 第13章 索引与约束
第13章 索引与约束
# 第13章 索引与约束
由于本书重点在于编程技术,前12章主要聚焦于SQL语言中可用于编写强大的查询(select)、插入(insert)、更新(update)和删除(delete)语句的元素。然而,其他数据库特性也会间接影响你编写的代码。本章将重点介绍其中两个特性:索引(indexes)和约束(constraints)。
# 索引
当你向表中插入一行数据时,数据库服务器不会尝试将数据放置在表内的特定位置。例如,如果你向department表添加一行数据,服务器不会根据dept_id列按数字顺序,也不会根据name列按字母顺序来放置该行数据。相反,服务器只是将数据放置在文件中下一个可用的位置(服务器为每个表维护一个空闲空间列表)。因此,当你查询department表时,服务器需要检查表中的每一行来回答查询。例如,假设你发出以下查询:
mysql> SELECT dept_id, name
-> FROM department
-> WHERE name LIKE 'A%';
+---------+------------------+
| dept_id | name |
+---------+------------------+
| 3 | Administration |
+---------+------------------+
1 row in set (0.03 sec)
2
3
4
5
6
7
8
9
为了找到所有名称以A开头的部门,服务器必须遍历department表中的每一行,并检查name列的内容;如果部门名称以A开头,那么该行就会被添加到结果集中。这种访问方式称为全表扫描(table scan)。
虽然这种方法对于只有三行数据的表来说效果不错,但想象一下,如果表中包含300万行数据,回答这个查询需要多长时间。在数据行数超过三行但少于300万行的某个节点,就会出现这样一种情况:如果没有额外的帮助,服务器无法在合理的时间内回答查询。这种帮助就来自于department表上的一个或多个索引。
即使你从未听说过数据库索引,你肯定也知道索引是什么(例如,本书就有索引)。索引只是一种在资源中查找特定项的机制。例如,每一本技术出版物末尾都有一个索引,它能让你在出版物中找到特定的单词或短语。索引按字母顺序列出这些单词和短语,读者可以快速定位到索引中的特定字母,找到所需的条目,然后找到该单词或短语所在的页面。
就像人们使用索引在出版物中查找单词一样,数据库服务器使用索引在表中定位行。索引是特殊的表,与普通数据表不同,它们按特定顺序保存。然而,索引并不包含有关实体的所有数据,它只包含用于在数据表中定位行的列(或多列),以及描述这些行物理位置的信息。因此,索引的作用是便于检索表中部分行和列的数据,而无需检查表中的每一行。
# 索引创建
回到department表,你可能会决定在name列上添加一个索引,以加快任何指定完整或部分部门名称的查询,以及任何指定部门名称的更新或删除操作。在MySQL数据库中,添加这样一个索引的方法如下:
mysql> ALTER TABLE department
-> ADD INDEX dept_name_idx (name);
Query OK, 3 rows affected (0.08 sec)
Records: 3 Duplicates: 0 Warnings: 0
2
3
4
这条语句在department.name列上创建了一个索引(确切地说是B树索引,稍后会详细介绍);此外,该索引被命名为dept_name_idx。有了这个索引后,如果查询优化器(我们在第3章中讨论过)认为使用该索引有益,就会选择使用它(例如,由于department表中只有三行数据,优化器很可能会选择忽略该索引并读取整个表)。如果一个表上有多个索引,优化器必须决定哪个索引对特定的SQL语句最有益。
MySQL将索引视为表的可选组件,这就是为什么必须使用alter table命令来添加或删除索引。包括SQL Server和Oracle Database在内的其他数据库服务器,将索引视为独立的模式对象(schema objects)。因此,对于SQL Server和Oracle,你可以使用create index命令来创建索引,如下所示:
CREATE INDEX dept_name_idx ON department (name);
从MySQL 5.0版本开始,也提供了create index命令,不过它会映射到alter table命令。
所有数据库服务器都允许查看可用的索引。MySQL用户可以使用show命令查看特定表上的所有索引,如下所示:
mysql> SHOW INDEX FROM department \G
*************************** 1. row ***************************
1. row ***************************
Table: department
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: dept_id
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment: Index_Comment:
*************************** 2. row ***************************
Table: department
Non_unique: 1
Key_name: dept_name_idx
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 3
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment: Index_Comment:
2 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
输出结果显示department表上有两个索引:一个是在dept_id列上名为PRIMARY的索引,另一个是在name列上名为dept_name_idx的索引。由于到目前为止我只创建了一个索引(dept_name_idx),你可能想知道另一个索引是从哪里来的;在创建department表时,create table语句包含一个约束,将dept_id列指定为表的主键。创建该表的语句如下:
CREATE TABLE department
(
dept_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
CONSTRAINT pk_department PRIMARY KEY (dept_id)
);
2
3
4
5
6
在创建表时,MySQL服务器会自动在主键列(在本例中是dept_id)上生成一个索引,并将该索引命名为PRIMARY。本章后面会介绍约束。
如果创建索引后,你发现该索引没有什么用处,可以通过以下命令删除它:
mysql> ALTER TABLE department
-> DROP INDEX dept_name_idx;
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
2
3
4
SQL Server和Oracle Database的用户必须使用drop index命令来删除索引,如下所示:
DROP INDEX dept_name_idx; -- Oracle
DROP INDEX dept_name_idx ON department -- SQL Server
2
MySQL现在也支持drop index命令。
# 唯一索引
在设计数据库时,考虑哪些列允许包含重复数据,哪些不允许,这一点很重要。例如,在individual表中允许有两个名为John Smith的客户,因为每一行都有不同的标识符(cust_id)、出生日期和税号(customer.fed_id)来区分他们。然而,你不会希望在department表中出现两个同名的部门。你可以通过在department.name列上创建唯一索引(unique index),来实施禁止部门名称重复的规则。
唯一索引有多种作用,除了具备普通索引的所有优点外,它还能作为一种机制,禁止在索引列中出现重复值。每当插入一行数据或修改索引列时,数据库服务器会检查唯一索引,查看该值是否已存在于表中的其他行。在department.name列上创建唯一索引的方法如下:
mysql> ALTER TABLE department
-> ADD UNIQUE dept_name_idx (name);
Query OK, 3 rows affected (0.04 sec)
Records: 3 Duplicates: 0 Warnings: 0
2
3
4
SQL Server和Oracle Database的用户在创建索引时,只需添加unique关键字,如下所示:
CREATE UNIQUE INDEX dept_name_idx ON department (name);
有了这个索引后,如果你试图添加另一个名为“Operations”的部门,将会收到一个错误:
mysql> INSERT INTO department (dept_id, name)
-> VALUES (999, 'Operations');
ERROR 1062 (23000): Duplicate entry 'Operations' for key 'dept_name_idx'
2
3
你不应该在主键列上创建唯一索引,因为服务器已经会检查主键值的唯一性。不过,如果你认为有必要,在同一个表上可以创建多个唯一索引。
# 多列索引
除了到目前为止展示的单列索引,你还可以创建跨多个列的索引。例如,如果你经常通过员工的名和姓来搜索员工,就可以在这两列上一起创建一个索引,如下所示:
mysql> ALTER TABLE employee
-> ADD INDEX emp_names_idx (lname, fname);
Query OK, 18 rows affected (0.10 sec)
Records: 18 Duplicates: 0 Warnings: 0
2
3
4
这个索引对于指定名和姓或只指定姓的查询很有用,但对于只指定员工名的查询则无法使用。要理解其中的原因,可以想想你是如何查找一个人的电话号码的;如果你知道一个人的名和姓,就可以使用电话簿快速找到号码,因为电话簿是按姓排序,然后再按名排序的。如果你只知道这个人的名,就需要遍历电话簿中的每一条记录,才能找到所有指定名的记录。
因此,在创建多列索引时,你应该仔细考虑将哪一列排在第一位,哪一列排在第二位,依此类推,以便让索引尽可能有用。不过要记住,如果你认为为了确保足够快的响应时间有必要的话,没有什么能阻止你使用相同的一组列,但以不同的顺序来创建多个索引。
# 索引类型
索引是一个强大的工具,但由于数据类型多种多样,单一的索引策略并不总是能满足需求。以下部分将介绍不同服务器提供的各种索引类型。
# B树索引
到目前为止展示的所有索引都是平衡树索引,更常被称为B树索引(B-tree indexes)。MySQL、Oracle Database和SQL Server都默认使用B树索引,所以除非你明确要求其他类型的索引,否则创建的就是B树索引。正如你可能预期的那样,B树索引是按树状结构组织的,有一个或多个层级的分支节点,通向单一层级的叶节点。分支节点用于在树中导航,而叶节点保存实际的值和位置信息。例如,在employee.lname列上创建的B树索引可能如下方图13 - 1所示。
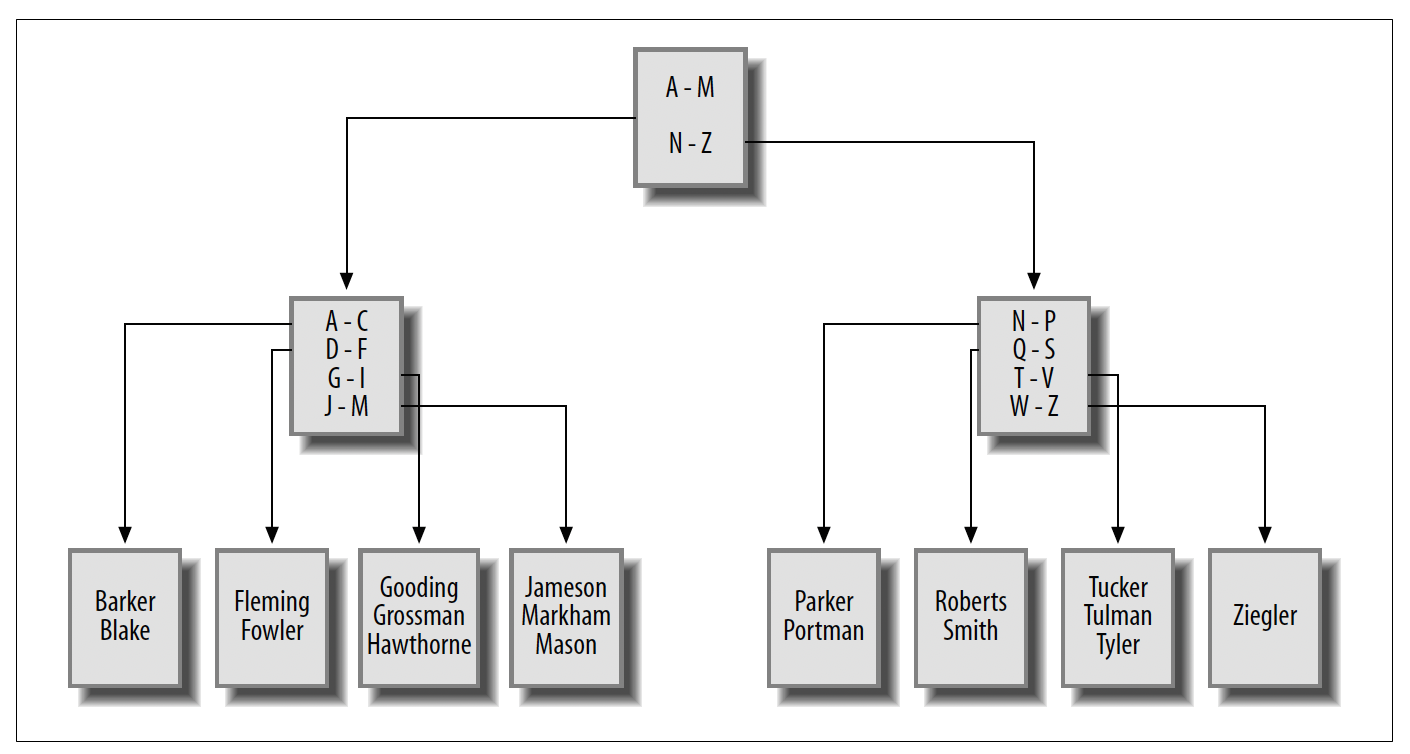 图13 - 1 B树示例
图13 - 1 B树示例
如果你发出一个查询,检索所有姓以G开头的员工,服务器会查看顶部的分支节点(称为根节点),并沿着链接找到处理姓以A到M开头的分支节点。这个分支节点又会将服务器导向一个包含姓以G到I开头的叶节点。然后,服务器开始读取叶节点中的值,直到遇到一个不以G开头的值(在本例中是'Hawthorne')。
随着在employee表中插入、更新和删除行,服务器会尝试保持树的平衡,这样根节点两侧的分支/叶节点数量就不会相差太大。服务器可以添加或删除分支节点,以便更均匀地重新分配值,甚至可以添加或删除整个层级的分支节点。通过保持树的平衡,服务器能够快速遍历到叶节点,找到所需的值,而无需遍历许多层级的分支节点。
# 位图索引(Bitmap indexes)
尽管B树索引(B-tree indexes)在处理包含许多不同值的列(如客户的名字/姓氏)时表现出色,但在基于只允许少量值的列构建索引时,它们可能会变得难以处理。例如,你可能决定在account.product_cd列上生成一个索引,以便能够快速检索特定类型(如支票账户、储蓄账户)的所有账户。然而,由于只有八种不同的产品,并且某些产品比其他产品更受欢迎,随着账户数量的增长,维护一个平衡的B树索引可能会变得困难。
对于在大量行中仅包含少量值的列(称为低基数(low-cardinality)数据),需要一种不同的索引策略。为了更有效地处理这种情况,Oracle数据库提供了位图索引(bitmap indexes),它为存储在列中的每个值生成一个位图。图13-2展示了account.product_cd列中数据的位图索引可能的样子。
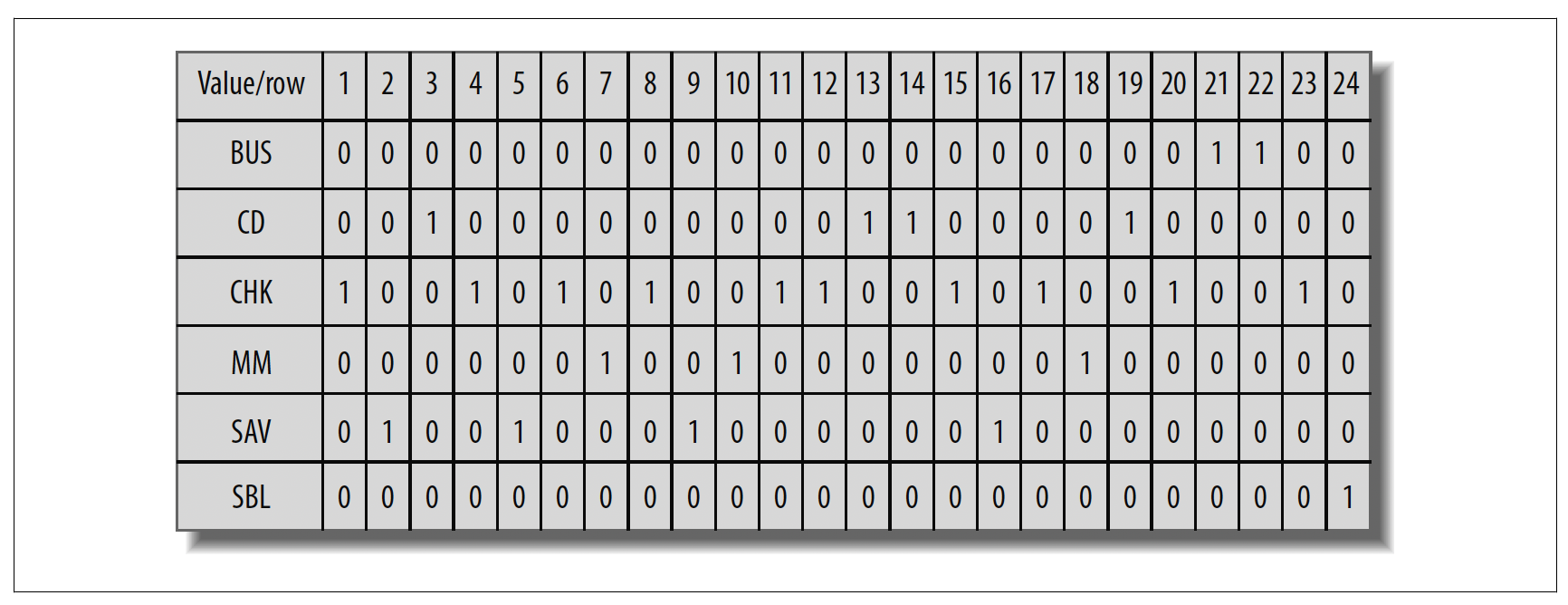
图13-2. 位图示例
该索引包含六个位图,对应product_cd列中的每个值(八种可用产品中有两种未使用),并且每个位图为account表中的24行中的每一行都包含一个0或1的值。因此,如果你要求服务器检索所有货币市场账户(product_cd = 'MM'),服务器只需在MM位图中找到所有1的值,并返回第7、10和18行。如果你查找多个值,服务器还可以组合位图;例如,如果你想检索所有货币市场账户和储蓄账户(product_cd = 'MM' 或 product_cd = 'SAV'),服务器可以对MM和SAV位图执行OR运算,并返回第2、5、7、9、10、16和18行。
位图索引是处理低基数数据的一种简洁紧凑的索引解决方案,但如果列中存储的值的数量相对于行数过高(称为高基数(high-cardinality)数据),这种索引策略就会失效,因为服务器需要维护太多的位图。例如,你永远不会在主键列上构建位图索引,因为这代表了可能的最高基数(每行都有不同的值)。
Oracle用户只需在CREATE INDEX语句中添加BITMAP关键字即可生成位图索引,如下所示:
CREATE BITMAP INDEX acc_prod_idx ON account (product_cd);
位图索引通常用于数据仓库环境,在这种环境中,大量数据通常在包含相对较少值的列(如销售季度、地理区域、产品、销售人员)上建立索引。
# 文本索引(Text indexes)
如果你的数据库存储文档,你可能需要允许用户在文档中搜索单词或短语。你肯定不希望每次请求搜索时,服务器都打开每个文档并扫描所需的文本,但传统的索引策略在这种情况下并不适用。为了处理这种情况,MySQL、SQL Server和Oracle数据库都提供了专门用于文档的索引和搜索机制;SQL Server和MySQL都有所谓的全文索引(full-text indexes,对于MySQL,全文索引仅在其MyISAM存储引擎中可用),而Oracle数据库则包含一组强大的工具,称为Oracle文本(Oracle Text)。文档搜索非常专业,我在这里就不举例了,但我希望你至少了解有哪些可用的工具。
# 索引的使用方式
通常,服务器使用索引来快速定位特定表中的行,然后服务器访问相关表以提取用户请求的其他信息。考虑以下查询:
mysql> SELECT emp_id, fname, lname
-> FROM employee
-> WHERE emp_id IN (1, 3, 9, 15);
+--------+-----------+-------------+
| emp_id | fname | lname |
+--------+-----------+-------------+
| 1 | Michael | Smith |
| 3 | Robert | Tyler |
| 9 | Jane | Grossman |
| 15 | Frank | Portman |
+--------+-----------+-------------+
4 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
对于此查询,服务器可以使用emp_id列上的主键索引在employee表中定位员工ID为1、3、9和15的记录,然后访问这四行以检索名字和姓氏列。
如果索引包含满足查询所需的所有内容,那么服务器就不需要访问相关表。为了说明这一点,让我们看看查询优化器在有不同索引的情况下如何处理相同的查询。
下面这个查询用于汇总特定客户的账户余额:
mysql> SELECT cust_id, SUM(avail_balance) tot_bal
-> FROM account
-> WHERE cust_id IN (1, 5, 9, 11)
-> GROUP BY cust_id;
+----------+-----------+
| cust_id | tot_bal |
+----------+-----------+
| 1 | 4557.75 |
| 5 | 2237.97 |
| 9 | 10971.22 |
| 11 | 9345.55 |
+----------+-----------+
4 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
为了查看MySQL的查询优化器如何决定执行该查询,我使用EXPLAIN语句让服务器显示查询的执行计划,而不是执行查询:
mysql> EXPLAIN SELECT cust_id, SUM(avail_balance) tot_bal
-> FROM account
-> WHERE cust_id IN (1, 5, 9, 11)
-> GROUP BY cust_id \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: account
type: index
possible_keys: fk_a_cust_id
key: fk_a_cust_id
key_len: 4
ref: NULL
rows: 24
Extra: Using where
1 row in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
每个数据库服务器都提供工具,让你查看查询优化器如何处理你的SQL语句。SQL Server允许你通过在运行SQL语句之前发出SET SHOWPLAN_TEXT ON语句来查看执行计划。Oracle数据库包含EXPLAIN PLAN语句,它将执行计划写入一个名为plan_table的特殊表中。
这里不深入探讨细节,执行计划告诉你以下内容:
fk_a_cust_id索引用于查找account表中满足WHERE子句的行。- 读取索引后,服务器预计会读取
account表的所有24行以收集可用余额数据,因为它不知道除了ID为1、5、9和11的客户之外,可能还有其他客户。
fk_a_cust_id索引是服务器自动生成的另一个索引,但这次是因为外键约束(foreign key constraint),而不是主键约束(primary key constraint)(本章后面会详细介绍)。fk_a_cust_id索引建立在account.cust_id列上,因此服务器使用该索引在account表中定位客户ID为1、5、9和11的记录,然后访问这些行以检索和汇总可用余额数据。
接下来,我将在cust_id和avail_balance列上添加一个名为acc_bal_idx的新索引:
mysql> ALTER TABLE account
-> ADD INDEX acc_bal_idx (cust_id, avail_balance);
Query OK, 24 rows affected (0.03 sec)
Records: 24 Duplicates: 0 Warnings: 0
2
3
4
有了这个索引后,让我们看看查询优化器如何处理相同的查询:
mysql> EXPLAIN SELECT cust_id, SUM(avail_balance) tot_bal
-> FROM account
-> WHERE cust_id IN (1, 5, 9, 11)
-> GROUP BY cust_id \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: account
type: range
possible_keys: acc_bal_idx
key: acc_bal_idx
key_len: 4
ref: NULL
rows: 8
Extra: Using where; Using index
1 row in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
比较这两个执行计划,可以发现以下差异:
- 优化器使用新的
acc_bal_idx索引,而不是fk_a_cust_id索引。 - 优化器预计只需要八行,而不是24行。
- 满足查询结果不需要访问
account表(在Extra列中由Using index表示)。
因此,服务器可以使用索引来帮助定位相关表中的行,或者只要索引包含查询所需的所有列,服务器就可以将索引当作表来使用。
我刚刚带你了解的过程是查询调优(query tuning)的一个示例。调优涉及查看SQL语句,并确定服务器执行该语句可用的资源。你可以决定修改SQL语句、调整数据库资源,或者两者都做,以使语句更高效地运行。调优是一个详细的主题,我强烈建议你阅读服务器的调优指南,或者挑选一本优秀的调优书籍,这样你就能了解针对你的服务器的所有不同方法。
# 索引的缺点
如果索引这么好,为什么不把所有内容都建立索引呢?要理解为什么索引并非越多越好,关键是要记住每个索引都是一个表(一种特殊类型的表,但仍然是表)。因此,每次向表中添加或从表中删除一行时,该表上的所有索引都必须进行修改。当一行被更新时,受影响的列上的任何索引也需要修改。因此,索引越多,服务器为了使所有模式对象(schema objects)保持最新状态就需要做更多的工作,这往往会降低速度。
索引还需要磁盘空间,并且需要管理员进行一定的维护,所以最好的策略是在明确有需求时再添加索引。如果你只是出于特殊目的(如每月的维护例行程序)需要一个索引,你可以随时添加索引、运行例行程序,然后删除索引,直到下次需要时再重新添加。在数据仓库的情况下,索引在工作时间内至关重要,因为用户要运行报告和即席查询(ad hoc queries),但在夜间将数据加载到数据仓库时却会带来问题,因此常见的做法是在加载数据之前删除索引,然后在数据仓库开始工作之前重新创建它们。
一般来说,你应该努力避免索引过多或过少。如果你不确定应该有多少个索引,可以采用以下默认策略:
- 确保所有主键列都建立索引(大多数服务器在创建主键约束时会自动创建唯一索引)。对于多列主键,可以考虑在主键列的子集上构建额外的索引,或者在所有主键列上构建索引,但顺序与主键约束定义不同。
- 在所有外键约束(foreign key constraints)中引用的列上构建索引。请记住,当删除父记录时,服务器会检查以确保没有子行,因此它必须发出查询以在列中搜索特定值。如果列上没有索引,则必须扫描整个表。
- 对任何经常用于检索数据的列建立索引。大多数日期列以及短(3到50个字符)字符串列都是很好的候选对象。
在构建了初始索引集之后,尝试捕获针对表的实际查询,并修改索引策略以适应最常见的访问路径。
# 约束(Constraints)
约束(constraint)只是对表的一个或多个列施加的限制。约束有几种不同的类型,包括:
- 主键约束(Primary key constraints):标识在表中保证唯一性的列或列组合。
- 外键约束(Foreign key constraints):限制一个或多个列只能包含在另一个表的主键列中找到的值,如果建立了级联更新(update cascade)或级联删除(delete cascade)规则,还可能限制其他表中的允许值。
- 唯一约束(Unique constraints):限制一个或多个列在表中包含唯一值(主键约束是一种特殊类型的唯一约束)。
- 检查约束(Check constraints):限制列的允许值。
没有约束,数据库的一致性就值得怀疑。例如,如果服务器允许你在customer表中更改客户ID,而不在account表中更改相同的客户ID,那么最终你会得到一些账户,它们不再指向有效的客户记录(称为孤立行(orphaned rows))。然而,有了主键和外键约束,如果尝试修改或删除被其他表引用的数据,服务器要么会抛出错误,要么会为你将更改传播到其他表(稍后会详细介绍)。
如果你想在MySQL服务器中使用外键约束,你的表必须使用InnoDB存储引擎。截至6.0.4版本,Falcon引擎不支持外键约束,但在更高版本中将会支持。
# 约束创建
约束通常在通过CREATE TABLE语句创建相关表的同时创建。为了说明这一点,以下是本书示例数据库的模式生成脚本中的一个示例:
CREATE TABLE product
(
product_cd VARCHAR(10) NOT NULL,
name VARCHAR(50) NOT NULL,
product_type_cd VARCHAR(10) NOT NULL,
date_offered DATE,
date_retired DATE,
CONSTRAINT fk_product_type_cd FOREIGN KEY (product_type_cd)
REFERENCES product_type (product_type_cd),
CONSTRAINT pk_product PRIMARY KEY (product_cd)
);
2
3
4
5
6
7
8
9
10
11
产品(product)表包含两个约束:一个用于指定product_cd列作为表的主键(primary key),另一个用于指定product_type_cd列作为指向产品类型(product_type)表的外键(foreign key)。或者,你也可以在创建product表时不添加约束,之后再通过ALTER TABLE语句添加主键和外键约束:
ALTER TABLE product
ADD CONSTRAINT pk_product PRIMARY KEY (product_cd);
ALTER TABLE product
ADD CONSTRAINT fk_product_type_cd FOREIGN KEY (product_type_cd) REFERENCES product_type (product_type_cd);
2
3
4
5
如果你想要删除主键或外键约束,同样可以使用ALTER TABLE语句,只不过要指定DROP而不是ADD,例如:
ALTER TABLE product DROP PRIMARY KEY;
ALTER TABLE product
DROP FOREIGN KEY fk_product_type_cd;
2
3
4
虽然删除主键约束的情况并不常见,但外键约束有时会在某些维护操作期间被删除,之后再重新建立。
# 约束和索引
正如你在本章前面所看到的,约束创建有时会涉及自动生成索引。然而,不同的数据库服务器在处理约束和索引之间的关系时表现有所不同。表13-1展示了MySQL、SQL Server和Oracle数据库处理约束和索引之间关系的方式。
表13-1. 约束生成
| 约束类型 | MySQL | SQL Server | Oracle数据库 |
|---|---|---|---|
| 主键约束 | 生成唯一索引 | 生成唯一索引 | 使用现有索引或创建新索引 |
| 外键约束 | 生成索引 | 不生成索引 | 不生成索引 |
| 唯一约束 | 生成唯一索引 | 生成唯一索引 | 使用现有索引或创建新索引 |
因此,MySQL会生成新索引来强制实施主键、外键和唯一约束;SQL Server会为主键和唯一约束生成新索引,但不会为外键约束生成;Oracle数据库与SQL Server的做法类似,不过如果存在合适的现有索引,Oracle会使用它来强制实施主键和唯一约束。尽管SQL Server和Oracle数据库都不会为外键约束生成索引,但这两个服务器的文档都建议为每个外键创建索引。
# 级联约束
在外键约束生效的情况下,如果用户尝试插入新行或更改现有行,使得外键列在父表中没有匹配的值,服务器会抛出错误。为了说明这一点,我们来看一下product表和product_type表中的数据:
mysql> SELECT product_type_cd, name
-> FROM product_type;
+----------------+------------------------------------+
| product_type_cd| name |
+----------------+------------------------------------+
| ACCOUNT | Customer Accounts |
| INSURANCE | Insurance Offerings |
| LOAN | Individual and Business Loans |
+----------------+------------------------------------+
3 rows in set (0.00 sec)
mysql> SELECT product_type_cd, product_cd, name
-> FROM product
-> ORDER BY product_type_cd;
+----------------+-------------+---------------------------------+
| product_type_cd| product_cd | name |
+----------------+-------------+---------------------------------+
| ACCOUNT | CD | certificate of deposit |
| ACCOUNT | CHK | checking account |
| ACCOUNT | MM | money market account |
| ACCOUNT | SAV | savings account |
| LOAN | AUT | auto loan |
| LOAN | BUS | business line of credit |
| LOAN | MRT | home mortgage |
| LOAN | SBL | small business loan |
+----------------+-------------+---------------------------------+
8 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
product_type表的product_type_cd列有三个不同的值(ACCOUNT、INSURANCE和LOAN)。在这三个值中,有两个(ACCOUNT和LOAN)在product表的product_type_cd列中被引用。
以下语句尝试将product表中的product_type_cd列更改为product_type表中不存在的值:
mysql> UPDATE product
-> SET product_type_cd = 'XYZ'
-> WHERE product_type_cd = 'LOAN';
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails ('bank'.'product', CONSTRAINT 'fk_product_type_cd' FOREIGN KEY ('product_type_cd') REFERENCES 'product_type' ('product_type_cd'))
2
3
4
由于product.product_type_cd列上的外键约束,服务器不允许更新成功,因为product_type表中没有product_type_cd列值为XYZ的行。因此,如果父表中没有相应的值,外键约束就不允许你更改子行。
然而,如果你尝试将product_type表中的父行更改为XYZ会发生什么呢?以下是一个尝试将LOAN产品类型更改为XYZ的更新语句:
mysql> UPDATE product_type
-> SET product_type_cd = 'XYZ'
-> WHERE product_type_cd = 'LOAN';
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails ('bank'.'product', CONSTRAINT 'fk_product_type_cd' FOREIGN KEY ('product_type_cd') REFERENCES 'product_type' ('product_type_cd'))
2
3
4
同样,会抛出一个错误;这一次是因为product表中有子行,其product_type_cd列的值为LOAN。这是外键约束的默认行为,但并非唯一可能的行为;相反,你可以指示服务器为你将更改传播到所有子行,从而保持数据的完整性。这种外键约束的变体称为级联更新(cascading update),可以通过删除现有外键并添加一个包含ON UPDATE CASCADE子句的新外键来实现:
mysql> ALTER TABLE product
-> DROP FOREIGN KEY fk_product_type_cd;
Query OK, 8 rows affected (0.02 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE product
-> ADD CONSTRAINT fk_product_type_cd FOREIGN KEY (product_type_cd)
-> REFERENCES product_type (product_type_cd)
-> ON UPDATE CASCADE;
Query OK, 8 rows affected (0.03 sec)
Records: 8 Duplicates: 0 Warnings: 0
2
3
4
5
6
7
8
9
10
11
在修改后的约束生效后,让我们看看再次尝试前面的更新语句会发生什么:
mysql> UPDATE product_type
-> SET product_type_cd = 'XYZ'
-> WHERE product_type_cd = 'LOAN';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
2
3
4
5
这一次,语句执行成功。为了验证更改是否传播到了product表,我们再次查看两个表中的数据:
mysql> SELECT product_type_cd, name
-> FROM product_type;
+----------------+------------------------------------+
| product_type_cd| name |
+----------------+------------------------------------+
| ACCOUNT | Customer Accounts |
| INSURANCE | Insurance Offerings |
| XYZ | Individual and Business Loans |
+----------------+------------------------------------+
3 rows in set (0.02 sec)
mysql> SELECT product_type_cd, product_cd, name
-> FROM product
-> ORDER BY product_type_cd;
+----------------+-------------+---------------------------------+
| product_type_cd| product_cd | name |
+----------------+-------------+---------------------------------+
| ACCOUNT | CD | certificate of deposit |
| ACCOUNT | CHK | checking account |
| ACCOUNT | MM | money market account |
| ACCOUNT | SAV | savings account |
| XYZ | AUT | auto loan |
| XYZ | BUS | business line of credit |
| XYZ | MRT | home mortgage |
| XYZ | SBL | small business loan |
+----------------+-------------+---------------------------------+
8 rows in set (0.01 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
如你所见,对product_type表的更改也传播到了product表。除了级联更新,你还可以指定级联删除(cascading delete)。级联删除会在从父表中删除一行时,从子表中删除相应的行。要指定级联删除,可以使用ON DELETE CASCADE子句,例如:
ALTER TABLE product
ADD CONSTRAINT fk_product_type_cd FOREIGN KEY (product_type_cd) REFERENCES product_type (product_type_cd)
ON UPDATE CASCADE ON DELETE CASCADE;
2
3
在这个版本的约束生效后,当product_type表中的一行被更新时,服务器会更新product表中的子行;当product_type表中的一行被删除时,服务器也会删除product表中的子行。
级联约束是约束直接影响你所编写代码的一种情况。你需要知道数据库中的哪些约束指定了级联更新和 / 或级联删除,这样你才能了解更新和删除语句的全部影响。
# 测试你的知识
完成以下练习,测试你对索引和约束的了解。完成后,将你的答案与附录C中的答案进行对比。
# 练习13-1
修改账户(account)表,使得每个客户对于每种产品不能拥有超过一个账户。
# 练习13-2
在交易(transaction)表上生成一个多列索引,该索引可用于以下两个查询:
SELECT txn_date, account_id, txn_type_cd, amount
FROM transaction
WHERE txn_date > cast('2008-12-31 23:59:59' as datetime);
SELECT txn_date, account_id, txn_type_cd, amount
FROM transaction
WHERE txn_date > cast('2008-12-31 23:59:59' as datetime) AND amount < 1000;
2
3
4
5
6
7