 4 Go语言中的等效标准模板库算法
4 Go语言中的等效标准模板库算法
# 4 Go语言中的等效标准模板库算法
许多从其他高性能编程语言(尤其是C++)转过来的程序员都理解标准模板库(Standard Templating Library,STL)的概念。这个库提供了常见的编程数据结构和函数,可访问一个通用库,以便快速迭代并大规模编写高性能代码。Go语言没有内置的标准模板库。本章将重点介绍如何在Go语言中运用一些最常见的标准模板库实践。标准模板库有四个常用的组件:
- 算法(Algorithms)
- 容器(Containers)
- 仿函数(Functors)
- 迭代器(Iterators)
熟悉这些主题将帮助你利用常用的已实现且经过优化的模式,更快速、高效地编写Go代码。在本章中,我们将学习以下内容:
- 如何在Go语言中使用标准模板库的实践方法
- 如何在Go语言中运用标准编程算法
- 容器如何存储数据
- 函数在Go语言中如何工作
- 如何正确使用迭代器
请记住,所有这些内容仍然是我们性能拼图的一部分。知道何时使用正确的算法、容器或仿函数,将帮助你编写性能更优的代码。
# 理解标准模板库中的算法
标准模板库中的算法用于执行排序、搜索、数据操作和计数等功能。在C++中,这些算法由<algorithm>头文件调用,并应用于元素范围。被修改的对象组不会影响它们所关联的容器的结构。本章本节将解释以下类型的算法,这里每个小标题中概述的模式都使用Go语言结构来实现这些算法:
- 排序(Sort)
- 反转(Reverse)
- 最小和最大元素
- 二分查找(Binary search)
理解所有这些算法的工作原理,将有助于你在需要使用这些技术通过算法来操作数据结构时,编写出高性能的代码。
# 排序
排序算法将数组按升序排列。排序不需要创建、销毁或复制新的容器,排序算法会对容器内的所有元素进行排序。我们可以使用Go语言的标准库sort来实现这一功能。Go语言的标准库sort针对不同的数据类型提供了辅助函数(IntsAreSorted、Float64sAreSorted和StringsAreSorted),用于对各自的数据类型进行排序。我们可以按照以下代码示例来实现排序算法:
package main
import (
"fmt"
"sort"
)
func main() {
intData := []int{3, 1, 2, 5, 6, 4}
stringData := []string{"foo", "bar", "baz"}
floatData := []float64{1.5, 3.6, 2.5, 10.6}
2
3
4
5
6
7
8
9
10
11
这段代码实例化了包含值的简单数据结构。之后,我们使用内置的排序函数对每个数据结构进行排序,如下所示:
sort.Ints(intData)
sort.Strings(stringData)
sort.Float64s(floatData)
fmt.Println("Sorted Integers: ", intData, "\nSorted Strings: ", stringData, "\nSorted Floats: ", floatData)
}
2
3
4
5
执行这段代码时,我们可以看到所有切片都已按顺序排好序,如下截图所示:
整数按从小到大排序,字符串按字母顺序排序,浮点数也按从小到大排序。这些是sort包中的默认排序方法。
# 反转
反转算法用于将数据集的值进行反转。Go语言的标准sort包没有内置的反转切片的方法。我们可以编写一个简单的反转函数来反转数据集的顺序,如下所示:
package main
import (
"fmt"
)
func reverse(s []string) []string {
for x, y := 0, len(s)-1; x < y; x, y = x+1, y-1 {
s[x], s[y] = s[y], s[x]
}
return s
}
func main() {
s := []string{"foo", "bar", "baz", "go", "stop"}
reversedS := reverse(s)
fmt.Println(reversedS)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这个函数遍历切片,递增x并递减y,直到它们相遇,然后交换切片中的元素,如下截图所示:
正如我们所见,使用reverse()函数成功反转了我们的切片。使用标准库能让原本手工编写起来困难的函数变得简单、简洁且可复用。
# 最小元素和最大元素
我们可以分别使用min_element和max_element算法来查找数据集中的最小和最大值。在Go语言中,我们可以使用简单的迭代器来实现min_element和max_element:
- 首先,编写一个函数来查找切片中的最小整数:
package main
import "fmt"
func findMinInt(a []int) int {
var minInt int = a[0]
for _, i := range a {
if minInt > i {
minInt = i
}
}
return minInt
}
2
3
4
5
6
7
8
9
10
11
12
13
- 接下来,按照相同的过程,尝试查找切片中的最大整数:
func findMaxInt(b []int) int {
var max int = b[0]
for _, i := range b {
if max < i {
max = i
}
}
return max
}
2
3
4
5
6
7
8
9
- 最后,使用这些函数来打印得到的最小值和最大值:
func main() {
intData := []int{3, 1, 2, 5, 6, 4}
minResult := findMinInt(intData)
maxResult := findMaxInt(intData)
fmt.Println("Minimum value in array: ", minResult)
fmt.Println("Maximum value in array: ", maxResult)
}
2
3
4
5
6
7
这些函数遍历整数切片,并找到切片中的最小值和最大值,如下截图所示:
从我们的执行结果可以看出,成功找到了最小值和最大值。
Go语言的math包中还定义了math.Min和math.Max。它们仅用于比较float64数据类型。浮点数比较并非易事,因此Go语言的设计者决定在math库中设置默认的Min和Max签名,在这个库中应该使用浮点数。如果Go语言有泛型,我们上面编写的主函数可能就可以适用于不同的类型。这是Go语言设计的一部分,即保持简单和统一。
# 二分查找
二分查找是一种用于在已排序数组中查找特定元素位置的算法。它首先定位数组的中间元素,如果没有匹配项,该算法会选取可能包含目标元素的那一半数组,并使用中间值来查找目标。正如我们在第2章“数据结构和算法”中所学,二分查找是一种高效的算法,时间复杂度为O(log n)。Go语言的标准库sort包有一个内置的二分查找函数。我们可以这样使用它:
package main
import (
"fmt"
"sort"
)
func main() {
data := []int{1, 2, 3, 4, 5, 6}
findInt := 2
out := sort.Search(len(data), func(i int) bool { return data[i] >= findInt })
fmt.Printf("Integer %d was found in %d at position %d\n", findInt, data, out)
}
2
3
4
5
6
7
8
9
10
11
12
13
二分查找算法正确找到了我们要搜索的整数2,并且它在预期的位置(零索引切片中的位置1)。我们可以在下面的截图中看到二分查找的执行结果:
总之,标准模板库中的算法都能很好地在Go语言中实现。Go语言的默认函数和迭代器使得编写简单、可复用的算法变得容易。在下一节中,我们将学习容器。
# 理解容器
在标准模板库(STL)中,容器分为三类:
- 序列容器
- 序列容器适配器
- 关联容器
我们将在以下部分介绍这三种类型的容器。
# 序列容器
序列容器存储特定类型的数据元素。目前序列容器有五种实现:数组(array)、切片(vector,Go语言中实际为slice)、双端队列(deque)、链表(list)和单向链表(forward_list)。这些序列容器便于按顺序引用数据。能够使用这些序列容器是编写高效代码和复用标准库中模块化代码的便捷方式。我们将在以下小节中详细探讨。
# 数组
Go语言中的数组与C++中的数组类似。Go语言的数组结构在编译时静态定义,大小不可改变。在Go语言中,数组的实现方式如下:
arrayExample := [5]string{"foo", "bar", "baz", "go", "rules"}
这个数组存储了arrayExample变量中定义的字符串值,arrayExample被定义为一个数组。
# 切片(Vector)
Go语言最初有向量(vector)的实现,但在语言开发早期(2011年10月11日)就被移除了。人们认为切片更好(这也是相关拉取请求的标题),于是切片成为了Go语言中事实上的向量实现。我们可以这样实现一个切片:
sliceExample := []string{"slices", "are", "cool", "in", "go"}
切片的优势在于,和标准模板库中的向量一样,它可以根据添加或删除操作进行增长或收缩。在下面的代码示例中,我们创建一个切片,向切片中追加一个值,并从切片中删除一个值:
package main
import "fmt"
// Remove i indexed item in slice
func remove(s []string, i int) []string {
copy(s[i:], s[i+1:])
return s[:len(s)-1]
}
func main() {
slice := []string{"foo", "bar", "baz"} // 创建一个切片
slice = append(slice, "tri") // 向切片追加一个值
fmt.Println("Appended Slice: ", slice) // 打印切片 [foo, bar baz, tri]
slice = remove(slice, 2) // 删除切片中索引为2的元素(即baz)
fmt.Println("After Removed Item: ", slice) // 打印切片 [foo, bar, tri]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
当我们执行这个切片示例时,可以看到追加和删除操作的实际效果,如下截图所示:
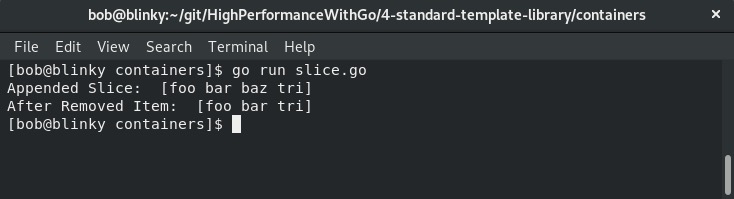
我们可以看到tri元素被追加到了切片的末尾,并且根据remove()函数的调用,baz元素(切片中的第3个元素)被删除了。
# 双端队列(Deque)
双端队列(deque,即double - ended queue的缩写)是一种可以扩展的容器。这种扩展可以发生在容器的前端或后端。当需要频繁引用队列的头部或尾部时,通常会使用双端队列。下面的代码块是双端队列的一个简单实现:
package main
import (
"fmt"
"gopkg.in/karalabe/cookiejar.v1/collections/deque"
)
func main() {
d := deque.New()
elements := []string{"foo", "bar", "baz"}
for i := range elements {
d.PushLeft(elements[i])
}
fmt.Println(d.PopLeft()) // 队列变为 => ["foo", "bar"]
fmt.Println(d.PopRight()) // 队列变为 => ["bar"]
fmt.Println(d.PopLeft()) // 队列变为 => 空
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
双端队列包(deque package)将一个元素切片通过PushLeft函数压入队列。接下来,我们可以从双端队列的左端和右端弹出元素,直到队列为空。我们可以在下面的截图中看到双端队列逻辑的执行情况:
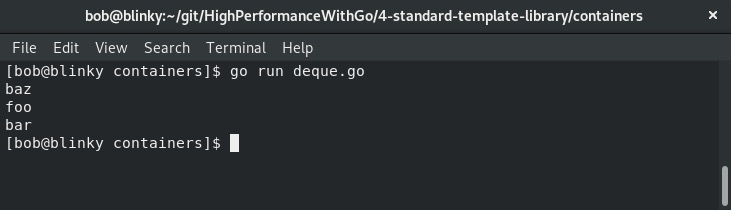
我们的结果展示了对双端队列操作的输出,以及如何从队列的两端取出元素。能够从队列的两端取出元素在数据操作中很有优势,这就是为什么双端队列是一种受欢迎的数据结构选择。
# 链表(List)
链表(list)是Go语言对双向链表的实现,它内置于标准库的container/list包中。使用通用双向链表的实现,我们可以执行许多操作,如下代码所示:
package main
import (
"container/list"
"fmt"
)
func main() {
ll := list.New()
three := ll.PushBack(3) // 栈表示 -> [3]
four := ll.InsertBefore(4, three) // 栈表示 -> [4 3]
ll.InsertBefore(2, three) // 栈表示 ->
// [4 2 3]
ll.MoveToBack(four) // 栈表示 ->
// [2 3 4]
ll.PushFront(1) // 栈表示 ->
// [1 2 3 4]
listLength := ll.Len()
fmt.Printf("ll type: %T\n", ll)
fmt.Println("ll length: :", listLength)
for e := ll.Front(); e != nil; e = e.Next() {
fmt.Println(e.Value)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
双向链表与双端队列容器类似,但如果需要,它允许在栈中间进行插入和删除操作。在实际应用中,双向链表的使用更为频繁。我们可以在下面的截图中看到双向链表代码的执行情况:
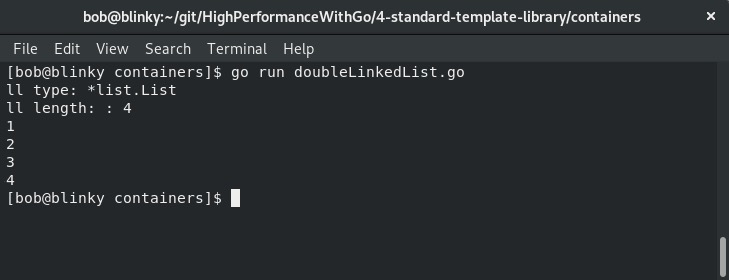
从程序的输出中可以看到,所有元素都按照在栈中排列的顺序显示。链表是编程的基础,因为它是当今许多计算机科学所基于的基本算法。
# 单向链表(Forward list)
单向链表(forward list)是单链表的一种实现。单链表通常比双向链表的内存占用更小;然而,遍历单链表的效率不高,尤其是反向遍历。下面让我们看看如何实现一个单向链表:
- 首先,初始化程序并定义结构:
package main
import "fmt"
type SinglyLinkedList struct {
head *LinkedListNode
}
type LinkedListNode struct {
data string
next *LinkedListNode
}
2
3
4
5
6
7
8
9
10
11
12
- 然后创建
Append函数,并在main函数中使用:
func (ll *SinglyLinkedList) Append(node *LinkedListNode) {
if ll.head == nil {
ll.head = node
return
}
currentNode := ll.head
for currentNode.next != nil {
currentNode = currentNode.next
}
currentNode.next = node
}
func main() {
ll := &SinglyLinkedList{}
ll.Append(&LinkedListNode{data: "hello"})
ll.Append(&LinkedListNode{data: "high"})
ll.Append(&LinkedListNode{data: "performance"})
ll.Append(&LinkedListNode{data: "go"})
for e := ll.head; e != nil; e = e.next {
fmt.Println(e.data)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
从下面截图的输出结果可以看出,我们追加到单链表中的所有数据都可以访问到:
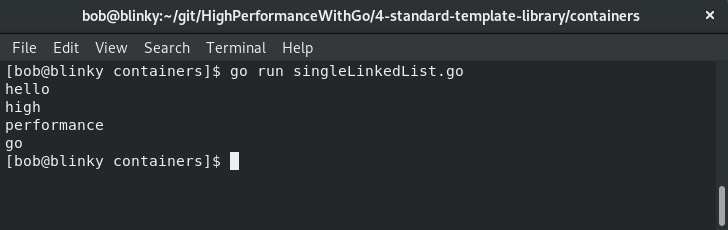
这个数据结构的初始元素按照在代码块中添加的顺序放入列表。这是预期的,因为单链表通常用于保持数据结构中数据的顺序。
# 容器适配器
容器适配器对顺序容器进行适配,改变其使用方式,使原始顺序容器能够以预期的方式运行。在研究这些容器适配器时,我们将了解它们的创建方式以及在实际中的使用方法。
# 队列(Queue)
队列是遵循先进先出(FIFO,即first in first out)排队方法的容器。这意味着我们可以向容器中添加元素,并从容器的另一端取出元素。我们可以通过对切片进行追加和出队操作来创建最简单形式的队列,如下代码所示:
package main
import "fmt"
func main() {
var simpleQueue []string
simpleQueue = append(simpleQueue, "Performance ")
simpleQueue = append(simpleQueue, "Go")
for len(simpleQueue) > 0 {
fmt.Println(simpleQueue[0]) // 第一个元素
simpleQueue = simpleQueue[1:] // 出队
}
fmt.Println(simpleQueue) // 所有元素都已出队,所以结果应该是 []
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在我们的示例中,我们向simpleQueue中追加字符串,然后通过删除切片的第一个元素来出队:
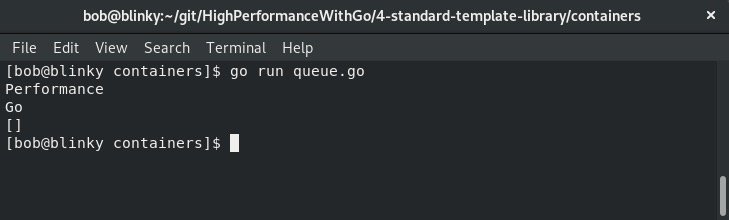
从输出中可以看到,我们正确地向队列中添加了元素并将其删除。
# 优先队列(Priority queue)
优先队列是一种使用堆来维护容器内元素优先级列表的容器。优先队列很有用,因为可以按优先级对结果集进行排序。优先队列在许多实际应用中都有使用,从负载均衡Web请求到数据压缩,再到迪杰斯特拉算法(Dijkstra's algorithm)。
在我们的优先队列示例中,创建一个新的优先队列,并插入几个具有给定优先级的不同编程语言。一开始将Java设为最高优先级,然后Go变为最高优先级。添加PHP后,Java的优先级被降至第3位。下面的代码是一个优先队列的示例。在这里,我们实例化必要的对象,创建一个新的优先队列,向优先队列中插入元素,更改这些元素的优先级,并从栈中弹出元素:
package main
import (
"fmt"
pq "github.com/jupp0r/go-priority-queue"
)
func main() {
priorityQueue := pq.New()
priorityQueue.Insert("java", 1)
priorityQueue.Insert("golang", 1)
priorityQueue.Insert("php", 2)
priorityQueue.UpdatePriority("java", 3)
for priorityQueue.Len() > 0 {
val, err := priorityQueue.Pop()
if err != nil {
panic(err)
}
fmt.Println(val)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
执行这段示例代码后,我们可以看到根据设置的优先队列值,编程语言得到了正确排序,如下代码所示:
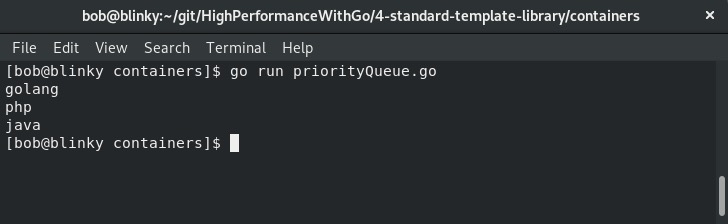
优先队列是一种常用的重要数据结构。使用它可以先处理数据结构中最重要的元素,能够使用标准模板库(STL)的等效实现,有助于我们节省时间和精力,同时对传入的请求进行优先级排序。
# 栈(Stack)
栈通过入栈(push)和出栈(pop)操作在容器中添加和移除元素,以此实现数据的分组管理。栈通常遵循后进先出(LIFO,即last in first out)的操作顺序,而查看栈顶元素(Peek)操作通常能让你在不移除栈顶元素的情况下,查看栈顶的内容。栈在处理内存有限的场景时非常实用,因为它们能有效利用已分配的内存。以下代码是栈的一个简单实现:
package main
import (
"fmt"
stack "github.com/golang-collections/collections/stack"
)
func main() {
// 创建一个新栈
fmt.Println("Creating New Stack")
exstack := stack.New()
fmt.Println("Pushing 1 to stack")
exstack.Push(1)
fmt.Println("Top of Stack is : ", exstack.Peek())
fmt.Println("Popping 1 from stack")
exstack.Pop()
fmt.Println("Stack length is : ", exstack.Len())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
我们可以看到程序的输出如下:
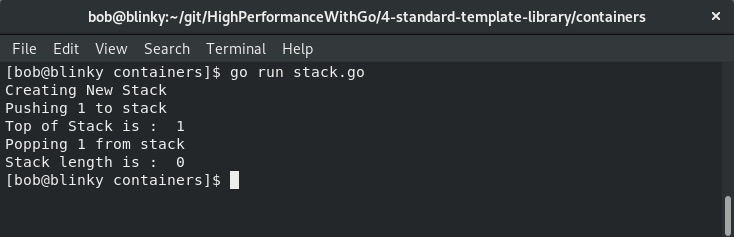
可以看出,栈操作按预期执行。在计算机科学中,能够熟练运用栈操作至关重要,因为许多底层编程技术都基于此。
# 关联容器
关联容器是实现关联数组的容器。这些数组是有序的,仅在算法对每个元素施加的约束上有所不同。标准模板库(STL)中提到的关联容器主要有集合(set)、映射(map)、多重集合(multiset)和多重映射(multimap)。我们将在以下部分深入探讨这些容器。
# 集合(Set)
集合仅用于存储键(keys)。Go语言中没有专门的集合类型,因此,常通过使用键值类型为布尔值的映射(map)来构建集合。以下代码块实现了一个与标准模板库(STL)中集合等效的功能:
package main
import "fmt"
func main() {
s := make(map[int]bool)
for i := 0; i < 5; i++ {
s[i] = true
}
delete(s, 4)
if s[2] {
fmt.Println("s[2] is set")
}
if!s[4] {
fmt.Println("s[4] was deleted")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
运行结果表明,我们能够成功设置和删除相应的值:
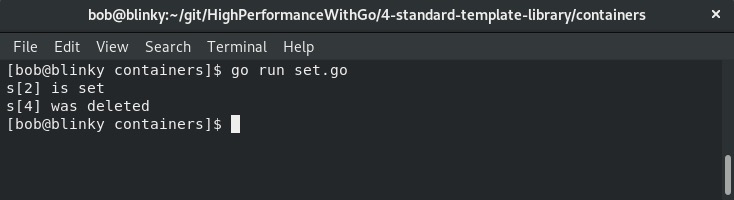
从输出中可以看出,代码能够正确操作集合,这对于常见的键值配对操作至关重要。
# 多重集合(Multiset)
多重集合是无序集合,每个元素都关联一个计数。多重集合有许多便捷的操作,例如求差集、缩放集合或检查集合的基数。
在我们的示例中,构建一个多重集合x,将其缩放2倍得到多重集合y,验证x是否为y的子集,并检查x的基数。以下代码展示了多重集合的实现示例:
package main
import (
"fmt"
"github.com/soniakeys/multiset"
)
func main() {
x := multiset.Multiset{"foo": 1, "bar": 2, "baz": 3}
fmt.Println("x: ", x)
// 创建x的缩放版本
y := multiset.Scale(x, 2)
fmt.Println("y: ", y)
fmt.Print("x is a subset of y: ")
fmt.Println(multiset.Subset(x, y))
fmt.Print("Cardinality of x: ")
fmt.Println(x.Cardinality())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
执行这段代码时,我们可以看到x、x的缩放版本y、x是否为y子集的验证结果以及x的基数计算结果。以下是运行多重集代码片段的输出:
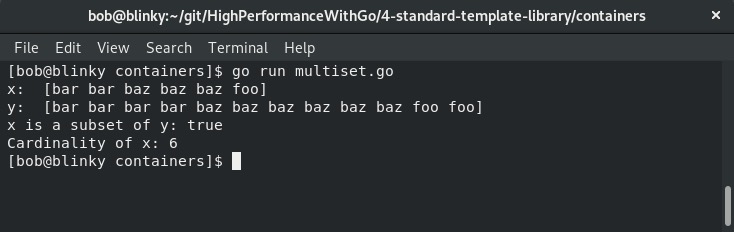
多重集合在集合操作中非常有用,因其每个元素可以有多个实例。购物车就是多重集合的一个很好的实际例子——你可以在购物车中添加许多商品,同一商品也可以有多个数量。
# 映射(Map)
映射是一种用于存储键值对的容器。Go语言内置的映射类型使用哈希表来存储键及其关联的值。
在Go语言中,实例化一个映射很简单,如下代码所示:
package main
import "fmt"
func main() {
m := make(map[int]string)
m[1] = "car"
m[2] = "train"
m[3] = "plane"
fmt.Println("Full Map:\t ", m)
fmt.Println("m[3] value:\t ", m[3])
fmt.Println("Length of map:\t ", len(m))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
现在,让我们看看输出结果:
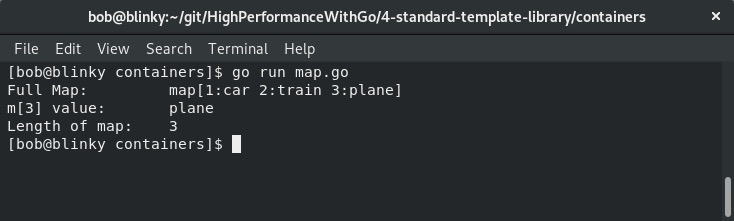
在上述执行结果中,可以看到我们能够创建映射、通过键引用映射中的值,还能使用内置的Len()函数获取映射中的元素数量。
# 多重映射(Multimap)
多重映射是一种一个键可以返回一个或多个值的映射。多重映射的一个实际应用场景是网页查询字符串。例如,在下面的示例URL中,查询字符串可以为同一键分配多个值:https://www.example.com/?foo=bar&foo=baz&a=b。
在我们的示例中,将创建一个汽车的多重映射。汽车结构体(car struct)中,每辆车都关联一个年份和款式。我们将把这些不同类型的数据聚合在一起。以下代码片段展示了多重映射的实现:
package main
import (
"fmt"
"github.com/jwangsadinata/go-multimap/slicemultimap"
)
type cars []struct {
year int
style string
}
func main() {
newCars := cars{{2019, "convertible"}, {1966, "fastback"}, {2019, "SUV"}, {1920, "truck"}}
multimap := slicemultimap.New()
for _, car := range newCars {
multimap.Put(car.year, car.style)
}
for _, style := range multimap.KeySet() {
color, _ := multimap.Get(style)
fmt.Printf("%v: %v\n", style, color)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
我们有多个2019款的汽车(一辆敞篷车和一辆SUV)。在输出结果中,可以看到这些值被聚合在一起:
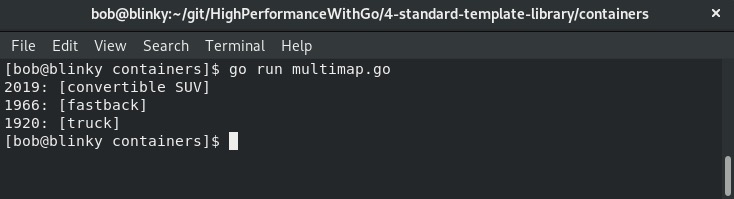
当你想要在映射中捕获一对多的关联关系时,多重映射就非常有用。在下一节中,我们将探讨函数对象。
# 理解函数对象
函数对象,也称为仿函数(functors),用于生成、测试和操作数据。如果你将一个对象声明为仿函数,就可以像调用函数一样使用该对象。通常,标准模板库(STL)中的算法需要一个参数来完成指定任务,仿函数是辅助完成这些任务的有效方式。在本节中,我们将学习以下内容:
- 仿函数
- 内部迭代器和外部迭代器
- 生成器
- 隐式迭代器
# 仿函数
仿函数是一种函数式编程范式,它在保持数据结构不变的同时,对结构进行转换操作。
在我们的示例中,取一个整数切片intSlice,并将其提升为一个仿函数。IntSliceFunctor是一个接口,包含以下内容:
fmt.Stringer,用于定义值的字符串表示格式。Map(fn func(int) int) IntSliceFunctor,此映射操作将fn应用于切片中的每个元素。- 便捷函数
Ints() []int,可用于获取仿函数所持有的整数切片。
将切片提升为仿函数后,我们可以对新创建的仿函数执行操作。在示例中,我们进行了平方运算和取模三运算。以下是仿函数的实现示例:
package main
import (
"fmt"
"github.com/go-functional/core/functor"
)
func main() {
intSlice := []int{1, 3, 5, 7}
fmt.Println("Int Slice:\t", intSlice)
intFunctor := functor.LiftIntSlice(intSlice)
fmt.Println("Lifted Slice:\t", intFunctor)
// 对给定的仿函数应用平方运算
squareFunc := func(i int) int {
return i * i
}
// 对给定的仿函数应用取模3运算
modThreeFunc := func(i int) int {
return i % 3
}
squared := intFunctor.Map(squareFunc)
fmt.Println("Squared: \t", squared)
modded := squared.Map(modThreeFunc)
fmt.Println("Modded: \t", modded)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
在执行这段代码时,可以看到使用仿函数进行的函数操作按预期工作。我们将初始的intSlice提升为仿函数,使用squareFunc对每个值进行平方运算,再使用modThreeFunc对每个值进行取模3运算:
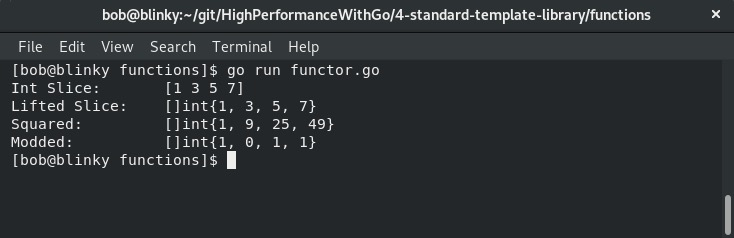
仿函数是一种非常强大的语言结构。它以易于修改的方式对容器进行抽象,还实现了关注点分离——例如,可以将迭代逻辑与计算逻辑分离。仿函数的参数化更简单,并且还可以是有状态的。
# 迭代器
我们在第3章“理解并发(Understanding Concurrency)”中讨论过迭代器。迭代器是用于遍历列表和其他容器的对象。迭代器通常作为容器接口的一部分来实现,这对程序员来说是一种重要的方法。迭代器通常分为以下几类:
- 内部迭代器
- 外部迭代器
- 生成器
- 隐式迭代器
我们将在以下部分更详细地介绍这些类别。
# 内部迭代器(Internal iterators)
内部迭代器表现为高阶函数(通常会用到匿名函数,正如我们在第3章“理解并发(Understanding Concurrency)”中看到的那样)。高阶函数以函数作为参数,并返回函数作为输出。匿名函数是指未绑定到标识符的函数。
内部迭代器通常会将自身映射为对容器中的每个元素应用某个函数。这个函数既可以用变量标识符来表示,也可以匿名表示。Go语言的作者提到,Go语言中可以使用apply/reduce操作,但不建议这么做(这是因为在Go语言中,for循环往往更受青睐)。这种模式遵循了Go语言“简单优于巧妙”的理念。
# 外部迭代器(External iterators)
外部迭代器用于访问对象中的元素,并指向下一个元素(分别称为元素访问和遍历)。Go语言大量使用for循环迭代器。for循环是Go语言唯一的原生循环结构,它极大地简化了程序的构建过程。一个for循环就像下面这样简单:
package main
import "fmt"
func main() {
for i := 0; i < 5; i++ {
fmt.Println("Hi Gophers!")
}
}
2
3
4
5
6
7
8
9
我们可以看到如下输出:
我们的for循环迭代器很简单,但它说明了一个重要的观点——有时候,简单性在处理难题时也能发挥作用,就像预期的那样。
# 生成器(Generators)
生成器在函数被调用时返回序列中的下一个值。正如你在下面的代码块中看到的,在Go语言中可以使用匿名函数来实现生成器迭代器模式:
package main
import "fmt"
func incrementCounter() func() int {
initializedNumber := 0
return func() int {
initializedNumber++
return initializedNumber
}
}
func main() {
n1 := incrementCounter()
fmt.Println("n1 increment counter #1: ", n1())
fmt.Println("n1 increment counter #2: ", n1())
n2 := incrementCounter()
fmt.Println("n2 increment counter #1: ", n2())
fmt.Println("n1 increment counter #3: ", n1())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
当调用incrementCounter()时,函数中表示的整数会自增。能够以这种方式并发使用匿名函数,对许多从其他语言转向Go语言的程序员来说很有吸引力。它提供了一种简洁的方式来利用Go语言的并发特性。
# 隐式迭代器(Implicit Iterators)
隐式迭代器为程序员提供了一种便捷的方式来遍历存储在容器中的元素。在Go语言中,这通常通过内置的range来实现。内置的range允许你遍历容器。下面是一个实现隐式迭代器的代码片段:
package main
import "fmt"
func main() {
stringExample := []string{"foo", "bar", "baz"}
for i, out := range stringExample {
fmt.Println(i, out)
}
}
2
3
4
5
6
7
8
9
10
11
我们可以看到如下输出结果:
这个输出展示了我们对stringExample变量的范围进行的迭代。range函数是一个非常强大的结构,简洁易读。
# 总结
在本章中,我们学习了如何在Go语言中使用标准模板库(STL,Standard Template Library)的实践方法。我们还学习了如何在Go语言中运用标准编程算法,了解了容器如何存储数据,函数在Go语言中的工作方式,以及如何正确使用迭代器。在我们继续Go语言性能优化的旅程中,编写代码时应始终将这些算法、容器、函子(functors)和迭代器作为优先选择。这样做将帮助我们快速、简洁地编写地道的Go语言代码。选择这些标准模板库(STL)习惯用法的恰当组合,将有助于我们更快速、更高效地处理手头的数据。在下一章中,我们将学习如何在Go语言中计算向量和矩阵。