 14 集群与作业队列
14 集群与作业队列
# 14 集群与作业队列
在Go语言中,集群和作业队列是让分布式系统同步工作并传递一致消息的有效方式。分布式计算难度较大,在集群和作业队列中留意潜在的性能优化至关重要。
本章我们将学习以下内容:
- 使用层次聚类和质心算法进行聚类
- 将Goroutine用作队列
- 把带缓冲的通道当作作业队列
- 实现第三方队列系统(Kafka和RabbitMQ)
了解不同的聚类系统有助于识别数据集中的大规模数据组,并准确对其分类。学习队列系统能帮助你将大量信息从数据结构转移到特定的队列机制中,从而实时将大量数据传递给不同系统。
# Go语言中的聚类
聚类是一种方法,可用于在给定的数据集中查找具有一致性的数据组。通过比较技术,我们能在数据集中寻找具有相似特征的项目组。然后,这些单独的数据点会被划分为不同的簇。聚类通常用于解决多目标问题。
聚类一般分为两类,每类又有不同的子类:
- 硬聚类(Hard clustering):数据集中的数据点要么明确属于某个簇,要么不属于。硬聚类还可进一步分类如下:
- 严格划分(Strict partitioning):一个对象只能属于一个簇。
- 含离群点的严格划分(Strict partitioning with outliers):这是严格划分的一种,同时引入了对象可被归类为离群点的概念(即不属于任何簇)。
- 重叠聚类(Overlapping clustering):单个对象可以与一个或多个簇相关联。
- 软聚类(Soft clustering):根据明确的标准,为数据点分配其与特定簇相关联的概率。它还可进一步分类如下:
- 子空间(Subspace):簇利用二维子空间进一步划分为两个维度。
- 层次聚类(Hierarchical):使用层次模型进行聚类;与子簇相关联的对象也与父簇相关联 。
聚类所使用的算法类型也有很多。如下表所示:
| 名称 | 定义 |
|---|---|
| 层次聚类(Hierarchical) | 用于尝试构建簇的层次结构。通常基于自上而下或自下而上的方法,试图将数据点从一个簇分割成多个簇(自上而下),或者从多个簇合并为少数簇(自下而上)。 |
| 质心(Centroid) | 用于找到一个特定的点位置,作为簇的中心。 |
| 密度(Density) | 用于在数据集中寻找数据点密集的区域。 |
| 分布(Distribution) | 利用分布模型对簇内的数据点进行排序和分类。 |
在本书中,我们将重点关注层次聚类和质心算法,因为它们在计算机科学(尤其是机器学习)中应用广泛。
# K近邻算法
层次聚类是一种聚类方法,其中与子簇相关联的对象也与父簇相关联。该算法开始时,数据结构中的所有单个数据点都被分配到各自的簇中。彼此距离最近的簇会合并。这个过程持续进行,直到所有数据点都与其他数据点相关联。层次聚类通常使用一种名为树形图(dendrogram)的图表技术来展示。层次聚类的时间复杂度为O(n²),因此通常不用于大型数据集。
K近邻(K-nearest neighbors,KNN)算法是一种常用于机器学习的层次算法。在Go语言中,最常用的寻找KNN数据的方法之一是使用golearn包。一个经典的KNN示例是鸢尾花分类,常被用作机器学习的示例,可在https://github.com/sjwhitworth/golearn/blob/master/examples/knnclassifier/knnclassifier_iris.go查看。
给定一个包含鸢尾花萼片和花瓣长度及宽度的数据集,我们可以看到关于该数据集的计算数据:
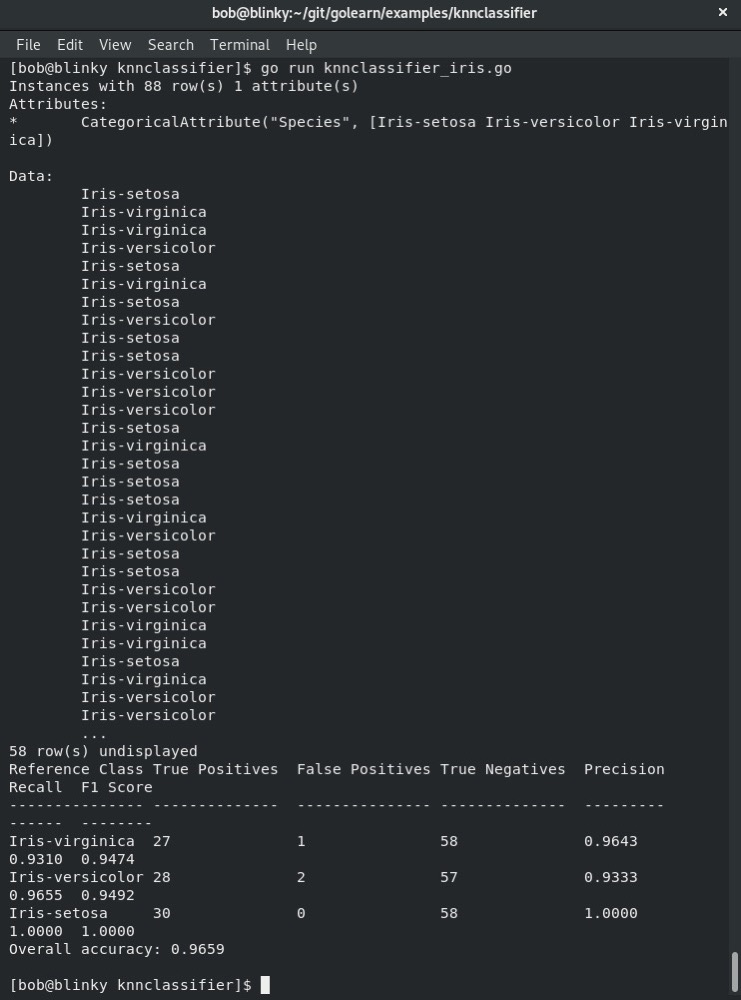
我们可以看到这个预测模型的计算准确率。在上述输出中,有以下描述信息:
| 描述符 | 定义 |
|---|---|
| 参考类别(Reference Class) | 与输出相关联的标题。 |
| 真正例(True Positives) | 模型正确预测出的肯定响应。 |
| 假正例(False Positives) | 模型错误预测出的肯定响应。 |
| 真反例(True Negatives) | 模型正确预测出的否定响应。 |
| 精度(Precision) | 不将实际为负的实例标记为正的能力。 |
| 召回率(Recall) | 真正例数 /(真正例数 + 假反例数)的比值。 |
| F1分数(F1 Score) | 精度和召回率的加权调和平均值。该值介于0.0到1.0之间,1.0表示最佳结果。 |
最后,也是非常重要的一点,我们有一个总体准确率,它能告诉我们算法预测结果的准确程度。
# K均值聚类
K均值聚类是机器学习中最常用的聚类算法之一。K均值聚类试图识别数据集中数据点的潜在模式。在K均值聚类中,我们将k定义为簇质心(具有均匀密度的对象的中心)的数量。然后,根据这些质心对不同的数据点进行分类。
我们可以使用K均值聚类库(可在https://github.com/muesli/kmeans找到)对数据集进行K均值聚类。下面来看看具体步骤:
- 首先,实例化主包并导入所需的包:
package main
import (
"fmt"
"log"
"math/rand"
"github.com/muesli/clusters"
"github.com/muesli/kmeans"
)
2
3
4
5
6
7
8
9
- 接下来,使用
createDataset函数创建一个随机的二维数据集:
func createDataset(datasetSize int) clusters.Observations {
var dataset clusters.Observations
for i := 1; i < datasetSize; i++ {
dataset = append(dataset, clusters.Coordinates{
rand.Float64(),
rand.Float64(),
})
}
return dataset
}
2
3
4
5
6
7
8
9
10
- 然后,创建一个函数用于打印数据,方便查看:
func printCluster(clusters clusters.Clusters) {
for i, c := range clusters {
fmt.Printf("\nCluster %d center points: x: %.2f y: %.2f\n", i,
c.Center[0], c.Center[1])
fmt.Printf("\nDatapoints assigned to this cluster: : %+v\n\n",
c.Observations)
}
}
2
3
4
5
6
7
8
在主函数中,我们定义簇的数量、数据集大小和阈值大小。 4. 现在,我们可以创建一个新的随机二维数据集,并对该数据集进行K均值聚类。绘制结果并打印簇,如下所示:
func main() {
var clusterSize = 3
var datasetSize = 30
var thresholdSize = 0.01
rand.Seed(time.Now().UnixNano())
dataset := createDataset(datasetSize)
fmt.Println("Dataset: ", dataset)
km, err := kmeans.NewWithOptions(thresholdSize,
kmeans.SimplePlotter{})
if err != nil {
log.Printf("Your K-Means configuration struct was not initialized properly")
}
clusters, err := km.Partition(dataset, clusterSize)
if err != nil {
log.Printf("There was an error in creating your K-Means relation")
}
printCluster(clusters)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
执行这个函数后,我们将能够看到数据点被分组到各自的簇中:
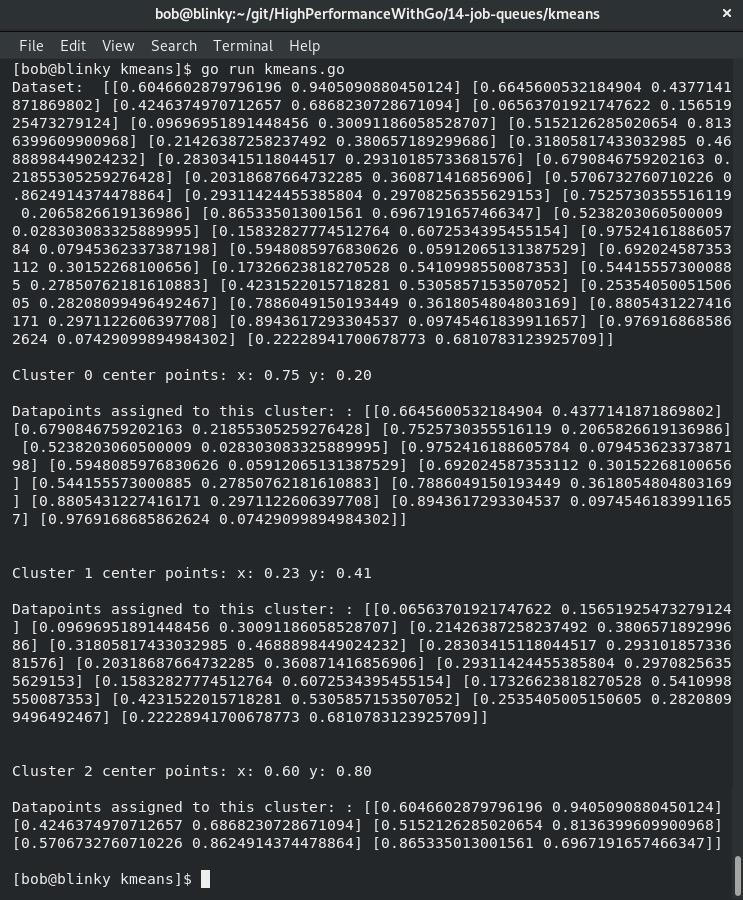
从结果中,我们可以看到:
- 初始(随机生成)的二维数据集
- 定义的三个簇
- 分配给每个簇的相关数据点
这个程序还会为聚类的每个步骤生成.png图像。最后生成的图像是数据点聚类的可视化展示:
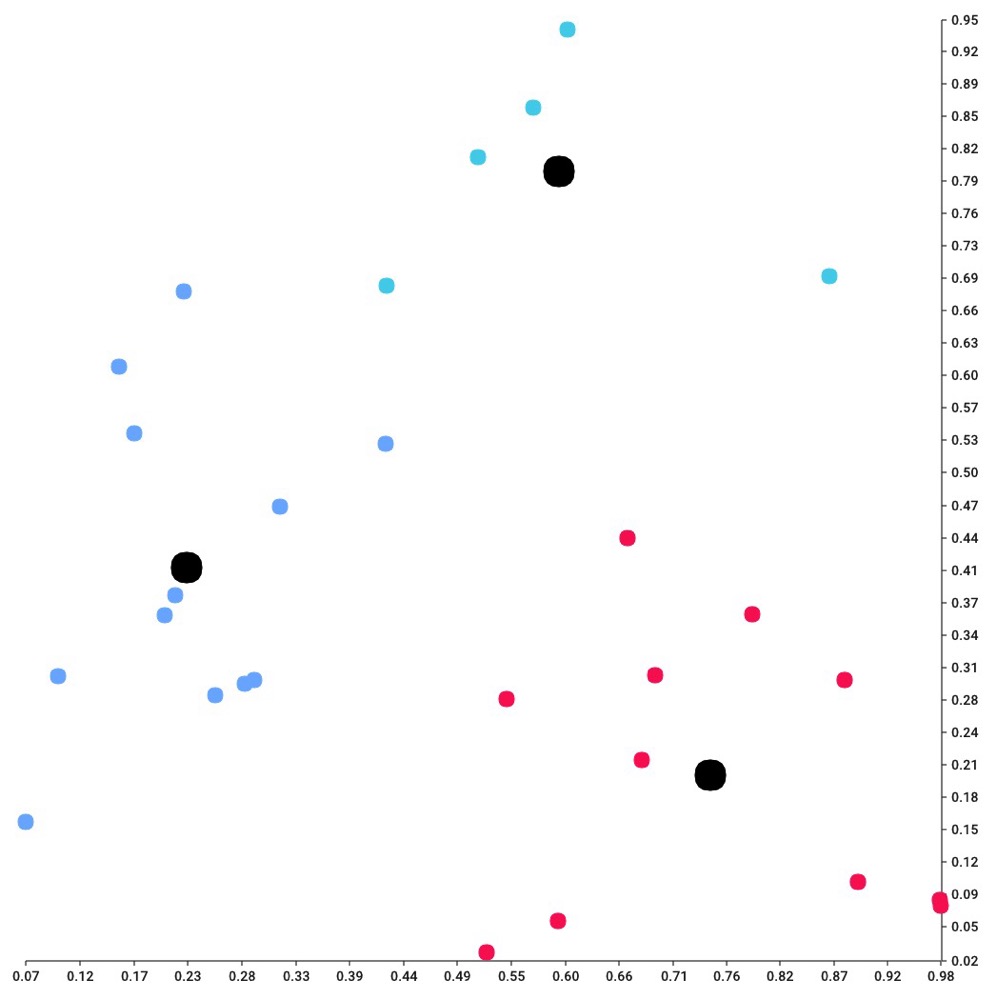
如果想将一个大型数据集划分为较小的组,K均值聚类(K-means clustering)是一种非常不错的算法。它的时间复杂度为O(n),因此对于大型数据集而言,该算法通常具有很强的实用性。K均值聚类在实际应用中,对于二维数据集有以下用途:
- 利用GPS坐标在地图上识别犯罪高发区域
- 为值班开发人员识别页面聚类
- 根据步数输出和休息日数量来识别运动员的表现特征
在下一节中,让我们探索Go语言中的作业队列(job queues)。
# 探索Go语言中的作业队列
作业队列常用于计算机系统中处理工作单元。它们通常用于调度同步和异步函数。在处理较大的数据集时,可能存在一些数据结构和算法需要花费大量时间来处理。这可能是因为系统正在处理非常大的数据段,也可能是应用于数据集的算法非常复杂,或者两者兼而有之。将这些作业添加到作业队列中,并以不同的顺序或在不同的时间执行,有助于维持系统的稳定性,为终端用户提供更好的体验。作业队列也常用于异步作业,因为作业完成的时间对终端用户的影响较小。如果实现了优先级队列,作业系统还可以对作业进行优先级排序。这使得系统可以先处理最重要的作业,然后再处理没有明确截止日期的作业。
# 将Goroutine用作作业队列
或许你特定的任务并不需要作业队列。对于某些任务而言,使用Goroutine通常就足够了。假设在某个特定任务中,我们想要异步发送一封电子邮件。我们可以在函数中使用Goroutine来发送这封邮件。
在这个示例中,我将通过Gmail发送电子邮件。为此,你可能需要开启“允许安全性较低的应用访问”功能,以便进行邮件认证(https://myaccount.google.com/lesssecureapps?pli=1)。长期来看,并不建议这样做,这只是展示实际邮件交互的一种简单方式。如果你对构建更强大的邮件解决方案感兴趣,可以使用Gmail API,访问地址为https://developers.google.com/gmail/api/quickstart/go。让我们开始吧:
- 首先,实例化主包,并将必要的包导入到示例程序中:
package main
import (
"log"
"time"
"gopkg.in/gomail.v2"
)
2
3
4
5
6
7
- 然后,创建主函数,它将执行以下操作:
- 记录“正在工作(Doing Work)”这一行日志(代表函数中正在执行的其他操作)。
- 记录“正在发送邮件(Sending Emails)”这一行日志(代表将邮件添加到Goroutine的时间点)。
- 启动一个Goroutine来发送邮件。
- 休眠一段时间,确保Goroutine完成任务(如果愿意,我们也可以在这里使用WaitGroup):
func main() {
log.Printf("Doing Work")
log.Printf("Sending Emails!")
go sendMail()
time.Sleep(time.Second)
log.Printf("Done Sending Emails!")
}
2
3
4
5
6
7
在sendMail函数中,我们传入收件人信息,设置发送邮件所需的正确邮件头,并使用gomail的拨号器发送邮件。如果你希望程序成功执行,需要更改发件人、收件人、用户名和密码变量:
func sendMail() {
var sender = "USERNAME@gmail.com"
var recipient = "RECIPIENT@gmail.com"
var username = "USERNAME@gmail.com"
var password = "PASSWORD"
var host = "smtp.gmail.com"
var port = 587
email := gomail.NewMessage()
email.SetHeader("From", sender)
email.SetHeader("To", recipient)
email.SetHeader("Subject", "Test Email From Goroutine")
email.SetBody("text/plain", "This email is being sent from a Goroutine!")
dialer := gomail.NewDialer(host, port, username, password)
err := dialer.DialAndSend(email)
if err != nil {
log.Println("Could not send email")
panic(err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
从输出结果可以看出,我们能够有效地完成一些工作并发送电子邮件:
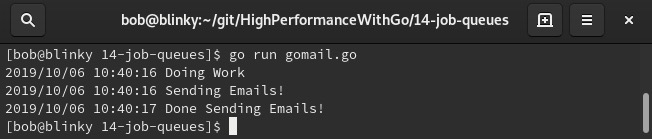
本书一直强调,执行任务的最高效方法往往是最简单的方法。如果执行简单任务时不需要构建新的作业队列系统,那就应该避免构建。在大公司中,通常会有专门的团队来维护大规模数据的作业队列系统。从性能和成本的角度来看,这些系统成本高昂。虽然在管理大规模数据系统方面,它们往往至关重要,但如果不提醒你在将分布式作业队列添加到技术栈之前要仔细考虑,我会觉得有所失职。
# 将缓冲通道(Buffered channels)用作作业队列
Go语言的缓冲通道是工作队列的一个完美示例。正如我们在第3章“理解并发(Understanding Concurrency)”中所学,缓冲通道是具有固定大小的通道。它们通常比无界通道的性能更高。缓冲通道可用于从你启动的特定数量的Goroutine中检索值。由于它们采用先进先出(FIFO)的排队机制,因此可以有效地用作固定大小的排队机制,我们可以按照请求到达的顺序来处理它们。我们可以使用缓冲通道编写一个简单的作业队列。让我们来看看:
- 首先,实例化主包,导入所需的库,并设置常量:
package main
import (
"log"
"net/http"
)
const queueSize = 50
const workers = 10
const port = "1234"
2
3
4
5
6
7
8
9
10
- 然后,创建一个作业结构体。该结构体用于记录作业名称和负载,如下代码块所示:
type job struct {
name string
payload string
}
2
3
4
- 我们的
runJob函数只是打印一条成功消息。如果有需要,我们可以在这里添加更复杂的工作:
func runJob(id int, individualJob job) {
log.Printf("Worker %d: Completed: %s with payload %s", id, individualJob.name, individualJob.payload)
}
2
3
主函数创建一个具有指定queueSize的jobQueue通道。然后,它遍历所有工作线程,并为每个工作线程启动一个Goroutine。最后,它遍历作业队列并运行必要的作业:
func main() {
jobQueue := make(chan job, queueSize)
for i := 1; i <= workers; i++ {
go func(i int) {
for j := range jobQueue {
runJob(i, j)
}
}(i)
}
2
3
4
5
6
7
8
9
10
这里还有一个HTTP处理函数,用于接收来自外部源的请求(在我们的示例中,它将是一个简单的cURL请求,但你也可能会收到来自外部系统的许多不同请求):
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
submittedJob := job{r.FormValue("name"), r.FormValue("payload")}
jobQueue <- submittedJob
})
http.ListenAndServe(":"+port, nil)
2
3
4
5
- 之后,启动作业队列并执行一个请求来测试该命令:
for i in {1..15}; do curl localhost:1234/ -d id=$i -d name=job$i -d payload=”Hi from Job $i” ; done
以下截图展示了不同工作线程完成不同作业的结果:
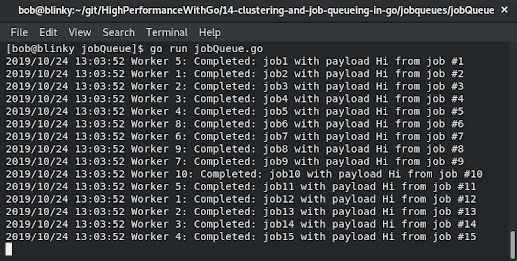
请注意,各个工作线程在有能力处理作业时会捡起这些作业。随着系统的不断扩展,这种机制在处理这些作业时非常有帮助。
# 集成作业队列
有时候,我们可能不想使用Go语言内置的排队系统。也许我们已经有一个包含其他消息队列系统的管道,或者我们知道将不得不处理非常大量的数据输入。常用于这项任务的两个系统是Apache Kafka和RabbitMQ。让我们快速了解一下如何使用Go语言与这两个系统进行集成。
# Kafka
Apache Kafka被称为分布式流系统,这其实就是分布式作业队列的另一种说法。Kafka是用Java编写的,它使用发布/订阅模型进行消息队列处理。它通常用于编写实时流数据管道。
我们假设你已经设置好了Kafka实例。如果还没有,可以使用以下bash脚本快速搭建一个Kafka实例:
#!/bin/bash
rm -rf kafka_2.12-2.3.0
wget -c http://apache.cs.utah.edu/kafka/2.3.0/kafka_2.12-2.3.0.tgz
tar xvf kafka_2.12-2.3.0.tgz
./kafka_2.12-2.3.0/bin/zookeeper-server-start.sh kafka_2.12-2.3.0/config/zookeeper.properties &
./kafka_2.12-2.3.0/bin/kafka-server-start.sh kafka_2.12-2.3.0/config/server.properties
wait
2
3
4
5
6
7
我们可以这样执行这个bash脚本:
./testKafka.sh
完成这些操作后,我们可以运行Kafka的读写Go程序,以便从Kafka进行读写操作。让我们来研究一下这些程序。
我们可以使用writeToKafka.go程序向Kafka写入数据。让我们来看看:
- 首先,初始化主包并导入所需的包:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/segmentio/kafka-go"
)
2
3
4
5
6
7
8
9
- 在主函数中,我们创建与Kafka的连接,设置写入截止时间,然后向Kafka的主题/分区写入消息。在这个示例中,只是简单地从1到10计数的消息:
func main() {
var topic = "go-example"
var partition = 0
var connectionType = "tcp"
var connectionHost = "0.0.0.0"
var connectionPort = ":9092"
connection, err := kafka.DialLeader(context.Background(), connectionType, connectionHost+connectionPort, topic, partition)
if err != nil {
log.Fatal(err)
}
connection.SetWriteDeadline(time.Now().Add(10 * time.Second))
for i := 0; i < 10; i++ {
connection.WriteMessages(
kafka.Message{Value: []byte(fmt.Sprintf("Message : %v", i))},
)
}
connection.Close()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
readFromKafka.go程序实例化主包并导入所有必要的包,如下所示:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/segmentio/kafka-go"
)
2
3
4
5
6
7
8
9
- 然后,主函数设置Kafka的主题和分区,接着创建连接,设置连接截止时间,并设置批量读取大小。关于Kafka主题和分区的更多信息,可以在http://kafka.apache.org/documentation/#intro_topics找到。
- 我们可以看到,主题和分区已设置为变量,并且连接已经实例化:
func main() {
var topic = "go-example"
var partition = 0
var connectionType = "tcp"
var connectionHost = "0.0.0.0"
var connectionPort = ":9092"
connection, err := kafka.DialLeader(context.Background(), connectionType, connectionHost+connectionPort, topic, partition)
if err != nil {
log.Fatal("Could not create a Kafka Connection")
}
2
3
4
5
6
7
8
9
10
- 然后,设置连接的截止时间并读取批量消息。最后,关闭连接:
connection.SetReadDeadline(time.Now().Add(1 * time.Second))
readBatch := connection.ReadBatch(500, 500000)
byteString := make([]byte, 500)
for {
_, err := readBatch.Read(byteString)
if err != nil {
break
}
fmt.Println(string(byteString))
}
readBatch.Close()
connection.Close()
2
3
4
5
6
7
8
9
10
11
12
- 执行
readFromKafka.go和writeFromKafka.go文件后,我们可以看到如下输出结果:
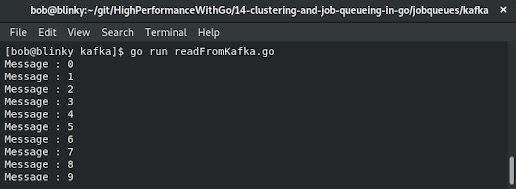
我们的Kafka实例现在包含了从writeToKafka.go程序发送的消息,这些消息现在可以被readFromKafka.go程序消费。
在使用完Kafka和Zookeeper服务后,若要停止它们,可以执行以下命令:
./kafka_2.12-2.3.0/bin/kafka-server-stop.sh
./kafka_2.12-2.3.0/bin/zookeeper-server-stop.sh
2
许多企业将Kafka用作消息代理系统,因此,了解如何使用Go语言在这些系统中进行读写操作,有助于在企业环境中大规模创建相关应用。
# RabbitMQ
RabbitMQ是一个用Erlang编写的流行开源消息代理。它使用一种名为高级消息队列协议(Advanced Message Queueing Protocol,AMQP)的协议,通过其队列系统传递消息。事不宜迟,让我们搭建一个RabbitMQ实例,并使用Go语言向其发送消息和从其接收消息:
- 首先,我们需要使用Docker启动一个RabbitMQ实例:
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3-management
- 这样,我们就在主机上运行了一个带有管理界面的RabbitMQ实例。
- 现在,我们可以使用Go语言的AMQP库(https://github.com/streadway/amqp ),通过Go语言与RabbitMQ系统进行消息传递。
我们先创建一个监听器。下面逐步来看这个过程:
- 首先,实例化主包并导入必要的依赖项,同时设置显式变量:
package main
import (
"log"
"github.com/streadway/amqp"
)
func main() {
var username = "guest"
var password = "guest"
var protocol = "amqp://"
var host = "0.0.0.0"
var port = ":5672/"
var queueName = "go-queue"
2
3
4
5
6
7
8
9
10
11
12
13
14
- 然后,创建到AMQP服务器的连接:
connectionString := protocol + username + ":" + password + "@" + host + port
connection, err := amqp.Dial(connectionString)
if err != nil {
log.Printf("Could not connect to Local RabbitMQ instance on " + host)
}
defer connection.Close()
ch, err := connection.Channel()
if err != nil {
log.Printf("Could not connect to channel")
}
defer ch.Close()
2
3
4
5
6
7
8
9
10
11
12
- 接下来,声明要监听的队列,并从该队列消费消息:
queue, err := ch.QueueDeclare(queueName, false, false, false, false, nil)
if err != nil {
log.Printf("Could not declare queue : " + queueName)
}
messages, err := ch.Consume(queue.Name, "", true, false, false, false, nil)
if err != nil {
log.Printf("Could not register a consumer")
}
listener := make(chan bool)
go func() {
for i := range messages {
log.Printf("Received message: %s", i.Body)
}
}()
log.Printf("Listening for messages on %s:%s on queue %s", host, port, queueName)
<-listener
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 现在,我们可以创建发送函数。同样,声明包、导入依赖项并设置变量:
package main
import (
"log"
"github.com/streadway/amqp"
)
func main() {
var username = "guest"
var password = "guest"
var protocol = "amqp://"
var host = "0.0.0.0"
var port = ":5672/"
var queueName = "go-queue"
2
3
4
5
6
7
8
9
10
11
12
13
14
- 我们使用与监听器相同的连接方法。在生产环境中,我们可能会将其抽象出来,但这里为了便于理解而包含了完整代码:
connectionString := protocol + username + ":" + password + "@" + host + port
connection, err := amqp.Dial(connectionString)
if err != nil {
log.Printf("Could not connect to Local RabbitMQ instance on " + host)
}
defer connection.Close()
ch, err := connection.Channel()
if err != nil {
log.Printf("Could not connect to channel")
}
defer ch.Close()
2
3
4
5
6
7
8
9
10
11
12
- 然后,声明要使用的队列,并向该队列发布消息体:
queue, err := ch.QueueDeclare(queueName, false, false, false, false, nil)
if err != nil {
log.Printf("Could not declare queue : " + queueName)
}
messageBody := "Hello Gophers!"
err = ch.Publish("", queue.Name, false, false,
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(messageBody),
})
log.Printf("Message sent on queue %s : %s", queueName, messageBody)
if err != nil {
log.Printf("Message not sent successfully on queue %s", queueName, messageBody)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 创建好这两个程序后,我们可以进行测试。使用
while true循环反复运行消息发送程序:
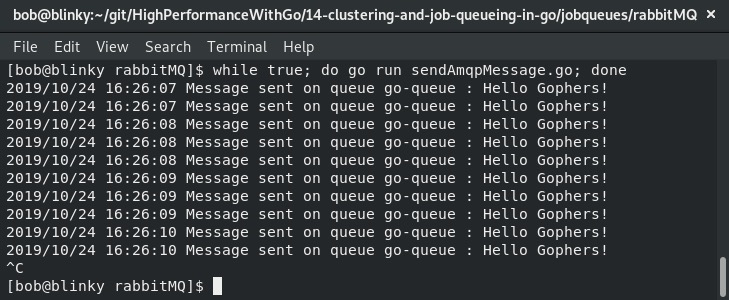
执行上述操作后,我们应该能在接收端看到消息:
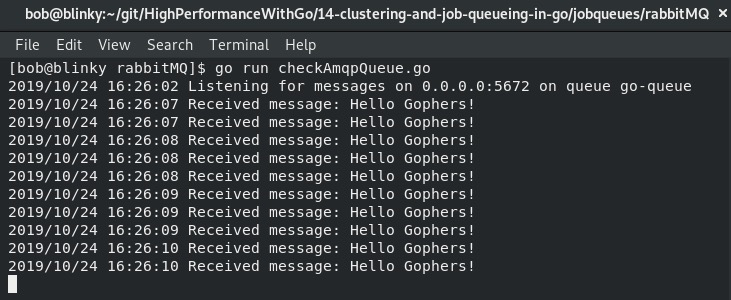
我们还可以通过访问RabbitMQ管理界面(位于http://0.0.0.0:15672 ,默认用户名和密码均为guest)查看此活动的输出:
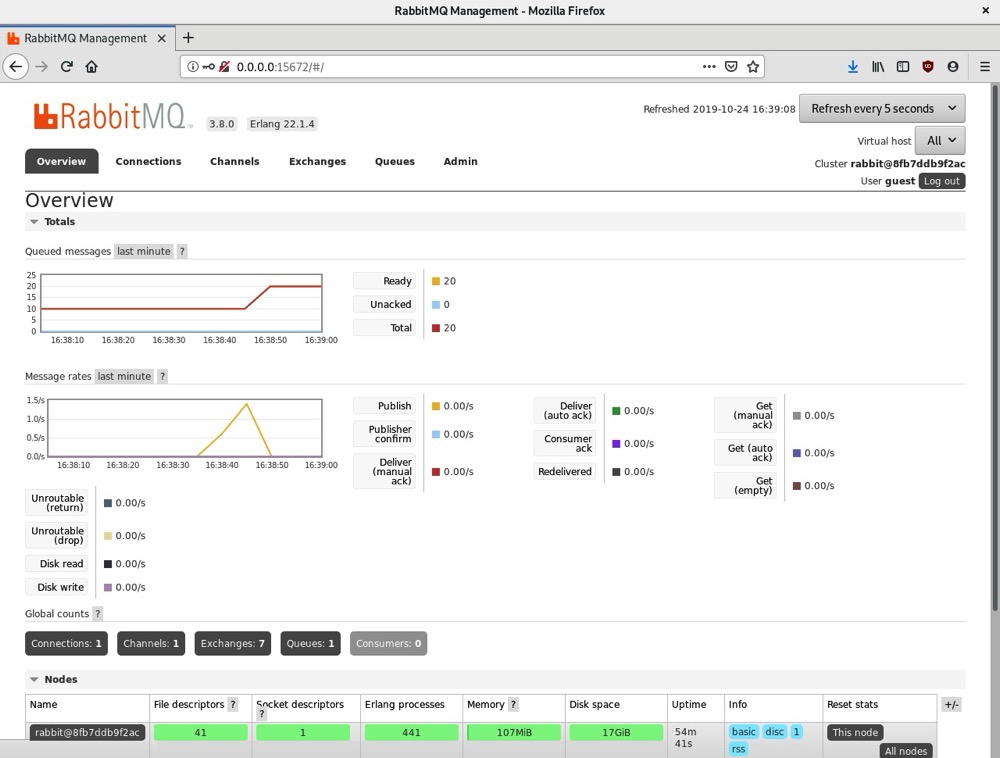
该管理界面为我们提供了关于RabbitMQ作业队列的各种信息,包括排队消息数量、发布/订阅模型状态,以及RabbitMQ系统各个部分(连接、通道、交换器和队列)的相关结果。了解这个队列系统的工作原理,在你需要与RabbitMQ队列进行通信时会很有帮助。
# 总结
在本章中,我们学习了使用分层算法和质心算法进行集群,将goroutine用作队列,将带缓冲的通道用作作业队列,以及实现第三方队列系统(Kafka和RabbitMQ)。
学习所有这些集群和作业队列技术,有助于你更好地运用算法和分布式系统,解决计算机科学相关问题。在下一章中,我们将学习如何使用Prometheus导出器、应用性能管理工具(APM,Application Performance Management )、服务级别指标/服务级别目标(SLI/SLO,Service-Level Indicator/Service-Level Objective )以及日志记录,来度量和比较不同版本的代码质量。