 9 Go语言中的GPU并行化
9 Go语言中的GPU并行化
# 9 Go语言中的GPU并行化
在当今的高性能计算架构中,GPU加速编程正变得越来越重要。它广泛应用于人工智能(Artificial Intelligence,AI)和机器学习(Machine Learning,ML)等领域。GPU常用于这些任务,是因为它们在并行计算方面表现出色。
在本章中,我们将学习Cgo、GPU加速编程、CUDA(Compute Unified Device Architecture,统一计算设备架构的缩写)、make命令、Go程序的C风格链接,以及在Docker容器中执行启用GPU的进程。学习这些内容将帮助我们利用GPU为基于Go语言的CUDA程序提供支持。这也有助于我们探索如何有效地使用GPU,通过Go语言解决计算问题:
- Cgo——在Go语言中编写C代码
- GPU加速计算——利用硬件
- 在谷歌云平台(GCP)上使用CUDA
- CUDA——为程序提供动力
# Cgo——在Go语言中编写C代码
Cgo是Go标准库内置的一个库,它允许用户在Go代码中调用底层的C程序。Cgo通常用于处理那些目前用C语言编写,但没有等效Go代码的功能。
Cgo应该谨慎使用,只有在没有可用的等效Go库时才考虑。Cgo给Go程序带来了一些限制:
- 不必要的复杂性
- 故障排查困难
- 增加了构建和编译C代码的复杂性
- 许多Go语言的工具无法在Cgo程序中使用
- 交叉编译无法按预期工作,甚至根本无法工作
- C代码的复杂性
- 原生Go语言调用比Cgo调用快得多
- 构建时间更长
如果你能够(或必须)接受这些限制,对于你正在进行的项目而言,Cgo可能是一种必要的资源。
在一些情况下使用Cgo是合适的,主要示例如下:
当你必须使用专有软件开发工具包(Software Development Kit,SDK)或专有库时。
当你有一个用C语言编写的遗留软件,由于业务逻辑验证的原因很难移植到Go语言时。
当你已经将Go运行时的性能发挥到极限,还需要进一步优化时。不过这种情况非常罕见。
更多关于Cgo的优秀文档可在以下网址找到:
https://golang.org/cmd/cgo/
https://blog.golang.org/c-go-cgo
在下一节中,我们将通过一个简单的Cgo示例,熟悉Cgo的工作原理,以及它的优点和缺点。
# 一个简单的Cgo示例
让我们看一个相对简单的Cgo示例。在这个示例中,我们将编写一个简单的函数,通过C语言绑定打印“Hello Gophers”,然后在Go程序中调用这段C代码。在这个函数中,我们返回一个常量字符串。接着在Go程序中调用hello_gophers这个C函数。我们还使用C.GoString函数来转换C字符串类型和Go字符串类型:
package main
/*
#include <stdio.h>
const char* hello_gophers() {
return "Hello Gophers!";
}
*/
import "C"
import "fmt"
func main() {
fmt.Println(C.GoString(C.hello_gophers()))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
执行这个程序后,我们可以看到一个简单的“Hello Gophers!”输出:

这个示例虽然简单,但展示了如何在Go程序中绑定C函数。为了进一步强调执行时间的差异,我们可以对Cgo函数和Go函数进行基准测试:
package benchmark
/*
#include <stdio.h>
const char* hello_gophers() {
return "Hello Gophers!";
}
*/
import "C"
import "fmt"
func CgoPrint(n int) {
for i := 0; i < n; i++ {
fmt.Sprintf(C.GoString(C.hello_gophers()))
}
}
func GoPrint(n int) {
for i := 0; i < n; i++ {
fmt.Sprintf("Hello Gophers!")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
然后我们可以使用这些函数,对绑定的C函数和普通的GoPrint函数进行基准测试:
package benchmark
import "testing"
func BenchmarkCPrint(b *testing.B) {
CgoPrint(b.N)
}
func BenchmarkGoPrint(b *testing.B) {
GoPrint(b.N)
}
2
3
4
5
6
7
8
9
10
执行之后,我们可以看到以下输出:
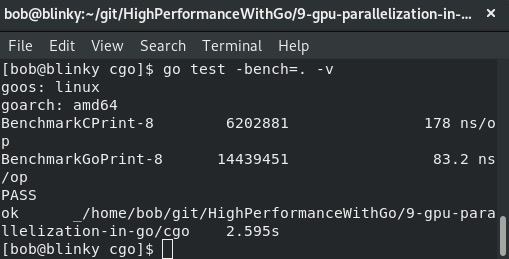
注意,绑定的Cgo函数的执行时间大约是原生Go函数的10倍。在某些情况下,这是可以接受的。这个基准测试进一步证实了我们应该仅在合理的情况下使用Cgo绑定。重要的是要记住,在某些特定情况下使用Cgo是合理的,比如当我们必须执行Go语言原生功能无法实现的操作时。
在下一节中,我们将学习GPU加速编程和英伟达(NVIDIA)的CUDA平台。
# GPU加速计算——利用硬件
在现代计算机中,有几个硬件组件承担了系统的大部分工作。中央处理器(CPU)执行来自计算机其他部分的大多数指令操作,并输出这些操作的结果。内存是用于数据存储和操作的快速短期存储设备。硬盘用于长期数据存储和操作,而网络设备则用于在网络中的计算设备之间传输这些数据。在现代计算系统中,经常使用的另一种设备是独立GPU。无论是用于以高保真图形显示最新的电脑游戏、解码4K视频,还是进行复杂的金融数据运算,GPU正成为高速计算的热门选择。
GPU专为高效执行特定任务而设计。随着高通量计算的广泛应用,将GPU用作通用图形处理单元(General-Purpose Graphics Processing Units,GPGPU)的情况越来越普遍。
有许多不同的API可用于GPU编程,以充分发挥GPU的性能,包括:
- OpenCL:https://www.khronos.org/opencl/
- OpenMP:https://www.openmp.org/
- 英伟达的CUDA平台:https://developer.nvidia.com/cuda-zone
英伟达的CUDA库成熟、性能出色,并且被广泛认可。在本章的示例中,我们将使用CUDA库。下面让我们进一步了解CUDA平台。
英伟达的CUDA平台是英伟达团队编写的一个API,用于通过支持CUDA的显卡提高并行性和运算速度。使用通用图形处理单元(GPGPU)对数据结构执行并行算法可以显著缩短计算时间。目前许多机器学习和人工智能工具集在底层都使用CUDA,包括但不限于以下工具:
- TensorFlow:https://www.tensorflow.org/install/gpu
- Numba:https://devblogs.nvidia.com/gpu-accelerated-graph-analytics-python-numba/
- PyTorch:https://pytorch.org/
CUDA提供了一个用于在C++中访问这些处理习惯用法的API。它使用内核(kernels)的概念,内核是从C++代码中调用并在GPU设备上执行的函数。内核是代码中并行执行的部分。CUDA使用C++语法规则来处理指令。
你可以在云端的许多地方使用GPU来执行计算任务,例如:
- 谷歌云GPU:https://cloud.google.com/gpu/
- 支持GPU的AWS EC2实例:https://aws.amazon.com/nvidia/
- Paperspace:https://www.paperspace.com/
- FloydHub:https://www.floydhub.com/
你也可以在本地工作站上运行CUDA程序,所需条件如下:
- 一块支持CUDA的GPU(我在示例中使用的是英伟达GTX670)
- 一个安装了GCC编译器和工具链的操作系统(我在示例中使用的是Fedora 29)
在下一节中,我们将介绍如何配置工作站以进行CUDA处理:
- 首先,我们必须为宿主机安装适当的内核开发工具和内核头文件。在我们的Fedora示例主机上,可以通过执行以下命令来安装:
sudo dnf install kernel-devel-$(uname -r) kernel-headers-$(uname -r)
- 我们还需要安装gcc和相应的构建工具。可以通过以下命令进行安装:
sudo dnf groupinstall "Development Tools"
- 安装完先决条件后,我们可以获取英伟达提供的用于CUDA的本地.run文件安装程序。在撰写本文时,
cuda_10.2.89_440.33.01_linux.run软件包是最新版本。你可以从https://developer.nvidia.com/cuda-downloads找到最新的CUDA工具包进行下载:
wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
- 然后我们可以使用以下代码安装这个软件包:
sudo ./cuda_10.2.89_440.33.01_linux.run
这将弹出一个安装提示,如下截图所示:
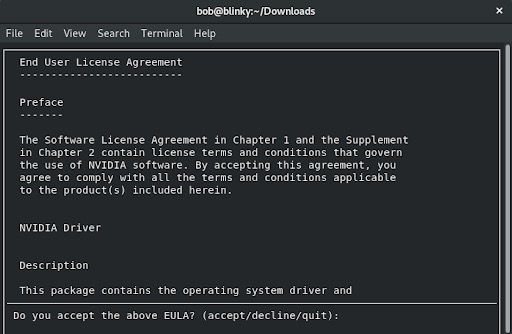
- 接受最终用户许可协议(EULA)后,我们可以选择安装必要的依赖项并选择“Install”(安装):
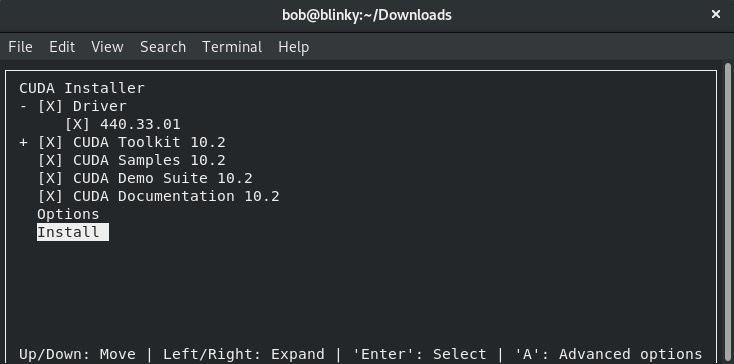
接受安装提示后,CUDA安装程序应能成功完成安装。如果在安装过程中出现任何错误,查看以下位置可能有助于解决安装问题:
- /var/log/cuda-installer.log
- /var/log/nvidia-installer.log
在下一节中,我们将讨论如何在宿主机上进行CUDA处理。
# CUDA——利用主机进程
成功安装CUDA后,你需要设置一些环境变量,以便将安装的内容添加到执行路径中。如果你在主机上无法访问Docker,或者更倾向于使用裸机来执行GPU密集型操作,这个功能就能按预期工作。如果你想要使用更具可重复性的构建方式,可以使用下文中“用于GPU编程的Docker”部分定义的Docker配置。
我们需要更新PATH环境变量,将刚安装的CUDA二进制文件路径包含进去。可以通过执行以下命令来实现:
export PATH=$PATH:/usr/local/cuda-10.2/bin:/usr/local/cuda-10.2/NsightCompute-2019.1
我们还需要更新LD_LIBRARY_PATH变量,这是一个环境变量,操作系统在链接动态和共享库时会查找它。我们可以通过执行以下命令添加CUDA库:
export LD_LIBRARY_PATH=:/usr/local/cuda-10.2/lib64
这会将CUDA库添加到库路径中。在本章结尾部分的示例中,我们将使用GNU Makefile以编程方式将这些路径添加到PATH中。在下一节中,我们将讨论如何结合Docker使用CUDA。
# 用于GPU编程的Docker
如果你想在本章中使用Docker进行GPU编程,可以执行以下步骤,但要使用这种方式,你的计算机必须配备兼容的NVIDIA CUDA GPU。你可以在https://developer.nvidia.com/cuda-gpus上找到支持的显卡完整列表。
在生产环境中,我们可能不会以这种方式使用Docker进行GPU加速计算,因为对于GPU加速编程来说,你很可能希望尽可能接近硬件,但在本章中我选择使用这种方法,以便为本书的读者提供可重复的构建方式。大多数情况下,可重复构建是可以接受的,它可以弥补使用容器化方法带来的轻微性能损失。
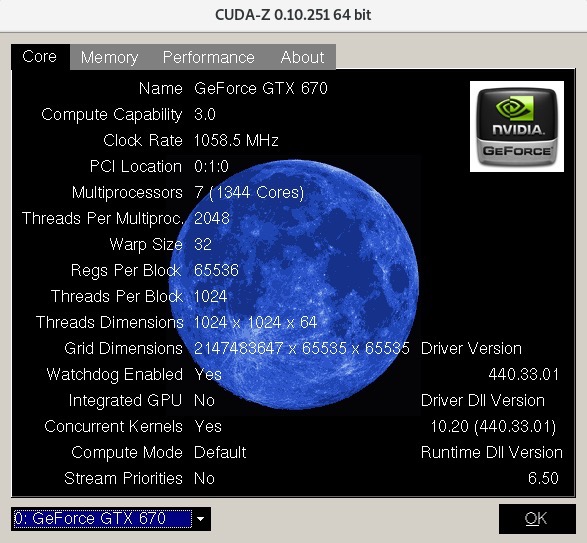
如果你不确定你的NVIDIA GPU支持哪些功能,可以使用cuda-z工具来获取有关你的显卡的更多信息。该程序的可执行文件可以在http://cuda-z.sourceforge.net/上找到。
下载适合你特定操作系统的版本后,你应该可以像这样执行该文件:
./CUDA-Z-0.10.251-64bit.run
你会看到一个输出,它会提供有关你当前使用的显卡的各种信息:
确定你的显卡支持所需的GPU处理后,我们就可以使用Docker连接到你的GPU进行处理。为此,我们将执行以下步骤:
- 为你的计算机启用NVIDIA容器工具包(NVIDIA container toolkit)。在我的Fedora测试系统上,我需要做一个小调整,将我的发行版改为
centos7,不过安装的RPM包仍然可以正常工作:
distribution=$( . /etc/os-release;echo $ID$VERSION_ID)
curl -s -L
https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker .
repo | sudo tee /etc/yum .repos .d/nvidia-docker .repo
2
3
4
在其他操作系统上安装的完整说明可以在https://github.com/NVIDIA/nvidia-docker#quickstart上找到。
2. 安装nvidia-container-toolkit:
sudo yum install -y nvidia-container-toolkit
- 重启Docker以应用这些新更改:
sudo systemctl restart docker
- 禁用SELinux,以便你的计算机能够使用GPU处理这些请求:
setenforce 0 #以root身份执行
- 执行一个测试
docker run命令,确保你能够在Docker中执行GPU操作,并查看有关你特定NVIDIA显卡的信息:
docker run --gpus all tensorflow/tensorflow:latest-gpu nvidia-smi
在下一节中,我们将介绍如何在谷歌云平台(Google Cloud Platform,GCP)上设置支持CUDA GPU的机器。
# 在GCP上使用CUDA
如果你没有必要的硬件,或者希望在云端运行GPU代码的工作负载,你可能会决定在共享托管环境中使用CUDA。在下面的示例中,我们将向你展示如何在GCP上设置使用GPU。
提示 还有许多其他托管GPU提供商(你可以在本章“GPU加速计算——利用硬件”部分看到列出的所有提供商),我们在这里将以GCP的GPU实例为例。
你可以在https://cloud.google.com/gpu上了解更多关于GCP的GPU产品信息。
# 创建带GPU的虚拟机
为了能够在GCP上使用GPU,我们需要创建一个谷歌计算引擎(Google Compute Engine)实例。
你可能需要提高你的GPU配额。为此,你可以按照以下URL中的步骤操作:https://cloud.google.com/compute/quotas#requesting_additional_quota
在撰写本文时,NVIDIA P4 GPU是该平台上最便宜的,并且有足够的性能来演示我们的工作。你可以通过在IAM管理配额页面上查看NVIDIA P4 GPUs指标来验证你的配额:
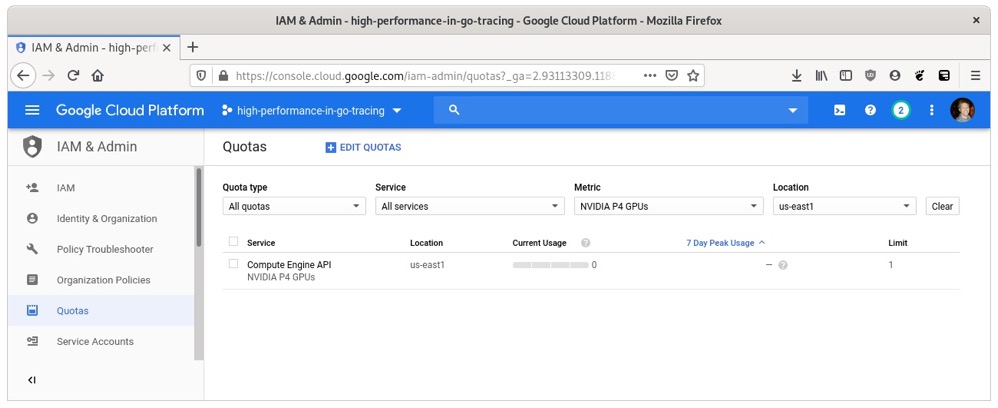
要创建实例,我们可以访问谷歌云控制台的虚拟机实例页面。该页面的截图如下。点击屏幕中央的“创建”按钮:
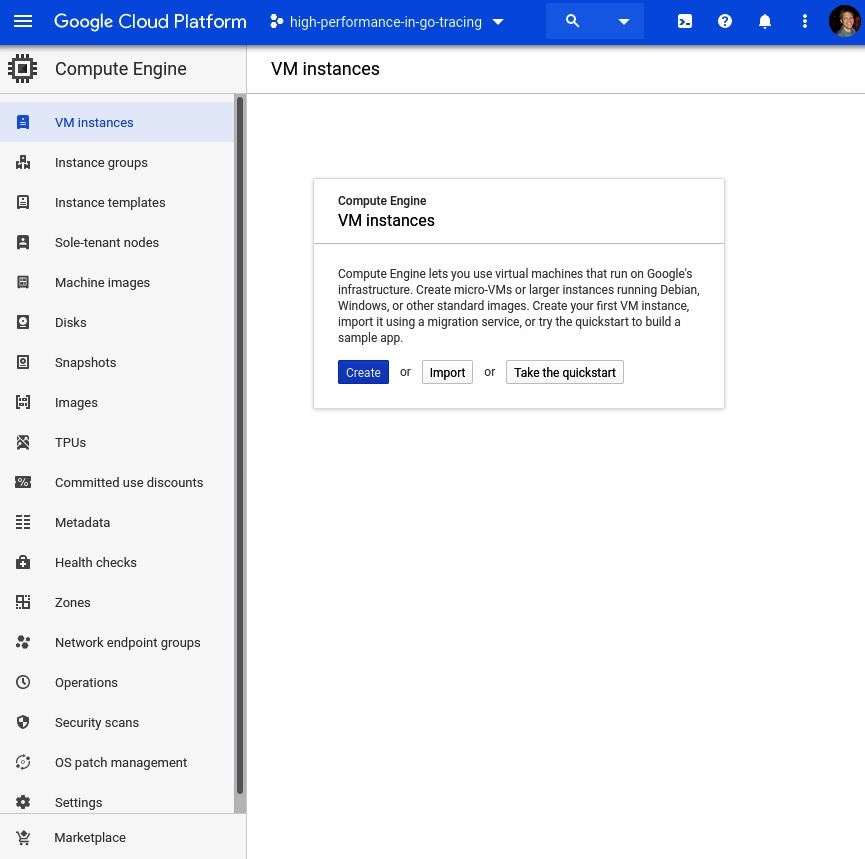
接下来,我们创建一个附加了GPU的Ubuntu 18.04虚拟机。这个示例中我们的虚拟机实例配置如下截图所示:
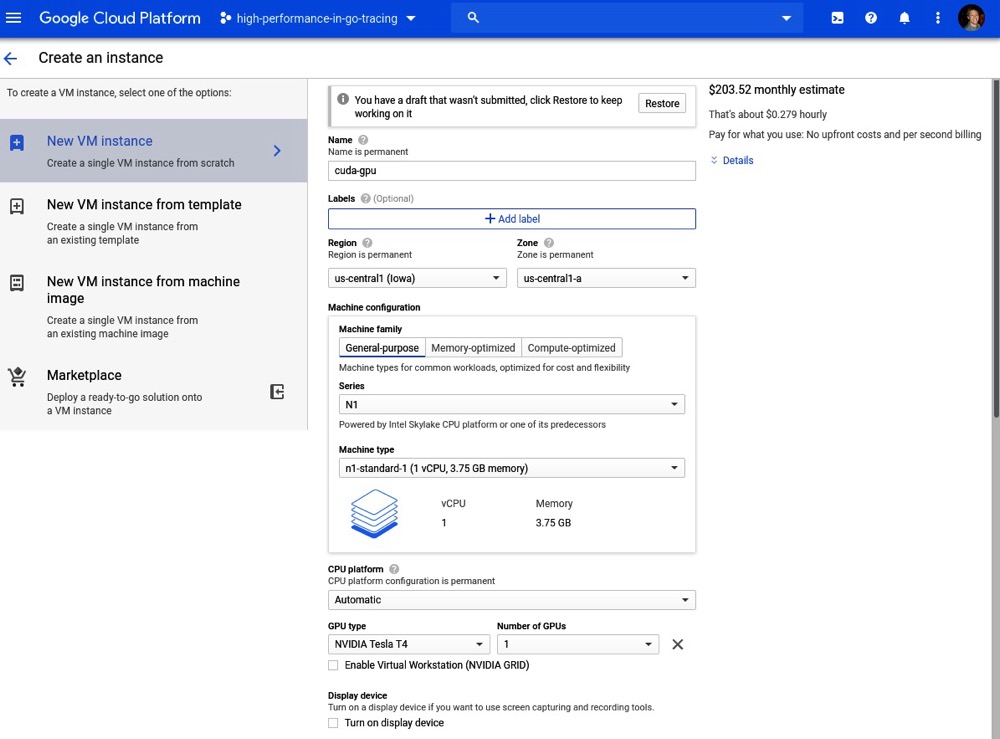
我们在这里使用Ubuntu 18.04作为示例,而不是Fedora 29,以展示如何为多种架构设置CUDA。
我们的操作系统和其他配置参数如下截图所示:
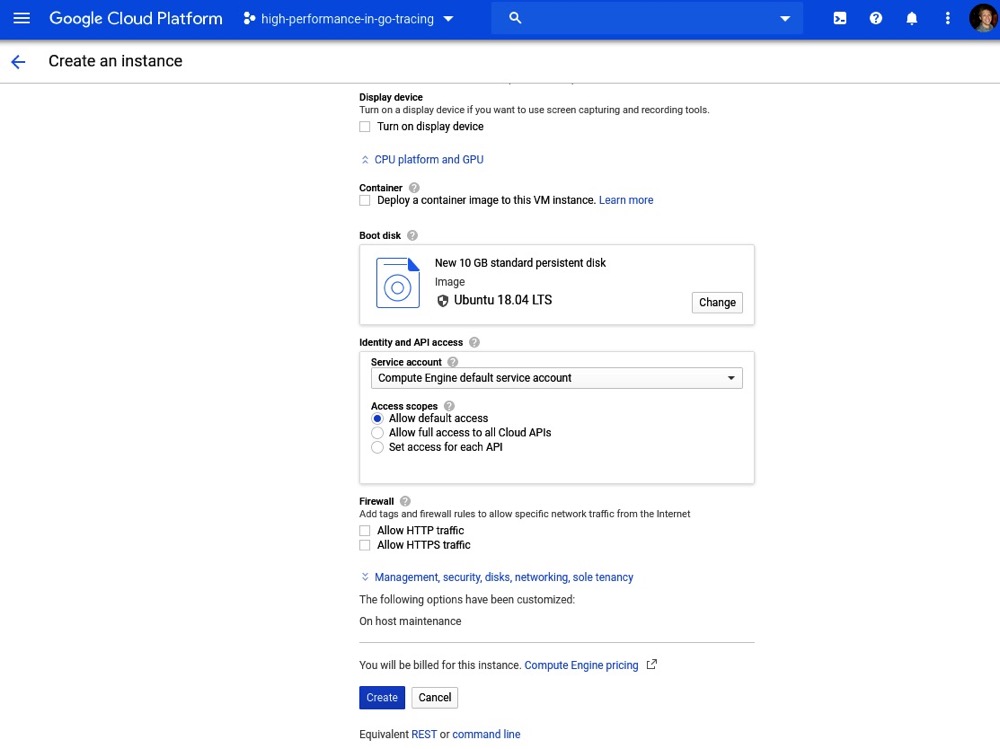
点击“创建”按钮后,我们会回到虚拟机实例页面。等待你的虚拟机完全配置完成(它的名称左侧会有一个绿色的对勾):

接下来,我们可以通过SSH连接到该实例,如下截图所示:
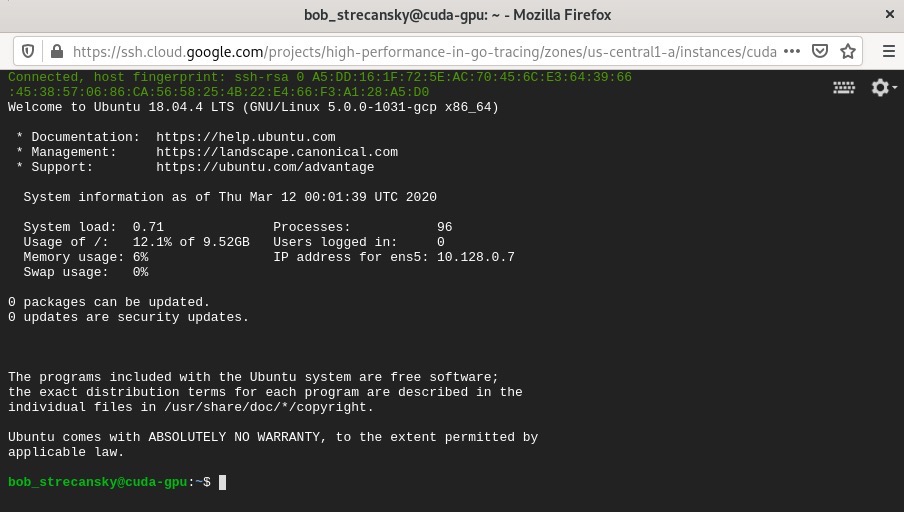
在接下来的小节中,我们将安装运行支持GPU的CGo程序所需的所有依赖项。为了方便你操作,在解释结束后我还提供了一个执行所有这些操作的脚本。
# 安装CUDA驱动
按照https://cloud.google.com/compute/docs/gpus/install-drivers-gpu上的说明来安装NVIDIA CUDA驱动:
- 获取CUDA存储库:
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb
- 安装.deb软件包:
sudo dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb
- 将NVIDIA GPG密钥添加到apt源密钥环:
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
- 安装NVIDIA CUDA驱动:
sudo apt-get update && sudo apt-get install cuda
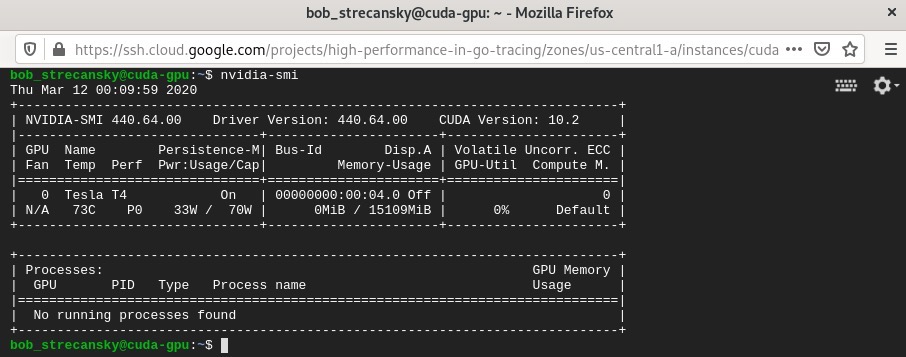
- 现在我们的谷歌云平台虚拟机(GCP VM)上有了一个支持CUDA的GPU。我们可以使用
nvidia-smi命令来验证:
nvidia-smi
- 我们将在截图中看到以下输出:
# 在GCP上安装Docker CE
接下来,我们需要在支持CUDA的谷歌计算引擎虚拟机(GCE VM)上安装Docker CE。要在虚拟机上安装Docker CE,我们可以按照此页面上的说明操作:https://docs.docker.com/install/linux/docker-ce/ubuntu/ 。
在撰写本书时,需要执行以下步骤:
- 验证主机上没有其他Docker版本:
sudo apt-get remove docker docker-engine docker.io containerd runc
- 确保我们的存储库是最新的:
sudo apt-get update
- 安装安装Docker CE所需的依赖项:
sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
- 添加Docker CE存储库:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
2
- 运行更新以确保Docker CE存储库是最新的:
sudo apt-get update
- 安装必要的Docker依赖项:
sudo apt-get install docker-ce docker-ce-cli containerd.io
现在我们的主机上有了一个可用的Docker CE实例。
# 在GCP上安装NVIDIA Docker
要在虚拟机上安装NVIDIA Docker驱动,我们可以按照此页面上的说明操作:https://github.com/NVIDIA/nvidia-docker#ubuntu-16041804-debian-jessiestretchbuster 。
- 设置一个发行版变量:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
- 添加nvidia-docker存储库的GPG密钥和apt存储库:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
2
- 安装nvidia-container-toolkit:
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
- 重启虚拟机以使此驱动生效。
# 整合脚本
以下bash脚本将一起执行上述所有操作。首先,我们安装CUDA驱动:
#!/bin/bash
# 安装CUDA驱动
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb
dpkg -i cuda-repo-ubuntu1804_10.0.130-1_amd64.deb
apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
apt-get -y update && sudo apt-get -y install cuda
2
3
4
5
6
然后我们安装Docker CE:
# 安装Docker CE
apt-get remove docker docker-engine docker.io containerd runc
apt-get update
apt-get -y install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
apt-get -y update
apt-get -y install docker-ce docker-ce-cli containerd.io
2
3
4
5
6
7
8
最后我们安装nvidia-docker驱动:
# 安装nvidia-docker
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get -y update && sudo apt-get -y install nvidia-container-toolkit
usermod -aG docker $USER
systemctl restart docker
2
3
4
5
6
7
此脚本包含在仓库https://git/HighPerformanceWithGo/9-gpu-parallelization-in-go/gcp_scripts中,可以在该目录下通过运行以下命令来执行:
sudo bash nvidia-cuda-gcp-setup.sh
在下一节中,我们将介绍一个使用Cgo执行的CUDA示例程序。
# 使用CUDA为程序赋能
安装并运行所有CUDA依赖项后,我们可以从一个简单的CUDA C++程序开始:
- 首先,我们将包含所有必要的头文件,并定义要处理的元素数量。
1 << 20等于1,048,576,这个元素数量足以进行充分的GPU测试。如果你想查看处理时间的差异,可以调整这个值:
#include <cstdlib>
#include <iostream>
const int ELEMENTS = 1 << 20;
2
3
4
我们的multiply函数被包装在一个global说明符中。这允许CUDA特定的C++编译器nvcc在GPU上运行特定的函数。这个multiply函数相对简单:它接受a和b数组,使用一些CUDA特性将它们相乘,并将结果返回在c数组中:
global void multiply(int j, float * a, float * b, float * c) {
int index = threadIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < j; i += stride)
c[i] = a[i] * b[i];
}
2
3
4
5
6
这里的CUDA特性指的是GPU的并行处理功能。这些变量的定义如下:
gridDim.x:处理器上可用的线程块数量blockDim.x:每个块中的线程数量blockIdx.x:网格中当前块的索引threadId.x:块中当前线程的索引
然后,我们需要添加一个extern "C"调用,为这个特定函数提供C风格的链接,这样我们就可以从Go代码中有效地调用这个函数。cuda_multiply函数创建了三个数组:
a和b,存储1到10之间的随机数c,存储a和b相乘的结果
extern "C" {
int cuda_multiply(void) {
float * a, * b, * c;
cudaMallocManaged(&a, ELEMENTS * sizeof(float));
cudaMallocManaged(&b, ELEMENTS * sizeof(float));
cudaMallocManaged(&c, ELEMENTS * sizeof(float));
2
3
4
5
6
- 然后我们创建随机浮点数数组:
for (int i = 0; i < ELEMENTS; i++) {
a[i] = rand() % 10;
b[i] = rand() % 10;
}
2
3
4
然后,我们根据块大小执行multiply函数(在文件开头定义)。我们根据元素数量计算要使用的块数:
int blockSize = 256;
int numBlocks = (ELEMENTS + blockSize - 1) / blockSize;
multiply<<<numBlocks, blockSize>>>(ELEMENTS, a, b, c);
2
3
乘法完成后,在主机上访问信息之前,我们将等待GPU完成计算:cudaDeviceSynchronize();。
3. 然后,我们可以将执行的乘法结果打印到屏幕上,以便最终用户看到我们正在执行的计算。由于在这个特定代码中,向标准输出打印并不能很好地展示性能,所以代码中这部分被注释掉了。如果你想查看正在进行的计算,可以取消注释:
//for (int k = 0; k < ELEMENTS; k++) {
// std::cout << k << ":" << a[k] << "*" << b[k] << "=" << c[k] << "\n";
//}
2
3
- 然后,我们通过对每个数组指针调用
cudaFree,释放为multiply函数分配的GPU内存,最后返回0结束程序:
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
}
2
3
4
5
6
- 然后,我们添加头文件
cuda_multiply.h:
int cuda_multiply(void);
本章中的Go程序只是对我们用一些语法糖创建的cuda_multiply.cu函数的一个包装。
6. 我们实例化main函数并导入必要的包:
package main
import (
"fmt"
"time"
)
2
3
4
5
6
- 然后,我们添加必要的CFLAGS和LDFLAGS,以便引用我们用
nvcc make创建的库以及系统库。需要注意的是,这些注释在cgo代码中称为前导码,在编译包的C部分时用作头文件。我们可以在这里包含任何必要的C代码,以使我们代码的Go部分更易于处理。如果你打算使用以下任何一种标志样式,必须在前面加上#cgo指令来调整底层编译器的行为:
- CFLAGS
- CPPFLAGS
- CXXFLAGS
- FFLAGS
- LDFLAGS
- 接着,我们导入伪包
C,这使我们能够执行之前编写的C代码(回想一下在cuda_multiply.cu文件中使用的extern C调用)。我们还在这个函数周围添加了一个计时包装器,以便查看执行该函数所需的时间:
//#cgo CFLAGS: -I.
//#cgo LDFLAGS: -L. -lmultiply
//#cgo LDFLAGS: -lcudart
//#include <cuda_multiply.h>
import "C"
func main() {
fmt.Printf("Invoking cuda library...\n")
start := time.Now()
C.cuda_multiply()
elapsed := time.Since(start)
fmt.Println("\nCuda Execution took", elapsed)
}
2
3
4
5
6
7
8
9
10
11
12
13
- 为接下来要构建的Docker容器提供了一个
Makefile文件。我们的Makefile定义了构建nvcc库、运行Go代码以及清理nvcc库的方法:
#target:
nvcc -o libmultiply.so --shared -Xcompiler -fPIC cuda_multiply.cu
#go:
go run cuda_multiply.go
#clean:
rm *.so
2
3
4
5
6
我们的Dockerfile将所有内容整合在一起,使我们的演示能够轻松重现:
FROM tensorflow/tensorflow:latest-gpu
ENV LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64
RUN ln -s /usr/local/cuda-10.1/lib64/libcudart.so /usr/lib/libcudart.so
RUN apt-get install -y golang
COPY . /tmp
WORKDIR /tmp
RUN make
RUN mv libmultiply.so /usr/lib/libmultiply.so
ENTRYPOINT ["/usr/bin/go", "run", "cuda_multiply.go"]
2
3
4
5
6
7
8
9
- 接下来,我们将构建并运行Docker容器。以下是缓存构建的输出,为简洁起见省略了构建步骤:
$ sudo docker build -t cuda-go .
Sending build context to Docker daemon 8.704kB
Step 1/9 : FROM tensorflow/tensorflow:latest-gpu
---> 3c0df9ad26cc
Step 2/9 : ENV LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64
---> Using cache
---> 65aba605af5a
Step 3/9 : RUN ln -s /usr/local/cuda-10.1/lib64/libcudart.so /usr/lib/libcudart.so
---> Using cache
---> a0885eb3c1a8
Step 4/9 : RUN apt-get install -y golang
---> Using cache
---> bd85bd4a8c5e
Step 5/9 : COPY . /tmp
---> 402d800b4708
Step 6/9 : WORKDIR /tmp
---> Running in ee3664a4669f
Removing intermediate container ee3664a4669f
---> 96ba0678c758
Step 7/9 : RUN make
---> Running in 05df1a58cfd9
nvcc -o libmultiply.so --shared -Xcompiler -fPIC cuda_multiply.cu
Removing intermediate container 05df1a58cfd9
---> 0095c3bd2f58
Step 8/9 : RUN mv libmultiply.so /usr/lib/libmultiply.so
---> Running in 493ab6397c29
Removing intermediate container 493ab6397c29
---> 000fcf47898c
Step 9/9 : ENTRYPOINT ["/usr/bin/go", "run", "cuda_multiply.go"]
---> Running in 554b8bf32a1e
Removing intermediate container 554b8bf32a1e
---> d62266019675
Successfully built d62266019675
Successfully tagged cuda-go:latest
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
然后,我们可以使用以下命令执行Docker容器(根据Docker守护进程的配置,可能需要使用sudo):
sudo docker run --gpus all -it --rm cuda-go
以下是上述命令的输出:
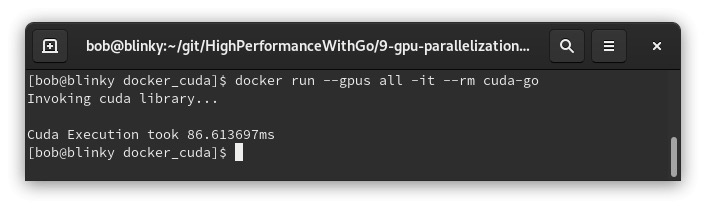
对于如此大规模的乘法计算而言,这个结果相当出色!在高计算负载的情况下,GPU编程通常是实现快速计算的良好解决方案。在同一台机器上,一个仅使用CPU的等效C++程序运行大约需要340毫秒。
# 总结
在本章中,我们学习了cgo、GPU加速编程、CUDA、Make命令、Go程序的C风格链接,以及在Docker容器中执行启用GPU的进程。了解所有这些单独的元素有助于我们开发一个高性能的由GPU驱动的应用程序,该应用程序能够进行一些非常大规模的数学计算。通过重复这些步骤,可以高效地进行许多大规模的计算。我们还学习了如何在谷歌云平台(GCP)中设置启用GPU的虚拟机(VM),以便我们能够使用云资源进行GPU计算。
在下一章中,我们将讨论Go语言中的运行时评估。