 7. 构建API
7. 构建API
# 7. 构建API
服务很少孤立运行。它们通过网络相互交互,以实现宏观行为。通过特定(通常是标准化的)协议,在特定端点进行数据交换。这种通信有两种形式:
- 使用应用程序编程接口(Application Programming Interface,API)—— 一种基于网络协议(如超文本传输协议(Hypertext Transfer Protocol,HTTP))的请求/响应模型。
- 使用消息传递—— 服务之间通过交换消息来传输数据。
消息传递的内容在第6章“消息传递”中介绍。本章重点关注第一种通信模型。
# 端点
在API模型中,每当一个服务有需求时,它会向一个已知端点发起网络请求,并获取响应。发起调用的服务通常被称为客户端,另一个则是服务器。需要注意的是,在不同的交互场景中,一个服务可以(而且经常)既是客户端又是服务器。
# 网络基础
为了实现网络通信,一套数据交换规则至关重要。这些规则通常通过协议进行标准化,并被划分为不同的层次,通信栈的每一层都处理特定的任务。下图展示了传统的网络层次和相关协议:

大多数API网络通信是基于传输控制协议(Transmission Control Protocol,TCP)进行的。在实际数据交换之前,客户端需要与服务器建立连接。为此,客户端需要知道以下信息:
- 托管服务的机器的IP地址。
- 服务监听请求的网络端口。
- 网络连接建立后,客户端需要一些应用层的特定信息来进行通信,包括:
- 特定于应用协议的端点(例如,在HTTP中是URL)。
- 数据契约——需要哪些数据、序列化格式等。
# 服务发现
进行通信的第一步是确定端点,这个过程称为服务发现。但以下事实使这个过程变得复杂:
- 端点地址(例如IP地址)通常是动态的,并且经常变化。
- 服务通常部署在由多个冗余实例组成的集群中,因此可以处理请求的实例(端点)不止一个。
- 实例的数量会随着时间变化——根据负载自动进行扩展或缩减。
本质上,服务发现有两种方式,如下所示:
- 服务器端服务发现
- 客户端服务发现
# 服务器端服务发现
如前所述,服务部署在集群中,客户端通常不(也不应该)关心具体是哪个服务实例在处理请求。在服务器端服务发现架构中,这样的集群前面有一个负载均衡器(Load Balancer,LB),它接收请求并将其路由到合适的服务实例,如下图所示:
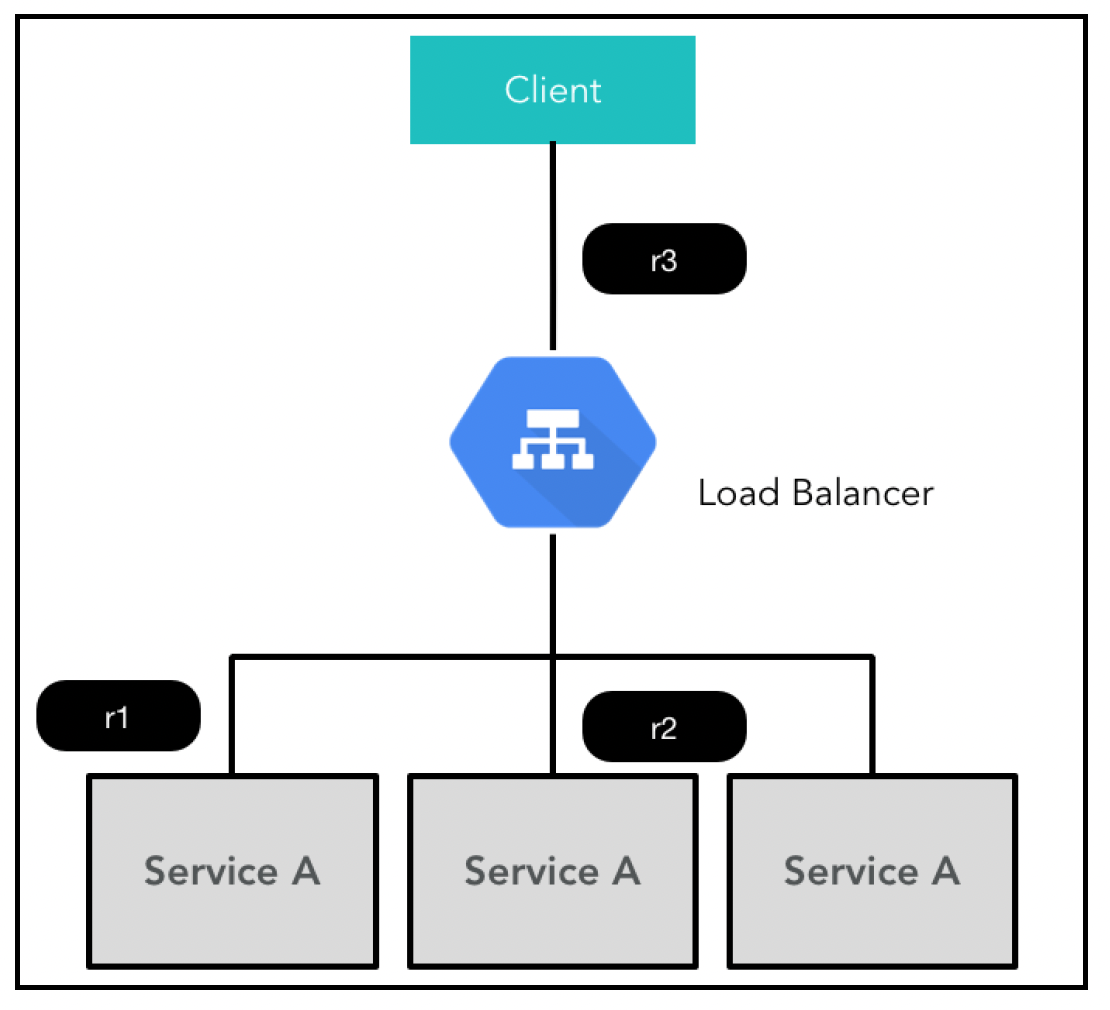
通常,负载均衡器有一组虚拟IP地址(Virtual IP Addresses,VIPs),每个服务对应一个。这是服务的集合网络(IP层)端点。针对这个VIP有一个后端实例的静态列表,负载均衡器将来自客户端的请求多路复用到这组后端实例上。尽管这个列表是静态的,但有各种机制可以实现自动重新配置,例如在实例启动和停止时。
一个流行的开源负载均衡器是NGINX(https://www.nginx.com/)。它专为高性能和可扩展性而设计。它由一组有限的工作进程(通常每个CPU核心一个)组成,这些工作进程使用非阻塞的事件驱动I/O(利用原生内核的非阻塞机制,如epoll和kqueue)来路由请求。下图展示了一个工作进程的架构,更多信息可在https://www.nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/上查看。
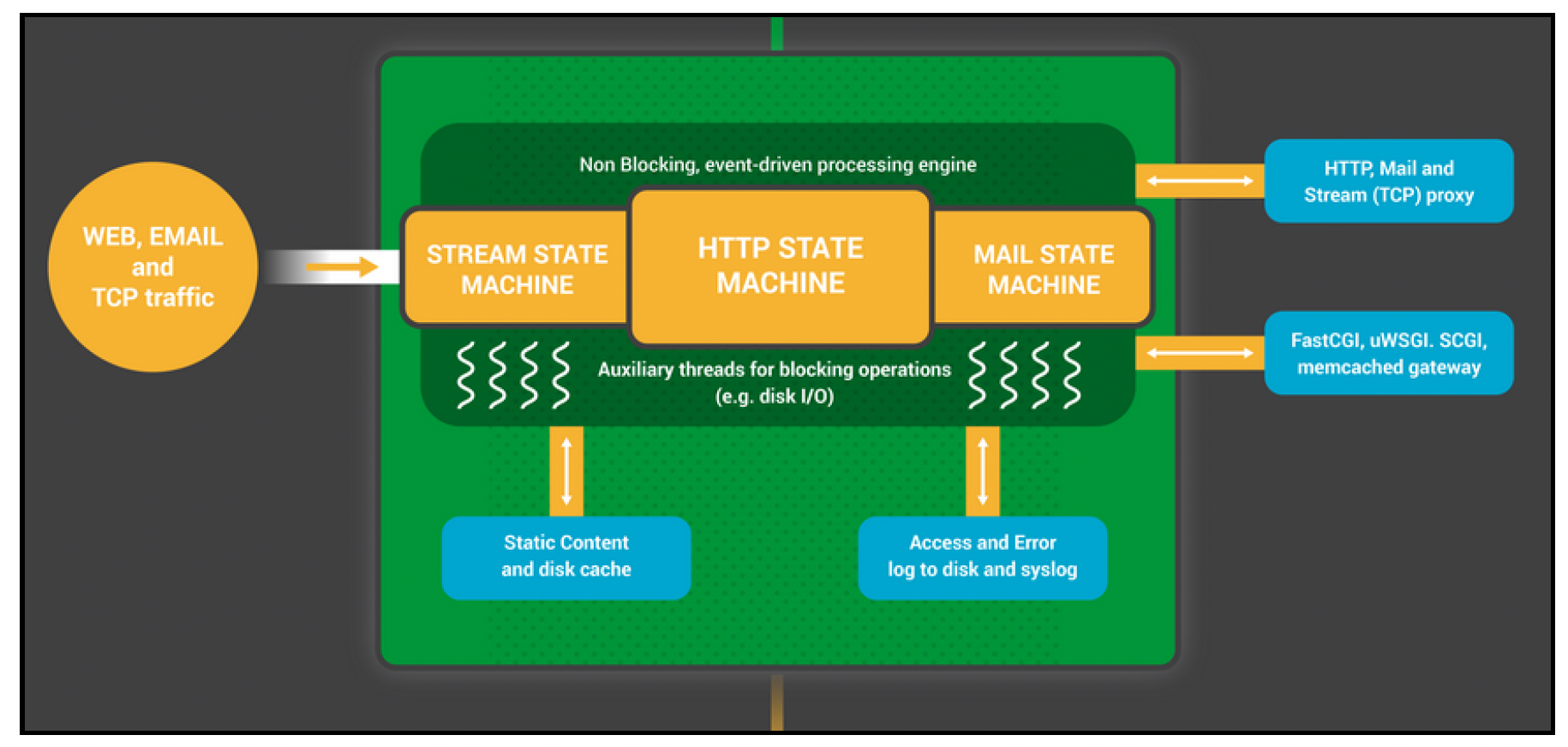
NGINX对后端实例的配置是静态的,但可以使用辅助组件(如Consul Template)构建动态配置。本质上,这些解决方案会监听有关新实例或失效实例的事件,重写NGINX配置文件,并优雅地重启NGINX进程。
为了连接服务,客户端通常从公布的URL开始,该URL会由域名系统(Domain Name Service,DNS)转换为服务的VIP。然后,客户端使用这个VIP和公布的服务端口来发起连接。
负载均衡器还经常具备健康检查功能,以确定正确的后端实例集。那些没有定期进行健康检查的实例会被标记为不健康,并从VIP的后端实例集中移除。
在某些情况下,客户端可能需要在用户会话期间持续与特定的服务实例进行交互。这样做的原因之一可能是性能方面的考虑(响应请求所需的状态可能缓存在该实例上)。大多数负载均衡器通过粘性会话(sticky sessions)来支持这一功能。在这里,客户端传入一个标识符(通常是一个cookie),负载均衡器使用这个标识符进行路由,而不是采用默认的随机路由方法。
服务器端服务发现有几个主要优点,包括:
- 客户端无需了解服务实例的具体情况。
- 很容易实现高可用性和容错能力。
也存在一些缺点:
- 负载均衡器可能成为单点故障(Single Point of Failure,SPOF),需要进行弹性设计。
- 如果客户端因某些原因认为选择特定的服务实例会更好,此时却无法做到。
# 客户端服务发现
在客户端服务发现中,客户端负责确定可用服务实例的端点,然后将请求路由到这些端点。客户端查询服务注册表,这是一个包含可用服务实例信息的数据库,然后将请求路由到它认为是最佳选择的实例。这可以像简单的轮询负载均衡算法那样简单,也可以是更复杂的算法,例如考虑服务器实例的网络往返时间等因素。每个服务器实例在启动时都会连接到服务注册表,并定期向注册表更新其健康状态。该架构如下图所示:
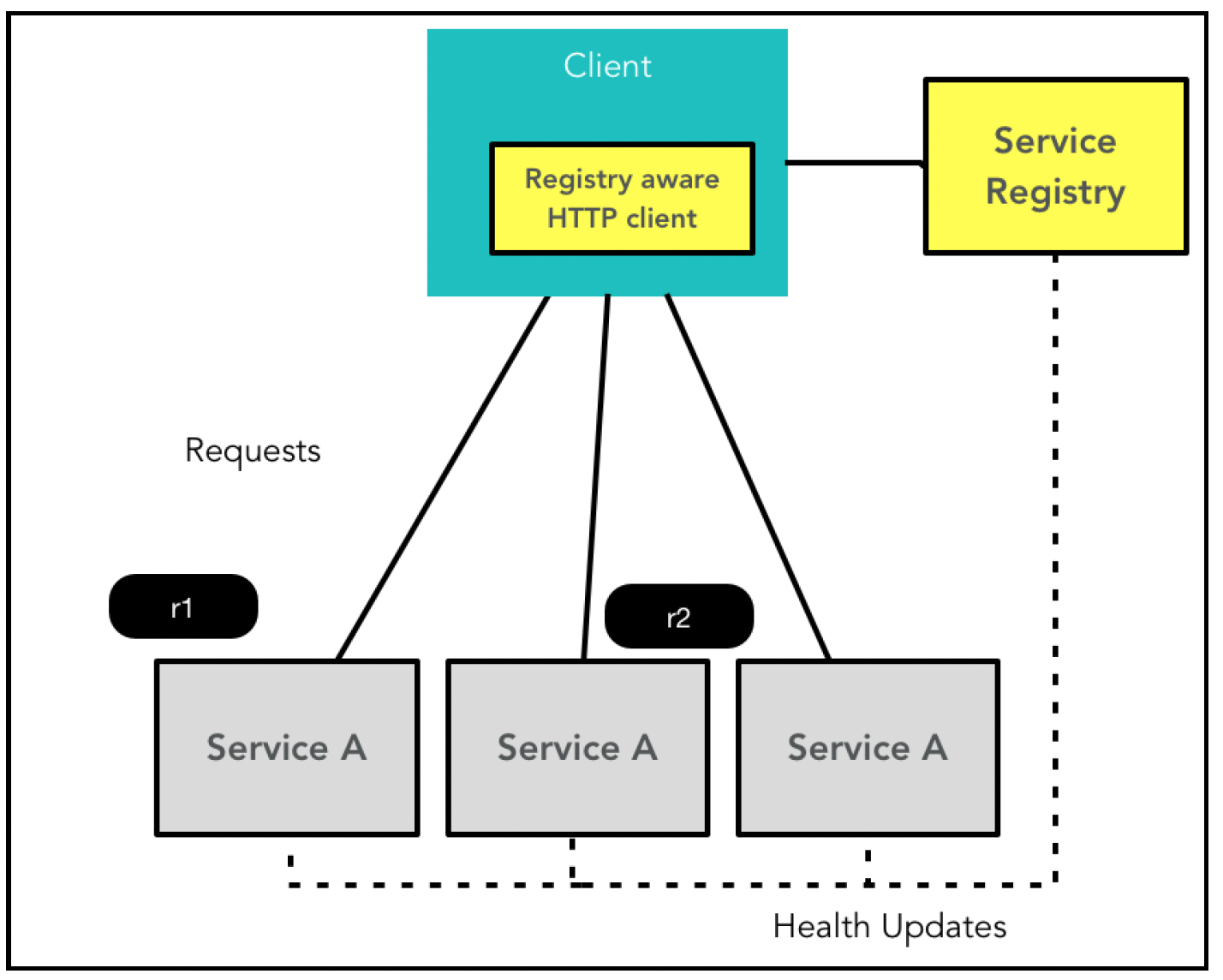
如你所见,我们需要一个特殊的支持服务注册表的HTTP客户端,它可以管理与多个服务器实例的连接并进行请求路由。
Netflix Eureka是Netflix开源软件栈中的一个服务注册表,Netflix Ribbon是一个用Java编写的进程间通信(IPC)客户端,它与Eureka配合使用,在服务实例之间进行负载均衡。非Java应用程序可以使用其REST API与Eureka进行交互。在Go语言中,https://github.com/hudl/fargo是一个实现此功能的客户端。它可以向Eureka注册实例、(通过心跳机制)检查实例健康状况,还可以向Eureka查询某个应用程序的实例集。目前实现的负载均衡算法是随机算法。要连接到Eureka并获取应用程序和实例的列表,可以使用以下代码:
c = fargo.NewConn("http://127.0.0.1:8080/eureka/v2")
c.GetApps() // 返回一个map[String]fargo.Application
2
一个服务实例可以使用以下代码向Eureka注册其信息:
c.UpdateApp(&app)
Consul(https://www.consul.io/)是另一个开源的服务发现平台。它在服务目录中组织服务,并在其上提供DNS和HTTP API接口。它会监控已注册的服务实例,并为每个服务管理一个健康实例集。可以使用Catalog.Services方法(https://godoc.org/github.com/hashicorp/consul/api#Catalog.Services)查询某个服务的实例,具体可参考https://www.consul.io/api/catalog.html。QueryOption参数可用于调整客户端感兴趣的节点,例如使用QueryOptions{Near: "_agent"}将使Consul首先返回距离客户端最近的节点(从网络延迟最小的角度)。
# 数据序列化
本节将简要介绍三种主要的数据序列化选项:XML、JSON和谷歌协议缓冲区(Google Protocol Buffers,Protobuf)。还会对这些以及其他(较少使用的)格式的序列化/反序列化进行基准测试。
# XML
可扩展标记语言(Extensible Markup Language,XML)是一种定义可序列化格式的标准,它允许生产者以文本格式编码数据,而无需与所有消费者明确约定数据格式。它源自标准通用标记语言(Standard Generalized Markup Language,SGML),并且与语言无关。
以下XML代码片段描述了一个酒店对象:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<city>New York</city>
<name>Taj</name>
<no_rooms>3</no_rooms>
</root>
2
3
4
5
6
XML文档可以是分层结构的。以下代码片段描述了一个酒店连锁:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<chain>
<element>
<city>New York</city>
<name>Taj</name>
<no_rooms>3</no_rooms>
</element>
<element>
<city>New Jersey</city>
<name>Leela</name>
<no_rooms>5</no_rooms>
</element>
</chain>
</root>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
XML文档有一个模式,有一种名为XML模式定义(XML Schema Definition,XSD)的标准来描述它。这便于进行契约通信,也可以根据模式对文档进行验证。
# JSON
JavaScript对象表示法(JavaScript Object Notation,JSON)是一种轻量级的数据格式,它基于JavaScript表示对象的方式。它在RFC 4627中被正式定义。
对象是JSON中最简单的实体,以下代码片段是一个示例:
{
"name": "Taj",
"city": "New York",
"no_rooms": 3
}
2
3
4
5
它有三个带有特定值的字段。字段名始终是字符串,而值可以是不同的类型,如整数、浮点数、字符串等。
JSON也有数组的概念。因此,一个酒店连锁可以这样描述:
{
"chain": [{
"name": "Taj",
"city": "New York",
"no_rooms": 3
},
{
"name": "Leela",
"city": "New Jersey",
"no_rooms": 5
}]
}
2
3
4
5
6
7
8
9
10
11
12
与XML一样,JSON具有自描述性和层次性,可以在运行时解析为对象。有一种用于模式定义的标准,称为JSON模式(JSON Schema),但它不像XSD那样被广泛使用。
# Protobuf
Protobuf(即Protocol Buffers的缩写)是一种与语言无关的序列化格式,由谷歌开发。每个协议缓冲区消息都是一个小型的逻辑信息记录,包含一系列的名称 - 值对。与XML或JSON不同,使用Protobuf时,你首先需要在.proto文件中定义模式。以下是一个描述酒店对象的.proto文件:
message Hotel {
required string name = 1;
required string city = 2;
optional int no_rooms = 3;
}
2
3
4
5
每个消息类型都是一个编号字段的列表,每个字段都有类型和名称。定义好.proto文件后,运行协议缓冲区编译器,就可以生成对应语言的对象代码,其中包含字段的获取/设置函数,以及对象的序列化/反序列化函数。
# 性能
不同的序列化格式在对象的序列化/反序列化方面具有不同的特性。这会对系统的整体性能产生重要影响,尤其是在微服务架构中,单个用户请求由多个服务通过API或消息传递(使用序列化对象)进行通信来处理。
https://github.com/alecthomas/go_serialization_benchmarks 页面提供了各种序列化格式的相关基准测试。一般来说,从模式文件生成代码的格式(如Protobuf)比通用模式(如JSON)性能更好,因为JSON需要使用反射来确定对象的布局(字段和类型)。然而,这类序列化格式在调试时会稍微困难一些。例如,你不能通过简单的curl请求获取数据,而是需要一个解码器进行反序列化,才能理解编码后的数据。
# 表述性状态转移(REST)
我们已经了解了如何使用服务发现来获取服务的实例集,以及如何对数据进行序列化以便在客户端和服务器之间传输。现在,让我们来看看客户端与任何实例之间最流行的交互方式之一。
# 概念
REST,即表述性状态转移(Representational State Transfer),是一种基于HTTP进行API交互的架构风格。它是客户端和服务器之间通信的应用层标准,其特点是无状态性和清晰的客户端 - 服务器关注点分离。
这种风格的关键抽象是资源,资源可以是任何东西:文档、票据、用户、其他资源的集合等等。在RESTful服务中,接口由一组分层的资源和为每个资源定义的方法组成,以实现状态转移。每个资源都有一个唯一的ID,用于标识它。状态转移可以是从服务器到客户端(获取信息),也可以是从客户端到服务器(设置信息)。
HTTP的GET动词类似于用户在网站上点击链接时发生的情况。URL所描述的对象的全部内容会从服务器传输到客户端,并在浏览器中呈现。
几乎所有的RESTful API都使用HTTP作为传输层。每个资源都有一个统一资源标识符(Uniform Resource Identifier,URI)。HTTP动词,如GET、POST、PUT、DELETE和PATCH,用作资源的操作方法。
例如,以下是一个简化的酒店API示例:
| URI | 动词 | 含义 |
|---|---|---|
| /hotels | GET | 获取网站上所有酒店的列表。通常至少会是一个JSON数组,每个酒店对应一个元组,包括酒店的URI、唯一ID,可能还有显示名称。 |
| /hotels | POST | 创建一个新酒店。会接收创建新酒店所需的所有属性。 |
| /hotels/<id> | GET | 获取特定酒店(其标识符为<id>)的信息(所有属性)。 |
| /hotels/<id> | DELETE | 删除指定ID的酒店。 |
| /hotels<id> | PUT | 更新酒店的属性。使用与创建(POST)相同的参数。 |
# 约束条件
“REST” 这个术语是罗伊·菲尔丁(Roy Fielding)在2000年的博士论文中提出并定义的。该论文的主要关注点是对期望成为RESTful的API的一组约束条件。主要约束条件如下文所述。
# 客户端 - 服务器模型
这个约束条件表明客户端(视图/显示方面)和业务逻辑部分之间的关注点分离。通过分离这两者,用户界面变得可移植/可替换,后端也得到了简化。
# 无状态性
这个约束条件要求从客户端到服务器的每个请求都必须包含处理该请求所需的所有信息。服务器不能在不同请求之间存储上下文信息。这也意味着会话状态(用于用户交互的有状态处理)完全保存在客户端,并在每次请求时传输到服务器。
无状态性提高了系统的可见性、可靠性和可扩展性。可见性提高是因为监控系统只需单独查看单个请求就能理解该请求。正如我们在第9章 “反脆弱系统” 中看到的,可靠性提高是因为单个服务器故障不会导致信息丢失,请求可以重试。可扩展性提高是因为可以根据负载增加或减少服务器实例,并且客户端请求可以由任何一个实例处理。
与大多数架构选择一样,这里也存在权衡。无状态性使得客户端和服务器之间的通信携带重复信息,因此可能会更繁琐。这种设计选择还意味着用户行为在客户端进行控制,因此多个客户端必须一致地编写相关代码。
# 可缓存性
为了克服前面提到的网络效率限制,引入了缓存机制。本质上,服务器可以将每个响应标记为可缓存或不可缓存。如果响应是可缓存的,客户端可以缓存该响应,并在未来的请求中重用。为了避免数据过时,通常会为缓存数据添加生存时间(Time-To-Live,TTL),以便在指定时间后使其失效。
# 统一接口
REST范式提倡在客户端和服务器之间的所有交互中使用统一接口。如前所述,关键抽象是资源。资源由唯一的分层名称标识,并且可以有多种表示形式。
这种表示形式的主要优点是,它为各种信息提供了通用的表示方式,而无需指定可能不会增加价值(反而会使资源定义复杂化)的实现/类型。这也允许通过内容协商延迟绑定对资源表示的引用,因此一个客户端可以请求资源的JSON表示形式,而另一个客户端可以请求XML版本。
# 理查森成熟度模型(Richardson Maturity Model)
理查森成熟度模型用于衡量一个API定义的RESTful程度。它定义了四个级别(0 - 3),其中3级表示最符合RESTful规范的API。
# 级别0 - POX的泥潭
在级别0,API将实现协议(通常是HTTP,但不一定是)仅用作传输协议。没有利用该协议来表示状态,只是用于来回传递请求和响应。系统通常只有一个入口点(URI)和一种方法(在HTTP的情况下通常是POST)。对于酒店API来说,这意味着URL将是/hotels,并且所有API都将是对该URL的POST请求,请求负载携带有关请求类型和相关数据的更多信息。示例包括SOAP和XML - RPC。
# 级别1 - 资源
在这个级别,API使用不同的URL来区分多个资源。然而,通常仍然只有一种交互方法(POST)。这比上一级别有所改进,因为现在有了资源的分层定义。API不再只是通过/hotels进行请求,而是为每个酒店分配ID,并使用ID来确定请求针对的是哪个酒店,因此API将具有/hotels/<id>形式的URL。
# 级别2 - HTTP动词
这个级别表明API使用协议属性(即HTTP动词)来定义API的性质。因此,GET用于读取操作,POST用于创建新资源,PUT用于更新资源,DELETE用于删除资源。API还使用标准响应代码,如200(OK)和202(ACCEPTED)来描述请求的结果。
一般来说,大多数REST API实现都处于这个级别。
# 级别3 - 超媒体控制
级别3是最高级别,它使用超文本作为应用程序状态引擎(Hypertext As The Engine Of Application State,HATEOAS),允许客户端发现资源和标识符。例如,假设我们使用以下API请求获取酒店(xyz)的详细信息:
GET /hotels/xyz
上述请求将返回以下类型的响应:
{
"city": "Delhi",
"display_name": "Hotel Xyz",
"star_rating": 4,
"links": [
{
"href": "xyz/book",
"rel": "book",
"type": "POST"
},
{
"href": "xyz/rooms",
"rel": "rooms",
"type": "GET"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
该响应除了(按照级别2的要求)提供酒店的详细信息外,还向客户端提供了有关可以对该资源执行哪些操作以及如何执行这些操作的信息。例如,对/hotels/xyz/rooms进行GET请求将获取该酒店的可用房间信息。因此,客户端无需硬编码每个资源表示形式,而是可以通过资源层次结构推断出新的资源和操作。这是一种按需代码的形式。
rel属性定义了HATEOAS链接的关系类型。有些是预定义的(不应更改其行为),而有些可以由应用程序定义。以下是相关链接:
- IANA链接关系:http://www.iana.org/assignments/link-relations/link-relations.xml
- HTML5规范链接:http://www.w3.org/TR/html5/links.html
- RFC 5988 - 网络链接:http://tools.ietf.org/html/rfc5988
# 使用Gin构建REST服务
在本节中,我们将使用前面描述的设计模式,用Golang构建一个REST API。使用Golang标准库中的net/http包设置一个Web服务器相对比较简单。以下是一个 “Hello World” 程序:
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
// 设置路由器
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
log.Println("path", r.URL.Path)
fmt.Fprintf(w, "pong! on %s\n", r.URL.Path)
})
// 监听并服务
err := http.ListenAndServe(":9090", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
它在特定的URL路径上设置了一个处理程序,该处理程序接收请求指针和响应写入器。
ListenAndServe()方法执行以下操作:
- 实例化一个HTTP服务器。
- 调用
net.Listen("tcp", addr)监听指定端口(这里是9090)的TCP连接。 - 启动一个循环,并在循环体中接受请求。
- 为每个请求启动一个Goroutine。
- 读取请求数据。
- 查找该URL的处理程序,并执行其中的代码。
任何Go语言Web应用程序的关键在于能够将每个请求作为一个单独的Goroutine来处理,如下图所示:
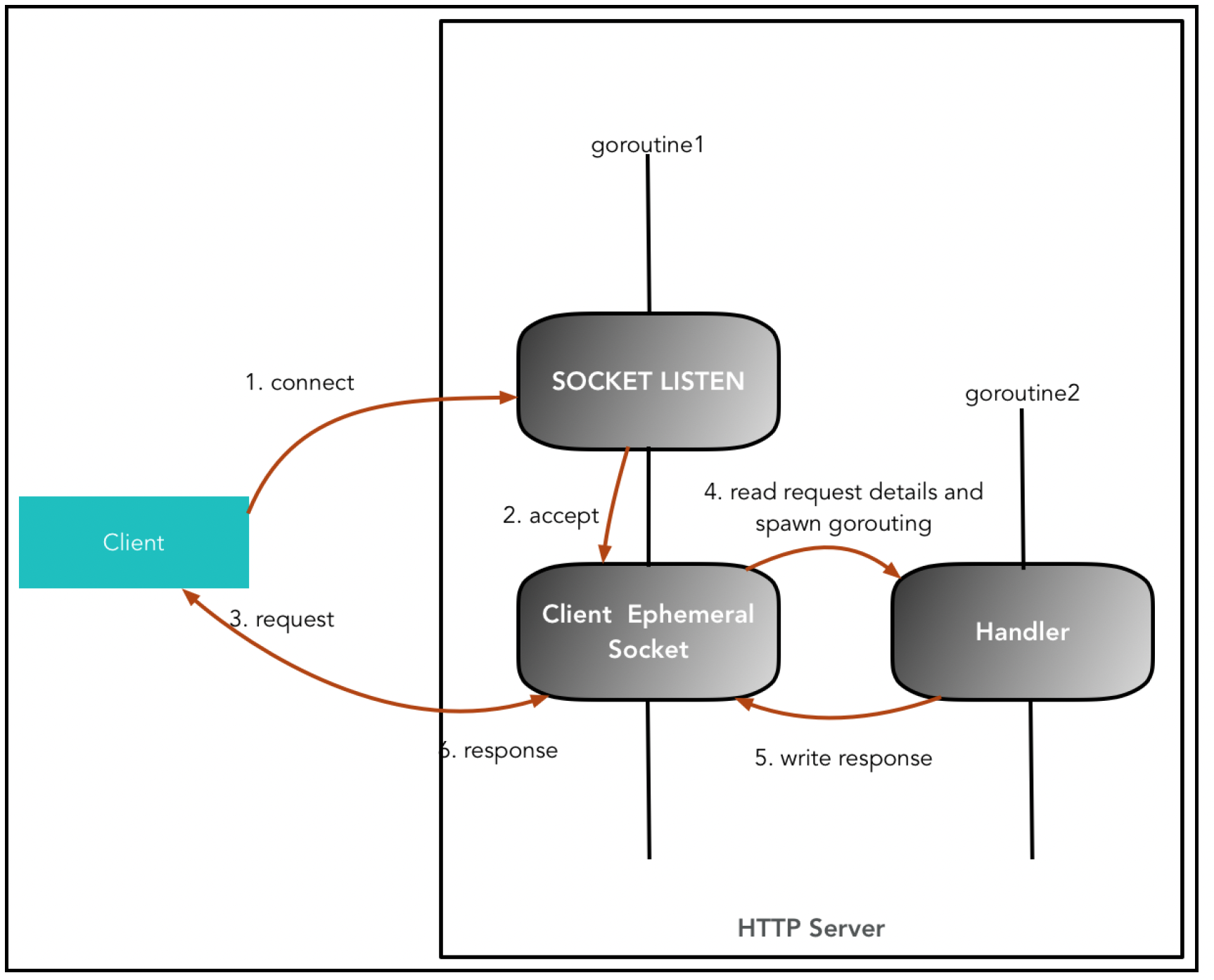
这种能力极大地提高了服务器的可扩展性和资源效率。
# Gin简介
Go标准库功能强大,但对于实际产品来说,在中间件、路由、持久化等方面会出现许多额外需求。建议使用合适的Web框架作为API项目的指导框架。Gin就是一个受欢迎的框架,它的一些特性如下:
- 基于基数树(Radix tree)的Go(Golang)路由。
- 由于对内存分配的可控设计,内存占用小且性能可预测。
- 中间件框架,在最终处理程序之前可以链式调用各种中间件。
- 请求处理过程中的恐慌(panic)恢复机制。
- 路由分组,在不同的URL路由层次结构上可以使用各种中间件。
- JSON验证。
- 错误管理。
# 示例应用程序
我们将使用前面描述的酒店API示例,并构建一个完整可用的版本。重申一下,具体的API如下:
| URI | 动词 | 含义 |
|---|---|---|
| /hotels | GET | 获取网站上所有酒店的列表。通常至少会是一个JSON数组,每个酒店对应一个元组,包括酒店的URI、唯一ID,可能还有显示名称。 |
| /hotels | POST | 创建一个新酒店。会接收创建新酒店所需的所有属性。 |
| /hotels/<id> | GET | 获取特定酒店(其标识符为<id>)的信息(所有属性)。 |
| /hotels/<id> | DELETE | 删除指定ID的酒店。 |
| /hotels<id> | PUT | 更新酒店的属性。使用与创建(POST)相同的参数。 |
一般来说,这样的创建、读取、更新、删除(Create Read Update Delete,CRUD)应用程序会使用数据库进行持久化存储。但为了简单起见,我们将使用Golang的内存映射(map)。当然,这在多个实例的情况下无法正常工作,但足以用于描述RESTful API。
以下代码以非线程安全的方式使用映射。在实际代码中,为了实现并发访问,应该使用互斥锁(Mutex)来保护映射。
# 路由
程序的核心是一个API路由器,它将不同的URL(和动词)多路复用到特定的处理程序。有关路由器的更多描述,请参阅下一节(更高级的模式)。这部分代码如下:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
router := gin.Default()
v1 := router.Group("/v1/hotels")
{
v1.POST("/", createHotel)
v1.GET("/", getAllHotels)
v1.GET("/:id", getHotel)
v1.PUT("/:id", updateHotel)
v1.DELETE("/:id", deleteHotel)
}
router.Run()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
可以看到,有一个名为v1的路由器组。它定义了一个特定的API版本,并包含五条路由。对API进行版本控制总是一个好主意,因为API契约可能会发生变化,并非所有客户端都会同时升级到最新版本。
处理程序使用router.Group()方法返回的RouterGroup对象上基于HTTP动词的方法,将特定的URL映射到处理程序。请注意,这里的URL是相对于组级别指定的URL而言的。
/:id路径表示id应该是路径参数,也就是说,URL中这个位置的任何字符串都会匹配,并且匹配的特定字符串在分配的处理程序中可用。我们将在 “读取” 小节中了解如何使用它。
# 创建
在了解createHotel函数的功能之前,我们先定义一个Hotel对象。同样,以前面描述的示例以及超媒体作为应用状态的引擎(HATEOAS)链接为例,我们的酒店类型如下:
type Hotel struct {
Id string `json:"id" binding:"required"`
DisplayName string `json:"display_name" `
StarRating int `json:"star_rating" `
NoRooms int `json:"no_rooms" `
Links []Link `json:"links"`
}
// HATEOAS链接
type Link struct {
Href string `json:"href"`
Rel string `json:"rel"`
Type string `json:"type"`
}
2
3
4
5
6
7
8
9
10
11
12
13
14
Hotel结构体定义了酒店的基本元数据。Links结构体定义了HATEOAS链接。
我们还定义了一个内存存储库来存放酒店信息。如前所述,这实际上应该是一个数据库接口,但这里使用映射(map)抽象掉了与数据库相关的复杂性,以便我们专注于API方面的内容:
var (
repository map[string]*Hotel
)
func init() {
repository = make(map[string]*Hotel)
}
2
3
4
5
6
7
现在,来看createHotel函数:
func createHotel(c *gin.Context) {
var hotel Hotel
if err:= c.ShouldBindJSON(&hotel); err == nil {
// 添加HATEOS链接
hotel.generateHateosLinks(c.Request.URL.String())
// 将酒店添加到存储库
repository[hotel.Id] = &hotel
// 返回OK
c.JSON(http.StatusAccepted, gin.H{"status": "created"})
} else {
// 某些参数不正确
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这段代码使用Gin请求上下文对象的ShouldBindJSON方法来验证、解析并反序列化请求体,从而得到一个Hotel对象。如果出现错误,我们返回http.StatusBadRequest,即HTTP状态码400。这表明请求存在问题(详细信息可查看RFC 7231,6.5.1)。如果成功获取Hotel对象,我们就将其存储在映射存储库中,并返回http.StatusAccepted(HTTP状态码202)。
创建Hotel对象时,并非所有属性都是必需的,特别是HATEOAS链接不会存在(客户端不知道它们是如何生成的)。generateHateosLinks()方法用于生成这些链接(目前仅生成一个预订链接),代码如下:
func (h *Hotel) generateHateosLinks(url string) {
// 预订链接
postLink:= Link{
Href: url + "book",
Rel: "book",
Type: "POST",
}
h.Links = append(h.Links, postLink)
}
2
3
4
5
6
7
8
9
该方法获取URL并在其后追加book,以生成如下类型的HATEOS链接:
"links": [
{
"href": "xyz/book",
"rel": "book",
"type": "POST"
}
]
2
3
4
5
6
7
要创建一家酒店,可以使用如下的CURL请求:
curl -d '{"id":"xyz", "display_name":"HotelXyz", "star_rating":4, "no_rooms": 150}' -H "Content-Type: application/json" -X POST 127.0.0.1 :8080/v1/hotels
# 读取
创建酒店之后,下一步自然是检索已创建的酒店信息。这里有两个API:
GET /v1/hotels:返回我们拥有的所有酒店信息。GET /v1/hotels/<id>:返回特定酒店的数据。
getHotel()函数用于检索特定酒店的信息,酒店的ID在路径参数中指定。代码非常简单直接:
func getHotel(c *gin.Context) {
// 从路径参数中获取ID
hotelId:= c.Param("id")
// 从存储库中获取酒店对象
hotel, found:= repository[hotelId]
fmt.Println(hotel, found, hotelId)
if !found {
c.JSON(http.StatusNotFound, gin.H{"status": "hotel with id not found"})
} else {
c.JSON(http.StatusOK, gin.H{"result": hotel})
}
}
2
3
4
5
6
7
8
9
10
11
12
Gin请求上下文对象的Param()方法用于获取名为:id的路径参数。例如,如果URL是/v1/hotels/abc,由于getHotel()处理程序是为/v1/hotels/:id路径定义的,其中ID是路径参数,所以hotelId的值将是abc。
代码的其余部分很容易理解。如果未找到具有该ID的酒店,则返回HTTP状态码404(http.StatusNotFound)。否则,将Hotel对象序列化为JSON格式并发送给客户端。
API调用如下所示:
curl 127.0.0.1:8080/v1/hotels/xyz
响应如下:
{
"result":{
"xyz":{
"id":"xyz",
"display_name":"HotelXyz",
"star_rating":4,
"no_rooms":150,
"links":[
{
"href":"/v1/hotels/book",
"rel":"book",
"type":"POST"
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
注意在创建处理程序中填充的HATEOAS链接。
现在,来看getAllHotels()函数。它只是将存储库转储为一个JSON映射。代码如下:
func getAllHotels(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{"result": repository})
}
2
3
可以使用如下方式调用此API:
curl 127.0.0.1:8080/v1/hotels
这将返回所有酒店的JSON映射:
{
"result":{
"xyz":{
"id":"xyz",
"display_name":"HotelXyz",
"star_rating":4,
"no_rooms":150,
"links":[
{
"href":"/v1/hotels/book",
"rel":"book",
"type":"POST"
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 更新
我们遵循使用PUT方法来更新对象的标准做法(当然,有些人可能对此有争议)。updateHotel()处理程序与用于读取的GET方法定义在相同的路径上,但它处理PUT请求。处理程序代码如下:
func updateHotel(c *gin.Context) {
// 从存储库中获取酒店对象
hotelId:= c.Param("id")
hotel, found:= repository[hotelId]
if !found {
c.JSON(http.StatusNotFound, gin.H{"status": "hotel with id not found"})
} else {
// 更新
if err:= c.ShouldBindJSON(&hotel); err == nil {
repository[hotel.Id] = hotel
// 返回OK
c.JSON(http.StatusOK, gin.H{"status": "ok"})
} else {
// 某些参数不正确
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
如果在存储库中未找到具有该id的酒店,代码将直接返回HTTP状态码404(http.StatusNotFound)。否则,我们获取更新内容并将修改后的对象存储在存储库中。
例如,我们可以进行如下API调用,来更新已创建酒店的星级:
curl -d '{"id":"xyz", "star_rating":5}' -H "Content-Type: application/json" -X PUT 127.0.0.1:8080/v1/hotels/xyz
# 删除
删除处理程序也与读取和更新定义在相同的路径上。代码非常简单:
func deleteHotel(c *gin.Context) {
hotelId:= c.Param("id")
_, found:= repository[hotelId]
if !found {
c.JSON(http.StatusNotFound, gin.H{"status": "hotel with id not found"})
} else {
delete(repository, hotelId)
// 返回OK
c.JSON(http.StatusOK, gin.H{"status": "ok"})
}
}
2
3
4
5
6
7
8
9
10
11
如果未找到具有该id的酒店,则返回404(http.StatusNotFound),否则从映射中删除该酒店,并返回HTTP状态码200(http.StatusOK)。
# GraphQL
REST API范式非常优雅,使用它对大多数现实世界的用例进行建模并不困难。然而,对于现代快节奏的Web开发需求而言,严格的服务器定义端点和模式可能会降低开发人员的工作效率。此外,如前所述,该标准在网络效率方面确实存在不足,尤其是当客户端只需要资源属性的一个子集时。例如,假设我们正在开发一个移动应用程序,其中有一个搜索结果页面。在这个页面中,我们不想获取酒店的所有属性,因为我们可能没有足够的屏幕空间(或考虑到可用性因素)来展示所有数据。
要使用REST API实现这一点,需要有一个固定的URL和模式来提供所有酒店的信息。但是,如果应用程序部署在平板电脑上,我们可能希望展示比手机应用更多的信息。我们可以通过创建另一个资源或使用一些查询参数来指示设备类型来实现这一点,但这两种方法都不一定简洁。客户端需求和服务器代码之间仍然存在耦合。
# 模式
为了解决上述限制,Facebook开发了一种新的API方式,称为GraphQL。这是一种API,其风格与数据库查询结构更为兼容,它具有不同类型的模式以及用于执行查询和变更的运行时环境。
GraphQL使用模式定义语言(Schema Definition Language,SDL)来定义API中各种类型的模式,如下所示:
type Hotel {
id: String!
displayName: String!
city: String !
noRooms: Int
starRating: Int
}
2
3
4
5
6
7
这是酒店的模式。它有四个字段:id、displayName、noRooms和starRating,每个字段都有其基本类型的描述。!符号表示该字段是必填项。
也可以描述不同类型之间的关系。例如,我们可以定义一个HotelChain(酒店连锁)类型,它包含一组酒店:
type HotelChain {
name: String!
hotels: [Hotel!]!
}
2
3
4
这里的方括号表示数组。
注意,github.com/graphql-go/graphql为Golang提供了对GraphQL的支持。以下代码片段展示了如何在Golang中定义结构体以及在GraphQL中定义等效类型:
type Hotel struct {
Id string `json:"id"`
DisplayName string `json:"displayName"`
City string `json:"city"`
NoRooms int `json:"noRooms"`
StarRating int `json:"starRating"`
}
// 为我们的Golang结构体`Hotel`定义自定义的GraphQL对象类型`hotelType`
// 注意
// - 字段映射使用结构体中字段的json标签
// - 字段类型与结构体中的字段类型匹配
var hotelType = graphql.NewObject(graphql.ObjectConfig{
Name: "Hotel",
Fields: graphql.Fields{
"id": &graphql.Field{
Type: graphql.String,
},
"displayName": &graphql.Field{
Type: graphql.String,
},
"city": &graphql.Field{
Type: graphql.String,
},
"noRooms": &graphql.Field{
Type: graphql.Int,
},
"starRating": &graphql.Field{
Type: graphql.Int,
},
},
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
定义好类型后,我们就可以定义模式,包括根查询和变更结构:
// 定义模式,包含我们的根查询和根变更
var schema, schemaErr = graphql.NewSchema(graphql.SchemaConfig{
Query: rootQuery,
Mutation: rootMutation,
})
2
3
4
5
我们稍后将详细介绍rootQuery和rootMutation结构。现在已经定义了所需的完整模式。
# 端点
在使用REST API时,每个资源都有特定的端点。这个端点有多种方法(动词),它们以特定方式提供或获取数据来实现相应的功能。
然而,GraphQL的方法却完全相反。GraphQL通常只有一个端点。数据的结构并不固定,相反,该协议完全由客户端驱动。例如,在检索数据时,客户端会精确指定它需要的数据。
在Go语言中,我们通常将GraphQL端点作为HTTP处理器进行连接,如下所示:
http.HandleFunc("/graphql", func(w http.ResponseWriter, r *http.Request) {
fmt.Println("[in handler]", r.URL.Query())
result := executeQuery(r.URL.Query()["query"][0], schema)
json.NewEncoder(w).Encode(result)
})
fmt.Println("Graphql server is running on port 8080")
http.ListenAndServe(":8080", nil)
2
3
4
5
6
7
这里的executeQuery()是一个辅助函数,它使用graphql-go.Do()函数,根据我们之前定义的模式来处理GraphQL查询:
func executeQuery(query string, schema graphql.Schema) *graphql.Result {
result := graphql.Do(graphql.Params{
Schema: schema,
RequestString: query,
})
if len(result.Errors) > 0 {
fmt.Printf("wrong result, unexpected errors: %v", result.Errors)
}
return result
}
2
3
4
5
6
7
8
9
10
# 查询
让我们看看在GraphQL中检索数据是如何工作的。下面的代码片段是一个查询系统中所有酒店的示例,而且只查询酒店的ID。这个查询会从客户端发送到服务器:
{
allHotels {
id
}
}
2
3
4
5
这个查询中的allHotels字段被称为查询的根字段。根字段下面的所有内容都是查询的有效负载。
服务器将以JSON格式响应,详细列出数据库中所有酒店的ID,如下所示:
{
"allHotels": [
{ "id": "xyz" },
{ "id": "abc" },
{ "id": "pqr" }
]
}
2
3
4
5
6
7
如果客户端需要酒店的显示名称(或任何其他字段),它必须在查询中明确请求,如下所示:
{
allHotels {
Id
displayName
}
}
2
3
4
5
6
即使对于嵌套字段,也可以精确指定所需字段。因此,要获取酒店连锁品牌的名称以及该连锁中每家酒店的显示名称,可以使用以下查询:
{
allHotelsinChain {
name
hotels {
displayName
}
}
}
2
3
4
5
6
7
8
查询通过根字段名称明确指定,并且还可以接受参数,如下所示:
{
allHotels (city: Delhi) {
id
displayName
}
}
2
3
4
5
6
上述查询将城市名称作为参数,并返回特定城市中的所有酒店,以及每家酒店的ID和显示名称。
在graphql-go中,我们之前定义的rootQuery结构用于处理所有查询。我们使用graphql.NewObject()函数创建它。这会创建一个graphql-go术语中的对象,该对象有字段、名称以及解析函数,解析函数描述了调用该对象时要执行的操作:
var rootQuery = graphql.NewObject(graphql.ObjectConfig{
Name: "RootQuery",
Fields: graphql.Fields{
"hotel": &graphql.Field{
Type: hotelType,
Description: "Get a hotel with this id",
Args: graphql.FieldConfigArgument{
"id": &graphql.ArgumentConfig{
Type: graphql.String,
},
},
Resolve: func(params graphql.ResolveParams) (interface{}, error) {
id, _ := params.Args["id"].(string)
return hotels[id], nil
},
},
},
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这里我们描述了一个查询,它接受酒店ID,并从一个名为hotels的内存映射中获取酒店对象。当然,在实际应用中,人们会使用数据库来存储和检索实体,但这里使用映射是为了简化操作,帮助我们专注于API语义。就像REST API部分的示例一样,map只是一个全局变量:
// 存储库
var hotels map[string]Hotel
func init() {
hotels = make(map[string]Hotel)
}
2
3
4
5
6
以下CURL请求展示了如何查询具有特定ID的酒店:
curl -g 'http://localhost:8080/graphql?query={hotel(id:"XVlBzgba"){displayName,city,noRooms,starRating}}'
有关实际创建酒店对象的示例,请参阅以下变更(Mutation)示例。
# 变更
除了检索数据,API还需要支持对数据的更改或变更操作。通常有三种变更操作:
- 创建新数据
- 更新现有数据
- 删除数据
变更操作遵循与查询类似的结构:
mutation {
createHotel(name: "Taj", noRooms: 30) {
id
}
}
2
3
4
5
这里的变更操作有一个createHotel根字段,它唯一标识了这个变更。我们为其提供了name和noRooms参数,值分别为Taj和30。与查询类似,这里的有效负载描述了我们对新创建对象属性的期望;这里我们请求的是新酒店的ID。
继续以graphql-go中的酒店示例来说,变更根对象定义了所有不同的变更操作(更新、创建、删除等)。例如,一个简单的创建变更操作定义如下:
// 根变更
var rootMutation = graphql.NewObject(graphql.ObjectConfig{
Name: "RootMutation",
Fields: graphql.Fields{
"createHotel": &graphql.Field{
Type: hotelType, // 此字段的返回类型
Description: "Create new hotel",
Args: graphql.FieldConfigArgument{
"displayName": &graphql.ArgumentConfig{
Type: graphql.NewNonNull(graphql.String),
},
"city": &graphql.ArgumentConfig{
Type: graphql.NewNonNull(graphql.String),
},
"noRooms": &graphql.ArgumentConfig{
Type: graphql.NewNonNull(graphql.Int),
},
"starRating": &graphql.ArgumentConfig{
Type: graphql.NewNonNull(graphql.Int),
},
},
Resolve: func(params graphql.ResolveParams) (interface{}, error) {
// 整理并转换参数值
displayName, _ := params.Args["displayName"].(string)
city, _ := params.Args["city"].(string)
noRooms, _ := params.Args["noRooms"].(int)
starRating, _ := params.Args["starRating"].(int)
// 在“数据库”中创建
newHotel := Hotel{
Id: randomId(),
DisplayName: displayName,
City: city,
NoRooms: noRooms,
StarRating: starRating,
}
hotels[newHotel.Id] = newHotel
// 返回新的酒店对象
return newHotel, nil
},
},
},
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
这里我们在为酒店生成ID后,使用前面描述的映射来存储酒店对象。ID是使用辅助函数randomId()生成的:
// 随机ID生成器
var letterRunes = []rune("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
func randomId() string {
b := make([]rune, 8)
for i := range b {
b[i] = letterRunes[rand.Intn(len(letterRunes))]
}
return string(b)
}
2
3
4
5
6
7
8
9
10
请注意,这不是生成ID的好方法,一个主要原因是可能会发生冲突。通常在使用数据库时,ID会作为对象的主键自动生成。
以下CURL请求展示了如何使用前面的定义创建一家酒店:
curl -g 'http://localhost:8080/graphql?query=mutation+_{createHotel(displayName:"HotelX",city:"NY",noRooms:300,starRating:5){id}}'
# 订阅
通过订阅,客户端可以获取不同事件的更新。客户端与服务器保持持久连接,服务器将数据流式传输给客户端。
例如,如果作为客户端的我们想知道新创建的酒店信息,可以发送如下订阅请求:
subscription {
newHotel {
name
id
}
}
2
3
4
5
6
之后,客户端和服务器之间会建立连接。然后,每当执行创建酒店的新变更操作时,以下形式的事件就会流式传输给感兴趣的客户端:
{
"newHotel": {
"name": "Taj",
"id": "cdab123"
}
}
2
3
4
5
6
# 更高级的模式
既然我们已经了解了各种API范式,现在让我们讨论API设计的高级模式。其中一些模式用于解决一组实例中的常见问题,另一些则描述了API服务器中代码结构的设计模式。
# 模型 - 视图 - 控制器(Model-View-Controller,MVC)
MVC设计模式是设计API系统时最常用的模式。MVC背后的主要思想是分离表示层(https://martinfowler.com/eaaDev/SeparatedPresentation.html),架构师努力在对现实世界进行建模的领域对象和作为视觉表示元素(或图形用户界面,GUI)的表示对象之间做出清晰的划分。该模式为每个组件定义了明确的职责:
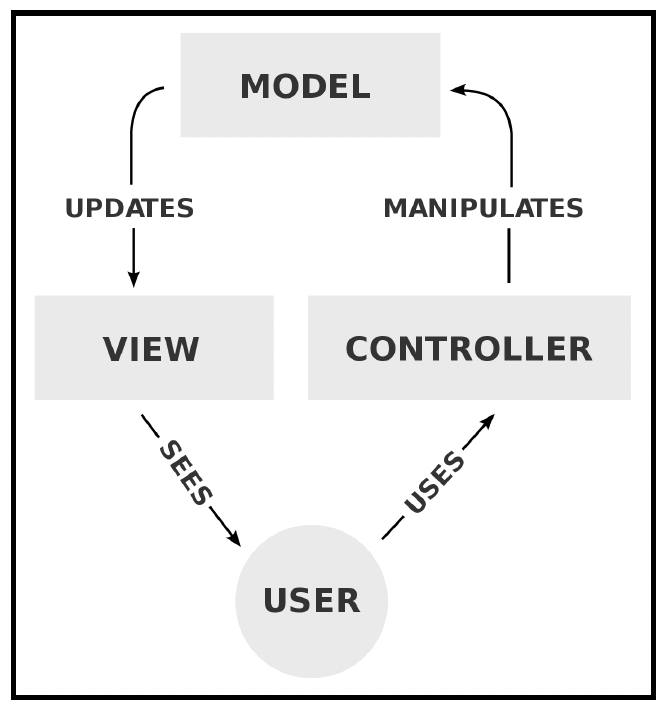
让我们详细了解每个组件:
- 模型(Model):
- 管理应用程序状态并公开数据实体。
- 封装管理数据的业务逻辑,例如访问规则。
- 负责数据持久化。
- 与用户界面或表示层解耦,可以与不同的用户界面一起使用。
- 视图(View):
- 负责用户界面。
- 处理信息的呈现和用户操作。
- 无状态。
- 通常可以使用模板进行高度配置。
- 控制器(Controller):
- 充当模型和视图组件之间的中介。
- 负责在模型发生变化时更新视图。
- 负责根据用户交互协调模型的更新。
- 通常围绕功能承载业务逻辑。
在传统的Web应用程序中,视图主要由模板组成,这些模板接收一些参数,渲染类似HTML页面的内容,然后发送给像浏览器这样的简单客户端。然而,随着现代应用中富客户端的出现,视图越来越多地体现在客户端。它可以是移动应用程序,也可以是智能JavaScript代码,这些代码渲染用户界面元素,并使用API与后端进行交互。用户界面代码本身通常也遵循MVC模式的变体:一种常见的变体是模型 - 视图 - 视图模型(Model-View-ViewModel,MVVM)模式,其中视图模型是用户界面的语义定义,而视图更关注实际的图形用户界面/用户体验细节,以及与特定用户界面形式因素的绑定。
对于设计后端API,大多数语言都支持Web框架,其关键特性是HTTP路由器,它本质上是将请求URL(或URL的前缀)映射到处理函数(即控制器)。我们已经在Gin框架中看到了它的工作原理。像Gin或httprouter(Go语言中另一个流行的路由器)中的高性能路由器都是基于基数树(紧凑前缀树)的,本质上URL会在树中进行查找,以确定相应的处理函数。
有人可能会想,为什么路由器不使用哈希映射(HashMap)呢?这是为了支持路径参数(例如/v1/hotels/:id/book)。使用树结构进行导航可以让我们分配并跳转到带有路径参数的URL段,以找到所需的处理函数。通常每个方法都有一个路由器实例,以便高效地表示路由器。
控制器通常定义了解析路径/查询参数的逻辑,并与模型进行交互。它承载了API处理方式的主要应用业务逻辑。通常,Web框架为控制器提供了特定的格式,以便为API编写控制器的开发人员可以访问诸如查询参数、请求体等上下文信息。有时一组处理函数需要执行类似的操作(例如授权),这种处理通常通过Web框架中的中间件来完成。适用的处理会在特定处理函数的每个请求处理开始或结束时执行。
在Go语言中,模型组件定义了实体(通常是结构体)、辅助的获取/设置方法、持久化以及访问权限等方面的业务逻辑。实现持久化的一种方式是使用对象关系模型(Object Relational Models,ORMs),它有助于将Go语言结构与数据库中数据的表示方式进行映射。我们将在第8章“数据建模”中更详细地介绍ORM和持久化。
# 负载均衡健康检查
为了实现可靠性和可扩展性(如第4章“应用程序扩展”和第9章“反脆弱系统”所述),服务通常部署在冗余实例集群中。只有让客户端访问健康的实例,才能避免服务不可用的问题,这一点至关重要。
健康检查在这方面发挥着重要作用。一般来说,这种模式要求每个服务实例执行深度健康检查(即检查所有子系统),并将实例的健康状况告知负载均衡器(LB,Load Balancer)或服务注册表。通常,负载均衡器或服务注册表会有一个代理,它会调用每个服务后端实例,并期望在给定时间内收到响应。为确保健康检查API具有良好的性能(低延迟),可以将实际的深度健康检查与健康URL API响应异步处理。
# API网关
在微服务架构中,单个微服务提供的API粒度通常与客户端的需求不一致,而且微服务的集合也经常变化。在这种情况下,客户端不希望承担协调、处理和整合来自多个服务的API响应的额外开销。此外,现代应用程序有多种用户界面,它们的需求和网络性能各不相同。例如,桌面客户端(包括浏览器)通常会展示更丰富的界面,并能访问稳定的网络连接。而移动应用程序屏幕空间有限,还需要应对较慢且不太稳定的移动网络。
API网关模式为这些问题提供了解决方案,它为所有后端服务实现了一个单一入口点。至少,它会将特定的URL路由到后端服务,并提供身份验证、限流等通用功能。
有些API网关还可能实现复杂的功能,如聚合(调用多个服务并组合成一个综合响应)。
该模式如下图所示:
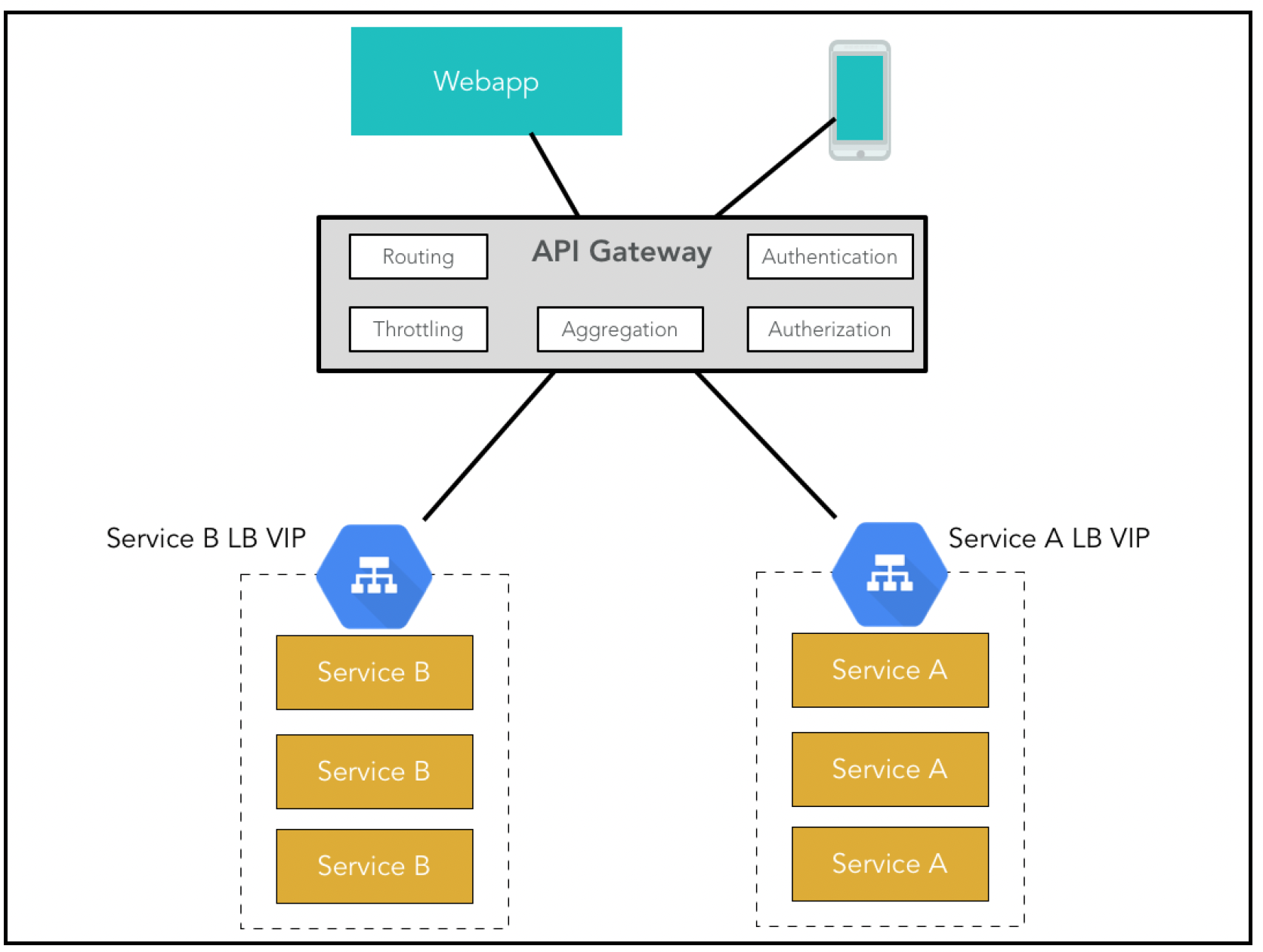
人们发现,单点API聚合存在一个问题,即不同的客户端通常有非常不同的交互模型。通用的API网关变成了一种反模式,因为它没有做到关注点分离。这也会导致推出新功能时出现开发瓶颈,因为现在的功能部署必须与这个中心团队协调,而且所有更改都在同一个工件上进行。
解决这个问题的一种方法是为每个前端设置一个API网关,即所谓的后端为前端(Backend For Frontend,BFF)模式。每个BFF都特定于一个客户端(用户体验),通常由与客户端相同的团队维护。这样就有了以下两个优点:
- 与API网关模式一样,大部分繁重的API调用和聚合工作转移到了后端。
- 不会在一个单体代码库中耦合不同的关注点。该模式如下图所示:
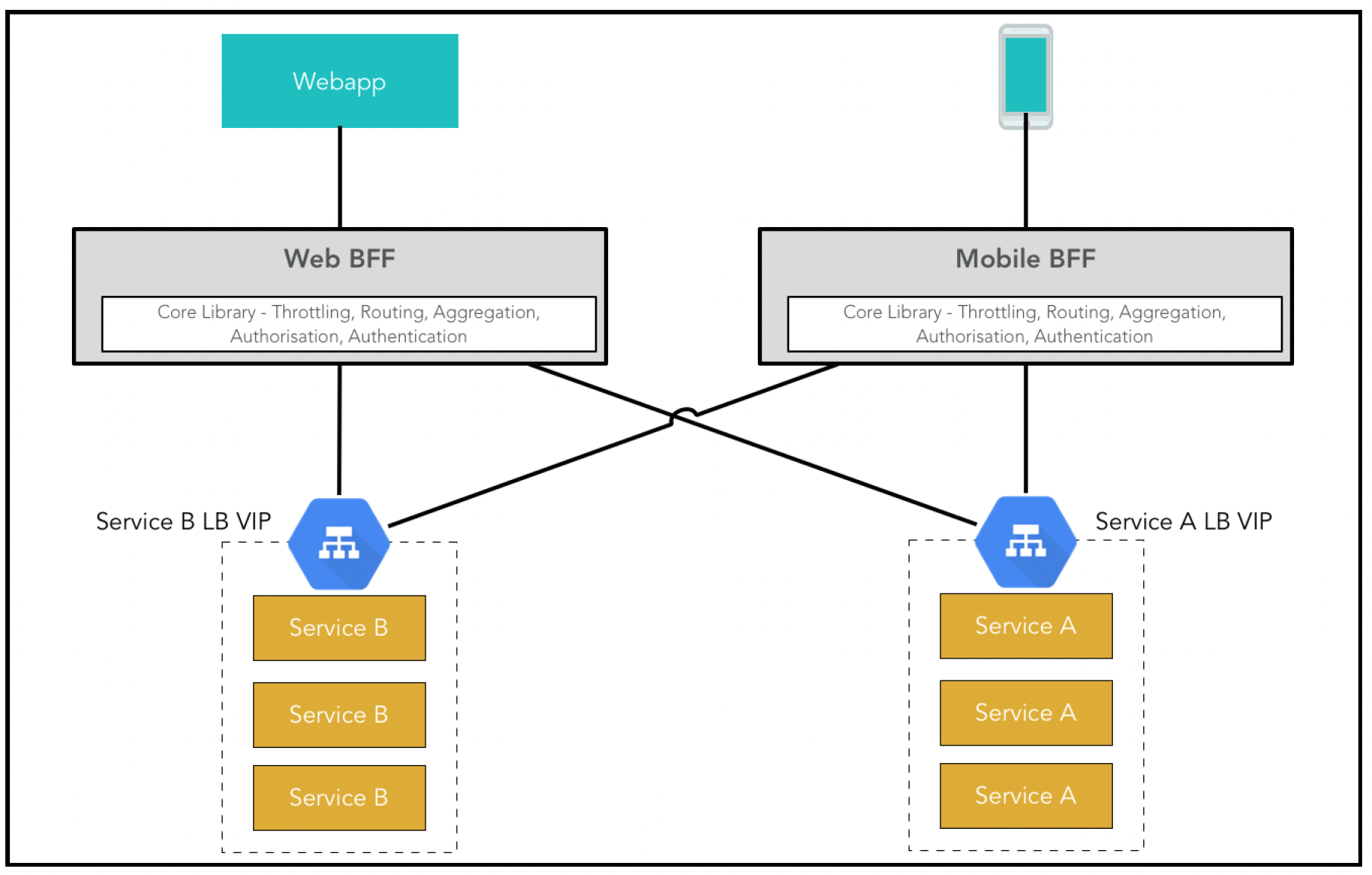
如你所见,通常会有一个共享库来存放通用代码,每个BFF服务中只有特定于客户端/用户界面的部分有所不同。
有时,聚合可能非常复杂,并且有很多用例。在这种情况下,最好将单独的聚合服务提取出来。以我们的旅游网站为例,搜索功能就是这样一个用例。在这种情况下,架构如下所示:

# Go kit
在Java/Scala生态系统中,有许多框架有助于构建基于API的解决方案。例如Netflix的开源技术栈和Twitter的Finagle。Go kit(https://gokit.io/ )是一组包的集合,它们共同构成了一个略有倾向性的框架,用于快速构建面向服务的架构。
Go kit通过装饰器设计模式实现关注点分离。它主要分为三层(包含一些子层):
- 传输层(Transport layer)
- 端点层(Endpoint layer)
- 服务层(Service layer)
如下图所示:
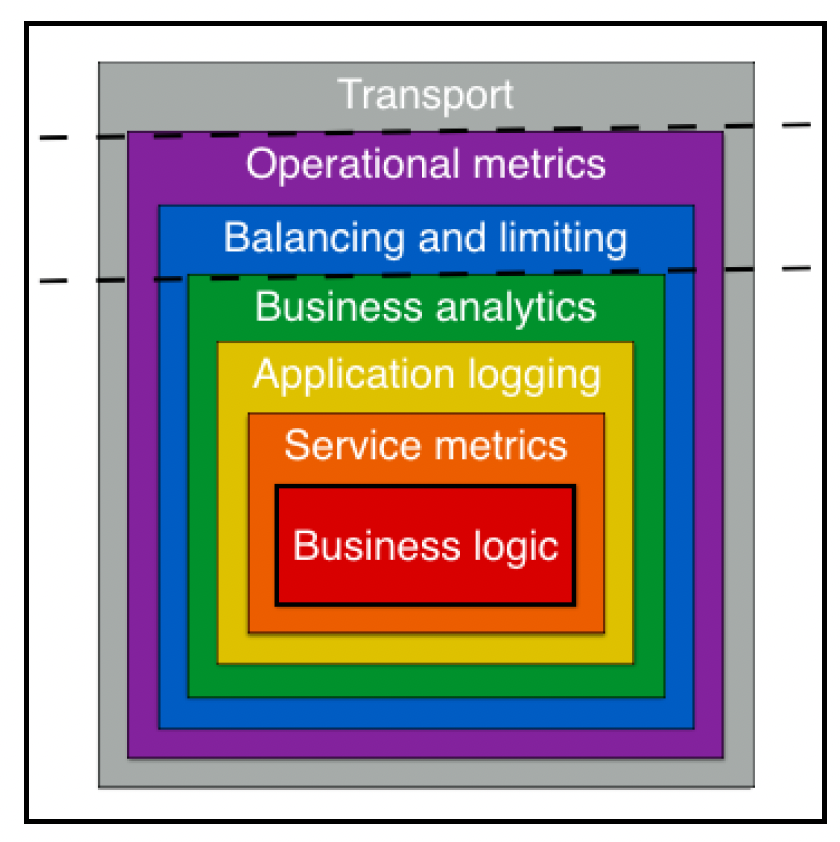 参考:http://gokit.io/faq/#introduction-mdash-understanding-go-kit-key-concepts
参考:http://gokit.io/faq/#introduction-mdash-understanding-go-kit-key-concepts
传输层定义了各种传输协议(如HTTP和gRPC(Google RPC))的绑定并实现其协议特定功能。
最内层的服务层以与传输无关的方式实现业务逻辑。这与Java世界类似,需要为服务定义一个接口并提供实现。这提供了另一层解耦,确保契约和实现不会混淆,能够清晰地分开维护。可以编写服务中间件来提供日志记录、分析、检测等跨领域功能。
中间的端点层在某种程度上相当于MVC模式中的控制器。它是连接服务层的地方,并实现安全和反脆弱逻辑。
我们以一个统计字符串中元音数量的服务为例。首先是服务实现:
// CountVowels统计字符串中的元音数量。
type VowelsService interface {
Count(context.Context, string) int
}
// VowelsServiceImpl是VowelsService的具体实现
type VowelsServiceImpl struct{}
var vowels = map[rune]bool{
'a': true,
'e': true,
'i': true,
'o': true,
'u': true,
}
func (VowelsServiceImpl) Count(_ context.Context, s string) int {
count := 0
for _, c := range s {
if _, ok := vowels[c]; ok {
count++
}
}
return count
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
该服务有一个接口,本质上是接收一个字符串并返回其中的元音数量。实现部分使用了一个查找字典来统计字符串中的元音。
接下来,我们定义服务的输入和输出响应格式:
// 对于每个方法,我们定义请求和响应结构体
type countVowelsRequest struct {
Input string `json:"input"`
}
type countVowelsResponse struct {
Result int `json:"result"`
}
2
3
4
5
6
7
8
利用这些,我们现在可以定义端点:
// 一个端点代表服务接口中的单个RPC
func makeEndpoint(svc VowelsService) endpoint.Endpoint {
return func(ctx context.Context, request interface{}) (interface{}, error) {
req := request.(countVowelsRequest)
result := svc.Count(ctx, req.Input)
return countVowelsResponse{result}, nil
}
}
2
3
4
5
6
7
8
到目前为止,我们还没有定义数据如何到达端点或从端点获取。
最后,我们使用选择的传输方式连接端点。在下面的示例中,我们使用HTTP作为传输方式:
func main() {
svc := VowelsServiceImpl{}
countHandler := httptransport.NewServer(
makeEndpoint(svc),
decodecountVowelsRequest,
encodeResponse,
)
http.Handle("/count", countHandler)
log.Fatal(http.ListenAndServe(":8080", nil))
}
func decodecountVowelsRequest(_ context.Context, r *http.Request) (interface{}, error) {
var request countVowelsRequest
if err := json.NewDecoder(r.Body).Decode(&request); err != nil {
return nil, err
}
return request, nil
}
func encodeResponse(_ context.Context, w http.ResponseWriter, response interface{}) error {
return json.NewEncoder(w).Encode(response)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
它使用JSON作为序列化格式,并使用标准的net/http包来定义一个HTTP服务器。
前面这个简单的示例旨在展示Go kit的一个最小可工作示例。Go kit还有许多更丰富的结构,如中间件;更多详细信息,请参考https://gokit.io/ 。
# 总结
在本章中,我们详细研究了REST和GraphQL API模型。我们运用Go语言中的原理和适用的结构/库构建了实际的服务。我们还了解了一个功能丰富且受欢迎的API框架Go kit。
在下一章中,我们将介绍实体关系这种数据建模方式,并描述各种持久化存储。我们还将深入研究MySQL、Redis和Cassandra。