 5. 分布式架构
5. 分布式架构
# 5. 分布式架构
现代系统很少部署在单一机器上。随着高速局域网互连技术的普及、基于云的按使用付费环境的出现,以及基于微服务的架构兴起,系统越来越多地由部署在多台计算机上的独立服务组成。这些服务协同工作,为用户提供统一连贯的体验。
分布式架构有两个关键要素:
- 组件:具有明确定义接口的模块化单元(如服务和数据库)。
- 互连:组件之间的通信链路(有时还承担组件之间的调解/协调职责)。
在非分布式计算的早期,组件都托管在单个进程内,本质上是由驱动(主)程序编排/启动的软件模块。然而,很快系统就超出了单台机器的承载能力,托管在不同机器上的组件必须相互通信。互连方式开始包含网络链路:
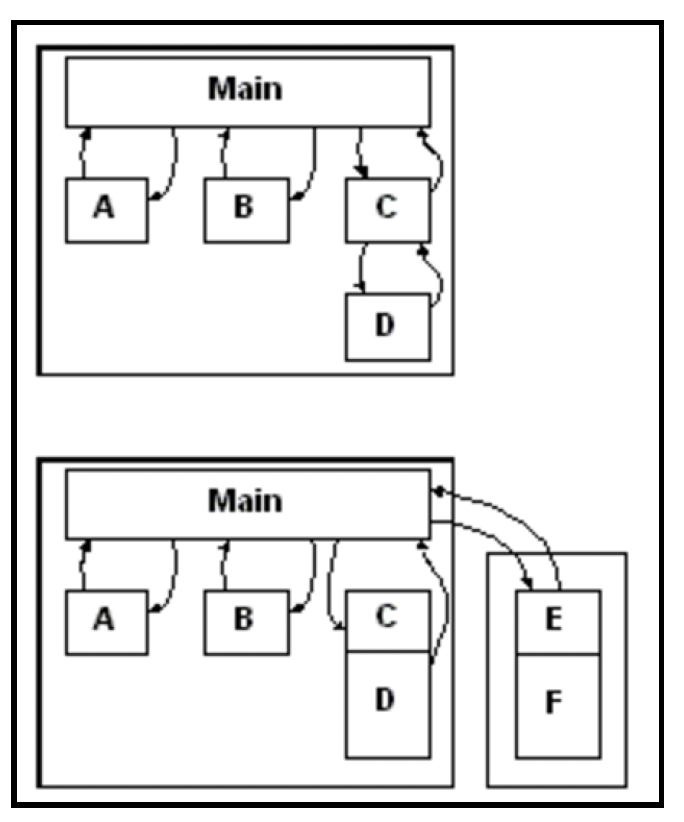
这种转变意味着程序必须使用消息传递,而非基于本地共享内存的通信方式,来进行通信和同步。
除了满足主要需求外,每个分布式系统都有一些通用目标:
- 可扩展性:应能根据需求轻松扩展分配给系统的资源。
- 分布式透明性:系统应隐藏其分布式的事实,让客户端无需了解每个服务或资源的具体位置。
- 一致性:客户端应明确系统所提供的一致性保证。例如,能否保证写操作之后的读操作返回的是最后写入的值?
- 为特定任务选择合适的工具:构成分布式系统的服务和互连方式应具备可扩展性。即使新服务基于不同的操作系统或编程语言,也应能相对轻松地添加到现有环境中。技术栈的异构性是分布式系统的一大关键优势。
- 安全性:当计算在多台机器上进行,且数据通过消息流动时,必须考虑各种选择对身份验证/授权和隐私的影响。
- 可调试性:应能够调试并定位构成系统的服务中存在的问题。我们应具备跟踪用户请求的能力,了解系统中的各个组件是如何处理这些请求的。
本章将讨论从单机架构转变为分布式架构时会涉及的内容。在接下来的部分,我们将涵盖以下主题:
- 拓扑结构:对分布式系统的高层次概述。
- 特性:分布式系统的独特特征。
- 一致性:数据分布式存储时如何实现一致性。
- 共识:多个独立系统如何就某件事达成一致。
- 架构模式:分布式系统中的常见设计模式。
# 拓扑结构
分布式系统由一系列通过网络连接的服务组成。每个服务都有特定的用途。有些服务可能会对外暴露,以便与客户端(用例术语中的参与者)进行交互。有些服务可能只是托管数据,并为上游服务进行数据转换。这些服务相互通信,以实现宏观行为并满足系统的需求。
服务之间通过网络进行交互,交互方式主要有以下两种:
- 应用程序编程接口(Application Programming Interface,API)
- 消息传递
无论采用哪种通道,数据都通过网络以标准化格式进行交换。
API范式最为常见。如第7章“构建API”所述,服务之间通过网络相互通信,它们向特定端点发送请求并接收响应。构建API最常用的机制是使用超文本传输协议(Hypertext Transfer Protocol,HTTP)和表述性状态转移(Representational State Transfer,REST)标准。多个服务实例由负载均衡器(Load Balancer,LB)托管在虚拟IP(Virtual IP,VIP)地址之后。
这种范式存在三个缺点:
- 通信阻塞:
- 调用方必须了解被调用方:
- 难以高效实现一对多通信范式:
第二种通信范式是消息传递。在这种方式下,服务通常通过消息代理进行异步通信。由于以下原因,这种范式的耦合度更低且更具可扩展性:
- 消息生产者无需了解消费者:
- 消息生产者生产消息时,消费者无需处于运行状态:
然而,这种模式也有其自身的复杂性:消息代理成为系统的关键故障点,并且与HTTP/JSON相比,通信的更改/扩展难度更大。第6章“消息传递”将详细介绍消息传递。
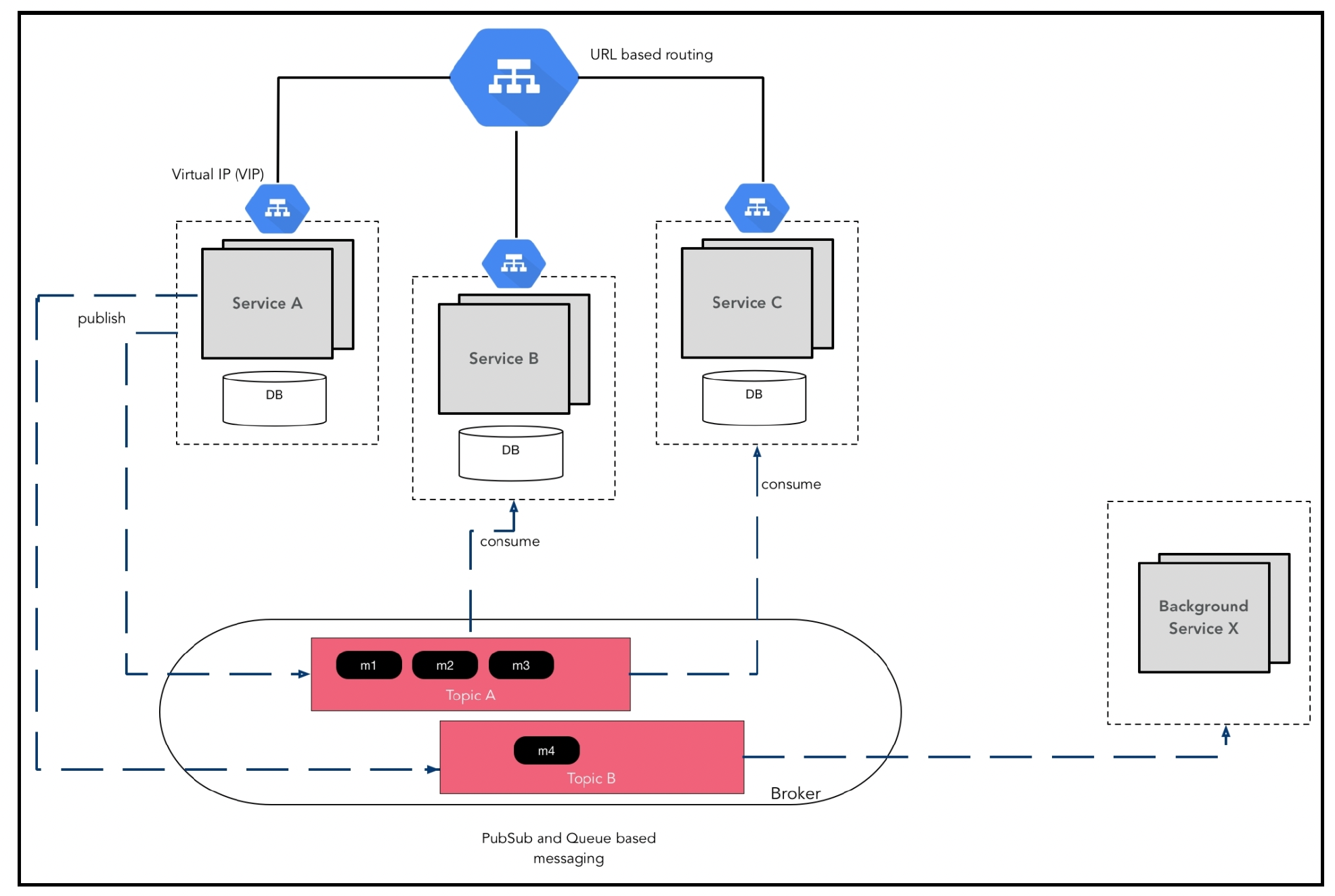
一个典型的分布式系统如下图所示:

其工作原理如下:
- 系统中有四个服务。服务A、服务B和服务C都用于处理来自客户端的请求,它们位于负载均衡器之后。
- 服务X处理来自其他服务的请求,并负责处理后台任务(例如向客户发送电子邮件)。
- 每个服务都有多个实例,以实现冗余和可扩展性。
- 每个服务都有自己的数据库。共享数据库是一种反模式,会导致服务之间产生耦合。
- 部分数据库可能是复制数据存储,因此并非连接到单个数据库实例,而是有多个实例。
- 服务之间使用消息传递进行异步通信。
- 整个集群在远程数据中心进行复制,以便在主数据中心发生故障时确保业务连续性。
在本章中,我们将探讨构建此类系统的各个方面。首先,我们列出一些分布式系统不太明显的特性。
# 分布式系统的常见误解
与单一程序相比,分布式系统的设计难度更大且更容易出错。1994年,在太阳微系统公司工作的彼得·多伊奇(Peter Deutsch)撰写了关于开发人员/架构师常犯的错误假设的文章,这些假设会导致分布式系统出现问题。1997年,詹姆斯·高斯林(James Gosling)对这份清单进行了补充,形成了通常所说的分布式计算的八大谬误。具体内容如下。
# 网络是可靠的
网络的各个组件总会出现问题,可能是电源故障,也可能是电缆切断。网络通常在硬件层面通过一组冗余链路进行架构设计,软件负责在两个系统之间提供有序、可靠的消息传输通道。这种软件通常被称为网络层(TCP/IP)。即便网络层努力在不可靠的链路上实现稳定,但应用程序仍常常会遭遇故障,因此需要妥善处理这些情况。
对于分布式数据存储而言,这种脆弱性尤为突出。在后面的“一致性”部分,我们将探讨在这种情况下如何实现一致性。在第7章“构建API”中,针对外部调用,我们将研究如何使用一种名为Hystrix的模式,使应用程序免受网络中断的影响。
# 延迟为零
延迟是指请求和响应从一个地方传输到另一个地方所需的时间。对延迟或分布情况的错误假设,可能会在系统原本优秀的面向对象(Object - Oriented,OO)设计中引发严重的性能问题。OO原则强调关注点分离,但如果对对象的分布情况缺乏认知,可能会导致系统过度通信且变得脆弱。网络延迟还会影响数据备份或恢复的能力,进而影响正常运行时间的保证。第7章“构建API”将详细介绍这部分内容。
延迟差异如下图所示:
 (原始来源:杰夫·迪恩 —— https://gist.github.com/jboner/2841832)
(原始来源:杰夫·迪恩 —— https://gist.github.com/jboner/2841832)
考虑延迟因素意味着要尽量减少网络通信。有以下几种解决方法:
- 将频繁通信的组件部署在一起:
- 批量处理:在一个元请求负载中包含多个请求。然后服务器会发送一个元响应,其中包含针对批量请求中每个请求的单独响应。
- 在每个请求/响应中携带所有必要数据:例如,携带用户配置文件对象,而不只是用户ID。这减少了对配置文件服务的调用次数,否则可能会产生更多调用。
http://blogs.msdn.com/oldnewthing/archive/2006/04/07/570801.aspx中描述了一个解决延迟问题的很好的例子。在Windows系统中列出文件夹内容,不仅要获取文件名,还需要获取相关元数据。但没有一个单独的调用能够返回所有所需信息,多次往返操作会导致用户体验性能下降,在处理远程文件系统时尤为明显。解决方案是进行批量调用。
为最小化延迟而进行的设计与其他设计目标(如位置透明性)相矛盾。虽然拥有更简单(即不考虑分布情况)的架构总是好的,但有时需要额外的构造来解决延迟问题。对于每个用例,都需要仔细权衡复杂性与解决延迟问题之间的关系。
# 带宽是无限的
带宽是网络传输数据的能力。尽管多年来网络带宽不断提升,但需要传输的信息量也在呈指数级增长。也就是说,这是所有谬误中最不那么绝对的一个(意味着在许多情况下,做出这个假设并无大碍)。
认识到带宽并非无限,对解决延迟问题有平衡作用,即不会过度使用少数非常大的消息。对于延迟和带宽问题,建议模拟生产拓扑结构,以确定需要优化的方向。
# 网络是安全的
唯一完全安全的系统是未连接到任何网络的系统!我们必须从一开始就将安全性融入架构设计中。敏感信息,如客户姓名和地址,在存储时必须进行加密。数据在传输过程中也应加密,这意味着API通信应使用HTTPS(而非HTTP),基于消息的通信应加密消息。对于敏感资源,必须启用身份验证。第8章“数据建模”将涵盖这些及其他与安全相关的详细内容。
# 拓扑结构不会改变
拓扑结构是对组件和互连的定义/示意图。在大多数现代系统中,功能更新速度很快,应用程序的部署拓扑结构很少是静态的。事实上,人们选择分布式系统和云部署的原因之一,就是能够根据需要更改拓扑结构。
从代码角度来看,这意味着什么呢?这意味着不要为各种服务假定固定的位置(端点)。我们需要构建服务发现机制,以便服务的客户端能够确定如何访问特定服务。客户端发现服务端点的方式有两种:
- 客户端发现:每个服务实例在启动时会向服务注册表注册自身(连接端点),在实例终止时从服务注册表中移除。客户端负责查询服务注册表以获取合适的实例端点,并直接与该端点进行通信。Netflix开源软件(OSS)提供了支持客户端发现模式的框架。Netflix Eureka是一个服务注册表,Netflix Ribbon是一个进程间通信(IPC)客户端,它与Eureka配合使用,在可用的服务实例之间进行负载均衡。
- 服务器端发现:客户端完全无需了解服务实例的分布情况。客户端请求通过一个位于知名URI的路由器(负载均衡器)进行转发。负载均衡器会定期ping每个服务实例,以确定该服务的健康实例集。当收到客户端请求时,负载均衡器使用多种算法(如轮询、随机或亲和性算法)之一,将请求路由到最合适的服务实例。
服务器端发现在编码实现上要简单得多。然而,它可能会导致额外的跳转(客户端 | 路由器 | 服务)。客户端发现服务还允许客户端选择最佳实例。因此,这两者之间的权衡在于,服务器端发现在可扩展性方面更具优势,而客户端发现则能提供更精细的控制。在实践中,服务器端发现机制更为常用。
# 只有一个管理员
在分布式系统中,更有可能涉及多个管理域。这不仅意味着组织内部的多个团队,还可能包括外部公司。这其中可能会存在冲突,例如,你可能需要将用户ID传递给第三方服务用于用户监控等目的。然而,这可能与负责维护客户信息的身份/配置文件服务团队的政策相冲突。架构师需要构建衔接系统,使这些多个管理/策略域能够协同工作。以用户ID为例,一种可能的解决方案是构建混淆逻辑,将ID传递给第三方服务。
# 传输成本为零
接下来是谬误列表中的第七条谬误:传输成本为零。这里的成本可以从两个方面来考虑:
- 设置和运行网络基础设施的成本。虽然世上没有免费的午餐,但这些成本已经大幅降低。在基于云的部署中,你实际上可以按每千兆字节或每小时的用量购买所需资源。
- 数据在内存和网络之间传输时进行序列化和反序列化的成本。这是切实存在的成本,并且需要从延迟的角度来考量。虽然存在一些优化方法,例如Google的protobufs在序列化/反序列化方面比JSON更快。但是采用二进制协议可能会影响调试的便捷性,需要使用定制工具来调试系统间的交互;你不能像处理JSON那样,简单地将服务URL粘贴到浏览器中查看返回内容。
序列化方式有多种选择,在应用程序的特定环境中考虑每种方式的适用性非常重要。下表简要比较了Go语言中各种框架的序列化性能(https://github.com/alecthomas/go_serialization_benchmarks):
| 基准测试 | 时间(纳秒/操作) |
|---|---|
| BinaryMarshal-8 | 1,306 |
| BinaryUnmarshal-8 | 1,497 |
| BsonMarshal-8 | 1,415 |
| BsonUnmarshal-8 | 1,996 |
| EasyJsonMarshal-8 | 1,288 |
| EasyJsonUnmarshal-8 | 1,330 |
| FlatBuffersMarshal-8 | 389 |
| FlatBuffersUnmarshal-8 | 252 |
| GencodeMarshal-8 | 166 |
| GencodeUnmarshal-8 | 181 |
| GencodeUnsafeMarshal-8 | 104 |
| GencodeUnsafeUnmarshal-8 | 144 |
| GoAvro2BinaryMarshal-8 | 922 |
| GoAvro2BinaryUnmarshal-8 | 989 |
| GoAvro2TextMarshal-8 | 2,797 |
| GoAvro2TextUnmarshal-8 | 2,665 |
| GoAvroMarshal-8 | 2,403 |
| GoAvroUnmarshal-8 | 5,876 |
| GobMarshal-8 | 1,009 |
| GobUnmarshal-8 | 1,032 |
| GogoprotobufMarshal-8 | 152 |
| GogoprotobufUnmarshal-8 | 221 |
| GoprotobufMarshal-8 | 506 |
| GoprotobufUnmarshal-8 | 691 |
| JsonMarshal-8 | 2,980 |
| JsonUnmarshal-8 | 3,120 |
| MsgpMarshal-8 | 178 |
| MsgpUnmarshal-8 | 338 |
| ProtobufMarshal-8 | 901 |
| ProtobufUnmarshal-8 | 692 |
# 网络是同质的
Java的创造者詹姆斯·高斯林(James Gosling)在1997年将这条谬误添加到了最初的七条谬误中。网络并非是畅通无阻的单一管道,而是由具有不同特性的多个链路或网段组成。对于对性能有严格要求的应用,架构师需要考虑这一因素,以获得所需的性能特性。
# 一致性
考虑一个系统,其中有多个进程对一个复制的分布式数据存储进行操作。一个逻辑数据存储在物理上分布并在多个进程间复制的一般架构如下所示:
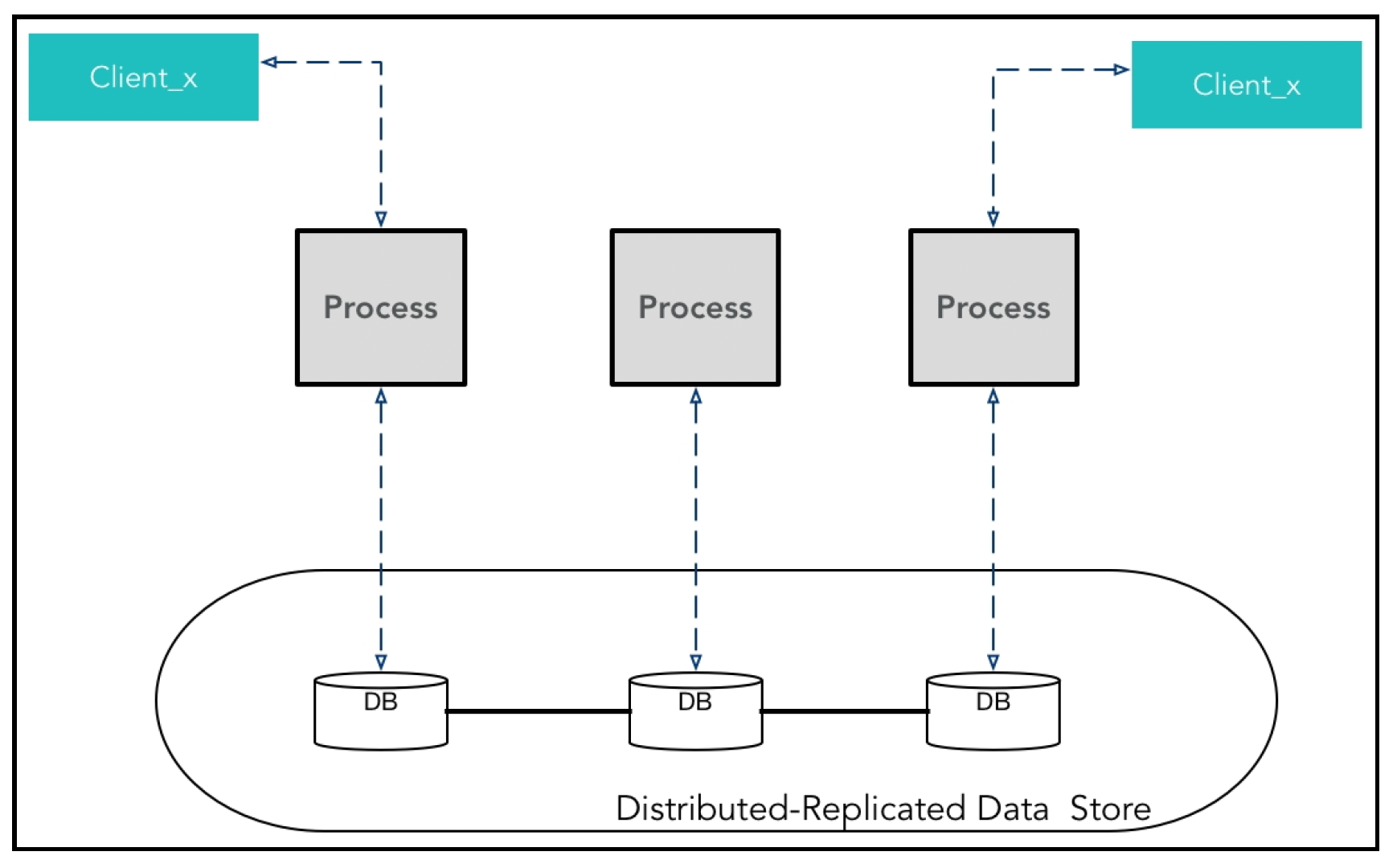
需要考虑以下几个特点:
- 每个进程可能是同一服务的多个实例,也可能是不同的应用程序在尝试访问数据(不推荐这种做法!)。
- 客户端可能是移动设备。例如,在上图中,有时Client_x与一个实例进行通信,但这种情况可能会发生变化。
鉴于我们对分布式系统特性的了解,进程中的应用程序代码应该对数据存储有怎样的一致性预期呢?答案并非唯一,存在多种一致性模型,下面将进行介绍。
# ACID
ACID是以下几个单词的缩写:
- 原子性(Atomicity):事务中的所有操作要么全部成功,要么全部回滚。
- 一致性(Consistent):事务完成时,数据库的完整性约束是有效的。
- 隔离性(Isolated):同时发生的事务不会相互干扰。有冲突的并发访问由数据库进行协调,使得事务看起来是顺序执行的。
- 持久性(Durable):无论硬件或软件发生何种故障,事务所做的更新都是永久性的。
这是所有一致性模型中最严格的一种。大多数开发者都熟悉并依赖数据库的ACID属性。当数据存储提供这种一致性时,编码会变得容易得多,但代价是这类系统通常扩展性不佳(详见第8章 “数据建模”)。
# 以客户端为中心的一致性模型
虽然ACID事务可靠且提供了简单的编程模型,但对于大规模数据集来说,它们的扩展性并不好。例如,在上图中,如果需要遵循ACID语义,所有不同的节点都需要在事务管理器的驱动下协调分布式事务。下面展示了XA资源规范中典型的两阶段分布式事务:
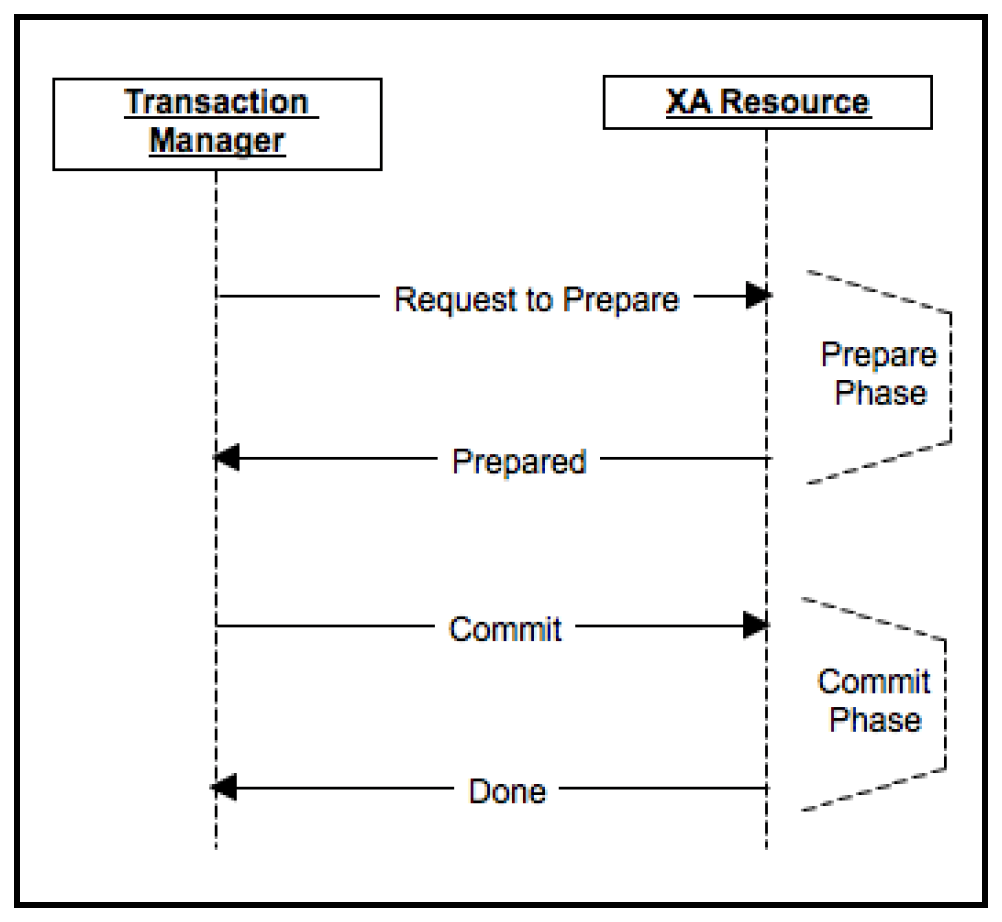
XA事务使用两个事务ID:一个全局事务ID和每个XA资源的本地事务ID(xid)。在两阶段协议的第一阶段(准备阶段),事务管理器通过调用每个参与事务的资源的prepare(xid)方法来对其进行准备。资源可以返回OK或ABORT投票。在收到每个资源的OK投票后,管理器决定执行commit(xid)操作(提交阶段)。如果一个XA资源发送ABORT,那么会调用每个资源的end(xid)方法进行回滚。这里存在多种边界情况,例如,一个节点可能在回复OK后但在提交前重启。
虽然许多供应商声称提供完全可靠的分布式事务支持,但以我的个人经验来看,这类保证往往都有一些附加条件。这样一个全局协调的锁定系统也是可扩展性的瓶颈,因此在分布式系统中最好避免使用。
在大多数用例中,我们需要的是系统的可用性以及以下保证:
- 最终,所有客户端的数据都会保持一致。
- 从单个客户端的角度来看,数据应该是一致的 —— 写操作之后的读操作应该返回新的值。
即便如此,仍然有多种可能的选择。让我们从客户端的角度来看一下一致性频谱中的选项。
# 强一致性
这是所有模型中最严格的一种。在任何更新之后,任何进程的后续访问都将返回更新后的值。
在这个模型中,对数据项X的任何读取操作都会返回与X最近一次写入结果相对应的值。如下图所示:
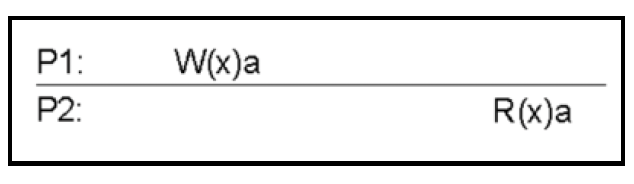
这里,P1将a写入X,之后当P2读取X时,它会得到a。
这是最严格的一致性形式。其实现需要绝对的全局时间,并且要确保在任何进程上进行的写操作能同时在所有进程上可用。构建这样的保证几乎是不可能的。
# 弱一致性
这个模型处于频谱的另一端。数据存储不提供任何保证,如果需要,客户端代码必须自行确保一致性。无法保证后续的访问会返回写入的值。从更新完成到确保任何观察者都能始终看到更新后的值之间的这段时间,被称为不一致窗口。
# 最终一致性
这是弱一致性的一种特定形式,存储系统保证在写入操作停止后,最终所有的访问都将返回最后更新的值。在没有故障发生的情况下,可以计算出不一致窗口的最大时长(考虑网络延迟和负载等因素)。
这类系统的一个例子是域名系统(Domain Name System,DNS)。对域名的更新会按照一定的模式进行分发,因此在初始更新阶段,并非所有节点都能获取到最新信息。一些节点会托管带有生存时间(time-to-live,TTL)的缓存,缓存过期后它们才会获取到最新的更新。
对于最终一致性,在确定不一致窗口期间的保证时,有一系列的模型需要考虑。下一节将对它们进行介绍。
# 顺序一致性
这个模型比严格一致性稍弱一些。与写操作能立即对所有进程可用不同,不同进程对变量的写操作顺序在所有进程中必须保持一致。每个进程的操作应该按照程序中编写的顺序出现在这个序列中。
莱斯利·兰波特(Leslie Lamport)提到,如果任何执行的结果与所有处理器的操作按某种顺序执行的结果相同,并且每个处理器的操作按其程序指定的顺序出现在这个序列中,那么就满足顺序一致性(参考:莱斯利·兰波特发表于《IEEE Transactions》的论文“How to make a multiprocessor computer that correctly executes multiprocess programs and computers”)。
左边的图展示了一个顺序一致的系统(在这里,所有进程都看到b在a之前被写入)。然而,右边的系统则不是顺序一致的(P3看到X的值为b,而P4看到的值为a):

# 因果一致性
这个模型放宽了顺序一致性模型的要求,以实现更好的并发性。如果进程P1向x写入了一个值,并且这个值被进程P2读取,那么P2随后的任何访问都将返回更新后的值。此外,P2的任何写入操作都将取代之前的写入。因此,下图中的行为是允许的,因为b和c的写入之间没有因果关系:

# 会话一致性
一种重要的一致性形式是读己写(Read-Your-Write)。在这种情况下,保证在一个进程将X的值更新为b之后,该进程后续的所有读取操作都将读取到b。
它的一个重要实际变体是会话一致性,即所有的访问都在一个会话的上下文中进行。对于一个有效的会话,系统保证任何进程都具有读己写语义。然而,当会话过期或被删除时,就不再保证顺序性。
# 单调读一致性
这里的保证是,如果一个进程P1看到了对象x的某个特定值,那么该进程未来的所有访问都不会返回在x最后一次被写入之前写入的值,也就是说,每个进程按照时间顺序看到对象的写入操作。
# 单调写一致性
存储系统保证一个进程对对象(x)的写操作在该进程对x的任何后续写操作之前完成,也就是说,同一进程内的并发写操作是顺序执行的。
# 以存储系统为中心的一致性模型
本节从存储系统的角度讨论一致性。通常,存储系统会有多个副本,以实现弹性(冗余)和可扩展性。作为接受写操作的一部分,存储系统需要决定在向客户端确认写操作之前,需要更新多少个副本。
定义以下术语:
- N:存储系统中的节点数量。
- W:在向客户端确认写操作之前需要更新的副本数量。
- R:进行读操作时联系的副本数量(关于仲裁,见下文)。
如果W + R > N,那么进程就永远不会看到不一致的数据,从而保证了强一致性。这种配置的问题在于,如果某些节点发生故障,整个写操作可能会失败,从而影响系统的可用性(见CAP定理部分)。
对于需要容错单台机器故障的系统,N通常是大于或等于3的奇数。在这种情况下,W和R都可以设为2,以实现较好的一致性。
如果系统需要优化读操作,那么所有读操作都应该从本地节点提供服务。为此,写操作应该更新所有副本。此时,W = N且R = 1。
当W + R <= N时,就会出现弱一致性或最终一致性。
存储系统是否支持读己写、会话一致性和单调一致性,取决于客户端的粘性。如果每个进程每次都联系同一个存储节点(除非发生故障),那么这类模型更容易满足。但这会使负载均衡和容错变得困难。
通常,所有这些选择在存储系统中都是可调整的。你需要仔细分析用例,对参数进行微调。我们将在第8章 “数据建模” 中介绍一些这类系统的实际示例。
# CAP定理
从前面的讨论可以看出,分布式系统中的一致性是一个复杂的话题。然而,有一个定理简洁地总结了其中最重要的影响,这就是CAP定理。它由埃里克·布鲁尔(Eric Brewer)在1998年提出,该定理指出,分布式计算机系统不可能同时提供以下三项保证:
- 一致性(Consistency,C):这里的一致性指严格一致性。保证任何客户端的读操作都能返回最新的写操作结果。
- 可用性(Availability,A):系统能够在任何给定时间处理请求,并提供合法的响应。
- 分区容错性(Partition-tolerance,P):即使节点之间出现网络连接丢失或消息丢失的情况,系统仍能保持运行。
根据CAP定理,这三项中只能实现任意两项。在存在分区容错的情况下,系统必须在可用性(这样的系统称为AP系统)和一致性(CP系统)之间做出选择:
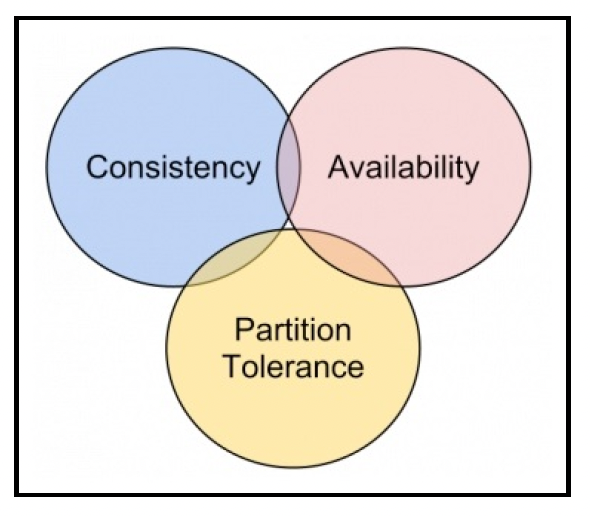
CAP定理的核心选择发生在一个数据节点想要与其他节点通信(可能是为了复制数据)但出现超时的情况。此时,代码必须在两个操作之间做出决定:
- 终止操作,并向客户端声明系统不可用。
- 在本地和其他可达节点上继续操作,从而牺牲一致性。
我们总是可以重试通信,但必须在某个时刻做出决定。
无限期重试实际上就是我们提到的第一种选择 —— 选择一致性而放弃可用性。
通常,大多数现代系统,如Cassandra,会将CP或AP的选择作为用户可调整的选项。然而,理解这种权衡并使应用程序在软状态(最终一致性模型)下工作,可以大幅提高应用程序的可扩展性。
# 共识
继续以我们在 “一致性” 部分讨论的示例系统为例,让我们看看这些独立的实例如何达成共识。共识可以有多种形式,例如,如果需要由单个服务实例向客户发送电子邮件,那么所有实例都需要就哪个实例为哪个客户提供服务达成一致。
广义来说,共识是分布式系统中所有节点就某个变量的特定值达成一致的过程。这个看似简单的问题在分布式系统领域有着广泛的应用。以下是一些例子:
- 领导者选举:在节点集群中,选择一个节点来处理交互。
- 分布式锁管理器:处理多台机器之间的互斥问题。
- 分布式事务:在一组机器上实现一致的事务。
为便于讨论,假设存在N个进程试图就某个值达成共识。期望的结果是:
- 一致性(Agreement):所有无故障的进程就同一个值达成一致。
- 有效性(Validity):所选的值必须是之前提出过的值。这排除了一些简单/理论上的解决方案。
- 活性(Liveliness):共识过程应该在有限的时间内终止。
在理论上的最坏情况下,由于我们无法假设进程达成一致所需的时间或网络的速度,因此根本无法保证达成共识。费舍尔(Fischer)、林奇(Lynch)和帕特森(Patterson)在他们的论文(FLP[85])中证明了这一点。
# 两军问题
这个问题是分布式系统中的一个例子,其中进程是可靠的,但网络不可靠。问题描述如下:
一支军队的两个师分别由将军A1和A2率领。他们都想攻打由将军C率领的另一支军队。只有A1和A2同时进攻,他们才能战胜C。A1和A2在地理位置上相互分离,只能通过信使进行通信,然而这个通信渠道并不可靠!信使可能会被抓获并杀害,因此消息可能无法送达对方将军手中!需要注意的是,不仅消息本身,消息的确认也至关重要,只有这样A1和A2两位将军才能完全确定进攻计划:
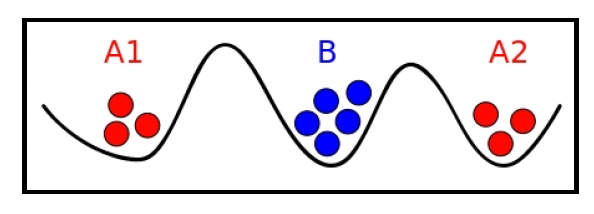 (图片来源:维基百科)
(图片来源:维基百科)
这个问题无法可靠地解决。当然,它存在一种解决方案:一条消息及其确认信息就足以让两支军队成功进攻。但在不可靠的网络环境下,无法保证这种情况一定会发生。
以下部分将介绍进程(这里可看作将军的替代)在不可靠网络中达成共识的方法。 如果我们假设其中一位将军可能会采取不合作的行为,这个问题会变得更加复杂,这就是所谓的拜占庭军队问题。想了解更多相关内容,可以阅读莱斯利·兰伯特(Leslie Lamport)的论文:http://research.microsoft.com/en - us/um/people/lamport/pubs/byz.pdf。
# 基于时间因果关系的共识
在这个模型中,没有显式的阻塞。每当一个进程(Px)从另一个进程(P1)接收到一个值时,如果这个值是在更晚的时间点产生的,那么Px会用P1传来的值覆盖自己原有的值。
通常情况下,为所有进程提供一个共同的时钟源并不容易。通常使用的替代方案是向量时钟(由莱斯利·兰伯特设计)。本质上,向量时钟是一个计数器向量或数组,每个进程对应一个计数器。每当一个进程发送或接收一条消息时,这个计数器就会增加。当一个进程共享信息(值)时,它也会共享自己的向量时钟。接收进程会将自身向量中每个元素的值更新为接收到的向量和自身向量中对应元素的最大值。
这样做的意义在于,如果接收到的向量中的每个元素都大于(或等于)接收进程中的向量,那么接收进程可以认为它接收到了一个更新的值,这个值是在其当前状态之后产生的。换句话说:发送值的进程和接收进程看到了相同的历史状态,并且现在知道了一个更新的值。因此,接收进程可以信任这个新值。
当向量时钟Va的每个计数器的值都大于另一个向量时钟Vb时,Va被称为Vb的后继。
另一方面,如果不满足这种情况,那么发送进程并没有看到接收进程所看到的所有信息,通过因果关系无法达成共识,此时必须采用其他机制。
为了说明这一点,让我们来看一个示例共识问题:
爱丽丝(Alice)、鲍勃(Bob)、查理(Charlie)和大卫(David)计划一起去看电影,但需要确定具体日期。然而,他们住在不同的地方,只能通过打电话相互确认(并且无法进行群聊!)。事件的顺序如下:
- 爱丽丝和鲍勃见面,他们都决定在周三去看电影。
- 大卫和查理决定在周一去看电影。
- 大卫和鲍勃交谈后,决定还是在周三去看电影。
- 鲍勃打电话给查理,但查理说他已经和大卫通过话,决定在周一去看电影!
- 大卫的手机关机了,鲍勃和查理都不知道大卫心里想的是哪一天。
如果我们能知道时间顺序,这个问题的解决方案就很简单。在这种情况下,鲍勃和查理会知道大卫的最新答案,从而达成共识。
在向量时钟的场景下,顺序大致如下(注意,VC = 向量时钟):
- 爱丽丝想到周三去看电影,并向鲍勃发送消息(日期 = 周三,VC = [爱丽丝:1])。
- 鲍勃确认并更新他的值和向量时钟。因此,鲍勃的状态如下:日期 = 周三,VC = [爱丽丝:1,鲍勃:1]。
- 大卫打电话给查理,他们都决定在周一去看电影。现在,他们两人的情况如下:
| 大卫 | 查理 |
| ------------------------------- | --------------------------------------- |
| 日期 = 周一
VC = [大卫:1] | 日期 = 周一
VC = [大卫:1,查理:1] | - 鲍勃打电话给大卫,他们决定坚持在周三去看电影。现在,他们两人的情况如下:
| 鲍勃 | 大卫 |
| ------------------------------------------------- | --------------------------------------------------------- |
| 日期 = 周三
VC = [爱丽丝:1,鲍勃:2,大卫:2] | 日期 = 周三
VC = [爱丽丝:1,鲍勃:1,大卫:2,查理:1] | - 鲍勃打电话给查理,提议周三去看电影。查理面临两个冲突的状态:
- 周一:VC = [大卫:1,查理:1]
- 周三:[爱丽丝:1,鲍勃:2,大卫:2]
查理可以看出,大卫在说周一之后又答应了周三,于是达成了共识!
Labix包在Go语言中提供了向量时钟支持:https://labix.org/vclock。这是该网站上的一个“Hello World”示例:
package main
import (
"fmt"
"labix.org/v1/vclock"
)
func main() {
vc1 := vclock.New()
vc1.Update("A", 1)
vc2 := vc1.Copy()
vc2.Update("B", 0)
fmt.Println(vc2.Compare(vc1, vclock.Ancestor)) // true
fmt.Println(vc1.Compare(vc2, vclock.Descendant)) // true
vc1.Update("C", 5)
fmt.Println(vc1.Compare(vc2, vclock.Descendant)) // false
fmt.Println(vc1.Compare(vc2, vclock.Concurrent)) // true
vc2.Merge(vc1)
fmt.Println(vc1.Compare(vc2, vclock.Descendant)) // true
data := vc2.Bytes()
fmt.Printf("%#v\n", string(data))
vc3, err := vclock.FromBytes(data)
if err != nil {
panic(err)
}
fmt.Println (vc3.Compare(vc2, vclock.Equal)) // 将会输出true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 多阶段提交
达成共识的一种方法是,提议进程将提议的值发送给其他所有进程,并促使它们接受或拒绝该提议。提议进程认为,如果收到所有进程的接受响应,就达成了共识。
分布式提交主要有两个版本:
- 两阶段提交(Two - phase commit)
- 三阶段提交(Three - phase commit)
# 两阶段提交
如前所述,假设存在一个提议进程(P0)和一组其他进程[P1...PN](我们称它们为执行进程),这些执行进程需要执行值的更新操作。在两阶段提交协议中,提议进程(P0)通过两个阶段来协调共识:
- 准备阶段:P0向其他执行进程[P1...PN]发送一条消息“Prepare Update V = x”。每个执行进程要么投票“PREPARED”(准备好),要么投票“NO”(拒绝)。如果投票“PREPARED”,可能会在本地暂存更改。例如,如果存在另一个并发事务,进程可能会投“NO”票。
- 提交阶段:一旦收到所有响应,P0会发送“COMMIT”(提交)或“ABORT”(中止)消息。每个执行进程会服从这个命令,从而完成事务。
为了便于处理诸如重启等情况,每个进程在发送消息之前,会将当前状态记录在持久存储中。例如,一旦所有执行进程都回复“PREPARED”,P0可以记录自己进入了提交阶段。
这个算法在提交阶段容易受到故障的影响:
- P0可能在准备阶段之后崩溃。此时,其他所有执行进程都在等待P0,在P0恢复正常之前,系统在共识方面会陷入停滞。P0并不知道崩溃的节点是希望继续执行事务还是中止事务。
- 如果一个执行进程在第二阶段崩溃,P0无法知道该进程是在提交之前还是之后发生故障的。
总之,两阶段提交最大的缺点就是我们刚刚描述的阻塞问题。如果其中一个进程在关键阶段出现故障,整个系统就会陷入停顿。
# 三阶段提交
非阻塞提交协议指的是,单个进程的故障不会阻止其他进程决定事务是提交还是中止。实现这种行为的一种方法是将提交阶段分为两个子阶段:
- 2.a - 预提交阶段:在收到执行进程的“PREPARED”消息后,P0进入预提交阶段。P0向所有执行进程发送“preCommit”消息。在这个阶段,执行进程会暂存更改(可能会获取锁),但实际上并不提交。
- 2.b - 提交阶段:如果P0在预提交阶段收到所有执行进程的“YES”响应,它会向所有执行进程发送“COMMIT”消息,从而完成事务。如果在预提交阶段有任何执行进程回复“NO”或没有回复,事务将被中止。
如下图所示:
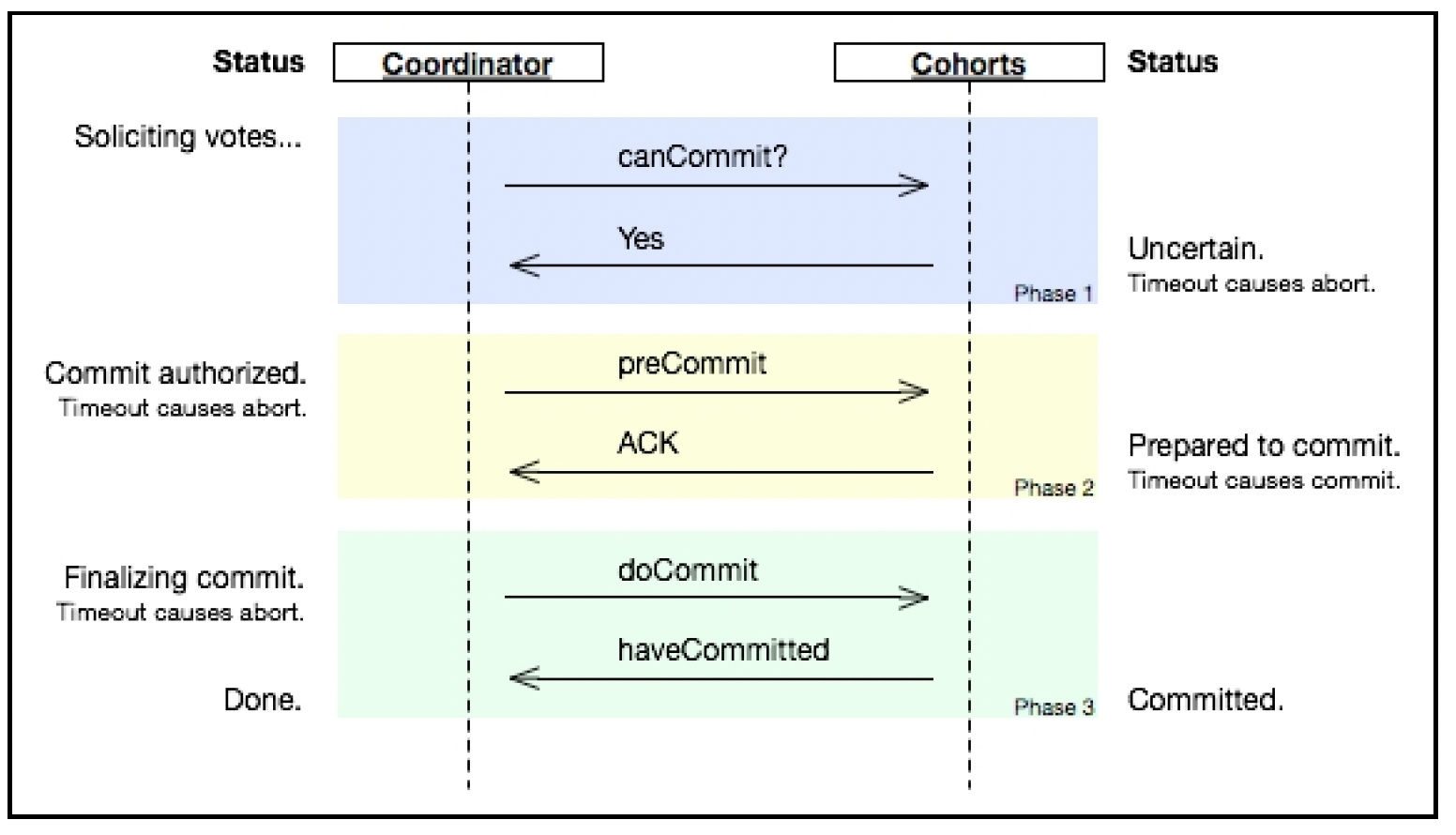 (图片来源:维基百科,这里的协调者(Coordinator)和参与者(Cohorts)分别是P0和执行进程的别称)
(图片来源:维基百科,这里的协调者(Coordinator)和参与者(Cohorts)分别是P0和执行进程的别称)
预提交阶段有助于算法从进程故障的情况中恢复。进程现在可以设置超时时间,如果执行进程没有收到P0的回应,它们可以选举一个新的协调者来推动事务完成。新的协调者可以查询其他执行进程,检查事务的当前状态;如果处于2.b - 提交阶段,那么它就知道发生了一些故障,但所有进程都打算提交事务。
另一方面,如果一个执行进程向新的协调者回复说它没有收到“Prepare - to - Commit”消息,那么新的协调者可以认为P0在进入第三阶段之前就发生了故障。由于其他执行进程尚未进行任何更改,事务可以安全地中止。
这个算法并不完美,尤其容易受到网络故障的影响。
# Paxos算法
Paxos是一种灵活且具有容错能力的共识协议,由莱斯利·兰伯特在他的论文《兼职议会》(The part - time parliament,发表于ACM Trans. on Comp. Syst. 16 (2), 133 - 169 (1998))中提出。
为了全面描述该算法和结构,我们必须对前面提到的拓扑假设进行扩展。与单个P0进程进行更改不同,在Paxos的术语中,一个进程(或节点)可以承担以下三个角色之一:
- 提议者(Proposer):这是推动达成共识的节点。
- 接受者(Acceptor):这些节点独立接受或拒绝提议。
- 学习者(Learner):学习者并不直接参与共识构建过程,它们从接受者那里得知被接受的值。通常,学习者和接受者被封装在一个组件中。
Paxos算法的基本步骤与两阶段提交非常相似。与两阶段协议一样,在标准的Paxos算法中,提议者向接受者发送两种类型的消息:“Prepare”(准备)和“Accept”(接受)。然而,在准备阶段,除了提议的值,它们还会发送一个提案编号(n)。这些提案编号必须是正整数,单调递增,并且在所有进程中是唯一的。一种实现方式是使用两个整数构建提案编号,一个用于标识进程本身,另一个是每个进程的计数器。每当接受者收到相互冲突的提案时,它会选择提案编号更高的那个。接受者必须记住它曾经接受的编号最高的提案,以及它回复过的编号最高的准备请求的编号。
各个阶段描述如下: 阶段1:
准备:提议者构造一个包含值(v)和提案编号N(N大于该进程之前使用的任何编号)的“Prepare”消息,然后将这个消息发送给一组接受者(法定人数)。
承诺:当接受者收到“Prepare”消息时,它会检查提案编号(N)是否高于之前接受的任何提案编号。如果是,它会记录最新接受的值和序列号N。任何提案编号小于N的“Prepare”消息都会被忽略(尽管不需要回复,但发送“NACK”(否定应答)会帮助算法更快收敛)。如果接受者在过去某个时刻接受过提案,它必须在回复提议者时包含之前的提案编号和之前的值。
一个接受者可能处于已经接受了多个提案的状态。
阶段2:
- 接受请求:一旦提议者收到大多数节点的响应消息,它就会将算法推进到接受阶段。提议者本质上希望接受者提交它们所接受的内容。这里有三种情况:
- 如果大多数接受者回复“NACK”消息或没有回复,提议者将放弃该提案,回到初始状态/阶段。
- 如果到目前为止没有接受者接受过任何提案,提议者可以选择原始值v和提案编号N。
- 如果有接受者之前接受过提案,提议者将获得这些提案的值和序列号。在这种情况下,如果w是具有更高序列号的已接受值,Paxos算法会强制提议者推动对w(而不是v)的接受。这可以防止新的提议者在恢复后使系统偏离共识。
提议者将包含所选值的“Accept”消息发送给所有接受者:
- 接受:当接受者收到“Accept”消息时,它会检查以下条件:
- 该值来自之前接受过的某个提案。
- 消息中的序列号是接受者认可的最高提案编号。
- 如果两个条件都满足,接受者会向提议者发送“Accept”消息。否则,发送“Reject”(拒绝)消息。
Paxos算法比多阶段提交算法更具容错能力,原因如下:
- 提议者容错:如果一个提议者在过程中发生故障,另一个节点可以承担这个角色并提出自己的提案。
- 如果存在相互竞争的提议者,特别是在早期提议者恢复之后,由于序列号的顺序约束,只会选择之前已接受的值。
- 网络分区对Paxos算法的影响不像对三阶段提交协议那么大,因为只需要大多数接受者达成一致即可。如果大多数接受者达成一致,就能达成共识,即使其他节点无法访问;如果没有达到大多数,这一轮就失败。
Paxos算法的一个潜在问题是,两个竞争的提议者可能会不断提出编号越来越高的提案。接受者可能会忽略提案编号较低的消息,这可能会导致提议者不断尝试使用更高的提案编号。为了克服这个问题并确保取得进展,通常会在提议者中选择一个特殊的提议者。这个领导者(Leader)会对提案进行排序,避免出现这种情况。领导者选举将在后面的章节中介绍。
Paxos算法在Go语言中的实现可以在https://github.com/go - distributed/epaxos和https://github.com/kkdai/paxos找到。
# Raft算法
Raft是一种共识算法,与Paxos算法类似,但它的状态更少,算法也更简单。
在任何给定时间,每个Raft实例都处于以下三种状态之一:领导者(leader)、跟随者(follower)或候选人(candidate)。每个实例最初都是跟随者。在这种状态下,实例是被动的,只负责响应消息:根据日志条目消息复制领导者的状态,并回答候选人的选举消息。如果在一段时间内没有收到任何消息,实例会将自己提升为候选人状态,发起选举,目标是成为领导者。在候选人状态下,实例会向其他实例(它们的对等节点)请求投票。如果它获得了大多数(法定人数)的选票,就会被提升为领导者。选举是按任期(term)进行的,任期是一个逻辑时间单位。
领导者选举将在后面的章节中介绍。
当一个实例被提升为领导者时,它需要做三件事:
- 处理写操作,即处理来自客户端的状态更改请求。
- 将状态更改复制到所有跟随者。
- 在不允许读取过期数据的情况下处理读操作。
在Raft算法中,处理写操作本质上就是向日志中追加记录。领导者将记录追加到持久存储中,然后在跟随者中启动复制操作。日志是Raft架构的关键组件。共识问题本质上可以归结为复制日志。如果所有实例具有相同顺序的相同日志条目,那么系统就是一致的。
如果对法定人数(大多数)的实例进行的复制操作成功,那么一次写操作就被认为是已提交的。对于一个有n个实例的集群,法定人数由(n/2 + 1)个节点组成。在写操作提交之前阻塞客户端请求,这是一种设计选择。
一旦日志条目被提交,它就可以应用到实例上的有限状态机中。有限状态机承载特定于应用程序的代码,用于处理更改。这段代码应该是确定性的,因为所有节点按照相同的顺序处理相同的数据,所以输出应该是相同的。
与Paxos算法相比,Raft算法更简单,https://ramcloud.stanford.edu/raft.pdf提供了很多实现细节。因此,它比Paxos算法更受欢迎。Hashicorp在Go语言中的实现非常全面,你可以在https://github.com/hashicorp/raft上查看。
# 领导者选举
在由多个实例组成的集群中,所有实例都具备执行相同任务的能力,此时让其中一个实例担任领导者(Leader)的角色,并协调其他实例的行动通常非常重要。例如,对于一组代表复制数据存储的实例,领导者总是从客户端接收写入请求,并确保该写入操作在其余实例上进行复制。这避免了处理诸如并发写入冲突和资源争用/死锁等问题。由领导者协调行动是实现一致性和共识的常见工程模式:
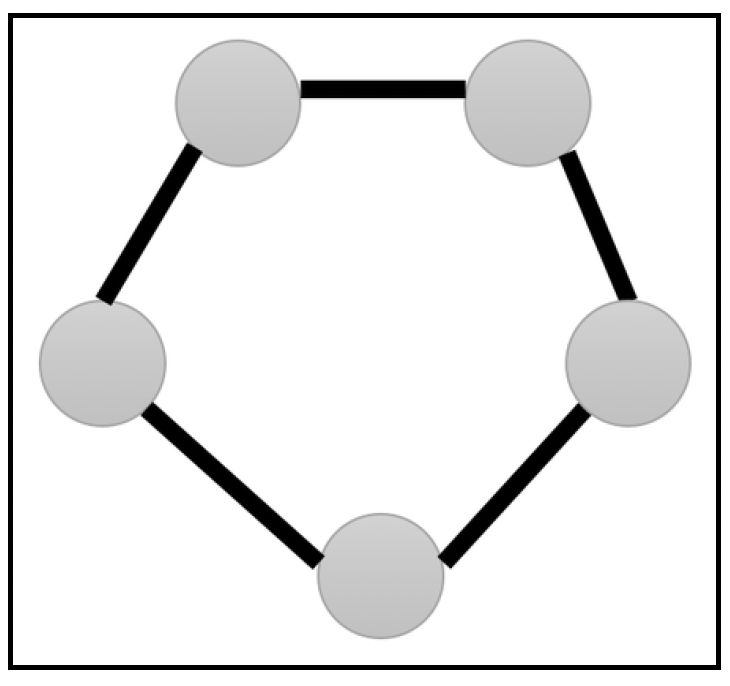
在一组实例/节点中选举领导者有几种经过深入研究的策略,包括:
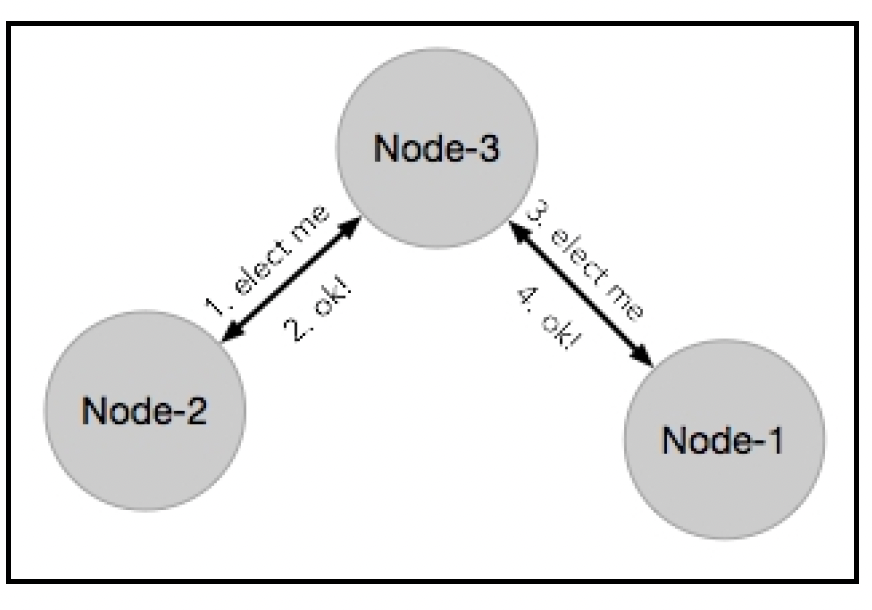
- 基于ID选择:每个实例都会被赋予一个唯一的ID。每当进行选举时,实例之间会交换ID,ID最小(或最大)的实例成为领导者。在基于环形拓扑结构的实例中选举领导者,存在时间复杂度为O(n²)和O(nlogn)的算法,如上图所示。恶霸算法(Bully Algorithm)是一种著名的领导者选举算法,稍后将对其进行描述。
- 互斥锁竞争:实例之间相互竞争,以原子操作的方式锁定一个共享的互斥锁(mutex/lock)。获得锁的实例成为领导者。这种方法存在一个问题,即如果领导者在持有锁的情况下发生故障,就会出现问题。
通常,领导者和实例之间会有一个心跳机制(keepalive mechanism),以确保在领导者发生故障时进行新的选举。
大多数分布式系统将时间划分为称为时期(epochs)或轮次(rounds)的单位。这些不一定是实际的时间单位,一个简单的选举计数器就可以。在交换消息时,这个数字会携带在消息负载中,这样一个节点就不会在同一次选举中对两个不同的领导者进行投票:
# 分布式架构
本节将阐述构建分布式架构的不同模式。这些模式是在考虑了前面提到的各种问题以及多年来积累的经验教训的基础上提炼出来的。请注意,这些模式并非相互排斥,相反,它们可以被视为构建各种功能的模板。
# 基于对象的系统
最简单(也是最早)的分布式系统由使用远程过程调用(Remote Procedure Calls,RPCs)或远程方法调用(Remote Method Invocations,RMIs)相互交互的对象组成:
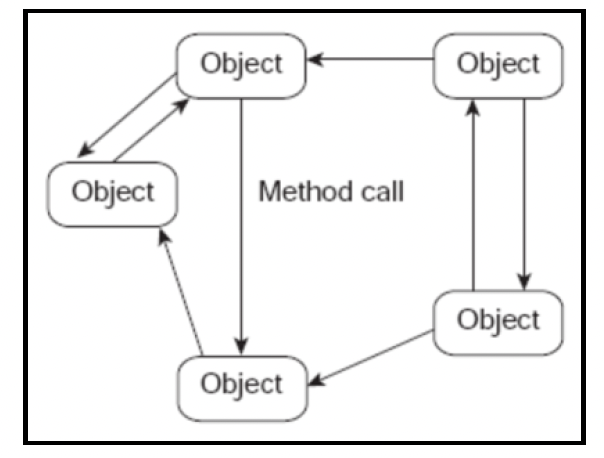
每台机器上的架构都包含三层:
- 存根/骨架层:这些是客户端的存根(stub)或代理,以及服务器的骨架(skeleton)。存根是客户端对远程对象的引用,它实现了远程对象的精确接口。存根将请求转发到服务器上的实际对象和远程引用层。
- 远程引用层:负责执行调用的语义。它将通信细节委托给传输层。
- 传输层:负责连接管理和远程对象跟踪。
这种类型的架构主要有两个生态系统:
- 公共对象请求代理体系结构(Common Object Request Broker Architecture,CORBA):由一个名为对象管理组织(Object Management Group,OMG)的组织定义,是Java世界中的RPC框架。
- 分布式组件对象模型(Distributed Component Object Model,DCOM):由微软发起。
在Go语言中,标准库(stdlib)中有一个rpc包,它允许我们通过远程过程调用导出任何对象方法。
例如,假设有以下乘法服务:
type Args struct {
A, B int
}
type MuliplyService struct{}
func (t *Arith) Do(args *Args, reply *int) error {
*reply = args.A * args.B
return nil
}
2
3
4
5
6
7
8
9
10
然后,你可以使用rpc包启用它的远程调用,如下所示:
func main() {
service := new(MuliplyService)
rpc.Register(MuliplyService)
rpc.HandleHTTP()
l, err := net.Listen("tcp", ":1234")
if err != nil {
log.Fatal("listen error:", err)
}
go http.Serve(l, nil)
}
2
3
4
5
6
7
8
9
10
想要进行RPC调用的客户端可以连接到这个服务器并发出请求,如下所示:
client, err := rpc.DialHTTP(
"tcp",
serverAddress+":1234")
if err != nil {
log.Fatal("dialing:", err)
}
// 同步rpc
args := &server.Args{3, 4}
var reply int
client.Call("Multiply.Do", args, &reply)
fmt.Printf(" %d*%d=%d", args.A, args.B, reply)
2
3
4
5
6
7
8
9
10
11
近年来,这种架构风格由于以下原因逐渐失宠:
- 它试图为远程对象添加包装器,并伪造对远程对象的本地引用。但正如我们从前面提到的八大谬论中看到的,远程行为与本地行为永远不会相同,而且这种架构在轻松解决这种阻抗不匹配问题方面没有留下太多空间。
- 调用方和被调用方在通信时都需要处于运行状态。但这通常不是应用程序构建的要求。
- 一些框架,如CORBA,由于是由委员会设计的,开始变得极其复杂。
# 分层架构
如第1章“用Go构建大型项目”中所述,组件被组织成多个层级,并且通信仅限制在相邻层级之间。这些层级分布在不同的机器上:
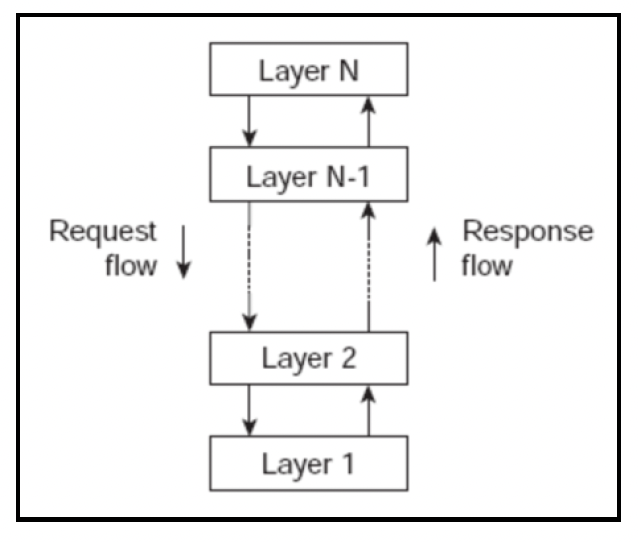
这种架构风格可以被看作是一个倒金字塔形的复用结构,其中每一层都聚合了其下一层的职责和抽象。当这些层级位于不同的机器上时,它们被称为层(tiers)。严格分层的最常见示例是,一层中的组件只能与同一层的组件或直接下层的组件进行交互。
应用程序的各个层级可能位于同一台物理计算机(网络栈)上,但在分布式系统中,它们当然位于不同的机器上。在这种情况下,它们被称为n层架构。例如,一个典型的Web应用程序设计包括以下部分:
- 表示层(Presentation layer):与用户界面相关的功能。
- HTTP服务器层:这是一个网络服务器,负责处理HTTP/HTTPS请求,以及诸如反向缓存、持久连接处理、透明SSL/TLS加密和负载均衡等功能。
- 业务逻辑层(Business Logic layer):承载根据业务规则进行的实际处理。这通常由部署在Web容器或框架中的代码来处理。在Go语言中,与其他语言(如Java的JAX - RX或Spring MVC)相比,容器往往要简单得多。
- 数据层(Data Layer):处理与持久化数据(数据库)的交互。这一层通常使用大部分可复用的代码构建,并根据应用程序的具体情况进行配置。在初始版本中,这一层与业务逻辑层位于同一位置。
将哪一层放置在哪一个层级是架构师必须认真考虑的重要设计决策。在责任分配方面有一个完整的范围:
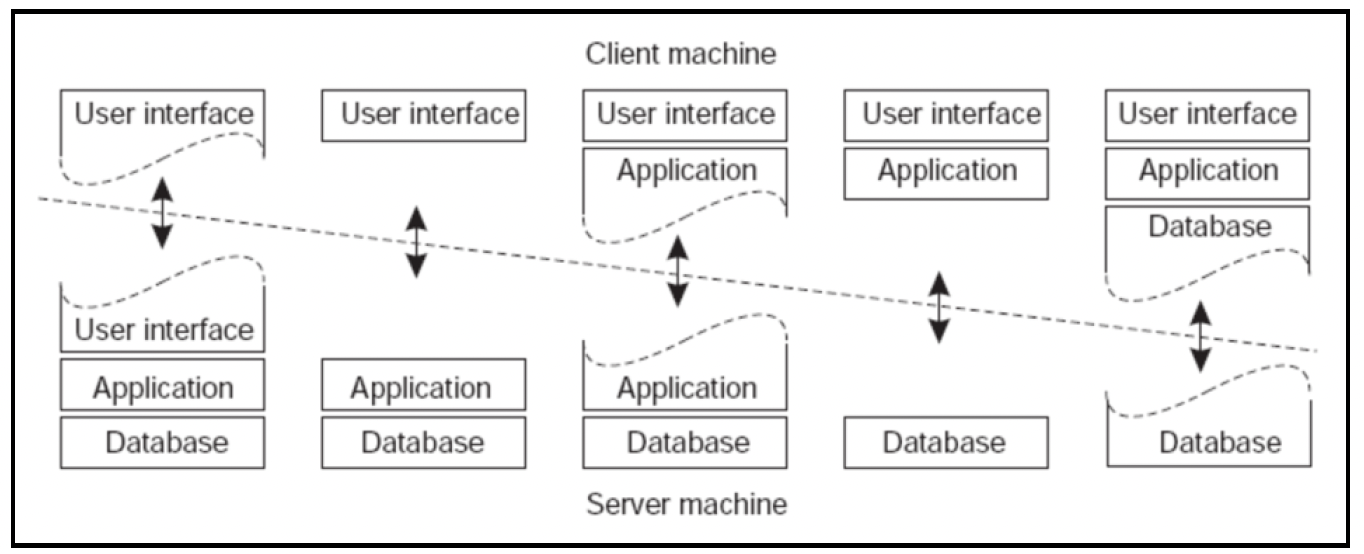
我们应该从让客户端尽可能简单开始(如上图左侧所示),因为这在复用(跨客户端)和可扩展性方面提供了最大的灵活性(通常,与客户端代码相比,服务器代码更容易更改和部署)。
然而,为了解决诸如延迟优化等问题,客户端可能会增加一些额外的层级。
# 对等(Peer-2-Peer,P2P)架构
在P2P架构模型中,所有参与者都是对等节点,它们之间没有中央协调器。每个实例承担一部分工作负载,或者与网络中的其他对等节点共享其资源。通常,在这种架构中,节点或实例既充当服务器又充当客户端。
虽然传统上这种范式意味着对等节点具有同等权限,但在实践中可能会有一些变化:
- 混合模式:有些实例可能具有特定的功能。
- 结构化P2P:节点可能会将自身组织成某种覆盖网络,处理流程可能类似于前面描述的分层架构模式。然而,关键的区别在于,这种覆盖网络是临时的、可丢弃的。
Bit-torrent就是P2P架构的一个例子。它是一个文件共享服务器,每个节点都可以传输自己拥有的任何内容,对于新的内容,它会查询一个中央服务(网页),以确定哪些节点托管了所需内容的哪些块:
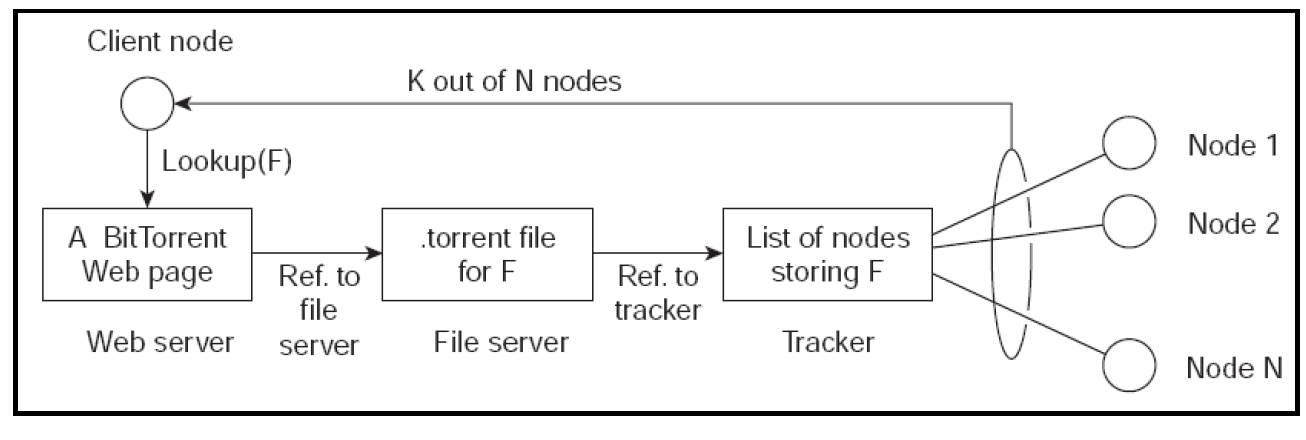 来源:http://www.bittorrent.org/
来源:http://www.bittorrent.org/
结构化P2P的一个例子是分布式哈希表(Distributed Hash Table,DHT)。如果你还记得,哈希表是一种允许存储键值对象的数据结构。在内部,数据存储在各个桶(bucket)中。一个好的哈希函数用于将键映射到一个哈希值,然后对一定数量的桶进行取模运算,以确定包含该键的桶。在一个桶内,键以适合搜索的格式存储(例如红黑树),但每个桶处理的数据规模比整个哈希表要小得多。
DHT允许设计一个分布在多台机器上的哈希表。当我们需要进行特定请求的路由时,通常会用到DHT —— 任何实例都可以接收请求,但它会查询DHT以确定将该请求路由到哪个实例来处理。那么,我们如何构建一个DHT呢?
最初(简单)的解决方案可能是对键进行哈希运算,然后对n取模以得到一个服务器地址。例如,对于三台服务器,六个键可以如下分配:
| 键 | 哈希值 | 服务器(哈希值对3取模) |
|---|---|---|
| Alice | 3333333333 | 0 |
| Bob | 7733228434 | 1 |
| Chris | 3734343434 | 2 |
| Doug | 6666666666 | 0 |
| Elgar | 3000034135 | 1 |
| Fred | 6000799124 | 3 |
这个方案很简单,并且运行良好。然而,问题在于重新分配。分布式系统的主要要求之一是可扩展性,即能够根据负载添加/删除服务器。在这里,如果我们将服务器数量更改为四,那么几乎所有键的哈希值以及服务器分配都将发生变化!这意味着在集群重新配置时,会有大量的数据移动和停机时间。
一种克服这一限制的方案称为一致性哈希(consistent hashing),它最早由麻省理工学院的卡格尔(Karger)等人在1997年的一篇学术论文中提出。该算法的基本思想是使用相同的哈希函数对托管缓存的服务器和键进行哈希运算。
这样做的原因是将缓存映射到一个区间,该区间将包含一定数量的对象哈希值。如果一个缓存被移除,其区间将由相邻区间的缓存接管。所有其他缓存保持不变。
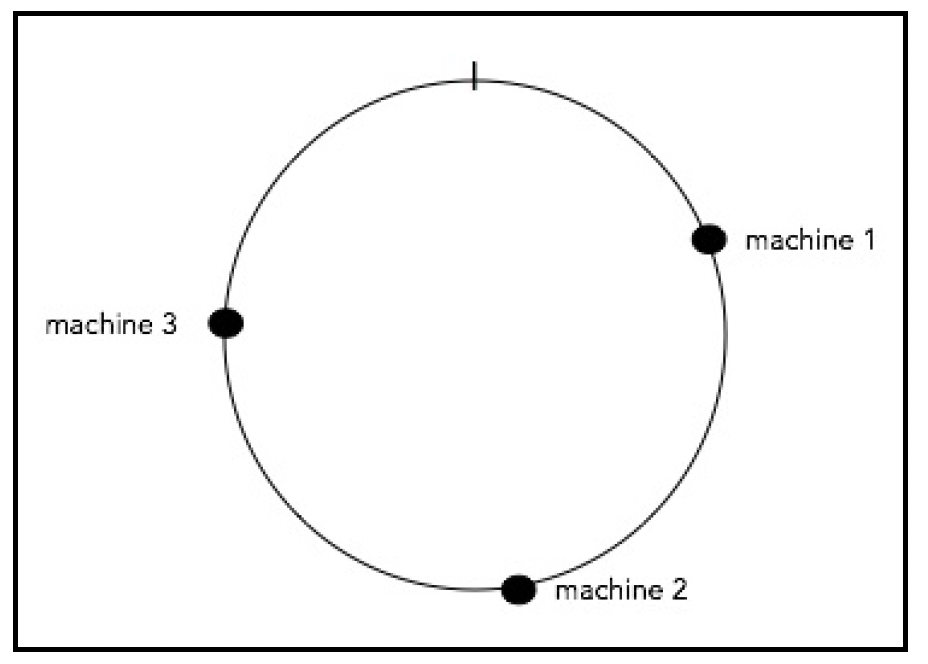
为了理解一致性哈希的工作原理,可以想象一个值范围从[0 - 1]的圆圈,也就是说,圆圈上的任何点的值都在0到1之间。接下来,我们选择一个哈希函数,并将其范围也映射到[0 - 1]。例如,如果哈希函数的范围是[0 - X],我们使用以下公式: ringKey = hash(key) % X
使用这个函数,我们可以将机器(实例)和对象(使用键)映射到[0 - 1]的范围内。
如果我们有三台机器,我们使用修改后的哈希函数将每台机器映射到圆圈上的一个点:
现在,我们可以看到0 - 1的范围已经在这些机器之间被划分成了区间!假设我们在哈希表中有一个键值对,我们需要做两件事:
- 使用修改后的哈希函数在圆圈上定位键。
- 找到从该点顺时针方向出现的第一台机器,并将键存储在那里。
下面的图表展示了这一过程:KeyX映射到一个点,从该点顺时针方向最近的机器是machine 3。因此,KeyX被分配给machine 3:
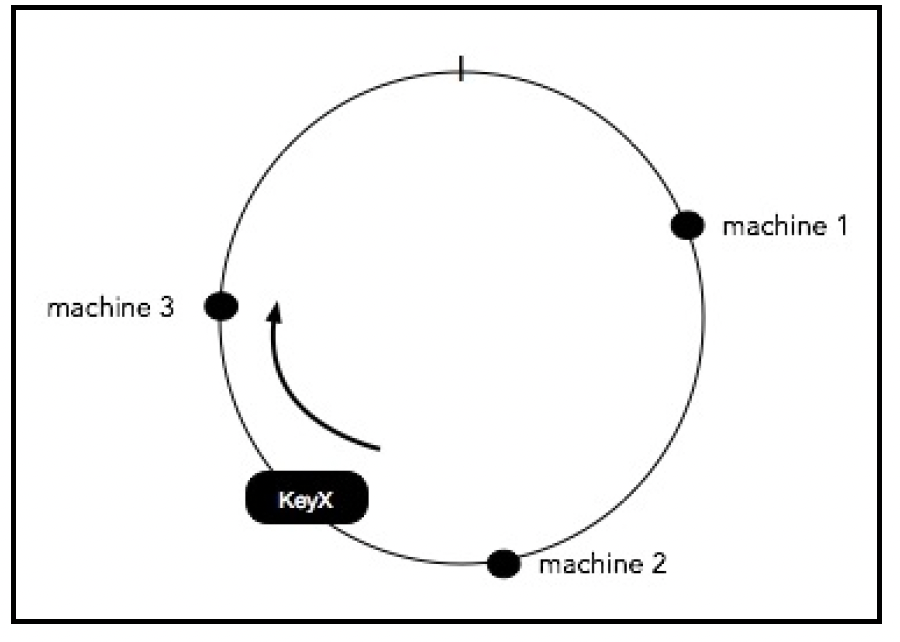
从编程的角度来看,通过以一种易于找到 “y之后的下一个更大数字” 的方式存储机器的点值,很容易实现顺时针查找最近的机器。一种方法是使用按排序顺序排列的机器哈希值链表。为了找到分配,只需遍历这个列表(或使用二分查找),找到第一个哈希值大于或等于键的哈希值的机器。我们可以将这个列表做成循环列表,这样,如果没有找到 “更大键” 的机器,计算就会环绕,列表中的第一台服务器将被分配。
现在,假设我们向集群中添加一台新机器:
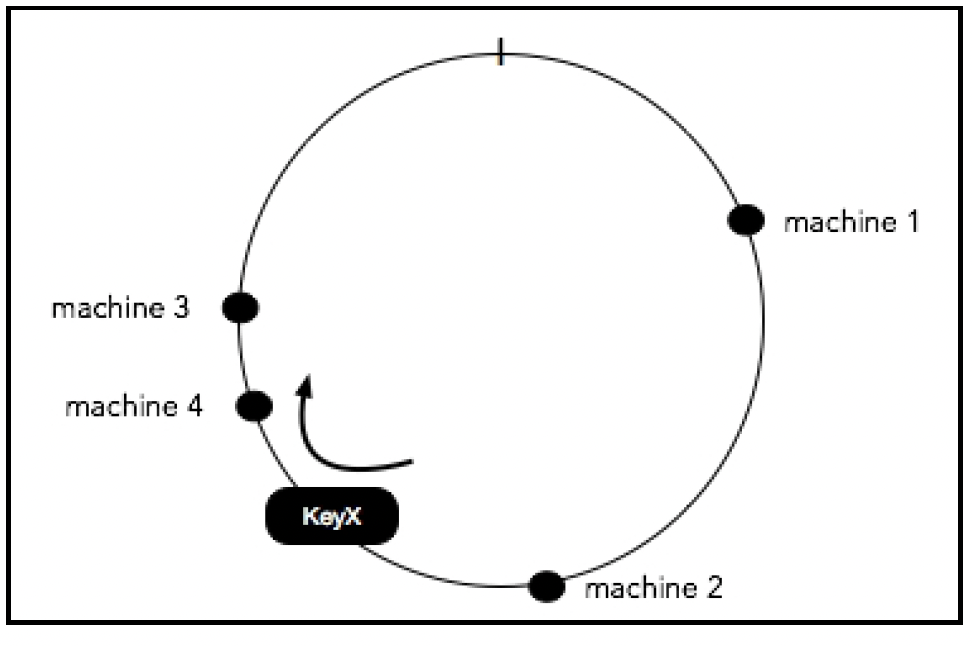
如你所见,与简单的哈希方法相比,大多数分配不会受到这个变化的影响,在简单哈希方法中,几乎每个分配都会改变。唯一的重新分配发生在原来顺时针方向的机器和新配置的机器之间。
为了消除哈希函数分布中的不规则性,每台机器不是被分配圆环上的一个点,而是被分配一组点(称为虚拟节点,vnodes)。以下图表描述了这个方案:
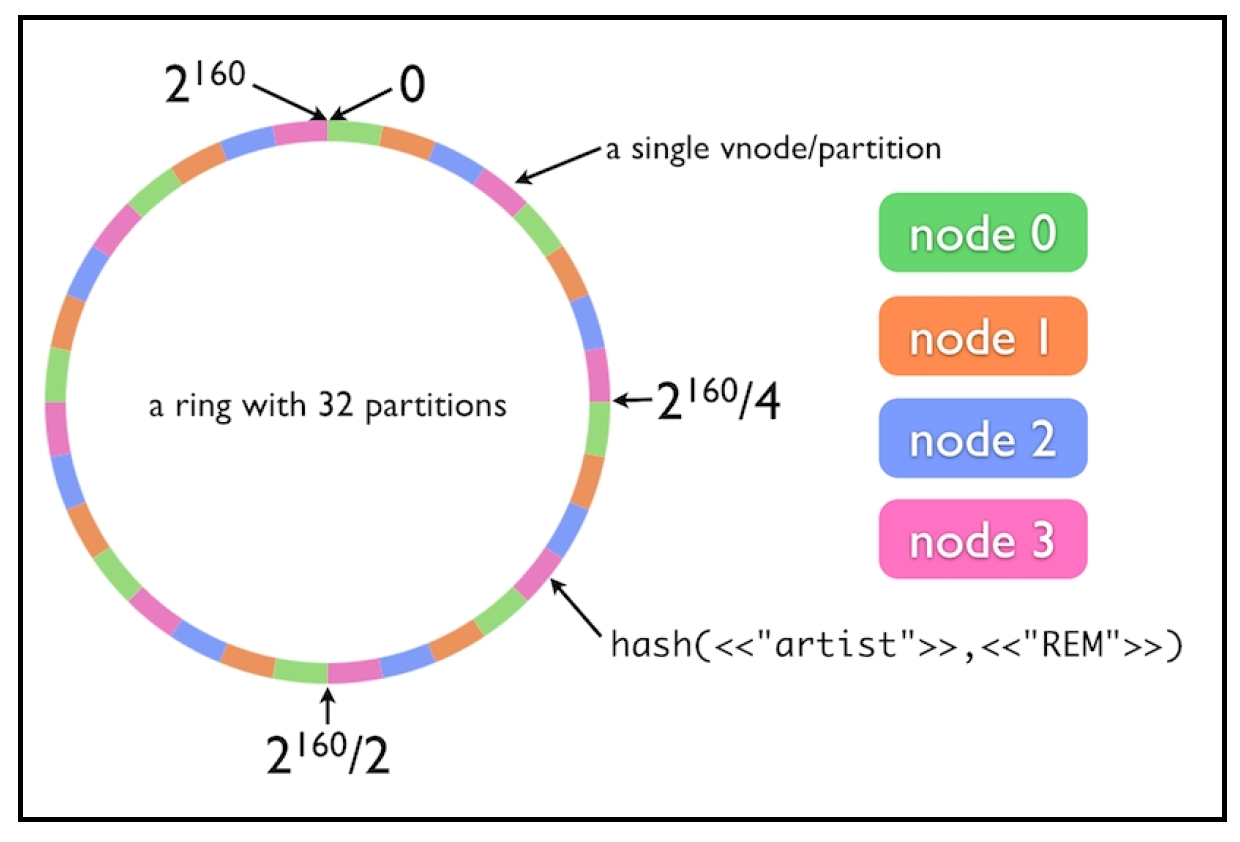 图片来源:http://efcasado.github.io/riak-core_intro/
图片来源:http://efcasado.github.io/riak-core_intro/
最近,一致性哈希有了一些改进,使其能够感知负载。其中一种算法是 “带负载限制的一致性哈希”(Consistent Hashing with Bounded Loads):https://research.googleblog.com/2017/04/consistent-hashing-with-bounded-loads.html 。
它使用一个大于1的一致性参数(ε)来控制负载(每个服务器上的键数量)的不均衡程度。例如,如果ε = 1.5,那么没有服务器的负载会超过平均负载的150%。该算法对一致性哈希的关键改进在于,如果最近的节点不符合均衡因子要求,就直接移动到环上的下一个节点。当ε值较大时,该算法就等同于原始的一致性哈希算法;然而,当ε值越接近1时,分布就越均匀,但也意味着需要更多的重新平衡操作(具备的一致性哈希特性就越少)。你可以在https://github.com/lafikl/consistent找到这篇论文的Go语言实现。
有时,在对等网络(P2P networks)中,覆盖网络会呈现分层结构,其中包含超级节点(Superpeers):
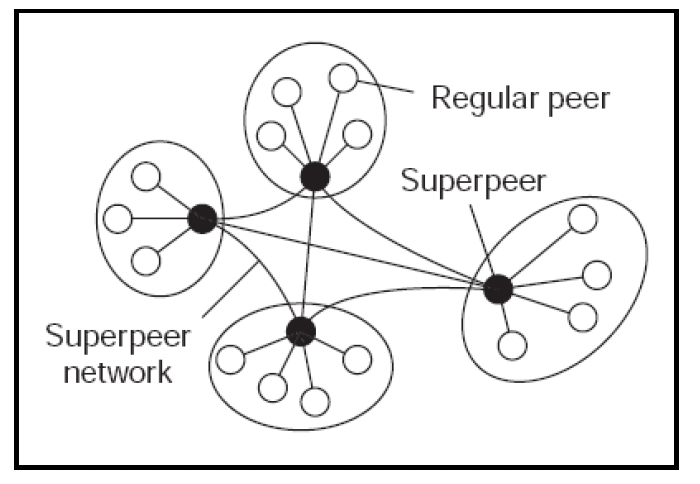
这些超级节点负责内部集群之间的通信,它们还会与其他超级节点建立连接,以构建交互结构。内容分发网络(CDNs,Content Delivery Networks)就是这种架构的一个例子。这里的每个边缘服务器都是一个对等节点。
# 分布式计算
有时,你的应用程序可能需要处理用传统数据库难以管理的数据。你可能还需要对数据执行各种计算或投影操作,而对每一列都维护索引既不可行也不高效。谷歌开创了一种通过分布式计算解决此类计算问题的新方法,这样相同的代码就可以在一组通用机器上处理不同的数据。这就是所谓的MapReduce。
MapReduce将整体处理过程定义为两个部分/函数,这两个部分/函数都以键值对作为输入并输出键值对。这两个函数如下:
- Map(映射):接受一个输入键值对,并生成一组中间键值对(这组键值对可能为空)。例如,Map函数可能会在文档的某一页内创建一个直方图(将单词映射到其出现次数)。
- Reduce(归约):获取中间键以及在Map步骤中生成的所有相关值的列表,也就是说,所有具有相同键的中间值会被聚合到一个列表中。在单词计数的示例中,每个Reduce实例会将单词作为键,并获取文档中每一页的计数列表。
其流程如下所示:
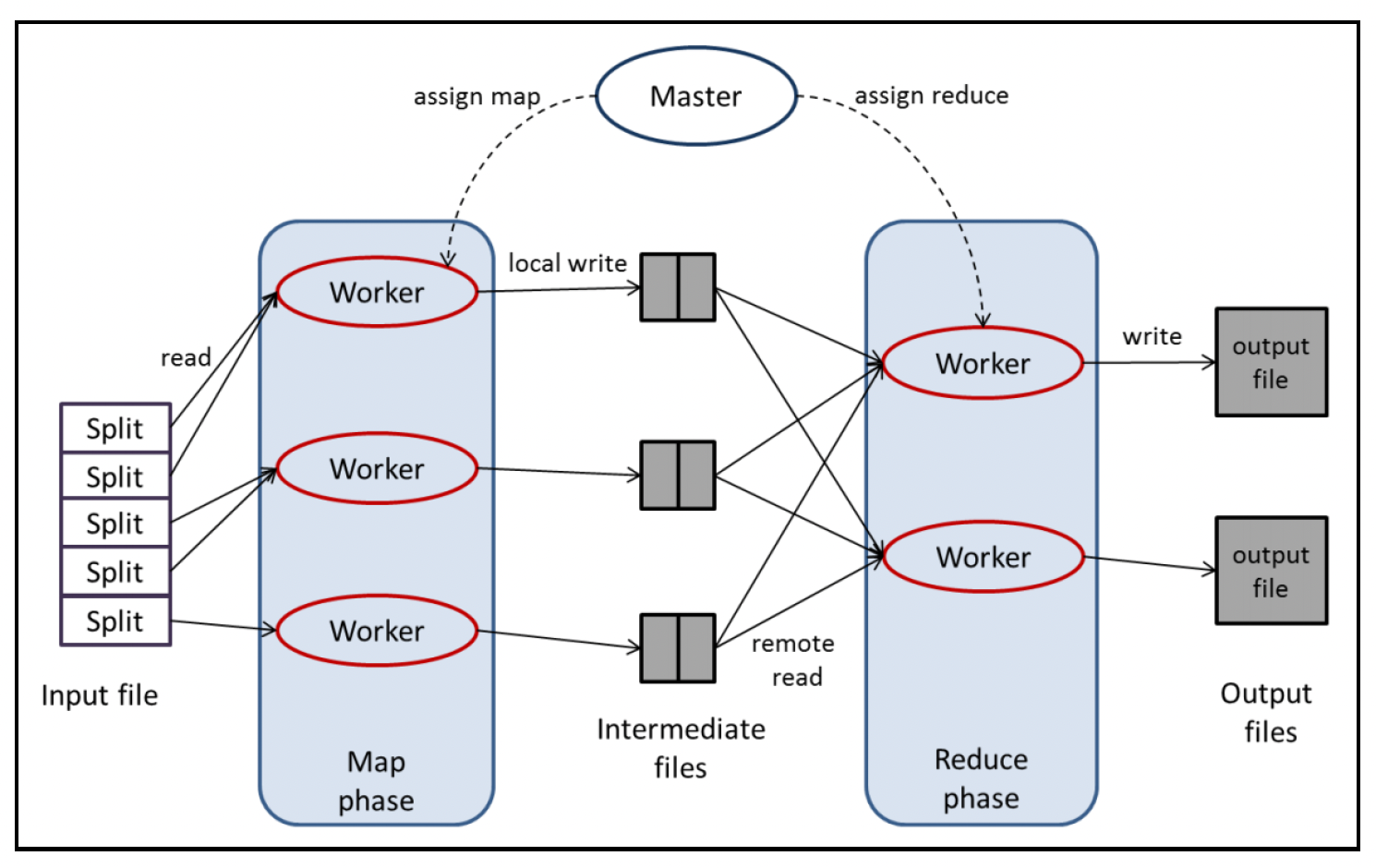
谷歌的框架中有谷歌文件系统(Google File System,GFS)和一个名为BigTable的分布式NoSQL数据库,它们为MapReduce框架提供支持。分布式MapReduce计算是通过主从架构实现的:主节点分配任务并控制一组从机器上的执行过程。
上图展示了我们讨论的单词计数示例。输入文档存储在GFS中,并被分割成多个块。主节点通过将Map和Reduce函数的代码发送给所有工作节点来启动任务。然后,在工作节点上生成Map任务,这些任务在文件中生成中间键值对。接着,生成Reduce任务,它们读取中间文件并写入最终输出。
Apache基金会创建了这种范式的开源版本,称为Hadoop。它使用Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)替代GFS,并使用YARN(Yet Another Resource Negotiator,另一种资源协调器 )。YARN是Hadoop的集群执行调度器,它在集群中的机器上生成/分配一定数量的容器(进程),并允许在这些容器上执行任意命令。HBase相当于BigTable。在Hadoop之上还有许多更高级的项目,例如,Hive可以通过将SQL查询转换为MapReduce函数来运行类似SQL的查询。
尽管MapReduce框架具有简单的编程模型,并且实现了轻松处理大数据的目标,但如果有实时响应要求,它就不太适用了。原因有两点:
- Hadoop最初是为批处理设计的。诸如调度、代码传输以及进程(映射器/归约器)的设置和拆除等操作,意味着即使是最小的计算任务也需要数秒才能完成。
- HDFS是为高吞吐量的数据输入/输出而设计的,并非为高性能设计。HDFS中的数据块非常大,每秒的输入/输出操作次数(IOPS)约为100到200MB。
优化磁盘输入/输出的一种方法是将数据存储在内存中。借助机器集群,单个机器的内存大小不再是限制因素。
内存计算并不意味着整个数据集都要存储在内存中;即使只是缓存经常使用的数据,也能显著缩短整体作业的执行时间。
Apache Spark就是基于这种模型构建的。它的主要抽象概念是弹性分布式数据集(Resilient Distributed Dataset,RDD)。本质上,这是一批可以一起处理的事件。与Hadoop类似的模型中,有一个主程序(驱动程序),它通过向运行在多个工作节点上的执行器进程发送任务来协调计算:
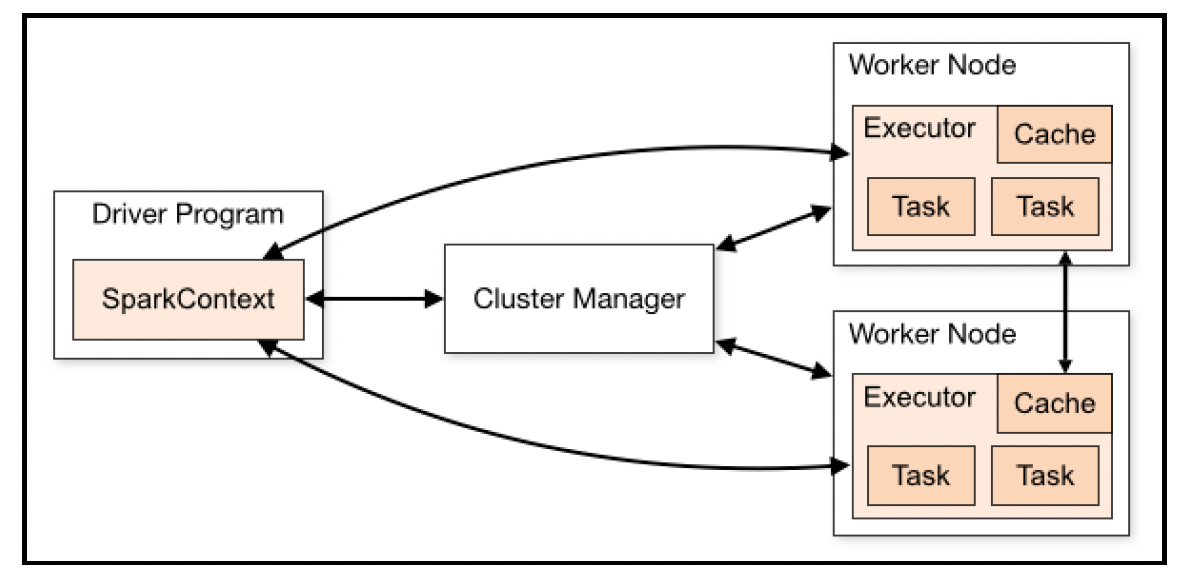 参考:https://spark.apache.org/docs/latest/cluster-overview.html
参考:https://spark.apache.org/docs/latest/cluster-overview.html
# 事件驱动架构(Event - Driven Architecture,EDA)
单体应用程序通常有一个单一的计算代码库,访问具有原子性、一致性、隔离性和持久性(ACID,Atomicity, Consistency, Isolation, and Durability)语义的单个关系数据库。因此,通常情况下,由外部请求触发的多表更新操作很容易通过在一个事务中发出更新语句来完成(第8章“数据建模”详细介绍了这些概念)。当这个单体应用程序被分解为微服务时,每个微服务都有自己的数据库(以避免耦合)。分布式事务是可行的,但由于以下原因通常应尽量避免:
- 与针对单个数据库的事务相比,分布式事务收敛所需的时间更长,也更容易出错。
- 并非所有微服务都使用关系数据库,它们会选择最适合自身用例的数据库。
事件驱动架构(EDA)倡导一种架构范式,其中系统行为是通过对事件做出反应来构成的。这里的事件意味着状态的重大变化,例如,当客户办理酒店入住手续时,该对象的状态就从已预订变为已消费。这可能会在系统中引发多种反应,从与卖家(酒店所有者)进行支付对账,到向客户发送电子邮件请求他们提供反馈。
以下展示了一个使用EDA的典型Web应用程序的示意图:
在这里,消息总线充当事件传递机制。服务监听消息队列中的主题,消费新消息,然后对其做出反应。第6章“消息传递”详细介绍了消息传递。这种范式的主要优点是组件之间松耦合,它们无需显式地相互引用。如果需要扩展行为,以便新系统能够对事件做出反应,原始的架构和现有的消费组件不会受到影响。
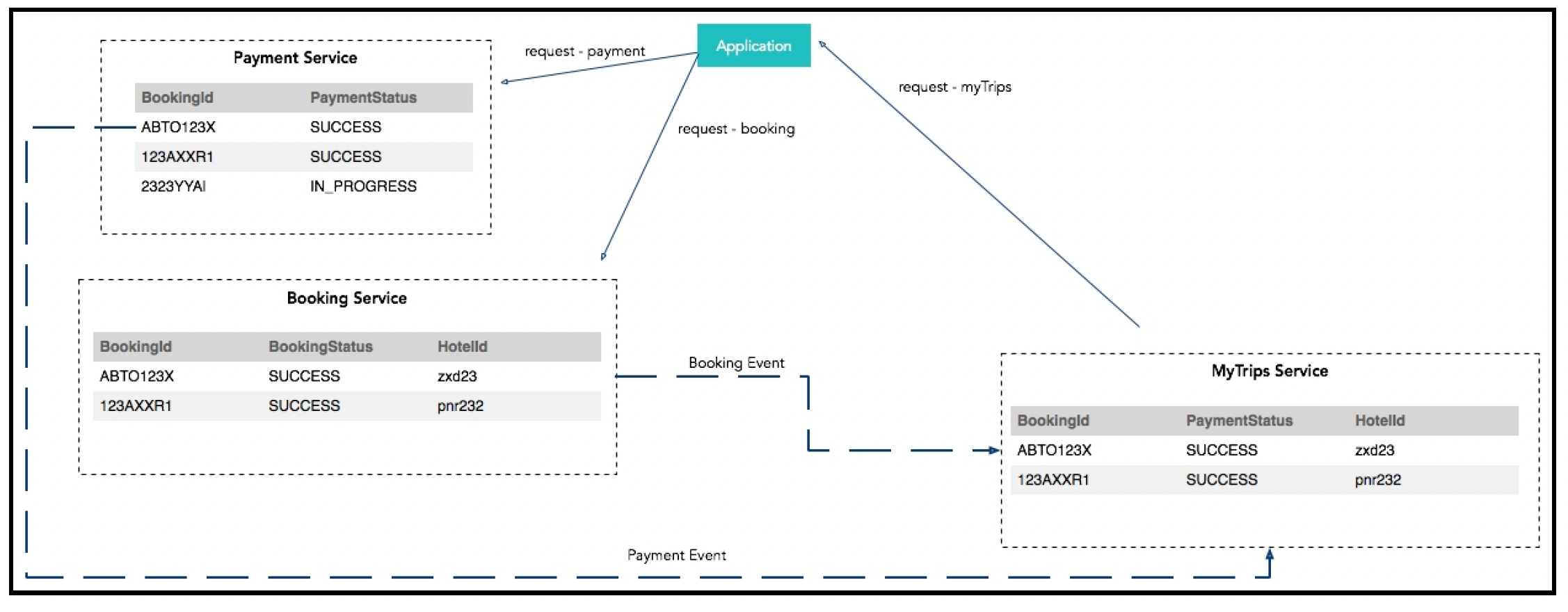
这种模式的另一个应用是准备物化视图(Materialized Views)。这里的场景是这样的:用户请求的实现依赖多个分布式服务,但系统需要展示关于整体请求的视图。例如,在酒店预订流程中,用户希望看到他们的预订在各个状态(如初始状态、已付款、预订已确认)下的进展情况,以及酒店入住时间等辅助细节。所有这些数据并非由一个服务提供,因此,为了准备这个视图,一种简单的方法可能是向所有服务查询数据并进行组合。但这并不总是最佳选择,因为服务通常会按照自身需求的格式来建模数据,而不是满足第三方的这种需求。另一种方法是提前以最适合视图的格式预先填充视图数据。以下是一个示例:
这种模式既实现了微服务所承诺的解耦,又能组合丰富的跨领域视图。
在一致性方面仍然有一些问题需要考虑,例如,如果预订服务更新了数据库,但在向消息总线发送事件之前崩溃了会怎样?对于前面提到的物化视图用例,你可以考虑构建对账策略,但这种解决方案无法扩展。解决方法是在本地微服务数据库中设置一个事件表,用于存储发送消息的意图。对主表和这个事件表的更新可以是原子操作(使用事务)。还有另一个后台工作进程/线程,它从事件表中获取数据并实际完成发送消息的操作:
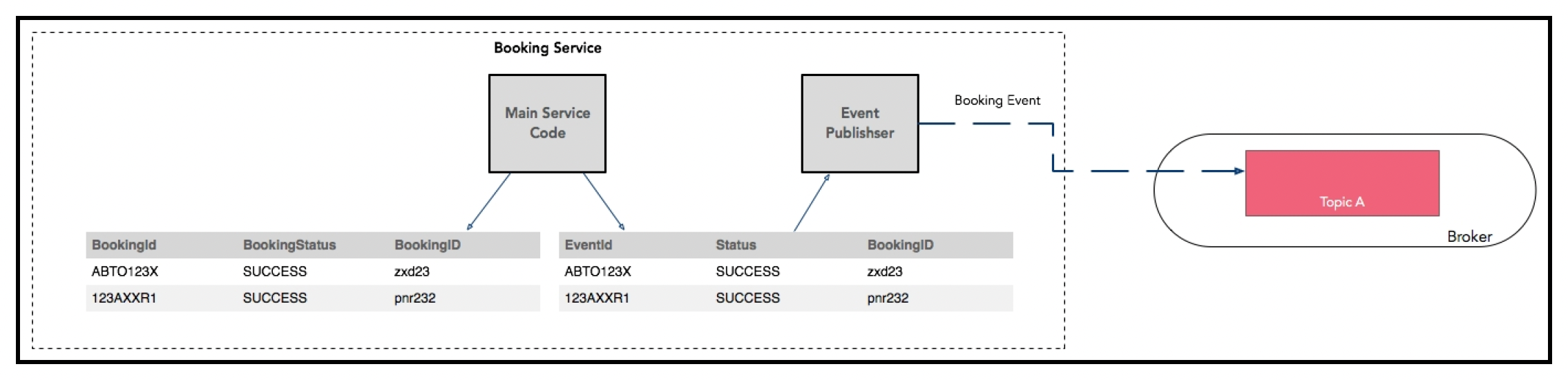
上述方法通常被称为事件溯源范式(event sourcing paradigm)。这种模式背后的主要理念是将数据操作建模为只追加日志中的一系列事件,而不是绝对的值。只有在需要时才组合当前状态,这很容易实现,例如,只需获取最新的更新即可。除了能够高效地计算各种目标之外,事件溯源模型的另一个关键优势是,由于它持久化的是事件而不是领域对象,因此在很大程度上避免了对象关系阻抗不匹配问题(https://en.wikipedia.org/wiki/Object-relational_impedance_mismatch)。
如果应用程序无法重写以进行事件溯源,另一种方法是将数据库更新挖掘为事件源,然后使用这些更新作为触发器来生成消息。
TIP 事件溯源在增加复杂性方面存在权衡。
还需要遵循命令查询职责分离(CQRS,Command and Query Responsibility Segregation)模式。CQRS意味着将应用程序逻辑分为两部分:命令端处理数据更新,查询端处理读取操作。代码的命令端不关心查询,它只是将数据的更改作为事件发送出去。在读取端,这些事件会以最适合读取(物化视图)的方式进行整理。
不同/分布式派生结果的一致性并不能始终得到保证。然而,最终所有派生结果都会保持一致。因此,应用程序应该能够处理最终一致性(在“一致性”小节中描述的BASE一致性模型 )。
# 参与者模型(The Actor model)
EDA的一种特定变体称为参与者模型。这里的“参与者”(Actors)指的是具备以下功能的服务:
- 抽象计算级别,代表一个基本的计算单元。
- 封装状态。
这些参与者都有邮箱,可以在其中接收消息。参与者按顺序从邮箱中取出每条消息,并执行与该消息对应的操作。每个参与者还有一些内部状态,这些状态会影响对消息的响应。
当然,系统中有多个参与者,它们通过消息进行异步通信。整个系统的行为由这些交互以及参与者的处理过程定义。
这与通道 - 协程(channel - goroutine)语义存在一些差异:
- 每个参与者都由其邮箱唯一标识。所以,当有人发送消息时,该消息是期望由特定参与者处理的。相比之下,通道是一种通用的管道,多个协程可以监听同一个管道。
- 通道是内存中的,而邮箱通常是跨机器的。
参与者模型也遵循分而治之的原则,将任务分解为足够小的部分,以便由一段顺序执行的代码处理。可以从交换的消息角度来理解这个系统。这与面向对象编程类似,但它还有一个强大的优势,即失败路径和参与者的处理方式可以与正常路径不同。这样在处理异常情况时就有了更多的灵活性。与其他消息传递系统相比,另一个关键优势是,生产者和消费者无需同时处于活动状态,也无需以相同的速度运行。
通常,一个参与者会承担某个任务的监督者角色,监控其他参与者中任务的执行情况。对于风险较高或耗时较长的任务,一个参与者可能会生成子参与者来执行子任务,而自身则负责监控子参与者之间分布式计算的活跃状态。
通道 - 协程模型更接近霍尔(Hoare)提出的通信顺序进程(Communicating Sequential Processes,CSP)模型。
Erlang是采用这种架构风格的著名语言示例。
# 流处理
为了进行实时处理,EDA架构范式有一些扩展。为了评估和区分它们,让我们考虑一个示例用例:
在我们的旅游网站上,我们想知道过去30分钟内的访问者数量,并在该数量超过某个阈值(比如100,000名访问者)时收到通知。假设每个访问者的操作都会产生一个事件。
分布式计算模型的第一种(也是最直接的)应用是让Hadoop进行计数。然而,这个任务需要在30分钟内完成并重新启动。使用Map - Reduce范式,这样的实时请求可能会导致系统变得脆弱,如果需求稍有变化、并行作业开始执行,或者数据量呈指数级增长,系统就会崩溃。你可以使用Apache Spark通过内存计算来提高性能。
然而,这些方法无法扩展,因为它们主要关注批处理(以及吞吐量优化),而不是低延迟计算(在前面的用例中,这是及时生成通知所必需的)。本质上,我们希望数据一到达就进行处理,而不是对事件进行批处理。这种模型称为流处理。
这里的思路是创建一个操作符图,然后将事件注入到这个处理图中。处理过程可以包括事件增强、分组、自定义处理或事件组合等操作。Apache Storm是一个流处理框架的示例。一个Storm程序由两个抽象概念定义:喷口(Spouts)和螺栓(Bolts)。喷口是流数据源(例如,一个Kafka主题)。螺栓是一个处理元素(由程序员编写的逻辑),它对一个或多个喷口的数据进行处理。一个Storm程序本质上就是一个由喷口和螺栓组成的图,称为拓扑(Topology)。
Kafka Streams是最新版本Kafka内置的另一个框架(第6章“消息传递”详细讨论了Kafka),它允许对每个事件进行计算。它使用Kafka分区模型对数据进行分区处理,并通过一个易于使用的编程库实现。这个库创建一组流任务,并为其分配Kafka分区进行处理。遗憾的是,在撰写本文时,Go程序还无法使用它。
Apache Samza是另一个流处理框架,它使用YARN生成处理任务,并使用Kafka为这些任务提供分区数据。Kasper(https://github.com/movio/kasper)是一个Go语言的处理库,它受到Apache Samza的启发。它以小批量的方式处理消息,并使用集中式键值存储(如Redis、Cassandra或Elasticsearch)在处理过程中维护状态。
还有复杂事件处理(Complex Event Processing,CEP)引擎,它允许用户对事件流(比如Kafka中的事件流)编写类似SQL的查询,其主要目标是实现毫秒级的响应时间。这种模式最初是为与股票市场相关的用例开发的。虽然CEP和流处理框架最初的需求不同,但随着时间的推移,这两种技术开始具备相同的功能集。
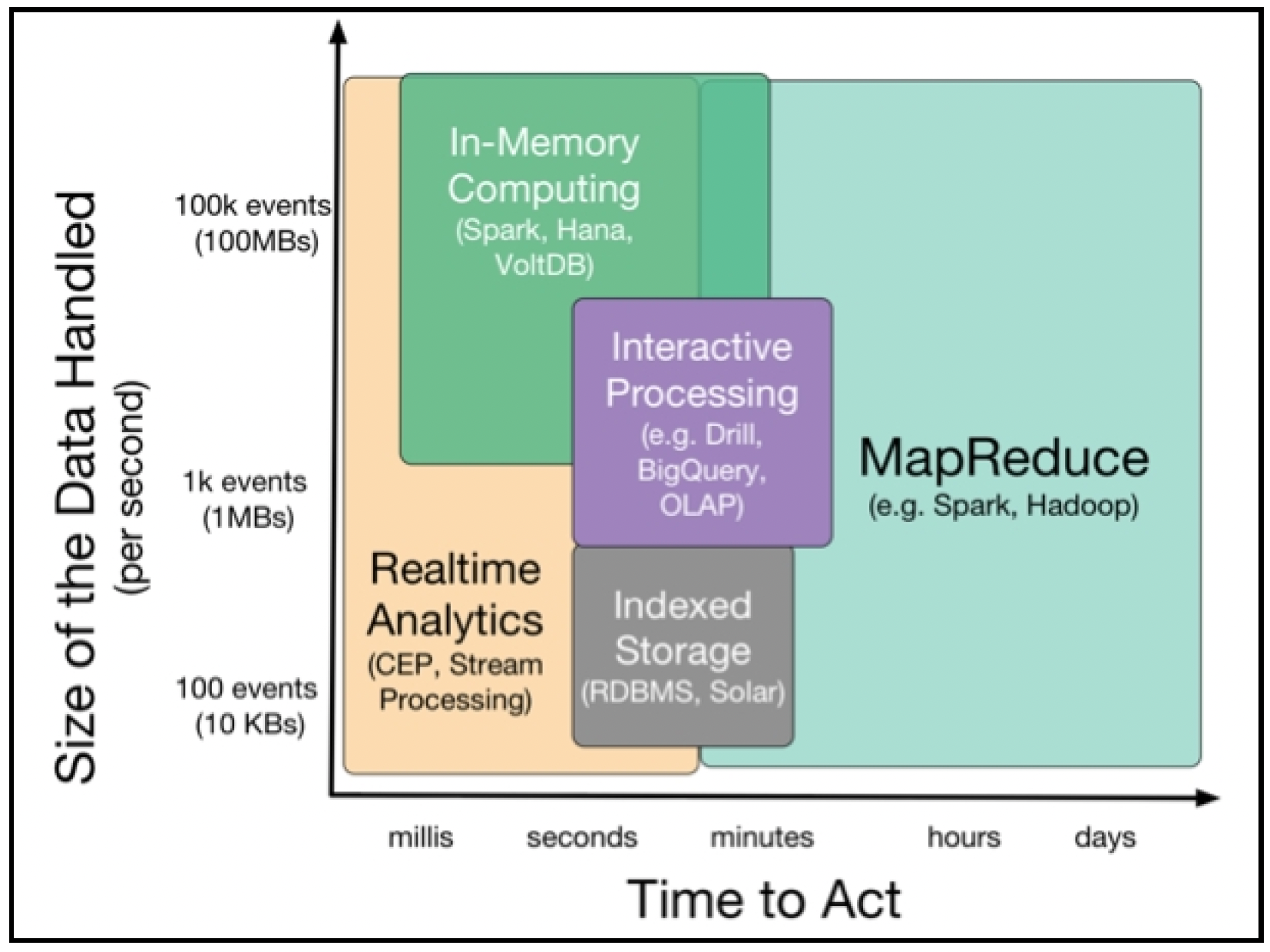
以下图表总结了不同的流处理技术:
# 总结
本章深入探讨了分布式系统及其特性。我们研究了一致性和共识的各个方面。
在下一章中,我们将更详细地研究消息传递和集成模式。我们将深入探讨几个常用的消息传递系统,并研究如何使用这些消息传递系统在Go语言中实现各种模式。