 2. 代码的封装
2. 代码的封装
# 2. 代码的封装
2000年,米哈伊·布迪乌(Mihai Budiu)采访布莱恩·克尼汉(Brian Kernighan)时(http://www.cs.cmu.edu/~mihaib/kernighan-interview/index.html),问了他这样一个问题:“从您的角度来看,您能讲讲C语言最糟糕的特性是什么吗?”
他是这样回答的: “我认为C语言真正的问题在于,它没有为构建大型程序提供足够的机制,无法在程序内部构建‘防火墙’,将各个部分隔离开来。这并不是说你不能做这些事情,不能在C语言中模拟面向对象编程或其他你想要的方法。你可以模拟,但编译器以及语言本身并不会给你提供任何帮助。”
当开发者感觉代码被随意放置时,就应该有所警惕。这通常意味着代码库缺乏连贯性,也没有从架构中提炼出明确的目标。这不仅仅关乎代码的美观性或可追溯性,良好的代码封装是打造可维护代码库的第一步。
正如我们在第1章“使用Go语言构建大型项目”中看到的,管理复杂性是架构的主要目标之一。实现这一目标的方法之一是封装,即将代码打包成更高层次的抽象,也就是克尼汉之前提到的“防火墙”。
本章将深入探讨在两个层面组织代码的方法:
- Go语言中的面向对象编程
- 包的代码布局、依赖关系等
但在深入探讨之前,我们需要明确模块设计的一个关键方面——契约(Contracts)。
# 契约
软件契约是对与软件组件交互的一种正式记录。它可以是一个接口(面向对象意义上的接口)、一个应用程序编程接口(API),或者一种协议(例如传输控制协议TCP)。契约能让系统中各种互不关联的组件协同工作。拥有清晰明确的契约是实现成功的分布式软件开发的前提条件。这里的“分布式”,不仅指一般意义上的分布式系统(由独立组件构成的软件),还包括分布式团队协作开发。
所有的库和产品都会实现契约,无论是显式的还是隐式的。契约可以通过文档记录(理想情况下,使用如RFC这样的正式文本),也可以嵌入到代码中(这种方式不太理想,除非能清晰标注)。
契约确实会发生变化。架构师的关键任务是确保做到以下几点:
- 契约具有持久性,不应是被动响应式的,并且不会出现变更放大的情况,即小的需求变更不会导致契约频繁变动。
- 契约要进行版本管理。你永远无法预知与你的组件交互的客户端处于何种状态。因此,为契约关联一个版本至关重要。一般来说,契约应该是向后兼容的(例如,组件的2.2版本应该能够与假定契约版本为1.1的客户端可靠地交互)。有时,向后兼容的成本可能很高。在这种情况下,你可以在充分考量后决定进行不兼容的变更。即便如此,与早期客户端的交互也应该能够优雅地失败,并明确传达一条错误信息,告知客户端该契约版本不再受支持。
- 契约应包含非功能性需求,通常称为服务级别协议(SLAs)。这些有助于客户端计算诸如超时等参数。
在这样的背景下,我们来看看面向对象编程在Go语言中是如何实现的。
# 面向对象
在面向对象编程中,核心思想是将代码分解为多个小型、易于管理的部分或对象。每个对象都有自己的标识、数据(或属性)以及逻辑(或行为)。例如,考虑在软件中对大象进行建模。 属性是对象的特性。以大象为例,属性包括:
- 体重
- 颜色
- 种类
- 位置
所有这些属性的集合描述了对象的当前状态。一个对象的状态通常与其他对象的状态相互独立。行为是对象能够执行的操作,就大象而言,它可以发出吼声。行为是对象与外部世界交互的接口。你可以通过调用对象的行为的各个构造(或函数)被称为方法。
类是一个蓝图,或者说是具有相同行为和属性的对象的模板。作为模板,它可以用作创建对象的规范。通常可以说,从一个类实例化的对象属于同一类型。所以,我们的大象类可以是如下这样:
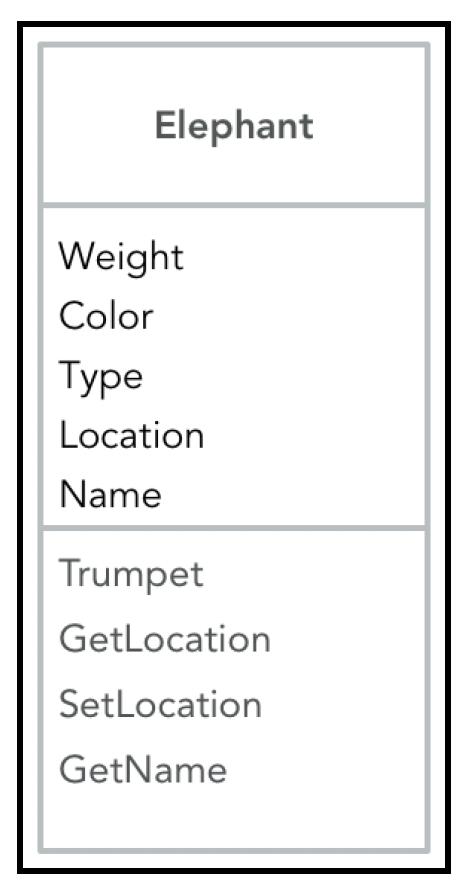
封装是类设计的关键指导原则。它意味着对外暴露对象行为的契约,同时隐藏易变的实现细节。私有属性和方法根据实际需求隐藏在“胶囊”内部。
与编写冗长的过程式程序不同,设计范式是将行为分解为小型、易于管理(并且理想情况下可复用)的组件(对象),每个组件都有一个明确定义的契约(接口)。这样做可以让作为类开发者的我,在不影响客户端的情况下更改实现。此外,我们还可以确保系统中的行为更加安全,因为我们无需担心客户端滥用实现结构,从而降低了整个系统的复杂性。
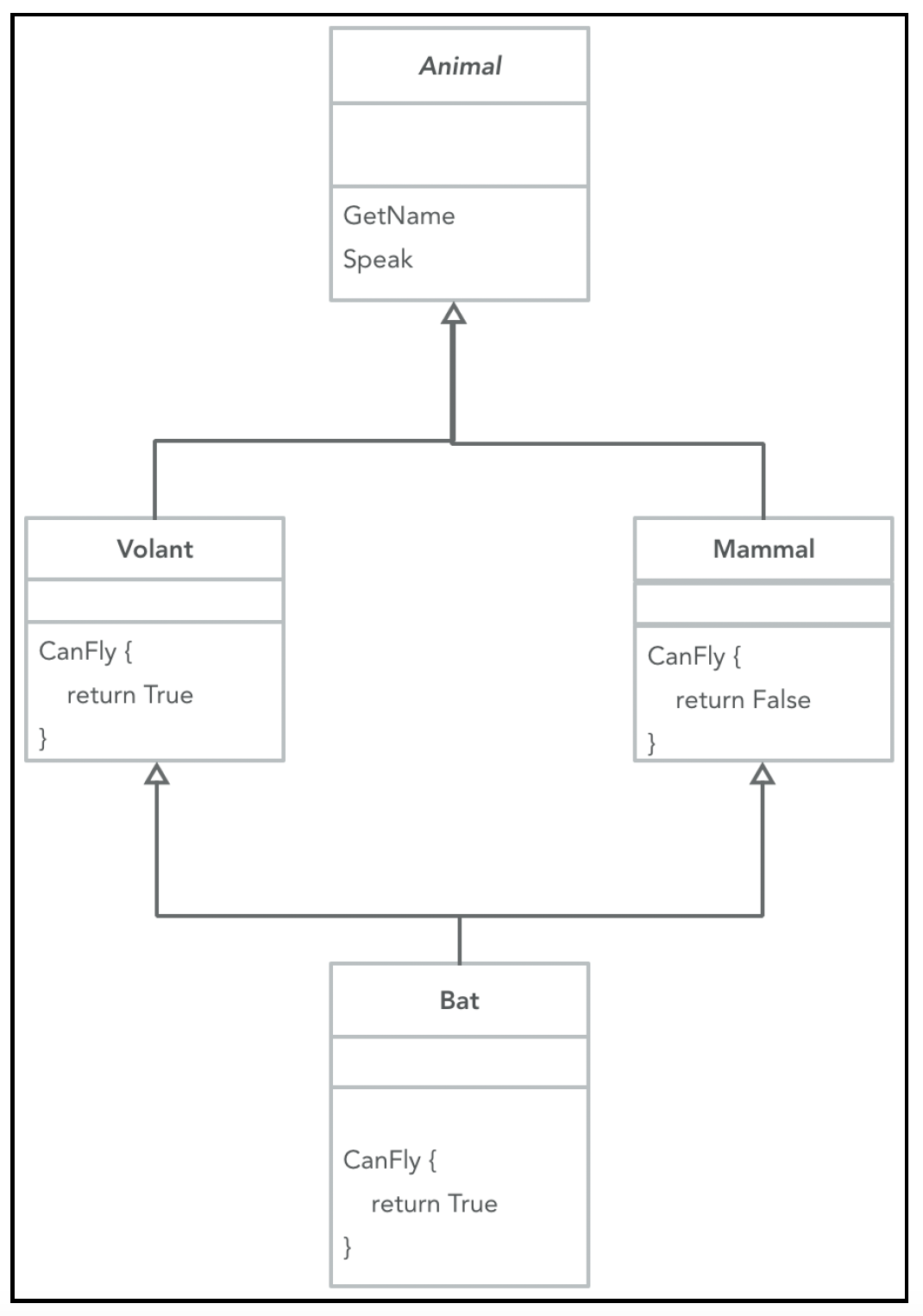
很多时候,我们会遇到一组非常相似的对象或类,将这些类作为一个整体来思考会很有帮助。例如,假设我们正在设计一个动物园,里面有多种动物。我们期望所有动物都有一些共同的行为,如果我们使用动物的抽象接口,而不是关注具体的动物种类,就能极大地简化代码。这种关系通常通过继承来建模,如下图所示:
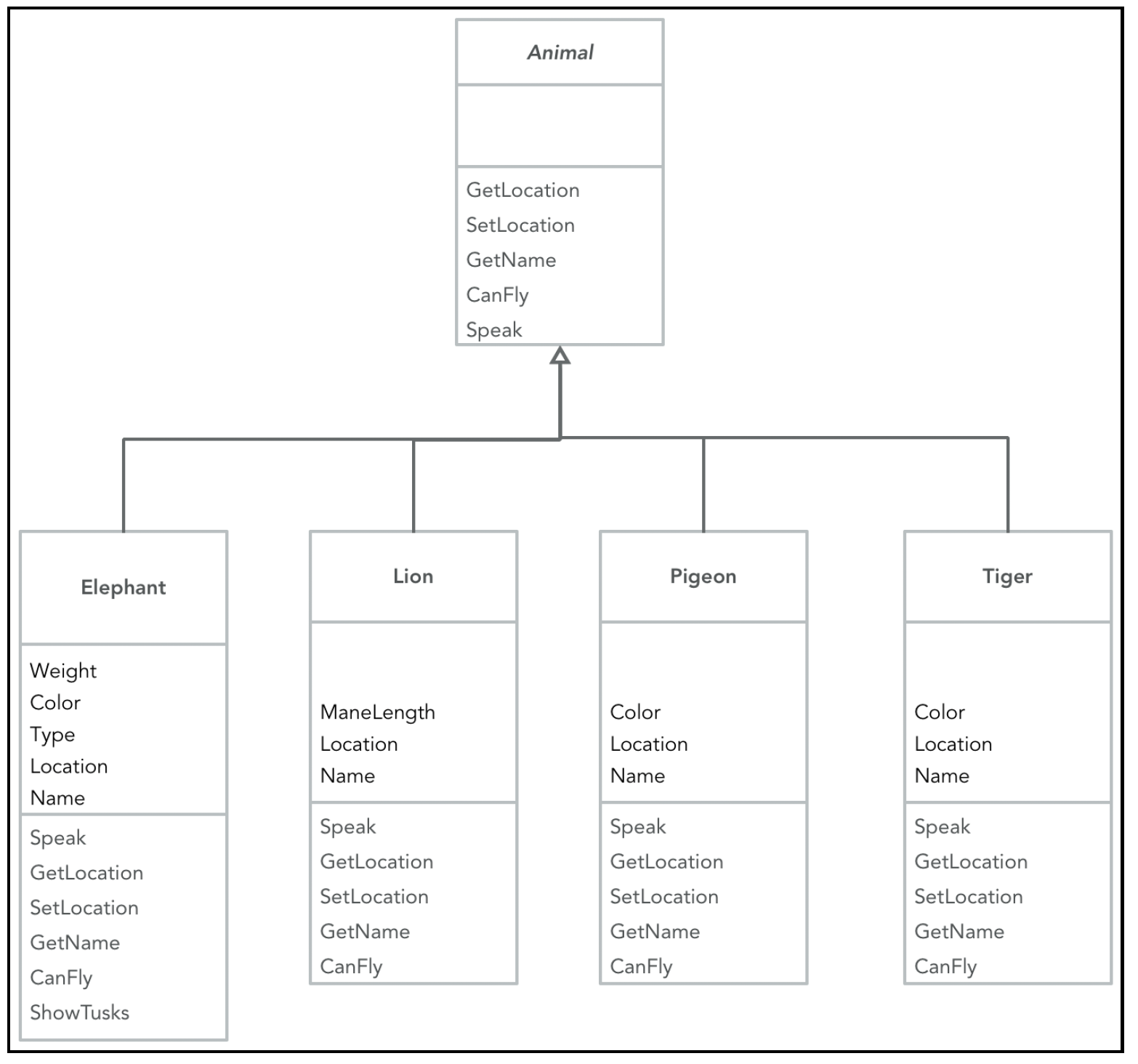
在这里,我们有一个动物接口,以及多个实现该接口定义的契约的动物类。子类可以有额外的属性或方法,但不能省略父类指定的方法。这种继承建模意味着一种“是”的关系(例如,老虎是一种动物)。现在,像动物园点名这样的功能,即我们想要获取动物园中所有动物的名字,就可以在不关注单个动物的情况下构建,并且即使有新动物入园或某些种类的动物离开,这个功能也依然有效。
你可能会注意到,每种动物都有独特的叫声,老虎咆哮,大象吼叫等等。然而,在点名过程中,我们并不关心具体是什么叫声,只要能让动物发出声音就行。每种动物发出声音的方式可能不同,但这与所讨论的功能无关。我们可以在动物接口上实现一个“Speak”方法,根据不同的动物,“Speak”方法的具体行为会有所不同。接口方法能够根据实际对象表现出不同行为的这种能力被称为多态性,它是许多设计模式的关键。
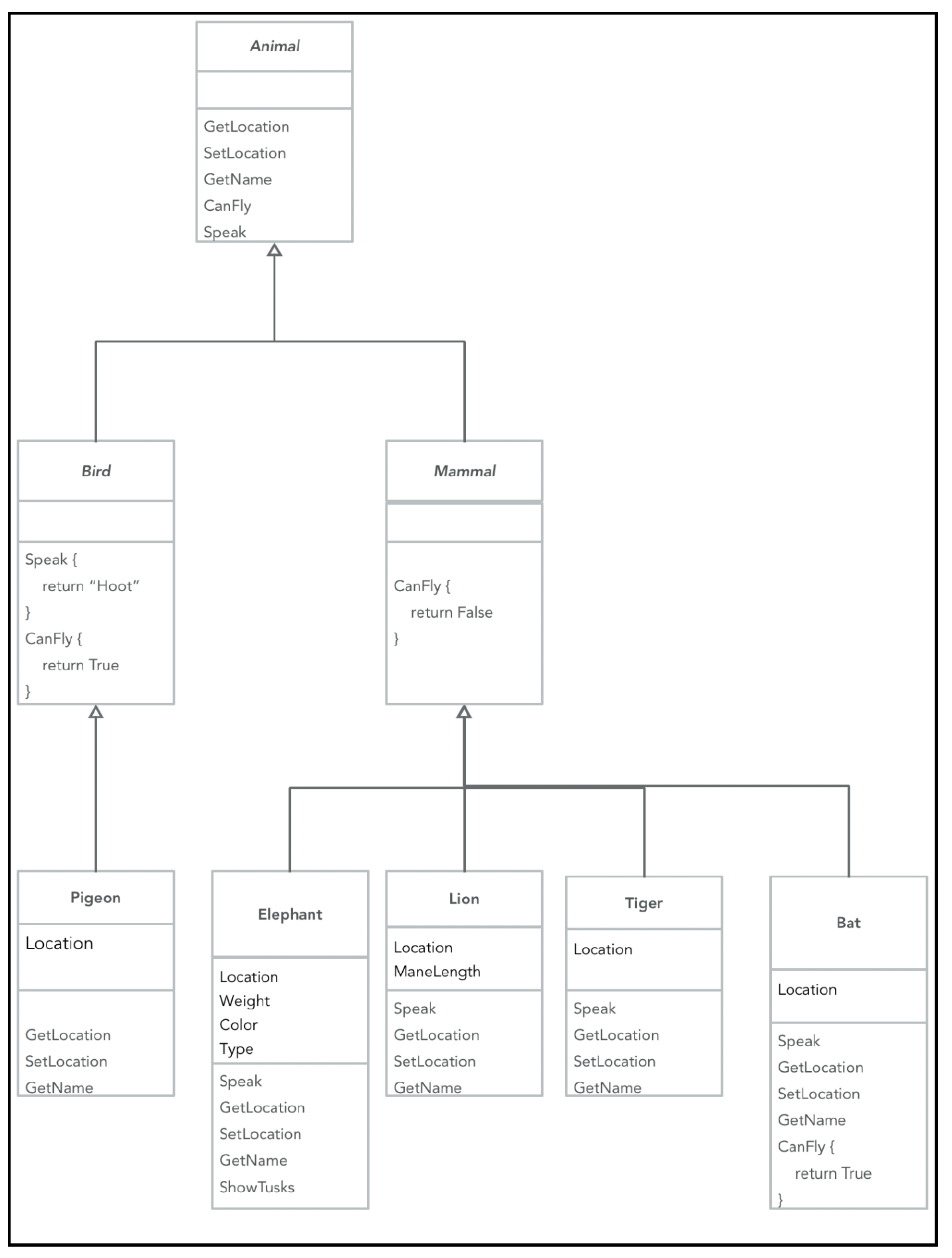
虽然继承很有用,但它也存在缺陷。它常常会导致类的层次结构变得复杂,有时最终对象的行为会分散在整个层次结构中。在继承层次结构中,超类往往很脆弱,因为对超类的一个小改动可能会产生连锁反应,影响到应用程序代码中的许多其他地方。最好的情况是出现编译时错误(对于编译型语言来说),但真正棘手的情况是没有编译时错误,却在一些边缘场景中出现微妙的行为变化,进而导致错误或漏洞。这类问题调试起来非常困难,毕竟你的代码并没有发生任何改变!在代码审查等流程中也很难发现这类问题,因为从设计上来说,基类(以及维护基类的开发者)并不关心(或了解)派生类的情况。
继承的一种替代方式是委托行为,也称为组合。它不是“是”的关系,而是“有”的关系。它指的是将简单类型组合起来,构建更复杂的类型。前面提到的动物关系可以这样建模:

在这里,并不存在继承体系,只有两种结构:
- 类实现接口 —— 接口是基类提供的契约。
- 功能复用是通过引用对象实现的,而不是通过类继承。
这就是为什么包括Go语言开发者在内的很多人都秉持 “组合优于继承”(Composition Over Inheritance)原则的原因。
在结束这个话题之前,还需要指出组合的另一个关键优势。通过组合构建对象和引用,能够将对象的创建推迟到真正有需要的时候,从而减小程序的内存占用。对象还可以动态改变被引用对象的状态,这使得你能够用简单的结构表达复杂的行为。第4章 “应用程序的扩展” 中详细介绍的状态设计模式就是一个例子。当需要效率和动态性时,组合至关重要!
# Go语言中的面向对象 —— 结构体(struct)
在Go语言中,与Java和C++中的类相对应的封装容器被称为结构体(struct)。它描述了类中对象的属性。一个结构体看起来是这样的:
type Animal struct {
Name string
canFly bool
}
2
3
4
这定义了一个包含上述字段的新类型。一旦定义了结构体,就可以像下面这样实例化它:
anAnimal := Animal{Name: "Lion", canFly: false}
这创建了一个Animal类型的新对象anAnimal。一旦有了像anAnimal这样的对象,就可以使用点号表示法来访问其字段,如下所示:
fmt.Println(anAnimal.Name)
你也可以对对象指针(而不是实际对象)使用点号表示法。指针会自动解引用。所以,在下面的例子中,aLionPtr.age在两种情况下都能正常工作:aLionPtr既可以是指向对象的指针,也可以是对对象本身的引用:
aLionPtr := &anAnimal
fmt.Println(aLionPtr.age)
2
方法是作用于特定结构体的函数。它们有一个接收者(receiver)子句,用于指定该方法作用于哪种类型。例如,考虑下面的结构体和方法:
// 这里再次定义Person结构体
type Person struct {
name string
age int
}
func (p Person) canVote() bool {
return p.Age > 18
}
2
3
4
5
6
7
8
9
在前面的例子中,func关键字和方法名之间的语言结构就是接收者:
( p Person )
这类似于其他面向对象语言中的self或this结构。你可以把接收者参数看作是其他语言中的this或self标识符。一个方法只能有一个接收者,并且可以使用指针接收者来定义方法:
func (t *type) doSomething(param1 int)
也可以使用非指针方法接收者:
func (t type) doSomething(param1 int)
指针接收者方法具有按引用传递(Pass-By-Reference)的语义,而非指针接收者方法是按值传递(Pass-By-Value)。一般来说,如果满足以下任意一个条件,就会使用指针接收者方法:
- 你想要实际修改接收者(读写操作,而不只是读取)。
- 结构体非常大,深度复制的成本很高。
切片(Slices)和映射(maps)本身就相当于引用,所以即使按值传递它们,也能修改对象。需要注意的是,指针接收者方法可以作用于非指针类型,反之亦然。例如,下面的代码会打印11 11,因为DoesNotGrow()方法作用于非指针接收者,所以其中的自增操作不会影响结构体中的实际值:
package main
import (
"fmt"
)
type Person struct {
Name string
Age int
}
func (p *Person) Grow() {
p.Age++
}
func (p Person) DoesNotGrow() {
p.Age++
}
func main() {
p := Person{"JY", 10}
p.Grow()
fmt.Println(p.Age)
ptr := &p
ptr.DoesNotGrow()
fmt.Println(p.Age)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这可能会让人感到困惑,但Go语言规范对此进行了说明(参考:https://golang.org/ref/spec#Method_sets)。
“如果(
x的类型的)方法集中包含m,并且参数列表可以赋给m的参数列表,那么方法调用x.m()就是有效的。如果x是可寻址的,并且&x的值的方法集中包含m,那么x.m()是(&x).m()的简写。”
如果你想知道什么是方法集,规范中是这样定义的:
“任何其他类型T的方法集由所有使用接收者类型T声明的方法组成。相应指针类型*T的方法集是所有使用接收者*T或T声明的方法的集合(也就是说,它也包含T的方法集)。”
# Go语言中的面向对象 —— 可见性
管理可见性是良好类设计的关键,进而也是系统健壮性的关键。与其他面向对象语言不同,Go语言中没有public或private关键字。结构体字段如果首字母小写,则为私有字段;如果首字母大写,则为公共字段。例如,考虑一个Pigeon包:
package pigeon
type Pigeon struct {
Name string
featherLength int
}
func (p *Pigeon) GetFeatherLength() int {
return p.featherLength
}
func (p *Pigeon) SetFeatherLength(length int) {
p.featherLength = length
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在这里,结构体内部有:
Name是公共属性,包外的代码可以引用它。featherLength是私有属性,包外的代码无法引用它。
这种包机制的影响是,下面的代码将无法编译(假设这段代码在Pigeon包之外):
func main() {
p := pigeon.Pigeon{"Tweety", 10} // 这行代码无法编译
}
2
3
因为featherLength没有在Pigeon包中暴露。正确实例化这个结构体对象的方式是使用提供的设置函数:
func main() {
p := pigeon.Pigeon{Name: "Tweety"}
p.SetFeatherLength(10)
fmt.Println(p.Name)
fmt.Println(p.GetFeatherLength())
// fmt.Println(p.featherLength) - 这行代码无法编译
}
2
3
4
5
6
7
首字母大写的约定也适用于方法。公共方法首字母大写,而私有方法首字母小写。
# Go语言中的面向对象 —— 接口(interface)
正如我们在第1章 “用Go语言构建大型项目” 中看到的,接口结构是Go语言实现多态性的关键 —— 从一组相关对象中抽象出细节,从而简化代码。接口定义了一个契约,客户端可以依赖这个契约,而无需了解(也就不存在耦合)实现该接口的实际类。接口是声明方法集的类型。与其他语言中的接口类似,Go语言的接口没有实现。接口是Go语言面向对象支持的核心。
许多面向对象语言都显式定义接口的实现;然而,Go语言有所不同。在Go语言中,实现是通过鸭子类型(duck typing)隐式完成的(正如我们在第1章 “用Go语言构建大型项目” 中看到的)。实现了接口所有方法的对象会自动实现该接口。这里没有继承、子类化或implements关键字。
鸭子类型在其他语言(如Python)中也存在,但Go语言的优势在于编译器能够捕获明显的错误,比如在期望传入字符串的地方传入了整数,或者调用时参数数量错误。
要使用接口,首先要像这样定义接口类型:
type LatLong struct {
Lat float64
Long float64
}
type Animal interface {
GetLocation() LatLong
SetLocation(LatLong)
CanFly() bool
Speak()
}
2
3
4
5
6
7
8
9
10
11
在Go语言中,所有实现都是隐式的。如果类型T的方法集是接口类型I声明的方法集的超集,那么类型T就隐式实现了接口类型I。这里,T也可以是接口类型。如果T是一个命名的非接口类型,那么*T也必须实现I,因为*T的方法集是T的方法集的超集。
例如,对于animal接口,我们可以定义Lion和Pigeon类来实现这个接口,代码如下:
// 狮子类
type Lion struct {
name string
maneLength int
location LatLong
}
func (lion *Lion) GetLocation() LatLong {
return lion.location
}
func (lion *Lion) SetLocation(loc LatLong) {
lion.location = loc
}
func (lion *Lion) CanFly() bool {
return false
}
func (lion *Lion) Speak() string {
return "roar"
}
func (lion *Lion) GetManeLength() int {
return lion.maneLength
}
func (lion *Lion) GetName() string {
return lion.name
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
下面是Pigeon类的代码:
// 鸽子类
type Pigeon struct {
name string
location LatLong
}
func (p *Pigeon) GetLocation() LatLong {
return p.location
}
func (p *Pigeon) SetLocation(loc LatLong) {
p.location = loc
}
func (p *Pigeon) CanFly() bool {
return true
}
func (p *Pigeon) Speak() string {
return "hoot"
}
func (p *Pigeon) GetName() string {
return p.name
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这样做的核心目的当然是实现多态性 —— 在期望使用animal接口的任何地方,都可以使用Lion和Pigeon。
正如在第1章 “用Go语言构建大型项目” 中所描述的,这也被称为鸭子类型 —— “如果它走路像鸭子、叫声像鸭子,那它就是鸭子”。具体来说,如果类型T实现了接口类型I,那么T类型的值就可以赋给I类型的值。调用接口值的方法时,会调用该接口值的动态值对应的方法。下面的代码展示了多态性:
// 交响乐
func makeThemSing(animals []Animal) {
for _, animal := range animals {
fmt.Println(animal.GetName() + " says " + animal.Speak())
}
}
func main() {
var myZoo []Animal
Leo := Lion{
"Leo",
10,
LatLong{10.40, 11.5},
}
myZoo = append(myZoo, &Leo)
Tweety := Pigeon{
"Tweety",
LatLong{10.40, 11.5},
}
myZoo = append(myZoo, &Tweety)
makeThemSing(myZoo) // 对集合进行一些操作
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
关于实现的一点说明:多态性通常通过以下两种方式之一实现:
- 静态准备所有方法调用的表(如C++和Java)。
- 每次调用时进行方法查找(JavaScript和Python)。
Go语言的方法表略有不同,它是在运行时计算的。本质上,接口由一对指针表示:一个指针指向有关类型和方法表(称为i - table)的信息,另一个指针引用相关数据。例如,看下面的赋值操作:
var aAnimal Animal
aAnimal = &Lion{
"Leo",
10,
LatLong{10.40, 11.5},
}
2
3
4
5
6
可以用如下图示来表示:
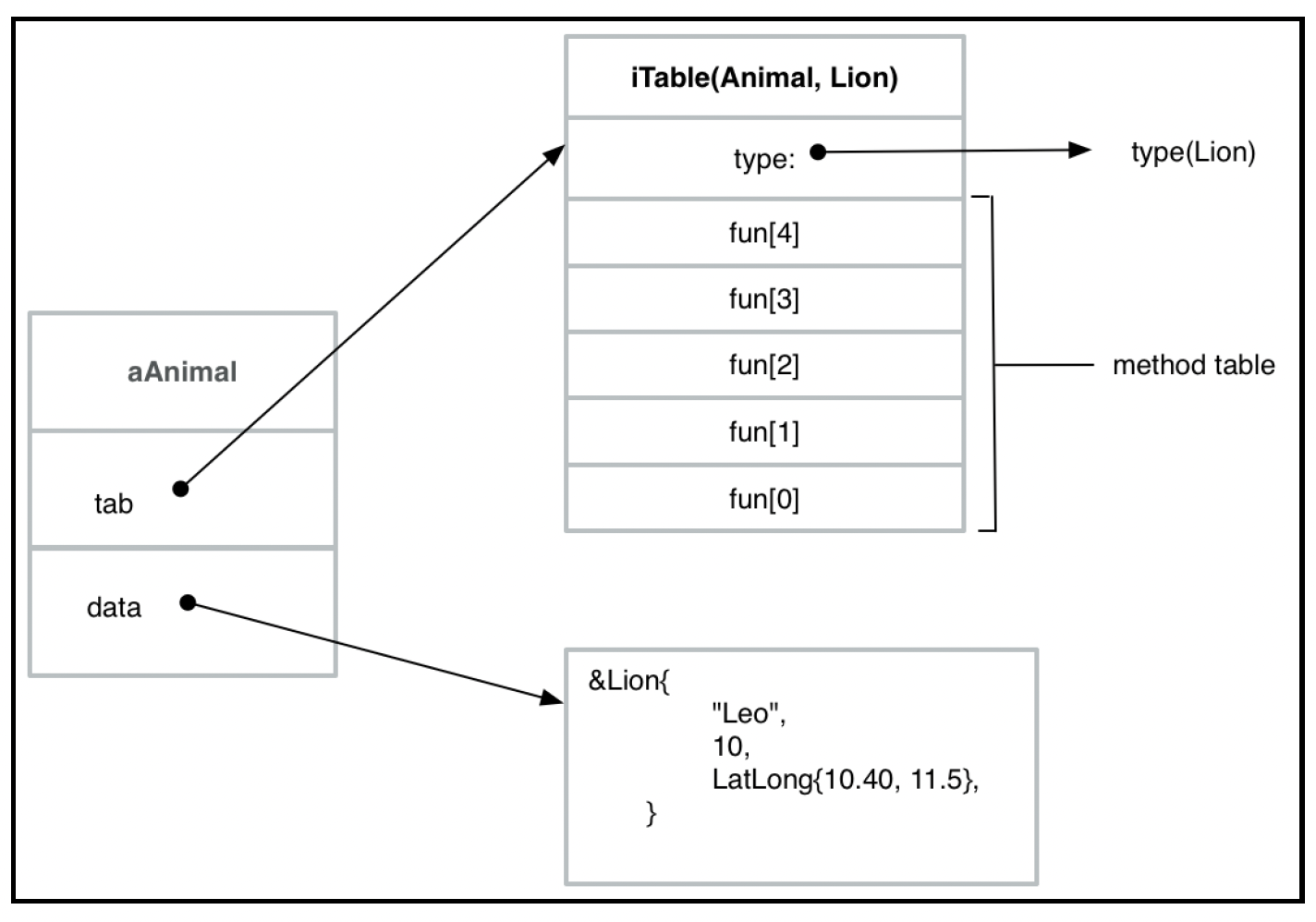
这个图有助于我们理解语言运行时是如何实现接口和多态性的。
# Go语言中的面向对象——嵌入
嵌入是一种允许从不同类中借用部分功能的机制。它相当于具有非虚成员的多重继承。
假设我们将Base结构体嵌入到Derived结构体中。与普通的(公有/受保护的)子类化类似,Base类的字段和方法在Derived结构体中可以直接使用。在内部,会创建一个隐藏的匿名字段,其名称与基结构体相同。以下代码示例展示了这种行为:
type Bird struct {
featherLength int
classification string
}
type Pigeon struct {
Bird
Name string
}
func main() {
p := Pigeon{Name: "Tweety"}
p.featherLength = 10
fmt.Println(p)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果在派生类中重新定义,基类的字段和方法会被遮蔽。一旦被遮蔽,访问基类成员的唯一方法是使用名为基结构体名称的隐藏字段:
type Bird struct {
featherLength int
classification string
}
type Pigeon struct {
Bird
featherLength float64
Name string
}
func main() {
p := Pigeon{Name: "Tweety"}
p.featherLength = 3.14
// featherLength指的是Pigeon结构体的成员,而不是Bird的
fmt.Println(p)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这可能看起来像继承,但嵌入并不提供多态性。嵌入与子类化有一个重要区别:当一个类型被嵌入时,该类型的方法可作为外部类型的方法使用;然而,在调用嵌入结构体的方法时,方法的接收者必须是内部(嵌入)类型,而不是外部类型。
嵌入也可以用于接口。Go标准库中的ReaderWriter接口就是一个著名的例子,它组合了Reader和Writer接口:
type ReadWriter interface {
Reader
Writer
}
2
3
4
Go语言允许在一个结构体中嵌入多个结构体。这使得从多个类中借用行为成为可能,类似于多重继承。不过需要注意:像Java这样的语言避免多重继承是有原因的,这就是所谓的菱形继承问题(deadly diamond of death problem)。这个问题是指当两个类B和C都继承自A,而第三个类D同时继承自B和C时产生的歧义。在这里,如果A中有一个方法被B和C重写,但D没有重写,那么就无法明确D所使用的到底是哪个版本的方法:
 也就是说,在Go语言中,由于嵌入本质上意味着继承的字段保留在继承结构体的命名空间(结构体)中,编译器会捕获任何歧义。
也就是说,在Go语言中,由于嵌入本质上意味着继承的字段保留在继承结构体的命名空间(结构体)中,编译器会捕获任何歧义。
若想了解更多关于方法重写的内容,请访问https://en.wikipedia.org/wiki/Method_overriding。
# 模块
最终,任何有价值的软件项目都会依赖其他项目、库或框架。包为你的代码提供了命名空间或 “防火墙”。这里说的 “防火墙” 是指将包中的代码与其他部分或包的变化隔离开来。包内部的实体(类型、函数、变量等)可以被导出(公有——在包外可见)或不导出(私有——在包外不可见)。控制可见性的方式与类的机制完全一样:如果标识符名称以大写字母开头,它会从包中导出,否则就是未导出的。
这是 “约定优于配置” 范式的一个例子,也是Go语言中实现封装的关键因素之一。经验法则是: 包中的所有代码都应该是私有的,除非其他客户端包明确需要。
Go标准库包含许多有用的包,可用于构建实际应用程序。例如,标准库提供了net/http包,可用于构建Web应用程序和Web服务。除了标准包之外,在Go语言中使用第三方包也是一种常见做法。你只需执行一个简单的go get命令,就可以在GitHub上挑选任何第三方包并在代码中使用。
虽然这种灵活性很好,但拥有一套打包理念和指导方针也很重要,这样开发人员就能确切知道代码的存放位置和查找方式。
# 代码布局
Go语言要求代码在文件系统中按照特定方式组织 —— 这种组织方式必须在工作区(workspace)的最高层级。虽然通常建议为所有项目使用一个工作区,但在实际情况中,我发现为每个项目使用一个工作区更具可扩展性。例如,考虑两个项目使用同一个依赖但版本不同的情况(下一节 “第三方依赖” 会详细介绍)。
以下是推荐的代码高层级结构:
bin:这个目录包含可执行文件,即编译器的输出结果。pkg:这个文件夹用于存放包对象。<package>:每个顶级包对应一个文件夹,这些包构成了项目的组件。vendor:这个文件夹存放第三方依赖。下一节 “第三方库” 会对此进行更多介绍。Makefile:它有助于组织各种任务,如编译、代码检查、测试,还可以用于管理代码阶段。下一节 “第三方库” 会更详细地介绍。scripts:包含各种脚本,如数据库配置/迁移脚本。Main driver:驱动组件并控制顶级对象生命周期的主文件。
这就是一个典型的Go语言工作区的样子:
├── Makefile
├── README.md
├── api
├── bin
├── db
├── lib
├── scheduler
├── scrapper.go
├── tests
├── vendor
├── pkg
└── src
└── github.com
├── fatih
│ └── structs
├── influxdata
│ └── influxdb
├── jasonlvhit
│ └── gocron
├── magiconair
│ └── properties
├── mattn
│ └── go-isatty
├── mitchellh
│ └── mapstructure
├── olivere
│ └── elastic
├── pkg
│ └── errors
├── sirupsen
│ └── logrus
├── spf13
│ ├── afero
│ ├── cast
│ ├── jwalterweatherman
│ ├── pflag
│ └── viper
├── uber-go
│ └── atomic
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
GOPATH环境变量指定了工作区的位置。它默认指向你主目录下一个名为go的目录。如果你想在其他位置工作,需要将GOPATH设置为该目录的路径,并将Go主目录作为备用路径。下一节将详细介绍如何操作。
# 第三方依赖
使用第三方库可以加快开发速度,但也会带来一些挑战。想想2016年JavaScript/NPM领域发生的事情 —— 11行JavaScript代码导致了像Node和Babel这样的大型项目出现问题。事情是这样的:
阿泽尔·科苏鲁(Azer Kosulu)对NPM感到不满,因为对一个名为Kik的库的品牌侵权调查对他不利。作为报复,他从NPM上删除了大约250个自己的模块,其中一个是left-pad。这个库用于在字符串左侧填充零或空格。碰巧的是,数千个项目(包括Node和Babel)都依赖这个库。由于NPM上没有了这个依赖,这些被广泛使用的应用程序就无法正常运行了(参考http://www.informit.com/articles/article.aspx?p=1941206)。
在专业软件开发中,我们需要避免受到这种影响。这就是为什么我强烈支持在自己的版本控制系统中管理依赖,并进行明确的版本控制。即便如此,还是有两种选择:
- 建立公司范围/跨项目的依赖仓库。
- 每个项目单独管理依赖。
第一种方法的一个常见问题是版本控制 —— 并非团队中的所有项目都始终希望使用相同的版本。在使用公共Go工作区的情况下,这会很难管理。为了避免这些问题并保持对依赖的控制,我通常建议采取以下措施:
- 将依赖与主代码一起存放在
vendor文件夹下的同一源代码树中。 - 为每个项目使用唯一的
GOPATH(和工作区),实际使用GOPATH的方式如下:$(PWD)/vendor:$(PWD)$(PWD)是源代码根目录。 - 使用
Makefile(如下所示)在将代码提交到父仓库之前管理vendor代码:
.PHONY: build doc fmt lint run test clean vet
TAGS = -tags 'newrelic_enabled'
default: build
build: fmt clean
go build -v -o ./myBin
doc:
godoc -http=:6060 -index
# https://github.com/golang/lint
# go get github.com/golang/lint/golint
lint:
golint ./src
clean:
rm -rf `find ./vendor/src -type d -name .git` \
&& rm -rf `find ./vendor/src -type d -name .hg` \
&& rm -rf `find ./vendor/src -type d -name .bzr` \
&& rm -rf `find ./vendor/src -type d -name .svn`
rm -rf ./bin/*
rm -rf ./pkg/*
rm -rf ./vendor/bin/*
rm -rf ./vendor/pkg/*
# http://godoc.org/code.google.com/p/go.tools/cmd/vet
# go get code.google.com/p/go.tools/cmd/vet
vet:
# go vet ./src/...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这种机制会对依赖进行快照,包含实际代码,并将其提交到vendor文件夹。这样,构建项目所需的所有内容都包含在Git仓库中。
与我交流过的一些人对在父仓库中管理依赖表示担忧,他们建议使用git submodules等替代方案。
子模块(Submodules)是存储在父仓库内的伪Git仓库。父仓库只为每个依赖在一个目录中存储每个子模块特定提交的SHA(哈希ID)。虽然从隔离的角度看,这看起来很方便、很整洁,但它可能会导致许多微妙的问题:
- 子模块易被覆盖:你需要运行显式的
git submodule update命令来拉取依赖的最新版本。如果不执行这个命令,即使执行普通的git pull,子模块也不会更新。如果不进行子模块更新,子模块仓库引用将仍然指向旧版本。如果其他人更新了子模块,你检出代码时也无法获取到更新。此外,在下次提交父仓库时,很容易提交旧的子模块版本,从而实际上撤销了对所有其他人的子模块更新!正确使用子模块需要严格的维护流程。 - 合并困难:如果你在进行变基(rebasing)操作,并且依赖中存在冲突,所有显示的内容都是不同的SHA。无法弄清楚具体的差异。
- 分离头指针:当你调用
git submodule update时,每个子模块会检出相应的SHA,这会使子模块进入分离头指针状态。你提交的任何更改仍会使子模块处于分离头指针状态。在这种情况下,像变基(合并其他更改)这样的操作不会显示为冲突,你的更改会被合并的内容覆盖。
虽然还有其他工具,如Git subtree,但考虑到简单性,我仍然建议将vendor文件夹(包含源代码)提交到父仓库中。
# 框架
一旦你的公司/团队开始编写Go代码,你会发现人们编写了很多相似的代码。理想情况下,你会希望将这些代码重构到一个框架包中,供公司内的多个项目使用。常见的可复用领域包括认证、日志记录、配置、辅助类等等。
这可以被视为vendor下的一个内部第三方包,并按照上述方式进行维护。
虽然通用代码有好处,但编写好这类代码也更具挑战性。我们需要确保有明确的编写指南。其中一些指南如下:
- 代码的配置应该外部化。例如,它不应该期望在
/etc/config/my_lib找到配置文件。 - 代码内部的日志记录器应该从环境中获取上下文信息。
- 代码应尽可能不自行处理错误。它应该将库事件转化为与契约相关的有意义的内容并发出。
# 测试
有两个关键因素会影响一个优秀应用程序的可测试性:
- 编写易于测试的代码
- 拥有独立且易于重现的测试用例
第一点是关于代码的结构,要将代码的业务逻辑与外部服务等依赖项隔离开来。这样就能在这些边界处模拟依赖项,使测试用例能够沿着各种有意义的路径执行测试。例如,假设你正在开发旅游市场平台上的航班搜索功能。这一功能包含两个方面:
- 从不同供应商获取某一航段的价格
- 运行一些业务逻辑对结果进行筛选和排序
现在,通过直接调用供应商接口可能无法可靠地重现各种错误场景。而且,给每个开发人员提供API密钥可能成本高昂(并且不安全)。这些都会影响我们整体代码的可测试性。为了解决这个问题,你可以像下面这样清晰地将这两部分分开:
- “卖家”(Seller)包:实现与卖家交互的逻辑,使用API获取价格(以及其他功能)。
- “搜索”(Search)包:实现汇总结果并进行排序的业务逻辑。
这两个包可以独立构建和测试。
为了测试底层的“Seller”包,你需要简单的Golang测试驱动代码,它沿着有意义的路径执行代码并验证输出。接下来会给出如何使用表格来组织测试的示例。
为了测试内部的“Search”包,你可以模拟“Seller”包返回模拟数据。模拟可以在接口层面进行(使用GoMock这样的工具,更多详细信息可访问https://github.com/golang/mock ),也可以使用构建标签在包层面进行。后者是一种简洁的模拟方式,本质上,你可以根据标签有选择地编译包的部分内容。例如,我们可以有一个单独的文件,为包中所有导出的方法实现模拟:
// +build AirlineAMock
// 航空公司A卖家的模拟
package airlineA
func NewClient() *airlineA {
return makeAMockClient()
}
func (a *airlineA ) getPrices( srcDate, dstDate TravelDate, src, dst Places) {
return getPricesFromLocalFile(srcDate, dstDate, srcDate, dstDate)
}
2
3
4
5
6
7
8
9
10
11
包中的其他文件可以加上// +build!AirlineAMock字符串作为前缀。这样,当使用以下命令构建包时,就会构建出包的模拟版本:
go build airlineA -tags 'AirlineAMock'
# 构建测试
很多时候在编写测试时,你会发现自己在复制粘贴代码。有经验的程序员都知道这绝非理想情况。为了遵循DRY原则(Don't Repeat Yourself,不要重复自己),一个很好的解决方案是表驱动测试(table - driven tests)。在这种测试方式中,测试用例以(完整输入,预期输出)元组的形式写在表格中,并由一个通用的驱动代码执行。
有时,表格中的每个条目可以包含额外信息,比如测试名称,以便让测试输出更易于阅读。下面是来自fmt包测试代码(http://golang.org/pkg/fmt/ )的一个很好的示例:
var flagtests = []struct {
in string
out string
}{
{"%a", "[%a]"},
{"%-a", "[%-a]"},
{"%+a", "[%+a]"},
{"%#a", "[%#a]"},
{"% a", "[% a]"},
{"%0a", "[%0a]"},
{"%1.2a", "[%1.2a]"},
{"%-1.2a", "[%-1.2a]"},
{"%+1.2a", "[%+1.2a]"},
{"%-+1.2a", "[%+-1.2a]"},
{"%-+1.2abc", "[%+-1.2a]bc"},
{"%-1.2abc", "[%-1.2a]bc"},
}
func TestFlagParser(t *testing.T) {
var flagprinter flagPrinter
for _, tt := range flagtests {
s := Sprintf(tt.in, &flagprinter)
if s != tt.out {
t.Errorf("Sprintf(%q, &flagprinter) => %q, want %q", tt.in, s, tt.out)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
给定一个测试用例表格,实际的测试只需遍历表格中的所有条目,针对每个条目执行必要的测试。测试代码可以一次性编写完善(包含良好的错误信息等),并在多个测试中复用。这种结构使得添加新测试的成本非常低。
从Go 1.7版本开始,testing包支持并行运行子测试,从而减少了总的测试执行时间。例如,下面的代码只需一秒就能运行完,而不是四秒:
func TestParallel(t *testing.T) {
tests := []struct {
dur time.Duration
}{
{time.Second},
{time.Second},
{time.Second},
{time.Second},
}
for _, tc := range tests {
t.Run("", func(subtest *testing.T) {
subtest.Parallel()
time.Sleep(tc.dur)
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
关于单元测试,最后要提醒一点。虽然自动化单元测试为开发快速推进提供了保障,但在很多情况下,我们为了方便选择的框架有时反而会成为阻碍。正如丹尼尔·勒布雷罗在他的博客(http://labs.ig.com/code-coverage-100-percent-tragedy )中恰如其分地总结的那样,一个常见的反模式是为简单的功能编写大量测试框架代码。这会导致代码脆弱且难以迭代。每种技术或建议都有其适用的场景,如果盲目应用这些建议,可能会让开发人员感到挫败,最终影响代码质量。
# 总结
总之,良好的代码封装很重要,因为它能让代码变更更快速、风险更低(由于模块内关注点的清晰分离,很容易确定要更改的内容和位置),这也会减少生产环境中的错误。
良好的代码封装还有助于工程中的非技术方面:团队的职责划分明确,冲突和沟通问题减少,团队成员的主人翁意识更强。
在下一章,我们将开始学习设计模式。这些模式是解决软件工程中各种常见场景的蓝图。