 第6章 集合操作
第6章 集合操作
# 6. 集合操作
尽管你可以逐行与数据库中的数据进行交互,但关系型数据库实际上都是围绕集合展开的。你已经了解了如何通过查询或子查询创建表,如何使用插入语句使表持久化,以及如何通过连接将表组合在一起;本章将探讨如何使用各种集合运算符组合多个表。
# 集合论基础
在世界上许多地方,基础集合论都包含在小学数学课程中。或许你还记得类似图6 - 1所示的内容。\
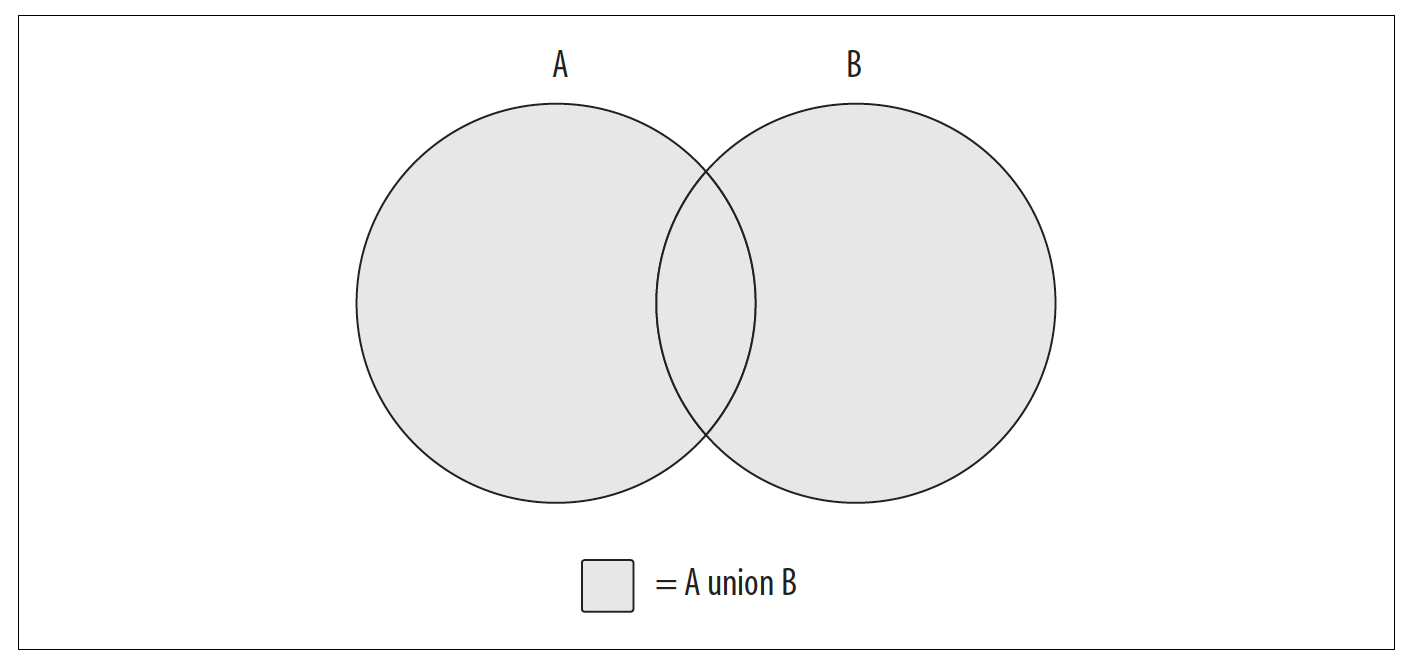 图6 - 1. 并集操作
图6 - 1. 并集操作
图6 - 1中的阴影部分表示集合A和集合B的并集,即两个集合的组合(任何重叠区域只包含一次)。这看起来是不是有点眼熟?如果是,那么你终于有机会运用这些知识了;如果不是,也不用担心,因为通过几个图表就很容易理解。
用圆圈表示两个数据集(A和B),想象有一个数据子集是两个集合共有的;这个共有数据由图6 - 1中重叠的区域表示。如果数据集之间没有重叠,集合论就会相当无趣,所以我用同一个图表来说明每个集合操作。还有另一种集合操作,它只关注两个数据集之间的重叠部分;这种操作被称为交集,如图6 - 2所示。
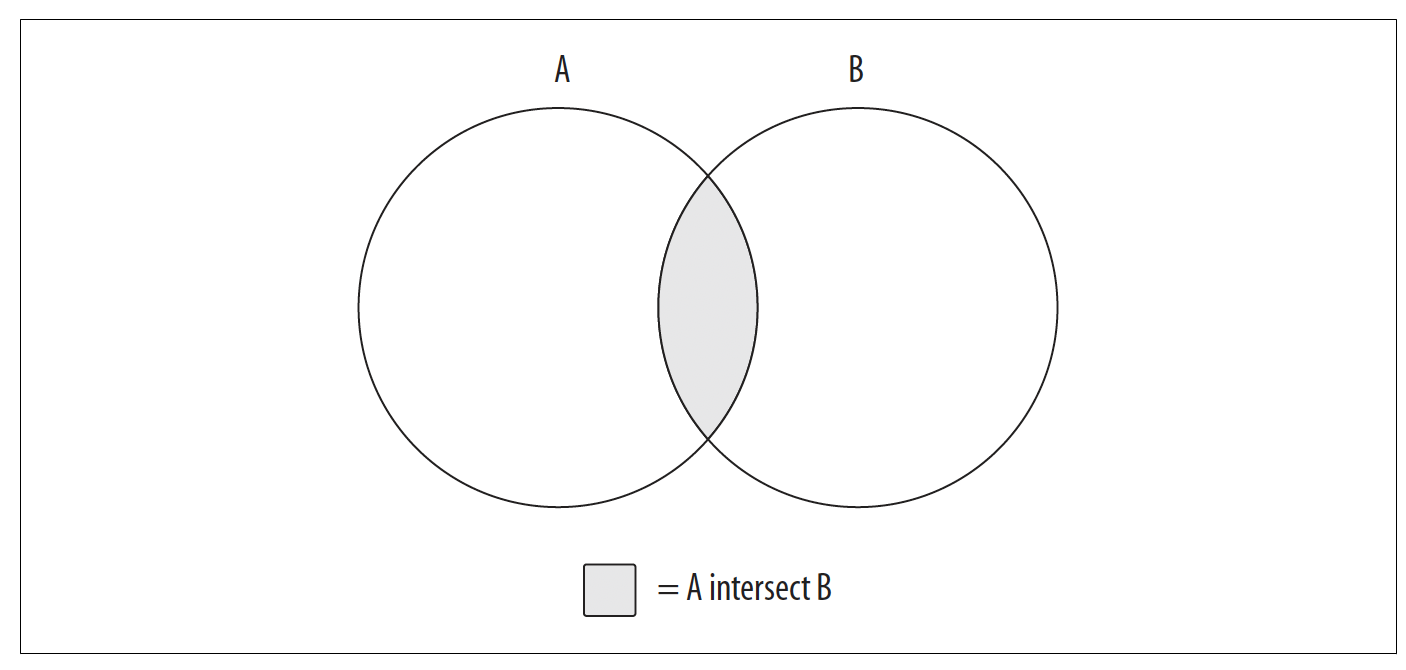
图6 - 2. 交集操作
集合A和集合B的交集生成的数据集,就是两个集合的重叠区域。如果两个集合没有重叠部分,那么交集操作会产生空集。
第三种也是最后一种集合操作,如图6 - 3所示,被称为差集操作。
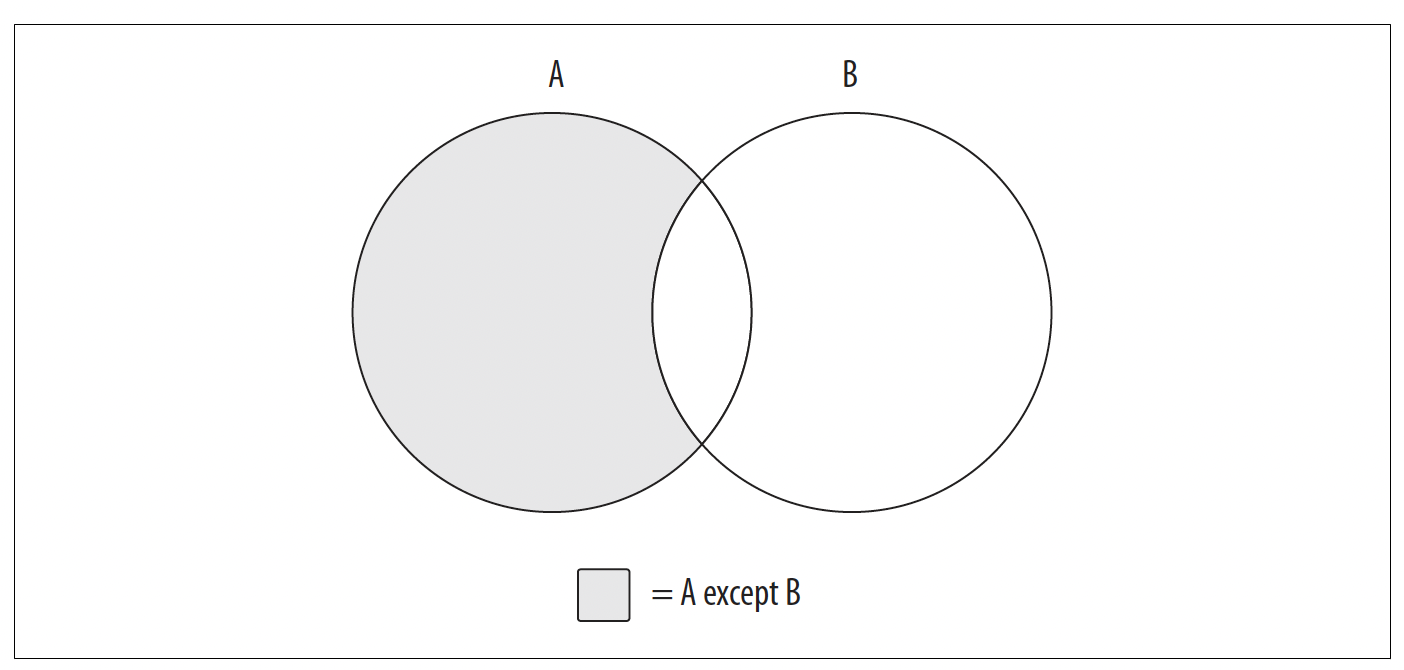
图6 - 3. 差集操作
图6 - 3展示了A差B的结果,即集合A的全部内容减去与集合B的任何重叠部分。如果两个集合没有重叠部分,那么A差B操作会得到集合A的全部内容。
通过使用这三种操作,或者将不同的操作组合在一起,你可以生成任何你需要的结果。例如,想象你想要构建一个如图6 - 4所示的集合。
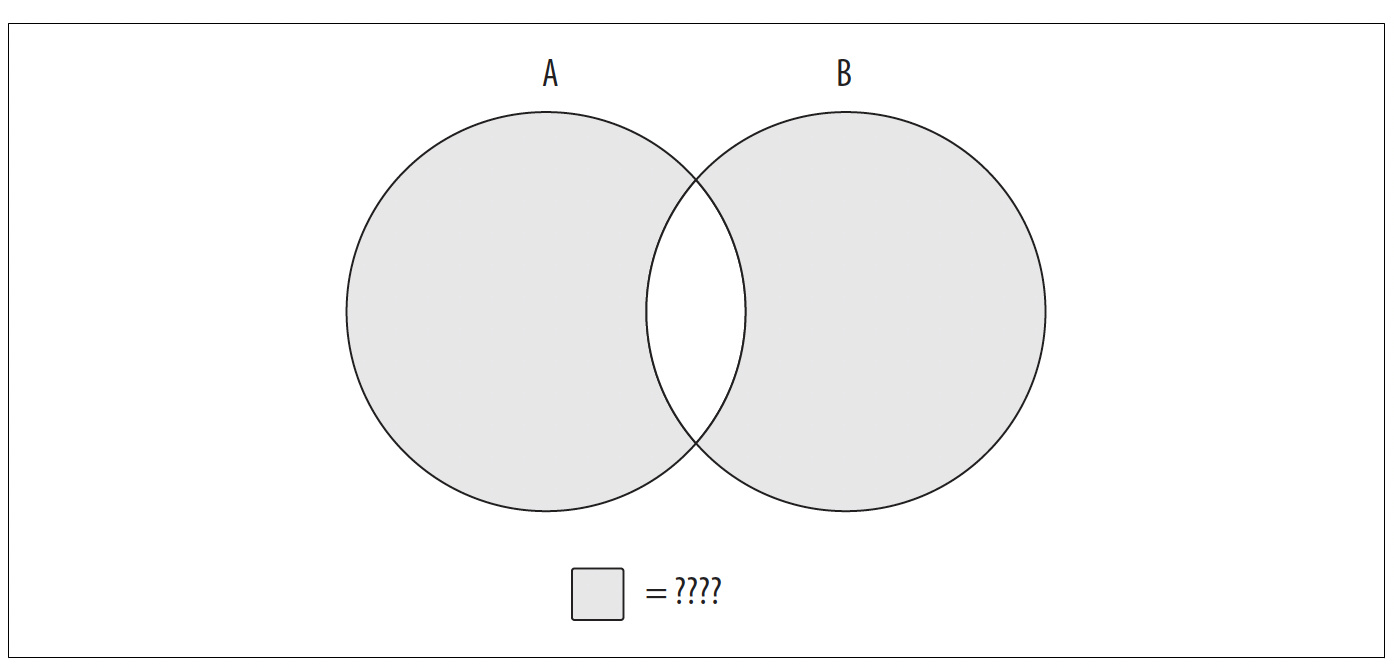
图6 - 4. 未知数据集
你要找的数据集包括集合A和集合B的所有内容,但不包括重叠区域。仅使用前面展示的三种操作中的一种无法实现这个结果;相反,你需要先构建一个包含集合A和集合B所有内容的数据集,然后使用第二种操作来去除重叠区域。如果组合后的集合表示为A并B,重叠区域表示为A交B,那么生成图6 - 4所示数据集所需的操作如下:
(A union B) except (A intersect B)
当然,通常有多种方法可以得到相同的结果;你也可以使用以下操作得到类似的结果:
(A except B) union (B except A)
虽然这些概念通过图表很容易理解,但接下来的部分将向你展示如何使用SQL集合运算符将这些概念应用到关系型数据库中。
# 集合论的实际应用
上一节图表中用于表示数据集的圆圈并没有传达关于数据集组成的任何信息。然而,在处理实际数据时,如果要组合数据集,就需要描述所涉及数据集的组成。例如,想象一下,如果你尝试生成product表和customer表的并集,会发生什么情况,这两个表的表定义如下:
mysql> DESC product;
+-----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+-------------+------+-----+---------+-------+
| product_cd | varchar(10) | NO | PRI | NULL | |
| name | varchar(50) | NO | | NULL | |
| product_type_cd | varchar(10) | NO | MUL | NULL | |
| date_offered | date | YES | | NULL | |
| date_retired | date | YES | | NULL | |
+-----------------+-------------+------+-----+---------+-------+
5 rows in set (0.23 sec)
mysql> DESC customer;
+--------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+------------------+------+-----+---------+----------------+
| cust_id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| fed_id | varchar(12) | NO | | NULL | |
| cust_type_cd | enum('I','B') | NO | | NULL | |
| address | varchar(30) | YES | | NULL | |
| city | varchar(20) | YES | | NULL | |
| state | varchar(20) | YES | | NULL | |
| postal_code | varchar(10) | YES | | NULL | |
+--------------+------------------+------+-----+---------+----------------+
7 rows in set (0.04 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
当进行组合时,结果表的第一列将是product.product_cd和customer.cust_id列的组合,第二列将是product.name和customer.fed_id列的组合,依此类推。虽然有些列对很容易组合(例如,两个数字列),但其他列对(如数字列与字符串列,或字符串列与日期列)应该如何组合并不明确。此外,由于product表只有五列,组合表的第六列和第七列将只包含customer表第六列和第七列的数据。显然,要组合的两个表之间需要有一些共性。
因此,在对两个数据集执行集合操作时,必须遵循以下准则:
- 两个数据集必须具有相同数量的列。
- 两个数据集中每列的数据类型必须相同(或者服务器必须能够将一种类型转换为另一种类型)。
有了这些规则,就更容易想象在实际中“重叠数据”的含义;要将两个表中的行视为相同,组合的两个集合中每对列必须包含相同的字符串、数字或日期。
你可以通过在两个select语句之间放置一个集合运算符来执行集合操作,如下所示:
mysql> SELECT 1 num, 'abc' str
-> UNION
-> SELECT 9 num, 'xyz' str;
+-----+-----+
| num | str |
+-----+-----+
| 1 | abc |
| 9 | xyz |
+-----+-----+
2 rows in set (0.02 sec)
2
3
4
5
6
7
8
9
10
每个单独的查询都会生成一个数据集,该数据集由一行包含一个数字列和一个字符串列的数据组成。这里的集合运算符是union,它告诉数据库服务器将两个集合中的所有行组合起来。因此,最终的集合包含两行两列。这个查询被称为复合查询,因为它由多个原本相互独立的查询组成。正如你稍后将看到的,如果需要多个集合操作才能获得最终结果,复合查询可能会包含两个以上的查询。
# 集合运算符
SQL语言包含三个集合运算符,允许你执行本章前面描述的各种集合操作。此外,每个集合运算符都有两种形式,一种会保留重复行,另一种会去除重复行(但不一定会去除所有重复行)。以下小节将定义每个运算符,并展示它们的用法。
# union运算符
union和union all运算符允许你组合多个数据集。两者的区别在于,union会对组合后的集合进行排序并去除重复行,而union all不会。使用union all时,最终数据集中的行数总是等于被组合集合中的行数之和。从服务器的角度来看,这个操作是最简单的集合操作,因为服务器无需检查重叠数据。下面的示例展示了如何使用union all运算符从两个客户子类型表中生成完整的客户数据集:
mysql> SELECT 'IND' type_cd, cust_id, lname name
-> FROM individual
-> UNION ALL
-> SELECT 'BUS' type_cd, cust_id, name
-> FROM business;
+---------+---------+------------------------+
| type_cd | cust_id | name |
+---------+---------+------------------------+
| IND | 1 | Hadley |
| IND | 2 | Tingley |
| IND | 3 | Tucker |
| IND | 4 | Hayward |
| IND | 5 | Frasier |
| IND | 6 | Spencer |
| IND | 7 | Young |
| IND | 8 | Blake |
| IND | 9 | Farley |
| BUS | 10 | Chilton Engineering |
| BUS | 11 | Northeast Cooling Inc. |
| BUS | 12 | Superior Auto Body |
| BUS | 13 | AAA Insurance Inc. |
+---------+---------+------------------------+
13 rows in set (0.04 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
该查询返回了所有13个客户,其中9行来自individual表,另外4行来自business表。business表使用单个列来存储公司名称,而individual表包含两个名称列,分别用于存储个人的名字和姓氏。在这个例子中,我选择只包含individual表中的姓氏。
为了强调union all运算符不会去除重复行这一点,下面是与前面示例相同的查询,但增加了一个对business表的查询:
mysql> SELECT 'IND' type_cd, cust_id, lname name
-> FROM individual
-> UNION ALL
-> SELECT 'BUS' type_cd, cust_id, name
-> FROM business
-> UNION ALL
-> SELECT 'BUS' type_cd, cust_id, name
-> FROM business;
+---------+---------+------------------------+
| type_cd | cust_id | name |
+---------+---------+------------------------+
| IND | 1 | Hadley |
| IND | 2 | Tingley |
| IND | 3 | Tucker |
| IND | 4 | Hayward |
| IND | 5 | Frasier |
| IND | 6 | Spencer |
| IND | 7 | Young |
| IND | 8 | Blake |
| IND | 9 | Farley |
| BUS | 10 | Chilton Engineering |
| BUS | 11 | Northeast Cooling Inc. |
| BUS | 12 | Superior Auto Body |
| BUS | 13 | AAA Insurance Inc. |
| BUS | 10 | Chilton Engineering |
| BUS | 11 | Northeast Cooling Inc. |
| BUS | 12 | Superior Auto Body |
| BUS | 13 | AAA Insurance Inc. |
+---------+---------+------------------------+
17 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
这个复合查询包含三个select语句,其中两个是相同的。从结果中可以看到,business表中的四行数据出现了两次(客户ID为10、11、12和13)。
虽然在复合查询中你不太可能重复相同的查询,但下面是另一个返回重复数据的复合查询:
mysql> SELECT emp_id
-> FROM employee
-> WHERE assigned_branch_id = 2
-> AND (title = 'Teller' OR title = 'Head Teller')
-> UNION ALL
-> SELECT DISTINCT open_emp_id
-> FROM account
-> WHERE open_branch_id = 2;
+--------+
| emp_id |
+--------+
| 10 |
| 11 |
| 12 |
| 10 |
+--------+
4 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
复合语句中的第一个查询检索分配到沃本分行(Woburn branch)的所有出纳员,而第二个查询返回在沃本分行开户的不同出纳员集合。在结果集中的四行数据中,有一行是重复的(员工ID为10)。如果你希望组合后的表排除重复行,则需要使用union运算符而不是union all:
mysql> SELECT emp_id
-> FROM employee
-> WHERE assigned_branch_id = 2
-> AND (title = 'Teller' OR title = 'Head Teller')
-> UNION
-> SELECT DISTINCT open_emp_id
-> FROM account
-> WHERE open_branch_id = 2;
+--------+
| emp_id |
+--------+
| 10 |
| 11 |
| 12 |
+--------+
3 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在这个查询版本中,结果集中只包含三个不同的行,而不是使用union all时返回的四行(三个不同的行,一个重复行)。
# 交集运算符(intersect Operator)
ANSI SQL规范中包含用于执行交集运算的intersect运算符。遗憾的是,MySQL 6.0版本并未实现intersect运算符。如果你使用的是Oracle或SQL Server 2008,就能够使用intersect运算符;然而,由于本书中的所有示例均使用MySQL,因此本节示例查询的结果集是虚构的,在MySQL 6.0及之前的版本中都无法执行。此外,我也不会显示MySQL提示符(mysql>),因为这些语句不会由MySQL服务器执行。
如果复合查询中的两个查询返回的数据集没有重叠部分,那么它们的交集将是一个空集。考虑以下查询:
SELECT emp_id, fname, lname
FROM employee
INTERSECT
SELECT cust_id, fname, lname
FROM individual;
Empty set (0.04 sec)
2
3
4
5
6
第一个查询返回每位员工的ID和姓名,而第二个查询返回每位客户的ID和姓名。这些数据集完全没有重叠,所以这两个数据集的交集为空集。
接下来要找出两个有重叠数据的查询,然后应用intersect运算符。为此,我使用与展示union和union all区别时相同的查询,只是这次使用intersect:
SELECT emp_id
FROM employee
WHERE assigned_branch_id = 2
AND (title = 'Teller' OR title = 'Head Teller')
INTERSECT
SELECT DISTINCT open_emp_id
FROM account
WHERE open_branch_id = 2;
+--------+
| emp_id |
+--------+
| 10 |
+--------+
1 row in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这两个查询的交集得到员工ID 10,这是在两个查询结果集中都能找到的唯一值。
除了intersect运算符(它会去除重叠区域中发现的任何重复行),ANSI SQL规范还要求有一个intersect all运算符,该运算符不会去除重复项。目前唯一实现了intersect all运算符的数据库服务器是IBM的DB2通用服务器。
# 差集运算符(except Operator)
ANSI SQL规范中包含用于执行差集运算的except运算符。同样遗憾的是,MySQL 6.0版本并未实现except运算符,所以本节的规则与上一节相同。
如果你使用的是Oracle数据库,则需要使用不符合ANSI标准的minus运算符来替代。
except运算符返回第一个表中与第二个表不重叠的部分。下面是上一节的示例,但使用except替代intersect:
SELECT emp_id
FROM employee
WHERE assigned_branch_id = 2
AND (title = 'Teller' OR title = 'Head Teller')
EXCEPT
SELECT DISTINCT open_emp_id
FROM account
WHERE open_branch_id = 2;
+--------+
| emp_id |
+--------+
| 11 |
| 12 |
+--------+
2 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在这个版本的查询中,结果集由第一个查询的三行数据减去员工ID 10组成,因为员工ID 10在两个查询的结果集中都存在。ANSI SQL规范中也有一个except all运算符,但同样只有IBM的DB2通用服务器实现了except all运算符。
except all运算符有点复杂,下面通过一个示例来演示如何处理重复数据。假设有两个数据集如下:
数据集A
+--------+
| emp_id |
+--------+
| 10 |
| 11 |
| 12 |
| 10 |
| 10 |
+--------+
2
3
4
5
6
7
8
9
数据集B
+--------+
| emp_id |
+--------+
| 10 |
| 10 |
+--------+
2
3
4
5
6
运算A except B得到以下结果:
+--------+
| emp_id |
+--------+
| 11 |
| 12 |
+--------+
2
3
4
5
6
如果将运算改为A except all B,则会得到以下结果:
+--------+
| emp_id |
+--------+
| 10 |
| 11 |
| 12 |
+--------+
2
3
4
5
6
7
因此,这两个运算的区别在于,except会从数据集A中删除所有重复数据,而except all只会针对数据集B中的每一个重复项,从数据集A中删除一个相应的重复项。
# 集合运算规则
以下部分概述了在使用复合查询时必须遵循的一些规则。
# 对复合查询结果进行排序
如果希望复合查询的结果是有序的,可以在最后一个查询之后添加order by子句。在order by子句中指定列名时,需要从复合查询的第一个查询的列名中进行选择。通常,复合查询中两个查询的列名是相同的,但并非必须如此,如下例所示:
SELECT emp_id, assigned_branch_id
FROM employee
WHERE title = 'Teller'
UNION
SELECT open_emp_id, open_branch_id
FROM account
WHERE product_cd = 'SAV'
ORDER BY emp_id;
+--------+---------------------+
| emp_id | assigned_branch_id |
+--------+---------------------+
| 1 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 1 |
| 10 | 2 |
| 11 | 2 |
| 12 | 2 |
| 14 | 3 |
| 15 | 3 |
| 16 | 4 |
| 17 | 4 |
| 18 | 4 |
+--------+---------------------+
12 rows in set (0.04 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在此示例中,两个查询中指定的列名不同。如果在order by子句中指定第二个查询的列名,将会看到以下错误:
SELECT emp_id, assigned_branch_id
FROM employee
WHERE title = 'Teller'
UNION
SELECT open_emp_id, open_branch_id
FROM account
WHERE product_cd = 'SAV'
ORDER BY open_emp_id;
ERROR 1054 (42S22): Unknown column 'open_emp_id' in 'order clause'
2
3
4
5
6
7
8
9
10
我建议为两个查询中的列赋予相同的列别名,以避免出现此问题。
# 集合运算优先级
如果复合查询包含两个以上使用不同集合运算符的查询,就需要考虑在复合语句中如何排列这些查询的顺序,以获得期望的结果。考虑以下包含三个查询的复合语句:
SELECT cust_id
FROM account
WHERE product_cd IN ('SAV', 'MM')
UNION ALL
SELECT a.cust_id
FROM account a
INNER JOIN branch b ON a.open_branch_id = b.branch_id
WHERE b.name = 'Woburn Branch'
UNION
SELECT cust_id
FROM account
WHERE avail_balance BETWEEN 500 AND 2500;
+---------+
| cust_id |
+---------+
| 1 |
| 2 |
| 3 |
| 4 |
| 8 |
| 9 |
| 7 |
| 11 |
| 5 |
+---------+
9 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这个复合查询包含三个查询,它们返回的是不唯一的客户ID集合;第一个和第二个查询之间使用union all运算符,第二个和第三个查询之间使用union运算符。虽然看起来union和union all运算符的位置似乎没有太大区别,但实际上是有影响的。下面是将集合运算符位置颠倒后的相同复合查询:
SELECT cust_id
FROM account
WHERE product_cd IN ('SAV', 'MM')
UNION
SELECT a.cust_id
FROM account a
INNER JOIN branch b ON a.open_branch_id = b.branch_id
WHERE b.name = 'Woburn Branch'
UNION ALL
SELECT cust_id
FROM account
WHERE avail_balance BETWEEN 500 AND 2500;
+---------+
| cust_id |
+---------+
| 1 |
| 2 |
| 3 |
| 4 |
| 8 |
| 9 |
| 7 |
| 11 |
| 1 |
| 1 |
| 2 |
| 3 |
| 3 |
| 4 |
| 4 |
| 5 |
| 9 |
+---------+
17 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
从结果可以明显看出,在使用不同的集合运算符时,复合查询的排列方式确实会产生影响。一般来说,包含三个或更多查询的复合查询是按从上到下的顺序进行计算的,但有以下注意事项:
- ANSI SQL规范要求
intersect运算符的优先级高于其他集合运算符。 - 可以通过将多个查询用括号括起来,来指定查询的组合顺序。
然而,由于MySQL尚未实现intersect运算符,也不允许在复合查询中使用括号,因此你需要仔细安排复合查询中的查询顺序,以获得期望的结果。如果你使用的是其他数据库服务器,可以将相邻的查询用括号括起来,以覆盖复合查询默认的从上到下的处理顺序,例如:
(SELECT cust_id
FROM account
WHERE product_cd IN ('SAV', 'MM')
UNION ALL
SELECT a.cust_id
FROM account a
INNER JOIN branch b ON a.open_branch_id = b.branch_id
WHERE b.name = 'Woburn Branch')
INTERSECT
(SELECT cust_id
FROM account
WHERE avail_balance BETWEEN 500 AND 2500
EXCEPT
SELECT cust_id
FROM account
WHERE product_cd = 'CD'
AND avail_balance < 1000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
对于这个复合查询,第一个和第二个查询将使用union all运算符进行组合,然后第三个和第四个查询将使用except运算符进行组合,最后,这两个操作的结果将使用intersect运算符进行组合,以生成最终的结果集。
# 知识测验
以下练习旨在测试你对集合运算的理解。答案见附录C。
# 练习6 - 1
如果集合A = {LMN OP},集合B = {PQ RST},以下运算会生成哪些集合?
- A
unionB - A
union allB - A
intersectB - A
exceptB
# 练习6 - 2
编写一个复合查询,查找所有个人客户的名字和姓氏,以及所有员工的名字和姓氏。
# 练习6 - 3
按lname列对练习6 - 2的结果进行排序。