 10 Go语言中的编译时评估
10 Go语言中的编译时评估
# 10 Go语言中的编译时评估
Go语言的作者在设计语言时尽量减少了依赖,并且每个文件都声明自身的依赖。常规的语法和模块支持也有助于开发者缩短编译时间,提高接口的适配性。在本章中,我们将了解运行时评估如何加快Go语言的编译速度,同时还会探讨使用容器构建Go代码以及利用Go构建缓存的方法。
在本章中,我们将涵盖以下主题:
- Go运行时
- GCTrace
- GOGC
- GOMAXPROCS
- GOTRACEBACK
- Go构建缓存
- 依赖管理(Vendoring)
- 缓存机制(Caching)
- 调试(Debugging)
- KeepAlive
- NumCPU
- ReadMemStats
这些主题对于理解Go运行时的工作原理,以及如何运用它编写高性能代码都非常有价值。
# 探索Go运行时
在Go语言的源代码中,我们可以通过访问https://golang.org/src/runtime/查看运行时的源代码。runtime包包含了与Go运行时进行交互的操作。这个包用于控制诸如协程(goroutines)、垃圾回收、反射和调度等功能,而这些功能对于Go语言的运行至关重要。在runtime包中,有许多环境变量,它们能帮助我们改变Go可执行文件的运行时行为。下面让我们来了解一些与Go运行时相关的重要环境变量。
# GODEBUG
GODEBUG是变量的控制器,用于在Go运行时进行调试。该变量包含一组以逗号分隔的name=val键值对。这些命名变量用于调整二进制文件返回的调试信息输出。这个变量的一个优点是,运行时允许你直接将其应用于已编译的二进制文件,而无需在构建时调用。这非常实用,因为它让你能够调试已经构建好的二进制文件(这些文件可能已经在生产环境中造成了问题)。可以传递给GODEBUG的变量如下:
| GODEBUG变量 | 启用值 | 描述 |
|---|---|---|
| allocfreetrace | 1 | 用于对每次内存分配进行性能分析。会为每个对象的分配和释放打印堆栈跟踪信息。每个堆栈跟踪信息包含内存块、大小、类型、协程ID以及各个元素的堆栈跟踪。 |
| clobberfree | 1 | 垃圾回收器(GC)在释放对象时,会用无效内容覆盖该对象的内容。 |
| cgocheck | 0 - 禁用 1(默认值) - 简单检查 2 - 详细检查 | 检查使用cgo的包,查看是否存在将Go指针错误传递给非Go代码的情况。设置为0表示禁用检查,设置为1表示进行简单检查(可能会遗漏一些错误,这是默认设置),设置为2表示进行详细检查,但这会使程序运行变慢。 |
| efence | 1 | 分配器将确保每个对象都分配在唯一的页面上,并且内存地址不会被重复使用。 |
| gccheckmark | 1 | 通过进行第二次标记传递来验证垃圾回收器当前的标记阶段。在第二次标记传递期间,程序会暂停。如果第二次传递发现了并发标记未找到的对象,垃圾回收器将引发恐慌(panic)。 |
| gcpacertrace | 1 | 打印与垃圾回收器相关的并发节奏器内部状态信息。 |
| gcshrinkstackoff | 1 | 正在移动的协程不能移动到更小的堆栈上。在这种模式下,协程的堆栈只会增长。 |
| gcstoptheworld | 1 - 禁用并发垃圾回收 2 - 禁用垃圾回收并禁用并发清扫 | 设置为1会禁用并发垃圾回收,这会使每次垃圾回收事件都变成程序暂停的情况。设置为2会禁用垃圾回收,并且在垃圾回收完成后禁用并发清扫。 |
| gctrace | 1 | 详见下一页的GCTrace标题内容。 |
| madvdontneed | 1 | 在Linux系统上,使用MADV_DONTNEED而不是MADV_FREE将内存返回给内核。使用这个标志会降低内存利用率,但会使常驻集大小(RSS)内存值下降得更快。 |
| memprofilerate | 0 - 关闭分析 1 - 包含每个分配的块 X - 更新 MemProfileRate的值 | 控制在内存分析中报告和记录的内存分配比例。更改X的值可以控制记录的内存分配比例。 |
| invalidptr | 0 - 禁用此检查 1 - 如果发现无效指针则崩溃 | 如果在存储指针的位置发现无效指针值,垃圾回收器和堆栈复制器将崩溃。 |
| sbrk | 1 | 使用操作系统提供的一个简单的、不回收内存的分配器,替代默认的内存分配器和垃圾回收器。 |
| scavenge | 1 | 启用堆清理器的调试模式。 |
| scheddetail | 1(与schedtrace=X一起使用) | 调度器每X毫秒返回与调度器、处理器、线程和协程相关的信息。 |
| schedtrace | X | 每X毫秒向标准错误输出(STDERR)打印一行调度器状态摘要。 |
| tracebackancestors | N | 扩展协程创建位置及其相关堆栈的回溯信息,报告N个祖先协程。如果N = 0,则不返回祖先信息。 |
其他包也有可以传递给GODEBUG的变量。这些通常是一些广为人知的包,可能需要对其运行时性能进行调整,比如crypto/tls和net/http。如果包中有在运行时可用的GODEBUG标志,那么包中应该包含相关文档说明。
# GCTRACE
GCTRACE用于在运行时查看打印到标准错误输出(stderr)的单行信息,该信息展示了每次垃圾回收(garbage collection)所收集的总内存量以及每次回收过程中的暂停时长。在撰写本文时,这行信息的格式如下:
gc# @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, #P
我们通过一个简单的HTTP服务器示例来展示它的工作原理。首先,编写一个简单的HTTP服务器,当访问本地主机(localhost)的8080端口根路径时,返回“Hello Gophers”:
package main
import (
"fmt"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello Gophers")
}
func main() {
http.HandleFunc("/", hello)
err := http.ListenAndServe(":8080", nil)
if err != nil {
fmt.Println(err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
接下来,构建并运行这个简单的Web服务器,然后使用Apache Bench(https://httpd.apache.org/docs/2.4/programs/ab.html)对主机进行负载模拟:
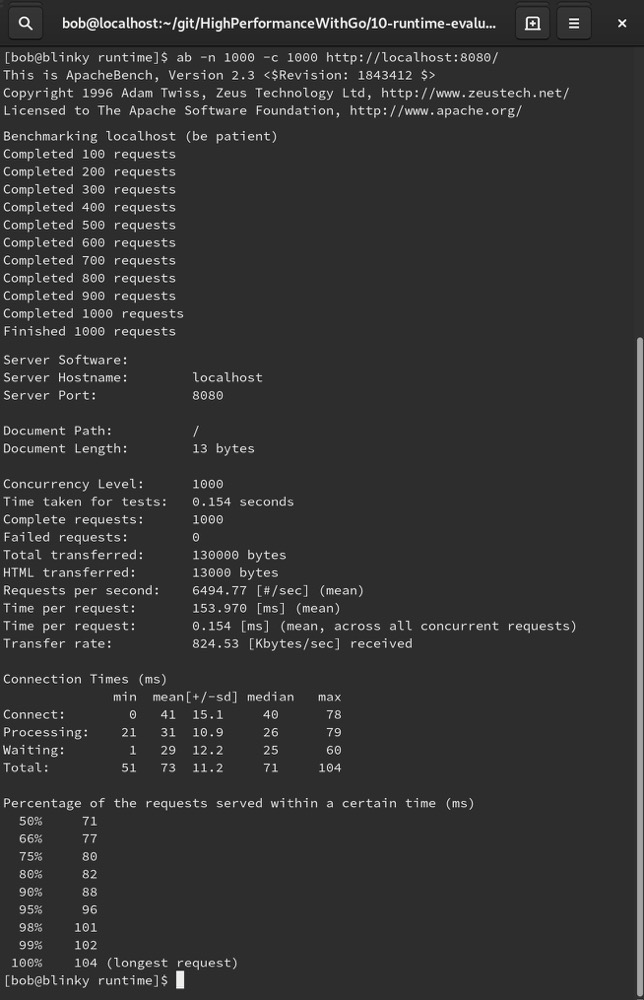
在看到Apache Bench的输出表明测试完成后,我们会在最初启动简单HTTP守护进程的终端中看到一些垃圾回收统计信息:
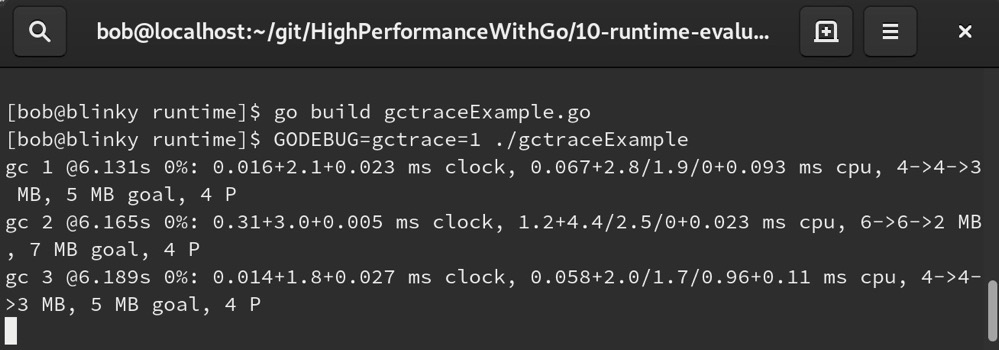
下面来解析这个示例中的垃圾回收输出:
| 输出 | 描述 |
|---|---|
gc 1 | 垃圾回收的次数。每次垃圾回收时,这个数字会递增。 |
@6.131s | 这次垃圾回收发生在程序启动后的6.131秒。 |
0% | 自程序启动以来,垃圾回收所花费时间的百分比。 |
0.016+2.1+0.023 ms clock | 垃圾回收各阶段的挂钟时间/CPU时间。可以表示为Tgc = Tseq + Tmark + Tsweep。Tseq:用户Go协程停止时间(停止世界扫描终止)。Tmark:堆标记时间(并发标记和扫描时间)。Tsweep:堆清理时间(清理世界标记终止)。 |
4->4->3 MB | 垃圾回收开始时、结束时以及活动堆的大小。 |
5 MB goal | 目标堆大小。 |
4 P | 正在使用的处理器数量为4。 |
如果稍作等待,终端应该会产生如下输出:
scvg1: 57 MB released
scvg1: inuse: 1, idle: 61, sys: 63, released: 57, consumed: 5 (MB)
2
这是gctrace > 0时产生的输出。每当Go运行时将内存释放回系统(也称为清理,scavenging)时,就会生成这样一个总结。在撰写本文时,这个输出遵循以下格式:
| 输出 | 描述 |
|---|---|
scvg1: 57 MB released | 清理周期的编号。每次清理时,这个数字会递增。这个数据点还告诉我们释放回操作系统的内存块大小。 |
inuse: 1 | 程序中使用的内存大小(以MB为单位,这也可以表示部分使用的内存跨度)。 |
idle: 61 | 等待清理的内存跨度大小(以MB为单位)。 |
sys: 3 | 从系统映射的内存大小(以MB为单位)。 |
released: 57 | 释放回系统的内存大小(以MB为单位)。 |
consumed: 5 | 从系统分配的内存大小(以MB为单位)。 |
垃圾回收和清理的输出示例都很重要,它们能以一种易于阅读的方式告诉我们系统中当前的内存使用状态。
# GOGC
GOGC变量用于调整Go垃圾回收系统的强度。垃圾回收器(在https://golang.org/src/runtime/mgc.go中实例化)读取GOGC变量的值,并据此确定垃圾回收器的行为。将其设置为off会关闭垃圾回收器。这在调试时通常很有用,但从长期来看并不可行,因为程序需要释放可执行文件堆中收集的内存。将该值设置为小于默认值100会使垃圾回收器更频繁地执行;设置为大于默认值100则会使垃圾回收器执行频率降低。对于多核大型机器而言,垃圾回收往往过于频繁,如果减少其执行频率,性能可能会有所提升。我们可以通过编译标准库来观察更改垃圾回收设置对编译时间的影响。在下面的代码示例中,可以看到标准库在不同设置下的编译情况及各自的耗时:
#!/bin/bash
export GOGC=off
printf "\nBuild with GOGC=off:"
time go build -a std
printf "\nBuild with GOGC=50:"
export GOGC=50
time go build -a std
for i in 0 500 1000 1500 2000
do
printf "\nBuild with GOGC = $i:"
export GOGC=$i
time go build -a std
done
2
3
4
5
6
7
8
9
10
11
12
13
14
输出展示了Go标准库在不同设置下的编译耗时:
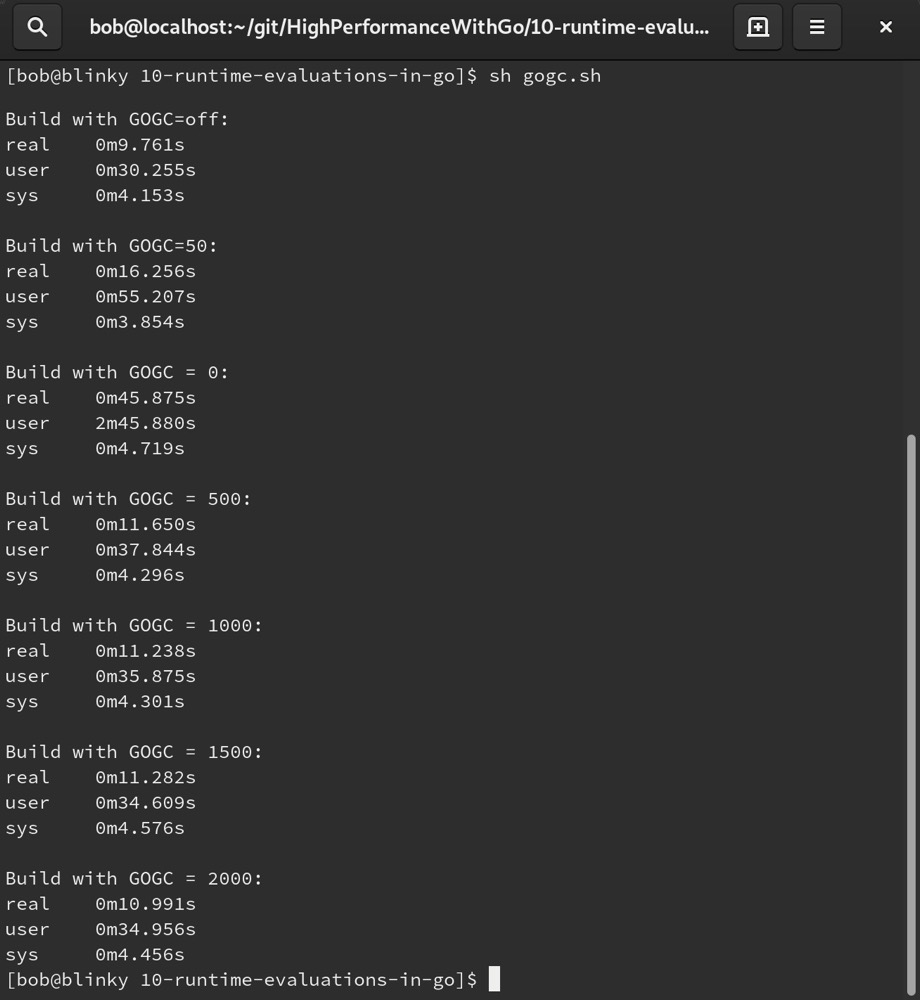
可以看到,调整垃圾回收设置会使编译时间产生巨大差异。具体情况会因架构、系统规格和Go版本的不同而有很大变化。需要认识到,这是我们在Go程序中可以调整的一个参数。在构建过程中,或者对于那些需要在执行期间榨取更多性能、对延迟敏感且受到高度监控的二进制文件而言,这个参数经常会被调整。
# GOMAXPROCS
GOMAXPROCS是一个可调整的变量,用于控制操作系统分配给Go二进制文件中Go协程(goroutine)的线程数量。默认情况下,GOMAXPROCS等于应用程序可用的核心数量。可以通过runtime包对其进行动态配置。需要注意的是,从Go 1.10版本开始,GOMAXPROCS没有上限。
如果有一个CPU密集型且并行化的函数(比如使用Go协程对字符串进行排序),调整GOMAXPROCS的值会带来显著的性能提升。在下面的代码示例中,我们将测试在设置不同GOMAXPROCS值的情况下构建标准库:
#!/bin/bash
for i in 1 2 3 4
do
export GOMAXPROCS=$i
printf "\nBuild with GOMAXPROCS=$i:"
time go build -a std
done
2
3
4
5
6
7
从结果中可以看到,调整GOMAXPROCS的总数会产生不同的效果:
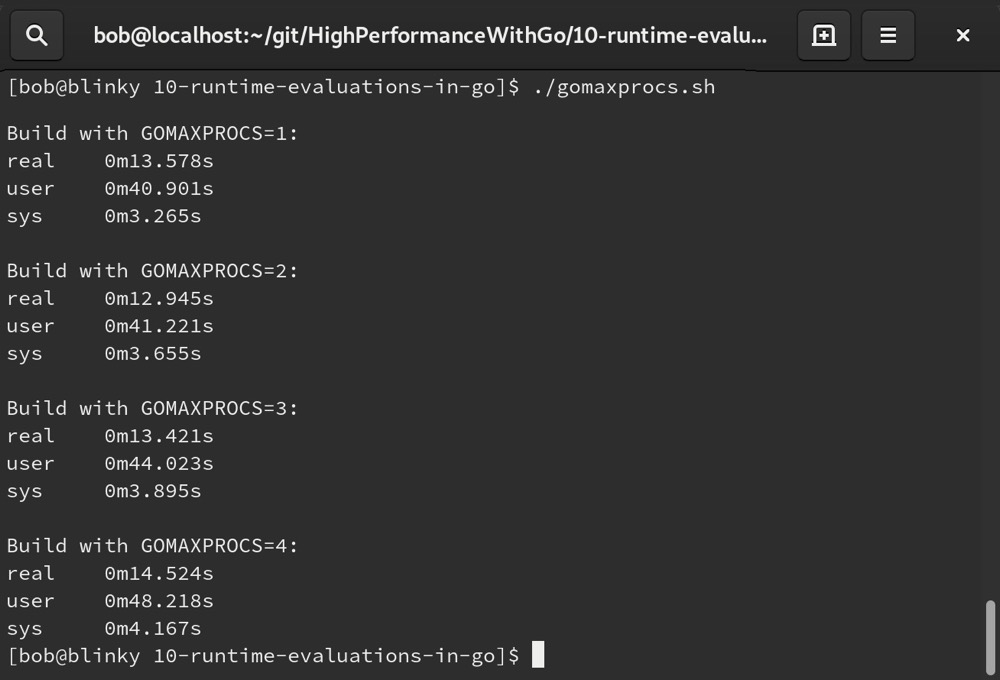
实际上,我们通常不应该手动设置GOMAXPROCS。只有在极少数情况下,比如根据系统可用资源限制特定二进制文件的CPU使用率,或者确实需要根据手头资源进行优化时,才会手动设置。然而在大多数情况下,GOMAXPROCS的默认值是合理的。
# GOTRACEBACK
GOTRACEBACK 允许你控制Go程序在出现意外运行时情况或未捕获的恐慌(panic)状态时生成的输出。设置 GOTRACEBACK 变量,你可以查看关于因特定错误或恐慌而实例化的协程(goroutine)的详细程度不同的信息。下面是一个通道/协程中断导致恐慌的示例:
package main
import (
"time"
)
func main() {
c := make(chan bool, 1)
go panicRoutine(c)
for i := 0; i < 2; i++ {
<-c
}
}
func panicRoutine(c chan bool) {
time.Sleep(100 * time.Millisecond)
panic("Goroutine Panic")
c <- true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
如果在输出中调整 GOTRACEBACK 变量,我们会看到不同详细程度的堆栈跟踪信息。设置 GOTRACEBACK=none 或 GOTRACEBACK=0 时,关于这个恐慌的信息极少:

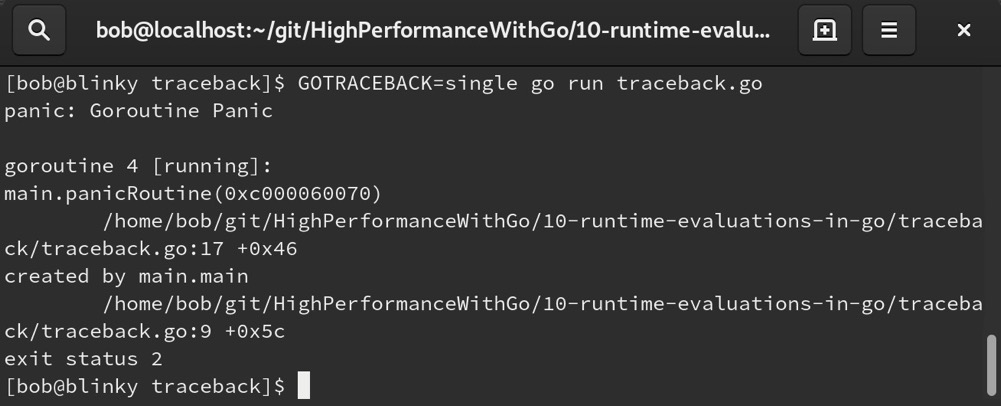
设置 GOTRACEBACK=single(Go运行时的默认选项),会为我们特定请求的当前协程生成一个单一的堆栈跟踪信息,如下所示:
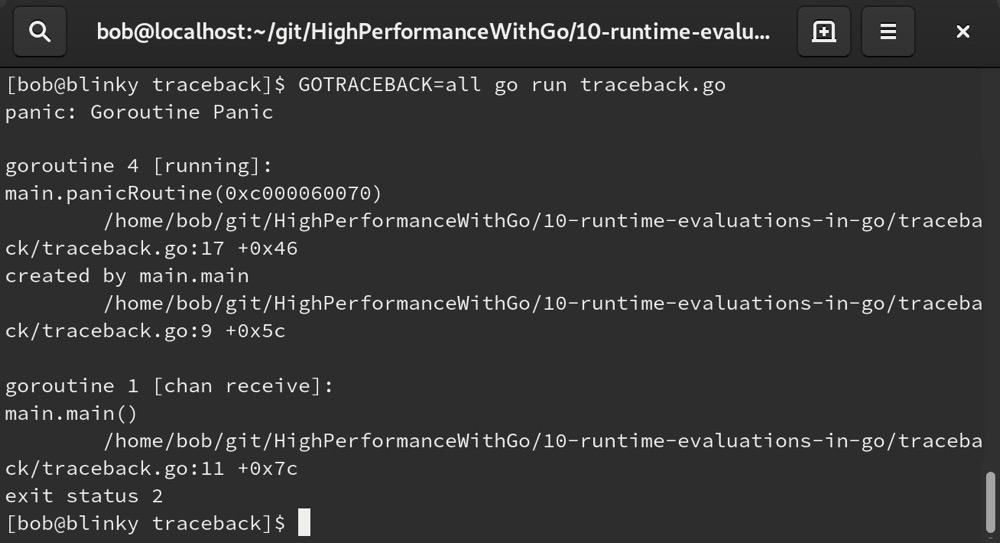
设置 GOTRACEBACK=all 或 GOTRACEBACK=1,会返回用户创建的所有协程的堆栈跟踪信息:
设置 GOTRACEBACK=system 或 GOTRACEBACK=2,会添加运行时创建的函数和协程的所有运行时堆栈帧信息。
最后,我们可以设置 GOTRACEBACK=crash。这与 system 的功能类似,但允许操作系统触发核心转储(core dump)。
大多数情况下,GOTRACEBACK=single 的默认设置能为我们提供足够的当前上下文信息,以便我们能深入了解程序为何以意外方式结束。
# Go构建缓存
在本章中,我们讨论了几种优化Go构建运行时的方法。我们还可以通过一些简单的调整来缩短Go的构建时间。Go团队一直在对运行时进行优化,而非构建时间。Go能够缓存构建时的依赖项,这有助于复用之前构建产生的通用工件。这些工件保存在 $GOPATH/pkg/ 目录中。我们在调用 go build 时使用 -i 标志,可以保留这些中间结果,以便重新利用。如果想要调试构建过程中发生的情况,可以使用 -x 标志运行构建,这样Go构建系统会输出更详细的信息。
# 管理依赖项(Vendoring dependencies)
管理依赖项也是提高构建一致性和质量的常用选择。在项目结构方面,Go语言的开发者接受了关于支持管理依赖项的反馈。将依赖项保存在仓库中会使仓库变得很大,但它有助于在构建时让第三方依赖项在本地可用。当我们使用Go 1.11及更高版本时,可以使用Go模块标志来支持基于vendor目录的构建。我们可以使用 go mod vendor 命令将所有依赖项捕获到 vendor/ 目录中,然后在构建时使用 go build -mod vendor 命令。
# 缓存和依赖项管理的改进
为了了解构建和缓存资源带来的改进,我们来构建一个包含第三方依赖项的项目。Prometheus(https://prometheus.io/ )是一个流行的时间序列数据库(也是用Go编写的),常用于指标收集。从系统的角度出发,我们可能希望在任何应用程序中启动一个Prometheus指标服务器,以便更深入地了解当前正在运行的二进制文件。为此,我们可以按如下方式导入Prometheus库:
package main
import (
"net/http"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
http.Handle("/promMetrics", promhttp.Handler())
http.ListenAndServe(":1234", nil)
}
2
3
4
5
6
7
8
9
10
11
12
在一个基本的二进制文件中实例化Prometheus服务器后,我们可以构建并执行这个二进制文件。要强制重新构建已经是最新版本的包,可以在 go build 时使用 -a 标志。如果你想知道在超长的构建时间里究竟是什么在耗费时间,还可以添加 -x 标志,它会非常详细地输出构建过程中发生的事情。
默认情况下,较新版本的Go语言会定义一个 GOCACHE。你可以使用 go env GOCACHE 查看它的位置。结合使用 GOCACHE 和 mod vendor,我们可以看到构建时间显著缩短。下面列表中的第一次构建是冷启动构建,会强制重新构建包以确保它们是最新的。第二次构建由于 mod vendor 存储了一些内容,速度快了很多。第三次构建应该缓存了大部分构建元素,相比之下非常迅速。如下截图展示了这一情况:
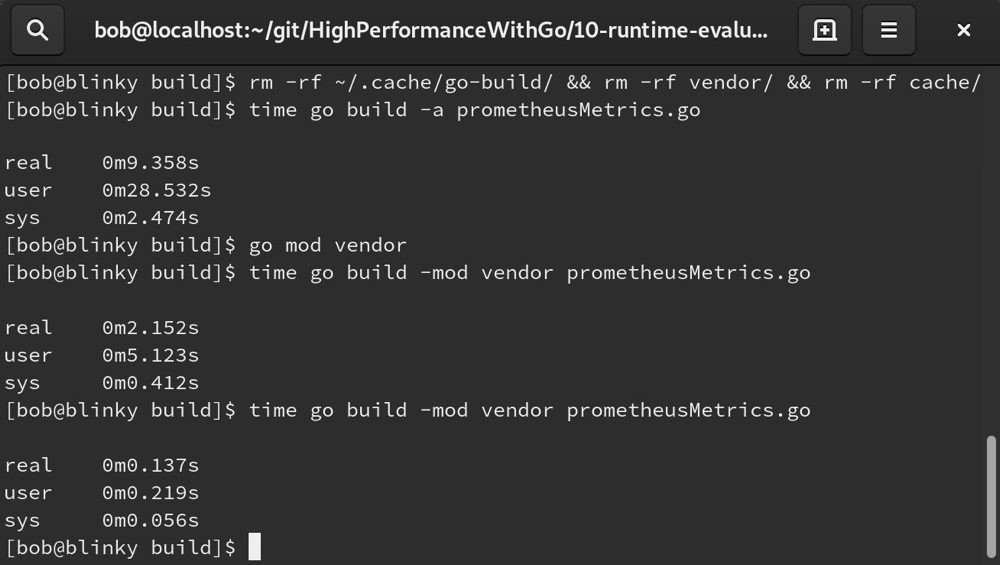
# 调试(Debug)
运行时(runtime)中的 debug 包为我们提供了许多用于调试的函数和类型。我们可以进行以下操作:
- 使用
FreeOSMemory()强制进行垃圾回收。 - 使用
PrintStack()将堆栈跟踪信息打印到标准错误输出(stderr)。 - 使用
ReadGCStats()读取垃圾回收统计信息。 - 使用
SetGCPercent()设置垃圾回收百分比。 - 使用
SetMaxStack()设置单个协程的最大堆栈大小。 - 使用
SetMaxThreads()设置操作系统线程的最大数量。 - 使用
SetPanicOnFault()控制在遇到意外地址错误时的运行时行为。 - 使用
SetTraceback()设置堆栈跟踪信息的数量。 - 使用
Stack()返回协程的堆栈跟踪信息。 - 使用
WriteHeapDump()写入堆转储(heap dump)信息。
# PProf/race/trace
我们将分别在第12章“分析Go代码性能”和第13章“跟踪Go代码”中详细介绍Go程序的性能分析(profiling)和跟踪(tracing)。需要注意的是,运行时库是这些工具的关键驱动因素。能够使用 pprof/race/trace 有助于你有效地调试代码并发现潜在错误。在下一节中,我们将学习运行时函数,以及它们对Go运行时库的重要性。
# 理解函数
Go运行时库还提供了一些函数,你可以将它们注入到程序的运行时,以输出运行时数据。下面我们来看几个典型的例子。所有可用的运行时函数的完整列表可以在https://golang.org/pkg/runtime/#pkg-index找到。这个包中的许多函数也包含在 runtime/pprof 包中,我们将在第12章“分析Go代码性能”中更详细地研究这个包。
# KeepAlive
runtime.KeepAlive()函数接受interface{}类型的参数,并确保传递给它的对象不会被释放,且其终结器(由runtime.SetFinalizer定义)不会被执行。这使得传递给KeepAlive的参数能够保持可达状态。编译器会设置OpKeepAlive,如静态单赋值(Static Single Assignment,SSA)包中所定义(https://golang.org/src/cmd/compile/internal/gc/ssa.go#L2947 ),这使得编译器能够了解接口作为变量的状态,并维持对象的存活上下文。
一般来说,在正常的实现中我们不应该调用KeepAlive。它用于确保垃圾回收器不会回收函数中不再被引用的值所占用的内存。
# NumCPU
NumCPU函数返回当前进程可用的逻辑CPU数量。
当二进制文件被调用时,运行时会在启动时验证可用的CPU数量。下面的代码片段展示了一个简单示例:
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Println("Number of CPUs Available: ", runtime.NumCPU())
}
2
3
4
5
6
7
8
9
10
现在,我们可以看到当前进程可用的CPU数量。在我的机器上,这个值是4:

通过这个示例,我们可以知道我的计算机有4个可用的CPU。
# ReadMemStats
ReadMemStats()函数用于读取内存分配器的统计信息,并将这些信息填充到一个变量(比如m)中。MemStats结构体包含了许多关于运行时内存使用情况的非常有价值的信息。让我们深入了解一下它能为我们提供哪些值。一个HTTP处理函数可以帮助我们查看二进制文件的内存使用情况,当我们在系统中发出更多请求并希望了解内存分配的使用位置时,这个函数会很有用:
- 首先,我们实例化程序和函数:
package main
import (
"fmt"
"net/http"
"runtime"
)
func memStats(w http.ResponseWriter, r *http.Request) {
var memStats runtime.MemStats
runtime.ReadMemStats(&memStats)
2
3
4
5
6
7
8
9
10
11
- 接下来,我们可以打印运行时提供给我们的各个内存统计值。让我们从
Alloc、Mallocs和Frees开始:
fmt.Fprintln(w, "Alloc:", memStats.Alloc)
fmt.Fprintln(w, "Total Alloc:", memStats.TotalAlloc)
fmt.Fprintln(w, "Sys:", memStats.Sys)
fmt.Fprintln(w, "Lookups:", memStats.Lookups)
fmt.Fprintln(w, "Mallocs:", memStats.Mallocs)
fmt.Fprintln(w, "Frees:", memStats.Frees)
2
3
4
5
6
- 现在,让我们查看堆(heap)信息:
fmt.Fprintln(w, "Heap|Alloc:", memStats.HeapAlloc)
fmt.Fprintln(w, "Heap|Sys:", memStats.HeapSys)
fmt.Fprintln(w, "Heap|Idle:", memStats.HeapIdle)
fmt.Fprintln(w, "Heap|In Use:", memStats.HeapInuse)
fmt.Fprintln(w, "Heap|Released:", memStats.HeapReleased)
fmt.Fprintln(w, "Heap|Objects:", memStats.HeapObjects)
2
3
4
5
6
- 接下来,我们查看栈(stack)/跨度(span)/缓存(cache)/桶(bucket)的分配情况:
fmt.Fprintln(w, "Stack In Use:", memStats.StackInuse)
fmt.Fprintln(w, "Stack Sys:", memStats.StackSys)
fmt.Fprintln(w, "MSpanInuse:", memStats.MSpanInuse)
fmt.Fprintln(w, "MSpan Sys:", memStats.MSpanSys)
fmt.Fprintln(w, "MCache In Use:", memStats.MCacheInuse)
fmt.Fprintln(w, "MCache Sys:", memStats.MCacheSys)
fmt.Fprintln(w, "Buck Hash Sys:", memStats.BuckHashSys)
2
3
4
5
6
7
- 然后,我们查看垃圾回收信息:
fmt.Fprintln(w, "EnableGC:", memStats.EnableGC)
fmt.Fprintln(w, "GCSys:", memStats.GCSys)
fmt.Fprintln(w, "Other Sys:", memStats.OtherSys)
fmt.Fprintln(w, "Next GC:", memStats.NextGC)
fmt.Fprintln(w, "Last GC:", memStats.LastGC)
fmt.Fprintln(w, "Num GC:", memStats.NumGC)
fmt.Fprintln(w, "Num Forced GC:", memStats.NumForcedGC)
2
3
4
5
6
7
- 现在,让我们查看垃圾回收中断信息:
fmt.Fprintln(w, "Pause Total NS:", memStats.PauseTotalNs)
fmt.Fprintln(w, "Pause Ns:", memStats.PauseNs)
fmt.Fprintln(w, "Pause End:", memStats.PauseEnd)
fmt.Fprintln(w, "GCCPUFraction:", memStats.GCCPUFraction)
fmt.Fprintln(w, "BySize Size:", memStats.BySize)
2
3
4
5
- 接下来,我们实例化一个简单的HTTP服务器:
func main() {
http.HandleFunc("/", memStats)
http.ListenAndServe(":1234", nil)
}
2
3
4
在这里,我们可以使用Apache bench工具对内存分配器产生一些负载:
ab -n 1000 -c 1000 http://localhost:1234/
最后,通过向localhost:1234发出请求,我们可以看到一些活跃的HTTP服务器信息以及响应:
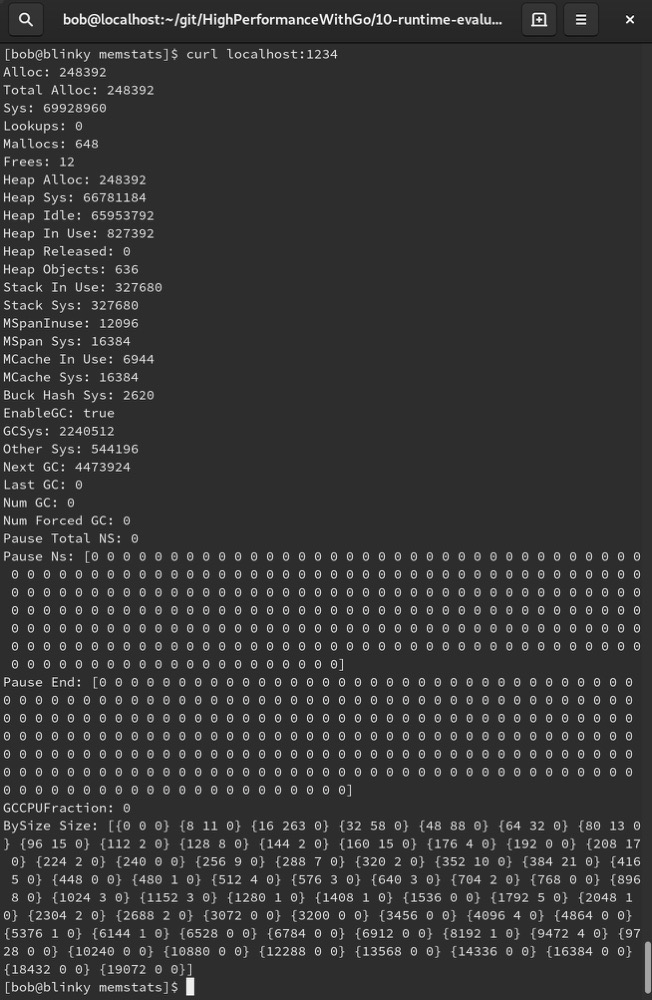
所有MemStats值的定义可以在文档 https://golang.org/pkg/runtime/#MemStats 中找到。
# 总结
在本章中,我们学习了GODEBUG、GCTRACE、GOGC、GOMAXPROCS和GOTRACEBACK这些运行时优化选项。我们还了解了GOBUILDCACHE和Go语言的供应商依赖管理。最后,我们学习了如何调试以及从代码中调用运行时函数。在排查Go代码问题时使用这些技术,将帮助你更轻松地发现问题和瓶颈。
在下一章中,我们将讨论有效部署Go代码的正确方法。