 10 案例研究:旅游网站
10 案例研究:旅游网站
# 10 案例研究:旅游网站
要理解架构,就需要一个大型的现实生活中的系统。否则,读者可能会迷失在细节中。他们或许明白如何运用特定的技术和Go语言结构,但在梳理和分析更宏观的构建模块时,可能并不清晰。为了避免这种情况,我们将以一个在线旅游网站作为案例,这样就能运用目前所学的多种技术,打造一个现实生活中的产品。
# 产品
我们将构建一个旅游相关的电子商务网站的部分功能。现实世界中类似的产品有缤客网(Booking.com)和亿客行(Expedia)。该网站将是一个市场平台:公司本身不持有任何库存,而是一个连接旅游产品卖家和买家的场所。让我们从列出相关参与者开始,详细说明需求。
# 参与者
该网站涉及以下几类人群:
- 顾客(Customers):那些想要购买旅游相关产品(机票、酒店、出租车服务等)的人。
- 卖家(Sellers):那些为市场提供库存的人。在本案例研究中,我们假设卖家会提供一个应用程序编程接口(API,Application Programming Interface),以便我们获取数据并进行预订。
# 需求
如前所述,我们要构建一个旅游市场平台,连接顾客和卖家。双方对平台有不同的需求,市场平台需要确保双方都能得到合理满足。下面的图表从宏观层面描述了该产品:
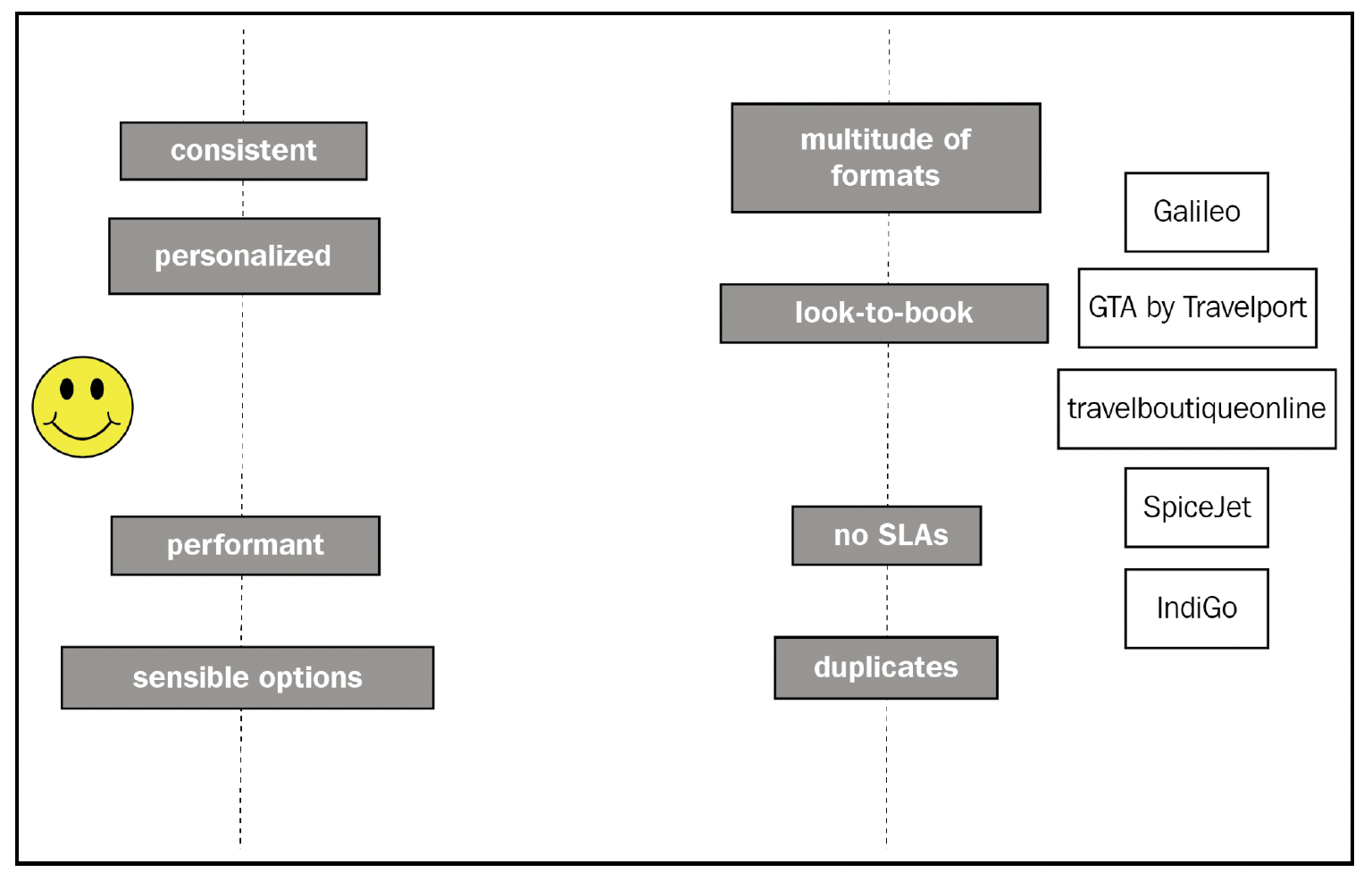
为了更清楚地说明顾客和卖家的需求,我们来看以下几点:
- 顾客应该能够搜索酒店和航班。关键功能需求包括:
- 能够展示来自不同卖家的搜索结果。
- 价格一致性:展示的价格应接近顾客最终支付的价格。
- 能够查看折扣和促销信息。
- 顾客应该能在搜索结果页面看到个性化价格。这些实际上是在标准价格基础上的折扣,折扣来自基于忠诚度积分的奖励计划。例如,如果酒店预订价格为500美元,而顾客钱包中有100积分,那么显示的价格应该是400美元。
- 顾客应该能够预订酒店和航班。这涉及处理支付以及获取卖家的确认信息。
- 顾客应该能够管理自己的预订,包括取消预订。
- 我们应该能够快速让卖家入驻平台。假设卖家提供了定义明确的搜索和预订API。
- 顾客购买产品后,应该收到电子邮件发票。
- 预订过程中出现问题时,顾客应该收到电子邮件通知。
- 网站搜索速度要快。顾客应该能在一秒内看到初始搜索结果。
- 顾客应该能看到接近最终支付的价格。这意味着我们不能一直缓存数据。
- 由于我们是一家新兴的初创公司,卖家不会给我们提供高标准的服务级别协议(SLA,Service-Level Agreement),不过他们会提供丰厚的佣金。
- 卖家有一个搜索预订比(look-to-book ratio)指标。如果我们搜索次数过多但预订量过少,卖家会向我们收费。
# 数据建模
正如前面所讨论的,在着手设计各种功能之前,先思考不同的实体及其关系是明智的。下表对此进行了概述:
| 实体名称 | 描述 | 关系 |
|---|---|---|
| 顾客(Customer) | 这是网站上最重要的用户。每个顾客都有一个唯一且持久的实体,用于描述诸如个人资料、预订/交互历史、支付偏好等信息。在持久化存储时,这个实体有一个唯一的顾客ID,其他实体可以通过该ID来引用特定的顾客。 | 许多其他实体通过顾客ID属性(主键)来引用顾客实体。 |
| 卖家(Seller) | 除了顾客,卖家是平台上第二重要的用户。如前所述,卖家具有不同的特点。从(本案例研究有限需求的)软件角度来看,卖家实际上就是一个API端点和一份特定的合同。 | 许多实体引用卖家。在数据库中,这些关系以外键的形式存在。更有趣的是,从架构角度来看,我们需要为每个卖家设置一个代理,它同时充当适配器,一端与卖家API交互,另一端与旅游网站平台的其他部分交互。后续章节将对此进行详细介绍。 |
| 库存保有单位(SKU,Stock-Keeping Unit) | 我们需要为库存中的每件商品设置一个唯一ID。虽然乍一看酒店和航班属于不同的类别,但可以决定为所有商品设置一个跨类别的唯一ID。“库存保有单位(SKU)”就是这类ID的标准术语。在所有产品线中使用这个唯一ID,能让设计适应未来的用例,比如“度假套餐(航班 + 酒店)”。 | 这将是大多数数据存储的主键的一部分。这个ID不应重复使用,因为可能需要对过去的交易进行审计。SKU形成一种层次结构;具体来说,有些SKU可能有一个父SKU。例如,一家酒店有一个SKU,它的父SKU将是酒店所在城市的ID。 |
| 日期(酒店入住/退房日期、航班出发/到达日期) | 人们希望在特定日期搜索和预订旅游产品。价格和可预订情况会因日期不同而有很大差异。RFC 3339是描述日期的标准,它有多种格式,我们需要选择一种便于在持久化实体和API交互中建模的格式。这在Go语言中会带来一些复杂问题,解决方案是对标准的时间数据类型进行封装。具体细节请参考预订部分。 | 日期在关系方面不太复杂,它们大多是其他实体的属性。 |
| 预订(Booking) | 预订描述了预订航班或酒店的意向。实际的预订过程可能很复杂且耗时,预订持久化实体实例封装了预订的所有状态信息。 | 引用了顾客、SKU和日期。 |
| 预订记录(Reservation) | 在进行预订的过程中,卖家需要完成预订操作。预订记录实体封装了这一信息。 | 一个预订实体引用(包含)多个预订记录实例。例如,往返机票预订可能涉及两个不同卖家的航班,因此会包含两个不同的预订记录。 |
| 钱包(Wallet) | 根据需求描述,我们希望通过忠诚度奖励计划实现个性化定价。本质上,每次预订时,顾客会获得一定积分。顾客可以在未来预订时使用这些积分。钱包余额用于在搜索结果页面显示折扣后的价格。 | 可以建模为每个顾客对应的金额。除了这个标量值,我们还应该存储每笔交易记录,本质上就是一个钱包账户的收支明细分类账。虽然需求中没有严格要求这样做,但这样做便于进行审计,并能处理未来相关的需求。 |
# 高层架构
这是一种基于微服务的方法,同时使用消息传递和API调用。正如第8章“数据建模”中所讨论的,消息传递系统有助于实现可扩展性和弹性。当需要快速即时响应时,服务间的API调用很有用。
下面的图表描述了高层解决方案架构:
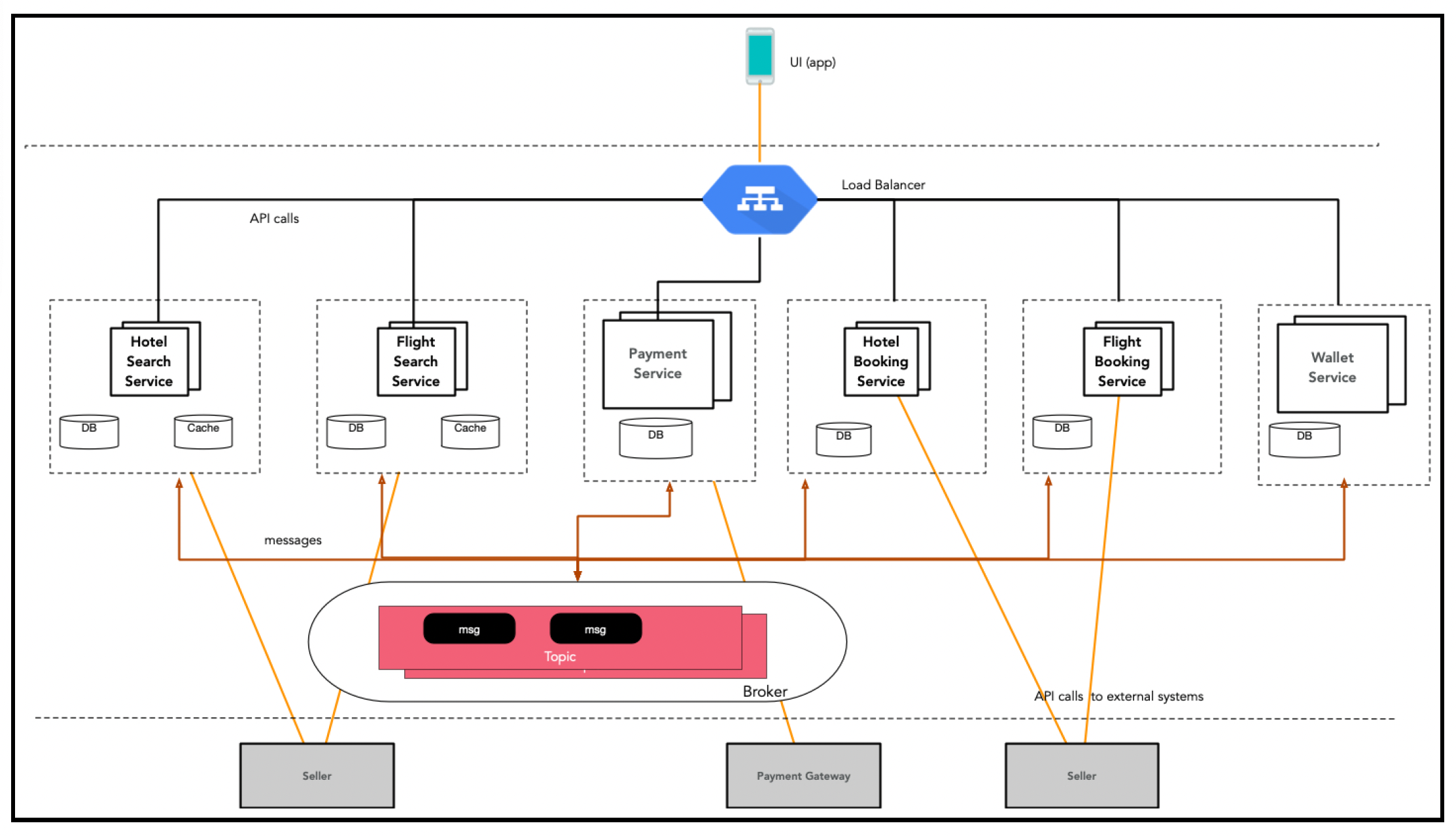
以下部分将详细介绍搜索和预订服务。
# 搜索
搜索功能是顾客最先接触到的产品功能。如果搜索体验不佳,将直接影响业务。如前所述,搜索的关键需求是性能和个性化。考虑到搜索预订比,另一个需求是确保我们不会因卖家收费而产生高额成本。让我们看看如何设计实现这些需求。
一般来说,搜索的输入是地点和日期。具体到航班搜索,输入如下:
- 去程日期。返程日期可选(仅适用于往返航班)。
- 出发地和目的地(机场)。
而酒店搜索参数包括:
- 入住和退房日期。
- 期望入住的城市/国家/酒店名称。
通常,旅游网站也会获取乘客人数。但由于这对架构影响不大,在本案例研究的解决方案设计中忽略这一因素。
对于航班和酒店搜索,响应结果都包括以下内容:
- 静态列表:这是与查询匹配的目录元素。目录本质上是可用商品的字典。对于航班来说,它是两个机场之间航班详细信息(航班名称、飞机类型、提供的服务等)的缓存。这里,实际的信息来源是外部卖家。同样,对于酒店,目录包含房间类型、图片、评分等内容。
- 动态部分:这是列表中每个元素的价格。价格会根据上下文(搜索者身份、搜索时间、是否有折扣等)而变化。通常我们希望获取最新的价格,所以相比静态列表,我们对价格的缓存策略不能过于激进。然而,我们也要优化搜索预订比带来的惩罚,所以这里的缓存生存时间(TTL,Time To Live)设置要灵活,下一节将详细讨论。
# 航班
如前所述,航班搜索的关键是出发地和目的地机场以及日期,顾客搜索时会用到这些信息。
为了满足性能和成本(搜索预订比)的要求,我们需要将卖家的数据导入到我们的系统中,而不是在有需求时随意调用卖家的搜索API。在导入数据的过程中,我们需要以相同的格式存储数据,以便进行高效搜索。
航班搜索中的一个主要微服务是航班目录(Flights Catalog)。它存储了关于航班的所有静态内容(飞机类型、机上提供的服务、标识等)。其高层设计如下图所示:

可以看到,有多个数据导入器从外部卖家获取列表信息,在将其索引到Elasticsearch之前,会对数据进行转换处理。例如,一些卖家可能通过基于XML的API提供数据,而另一些可能使用基于JSON的API。有些卖家可能使用协调世界时(UTC,Coordinated Universal Time)表示时间,而另一些可能会同时提供时区信息。我们需要确保系统的其他部分无需关注这些差异。有些卖家提供拉取式模型,即我们需要调用API获取详细信息。其他卖家提供数据推送系统(例如通过网络钩子(webhooks)),每当价格或库存发生变化时就推送数据。拉取式模型需要更多的工程工作,因为我们需要为目录所需的各种列表安排刷新轮询。
每个卖家都有一个专门的数据导入器。这段代码了解卖家API的具体细节,并将数据转换为目录和旅游网站其他部分存储的标准格式。这种适配器设计模式还能帮助我们快速、可靠地让新卖家入驻平台。你只需使用新卖家的API实现旅游网站端的接口,瞧!卖家就集成好了。
在航班目录(Flights Catalog)中需要注意的一个重要方面是,仅摄取静态数据,而不包括价格数据。这是基于以下原因:
- 价格可能波动极大(如下所述)。它们需要不同的存储和失效机制。
- 航班价格通常通过一个单独的API获取,该API有严格的限流限制。
为简化键的处理,我们可以将出发地、目的地和日期连接成一个字符串(简单的字符串拼接)。这个键随后用于摄取列表(航线)和进行实际搜索。这样的设计选择有助于保持代码其他部分的简洁性。在着手实施之前,你应该花时间研究领域内的实体,并确定这样的建模结构。
摄取器对静态内容所做的转换操作包括添加关键字,以辅助概念搜索。这一点很重要,因为许多地点或事物有多个同义名称。例如,“NY”和“New York”指的是同一个地方。一种有助于概念搜索的机器学习模型是word2vec。它由谷歌开发,本质上是一个双层神经网络,将每个单词映射到一个高维向量空间中,使得具有相同语境的单词(例如,出现在相似短语中的单词)在向量空间中的距离比其他单词更近。后者被称为词嵌入(word embedding),这是一种将单词映射到向量的有效方式,能让概念上相似的单词在词嵌入的n维空间中距离更近,其向量也更接近。如下图很好地展示了这一点:
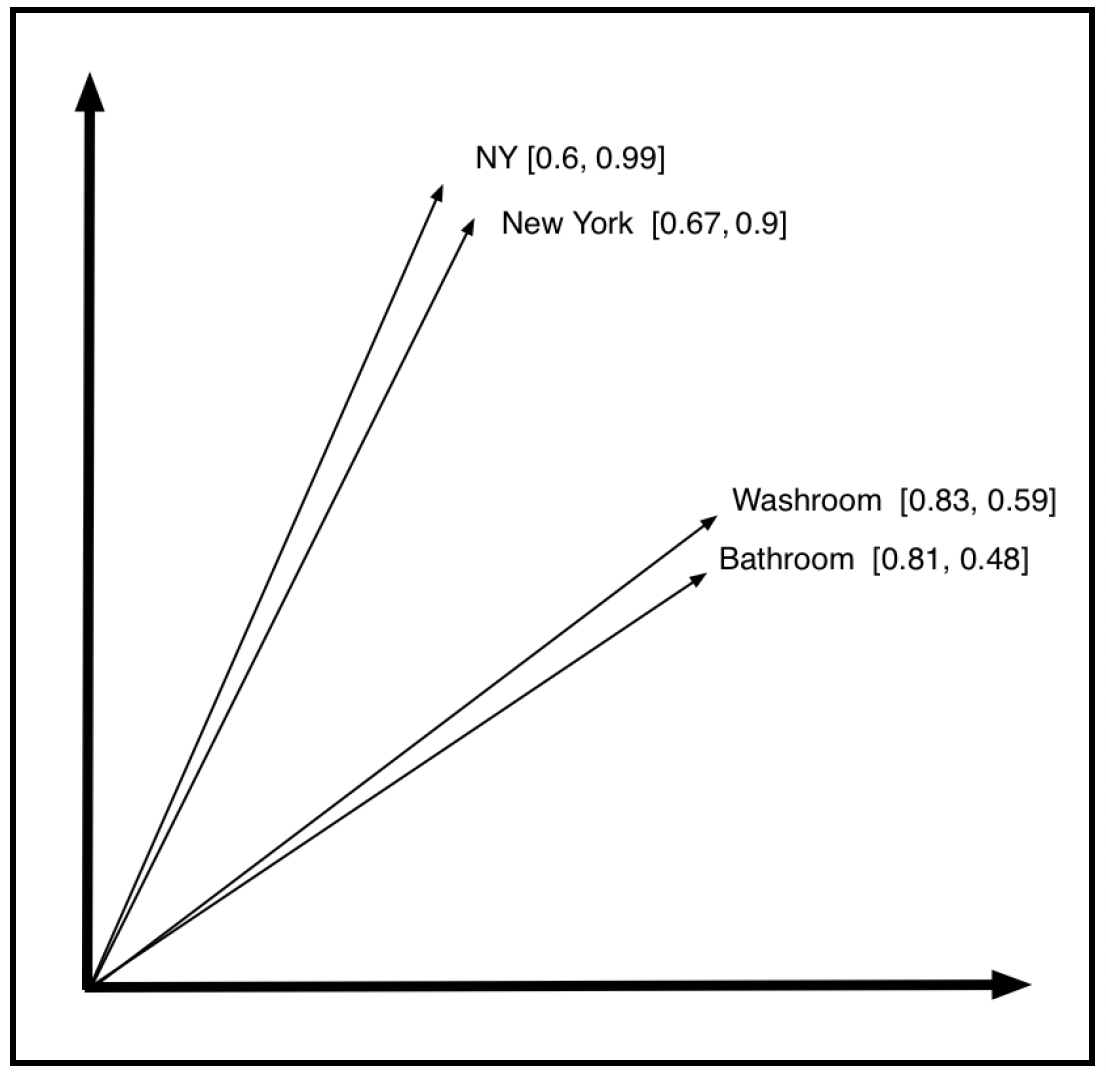
在搜索过程中,可能会使用多个机器学习模型以不同方式丰富原始数据。而且,在任何时候,可能都在评估不止一个版本的模型。将系统其他部分与这些具体细节相分离的关键在于,要有一个框架,让数据科学家可以迭代并部署新模型,同时数据摄取管道的其他部分保持不变。
经过所有转换后,数据被存储到Elasticsearch中。Elasticsearch本质上是Lucene索引的分布式集合(每个索引分布在集群中的多个节点(分片)上)。在将列表摄取到Elasticsearch之前,会将其转换为JSON文档(https://github.com/olivere/elastic是Go语言中最受欢迎的Elasticsearch客户端)。
我们这里的主要用例是使用倒排索引对文档中列出的各种属性进行基于n - gram的查询。在搜索过程中,我们可以使用各种可插拔的相似度函数对匹配的文档进行排名;其中一种流行且简单的函数是词频 - 逆文档频率(Term Frequency - Inverse Document Frequency,TF - IDF)。这里,TF是指查询关键字在列表中出现的次数,而IDF是指包含该关键字的列表数量的倒数。具体公式如下: $$ Wtd = TFtd * log(N / DFt) $$
考虑以下定义:
- TFtd:术语t在文档d中出现的次数
- DFt:包含术语t的文档数量
- N:文档总数
Wtd得分越高,该列表与关键字的相关性就越高。Elasticsearch提供了一个REST API用于在倒排索引中进行搜索。目录API在其基础上提供了一个轻量级包装,并执行诸如身份验证等辅助任务。
如前所述,航班价格需要缓存,以避免触及卖家的限流限制。然而,我们需要合理调整缓存的生存时间(TTL)。为设计出一个好的解决方案,我们需要了解领域或业务的特性。搜索未来(比如三个月后)的航班,其价格在接下来的三天内不太可能发生变化。然而,搜索当天或次日的航班,返回的价格则波动很大。因此,当天或次日航班的价格应短时间缓存。这种对TTL的智能调整有助于我们管理系统中的价格变化。
除了常规价格,我们还有价格个性化的需求,这可能涉及折扣券、促销活动、钱包余额等方面。这里有一个重要的思路:我们不必只缓存价格;实际上,应该尽可能多地缓存聚合响应。从前面的讨论可知,唯一不能缓存的是钱包折扣(因为钱包中的金额可能在多个地方使用)。因此,我们可以使用智能TTL缓存聚合响应,然后在每次搜索时调用钱包服务,获取可用于折扣的金额。
我们可以使用Redis作为键值存储。这是一种非常高效的基于TTL的键值查找方式。Redis高性能的原因在于它将数据存储在内存中。可能有人会问:将数据存储在内存中不会有风险吗?正如我们在第8章“数据建模”中看到的,Redis可以进行集群化部署以实现高可用性。因此,我们可以应对单台机器的故障。此外,这个存储只是一个缓存,并非事实的最终来源;所以,为了性能而牺牲一定的持久性是可以接受的。
随着航班被预订,当达到一定阈值后,我们需要使缓存失效,以确保价格和可用性信息不会过时。这将由预订服务(Booking Service)发送的消息驱动,如“预订”部分所述。
高层级的搜索设计如下图所示:
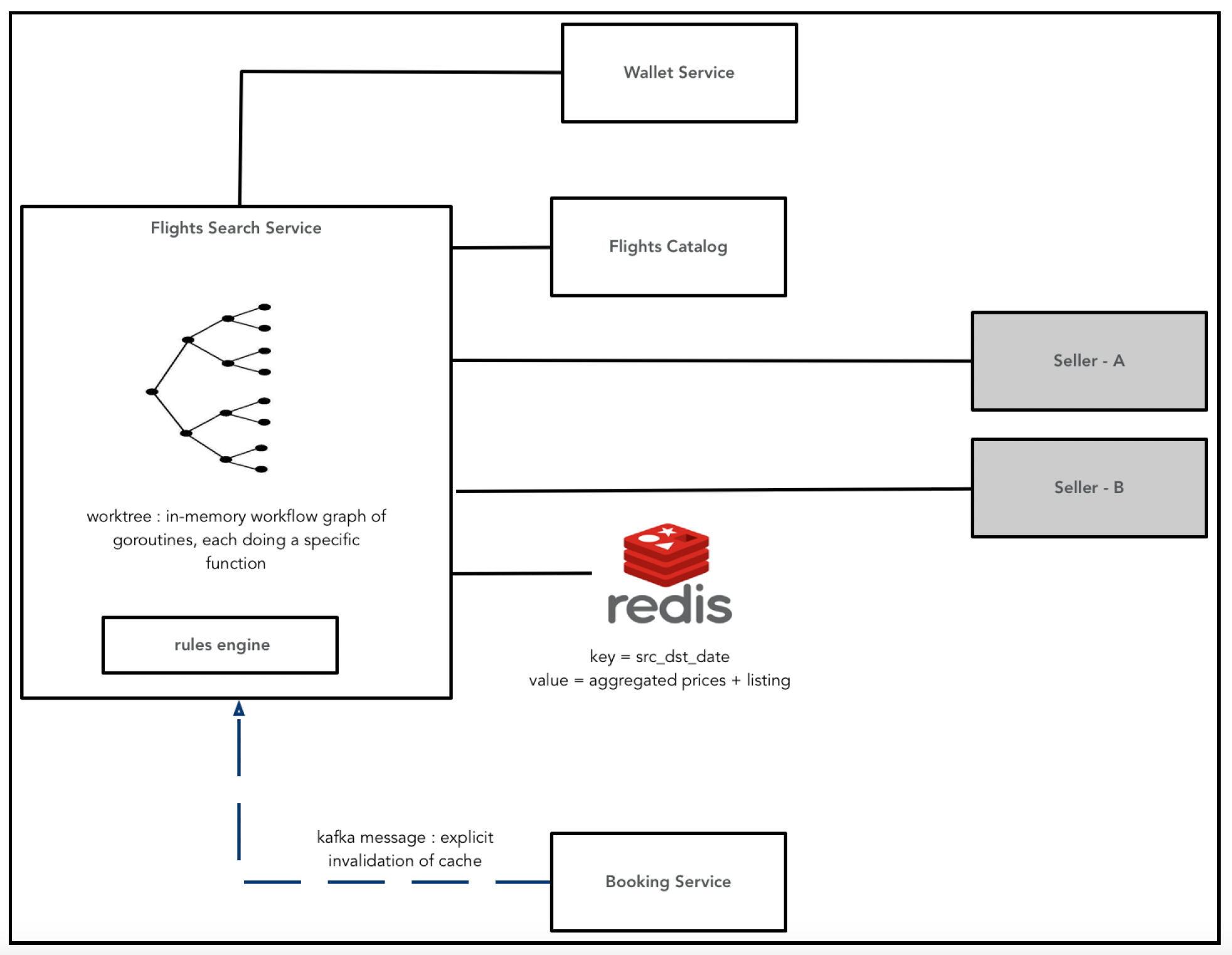
有关消息传递(Kafka)部分,请参考“预订”部分。
主要组件是航班搜索服务(Flights Search service)。它负责进行多项计算和API调用,其中大部分操作可以并发和并行化处理。并行调用涉及其他服务,如卖家服务、钱包服务、Redis缓存等。Go语言非常适合对这种并发情况进行建模:
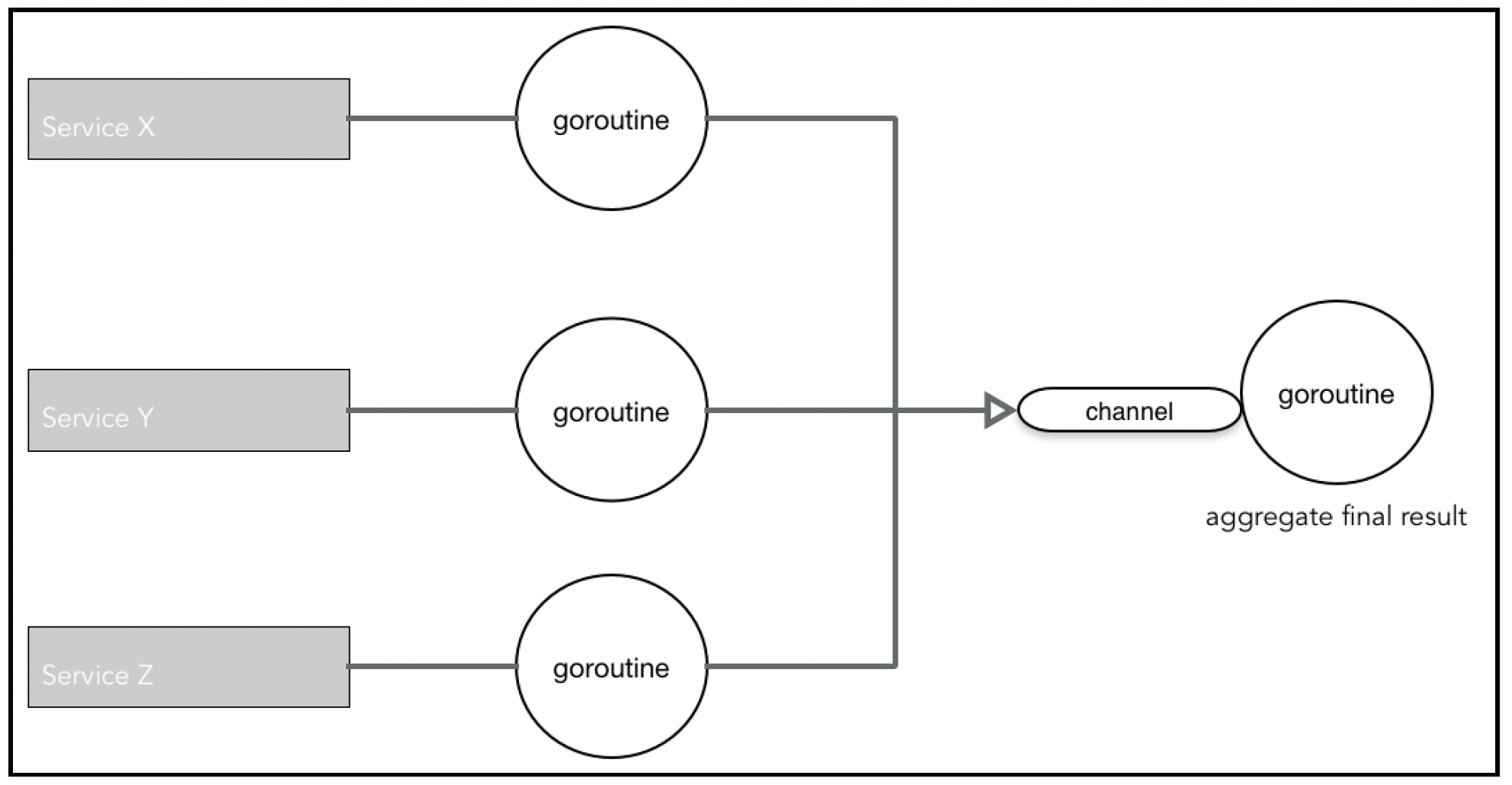
然而,我们需要开发一个框架,让开发人员无需担心样板代码,只需专注于业务逻辑。
接下来将介绍一个通用框架示例——CommandTree(代码位于https://github.com/cookingkode/worktree)。这个框架允许以MapReduce范式编写此类工作流程。树的叶子节点是映射器(mapper),它们通过生成一些数据(在这种情况下,通过调用API)启动处理过程,并将数据转换为通用格式。内部节点是归约器(reducer),它们对数据运行某种函数,然后将输出向上游传递。最后,树的根节点得到聚合后的最终结果。
该库的核心是CommandTree数据结构,它基于组合设计模式。它还利用了Go语言中函数是一等公民这一特性。其结构体定义如下:
type CommandTree struct {
Reducer func(inp []interface{}) interface{}
LeafFunctions []func(inp interface{}) interface{}
LeafFunctionsInput []interface{}
nChildren int
LeafFunctionsOutput []interface{}
}
2
3
4
5
6
7
叶子实体是节点的子节点,是映射器函数以及这些函数所需的数据。有一个名为AddMapper的方法,用于向CommandTree对象添加映射器,代码片段定义如下:
func (t *CommandTree) AddMapper(f func(inp interface{}) interface{}, input interface{}) int {
t.LeafFunctions = append(t.LeafFunctions, f)
t.LeafFunctionsInput = append(t.LeafFunctionsInput, input)
temp := t.nChildren
t.nChildren += 1
return temp
}
2
3
4
5
6
7
所有AddMapper()的调用者都会添加多个子映射器、它们的函数以及输入数据。
归约器本质上是一个函数引用,它接收映射器函数的所有输出,并为这个CommandTree生成最终输出。一个特定的库存单位(SKU)可能由多个卖家提供。在这种情况下,我们需要选择从哪个卖家展示该SKU。归约器就是可以承载这种逻辑的地方。CommandTree库的使用者可以使用以下辅助方法附加任何符合func(inp []interface{}) interface{}签名的函数:
func (t *CommandTree) AddReducer(f func(inp []interface{}) interface{}) {
t.Reducer = f
}
2
3
可以通过Run()方法启动CommandTree的处理过程(映射器和归约器的执行)。这个方法会为每个映射器生成一个goroutine,通过通道聚合数据,最后运行归约器以给出最终输出。为此需要编写相当多的包装代码:
// 映射器返回结果的包装结构体
type ResultFunction struct {
Child int // LeafFunctions数组的索引,用于标识映射器
Result interface{} // 映射器函数的通用结果
}
// 映射器函数的包装函数,以便将其作为goroutine启动
// 它接收结果通道的引用,并在将映射器函数的输出包装在ResultFunction中后,将其发送到同一通道,以标识映射器函数
func wrap(c chan ResultFunction, child int, todo func(inp interface{}) interface{}, inp interface{}) {
var result ResultFunction
startTime := time.Now()
result.Result = todo(inp)
endTime := time.Now()
log.Println("WRAP TOTAL ", endTime.Sub(startTime))
result.Child = child
c <- result
}
func (t *CommandTree) Run(_ interface{}) interface{} {
channel := make(chan ResultFunction, t.nChildren)
defer close(channel)
t.LeafFunctionsOutput = make([]interface{}, t.nChildren)
for i, f := range t.LeafFunctions {
go wrap(channel, i, f, t.LeafFunctionsInput[i])
}
remaining := t.nChildren
for remaining > 0 {
result := <-channel
remaining -= 1
t.LeafFunctionsOutput[result.Child] = result.Result
}
return t.Reducer(t.LeafFunctionsOutput)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
组合的关键在于Run()方法本身可以作为另一个CommandTree对象的映射器。这就是Run()方法签名如此设计的具体原因——这个函数的输入只是一个占位符,应该设为nil,如下所示:
// 由于输入是一个通用接口,传递多个参数的一种方式是使用复合结构
type TwoArgs struct {
X int
Y int
}
// 一个映射器,返回X和Y的乘积
func mult(i interface{}) interface{} {
args := i.(TwoArgs)
return args.X * args.Y
}
// 一个映射器,返回X和Y的和
func sum(i interface{}) interface{} {
args := i.(TwoArgs)
return args.X + args.Y
}
// 一个归约器,用于对映射器子节点的输出求和
func merge(results []interface{}) interface{} {
var sum int
for _, x := range results {
sum += x.(int)
}
return sum
}
// 最终,两级工作树的使用示例
func main() {
level2 := worktree.CommandTree{}
level2.AddMapper(mult, TwoArgs{2, 3})
level2.AddMapper(mult, TwoArgs{2, 2})
level2.AddReducer(merge)
level1 := worktree.CommandTree{}
level1.AddMapper(level2.Run, nil) // ← 嵌套使用时,Run的输入设为nil
level1.AddMapper(sum, TwoArgs{2, 2})
level1.AddReducer(merge)
fmt.Println(level1.Run(nil).(int)) // ← 执行整个树
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
这个框架能让搜索服务减少样板代码的数量,并且正如我们接下来将看到的,它甚至在酒店搜索中也可复用。
我们需要有能力分离业务规则,并在每次新摄取价格数据时运行这些规则。这就引出了设计中另一个有趣的方面:规则引擎。它允许用文本定义各种规则,比如格式规则。这里的规则可用于扩充计算缓存TTL和折扣金额等内容的代码。https://github.com/Knetic/govaluate是规则引擎库的一个不错选择。以下代码展示了一个规则示例:
bookingErrorsExpression, err :=
govaluate.NewEvaluableExpression("(bookingErrors * totalNoBoookings / 100) >= 90");
inputs := make(map[string]interface{})
inputs["bookingErrors"] = 96;
inputs["totalNoBoookings"] = 100;
bookingErrorsCrossedThreshold, err :=
bookingErrorsExpression.Evaluate(inputs);
// bookingErrorsCrossedThreshold现在将被设为"true"
2
3
4
5
6
7
8
底层设计需要明确确定哪些计算部分适合通过可配置表达式(规则引擎)来构建,哪些部分最好直接用代码编写。一个常见的设计缺陷是过度依赖规则;试图将每个计算都映射为规则可能效率低下,还会导致复杂性增加。你需要明智地评估哪些计算需要通用化或可配置,哪些最好编写成简单直接的代码。
在网站上,搜索框大致如下:
| 输入出发城市/机场: |
|---|
| 输入目的地城市/机场: |
| 去程日期: |
| 返程日期(往返机票可选): |
| 乘客数量: |
搜索键是出发地、目的地和旅行日期的拼接。对于往返机票,出发地/目的地的值会互换,返程日期将用于构成搜索键。这个搜索键随后被发送到航班搜索API,该API使用前面讨论的CommandTree模式构建计算树。这里的映射器将是对目录服务和Redis的调用。如果缓存中没有数据,就需要调用卖家服务获取价格和可用性信息。航班搜索服务会将根节点的归约值序列化后作为API响应返回。
聚合响应必须结合钱包服务的响应进行扩充,以便在用户界面上显示最终折扣价格。钱包服务的内容永远不能缓存,这是为了避免提供无法核对的折扣。
# 酒店
酒店搜索与航班搜索类似。客户会搜索特定城市的酒店,或者直接输入酒店名称。因此,我们希望有一个目录,能够根据列表中的多个关键字提供酒店信息。Elasticsearch能够处理这种情况,所以我们可以继续将其用作酒店静态列表的主要数据存储。
酒店搜索的一个主要区别在于卖家构建价格的方式。酒店经营者会为特定日期的每个房间定价,而客户的查询可能涉及入住和退房日期范围。简单的搜索算法只是从数据存储中获取入住和退房日期之间的价格,并将这些价格相加得到最终价格。然而,在搜索城市中的酒店时,对每个酒店都这样处理,无法达到所需的性能指标。因此,虽然需要缓存,但酒店价格的缓存解决方案在方式上与航班价格的缓存略有不同。实现良好性能的诀窍在于预先计算最常用的入住/退房日期组合的总价。这必须在从卖家摄取价格数据时完成。敏锐的读者可能会想到,预计算会导致大量的写入放大。因此,我们需要一个具有良好写入性能的价格存储解决方案。
Cassandra正是适合这项工作的工具。然而,我们需要仔细对数据进行建模。如我们所见,Cassandra是一个分区数据存储,实现良好读取性能的关键在于避免查询时的分散聚集操作。在酒店搜索场景中,查询是针对特定城市或酒店名称的。因此,我们可以优化价格存储,使其为整个城市提供服务。城市将成为我们Cassandra列族的分区键。数据模型如下所示:
| 字段/列 | 含义 |
|---|---|
| SKU | 酒店或城市的唯一ID。这是分区键,用于在Cassandra集群的节点之间分配信息。 |
| CheckInDate | 入住日期。这是表/列族聚类/排序的第一部分。这使得在特定酒店或城市中,对于给定的入住日期能够进行高效搜索。 |
| CheckOutDate | 退房日期。这是表/列族聚类/排序的第二部分。在特定节点上,数据首先按入住日期排序,然后按退房日期排序。因此,这使得在特定酒店或城市中,对于给定的入住日期能够进行高效搜索。 |
| ParentSKU | 对于酒店,这是所在城市;对于城市,该值为null。 |
| RoomId | 房间的唯一标识符。Elasticsearch将包含房间的静态信息,如图像等。 |
| BasePrice | 房间的基础价格。 |
| Taxes | 房间的税费。 |
因此,该存储的主键将是(库存保有单位(SKU)、入住日期(CheckInDate)、退房日期(CheckOutDate))。如前所述,这个复合键意味着SKU将作为分区键,而入住日期和退房日期将作为聚簇键。
微服务允许各个服务在基础设施方面采用多种技术。虽然这种灵活性很好,但重要的是,对于每个基础设施组件(数据库、消息传递等),将技术选择限制在少数几种方案内。这在很多方面都有帮助,比如便于团队之间分享经验,以及在生产环境中构建整体监控系统。
在网站上,搜索框主要会显示以下信息:
- 输入城市或酒店名称
- 入住日期
- 退房日期
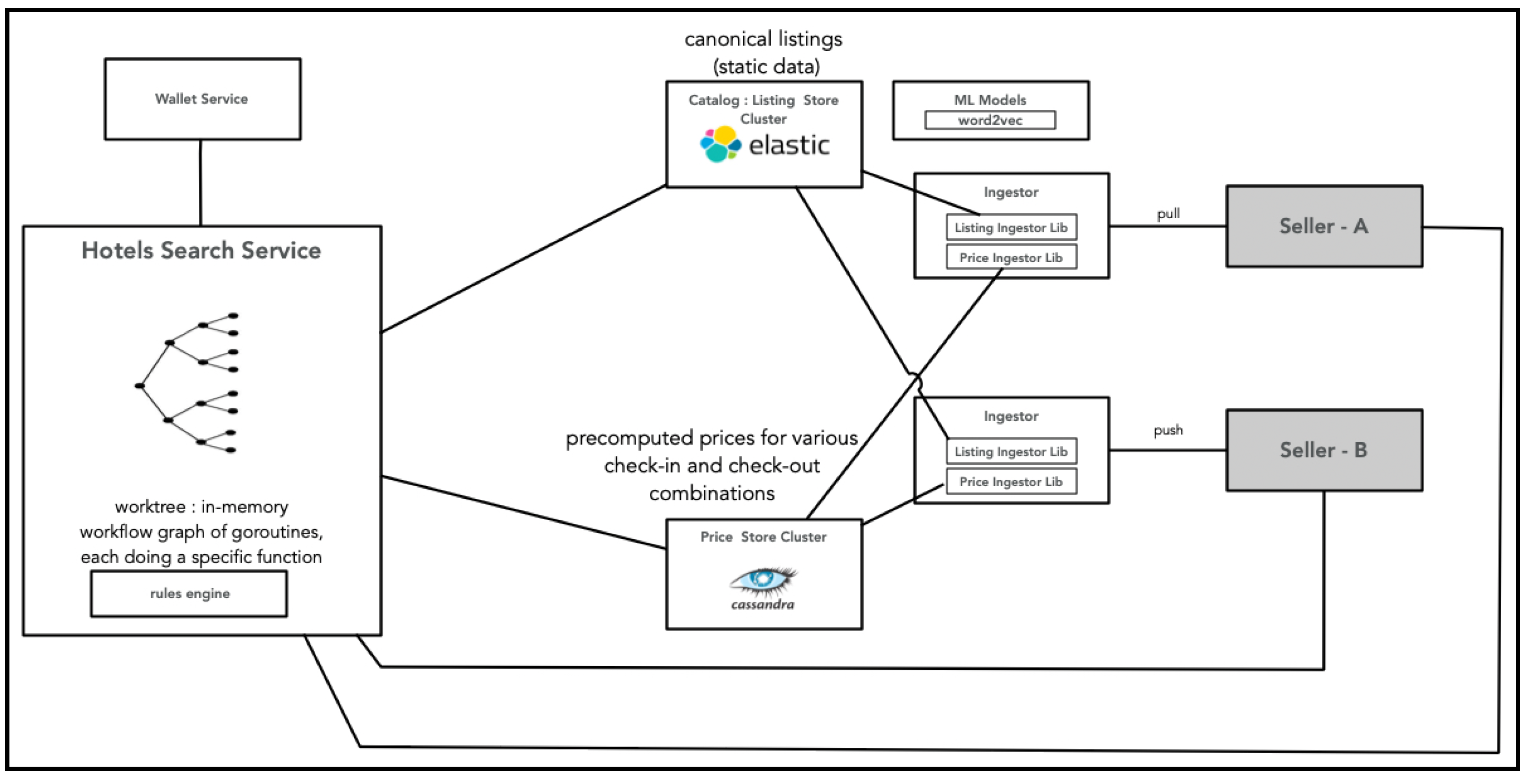
用户输入详细信息后,前端会调用酒店搜索服务(Hotel Search Service),而酒店搜索服务又会并行访问目录服务和价格存储服务。目录服务将返回实体(城市或酒店)的静态详细信息,例如房间信息、图片链接等。如前所述,价格存储服务返回定价信息。搜索服务将合并这两个响应(由于目录服务和价格存储服务都会按房间ID作为键来返回数据,这一过程效率较高),并将合并后的信息呈现给前端(用户界面)。
由于价格存储服务仅缓存最常使用的入住/退房日期组合,因此查询可能需要从卖家那里获取数据。当然,这在性能上不如从价格存储服务获取的结果,但由于我们无法高效存储所有可能的入住/退房日期组合,这种权衡是必要的。
除此之外,正如我们在航班搜索中所讨论的,还会调用钱包服务(Wallet Service),以获取适用于价格个性化的金额。
酒店搜索的高层架构总结如下图所示:
# 预订
预订流程与搜索流程相比,具有非常不同的特点和要求。在这里,可靠性比性能更重要。如果客户已经完成支付,那么他们应该获得预订确认。不过,好在预订量通常只是搜索量的一小部分,所以不像搜索流程那样对性能有严格要求。
此外,预订还涉及一系列工作流程。一旦完成支付,系统需要与卖家进行预订确认,并给客户发送电子邮件等。我们将设计一个事件驱动架构(EDA,Event-Driven Architecture)模式来处理预订流程。其流程应该与航班和酒店预订类似,所以我们可以深入研究酒店预订流程来获取相关思路。
高层架构如下图所示:
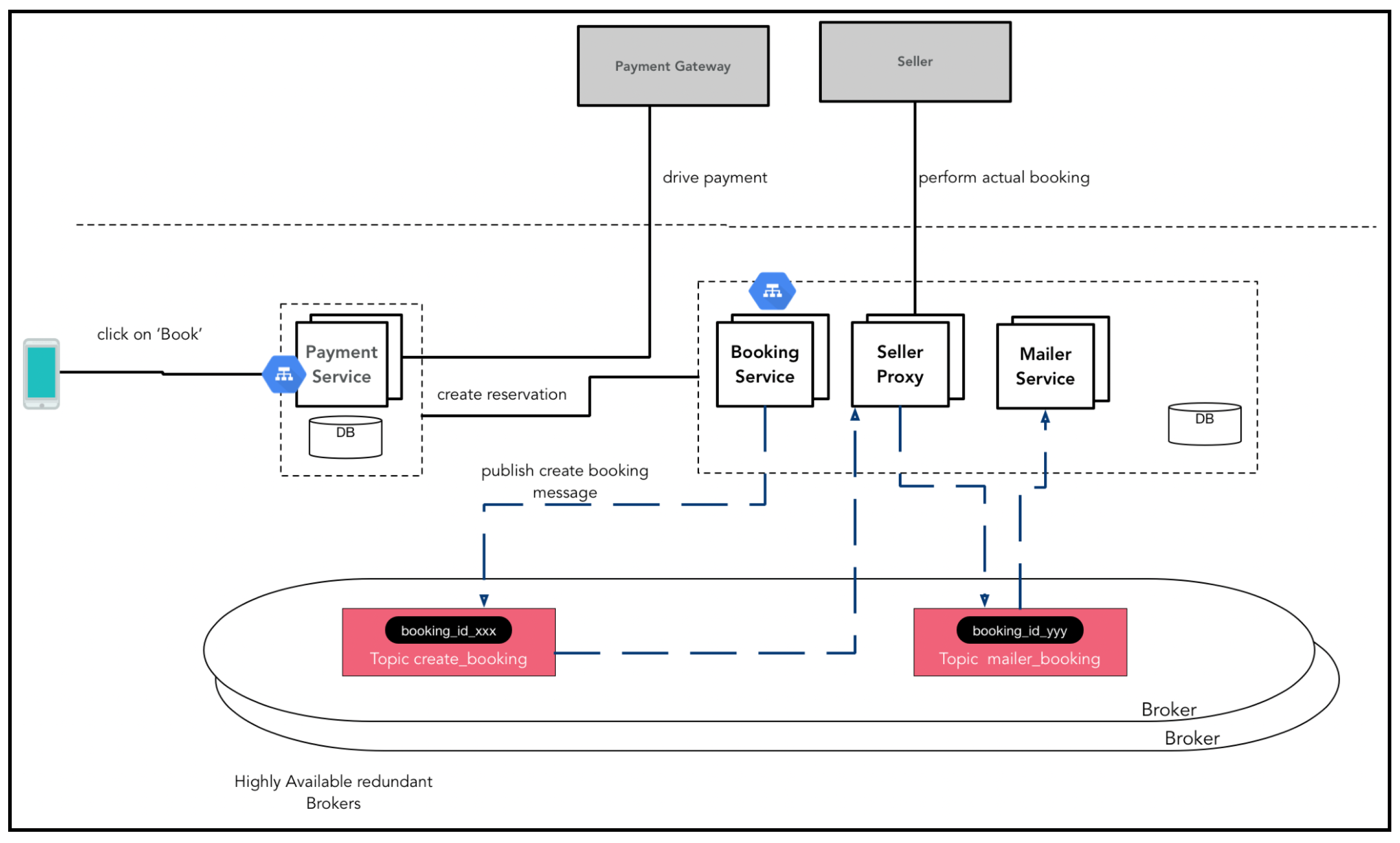
该架构的核心是消息传递层。在这个示例实现中,我们将使用Kafka。它负责在驱动预订流程各个阶段的不同微服务之间传递消息。以下部分将详细介绍这一点。
# 支付
当客户在网站上点击“预订”按钮时,首先需要进行支付。这是一个相当复杂且紧密相关的任务,在我们的案例中,最好由一个单独的微服务——支付服务(Payment Service)来完成。
以下序列图描述了使用信用卡进行支付的常见流程:
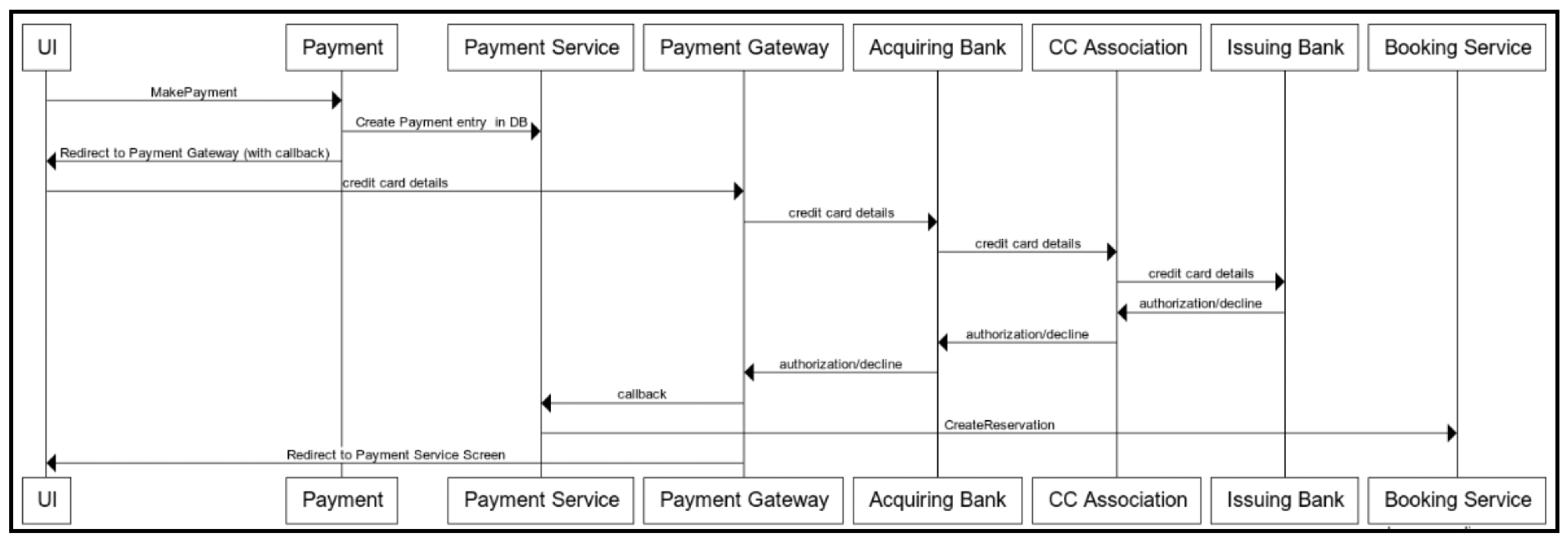
让我们来看一下以下步骤:
- 当客户在搜索结果页面点击“预订”按钮时,会调用支付服务(SKU)的
MakePaymentAPI。该API的参数描述了SKU(哪家酒店、哪个航班)和金额。 - 支付服务在其数据库中记录正在进行的支付,然后将用户界面重定向到支付网关(Payment Gateway),并附上回调URL。支付网关是一种非常专业的软件,通常是外部服务。
- 支付网关将消息转换为标准格式,然后将交易信息转发给旅游网站使用的支付处理器,即收单银行(acquiring bank)。收单银行是网站用于处理支付业务的合作银行。
- 收单银行的支付处理器将信息转发给信用卡组织(例如Visa、万事达卡或美国运通),信用卡组织再将交易信息发送给客户信用卡的发卡银行(给客户发行信用卡的银行)。
- 发卡银行收到信用卡信息,验证是否可以进行扣款,然后将授权或拒绝信息返回给信用卡组织。
- 信用卡组织将响应转发给收单银行,收单银行再将其转发给支付网关。
- 支付网关收到响应,然后触发在初始重定向时提供的回调。这使得支付服务能够了解支付状态。如果信用卡获得授权,支付服务会调用预订服务的API来创建预订(见“预订”部分)。
- 然后,用户界面会重定向回支付页面。随后,如果信用卡被授权,客户将被带到预订确认页面;如果支付被拒绝,客户会收到相应的错误信息。
# 预订
支付回调触发后,我们需要在预订数据库中创建一个预订实体。预订工作流程会经历多个阶段,这个持久化实体将负责为工作流程中涉及的所有微服务维护预订状态。
预订服务是一个REST API,我们将使用Gin(我们在第5章“分布式架构”中介绍过)来实现它。在支付回调期间调用的createReservation API定义如下:
func createReservation(c *gin.Context) {
var (
reservationDTO HotelReservationDTO
err error
)
if err = c.ShouldBindJSON(&reservationDTO); err == nil {
fmt.Printf("In createReservation : %+v\n", reservationDTO)
err = persistReservation(&reservationDTO)
sendMessageToPerformBooking(&reservationDTO)
//return OK
c.JSON(http.StatusAccepted, gin.H{"status": "created"})
}
if err != nil {
// some inputs parameters are not correct
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
HotelReservationDTO是一个数据传输对象,代表客户端和服务器都能理解的对象,它描述了预订的详细信息:
type HotelReservationDTO struct {
CustomerId uint `json:"customer_id" `
PaymentIdentifier uint `json:"payment_identifier" `
SKU uint `json:"entity_id" `
RoomId uint `json:"room_id" `
CheckIn ReservationTime `json:"check_in" gorm:"type:datetime"`
CheckOut ReservationTime `json:"check_out" gorm:"type:datetime"`
}
2
3
4
5
6
7
8
你可能想知道为什么我们使用ReservationTime而不是标准的time.Time。其实,ReservationTime只是对time.Time的一个简单包装,之所以需要这样做,是为了让编码/JSON包能够准确理解如何序列化/反序列化时间。目前,该包仅接受RFC3339特定格式的时间(例如,"2018-11-01T22:08:41+00:00"),但这对我们来说不太方便,因为我们希望输入像2018-12-07这样的日期。在Go语言中,解决方法是使用包装结构体,如下所示:
const reservationDateFormat = "2006-01-02"
type ReservationTime time.Time
func (t *ReservationTime) UnmarshalJSON(bytes []byte) error {
rawT, err := time.Parse(reservationDateFormat, strings.Replace(
string(bytes),
"\"",
"",
-1,
))
if err != nil {
return err
}
*t = ReservationTime(rawT)
return nil
}
func (t *ReservationTime) MarshalJSON() ([]byte, error) {
buf := fmt.Sprintf("\"%s\"",
time.Time(*t).Format(reservationDateFormat))
return []byte(buf), nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
从前面的代码来看,它的功能如下:
- 它使用
persistReservation()在数据库中创建预订实体。 - 然后使用
sendMessageToPerformBooking()向卖家代理发送一条Kafka消息,以实际进行预订。
为实现持久化,我们将使用MySQL作为关系型数据库。为避免编写大量重复代码,我们将使用对象关系映射(ORM,Object Relational Mapper )工具,具体使用gorm(https://github.com/jinzhu/gorm )。persistReservation()函数定义如下:
func persistReservation(res *HotelReservationDTO) error {
// Note the use of tx as the database handle once you are within a
// transaction
tx := db.Begin()
defer func() {
if r := recover(); r != nil {
tx.Rollback()
}
}()
if tx.Error != nil {
return tx.Error
}
//TODO : Check that there is no overlapping reservation
if err := tx.Create(&HotelReservation{
CustomerId: res.CustomerId,
PaymentIdentifier: res.PaymentIdentifier,
SKU: res.SKU,
RoomId: res.RoomId,
CheckIn: time.Time(res.CheckIn),
CheckOut: time.Time(res.CheckOut),
Id: makeId(res),
Status: Initial,
}).Error; err != nil {
tx.Rollback()
return err
}
fmt.Println("created hotel reservation..")
// update the entry for availability threshold
var threshold AvailabilityThreshold
tx.Where("entity_id = ? AND room_id = ?", res.SKU, res.RoomId).First(&threshold)
fmt.Printf("\nthreshold = %+v\n", threshold)
tx.Model(&threshold).Where("id = ?", threshold.ID)
.Update("availability", threshold.Availability-1)
// NOTE : availability is just a threshold for update here.
// Even if availability is 0, reservation is forwarded to the Seller
// And availability >0 in thresholds DB is not a guarantee of
// reservation
if threshold.Availability <= 1 {
// we have reached threshold
sendInvaliationMessageToPriceStore(threshold.SKU, threshold.RoomId)
}
return tx.Commit().Error
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
它通过启动一个事务来开始操作。这一点很重要,因为我们要更新多个表,需要ACID(原子性、一致性、隔离性、持久性)语义的支持。主要更新的两个表如下:

availability_thresholds表是使价格存储服务缓存保持最新的一种方式。进行几次预订后,预订服务会向价格存储服务发送一条消息。然后,价格存储服务会删除可用性阈值(availability字段)达到0的缓存。加载新数据后,价格存储服务会再向预订服务发送一条消息,以更新可用性。
插入预订信息时,一个关键属性是状态。在前面的代码中,状态处于初始状态,但随着工作流程的推进,状态会发生变化。状态被建模为枚举类型:
type Status int
const (
Initial Status = 0
BookingMade Status = 1
EmailSent Status = 2
)
2
3
4
5
6
sendMessageToPerformBooking()函数向create_booking主题发送一条Kafka消息,以启动工作流程的下一个阶段:卖家代理。以下代码对此进行了解释:
func sendMessageToPerformBooking(reservationDTO *HotelReservationDTO) {
log.Println("sending message to kickstart booking for ", reservationDTO)
bytes, err := json.Marshal(reservationDTO)
if err != nil {
log.Println("error sending message to Kafka ", err)
return
}
// We are not setting a message key, which means that all messages will
// be distributed randomly over the different partitions.
msg := &sarama.ProducerMessage{
Topic: "create_booking",
Value: sarama.ByteEncoder(bytes),
}
partition, offset, err := kafkaProducer.SendMessage(msg)
if err != nil {
fmt.Printf("FAILED to publish message: %s\n", err)
} else {
fmt.Printf("message sent | partition(%d)/offset(%d)\n", partition, offset)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
卖家代理微服务接收sendMessageToPerformBooking()发送的这条消息,并与卖家进行实际的预订操作。卖家代理代码首先进行一些初始化操作,主要是在create_booking主题上注册为消费者。
我们使用Sarama集群(https://github.com/bsm/sarama-cluster )库来使用Kafka的高级消费者API。代理会对各个消费者实例进行心跳检测,并将Kafka主题的分区分配给健康的实例。init()代码如下:
func init() {
// setup config, enable errors and notifications
config := cluster.NewConfig()
config.Consumer.Return.Errors = true
config.Group.Mode = cluster.ConsumerModePartitions
config.Group.Return.Notifications = true
// specify Broker co-ordinates and topics of interest
// should be done from config
brokers := []string{"localhost:9092"}
topics := []string{"create_booking"}
// trap SIGINT to trigger a shutdown.
signals = make(chan os.Signal, 1)
signal.Notify(signals, os.Interrupt)
// connect, and register specifiying the consumer group name
consumer, err := cluster.NewConsumer(brokers, "booking-service", topics, config)
if err != nil {
panic(err)
}
// process errors
go func() {
for err := range consumer.Errors() {
log.Printf("Error: %s\n", err.Error())
}
}()
// process notifications
go func() {
for ntf := range consumer.Notifications() {
log.Printf("Rebalanced: %+v\n", ntf)
}
}()
//start the listener thread
go handleCreateBookingMessage(consumer)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
实际工作由handleCreateBookingMessage()函数完成,该函数在末尾作为一个go协程启动:
func handleCreateBookingMessage(consumer *cluster.Consumer) {
for {
select {
case partition, ok := <-consumer.Partitions():
if!ok {
panic("kafka consumer : error getting paritions..")
}
// 启动一个单独的goroutine来消费消息
go func(pc cluster.PartitionConsumer) {
for msg := range pc.Messages() {
var reservationDTO HotelReservationDTO
if err := json.Unmarshal(msg.Value, &reservationDTO); err != nil {
fmt.Println("unmarshalling error", err)
// 即使出错也提交偏移量以避免毒丸消息
consumer.MarkOffset(msg, "")
continue
}
// 与卖家进行实际预订 - 就在这里!
// 更新数据库中的状态
updateReservationStatus(&reservationDTO, BookingMade)
fmt.Printf("processed create booking message %s-%d-%d-%s-%s\n",
msg.Topic,
msg.Partition,
msg.Offset,
msg.Key,
msg.Value) // <- 实际在这里处理消息
consumer.MarkOffset(msg, "") // 提交此消息的偏移量
}
}(partition)
case <-signals:
fmt.Println("consumer killed..")
return
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
它监听传入的Kafka消息,收到消息后会执行以下操作:
- 反序列化消息负载。
- 与卖家进行实际预订。
- 使用
updateReservationStatus(&reservationDTO, BookingMade)更新hotel_reservations数据库中的状态。 - 将消息标记为已读。
虽然未展示,但预订成功后,它还会为邮件服务发送一条触发消息,通知客户预订成功。
# 总结
航班和酒店的旅行搜索功能略有不同。但是通过提取诸如工作树(WorkTree)和列表摄取库(Listing Ingestor Lib)等通用元素,我们可以在不同地方复用已编写的代码。
在预订设计中,我们了解到事件驱动架构(EDA)模式如何帮助我们清晰地分离各种工作流程。我们使用像Kafka这样的持久队列而不是通道,因为我们希望在实例出现故障时仍能保持弹性。工作流程可能需要很长时间,我们不希望因为基础设施的短暂故障而给客户带来糟糕的体验,比如预订失败。
在下一章中,我们将探讨Go语言应用程序的部署细节。