 第7章:进程内线程同步
第7章:进程内线程同步
# 第7章:进程内线程同步
在理想的线程世界里,线程可以各自执行任务而互不干扰。但在现实中,线程有时必须相互同步。典型的例子是访问共享数据结构,比如动态数组。如果一个线程试图向数组中插入一个元素,其他线程就不应同时操作该数组,甚至不应读取它。虽然线程可能在不同时间进行操作,但由于涉及时间因素,它们也可能同时进行操作,这就可能导致数据损坏或引发异常。为了避免这种情况,线程有时需要同步它们的工作。
Windows提供了一系列丰富的原语来帮助实现这种(以及其他类型的)同步。在本章中,我们将探讨用户模式开发人员可通过Windows API使用的、用于在单个进程内同步线程的机制。在下一章中,我们将研究更多可用于同步不同进程中运行的线程的同步原语。
本章内容包括:
- 同步基础
- 原子操作
- 临界区
- 锁和资源获取即初始化(RAII)
- 死锁
- MD5计算器应用程序
- 读写锁
- 条件变量
- 等待地址
- 同步屏障
- C++标准库的情况如何?
# 同步基础
经典的同步是为了避免数据竞争。当两个或更多线程访问同一内存位置,且其中至少有一个线程在向该位置写入数据时,就会发生数据竞争。同时从同一位置读取数据从来都不是问题,但一旦涉及写入操作,情况就变得复杂了。数据可能会损坏,读取的数据可能不完整(部分数据在更改前读取,部分在更改后读取)。这就是需要同步的原因。
在第5章中,我们看到了一个将质数计算并行化的示例应用程序。该特定算法(分叉/合并)除了等待所有线程完成之外,不需要任何同步操作。这是比较理想的情况,因为通过增加CPU数量(至少在一定程度上)可以提高性能。同步操作并不理想,因为从定义上来说,它会降低性能,因为有些操作必须顺序执行,而不是并发执行。事实上,为一个问题增加更多线程/CPU所能获得的加速比,取决于代码中可并行化部分的比例。这可以用阿姆达尔定律(Amdahl’s Law)很好地描述:
加速比限制 = 1 / (1 - p)
关于阿姆达尔定律更深入的讨论可以在维基百科上找到:https://en.wikipedia.org/wiki/Amdahl%27s_law
其中p是可并行化代码的百分比。例如,如果80%的代码可以并行化,那么无论投入多少个处理器,最大加速比都是5。
大多数与同步相关的操作都要求线程等待某个条件,直到可以安全继续执行,以防止数据竞争。在接下来的部分,我们将研究Windows API提供的各种同步选项,从最简单的到更复杂的。
# 原子操作
有些看似简单快速的操作实际上并非线程安全的。即使是简单的C变量自增(x++)操作,在线程环境或多处理器环境下也不安全。例如,假设有两个线程在两个处理器上同时运行,对同一内存位置进行自增操作(图7-1)。
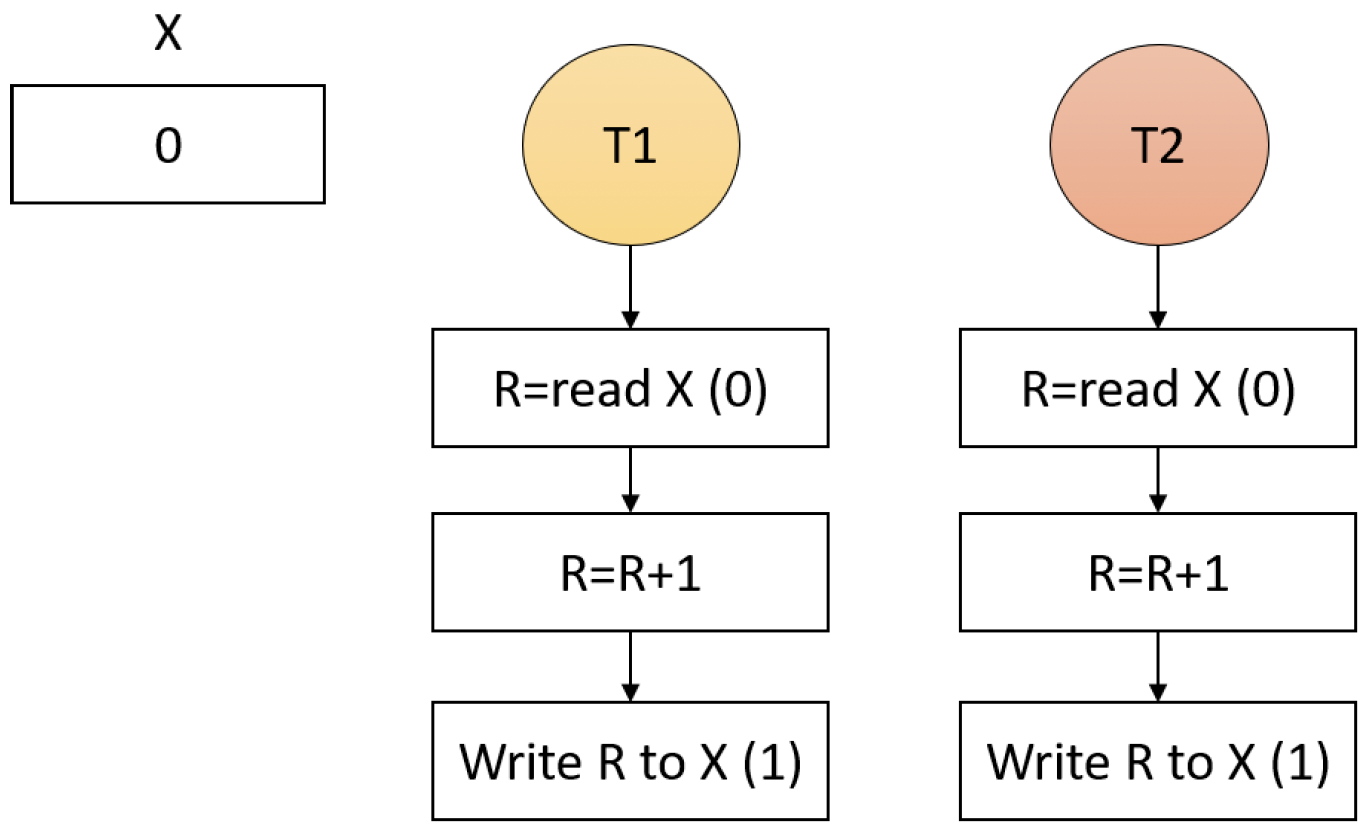
图7-1:多个线程进行简单自增操作
即使是简单的自增操作也涉及读取和写入。在图7-1中,每个线程可能会将初始值(0)读取到CPU寄存器中。每个线程对其所在处理器的寄存器进行自增操作,然后将结果写回。最终写入X的值是1,而不是2。这个示意图做了很大程度的简化,因为还有其他因素在起作用,比如CPU缓存。但即使忽略这些因素,这显然也是一个数据竞争问题。实际上,其中一个线程(比如T2)可能会被抢占(例如在R自增之后),当T1继续对X进行自增操作时,一旦T2再次获得CPU时间,它会将1写回X,实际上就抵消了线程T1所做的所有自增操作。
# 简单自增应用程序
图7-2所示的简单自增应用程序使用多个线程执行一项任务:对单个内存位置进行自增操作。该程序允许选择同时运行的线程数量以及每个线程应执行的自增次数。点击“运行”按钮后,操作开始。操作完成后,会显示实际结果、预期结果以及执行所需的时间。
图7-2:简单自增应用程序
“同步”组合框允许选择如何同步自增操作。第一个(也是默认)选项(“无”)是直接对共享内存位置使用++运算符,即完全不进行同步。使用默认选项点击“运行”后,会出现类似图7-3的结果。

图7-3:未进行同步的简单自增应用程序
注意,最终结果与预期结果相差甚远。这是因为缺乏同步,导致自增操作“丢失”。你可以再次点击“运行”,会得到不同的结果。这就是同步问题的本质。以下是负责使用简单++操作进行多线程自增的代码片段(在MainDlg.cpp中):
void CMainDlg::DoSimpleCount() {
auto handles = std::make_unique<HANDLE[]>(m_Threads);
for (int i = 0; i < m_Threads; i++) {
handles[i] = ::CreateThread(nullptr, 0, [](auto param) {
return ((CMainDlg*)param)->IncSimpleThread();
}, this, 0, nullptr);
}
::WaitForMultipleObjects(m_Threads, handles.get(), TRUE, INFINITE);
for (int i = 0; i < m_Threads; i++)
::CloseHandle(handles[i]);
}
DWORD CMainDlg::IncSimpleThread() {
for (int i = 0; i < m_Loops; i++)
m_Count++;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
正如我们在第5章中看到的,向线程传递信息是通过CreateThread函数的PVOID参数完成的。然而,在许多情况下,将线程函数作为实例函数会更方便,而不是静态函数或全局函数。一个有用的技巧是将this指针作为参数传递,并使用它来调用实例函数,这样就可以访问整个对象的状态。这使得IncSimpleThread函数可以是实例函数,而不是静态函数。
你可能想知道为什么不直接捕获this指针并直接使用数据成员呢?遗憾的是,API函数只能使用非捕获lambda函数。这就是需要使用这个技巧的原因。
在上述代码中,m_Threads是线程数量,m_Loops是要执行的迭代次数,m_Count是被自增的共享内存位置。
这显然是一个人为设计的示例,在同一内存位置进行了数百万次自增操作,很容易暴露出问题。在实际应用中,这些自增操作的频率要低得多,这意味着任何同步错误发生的可能性较小,实际上开发人员和质量保证人员可能会忽略这些问题,直到在客户的机器上才被发现。
# Interlocked函数家族
解决上述同步问题的方法是将自增操作作为原子操作执行,这样任何自增操作都与其他自增操作以及使用其他Interlocked函数对同一内存位置的其他访问隔离开来。这种原子操作和其他类似操作在Windows API中通过一组以Interlocked为前缀的函数来实现。在简单自增的情况下,使用的是InterlockedIncrement函数:
unsigned InterlockedIncrement(unsigned volatile *Addend);
该函数执行原子自增操作,并且除了实际更改内存位置外,还会返回新的值。在底层,这并不是一个真正的函数,而是一个编译器内部函数,它会向CPU发出一条特殊指令,以原子方式执行此操作。这非常好,因为利用硬件总是比软件更快。此外,由于没有使用显式的“锁”对象,使用这些函数不会出现死锁情况。
回到简单自增应用程序,组合框中的第二种同步方法将自增方法设置为InterlockedIncrement,在InterlockedThread函数中使用:
DWORD CMainDlg::IncInterlockedThread() {
for (int i = 0; i < m_Loops; i++)
::InterlockedIncrement((unsigned*)&m_Count);
return 0;
}
2
3
4
5
图7-4展示了在同步组合框中选择Interlocked选项后的一次运行示例。
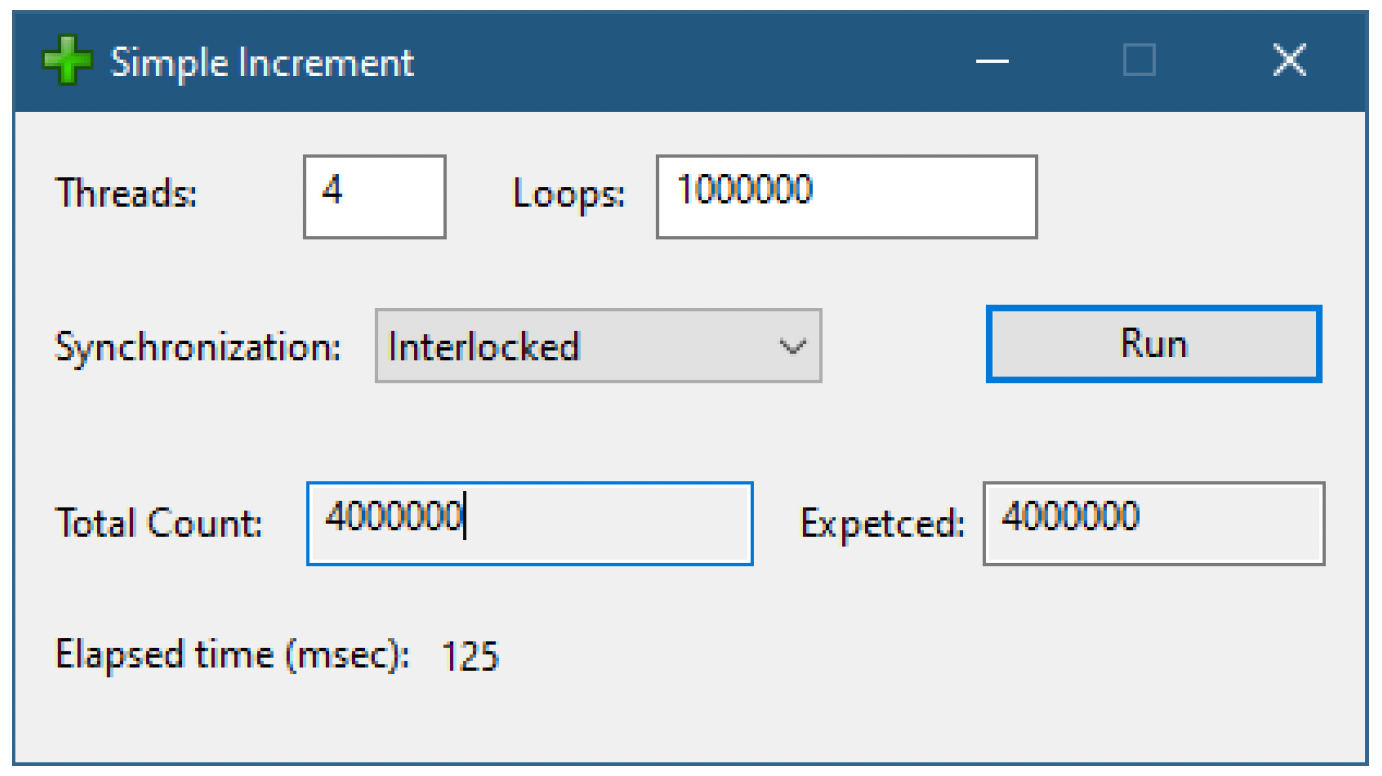
图7-4:使用Interlocked同步的简单自增应用程序
类似的简单函数还包括InterlockedDecrement、InterlockedAdd、InterlockedExchange、InterlockedAnd、InterlockedOr、InterlockedXor、InterlockedExchangePointer、InterlockedCompareExchange等。这些函数也有针对64位和16位值的版本,分别在函数名后加上后缀64和16(例如InterlockedIncrement64)。
还有一些扩展函数,如
InterlockedAndAcquire、InterlockedAndRelease和InterlockedAndNoFence(以及其他操作的类似函数)。这些特殊版本还指定了内存位置的获取/释放语义。本书不讨论这些变体,除非你清楚自己在做什么,否则应该使用“标准”函数,这些函数是最安全的。关于内存屏障(fences)和获取/释放语义的更多信息可以在网上找到。其中比较好的是赫伯·萨特(Herb Sutter)的演讲《Atomic<> Weapons》。你也可以(或者另外)观看我的(有所删减的)课程《Concurrency and the C++ Memory Model》。
InterlockedCompareExchange函数在进行无锁编程时使用得最为频繁。无锁编程是一种利用CPU内部指令来避免在软件中使用任何锁的编程范式。由于它并非特定于Windows系统,所以本书不会讨论这个主题。不过,Windows API提供了无锁的单向链表实现。这些函数使用SLIST_HEADER联合作为链表头,使用SLIST_ENTRY结构作为可以原子地添加到链表中或从链表中删除的节点。
这两种类型在SDK头文件中都有完整定义,但我们只需稍微关注一下SLIST_ENTRY:
typedef struct DECLSPEC_ALIGN(16) _SLIST_ENTRY {
struct _SLIST_ENTRY *Next;
} SLIST_ENTRY, *PSLIST_ENTRY;
2
3
SLIST_ENTRY和SLIST_HEADER必须按16字节边界对齐,这可以通过使用declspec(align(16))这个VC++编译器属性来修饰类型来实现。基于栈或静态分配这些类型可以正常工作,但通常情况下,你需要动态分配SLIST_ENTRY。C运行时库提供了_aligned_malloc函数,该函数可以确保内存分配时达到指定的对齐要求。
显然,这是一个经典的单链表节点项。但实际数据在哪里呢?通常的做法是,你的数据项将SLIST_ENTRY本身作为第一个成员。这样可以确保SLIST_ENTRY满足对齐要求。下面的示例展示了一种适合存储在上述链表中的数据项类型:
struct MyDataItem {
SLIST_ENTRY Entry;
int MyValue;
//...
};
2
3
4
5
由于对链表的操作必须是无锁的,并且链表是单向的,所以它实际上实现了一个栈。没有线程安全的方法可以在链表尾部添加节点。这就是为什么链表的主要操作使用“Push”(入栈)和“Pop”(出栈)这些基于栈的数据结构术语的原因。
表7-1列出了用于操作无锁单向链表的函数。
表7-1:单向链表操作函数
| 函数 | 描述 |
|---|---|
InitializeSListHead | 将链表头初始化为空链表 |
InterlockedPushEntrySList | 在链表头部插入一个节点 |
InterlockedPopEntrySList | 从链表头部删除一个节点 |
InterlockedPushListSListEx | 在链表头部插入多个节点 |
InterlockedFlushSList | 从链表中删除所有节点,并返回头部节点(如果有的话) |
QueryDepthSList | 返回链表中的节点数量。这个函数不是线程安全的,最好避免使用。更好的做法是自己使用InterlockedIncrement/InterlockedDecrement来跟踪节点数量 |
# 临界区(Critical Sections)
Interlocked系列函数在处理简单情况(如整数递增)时表现出色。然而,对于其他操作,则需要更通用的机制。临界区是一种经典的同步机制,它基于最多只有一个线程能够获取锁的原则。一旦一个线程获取了特定的锁,在获取该锁的线程释放它之前,其他线程都无法获取同一把锁。只有在此时,等待的线程中才有一个(且只有一个)能够获取该锁。这意味着在任何给定时刻,获取锁的线程不会超过一个。这个概念如图7-5所示。

获取锁的线程也是锁的所有者,这意味着两件事:
- 所有者线程是唯一能够释放临界区的线程。
- 如果所有者线程尝试再次(递归地)获取临界区,它会自动成功,并增加一个内部计数器。这意味着所有者线程现在必须释放临界区相同的次数才能真正释放它。
获取锁和释放锁之间的代码称为临界区(Critical Region)。
临界区本身由CRITICAL_SECTION结构表示,它实际上是对另一个结构RTL_CRITICAL_SECTION的类型定义。尽管该结构已完全定义,但你应将其视为不透明的。必须使用以下函数之一来初始化临界区:
void InitializeCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
BOOL InitializeCriticalSectionAndSpinCount(
LPCRITICAL_SECTION lpCriticalSection,
DWORD dwSpinCount);
BOOL InitializeCriticalSectionEx(
LPCRITICAL_SECTION lpCriticalSection,
DWORD dwSpinCount,
DWORD Flags);
2
3
4
5
6
7
8
9
10
初始化临界区涉及将其成员设置为某些初始值。这就是第一个函数返回void的原因。
第二个和第三个变体为临界区设置了一个自旋计数(spin count)。其原理是,如果一个线程无法获取临界区,它应该进入等待状态,因为其他线程持有该临界区。然而,进入等待状态需要线程切换到内核模式,这是有一定开销的。一种折中的方法是让线程自旋一小段时间,因为当前持有临界区的线程很可能很快就会释放它,这样就可以避免切换到内核模式。自旋计数的最大值是0x00ffffff(剩余的十六进制数字在内部用作标志)。
自旋计数应该设置为多少呢?这很难一概而论,因为它取决于实际的处理器类型和其他硬件因素。默认的自旋计数是2000(InitializeCriticalSection使用此值)。
如果系统只有一个处理器(或者进程映像文件的PE头中有“Single CPU”标志),自旋计数始终设置为零。这是合理的,因为当这个线程自旋时,另一个线程永远无法释放临界区,因为没有其他处理器可供运行。
最后一个初始化函数添加了一个标志参数。头文件中定义了几个标志,但只有一个有文档说明——CRITICAL_SECTION_NO_DEBUG_INFO(0x01000000),它指定临界区结构不应分配额外的调试结构,该调试结构可用于诊断临界区问题。
当不再需要临界区时,调用DeleteCriticalSection:
void DeleteCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
一旦初始化了临界区,线程就可以使用以下函数来获取和释放它:
void EnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
void LeaveCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
2
EnterCriticalSection尝试获取临界区,只有在获取成功时才会返回。如果调用线程已经是临界区的所有者,它会立即继续执行。相反,LeaveCriticalSection释放已经获取的临界区。
奇怪的是,任何线程都可以调用LeaveCriticalSection(不仅仅是当前所有者线程),并且调用会成功。我原本期望这个函数会抛出异常(因为它返回void)。但它只是释放临界区,将所有者线程ID重置为零。
在“简单递增”应用程序中展示了一个简单的示例。如果你在组合框中选择同步机制为“临界区”,然后点击“运行”,那么递增操作现在将受到临界区的保护(图7-6)。
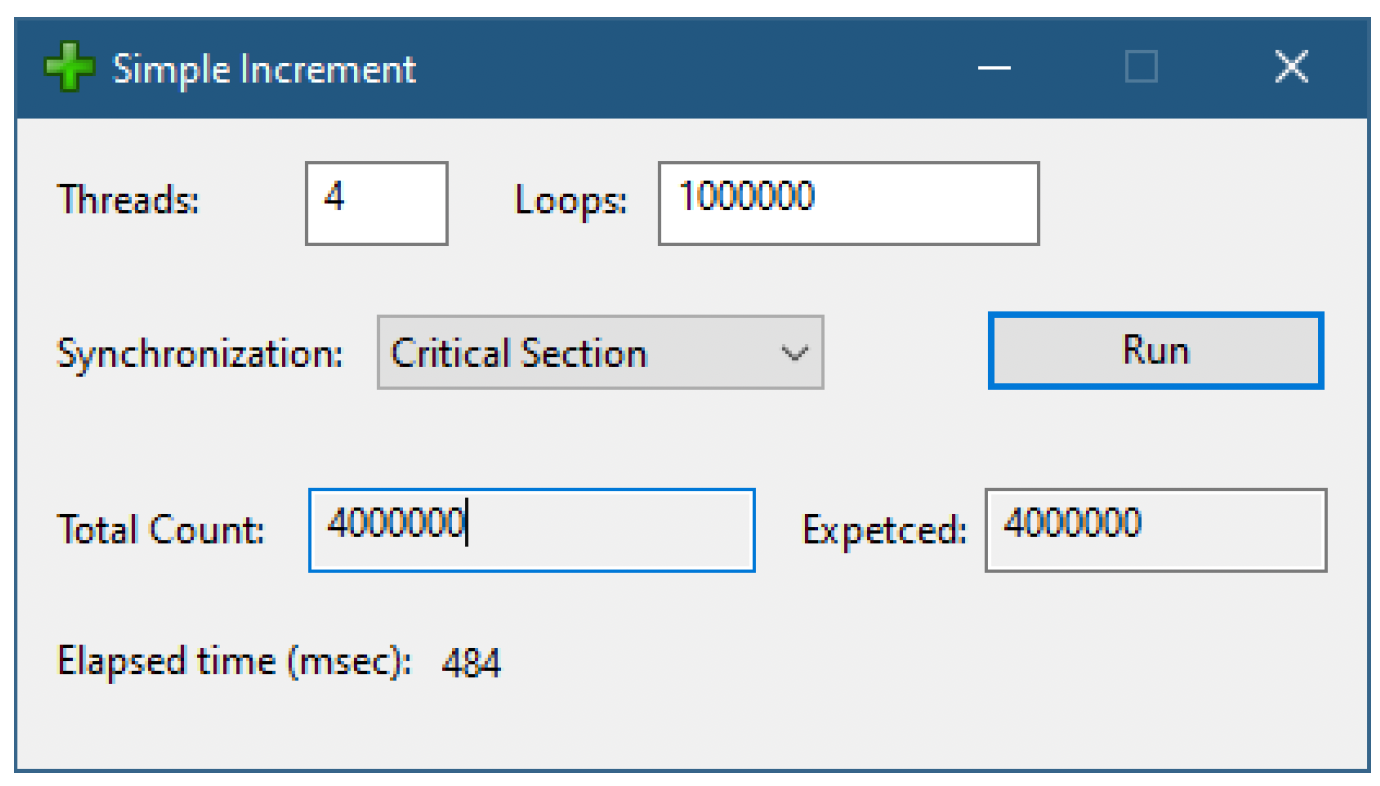
在“简单递增”应用程序中实现这种同步的代码如下:
// m_CritSection 是 CRITICAL_SECTION
void CMainDlg::DoCriticalSectionCount() {
auto handles = std::make_unique<HANDLE[]>(m_Threads);
::InitializeCriticalSection(&m_CritSection);
for (int i = 0; i < m_Threads; i++) {
handles[i] = ::CreateThread(nullptr , 0, [](auto param) {
return ((CMainDlg*)param)->IncCriticalSectionThread();
}, this , 0, nullptr);
}
::WaitForMultipleObjects(m_Threads, handles.get(), TRUE, INFINITE);
for (int i = 0; i < m_Threads; i++)
::CloseHandle(handles[i]);
::DeleteCriticalSection(&m_CritSection);
}
DWORD CMainDlg::IncCriticalSectionThread() {
for (int i = 0; i < m_Loops; i++) {
::EnterCriticalSection(&m_CritSection);
m_Count++;
::LeaveCriticalSection(&m_CritSection);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
每次调用EnterCriticalSection都必须在同一个函数中用LeaveCriticalSection进行匹配。在临界区内调用其他预期会调用LeaveCriticalSection的函数是非常危险的。为了避免可能出现的错误,始终在同一个函数中使用这一对函数。
EnterCriticalSection会一直等待临界区可用,它无法指定超时时间。但是有一种方法可以检查临界区是否空闲,如果空闲则获取它,否则继续执行。这正是TryEnterCriticalSection的功能:
BOOL TryEnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
# 锁和RAII
正如我们在上一节中看到的,EnterCriticalSection和LeaveCriticalSection是自然的一对函数。例如,如果在调用LeaveCriticalSection之前从函数返回,就很容易“忘记”调用它。这个错误很容易犯,即使没有这样的错误,开发人员也必须时刻留意,确保对该函数未来的任何修改都不会破坏这一对调用。
如果代码能够自动调用LeaveCriticalSection,而无需开发人员操心,那就更好了。有两种方法可以实现这种行为:终止处理程序(termination handlers)和C++的资源获取即初始化(Resource Acquisition Is Initialization,RAII)。
终止处理程序将在后续章节中详细讨论,这里先介绍其要点:
CRITICAL_SECTION cs;
void DoWork() {
::EnterCriticalSection(&cs);
try {
// 操作共享资源
}
finally {
::LeaveCriticalSection(&cs);
}
}
2
3
4
5
6
7
8
9
10
11
try和finally是微软为C语言扩展的两个关键字,用于在离开try块时运行finally块中的代码,无论在try块中发生什么情况。即使try块中有return语句,也会先调用finally块,然后才真正从函数返回。
如果你使用的是C语言(而不是C++),那么终止处理程序是你最好的选择。当使用C++时,利用构造函数和析构函数会更好(也更方便),它们可以在对象构造和销毁时自动执行代码(这在C++中被称为RAII惯用法)。
对于临界区,一个RAII类可能如下所示:
// AutoCriticalSection.h
struct AutoCriticalSection {
AutoCriticalSection(CRITICAL_SECTION& cs);
~AutoCriticalSection();
// 删除拷贝构造函数、移动构造函数、赋值运算符
AutoCriticalSection(const AutoCriticalSection&) = delete ;
AutoCriticalSection& operator=(const AutoCriticalSection&) = delete ;
AutoCriticalSection(AutoCriticalSection&&) = delete ;
AutoCriticalSection& operator=(AutoCriticalSection&&) = delete ;
private :
CRITICAL_SECTION& _cs;
};
// AutoCriticalSection.cpp
AutoCriticalSection::AutoCriticalSection(CRITICAL_SECTION& cs) : _cs(cs) {
::EnterCriticalSection(&_cs);
}
AutoCriticalSection::~AutoCriticalSection() {
::LeaveCriticalSection(&_cs);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这段代码是本章代码示例中ThreadingHelpers项目的一部分。
构造函数获取临界区,析构函数释放临界区。在“简单递增”应用程序中使用它的方式如下:
DWORD CMainDlg::IncCriticalSectionThread() {
for (int i = 0; i < m_Loops; i++) {
AutoCriticalSection locker(m_CritSection);
m_Count++;
}
return 0;
}
2
3
4
5
6
7
8
既然提到了RAII,将临界区本身封装在一个RAII类中可能是个好主意,这样临界区的初始化和删除也可以自动完成。以下是一种可能的实现:
// CriticalSection.h
class CriticalSection : public CRITICAL_SECTION {
public :
CriticalSection(DWORD spinCount = 0, DWORD flags = 0);
~CriticalSection();
void Lock();
void Unlock();
bool TryLock();
};
// CriticalSection.cpp
CriticalSection::CriticalSection(DWORD spinCount, DWORD flags) {
::InitializeCriticalSectionEx(this, (DWORD)spinCount, flags);
}
CriticalSection::~CriticalSection() {
::DeleteCriticalSection(this);
}
void CriticalSection::Lock() {
::EnterCriticalSection(this);
}
void CriticalSection::Unlock() {
::LeaveCriticalSection(this);
}
bool CriticalSection::TryLock() {
return ::TryEnterCriticalSection(this);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
Lock、Unlock和TryLock函数不是必需的,但在某些场景中可能会有所帮助。
从CRITICAL_SECTION派生类可以在需要CRITICAL_SECTION时传递CriticalSection。或者,也可以在结构中嵌入一个CRITICAL_SECTION成员,并使用一个可以将CriticalSection隐式转换为CRITICAL_SECTION的操作符。我将这个实现留给读者作为练习。
# 死锁(Deadlocks)
使用临界区看起来相当简单。即使我们使用各种RAII包装器,仍然存在死锁的风险。经典的死锁情况是,线程A持有锁1(例如一个临界区)并等待锁2,而锁2由线程B持有,同时线程B正在等待锁1。
避免死锁的理论方法很简单:始终按相同的顺序获取锁。这意味着每个需要多个锁的线程都应该始终以相同的顺序获取锁。这可以保证不会发生死锁(至少不会因为这些锁而发生死锁)。实际的问题是如何强制执行这种顺序;如果不编写代码,那就只能通过文档记录顺序,以便未来的代码继续遵循这些规则。另一种选择是编写一个“多锁”包装器,始终按相同的顺序获取锁。一种简单的实现方法是根据锁在内存中的地址来排序获取顺序。
编写一个用于临界区的多锁包装器。
# MD5计算器应用程序
MD5Calculator应用程序展示了临界区(Critical Section)的使用,这比简单的增量操作更有趣(也更复杂),在后面的章节中我们还会对其进行修改。该应用程序会在进程加载图像文件(EXE和DLL)时计算它们的MD5哈希值。由于进程通常会使用许多常见的DLL,因此最好缓存已经计算过的哈希值结果。该应用程序面临几个挑战:
- 在后台进行计算时,要显示响应迅速的用户界面。
- 接收系统中任何进程加载新图像(DLL/EXE)的通知。
- 管理包含文件及其MD5哈希值的缓存。
图7-7展示了应用程序在未进行任何活动前的主屏幕。
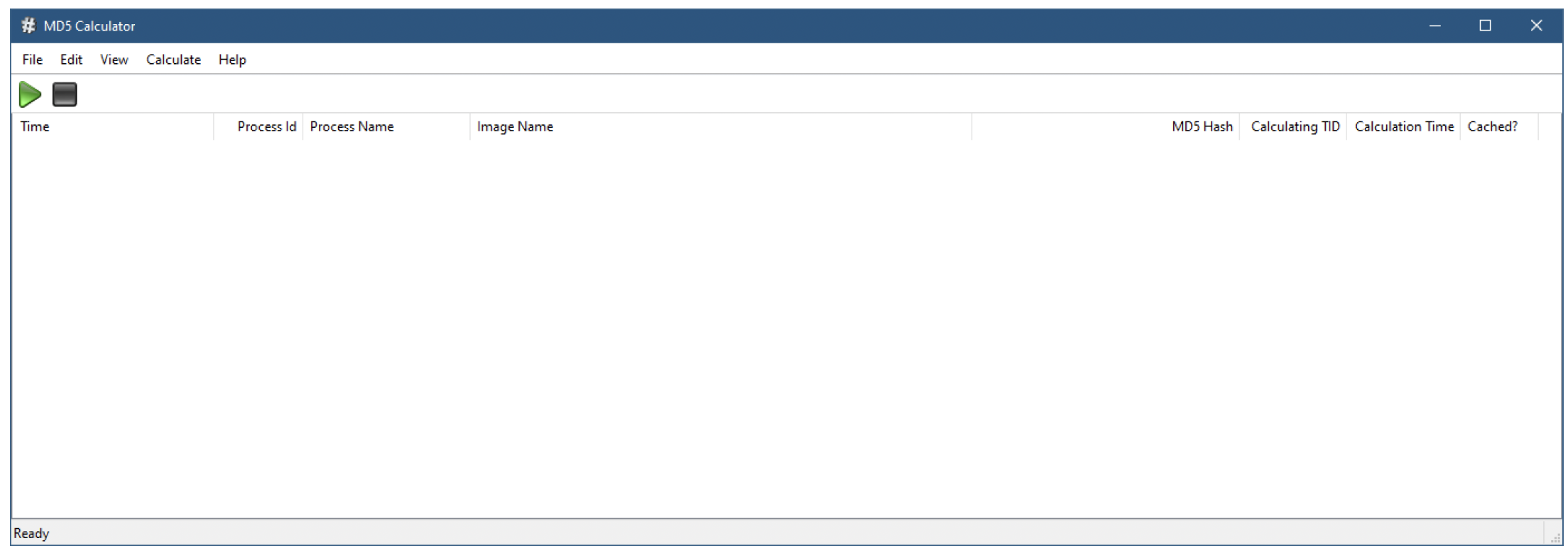 图7-7:MD5计算器应用程序
图7-7:MD5计算器应用程序
默认情况下,不会对MD5哈希值进行缓存。点击绿色的“开始”按钮(或“计算”/“开始”菜单项),会开始捕获图像加载情况,并为每个图像文件重新计算哈希值,即使加载的是重复文件也是如此(图7-8)。
 图7-8:未启用缓存运行的MD5计算器应用程序
图7-8:未启用缓存运行的MD5计算器应用程序
你可以启动一个新进程,比如“记事本”,并在列表视图底部观察其模块的加载情况。点击“停止”按钮可以停止捕获图像加载。你还可以使用“编辑”/“清除”菜单项来清空显示内容。
现在,你可以使用“计算”/“使用缓存”菜单项来切换缓存的使用状态。再次点击“开始”。注意,经过一些计算后,缓存开始发挥作用,当哈希值可以从缓存中获取时,“是否缓存?”列会显示更多的“是”(图7-9)。
 图7-9:启用缓存运行的MD5计算器应用程序
图7-9:启用缓存运行的MD5计算器应用程序
下面我们来详细介绍一下该应用程序中最重要的部分。
# 计算MD5哈希值
可以使用Windows加密API计算任何缓冲区的MD5哈希值。一个名为MD5Calculator的简单类用于进行计算(它属于一个名为HashCalc的静态库项目的一部分):
// MD5Calculator.h
class MD5Calculator {
public:
static std::vector<uint8_t> Calculate(PCWSTR path);
};
2
3
4
5
// MD5Calculator.cpp
#include <wincrypt.h>
#include "MD5Calculator .h"
#include <wil\resource.h>
std::vector<uint8_t> MD5Calculator::Calculate(PCWSTR path) {
std::vector<uint8_t> md5;
wil::unique_hfile hFile(::CreateFile(path, GENERIC_READ, FILE_SHARE_READ,
nullptr, OPEN_EXISTING, FILE_FLAG_SEQUENTIAL_SCAN, nullptr));
if (!hFile)
return md5;
wil::unique_handle hMemMap(::CreateFileMapping(hFile.get(), nullptr ,
PAGE_READONLY, 0, 0, nullptr));
if (!hMemMap)
return md5;
wil::unique_hcryptprov hProvider;
if (!::CryptAcquireContext(hProvider.addressof(), nullptr , nullptr ,
PROV_RSA_FULL, CRYPT_VERIFYCONTEXT))
return md5;
wil::unique_hcrypthash hHash;
if (!::CryptCreateHash(hProvider.get(), CALG_MD5, 0, 0, hHash.addressof()))
return md5;
wil::unique_mapview_ptr<BYTE> buffer((BYTE*)::MapViewOfFile(hMemMap.get(),
FILE_MAP_READ, 0, 0, 0));
if (!buffer)
return md5;
auto size = ::GetFileSize(hFile.get(), nullptr);
if (!::CryptHashData(hHash.get(), buffer.get(), size, 0))
return md5;
DWORD hashSize;
DWORD len = sizeof(DWORD);
if (!::CryptGetHashParam(hHash.get(), HP_HASHSIZE, (BYTE*)&hashSize,
&len, 0))
return md5;
md5.resize(len = hashSize);
::CryptGetHashParam(hHash.get(), HP_HASHVAL, md5.data(), &len, 0);
return md5;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
本书不详细介绍加密API。不过,计算哈希值的过程相当直观。在调用实际的哈希函数CryptHashData之前,需要进行几个准备步骤。该函数接受一个表示哈希算法的句柄、要哈希的缓冲区以及缓冲区的大小作为参数。
MD5Calculator::Calculate按顺序执行以下步骤:
- 使用CreateFile打开相关文件(第11章会详细讨论)。以只读方式打开文件,并使用可选标志FILE_FLAG_SEQUENTIAL_SCAN,该标志向文件系统提示读取操作将按顺序进行。
- 文件内容必须放入内存缓冲区,以便哈希函数使用。一种方法是分配一个与文件大小相同的缓冲区,然后使用ReadFile将文件内容读入缓冲区。更好的方法是使用内存映射文件(第14章会讨论),它可以将文件内容映射到内存(见下面第5步),而无需进行任何分配或读取操作。CreateFileMapping函数用于基于文件句柄(第一个参数)创建文件映射对象。
- 调用CryptAcquireContext,根据指定的提供程序(这里是PROV_RSA_FULL)获取一个加密提供程序句柄。
- 调用CryptCreateHash返回一个特定哈希算法(MD5对应的是CALG_MD5)的句柄。
- 调用MapViewOfFile将文件内容映射到内存,并返回一个指针。这个指针由WIL的unique_mapview_ptr<>封装,当变量超出作用域时,它会调用UnmapViewOfFile。
- 现在,一切准备就绪,可以调用CryptHashData来计算哈希值了。
- 剩下要做的就是获取哈希值的大小和哈希数据本身。这两步都可以通过调用CryptGetHashParam完成:第一次调用时使用HP_HASHSIZE获取哈希值大小(MD5的哈希值大小始终为16字节,但代码保持通用性)。
- 通过调用字节向量的resize方法为结果分配缓冲区。然后再次调用CryptGetHashParam,这次使用HP_HASHVAL获取实际的哈希值。
# 哈希缓存
缓存本身封装在HashCache类中,定义如下:
using Hash = std::vector<uint8_t>;
class HashCache {
public:
HashCache();
bool Add(PCWSTR path, const Hash& hash);
const Hash Get(PCWSTR path) const;
bool Remove(PCWSTR path);
void Clear();
private:
mutable CriticalSection _lock;
std::unordered_map<std::wstring, Hash> _cache;
};
2
3
4
5
6
7
8
9
10
11
12
缓存由C++标准库中的unordered_map<>对象管理,它将文件路径映射到其哈希值。哈希值本身存储为字节向量,尽管对于MD5哈希,本可以只使用一个16字节的数组。由于对缓存的访问可能由多个线程进行,因此必须保护unordered_map<>,防止并发访问。这里使用了临界区(Critical Section )。实现过程相当直观,用临界区保护每个操作:
HashCache::HashCache() {
_cache.reserve(512);
}
bool HashCache::Add(PCWSTR path, const Hash& hash) {
AutoCriticalSection locker(_lock);
auto it = _cache.find(path);
if (it == _cache.end()) {
_cache.insert({ path, hash });
return true;
}
return false;
}
const Hash HashCache::Get(PCWSTR path) const {
AutoCriticalSection locker(_lock);
auto it = _cache.find(path);
return it == _cache.end()? Hash() : it->second;
}
bool HashCache::Remove(PCWSTR path) {
AutoCriticalSection locker(_lock);
auto it = _cache.find(path);
if (it != _cache.end()) {
_cache.erase(it);
return true;
}
return false;
}
void HashCache::Clear() {
AutoCriticalSection locker(_lock);
_cache.clear();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
代码使用了之前定义的RAII(Resource Acquisition Is Initialization,资源获取即初始化 )风格的AutoCriticalSection类,无需使用终止处理程序(try/finally)即可完成获取和释放操作。
主视图类(CView)持有一个名为m_Cache的HashCache实例,在启用缓存使用(m_UseCache成员变量)时会用到它。
# 图像加载通知
接下来,拼图中相对独立的一块是获取图像加载的通知。从用户模式获取这些通知的一种强大方法是利用Windows事件跟踪(Event Tracing for Windows,ETW)。ETW是一种自Windows 2000起就存在的机制,它允许系统组件和其他应用程序生成丰富的事件,这些事件可以实时使用,也可以记录到文件中以便日后分析。图7-10展示了基本的ETW架构。
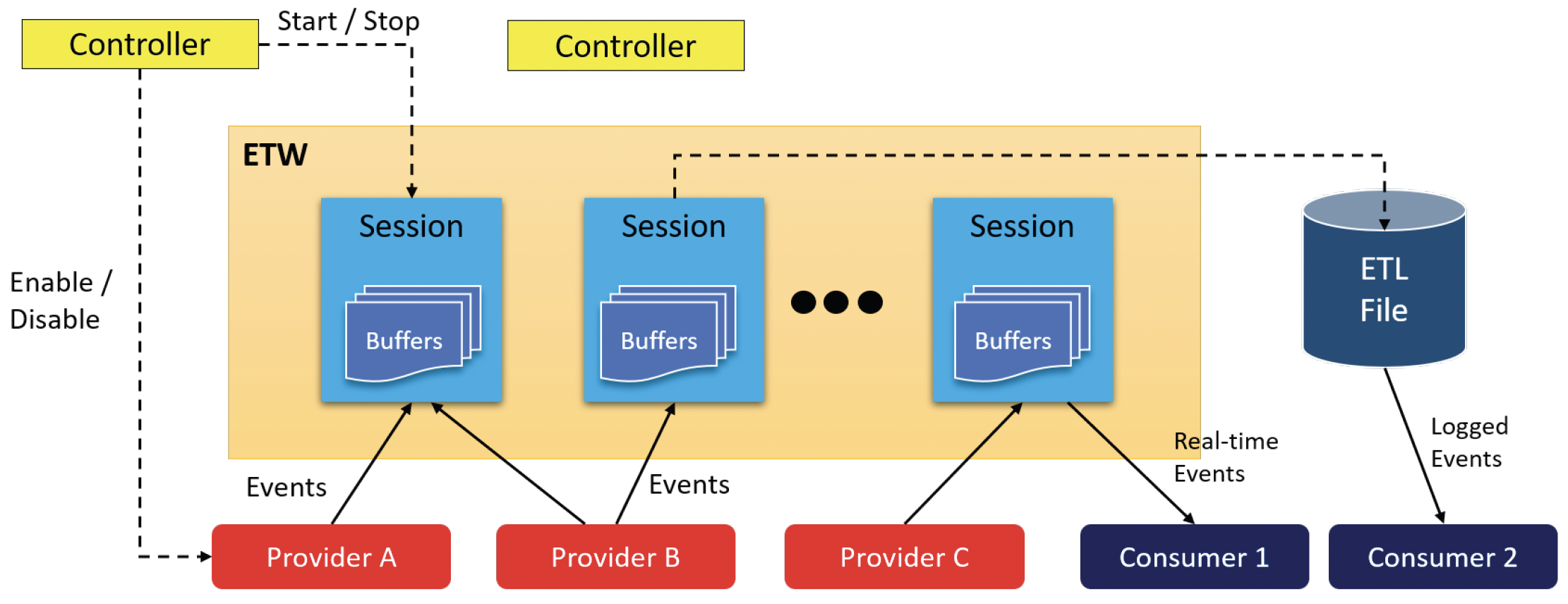
图7-10:ETW架构 ETW的主要组成部分如下:
- 提供程序(Providers)生成事件。
- 会话(Sessions)封装一个或多个提供程序以及一些配置。从会话开始到结束期间,事件会被捕获。
- 控制器(Controllers)启用或禁用提供程序,并启动和停止会话。
- 使用者(Consumers)实时使用事件或将事件记录到文件(ETL,即事件跟踪日志,event tracing log)中。在典型情况下,控制器也是使用者。
| 本书不全面探讨ETW。 |
|---|
在我们的场景中,我们需要使用内核提供程序,它可以发送一系列事件,其中之一就是图像加载事件。TraceManager类封装了与ETW基础设施的交互。它的定义如下:
class TraceManager final {
public:
~TraceManager();
bool Start(std::function<void(PEVENT_RECORD)> callback);
bool Stop();
private:
void OnEventRecord(PEVENT_RECORD rec);
DWORD Run();
private:
TRACEHANDLE _handle{ 0 };
TRACEHANDLE _hTrace{ 0 };
EVENT_TRACE_PROPERTIES* _properties;
std::unique_ptr<BYTE[]> _propertiesBuffer;
EVENT_TRACE_LOGFILE _traceLog = { 0 };
wil::unique_handle _hProcessThread;
std::function<void(PEVENT_RECORD)> _callback;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
TraceManager公开的接口相当简单。构造完成后,通过调用Start启动会话,调用Stop停止会话。私有Run方法用于在其自身线程中启动会话运行(稍后会详细介绍)。OnEventRecord函数是针对每个生成的事件调用的回调函数。各种私有数据成员主要用于构建和管理ETW会话。让我们来看看具体实现。
析构函数仅调用Stop:
TraceManager::~TraceManager() {
Stop();
}
2
3
Start是一个功能较多的函数,它会正确设置ETW会话,然后启动处理过程。它接受一个感兴趣的使用者提供的回调函数,用于对每个事件进行调用。它的首要任务是调用StartTrace,该函数用于配置并启动一个会话:
第7章:线程同步(进程内) 327
bool TraceManager::Start(std::function<void(PEVENT_RECORD)> cb) {
_callback = cb;
if (_handle || _hTrace)
return true;
auto size = sizeof(EVENT_TRACE_PROPERTIES) + sizeof(KERNEL_LOGGER_NAME);
_propertiesBuffer = std::make_unique<BYTE[]>(size);
::memset(_propertiesBuffer.get(), 0, size);
_properties = reinterpret_cast<EVENT_TRACE_PROPERTIES*>(_propertiesBuffer.get());
_properties->EnableFlags = EVENT_TRACE_FLAG_IMAGE_LOAD;
_properties->Wnode.BufferSize = (ULONG)size;
_properties->Wnode.Guid = SystemTraceControlGuid;
_properties->Wnode.Flags = WNODE_FLAG_TRACED_GUID;
_properties->Wnode.ClientContext = 1;
_properties->LogFileMode = EVENT_TRACE_REAL_TIME_MODE;
_properties->LoggerNameOffset = sizeof(EVENT_TRACE_PROPERTIES);
auto error = ::StartTrace(&_handle, KERNEL_LOGGER_NAME, _properties);
if (error != ERROR_SUCCESS && error != ERROR_ALREADY_EXISTS)
return false;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
首先,它检查是否已有会话在进行中,如果是,则直接返回。否则,它将回调函数保存到数据成员中,并继续准备EVENT_TRACE_PROPERTIES结构。重要的部分是将EnableFlags设置为EVENT_TRACE_FLAG_IMAGE_LOAD,这指定了我们关注与图像相关的事件;将LogFileMode设置为EVENT_TRACE_REAL_TIME_MODE,表明请求的是实时会话。
| 有关StartTrace的完整详细信息,请查看其文档。 |
|---|
ETW会话具有独特性,它们的生命周期可以比进程更长。这意味着StartTrace可能会失败,但如果最后一个错误是ERROR_ALREADY_EXISTS,那么会话已经在运行,我们可以作为使用者接入它。
接下来,我们需要通过调用OpenTrace来设置使用者:
第7章:线程同步(进程内) 328
_traceLog.Context = this;
_traceLog.LoggerName = KERNEL_LOGGER_NAME;
_traceLog.ProcessTraceMode = PROCESS_TRACE_MODE_EVENT_RECORD |
PROCESS_TRACE_MODE_REAL_TIME;
_traceLog.EventRecordCallback = [](PEVENT_RECORD record) {
((TraceManager*)record->UserContext)->OnEventRecord(record);
};
_hTrace = ::OpenTrace(&_traceLog);
if (!_hTrace)
return false;
2
3
4
5
6
7
8
9
10
11
每个事件的回调函数设置在EVENT_TRACE_LOGFILE结构(_traceLog)的EventRecordCallback成员中。它使用UserContext成员作为this指针(之前在Context成员中设置)来调用类的实例函数。这个函数(OnEventRecord)将调用在Start中早些时候传入的回调函数。
现在使用者已设置好,所以最后需要的操作是开始处理事件。为此,创建了一个单独的线程,因为ProcessTrace函数是阻塞式的,我们不希望调用者在调用Start时被阻塞:
_hProcessThread.reset(::CreateThread(nullptr, 0, [](auto param) {
return ((TraceManager*)param)->Run();
}, this, 0, nullptr));
return true;
2
3
4
5
Run成员函数仅调用ProcessTrace:
DWORD TraceManager::Run() {
auto error = ::ProcessTrace(&_hTrace, 1, nullptr, nullptr);
return error;
}
2
3
4
如前所述,OnEventRecord函数调用客户端的回调函数:
void TraceManager::OnEventRecord(PEVENT_RECORD rec) {
if (_callback)
_callback(rec);
}
2
3
4
最后,Stop函数关闭并停止跟踪:
bool TraceManager::Stop() {
if (_hTrace) {
::CloseTrace(_hTrace);
_hTrace = 0;
}
if (_handle) {
::StopTrace(_handle, KERNEL_LOGGER_NAME, _properties);
_handle = 0;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
主框架类(CMainFrm)持有一个TraceManager实例。当选择相应的菜单或工具栏项时,它会调用Start和Stop:
LRESULT CMainFrame::OnStartTrace(WORD, WORD, HWND, BOOL&) {
m_TraceManager.Start([this](auto record) {
m_view.OnEvent(record); // call the view
});
// UI updates omitted...
return 0;
}
LRESULT CMainFrame::OnStopTrace(WORD, WORD, HWND, BOOL&) {
m_TraceManager.Stop();
// UI updates omitted
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 事件解析
ETW事件通过EVENT_RECORD结构提供给事件回调函数,该结构包含了关于特定事件的所有信息。其定义如下:
typedef struct _EVENT_RECORD {
EVENT_HEADER EventHeader; // Event header
ETW_BUFFER_CONTEXT BufferContext; // Buffer context
USHORT ExtendedDataCount; // Number of extended data items
USHORT UserDataLength; // User data length
PEVENT_HEADER_EXTENDED_DATA_ITEM ExtendedData; // Pointer to an array of extended data items
PVOID UserData; // Pointer to user data
PVOID UserContext; // Context from OpenTrace
} EVENT_RECORD, *PEVENT_RECORD;
2
3
4
5
6
7
8
9
ETW事件属性可以包括字符串(ANSI和Unicode)、数字、自定义结构以及其他一些特殊类型。所有这些都作为EVENT_RECORD的一部分,从UserData地址开始以二进制Blob的形式存储。为了获取各种属性和值,需要进行一些解析。EventParser类是一个用于解析属性的辅助类。它将每个解析后的属性存储在一个EventProperty结构中,其定义如下:
struct EventProperty {
EventProperty(EVENT_PROPERTY_INFO& info);
std::wstring Name;
BYTE* Data;
ULONG Length;
EVENT_PROPERTY_INFO& Info;
template<typename T>
T GetValue() const {
static_assert(std::is_pod<T>() && !std::is_pointer<T>());
return *(T*)Data;
}
PCWSTR GetUnicodeString() const;
PCSTR GetAnsiString() const;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
每个属性都有一个名称(Name成员)、一个指向实际数据的指针(Data)、一个长度(Length)以及一个指向描述该属性的原始结构的引用(Info)。GetValue<>模板函数用于检索简单POD(“普通旧数据”,plain old data)类型(如数值类型)的属性值。static_assert语句指示编译器拒绝复杂类型,因为使用复杂类型会产生错误的值。
| static_assert在C++ 11中引入,并在C++ 14中得到增强。 |
|---|
GetUnicodeString和GetAnsiString将数据以相应的字符串类型返回。EventParser类的声明如下:
class EventParser {
public:
EventParser(PEVENT_RECORD record);
PTRACE_EVENT_INFO GetEventInfo() const;
PEVENT_RECORD GetEventRecord() const;
const EVENT_HEADER& GetEventHeader() const;
const std::vector<EventProperty>& GetProperties() const;
const EventProperty* GetProperty(PCWSTR name) const; // lookup by name
DWORD GetProcessId() const;
static std::wstring GetDosNameFromNtName(PCWSTR name);
private:
std::unique_ptr<BYTE[]> _buffer;
PTRACE_EVENT_INFO _info{ nullptr };
PEVENT_RECORD _record;
mutable std::vector<EventProperty> _properties;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
一个EventParser实例将EVENT_RECORD作为其输入。关于该事件的所有信息都存储在其中的某个地方。EventParser的任务是提取所需的信息。以下是除了GetDosNameFromNtName(我们将单独处理它)之外的实现:
EventProperty::EventProperty(EVENT_PROPERTY_INFO& info) : Info(info) {
}
EventParser::EventParser(PEVENT_RECORD record) : _record(record) {
ULONG size = 0;
auto error = ::TdhGetEventInformation(record, 0, nullptr, _info, &size);
if (error == ERROR_INSUFFICIENT_BUFFER) {
_buffer = std::make_unique<BYTE[]>(size);
_info = reinterpret_cast<PTRACE_EVENT_INFO>(_buffer.get());
error = ::TdhGetEventInformation(record, 0, nullptr, _info, &size);
}
::SetLastError(error);
}
PTRACE_EVENT_INFO EventParser::GetEventInfo() const {
return _info;
}
PEVENT_RECORD EventParser::GetEventRecord() const {
return _record;
}
const EVENT_HEADER& EventParser::GetEventHeader() const {
return _record->EventHeader;
}
const std::vector<EventProperty>& EventParser::GetProperties() const {
if (!_properties.empty())
return _properties;
_properties.reserve(_info->TopLevelPropertyCount);
auto userDataLength = _record->UserDataLength;
BYTE* data = (BYTE*)_record->UserData;
for (ULONG i = 0; i < _info->TopLevelPropertyCount; i++) {
auto& prop = _info->EventPropertyInfoArray[i];
EventProperty property(prop);
property.Name.assign((WCHAR*)((BYTE*)_info + prop.NameOffset));
auto len = prop.length;
property.Length = len;
property.Data = data;
data += len;
userDataLength -= len;
_properties.push_back(std::move(property));
}
return _properties;
}
const EventProperty* EventParser::GetProperty(PCWSTR name) const {
for (auto& prop : GetProperties())
if (prop.Name == name)
return ∝
return nullptr;
}
DWORD EventParser::GetProcessId() const {
return _record->EventHeader.ProcessId;
}
PCWSTR EventProperty::GetUnicodeString() const {
return (PCWSTR)Data;
}
PCSTR EventProperty::GetAnsiString() const {
return (PCSTR)Data;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
构造函数调用TdhGetEventInformation从EVENT_RECORD获取基本的事件详细信息和属性数组。该调用会进行两次:第一次将长度设为零以获取所需的长度,然后在分配所需的缓冲区后,进行第二次调用以检索实际数据。
Tdh函数需要包含头文件
<tdh.h>并链接tdh.lib库。如前所述,本书不详细讨论这些函数。
GetProperties函数负责遍历事件中的每个属性,提取重要信息并将其封装在一个EventProperty实例中。GetProperty辅助函数根据属性名称返回属性(如果存在)。
# 整合所有内容
既然我们已经有了各个独立的部分,就可以开始将它们集成到一个实际的应用程序中了。主视图类(CView)保存着实际显示的数据项。这些数据项采用EventData结构体的形式,在view.h中定义如下:
struct EventData {
CString FileName;
ULONGLONG Time;
DWORD ProcessId;
Hash MD5Hash;
DWORD CalculatingThreadId;
DWORD CalculationTime;
bool Cached : 1;
bool CalcDone : 1;
};
2
3
4
5
6
7
8
9
10
视图存储了这些项的向量、一个用于保护对向量访问的临界区(Critical Section)、缓存本身以及是否应该使用缓存:
class CView ... {
//...
private :
std::vector<EventData> m_Events;
HashCache m_Cache;
CriticalSection m_EventsLock;
bool m_UseCache{ false };
};
2
3
4
5
6
7
8
当一个事件到来时,会调用回调函数OnEvent。该回调函数需要获取事件详细信息,将它们存储在一个新的EventData对象中,然后继续计算MD5哈希值(或者使用缓存结果)。首先,它会过滤掉不需要的事件:
void CView::OnEvent(PEVENT_RECORD record) {
EventParser parser(record);
// ID 10 是一个加载图像事件
if (parser.GetEventHeader().EventDescriptor.Opcode != 10)
return ;
}
2
3
4
5
6
请记住,事件跟踪(ETW,Event Tracing for Windows)跟踪仅启用图像加载类型的事件。事实证明,实际上可能会发送四个事件。其中只有一个(操作码为10)是图像加载事件。有关完整详细信息,请参考 https://docs.microsoft.com/en-us/windows/win32/etw/image-load (opens new window)。
以下是图像加载事件集的结构:
[EventType(10, 2, 3, 4), EventTypeName("Load", "Unload", "DCStart", "DCEnd")]
class Image_Load : Image {
uint32 ImageBase;
uint32 ImageSize;
uint32 ProcessId;
uint32 ImageCheckSum;
uint32 TimeDateStamp;
uint32 Reserved0;
uint32 DefaultBase;
uint32 Reserved1;
uint32 Reserved2;
uint32 Reserved3;
uint32 Reserved4;
string FileName;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上述格式称为简化的托管对象格式(MOF,Managed Object Format)。它与事件跟踪(ETW)和Windows管理规范(WMI,Windows Management Instrumentation)一起使用。
一旦接收到正确的事件(操作码 = 10),就会检索感兴趣的属性(FileName),并在通过向视图发送自定义消息启动MD5哈希计算之前,用它来填充一个新的EventData实例:
auto fileName = parser.GetProperty(L"FileName");
if (fileName) {
EventData data;
data.FileName = parser.GetDosNameFromNtName(
fileName->GetUnicodeString()).c_str();
data.ProcessId = parser.GetProcessId();
data.Time = parser.GetEventHeader().TimeStamp.QuadPart;
data.CalcDone = false;
size_t size;
{
AutoCriticalSection locker(m_EventsLock);
m_Events.push_back(std::move(data));
size = m_Events.size();
}
int index = static_cast<int>(size - 1);
// 从UI线程启动工作
PostMessage(WM_START_CALC, index, size);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
有几点值得注意:
- 保护视图数据的临界区保持的时间尽可能短。这是通过使用一个人工块来实现的,这样一旦块退出,临界区就可以被释放。
- 计算不是在这个函数中启动的,因为它是由跟踪管理器(TraceManager)的线程调用的,该线程应该尽快释放,以便能够处理下一个事件。相反,调用
PostMessage会导致一条消息被异步发送到窗口,由UI线程处理,从而允许当前函数返回。
上述代码的最后一个有趣的细节是GetDosNameFromNtName的使用。事件跟踪(ETW)事件提供的文件名采用 “设备格式”,这是原生的NT格式,看起来像这样:“DeviceHarddiskVolume3SomeDirectorySomeFile.dll”。内部设备名称采用这种格式的原因将在第11章讨论。目前,这种路径应该转换为类似 “c:SomeDirectorySomeFile.dll” 的格式,以便用于哈希计算的CreateFile API可以使用。静态函数EventParser::GetDosNameFromNtName用于转换回Win32设备名称:
std::wstring EventParser::GetDosNameFromNtName(PCWSTR name) {
static std::vector<std::pair<std::wstring, std::wstring>> deviceNames;
static bool first = true;
if (first) {
auto drives = ::GetLogicalDrives();
int drive = 0;
while (drives) {
if (drives & 1) {
// 驱动器存在
WCHAR driveName[] = L"X:";
driveName[0] = (WCHAR)(drive + 'A');
WCHAR path[MAX_PATH];
if (::QueryDosDevice(driveName, path, MAX_PATH)) {
deviceNames.push_back({ path, driveName });
}
}
drive++;
drives >>= 1;
}
first = false;
}
for (auto& [ntName, dosName] : deviceNames) {
if (::_wcsnicmp(name, ntName.c_str(), ntName.size()) == 0)
return dosName + (name + ntName.size());
}
return L"";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
该函数使用一个静态的字符串对向量,每个字符串对将一个NT设备名称映射到一个驱动器盘符。函数第一次被调用时,它会获取所有驱动器盘符(GetLogicalDrives)作为一个位掩码,其中位0对应驱动器A,位1对应驱动器B,位2对应驱动器C,依此类推。对于每个驱动器,它会使用QueryDosDevice查询其NT设备名称(有关QueryDosDevice的更多信息,请参见第11章)。
有了传入的路径后,会在向量中搜索设备名称,并提取其对应的驱动器盘符。最后,将路径的其余部分附加到提取的驱动器盘符后面,并返回给调用者。
# 读写锁
使用临界区保护共享数据免受并发访问效果很好,但这是一种悲观的机制——它最多只允许一个线程访问共享数据。在某些场景中,一些线程读取数据,而其他线程写入数据,这时可以进行优化:如果一个线程读取数据,没有理由阻止其他仅读取数据的线程并发执行。这正是 “单写多读” 机制的作用。
Windows API提供了SRWLOCK结构体来表示这样一种锁(S代表 “Slim”)。其定义如下:
typedef RTL_SRWLOCK SRWLOCK, *PSRWLOCK;
那么RTL_SRWLOCK是什么呢?如下所示:
typedef struct _RTL_SRWLOCK {
PVOID Ptr;
} RTL_SRWLOCK, *PRTL_SRWLOCK;
2
3
显然,这只是一个不透明的数据,应该按此处理。初始化一个SRWLOCK可以使用InitializeSRWLock函数:
void InitializeSRWLock(_Out_ PSRWLOCK SRWLock);
或者,也可以通过将结构体赋值给SRWLOCK_INIT宏来静态初始化它,该宏只是将结构体清零。奇怪的是,SRWLOCK没有 “删除” 操作;这是因为它所有的内部信息都打包在那个指针大小的单元中。
有了初始化的SRWLOCK后,线程可以使用以下函数尝试获取共享锁或独占锁:
void AcquireSRWLockShared (_InOut_ PSRWLOCK SRWLock);
void AcquireSRWLockExclusive (_InOut_ PSRWLOCK SRWLock);
2
如果无法获取相关锁,线程将进入等待状态。一旦获取到锁,线程就可以继续执行,并按指定访问共享资源,这意味着线程有责任避免进行 “错误” 的访问。例如,如果一个线程获取了共享锁,它绝不能修改共享数据。
一旦工作完成,线程会使用相关的释放函数:
void ReleaseSRWLockShared (_Inout_ PSRWLOCK SRWLock);
void ReleaseSRWLockExclusive (_Inout_ PSRWLOCK SRWLock);
2
SRW锁存储的状态很少,所以它们的灵活性有限:
- 共享锁所有者不能直接将其锁升级为独占锁。它必须先释放共享锁,然后竞争独占锁。
- 独占锁所有者不能递归获取锁;这会导致死锁。
- 不能保证第一个请求获取锁的线程就是第一个获得锁的线程。正如文档所述:“SRW锁既不公平也不先进先出(FIFO,First In First Out)”。
假设这些限制是可以接受的,如果对数据的大多数操作是读取而不是写入,那么就有可能提高性能。
# RAII包装器
与临界区一样,为SRWLOCK提供资源获取即初始化(RAII,Resource Acquisition Is Initialization)包装器会很方便。这里有三个类,一个用于包装SRWLOCK,另外两个用于获取/释放锁:
class ReaderWriterLock : public SRWLOCK {
public :
ReaderWriterLock();
ReaderWriterLock(const ReaderWriterLock&) = delete ;
ReaderWriterLock& operator=(const ReaderWriterLock&) = delete ;
void LockShared();
void UnlockShared();
void LockExclusive();
void UnlockExclusive();
};
struct AutoReaderWriterLockExclusive {
AutoReaderWriterLockExclusive(SRWLOCK& lock);
~AutoReaderWriterLockExclusive();
private :
SRWLOCK& _lock;
};
struct AutoReaderWriterLockShared {
AutoReaderWriterLockShared(SRWLOCK& lock);
~AutoReaderWriterLockShared();
private :
SRWLOCK& _lock;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
实现相当简单:
ReaderWriterLock::ReaderWriterLock() {
::InitializeSRWLock(this);
}
void ReaderWriterLock::LockShared() {
::AcquireSRWLockShared(this);
}
void ReaderWriterLock::UnlockShared() {
::ReleaseSRWLockShared(this);
}
void ReaderWriterLock::LockExclusive() {
::AcquireSRWLockExclusive(this);
}
void ReaderWriterLock::UnlockExclusive() {
::ReleaseSRWLockExclusive(this);
}
AutoReaderWriterLockExclusive::AutoReaderWriterLockExclusive(SRWLOCK& lock)
: _lock(lock) {
::AcquireSRWLockExclusive(&_lock);
}
AutoReaderWriterLockExclusive::~AutoReaderWriterLockExclusive() {
::ReleaseSRWLockExclusive(&_lock);
}
AutoReaderWriterLockShared::AutoReaderWriterLockShared(SRWLOCK& lock)
: _lock(lock) {
::AcquireSRWLockShared(&_lock);
}
AutoReaderWriterLockShared::~AutoReaderWriterLockShared() {
::ReleaseSRWLockShared(&_lock);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
这些包装器是Threadinghelpers项目的一部分。
# MD5计算器2
有了MD5计算器,我们可以用SRW锁替换一些临界区,以潜在地提高并发性,因为可能同时发生多个读取操作。例如,哈希缓存对临界区的使用可以用SRWLOCK替换:
class HashCache {
public :
HashCache();
bool Add(PCWSTR path, const Hash& hash);
const Hash Get(PCWSTR path) const ;
bool Remove(PCWSTR path);
void Clear();
private :
mutable ReaderWriterLock _lock;
std::unordered_map<std::wstring, Hash> _cache;
};
2
3
4
5
6
7
8
9
10
11
12
实现如下:
bool HashCache::Add(PCWSTR path, const Hash& hash) {
AutoReaderWriterLockExclusive locker(_lock);
auto it = _cache.find(path);
if (it == _cache.end()) {
_cache.insert({ path, hash });
return true;
}
return false;
}
const Hash HashCache::Get(PCWSTR path) const {
AutoReaderWriterLockShared locker(_lock);
auto it = _cache.find(path);
return it == _cache.end() ? Hash() : it->second;
}
bool HashCache::Remove(PCWSTR path) {
AutoReaderWriterLockExclusive locker(_lock);
auto it = _cache.find(path);
if (it != _cache.end()) {
_cache.erase(it);
return true;
}
return false;
}
void HashCache::Clear() {
AutoReaderWriterLockExclusive locker(_lock);
_cache.clear();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
对CView类也可以进行类似的修改。
上述更改可以在MD5Calculator2项目中找到。
最后,SRW锁支持获取锁的Try变体函数:
BOOLEAN TryAcquireSRWLockExclusive (_Inout_ PSRWLOCK SRWLock);
BOOLEAN TryAcquireSRWLockShared (_Inout_ PSRWLOCK SRWLock);
2
如果获取到指定的锁,这些函数返回TRUE,否则返回FALSE。如果获取到锁,最终必须调用相应的释放函数。
# 条件变量
条件变量(Condition Variables)是另一种同步机制,它能够让线程在临界区(critical section)或SRW锁(SRW lock)上等待,直到特定条件发生。使用条件变量的一个经典场景是生产者/消费者模型。假设有一些线程负责生成数据项并将它们放入队列中,每个线程执行生成数据项所需的任何操作。与此同时,其他线程作为消费者,它们从队列中取出数据项并以某种方式进行处理(图7-11)。
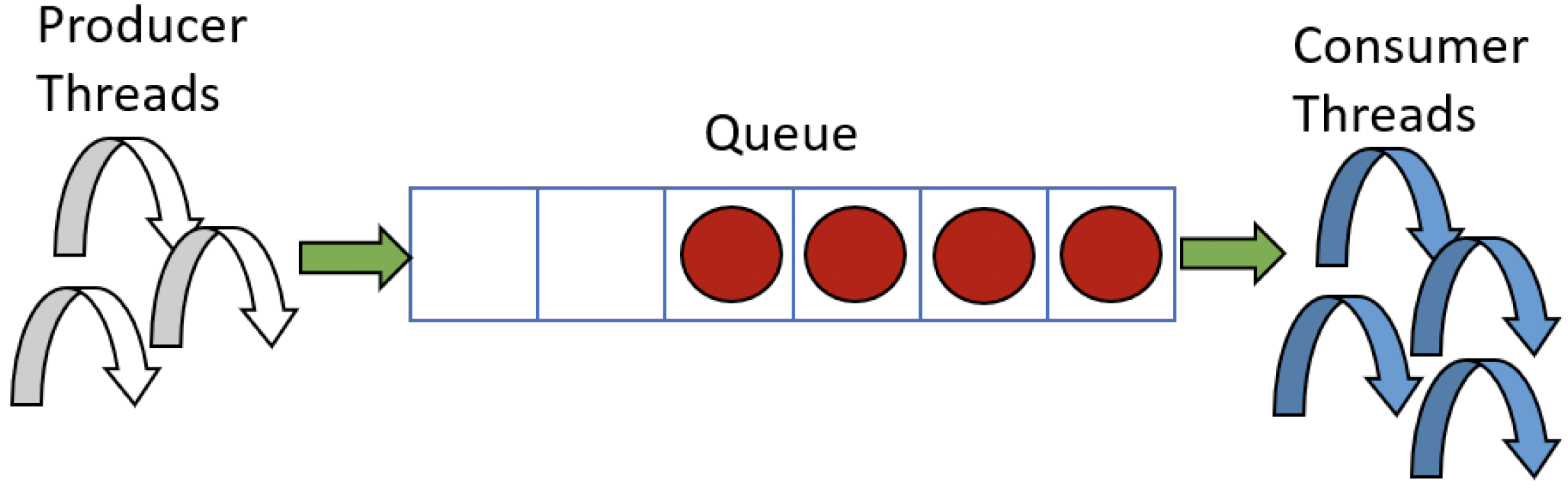 图7-11:生产者/消费者模型
图7-11:生产者/消费者模型
如果数据项的生成速度比消费者的处理速度快,那么队列将不会为空,消费者线程会继续工作。另一方面,如果消费者线程处理完了所有数据项,它们应该进入等待状态,直到有新的数据项生成,此时它们应该被唤醒。这正是条件变量所提供的功能。无事可做的消费者线程(队列已空)不应该通过不断轮询来检查队列是否变为非空状态,因为这样会无端消耗CPU周期。条件变量允许线程进行高效等待(不消耗CPU资源),直到被唤醒(通常由生产者线程唤醒)。
条件变量由一个不透明的CONDITION_VARIABLE结构体表示,它与SRWLOCK非常相似。必须通过调用InitializeConditionVariable函数来初始化条件变量:
void InitializeConditionVariable(_Out_ PCONDITION_VARIABLE ConditionVariable);
与SRWLOCK一样,也可以通过将CONDITION_VARIABLE设置为CONDITION_VARIABLE_INIT来进行静态初始化。
条件变量总是与临界区或SRW锁相关联。当一个线程需要等待条件变量发出信号时,它必须首先获取临界区/SRW锁,然后调用相关的睡眠函数:
BOOL SleepConditionVariableCS(
_Inout_ PCONDITION_VARIABLE ConditionVariable,
_Inout_ PCRITICAL_SECTION CriticalSection,
_In_ DWORD dwMilliseconds
);
BOOL SleepConditionVariableSRW(
_Inout_ PCONDITION_VARIABLE ConditionVariable,
_Inout_ PSRWLOCK SRWLock,
_In_ DWORD dwMilliseconds,
_In_ ULONG Flags
);
2
3
4
5
6
7
8
9
10
11
12
调用上述Sleep*函数之一的线程必须事先恰好获取一次相关的同步对象。该函数会原子性地释放同步对象并在条件变量上等待。在等待过程中,线程可以通过调用条件变量的唤醒函数之一被唤醒:
VOID WakeConditionVariable(_Inout_ PCONDITION_VARIABLE ConditionVariable);
VOID WakeAllConditionVariable(_Inout_ PCONDITION_VARIABLE ConditionVariable);
2
WakeConditionVariable会唤醒单个线程(如果有多个线程在条件变量上睡眠,则无法保证唤醒哪个线程),而WakeAllConditionVariable会唤醒所有在条件变量上等待的线程。
一旦被唤醒,线程会重新获取同步对象并继续执行。此时,线程应该重新检查它所等待的条件是否满足,如果不满足,则再次调用Sleep*函数。这是因为在该线程被唤醒之前,可能有另一个线程已经被唤醒并执行了一些操作,导致条件再次变为不满足。图7-12展示了这样一个线程(使用临界区)的操作流程。
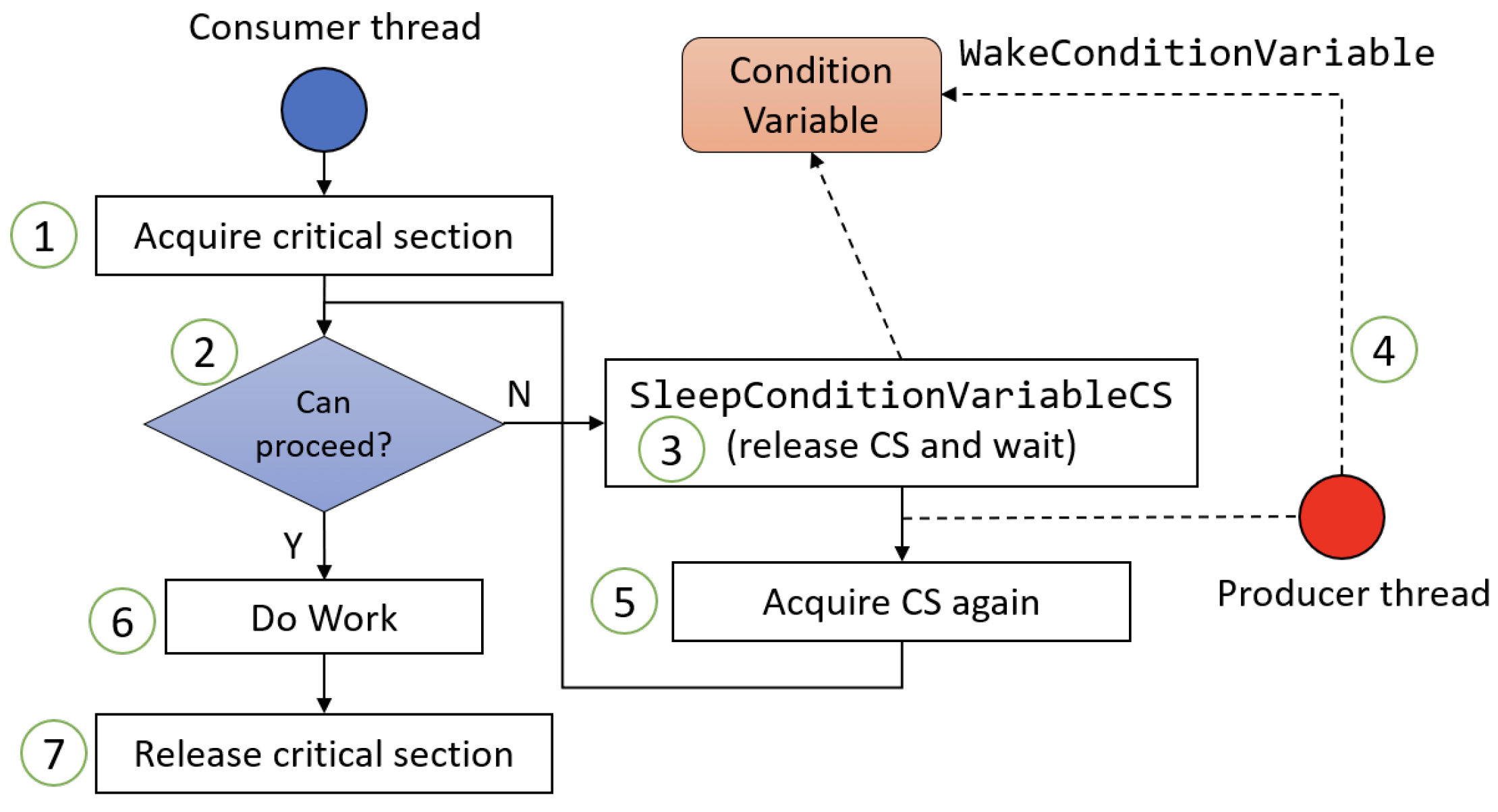 图7-12:使用条件变量的消费者线程操作流程
图7-12:使用条件变量的消费者线程操作流程
图7-12中涉及的步骤如下:
- 消费者线程获取临界区。
- 线程检查是否可以继续执行。例如,它可能检查它要处理的队列是否为空。
- 如果队列为空,线程调用
SleepConditionVariableCS函数,该函数会释放临界区(以便其他线程可以获取它)并进入睡眠(等待状态)。 - 某个时刻,生产者线程会调用
WakeConditionVariable函数唤醒消费者线程,例如,因为它向队列中添加了一个新的数据项。 SleepConditionVariableCS函数返回,重新获取临界区并返回检查是否可以继续执行。如果不可以,则继续等待。- 现在可以继续执行了,线程可以进行它的工作(例如从队列中取出一个数据项)。此时临界区仍然被持有。
- 最后,工作完成,必须释放临界区。
再回到Sleep*函数:如果这些函数成功返回TRUE,意味着线程已被唤醒并获取了同步原语。如果返回FALSE,则表示可能发生了错误。如果dwMillisecond参数不是INFINITE,则表示发生了错误。如果时间间隔是有限的,返回FALSE可能表示线程在该时间间隔内未被唤醒。在这种情况下,GetLastError函数会返回ERROR_TIMEOUT。
对于SRW锁,Flags参数指示是否应该进行独占获取。传入0表示独占访问,而传入CONDITION_VARIABLE_LOCKMODE_SHARED表示共享访问。
# 队列演示应用程序
队列演示应用程序展示了如何使用条件变量来唤醒访问共享队列的消费者线程和生产者线程。启动应用程序后,可以选择生产者线程和消费者线程的数量(图7-13)。
 图7-13:队列演示应用程序
图7-13:队列演示应用程序
点击“运行”按钮开始操作。生产者线程生成数据项(这些数据项是数字)并将它们压入队列。消费者线程从队列中弹出数据项,并检查这些数字是否为质数。如果队列为空,消费者线程会在条件变量上睡眠,直到被生产者线程唤醒。当前队列大小显示在底部,并会定期更新。
如果生产者线程生成的数据项比消费者线程能够处理的更多,队列大小将会增加,因为消费者线程试图赶上生产速度。点击“停止”按钮会停止生产者线程,让消费者线程有机会赶上并清空队列。另一方面,如果消费者线程“更快”(可能是因为数量较多),队列大小将大多为零,因为消费者线程足够快,能够在新的数据项进入队列之前取走并处理它。在运行过程中,会显示一些消费者线程的统计信息(图7-14)。你需要调整线程数量以观察有趣的行为。
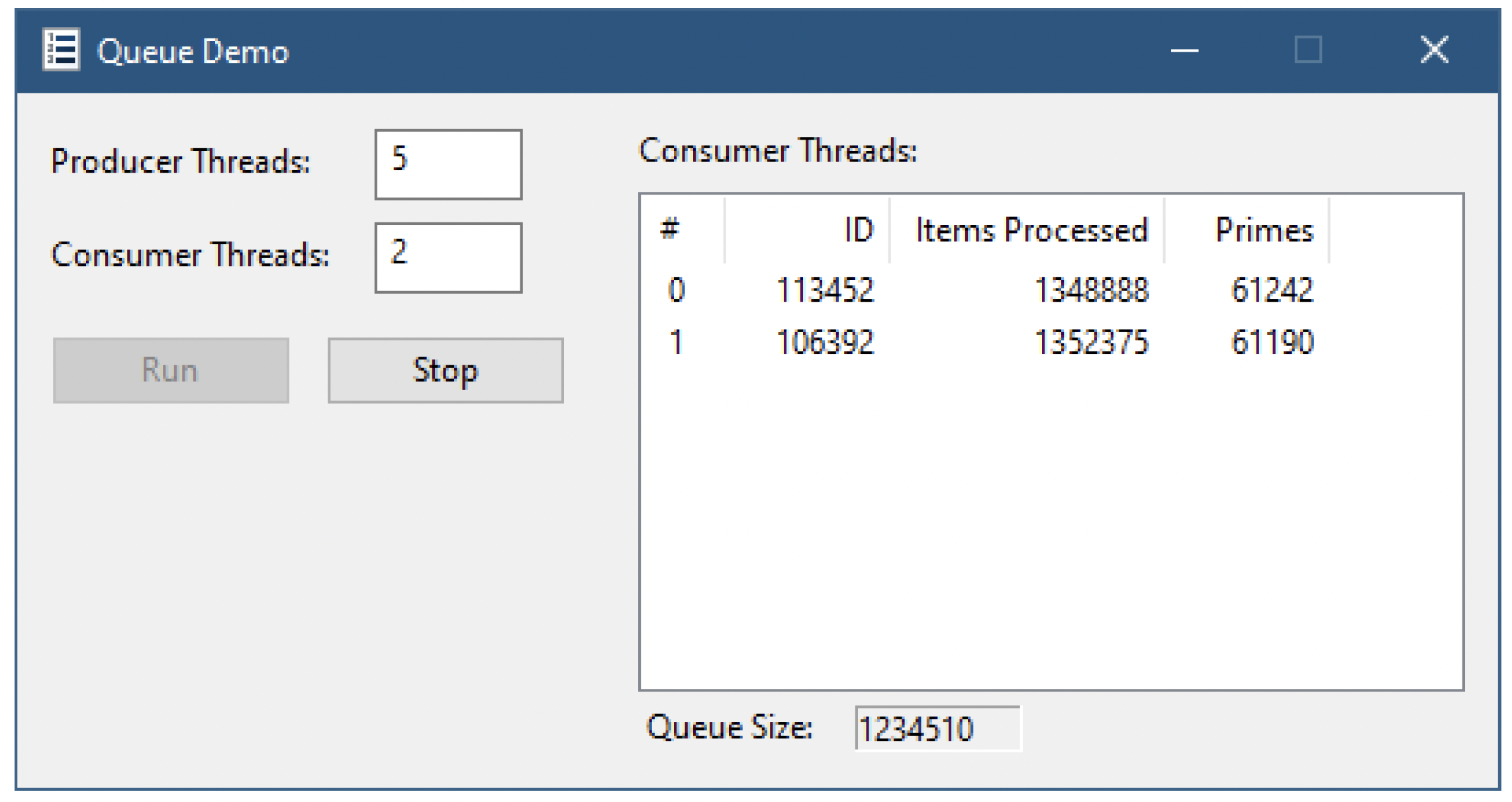 图7-14:运行中的队列演示应用程序
图7-14:运行中的队列演示应用程序
CMainDlg类定义了以下嵌套类型:
struct ConsumerThreadData {
unsigned ItemsProcessed{ 0 };
unsigned Primes{ 0 };
wil::unique_handle hThread;
};
struct WorkItem {
unsigned Data;
bool IsPrime;
};
2
3
4
5
6
7
8
9
10
ConsumerThreadData是由消费者线程操作的数据结构。每个消费者线程都有一个这样的对象。它存储了线程的句柄,以及已处理的数据项数量和找到的质数数量。存储在队列中的每个工作项由一个用于判断是否为质数的数字和一个结果(该应用程序中未直接使用)组成。
基于这些结构和应用程序的需求,存储了以下数据成员:
std::queue<WorkItem> m_Queue; // 队列
CriticalSection m_QueueLock; // 保护队列的临界区
CONDITION_VARIABLE m_QueueCondVar;
std::vector<wil::unique_handle> m_ProducerThreads;
std::vector<ConsumerThreadData> m_ConsumerThreads;
wil::unique_handle m_hAbortEvent;
static CMainDlg* m_pThis; // 简化对this的访问
2
3
4
5
6
7
生产者线程只存储它们的句柄,但实际上它们也可以像消费者线程一样存储更多的状态信息。CriticalSection类是ThreadingHelpers项目中的包装类,用于简化对临界区的操作。m_hAbortEvent是一个事件内核对象句柄,用于向生产者线程和消费者线程发送停止运行的信号。下一章将详细讨论事件内核对象。作为该应用程序的另一种选择,也可以使用一个volatile布尔变量。最后,静态成员m_pThis用于引用唯一的对话框实例,以便简化线程函数对实例方法的访问。
CMainDlg::OnInitDialog函数负责对话框的初始化工作,包括控件的初始化,同时也初始化m_pThis和中止事件:
LRESULT CMainDlg::OnInitDialog(UINT, WPARAM, LPARAM, BOOL&) {
m_pThis = this;
m_hAbortEvent.reset(::CreateEvent(nullptr, TRUE, FALSE, nullptr));
//...
2
3
4
点击“运行”按钮会调用OnRun函数,而OnRun函数只是调用Run函数来执行实际工作。Run函数首先获取消费者线程和生产者线程的数量,并进行一些合理性检查:
void CMainDlg::Run() {
int consumers = GetDlgItemInt(IDC_CONSUMERS);
if (consumers < 1 || consumers > 64) {
DisplayError(L"Consumer threads must be between 1 and 64");
return;
}
int producers = GetDlgItemInt(IDC_PRODUCERS);
if (producers < 1 || producers > 64) {
DisplayError(L"Producer threads must be between 1 and 64");
return;
}
2
3
4
5
6
7
8
9
10
11
12
上述代码中的数字64并没有特殊含义。如果需要,完全可以选择更大的数字。
接下来,需要为这次运行进行一些初始化操作:
bool abort = false;
::ResetEvent(m_hAbortEvent.get());
::InitializeConditionVariable(&m_QueueCondVar);
m_ThreadList.DeleteAllItems();
2
3
4
重置中止事件并初始化条件变量。清空显示消费者线程的列表视图中的现有项。现在是时候创建消费者线程了:
m_ConsumerThreads.clear();
m_ConsumerThreads.reserve(consumers);
for (int i = 0; i < consumers; i++) {
ConsumerThreadData data;
data.hThread.reset(::CreateThread(nullptr, 0, [](auto p) {
return m_pThis->ConsumerThread(PtrToLong(p));
}, LongToPtr(i), 0, nullptr));
if (!data.hThread) {
abort = true;
break;
}
m_ConsumerThreads.push_back(std::move(data));
}
if (abort) {
::SetEvent(m_hAbortEvent.get());
return;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
每个消费者线程都是通过正常的CreateThread函数创建的,将线程函数指向实例函数ConsumerThread,并传入一个值表示该消费者线程在消费者线程数组中的索引。
你可能认为直接将
ConsumerThreadData实例(代码中的data)的指针传递给线程函数会更简单。但这会导致崩溃或数据损坏,因为data在栈上,之后会被复制到向量中(从而移动到堆上),使得该指针变成无效指针。在这种情况下,我选择传入索引,因为它不会改变。
如果由于某种原因线程创建失败,循环将被中止,并设置事件以导致之前创建的所有生产者线程中止。
接下来,以类似的方式创建生产者线程:
m_ProducerThreads.clear();
m_ProducerThreads.reserve(producers);
for (int i = 0; i < producers; i++) {
wil::unique_handle hThread(::CreateThread(nullptr, 0, [](auto p) {
return m_pThis->ProducerThread();
}, this, 0, nullptr));
if (!hThread) {
DisplayError(L"Failed to create producer thread. Aborting");
abort = true;
break;
}
}
if (abort) {
::SetEvent(m_hAbortEvent.get());
return;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
生产者线程调用ProducerThread实例函数。与消费者线程不同,生产者线程不需要任何特殊的上下文,因为它们只是生成伪随机数。Run函数的最后一部分是将消费者线程的基本信息添加到列表视图中,并启动一个简单的定时器,用于定期更新队列大小:
CString text;
for (int i = 0; i < (int)m_ConsumerThreads.size(); i++) {
const auto& t = m_ConsumerThreads[i];
text.Format(L"%2d", i);
int n = m_ThreadList.InsertItem(i, text);
m_ThreadList.SetItemText(n, 1,
std::to_wstring(::GetThreadId(t.hThread.get())).c_str());
}
GetDlgItem(IDC_RUN).EnableWindow(FALSE);
GetDlgItem(IDC_STOP).EnableWindow(TRUE);
SetTimer(1, 500, nullptr);
2
3
4
5
6
7
8
9
10
11
12
13
以下是生产者线程的代码:
DWORD CMainDlg::ProducerThread() {
for (;;) {
if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0)
break;
WorkItem item;
item.IsPrime = false;
LARGE_INTEGER li;
::QueryPerformanceCounter(&li);
item.Data = li.LowPart;
{
AutoCriticalSection locker(m_QueueLock);
m_Queue.push(item);
}
::WakeConditionVariable(&m_QueueCondVar);
// 偶尔睡眠一会儿
if ((item.Data & 0x7f) == 0)
::Sleep(1);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这段代码使用了一个无限循环,只有在中止事件被触发时才会退出。然后准备一个WorkItem实例,生成的数字使用QueryPerformanceCounter返回值的低32位。在这个示例中,这种选择完全是任意的。接下来,线程获取临界区,以防止在工作项队列上出现同步问题,因为生产者线程、消费者线程(甚至UI线程可能也需要访问)会并发访问该队列。队列本身是标准的C++ std::queue<>类,但使用任何其他队列实现也可以。
一旦有新项被添加到队列中,线程会通过调用WakeConditionVariable来通知条件变量(condition variable),唤醒正在等待它的线程。在循环推送下一项之前的最后一段代码,是可能存在的一段睡眠(sleep)代码,用于让线程稍作延迟。
消费者线程的代码如下:
DWORD CMainDlg::ConsumerThread(int index) {
auto& data = m_ConsumerThreads[index];
auto tick = ::GetTickCount64();
for (;;) {
WorkItem value;
{
bool abort = false;
AutoCriticalSection locker(m_QueueLock);
while (m_Queue.empty()) {
if (::WaitForSingleObject(m_hAbortEvent.get(), 0) == WAIT_OBJECT_0) {
abort = true;
break;
}
::SleepConditionVariableCS(&m_QueueCondVar, &m_QueueLock, INFINITE);
}
if (abort)
break;
ATLASSERT(!m_Queue.empty());
value = m_Queue.front();
m_Queue.pop();
}
{
// 执行实际工作
bool isPrime = IsPrime(value.Data);
if (isPrime) {
value.IsPrime = true;
::InterlockedIncrement(&data.Primes);
}
::InterlockedIncrement(&data.ItemsProcessed);
}
auto current = ::GetTickCount64();
if (current - tick > 600) {
PostMessage(WM_UPDATE_THREAD, index);
tick = current;
}
}
PostMessage(WM_UPDATE_THREAD, index);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
该函数首先获取对这个消费者线程的数据结构的引用。然后构建一个无限循环。获取队列的临界区(critical section),如果队列为空,则进入一个内部while循环。如果队列为空,线程无事可做,因此它会调用SleepConditionVariableCS进入等待状态,直到被另一个线程唤醒。
在等待之前,它会释放临界区。当它醒来时(因为生产者调用了WakeConditionVariable),它会自动重新获取临界区(见图7 - 12),并且必须重新检查条件(队列是否为空),因为有可能另一个消费者线程更早醒来并从队列中取出了最后一项。此外,条件变量可能会出现虚假唤醒(spurious wake up),这也是重新检查条件的另一个原因。
如果队列不为空,消费者可以继续操作,通过调用m_Queue.front()获取队列中的第一项,并调用m_Queue.pop()将其从队列中移除(此时临界区仍然被持有)。
然后释放临界区(AutoCriticalSection作用域结束),接着通过调用辅助函数IsPrime对该项执行实际工作。如果需要,会增加该线程维护的相关计数器。使用InterlockedIncrement进行增加操作,是因为UI线程可能会并发访问这些值。最后,每隔600毫秒左右,会向窗口发送一条消息来更新该线程的统计信息。
WM_UPDATE_THREAD是应用程序定义的消息,它接收消费者线程索引,并更新已处理的项数和计算出的质数数量:
LRESULT CMainDlg::OnUpdateThread(UINT, WPARAM index, LPARAM, BOOL&) {
auto& data = m_ConsumerThreads[index];
int n = (int)index;
CString text;
text.Format(L"%u", ::InterlockedAdd((LONG*)&data.ItemsProcessed, 0));
m_ThreadList.SetItemText(n, 2, text);
text.Format(L"%u", ::InterlockedAdd((LONG*)&data.Primes, 0));
m_ThreadList.SetItemText(n, 3, text);
return 0;
}
2
3
4
5
6
7
8
9
10
对计数器的访问可能会与消费者线程并发进行,为了防止可能出现的读取不一致问题,使用带零参数的InterlockedAdd来缓解这种情况。直接读取计数器可能也行得通,但这可能取决于值在内存中的对齐方式以及目标处理器,所以谨慎行事总是好的。
另一个UI更新是通过使用定时器定期更新队列大小:
LRESULT CMainDlg::OnTimer(UINT, WPARAM id, LPARAM, BOOL&) {
if (id == 1) {
size_t size;
{
AutoCriticalSection locker(m_QueueLock);
size = m_Queue.size();
}
SetDlgItemInt(IDC_QUEUE_SIZE, (unsigned)size, FALSE);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
使用的定时器ID为1,通过if语句进行检查。对队列的任何访问都应该在临界区的保护下进行,然后在更新UI之前读取队列大小。
最后,点击“停止”按钮会调用OnStop函数,该函数只是简单地调用Stop:
void CMainDlg::Stop() {
// 向线程发出终止信号
::SetEvent(m_hAbortEvent.get());
::WakeAllConditionVariable(&m_QueueCondVar);
// 更新UI
GetDlgItem(IDC_RUN).EnableWindow(TRUE);
GetDlgItem(IDC_STOP).EnableWindow(FALSE);
}
2
3
4
5
6
7
8
该函数设置终止事件,使所有生产者退出其无限循环。条件变量用于唤醒所有消费者线程,这样如果队列中还有任何项,它们就可以清空队列。
编写一个基于资源获取即初始化(RAII,Resource Acquisition Is Initialization)的条件变量包装器。
修改队列演示应用程序,使用SRW锁(SRW lock)代替临界区。
# 等待地址变化
Windows 8和Server 2012增加了另一种同步机制,它允许线程高效地等待,直到某个地址处的值变为期望的值。然后它可以唤醒并继续工作。当然,也可以使用其他同步机制来实现类似的效果,比如使用条件变量,但是等待地址变化的方式更高效,并且由于不直接使用临界区(或其他软件同步原语),所以不易出现死锁。
线程可以通过调用WaitOnAddress进入等待状态,直到“被监控”的数据上出现某个特定值:
BOOL WaitOnAddress(
_In_ volatile VOID* Address,
_In_ PVOID CompareAddress,
_In_ SIZE_T AddressSize,
_In_opt_ DWORD dwMilliseconds);
2
3
4
5
本节中的函数需要链接到
synchronization.lib导入库。
该函数检查Address指向的值是否与CompareAddress指向的值相同。如果不同,调用会立即返回TRUE。否则,线程进入等待状态。要比较的值的大小在AddressSize参数中指定,它必须是1、2、4或8。最后一个参数表示等待时间,可以是INFINITE,表示无限期等待。
| 内核内部将等待的地址保存在一个哈希表中,以地址作为键。 |
|---|
其他某个线程可能会更改Address指向的值。不幸的是,这并不会自动唤醒等待的线程。相反,进行更改的线程必须调用其中一个“唤醒”函数:
VOID WakeByAddressSingle (_In_ PVOID Address);
VOID WakeByAddressAll (_In_ PVOID Address);
2
使用前一个函数,所有等待指定地址的线程都会被唤醒,而使用后一个函数只会唤醒一个线程。这种机制也可能出现虚假唤醒,所以被唤醒的线程应该重新检查值是否确实是期望的值。如果不是,线程应该通过再次调用WaitOnAddress返回等待状态(通常在一个循环中完成)。
一段典型的代码可能如下所示:
DWORD undesiredValue = 0;
DWORD actualValue = 0;
void Thread1() {
// 根据需要设置undesiredValue
while(actualValue == undesiredValue) {
::WaitOnAddress(&actualValue, &undesiredValue, sizeof(DWORD), INFINITE);
}
// actualValue != undesiredValue
}
void Thread2() {
//...
actualValue++;
::WakeByAddressSingle(&actualValue);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 同步屏障
Windows 8中引入的另一个同步原语是同步屏障(synchronization barrier)。这个对象允许对那些需要在工作中到达某个特定点后才能继续执行的线程进行同步。例如,假设有一个系统由几个部分组成,每个部分都需要分两个阶段进行初始化,然后主应用程序代码才能继续执行。一种简单的实现方法是按顺序调用每个初始化函数:
void RunApp() {
// 阶段1
InitSubsystem1();
InitSubsystem2();
InitSubsystem3();
InitSubsystem4();
// 阶段2
InitSubsystem1Phase2();
InitSubsystem2Phase2();
InitSubsystem3Phase2();
InitSubsystem4Phase2();
// 继续运行主应用程序代码...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这种方法可行,但是如果每个初始化操作都可以并发进行,即每个初始化操作由不同的线程执行。那么每个线程在所有其他线程完成第一阶段的初始化之前,都不能继续进行第二阶段的初始化。当然,使用其他同步原语的组合也可以实现这样的方案,但是同步屏障就是专门为这类目的而存在的。
同步屏障由不透明的SYNCHRONIZATION_BARRIER结构体表示,必须使用InitializeSynchronizationBarrier对其进行初始化:
BOOL InitializeSynchronizationBarrier(
_Out_ LPSYNCHRONIZATION_BARRIER lpBarrier,
_In_ LONG lTotalThreads,
_In_ LONG lSpinCount);
2
3
4
lTotalThreads是在所有线程都可以继续执行之前,需要到达屏障的线程总数。lSpinCount参数允许为到达屏障但尚未释放屏障时的线程设置自旋计数(spin count)。值为 - 1表示设置默认自旋。
| 文档中指出默认自旋为2000。然而,据我所知,目前自旋计数并未被使用。 |
|---|
一旦初始化完成,需要在屏障处等待的线程调用EnterSynchronizationBarrier:
BOOL EnterSynchronizationBarrier(
_Inout_ LPSYNCHRONIZATION_BARRIER lpBarrier,
_In_ DWORD dwFlags);
2
3
指定SYNCHRONIZATION_BARRIER_FLAGS_SPIN_ONLY标志会使线程自旋,直到屏障被释放。只有在预计屏障释放时间很短的情况下才应该使用这个标志。相反的标志SYNCHRONIZATION_BARRIER_FLAGS_BLOCK_ONLY指定如果屏障尚未释放,则线程不应自旋,而应进入等待状态。最后一个标志SYNCHRONIZATION_BARRIER_FLAGS_NO_DELETE是一种可能的优化,它告诉API在删除屏障时跳过一些所需的同步操作。如果指定了这个标志,所有进入屏障的线程都必须指定该标志。
只有在屏障被释放时,该函数才会对单个线程返回TRUE,对所有其他线程返回FALSE。在前面描述的场景中,下面是在单独线程中运行的一个初始化函数:
DWORD WINAPI InitSubSystem1(PVOID p) {
auto barrier = (PSYNCHRONIZATION_BARRIER)p;
// 阶段1
printf("Subsystem 1: Starting phase 1 initialization (TID: %u)...\n",
::GetCurrentThreadId());
// 执行工作...
printf("Subsystem 1: Ended phase 1 initialization...\n");
::EnterSynchronizationBarrier(barrier, 0);
printf("Subsystem 1: Starting phase 2 initialization...\n");
// 执行工作
printf("Subsystem 1: Ended phase 2 initialization...\n");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在第一阶段初始化完成后,调用EnterSynchronizationBarrier等待,直到所有其他线程完成它们的第一阶段初始化。主函数可以这样编写:
SYNCHRONIZATION_BARRIER sb;
InitializeSynchronizationBarrier(&sb, 4, -1);
LPTHREAD_START_ROUTINE functions[] = {
InitSubSystem1, InitSubSystem2, InitSubSystem3, InitSubSystem4
};
printf("System initialization started\n");
HANDLE hThread[4];
int i = 0;
for (auto f : functions) {
hThread[i++] = ::CreateThread(nullptr, 0, f, &sb, 0, nullptr);
}
::WaitForMultipleObjects(_countof(hThread), hThread, TRUE, INFINITE);
printf("System initialization complete\n");
// 关闭线程句柄...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
运行这段代码会产生如下输出:
System initialization started
Subsystem 1: Starting phase 1 initialization (TID: 79480)...
Subsystem 2: Starting phase 1 initialization (TID: 104836)...
Subsystem 3: Starting phase 1 initialization (TID: 32556)...
Subsystem 4: Starting phase 1 initialization (TID: 86268)...
Subsystem 2: Ended phase 1 initialization...
Subsystem 3: Ended phase 1 initialization...
Subsystem 1: Ended phase 1 initialization...
Subsystem 4: Ended phase 1 initialization...
Subsystem 4: Starting phase 2 initialization...
Subsystem 3: Starting phase 2 initialization...
Subsystem 1: Starting phase 2 initialization...
Subsystem 2: Starting phase 2 initialization...
Subsystem 3: Ended phase 2 initialization...
Subsystem 1: Ended phase 2 initialization...
Subsystem 4: Ended phase 2 initialization...
Subsystem 2: Ended phase 2 initialization...
System initialization complete
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
最后,应该使用DeleteSynchronizationBarrier删除同步屏障:
BOOL DeleteSynchronizationBarrier(_Inout_ LPSYNCHRONIZATION_BARRIER lpBarrier);
在调用EnterSynchronizationBarrier之后立即调用DeleteSynchronizationBarrier是可行的,因为该函数会等待所有线程到达屏障后才进行删除操作,除非所有线程都使用SYNCHRONIZATION_BARRIER_FLAGS_NO_DELETE标志,这样删除函数就不会做出这个保证。如果屏障永远不会被删除,这可能会很有用。
# C++标准库呢?
与第5章中同名的部分类似,C++标准库提供了同步原语,可以作为Windows API的替代方案,特别是对于跨平台代码。和往常一样,对这些对象的定制非常有限(如果有的话)。例如:
std::mutex,其行为类似于临界区,但不支持递归获取。std::recursive_mutex,其行为与临界区完全一样(支持递归获取)。std::shared_mutex,类似于SRW锁。std::condition_variable,相当于条件变量。- 其他。
显然,C++中可能缺少一些功能,比如等待地址变化和同步屏障。不过,这些功能可能会在未来的标准中添加。无论如何,所有C++标准库类型都仅在同一进程内有效,无法跨进程使用。
# 练习
- 创建一个线程安全的栈数据结构实现。如果出栈操作无法成功,阻塞线程直到有数据可用(使用条件变量)。
# 总结
在本章中,我们介绍了通过Windows API可用的各种同步机制。所有这些机制的共同点是,能够在同一进程中的线程之间进行某种意义上的同步。在下一章中,我们将利用内核对象扩展可用的同步原语,这些内核对象还可以在不同进程中的线程之间进行同步。