 第5章:线程基础
第5章:线程基础
# 第5章:线程基础
进程是管理对象,并不直接执行代码。要在Windows系统上完成任何任务,都必须创建线程。如我们所见,用户模式进程在创建时会包含一个单线程,该线程最终会执行可执行文件的主入口点。在许多情况下,这就足够了,应用程序可能不再需要更多线程。
然而,有些应用程序可能会受益于在进程内使用多个线程执行任务。每个线程都是一个独立的执行路径,从执行角度来看,它与同一时间可能处于活动状态的其他线程无关。在本章中,我们将探讨创建和管理线程的基础知识。在后续章节中,我们将深入研究线程的其他方面,如调度和同步。
本章内容包括:
- 引言
- 创建和管理线程
- 终止线程
- 线程栈
- 线程名称
- C++标准库相关问题
# 引言
我们首先要考虑的问题是,为什么一开始就要使用线程呢?基本上有两个可能的原因:
- 通过利用多个核心并发执行来提高性能。
- 改进应用程序设计。
尽管你可能会想出其他使用线程的理由,但这些理由在某种程度上都可以归入第二类。实际上,总是可以仅用一个线程进行设计(比如通过使用定时器),而无需创建更多线程。不过,第二个理由是合理的,并且实际上是主要原因。快速查看任务管理器中“性能/CPU”选项卡就会发现,其中有许多(数千个)线程,数量远远超过处理器的数量,但在任何时刻,CPU的使用率都很低,这意味着第一个理由并非主要因素(图5-1)。
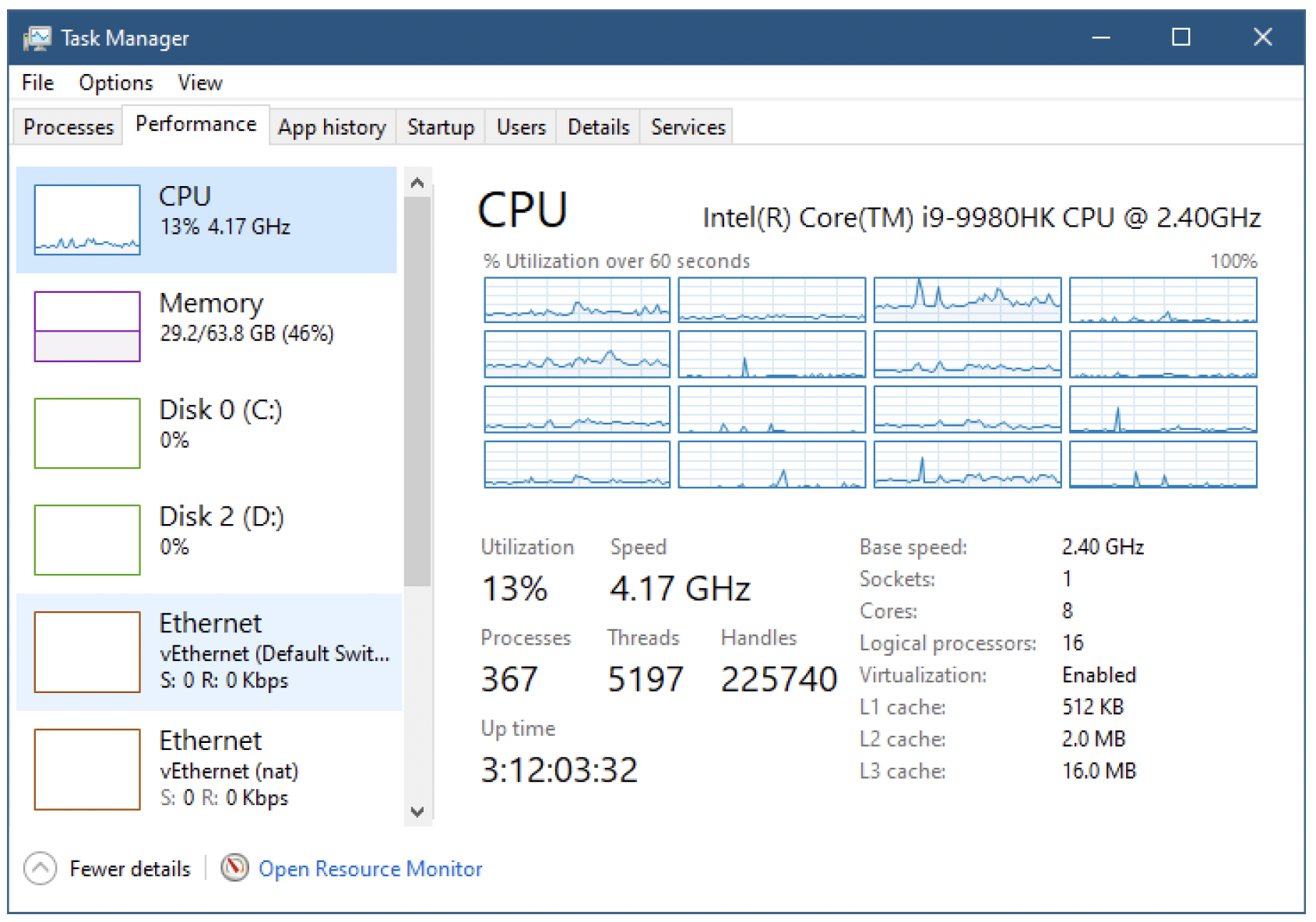
图5-1:任务管理器中的“性能/CPU”选项卡
线程抽象出了一个独立的执行路径,从执行的角度来看,它与同一时间可能处于活动状态的其他线程没有关联。一旦线程开始执行,在退出之前,它可能会执行以下任何操作:
- CPU密集型操作——依赖CPU运算来推进的计算或函数调用。
- I/O密集型操作——针对I/O设备(如磁盘或网络)执行的操作。在等待I/O操作完成时,线程处于等待状态,不会消耗CPU周期。
- 其他可能导致线程进入等待状态的操作,例如等待同步原语(如互斥锁)。
| 线程同步将在第7章详细讨论。 |
|---|
图5-1中CPU使用率未达到100%这一事实意味着,大多数线程处于等待状态(不想执行)。实际上,如果在该机器上有16个线程同时执行代码(图5-1),CPU使用率将达到100%。但实际上只有约13%,这意味着大约只有2个处理器在同时处于活动状态。
# 插槽、核心和逻辑处理器
在进一步讨论线程之前,我们必须认识到,线程是对处理器的一种抽象。但处理器的确切定义是什么呢?在如今多个核心构成一个典型CPU的时代,这些术语可能会让人感到困惑。图5-2展示了一个典型CPU的逻辑组成。

图5-2:CPU的逻辑组成
在图5-2中,有一个插槽(socket),它是安装在计算机主板上的物理芯片。笔记本电脑和家用电脑通常只有一个这样的插槽。大型服务器机器可能包含多个插槽。每个插槽都有多个核心(core),这些核心是独立的处理器(图5-2中有4个)。
在英特尔处理器上,每个核心可以划分为两个逻辑处理器,由于一种名为超线程(Hyper-threading)的技术,它们也被称为硬件线程。从Windows的角度来看,处理器的数量就是逻辑处理器的数量(图5-1中有16个)。这意味着在任何给定时刻,最多可以有16个线程正在运行。任务管理器也会显示插槽、核心和逻辑处理器的数量(图5-1)。
AMD公司有一项类似的技术,称为同步多线程(Simultaneous Multi Threading,SMT)。
| 超线程功能可以在BIOS设置中禁用。超线程的潜在缺点是,共享一个核心的每两个逻辑处理器也会共享二级缓存,因此可能会相互“干扰”。第6章将对缓存进行更详细的介绍。 |
|---|
# 创建和管理线程
创建线程的基本函数是CreateThread:
HANDLE WINAPI CreateThread(
_In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes,
_In_ SIZE_T dwStackSize,
_In_ LPTHREAD_START_ROUTINE lpStartAddress,
_In_opt_ LPVOID lpParameter,
_In_ DWORD dwCreationFlags,
_Out_opt_ LPDWORD lpThreadId);
2
3
4
5
6
7
现在,大家应该已经熟悉CreateThread的第一个参数了,它通常被设置为NULL。dwStackSize参数用于设置线程栈的大小,本章后面的“线程栈”部分将对此进行详细讨论。它通常被设置为0,这会根据PE文件头设置默认大小。我说“大小”是因为栈有一个初始大小和一个最大大小(后面也会讨论)。
lpStartAddress参数是最重要的,它指定了新线程要调用的用户函数。这个函数可以取任何名字,但它必须遵循以下原型:
DWORD WINAPI ThreadProc(_In_ PVOID pParameter);
线程函数必须返回一个32位的数字,这个数字被视为线程的退出代码,稍后可以使用GetExitCodeThread函数获取。WINAPI宏展开为stdcall关键字,表示标准调用约定,这是大多数Windows API常用的调用约定。最后,传递给该函数的参数是一个用户定义的值,它作为CreateThread的第四个参数传入,并直接传递给线程函数。这个值通常指向某个数据结构,其中包含了让线程完成工作所需的信息。
回到CreateThread函数,lpParameter参数刚刚已经讨论过了。在最简单的情况下,可以传入NULL。dwCreationFlags参数有三种可能的值(这些值可以组合使用)。指定CREATE_SUSPENDED标志会使线程以挂起状态创建。线程已准备就绪,但必须调用ResumeThread函数才能让它开始执行。另一个可能的值是STACK_SIZE_PARAM_IS_A_RESERVATION,它为栈大小参数赋予了另一种含义(在“线程栈”部分也会讨论)。最后,如果不指定这些标志(这是最常见的情况),则指示线程立即开始执行。CreateThread的最后一个可选参数是新线程生成的唯一线程ID。如果调用者对这个信息不感兴趣,可以简单地为这个参数指定NULL。
CreateThread的返回值是新创建线程的句柄。如果出现问题,返回值为NULL,可以调用GetLastError函数来获取错误代码。一旦不再需要这个句柄,就应该像处理其他内核对象句柄一样,使用CloseHandle函数将其关闭。
以下代码片段从主函数中创建一个线程,等待它退出,并输出其退出代码:
DWORD WINAPI DoWork(PVOID) {
printf("Thread ID running DoWork: %u\n", ::GetCurrentThreadId());
// simulate some heavy work...
::Sleep(3000);
// return a result
return 42;
}
int main() {
HANDLE hThread = ::CreateThread(nullptr, 0, DoWork, nullptr, 0, nullptr);
if (!hThread) {
printf("Failed to create thread (error=%d)\n", ::GetLastError());
return 1;
}
// print ID of main thread
printf("Main thread ID: %u\n", ::GetCurrentThreadId());
// wait for the thread to finish
::WaitForSingleObject(hThread, INFINITE);
DWORD result;
::GetExitCodeThread(hThread, &result);
printf("Thread done. Result: %u\n", result);
::CloseHandle(hThread);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
以下是一个示例输出:
Main thread ID: 19108
Thread ID running DoWork: 23700
Thread done. Result: 42
2
3
GetExitCodeThread函数用于获取线程函数的返回值:
BOOL GetExitCodeThread(
_In_ HANDLE hThread,
_Out_ LPDWORD lpExitCode);
2
3
你可能想知道,如果对一个尚未退出的线程调用这个函数会发生什么。该函数不会失败,但会返回STILL_ACTIVE(0x103 = 259)。
# 质数计数应用程序
下面的示例展示了多线程更为复杂的一种用法。质数计数应用程序(可在本章的示例中获取)使用指定数量的线程,统计某个数字范围内质数的数量。其原理是将工作分配给多个线程,每个线程负责统计各自数字范围内的质数数量。然后,主线程等待所有工作线程退出,这样就能简单地把所有线程的统计结果相加。图5-3展示了这一过程。

图5-3:质数计数器设计
创建多个执行任务的线程,并在汇总结果前等待它们退出,这种思路有时被称为“分治合并(Fork-Join)”,因为线程从某个初始线程“分叉(forked)”出来,完成任务后又“合并(joined back)”到初始线程。
| 这种模式的另一个名称是结构化并行(Structured Parallelism)。 |
|---|
该应用程序中使用的线程数量是算法的参数之一。一个有趣的问题是,使用多少个线程能最快完成计算?这个问题稍后会进行讨论;但首先,我们来看代码。
主函数(main function)在命令行中接收数字范围和线程数量:
int main(int argc, const char* argv[]) {
if (argc < 4) {
printf("Usage: PrimesCounter <from> <to> <threads>\n");
return 0;
}
int from = atoi(argv[1]);
int to = atoi(argv[2]);
int threads = atoi(argv[3]);
if (from < 1 || to < 1 || threads < 1 || threads > 64) {
printf("Invalid input.\n");
return 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
线程数量被限制为64。为什么是这个数字呢?这是WaitForMultipleObjects函数(稍后用于等待所有线程退出)一次能够等待的句柄(handle)的最大数量。
main函数接下来调用的是一个启动任务并返回结果的函数:
DWORD elapsed;
int count = CalcAllPrimes(from, to, threads, elapsed);
printf("Total primes: %d. Elapsed: %d msec\n", count, elapsed);
2
3
CalcPrimes函数接收从命令行提取的参数,返回统计出的质数总数,还通过最后一个elapsed参数(通过引用传递)返回以毫秒为单位的耗时。最后,结果会输出到控制台。
每个线程都需要知道自己负责的数字范围(起始数字“from”和结束数字“to”),以及存储结果的地方。由于线程函数可以返回一个32位无符号整数,这里可以利用它来存储结果。但在一般情况下,这种返回值可能不够灵活。常见的解决办法是定义一个结构体,其中包含线程所需的所有信息,包括输入和输出值。对于我们的应用程序,定义了如下结构体:
struct PrimesData {
int From, To;
int Count;
};
2
3
4
CalcAllPrimes函数必须为每个线程分配一个PrimesData实例,并初始化From和To数据成员:
int CalcAllPrimes(int from, int to, int threads, DWORD& elapsed) {
auto start = ::GetTickCount64();
// 为每个线程分配数据
auto data = std::make_unique<PrimesData[]>(threads);
// 分配一个句柄数组
auto handles = std::make_unique<HANDLE[]>(threads);
2
3
4
5
6
在开始任何任务前,使用GetTickCount64获取当前时间。这个API返回自Windows启动以来经过的毫秒数。虽然它不是最精确的API(QueryPerformanceCounter更精确),但对于本应用程序的目的来说已经足够。
GetTickCount64取代了旧的GetTickCount,它返回一个64位数字,而GetTickCount返回的是32位数字。32位的毫秒数在大约49.7天后会溢出并回滚到零。
代码使用std::unique_ptr<[]>来管理数组,当变量超出作用域时,数组会自动被清理。这用于PrimesData数组以及线程句柄数组。
接下来,函数计算每个线程的任务块大小,然后通过循环来正确创建线程:
int chunk = (to - from + 1) / threads;
for (int i = 0; i < threads; i++) {
auto& d = data[i];
d.From = i * chunk;
d.To = i == threads - 1 ? to : (i + 1) * chunk - 1;
DWORD tid;
handles[i] = ::CreateThread(nullptr , 0, CalcPrimes, &d, 0, &tid);
assert(handles[i]);
printf("Thread %d created. TID=%u\n", i + 1, tid);
}
2
3
4
5
6
7
8
9
10
11
12
每个线程的PrimesData实例会根据任务块大小正确初始化From和To。唯一的问题是,数字范围可能无法被线程数量整除。因此,最后一个线程负责处理剩余的数字(如果有的话)。调用CreateThread创建每个线程,将每个线程指向CalcPrimes函数(稍后讨论),并将其对应的PrimesData指针传递给它。最后,显示线程索引和ID。
CalcPrimes是线程函数,负责统计分配给该线程的数字范围内的质数数量:
DWORD WINAPI CalcPrimes(PVOID param) {
auto data = static_cast<PrimesData*>(param);
int from = data->From, to = data->To;
int count = 0;
for (int i = from; i <= to; i++)
if (IsPrime(i))
count++;
data->Count = count;
return count;
}
2
3
4
5
6
7
8
9
10
11
12
传递给线程的参数被转换为PrimesData指针。然后,通过一个简单的for循环检查数字是否为质数,如果是,则增加一个计数器,最终将其存储在PrimesData的Count成员中。IsPrime是一个简单的函数,如果数字是质数则返回true,否则返回false:
bool IsPrime(int n) {
if (n < 2)
return false;
if (n == 2)
return true;
int limit = (int)::sqrt(n);
for (int i = 2; i <= limit; i++)
if (n % i == 0)
return false;
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
IsPrime中使用的算法肯定不是最优的,但这不是重点。 |
|---|
回到CalcAllPrimes函数,所有线程在创建时都没有使用CREATE_SUSPENDED标志,所以它们会立即开始执行。剩下的就是等待所有线程退出:
::WaitForMultipleObjects(threads, handles.get(), TRUE, INFINITE);
关于等待函数的完整讨论将在第7章进行。上面的WaitForMultipleObjects函数按顺序接受以下参数:
- 数组中的句柄数量
- 要等待的句柄数组
- 一个布尔标志,指示是等待所有句柄都变为有信号状态(
TRUE)还是只要有一个句柄变为有信号状态(FALSE)。对于线程来说,“有信号状态”意味着“已退出”。 - 以毫秒为单位的超时时间,在这种情况下,
INFINITE表示无限期等待。
一旦所有线程退出,等待就结束了。剩下的就是收集结果:
elapsed = static_cast<DWORD>(::GetTickCount64() - start);
FILETIME dummy, kernel, user;
int total = 0;
for (int i = 0; i < threads; i++) {
::GetThreadTimes(handles[i], &dummy, &dummy, &kernel, &user);
int count = data[i].Count;
printf("Thread %2d Count: %7d. Execution time: %4u msec\n",
i + 1, count,
(user.dwLowDateTime + kernel.dwLowDateTime) / 10000);
total += count;
::CloseHandle(handles[i]);
}
return total;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上面的代码使用GetThreadTimes API来检索线程的计时信息:
BOOL GetThreadTimes(
_In_ HANDLE hThread,
_Out_ LPFILETIME lpCreationTime,
_Out_ LPFILETIME lpExitTime,
_Out_ LPFILETIME lpKernelTime,
_Out_ LPFILETIME lpUserTime
);
2
3
4
5
6
7
该函数返回线程的创建时间、退出时间、在内核模式下执行的时间以及在用户模式下执行的时间。对于这个应用程序,我想要显示执行时间,这意味着要将内核时间和用户时间相加,同时忽略创建时间和退出时间。
内核时间和用户时间以FILETIME结构体的形式报告,这是一个64位值,存储在两个32位值中:
typedef struct _FILETIME {
DWORD dwLowDateTime;
DWORD dwHighDateTime;
} FILETIME, *PFILETIME, *LPFILETIME;
2
3
4
这个值以100纳秒为单位(10的 -7次方秒),这意味着要得到以毫秒为单位的值,需要除以10000。代码假设以100纳秒为单位的耗时不超过32位值,在一般情况下,这可能并不正确。
# 运行质数计数器
以下是在相同数值范围内的几次运行结果,从使用单个线程的基准情况开始:
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 1
线程1已创建(范围从3到20000000)。线程ID(TID)=29760
线程1的计数:1270606。执行时间:9218毫秒
质数总数:1270606。耗时:9218毫秒
2
3
4
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 2
线程1已创建(范围从3到10000001)。线程ID(TID)=22824
线程2已创建(范围从10000002到20000000)。线程ID(TID)=41816
线程1的计数:664578。执行时间:3625毫秒
线程2的计数:606028。执行时间:5968毫秒
质数总数:1270606。耗时:5984毫秒
2
3
4
5
6
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 4
线程1已创建(范围从3到5000001)。线程ID(TID)=52384
线程2已创建(范围从5000002到10000000)。线程ID(TID)=47756
线程3已创建(范围从10000001到14999999)。线程ID(TID)=42296
线程4已创建(范围从15000000到20000000)。线程ID(TID)=34972
线程1的计数:348512。执行时间:1312毫秒
线程2的计数:316066。执行时间:2218毫秒
线程3的计数:306125。执行时间:2734毫秒
线程4的计数:299903。执行时间:3140毫秒
质数总数:1270606。耗时:3141毫秒
2
3
4
5
6
7
8
9
10
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 8
线程1已创建(范围从3到2500001)。线程ID(TID)=25200
线程2已创建(范围从2500002到5000000)。线程ID(TID)=48588
线程3已创建(范围从5000001到7499999)。线程ID(TID)=52904
线程4已创建(范围从7500000到9999998)。线程ID(TID)=18040
线程5已创建(范围从9999999到12499997)。线程ID(TID)=50340
线程6已创建(范围从12499998到14999996)。线程ID(TID)=43408
线程7已创建(范围从14999997到17499995)。线程ID(TID)=53376
线程8已创建(范围从17499996到20000000)。线程ID(TID)=33848
线程1的计数:183071。执行时间:578毫秒
线程2的计数:165441。执行时间:921毫秒
线程3的计数:159748。执行时间:1171毫秒
线程4的计数:156318。执行时间:1343毫秒
线程5的计数:154123。执行时间:1531毫秒
线程6的计数:152002。执行时间:1531毫秒
线程7的计数:150684。执行时间:1718毫秒
线程8的计数:149219。执行时间:1765毫秒
质数总数:1270606。耗时:1766毫秒
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 16
线程1已创建(范围从3到1250001)。线程ID(TID)=50844
线程2已创建(范围从1250002到2500000)。线程ID(TID)=9792
线程3已创建(范围从2500001到3749999)。线程ID(TID)=12600
线程4已创建(范围从3750000到4999998)。线程ID(TID)=52804
线程5已创建(范围从4999999到6249997)。线程ID(TID)=5408
线程6已创建(范围从6249998到7499996)。线程ID(TID)=42488
线程7已创建(范围从7499997到8749995)。线程ID(TID)=49336
线程8已创建(范围从8749996到9999994)。线程ID(TID)=13384
线程9已创建(范围从9999995到11249993)。线程ID(TID)=41508
线程10已创建(范围从11249994到12499992)。线程ID(TID)=12900
线程11已创建(范围从12499993到13749991)。线程ID(TID)=39512
线程12已创建(范围从13749992到14999990)。线程ID(TID)=3084
线程13已创建(范围从14999991到16249989)。线程ID(TID)=52760
线程14已创建(范围从16249990到17499988)。线程ID(TID)=17496
线程15已创建(范围从17499989到18749987)。线程ID(TID)=39956
线程16已创建(范围从18749988到20000000)。线程ID(TID)=31672
线程1的计数:96468。执行时间:281毫秒
线程2的计数:86603。执行时间:484毫秒
线程3的计数:83645。执行时间:562毫秒
线程4的计数:81795。执行时间:671毫秒
线程5的计数:80304。执行时间:781毫秒
线程6的计数:79445。执行时间:812毫秒
线程7的计数:78589。执行时间:859毫秒
线程8的计数:77729。执行时间:828毫秒
线程9的计数:77362。执行时间:906毫秒
线程10的计数:76761。执行时间:1000毫秒
线程11的计数:76174。执行时间:984毫秒
线程12的计数:75828。执行时间:1046毫秒
线程13的计数:75448。执行时间:1078毫秒
线程14的计数:75235。执行时间:1062毫秒
线程15的计数:74745。执行时间:1062毫秒
线程16的计数:74475。执行时间:1109毫秒
质数总数:1270606。耗时:1188毫秒
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 20
线程1已创建(范围从3到1000001)。线程ID(TID)=30496
线程2已创建(范围从1000002到2000000)。线程ID(TID)=7300
线程3已创建(范围从2000001到2999999)。线程ID(TID)=50580
线程4已创建(范围从3000000到3999998)。线程ID(TID)=21536
线程5已创建(范围从3999999到4999997)。线程ID(TID)=24664
线程6已创建(范围从4999998到5999996)。线程ID(TID)=34464
线程7已创建(范围从5999997到6999995)。线程ID(TID)=51124
线程8已创建(范围从6999996到7999994)。线程ID(TID)=29972
线程9已创建(范围从7999995到8999993)。线程ID(TID)=50092
线程10已创建(范围从8999994到9999992)。线程ID(TID)=49396
线程11已创建(范围从9999993到10999991)。线程ID(TID)=18264
线程12已创建(范围从10999992到11999990)。线程ID(TID)=33496
线程13已创建(范围从11999991到12999989)。线程ID(TID)=16924
线程14已创建(范围从12999990到13999988)。线程ID(TID)=44692
线程15已创建(范围从13999989到14999987)。线程ID(TID)=53132
线程16已创建(范围从14999988到15999986)。线程ID(TID)=53692
线程17已创建(范围从15999987到16999985)。线程ID(TID)=5848
线程18已创建(范围从16999986到17999984)。线程ID(TID)=12760
线程19已创建(范围从17999985到18999983)。线程ID(TID)=13180
线程20已创建(范围从18999984到20000000)。线程ID(TID)=49980
线程1的计数:78497。执行时间:218毫秒
线程2的计数:70435。执行时间:343毫秒
线程3的计数:67883。执行时间:421毫秒
线程4的计数:66330。执行时间:484毫秒
线程5的计数:65366。执行时间:578毫秒
线程6的计数:64337。执行时间:640毫秒
线程7的计数:63798。执行时间:640毫秒
线程8的计数:63130。执行时间:703毫秒
线程9的计数:62712。执行时间:718毫秒
线程10的计数:62090。执行时间:703毫秒
线程11的计数:61937。执行时间:781毫秒
线程12的计数:61544。执行时间:812毫秒
线程13的计数:61191。执行时间:796毫秒
线程14的计数:60826。执行时间:843毫秒
线程15的计数:60627。执行时间:875毫秒
线程16的计数:60425。执行时间:875毫秒
线程17的计数:60184。执行时间:875毫秒
线程18的计数:60053。执行时间:890毫秒
线程19的计数:59681。执行时间:875毫秒
线程20的计数:59560。执行时间:906毫秒
质数总数:1270606。耗时:1109毫秒
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
这些运行所使用的系统有16个逻辑处理器。从上述输出中可以得出一些有趣的观察结果:
- 随着线程数量增加,执行时间的改善并非呈线性(甚至相差甚远)。
- 使用比逻辑处理器数量更多的线程会减少执行时间。
为什么会得到这些结果呢?在分治合并(fork - join)风格的算法中,最优的线程数量是多少呢?答案似乎应该是“逻辑处理器的数量”,因为更多的线程会导致上下文切换(context switches)发生,这是由于并非所有线程都能同时执行,而使用较少的线程肯定会使一些处理器得不到充分利用。
然而,实际情况并非如此简单。我们得到上述两种观察结果的唯一原因是:线程之间的工作(就执行时间而言)分配并不均匀。这仅仅是因为所使用的算法:数字越大,需要完成的工作就越多,因为平方根函数(sqrt function)是单调函数,其输出与输入成反比。这往往是分治(fork-join)算法面临的挑战:工作的公平分配。图5-4展示了在一个有四个线程的示例案例中发生的情况。
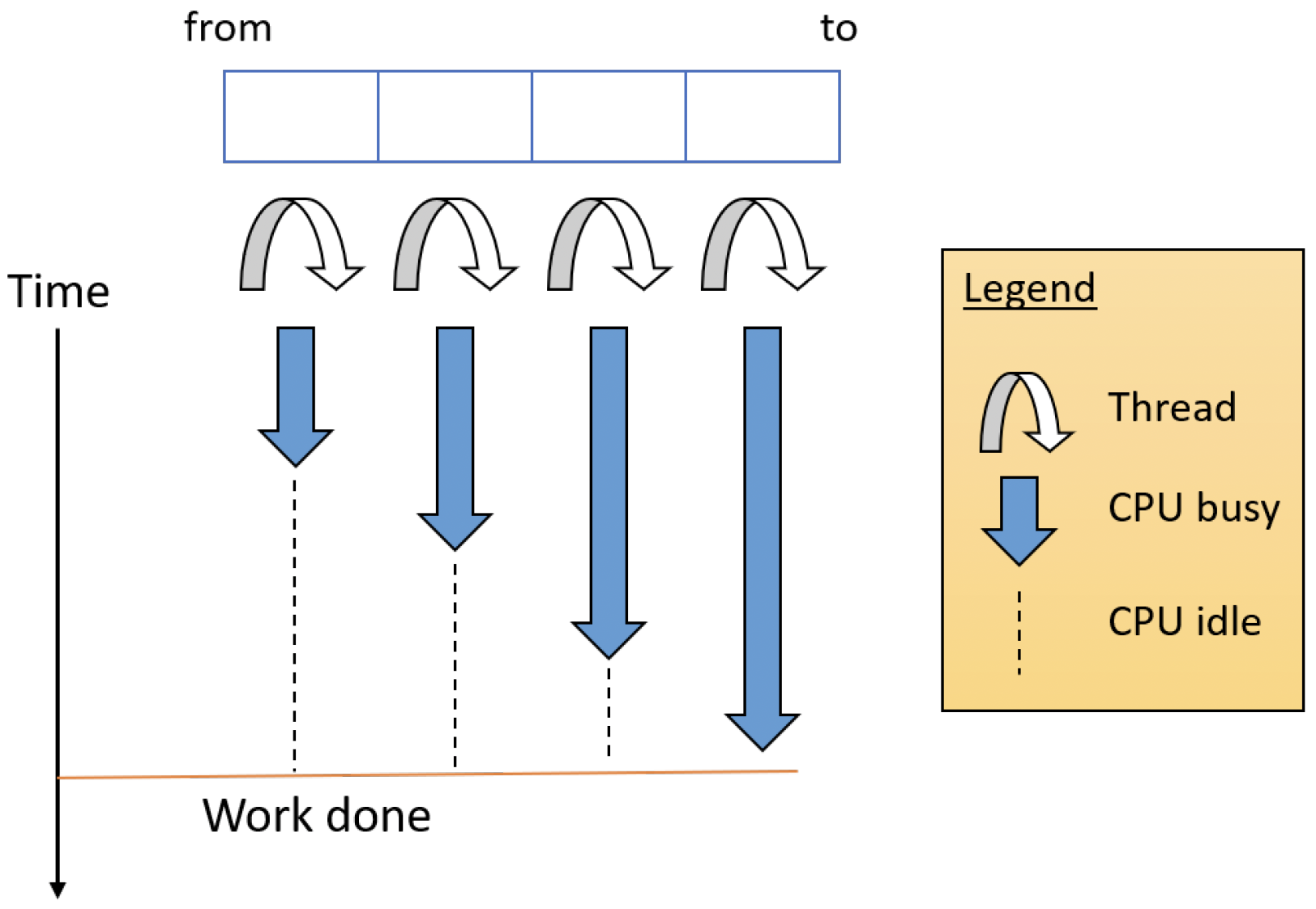
图5-4:使用4个线程的质数计数器
请注意,在上述输出中,后面的线程运行时间更长,仅仅是因为它们有更多的工作要做。现在,我们就不难理解为什么即使系统中只有16个逻辑处理器,使用20个线程时运行时间反而更短。较早完成的线程会释放处理器,使得那些(超过16个的) “额外” 线程能够获得处理器,从而推动工作继续进行。那么,这有极限吗?当然有,在某个时刻,上下文切换开销,再加上由于为线程栈分配更多内存而可能出现的页面错误(page faults),会使情况变得更糟。显然,要确定这个程序的最佳处理器数量并非易事。而且情况可能更糟:这个程序只进行受CPU限制的操作,不涉及输入/输出(I/O)。如果线程需要不时地进行I/O操作,这个问题就变得更加棘手。
# 终止线程
每个线程(无论好坏)在某个时刻都必须结束。线程有三种终止方式:
线程函数返回(最佳选择)
线程调用ExitThread(最好避免)
线程通过TerminateThread被终止(通常是个坏主意)
最佳选择是直接从线程函数返回。当线程开始执行时,线程函数实际上并不是线程执行的第一个或唯一的函数。事实上,线程是在NTDLL.dll中一个名为RtlUserThreadStart的函数内开始执行的,从概念上讲,这个函数会调用提供给CreateThread的线程实际函数。一旦线程函数返回,RtlUserThreadStart会进行一些清理工作并调用ExitThread。请注意,正如其函数原型所示,ExitThread只能由线程自身调用以终止自己:
void ExitThread(_In_ DWORD exitCode);
| 来自Kernel32.dll的ExitThread实际上是Nt - Dll.Dll中RtlExitUserThread的转发函数。 |
|---|
在线程函数中显式调用ExitThread至少存在一个问题,即C++析构函数不会被调用,因为ExitThread不会返回。因此,最好还是直接从线程函数返回,以便正确清理局部C++对象。
无论如何,ExitThread还会以DLL_THREAD_DETACH作为原因参数,调用进程中所有动态链接库(DLL)的DllMain函数。这使得DLL能够执行每个线程的相关操作。例如,DLL可以分配一些内存块,以便在每个线程的基础上管理某些内容。在许多情况下,这会与第10章讨论的线程局部存储(Thread Local Storage,TLS)结合使用。
终止线程的第三种方式是调用TerminateThread,这个操作可以从另一个线程(甚至属于另一个进程的线程)发起。唯一的条件是调用者能够获取具有THREAD_TERMINATE访问掩码的线程句柄。以下是TerminateThread的定义:
BOOL WINAPI TerminateThread(
_Inout_ HANDLE hThread,
_In_ DWORD dwExitCode);
2
3
使用这个调用终止线程几乎总是一个坏主意。问题在于线程在终止时已经完成的工作以及尚未完成的工作。如果线程在执行实际工作时被终止,就无法确定它执行了哪些指令,以及由于终止而未能执行哪些其他代码。应用程序的状态可能会变得不一致。举一个极端但并非不可能的例子,线程可能获取了一个临界区(见第7章),但没有机会释放它,这会导致死锁,因为等待该临界区的其他线程将永远等待下去。
TerminateThread的另一个问题是它不会以DLL_THREAD_DETACH为参数调用DLL的DllMain函数。这意味着DLL无法运行一些可能用于释放内存或执行其他操作的代码,来撤销线程创建时所做的工作。
这些与TerminateThread相关的问题表明,安全地调用这个函数的情况很少见,对于那些看似需要调用它的场景,应该有更好的处理方式。不过,如果确实需要调用,调用者必须获取一个权限足够的句柄,该句柄具有THREAD_TERMINATE访问权限。CreateThread和CreateProcess返回的线程句柄始终具有完全权限。对于其他情况,可以尝试使用OpenThread获取任意线程的句柄:
HANDLE OpenThread(
_In_ DWORD dwDesiredAccess,
_In_ BOOL bInheritHandle,
_In_ DWORD dwThreadId);
2
3
4
这个函数与第3章讨论的OpenProcess类似。如果能够获取请求的访问掩码,就会向调用者返回一个非空句柄。如果请求并获得了THREAD_TERMINATE权限,对TerminateThread的调用必然会成功。
# 线程栈
局部变量和函数的返回地址存储在线程栈中。线程栈的大小可以通过CreateThread的第二个参数指定,但实际上有两个值会影响线程栈:一个是保留内存大小,它是栈的最大大小;另一个是初始已提交内存大小,这部分内存可以直接使用。保留(Reserved)和已提交(Committed)这两个术语将在第12章深入讨论,这里简单介绍一下:保留内存只是将一个连续的地址空间范围标记为用于特定目的,这样进程地址空间中的新分配就不会来自这个范围。对于栈来说,这一点至关重要,因为栈必须是连续的。已提交内存意味着实际分配的内存,因此可以使用。
虽然可以立即分配最大栈大小,预先提交整个栈,但这会很浪费,因为线程在与栈相关的工作中可能并不需要整个范围的内存。内存管理器有一个优化方法:先提交较少量的内存,如果栈增长超过这个量,就触发栈的扩展,直到达到保留的上限。触发扩展是通过一个带有特殊标志PAGE_GUARD的页面实现的,如果访问这个页面就会引发异常。内存管理器会捕获这个异常,然后提交额外的页面,并将PAGE_GUARD页面下移一页(记住,栈是向低地址增长的)。图5-5展示了这种安排。
 图5-5:线程栈
图5-5:线程栈
| 保护页(guard page)的实际最小值是12KB,也就是3页。这确保了栈扩展时至少会有12KB的已提交内存可供栈使用。 |
|---|
通常,在调用CreateThread时,会将栈大小参数(第二个参数)设为零。在这种情况下,已提交和保留大小的默认值会从可移植可执行文件(Portable Executable,PE)头中存储的值获取。由内核创建的第一个线程不受我们控制,它总是使用这些默认值。你可以使用Windows SDK中的dumpbin实用工具来转储这些值。以下是对记事本(Notepad)的示例:
C:\>dumpbin /headers c:\windows\system32\notepad.exe
Microsoft (R) COFF/PE Dumper Version 14.24.28314.0
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\windows\system32\notepad.exe
PE signature found
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
8664 machine (x64)
7 number of sections
9E7797DD time date stamp
0 file pointer to symbol table
0 number of symbols
F0 size of optional header
22 characteristics
Executable
Application can handle large (>2GB) addresses
OPTIONAL HEADER VALUES
...
80000 size of stack reserve
11000 size of stack commit
100000 size of heap reserve
1000 size of heap commit
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
记事本中线程栈的默认已提交大小是0x11000(68KB),保留大小是0x80000(512KB)。这些值肯定会用于记事本的第一个线程。如果传递给CreateThread的栈参数为零,其他通过CreateThread显式创建的线程也会使用这些值。 你还可以在一些免费的图形工具中查看这些信息,比如我开发的PE Explorer v2。
你也可以使用VMMap Sysinternals工具查看这些信息。先运行记事本,然后运行VMMap。在对话框中选择记事本进程(图5-6),然后点击“确定”。
 图5-6:VMMap中的进程选择器
图5-6:VMMap中的进程选择器
VMMap的主窗口会打开。在中间的列表中选择“Stack”项,这会使下面的列表只显示线程栈相关信息(图5-7)。
 图5-7:在VMMap中选择栈
图5-7:在VMMap中选择栈
现在,在下面的窗格中打开其中一个栈项。你应该会看到已提交大小为0x11000字节(68KB),保护属性为“Read/Write”。然后是一个12KB的保护页范围,其余内存为保留状态(图5-8)。
 图5-8:VMMap中一个线程的栈
图5-8:VMMap中一个线程的栈
| 第12章将更全面地讨论VMMap。 |
|---|
CreateThread函数只有一个用于设置栈大小的参数,因此它只允许设置初始已提交内存或最大保留内存,不能同时设置两者。这取决于标志参数。如果标志参数包含STACK_SIZE_PARAM_IS_A_RESERVATION,那么这个值就是保留大小;否则,它就是预先提交的大小。
| CreateThread只允许设置其中一个值,这似乎是一个疏忽。原生函数(来自NtDll)NtCreateThreadEx允许同时设置这两个值。 |
|---|
Visual Studio允许通过项目属性,在“Linker/System”节点下更改默认的栈大小(图5-9)。这只是在PE头中设置请求的值。
 图5-9:Visual Studio中的栈大小设置
图5-9:Visual Studio中的栈大小设置
最后,线程可以调用SetThreadStackGuarantee来尝试确保有一定大小的栈可用:
BOOL SetThreadStackGuarantee(_Inout_ PULONG StackSizeInBytes);
如果函数调用成功,栈大小的增加是通过分配更多的保护页(这些保护页也被标记为已提交)来实现的,这意味着在需要扩展栈时,这些内存是有保障的。
# 线程名称
从Windows 10和Server 2016开始,线程可以有一个基于字符串的名称或描述,通过SetThreadDescription函数进行设置:
HRESULT SetThreadDescription(
_In_ HANDLE hThread,
_In_ PCWSTR lpThreadDescription
);
2
3
4
线程句柄必须具有THREAD_SET_LIMITED_INFORMATION访问掩码,对于几乎任何线程来说,获取这个掩码都很容易。名称/描述可以是任意内容。请注意,这个函数返回一个HRESULT值,其中S_OK(0)表示成功。需要注意的是,这与给其他内核对象命名不同;无法通过线程的名称/描述来查找线程。该名称只是存储在线程的内核对象中,可用作调试辅助工具。下面是一个设置当前线程名称的简单示例:
::SetThreadDescription(::GetCurrentThread(), L"My Super Thread");
Visual Studio 2019及更高版本会在调试器的“线程”窗口中显示线程的名称(如果有的话)(图5-10)。
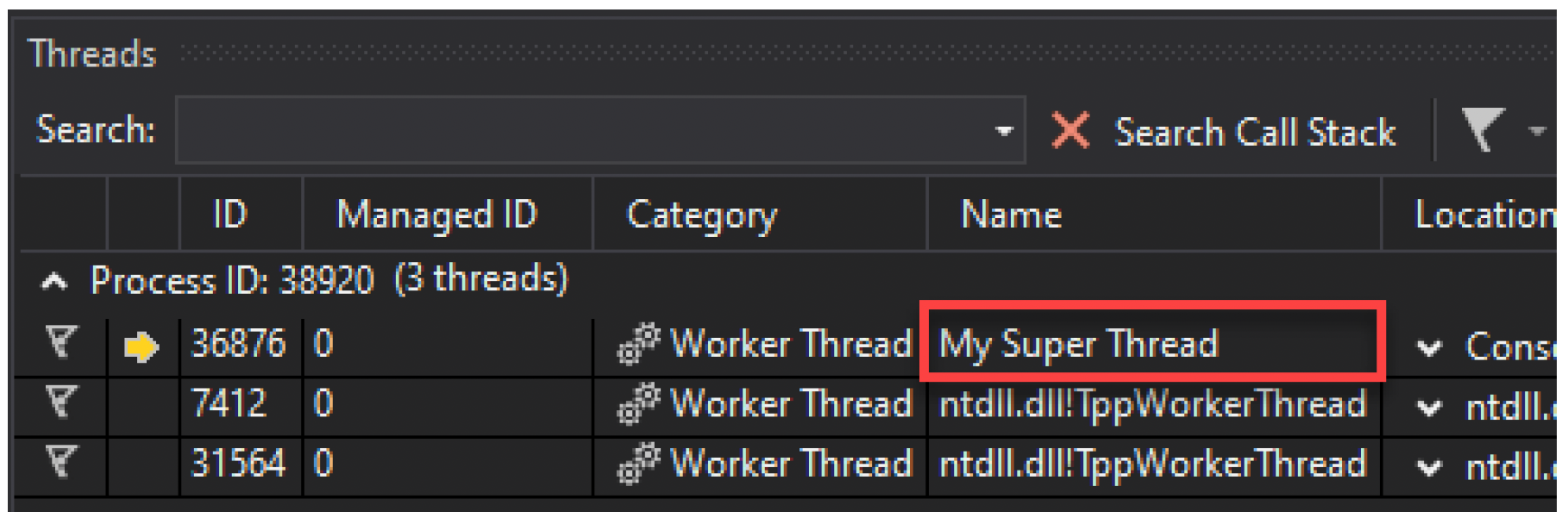 图5-10:Visual Studio调试器中的线程名称
图5-10:Visual Studio调试器中的线程名称
自然,也有与之对应的反向函数:
HRESULT GetThreadDescription(
_In_ HANDLE hThread,
_Out_ PWSTR* ppszThreadDescription
);
2
3
4
GetThreadDescription函数将结果返回给调用者分配的指针。调用该函数后,需要调用LocalFree来释放它所分配的内存。以下是一个示例:
PWSTR name;
if (SUCCEEDED(::GetThreadDescription(::GetCurrentThread(), &name))) {
printf("Name: %ws\n", name);
::LocalFree(name);
}
2
3
4
5
# C++标准库呢?
本书是关于Windows编程的,因此直接讨论C++可能不太合适。不过,从C++ 11标准开始,C++标准库提供了线程机制(实际上,在早期的C++标准中,甚至都没有提到“线程”这个词)。基本类型是std::thread,用于创建线程。其他类用于处理线程同步(详见第7章);还有更多相关内容。
使用C++标准库的最大好处在于它是标准的,这意味着它具有跨平台性。如果这一点比其他因素更重要,那么完全可以使用它。与使用Windows API相比,C++标准库的缺点是可定制性很少。C++标准库不支持线程优先级、亲缘性、CPU集(均在第6章讨论)、堆栈大小控制等。只有使用特定于Windows的API才能实现这种程度的控制。
# 练习
- 创建一个基于WTL(Windows Template Library,Windows模板库)对话框的应用程序,该应用程序能够在一定数字范围内计算质数(添加用于输入数字的编辑框)。在单独的线程中执行计算,这样UI线程就不会被阻塞。
- 在对话框中添加一个“取消”按钮,以便在计算质数的过程中进行取消操作。
- 创建一个控制台应用程序,使用多个线程并发计算曼德勃罗集(Mandelbrot set),从而加快计算速度。(你可以在维基百科上找到更多关于曼德勃罗集的信息。)线程数量以及输出位图的尺寸应该作为应用程序的输入。将总行数除以线程数,为每个线程分配相应的行范围。每个像素的值应为0(属于该集合)或1(不属于该集合)。将结果存储在一个二维数组中。
- 扩展该应用程序,将输出写入BMP或PPM格式(这两种格式都相对简单),以便可以在类似画图的应用程序中查看结果。
- 创建一个WTL应用程序,使用多个线程计算曼德勃罗集,同时不会冻结UI。添加平移/缩放功能,并根据需要重新计算。
# 总结
在本章中,我们学习了线程创建和管理的基础知识。在下一章中,我们将讨论线程调度及其相关属性,如优先级和亲缘性。