 1. 用Go构建大型项目
1. 用Go构建大型项目
# 1. 用Go构建大型项目
在有限的约束条件下解决小型封闭问题很容易。理解和在脑海中构建需求模型并找到解决方案也不难。然而,当问题变得更加复杂或约束条件增多时,没有计划地解决问题往往会以失败告终。另一方面,有时我们规划过度,以至于在新情况出现时,几乎没有空间做出反应。架构设计就是在长期和短期之间寻求平衡的精妙艺术。
本章提出一个问题:为什么要进行软件工程?它概述了制定和执行成功软件产品蓝图所需的要素。本章涵盖的主题包括:
- 从全局角度解决问题,以及架构师在其中应扮演的角色
- 软件架构的基本原则
- 深入探讨微服务
- Go语言简介
# 从全局角度解决问题
假设你计划从纽约前往洛杉矶旅行。有两个主要方面需要牢记:
- 出发前你需要做什么?
- 旅途中你需要做什么以确保不偏离路线?
一般来说,规划这样一次旅行有两种极端的选择:
- 开车出发,边走边想办法。
- 制定非常详细的计划——规划好路线,在每个路口做好方向标记,为爆胎等意外情况做好准备,计划好停车地点等等。
第一种方案能让你快速出发。但问题是,很可能你的旅行会充满意外。你的路线很可能不是最优的。如果你想告知在洛杉矶的朋友你到达目的地的时间,你的预估会因当前情况而有很大差异。没有长期规划,对未来结果的规划充其量只是尽力而为。
但另一种极端做法也充满陷阱。每个目标都有时间限制,花太多时间过度分析某件事可能意味着你会错过机会。更常见的情况是,如果你把这些指示交给别人,而在某个路口实际情况与你预测的不同,那么司机就几乎没有即兴发挥的空间了。
将这个类比延伸开来,软件产品的架构就是构建一个满足客户和其他利益相关者(包括开发者自身)需求的产品的规划!
为计算机编写代码让其理解并用于解决问题已经变得很容易。现代工具为我们承担了大部分繁重的工作。它们会给出语法建议、优化指令,甚至能纠正我们的一些错误。但是,编写能被其他开发者理解、在多种约束条件下仍能正常工作并且能随着需求变化而演进的代码,是极其困难的。
架构是构建系统的人赋予系统的形态。形态本质上意味着组成部分、这些部分的排列方式以及它们相互之间的通信方式。这种形态的目的是为了便于其中所包含的软件系统的开发、部署、操作和维护。在当今需求不断变化的世界里,构建一个我们可以快速有效执行的平台是成功的关键。
# 架构师的角色
架构师不是一个头衔或职级,而是一种角色。架构师的主要职责是为需要构建的内容定义蓝图,并确保团队其他成员有足够详细的信息来完成工作。在执行过程中,架构师要引导团队朝着这个设计方向前进,同时与所有利益相关者保持持续的沟通。
架构师也是开发者和非技术利益相关者的咨询对象,为他们解答哪些是可行的、哪些是不可行的,以及各种选择的成本影响(如工作量、权衡取舍、技术债务等)。
不编写代码也有可能完成架构师的工作。但在我个人看来,这会导致设计受限。如果不了解底层的细节、约束和复杂性,就不可能做出出色的设计。许多组织因为那些脱离实际、不参与实际软件开发任务的架构师的负面表现,而忽视架构师的作用。但另一方面,没有蓝图会导致代码库混乱无序,一个小的改动可能会在工作量和产品质量方面产生难以预料的影响。
本书不是软件工程的理论研究。本书是为那些希望在产品构建过程中亲力亲为,打造出色、可靠且高性能产品的架构师而写的!
那么,架构师应该提供哪些指导体系或规范呢?本质上,团队期望架构师提供以下内容:
# 需求澄清
明确和提炼软件的顶层功能和非功能需求是成功的关键前提。如果你不知道要构建什么,那么你构建出客户想要的东西的可能性就非常小。产品经理通常关注功能,但很少询问客户需要哪些非功能需求(或系统质量)。有时,利益相关者会告诉我们系统必须快速,但这太主观了。如果我们想要满足非功能需求,它们必须是具体的、可衡量的、可实现的和可测试的。架构师需要与所有利益相关者合作,确保功能和非功能需求清晰明确,便于开发人员理解和使用。
在当今敏捷开发的环境下,需求分析几乎是一项持续进行的活动。架构师帮助团队梳理需求,并对该做什么做出决策(这些决策并不总是显而易见的)。
# 北极星指标
除了需求,我们还需要为系统定义关键的工程原则。这些原则包括:
- 高层设计:将系统分解为高层组件。这是产品和代码在产品开发生命周期的每个阶段都需要遵循的蓝图。例如,一旦我们采用分层架构(见下一节),那么对于任何新需求,我们都可以轻松确定每个新组件应该属于哪一层。
- 质量属性:我们希望代码质量高,这意味着没有单元测试和90%代码覆盖率的代码将不被允许。
- 产品迭代速度:产品在时间上有一定的限制,为确保开发者的高生产率,团队应该从一开始就构建持续集成/持续部署(Continuous Integration / Continuous Deployment,CICD)管道。
- A/B测试:每个功能都应该有一个标识,以便只向特定百分比的用户展示。
这些通用的指导方针或原则,以及高层设计,有助于团队在每个阶段做出决策。
# 技术选型
一旦有了架构,我们就需要确定编程语言、框架等内容,并为各个组件选择合适的技术方案,包括数据库选型、供应商选择、技术策略、部署环境、升级策略等等。这些因素加在一起,常常会把一个原本简单的选择任务变成一场噩梦。最后,所有这些技术还必须能够很好地协同工作。
# 掌控全局的领导力
团队开始执行项目后,架构师需要为团队提供技术领导力。这并不意味着要做出每一个技术决策,而是要承担起责任,确保构建的各个组件符合制定的蓝图。架构师要在每次设计评审会议上向团队传达项目愿景。有时,还需要进行引导,比如在设计评审中向开发人员提出尖锐的问题(而不是直接给出解决方案)。
# 指导与辅导
参与这类产品开发的开发者通常需要并寻求超出其当前交付任务的指导和辅导。他们的核心目标之一是学习、讨论难题并提升技能。如果没有一个便于进行这种交流的环境,会导致开发者感到沮丧,人员流动也会增加。
在管理产品的技术管理工作时,架构师常常需要扮演开发者的教练和导师角色。这可能包括从技术反馈会议到职业规划咨询等一系列事情。
# 目标状态与当前状态
架构师和开发者在接到需求后,往往会提出漂亮而优雅的设计方案。但通常,项目一旦启动,团队就会面临快速交付的压力。商业利益相关者希望快速推出一些成果(最小可行产品),而不是等待最终完美产品的发布。从降低产品风险的角度来看,这是合理的,同时也能为团队提供关键反馈,让他们了解产品是否满足商业需求。
但这种运作模式也有很大的代价。为了按时完成项目,开发者在构建项目时可能会走捷径。因此,尽管在架构方面我们有一个清晰、完美的目标状态,但实际情况往往与之不符。
存在这种差距并非错误,而是很自然的现象。但团队要牢记目标状态,并在每次迭代中确定一系列小目标,逐步将产品推向目标状态,这一点很重要。这意味着架构师需要与产品经理和工程经理一起参与团队的迭代规划。
# 软件架构
本节将简要探讨软件架构的核心原则、它与设计的关系,以及用于分析和解决问题的各种架构视角或范式。
# 架构与设计
“架构”(architecture)一词通常用于指代高层次的内容,与低层次的细节有所区别,而“设计”(design)更多地涉及低层次的结构和决策。但二者本质上是相互关联的,如果它们之间缺乏协同作用,就无法打造出优秀的产品。低层次的细节和高层次的结构都是整体的一部分,它们构成了一个连续的架构体系,决定了系统的形态。二者缺一不可,从最高层次到最低层次的决策是一个连续统一体。
如果架构和设计工作相互独立,缺乏统一的主题和原则作为指导,开发人员对代码库的理解就会像著名寓言中盲人摸象一样片面。
另一方面,让架构师详细记录低层次设计的各个方面既不现实(也不可取)。关键在于为代码构建一个愿景和指导原则,以便开发人员在各个层次进行决策时能够有所依据。
# 架构是什么样的?
多年来出现了多种架构范式,但它们都有一个共同的核心目标:管理复杂性。我们如何将代码封装成组件,并把这些组件当作抽象实体来使用,进而推断和构建系统的各项功能呢?
这些组件将系统划分为不同部分,使每个部分都有特定的关注点和作用。每个组件都有明确的接口和职责,并且与其他组件相互隔离。这种抽象机制让我们无需担心组件的内部工作原理。
系统分解需要经过深思熟虑。有两个关键指标可用于评估组件的优劣,即内聚性(cohesion)和耦合性(coupling):
- 高内聚意味着一个组件只执行一项相关任务。
- 低耦合意味着组件之间的相互依赖程度较低。
一个组件应易于扩展,以便添加更多功能或数据。并且在必要时,它应能够完全被替换,同时不影响系统的其他部分。
罗伯特·塞西尔·马丁(人们更常称他为“鲍勃大叔”)是一位软件工程师兼作家。他在关于整洁架构的博客中,用一幅精美的图示描述了组件/分层的概念:
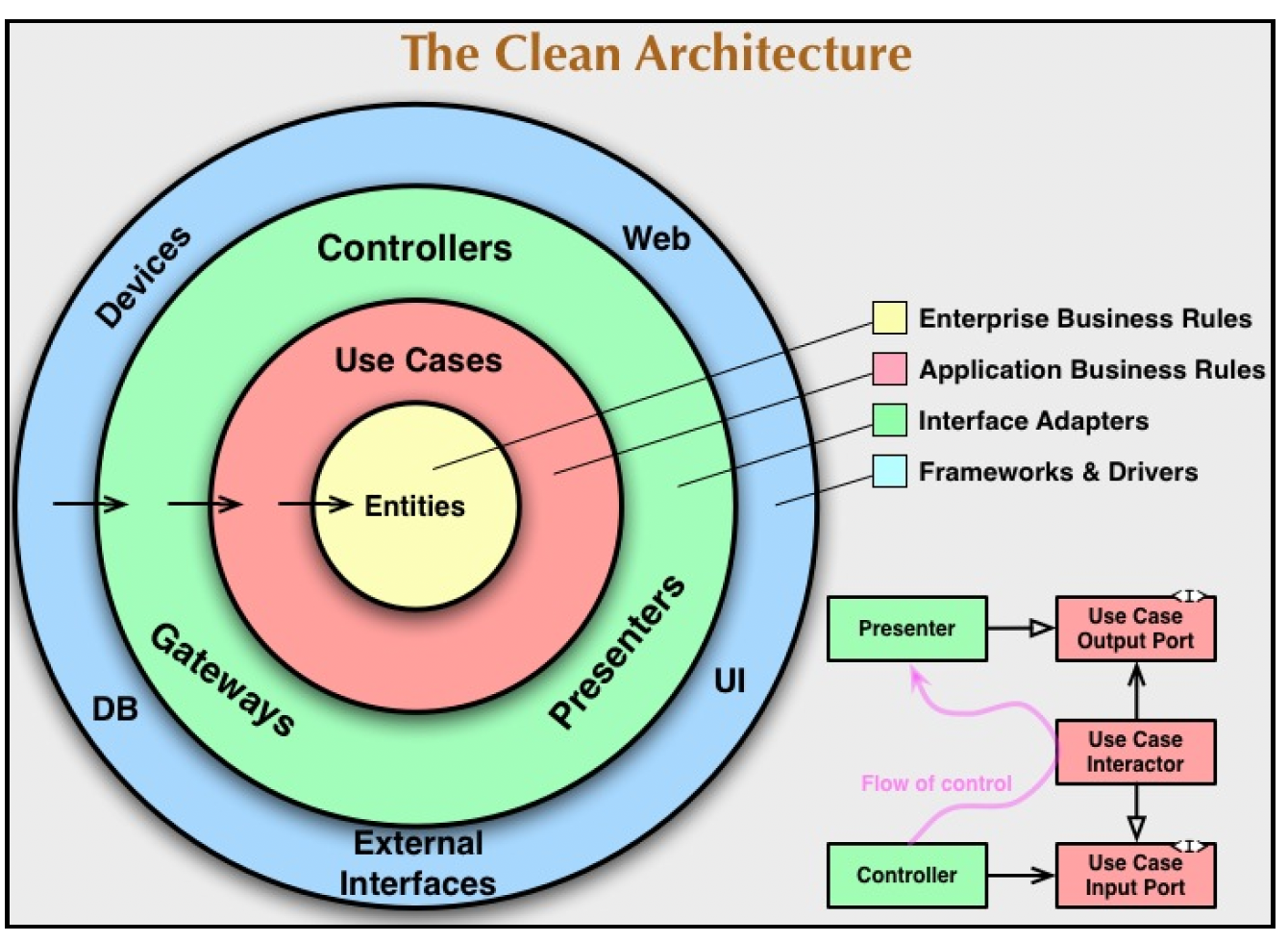 这些同心圆代表软件的不同层次(即不同的组件集合或更高级别的组件)。
这些同心圆代表软件的不同层次(即不同的组件集合或更高级别的组件)。
一般来说,内层的圆圈更抽象,处理业务规则和策略等内容。当外部情况发生变化时,它们是最不容易改变的部分。例如,你不会因为除了现有的网页产品外,还想在移动应用程序上展示员工详细信息,就去更改员工实体。
外层的圆圈是机制层。它们定义了如何利用现有机制来实现内层的功能。这一层包含数据库和Web框架等内容。这里的代码通常是复用的,而非重新编写。
控制器(或接口适配器)层将数据从机制层的格式转换为对业务逻辑最方便使用的格式。
使这种架构成功的关键规则是依赖规则。该规则指出,源代码的依赖关系只能指向内层。内层的任何内容(变量、类、数据和私有函数)都不应该了解外层的任何信息。各层之间的接口以及跨越这些边界的数据都有明确的定义和版本控制。如果一个软件系统遵循这条规则,那么任何一层都可以轻松替换或更改,而不会影响系统的其他部分。
这四层只是一种示意,不同的架构会有不同数量和类型的层次(圆圈)。关键在于对系统进行逻辑上的划分,这样当需要编写新代码时,开发人员就能清楚地知道代码应该放在何处。
以下是对常用的主要架构范式的简要总结:
| 架构范式 | 描述 |
|---|---|
| 基于包的架构(Package-based) | 系统被分解为多个包(这里,组件就是包),每个包都有明确的用途和接口。各组件之间的关注点有清晰的分离。然而,模块之间的独立程度和隔离强制程度各不相同:在某些情况下,各部分仅在逻辑上分离,一个组件的更改可能需要重新构建或重新部署另一个组件。 |
| 分层架构/多层架构/三层架构(Layering/N-tier/3-tier) | 这种架构将功能分离到不同的层中,组件被放置在特定的层里。通常,各层仅与下一层进行交互,从而降低了复杂性并实现了可复用性。层可以是包或服务。分层架构最著名的例子是网络协议栈(7层的OSI模型或TCP/IP协议栈 )。 |
| 异步/消息总线/参与者模型/通信顺序进程(Async / message-bus / actor model / Communicating Sequential Processes,CSP) | 其核心思想是系统之间通过消息(或事件)进行通信。这实现了清晰的解耦:产生事件的系统无需了解消费者的情况,支持1对多通信。在Unix系统中,这种范式通过管道实现:像cat和grep这样的简单工具通过管道组合在一起,实现更复杂的功能,比如在words.txt文件中搜索cat。在分布式系统中,消息通过网络传输。我们将在后面的章节详细介绍分布式系统。如果你想知道参与者模型或CSP是什么,本章后面会对这些范式进行解释。 |
| 面向对象架构(Object-oriented) | 这是一种架构风格,其中组件被建模为封装属性并暴露方法的对象。方法用于操作对象内部的数据。第3章“设计模式”将详细讨论这种方法。 |
| 模型 - 视图 - 控制器(Model-View-Controller,MVC)/ 分离表示层(separated presentation) | 在这种架构中,处理用户交互的逻辑放在视图组件中,为交互提供数据的部分放在模型组件中。控制器组件协调它们之间的交互。我们将在第6章“消息传递”中更详细地介绍这种架构。 |
| 微服务架构/面向服务的架构(Microservices / service-oriented architecture,SOA) | 在这种架构中,系统被设计为一组相互协作的独立服务,以提供必要的系统行为。每个服务封装自己的数据并具有特定的用途。与其他范式的关键区别在于,这里存在独立运行和部署的服务。本章后面会深入探讨这种架构风格。 |
# 微服务
尽管前面讨论的理论概念已经存在了几十年,但最近有一些情况变化得非常迅速。软件产品的复杂性在不断增加。例如,在面向对象编程中,我们可能一开始在两个类之间设计了清晰的接口,但在冲刺阶段,由于时间紧迫,开发人员可能会走捷径,在类之间引入耦合。这种技术债务很少会自行消除,它会不断积累,直到我们最初的设计目标完全模糊不清!
另一个变化是,现在的产品很少是孤立构建的,它们大量使用外部实体提供的服务。云环境中的托管服务就是一个生动的例子,比如亚马逊网络服务(Amazon Web Services,AWS)。在AWS中,从数据库到构建聊天机器人的服务,应有尽有。
我们必须努力实现关注点分离。组件之间的交互和契约越来越多地由应用程序编程接口(Application Programming Interface,API)驱动。组件之间不共享内存,因此它们只能通过网络调用进行通信。这样的组件被称为服务。服务接收来自客户端的请求并处理这些请求。客户端并不关心服务的内部实现。一个服务也可以作为另一个服务的客户端。
一个系统典型的初始架构如下所示:

该系统可以分为三个不同的层:
- 前端(移动应用程序或网页):这是用户与之交互的部分,它通过网络调用后端获取数据并实现相关功能。
- 后端部分:这一层包含处理特定请求的业务逻辑。这部分代码通常应该对前端的具体细节(比如发起调用的是应用程序还是网页)一无所知。
- 数据存储:这是持久化数据的存储库。
在早期阶段,团队(或公司)刚起步,开发人员在全新的环境中开展工作,且人数较少,一切都进展得很顺利,开发速度和质量都很高。每当出现问题时,开发人员都会互相帮助,因为每个人在一定程度上都了解系统组件,即使他们不是负责该组件的开发人员。然而,随着公司的发展,产品功能开始成倍增加,团队规模也不断扩大,会出现四个重大问题:
- 代码复杂度呈指数级增长,质量开始下降。在修复现有代码的漏洞以及开发新功能的过程中,现有代码和新功能之间会突然产生大量依赖关系。新开发人员不了解团队的内部知识,代码库的紧密结构开始瓦解。
- 运维工作(运行和维护应用程序)开始占用团队大量时间。这通常会导致公司聘请运维工程师(DevOps工程师),他们可以独立接手运维工作,并随时处理出现的问题。然而,这会导致开发人员与生产环境脱节,我们经常会遇到 “在我的环境中能运行,但在生产环境中却失败” 这样的经典问题。
- 产品会遇到可扩展性限制。例如,在流量增加的情况下,数据库可能无法满足延迟要求。我们可能会发现,为某个关键业务规则选择的算法延迟越来越高。仅仅因为数据量和请求量的增加,原本运行良好的功能突然开始出现问题。
- 开发人员开始编写大量测试用例来保证质量。然而,随着添加的代码越来越多,这些回归测试变得非常脆弱。开发人员的生产力大幅下降。
处于这种状态的应用程序被称为单体应用。有时候,单体架构并非不好(例如,如果有严格的性能或延迟要求),但总体而言,这种状态带来的成本会对产品产生非常负面的影响。一种为了实现软件可扩展性而流行起来的关键理念是微服务,这种范式通常被称为面向服务架构(Service - Oriented Architecture,SOA)。
微服务的基本概念很简单 —— 它是一个简单的、独立运行的应用程序,只专注于做一件事,并且把这件事做好。其目标是保持早期应用程序的简洁性、独立性和高效性。微服务不能孤立存在,没有哪个微服务是一座孤岛,它是更大系统的一部分,与其他微服务一起运行和协作,来完成通常由一个大型独立应用程序处理的任务。
每个微服务都是自治、独立、自包含的,并且可以单独部署和扩展。微服务架构的目标是构建一个由这样的微服务组成的系统。
单体应用和微服务之间的核心区别在于,单体应用会在一个应用程序(代码库)中包含所有功能和特性,并同时部署,每台服务器都托管整个应用程序的完整副本;而微服务只包含一个功能或特性,与其他微服务一起存在于微服务生态系统中:
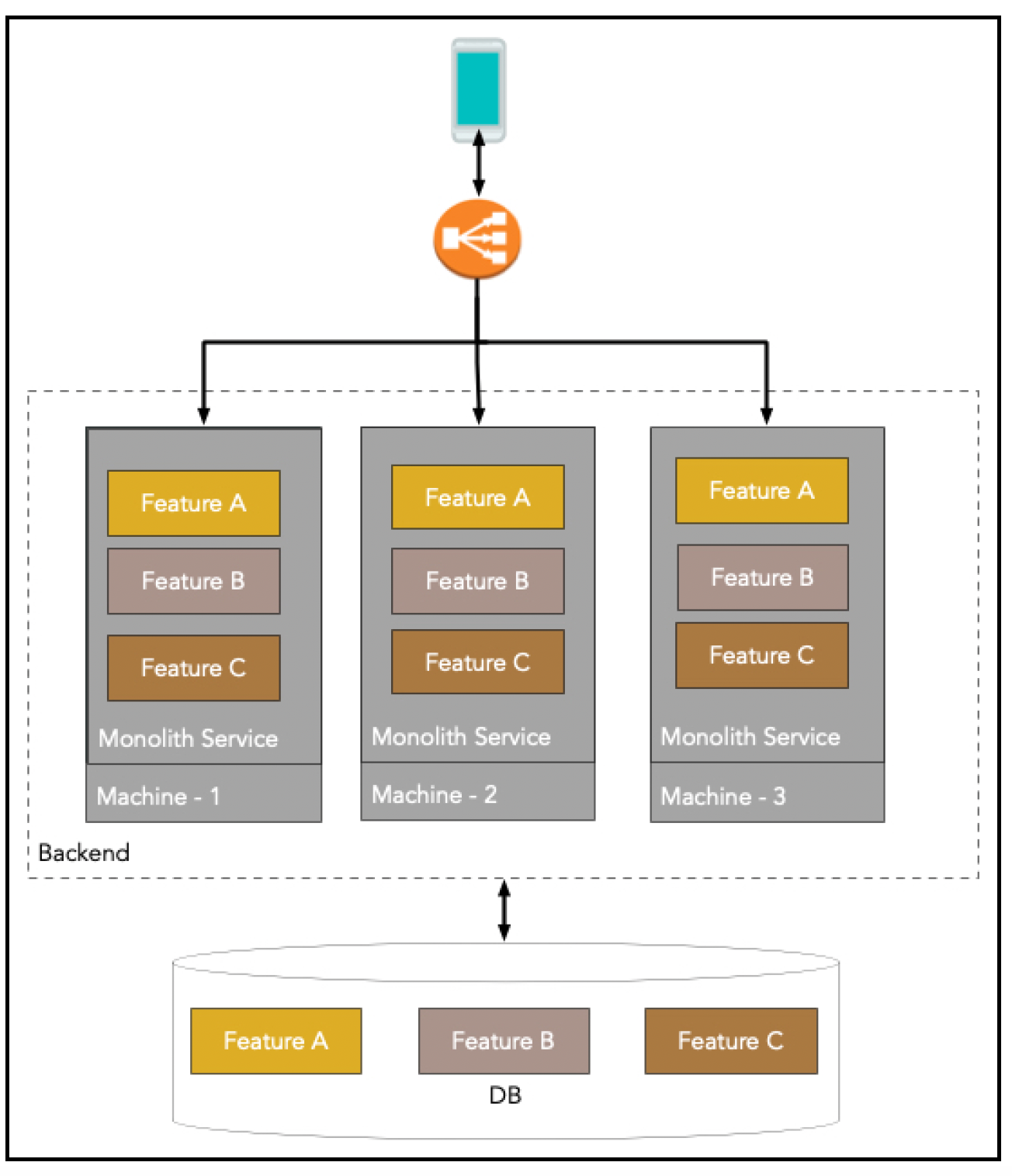
图示 单体架构
这里,只有一个可部署的工件,由包含所有特性的一个应用程序代码库构建而成。每台机器都运行相同代码库的一个副本。数据库是共享的,这通常会导致一些不明确的依赖关系(例如,功能A要求功能B使用特定模式维护表X,但却没有人告知功能B团队!)。
将其与微服务应用进行对比:
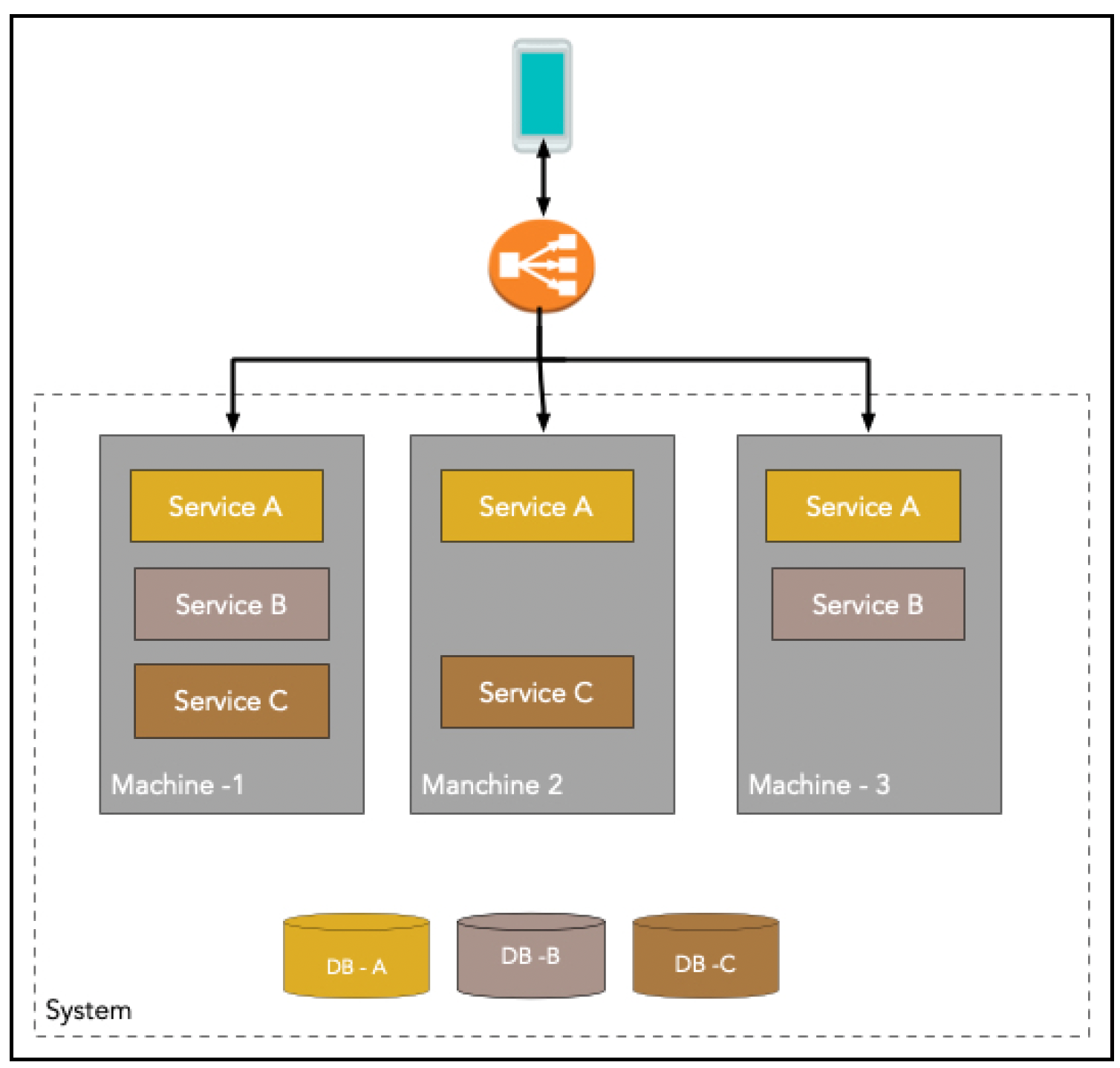
图示 基于微服务的架构
在这里,标准形式是每个功能本身都被打包成一个服务,具体来说就是一个微服务。每个微服务都可以单独部署和扩展,并且有自己独立的数据库。
总之,微服务有很多优势:
- 它们让我们能够更有效地使用组件化策略(即分而治之),组件之间界限清晰。
- 可以为每个任务创建合适的工具。
- 确保了更高的可测试性。
- 提高了开发人员的生产力和功能迭代速度。
# 微服务面临的挑战——效率
一个采用微服务架构的大型产品会包含数十个(甚至数百个)微服务,所有这些微服务都需要协同工作,以提供更高的价值。这种架构面临的一个挑战是部署问题 —— 我们需要多少台机器呢?
摩尔定律是英特尔联合创始人戈登·摩尔在1965年提出的一个观察结论。他指出,自集成电路发明以来,每平方英寸集成电路上的晶体管数量每年都会翻倍,并且这种趋势应该会持续下去。
在过去的40多年里,这条定律在很大程度上是成立的,这意味着高性能硬件已经成为一种常见资源。对于许多问题,通过增加硬件资源来解决问题对很多公司来说都是一种有效的解决方案。在AWS这样的云环境中更是如此,人们只需按下一个按钮,就能轻松获得更强大的计算能力:
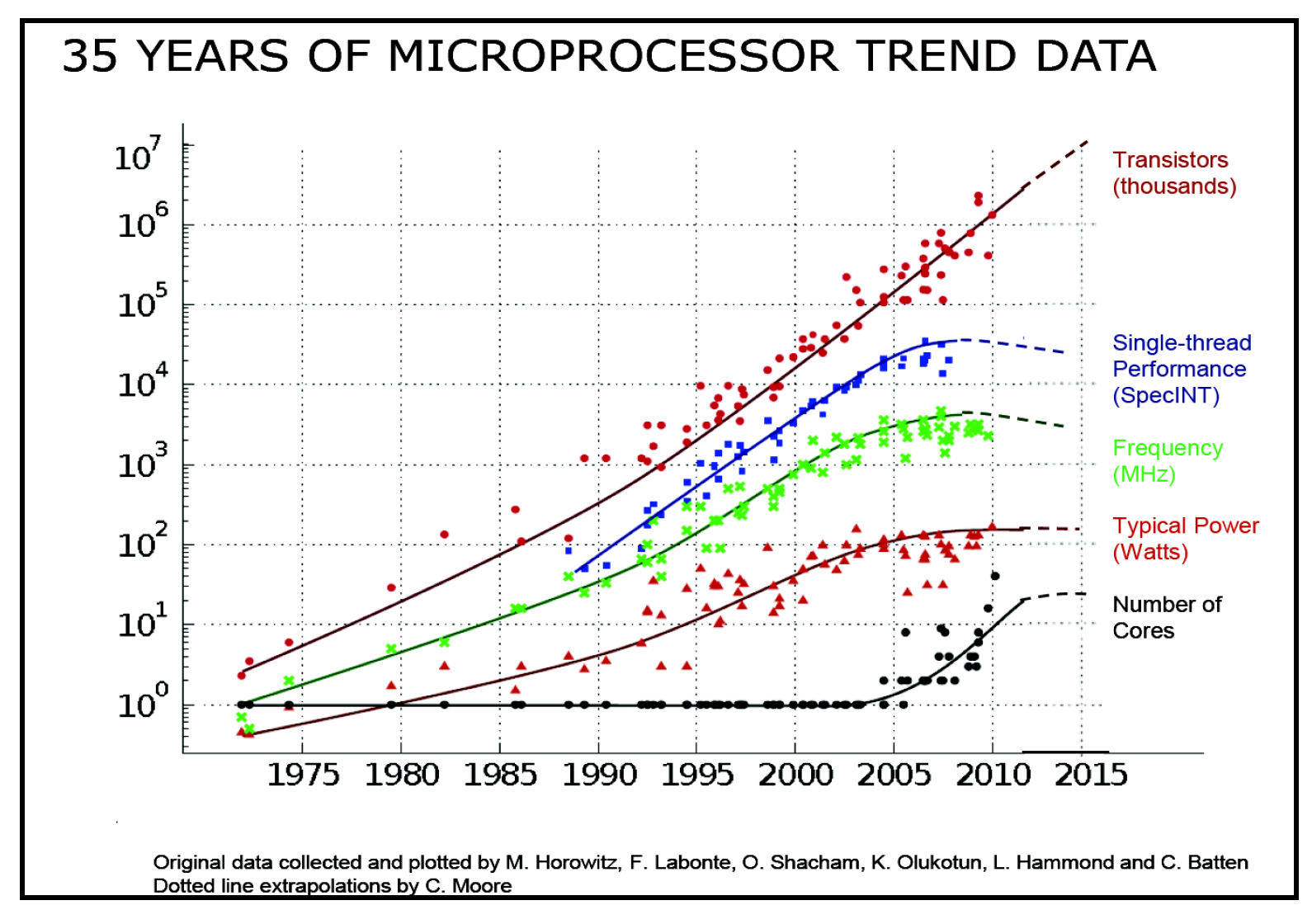
然而,在微服务范式下,我们不能再忽视效率或成本问题。微服务可能有数十个甚至数百个,每个服务又有多个实例。
除了部署之外,另一个与效率相关的挑战是开发人员的开发环境设置。开发人员为了开发某个功能,需要在自己的笔记本电脑上运行多个服务。虽然他们可能只对其中一个服务进行修改,但仍然需要运行其他服务的模拟版本或冲刺分支版本,以便对代码进行测试。
我们可能马上会想到一个解决方案:我们可以在同一台机器上共同托管微服务吗?要回答这个问题,首先要考虑的是语言运行时。例如,在Java中,每个微服务都需要一个单独的JVM进程来运行,以实现代码的隔离。然而,JVM对资源的需求往往很大,更糟糕的是,资源需求可能会突然增加,导致一个JVM进程因占用过多资源而使其他进程失败。
关于编程语言,另一个需要考虑的因素是并发原语。微服务通常是I/O密集型的,并且会花费大量时间相互通信。这些交互通常是并行的。如果使用Java,几乎所有的并行操作都需要一个线程(尽管可以在线程池中)。Java中的线程并不轻量,通常每个线程会占用大约1MB的堆内存(用于栈、内务管理数据等)。因此,在Java中编写并行代码时,高效地使用线程成为了一个额外的限制因素。其他需要担心的问题还包括线程池的大小设置,在很多情况下,这只能通过反复试验来确定。
因此,尽管微服务与编程语言无关,但有些语言比其他语言更适合微服务,或者对微服务的支持更好。在对微服务的友好程度方面,Go语言表现突出。它对资源的消耗极少,轻量级,速度非常快,并且对并发有出色的支持,这在跨多个核心运行时是一项强大的功能。Go语言还包含一个非常强大的标准库,用于编写用于通信的Web服务(在本书后面的内容中我们会看到)。
# 微服务面临的挑战——编程复杂性
在大型代码库中工作时,局部推理非常重要。这指的是开发人员通过检查一个例程本身就能理解其行为的能力,而无需检查整个系统。这是我们前面提到的内容的延伸,模块化是管理复杂性的关键。
在单线程系统中,当你查看一个操作某些状态的函数时,你只需要阅读代码并了解初始状态。孤立的线程用处不大。然而,当线程之间需要相互通信时,就可能会出现非常危险的情况!相比之下,在多线程系统中,任何一个线程都有可能干扰函数的执行(甚至可能在你都不知道自己正在使用的某个库的内部!)。因此,理解一个函数不仅意味着理解函数中的代码,还需要全面了解所有可能导致函数状态发生变化的交互情况。
众所周知,人类一次大约能处理七件事情。在一个大型系统中,可能有数百万个函数和数十亿种可能的交互,如果无法进行局部推理,后果将不堪设想。
同步原语,如互斥锁(mutexes)和信号量(semaphores),确实会有所帮助,但它们也带来了一些问题,包括以下几点:
- 死锁:两个线程以稍有不同的模式请求资源,导致双方都被阻塞:
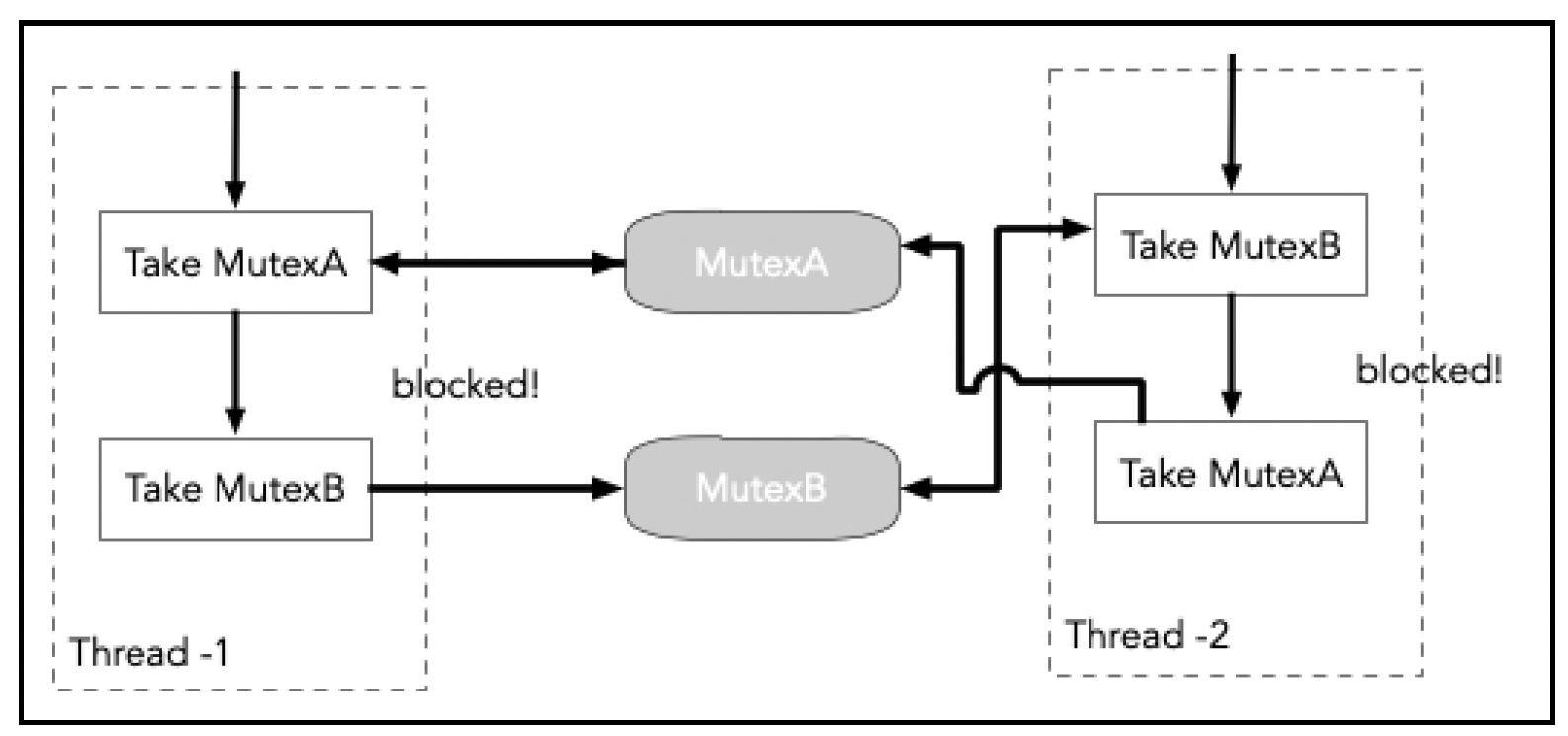
- 优先级反转:高优先级进程等待低优先级的慢速进程。
- 饥饿:一个进程占用资源的时间比另一个同样重要的进程长得多。
在下一节中,我们将了解Go语言如何帮助我们克服这些挑战,真正地采用微服务架构,而无需担心效率限制或代码复杂性增加的问题。
# Go语言
谷歌的规模是前所未有的。其代码库有数百万行,数千名工程师参与开发。在这样一个环境中,不同的人会进行大量的修改,这就会出现许多软件工程方面的挑战,特别是以下这些:
- 代码变得难以阅读,文档也不完善。组件之间的契约难以推断。
- 构建速度缓慢。代码编译测试的开发周期变得越来越困难,由于使用同步原语编写高效代码难度较大,对并发系统进行建模的效率也不高。
- 手动内存管理经常会导致漏洞。
- 存在不受控制的依赖关系。
- 由于实现方式多种多样,编程风格也各不相同,这给代码审查等工作带来了困难。
Go编程语言是由罗伯特·格里塞默(Robert Griesemer)、罗布·派克(Rob Pike)和肯·汤普森(Ken Thompson)在2007年末构思出来的一种开源编程语言,旨在简化编程并让编程再次变得有趣。它由谷歌赞助,但却是一个真正的开源项目 —— 谷歌先将代码提交到开源项目,然后再将公共代码库引入内部使用。
这种语言是由编写、阅读、调试和维护大型软件系统的人设计的,也是为他们服务的。它是一种静态类型的编译语言,内置的并发和垃圾回收功能是其核心特性。包括我在内的一些开发人员欣赏它简约而富有表现力的设计。当然,也有人对它缺乏泛型等特性感到不满。
自诞生以来,Go语言一直在不断发展,并且已经获得了相当多的行业支持。它被用于多个网络规模的实际系统中(数据来源:https://madnight.github.io/githut/):

如果你想快速了解Go语言受欢迎的原因,可以参考https://smartbear.com/blog/develop/an-introduction-to-the-go-language-boldly-going-wh/中的 “WHY GO?” 部分。
在本书接下来探讨如何利用Go语言的特性进行软件架构和工程设计之前,我们先快速回顾一下该语言的各个特性。
TIP 以下部分不会详尽介绍Go语言的语法,只是进行回顾。如果你是Go语言的新手,可以在阅读以下内容的同时,访问https://tour.golang.org/welcome/1进行Go语言之旅。
# Hello World!
任何语言的介绍都少不了经典的Hello World程序(http://en.wikipedia.org/wiki/Hello_world )。这个程序首先定义了一个名为main的包,然后导入Go标准的输入/输出格式化包(fmt),最后定义了main函数,这是每个Go程序的标准入口点。这里的main函数只是输出 “Hello World!”:
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
2
3
4
5
6
7
Go语言的设计目标是拥有简洁、极简的代码。因此,与C家族的其他语言相比,它的语法规模较小,大约只有25个关键字。 “少即是多,而且是指数级的多。” —— 罗布·派克
Go语言的语句通常与C语言类似,对于熟悉C和Java等语言的程序员来说,大多数基本类型应该都很熟悉。这使得非Go语言开发人员能够快速上手。话虽如此,Go语言对C语言的语义进行了许多修改,主要是为了避免与低级资源管理(即内存分配、指针运算和隐式转换)相关的可靠性问题,目的是提高健壮性。此外,尽管语法相似,但Go语言引入了许多现代编程结构,包括并发和垃圾回收。
# 数据类型和结构
Go语言支持许多基本数据类型,包括int、bool、int32和float64。该语言规范与常见的C/Java语法最明显的区别之一,就体现在声明语法上:在Go语言中,声明的变量名出现在类型之前。例如,看下面这段代码:
var count int
它声明了一个整数类型(int)的变量count。当变量的类型可以从初始值明确推断出来时,Go语言提供了一种更简短的变量声明语法pi := 3.14 。
需要注意的是,Go语言是强类型语言,所以下面这段代码是无法编译通过的:
var a int = 10
var b int32 = 20
c := a + b
2
3
Go语言中有一个独特的数据类型error,用于存储错误信息。还有一个很实用的errors包,可用于处理这种类型的变量:
err := errors.New("Some Error")
if err != nil {
fmt.Print(err)
}
2
3
4
和C语言一样,Go语言也让程序员能够控制指针。例如,下面的代码定义了一个点(Point)结构体的布局,以及一个指向Point结构体的指针:
type Point Struct {
X, Y int
}
2
3
Go语言还原生支持复合数据结构,如string、map、array和slice。语言运行时负责处理内存管理的细节,并为程序员提供原生类型进行操作:
var a[10]int // 一个类型为[10]int的数组
a[0] = 1 // 数组是从0开始索引的
a[1] = 2 // 给元素赋值
var aSlice []int // slice类似于数组,但无需预先指定大小
var ranks map[string]int = make(map[string]int) // make用于分配map内存
ranks["Joe"] = 1 // 设置值
ranks["Jane"] = 2
rankOfJoe := ranks["Joe"] // 获取值
string s = "something"
suff := "new"
fullString := s + suff // + 用于字符串拼接
2
3
4
5
6
7
8
9
10
11
Go语言有两个操作符make()和new(),它们很容易让人混淆。new()仅仅分配内存,而make()用于初始化诸如map之类的结构。因此,make()需要与map、slice或channel一起使用。
slice在内部是作为结构体处理的,结构体中的字段定义了当前内存范围的起始位置、当前长度和内存范围大小。
# 函数和方法
和C/C++一样,Go语言中也有被称为函数的代码块,通过func关键字进行定义。函数有名称、一些参数、代码主体,并且可以选择性地返回一系列结果。下面这段代码定义了一个计算圆面积的函数:
func area(radius int) float64 {
var pi float64 = 3.14
return pi*radius*radius
}
2
3
4
该函数接受一个int类型的变量radius,并返回一个float64类型的值。在函数内部,声明了一个float64类型的变量pi。
Go语言中的函数可以返回多个值。常见的情况是同时返回函数结果和错误值,如下例所示:
func GetX() (x X, err error)
myX, err := GetX()
if err != nil {
...
}
2
3
4
5
Go语言是一种面向对象的语言,具有结构体和方法的概念。struct类似于类,用于封装数据和相关操作。例如,看下面这段代码:
type Circle struct {
Radius int
color String
}
2
3
4
它定义了一个Circle结构体,包含两个成员字段:
Radius,int类型,是公共字段。color,String类型,是私有字段。
我们将在第3章 “设计模式” 中更详细地探讨类的设计以及公共/私有可见性。
方法是带有一个特殊参数(称为接收者)的函数,可以使用标准的点号表示法将接收者传递给函数。这个接收者类似于其他语言中的self或this关键字。
方法声明语法是将接收者放在函数名前面的括号中。下面是将前面的Area函数声明为方法的代码:
func (c Circle) Area() float64 {
var pi float64 = 3.14
return pi*c.radius*c.radius
}
2
3
4
接收者既可以是指针(引用),也可以是非指针(值)。
提示:指针引用的作用和普通的按引用传递变量类似,比如当你想要修改结构体,或者结构体体积较大等情况时。在前面Area()函数的例子中,c Circle接收者是按值传递的。如果写成c *Circle,那就是按引用传递。
最后,关于函数,需要注意的是,Go语言支持头等函数(first-class functions)和闭包(closures):
areaSquared := func(radius int) float64 {
return area*area
}
2
3
在函数语法的设计上,有一个决策体现了我最喜欢的Go语言设计习惯之一 —— 保持清晰明确。使用默认参数很容易修改API契约并实现函数重载,这在短期内可能会带来便利,但从长远来看,会导致代码复杂混乱。Go语言鼓励开发者针对每个需求使用单独的、命名清晰的函数,这使得代码可读性大大提高。如果确实需要函数重载,或者需要一个能接受可变数量参数的函数,那么可以使用Go语言类型安全的可变参数函数。
# 流程控制
代码中流程控制的主要方式是常见的if语句。Go语言中有if语句,但不强制要求在条件表达式周围使用括号。例如:
if val > 100 {
fmt.Println("val is greater than 100")
} else {
fmt.Println("val is less than or equal to 100")
}
2
3
4
5
在Go语言中,定义循环只有一个迭代关键字for,没有像C或Java等其他语言中的while或do...while关键字。这符合Go语言的极简主义和简洁性设计原则 —— 能用while循环实现的功能,用for循环同样可以实现,那为什么要设置两种结构呢?其语法如下:
func naiveSum(n Int) (int){
sum := 0;
for i:=0; i < n ; i++ {
sum += index
}
return sum
}
2
3
4
5
6
7
可以看到,循环条件周围同样没有括号。而且,i变量是在循环作用域内定义的(使用i:= 0)。这种语法对于C++或Java程序员来说应该很熟悉。
需要注意的是,for循环并不一定要严格遵循初始的三元组形式(声明、检查、递增)。它可以像其他语言中的while循环一样,只进行条件检查:
i:= 0
for i <= 2 {
fmt.Println(i)
i = i + 1
}
2
3
4
5
最后,while(true)语句在Go语言中的写法如下:
for {
// 无限循环
}
2
3
Go语言中有一个range操作符,用于遍历数组和map。下面展示了使用range操作符遍历map的示例:
// 遍历myMap的键(k)和值(v)
for k,v := range myMap {
fmt.Println("key:",k)
fmt.Println("val:",v)
}
// 只遍历键
for key := range myMap {
fmt.Println("Got Key :", key)
}
2
3
4
5
6
7
8
9
range操作符用于遍历数组时,逻辑也很直观:
input := []int{100, 200, 300}
// 遍历数组并获取索引和元素
for i, n := range input {
if n == 200 {
fmt.Println("200 is at index : ", i)
}
}
sum := 0
// 在这次遍历中,跳过索引,因为不需要
for _, n := range input {
sum += n
}
fmt.Println ("sum:", sum)
2
3
4
5
6
7
8
9
10
11
12
13
# 包(Packaging)
在Go语言中,代码被组织成包(package)。这些包为代码提供了命名空间。例如,每个Go源文件,比如encoding/json/json.go,都以一个包声明语句开头,如下所示:
package json
这里,json是包名,它是一个简单的标识符。包名通常很简洁。
包很少是孤立存在的,它们存在依赖关系。如果一个包中的代码想要使用另一个包中的内容,就需要明确地声明这种依赖关系。被依赖的包可以是同一项目中的其他包、Go语言标准库中的包,或者是GitHub上的第三方包。为了声明依赖包,在包声明语句之后,每个源文件可能会有一个或多个导入语句,这些语句由import关键字和包标识符组成:
import "encoding/json”
从依赖关系的角度来看,Go语言的一个重要设计决策是,语言规范要求将未使用的依赖声明视为编译时错误(而不像大多数其他构建系统那样只是警告)。如果源文件导入了一个未使用的包,程序将无法编译。这样做是为了通过让编译器仅处理那些需要的包来加快构建时间。对于程序员来说,这也意味着代码往往更整洁,不会堆积过多未使用的导入。不利的一面是,如果你在编码时尝试使用不同的包,可能会觉得编译器错误很烦人!
一旦导入了一个包,在导入的源文件中,包名就可以限定来自该包的项目:
var dec = json.NewDecoder(reader)
Go语言在定义包内标识符(函数/变量)的可见性方面采用了一种不同寻常的方法。与private和public关键字不同,在Go语言中,标识符的名称本身就包含了可见性定义。标识符首字母的大小写决定了其可见性。如果首字母是大写字母,那么该标识符是公共的,可以从包中导出。这样的标识符可以在包外使用。其他所有标识符在包外不可见(因此也无法使用)。考虑以下代码片段:
package circles
func AreaOf(c Circle) float64 {
}
func colorOf(c Circle) string {
}
2
3
4
5
6
7
在前面的代码块中,AreaOf函数被导出,可以在circles包外可见,而colorOf函数仅在包内可见。
我们将在第3章“设计模式”中更详细地探讨Go代码的包组织。
# 并发(Concurrency)
现实生活是并发的。随着基于API的交互和多核计算机的出现,如今编写的任何一个稍微复杂点的程序都需要能够并行调度多个操作,并且这些操作需要利用可用的内核并发执行。像C++或Java这样的语言,在很长一段时间里都没有在语言层面支持并发。最近,Java 8通过流处理(stream processing)增加了对并行性的支持,但它仍然遵循一种低效的分治(fork - join)过程,而且并行流之间的通信很难设计。
通信顺序进程(Communicating Sequential Processes,CSP)是一种用于描述并发系统中交互模式的形式语言。它最早由托尼·霍尔(Tony Hoare)在1978年的一篇论文中提出。CSP的关键概念是进程。本质上,一个进程内的代码是顺序执行的。在某个时刻,这段代码可以启动另一个进程。很多时候,这些进程需要进行通信。与共享内存和锁的通信范式相比,CSP倡导消息传递的通信范式。共享内存模型,如下图所示,充满了风险:
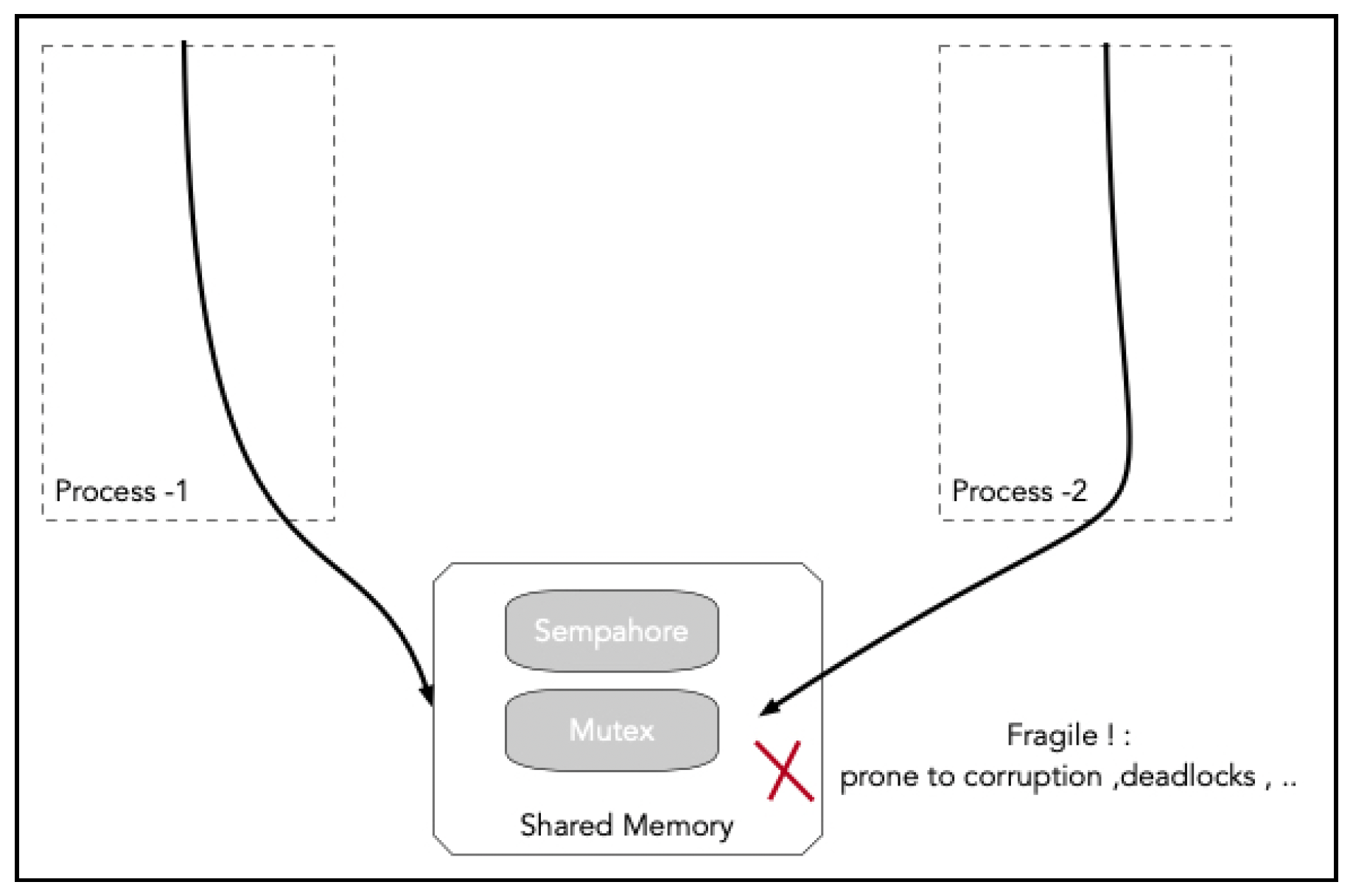
如果一个进程在临界区内行为异常或崩溃,很容易出现死锁和数据损坏。这样的系统在从故障中恢复时也会遇到困难。
相比之下,CSP通过通道(channel)的概念来促进消息传递,通道本质上是具有send()和recv()简单逻辑接口的队列。这些操作可以是阻塞的。这个模型如下图所示:
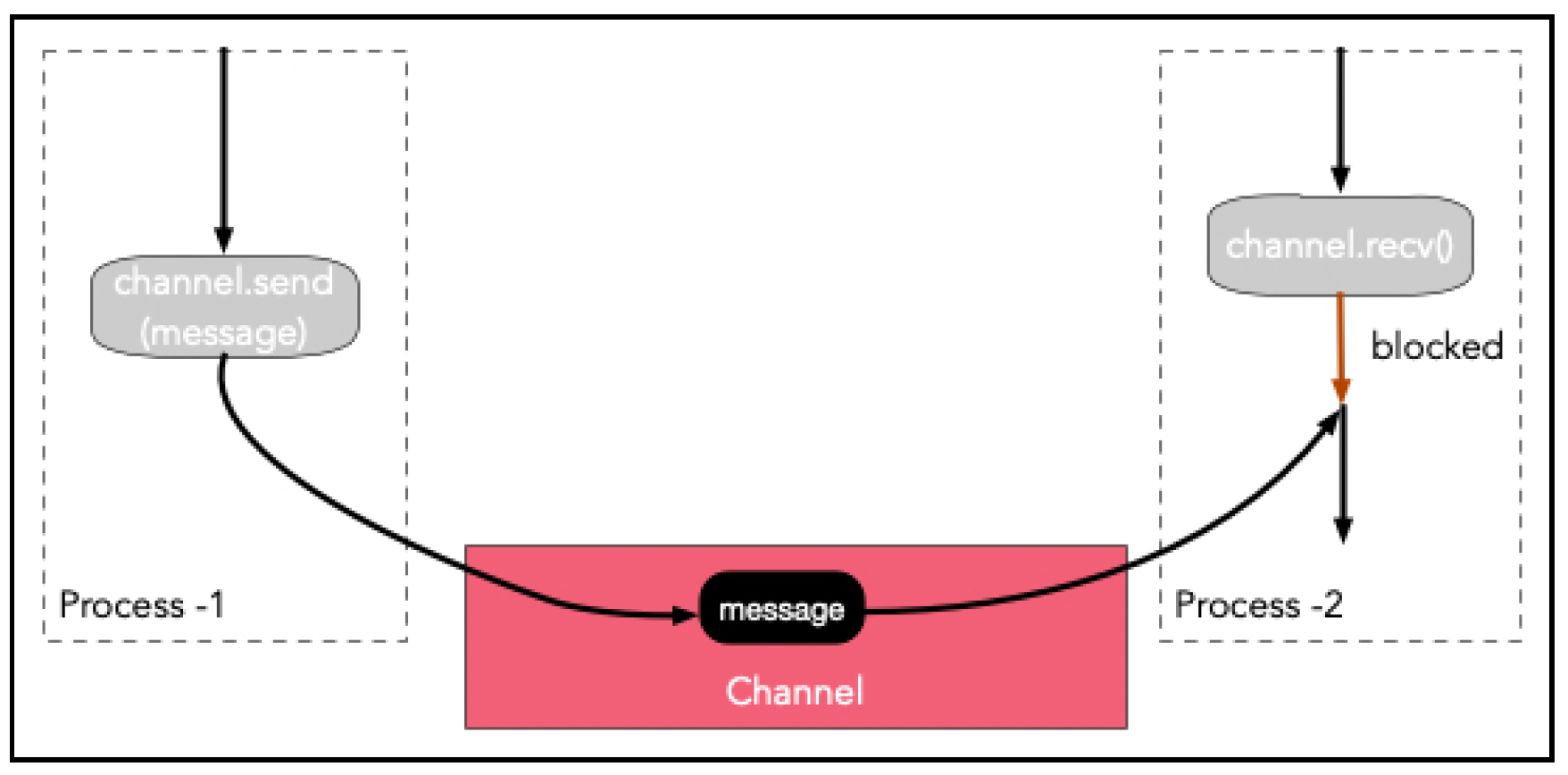
Go语言使用了一种带有一流通道(first - class channels)的CSP变体。过程被称为协程(goroutine)。Go语言使代码大部分是常规的过程式代码,但允许通过独立执行的函数(协程)进行并发组合。在过程式编程中,我们可以直接内联调用一个函数;然而,在Go语言中,我们还可以从一个函数中创建一个协程,让它独立执行。
通道也是Go语言的一流原语。在通道上共享数据是合法的,并且通过通道传递指针是一种惯用(且高效)的做法。
main()函数本身就是一个协程,并且可以使用go关键字创建一个新的协程。例如,下面的代码片段修改了“Hello World”程序来创建一个协程:
package main
import (
"fmt"
"time"
)
func say(what string){
fmt.Println(what)
}
func main() {
message := "Hello world!"
go say(message)
time.Sleep(5*time.Second)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
注意,在执行go say(message)语句之后,main()协程会立即执行下一条语句。这里time.Sleep()函数很重要,它可以防止程序退出!协程的示意图如下所示:
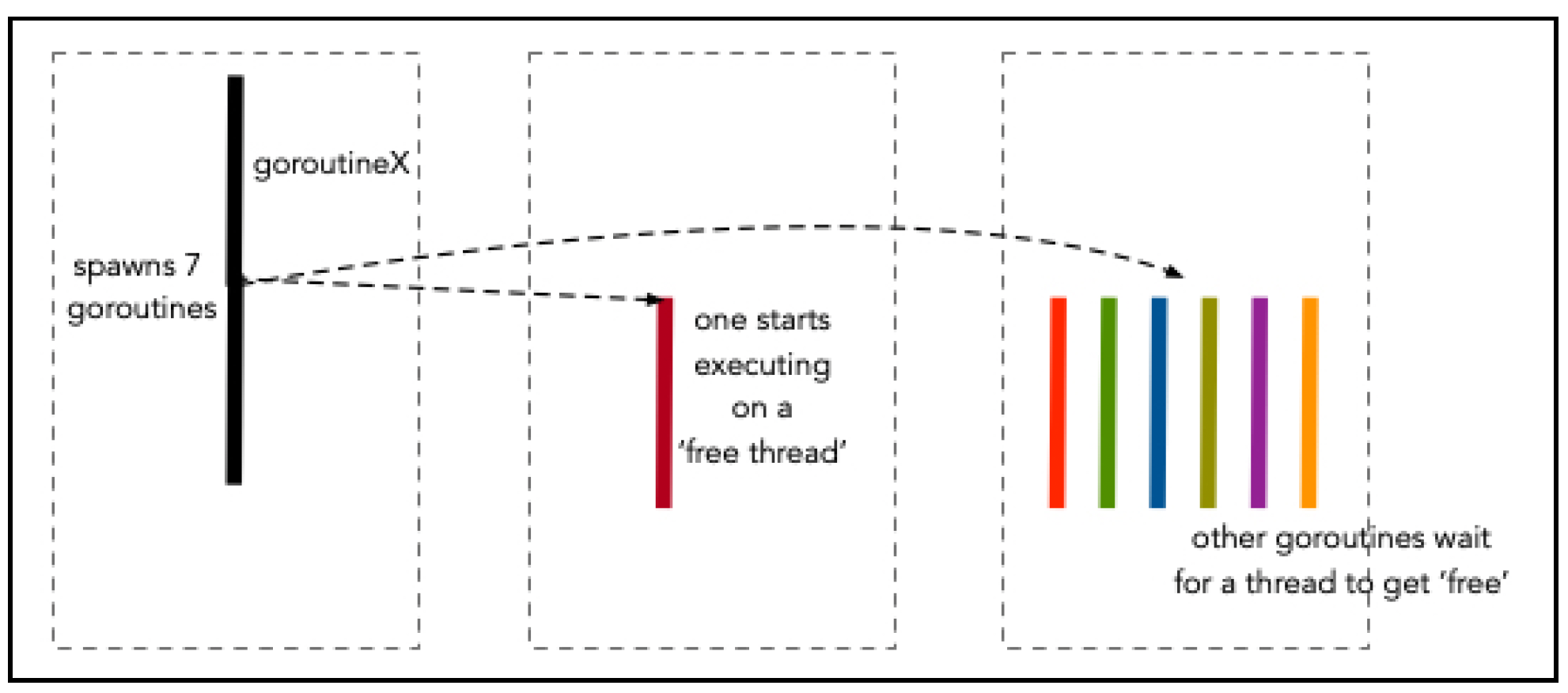
我们将在第4章“扩展应用程序”中进一步探讨通道和更多并发结构。
# 垃圾回收(Garbage collection)
Go语言没有显式的内存释放操作:释放已分配内存的唯一方法是通过垃圾回收。在并发系统中,这是一个必备的功能,因为对象的所有权可能会以不明显的方式(通过多个引用)发生变化。这使得程序员可以专注于对系统的并发方面进行建模和编码,而不必担心繁琐的资源管理细节。当然,垃圾回收会带来实现上的复杂性和延迟。尽管如此,最终由于垃圾回收,这种语言使用起来要容易得多。
并非所有内容都会自动为程序员释放。有时,程序员必须显式调用以释放对象的内存。
# 面向对象(Object - orientation)
Go语言的作者认为,软件开发中常见的类型层次结构模型很容易被滥用。例如,考虑下面这个类及其相关描述:

在如此庞大的类层次结构中编码通常会生成脆弱的代码。早期的决策很难更改,基类的更改可能会在后续产生严重的后果。然而具有讽刺意味的是,在早期,所有的需求可能并不明确,对系统的理解也不够深入,难以设计出优秀的基类。
Go语言的面向对象方式是:组合优于继承。对于多态行为,Go语言使用接口(interface)和鸭子类型(duck typing):“如果它看起来像鸭子,叫起来也像鸭子,那它就是鸭子。”
鸭子类型意味着,任何一个类,只要拥有某个接口所声明的所有方法,就可以说它实现了该接口。
我们将在后面的第3章“设计模式”中更详细地探讨Go语言中的面向对象。
# 总结
在本章中,我们探讨了在进行大型项目构建时制定计划的重要性。我们回顾了各种设计范式以及Go语言的关键特性。这里对这些主题的讨论是有针对性且非常精炼的。为了获得更多见解,我强烈推荐阅读罗伯特·C·马丁(Robert C. Martin)所著的《清洁架构:软件结构与设计的工匠指南》(Clean Architecture: A Craftsman's Guide to Software Structure and Design)以及《Go语言之旅》(A tour of Go,https://tour.golang.org/welcome/1)。
在下一章中,我们将研究本书后续部分要处理的案例研究的问题陈述。在本书每一部分的结尾,我们都会应用该部分章节中学到的知识,为案例研究的特定方面构建解决方案。