 13 跟踪Go代码
13 跟踪Go代码
# 13 跟踪Go代码
跟踪Go程序是检查Go程序中函数与服务之间互操作性的绝佳方式。跟踪能够让你在系统中传递上下文信息,并评估程序在哪些地方出现了阻塞,无论是因为第三方API调用、缓慢的消息队列,还是一个时间复杂度为O(n²)的函数。跟踪将帮助你找到瓶颈所在。在本章中,我们将学习以下内容:
- 实现跟踪的过程
- 跟踪中的采样过程
- 解读跟踪结果的过程
- 比较跟踪结果的过程
能够实现跟踪并解读结果,有助于开发者理解和排查分布式系统中的问题。
# 实现跟踪检测
Go语言的并发模型使用协程(goroutines),功能非常强大。但高并发也存在一个缺点,那就是在调试这种高并发模型时会遇到困难。为了避免这种困难,Go语言的开发者创建了go tool trace工具。该工具在Go 1.5版本中发布,用于调查和解决并发问题。Go跟踪工具会挂钩到协程调度器上,以便能够生成关于协程的有用信息。使用Go跟踪工具,你可能想要研究的一些实现细节包括:
- 延迟(Latency)
- 资源竞争(Contention of resources)
- 并行性不佳(Poor parallelism)
- 与I/O相关的事件(I/O-related events)
- 系统调用(Syscalls)
- 通道(Channels)
- 锁(Locks)
- 垃圾回收(Garbage Collection,GC)
- 协程(Goroutines)
排查所有这些问题将帮助你构建一个更具弹性的分布式系统。在下一节中,我们将讨论跟踪格式以及它如何应用于Go代码。
# 理解跟踪格式
Go语言的跟踪信息可能包含大量内容,并且每秒可以捕获许多请求。因此,跟踪信息以二进制格式捕获。跟踪输出的结构是固定的。在以下输出中,我们可以看到跟踪信息遵循特定的模式 —— 它们被定义,并且事件通过十六进制前缀和一些关于特定跟踪事件的信息进行分类。了解这种跟踪格式有助于我们理解如何使用Go团队提供的工具来存储和检索跟踪事件:
Trace = "gotrace" Version {Event} .
Event = EventProcStart | EventProcStop | EventFreq | EventStack |
EventGomaxprocs | EventGCStart | EventGCDone | EventGCScanStart |
EventGCScanDone | EventGCSweepStart | EventGCSweepDone | EventGoCreate |
EventGoStart | EventGoEnd | EventGoStop | EventGoYield | EventGoPreempt |
EventGoSleep | EventGoBlock | EventGoBlockSend | EventGoBlockRecv |
EventGoBlockSelect | EventGoBlockSync | EventGoBlockCond | EventGoBlockNet |
EventGoUnblock | EventGoSysCall | EventGoSysExit | EventGoSysBlock |
EventUser | EventUserStart | EventUserEnd .
EventProcStart = "\x00" ProcID MachineID Timestamp .
EventProcStop = "\x01" TimeDiff .
EventFreq = "\x02" Frequency .
EventStack = "\x03" StackID StackLen {PC} .
EventGomaxprocs = "\x04" TimeDiff Procs .
EventGCStart = "\x05" TimeDiff StackID .
EventGCDone = "\x06" TimeDiff .
EventGCScanStart= "\x07" TimeDiff .
EventGCScanDone = "\x08" TimeDiff .
EventGCSweepStart = "\x09" TimeDiff StackID .
EventGCSweepDone= "\x0a" TimeDiff .
EventGoCreate = "\x0b" TimeDiff GoID PC StackID .
EventGoStart = "\x0c" TimeDiff GoID .
EventGoEnd = "\x0d" TimeDiff .
EventGoStop = "\x0e" TimeDiff StackID .
EventGoYield = "\x0f" TimeDiff StackID .
EventGoPreempt = "\x10" TimeDiff StackID .
EventGoSleep = "\x11" TimeDiff StackID .
EventGoBlock = "\x12" TimeDiff StackID .
EventGoBlockSend= "\x13" TimeDiff StackID .
EventGoBlockRecv= "\x14" TimeDiff StackID .
EventGoBlockSelect = "\x15" TimeDiff StackID .
EventGoBlockSync= "\x16" TimeDiff StackID .
EventGoBlockCond= "\x17" TimeDiff StackID .
EventGoBlockNet = "\x18" TimeDiff StackID .
EventGoUnblock = "\x19" TimeDiff GoID StackID .
EventGoSysCall = "\x1a" TimeDiff StackID .
EventGoSysExit = "\x1b" TimeDiff GoID .
EventGoSysBlock = "\x1c" TimeDiff .
EventUser = "\x1d" TimeDiff StackID MsgLen Msg .
EventUserStart = "\x1e" TimeDiff StackID MsgLen Msg .
EventUserEnd = "\x1f" TimeDiff StackID MsgLen Msg .
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
有关Go执行跟踪器的更多信息,可以在Dmitry Vyukov发布的原始规范文档中找到,文档链接为 https://docs.google.com/document/u/1/d/1FP5apqzBgr7ahCCgFO-yoVhk4YZrNIDNf9RybngBc14/pub (opens new window) 。
能够查看跟踪信息的所有这些元素,有助于我们理解如何将跟踪信息分解为原子块。在下一节中,我们将讨论跟踪信息的收集。
# 理解跟踪信息收集
能够收集跟踪信息是在分布式系统中实现跟踪的关键。如果我们不在某个地方聚合这些跟踪信息,就无法大规模地理解它们的意义。我们可以通过三种方法收集跟踪数据:
- 手动调用
trace.Start和trace.Stop来触发数据跟踪。 - 使用测试标志
-trace=[OUTPUTFILE]。 - 使用
runtime/trace包进行检测。
为了理解如何在代码中实现跟踪,我们来看一个简单的示例程序:
- 首先实例化包并导入必要的包:
package main
import (
"os"
"runtime/trace"
)
2
3
4
5
6
- 然后调用
main函数。我们将跟踪输出写入一个文件trace.out,稍后会用到这个文件:
func main() {
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
2
3
4
5
6
- 接下来,实现我们想要在程序中使用的跟踪功能,并在函数返回时延迟结束跟踪:
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
2
3
4
5
- 然后编写我们想要实现的代码。这里的示例只是在一个匿名函数中通过通道传递字符串“Hi Gophers”:
ch := make(chan string)
go func() {
ch <- "Hi Gophers"
}()
<-ch
2
3
4
5
现在我们已经在(诚然很简单的)程序中实现了跟踪功能,需要执行程序以生成跟踪输出:

- 要查看跟踪信息,可能需要安装额外的包。在我测试的Fedora系统上,我必须安装
golang-misc包:sudo dnf install golang-misc。 - 创建跟踪信息后,可以使用
go tool trace trace.out命令打开创建的跟踪信息。
这将启动一个HTTP服务器,用于提供跟踪输出。我们可以在以下截图中看到该输出:

我们可以在Chrome浏览器中查看跟踪输出结果。需要注意的是,我们需要使用兼容的浏览器,即Chrome浏览器。在撰写本书时,Firefox浏览器打开跟踪输出会显示空白页面。以下是在Chrome浏览器中跟踪输出的界面:
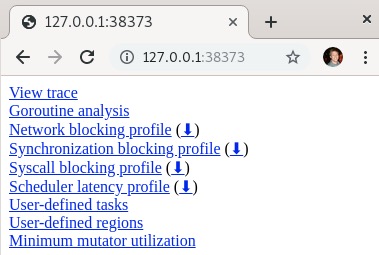
这个HTML页面提供了许多不同且有用的输出选项。让我们在下面的表格中逐一查看:
| 链接 | 描述 |
|---|---|
| View trace | 查看图形用户界面(GUI)形式的跟踪输出。 |
| Goroutine analysis | 显示不同的协程信息。 |
| Network blocking profile | 显示网络阻塞情况;可以创建单独的分析报告。 |
| Synchronization blocking profile | 显示同步阻塞情况;可以创建单独的分析报告。 |
| Syscall blocking profile | 显示系统调用阻塞情况;可以创建单独的分析报告。 |
| Scheduler latency profile | 显示与调度器相关的所有延迟;可以创建单独的分析报告。 |
| User-defined tasks | 允许查看任务数据类型;用于跟踪用户定义的逻辑操作。使用trace.NewTask()格式进行调用。 |
| User-defined regions | 允许查看区域数据类型;用于跟踪一段代码区域。使用trace.WithRegion()格式进行调用。 |
| Minimum mutator utilization | 创建一个可视化图表,展示垃圾回收器在何时何地从程序中抢占工作。这有助于了解生产服务是否受垃圾回收的限制。 |
我们可以先在网页浏览器中查看跟踪信息:
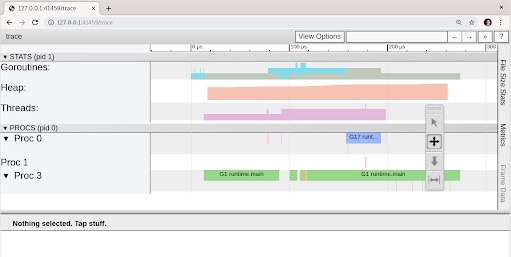
查看这些跟踪信息时,我们首先能做的一件事是查看帮助菜单,它位于屏幕右上角的问号图标处。这个信息菜单详细介绍了跟踪工具的各项功能:
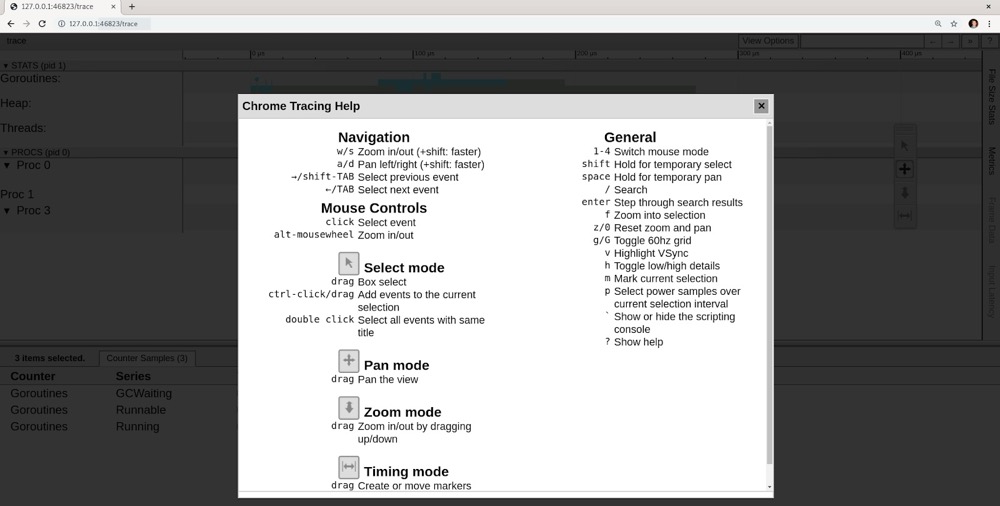
能够在跟踪窗口中快速有效地进行操作,有助于你快速浏览跟踪信息。当你试图快速排查生产环境中的问题时,这会非常有用。
# 在跟踪窗口中操作
借鉴许多第一人称角色扮演电子游戏的操作方式,我们可以使用经典的WASD按键在跟踪信息中进行移动。这些按键的功能如下:
- W键:放大跟踪的时间窗口。
- S键:缩小时间窗口。
- A键:时间回溯。
- D键:时间前进。 我们也可以通过点击并拖动鼠标来实现时间的前后移动。
使用鼠标指针选择或点击数字键,可用于操作时间信息。数字键的功能如下:
- 1键:用于选择想要检查的跟踪部分。
- 2键:用于平移视图。
- 3键:调用缩放功能。
- 4键:用于选择特定的时间点。 现在,我们可以使用“/”键在跟踪信息中搜索,按回车键浏览搜索结果。
屏幕右侧还提供文件大小统计、指标、帧数据和输入延迟窗口。点击这些按钮会弹出一个窗口,展示跟踪信息中各项具体统计数据的更多详细内容。
如果点击跟踪信息中“goroutines”(Go协程)行的蓝色区域,就能查看一些Go协程的相关统计信息:
- “GCWaiting”:等待垃圾回收运行的次数(当前值为0)。
- 可运行的Go协程数量(当前值为1)。
- 正在运行的Go协程数量(当前值为1)。
下面的截图展示了部分Go协程的统计信息示例:
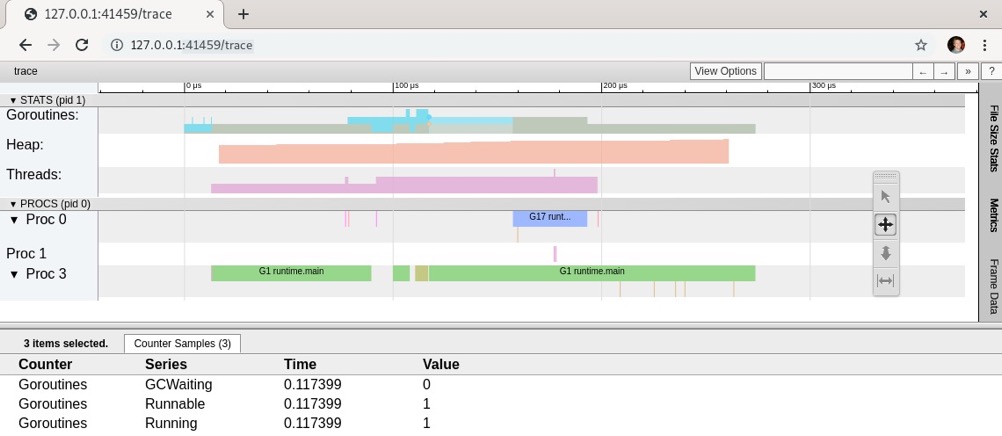
Go协程的信息对终端用户调试程序很有帮助。在Go跟踪工具中观察Go协程,有助于我们判断某个Go协程何时出现竞争。它可能在等待通道清空,可能被系统调用阻塞,也可能被调度器阻塞。如果有大量Go协程处于等待状态,这意味着程序可能创建了过多的Go协程,进而导致调度器资源分配过度。掌握这些信息,能帮助我们做出明智决策,优化程序,更有效地利用Go协程。
点击“Heap”(堆)行的橙色条,会显示堆的信息:
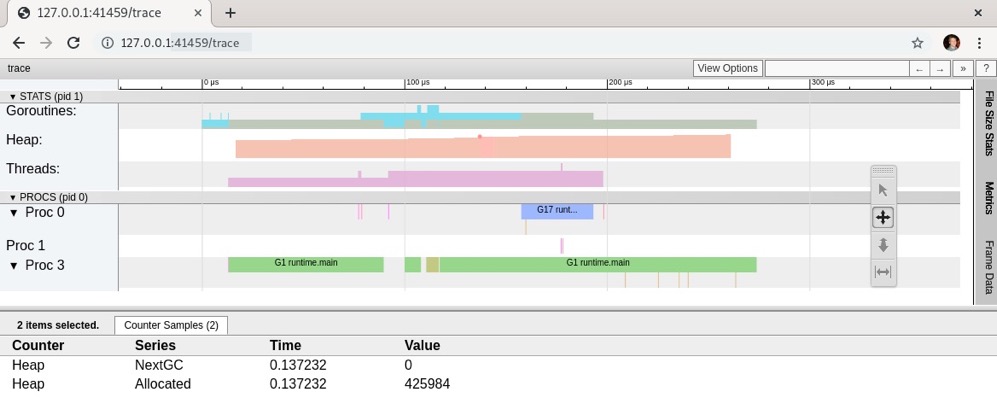
在选定的时间点(0.137232),我们可以看到堆分配了425984字节,约425KB。了解当前分配给堆的内存量,有助于判断程序中是否存在内存竞争问题。正如我们在第12章“Go代码性能分析”中所学,性能分析通常是查看堆信息的更好方法,但在跟踪信息的背景下对内存分配有一个大致了解也常常很有帮助。
接下来,我们查看线程信息。点击活动线程(跟踪信息中“Threads”行的品红色块),会显示处于“InSyscall”和“Running”状态的线程数量:
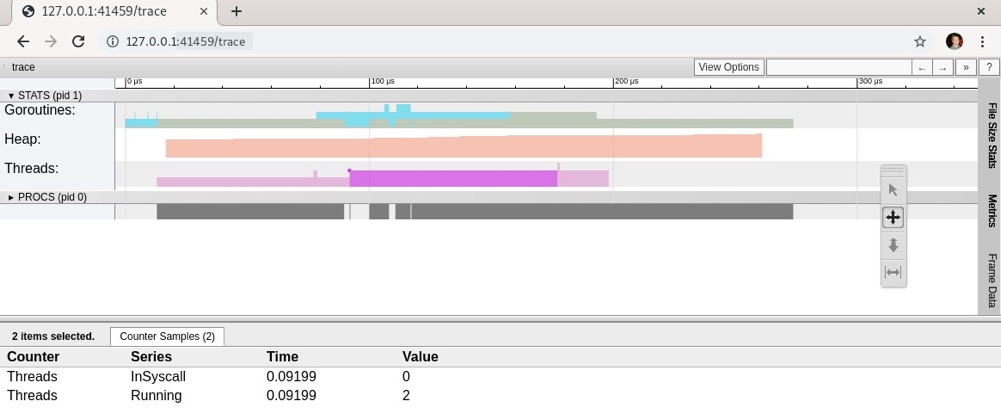
了解正在运行的操作系统线程数量以及当前被系统调用阻塞的线程数量,会很有帮助。
接下来,我们可以查看每个正在运行的进程。点击进程,会显示如下截图中的所有详细信息。如果将鼠标悬停在跟踪信息底部窗格的某个事件上,就能看到进程之间的关联,如下截图中的红色箭头所示:
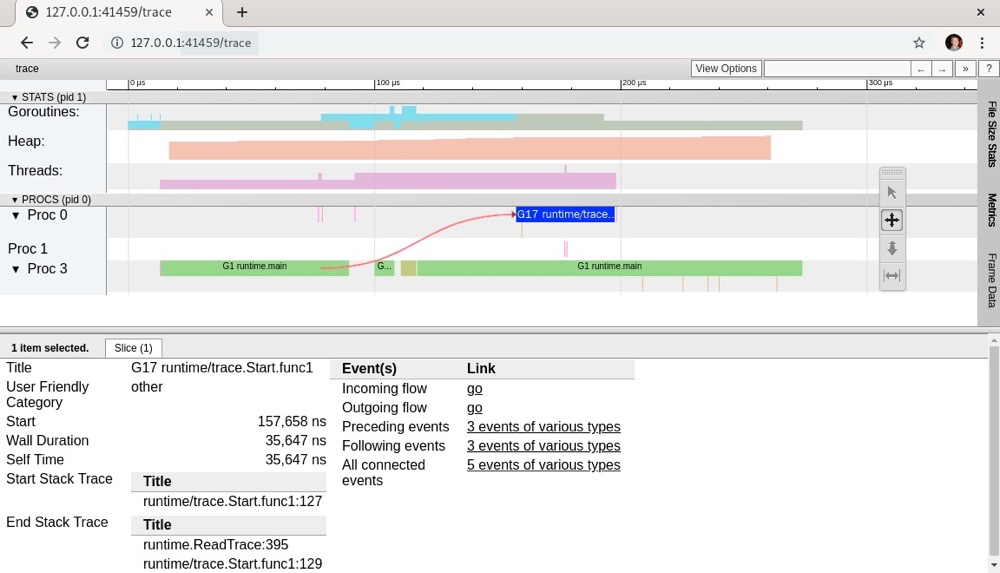
了解进程的端到端流程,通常有助于诊断有问题的进程。在下一节中,我们将学习如何探索类似pprof的跟踪信息。
# 探索类似pprof的跟踪信息
Go工具跟踪(Go tool trace)还能生成四种不同类型的跟踪信息,这些信息可能与你的故障排查需求相关:
net:网络阻塞分析(network-blocking profile)。sync:同步阻塞分析(synchronization-blocking profile)。syscall:系统调用阻塞分析(syscall-blocking profile)。sched:调度器延迟分析(scheduler-latency profile)。
下面来看一个在Web服务器上使用这些跟踪分析的示例:
- 首先,初始化
main函数并导入必要的包。注意_ "net/http/pprof"中使用的空白标识符,用于明确包名,确保我们能够进行跟踪调用:
package main
import (
"io"
"net/http"
_ "net/http/pprof"
"time"
)
2
3
4
5
6
7
8
- 接着,设置一个简单的Web服务器,它会等待5秒钟,然后向终端用户返回一个字符串:
func main() {
handler := func(w http.ResponseWriter, req *http.Request) {
time.Sleep(5 * time.Second)
io.WriteString(w, "Network Trace Profile Test")
}
http.HandleFunc("/", handler)
http.ListenAndServe(":1234", nil)
}
2
3
4
5
6
7
8
- 执行
go run netTracePprof.go运行服务器后,我们可以进行跟踪:curl localhost:1234/debug/pprof/trace?seconds=10 > trace.out。下面的截图展示了curl命令的输出: 
- 同时,在另一个终端中,我们向示例Web服务器的“/”路径发出请求:
curl localhost:1234/。之后,在运行跟踪命令的目录中会生成一个trace.out文件。然后,我们可以使用go tool trace trace.out打开跟踪结果。这样就能看到跟踪结果。
利用生成的HTTP页面中的网络阻塞分析,我们可以查看网络阻塞的跟踪信息:
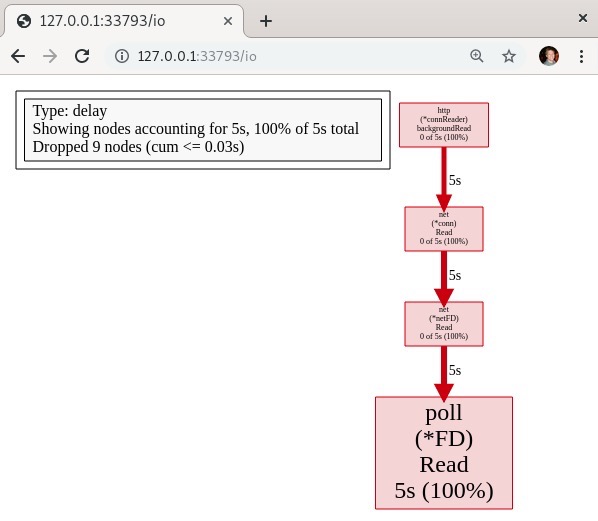
不出所料,我们看到了5秒钟的等待时间,这正是我们在处理这个特定Web请求的处理函数中设置的等待时长。如果需要,我们可以下载这个分析文件,并使用第12章“Go代码性能分析”中讨论的上游pprof工具进行查看。在跟踪结果的HTML窗口中,网页分析旁边有一个下载按钮:
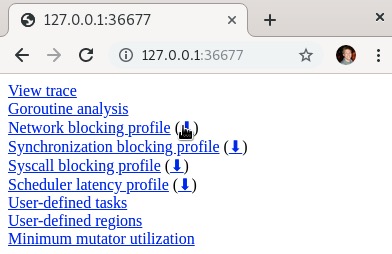
下载这个分析文件后,我们可以使用第12章中安装的上游pprof工具进行查看:
$ pprof -http=:1235 ~/Downloads/io.profile
然后,我们可以查看火焰图(flame graph)等内容:
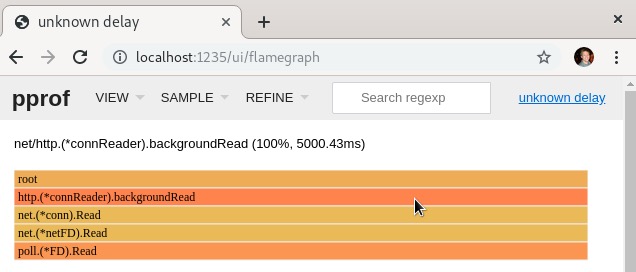
下面的截图展示了“peek UI”的界面:
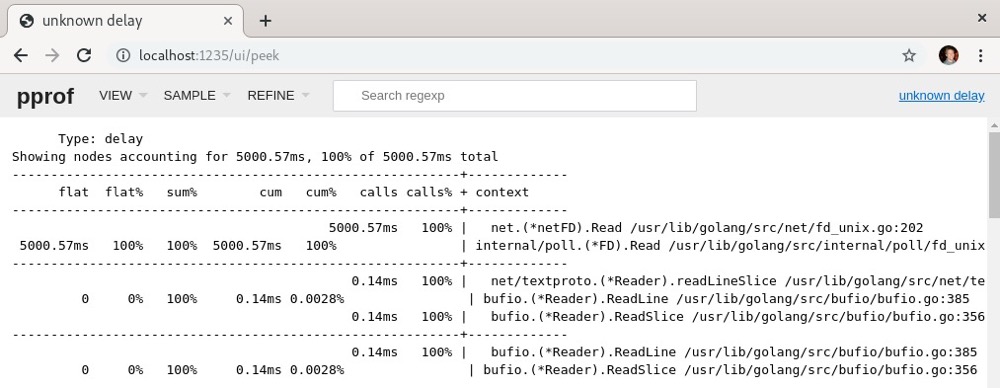
火焰图和“peek UI”都有助于让这些复杂的调试视图变得更加简洁明了。在下一节中,我们将了解Go语言中的分布式跟踪(distributed tracing)是什么。
# Go语言分布式追踪
为Go程序实现并研究单个追踪(traces)是一项很有价值的工作,它能针对程序请求产生的数据提供大量输出信息。随着企业拥有越来越多的分布式代码库,其中复杂的调用相互交织,从长远来看,单独追踪每个调用变得难以实现。有两个项目致力于为Go语言的分布式追踪提供帮助,它们分别是OpenCensus Go库和OpenTelemetry库:
这些项目的维护者决定将这两个项目合并,共同开发一个名为OpenTelemetry的代码库。这个新代码库将简化分布式追踪在多种语言和基础设施中的集成。你可以在https://github.com/open-telemetry/opentelemetry-go上了解更多关于OpenTelemetry在Go语言中的实现。
在撰写本书时,OpenTelemetry尚未准备好用于生产环境。OpenTelemetry将与OpenCensus和OpenTracing保持向后兼容,并且还会提供安全补丁。在本书的下一部分,我们将探讨如何使用OpenCensus实现Go程序。未来,利用我们在介绍OpenCensus实现追踪时所讨论的策略,使用OpenTelemetry实现程序应该会相对简单。
在下一节中,我们将了解如何为应用程序实现OpenCensus。
# 为应用程序实现OpenCensus
让我们通过一个实际示例来展示如何在应用程序中使用OpenCensus进行追踪。首先,我们要确保在机器上安装了Docker。你可以参考https://docs.docker.com/上的安装文档,确保Docker已正确安装并能在你的机器上正常运行。完成安装后,我们就可以开始创建、实现并查看一个示例应用程序了。安装好Docker后,我们可以拉取用于检测的重要镜像。在我们的示例中,将使用Redis(一种键值存储)在应用程序中存储键值事件,并使用Zipkin(一个分布式追踪系统)来查看这些追踪信息。
让我们拉取这个项目所需的依赖项:
- Redis,我们将在示例应用中使用的键值存储:
docker pull redis:latest
- Zipkin,一个分布式追踪系统:
docker pull openzipkin/zipkin
- 启动Redis服务器并让它在后台运行:
docker run -it -d -p 6379:6379 redis
- 对Zipkin服务器执行相同操作:
docker run -it -d -p 9411:9411 openzipkin/zipkin
准备好所有依赖项后,我们就可以开始编写应用程序了:
- 首先,实例化主包并添加必要的导入:
package main
import (
"context"
"log"
"net/http"
"time"
"contrib.go.opencensus.io/exporter/zipkin"
"go.opencensus.io/trace"
"github.com/go-redis/redis"
"github.com/openzipkin/zipkin-go"
"github.com/openzipkin/zipkin-go/reporter/http"
)
2
3
4
5
6
7
8
9
10
11
12
13
14
- 我们的
tracingServer函数定义了以下内容:- 设置一个新的Zipkin端点。
- 初始化一个新的HTTP报告器,这是我们发送跨度(spans)的端点。
- 设置一个新的导出器,它返回一个
trace.Exporter(这就是我们将跨度上传到Zipkin服务器的方式)。 - 向追踪处理程序注册我们的导出器。
- 应用采样率配置。在这个示例中,我们将示例设置为始终进行追踪,但也可以将其设置为仅对较小比例的请求进行追踪:
func tracingServer() {
l, err := zipkin.NewEndpoint("oc-zipkin", "192.168.1.5:5454")
if err != nil {
log.Fatalf("Failed to create the local zipkinEndpoint: %v", err)
}
r := http.NewReporter("http://localhost:9411/api/v2/spans")
z := zipkin.NewExporter(r, l)
trace.RegisterExporter(z)
trace.ApplyConfig(trace.Config{DefaultSampler: trace.AlwaysSample()})
}
2
3
4
5
6
7
8
9
10
- 在
makeRequest函数中,我们执行以下操作:- 创建一个新的跨度。
- 向给定的HTTP URL发出请求。
- 设置睡眠超时时间以模拟额外的延迟。
- 为跨度添加注释。
- 返回响应状态:
func makeRequest(ctx context.Context, url string) string {
log.Printf("Retrieving URL")
_, span := trace.StartSpan(ctx, "httpRequest")
defer span.End()
res, _ := http.Get(url)
defer res.Body.Close()
time.Sleep(100 * time.Millisecond)
log.Printf("URL Response : %s", res.Status)
span.Annotate([]trace.Attribute{
trace.StringAttribute("URL Response Code", res.Status),
}, "HTTP Response Status Code:"+res.Status)
time.Sleep(50 * time.Millisecond)
return res.Status
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 在
writeToRedis函数中,我们执行以下操作:- 启动一个新的跨度。
- 连接到本地Redis服务器。
- 设置特定的键值对:
func writeToRedis(ctx context.Context, key string, value string) {
log.Printf("Writing to Redis")
_, span := trace.StartSpan(ctx, "redisWrite")
defer span.End()
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
err := client.Set(key, value, 0).Err()
if err != nil {
panic(err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 然后,我们在主函数中将这些功能整合起来:
func main() {
tracingServer()
ctx, span := trace.StartSpan(context.Background(), "main")
defer span.End()
for i := 0; i < 10; i++ {
url := "https://golang.org/"
respStatus := makeRequest(ctx, url)
writeToRedis(ctx, url, respStatus)
}
}
2
3
4
5
6
7
8
9
10
- 执行
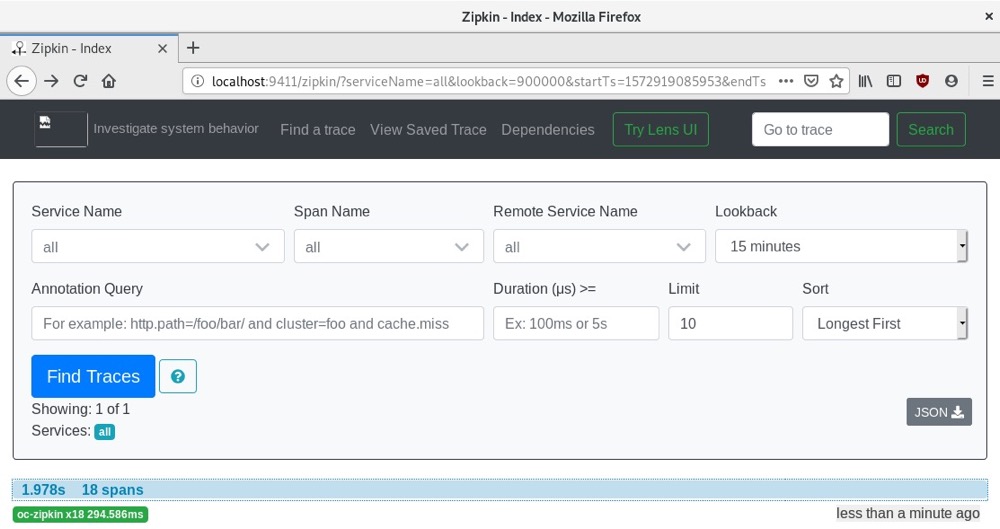
go run ocZipkin.go运行程序后,我们可以查看Zipkin服务器。如果从追踪列表中选择其中一个追踪,就能看到创建的追踪信息:
- 如果点击其中一个跨度,我们可以进一步查看详细信息:
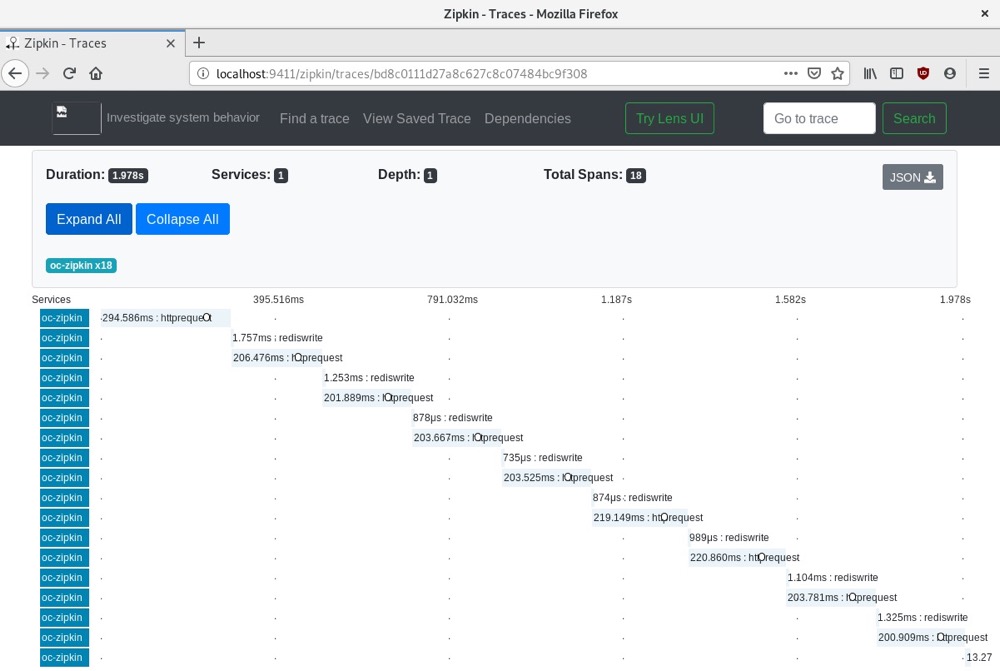
我们可以看到代码中对httprequest和rediswrite函数的调用。随着我们在代码中实现更多的跨度,追踪信息会越来越详细,这将帮助我们诊断代码中哪些地方延迟最大。
如果点击追踪中的单个元素,我们可以看到在代码中编写的注释:
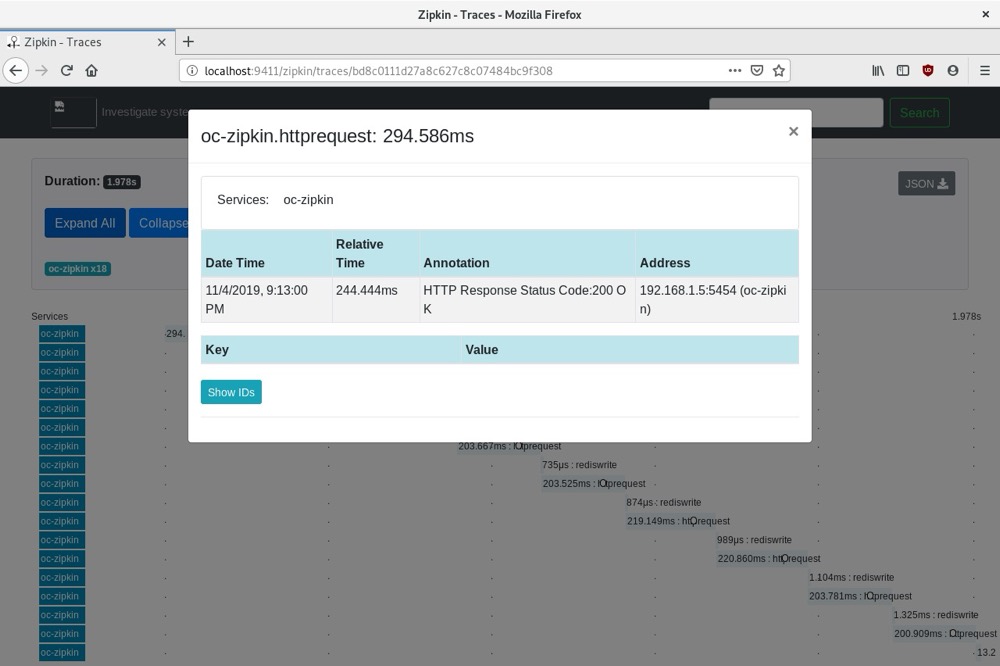
当我们试图了解最终用户的特定行为时,注释会很有用。我们还可以看到traceId、spanId和parentId的详细信息。
# 总结
在本章中,我们全面学习了追踪相关的知识。我们了解了如何在特定代码段上实现单个追踪并进行分析,以理解其行为。我们还学习了如何实现和分析分布式追踪,以发现分布式系统中的问题。掌握这些技能将有助于调试分布式系统,进而在排查分布式系统故障时缩短平均故障解决时间(MTTR,Mean Time To Resolution)。
在第14章“集群和作业队列”中,我们将学习如何评估集群和作业队列,以进行性能优化。