 15 跨版本比较代码质量
15 跨版本比较代码质量
# 15 跨版本比较代码质量
在编写、调试、分析和监控Go代码之后,你需要长期监测应用程序的性能是否出现退化。如果无法持续提供基础架构中其他系统所依赖的性能水平,那么在代码中添加新功能就毫无意义。
在本章中,我们将学习以下主题:
- 使用Go Prometheus导出器
- 应用性能监测(APM,Application Performance Monitoring)工具
- 服务级别指标和服务级别目标(SLIs和SLOs,Service-Level Indicators and Service-Level Objectives)
- 利用日志记录
理解这些概念有助于你长期编写高性能的代码。在处理大规模项目时,工作量的增加并不总能带来相应的产出提升。工程师数量增加10倍并不一定能保证产出也提高10倍。随着软件团队的壮大和产品功能的增加,能够以编程方式量化代码性能变得非常重要。推广高性能代码总是有益的,无论你是在企业环境中工作,还是参与小型开源项目,运用本章介绍的一些技术将有助于你长期提升代码性能。
# Go Prometheus导出器 - 从Go应用程序导出数据
跟踪应用程序长期变化的最佳方法之一是使用时间序列数据来监测并在发生重要变化时发出警报。Prometheus(https://prometheus.io/ )是执行这项任务的优秀工具。Prometheus是一个开源的时间序列监测工具,它通过HTTP使用拉取模型来驱动监测和警报功能。它是用Go语言编写的,并且为Go程序提供了一流的客户端库。以下步骤展示了Go Prometheus HTTP库的一个非常简单的实现:
- 首先,实例化包并导入必要的库:
package main
import (
"net/http"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
2
3
4
5
6
- 然后,在主函数中,实例化一个新的服务器,并让它使用一个新的
ServeMux,该ServeMux返回一个Prometheus处理器(promhttp.Handler()):
func main() {
mux := http.NewServeMux()
mux.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":1234", mux)
}
2
3
4
5
完成这些操作后,我们可以看到默认的Prometheus导出器返回了一些值。这些值都有详细的注释,包括以下内容:
- Go垃圾回收信息
- 协程(Goroutine)信息
- Go环境版本
- Go内存统计信息
- Go CPU利用率统计信息
- HTTP处理器统计信息
- 接下来,为我们的Go服务构建二进制文件:
GOOS=linux go build promExporter.go
- 接着创建一个Docker网络,用于将我们的服务连接在一起:
docker network create prometheus
- 然后创建我们的Prometheus导出器服务:
docker build -t promexporter -f Dockerfile.promExporter.
- 下一步,在Docker主机上运行我们的Prometheus导出器服务:
docker run -it --rm --name promExporter -d -p 1234:1234 --net prometheus promexporter
在下面的截图中,我们可以看到这个响应的截断输出。为简洁起见,省略了注释和Go内置的统计信息。你可以在服务器的响应中看到键值对形式的结果:
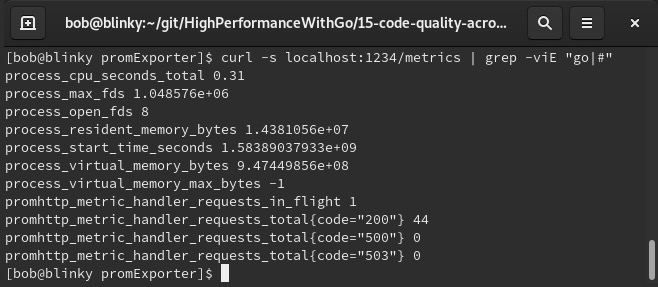
设置好这个服务器后,我们可以按一定的节奏对其进行监测。我们可以在容器中同时运行指标服务和Prometheus,并让它们相互通信。对于Prometheus容器,我们可以使用一个简单的prometheus.yml定义:
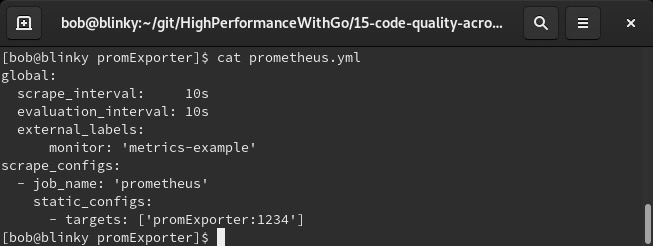
如果你不想使用Docker主机,在YAML文件的
scrape_configs->static_configs->targets部分,可以用IP地址或主机名替换promExporter。
- 构建好二进制文件后,我们可以创建两个单独的Dockerfile:一个用于包含Prometheus导出器服务的容器,另一个用于包含Prometheus服务的容器。我们的Prometheus服务的Dockerfile基于Prometheus基础镜像,并将我们的YAML配置添加到镜像的适当位置。
Dockerfile.promservice的配置如下:
FROM prom/prometheus
ADD prometheus.yml /etc/prometheus/
2
- 一旦创建好
Dockerfile.promservice,我们就可以构建Prometheus服务:
docker build -t prom -f Dockerfile.promservice.
- 然后在Docker主机上运行Prometheus服务:
docker run -it --rm --name prom -d -p 9090:9090 --net prometheus prom
现在,我们在本地环境中运行了一个Prometheus实例。 10. Prometheus服务启动并运行后,我们可以访问http://[IP地址]:9090/ ,就会看到我们的Prometheus实例:
 11. 我们可以通过查看同一URL中的
11. 我们可以通过查看同一URL中的/targets路径来验证是否正在抓取目标:

- 接下来,我们向主机发出几个请求:
for i in {1..10}; do curl -s localhost:1234/metrics -o /dev/null; done
- 然后,我们可以在Prometheus实例中查看
curl请求的结果:
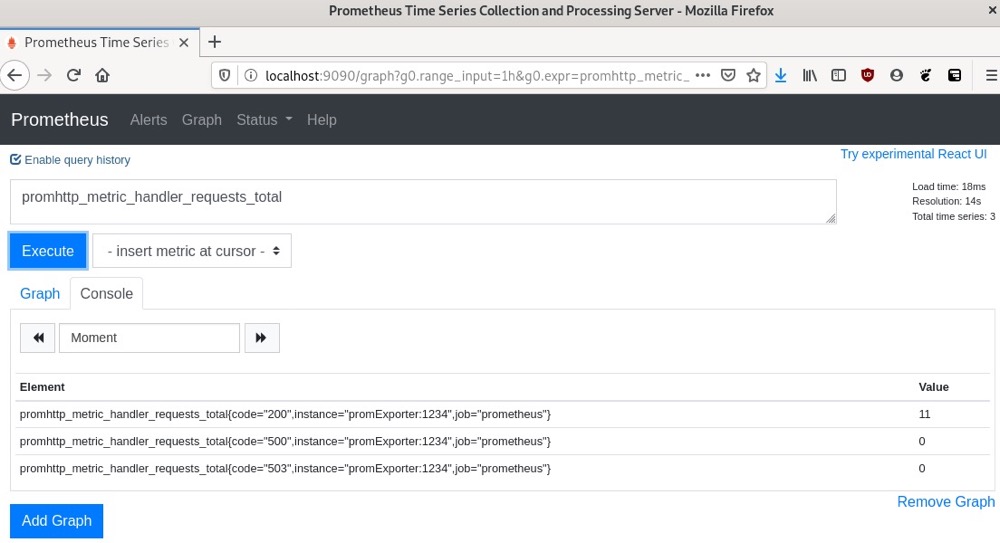
通过这些结果,我们可以看到状态码为200、500和503的HTTP响应总数。我们的示例很简单,但在这里我们可以使用许多不同类型的指标来验证我们的各种假设。在本章后面的SLI/SLO示例中,我们将进行一个更复杂的指标收集示例。
在下一节中,我们将讨论APM以及它如何用于维护高性能的分布式系统。
# 应用性能管理(APM)——监控分布式系统性能
如今市场上有许多应用性能管理(APM,Application Performance Management)工具。它们常被用于长期监测软件的性能和可靠性。在撰写本书时,适用于Go语言的部分产品如下:
- Elastic APM代理:https://www.elastic.co/guide/en/apm/agent/go/current/index.html
- New Relic APM:https://newrelic.com/golang
- Datadog:https://docs.datadoghq.com/tracing/setup/go/
- SignalFX:https://docs.signalfx.com/en/latest/apm/apm-instrument/apm-go.html
- AppDynamics:https://www.appdynamics.com/supported-technologies/go
- Honeycomb APM:https://docs.honeycomb.io/getting-data-in/go/
- AWS XRay:https://docs.aws.amazon.com/xray/latest/devguide/xray-sdk-go.html
- 谷歌的APM产品套件:https://cloud.google.com/apm/
这些工具大多是闭源的付费服务。聚合分布式跟踪数据是一项具有挑战性的商业价值主张。这里列出的供应商(以及一些未提及的供应商)将数据存储、聚合和分析功能整合在一起,打造出一站式的APM服务平台。我们也可以使用在第13章“Go代码跟踪”中创建的OpenCensus/Zipkin开源示例,在系统中进行分布式跟踪。在代码库的特定部分实现跨度(span)跟踪,有助于我们监测应用程序的长期性能。
让我们来看一个谷歌APM解决方案的示例。在撰写本文时,谷歌云每月提供250万个跨度采集和2500万个跨度扫描的服务,这对于示例来说已经足够了。
# 谷歌云环境设置
我们首先要做的是创建一个谷歌云平台(GCP,Google Cloud Platform )项目并获取应用程序凭据:
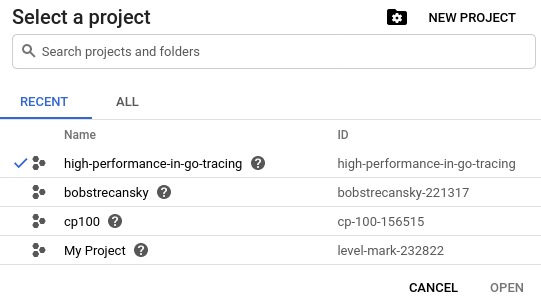
- 首先,登录到https://console.cloud.google.com/ 。登录后,点击页面顶部的项目选择器下拉菜单:

- 然后,在屏幕右上角为我们的特定应用创建一个新项目,如下截图所示:
接着,访问服务账号密钥页面https://console.cloud.google.com/apis/credentials/serviceaccountkey ,在这里我们可以创建一个服务账号密钥。
为我们的应用创建一个服务账号密钥。确保选择“Cloud Trace Agent”(云跟踪代理),因为这是我们向谷歌云跟踪添加跟踪数据所必需的。如下截图所示:
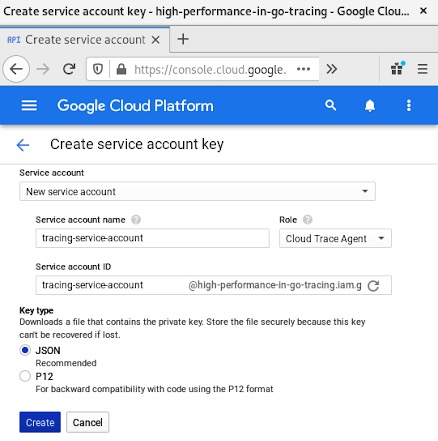
点击“Create”(创建)后,浏览器会提示我们下载新的凭据。为便于参考,我们将这个密钥命名为high-performance-in-go-tracing.json 。你可以根据自己的喜好命名密钥。
将这个密钥保存在本地后,我们可以将其设置为环境变量。在终端中输入以下命令:
export GOOGLE_APPLICATION_CREDENTIALS=/home/bob/service-accounts-private-key.json
这会将服务账号凭据保存为一个特殊的环境变量GOOGLE_APPLICATION_CREDENTIALS,我们将在接下来的示例中使用它。
# 谷歌云跟踪代码
设置好应用程序凭据后,我们就可以着手编写第一个能被APM捕获的跟踪代码了:
- 首先,实例化必要的包并设置服务器主机/端口常量:
package main
import (
"context"
"fmt"
"log"
"net/http"
"os"
"time"
"contrib.go.opencensus.io/exporter/stackdriver"
"go.opencensus.io/trace"
)
const server = ":1234"
2
3
4
5
6
7
8
9
10
11
12
13
14
- 接下来,在
init()函数中,设置StackDriver导出器,并注册跟踪器,以便对每个传入的Web请求进行采样。在生产环境中,我们可能应该减少采样的请求数量,因为采样会给请求增加额外的延迟:
func init() {
exporter, err := stackdriver.NewExporter(stackdriver.Options{
ProjectID: os.Getenv("GOOGLE_CLOUD_PROJECT"),
})
if err != nil {
log.Fatal("Can't initialize GOOGLE_CLOUD_PROJECT environment variable", err)
}
trace.RegisterExporter(exporter)
trace.ApplyConfig(trace.Config{DefaultSampler: trace.AlwaysSample()})
}
2
3
4
5
6
7
8
9
10
11
- 然后,创建一个
sleep函数,它接受一个上下文(context),执行睡眠操作,并向终端用户写入一条消息。在这个函数中,我将跨度的结束操作延迟到函数末尾:
func sleep(ctx context.Context, w http.ResponseWriter, r *http.Request) {
_, span := trace.StartSpan(ctx, "sleep")
defer span.End()
time.Sleep(1 * time.Second)
fmt.Fprintln(w, "Done Sleeping")
}
2
3
4
5
6
- 我们的
githubRequest函数向https://github.com 发出请求,并将状态返回给终端用户。在这个函数中,我显式调用了跨度的结束操作:
func githubRequest(ctx context.Context, w http.ResponseWriter, r *http.Request) {
_, span := trace.StartSpan(ctx, "githubRequest")
defer span.End()
res, err := http.Get("https://github.com")
if err != nil {
log.Fatal(err)
}
res.Body.Close()
fmt.Fprintln(w, "Request to https://github.com completed with a status of: ", res.Status)
span.End()
}
2
3
4
5
6
7
8
9
10
11
我们的main函数设置了一个HTTP处理函数,该函数会执行githubRequest和sleep函数:
func main() {
h := http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ctx, span := trace.StartSpan(context.Background(), "function/main")
defer span.End()
githubRequest(ctx, w, r)
sleep(ctx, w, r)
})
http.Handle("/", h)
log.Printf("serving at : %s", server)
err := http.ListenAndServe(server, nil)
if err != nil {
log.Fatal("Couldn't start HTTP server: %s", err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
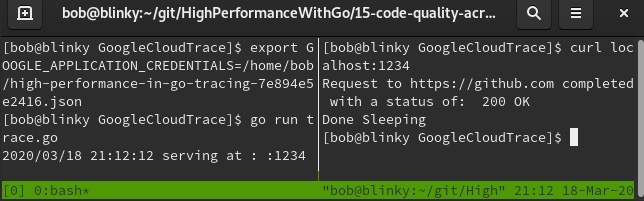
- 执行
main函数后,向localhost:1234发出请求并查看响应:
- 之后,访问谷歌云控制台并选择我们生成的跟踪数据:
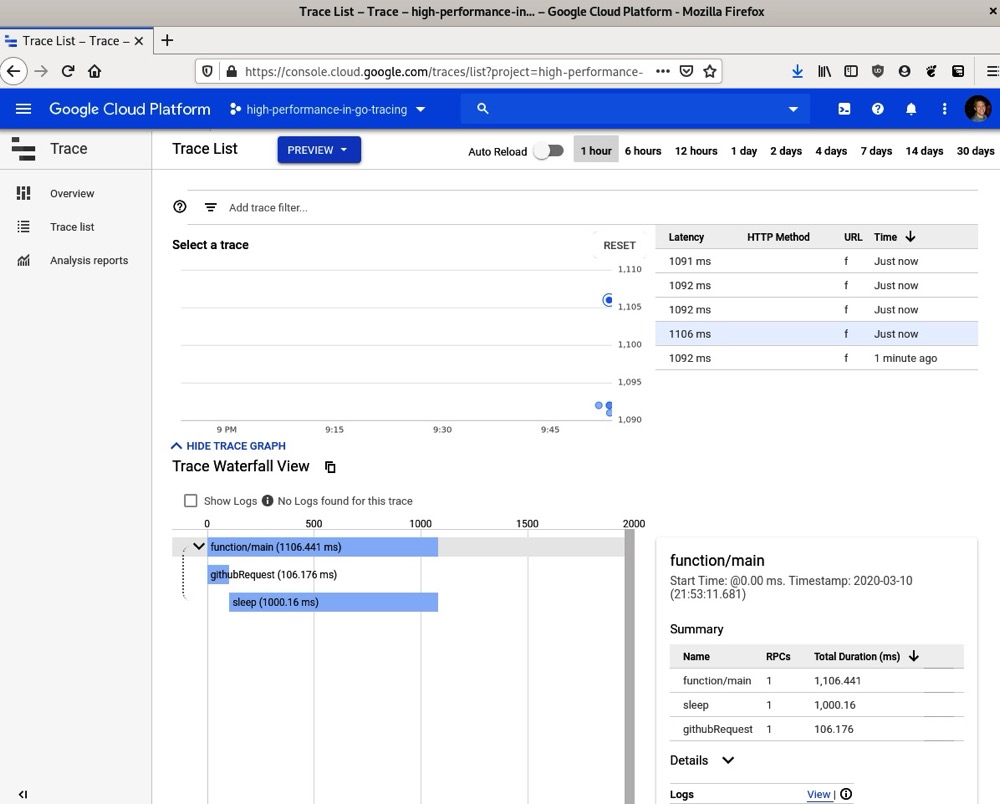
在这个跟踪示例中,我们可以看到各种相关细节:
- 所有已采集的跟踪样本(我在这里添加了许多不同的样本以填充字段)。
- 请求流的瀑布图。对于只有Web请求和睡眠操作的示例来说,这个图有点小,但在分布式系统中传递上下文时,这个图会迅速变得复杂起来。
- 每个跟踪的摘要信息。如果你点击图中的某个跟踪条,你可以看到关于该特定跟踪的更多详细信息。
将分布式跟踪作为APM解决方案,对于确定耗时最长的Web请求位置非常有帮助。找到实际的瓶颈通常比翻阅日志更具实际意义。谷歌的APM还允许你根据生成的跟踪数据运行报告。在发出超过100个请求后,你可以执行分析报告并查看结果。密度分布延迟图表以图形的形式展示请求延迟的分布情况。由于我们进行了长时间的睡眠并向外部服务发出了单个请求,我们的示例结果应该大多相似。下面的截图展示了密度分布图:
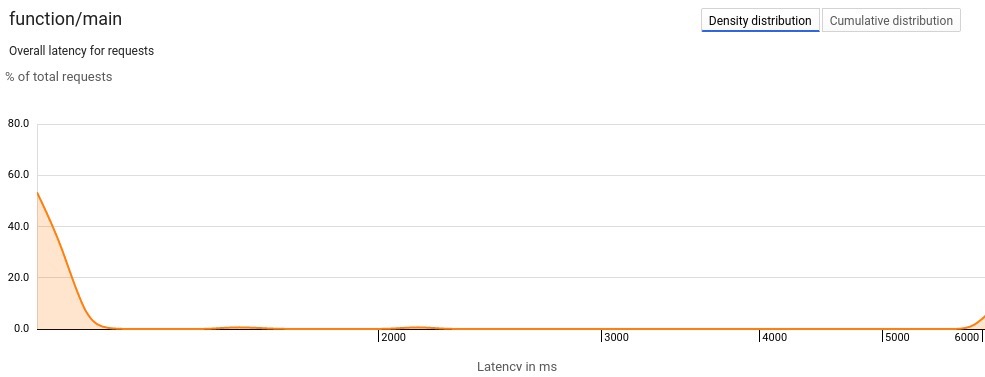
我们还可以在这个平台上查看累积延迟,它会显示比x轴上的值更短的请求所占的百分比:
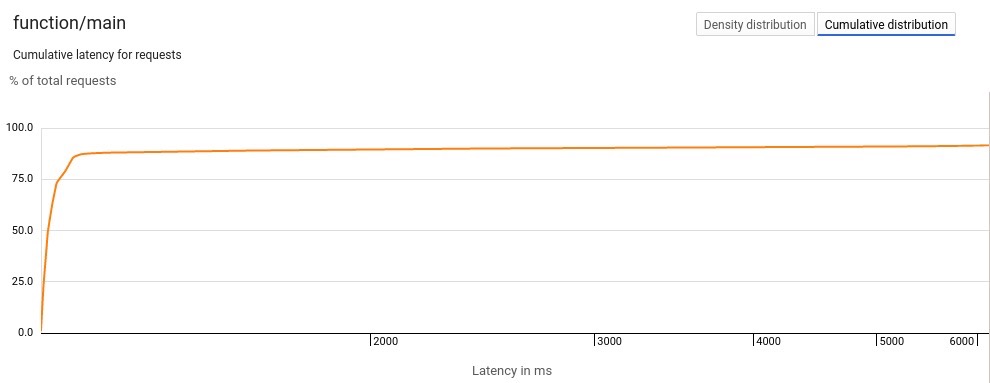
我们还可以查看相关请求的延迟概况:

此外,我们还可以看到分布式系统中潜在的瓶颈:
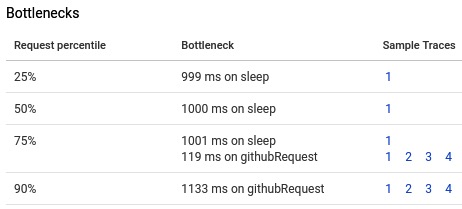
这些分析工具帮助我们推断出可以在分布式系统的哪些方面进行改进。APM帮助许多公司为客户提供高性能的应用程序。这些工具格外有价值,因为它们从客户体验的角度审视性能。在下一节中,我们将讨论如何使用服务级别指标(SLI,Service Level Indicator )和服务级别目标(SLO,Service Level Objective )来设定目标。
# 服务级别指标(SLIs)和服务级别目标(SLOs)——设定目标
服务级别指标(Service-Level Indicators,SLIs)和服务级别目标(Service-Level Objectives,SLOs)是由谷歌引入计算机科学领域的两种范式。它们在《SRE工作手册》(https://landing.google.com/sre/sre-book/chapters/service-level-objectives/)中有定义,是衡量计算系统中可操作项目的绝佳方式。这些衡量指标通常遵循谷歌的四个黄金信号:
- 延迟(Latency):完成一个请求所需的时间(通常以毫秒为单位)。
- 流量(Traffic):服务接收的流量大小(通常以每秒请求数来衡量)。
- 错误(Errors):失败请求占总请求的百分比(通常以百分比衡量)。
- 饱和度(Saturation):硬件饱和度的度量(通常通过排队请求数来衡量)。
这些度量指标可用于创建一个或多个服务级别协议(SLAs)。这些协议通常提供给期望从你的应用程序获得特定服务水平的客户。
我们可以使用Prometheus来测量这些指标。Prometheus有多种计数方法,包括仪表盘(gauges)、计数器(counters)和直方图(histograms)。我们将使用这些不同的工具来测量系统中的这些指标。
为了测试我们的系统,我们将使用hey负载生成器。这是一个与我们在前几章中使用的ab类似的工具,但在这个特定场景中,它能更好地展示分布情况。我们可以通过运行以下命令获取它:
go get -u github.com/rakyll/hey
为了读取一些相关值,我们需要启动Prometheus服务。如果在上一个示例中你的Prometheus服务没有在运行,我们可以执行以下命令:
docker build -t slislo -f Dockerfile.promservice.
docker run -it --rm --name slislo -d -p 9090:9090 --net host slislo
2
这将启动我们的Prometheus实例并测量请求:
- 我们的代码首先实例化
main包并导入必要的Prometheus包:
package main
import (
"math/rand"
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
2
3
4
5
6
7
8
9
10
- 然后在
main函数中收集饱和度、请求数和延迟数据。我们使用仪表盘(gauge)来衡量饱和度,使用计数器(counter)来统计请求数,使用直方图(histogram)来记录延迟:
saturation := prometheus.NewGauge(prometheus.GaugeOpts{
Name: "saturation",
Help: "A gauge of the saturation golden signal",
})
requests := prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "requests",
Help: "A counter for the requests golden signal",
},
[]string{"code", "method"},
)
latency := prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "latency",
Help: "A histogram of latencies for the latency golden signal",
Buckets: []float64{.025, .05, 0.1, 0.25, 0.5, 0.75},
},
[]string{"handler", "method"},
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 接着创建
goldenSignalHandler,它会随机生成一个0到1秒之间的延迟。为了更明显地展示信号,如果随机数能被4整除,我们返回404错误状态;如果能被5整除,我们返回500错误。然后返回响应并记录请求已完成。
goldenSignalChain将这些指标关联在一起:
goldenSignalChain := promhttp.InstrumentHandlerInFlight(
saturation,
promhttp.InstrumentHandlerDuration(
latency.MustCurryWith(prometheus.Labels{"handler": "signals"}),
promhttp.InstrumentHandlerCounter(requests, goldenSignalHandler),
),
)
2
3
4
5
6
7
- 然后向Prometheus注册所有测量指标(饱和度、请求数和延迟),处理HTTP请求,并启动HTTP服务器:
prometheus.MustRegister(saturation, requests, latency)
http.Handle("/metrics", promhttp.Handler())
http.Handle("/signals", goldenSignalChain)
http.ListenAndServe(":1234", nil)
2
3
4
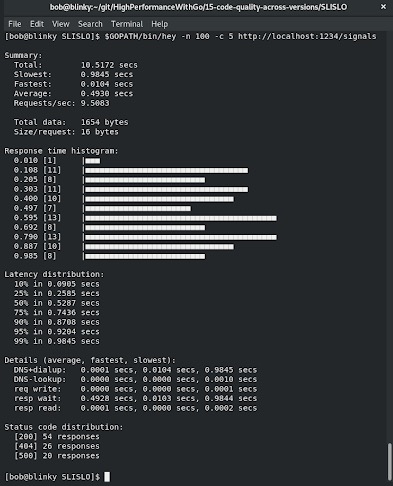
- 执行
go run SLISLO.go启动HTTP服务器后,我们可以向HTTP服务器发出hey请求。hey调用的输出如下截图所示。请记住,这些都是随机值,如果你执行相同的测试,结果会有所不同:
然后我们可以查看各个黄金信号的情况。
# 测量流量
要测量流量,我们可以使用Prometheus查询sum(rate(requests[1m]))。
我们可以在任何给定的时间间隔内测量速率。可以通过几种不同的方式配置这个速率,看看哪种方式最符合系统的需求。
# 测量延迟
要测量延迟,我们可以查看latency_bucket Prometheus查询。我们的请求被归类到具有不同延迟数值的直方图中,这个查询反映了这一情况。
# 测量错误
要测量系统中的错误数量,我们需要找出响应代码成功的请求与响应代码不成功的请求的比例。我们可以使用以下查询来获取:sum(requests {code!="200"}) / (sum(requests {code="200"}) + sum(requests {code!="200"}))。
监控这个比例很重要。计算机系统可能会出现故障,用户也可能会发出错误的请求,但200响应与非200响应的比例应该相对较小。
# 测量饱和度
我们可以使用prometheus查询saturation来测量饱和度。我们需要验证系统没有饱和,这个查询可以帮助我们完成这项操作 。
# Grafana
我们可以将所有这些黄金信号整合到Grafana仪表盘上。我们可以通过以下命令在本地运行Grafana:
docker run -it --rm --name grafana -d -p 3000:3000 --net prometheus grafana/grafana
我们需要访问http://localhost:3000 ,使用默认的用户名和密码组合登录Grafana门户:
- 用户名:admin
- 密码:admin
登录后,我们可以根据自己的喜好设置新密码。
登录后,我们点击页面顶部的“添加数据源”,并在下一页选择“Prometheus”。然后输入本地IP地址,点击“保存并测试”。如果一切正常,我们应该会在屏幕底部看到“数据源正常工作”的弹出提示:
完成此操作后,我们访问 http://localhost:3000/dashboard/import 。
然后在右上角选择“上传.json文件”,上传为这个仪表盘创建的JSON文件,文件地址为https://github.com/bobstrecansky/HighPerformanceWithGo/blob/master/15-code-quality-across-versions/SLISLO/four_golden_signals_grafana_dashboard.json 。
上传此JSON文件并导入数据源后,我们将能够看到请求速率、持续时间延迟区间、错误率和饱和度图表,如下截图所示:
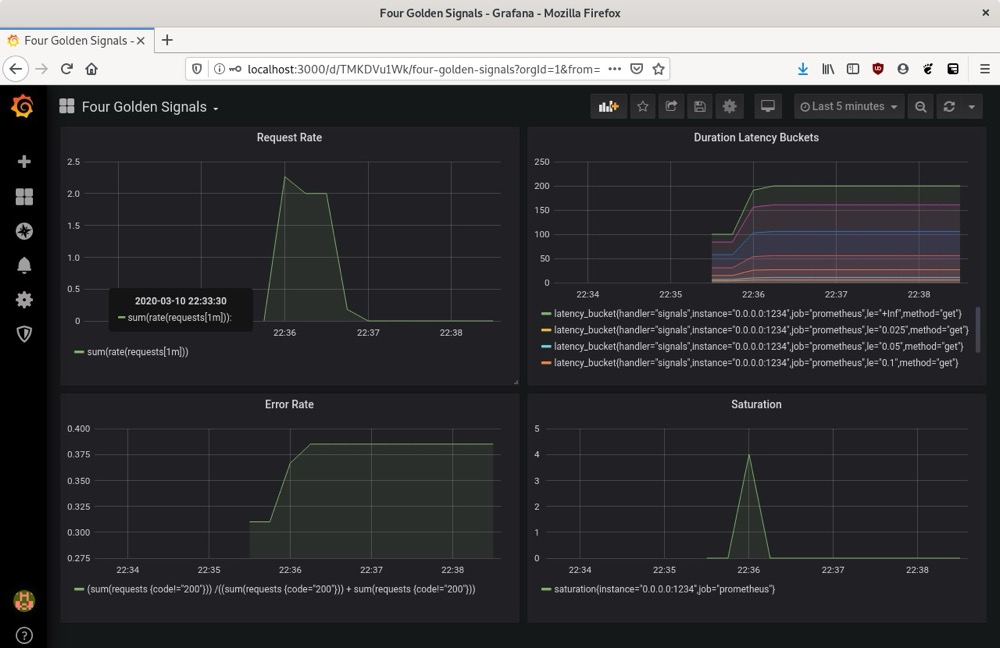
了解这些统计信息有助于维护系统的稳定性。获取这些统计信息后,你可以使用Prometheus Alertmanager根据感兴趣的监控阈值设置警报。
(提示)有关配置Alertmanager的更多信息,可以在https://prometheus.io/docs/alerting/alertmanager/ 上找到。
在下一节中,我们将学习如何跟踪数据,也就是日志记录(logging)。
# 日志记录 - 跟踪数据
日志记录,即记录系统中发生的事件,这对于创建高性能的软件系统至关重要。能够在编程系统中记录和验证事件,是确保在应用程序的各个版本中保持代码质量的好方法。日志通常可以快速揭示软件中的错误,并且能够快速获取这些信息通常有助于缩短平均恢复时间(MTTR)。
Go语言有许多不同的日志记录包。一些最受欢迎的包如下:
- Go官方维护者提供的标准内置
log包 - Glog包:https://github.com/golang/glog
- 优步(Uber)的Zap包:https://github.com/uber-go/zap
- 零分配JSON日志记录器:https://github.com/rs/zerolog
- Logrus包:https://github.com/sirupsen/logrus
我们将以Zap包为例,正如基准测试所示,使用标准库日志记录器通常就足够了(如果您注意到的话,本书到目前为止使用的就是这个包进行日志记录)。像Zap这样的结构化日志记录包能带来不错的体验,因为它提供了标准库日志记录器没有的一些功能,例如:
- 日志级别
- 结构化日志(特别是JSON格式)
- 类型化日志
在日志记录器的对比基准测试中,Zap的表现也最佳。Zap有两种不同类型的日志记录方式,即结构化日志记录器(sugared logger)和结构化记录器(structured logger)。结构化记录器的性能略高一些,而结构化日志记录器的类型限制更宽松。由于本书关注性能,我们将重点介绍结构化记录器,因为它性能更佳,但这两种日志记录方式都完全适用于生产环境。
拥有一个具有不同日志级别的记录器非常重要,因为它能让你确定哪些日志需要紧急关注,哪些日志只是返回信息。这也能让你根据遇到日志关键节点时修复的紧急程度,为团队设定优先级。
结构化日志有助于被其他系统接收。JSON格式的日志记录正越来越受欢迎,因为像以下这样的日志聚合工具都支持JSON日志:
- ELK堆栈(ElasticSearch、Logstash和Kibana)
- Loggly
- Splunk
- Sumologic
- Datadog
- 谷歌云平台的Stackdriver Logging
正如我们在应用性能管理(APM)解决方案中看到的,我们可以利用这些日志服务,将大量日志集中聚合到一个地方,无论是在本地还是云端。
类型化日志能让你以一种对程序或业务有意义的方式组织日志数据。保持日志的一致性,能让系统管理员和网站可靠性工程师更快地诊断问题,从而缩短生产事故的MTTR。
让我们看一个使用Zap进行日志记录的示例:
- 首先,实例化我们的包,并导入
time包和Zap日志记录器:
package main
import (
"time"
"go.uber.org/zap"
)
2
3
4
5
6
- 然后,设置一个生产环境的日志配置,使其将日志输出到标准输出(遵循十二要素应用原则)。这些日志通常会被发送到日志路由器,如Fluentd(https://www.fluentd.org/),我们可以测试Zap中所有不同的日志级别:
func main() {
c := zap.NewProductionConfig()
c.OutputPaths = []string{"stdout"}
logger, _ := c.Build()
logger.Debug("We can use this logging level to debug. This won't be printed, as the NewProduction logger only prints info and above log levels.")
logger.Info("This is an INFO message for your code. We can log individual structured things here", zap.String("url", "https://reddit.com"), zap.Int("connectionAttempts", 3), zap.Time("requestTime", time.Now()))
logger.Warn("This is a WARNING message for your code. It will not exit your program.")
logger.Error("This is an ERROR message for your code. It will not exit your program, but it will print your error message -> ")
logger.Fatal("This is a Fatal message for your code. It will exit your program with an os.Exit(1).")
logger.Panic("This is a panic message for your code. It will exit your program. We won't see this execute because we have already exited from the above logger.Fatal log message. This also exits with an os.Exit(1)")
}
2
3
4
5
6
7
8
9
10
11
运行日志记录器后,我们可以看到一些非常清晰的JSON输出。我们还可以使用像jq(https://stedolan.github.io/jq/)这样的工具,以便在本地环境中更方便地处理这些日志:
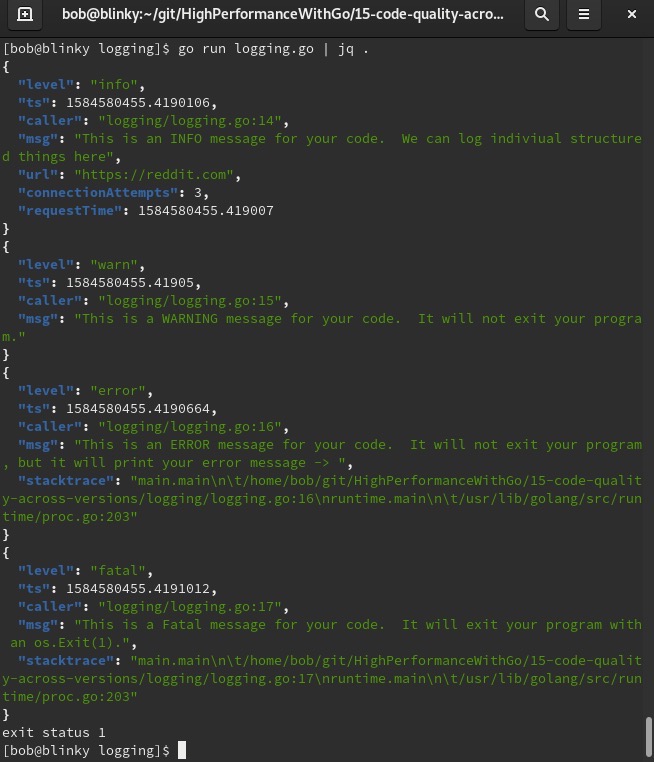
正如我们提到的,在Go应用程序中使用结构化、分级的日志记录器将帮助你更快、更有效地进行故障排查。
# 总结
在本章中,我们讨论了跨版本比较代码质量的不同方法:
- 使用Go Prometheus导出器
- APM工具
- 服务级别指标(SLIs)和服务级别目标(SLOs)
- 使用日志记录
综合运用这些技术,可以帮助你确定应用程序在哪些方面未达到预期性能。了解这些内容有助于你快速迭代,开发出尽可能优秀的软件。
在本书中,你学习了应用性能以及它与Go语言的关系。希望本书能帮助你在编写应用程序时关注Web性能。始终将性能牢记于心。每个人都喜欢高性能的应用程序,希望本书能帮助你作为开发者为此贡献自己的力量。