 第十章 存储引擎
第十章 存储引擎
# 第十章 存储引擎
在本章中,我们将更详细地探讨MySQL中最主要的存储引擎。遗憾的是,由于存储引擎种类繁多,且部分引擎结构复杂,我们无法在代码层面上对每一个都进行详尽分析。实际上,像MyISAM和InnoDB这样的存储引擎,每一个都值得用一本上千页的书来专门介绍。不过,对于那些想要深入学习的人,我会提供相关源代码的指引。
不同的存储引擎具备不同的功能。表10-1对不同的存储引擎进行了比较。 表10-1. MySQL存储引擎比较
| MyISAM | InnoDB | 内存(Memory) | 合并(Merge) | NDB | 归档(Archive) | 联邦(Federated) | |
|---|---|---|---|---|---|---|---|
| 事务 索引 | 不支持 B树、R树、全文索引 | 支持 B树 | 不支持 哈希、B树 | 不支持 B树、R树 | 支持 哈希、B树 | 不支持 无 | 不支持 取决于远程表引擎 |
| 存储位置 | 本地磁盘 | 本地磁盘 | 随机存取存储器(RAM) | 本地磁盘 | 远程和本地集群节点 | 本地磁盘 | 远程MySQL服务器实例 |
| 缓存 | 键缓存 | 键和数据缓存 | 不适用 | 与MyISAM相同 | 键和数据缓存 | 无 | 取决于远程表引擎 |
| 锁定 | 表级锁定 | 行级锁定 | 表级锁定 | 表级锁定 | 行级锁定 | 行级锁定 | 依赖于远程表引擎 |
| 外键 | 不支持 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 | 取决于远程表引擎 |
# 架构的共性
尽管存储引擎在实现上有很大的自由度,但所有存储引擎都必须与MySQL主服务器代码集成。因此,它们有一些共同之处。除了必须支持数据库中表、记录、列、键、读写操作等基本概念,以及存储引擎接口要求规定的其他方面外,每个存储引擎还继承了核心表操作代码的特性和属性。换句话说,无论是否需要,它们都会获得一些功能和架构设计。
无论使用哪种存储引擎,每张表都有一个.frm文件,其中包含表定义,如列名、列类型和大小、键信息以及其他表属性。.frm文件本质上收集并存储了CREATE TABLE语句中的信息。在5.1版本之前,文件名始终与表名相同,并且位于与数据库名对应的目录中。5.1版本对此进行了更改。现在,表名和数据库名在sql/sql_table.cc中的build_table_filename()函数中进行编码。代码使用sql/table.cc中的openfrm()函数读取和解析这些文件,并使用同一源文件中的create_frm()函数写入文件。
无论使用哪种存储引擎,服务器都会从.frm文件中读取表定义,并将其存储在所谓的表缓存(table cache)中。这样,下次访问该表时,服务器无需重新读取和解析.frm文件,而是可以使用缓存的信息。
MySQL服务器利用表锁定机制。因此,每个存储引擎既可以利用这一特性,也可以请求表锁管理器始终授予写锁,从而绕过核心代码的表锁定。在这种情况下,存储引擎自身需要负责确保并发访问时的数据一致性。
# MyISAM
MyISAM存储引擎在MySQL的发展历史中由来已久。MySQL首次发布时,最初的存储引擎是ISAM。然而,在那个时候,代码中并没有对存储引擎进行抽象,对于试图扩展MySQL的用户或开发者来说并不直观。当引入存储引擎抽象后,ISAM经过重构和增强,成为了MyISAM。
# MyISAM架构
MyISAM将数据存储在本地磁盘上。除了所有存储引擎都有的.frm文件外,它还使用另外两个文件:一个数据文件(.MYD)和一个索引文件(.MYI)。
# 数据文件
数据文件的格式相当简单。它本质上是表记录与一些必要元信息的拼接。有两种记录格式:固定长度和可变长度。
- 固定长度记录以记录头开始。如果表中没有
BIT类型的字段,头的长度可以使用公式len = (8 + n)/8计算,其中n是表中可能包含NULL值的列数。记录头的第一位表示该记录是否有效或已被删除。如果该位被设置(值为1),则记录有效;已删除的记录该位会被清零(值为0)。对于有效记录,后续位表示其对应的可能为NULL的列是否实际为NULL。在此之后,头的其余位仅作为填充位,没有实际意义。
在MySQL 5.0.3及更高版本中,如果存在BIT类型的字段,情况会变得复杂,因为在某些情况下,位值也可能存储在头中。因此,为了计算头的长度,前一段公式中的n应该增加存储在头中的位数。如果一个字段被定义为BIT(K),表示它存储k位,那么存储在头中的位数为k mod 8。例如,如果字段是BIT(19),那么这19位中有3位存储在头中。
如果头的第一位表示记录已被删除,后续位则作为指向已删除记录链中下一个已删除记录的指针。已删除记录链允许插入操作覆盖旧的已删除记录,而不是将新记录追加到文件末尾。
紧跟在头之后的,是按照表中列顺序拼接的记录列值。记录中的整数和浮点数以小端序(低位字节在前)存储。
你可以在storage/myisam/mi_statrec.c中找到固定长度记录存储的详细信息。
对于可变长度记录,格式更为复杂。第一个字节包含一个特殊代码,用于描述记录的子类型。后续字节的含义因每个子类型而异,但共同之处在于,会有一系列字节包含记录的长度、块中未使用的字节数、NULL值指示标志,并且如果记录无法完全放入先前创建的空间而必须拆分,可能还会有一个指向记录续接部分的指针。当一条记录被删除,而要插入其位置的新记录大小超过原记录时,就会发生这种情况。你可以通过研究storage/myisam/mi_dynrec.c中_mi_get_block_info()函数的switch语句,了解不同代码的含义。
# 索引文件
MyISAM索引文件比数据文件复杂得多。简而言之,它们由一个详细的头和实际的键页组成,头部分描述了各种键和列的属性,并包含大量元信息。其基本结构如图10-1所示。
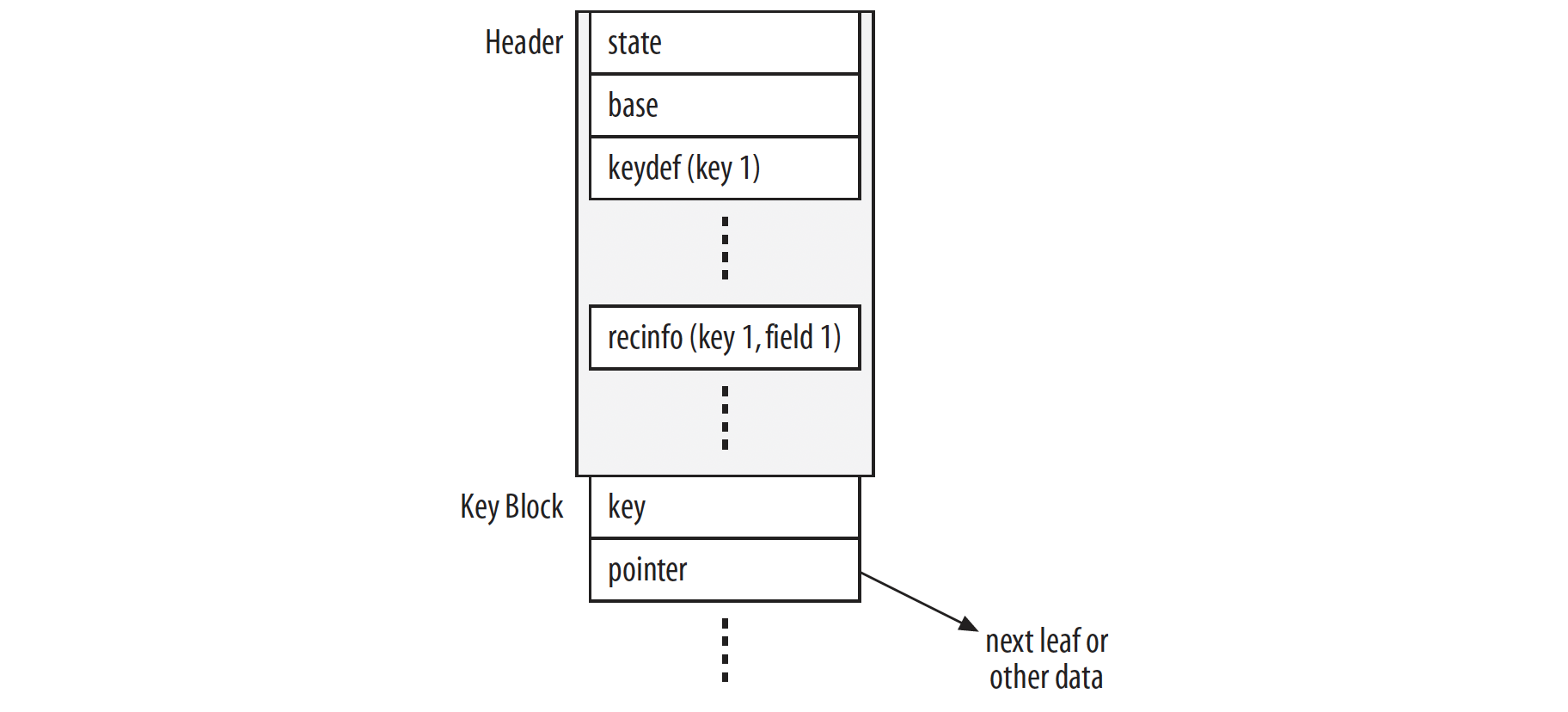
图10-1. MyISAM中索引(.MYI)文件的结构
头部分由以下几种类型的部分组成:状态(state)、基础(base)、键定义(keydef)和记录信息(recinfo)。状态和基础部分只出现一次,键定义部分每个键出现一次,记录信息部分每个键的每个字段出现一次。请注意,表中的每条记录都以一个特殊字段开头,用于标记已删除记录和NULL字段,这个额外字段也会有自己的记录信息部分。
状态部分由storage/myisam/mi_open.c中的mi_state_info_write()函数写入,由mi_state_info_read()函数读取。它包含诸如键和数据文件长度、时间戳、表打开次数、键的数量、已删除和实际记录的数量、每个键的根键块指针等信息,以及许多其他参数。在代码中,状态部分的信息存储在MI_STATE_INFO结构体中,该结构体在storage/myisam/myisamdef.h中定义。
基础部分紧跟在状态部分之后。在很多方面,它在概念上与状态部分类似。它存储表中的记录数量、字段总数(包括处理NULL值和已删除记录的额外字段)、各种限制值(如最大键长度和最大键块长度)以及许多其他项目。基础部分由所有访问该表的线程共享,而每个线程都有自己的状态部分副本。基础部分由storage/myisam/mi_open.c中的mi_base_info_write()函数写入,由my_n_base_info_read()函数读取。存储基础部分数据的内部结构是MI_BASE_INFO,在storage/myisam/myisamdef.h中定义。
在基础部分之后,可能会有一个或多个键定义部分,每个键对应一个。每个键定义部分以一个相对较短的头开始,包含键部分的数量、键算法的类型(B树或R树)、特殊选项标志、用于此键的块长度以及键长度限制。随后是一个或多个键段(keyseg)部分,每个键段对应键中的一列。每个键段部分包含关于相应键部分(或列)的信息。键定义部分由storage/myisam/mi_open.c中的mi_keydef_write()函数写入,由mi_keydef_read()函数读取。存储基础部分数据的内部结构是MI_KEYDEF,在storage/myisam/myisamdef.h中定义。
记录信息部分紧跟在键定义部分之后。每个记录信息部分由字段类型代码、字段长度、一个指示字段值是否可以为NULL的标志以及NULL标记的偏移量组成。记录信息部分由myisam/mi_open.c中的mi_recinfo_write()函数写入,由mi_recinfo_read()函数读取。存储基础部分数据的内部结构是MI_COLUMNDEF,在include/myisam.h中定义。
记录信息部分之后是键块(页)。MyISAM支持两种存储结构,B树和R树。因此,每个块是B树或R树的叶子节点,包含键值以及指向其他块或数据文件中叶子节点偏移量的指针。每个块都有一个2字节的头。第一位用于指示这是否是一个叶子节点(如果该位被清零,则表示是叶子节点)。其余位包含块中已使用部分的大小。
# MyISAM键类型
MyISAM支持三种类型的键:常规B树、全文(使用B树)和空间(使用R树)。
- B树键:B树是一种非常常见的存储结构,许多其他文献都对其进行了详细介绍;因此,我们只对MyISAM的B树进行简要介绍。有兴趣深入了解的读者可参考
storage/myisam目录下的mi_key.c、mi_search.c、mi_write.c和mi_delete.c文件。
MyISAM的B树由叶子节点和非叶子节点(或页)组成。默认情况下,每个页大小为1024字节。可以通过测试myisam_block_size变量来更改页大小。通过查看页第一个字节的最高位,可以区分非叶子节点和叶子节点。非叶子节点的该位会被设置。
叶子节点和非叶子节点都包含键值和指向数据文件中记录位置的指针。非叶子节点还包含指向子节点的指针。节点中的键值可以通过用引用指针替换公共前缀来进行压缩。
# 全文键
全文键本质上是一种B树,它为每个索引列或列集合中的每个单词存储一个指向记录的指针以及相关性权重。可以使用类似如下的语法创建全文键:
CREATE FULLTEXT INDEX ft_ind ON t1(col1);
或者使用标准索引创建语法的任何其他变体,并添加FULLTEXT修饰符。创建全文索引后,可以使用myisam_ftdump实用工具,通过类似如下的命令查看索引的详细信息:
$ myisam_ftdump -d /var/lib/mysql/test/t1 1
第一个非选项参数是表的完整路径(数据目录、数据库名和表名)。第二个参数是键的编号。获取键编号的一种方法是执行SHOW CREATE TABLE,统计键的数量,索引的序号减1就是该实用工具要使用的键编号 。如果表有一个主键、一个全文键且没有其他键,那么该编号将是1。
myisam_ftdump生成的输出类似如下:
188 0.6668773 argument
310 0.7772509 column
310 0.7772509 columns
188 0.6668773 count
188 0.6668773 create
310 0.7772509 created
188 0.6668773 database
188 0.6668773 datadir
310 0.7772509 essentially
188 0.6668773 execute
188 1.1291214 full
310 1.3160002 full
188 0.6668773 index
310 0.7772509 indexed
188 1.1291214 keys
188 0.6668773 minus
188 1.7401749 number
188 0.6668773 option
188 0.6668773 ordinal
188 0.6668773 path
310 0.7772509 pointer
188 0.6668773 primary
310 0.7772509 record
310 0.7772509 relevancy
188 0.6668773 show
310 0.7772509 similar
310 0.7772509 stores
310 0.7772509 syntax
188 1.5913655 table
188 0.6668773 text
310 1.3160002 text
310 0.7772509 tree
188 0.6668773 utility
310 0.7772509 weight
310 0.7772509 word
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
第一列显示数据文件中包含搜索关键词的记录起始位置(以字节为单位)。第二列是一个经过特殊计算的相关性评分(详细信息在storage/myisam/ft_nlq_search.c中的walk_and_match()函数中;务必查看storage/myisam/ft_defs.h中的GWS_IN_USE、GWS_PROB和GWS_IDF宏)。第三列是搜索词。
# 全文SELECT
全文查找本质上是在全文索引中执行B树搜索,找到合适的记录位置,借助树中存储的各个关键词相关性值计算每个记录对于搜索的相关性排名,然后根据计算出的记录相关性评分对记录进行排序。在SQL层面,可通过MATCH()...AGAINST()语法使用全文功能。在下面的示例中,我们假设documents表在(title,body)上有一个全文键。可以使用类似如下的查询来检索结果:
SELECT title,body FROM documents WHERE MATCH(title,body) AGAINST ('mysql internals')
# 全文INSERT
全文插入会解析记录的相应列(见storage/myisam/ft_parser.c),将其分解为一系列单词。停用词(如a、and、the)会被忽略(见storage/myisam/ft_stopwords.c和storage/myisam/ft_static.c)。计算单词频率,最终得到记录中每个关键词的相对权重。然后将带有权重的关键词和记录位置插入到全文索引中。详细信息见storage/myisam/ft_update.c。
# 空间键
空间键的概念源于以下类型的问题。假设你有每个兴趣点的纬度和经度,并且想要确定哪些点位于给定的边界矩形内。在实际应用中,兴趣点可能是餐厅,而边界矩形可能是邮政编码区域。
使用传统的B树方法,可以将纬度和经度存储在表中,并在其中一个或两者上创建键,甚至创建包含两者的复合键。虽然这比全表扫描要好,但无法避免不能有效利用两个坐标范围的问题。你可以检索一个坐标范围的所有值,但另一个坐标的范围却不能得到很好的利用。即使在MySQL 5.0中引入了index_merge优化,允许在查询优化期间在同一个表中使用多个键,B树键对于这类问题来说仍然不够理想。
1984年,Antonin Gutman提出了对传统B树的扩展来应对这一挑战。扩展后的B树被命名为R树,其中R代表区域(region)。传统B树节点包含键值以及指向子节点和 / 或实际记录的指针,或者指向实际记录的指针,而R树用包含节点给定元素下所有子节点的边界框替换了键值。
由于R树的特性,键值是n维空间中的几何对象。在MySQL中,为了创建R树索引,列必须是GEOMETRY类型,或者MySQL必须有办法将其转换为GEOMETRY类型。因此,要在stores表中名为gps_coord的GEOMETRY类型列上创建索引,可使用以下语法:
CREATE SPATIAL INDEX sp_ind ON stores(gps_coord)
要插入gps_coord为(-110.5, 40.5)的记录,可使用以下语法:
INSERT INTO stores (id,gps_coord) VALUES (1,GeomFromText('POINT(-110.5 40.5)')
要检索顶点为(-111,40)、(-111,41)、(-110,41)、(-110,40)的矩形区域内的所有记录,可以使用以下语法:
SELECT id, AsText(gps_coord) FROM stores WHERE
MBRContains(GeomFromText('POLYGON((-111 40,-111 41,-110 41,-110 40,-111 40))'), gps_coord)
2
请注意,边界多边形不一定是矩形,GEOMETRY列的值也不一定是点。实际上,同一列可以包含点、线、多边形和其他几何对象。
插入算法(见storage/myisam/rt_index.c中的rtree_insert_req()函数)会从根节点开始遍历节点,寻找与搜索键合并时扩展最小的边界框(见storage/myisam/rt_index.c中的rtree_pick_key()函数)。扩展的度量方式有两种:按面积(在n维意义上)或按周长。默认情况下,使用按面积扩展的方式。不过,可以通过在编译标志中添加-DPICK_BY_PERIMETER来编译MySQL,从而使用按周长扩展的方式。
一旦在节点中找到合适的边界框,就以同样的方式检查子节点,直到到达叶节点。执行插入操作(见storage/myisam/rt_key.c中的rtree_add_key()函数)。相应地更新上层边界框(见storage/myisam/rt_key.c中的rtree_set_key_mbr()函数)。如果节点已满,则需要进行分裂。
分裂操作在storge/myisam/rt_split.c中的rtree_split_page()函数中完成。首先,检查所有键对(边界框),找到如果合并将浪费最多面积(在n维意义上)的一对。浪费的面积计算为并集的最小边界框面积减去该对中每个键的面积之和(见storage/myisam/rt_split.c中的pick_seeds()函数)。将每一个键放入单独的组中。
然后分配剩余的键。将尚未选择的每个键假设性地添加到两个组中。然后,算法计算每个组因添加该键而导致的最小边界框面积的增加量,并比较这些增加量。增加量的差值作为该键对一个组或另一个组的偏好度量。选择偏好度量最大的键加入其导致最小边界框面积增加较小的组。重复此过程,直到分配完所有键(见storage/myisam/rt_split.c中的pick_next()函数)。
这种分裂算法被称为二次成本分裂,因为它相对于节点中的键数量的复杂度为$O(N^2)$ 。存在更快的分裂算法(线性成本)和更慢的算法(穷举分裂)。较慢的算法会生成更平衡的树。二次成本算法是在保持树的平衡和维持良好的插入速度之间的一个不错的权衡。
R树搜索与B树搜索非常相似。从根节点开始。如果未找到匹配项,我们会扫描当前节点,直到找到感兴趣的边界矩形,在最简单的情况下,该边界矩形将包含搜索矩形。除非我们处于叶节点,否则进入匹配的节点。如果在叶节点,则跟随记录指针检索记录。见storage/myisam/rt_index.c中的rtree_find_first()、rtree_find_next()和rtree_find_req()函数,以及storage/myisam/rt_mbr.c中的rtree_key_cmp()函数。
要删除一条记录,需找到搜索键并从叶节点中删除。然后,如果这使得节点的填充率小于三分之一,则将整个节点及其子节点一起移除并放入重新插入列表中。匹配的键也会从父节点中删除,并以这种方式向上传播删除操作。删除完成后,处理重新插入列表,将移除的键值恢复到树中。详细信息见storage/myisam/rt_index.c中的rtree_delete()、rtree_delete_req()、rtree_fill_reinsert_list()和rtree_insert_level()函数。
# InnoDB
InnoDB是目前MySQL中最复杂的存储引擎之一。它支持事务、多版本控制、行级锁和外键。它拥有一套完善的I/O和内存管理系统,具备内部死锁检测机制,能够实现快速可靠的崩溃恢复。它还采用了多种算法来克服传统支持事务的数据库在性能上的限制。
与总是将数据存储在文件中的MyISAM不同,InnoDB使用表空间(tablespace)。表空间可以存储在文件中,也可以存储在原始分区上。所有表可以存储在一个公共表空间中,或者每个表都可以有自己的表空间。
数据存储在一种称为聚簇索引(clustered index)的特殊结构中,聚簇索引是一种B树结构,主键作为键值,数据部分存储的是实际记录(而非指针)。因此,每个InnoDB表都必须有一个主键。如果没有提供主键,会添加一个用户通常不可见的特殊行ID列作为主键。二级键会存储用于标识记录的主键值。B树的代码可以在innobase/btr/btr0btr.c中找到。
主键和二级键都存储在磁盘上的B树中。不过,在缓存索引页时,InnoDB会在内存中构建自适应哈希索引(adaptive hash index),以加快对缓存页的索引查找速度。处理InnoDB自适应哈希的代码可以在storage/innobase/ha/ha0ha.c中找到。
MyISAM仅缓存键页,而InnoDB会同时缓存键和数据。这种方式既有优点也有缺点。一方面,数据缓存无需依赖操作系统的文件缓存,即使操作系统的文件缓存出现问题,也能获得良好的性能。此外,与操作系统的文件缓存相比,访问数据时避免了额外的系统调用。另一方面,如果操作系统的文件缓存仍然启用,就可能出现双重缓存(即相同的数据同时缓存在操作系统的文件缓存和数据缓冲区中),这只会浪费内存。不过,可以通过将innodb_flush_method设置为O_DIRECT启动InnoDB来禁用操作系统的文件缓存。处理数据和键缓存的代码可以在storage/innobase/buf/buf0buf.c中找到。
InnoDB引擎维护两种日志:回滚日志(undo log)和重做日志(redo log)。回滚日志用于回滚事务,以及在需要的事务隔离级别下,为查询显示数据的旧版本。处理回滚日志的代码可以在storage/innobase/log/log0log.c中找到。
重做日志的目的是存储用于崩溃恢复的信息。它允许恢复过程重新执行在崩溃前可能完成也可能未完成的事务。重新执行这些事务后,数据库将恢复到一致状态。处理重做日志的代码可以在storage/innobase/log/log0recv.c中找到。
InnoDB的数据行有两种不同的格式:一种是较旧的、不太紧凑的格式(5.0.3版本之前),另一种是较新的、更紧凑的格式(5.0.3及更高版本)。两种格式存储的信息大多相同,但新格式占用的空间更少。记录开头是记录中字段数据偏移量的列表。接着是4位用于标记记录是否已删除及其他用途;4位用于显示该记录拥有的记录数量;还有13位用于表示记录的堆号。旧格式有10位用于包含记录中的字段数量,后面跟着1位表示字段偏移量使用1字节还是2字节。新格式有3位表示记录类型。两种格式都接着一个2字节的下一键指针。记录的其余部分包含实际的字段数据。处理记录格式和操作的代码可以在storage/innobase/rem/rem0rec.c中找到。
记录格式的复杂性是为了优化插入操作。传统的B树在插入新记录时,平均需要移动一半的记录。InnoDB采用了一种非常巧妙的方法来避免这种情况。记录按自然顺序插入到页中。堆号表示记录在页中的顺序。下一键指针表示按主键顺序的下一条记录的位置。
为了在页中高效定位键,InnoDB维护了一种额外的结构,称为页目录(page directory)。它是一个指向页内键的稀疏排序指针数组。通过二分查找可以定位给定的记录。之后,由于索引是稀疏的,可能仍需要在记录链表中检查更多的键。记录拥有的数量表示在到达下一个有页目录指针指向它的记录之前,还需要检查多少条记录,从而包含了查找给定键何时停止的信息。处理InnoDB页的代码可以在storage/innobase/page/page0page.c中找到。
每个InnoDB数据行都有两个额外的内部字段,用于存储事务、恢复和多版本控制所需的信息。一个字段长6字节,包含最后修改该记录的事务ID。它还包含一个7字节的字段,称为回滚指针(roll pointer)。回滚指针指向回滚段中回滚日志里的记录。这个指针可用于回滚事务,或者在当前事务隔离级别需要时显示数据的旧版本。
# Memory(堆)
MEMORY存储引擎,以前称为HEAP,它将数据存储在内存中。该代码最初的目的是让优化器在执行可以一次性完成的SELECT操作时,能够创建和使用临时表。在3.23版本引入存储引擎架构后,让用户访问这个用于临时表的内存表引擎变得相当容易。
这个简单的功能为MySQL用户带来了诸多好处。内存表可用于在执行一组复杂查询时存储临时结果;作为一个快速的数据累加器,定期将数据刷新到磁盘;作为某个大型磁盘表部分数据的快速缓存;还有许多其他用途。
MEMORY引擎支持两种类型的键:哈希(hash)键和B树(B-tree)键。表的定义在服务器重启后仍然保留。然而,数据行仅在服务器运行期间存在,服务器重启后数据会丢失。
如果知道键的精确值,哈希索引查找比B树索引查找更快。但是,如果只知道键值的前缀,或者只知道范围的边界值,哈希索引就无法发挥作用。而B树则可以通过索引来处理这类请求。
在大多数操作上,MEMORY表通常比类似的MyISAM表速度更快。不过,如果MyISAM表足够小,能完全放入操作系统的文件缓存中,那么两者的速度差异可能没有你想象的那么大:大概在1.5倍左右。MEMORY表的速度提升源于两个方面:更简单的算法和无需进行I/O系统调用。
对MEMORY表感兴趣的人可以参考sql/ha_heap.h、sql/ha_heap.cc以及storage/heap目录下的.c和.h文件。
# MyISAM Merge
MERGE存储引擎将一组结构相同的MyISAM表组合成一个逻辑单元。对其中一个MyISAM表或MERGE表仍可以进行读写操作。
MERGE引擎的创建是为了解决一个常见问题。假设你的系统随时间收集了一些历史数据。大多数查询都限制在一个相当窄且容易预测的时间范围内。然而,偶尔你也需要查询整个表。如果将所有数据都放在一个MyISAM表中,由于多种原因,性能会不佳,比如锁争用、不必要的I/O增加,或者在崩溃时修复时间较长。将所有数据按时间存储在不同的表中,又会使那些需要查询多个表的操作变得不必要的复杂。
MERGE表提供了一个很好的解决方案。现在,当时间范围足够窄时,你可以查询单个表;当时间范围较宽时,可以查询MERGE表。有关MERGE的更多信息,请参考sql/ha_myisammrg.h、sql/ha_myisammrg.cc以及storage/myisammrg目录下的.c文件。
# NDB
NDB是Network DataBase的缩写。这个存储引擎能够将数据存储在一个具有故障安全功能的数据库服务器集群上。2003年,MySQL AB收购了爱立信(一家瑞典电信公司)的一个部门,该部门开发了NDB代码用于处理爱立信的电话系统,之后MySQL AB开始将其集成到MySQL中。
运行中的MySQL服务器为访问NDB集群提供了一个中心点。查询由MySQL解析器解析,然后传递给优化器。然后,如果表的存储引擎是NDB,在执行查询时会调用NDB处理程序类的相应方法(见sql/ha_ndbcluster.h和sql/ha_ndbcluster.cc)。此时,对处理程序类方法的调用会被转换为NDB API调用(见ndb/src/ndbapi目录下的.hpp和.cpp文件),这些API调用进而与集群节点进行通信。
集群节点分为两种类型:管理节点(ndb_mgmd)和数据节点(ndbd)。管理节点负责控制集群,数据节点存储并复制数据。
NDB支持事务、行级锁定、B树和哈希键、内部同步复制两阶段提交(与MySQL服务器复制分开),以及基于主键的数据分区。每个数据节点在启动时会将其整个数据集加载到内存中,并在关闭时将数据写入磁盘。还会定期异步写入磁盘,以确保在整个集群发生灾难性故障(例如所有节点同时断电)时不会丢失太多数据。其思路是,如果你有大量数据集,可以设置足够多的数据节点,使它们的内存总和足以以这种方式运行集群。目前正在进行一些工作,以支持从磁盘运行集群。
正如人们所预期的,NDB的性能在很大程度上取决于连接集群节点的网络速度。NDB集群可以通过以太网使用TCP/IP协议,或者通过SCI总线连接并使用SCI套接字。如果节点在同一台计算机上,也可以使用共享内存。虽然使用SCI可以显著提高速度,但到目前为止,通过以太网的TCP/IP协议是更简单且经过更好测试的方法。
需要记住的是,NDB是为特定目的(满足大型电话数据库应用的需求)而创建的,并且它很好地实现了这一目的。它非常适合遵循类似设计理念的相似应用。然而,它有相当多的限制,在你能够设置一个集群,并对所有表运行ALTER TABLE ...ENGINE=NDB,且期望任何应用都能正常工作之前,还有很长的路要走。
# Archive
ARCHIVE存储引擎的目的是提供一种功能,能够以最小的空间存储大量数据。其理念是对数据进行压缩和归档,同时仍能偶尔以最小的麻烦对其进行查询或追加操作。这个引擎是由MySQL AB的架构总监布莱恩·阿克(Brian Aker)在几次富有灵感的编码过程中创建的。布莱恩有一种惊人的能力,能在履行其他职责的间隙,在很短的时间内编写出非常有用的代码。
与MyISAM、InnoDB或NDB相比,这是一个非常简单的存储引擎。它仅支持两种操作:SELECT和INSERT。这种简化有很大的好处。在压缩的数据文件中删除或更新记录是一项成本很高的操作。无需担心更新和删除数据,就可以将记录保持在压缩格式。此外,这种限制使得篡改现有数据变得困难:删除或更新记录的唯一方法是将其转换为另一个存储引擎,运行修改查询,然后再转换回ARCHIVE存储引擎。由于无需担心更新和删除操作,解决高性能并发访问的问题就变得很容易。因为数据文件不会因记录删除而产生空洞,所以INSERT和SELECT操作可以并发进行,除非SELECT尝试读取当前正在文件末尾写入的记录。因此,就性能而言,ARCHIVE引擎提供了行级锁的效果。
目前,ARCHIVE存储引擎不支持键。MySQL开发者之间有一些关于未来是否支持键的讨论。
ARCHIVE存储引擎的源代码可以在storage/archive目录中找到。对实现自己的存储引擎感兴趣的读者,建议研究这段代码。它足够简单,相当容易理解,并且就我们目前所涵盖的示例而言,它也具备足够的实用性,可作为下一步学习的参考。
# Federated
这是另一个简单的存储引擎,同样是布莱恩·阿克编码灵感的成果。它的目的是允许像访问本地表一样访问存储在远程MySQL服务器上的表。
FEDERATED存储引擎在CREATE TABLE语句的注释字段中存储有关如何访问远程服务器以及映射到哪个表的信息。这些信息存储在.frm文件中。这个存储引擎不会创建或使用其他数据文件。当优化器请求存储引擎提供数据时,存储引擎会使用常规的MySQL客户端/服务器通信协议向远程服务器发出SQL查询,并从远程表中检索数据。在处理更新表的查询时,存储引擎会将它们转换为对远程服务器的相应更新查询,并通过标准的客户端/服务器协议发送这些查询。
这个存储引擎也是一个很好的学习示例。你可以在storage/federated/ha_federated.h和storage/fedrated/ha_federated.cc中找到它的实现代码。