法。如果算法的目标是实现稳定排序,通常会使用归并排序。稳定排序确保输入数组中具有相同键的两个对象在结果数组中保持相同的顺序。如果我们想确保数组中键值对的顺序正确,那么稳定性就很重要。Go语言标准库中提供了稳定排序的实现,如下代码片段所示:
func stable(data Interface, n int) {
blockSize := 20 // 必须大于0
a, b := 0, blockSize
for b <= n {
insertionSort(data, a, b)
a = b
b += blockSize
}
insertionSort(data, a, n)
for blockSize < n {
a, b = 0, 2*blockSize
for b <= n {
symMerge(data, a, a+blockSize, b)
a = b
b += 2 * blockSize
}
if m := a + blockSize; m < n {
symMerge(data, a, m, n)
}
blockSize *= 2
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这段代码可以在标准库中找到,路径为https://golang.org/src/sort/sort.go#L356 。当需要保持顺序时,稳定排序算法就很重要。
# 快速排序(Quick sort)
正如我们在O(n log n)准线性时间部分中看到的,Go语言标准库中有快速排序算法。快速排序最初在Unix系统中作为标准库的默认排序例程实现。从那以后,它不断发展,并在C语言中作为qsort函数使用。由于它被广泛熟知且历史悠久,如今在许多计算机科学问题中,它通常被用作排序算法。根据我们的算法表可以推断,快速排序算法的标准实现平均时间复杂度为O(nlog n)。它还有一个优点,即最坏情况下空间复杂度为O(log n),这使得它非常适合原地移动操作。
现在我们已经了解了排序算法,接下来将介绍搜索算法。
# 理解搜索算法
搜索算法通常用于从数据集中检索元素或检查元素是否存在。搜索算法一般分为两类:线性搜索(linear search)和区间搜索(interval search)。
# 线性搜索
在线性搜索算法中,遍历切片或数组时,会依次检查其中的每个元素。这个算法并不是最有效的,因为它的时间复杂度为O(n),因为它可能会遍历列表中的每个元素。
线性搜索算法可以简单地通过遍历切片来实现,如下代码片段所示:
func LinearSearch(data []int, searchVal int) bool {
for _, key := range data {
if key == searchVal {
return true
}
}
return false
}
2
3
4
5
6
7
8
这个函数表明,对于较大的数据集,它的开销会迅速增加。对于包含10个元素的数据集,这个算法不会花费很长时间,因为它最多只会遍历10个值。但如果我们的数据集包含100万个元素,这个函数返回结果的时间会长得多。
# 二分查找(Binary search)
一种更常用的模式(也是你最可能想要用于实现高性能搜索算法的模式)是二分查找。二分查找算法的实现可以在Go语言标准库中找到,路径为https://golang.org/src/sort/search.go ,本章前面的排序搜索函数中已经展示过。二分查找的时间复杂度为O(log n),相比之下,我们之前编写的线性搜索函数时间复杂度为O(n)。二分查找使用频率较高,特别是当需要搜索的数据集达到一定规模时。尽早实现二分查找也是明智之举——如果数据集在你不知情的情况下不断增长,至少所使用的算法复杂度不会增加。在下面的代码中,我们使用Go语言搜索函数的便捷包装函数SearchInts来对整数数组进行二分查找:
package main
import (
"fmt"
"sort"
)
func main() {
intArray := []int{0, 2, 3, 5, 11, 16, 34}
searchNumber := 34
sorted := sort.SearchInts(intArray, searchNumber)
if sorted < len(intArray) {
fmt.Printf("Found element %d at array position %d\n", searchNumber, sorted)
} else {
fmt.Printf("Element %d not found in array %v\n", searchNumber, intArray)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这个函数的输出如下:

这表明二分查找库能够在我们搜索的数组(intArray)中找到我们要查找的数字(34)。它在数组的第6个位置找到了整数34(这是正确的,数组是从0开始索引的)。
下一节将介绍另一种数据结构:树(trees)。
# 探索树结构
树是一种非线性数据结构,在计算机科学中用于存储信息。它通常用于存储具有关系的数据,特别是当这些关系形成层次结构时。树的搜索也很简单(在“理解排序算法”部分的数组排序算法图展示了许多树的操作时间复杂度为O(log n))。对于许多问题,树是最佳解决方案,因为它能很好地表示层次结构数据。树是由节点组成的,这些节点不会形成环。
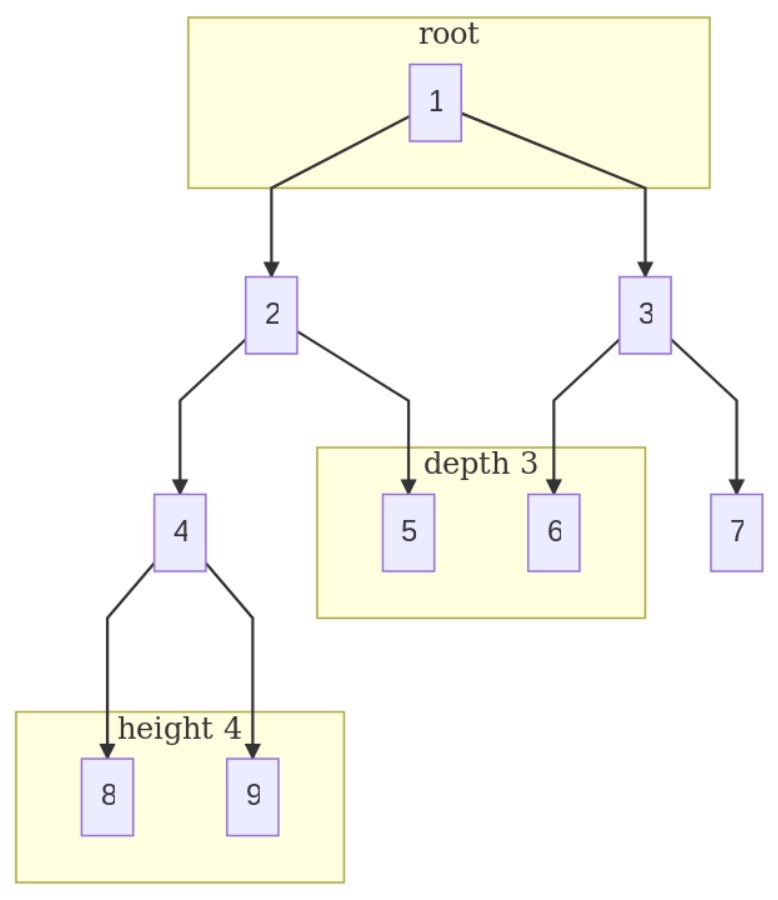
每棵树都由称为节点的元素组成。我们从根节点开始(在下面的二叉树图中,黄色框标记为根节点)。每个节点都有一个左引用指针和一个右引用指针(在我们的例子中是数字2和7),以及一个数据元素(在这个例子中是数字1)。随着树的生长,节点的深度(从根节点到给定节点的边数)会增加。在这个图中,节点4、5、6和7的深度都是3。节点的高度是从该节点到树中最深叶子节点的边数(如下面二叉树图中高度为4的框所示)。整棵树的高度与根节点的高度相等。
# 二叉树(Binary trees)
二叉树是计算机科学中一种重要的数据结构。它们常用于搜索、优先队列和数据库。二叉树效率高,因为它们易于以并发方式遍历。Go语言有强大的并发原语(我们将在第3章“理解并发(Understanding Concurrency)”中讨论),这使得我们可以很容易地实现并发遍历。使用goroutine和通道遍历二叉树可以加快我们遍历层次结构数据的速度。下面的图展示了一棵平衡二叉树:
有几种特殊的二叉树:
- 满二叉树(Full binary tree):除了叶子节点外,每个节点都有2个子节点。
- 完全二叉树(Complete binary tree):一棵树除了底层外完全填满,底层必须从左到右填充。
- 完美二叉树(Perfect binary tree):一种完全二叉树,其中所有节点都有两个子节点,并且树的所有叶子节点都在同一层。
# 双向链表(Doubly linked list)
双向链表也是Go语言标准库的一部分。这是一个相对较大的包,为方便起见,该包的函数签名如下代码片段所示:
func (e *Element) Next() *Element {
func (e *Element) Prev() *Element {
func (l *List) Init() *List {
func New() *List { return new(List).Init() }
func (l *List) Len() int { return l.len }
func (l *List) Front() *Element {
func (l *List) Back() *Element {
func (l *List) lazyInit() {
func (l *List) insert(e, at *Element) *Element {
func (l *List) insertValue(v interface{}, at *Element) *Element {
func (l *List) remove(e *Element) *Element {
func (l *List) move(e, at *Element) *Element {
func (l *List) Remove(e *Element) interface{} {
func (l *List) PushFront(v interface{}) *Element {
func (l *List) PushBack(v interface{}) *Element {
func (l *List) InsertBefore(v interface{}, mark *Element) *Element {
func (l *List) InsertAfter(v interface{}, mark *Element) *Element {
func (l *List) MoveToFront(e *Element) {
func (l *List) MoveToBack(e *Element) {
func (l *List) MoveBefore(e, mark *Element) {
func (l *List) MoveAfter(e, mark *Element) {
func (l *List) PushBackList(other *List) {
func (l *List) PushFrontList(other *List) {
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这些函数签名(及其对应的方法)可以在Go语言标准库中找到,路径为https://golang.org/src/container/list/list.go 。
最后,我们将介绍队列(queues)。
# 探索队列
队列是计算机科学中常用的一种模式,用于实现先进先出(FIFO,First In First Out)的数据缓冲区。最先进入队列的元素也是最先离开的元素。这以有序的方式进行,以便处理已排序的数据。将数据添加到队列称为入队(enqueueing),从队列末尾移除数据称为出队(dequeuing)。队列通常用作一种数据存储和后续处理的机制。
队列的优势在于它们没有固定的容量。可以随时向队列中添加新元素,这使得队列成为异步实现(如键盘缓冲区或打印机队列)的理想解决方案。队列用于需要按接收顺序完成任务的场景,但在实时场景中,由于外部因素,可能无法按顺序执行。
# 常见的队列函数
通常,还会添加一些其他小的队列操作,以使队列更有用:
isfull():通常用于检查队列是否已满。isempty():通常用于检查队列是否为空。peek():检索即将出队的元素,但不出队。
这些函数很有用,因为正常的入队操作如下:
- 检查队列是否已满,如果已满则返回错误。
- 增加队尾指针;返回下一个空位置。
- 将数据元素添加到队尾指针指向的位置。完成这些步骤后,我们就可以将下一个元素入队。
出队操作也同样简单,步骤如下:
- 检查队列是否为空,如果为空则返回错误。
- 访问队列头部的数据。
- 将队头指针增加到下一个可用元素。
完成这些步骤后,我们就从队列中出队了这个元素。
# 常见的队列模式
拥有优化的队列机制对编写高性能的Go代码非常有帮助。能够将非关键任务推送到队列中,可以让你更快地完成关键任务。另一个需要考虑的点是,你使用的队列机制不一定是Go语言内置的队列。在分布式系统中,你可以将数据推送到外部机制,如Kafka(https://kafka.apache.org/ )或RabbitMQ(https://www.rabbitmq.com/ )。管理自己的消息队列在操作上可能成本很高,因此现在使用单独的消息队列系统很常见。我们将在第14章“集群和作业队列(Clusters and Job Queues)”中详细介绍这部分内容,届时我们将探讨集群和作业队列。
# 总结
在本章中,我们学习了如何对Go程序进行基准测试(benchmarking)。了解了大O符号(Big O notation)如何帮助你围绕问题集设计高效的数据结构和算法。我们还学习了搜索和排序算法、树和队列,以便使我们的数据结构和算法对当前问题产生最大的影响。
在第3章“理解并发(Understanding Concurrency)”中,我们将学习一些最重要的Go语言结构,以及它们如何影响性能。闭包(Closures)、通道(channels)和goroutine可以帮助我们在并行和并发方面做出强大的设计决策。