 8 数据建模
8 数据建模
# 8 数据建模
在当今的商业领域,最有价值的资产是数据,但数据需要经过恰当的采集和结构化处理,才能发挥其最大价值。本章将讨论如何对实体、它们之间的关系以及存储库进行建模。我们还将深入探讨一些流行的数据存储方式,并通过在Golang中使用它们来展示数据建模的原则。
在本章中,我们将涵盖以下主题:
- 实体关系建模
- 实现各种一致性保证
- 关系型数据建模以及对MySQL的深入实践
- 键值存储以及对Redis的深入实践
- 列式存储以及对Cassandra的深入实践
- 数据存储扩展模式
# 实体与关系
在需求分析阶段,我们会确定围绕系统设计的关键对象(感兴趣的事物)。在数据库术语中,这些对象被称为实体(entities)。它们是能够独立存在且可被唯一标识的对象。在面向对象设计中,重点在于对行为进行建模,而实体关系建模则更关注实体的属性和关系。在实体关系分析中,关系是从静态属性推导出来的,这与面向对象分析中从行为/交互推导关系有所不同。
实体通常可以从需求描述中的名词识别出来。例如,在旅游网站中,“酒店”(Hotel)就是一个关键实体。需求分析能让我们了解实体的属性。比如,“酒店”实体可能具有以下属性:

关系定义了两个实体之间的关联方式。通常可以从连接两个或多个名词的动词识别出关系。例如,一家酒店可以有多个房间,每个房间都可以在特定的日期范围内被预订,这意味着存在以下关系:

像上面这样的图被称为实体关系图。它记录并有助于可视化系统中的数据结构。
在需求分析的早期阶段,实体和关系仍处于概念层面。然而,随着工程推进,这些会逐渐具体化为特定存储引擎的数据库、模式和其他结构。而且,随着我们对业务领域理解的加深,最初的数据设计可能会经历迭代,包括以下方面:
- 泛化(Generalization):形成实体层次结构,以区分各种相关实体。
- 规范化(Normalization):消除建模实体中的冗余(我们将在关系模型部分详细学习这一点)。
- 反规范化(Denormalization):明确在某些用例中需要冗余,且冗余有助于提高性能(在“数据存储扩展”部分会更详细地介绍)。
- 约束/业务规则(Constraints/business rules):对实体属性可接受的值以及实体之间的关系进行规范。
- 对象关系映射(Object relational mapper):将计算空间中的对象与存储系统中持久化的实体进行映射。
# 一致性保证
除了对实体及其关系进行建模外,持久层(数据库)为应用程序提供的一致性保证是关键的设计选择。如果某个用例涉及对两个或更多实体的修改,那么存储系统提供的这些保证在系统架构和服务级别协议(SLAs)中起着关键作用。例如,考虑银行应用程序中的账户转账用例。转账完成后,无论基础设施出现何种故障,净借记/贷记金额都应该相符。这种逻辑工作单元(从账户x借记并向账户y贷记)被称为事务(transactions)。
让我们来看看数据库(以及一般的存储系统)为事务提供的一些保证。
# ACID(原子性、一致性、隔离性、持久性 )
ACID是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)的首字母缩写。它代表了存储系统在涉及事务时提供的一组最广泛支持(也是最需要的!)的保证。符合ACID规范的数据库提供了一个环境,在这个环境中,无需使应用程序过于复杂就能实现较高水平的一致性。这个概念由国际标准化组织(ISO,ISO/IEC 10026-1:1992 Section 4)进行了标准化。下面我们详细了解一下每一种保证。
# 原子性
一个事务要么完全执行,要么完全不执行,这就是原子性。在任何情况下,数据库都不会处于部分修改的不一致状态。应用程序代码可以在一个会话中对一个事务发出读和写操作,然后提交(使所有更改生效并可见)或中止(不进行任何更改)。即使执行读写操作的应用程序实例或数据库实例崩溃,事务也会暂停并在之后恢复,但原子性约束永远不会被违反。
让我们看一个原子性的例子。考虑下面这个简单的伪代码,它将100美元从账户abc转到xyz:
amountToTransfer:= 100
beginTransaction()
srcValue:= getAccountBalance('abc')
srcValue:= srcValue - amountToTransfer
dstValue:= getAccountBalance('xyz')
dstValue:= dstValue + amountToTransfer
commitTransaction()
2
3
4
5
6
7
如果abc和xyz账户的余额分别为200美元和300美元,那么事务提交后,余额将分别变为100美元和400美元。如果发生崩溃或应用程序遇到错误,事务将回滚,余额将保持在初始金额,即分别为200美元和300美元。
# 一致性
存储系统通过确保在任何事务结束时系统都处于有效状态,来强制事务的一致性。如果事务成功完成,那么存储系统中定义的所有约束都将继续适用,系统将处于有效状态。如果事务中发生任何错误并进行回滚,那么系统将保持在原始的一致状态。
同样以账户转账系统为例。系统定义了一个约束,即不允许透支,也就是说账户余额永远不能小于零。在前面的例子中,如果发起转账时abc账户余额为50美元,那么该事务将被中止并回滚,因为提交该事务会使系统处于不一致状态,即违反了完整性或业务约束。
# 隔离性
隔离性属性保证事务之间不会相互干扰。当有多个并行事务处理共享实体时,系统会为所有事务提供系统的一致视图。
让我们通过分析并发事务的不同影响来展开讨论:
- 丢失更新(Lost updates):假设有两个事务独立地更新一个实体。在这种情况下,一个事务会在另一个事务之后完成,最后一个事务的更新会覆盖前一个事务的更新。例如,如果一个在线编辑器为两位作者修改同一文档的两个事务,那么最后一次更新会覆盖原作者的更新,即使他们可能在处理完全不同的页面!为了避免这种情况,事务可以在修改时锁定整个文档,以便在修改期间进行串行访问。
- 脏读(Dirty reads):如果一个事务被允许读取某些实体已修改但尚未提交的值,那么它的逻辑是基于仍处于“脏”状态(即未提交)的输入进行处理的。如果另一个事务回滚,那么这个事务可能会使系统处于不理想的状态。继续以在线编辑器为例,第二个事务(作者)开始编辑当前正被第一个事务(作者)修改的文档。第二个事务在此时复制修改内容,并在其基础上更新自己的更改。与此同时,第一个事务回滚(或更改了一些之前的数据),现在第二个事务要提交的文档将处于一种不完整的状态。如果在读取时,事务被阻塞,直到竞争的前一个事务完成,就可以避免这个问题。
- 不可重复读(Non-repeatable reads):在这种情况下,一个事务在其生命周期内多次读取同一个实体,每次返回的数据都不同,即使该事务没有进行任何修改。这与脏读的不同之处在于,数据的更改可能是由于已提交的事务导致的。然而,这种现象仍可能导致错误的计算。如果在有读取该实体的并发事务完成之前,阻塞所有对该实体的写入操作,就可以避免这类问题。
- 幻读(Phantom reads):当一个事务正在读取的实体在另一个事务中被删除时,就会发生幻读。当一个事务处理一系列实体(例如某个特定作者的文档),而由于插入操作导致这个范围发生变化时,也会出现幻读。同样,通过阻塞正在修改其他事务当前正在读取的实体的事务,可以解决这个问题。
国际标准化组织(ISO)定义了不同级别的隔离保证,每个级别都规定了一个事务与其他事务必须隔离的程度。这里的隔离指的就是我们刚刚讨论的并发效应。这些级别及其对并发效应的影响定义如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read uncommitted) | 是 | 是 | 是 |
| 读已提交(Read committed) | 否 | 是 | 是 |
| 可重复读(Repeatable) | 否 | 否 | 是 |
| 快照(Snapshot) | 否 | 否 | 否 |
| 可串行化(Serializable) | 否 | 否 | 否 |
本质上,隔离级别控制以下方面:
在事务(T1)期间,何时对正在被另一个事务(T2)修改的实体进行读取操作。
T2的读取操作被阻塞,直到竞争的T2事务完成(排他锁)。
T1读取在T2开始之前已提交的值。
T1读取T2已修改但尚未提交的值,且不会被阻塞。
更宽松的隔离级别会增加系统中的并发性(从而提高吞吐量、响应性和可扩展性等方面),但可能会存在一致性问题,例如读取未提交的数据或更新丢失(丢失更新)。另一方面,更严格(或更高)的隔离级别能提供更严格的一致性,但会降低并发性(更多阻塞),并需要更多的系统资源。
请注意,可串行化和快照隔离级别提供相同的隔离保证,但在实现方式上存在差异。在可串行化隔离级别中,会对事务涉及的所有实体进行排他范围锁定。相比之下,在快照隔离级别中,会对事务涉及的所有实体进行复制(快照),读写操作针对这些副本(版本)进行。在提交时,存储系统会进行相同的一致性检查,但由于竞争事务不会被阻塞,快照隔离级别提供了更高的并发性,尽管这是以更多的存储资源为代价的。
**注意:**选择事务隔离级别不会影响为执行数据修改而获取的写锁。无论隔离级别如何,事务在修改任何数据时总是会获取排他锁,并持有该锁直到事务完成。
# 持久性
一个事务如果在提交后,对存储系统的更改能够持久保存,而不受硬件重启的影响,那么这个事务就具有持久性。所以,如果存储系统仅将数据保存在内存中,就无法满足这个保证,因为重启后存储系统会丢失数据。持久性通常还涉及保存事务日志,这样即使发生磁盘故障,也可以重放日志使系统恢复到一致状态。
# BASE(基本可用、软状态、最终一致性 )
2000年,埃里克·布鲁尔(Eric Brewer)在ACM分布式计算原理研讨会上的主题演讲中向世界介绍了CAP定理。该定理指出,在存在网络分区的情况下,系统设计只能提供可用性或一致性。我们将在第5章“分布式架构”中更深入地探讨CAP定理,但它对存储系统的直接影响是,为分布式系统提供符合ACID规范的功能在工程实现上难度较大,且扩展性不佳。
为了克服这个问题,一些现代存储系统提供了另一种一致性模型,称为BASE,即基本可用(Basically Available)、软状态(Soft state)、最终一致性(Eventual consistency)的缩写。让我们来看看这意味着什么:
- 基本可用(Basically Available):该系统保证对请求会有响应,但响应并不总是一致的。
- 软状态(Soft state):即使没有外部输入,系统的状态也可能随时间变化。
- 最终一致性(Eventual consistency):系统最终会达到一致状态。通常,当各种并发操作协调完成并达到稳定状态时,就会实现最终一致性。
# 关系模型
最常见的数据存储方式是基于关系模型的概念,这一概念由埃德加·科德(Edgar Codd)博士在20世纪70年代初提出。在关系模型中,一个实体被存储为属性(或列)的元组(或行)。数据库就是一组行,所有行都具有相同的列集(或模式)。表是使用静态数据模式定义的;实体之间的关系通过外键或关系表进行建模;不同表中的行可以通过外键进行引用。
有多种方式可以表示前面介绍的概念数据模型。然而,并非所有表示方式都适用于所有用例。为了确定最优的关系结构,科德博士对数据结构提出了一系列越来越严格的约束。随着每一级约束/规则的引入,数据表示中的冗余量会减少。这种引入约束并重构结构以减少冗余的过程称为规范化(normalization),每一级约束称为一种范式(normal form)。让我们来看看各种范式。
# 第一范式
如果一个表满足以下约束条件,则称其处于第一范式(1NF,first normal form):
- 每列必须只有单个值。
- 列必须具有唯一的名称。
- 每列必须具有相同数据类型的属性。
- 任意两行不能完全相同。
这里的约束是每个属性(列)都应该是单值属性。例如,下面的酒店预订表就违反了第一范式,因为“电话”列中有多个电话号码:
| 房间ID | 酒店ID | 日期 | 酒店名称 | 酒店描述 | 电话 | 星级 | 是否可免费取消 | 用户ID |
|---|---|---|---|---|---|---|---|---|
| 1 | 12321 | 01/01/2018 | 费尔菲尔德万豪酒店(旧金山国际机场店) | 五星级酒店,适合休闲和商务旅客 | +1-408-123123 | 5 | 否 | abc |
| 1 | 12321 | 01/02/2018 | 费尔菲尔德万豪酒店(旧金山国际机场店) | 五星级酒店,适合休闲和商务旅客 | +1-408-123123 | 5 | 否 | pqr |
| 2 | 12321 | 01/01/2018 | 费尔菲尔德万豪酒店(旧金山国际机场店) | 五星级酒店,适合休闲和商务旅客 | +1-408-123123 | 5 | 否 | xyz |
| 1 | 456 | 01/01/2018 | 门洛帕克假日酒店 | 经济型商务酒店 | +1-408-123789 +1-408-123456 | 4 | 是 | zzz |
要使该表符合第一范式,需要将其重构如下:
| 房间ID | 酒店ID | 日期 | 酒店名称 | 酒店描述 | 电话 | 星级 | 是否可免费取消 | 用户ID |
|---|---|---|---|---|---|---|---|---|
| 1 | 12321 | 01/01/2018 | 费尔菲尔德万豪酒店(旧金山国际机场店) | 五星级酒店,适合休闲和商务旅客 | +1-408-123123 | 5 | 否 | abc |
| 1 | 12321 | 01/02/2018 | 费尔菲尔德万豪酒店(旧金山国际机场店) | 五星级酒店,适合休闲和商务旅客 | +1-408-123123 | 5 | 否 | pqr |
| 2 | 12321 | 01/01/2018 | 费尔菲尔德万豪酒店(旧金山国际机场店) | 五星级酒店,适合休闲和商务旅客 | +1-408-123123 | 5 | 否 | xyz |
| 1 | 456 | 01/01/2018 | 门洛帕克假日酒店 | 经济型商务酒店 | +1-408-123456 | 4 | 是 | zzz |
| 1 | 456 | 01/01/2018 | 门洛帕克假日酒店 | 经济型商务酒店 | +1-408-123789 | 4 | 是 | zzz |
第一范式消除了重复组的现象,重复组是指对于给定的实体类型,一组属性可以取多个值。
# 第二范式
酒店预订表的主键(唯一标识一行数据的一组属性)是房间ID(RoomId)、酒店ID(HotelId)和日期(Date)。在前面的表格中,我们可以看到有大量的数据重复。例如,酒店描述(HotelDescription)只依赖于酒店ID,而不依赖于预订的其他属性。这种数据重复的问题在于,描述中的任何错误或更改都需要在很多地方进行修改 。
为了避免这种冗余,科德(Codd)的第二个约束规定:“每个属性都必须依赖于整个主键。”
为了满足这个条件,该表必须重构为两个表,如下所示:
- 预订表(Reservations): | 房间ID | 酒店ID | 日期 | 用户ID | | ------ | ------ | ---------- | ------ | | 1 | 12321 | 01/01/2018 | abc | | 1 | 12321 | 01/02/2018 | pqr | | 2 | 12321 | 01/01/2018 | xyz | | 1 | 456 | 01/01/2018 | zzz |
- 酒店表(Hotels): | 酒店ID | 酒店名称 | 酒店描述 | 电话 | 星级 | 免费取消 | | ------ | ---------------------------------- | ------------------------------ | ------------- | ---- | -------- | | 12321 | 费尔菲尔德万豪酒店(旧金山机场店) | 适合休闲和商务旅客的五星级酒店 | +1-408-123123 | 5 | 否 | | 12321 | 费尔菲尔德万豪酒店(旧金山机场店) | 适合休闲和商务旅客的五星级酒店 | +1-408-123123 | 5 | 否 | | 12321 | 费尔菲尔德万豪酒店(旧金山机场店) | 适合休闲和商务旅客的五星级酒店 | +1-408-123123 | 5 | 否 | | 456 | 门洛帕克假日酒店 | 价格实惠的商务酒店 | +1-408-123456 | 4 | 是 | | 456 | 门洛帕克假日酒店 | 价格实惠的商务酒店 | +1-408-123789 | 4 | 是 |
现在,使用这个模式,预订表中的冗余信息大大减少,并且所有非键字段都依赖于主键。
# 第三范式
通过对业务领域的进一步研究发现,免费取消(FreeCancellation)这一列依赖于星级(StartRating)——五星级酒店不提供免费取消服务,而其他星级的酒店提供。在数据库中记录免费取消选项而不是在代码中硬编码是一种不错的设计,这样在更改该政策时更容易,无需修改或发布代码。然而,信息的重复确实会引入冗余,还可能导致一致性问题。比如说,如果四星级酒店也不再提供免费取消服务,最好将这种关系单独建模。
科德的第三个约束规定:“每个属性必须只依赖于主键。” 为了满足这个条件,我们进一步重构酒店表,如下所示:
- 酒店表(Hotels): | 酒店ID | 酒店名称 | 酒店描述 | 电话 | 星级 | | ------ | ---------------------------------- | ------------------------------ | ------------- | ---- | | 12321 | 费尔菲尔德万豪酒店(旧金山机场店) | 适合休闲和商务旅客的五星级酒店 | +1-408-123123 | 5 | | 12321 | 费尔菲尔德万豪酒店(旧金山机场店) | 适合休闲和商务旅客的五星级酒店 | +1-408-123123 | 5 | | 12321 | 费尔菲尔德万豪酒店(旧金山机场店) | 适合休闲和商务旅客的五星级酒店 | +1-408-123123 | 5 | | 456 | 门洛帕克假日酒店 | 价格实惠的商务酒店 | +1-408-123456 | 4 | | 456 | 门洛帕克假日酒店 | 价格实惠的商务酒店 | +1-408-123789 | 4 |
- 取消政策表(Cancellation policy): | 星级 | 免费取消 | | ---- | -------- | | 5 | 否 | | 4 | 是 | | 3 | 是 | | 2 | 是 | | 1 | 是 |
# 巴斯范式
到目前为止,我们讨论的范式都集中在键和非键属性之间的关系上。通过确保每个属性都依赖于整个主键,而不是其他任何东西,我们减少了冗余。
但在某些情况下,复合键的各个部分之间可能存在依赖关系。下一个约束规定:“主键的任何部分都不能依赖于主键的其他部分。”
例如,假设我们的航班预订表有以下结构:
| 航班号 | 航空公司 | 日期 | 用户ID | 座位 |
|---|---|---|---|---|
| AN-501 | 阿联酋航空 | 01/01/2018 | abc | 5A |
| SQ-502 | 新加坡航空 | 01/01/2018 | pqr | 42B |
| SQ-502 | 新加坡航空 | 02/01/2018 | xyz | 5C |
| SQ-503 | 新加坡航空 | 03/01/2018 | xyx | 4C |
这里,主键被定义为一个复合键,由航班号、航空公司和日期组成。但可以发现,航空公司名称可以从航班号推断出来。因此,主键的一部分依赖于其他属性。为了满足巴斯范式(Boyce-Codd Normal Form,BCNF),我们将这个表重构为两个表:
- 预订表(Reservations): | 航班号 | 日期 | 用户ID | 座位 | | ------ | ---------- | ------ | ---- | | AN-501 | 01/01/2018 | abc | 5A | | SQ-502 | 01/01/2018 | pqr | 42B | | SQ-502 | 02/01/2018 | xyz | 5C | | SQ-503 | 03/01/2018 | xyx | 4C |
- 航班详情表(FlightDetails): | 航班号 | 航空公司 | | ------ | ---------- | | AN-501 | 阿联酋航空 | | SQ-502 | 新加坡航空 | | SQ-502 | 新加坡航空 | | SQ-503 | 新加坡航空 |
# 第四范式
前四种范式(第一范式到第三范式以及巴斯范式)应用了一些结构约束,以便确定是否符合规范。而第四范式则稍微有些微妙。
为了说明这一点,假设我们要在一个旅游网站上构建一个度假功能。度假意味着活动和酒店的组合。为了对此进行建模,创建了一个表,用于定义所有可能的度假目的地以及可用的选项:
| 目的地 | 酒店ID | 活动ID |
|---|---|---|
| 新加坡 | ABxx2 | 124 |
| 新加坡 | ABxx2 | 567 |
| 新加坡 | Psawe212 | 124 |
| 迪拜 | sa0943 | 124 |
| 迪拜 | we1321 | 124 |
这个表记录了在某个目的地所有可能的活动/酒店选项。
这里观察到的冗余是存在多值依赖。当对于第一个属性的每个值,都有一个或多个第二个属性的相关值时,两个属性之间就存在这种类型的依赖。例如,活动ID为124(浮潜)在新加坡可用这一事实被存储了多次。
第四个约束规定:“主键内不能存在独立的依赖集。” 这就引出了第四范式。为了使模型符合第四范式,前面的表可以分解为两个表:
- 度假活动表(HolidayActivities): | 目的地 | 活动ID | | ------ | ------ | | 新加坡 | 124 | | 新加坡 | 567 | | 迪拜 | 124 |
- 度假酒店表(HolidayHotels): | 目的地 | 酒店ID | | ------ | -------- | | 新加坡 | ABxx2 | | 新加坡 | Psawe212 | | 迪拜 | sa0943 | | 迪拜 | we1321 |
# SQL
结构化查询语言(Structured Query Language,SQL)已成为关系型数据通用的数据定义、操作和查询语言。几乎所有的关系型数据库管理系统都采用了它。除了用于插入、更新、检索和删除数据的结构,SQL还定义了事务结构,以确保原子性、一致性、隔离性和持久性(ACID)语义,并进行连接操作(见 “视图” 部分)。
对SQL的详细描述超出了本书的范围。如果想了解更多关于SQL的内容,可以在谷歌上快速搜索SQL语法和教程,或者查阅相关主题的众多书籍。
# 索引
数据库的主要目标是将数据持久化存储在磁盘上。然而,我们确实需要从存储的数据中高效地搜索和检索数据。数据库索引(Database index)是一种数据结构,有助于快速定位具有特定属性(键)的数据。大多数索引实现使用平衡的N叉树变体,如B+树,来高效地实现索引。
B+树是一种N叉树,与B树类似,但区别在于B+树的数据结构只包含键,值存储在外部。与二叉树相比,B+树的主要优势在于每个节点具有较高的扇出(指向子节点的指针)。这使得在键空间中进行搜索更加高效。这对数据库至关重要,因为更多的搜索意味着更多的I/O操作(I/O操作比内存访问昂贵得多)。B+树只存储键(这是B树和B+树的区别)的原因是,这样可以将更多的搜索信息打包到一个磁盘块中,从而提高缓存效率并减少磁盘I/O操作。B+树的叶子节点通常相互链接形成一个链表,这使得范围查询或有序迭代更加高效。
下图展示了一个最大度数为3且插入了6个键的B+树:
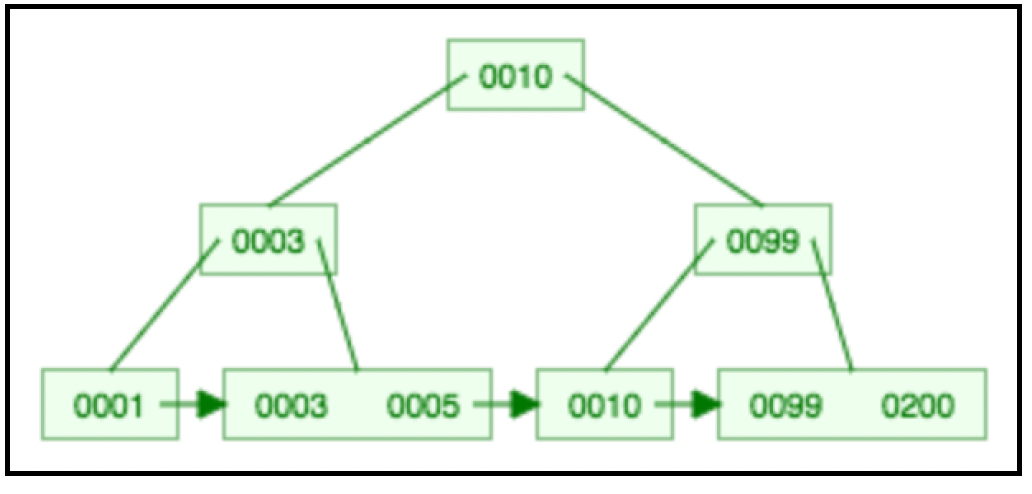
更多详细信息,请参考http://www.cburch.com/cs/340/reading/btree/index.html。
# 视图
关系理论包含一种用于组合表(关系)以形成数据视图的结构。视图(View)只不过是从其他关系组合而成的一种关系。由于这是派生数据,因此不必应用规范化规则。视图是通过对表进行连接操作构建的。
SQL的JOIN子句用于根据一个公共列组合两个或多个表中的行。不同类型的连接会产生不同的视图。为了演示这一点,考虑两个关于预订和客户的规范化表:
- 预订表(Reservations): | 预订ID | 客户ID | 日期 | | ------ | ------ | ---------- | | 123123 | axy | 01/02/2018 | | 123124 | axy | 01/03/2018 | | 123125 | pqr | 02/02/2018 | | 123126 | xyz | 03/02/2018 | | 123127 | abc | 03/02/2018 |
- 客户表(Customers): | 客户ID | 客户姓名 | 电话 | | ------ | --------------- | ------------- | | axy | 亚历克斯·黑尔斯 | +1-408-123421 | | pqr | 克里斯·卡尔 | +1-408-723777 | | xyz | 斯图尔特·布罗德 | +1-408-888213 | | yyy | 克里斯·盖尔 | +1-408-666999 |
客户ID列在两个表中都存在,用作公共映射列。为了演示不同类型的连接,这两个表之间故意设置了一些差异。
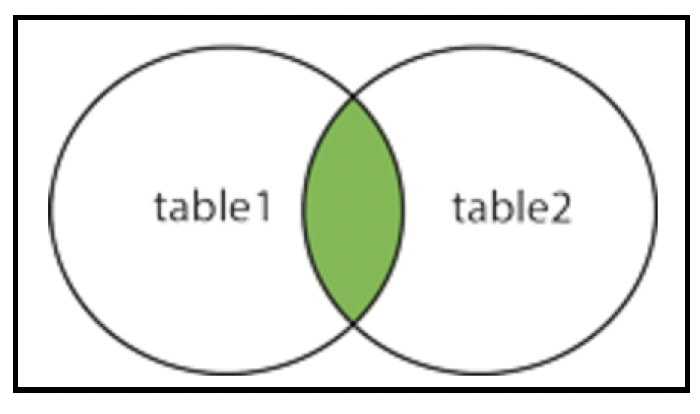
# 内连接
内连接(Inner join)是一种集合交集操作,也是连接的默认行为。这种连接返回在两个表中都有匹配值的行:
以下查询执行内连接:
SELECT Reservations.ReservationId,
Customers.CustomerName,Reservations.Date
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
2
3
4
5
它产生以下结果:
| 预订ID | 客户姓名 | 日期 |
|---|---|---|
| 123123 | 亚历克斯·黑尔斯 | 01/02/2018 |
| 123124 | 亚历克斯·黑尔斯 | 01/03/2018 |
| 123125 | 克里斯·卡尔 | 02/02/2018 |
| 123126 | 斯图尔特·布罗德 | 03/02/2018 |
只返回两个表中都存在的行。
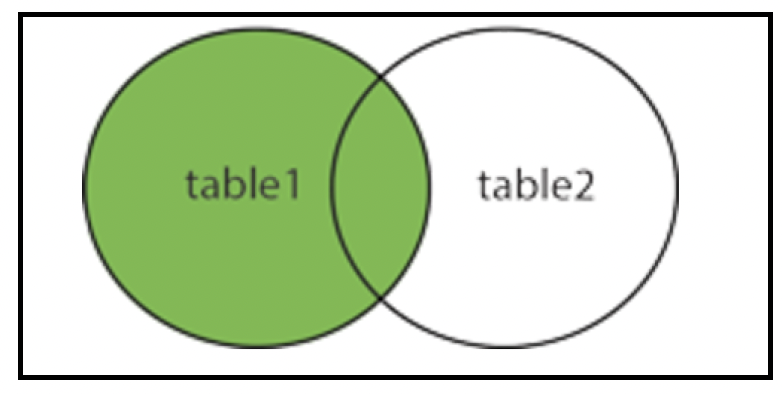
# 左外连接(Left outer join)
在这种连接中,会返回左表中的所有记录,以及右表中匹配的记录。若右表中没有匹配记录,对应字段的值为null:
以下查询执行左连接:
SELECT Reservations.ReservationId, Customers.CustomerName,Reservations.Date
FROM Orders
LEFT JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
2
3
4
它产生的结果如下:
| ReservationId | CustomerName | Date |
|---|---|---|
| 123123 | Alex Hales | 01/02/2018 |
| 123124 | Alex Hales | 01/03/2018 |
| 123125 | Chris Call | 02/02/2018 |
| 123126 | Stuart Broad | 03/02/2018 |
| 123127 | NULL | 03/02/2018 |
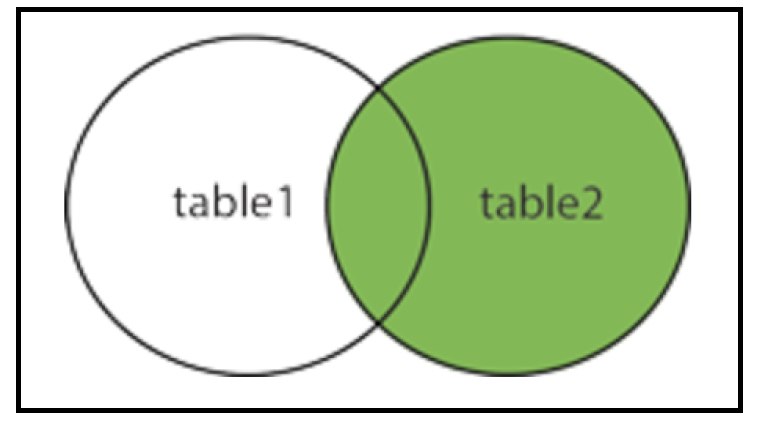
# 右外连接(Right outer join)
这是左连接的对应操作,它返回右表中的所有记录以及左表中匹配的记录。当左表中没有匹配记录时,左表列的结果为null:
以下查询执行右连接:
SELECT Reservations.ReservationId, Customers.CustomerName,Reservations.Date
FROM Orders
RIGHT JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
2
3
4
它产生的结果如下:
| ReservationId | CustomerName | Date |
|---|---|---|
| 123123 | Alex Hales | 01/02/2018 |
| 123125 | Chris Call | 02/02/2018 |
| 123126 | Stuart Broad | 03/02/2018 |
| Null | Chris Gayle | NULL |
# 全外连接(Full outer join)
这种连接对两个表进行并集操作。它返回左表或右表中有匹配的所有行:
以下查询执行全外连接:
SELECT Reservations.ReservationId, Customers.CustomerName,Reservations.Date
FROM Orders
FULL OUTER JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
2
3
4
它产生的结果如下:
| ReservationId | CustomerName | Date |
|---|---|---|
| 123123 | Alex Hales | 01/02/2018 |
| 123125 | Chris Call | 02/02/2018 |
| 123126 | Stuart Broad | 03/02/2018 |
| Null | Chris Gayle | Null |
| 123127 | Null | 03/02/2018 |
# 深入探究MySQL
MySQL是一个开源的关系型数据库管理系统。它独特的设计特点是将查询处理和其他服务器任务与存储引擎(负责数据的存储和检索)分离开来。这种关注点分离的设计让你可以在不改变数据模型的情况下权衡各种功能。其架构如下图所示,并在以下部分进行描述:
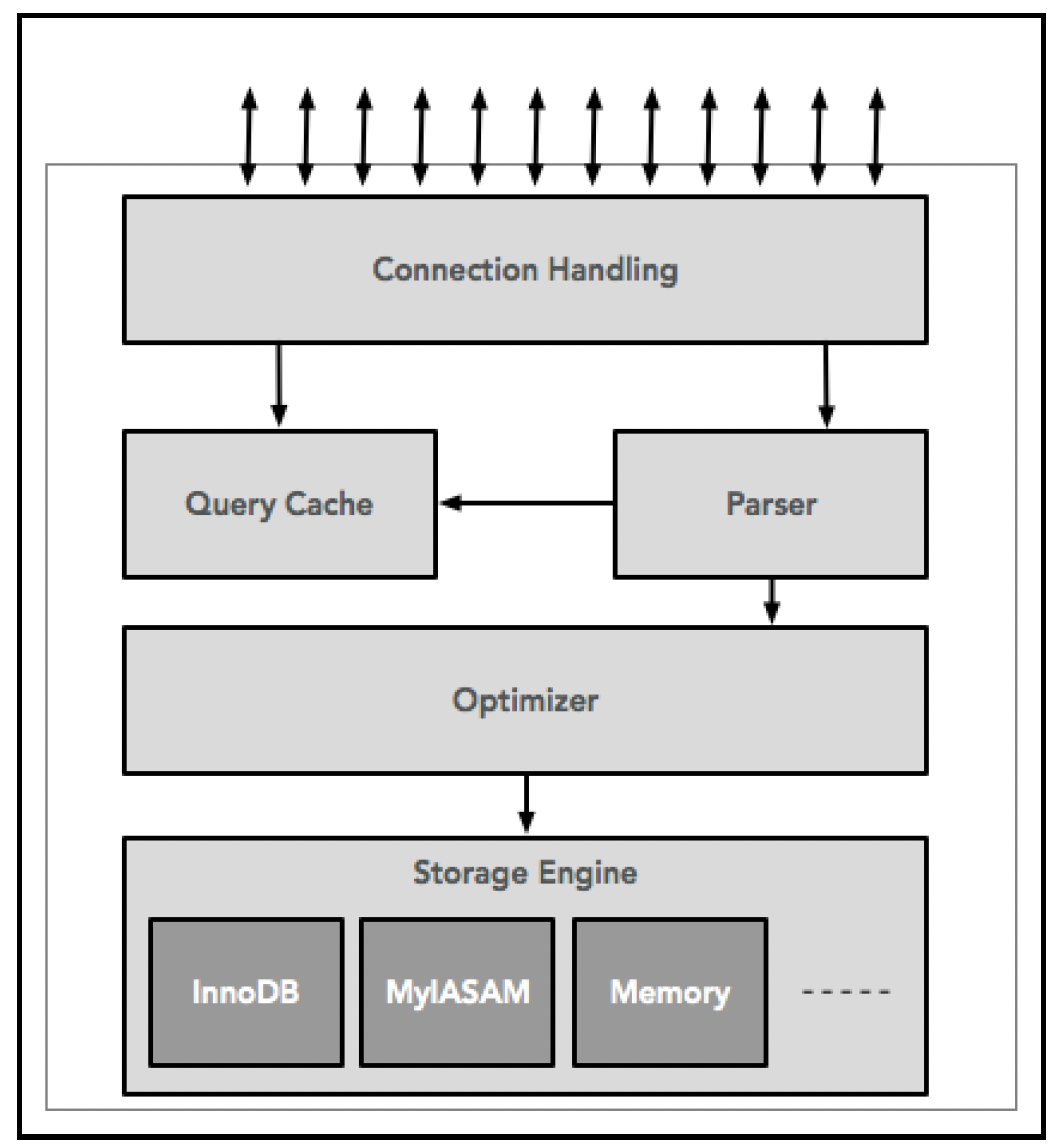
# 连接管理(Connection management)
每个客户端连接在MySQL进程中都有自己的线程。所有客户端查询都由该线程处理。为了提高效率,线程是池化管理的。身份验证基于用户名和密码进行。也可以通过SSL连接使用X.509证书。客户端通过身份验证后,服务器会验证客户端对该查询是否具有正确的授权。
# 查询执行(Query execution)
连接管理之后,涉及的下一个组件是查询缓存。它存储最近执行的读(SELECT)语句的结果集。在进一步处理之前,如果查询缓存命中,就直接从缓存中返回结果。
MySQL会解析查询,创建一个名为解析树的内部结构,然后对其进行查询规划和优化。这些操作包括重写查询、选择索引、选择读取表的顺序等。可以通过查询中的特殊关键字向优化器传递提示。
优化器组件还负责EXPLAIN功能,该功能可帮助开发人员了解查询的执行情况。使用EXPLAIN非常简单,只需在查询前加上EXPLAIN关键字即可:
EXPLAIN SELECT * FROM hotel_reservations LIMIT 10;
它产生的输出如下:
********************** 1. row **********************
id: 1
select_type: SIMPLE
table: hotel_reservations
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2
Extra:
1 row in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
输出中包含大量信息,其中最重要的部分如下:
id:查询中每个SELECT的标识符。这对于嵌套查询很重要。select_type:SELECT查询的类型。可能的值如下:Simple:该查询是一个简单的SELECT查询,没有任何子查询或UNION。Primary:SELECT位于JOIN最外层查询中。Derived:SELECT是FROM子句中某个子查询的一部分。Subquery:它是子查询中的第一个SELECT。Dependent subquery:这是一个依赖于外部查询的子查询。Uncachable subquery:这是一个不可缓存的子查询(查询可缓存有特定条件)。Union:SELECT是UNION中的第二个或后续语句。Dependent union:UNION中第二个或后续的SELECT依赖于外部查询。Union result:SELECT是UNION的结果。
type:这是最重要的字段之一,描述MySQL计划如何连接使用的表。可以通过它推断是否缺少索引以及查询是否需要重新设计。重要的值如下:const:表只有一个匹配行,且该行已建立索引。这使得连接速度最快,因为该值只需读取一次,在连接其他表时可有效视为常量。eq_ref:连接使用了索引的所有部分,并且索引是主键或唯一非空索引。这是查询的次优执行计划。ref:对于前一个表的每一行组合,都会读取索引列的所有匹配行。这种连接类型出现在使用=或<=>运算符比较索引列时。fulltext:查询使用全文搜索索引,用于文本字段的信息检索。index_merge:连接使用索引列表生成结果集。EXPLAIN输出的key列将包含使用的索引。unique_subquery:IN子查询从表中仅返回一个结果,并使用主键。index_subquery:与unique_subquery类似,但返回多个结果行。range:索引用于在特定范围内查找匹配行,通常是在使用BETWEEN、IN、>和>=等运算符将键列与常量进行比较时。index:扫描整个索引。all:扫描整个表。这是最差的连接类型,表明缺少合适的索引。
possible_keys:显示MySQL可以(但实际执行中可能未使用)用于从表中查找行的键。如果该列为NULL,则表示未找到相关索引。key:指示MySQL实际使用的索引。优化器总是寻找可用于查询的最佳键,有时它可能会找到一些未在possible_key中列出但更优的键。rows:列出执行查询时检查的行数。这是另一个在优化查询时值得关注的重要列,特别是对于使用JOIN和子查询的查询。Extra:包含有关查询执行计划的其他信息。该列中的using temporary和using filesort等值可能表明查询存在问题。有关可能值及其含义的完整列表,请参考MySQL文档(https://dev.mysql.com/doc/refman/5.6/en/explain-output.html#explain-extra-information)。
为了演示如何使用EXPLAIN帮助调试,考虑以下查询:
EXPLAIN SELECT * FROM
hotel_reservations r
INNER JOIN orders o ON r.reservationNumber = o.orderNumber
INNER JOIN customers c on c.id = o.customerId
WHERE o.orderNumber = PQR1111
2
3
4
5
这将产生以下输出:
********************** 1. row ********************
id: 1
select_type: SIMPLE
table: c
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 70
Extra:
********************** 2. row ********************
id: 1
select_type: SIMPLE
table: o
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 210
Extra: Using join buffer
********************** 3. row ********************
id: 1
select_type: SIMPLE
table: r
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3000
Extra: Using where; Using join buffer
3 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
上述结果表明该查询存在问题。所有表的连接类型都显示为ALL(最差的类型),这意味着MySQL无法识别任何有助于连接的索引。rows列显示数据库必须扫描每个表的所有记录来执行查询。这意味着为了执行该查询,它将读取70×210×3,000 = 44,100,000行来查找匹配结果。这性能非常差,并且随着数据量的增长会进一步恶化。改进该查询的一个明显方法是添加索引,如下所示:
ALTER TABLE customers
ADD PRIMARY KEY (id);
ALTER TABLE orders
ADD PRIMARY KEY (orderNumber),
ADD KEY (customerId);
ALTER TABLE hotel_reservations
ADD PRIMARY KEY (reservationNumber);
2
3
4
5
6
7
这将使MySQL能够利用索引,避免全表扫描。
# 存储引擎(Storage engines)
MySQL将每个数据库存储为文件系统中MySQL数据目录下的一个子目录。负责这项维护工作的MySQL架构组件称为存储引擎。ACID(原子性、一致性、隔离性、持久性)合规性也主要由这一层实现。它采用可插拔架构,允许使用不同存储引擎的插件,以下部分将对此进行介绍。
# InnoDB
InnoDB是MySQL的默认事务性存储引擎,也是最重要且应用最广泛的引擎插件。它完全符合ACID规范,支持事务处理。其性能和自动崩溃恢复功能使其在非事务性存储需求场景中也很受欢迎。除非有充分的理由使用其他引擎,否则建议你在表中使用InnoDB。
InnoDB将数据存储在一系列一个或多个数据文件中,这些文件统称为表空间(tablespace)。每个表空间包含页(块)、区和段。InnoDB的实现包含一系列优化,包括用于从磁盘预取数据的预读功能、一个自适应哈希索引(它会在内存中自动构建哈希索引以实现快速查找)以及一个插入缓冲区来加速写入操作:
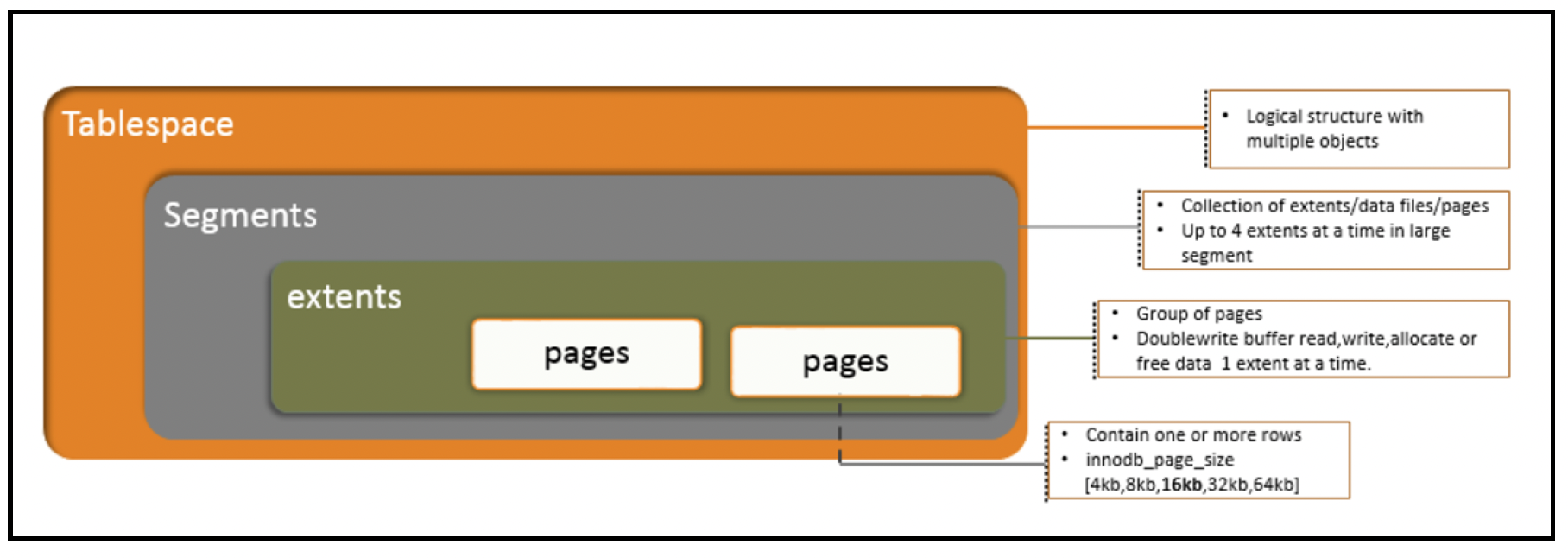
InnoDB默认使用可重复读(REPEATABLE READ)隔离级别,并使用多版本并发控制(Multiversion Concurrency Control,MVCC)来实现高并发。对于每一行,引擎会存储两个额外的隐藏字段,用于记录行版本以及该行被删除或过期的时间。每个事务使用一个系统范围的数字来标识版本(而不是使用时间戳)。因此,对于可重复读隔离级别,以下规则适用于每个操作:
- 事务开始时,会生成一个新的事务ID。
SELECT:引擎检查每一行,确保它满足两个条件:- InnoDB必须找到一个版本小于或等于当前事务ID的行。这确保了该行在事务开始之前就已存在,或者是该事务创建或修改了该行。
- 行的删除版本必须为
null或大于事务的版本。这确保了事务开始时该行是可用的(未被删除)。
INSERT:事务ID存储在新行的版本ID中。DELETE:事务ID存储为行的删除ID。UPDATE:InnoDB创建该行的一个新副本,并使用事务ID作为新行的版本号。
MVCC的优点是提高了并发性,缺点是增加了存储和维护成本。
# MyISAM
这是MySQL中最初且最古老的存储引擎。它不支持事务。其设计更侧重于速度和紧凑的数据存储,比InnoDB简单得多。索引结构本质上是数据文件内偏移量的列表。插入操作只是在数据文件末尾追加内容。然而,删除和更新操作就没那么简单了,因为它们会在数据文件中留下空洞或导致文件碎片化。
MyISAM确实存在一些严重的可扩展性限制,其中最重要的有以下几点:
- 键缓存(Key cache):互斥锁(Mutexes)保护键缓存,并对其访问进行序列化。
- 表锁定(Table locking):读取操作会对所有需要读取的表获取读锁。写入操作则获取排他(写)锁。本质上,同一时间只允许一个会话更新表,这给更新操作带来了巨大的序列化瓶颈。
因此,即使是中等的写入负载,它的效率也相当低。
# 其他插件
MySQL还有多种其他存储引擎,用于实验性或特定的用例。以下是其中一些:
- 归档引擎(The archive engine):归档引擎不是事务性存储引擎,它只是针对高速插入和压缩存储进行了优化。它仅支持INSERT和SELECT查询,在MySQL 5.1之前不支持索引。与MyISAM相比,它的I/O效率更高。因此,归档表最适合用于日志记录和数据采集。
- CSV引擎(The CSV engine):CSV插件可以将逗号分隔值(CSV)文件用作表。然而,该文件不支持索引。因此,CSV表作为数据交换格式很有用,因为表可以自动从CSV文件构建,同时也允许其他程序访问这些文件。
- 内存引擎(The memory engine):这个插件(以前称为HEAP表)将数据存储在内存中,因此在需要快速访问数据且重启后数据持久性不是很重要的情况下很有用。它们可用作查找表/映射表,但一般建议在这些用例中使用键值存储(key-value stores)。
# 高可用性/可扩展性
MySQL有一个名为分区(partitioning)的功能,通过它,表的数据会透明地分布在多个物理数据库中,这些物理数据库称为分区/片段。默认情况下,表的主键MD5哈希值用于在各个片段之间进行分区。如果一个事务或查询需要访问多个片段的数据,那么其中一个节点将承担事务协调器的角色,协调其他节点的工作。这个协调器还会在将结果转发给应用程序之前对其进行合并。
典型的高可用性配置包括一个主数据库,负责处理数据写入操作,并复制到多个从数据库,从数据库负责处理所有读取操作。主服务器不断将二进制日志事件(描述更改内容)推送给连接的从服务器。如果主服务器发生故障,一个从服务器可以提升为主服务器。这里的复制是异步的。
MySQL Cluster是主从架构的另一种替代方案,它允许一组节点同时处理读写操作。MySQL Cluster通过NDB或NDBCLUSTER存储引擎实现(NDB代表网络数据库,Network Database)。它存在一些已知的限制,可在此处查看:https://dev.mysql.com/doc/refman/5.6/en/mysql-cluster-limitations.html 。
# 对象关系映射器(Object Relational Mappers,ORMs)
虽然应用程序代码肯定可以使用SQL语句与数据库进行交互,但你需要注意确保数据库交互不会分散在各个应用层中。数据访问层(Data Access Layer,DAL)是负责处理实体及其与数据库交互的层。应用程序的其余部分则与数据库交互的细节相分离。
对象关系映射器(ORMs)是一种特殊形式的DAL,它将数据库实体转换为对象。通常,这是通过通用的粘合代码在幕后无缝完成的。
GORM是Go语言中最受欢迎的ORM。要安装它,我们运行以下命令:
go get "github.com/jinzhu/gorm"
要使用GORM,你还必须指定要使用的数据库以及驱动程序和方言。因此,在你的应用程序中导入GORM的方式如下:
import (
_ "github.com/go-sql-driver/mysql"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
2
3
4
5
要连接到MySQL数据库,代码如下:
db, err := gorm.Open("mysql",
"root:@tcp(127.0.0.1:3306)/users?charset=utf8&parseTime=True")
if err != nil {
panic("failed to connect database")
}
2
3
4
5
注意parseTime标志,它用于使GORM能够将MySQL的DateTime字段转换为Golang的Time结构体。连接成功后,db句柄可用于执行操作。
在查看操作之前,让我们看看由GORM管理的实体是什么样的。它是一个普通的Go结构体,嵌入了GORM的gorm.Model结构体。这个基础结构体提供了一些标准字段,如时间戳,如下例所示。我们定义一个User实体/模型:
type User struct {
gorm.Model
Name string
Age uint
}
2
3
4
5
GORM具有迁移功能,可使数据库结构与实体定义保持同步。虽然在开发环境中这很方便,但在生产环境中一般不建议使用,因为担心未经检查或不必要的数据库更改会导致数据丢失。但由于这是一个开发示例,我们可以通过以下代码启动模式迁移:
// 迁移模式
db.AutoMigrate(&User{})
2
这将创建一个名为users的表,如下所示:
+------------+------------------+------+-----+---------+----------------+
| Field | Type | NULL | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
|id<br/>created_at<br/>updated_at<br/>deleted_at<br/>name age|int(10) unsigned<br/>timestamp<br/>timestamp<br/>timestamp<br/>varchar(255)<br/>int(10) unsigned|NO<br/>YES<br/>YES<br/>YES<br/>YES<br/>YES|PRI<br/><br/>MUL|NULL<br/>NULL<br/>NULL<br/>NULL<br/>NULL<br/>NULL|auto_increment|
|---|---|---|---|---|---|
+------------+------------------+------+-----+---------+----------------+
2
3
4
5
6
注意id、created_at、updated_at和deleted_at(用于软删除)时间戳。它们是从gorm.Model继承的额外字段。
表名是根据结构体名称推断出来的,它是模型名称的复数形式,并且将驼峰式命名转换为下划线命名。例如,如果模型名称是UserModel,表名就会是user_models。
现在我们有了数据库,就可以创建以下用户:
// 创建
db.Create(&User{Name: "James Bond", Age: 40})
2
这将通过一条SQL查询在数据库中插入一条记录:
INSERT INTO users (name,age) VALUES ('James Bond',40);
我们可以使用各种字段查询数据库:
// 读取
var user User
db.First(&user, 1) // 查找id为1的用户
fmt.Println(user)
db.First(&user, "Name = ?", "James Bond") // 查找James Bond
fmt.Println(user)
2
3
4
5
6
这将转换为SQL查询:
SELECT * FROM users WHERE name='James Bond' limit 1;
实体可以按如下方式更新:
// 更新 - 更新Bond的年龄
db.Model(&user).Update("Age", 41)
2
这将更新实体以及数据库中的记录。
GORM中的删除操作有点特别。主要的API很简单:
// 删除 - 删除用户
db.Delete(&user)
2
然而,如果实体有deleted_at字段,GORM不会真正删除该条目,而是将deleted_at的值设置为当前时间。通过GORM进行读取操作时,这些记录将被跳过。所以,前面的查询实际上是这样的:
SELECT * FROM users WHERE name='James Bond' AND deleted_at IS NULL limit 1;
要真正从数据库中删除数据,可以使用Unscoped API:
db.Unscoped().Delete(&user)
完整的写入、读取和删除的示例程序如下:
package main
import (
"fmt"
_ "github.com/go-sql-driver/mysql"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
type User struct {
gorm.Model
Name string
Age uint
}
func main() {
db, err := gorm.Open("mysql",
"root:@tcp(127.0.0.1:3306)/users?charset=utf8&parseTime=True")
if err != nil {
panic("failed to connect database")
}
defer db.Close()
// 迁移模式
db.AutoMigrate(&User{})
// 创建
db.Create(&User{Name: "James Bond", Age: 40})
// 读取
var user User
db.First(&user, 1) // 查找id为1的用户
fmt.Println(user)
db.First(&user, "Name = ?", "James Bond") // 查找James Bond
fmt.Println(user)
// 更新 - 更新Bond的年龄
db.Model(&user).Update("Age", 41)
fmt.Println(user)
// 删除 - 删除用户
db.Delete(&user)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
这个程序不会删除James Bond的条目,因为Delete()只是软删除。程序运行后,数据库将有以下条目:
mysql> SELECT * FROM users WHERE name='James Bond' ;
+----+---------------------+---------------------+---------------------+---
---------+------+
| id | created_at | updated_at | deleted_at |
name | age |
+----+---------------------+---------------------+---------------------+---
---------+------+
| 5 | 2018-05-06 08:44:22 | 2018-05-06 08:44:22 | 2018-05-06 08:44:22 |
James Bond | 41 |
+----+---------------------+---------------------+---------------------+---
---------+------+
1 row in set (0 .01 sec)
2
3
4
5
6
7
8
9
10
11
12
GORM支持事务。例如,以下代码要么同时创建userA和userB,要么都不创建:
func createTwoUsers(db *gorm.DB) {
userA := User{Name: "UserA", Age: 20}
userB := User{Name: "UserB", Age: 20}
tx := db.Begin()
if err := tx.Create(&userA).Error; err != nil {
tx.Rollback()
}
if err := tx.Create(&userB).Error; err != nil {
tx.Rollback()
}
// 提交!
tx.Commit()
}
2
3
4
5
6
7
8
9
10
11
12
13
GORM还支持关系映射,它将对象关系转换到数据库结构中。关系可以是“属于”(belongs-to)、“一对一”(one-to-one)、“一对多”(one-to-many)和“多对多”(many-to-many)。
例如,以下程序定义了酒店和酒店连锁之间的“属于”关系:
package main
import (
_ "fmt"
_ "github.com/go-sql-driver/mysql"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
type HotelChain struct {
gorm.Model
Name string
}
type Hotel struct {
gorm.Model
Name string
NoRooms uint
Chain HotelChain `gorm:"foreignkey:ChainId"` // 使用ChainId作为外键
ChainId uint
}
func main() {
db, err := gorm.Open("mysql",
"root:@tcp(127.0.0.1:3306)/users?charset=utf8&parseTime=True")
if err != nil {
panic("failed to connect database")
}
defer db.Close()
// 迁移模式
db.AutoMigrate(&HotelChain{})
db.AutoMigrate(&Hotel{})
db.Model(&Hotel{}).AddForeignKey("chain_id", "hotel_chains(id)",
"CASCADE", "CASCADE")
// 创建一些实体并保存
taj := HotelChain{Name: "Taj"}
db.Save(&taj)
vivanta := Hotel{Name: "Vivanta by the sea", NoRooms: 400, Chain: taj}
db.Save(&vivanta)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
需要使用AddForeignKey()方法,因为GORM不会设置外键索引和约束。这是一个未解决的问题。
# 键值存储(Key/value stores)
现代系统对存储系统有很高的要求。需要在每秒查询数(QPS)、并发连接数、数据大小等方面对存储系统进行扩展。此外,许多应用程序在某些用例中需要超快的请求响应。虽然关系型系统已经并将继续提供可靠的持久化技术,但传统的纵向扩展方法,即使用更好的硬件设备,已无法满足需求。在分布式系统中提供ACID语义极其困难,这使得关系型数据库的横向扩展成为一项艰巨的任务。请注意,虽然存在分布式事务等机制,但使用它们非常复杂,并且通常会导致系统非常脆弱。在分布式数据库中,连接操作(joins)的效率尤其低。在单实例数据库中,连接操作可以通过索引和数据局部性高效处理。但在分布式节点中,连接操作需要在网络中移动数据以执行必要的比较操作。这些低效率使得分布式连接与单节点系统相比效率低下。
我们将在本章后面深入探讨数据扩展的问题,但在本节中,我们将介绍一类新的存储系统,称为键值存储。
# 概念
基于键值的存储系统的概念与编程语言中的哈希表类似。与关系模型一样,实体作为元组存储,但只有一个键可以唯一标识该元组。存储级别不维护关系。元组中的值部分对存储系统来说基本上是不透明的。
这些减少的约束带来的优势是系统的可扩展性。利用分布式哈希表等概念,数据空间现在可以轻松地分布在多个实例上。读写操作只需要访问一个分片(节点),因为不存在会影响其他元组的关系。通过在新节点上高效地重新分配元组,可以轻松实现横向扩展。这些系统的另一个优势是性能,它们通常比关系型系统快一个数量级。我们将在“数据扩展”部分详细介绍分布式哈希表。
键值存储的一种变体是文档存储(document stores)。这里的数据具有结构,通常是XML或JSON格式。然而,这些系统允许在同一个数据库中存储不同模式的文档。这使得可以存储实体的可选列等内容。这些值被称为文档,因此得名。与键值存储相比,文档存储允许对文档进行更复杂的查询和聚合操作。
在下一节中,我们将深入探讨一种非常流行的键值存储——Redis。
# Redis深度解析
Redis是一个开源的键值存储系统,主要将数据存储在内存中,但也提供了持久化选项。除了普通的键值映射,Redis还提供了高级的数据结构,如数据结构和发布/订阅消息通道。
# 架构
Redis服务器是一个用C语言编写的单线程程序,它使用epoll/kqueue来实现异步I/O。你可能会疑惑单线程系统是否能够扩展,但Redis的扩展性非常出色!这里的关键在于,对于存储系统而言,CPU很少成为瓶颈,大部分时间都花在了I/O(网络或存储)上。像epoll/kqueue这样的内核机制允许应用程序发起I/O操作,而不会被该操作阻塞。通过这种方式,单个线程就可以多路复用大量的I/O操作。
单线程架构还带来了一个关键优势——不存在竞态条件。由于没有多个线程,也就无需进行同步。这意味着不存在锁争用或棘手的死锁问题。
从Jak Sprats在Redis群组上分享的基准测试(http://nosql.mypopescu.com/post/1078083613/redis-a-concurrency-benchmark)中,可以看出这种架构的性能:
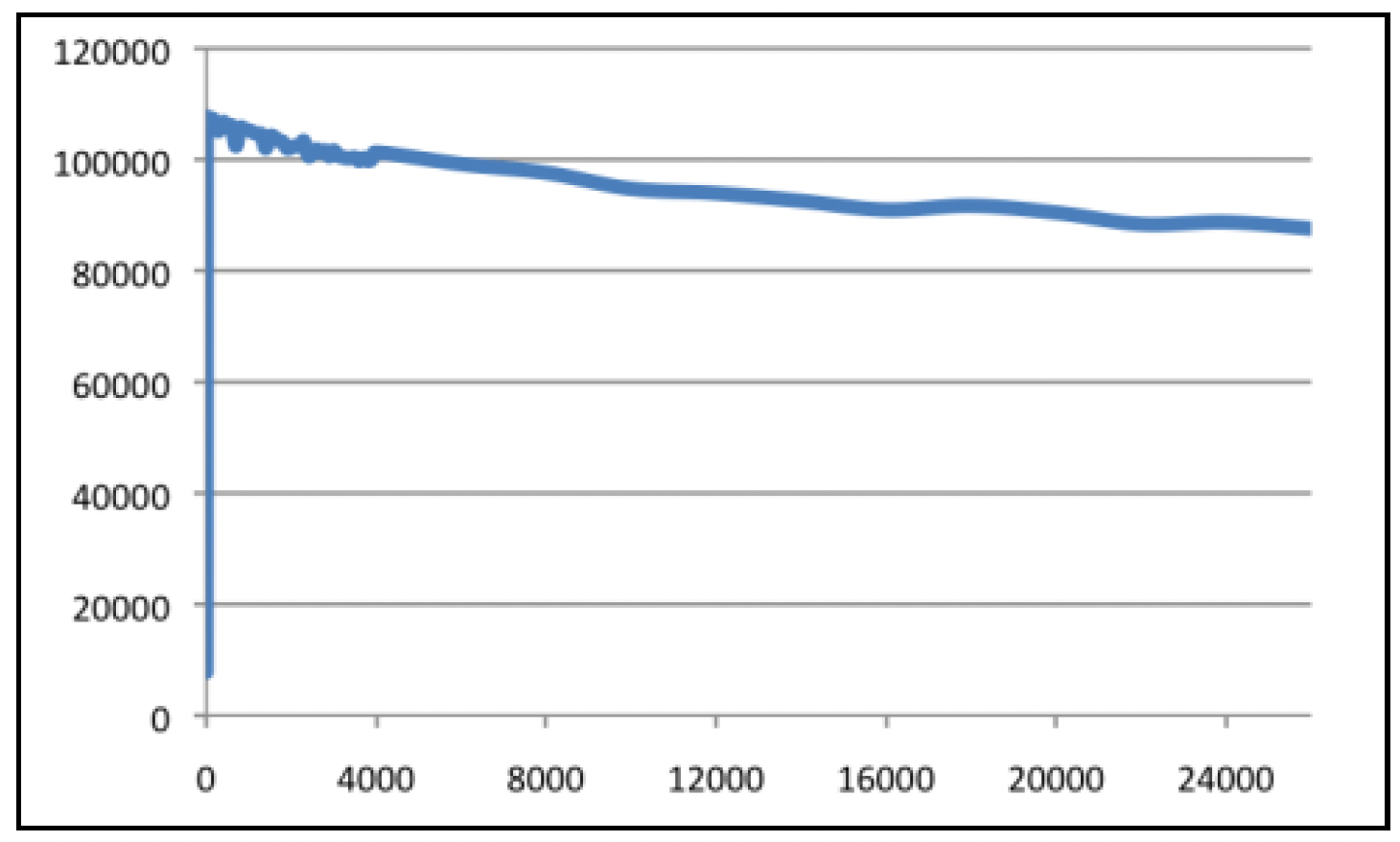
横坐标是并发请求的数量,纵坐标是每秒查询率(QPS)表示的性能。该基准测试显示,在26000个并发请求的情况下,性能达到了90000 QPS!
更多基准测试详情可查看:https://redis.io/topics/benchmarks。
# 数据结构
Redis拥有丰富的数据结构,但不包含映射(maps)。以下是一些常见的数据结构:
- 列表(Lists):本质上是一个字符串元素的链表,元素按插入顺序排列(先进先出)。
- 集合(Sets):由唯一的、无序的字符串元素组成的集合。
- 有序集合(Sorted sets):一种类似于集合的数据结构,但每个字符串元素都与一个分数(浮点数)相关联。有序集合中的元素可以按照分数顺序进行访问(迭代器)。这使得它适用于排行榜之类的用例,比如 “十佳酒店”。
- 哈希(Hashes):这是一种具有额外字段和相关值层次的映射。它允许对值进行部分更新(仅更新某个字段),并且能高效检索(获取哈希的所有字段)。
- 位图(Bitmap):一种位数组,具备设置/清除单个位、统计所有设置为1的位的数量、查找第一个设置位等功能。
- HyperLogLogs:HyperLogLog是一种概率性数据结构,能够高效地估算集合的基数。本章后面会详细介绍概率性数据结构。
- 发布/订阅(Pub/sub):这种结构允许客户端向抽象通道发送(发布)消息,其他客户端(订阅者)则可以从这些通道消费消息。第6章“消息传递”中介绍了这种范式的详细内容。需要注意的是,消息不会被存储,只有当前正在监听的订阅者才能收到发布的消息。
更多详细信息,请参考:https://redis.io/commands。
# 持久化
Redis的持久化可以通过快照或日志记录来实现。
- 快照(Snapshotting):快照意味着定期将内存中的所有对象写入磁盘,保存为RBD文件。默认情况下,定期写入的配置值如下:
- 60秒内发生10000次更改
- 5分钟内发生10次更改
- 15分钟内发生1次更改 当需要写入磁盘时,Redis会派生一个子进程进行保存操作,这个子进程负责将内存中的所有数据序列化,将序列化后的数据写入临时文件,然后将临时文件重命名为实际的文件。虽然派生进程(fork)看起来开销很大,但由于大多数操作系统提供的写时复制(copy-on-write)语义,实际并非如此。只有当父进程或子进程对某个页面进行更改时,该页面才会被复制。在许多操作系统(如Linux)中,当发生fork时,内核无法预测实际需要的空间,只能预估最坏情况,即所有页面都被复制。在一些操作系统(如Linux)中,如果可用的空闲内存小于父进程的所有内存页面,默认情况下fork操作会失败。在Linux中,可以通过设置overcommit_memory来关闭这个限制,对于占用大量内存的Redis来说,这是必要的。
- 日志记录(Journaling):另一种方法是日志记录,它通过记录服务器执行的每一个写操作来实现持久化。日志记录是通过追加到文件的方式完成的,这种方式效率很高。在服务器启动时,可以重放日志以重建原始数据集。这种模式称为追加式文件(append-only file,AOF)模式。
AOF模式提供了更高的可靠性,但会牺牲一定的性能,因为现在所有的写操作都必须记录到磁盘。默认的fsync策略是每秒刷新一次,但这存在数据丢失的风险。如果为了避免这种情况而将设置改为每次写操作都进行fsync,那么写操作的性能会显著变慢。AOF的另一个缺点是,对于像计数器这样的用例,文件可能会快速增大,但实际价值却很小(旧的计数值并不需要!)。
我通常建议不要启用持久化,而是使用高可用性解决方案(在“集群”部分介绍)。此外,作为唯一事实来源的数据,理论上不应该存储在Redis中。
这并不是Redis实现的唯一持久化方式。它还包含一个手动编写的虚拟内存管理器,其用途与操作系统的虚拟内存交换(将未使用的内存部分移动到磁盘以释放内存)相同。Salvatore Sanfilippo(Redis的创造者)在http://oldblog.antirez.com/post/redis-virtual-memory-story.html中对此进行了描述,并解释了为什么操作系统的虚拟内存管理对Redis来说不够好。
# 集群
Redis支持主从复制。一个主Redis服务器可以有多个从Redis服务器。Sentinel是一个基于这种基本复制结构提供高可用性(HA)的工具。它具备以下功能:
- 监控(Monitoring):确保所有Redis实例都按预期工作。
- 通知(Notification):记录任何Redis实例是否出现问题。
- 自动故障转移(Automatic failover):如果主服务器工作异常,Sentinel可以将一个从服务器提升为主服务器,并重新配置其他从服务器使用新的主服务器。
- 配置提供(Configuration provider):Sentinel作为客户端服务发现的权威来源,客户端连接到Sentinel以获取当前Redis主服务器的地址。
更多信息,请查看以下资源:
- https://redis.io/topics/sentinel
- Go语言Redis客户端对Sentinel的支持:https://github.com/mediocregopher/radix.v2/tree/master/sentinel
最近,Redis还推出了Redis Cluster。在Redis Cluster中,键分布在一组节点上,并且在添加或删除新节点时会自动进行重新平衡。这种分布是通过对键空间进行分区实现的,键空间被划分为16384个槽(slot),每个槽可以由其中一个Redis节点托管。连接到集群需要专门的客户端,每个客户端都有一个分片到Redis节点实例的拓扑映射。通过在多个分片节点上复制数据来实现高可用性。Redis Cluster也存在一些限制。更多信息可查看https://redis.io/topics/cluster-tutorial。
# 用例
Redis有多种用例,以下是其中一些:
- 会话缓存(Session cache):Redis最常见的用例之一是存储会话,通常将会话存储为哈希。原因是用户会话通常会有大量的I/O操作,因为用户的每个API请求都需要会话信息,并且经常会导致一些更新操作。将会话存储在数据库中是一种选择,但数据库的性能特点不利于API性能的提升。Redis非常适合这个用例,因为会话信息虽然重要,但并非绝对不可或缺。因此,持久性并不是一个大问题。
- 应用程序缓存(Application cache):Redis可以作为数据库中数据的外部缓存。这使得应用程序可以从缓存中存储/访问频繁访问或很少更改的数据,从而避免通常较慢的数据库带来的性能损失。
- 分布式列表(Distributed lists):如果你想在多个应用程序实例之间维护列表,比如最新项目列表,Redis的列表数据结构非常合适。可以分别使用LPUSH/RPUSH命令将项目推到列表的头部或尾部。其他命令,如LTRIM/RTRIM,可以用于修剪列表。
- 统计数据(Keeping stats):Redis便于实现分布式计数器。INCRBY命令可用于原子性地增加计数器,而其他命令,如GETSET,可以用于清除计数器。
- 队列和发布/订阅(Queues and Pub/Sub):Redis的队列和发布/订阅通道可用于交换消息,实现诸如后台工作者之类的功能。
# 在Go语言中的使用
先暂时抛开理论,让我们看看如何在Go语言中使用Redis。在撰写本书时,Go语言中有两个主要的Redis客户端:
- Redigo(https://github.com/garyburd/redigo):为Redis命令提供了类似打印的API。它还支持管道操作、发布/订阅、连接池和脚本功能。它易于使用,参考文档位于https://godoc.org/github.com/garyburd/redigo/redis。
- Radix(https://github.com/mediocregopher/radix.v2):为大多数Redis命令提供了易于使用的包,包括管道操作、连接池、发布/订阅和脚本功能,并且还提供了集群支持。Radix.v2包被拆分为六个子包(cluster、pool、pubsub、Redis、sentinel和util)。
例如,我们想要在Redis中维护酒店的点赞数。以下结构体定义了我们要建模的实体:
type Hotel struct {
Id string
Name string
City string
StarRating string
Likes int
}
2
3
4
5
6
7
这里我们将使用Radix客户端。要安装它,可以使用以下命令:
go get github.com/mediocregopher/radix.v2
第一步当然是连接。可以这样实现:
conn, err := redis.Dial("tcp", "localhost:6379")
if err != nil {
panic(err)
}
defer conn.Close()
2
3
4
5
这段代码连接到本地主机。当然,在生产代码中,你应该将这个值作为配置项。
接下来,看看如何在Redis中保存酒店实体。以下代码获取一个酒店并将其保存到Redis中:
func setHotel(conn *redis.Client, h *Hotel) error {
resp := conn.Cmd("HMSET",
"hotels:"+h.Id,
"name", h.Name,
"city", h.City,
"likes", h.Likes,
"rating", h.StarRating)
if resp.Err != nil {
fmt.Println("save err", resp.Err)
return resp.Err
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
可以看到,我们使用哈希数据结构来存储点赞数。这是因为我们知道点赞数属性会被独立地增加。HMSET是用于哈希对象的多个设置命令。每个酒店通过“hotels”与酒店ID连接的字符串来标识。
以下代码从Redis中获取特定酒店:
func getHotel(conn *redis.Client, id string) (*Hotel, error) {
reply, err := conn.Cmd("HGETALL", "hotels:"+id).Map()
if err != nil {
return nil, err
}
h := new(Hotel)
h.Id = id
h.Name = reply["name"]
h.City = reply["city"]
if h.Likes, err = strconv.Atoi(reply["likes"]); err != nil {
fmt.Println("likes err", err)
return nil, err
}
if h.StarRating, err = strconv.Atoi(reply["rating"]); err != nil {
fmt.Println("ratings err", err)
return nil, err
}
return h, nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这里我们使用HGETALL命令获取哈希的所有字段。然后,使用响应对象的Map()方法获取字段名到值的映射。接着,从各个字段构建酒店对象。
现在,来处理点赞数。这里的关键方法是增加酒店的点赞数。除了维护点赞数,我们还需要确定最受欢迎的酒店。为了满足后一个需求,我们使用有序集合数据集。以下代码片段实现了给酒店点赞的功能:
func incrementLikes(conn *redis.Client, id string) error {
// 进行合理性检查,确保酒店存在!
exists, err := conn.Cmd("EXISTS", "hotels:"+id).Int()
if err != nil || exists == 0 {
return errors.New("no such hotel")
}
// 使用MULTI命令通知Redis我们开始一个新事务
err = conn.Cmd("MULTI").Err
if err != nil {
return err
}
// 将酒店相册哈希中的点赞数增加1。
// 因为我们发起了MULTI命令,所以这个HINCRBY命令会被排队,而不是立即执行。
// 我们仍然检查回复的Err字段,以查看排队过程中是否有错误
err = conn.Cmd("HINCRBY", "hotels:"+id, "likes", 1).Err
if err != nil {
return err
}
// 现在增加排行榜有序集合中的点赞数
err = conn.Cmd("ZINCRBY", "likes", 1, id).Err
if err != nil {
return err
}
// 原子性地执行事务中的两个命令
// EXEC返回两个命令的回复,作为一个数组
err = conn.Cmd("EXEC").Err
if err != nil {
return err
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这段代码使用Redis的MULTI选项启动一个事务,原子性地更新酒店的点赞数和点赞数的有序集合。
以下代码片段获取点赞数排名前三的酒店:
func top3LikedHotels(conn *redis.Client) ([]string, error) {
// 使用ZREVRANGE命令从点赞数有序集合中获取酒店,分数最高的排在前面
// 起始和结束值是基于零的索引,所以我们分别使用0和2来限制回复为排名前三的酒店
reply, err := conn.Cmd("ZREVRANGE", "likes", 0, 2).List()
if err != nil {
return nil, err
}
return reply, nil
}
2
3
4
5
6
7
8
9
ZREVRANGE命令按排名反向顺序返回有序集合的成员。由于它返回的是数组响应,我们使用List()辅助函数将响应转换为[]string。
# 宽列存储
宽列存储(Wide column stores),即面向列的数据库系统,是一种按列而不是按行存储数据的存储系统。例如,考虑以下简单表格:
| FirstName | LastName | Age |
|---|---|---|
| John | Smith | 42 |
| Bill | Cox | 23 |
| Jeff | Dean | 35 |
在关系型数据库管理系统(RBDMS)中,元组按行存储,因此磁盘上的数据存储方式如下:
John,Smith,42 |Bill,Cox,23 |Jeff,Dean,35
在联机事务处理(online-transaction-processing,OLTP)应用程序中,I/O模式主要是读取和写入整个记录的所有值。因此,按行存储对于OLTP数据库来说是最优的。
然而,在列数据库中,所有列存储在一起。所以,元组的存储方式如下:
John,Bill,Jeff |Smith,Cox,Dean |42,23,35
这样做的优点是,如果我们想要读取像FirstName这样的值,在按行存储的情况下,读取一个磁盘块只能获取少量信息,而在列存储中读取一个磁盘块能获取更多相关信息。另一个优点是,由于每个块存储的是相似类型的数据,我们可以对块进行高效压缩,进一步减少磁盘空间和I/O操作。
这类数据库在分析场景中很有用。例如亚马逊的Redshift和Vertica。具体细节超出了本书的范围。
# 列族存储
一种越来越流行的新型存储是列族存储(column family stores),它对行进行分区,使一个表可以分布在多台机器上。在每台机器上,行数据被组织成多维排序映射。这种分布方式有助于将存储扩展到处理大量数据,而排序属性则有助于进行范围扫描等操作。这种设计最初由谷歌的BigTable团队提出(https://ai.google/research/pubs/pub27898)。
在接下来的部分,我们将详细介绍一个示例:Cassandra。
# Cassandra深度解析
Apache Cassandra是BigTable理念的开源实现,但它也包含了其他的设计结构。例如,它还融入了亚马逊Dynamo的一些容错和数据复制设计原则。Cassandra最初由Facebook开发,之后被开源发布。
以下部分将描述Cassandra的内部机制,然后我们会编写Go代码来使用Cassandra。
# 数据分布
一种简单的在一组节点上对行进行分区的方法是使用哈希。你可以选择一个哈希函数,例如使用hash(key_x) % n_nodes来确定存储key_x对应数据的节点。但这种方案的问题在于,添加或删除节点意味着几乎所有键的hash(key_x) % n_nodes值都会改变,因此集群扩展就意味着要移动大量数据。
为了解决这个问题,Cassandra使用了一种称为一致性哈希(consistent hashing)的概念。我们在第5章“分布式架构”中已经介绍过一致性哈希。这里简单回顾一下:
假设有一个值范围从[0 - 1]的圆环,也就是说,圆环上的任意一点的值都在0到1之间。接下来,我们选择一个哈希函数,并将其映射到[0 - 1]范围。例如,如果哈希函数的范围是[0 - X],我们使用以下函数:
ringKey = hash(key) % X
通过这个函数,我们可以将机器(实例)和对象(通过键)映射到[0 - 1]的范围内。
如果我们有三台机器,使用修改后的哈希函数将每台机器映射到圆环上的一个点:
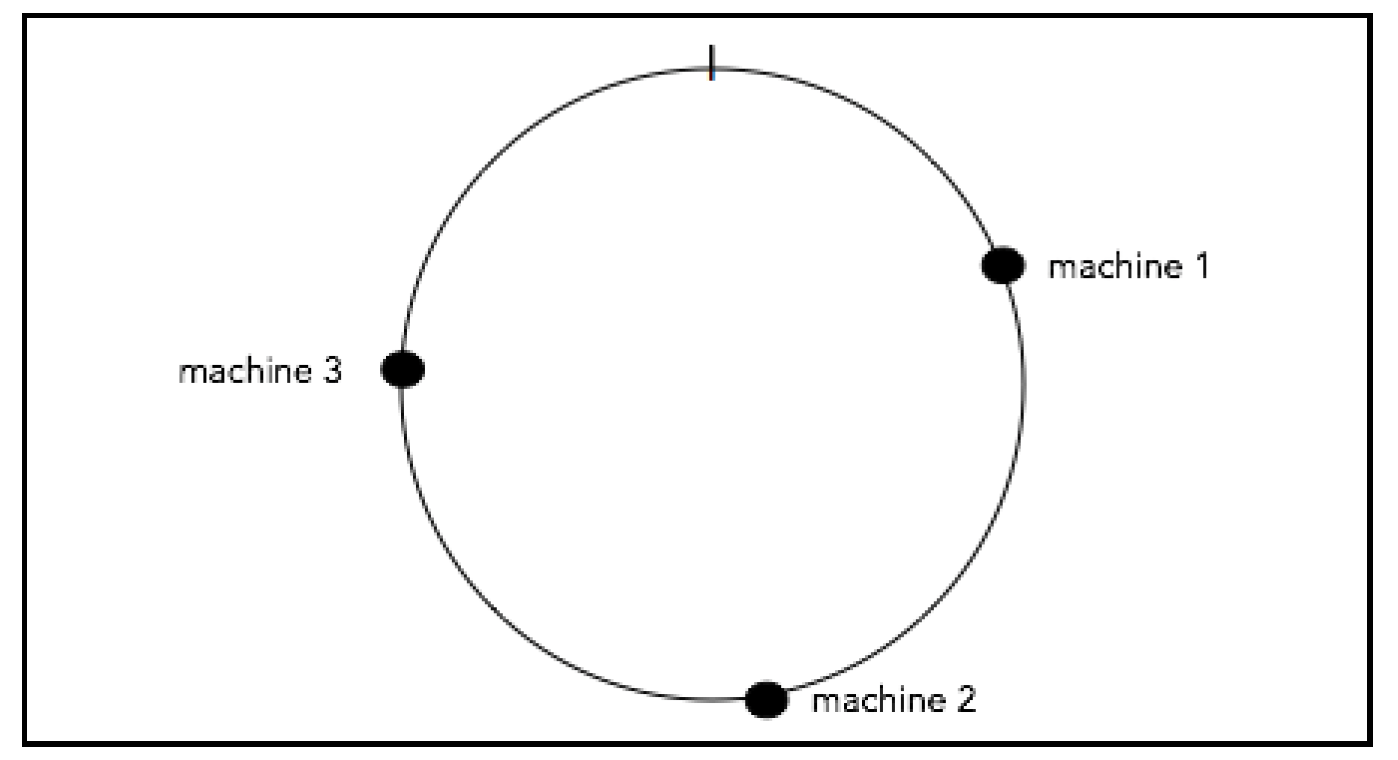
现在,我们可以看到0 - 1的范围被这几台机器划分成了不同的区间。假设在哈希表中有一个键值对。我们需要做两件事:
- 使用修改后的哈希函数在圆环上定位该键。
- 找到从该点顺时针方向出现的第一台机器,并将键存储在那里。
如下图所示:
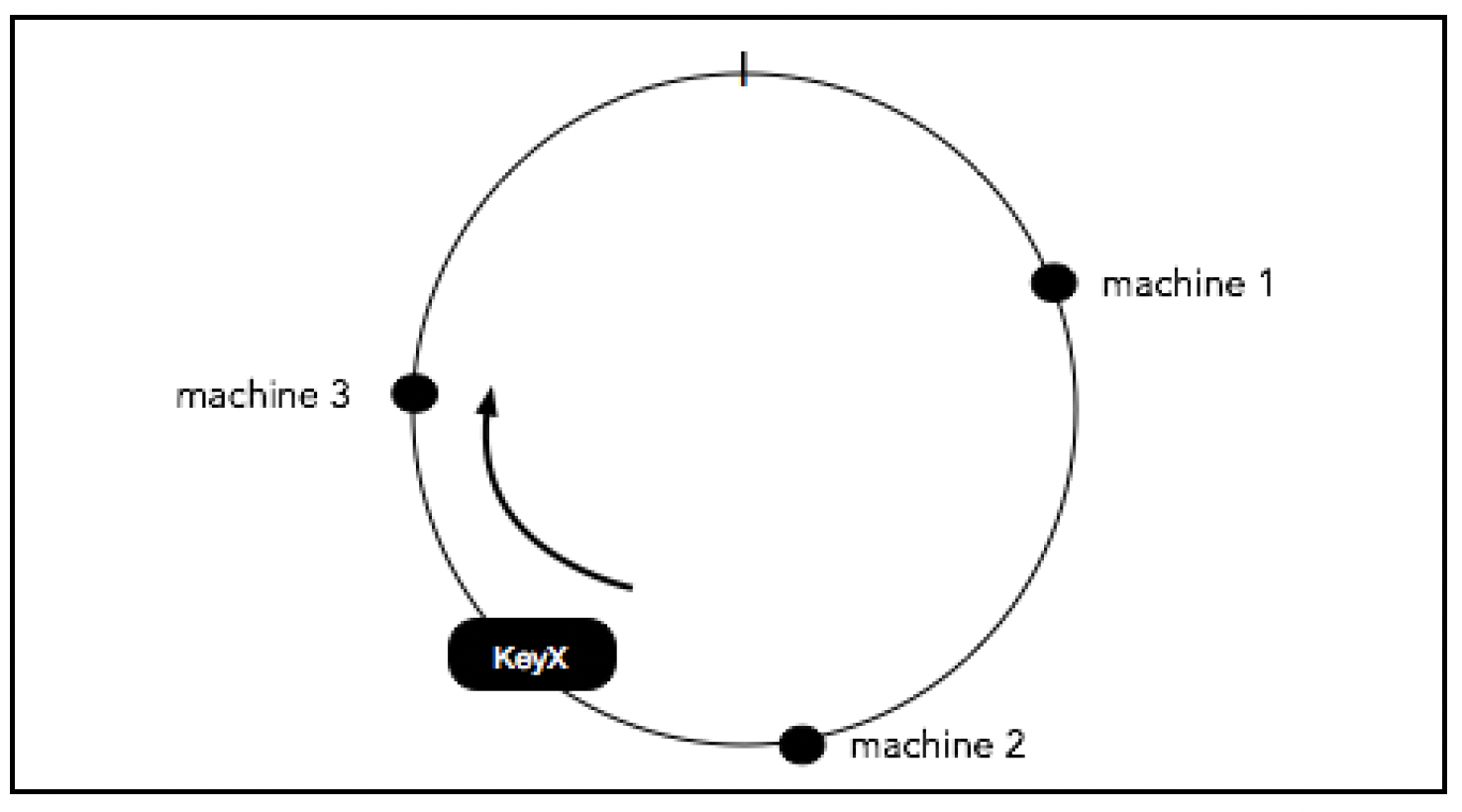
KeyX映射到一个点,从该点顺时针方向最近的机器是machine 3。因此,KeyX被分配到machine 3。
从编程的角度来看,通过以一种易于找到大于y的下一个最大数的方式存储机器的点值,就可以很容易实现顺时针查找最近的机器。一种方法是使用按排序顺序排列的机器哈希值链表来确定分配。只需遍历这个链表(或使用二分查找),找到第一个哈希值大于或等于键哈希值的机器。我们可以将这个链表设置为循环链表,这样,如果没有找到“更大键”的机器,计算就会环绕,链表中的第一台服务器将被分配。
现在,假设我们向集群中再添加一台机器,如下所示:
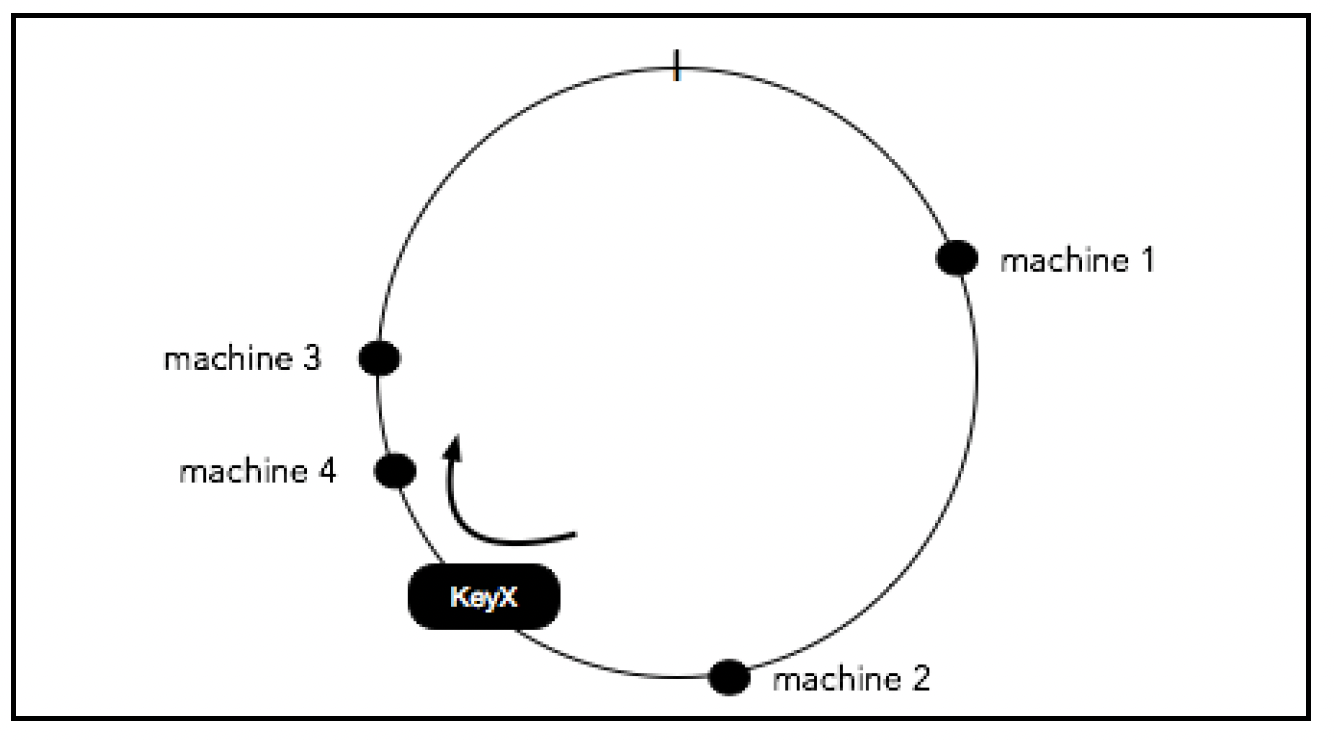
可以看到,与简单的哈希方法不同,大多数分配不会受到这个变化的影响,在简单哈希方法中,几乎每个分配都会改变。唯一的重新分配发生在原来顺时针方向的机器和新配置的机器之间。
Cassandra中的分区器(partitioner)用于生成令牌(相当于前面描述中的哈希值),因此对于确定给定键应存储到哪个节点至关重要。默认的分区器使用MurmurHash来计算哈希值。
一致性哈希的一个问题是可能会出现负载分配不均的情况——有些机器可能会比其他机器存储更多数据或更繁忙。为了克服这个问题,Cassandra(在1.2版本中)引入了虚拟节点(virtual nodes)的概念。如下图所示:
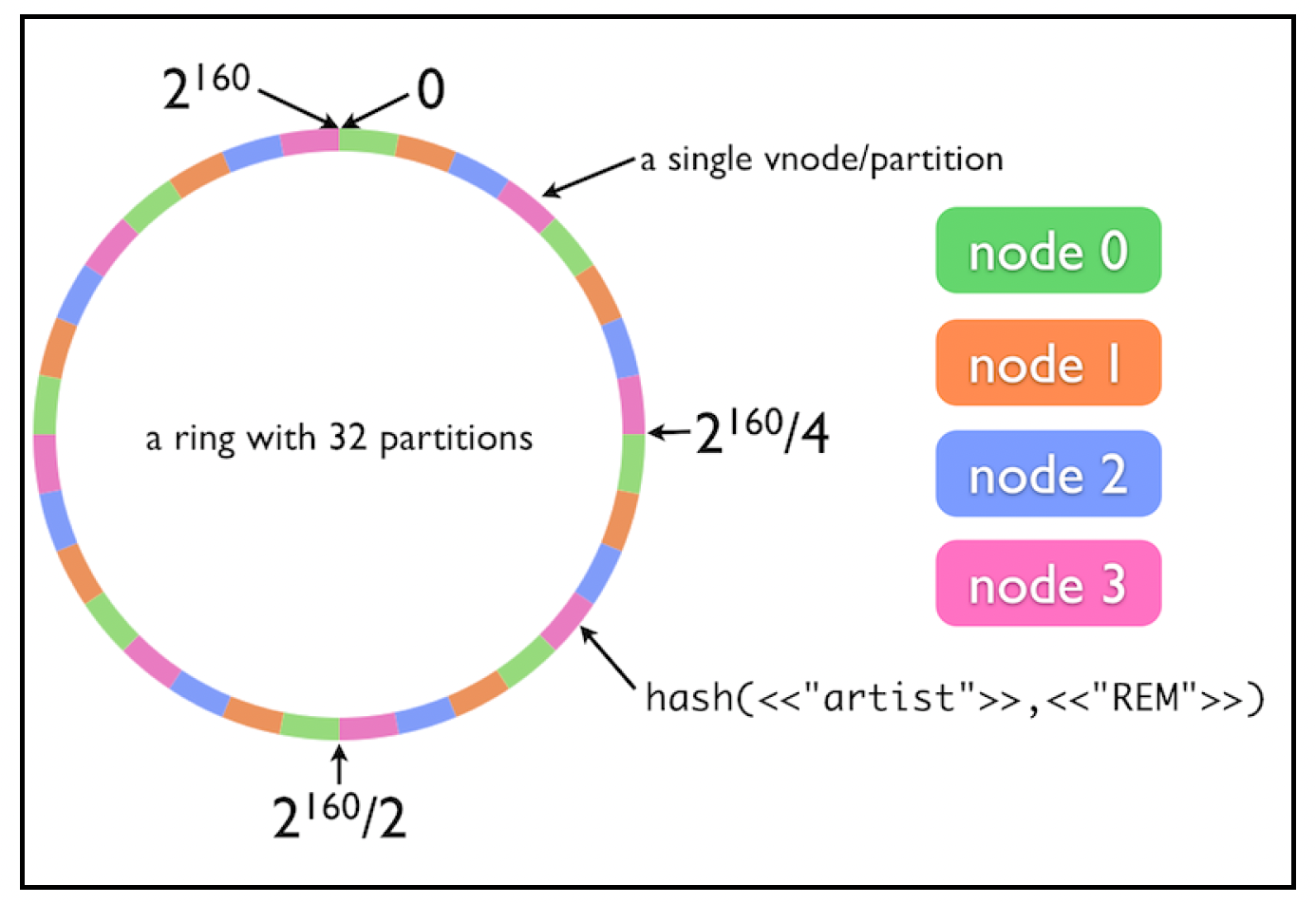
在这里,不是将实际的机器分配到哈希环上,而是将一组虚拟节点分配到哈希环上,并且每台机器会随机分配到等量的虚拟节点。
Cassandra在多个节点上存储副本以确保可靠性和容错性。实际副本的数量由可调整的复制因子决定。副本节点的选择方式取决于配置的复制策略。在SimpleStrategy策略中,一旦在哈希环上找到一个节点,就会继续查找,直到找到所需数量的副本节点。更复杂的策略会考虑节点的机架、数据中心和其他属性,这样所有副本就不会都位于同一个故障域中。
只要存在复制,就会有一致性问题。Cassandra通过可调一致性(tunable consistency)将一致性选项委托给客户端。客户端可以为读写操作选择仲裁级别(quorum levels)——为每个用例选择合适的一致性值。
# 写入路径
Cassandra是无主架构——不存在主节点和从节点/副本之分。客户端可以连接到Cassandra集群中的任何节点。连接后,该节点将充当协调器,代表客户端与集群的其他部分进行所需的交互。
在单个节点上,Cassandra使用日志结构合并树(log-structured merge trees)来存储数据。写入操作的生命周期很简单,就是更新内存中的行/列值表,并写入提交日志(以确保持久性):
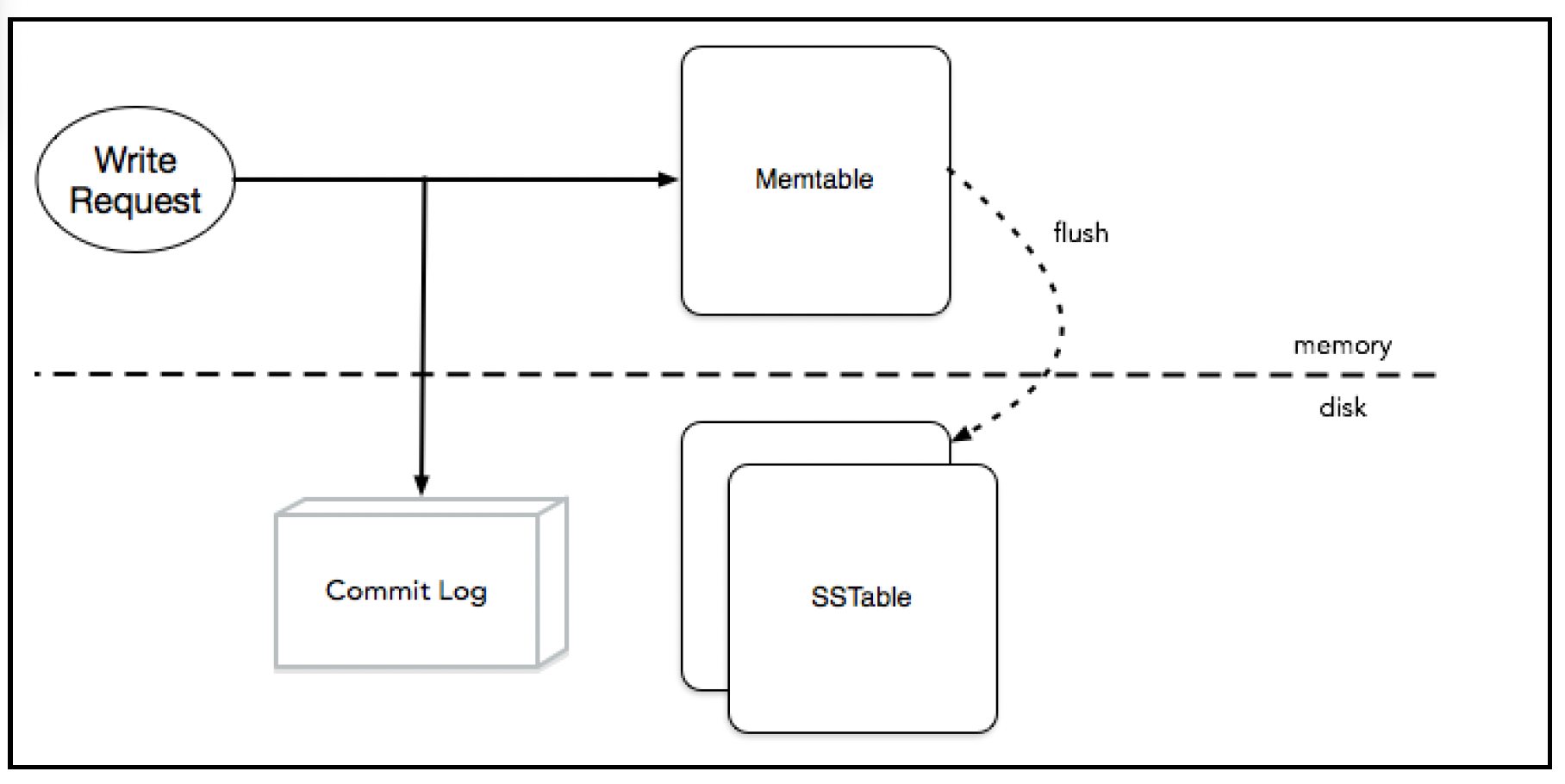
定期地,内存中的表(称为memtable)会被刷新到磁盘,并转换为SSTable格式——其中键按排序形式存储。显然,这会导致产生大量的SSTable。为了保证系统正常运行,Cassandra会进行压缩操作,将多个SSTable合并成一个大的SSTable。由于每个SSTable中的键都是有序的,压缩操作就像合并多个有序列表一样高效。
有多种压缩算法,每种算法都是为了优化特定方面,如磁盘I/O或读取性能。
# 读取路径
读取路径不一定像写入路径那样高效。为了获取某一行所需的列,读取操作可能需要从memtable和可能包含部分数据的各种SSTable中获取数据。读取操作实际上是对所有这些数据结构进行合并:
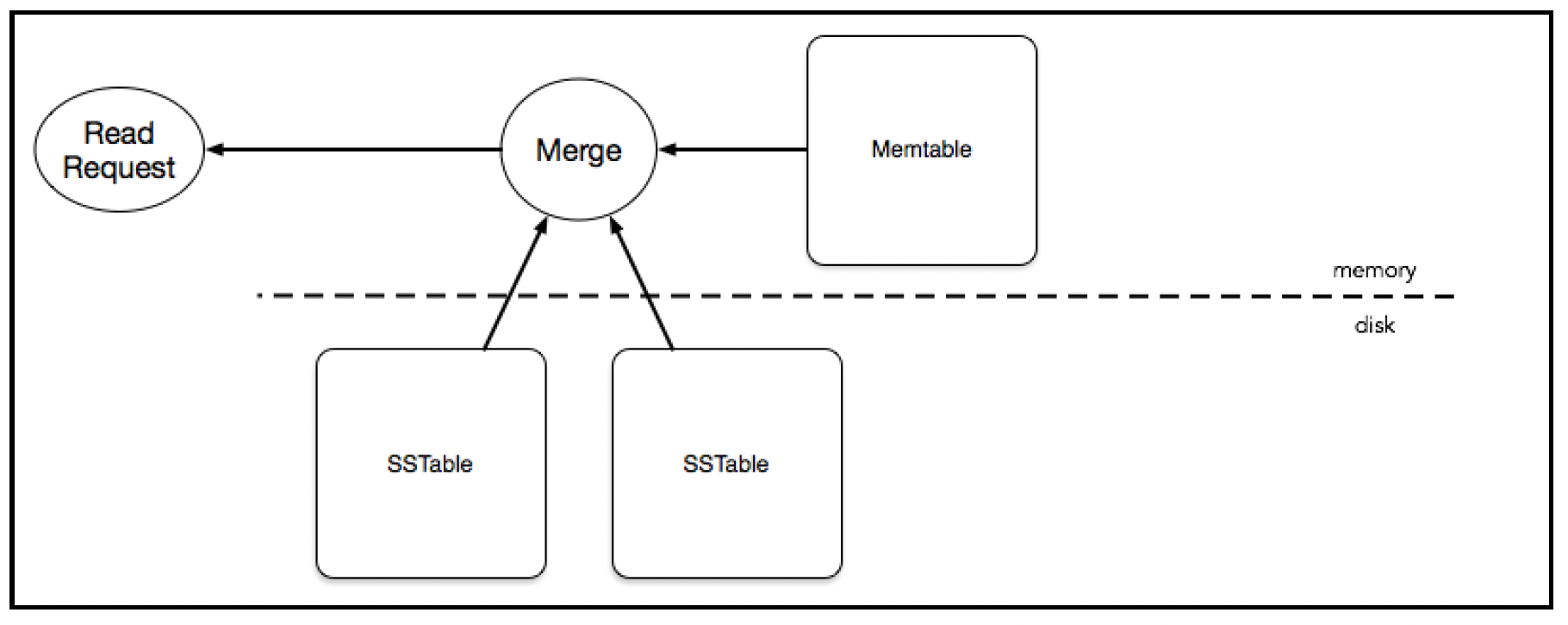
还有一些辅助数据结构,如布隆过滤器(bloom filters),它有助于确定某个SSTable是否包含给定的行,从而避免对每个SSTable进行读取(昂贵的磁盘I/O操作)。压缩操作也有助于提高读取性能,因为需要比较的SSTable数量减少了。SSTable格式包含一个偏移量查找表,有助于确定给定键在SSTable文件中的偏移量。
# 在Go语言中的使用
gocql(https://github.com/gocql/gocql)是一个快速且受欢迎的Cassandra Go客户端,它使用原生传输协议与Cassandra服务器进行通信。其各种特性的文档可在http://gocql.github.io/上查看。我们将使用它来演示在Go语言中如何使用Cassandra。你可以使用以下命令安装它:
go get github.com/gocql/gocql
让我们继续以员工示例为例。我们想要在Cassandra中持久化以下结构体:
type User struct {
Id gocql.UUID
FirstName string
LastName string
Age int
}
2
3
4
5
6
这里,ID是一个UUID,是系统中每个员工的唯一标识符。数据类型来自gocql包。
为了管理Cassandra,我们使用cqlsh客户端。首先要做的是在Cassandra中创建一个键空间(keyspace)。键空间相当于关系型数据库中的数据库。在cqlsh提示符下输入以下内容来创建键空间:
CREATE KEYSPACE roster WITH replication = {'class': 'SimpleStrategy','replication_factor': 1};
我们可以在这里传递关于复制的可调整参数。
接下来,在这个键空间中创建一个名为employees的表:
create table employees (
id UUID,
firstname varchar,
lastname varchar,
age int,
PRIMARY KEY(id)
);
2
3
4
5
6
7
现在Cassandra已经准备好,让我们编写一些Go代码。首先要做的是连接到Cassandra集群。以下代码实现了这一点:
// 连接到集群
cluster := gocql.NewCluster("127.0.0.1")
cluster.Keyspace = "roster"
session, _ := cluster.CreateSession()
defer session.Close()
2
3
4
5
gocql.NewCluster()方法接受Cassandra集群中一些节点的IP地址或主机名,让客户端发现集群拓扑结构。接下来,使用集群信息创建一个会话,用于进行其余的I/O操作。
现在,让我们创建一个用户并将其插入到Cassandra中:
// 为用户生成一个唯一ID
id := gocql.TimeUUID()
// 在内存中创建员工
newEmployee := User{
Id: id,
FirstName: "James",
LastName: "Bond",
Age: 45,
}
// 插入员工数据
if err := session.Query("INSERT INTO employees (id, firstname, lastname, age ) VALUES (?,?,?,?)",
newEmployee.Id,
newEmployee.FirstName,
newEmployee.LastName,
newEmployee.Age).Exec(); err != nil {
fmt.Println("insert error")
log.Fatal(err)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
session.Query()方法接受一个直接的CQL字符串。问号(?)表示位置参数(就像在标准SQL中一样),会用给定的值进行替换。
以下代码展示了读取操作,并验证员工数据是否确实已插入:
// 使用select语句获取我们刚刚插入的员工
var userFromDB User
if err := session.Query("SELECT id, firstname, lastname, age FROM employees WHERE id=?", id).Scan(&userFromDB.Id, &userFromDB.FirstName, &userFromDB.LastName, &userFromDB.Age); err != nil {
fmt.Println("select error")
log.Fatal(err)
}
fmt.Println(userFromDB)
2
3
4
5
6
7
这应该会打印出James Bond的员工信息,表明数据已正确插入。接下来,我们更新数据:
// 更新James Bond的年龄
if err := session.Query("UPDATE employees SET age = 46 WHERE id =?", id).Exec(); err != nil {
fmt.Println("udpate error")
log.Fatal(err)
}
2
3
4
5
我们可以通过读取操作来确认James Bond的年龄确实增加了一岁:
var newAge int
// 选择并显示更改
iter := session.Query("SELECT age FROM employees WHERE id =?", id).Iter()
for iter.Scan(&newAge) {
fmt.Println(newAge)
}
if err := iter.Close(); err != nil {
log.Fatal(err)
}
2
3
4
5
6
7
8
9
这应该会打印出46。
最后,我们从员工名单中删除James Bond:
// 删除员工
if err := session.Query("DELETE FROM employees WHERE id =?", id).Exec(); err != nil {
fmt.Println("delete error")
log.Fatal(err)
}
2
3
4
5
# 提升数据性能的模式
到目前为止,我们已经研究了各种基本的数据建模方法。在某些情况下,我们需要对与数据交互的标准方式进行一些调整,以满足某些用例的性能需求。本节将讨论这些类型的模式。
# 分片(Sharding)
无论单例数据库多么强大,在存储空间和计算资源方面都存在限制。单台服务器在可用性方面也不是很理想。像Cassandra这样的存储系统通过对数据进行透明分区来分布数据。然而,许多系统(包括大多数关系型数据库管理系统)在内部并不对数据进行分区。
解决方案是分片。这意味着将数据存储划分为一组水平分区或分片。每个分片具有相同的模式,但包含自己独特的行集。因此,每个分片本身就是一个数据库。应用程序(或驱动程序)知道如何将对特定数据的请求路由到特定的分片。这样做的好处如下:
- 可以通过添加额外的分片/节点来扩展系统。
- 负载在各个分片之间进行平衡,从而减少资源争用。
- 可以采用智能的放置策略,将数据存储在靠近需要使用它的计算资源的位置。
在云端,可以将分片物理上放置在靠近访问数据的用户的位置,这在存储和访问大量数据时可以提高可扩展性。
分布数据并不难。如果不需要特定的关联性,可以通过哈希函数进行分布。然而,正如在Cassandra深度解析部分所描述的,当拓扑结构发生变化时,数据重新分配是一个挑战。有三种主要方法来解决查找问题:
- 一致性哈希(Consistent Hashing):我们在前面的Cassandra集群部分已经介绍过。
- 客户端路由(Client-side Routing):客户端有一个查找映射表,用于确定哪个分片(节点)存储特定的键(哈希值)。每当拓扑结构发生变化时,客户端会获取更新后的映射表。Redis Cluster就是以这种方式进行分片的。
- 代理路由(Brokered Routing):有一个中央服务,它接收I/O请求,并根据拓扑映射表将请求路由到合适的分片。MongoDB的分片采用这种方法。
# 反规范化(Denormalization)
规范化过程旨在消除建模数据中的冗余。这有助于实现高效的更新操作,即写入操作无需为了保证整体一致性和数据完整性而在多个地方更新数据。
然而,这种方法存在局限性。一个主要的局限是性能问题:某些读取操作可能需要进行大量的数据库操作(连接、扫描等),导致计算成本过高。例如,假设我们有一个旅游网站的经销商用例。这些经销商会像普通旅行社一样为客户进行库存管理和预订,并从旅游网站获得每月末支付的费用。假设预订数据的建模如下:
- 预订(Bookings):
- 预订ID(BookingId)
- 日期(Date)
- 库存单位(SKU)
- 经销商ID(ResellerId)
- 金额(Amount)
- 费用(Fee)
- 经销商(Resellers):
- 经销商ID(ResellerId)
- 名称(Name)
- 地址(Address)
这里,预订表中的经销商ID是经销商表的外键。每次进行预订时,预订数据库事务会填充经销商ID和适用的费用。
现在,有一个新需求,代理商需要计算出当月应得的总费用。这可以通过在预订表上按经销商ID进行分组、扫描所需的时间范围,然后对费用进行求和来实现。
然而,这种方式的性能可能无法接受,并且根据定义的隔离级别,可能会在写入(业务关键)路径上造成瓶颈。解决这个问题的一种方法是在经销商表中维护当月应得费用的计数,如下所示:
- 经销商ID(ResellerId)
- 名称(Name)
- 地址(Address)
- 应得费用(Fees due)
每次进行预订时,数据库事务会将当前预订的费用添加到应得费用列中;获取当前应得费用只需简单地查询表即可。当然,我们做出的权衡是,写入路径需要做更多的工作来维护这些聚合数据。在许多情况下,这种权衡是一个合理的选择。
对于反规范化的模式,在事务中进行更新非常重要。
我们进行反规范化的另一个原因是为了保留变更历史。规范化模式保留了系统的当前状态,而很多时候用例需要变更日志。反规范化通过将数据变更与当前数据状态分开建模来实现这一目的。
# 物化视图(Materialized views)
当需要在更多的计数器(如应得费用)上提高读取性能时,会发生什么情况呢?你可以通过不断更新多个反规范化表来增加写入事务的复杂度,但在某些时候,这种开销会变得难以承受。此外,所需的数据计数器或视图的业务领域可能与事件最初发生的领域不同。因此,尝试更新所有视图可能会违反关注点分离原则。
处理这种情况的另一种模式是事件溯源(event sourcing)和物化视图。
在事件溯源中,进行业务交易的服务会发出一个描述变更的事件。在前面的预订示例中,它可以是一个预订事件(Booking Event)。这个事件会通过消息主题发送出去,从而采用发布/订阅(PubSub)机制将事件广播给感兴趣的各方。
物化视图是指利用这个事件构建一个聚合/合并视图,以满足特定的用例需求。换句话说,数据以最适合特定视图的方式进行物化。在预订示例中,计算应得费用的另一种方法可能是让一个单独的服务提供应得费用的API/视图,并根据预订事件为每个经销商计算费用。假设出现了新的需求,比如统计过去10分钟内的预订情况,那么这样的用例可以通过一个新的API来满足,该API使用相同的预订事件。
物化视图与反规范化相比,权衡之处在于牺牲了时间一致性——系统最终会达到一致状态。当然,其好处是解决方案的可扩展性。
# 总结
在本章中,我们涵盖了实体建模、一致性保证,并探讨了各种数据库选项。我们深入研究了MySQL、Cassandra和Redis,并编写了Go代码,以便实际了解如何使用它们进行数据建模。本章最后介绍了在数据扩展时处理数据性能的模式。
在下一章中,我们将探讨如何构建高度可靠、容错的系统。