 3 理解并发
3 理解并发
# 3 理解并发
迭代器(Iterators)和生成器(Generators)对Go语言至关重要。在Go语言中,利用通道(Channels)和协程(Goroutines)实现并行和并发是惯用方式,也是用该语言编写高性能、易读代码的最佳途径之一。为了理解如何在Go语言环境中使用迭代器和生成器,我们首先要探讨一些Go语言的基本结构,随后深入研究该语言现有的迭代器和生成器的相关结构。
在本章中,我们将涵盖以下主题:
- 闭包(Closures)
- 协程(Goroutines)
- 通道(Channels)
- 信号量(Semaphores)
- 等待组(WaitGroups)
- 迭代器(Iterators)
- 生成器(Generators)
理解Go语言的基本结构,以及何时何地使用恰当的迭代器和生成器,对于编写高性能的Go代码至关重要。
# 理解闭包
Go语言最重要的特性之一是它支持头等函数(first-class functions)。头等函数是指能够作为变量传递给其他函数,也能从其他函数返回的函数。这一点很关键,因为我们可以将它们用作闭包(Closures)。
闭包非常有用,因为它不仅是让代码遵循“不要重复自己”(DRY, Don't Repeat Yourself)原则的好方法,还有助于隔离数据。到目前为止,保持数据集较小一直是本书的核心原则,本章(以及后续章节)也不例外。能够隔离想要操作的数据,有助于持续编写出高性能的代码。
闭包保留局部作用域,并且可以访问外部函数的作用域、参数以及全局变量 。闭包是引用了其函数体外部变量的函数。这些函数能够为被引用的变量赋值并访问这些值,因此我们可以在函数之间传递闭包。
# 匿名函数
理解Go语言中闭包的第一步是理解匿名函数。匿名函数是通过变量来创建的函数,它们没有名称或标识符,这就是“匿名函数”名称的由来。
在屏幕上打印“Hello Go”的普通函数调用如下代码块所示:
func HelloGo(){
fmt.Println("Hello Go")
}
2
3
接下来,我们可以调用HelloGo(),该函数会打印“Hello Go”字符串。
如果我们想将HelloGo()函数实例化为匿名函数,可以按照以下代码块中的方式调用:
// 注意这个匿名函数调用后面的()
func() {
fmt.Println("Hello Go")
}()
2
3
4
上述匿名函数与HelloGo()函数在词法上类似。
我们还可以将函数存储为变量,以便后续使用,如下代码块所示:
fmt.Println("Hello Go from an Anonymous Function Assigned to a Variable")
}
2
HelloGo()函数、匿名函数以及赋给hello变量的函数,这三者在词法上都类似。
在我们给hello变量赋值后,可以通过简单调用hello()来调用这个函数,此时之前定义的匿名函数将被调用,“Hello Go”会以与之前调用匿名函数时相同的方式打印到屏幕上。
我们可以通过以下代码块来查看它们的工作方式:
package main
import "fmt"
func helloGo() {
fmt.Println("Hello Go from a Function")
}
func main() {
helloGo()
func() { fmt.Println("Hello Go from an Anonymous Function") }()
var hello func() = func() { fmt.Println("Hello Go from an Anonymous Function Variable") }
hello()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这个程序的输出显示了三条打印语句,它们都很相似,只是打印内容略有不同,以展示它们的返回方式,如下截图所示:
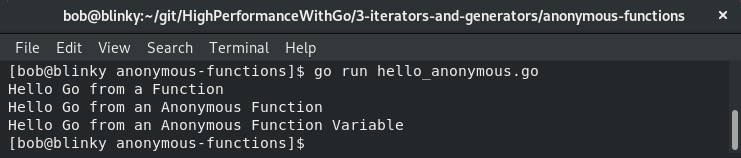
匿名函数是Go语言的强大功能之一。在本章后续内容中,我们将看到如何基于匿名函数构建出非常有用的功能。
# 与闭包相关的匿名函数
此时,你可能想知道为什么匿名函数很实用,以及它们与闭包有什么关系。一旦我们有了匿名函数,就可以利用闭包来引用在其定义之外声明的变量。我们可以从下面的代码块中看到这一点:
package main
import "fmt"
func incrementCounter() func() int {
var initializedNumber = 0
return func() int {
initializedNumber++
return initializedNumber
}
}
func main() {
n1 := incrementCounter()
fmt.Println("n1 increment counter #1: ", n1()) // 第一次调用n1
fmt.Println("n1 increment counter #2: ", n1()) // 注意第二次调用;n1被调用了两次,所以n1 == 2
n2 := incrementCounter() // initializedNumber的新实例
fmt.Println("n2 increment counter #1: ", n2()) // n2只被调用了一次,所以n2 == 1
fmt.Println("n1 increment counter #3: ", n1()) // n2的调用不会改变n1的状态
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
当我们执行这段代码时,会得到以下输出结果:
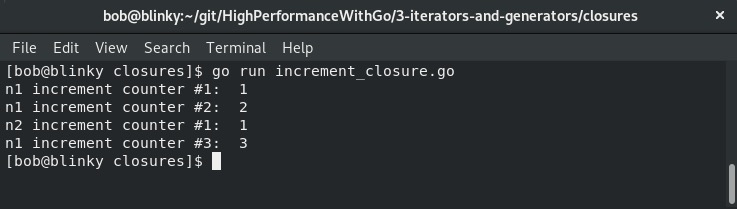
在这个代码示例中,我们可以看到闭包如何有助于数据隔离。n1变量由incrementCounter()函数初始化。这个匿名函数将initializedNumber设为0,并返回initializedNumber变量的递增计数。
当我们创建n2变量时,同样的过程再次发生。会调用一个新的incrementCounter匿名函数,并返回一个新的initializedNumber变量。在main函数中,我们可以注意到n1和n2各自维护着独立的状态。即使在第三次调用n1()函数后,我们也能看到这一点。能够在函数调用之间持久化这些数据,同时将数据与其他调用隔离开来,这正是匿名函数的强大之处。
# 用于嵌套和延迟工作的闭包
闭包通常也是嵌套和延迟工作的好方法。在下面的示例中,我们可以看到一个函数闭包,它允许我们嵌套工作:
package main
import (
"fmt"
"sort"
)
func main() {
input := []string{"foo", "bar", "baz"}
var result []string
// 闭包回调
func() {
result = append(input, "abc") // 向数组追加元素
result = append(result, "def") // 再次向数组追加元素
sort.Sort(sort.StringSlice(result)) // 对更大的数组进行排序
}()
fmt.Print(result)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在这个例子中,我们可以看到先向字符串切片追加了两次元素,然后对结果进行了排序。稍后我们将看到如何在协程中嵌套匿名函数来提升性能。
# 带有闭包的HTTP处理程序
闭包在Go语言的HTTP调用中也常被用作中间件(middleware)。你可以将普通的HTTP函数调用包装在闭包中,以便在需要时为调用添加额外信息,并在不同函数中复用中间件。
在我们的示例中,将设置一个包含四条不同路由的HTTP服务器:
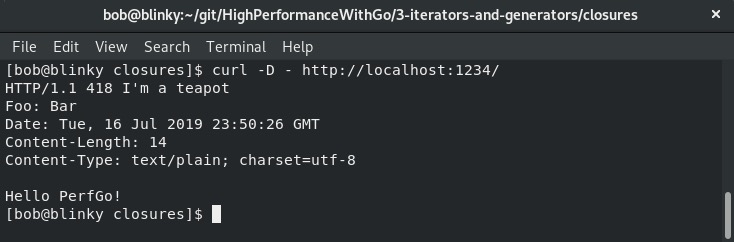
/:提供以下内容:- 一个HTTP 418状态码的HTTP响应(源自
newStatusCode中间件)。 - 一个
Foo:Bar头部(源自addHeader中间件)。 - 一个“Hello PerfGo!”响应(源自
writeResponse中间件)。
- 一个HTTP 418状态码的HTTP响应(源自
/onlyHeader:提供一个仅添加了Foo:Bar头部的HTTP响应。/onlyStatus:提供一个仅更改了状态码的HTTP响应。/admin:检查是否存在user: admin头部。如果存在,它会打印管理员门户信息以及所有相关的常规值。如果不存在,则返回未经授权的响应。
选择这些示例是因为它们易于理解。在Go语言的HTTP处理程序中使用闭包也很方便,因为它们可以:
- 将数据库信息与数据库调用隔离开。
- 执行授权请求。
- 用隔离的数据(例如计时信息)包装其他函数。
- 在可接受的超时时间内透明地与其他第三方服务通信。
位于[https://golang.org/doc/articles/wiki/]的《Go语言编写Web应用程序》文档给出了许多其他典型示例,如设置模板、实时编辑页面、验证用户输入等。接下来让我们看看下面代码块中的示例代码,它展示了HTTP处理程序中的闭包。首先,初始化包并创建一个adminCheck函数,该函数用于判断用户是否有权使用系统:
package main
import (
"fmt"
"net/http"
)
// 检查是否存在"user:admin"头部,这是访问admin路径的正确凭据
func adminCheck(h http.Handler) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.Header.Get("user") != "admin" {
http.Error(w, "Not Authorized", 401)
return
}
fmt.Fprintln(w, "Admin Portal")
h.ServeHTTP(w, r)
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
接下来,设置一些其他示例,例如设置HTTP 418(“我是一个茶壶”状态码)、添加foo:bar HTTP头部以及设置特定的HTTP响应:
// 为响应设置HTTP 418(“我是一个茶壶”)状态码
func newStatusCode(h http.Handler) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(http.StatusTeapot)
h.ServeHTTP(w, r)
})
}
// 添加一个头部,Foo:Bar
func addHeader(h http.Handler) http.HandlerFunc {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Header().Add("Foo", "Bar")
h.ServeHTTP(w, r)
})
}
// 写入HTTP响应
func writeResponse(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello PerfGo!")
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
最后,用一个HTTP处理程序将所有内容包装起来:
// 将中间件包装在一起
func main() {
handler := http.HandlerFunc(writeResponse)
http.Handle("/", addHeader(newStatusCode(handler)))
http.Handle("/onlyHeader", addHeader(handler))
http.Handle("/onlyStatus", newStatusCode(handler))
http.Handle("/admin", adminCheck(handler))
http.ListenAndServe(":1234", nil)
}
2
3
4
5
6
7
8
9
下面是路由测试示例。这是修改了头部和HTTP状态码后的输出:
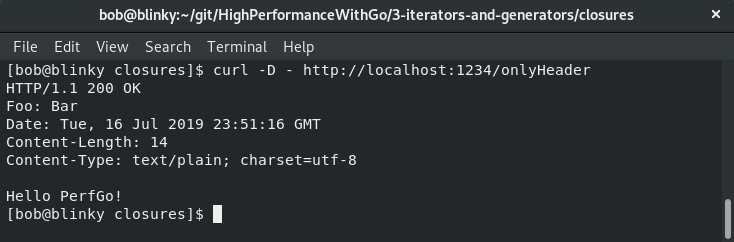
这是仅修改了头部的输出:
这是仅修改了状态码的输出:
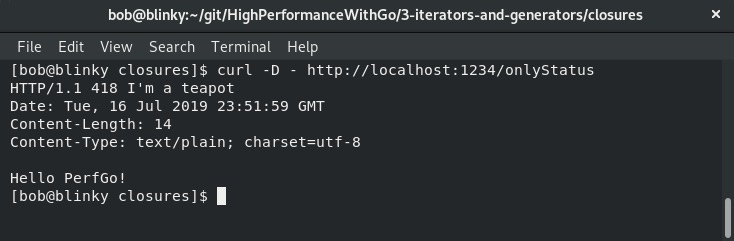
这是管理员未授权的输出:
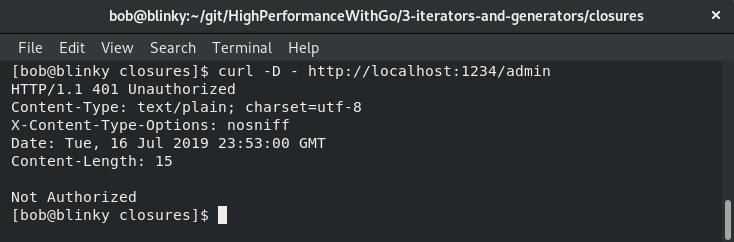
这是管理员授权的输出:
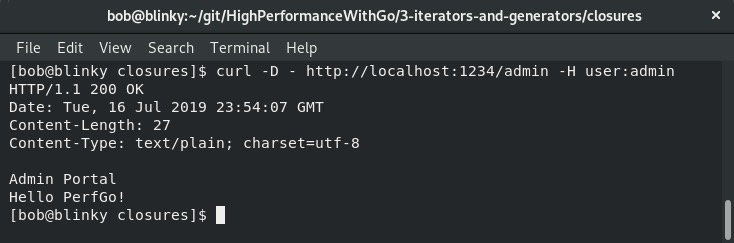
能够使用匿名函数添加中间件,有助于在保持代码复杂度较低的同时快速进行迭代。在下一节中,我们将探索协程。
# 探索Go协程
Go语言在设计时就充分考虑了并发特性。并发是指能够执行独立进程的能力。Go协程(goroutine)是Go语言中用于实现并发的一种结构。
它们常被称为轻量级线程,这是有充分理由的。在其他语言中,线程由操作系统(OS)管理。这意味着线程需要使用较大的调用栈,并且在给定的内存栈大小下,通常能处理的并发量较少。而Go协程是在Go运行时环境中并发运行的函数或方法,它不与底层操作系统直接关联。Go语言的调度器负责管理Go协程的生命周期。系统调度器本身也存在大量开销,因此,限制所使用的线程数量有助于提升性能。
# Go调度器
Go运行时调度器在管理Go协程生命周期时涉及多个不同部分。Go调度器在其第二次迭代中进行了改进,此次改进源于德米特里·维尤科夫(Dmitry Vyukov)撰写的一份设计文档,该文档在Go 1.1版本发布。在这份设计文档中,维尤科夫讨论了最初的Go调度器,以及如何实现一种工作共享和工作窃取(work-stealing)调度器,这一概念最初由罗伯特·D·布卢姆ofe博士(Dr Robert D. Blumofe)和查尔斯·E·莱瑟森博士(Dr. Charles E. Leiserson)在麻省理工学院一篇题为《通过工作窃取调度多线程计算》(Scheduling Multithreaded Computations by Work Stealing)的论文中提出。这篇论文的基本理念是确保动态的多线程计算,以便在满足内存需求的同时有效利用处理器资源。
Go协程在创建时栈大小仅为2KB。这也是在许多并发编程场景中更倾向于使用Go协程的原因之一——因为在一个程序中轻松创建数万甚至数十万个Go协程是可行的。而其他语言中的线程可能会占用数兆字节的空间,这使得它们的灵活性大大降低。如果Go协程需要更多内存,Go语言的函数能够在可用内存空间的其他位置分配更多内存,以满足Go协程栈空间增长的需求。默认情况下,运行时会为新栈分配两倍的内存。
Go协程仅在进行系统调用时才会阻塞正在运行的线程。发生这种情况时,运行时会从调度器结构体中取出另一个线程,这些线程用于等待执行的其他Go协程。
工作共享是指调度器将新线程迁移到其他处理器以实现工作分配的过程。工作窃取也执行类似的操作,只不过是由未充分利用的处理器从其他处理器那里窃取线程。Go语言遵循工作窃取模式,这使得Go调度器的效率大大提高,进而为运行在内核调度器之上的Go协程提供了更高的吞吐量。最后,Go调度器实现了自旋线程(spinning threads)。自旋线程会利用额外的CPU周期,而不是抢占线程。线程以三种不同的方式自旋:
- 当线程未绑定到处理器时。
- 当使一个Go协程准备好运行会将一个操作系统线程释放到空闲处理器上时。
- 当线程正在运行但没有绑定任何Go协程时。这个空闲线程会继续寻找可运行的Go协程来执行。
# Go调度器中Go协程的内部机制
Go调度器有三个关键结构体来处理Go协程的工作负载:M结构体、P结构体和G结构体。这三个结构体协同工作,以高效的方式处理Go协程。让我们更深入地了解一下它们。如果你想查看这些结构体的源代码,可以在https://github.com/golang/go/blob/master/src/runtime/runtime2.go/找到 。
# M结构体
M结构体中的“M”代表机器(machine)。M结构体表示一个操作系统线程。它包含一个指针,指向可运行的Go协程全局队列(由P结构体定义)。M从P结构体中获取工作。M包含准备好执行的空闲和等待的Go协程。M结构体的一些重要参数如下:
- 一个包含调度栈的Go协程(go)
- 线程本地存储(tls)
- 用于执行Go代码的P结构体(p)
# P结构体
这个结构体中的“P”代表处理器(processor)。P结构体表示一个逻辑处理器。它由GOMAXPROCS设置(在Go 1.5版本之后,该值应与可用核心数相等)。P维护着所有Go协程(由G结构体定义)的队列。当你使用Go执行器调用一个新的Go协程时,这个新的Go协程会被插入到P的队列中。如果P没有关联的M结构体,它将分配一个新的M。P结构体的一些重要参数如下:
- P结构体的ID(id)
- 一个指向相关M结构体的反向链接(如果适用,m)
- 一个可用的延迟调用结构体(defer struct)池(deferpool)
- 可运行的Go协程队列(runq)
- 一个包含可用G结构体的结构体(gFree)
# G结构体
这个结构体中的“G”代表Go协程(goroutine)。G结构体表示单个Go协程的栈参数。它包含一些对Go协程很重要的不同参数信息。每个新的Go协程以及运行时的Go协程都会创建G结构体。G结构体的一些重要参数如下:
- 栈指针的当前值(stack.lo和stack.hi)
- Go栈和C栈增长序言(prologue)的当前值(stackguard0和stackguard1)
- 当前的M结构体(m)
# Go协程的实际应用
现在我们对Go协程的基本原理有了初步了解,接下来看看它们在实际中的应用。在下面的代码块中,我们将看到如何使用go关键字调用一个Go协程:
package main
import (
"fmt"
"time"
)
func printSleep(s string) {
for index, stringVal := range s {
fmt.Printf("%#U at index %d\n", stringVal, index)
time.Sleep(1 * time.Millisecond) // printSleep睡眠定时器
}
}
func main() {
const t time.Duration = 9
go printSleep("HELLO GOPHERS")
time.Sleep(t * time.Millisecond) // 主函数睡眠定时器
fmt.Println("sleep complete")
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在这个函数执行过程中,在主函数的睡眠定时器结束之前,我们只会得到被Go协程调用包裹的printSleep()函数的部分返回结果(打印“HELLO GOPHERS”的部分内容)。为什么会这样呢?如果main()函数所在的Go协程完成执行,它就会被关闭,程序也会终止,剩余未执行完的Go协程将不会再运行。我们能够得到前九个字符的输出,是因为这些Go协程在主函数完成执行之前就已经执行完毕。如果我们将const t的持续时间更改为14,我们将收到完整的“HELLO GOPHERS”字符串。这是因为在围绕go printSleep()生成的所有Go协程执行完毕之前,主函数不会完成执行。只有正确使用Go协程,它们才能发挥强大的作用。
Go语言中另一个有助于管理并发Go协程的内置特性是通道(channel),这也是我们下一节要讨论的主题。
# 介绍通道
通道(Channel)是一种允许在Go程序中进行值的发送和接收的机制。通道通常与Go协程(goroutine)一起使用,以便在不同的Go协程之间并发地传递数据。Go语言中有两种主要类型的通道:无缓冲通道(unbuffered channels)和有缓冲通道(buffered channels)。
# 通道的内部机制
通道通过Go语言内置的make()函数创建,在创建过程中会生成一个hchan结构体。hchan结构体包含队列中的数据数量、队列的大小、指向缓冲区数组的指针、发送和接收的索引、发送和接收的等待列表,以及一个互斥锁(mutex lock)。以下代码块展示了其结构:
type hchan struct {
qcount uint // 队列中的数据总数
dataqsiz uint // 循环队列的大小
buf unsafe.Pointer // 指向包含dataqsiz个元素的数组
elemsize uint16
closed uint32
elemtype *_type // 元素类型
sendx uint // 发送索引
recvx uint // 接收索引
recvq waitq // 接收等待者列表
sendq waitq // 发送等待者列表
// lock保护hchan中的所有字段,以及阻塞在这个通道上的sudogs中的几个字段。
//
// 持有这个锁时,不要更改另一个G的状态(特别是不要使一个G准备好运行),因为这可能会与栈收缩导致死锁。
lock mutex
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段代码引用自https://golang.org/src/runtime/chan.go#L32 。
# 有缓冲通道
有缓冲通道是具有固定大小的通道。通常情况下,它们比无缓冲通道的性能更高。有缓冲通道在从你启动的特定数量的Go协程中获取值时非常有用。由于它们采用先进先出(FIFO,first in first out)的排队机制,因此可以有效地用作固定大小的队列机制,这样我们就可以按照请求进入的顺序处理它们。在使用通道之前,需要通过调用make()函数来创建通道。一旦创建了有缓冲通道,它就可以立即投入使用。只要通道中还有空间,有缓冲通道在写入数据时就不会阻塞。需要记住的是,数据在通道中按照箭头所指的方向流动。在下面的代码示例中,我们执行了以下操作:
- 向
buffered_channel通道写入foo和bar。 - 检查通道的长度,此时长度为2,因为我们添加了两个字符串。
- 从通道中取出
foo和bar。 - 再次检查通道的长度,此时长度为0,因为我们已经移除了这两个字符串。
- 向通道中添加
baz。 - 从通道中取出
baz并存储到变量out中。 - 打印结果变量
out,其值为baz(这是我们最后添加到通道中的元素)。 - 关闭
buffered_channel通道,表示不再有数据通过该通道传输。
让我们来看下面的代码块:
package main
import "fmt"
func main() {
buffered_channel := make(chan string, 2)
buffered_channel <- "foo"
buffered_channel <- "bar"
// 因为两个元素都添加到了通道中,所以通道长度为2
fmt.Println("Channel Length After Add: ", len(buffered_channel))
// 从栈中取出foo和bar
fmt.Println(<-buffered_channel)
fmt.Println(<-buffered_channel)
// 因为两个元素都从通道中移除了,所以通道长度为0
fmt.Println("Channel Length After Pop: ", len(buffered_channel))
// 将baz推送到栈中
buffered_channel <- "baz"
// 将baz存储为变量out
out := <-buffered_channel
fmt.Println(out)
close(buffered_channel)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这段代码可以在https://github.com/bobstrecansky/HighPerformanceWithGo/blob/master/3 - iterators - and - generators/channels/buffered_channel.go找到。
从我们的代码示例中可以看到,我们能够向通道中推送数据并从中取出数据。还需要注意的是,内置的len()函数返回的是通道缓冲区中未读取(或排队)的元素数量。除了len()函数,我们还可以使用内置的cap()函数来获取缓冲区的总容量。这两个函数结合使用,通常可以帮助我们了解通道的当前状态,特别是当通道的行为不符合预期时。养成关闭通道的习惯也很重要。当你关闭一个通道时,这是在告知Go调度器不会再有值通过该通道发送。同样需要注意的是,如果你尝试向一个已关闭的通道或已满的通道写入数据,程序将会发生恐慌(panic)。
以下程序会发生恐慌:
package main
func main() {
ch := make(chan string, 1)
close(ch)
ch <- "foo"
}
2
3
4
5
6
7
我们会得到如下截图所示的错误信息:
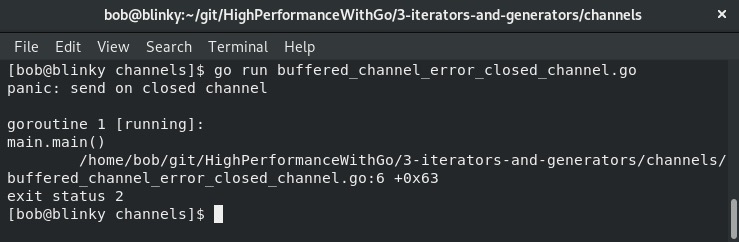
这是因为我们试图将数据(字符串foo)发送到一个已经关闭的通道(ch)中。
以下程序也会发生恐慌:
package main
func main() {
ch := make(chan string, 1)
ch <- "foo"
ch <- "bar"
}
2
3
4
5
6
7
我们会看到如下错误信息:
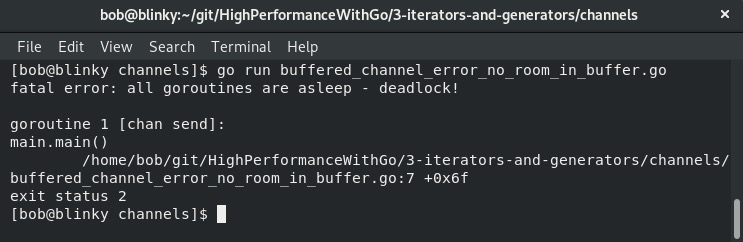
程序发生恐慌是因为Go协程会阻塞并等待。运行时会检测到这个错误并终止程序。
# 遍历通道
你可能想要知道有缓冲通道中存在的所有值。我们可以通过在想要检查的通道上使用内置的range来实现这一点。在下面的代码示例中,我们向通道中添加三个元素,关闭通道,然后使用fmt输出通道中的所有元素:
package main
import "fmt"
func main() {
bufferedChannel := make(chan int, 3)
bufferedChannel <- 1
bufferedChannel <- 3
bufferedChannel <- 5
close(bufferedChannel)
for i := range bufferedChannel {
fmt.Println(i)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
运行结果展示了有缓冲通道中的所有值:
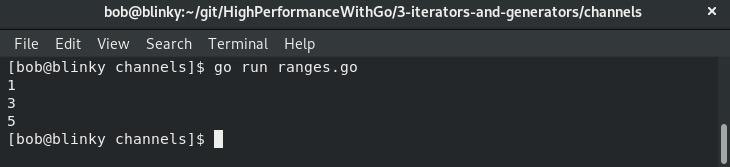
需要提醒的是,确保关闭通道。如果我们删除前面的close(bufferedChannel)函数,程序将会发生死锁。
# 无缓冲通道
无缓冲通道是Go语言中通道的默认配置。无缓冲通道很灵活,因为它们不需要定义有限的通道大小。当从通道接收数据的一方比发送数据的一方处理速度慢时,无缓冲通道通常是最佳选择。由于它们是同步的,所以在读写操作时都会阻塞。发送方会阻塞通道,直到接收方接收到数据。无缓冲通道常与goroutine一起使用,以确保数据按预期顺序处理。
在下面的示例代码块中,我们执行以下操作:
- 创建一个布尔型通道来维护状态。
- 创建一个未排序的切片。
- 使用
sortInts()函数对切片进行排序。 - 向通道发送
true,以便进入函数的下一部分。 - 在切片中搜索给定的整数。
- 向通道发送
true,表示通道上的事务已完成。 - 返回通道值,完成Go函数的执行。
首先,我们导入所需的包,并创建一个在通道上对整数切片进行排序的函数:
package main
import (
"fmt"
"sort"
)
func sortInts(intArray[] int, done chan bool) {
sort.Ints(intArray)
fmt.Printf("Sorted Array: %v\n", intArray)
done <- true
}
2
3
4
5
6
7
8
9
10
11
12
接下来,我们创建一个searchInts函数,用于在通道上搜索整数:
func searchInts(intArray []int, searchNumber int, done chan bool) {
sorted := sort.SearchInts(intArray, searchNumber)
if sorted < len(intArray) {
fmt.Printf("Found element %d at array position %d\n", searchNumber, sorted)
} else {
fmt.Printf("Element %d not found in array %v\n", searchNumber, intArray)
}
done <- true
}
2
3
4
5
6
7
8
9
最后,我们在主函数中将它们整合在一起:
func main() {
ch := make(chan bool)
go func() {
s := []int{2, 11, 3, 34, 5, 0, 16} // 未排序
fmt.Println("Unsorted Array: ", s)
searchNumber := 16
sortInts(s, ch)
searchInts(s, searchNumber, ch)
}()
<-ch
}
2
3
4
5
6
7
8
9
10
11
我们可以从下面的截图中看到这个程序的输出:
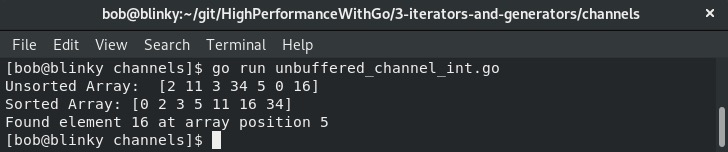
这是使用通道并发执行操作的一种很好的方式。
# select语句
select语句是一种结构,它能让你以一种有意义的方式组合goroutine和通道。我们可以复用Go函数,以便在goroutine运行时执行相应的分支。在我们的示例中,我们创建了三个不同的通道:一个字符串通道、一个布尔通道和一个符文(rune)通道。接下来,在下面的代码块中,我们通过运行一些匿名函数,向这些通道填充数据,并使用内置的select语句从通道中返回值。
- 首先,初始化包并设置三个独立的通道:
package main
import (
"fmt"
"time"
)
func main() {
// 创建3个通道
ch1 := make(chan string)
ch2 := make(chan bool)
ch3 := make(chan rune)
2
3
4
5
6
7
8
9
10
11
12
- 接着,通过匿名函数向每个通道传递合适的变量:
// 向ch1传递数据的字符串匿名函数
go func() {
ch1 <- "channels are fun"
}()
// 向ch2传递数据的布尔匿名函数
go func() {
ch2 <- true
}()
// 向ch3传递数据的符文匿名函数,带有1秒的延迟
go func() {
time.Sleep(1 * time.Second)
ch3 <- 'r'
}()
2
3
4
5
6
7
8
9
10
11
12
13
- 最后,使用
select语句处理这些通道:
// 使用select内置函数从通道返回值
for i := 0; i < 3; i++ {
select {
case msg1 := <-ch1:
fmt.Println("Channel 1 message: ", msg1)
case msg2 := <-ch2:
fmt.Println("Channel 2 message: ", msg2)
case msg3 := <-ch3:
fmt.Println("Channel 3 message: ", msg3)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
这个程序的输出结果可以从下面的截图中看到:
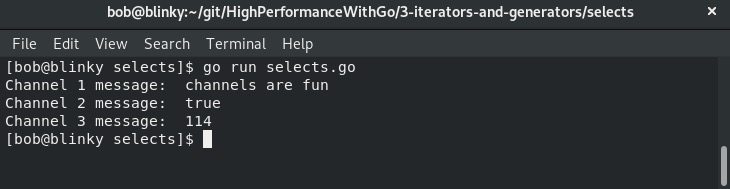
你会注意到,这里符文匿名函数的返回值最后出现。这是因为在该匿名函数中插入了延迟。如果多个通道都有数据准备好,select语句会随机返回其中一个通道的值;当goroutine的结果按顺序准备好时,它会按顺序返回。
在下一节中,我们将学习什么是信号量(Semaphores)。
# 信号量介绍
信号量是另一种控制goroutine如何执行并行任务的方法。信号量很方便,因为它让我们能够使用工作池模式,而且在工作完成且工作线程空闲后,我们无需关闭工作线程。Go语言中带权重信号量的概念相对较新,sync包中信号量的实现是在2017年初完成的,所以它是最新的并行任务结构之一。
如果我们看下面代码块中的一个简单循环示例,给每个请求添加100毫秒的延迟,并向数组中添加一个元素,我们很快会发现,由于这些任务是串行执行的,所需的时间会增加:
package main
import (
"fmt"
"time"
)
func main() {
var out = make([]string, 5)
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
out[i] = "This loop is slow\n"
}
fmt.Println(out)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们可以使用相同的结构创建一个带权重信号量的实现。在下面的代码块中可以看到:
- 首先,初始化程序并设置信号量变量:
package main
import (
"context"
"fmt"
"runtime"
"time"
"golang.org/x/sync/semaphore"
)
func main() {
ctx := context.Background()
var (
sem = semaphore.NewWeighted(int64(runtime.GOMAXPROCS(0)))
result = make([]string, 5)
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 然后,编写信号量相关代码:
for i := range result {
if err := sem.Acquire(ctx, 1); err != nil {
break
}
go func(i int) {
defer sem.Release(1)
time.Sleep(100 * time.Millisecond)
result[i] = "Semaphores are Cool \n"
}(i)
}
if err := sem.Acquire(ctx, int64(runtime.GOMAXPROCS(0))); err != nil {
fmt.Println("Error acquiring semaphore")
}
fmt.Println(result)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这两个函数的执行时间差异非常明显,可以从下面的输出中看出:
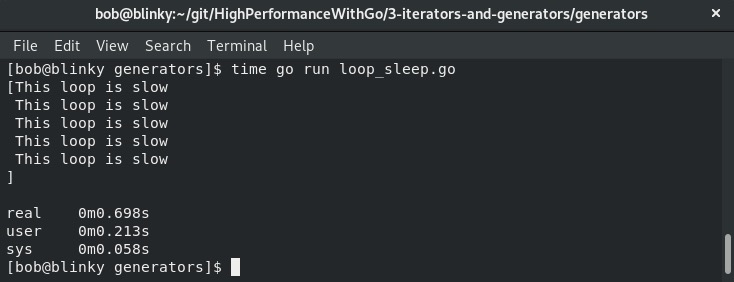
信号量实现的运行速度比串行执行快两倍多,如下图所示:
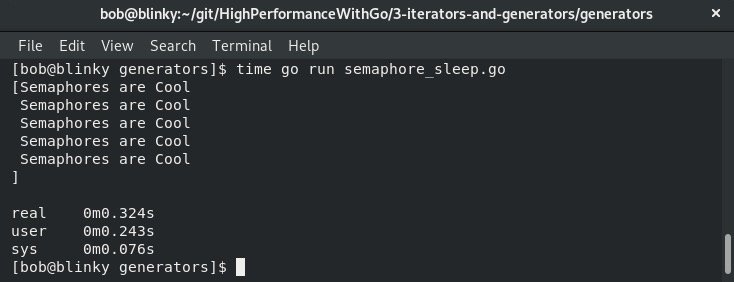
信号量的实现速度快了两倍多。这还是在仅设置了 5 次 100 毫秒阻塞休眠的情况下。随着规模的不断扩大,能够并行处理事务变得越来越重要。
在下一节中,我们将讨论等待组(WaitGroups)。
# 理解等待组
等待组(WaitGroups)通常用于确认多个goroutine都已完成任务。我们这样做是为了确保所有期望完成的并发工作都已完成。
在下面代码块的示例中,我们使用等待组向四个网站发出请求。这个等待组会一直等待,直到所有请求都完成,并且只有在所有等待组的值都返回后,才会结束主函数:
- 首先,初始化包并设置数据获取函数:
package main
import (
"fmt"
"net/http"
"sync"
"time"
)
func retrieve(url string, wg *sync.WaitGroup) {
// 当goroutine完成时,等待组计数器减1
defer wg.Done()
start := time.Now()
res, err := http.Get(url)
end := time.Since(start)
if err != nil {
panic(err)
}
// 打印响应的状态码
fmt.Println(url, res.StatusCode, end)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 在主函数中,我们在goroutine中使用等待组调用数据获取函数:
func main() {
var wg sync.WaitGroup
var urls = []string{"https://godoc.org", "https://www.packtpub.com", "https://kubernetes.io/"}
for i := range urls {
// 当调用新的goroutine时,等待组计数器加1
wg.Add(1)
go retrieve(urls[i], &wg)
}
// 等待所有goroutine完成
wg.Wait()
}
2
3
4
5
6
7
8
9
10
11
从下面的输出中可以看到,我们获取了所有网络请求的测量数据、响应代码和各自的时间:
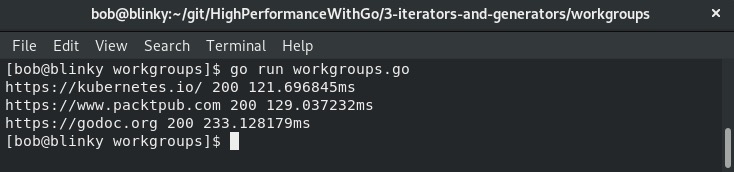
通常情况下,我们希望所有的goroutine都能完成任务。等待组可以帮助我们实现这一点。在下一节中,我们将讨论迭代过程。
# 迭代器与迭代过程
迭代是一种遍历一组数据(通常是列表),以便从该列表中检索信息的方法。Go语言有多种不同的迭代器模式,各有优缺点:
| 迭代器 | 优点 | 缺点 |
|---|---|---|
| for循环 | 实现最简单 | 没有默认的并发能力。 |
| 带回调的迭代器函数 | 实现简单 | 不符合Go语言的常规风格,可读性较差。 |
| 通道(Channels) | 实现简单 | 与其他一些迭代器相比,计算成本更高(但成本差异较小)。是唯一一种天生支持并发的迭代器。 |
| 有状态的迭代器 | 实现难度较大 | 调用接口友好。适用于复杂的迭代器(在标准库中常用)。 |
为了验证对每种迭代器所需时间的假设,对它们进行相互基准测试非常重要。在以下测试中,我们计算从0到n的总和,并对不同迭代器进行基准测试。
下面的代码块展示了一个简单的for循环迭代器:
package iterators
var sumLoops int
func simpleLoop(n int) int {
for i := 0; i < n; i++ {
sumLoops += i
}
return sumLoops
}
2
3
4
5
6
7
8
9
10
下面的代码块展示了一个回调迭代器:
package iterators
var sumCallback int
func CallbackLoop(top int) {
err := callbackLoopIterator(top, func(n int) error {
sumCallback += n
return nil
})
if err != nil {
panic(err)
}
}
func callbackLoopIterator(top int, callback func(n int) error) error {
for i := 0; i < top; i++ {
err := callback(i)
if err != nil {
return err
}
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
下面的代码块将逐步展示Next()函数的使用。首先,我们初始化包变量和结构体,然后创建一个CounterIterator:
package iterators
var sumNext int
type CounterStruct struct {
err error
max int
cur int
}
func NewCounterIterator(top int) *CounterStruct {
var err error
return &CounterStruct{
err: err,
max: top,
cur: 0,
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
接着是Next()函数、Value()函数和NextLoop()函数:
func (i *CounterStruct) Next() bool {
if i.err != nil {
return false
}
i.cur++
return i.cur <= i.max
}
func (i *CounterStruct) Value() int {
if i.err != nil || i.cur > i.max {
panic("Value is not valid after iterator finished")
}
return i.cur
}
func NextLoop(top int) {
nextIterator := NewCounterIterator(top)
for nextIterator.Next() {
fmt.Print(nextIterator.Value())
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
下一个代码块展示了带缓冲通道的实现:
package iterators
var sumBufferedChan int
func BufferedChanLoop(n int) int {
ch := make(chan int, n)
go func() {
defer close(ch)
for i := 0; i < n; i++ {
ch <- i
}
}()
for j := range ch {
sumBufferedChan += j
}
return sumBufferedChan
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
下一个代码块展示了无缓冲通道的实现:
package iterators
var sumUnbufferedChan int
func UnbufferedChanLoop(n int) int {
ch := make(chan int)
go func() {
defer close(ch)
for i := 0; i < n; i++ {
ch <- i
}
}()
for j := range ch {
sumUnbufferedChan += j
}
return sumUnbufferedChan
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
将这些代码编译到一起后,我们可以进行测试基准。下面的代码块展示了测试基准,我们再逐步来看。
首先,初始化包并设置简单循环和回调循环的基准测试:
package iterators
import "testing"
func benchmarkLoop(i int, b *testing.B) {
for n := 0; n < b.N; n++ {
simpleLoop(i)
}
}
func benchmarkCallback(i int, b *testing.B) {
b.ResetTimer()
for n := 0; n < b.N; n++ {
CallbackLoop(i)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
接着是Next()和带缓冲通道的基准测试:
func benchmarkNext(i int, b *testing.B) {
b.ResetTimer()
for n := 0; n < b.N; n++ {
NextLoop(i)
}
}
func benchmarkBufferedChan(i int, b *testing.B) {
b.ResetTimer()
for n := 0; n < b.N; n++ {
BufferedChanLoop(i)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
最后,设置无缓冲通道的基准测试,并为每个基准测试创建循环函数:
func benchmarkUnbufferedChan(i int, b *testing.B) {
b.ResetTimer()
for n := 0; n < b.N; n++ {
UnbufferedChanLoop(i)
}
}
func BenchmarkLoop10000000(b *testing.B) {
benchmarkLoop(1000000, b)
}
func BenchmarkCallback10000000(b *testing.B) {
benchmarkCallback(1000000, b)
}
func BenchmarkNext10000000(b *testing.B) {
benchmarkNext(1000000, b)
}
func BenchmarkBufferedChan10000000(b *testing.B) {
benchmarkBufferedChan(1000000, b)
}
func BenchmarkUnbufferedChan10000000(b *testing.B) {
benchmarkUnbufferedChan(1000000, b)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
基准测试的结果如下截图所示:
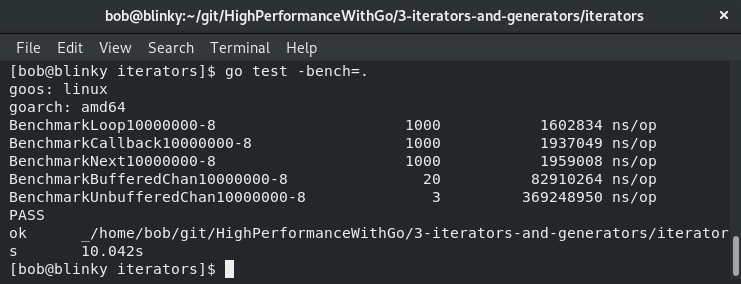
这些迭代器测试的上下文非常重要。因为在这些测试中我们只是进行简单的加法运算,所以简单的迭代结构是关键。如果在每次调用中加入延迟,那么并发通道迭代器的性能会好得多。并发是一种强大的功能,尤其在合适的场景下。
在下一节中,我们将讨论生成器。
# 生成器简介
生成器是一种在循环结构中返回下一个顺序值的例程。生成器通常用于实现迭代器并引入并行性。在Go语言中,通过使用协程(Goroutines)来实现生成器。为了在Go语言中实现并行性,我们可以使用与消费者并行运行的生成器来生成值。它们通常在循环结构中使用。生成器本身也可以并行化,通常在生成输出成本较高且输出顺序无关紧要的情况下会这样做。
# 总结
在本章中,我们学习了Go语言中用于迭代器和生成器的许多基本结构。理解匿名函数和闭包有助于我们建立这些函数工作原理的基础知识。然后,我们学习了协程和通道的工作方式,以及如何有效地实现它们。我们还学习了信号量(semaphores)和等待组(WaitGroups),以及它们在Go语言中的作用。理解这些技能将帮助我们更有效地解析计算机程序中的信息,实现更高效的并发数据处理。在第4章“Go语言中的标准模板库(STL)等效实现”中,我们将学习Go语言中标准模板库(STL)的实际应用。