 第10章:高级线程
第10章:高级线程
# 第10章:高级线程
本章将介绍前几章未涉及的与线程相关的主题。
本章内容:
- 线程本地存储(Thread Local Storage)
- 远程线程(Remote Threads)
- 线程枚举(Thread Enumeration)
- 缓存和缓存行(Caches and Cache Lines)
- 等待链遍历(Wait Chain Traversal)
- 用户模式调度(User Mode Scheduling)
- 一次性初始化(Init Once Initialization)
- 调试多线程应用程序(Debugging Multithreaded Applications)
# 线程本地存储
线程自然可以访问其栈数据和进程范围内的全局变量。然而,有时按线程逐个进行存储会很方便,并且能以统一的方式访问。我们熟悉的GetLastError函数就是一个典型的例子。尽管任何线程都可以调用GetLastError,但每个调用该函数的线程得到的结果都是不同的。处理这种情况的一种方法是存储一个以线程ID为键的哈希表,然后根据该键查找值。这种方法可行,但存在一些缺点。其一,由于多个线程可能同时访问哈希表,因此需要对其进行同步。其二,查找正确线程的速度可能不如预期的快。
线程本地存储(Thread Local Storage,TLS)是一种用户模式机制,它允许按线程进行数据存储,进程中的每个线程都可以访问这些数据,但只能访问属于自己的数据;不过,访问方法是统一的。
GetLastError存储的值并非存储在TLS中,而是作为为每个线程维护的线程环境块(Thread Environment Block,TEB)结构的一部分进行存储,但原理是相同的。
TLS使用的另一个经典示例是在C/C++标准库中。在20世纪70年代初构思C标准库时,还没有多线程的概念。因此,C运行时会维护一组全局变量作为某些操作的状态。例如,下面这段经典的C代码尝试打开一个文件并处理可能出现的错误:
FILE* fp = fopen("somefile.txt", "r");
if (fp == NULL) {
// 出现问题
switch (errno) {
case ENOENT: // 没有此文件
//
break;
case EFBIG:
//
break;
//
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
任何I/O错误都会反映在全局变量errno中。但在多线程应用程序中,这就成了一个问题。假设线程1进行了一次I/O函数调用,导致errno发生改变。在它检查errno的值之前,线程2也进行了一次I/O调用,再次改变了errno。这就使得线程1检查到的是由于线程2的活动而产生的值。
最终结果是,errno不能是一个全局变量。所以如今,errno不是一个变量,而是一个宏,它会调用errno()函数,该函数使用线程本地存储来检索当前线程的值。类似地,像fopen这样的I/O函数的实现会使用TLS将错误结果存储到当前线程中。
| 同样的概念也适用于C/C++运行时库维护的其他全局变量。 |
|---|
# 动态TLS
Windows API提供了4个用于TLS的函数。第一个函数为进程中的每个线程(以及未来的线程)分配一个槽:
DWORD TlsAlloc();
该函数返回一个可用的槽索引,并将所有现有线程对应的单元格清零。如果函数返回TLS_OUT_OF_INDEXES(定义为0xffffffff),则意味着函数失败,所有可用的槽都已被分配。保证可用的槽数量定义为TLS_MINIMUM_AVAILABLE(目前为64)。这似乎很多,但实际情况并非一定如此。TLS在DLL中非常有用,DLL可能希望按线程存储一些信息,因此在加载时可能会分配大量槽,并在需要时使用。查看一个典型的进程,其中DLL的数量很容易超过100个。实际上,可用槽的数量大于64。如果尝试分配槽直到失败,就可以了解有多少个槽可用:
int slots = 0;
while (true) {
DWORD slot = ::TlsAlloc();
if (slot == TLS_OUT_OF_INDEXES) {
printf("Out of TLS indices!\n");
break;
}
slots++;
}
printf("Allocated: %d\n", slots);
2
3
4
5
6
7
8
9
10
11
在我的Windows 10 2004版本的基本控制台应用程序中运行这段代码,得到了1084个槽。如果检查实际的槽值,会发现有些槽已经被分配了。
在内部,会预先分配64个槽,因此这些槽始终可用。如果请求更多的槽,在可能的情况下会再分配1024个(请记住,每个线程都需要自己的TLS数组)。不过,不应依赖这个数量或这种行为。
TLS中的每个单元格都是一个指针大小的值,因此这里的最佳实践是使用单个槽,并动态分配存储在TLS中所需的所有信息的结构,然后将数据的指针存储在槽中。
一旦获得了索引,就可以使用两个函数在槽中存储或检索值:
BOOL TlsSetValue(
_In_ DWORD dwTlsIndex,
_In_opt_ PVOID pTlsValue);
PVOID TlsGetValue(_In_ DWORD dwTlsIndex);
2
3
4
5
这些函数使用起来相当简单。调用这些函数的线程只能访问特定槽索引中属于自己的值。没有直接的方法可以访问另一个线程的TLS槽,否则就违背了TLS的目的。这也意味着在访问TLS时,永远不需要进行同步,因为只有单个线程可以访问内存中的相同地址。TLS数组如图10-1所示。
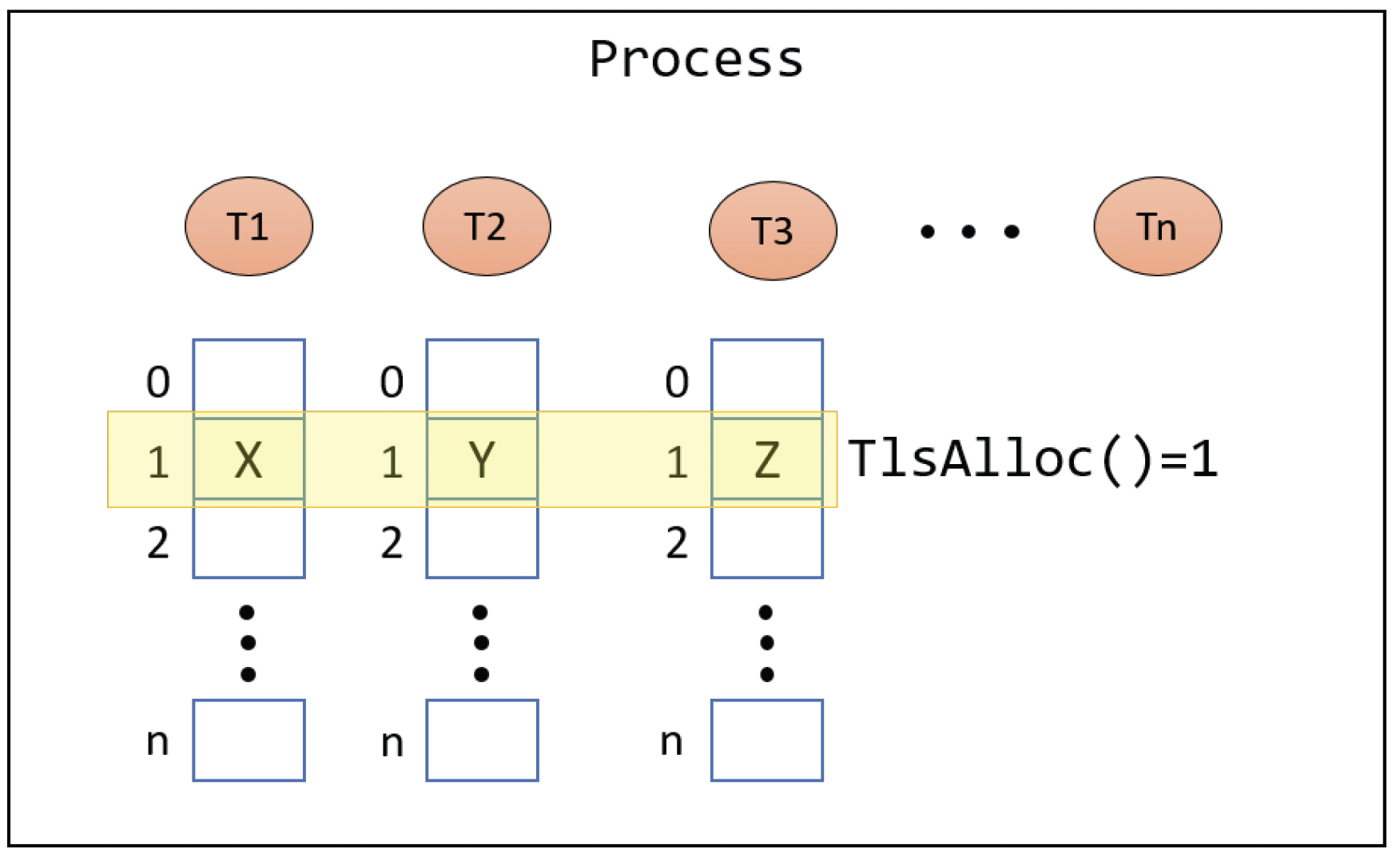 图10-1:线程本地存储
图10-1:线程本地存储
最后,由TlsAlloc分配的TLS索引需要使用TlsFree释放:
BOOL TlsFree(_In_ DWORD dwTlsIndex);
TLS的一种非标准用法是在不实际传递参数的情况下向函数传递参数。例如,假设有一个已经存在的函数,并且其原型不能更改。如果该函数在调用时需要额外的上下文,如何传递额外的参数呢?TLS是解决这个问题的一个不错的方案。唯一需要共享的是为此目的分配的TLS索引。
下面是一个更具体的示例。假设我们有一个名为Transaction的类,用于管理某种事务。操作可能属于某个事务,但也可能在没有事务的情况下被调用。如何对这种约束进行建模呢?也许显而易见的答案是在系统中的每个函数中添加一个Transaction*参数,以便每个函数可以根据它是否属于某个事务来做出决策。
然而,如果这些函数已经存在,这可能会有问题。添加另一个参数并非易事,可能会产生连锁反应。在某些情况下,如果涉及虚函数,不破坏大部分代码就无法完成修改,因为对虚函数签名的任何更改都可能产生失控的级联效应。
当然,还有一种替代方法,即(再次)管理一个以线程ID为键的事务对象哈希表,但这效率较低(管理哈希表需要加锁),因为事务是单线程的,它按线程逐个传播。
TLS提供了一个优雅的解决方案。下面是Transaction类的声明示例:
class Transaction {
public:
Transaction();
~Transaction();
static Transaction* GetCurrent();
void AddLog(PCWSTR text);
void AddError(PCWSTR text);
private:
int _errors = 0;
// 需要C++17编译器
inline static DWORD _tlsIndex = TLS_OUT_OF_INDEXES;
};
// C++17之前的编译器
DWORD Transaction::_tlsIndex = TLS_OUT_OF_INDEXES;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
每当涉及事务范围时,函数可以通过调用Transaction::GetCurrent()间接从TLS中获取事务。如果返回值为NULL,则表示没有事务。否则,表示存在事务,代码可以使用它。下面是Transaction类的概念性实现:
Transaction::Transaction() {
if (_tlsIndex == TLS_OUT_OF_INDEXES)
_tlsIndex = ::TlsAlloc();
::TlsSetValue(_tlsIndex, this);
}
Transaction::~Transaction() {
if (_errors == 0) {
// 提交事务
}
else {
// 中止/回滚事务
}
::TlsSetValue(_tlsIndex, nullptr);
}
Transaction* Transaction::GetCurrent() {
if (_tlsIndex == TLS_OUT_OF_INDEXES)
return nullptr;
return static_cast<Transaction*>(::TlsGetValue(_tlsIndex));
}
void Transaction::AddError(PCWSTR) {
_errors++;
// 更多代码
}
void Transaction::AddLog(PCWSTR) {
// 更多代码
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
构造函数分配一个TLS索引(仅一次),然后将自身地址设置为TLS槽中的值。析构函数决定是提交还是中止事务,然后将TLS值设置为NULL,表示没有事务。
GetCurrent函数只是检索TLS槽中的值,并将其转换为Transaction*。下面是使用这个类的示例代码:
bool DoWork() {
// 更多代码
}
void f1() {
auto tn = Transaction::GetCurrent();
if (tn)
tn->AddLog(L"f1 working");
if (!DoWork()) {
if (tn)
tn->AddError(L"Failed in DoWork");
else
printf("Failed in DoWork");
}
}
void do_something() {
Transaction t;
f1();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这种有时被称为环境事务(ambient transaction)的概念在.NET Framework中通过TransactionScope类使用。 |
|---|
# 静态线程本地存储(TLS,Thread Local Storage)
线程本地存储还有一种更简单的形式,可通过在全局变量或静态变量上使用微软扩展关键字,或者使用C++ 11及更高版本的编译器来实现。下面我们来看看这两种方法。
微软特定的说明符declspec(thread)可用于指定一个线程本地变量,示例如下:
declspec(thread) int counter;
变量counter现在是线程本地的,每个线程都有自己的counter值。类似地,在C++ 11及更高版本中,可以使用thread_local关键字以跨平台的方式实现同样的功能,示例如下:
thread_local int counter;
效果是一样的。这种线程本地存储之所以称为 “静态的”,是因为它不需要任何分配操作,也无法被销毁。在内部,编译器会将所有线程本地变量整合到一块,并将这些信息存储在PE(Portable Executable,可移植可执行文件)文件中一个名为.tls的节里。当进程启动时,读取这些信息的加载器(NTDLL)会调用TlsAlloc来分配一个槽,并为每个启动的线程动态分配一个内存块,这个内存块包含了所有的线程本地变量。这之所以可行,是因为每个用户模式线程在调用传递给CreateThread的 “真正” 函数之前,都会先在NTDLL提供的函数中启动。
图10-2展示了PE文件中的线程本地存储数据,其中编译了以下代码行:thread_local int counter = 5;。在.tls节的二进制数据中可以清楚地看到值 “5”。此外,似乎还有更多线程本地存储数据,这些数据是某些Windows DLL(Dynamic - Link Library,动态链接库)的一部分,并非由应用程序直接创建。
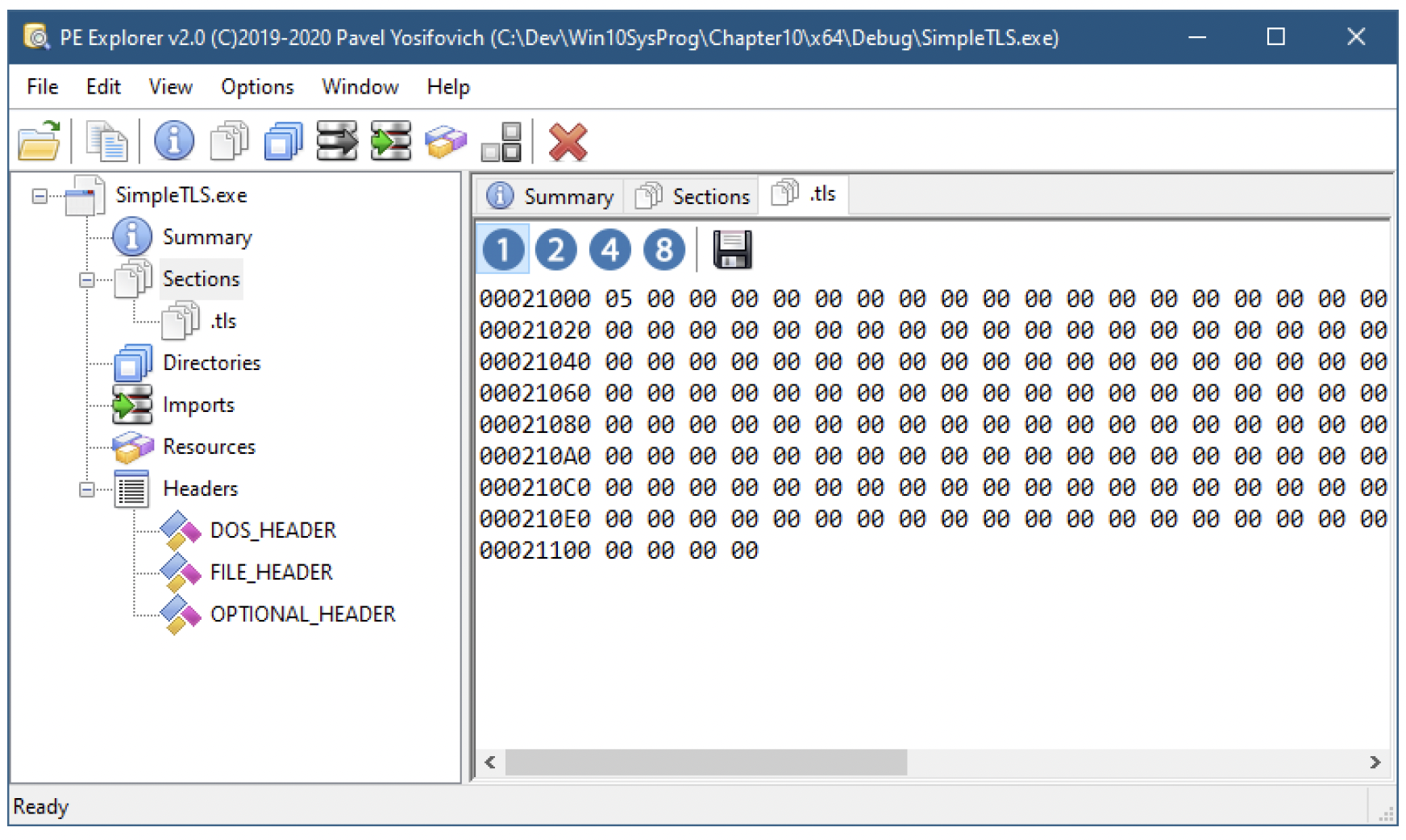
图10-2:PE文件中的线程本地存储(TLS)
# 远程线程
我们多次使用的CreateThread函数是在当前进程中创建线程。然而,在某些情况下,一个进程可能希望在另一个进程中创建线程。调试器就是这种应用场景的典型例子。当需要强制设置断点时,比如用户按下 “中断” 按钮,调试器会在目标进程中创建一个线程,并将其指向DebugBreak函数(或者是一个会发出中断指令的CPU内部函数),从而使进程中断并通知调试器。
能够实现这一功能的函数是CreateRemoteThread和CreateRemoteThreadEx:
HANDLE WINAPI CreateRemoteThread(
_In_ HANDLE hProcess,
_In_ LPSECURITY_ATTRIBUTES lpThreadAttributes,
_In_ SIZE_T dwStackSize,
_In_ LPTHREAD_START_ROUTINE lpStartAddress,
_In_ LPVOID lpParameter,
_In_ DWORD dwCreationFlags,
_Out_opt_ LPDWORD lpThreadId
);
2
3
4
5
6
7
8
9
HANDLE CreateRemoteThreadEx(
_In_ HANDLE hProcess,
_In_opt_ LPSECURITY_ATTRIBUTES lpThreadAttributes,
_In_ SIZE_T dwStackSize,
_In_ LPTHREAD_START_ROUTINE lpStartAddress,
_In_opt_ LPVOID lpParameter,
_In_ DWORD dwCreationFlags,
_In_opt_ LPPROC_THREAD_ATTRIBUTE_LIST lpAttributeList,
_Out_opt_ LPDWORD lpThreadId
);
2
3
4
5
6
7
8
9
10
与CreateThread相比,CreateRemoteThread只增加了一个参数 —— 第一个参数hProcess,即目标进程的句柄。这个句柄必须具备相当多的访问权限,包括PROCESS_CREATE_THREAD、PROCESS_QUERY_INFORMATION、PROCESS_VM_OPERATION、PROCESS_VM_WRITE和PROCESS_VM_READ。这是合理的,因为在另一个进程中创建线程是一种非常侵入性的操作。
该句柄也可以是GetCurrentProcess(),此时这个函数就和CreateThread完全一样了。
最有趣的参数是函数指针本身(lpStartAddress)。函数的地址是相对于目标进程的,这意味着线程需要执行的代码必须以某种方式已经存在于目标进程中。一种思路是使用一个确保存在于目标进程且地址已知的函数。Windows API函数通常属于这种类型。由于Windows子系统DLL(如kernel32.dll、kernelbase.dll、user32.dll等,当然还有ntdll.dll)在所有进程中都被映射到相同的地址,因此从调用进程获取的地址也可以在目标进程中使用。
与CreateRemoteThread相比,CreateRemoteThreadEx增加了另一个参数:属性列表(lpAttributeList)。这和第3章讨论的属性列表是一样的。有些属性与进程相关(见第3章),但也有一些与线程相关,这就是指定这些线程相关属性的方式。请注意,这对本地线程和远程线程同样适用。有关属性列表,请参考表3 - 9,其中一些属性是针对线程的。
# 入侵(Breakin)应用程序
入侵示例应用程序通过远程线程调用DebugBreak函数,对一个进程进行远程入侵,这和调试器的做法类似。
从技术上讲,已经有一个函数可以执行此操作 —— DebugBreakProcess。
第一步是从命令行获取进程ID,并打开一个权限足够的句柄:
int main(int argc, const char* argv[]) {
if (argc < 2) {
printf("Usage: breakin <pid>\n");
return 0;
}
int pid = atoi(argv[1]);
auto hProcess = ::OpenProcess(PROCESS_CREATE_THREAD | PROCESS_QUERY_INFORMATION |
PROCESS_VM_OPERATION | PROCESS_VM_READ | PROCESS_VM_WRITE,
FALSE, pid);
if (!hProcess)
return Error("Failed to open process");
2
3
4
5
6
7
8
9
10
11
12
上述代码没有新内容。重要的是要请求最小的访问权限,以使CreateRemoteThread能够成功执行。
接下来是调用CreateRemoteThread。我们利用了kernel32.dll在每个进程中都被映射到相同地址这一事实,所以DebugBreak函数在每个进程中的地址也是相同的。这意味着我们可以在本进程中定位这个函数,并指示远程线程使用相同的函数地址:
auto hThread = ::CreateRemoteThread(hProcess, nullptr , 0,
(LPTHREAD_START_ROUTINE)::GetProcAddress(
::GetModuleHandle(L"kernel32"), "DebugBreak"),
nullptr , 0, nullptr);
if (!hThread)
return Error("Failed to create remote thread");
printf("Remote thread created successfully!\n");
::CloseHandle(hThread);
::CloseHandle(hProcess);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
GetModuleHandle返回本进程中已加载模块(kernel32.dll)的地址,GetProcAddress检索函数的地址。这些与DLL相关的函数将在第15章详细讨论。
这段代码中还有另一个隐藏的假设,与线程函数的参数有关。标准的线程函数如下所示:
DWORD WINAPI ThreadFunction(PVOID param);
这意味着我们让远程线程(或者任何线程)运行的任何函数都必须具有这个原型,或者 “足够相似”。在这种情况下,“足够相似” 是可行的,因为DebugBreak不接受任何参数,所以我们可以传递NULL作为param的值,而且返回类型反正也不会被使用,所以这样也没问题。如果函数需要不止一个参数,那就会有问题,因为没有简单的方法来传递这些参数。
我们可以通过运行某个进程(例如notepad),用某个调试器进行附加,然后让进程自由运行来测试入侵应用程序。然后,我们可以使用入侵应用程序强制设置一个断点。结果应该是在进程中设置了一个断点,调试器重新获得控制权。
如果对一个没有被调试的进程执行此操作会发生什么呢?试试看,自己找出答案!
CreateRemoteThread(Ex)更有用的一个应用场景是将DLL注入到目标进程中。由于这需要处理虚拟内存和DLL相关的操作,我们将这个示例应用推迟到第15章再进行讲解。
# 线程枚举
在第3章中,我们介绍了几种枚举系统中正在运行的进程的方法。那么线程呢?工具帮助函数CreateToolhelp32Snapshot提供了一个标志TH32_SNAPTHREAD,可以用来枚举系统中的所有线程。
HANDLE CreateToolhelp32Snapshot(
DWORD dwFlags,
DWORD th32ProcessID
);
2
3
4
这个快照包含了所有进程中的所有线程,无法指定特定的进程ID来枚举线程。CreateToolhelp32Snapshot的第二个参数确实包含一个进程ID,但这个参数只有在枚举模块或堆时才有用。
一旦创建了快照,你可以通过调用Thread32First一次,然后通过调用Thread32Next进行迭代,直到它返回false,从而遍历快照中的线程:
BOOL Thread32First(
HANDLE hSnapshot,
LPTHREADENTRY32 lpte
);
BOOL Thread32Next(
HANDLE hSnapshot,
LPTHREADENTRY32 lpte
);
2
3
4
5
6
7
8
9
这两个函数都会在THREADENTRY32结构中返回信息,该结构定义如下:
typedef struct tagTHREADENTRY32 {
DWORD dwSize; // must be set before calls
DWORD cntUsage;
DWORD th32ThreadID; // this thread
DWORD th32OwnerProcessID; // Process this thread is associated with
LONG tpBasePri; // base priority
LONG tpDeltaPri; // not used
DWORD dwFlags; // not used
} THREADENTRY32;
2
3
4
5
6
7
8
9
# thlist应用程序
thlist应用程序根据命令行是否提供进程ID,列出特定进程中的所有线程,或者列出系统中的所有线程。该函数还会列出每个线程所属进程的映像名称。
这个应用程序的核心是一个辅助函数EnumThreads,它返回一个ThreadInfo结构体的向量,ThreadInfo结构体定义如下:
struct ThreadInfo {
DWORD Id;
DWORD Pid;
int Priority;
FILETIME CreateTime;
DWORD CPUTime;
std::wstring ProcessName;
};
2
3
4
5
6
7
8
线程的创建时间和CPU使用时间并没有在THREADENTRY32结构中提供。获取这些信息需要打开线程的句柄,如果打开成功,就可以获取到相关信息。可以像打开进程一样,通过向OpenThread函数提供线程ID和所需的访问权限来打开一个线程:
HANDLE OpenThread(
_In_ DWORD dwDesiredAccess,
_In_ BOOL bInheritHandle,
_In_ DWORD dwThreadId
);
2
3
4
5
EnumThreads函数首先为进程和线程创建一个快照:
std::vector<ThreadInfo> EnumThreads(int pid) {
std::vector<ThreadInfo> threads;
HANDLE hSnapshot = ::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS | TH32CS_SNAPTHREAD, 0);
if (hSnapshot == INVALID_HANDLE_VALUE)
return threads;
2
3
4
5
这个快照包含进程和线程。首先,我们枚举进程,以便创建进程ID与其相关信息之间的映射。这样,在遍历线程时就可以很容易地找到对应的进程:
PROCESSENTRY32 pe;
pe.dwSize = sizeof(pe);
std::unordered_map<DWORD, PROCESSENTRY32> processes;
processes.reserve(512);
::Process32First(hSnapshot, &pe);
// skip idle process
while (::Process32Next(hSnapshot, &pe)) {
processes.insert({ pe.th32ProcessID, pe });
}
2
3
4
5
6
7
8
9
10
对于发现的每个进程,都会在一个unordered_map<>中插入一个条目,这样在第二阶段查找进程时速度会更快。进程ID为0的空闲进程会被跳过,因为它不是一个真正的进程,也没有特别的意义(Process32First会被调用,但结果不会被处理)。
现在开始线程枚举本身的操作。THREADENTRY32 结构会用合适的大小进行初始化:
threads.reserve(4096);
THREADENTRY32 te;
te.dwSize = sizeof(te);
2
3
接下来进行线程迭代。对于每个线程,会在 unordered_map<> 中查找对应的进程,以定位进程映像名称:
::Thread32First(hSnapshot, &te);
do {
if (te.th32OwnerProcessID > 0 && (pid == 0 || te.th32OwnerProcessID == pid)) {
ThreadInfo ti;
ti.Id = te.th32ThreadID;
ti.Pid = te.th32OwnerProcessID;
ti.Priority = te.tpBasePri;
ti.ProcessName = processes[ti.Pid].szExeFile;
2
3
4
5
6
7
8
上述 if 语句会进行检查,如果指定了进程ID(非零),则仅处理该进程中的线程;否则,会处理所有线程。
接下来,我们需要获取一些不在枚举范围内的线程信息:
auto hThread = ::OpenThread(THREAD_QUERY_LIMITED_INFORMATION, FALSE, ti.Id);
if (hThread) {
FILETIME user, kernel, exit;
::GetThreadTimes(hThread, &ti.CreateTime, &exit, &kernel, &user);
ti.CPUTime = DWORD((*(ULONGLONG*)&kernel + *(ULONGLONG*)&user) / 10000000);
::CloseHandle(hThread);
}
else {
ti.CPUTime = 0;
ti.CreateTime.dwHighDateTime = ti.CreateTime.dwLowDateTime = 0;
}
2
3
4
5
6
7
8
9
10
11
THREAD_QUERY_LIMITED_INFORMATION 是使用 GetThreadTimes 检索线程的一些基本信息(如创建时间和执行时间)所需的访问掩码:
BOOL GetThreadTimes(
_In_ HANDLE hThread,
_Out_ LPFILETIME lpCreationTime,
_Out_ LPFILETIME lpExitTime,
_Out_ LPFILETIME lpKernelTime,
_Out_ LPFILETIME lpUserTime
);
2
3
4
5
6
7
该函数与我们之前使用过的 GetProcessTimes 类似,但它是基于线程进行操作的。创建时间和退出时间以从1601年1月1日协调世界时(UTC)开始的100纳秒为单位,内核和用户执行时间也以100纳秒为单位进行度量。上述代码将内核时间和用户时间的总和除以10000000,将其转换为秒为单位。
剩下要做的就是将 ThreadInfo 对象添加到向量中,并继续迭代:
threads.push_back(std::move(ti));
}
} while (::Thread32Next(hSnapshot, &te));
::CloseHandle(hSnapshot);
return threads;
2
3
4
5
主函数调用 EnumThreads 并通过各种格式处理来展示信息:
int main(int argc, const char* argv[]) {
DWORD pid = 0;
if (argc > 1)
pid = atoi(argv[1]);
auto threads = EnumThreads(pid);
printf("%6s %6s %5s %18s %11s %s\n", "TID", "PID", "Pri", "Started", "CPU Time", "Process Name");
printf("%s\n", std::string(60, '-').c_str());
for (auto& t : threads) {
printf("%6d %6d %5d %18ws %11ws %ws\n", t.Id, t.Pid, t.Priority,
t.CreateTime.dwLowDateTime + t.CreateTime.dwHighDateTime == 0?
L"(Unknown)" : (PCWSTR)CTime(t.CreateTime).Format(L"%x %X"),
(PCWSTR)CTimeSpan(t.CPUTime).Format(L"%D:%H:%M:%S"),
t.ProcessName.c_str());
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
运行该应用程序时,如果不传入任何参数,会转储系统中的所有线程。如果传入一个进程ID运行,输出将限制为该进程的线程:
C:\>thlist.exe 11740
TID PID Pri Started CPU Time Process Name
|11744|11740|8|03/22/20|12:12:08|0:00:02:06|explorer.exe|
|---|---|---|---|---|---|---|
|11904|11740|8|03/22/20|12:12:08|0:00:00:27|explorer.exe|
|13280|11740|9|03/22/20|12:12:10|0:00:17:14|explorer.exe|
|11936|11740|8|03/22/20|12:12:11|0:00:00:27|explorer.exe|
|11716<br/>...|11740|8|03/22/20|12:12:11|0:00:00:32|explorer.exe|
|5080|11740|8|03/25/20|11:14:36|0:00:00:00|explorer.exe|
|17064|11740|8|03/25/20|11:14:36|0:00:00:00|explorer.exe|
|41084|11740|8|03/25/20|11:14:37|0:00:00:00|explorer.exe|
|48916|11740|8|03/25/20|11:14:44|0:00:00:00|explorer.exe|
2
3
4
5
6
7
8
9
10
11
12
第3章中描述的用于进程枚举的原生应用程序编程接口(API,Application Programming Interface)也提供了枚举每个进程中线程的功能。
# 缓存和缓存行
在微处理器发展的早期,中央处理器(CPU,Central Processing Unit)的速度和内存(随机存取存储器,RAM,Random Access Memory)的速度相当。后来CPU速度不断提升,而内存速度却滞后了。这就导致CPU经常处于等待状态,等待内存进行数据的读取或写入操作。为了弥补这一差距,在CPU和内存之间引入了缓存,如图10-3所示。
 图10-3:CPU和内存之间的缓存
图10-3:CPU和内存之间的缓存
与主内存相比,缓存是一种高速内存,这使得CPU等待的时间减少。当然,缓存的容量远小于主内存,但在当今的系统中,缓存的存在至关重要,其重要性怎么强调都不为过。
SumMatrix 项目通过以下两种方式对比对矩阵进行求和的操作:
long long SumMatrix1(const Matrix<int>& m) {
long long sum = 0;
for (int r = 0; r < m.Rows(); ++r)
for (int c = 0; c < m.Columns(); ++c)
sum += m[r][c];
return sum;
}
long long SumMatrix2(const Matrix<int>& m) {
long long sum = 0;
for (int c = 0; c < m.Columns(); ++c)
for (int r = 0; r < m.Rows(); ++r)
sum += m[r][c];
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Matrix<> 类是对一维数组的简单封装。从算法角度来看,这两个函数对矩阵元素求和所需的时间应该是相同的。毕竟,代码都会遍历矩阵的所有元素一次。但实际结果可能会令人惊讶。以下是在我的机器上使用不同大小的矩阵进行运行的结果,以及对元素求和所需的时间(所有操作均为单线程):
Type Size Sum Time (nsec)
Row major 256 X 256 2147516416 34 usec
Col Major 256 X 256 2147516416 81 usec
Row major 512 X 512 34359869440 130 usec
Col Major 512 X 512 34359869440 796 usec
Row major 1024 X 1024 549756338176 624 usec
Col Major 1024 X 1024 549756338176 3080 usec
Row major 2048 X 2048 8796095119360 2369 usec
Col Major 2048 X 2048 8796095119360 43230 usec
Row major 4096 X 4096 140737496743936 8953 usec
Col Major 4096 X 4096 140737496743936 190985 usec
Row major 8192 X 8192 2251799847239680 35258 usec
Col Major 8192 X 8192 2251799847239680 1035334 usec
Row major 16384 X 16384 36028797153181696 142603 usec
Col Major 16384 X 16384 36028797153181696 4562040 usec
2
3
4
5
6
7
8
9
10
11
12
13
14
15
两者的差异非常显著,这是由缓存导致的。当CPU读取数据时,它读取的并非单个整数或指令要求读取的单个数据,而是读取一整个缓存行(通常为64字节)并将其放入内部缓存中。然后,当读取内存中的下一个整数时,由于该整数已在缓存中,因此无需访问内存。这是最理想的情况,SumMatrix1 就是这样工作的——它按线性方式遍历内存。
另一方面,SumMatrix2 读取一个整数(以及缓存行中的其他数据),而下一个整数在内存中的位置较远,位于不同的缓存行(对于除最小矩阵之外的所有矩阵都是如此),这就需要读取另一个缓存行,可能还会丢弃可能很快就会用到的数据,从而使情况变得更糟。
从技术上讲,大多数CPU中实现了3级缓存。缓存离处理器越近,速度就越快,容量也就越小。图10-4展示了一个具有超线程技术的4核CPU的典型缓存配置。
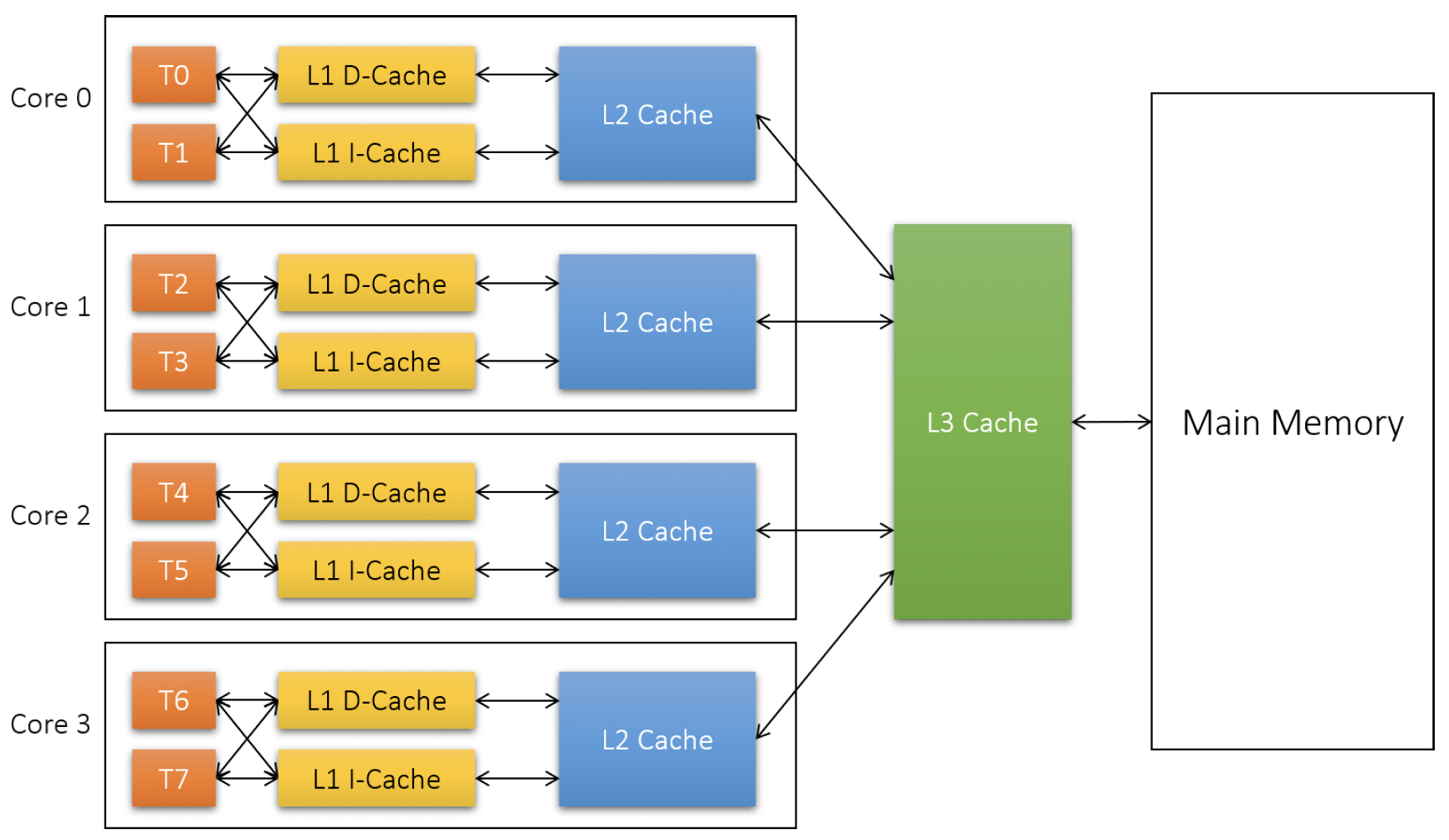
图10-4:CPU中的缓存级别
1级缓存由数据缓存(D - cache)和指令缓存(I - cache)组成,每个逻辑处理器都有一套。然后是2级缓存,它由属于同一核心的逻辑处理器共享。最后,3级缓存是系统范围的。这些缓存的容量相当小,大约比主内存小3个数量级。在系统的任务管理器的“性能”/“CPU”选项卡中可以很容易看到缓存的大小,如图10-5所示。
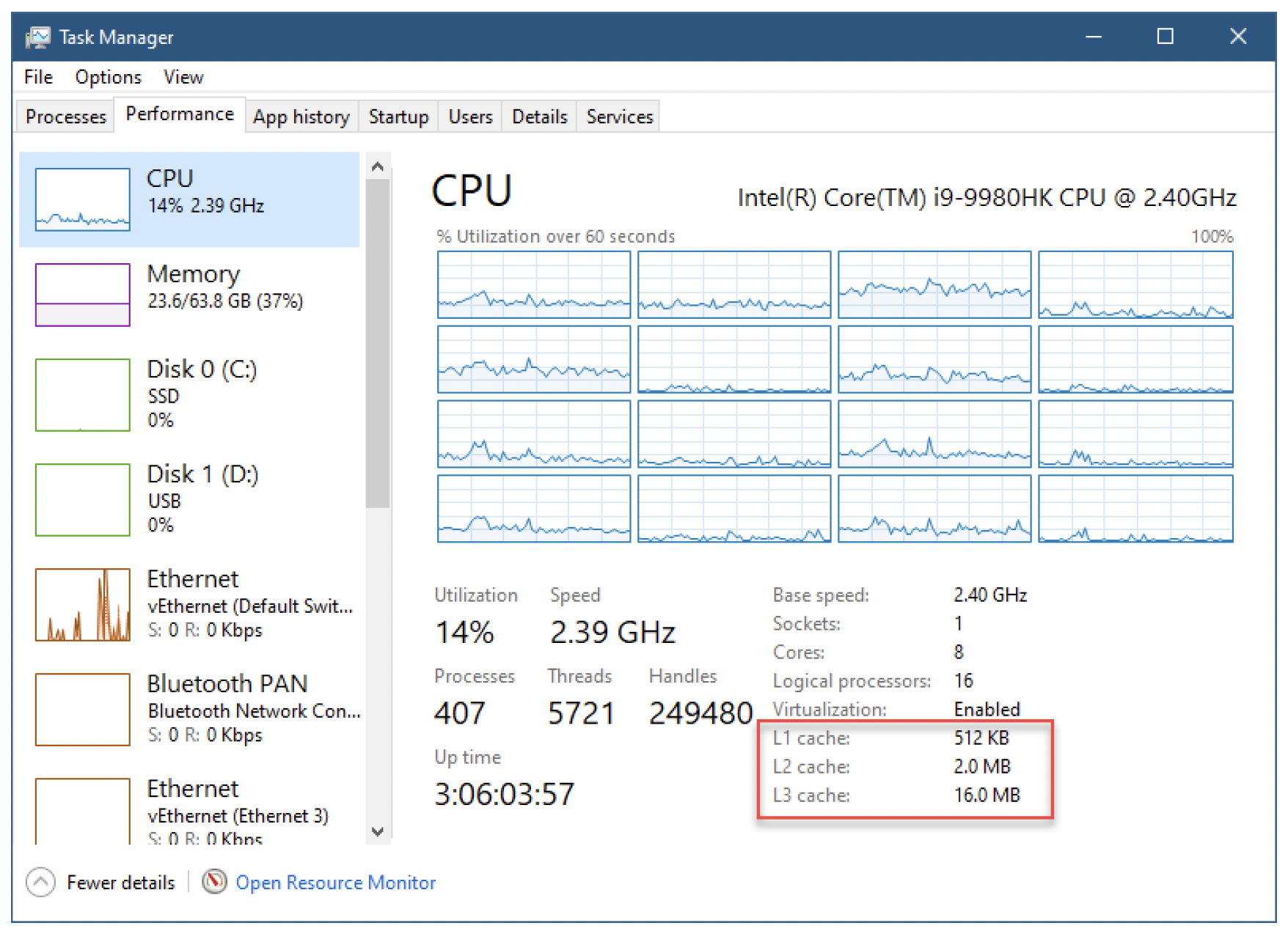 图10-5:任务管理器中的缓存大小
图10-5:任务管理器中的缓存大小
在图10-5中,3级缓存的大小为16MB(系统范围)。2级缓存的大小为2MB,但这是所有核心的总和。由于该系统有8个核心,因此每个2级缓存实际大小为2MB / 8 = 256KB。同样,1级缓存大小为512KB,分布在16个逻辑处理器上,每个缓存大小为512KB / 16 = 32KB。关键在于,与主内存大小(以GB为单位)相比,缓存大小较小。
还有另一种重要的缓存,任务管理器中并未显示,称为转换后备缓冲器(TLB,Translation Lookaside Buffer)。这是一种CPU缓存,专门用于快速将虚拟地址转换为物理地址。我们将在第12章进一步讨论这种缓存。
让我们来看另一个示例,在这个示例中,缓存和缓存行起着重要(甚至是关键)的作用。FalseSharing 项目展示了遍历一个大型数组,统计数组中偶数的数量。这是通过多个线程来完成的——每个线程被分配数组的一个连续部分。统计结果存储在另一个数组中,每个单元格由相应的线程进行修改。图10-6展示了4个线程的这种安排。
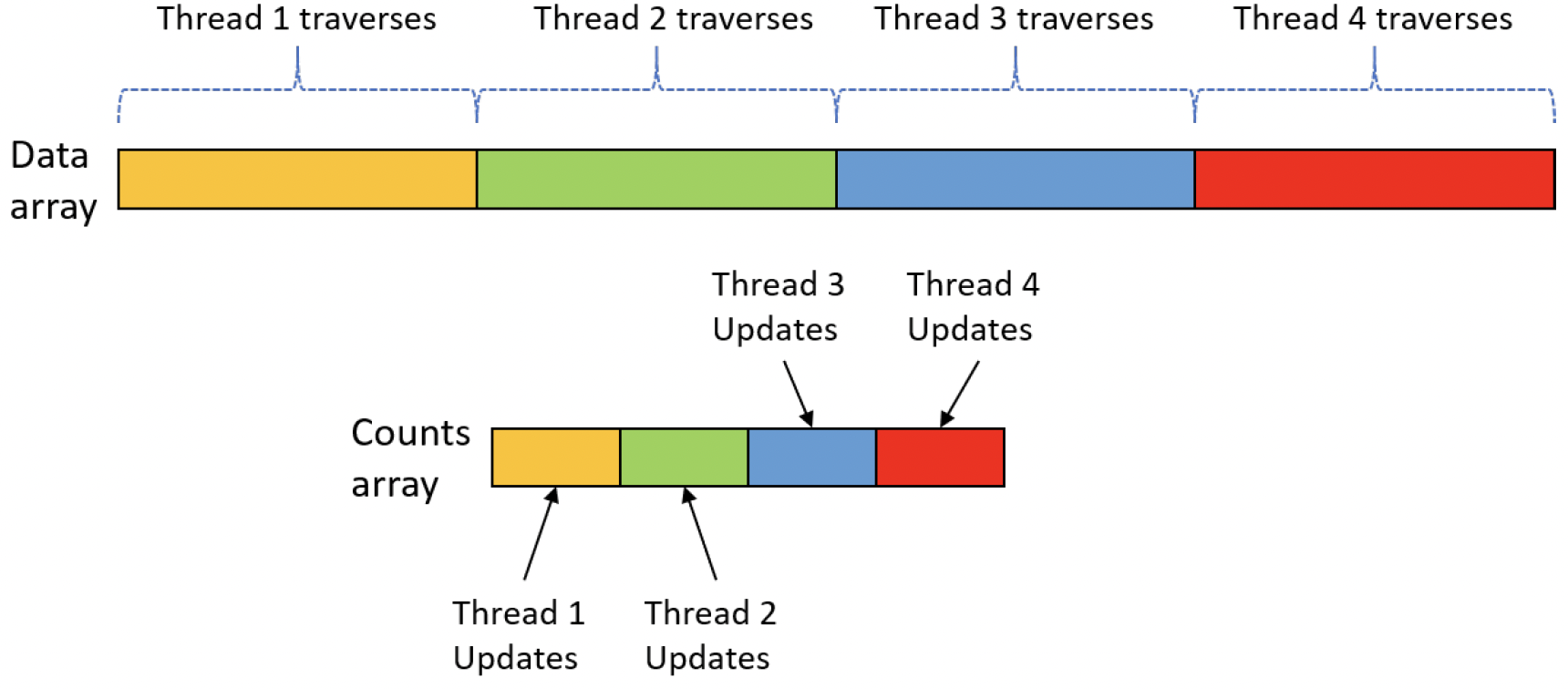 图10-6:伪共享应用程序
图10-6:伪共享应用程序
以下是统计偶数的第一个版本:
using namespace std;
struct ThreadData {
long long start, end;
const int* data;
long long* counters;
};
long long CountEvenNumbers1(const int* data, long long size, int nthreads) {
auto counters_buffer = make_unique<long long[]>(nthreads);
auto counters = counters_buffer.get();
auto tdata = make_unique<ThreadData[]>(nthreads);
long long chunk = size / nthreads;
vector<wil::unique_handle> threads;
vector<HANDLE> handles;
for (int i = 0; i < nthreads; i++) {
long long start = i * chunk;
long long end = i == nthreads - 1? size : ((long long)i + 1) * chunk;
auto& d = tdata[i];
d.start = start;
d.end = end;
d.counters = counters + i;
d.data = data;
wil::unique_handle hThread(::CreateThread(nullptr, 0, [](auto param) ->
DWORD {
auto d = (ThreadData*)param;
auto start = d->start, end = d->end;
auto counters = d->counters;
auto data = d->data;
for (; start < end; ++start)
if (data[start] % 2 == 0)
++(*counters);
return 0;
}, tdata.get() + i, 0, nullptr));
handles.push_back(hThread.get());
threads.push_back(move(hThread));
}
::WaitForMultipleObjects(nthreads, handles.data(), TRUE, INFINITE);
long long sum = 0;
for (int i = 0; i < nthreads; i++)
sum += counters[i];
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
CountEvenNumbers1函数接受一个指向数据的指针、数据大小以及用于划分数据数组的线程数量作为参数。接着,它会分配counters_buffer,这是每个线程用来递增其指定单元格的缓冲区。然后,会分配一个ThreadData数组(tdata),这样每个线程都能接收各自的迭代参数。接下来,创建两个向量对象来保存线程句柄。一个向量将线程句柄保存为wil::unique_handle类型,这样当对象超出作用域时,句柄会自动关闭。第二个向量(handles)将句柄保存为普通的HANDLE实例,以便可以直接将其传递给WaitForMultipleObjects函数。
此外,还会计算数据块的大小。
现在,开始一个循环,为每个线程准备数据,并调用CreateThread函数启动线程。数据分块的方式与第5章中计算质数的应用程序几乎相同。我们仔细看一下线程中的循环:
for (; start < end; ++start)
if (data[start] % 2 == 0)
++(*counters);
2
3
对于每个偶数,counters指针所指向的内容会递增1。请注意,这里不存在数据竞争问题——每个线程都有自己的单元格,所以最终结果应该是正确的。这段代码的问题在于,当某个线程写入单个计数值时,会写入一整个缓存行,这会使其他处理器上查看该内存的缓存失效,迫使它们再次从主内存读取数据来刷新缓存,而我们知道从主内存读取数据的速度很慢。这种情况被称为伪共享(false sharing)。
另一种方法是,至少不要频繁地写入与其他线程共享缓存行的单元格。下面是CountEvenNumbers2函数中线程块内的代码,该函数在其他方面与CountEvenNumbers1函数相同:
auto d = (ThreadData*)param;
auto start = d->start, end = d->end;
auto data = d->data;
size_t count = 0;
for (; start < end; ++start)
if (data[start] % 2 == 0)
count++;
*(d->counters) = count;
return 0;
}, tdata.get() + i, 0, nullptr));
2
3
4
5
6
7
8
9
10
11
12
主要的区别在于,将计数保存在一个局部变量(count)中,并且仅在循环结束时,才将结果写入到结果数组的单元格中。由于count位于线程的栈上,而栈的大小至少为4KB,所以它不可能与其他线程中的count变量位于同一个缓存行上。这大大提高了性能。当然,一般来说,使用局部变量可能比间接访问内存更快,因为编译器更容易将这个变量缓存到寄存器中。但真正的影响在于避免了线程之间共享缓存行。
主函数使用不同数量的线程对这两种实现方式进行测试,如下所示:
const long long size = (1LL << 32) - 1; // just a large number
cout << "Initializing data..." << endl;
auto data = make_unique<int[]>(size);
for (long long i = 0; i < size; i++)
data[i] = (unsigned)i + 1;
auto processors = min(8, ::GetActiveProcessorCount(ALL_PROCESSOR_GROUPS));
cout << "Option 1" << endl;
for (WORD i = 1; i <= processors; ++i) {
auto start = ::GetTickCount64();
auto count = CountEvenNumbers1(data.get(), size, i);
auto end = ::GetTickCount64();
auto duration = end - start;
cout << setw(2) << i << " threads " << "count: " << count << " time: "
<< duration << " msec" << endl;
}
cout << endl << "Option 2" << endl;
for (WORD i = 1; i <= processors; ++i) {
auto start = ::GetTickCount64();
auto count = CountEvenNumbers2(data.get(), size, i);
auto end = ::GetTickCount64();
auto duration = end - start;
cout << setw(2) << i << " threads " << "count: " << count << " time: "
<< duration << " msec" << endl;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
你必须将此程序作为64位进程运行,因为它分配了大约16GB的内存。
该函数最多使用8个线程(只是为了限制运行时间)。在一个运行良好的程序中,由于不需要也没有使用同步机制,我们预期性能会有近乎线性的提升。
但是,在存在伪共享问题的版本(第一种实现方式)中,增加线程带来的性能提升并不明显,而且在某些线程数量下,性能反而会变差:
Initializing data...
Option 1
1 threads count: 2147483647 time: 4843 msec
2 threads count: 2147483647 time: 3391 msec
3 threads count: 2147483647 time: 2468 msec
4 threads count: 2147483647 time: 2125 msec
5 threads count: 2147483647 time: 2453 msec
6 threads count: 2147483647 time: 1906 msec
7 threads count: 2147483647 time: 2109 msec
8 threads count: 2147483647 time: 2532 msec
Option 2
1 threads count: 2147483647 time: 4046 msec
2 threads count: 2147483647 time: 2313 msec
3 threads count: 2147483647 time: 1625 msec
4 threads count: 2147483647 time: 1328 msec
5 threads count: 2147483647 time: 1062 msec
6 threads count: 2147483647 time: 953 msec
7 threads count: 2147483647 time: 859 msec
8 threads count: 2147483647 time: 855 msec
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
注意,在存在伪共享问题的选项(1)中,在某些情况下,增加线程会降低性能。而在优化后的选项(2)中,性能则持续提升。
# 等待链遍历
在第7章和第8章中,我们介绍了各种用于同步线程活动的同步原语。同步的一个潜在问题是可能会发生死锁。如果在一个较为复杂的应用程序中发生死锁,很难发现死锁发生的位置。使用调试器的一些技术可以帮助定位这类死锁。在本节中,我们将介绍一种编程技术——等待链遍历(Wait Chain Traversal,WCT),它可以识别多种死锁情况。
WCTAPI提供了从感兴趣的线程开始遍历等待链的功能。等待链包含一个由线程和对象交替组成的序列。链中的每个线程都在等待它后面的对象,而这个对象由链中的下一个线程所拥有,依此类推。例如,一个线程可能是临界区(Critical Section)的所有者,并且在等待一个互斥锁(Mutex),而这个互斥锁由另一个线程所拥有——这就是一个等待链的例子。
等待链分析能够跟踪涉及以下对象的链:
- 临界区(Critical sections)
- 互斥锁(Mutexes,包括跨进程的互斥锁)
- 异步本地过程调用(Asynchronous Local Procedure Calls,ALPC)——Windows组件使用的内部进程间通信机制
SendMessage——SendMessageAPI是同步的,如果从不是窗口所有者的线程调用,会导致该线程阻塞- 对线程和进程的等待操作
- 组件对象模型(Component Object Model,COM)跨单元调用(有关COM的更多信息,请参见第18章)
- 套接字(Sockets)和简单消息块(Simple Message Block,SMB)操作
要开始等待链分析,必须使用OpenThreadWaitChainSession函数打开一个WCT会话句柄:
HWCT OpenThreadWaitChainSession (
_In_ DWORD Flags,
_In_opt_ PWAITCHAINCALLBACK callback);
2
3
该函数为WCT打开一个会话,并指定该会话是同步还是异步的。将Flags指定为0会设置一个同步会话,这意味着执行分析的线程会被阻塞,直到分析完成。指定WCT_ASYNC_OPEN_FLAG(值为1)表示一个异步会话,在这种情况下,callback参数应该指向一个在分析完成时被调用的函数。如果成功,OpenThreadWaitChainSession函数会返回一个不透明的WCT会话句柄;否则,返回NULL。
我们将使用更简单的同步会话,并在后面描述异步会话的差异。
一旦获得了WCT句柄,就可以使用GetThreadWaitChain函数对特定线程进行等待链分析:
BOOL GetThreadWaitChain (
_In_ HWCT WctHandle,
_In_opt_ DWORD_PTR Context,
_In_ DWORD Flags,
_In_ DWORD ThreadId,
_Inout_ LPDWORD NodeCount,
_Out_writes_(*NodeCount) PWAITCHAIN_NODE_INFO NodeInfoArray,
_Out_ LPBOOL IsCycle);
2
3
4
5
6
7
8
WctHandle是从OpenThreadWaitChainSession函数获得的句柄。Context是一个可选值,如果是异步会话,它会原样传递给OpenThreadWaitChainSession函数提供的回调函数。Flags用于指定应考虑哪些跨进程情况,具体说明见表10-1。
表10-1:GetThreadWaitChain函数的标志位
| 标志位 | 描述 |
|---|---|
WCT_OUT_OF_PROC_FLAG (1) | 如果没有这个标志位,则不会尝试进行跨进程分析 |
WCT_OUT_OF_PROC_COM_FLAG (2) | 进行COM分析时必需 |
WCT_OUT_OF_PROC_CS_FLAG (4) | 进行临界区分析时必需 |
WCT_NETWORK_IO_FLAG (8) | 进行套接字/SMB分析时必需 |
WCTP_GETINFO_ALL_FLAGS | 组合了上述所有标志位 |
ThreadId是开始等待链分析的线程ID。如果该线程属于一个具有更高完整性级别的进程(有关更多信息,请参见第16章),分析可能会失败。以管理员权限运行并启用调试权限有助于访问此类进程。
NodeCount指向函数愿意获取的分析节点数量。返回时,它指定实际写入的节点数量。最大分析深度(即可以返回的最大节点数)由WCT_MAX_NODE_COUNT定义(当前定义为16)。NodeInfoArray是节点对象的输出数组。最后一个输出参数IsCycle用于指示分析中是否存在循环,如果存在死锁,则返回TRUE。
每个分析节点的类型为WAITCHAIN_NODE_INFO,定义如下:
typedef struct _WAITCHAIN_NODE_INFO {
WCT_OBJECT_TYPE ObjectType;
WCT_OBJECT_STATUS ObjectStatus;
union {
struct {
WCHAR ObjectName[WCT_OBJNAME_LENGTH];
LARGE_INTEGER Timeout; // Not implemented
BOOL Alertable; // Not implemented
} LockObject;
struct {
DWORD ProcessId;
DWORD ThreadId;
DWORD WaitTime;
DWORD ContextSwitches;
} ThreadObject;
};
} WAITCHAIN_NODE_INFO, *PWAITCHAIN_NODE_INFO;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
每个节点代表链中的一个对象。链总是以一个线程对象开始,如果该线程在等待某个对象,则接着是一个对象,然后是拥有该对象的线程,依此类推。
ObjectType和ObjectStatus始终有效。它们的定义如下:
typedef enum _WCT_OBJECT_TYPE {
WctCriticalSectionType = 1,
WctSendMessageType,
WctMutexType,
WctAlpcType,
WctComType,
WctThreadWaitType,
WctProcessWaitType,
WctThreadType,
WctComActivationType,
WctUnknownType,
WctSocketIoType,
WctSmbIoType,
WctMaxType
} WCT_OBJECT_TYPE;
typedef enum _WCT_OBJECT_STATUS {
WctStatusNoAccess = 1, // ACCESS_DENIED for this object
WctStatusRunning, // Thread status
WctStatusBlocked, // Thread status
WctStatusPidOnly, // Thread status
WctStatusPidOnlyRpcss, // Thread status
WctStatusOwned, // Dispatcher object status
WctStatusNotOwned, // Dispatcher object status
WctStatusAbandoned, // Dispatcher object status
WctStatusUnknown, // All objects
WctStatusError, // All objects
WctStatusMax
} WCT_OBJECT_STATUS;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
ObjectType指示当前节点代表的对象类型。如果是线程(WctThreadType),则匿名联合中的ThreadObject部分会提供更多信息:线程ID、该线程所属进程的ID、线程等待的时间以及发生的上下文切换次数。
如果对象类型不是线程,它可能是一个锁对象(如临界区或互斥锁),或者其他类型的对象(如SendMessage调用或COM对象)。如果是锁对象,则联合中的LockObject部分有效,并提供对象的名称(如果有)。
ObjectStatus根据上述WCT_OBJECT_STATUS枚举定义,指示节点所描述对象的状态。
此时,剩下要做的就是遍历返回的节点数组,利用这些信息进行某种形式的分析。
最后,当不再需要WCT时,必须使用CloseThreadWaitChainSession函数关闭会话:
VOID CloseThreadWaitChainSession(_In_ HWCT WctHandle);
# 死锁检测应用程序
有了WCT提供的信息,构建一个能够识别死锁的工具并不困难。DeadlockDetector项目正是这样做的。图10-7展示了该应用程序启动时的窗口。
 图10-7:启动时的死锁检测器
图10-7:启动时的死锁检测器
“进程”(Processes)组合框允许选择要分析的进程。点击“检测死锁”(Detect Deadlocks)会枚举所选进程中的所有线程,然后对进程中的每个线程执行等待链分析,并在树形视图中显示结果,其中每个根节点代表一个线程。图10-8展示了该应用程序使用其中一个示例应用程序“SimpleDeadlock1”检测死锁的情况。
图10-8:死锁检测器检测到互斥锁死锁

该应用程序首先使用Toolhelp函数枚举进程,就像我们多次做过的那样,所以这里我不再重复代码。然后,将结果填充到组合框中。
一旦用户点击“检测死锁”,消息处理程序会首先打开一个WCT(等待链跟踪,Wait Chain Traversal)会话以进行同步分析:
LRESULT CMainDlg::OnDetect(WORD, WORD wID, HWND, BOOL&) {
auto hWct = ::OpenThreadWaitChainSession(0, nullptr);
if (hWct == nullptr) {
AtlMessageBox(*this, L"Failed to open WCT session", IDR_MAINFRAME, MB_ICONERROR);
return 0;
}
2
3
4
5
6
然后,从组合框中所选项目中提取所选进程ID,并调用函数枚举该进程中的线程:
auto pid = (DWORD)m_ProcCombo.GetItemData(m_ProcCombo.GetCurSel());
auto threads = EnumThreads(pid);
2
线程枚举函数返回一个vector<DWORD>,即进程中所有线程ID的向量。用于线程枚举的代码与本章前面“线程枚举”部分使用的代码非常相似。
此时,我们需要对所有线程ID开始一个循环,并对每个线程执行分析:
m_Tree.DeleteAllItems();
int failures = 0;
for (auto& tid : threads) {
if (!DoWaitChain(hWct, tid))
failures++;
}
if (failures == threads.size()) {
AtlMessageBox(*this, L"Failed to analyze wait chain. (try running elevated)",
IDR_MAINFRAME, MB_ICONEXCLAMATION);
}
::CloseThreadWaitChainSession(hWct);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果所有线程的分析都失败,这意味着无法访问目标进程,并会显示相应的错误消息。DoWaitChain函数启动对特定线程ID的分析:
bool CMainDlg::DoWaitChain(HWCT hWct, DWORD tid) {
WAITCHAIN_NODE_INFO nodes[WCT_MAX_NODE_COUNT];
DWORD nodeCount = WCT_MAX_NODE_COUNT;
BOOL cycle;
auto success = ::GetThreadWaitChain(hWct, 0, WCTP_GETINFO_ALL_FLAGS, tid,
&nodeCount, nodes, &cycle);
if (success) {
ParseThreadNodes(nodes, nodeCount, cycle);
}
return success;
}
2
3
4
5
6
7
8
9
10
11
12
该函数在栈上为节点分配最大尺寸的数组,然后将nodeCount初始化为最大值。接下来,调用GetThreadWaitChain进行实际分析。如果成功,通过调用ParseThreadNodes处理返回的节点链。GetThreadWaitChain为什么会失败呢?除了前面提到的原因(访问被拒绝),还有可能是相关线程已经退出,因为线程枚举是基于当前正在执行的线程的快照,在此期间部分线程有可能终止。当然,相反的情况也可能发生——进程中可能创建了新线程,但当前未被分析。通常这不是大问题,因为新线程不太可能导致问题。无论如何,可以重新枚举线程并重复分析。
ParseThreadNodes首先定义对象类型和状态类型的文本表示:
void CMainDlg::ParseThreadNodes(const WAITCHAIN_NODE_INFO* nodes, DWORD count,
bool cycle) {
static PCWSTR objectTypes[] = {
L"Critical Section",
L"Send Message",
L"Mutex",
L"ALPC",
L"COM",
L"Thread Wait",
L"Process Wait",
L"Thread",
L"COM Activation",
L"Unknown",
L"Socket",
L"SMB",
};
static PCWSTR statusTypes[] = {
L"No Access",
L"Running",
L"Blocked",
L"PID only",
L"PID only RPCSS",
L"Owned",
L"Not Owned",
L"Abandoned",
L"Unknown",
L"Error"
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
然后,开始对实际返回的节点进行循环,处理每个对象,并将其信息作为子节点添加到树中。使用switch语句区分三种对象类型:线程、锁对象和其他所有对象。对于每种类型,提取可用信息并放入树中:
HTREEITEM hCurrentNode = TVI_ROOT;
CString text;
for (DWORD i = 0; i < count; i++) {
auto& node = nodes[i];
auto type = node.ObjectType;
auto status = node.ObjectStatus;
switch (type) {
case WctThreadType:
text.Format(L"Thread %u (PID: %u) Wait: %u (%s)",
node.ThreadObject.ThreadId, node.ThreadObject.ProcessId,
node.ThreadObject.WaitTime, statusTypes[status - 1]);
break;
case WctCriticalSectionType:
case WctMutexType:
case WctThreadWaitType: case WctProcessWaitType:
// 可等待对象
text.Format(L"%s (%s) Name: %s",
objectTypes[type - 1], statusTypes[status - 1],
node.LockObject.ObjectName);
break;
default:
// 其他对象
text.Format(L"%s (%s)", objectTypes[type - 1],
statusTypes[node.ObjectStatus - 1]);
break;
}
auto hOld = hCurrentNode;
hCurrentNode = m_Tree.InsertItem(text, hCurrentNode, TVI_LAST);
m_Tree.Expand(hOld, TVE_EXPAND);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
最后,如果存在循环(即死锁),则添加另一个文本为“Deadlock!”的叶节点:
if (cycle) {
m_Tree.InsertItem(L"Deadlock!", hCurrentNode, TVI_LAST);
m_Tree.Expand(hCurrentNode, TVE_EXPAND);
}
2
3
4
还有最后一个值得一提的细节。对于COM分析,需要进行特殊注册,以便将COM基础结构连接到WCT。在OnInitDialog中使用以下代码进行该连接:
auto comLib = ::GetModuleHandle(L"ole32");
if (comLib) {
::RegisterWaitChainCOMCallback(
(PCOGETCALLSTATE)::GetProcAddress(comLib, "CoGetCallState"),
(PCOGETACTIVATIONSTATE)::GetProcAddress(comLib, "CoGetActivationState"));
}
2
3
4
5
6
# 异步WCT会话
如果会话配置为异步,提供给OpenThreadWaitChainSession的回调函数必须具有以下原型:
typedef VOID (CALLBACK *PWAITCHAINCALLBACK) (
HWCT WctHandle,
DWORD_PTR Context,
DWORD CallbackStatus,
LPDWORD NodeCount,
PWAITCHAIN_NODE_INFO NodeInfoArray,
LPBOOL IsCycle);
2
3
4
5
6
7
对OpenThreadWaitChainSession的调用始终返回FALSE,但如果GetLastError返回ERROR_IO_PENDING,这意味着调用成功在WCT管理的线程上启动了分析。分析完成后,会使用结果调用回调函数。大多数参数与OpenThreadWaitChainSession的参数类似,除了CallbackStatus,它指示分析是否成功或失败的原因。ERROR_SUCCESS(0)表示成功,失败原因有多种。最常见的失败原因是ERROR_ACCESS_DENIED,如前所述,通过以管理员权限运行并启用“调试”(Debug)权限可以避免该问题。
| DeadlockDetector项目在DeadlockDetector.cpp中包含一个启用“调试”权限的函数(第3章也使用了这样的函数)。 |
|---|
# 用户模式调度(User Mode Scheduling)
第6章详细讨论了调度。内核调度器负责确定哪个线程应该在哪个处理器上运行,并在需要时进行上下文切换。在某些极端情况下,这种方式可能不够高效。在某些场景中,能够在用户模式而非内核模式下控制调度会更有优势。这些决策不应需要从用户模式切换到内核模式,因为这种切换成本不低。
在过去(并且仍然受支持),Windows提供了纤程(fibers),试图提供一种用户模式调度机制。然而,内核并不识别纤程,这导致了许多问题,例如线程局部存储(Thread Local Storage)无法正确传播、线程环境块(Thread Environment Block)结构与当前执行的纤程不一致等。如今不应再使用纤程,因此本书不会对其进行描述。
从Windows 7和Windows 2008 R2开始,Windows支持一种名为用户模式调度(User Mode Scheduling,UMS)的替代机制,其中用户模式线程成为某种调度器,可以在用户模式下调度线程,而无需进行用户模式/内核模式转换。内核知道这种机制,所以UMS不存在纤程的缺点,因为它使用的是真正的线程,而不是共享线程的纤程。
不幸的是,构建一个使用UMS的实际系统绝非易事,所以本书不会深入描述UMS。相反,自2010年起,微软提供了一个名为并发运行时(Concurrency Runtime,缩写为Concrt,发音为“concert”)的库,它在幕后使用UMS,以便在需要并发执行时高效地使用线程。
第3章的“质数计数器”(Primes Counter)应用程序被用作示例。在该应用程序中,我们创建了多个线程(这是应用程序的一个参数),并将计算质数的工作分配给这些线程,让每个线程计算其负责部分的质数数量,最后汇总所有线程的结果。
我们面临的一个问题是,很难公平地分配工作,使每个线程的工作量大致相同。否则,提前完成的线程会导致CPU空闲。我们试图通过增加线程数量来弥补,但这在内存和上下文切换方面也有成本。
在某些情况下,与在应用程序中进行工作分区、线程创建和管理的复杂操作相比,并发运行时使用非常简单的代码就能提供很好的解决方案。
第3章的应用程序在本章的项目中也有,增加了使用concrt计算一定范围内质数数量的功能,与之前的功能相同。
首先需要包含一个头文件:
#include <ppl.h>
ppl.h提供了一些便捷函数,我们稍后会使用其中一个。它包含了concrt的“核心”文件concrt.h。
在main函数中,完成现有计算代码后,我们这样使用concrt:
count = 0;
concurrency::parallel_for(from, to + 1, [&count](int n) {
if (IsPrime(n))
::InterlockedIncrement((unsigned*)&count);
});
auto end = ::GetTickCount64();
printf("Using concrt: Primes: %d, Elapsed: %u msec\n", count, (ULONG)(end - start));
2
3
4
5
6
7
8
parallel_for函数如其名所示:它会自动并行化一个for循环。你只需指定初始值和最终值加一,以及每次迭代要运行的函数(这里以lambda表达式提供)。这段代码会以某种方式并发运行。注意,这里没有说明要创建多少个线程或如何管理它们。唯一需要注意的是对共享变量count的同步操作。在原始的分区方案中,这是不需要的,因为每个线程都在增加自己的计数器。
这是在我的系统上的一个示例运行结果:
C:\>PrimesCounter.exe 3 20000000 16
Thread 1 created (3 to 1250001). TID=42576
Thread 2 created (1250002 to 2500000). TID=30636
Thread 3 created (2500001 to 3749999). TID=16944
...
Thread 15 created (17499989 to 18749987). TID=32580
Thread 16 created (18749988 to 20000000). TID=55440
Thread 1 Count: 96468. Execution time: 515 msec
Thread 2 Count: 86603. Execution time: 796 msec
...
Thread 15 Count: 74745. Execution time: 1906 msec
Thread 16 Count: 74475. Execution time: 1906 msec
Total primes: 1270606. Elapsed: 1985 msec
Using concrt: Primes: 1270606, Elapsed: 1640 msec
2
3
4
5
6
7
8
9
10
11
12
13
14
无论我为这个问题分配多少个线程,concrt版本总是比手动分区的版本表现更好。而且它只用了很少的代码,效率也更高——它创建的线程数量永远不会超过系统中的逻辑处理器数量。
SQL Server使用UMS来提高性能,因为它是一个高度多线程的服务器应用程序。
# Init Once初始化
许多应用程序中一个常见的模式是使用单例对象(singleton object)。在某些观点中,这是一种反模式,但本书不讨论这个争议。事实是,单例对象很有用,有时甚至是必要的。单例对象的一个常见要求是只初始化一次。在多线程应用程序中,多个线程可能在初始时同时访问单例对象,但单例对象必须只初始化一次。如何实现这一点呢?
有几种众所周知的算法,如果正确实现,就可以完成这项工作。这不是一本通用的算法书籍,所以这里不描述这些算法。不过,Windows API提供了一种内置方式来调用一个函数,并保证该函数只被调用一次。
在C++ 11及更高版本中,函数中的静态变量保证只初始化一次。此外,C++ 11有
std::call_once函数,它动态地实现了相同的功能。
一次性初始化(One-Time Initializing)API 从 Windows 8 和 Server 2012 开始可用。最简单的版本是同步初始化,这里将对其进行介绍。有关异步版本,请查阅官方文档。
INIT_ONCE 类型的变量用于控制一次性初始化。它必须以静态方式(全局变量或静态变量)进行初始化,这样才能确保其初始化只执行一次。初始化它的最简单方法是将其值设置为 INIT_ONCE_STATIC_INIT,如下所示:
INIT_ONCE init = INIT_ONCE_STATIC_INIT;
INIT_ONCE 只是一个不透明指针的包装器。另一种方法是使用 InitOnceInitialize 对其进行初始化:
VOID InitOnceInitialize(_Out_ PINIT_ONCE InitOnce);
然后,在需要进行初始化时,调用 InitOnceExecuteOnce:
BOOL InitOnceExecuteOnce(
_Inout_ PINIT_ONCE InitOnce,
_In_ __callback PINIT_ONCE_FN InitFn,
_Inout_opt_ PVOID Parameter,
_Outptr_opt_result_maybenull_ LPVOID* Context
);
2
3
4
5
6
InitOnce 参数是之前初始化的变量,用于控制此次初始化。InitFn 是确保只会被调用一次的函数。Parameter 是一个可选的上下文值,会被传递到初始化函数中,而 Context 是初始化函数的可选结果。该函数本身必须具有以下原型:
BOOL (WINAPI *PINIT_ONCE_FN) (
_Inout_ PINIT_ONCE InitOnce,
_Inout_opt_ PVOID Parameter,
_Outptr_opt_result_maybenull_ PVOID *Context
);
2
3
4
5
如果回调函数返回 TRUE,则认为初始化成功。否则,认为初始化失败,InitOnceExecuteOnce 将返回 FALSE。Parameter 是从 InitOnceExecuteOnce 传入的值。上下文可以返回一些值,但最右边的 INIT_ONCE_CTX_RESERVED_BITS(2 位)必须清零,这意味着如果它是一个地址,必须按 4 字节对齐。
# 调试多线程应用程序
编写正确且高效的多线程应用程序并非易事。一旦出现错误(错误很可能会出现),调试就变得至关重要,而且这比调试单线程应用程序要困难得多。涵盖调试的所有方面超出了本书的范围。相反,我想提及一些 Visual Studio 中可用的技巧和辅助工具,这些对多线程应用程序尤其有用。
| 调试是一个庞大的主题,Visual Studio 也不是唯一的调试器。实际上,在生产环境中,会使用其他底层且占用资源少的调试器,比如 WinDbg。本节仅介绍 Visual Studio 调试,通常在开发者的工作站上进行。 |
|---|
# 断点
在代码的多线程部分设置断点时,任何线程都可能触发它,并且所有线程都会因此暂停。执行调试器的单步操作会恢复所有线程,而不只是你可能想要隔离的那个线程。隔离某个线程的一种方法是使用“线程”窗口冻结所有其他线程,如图 10-9所示。
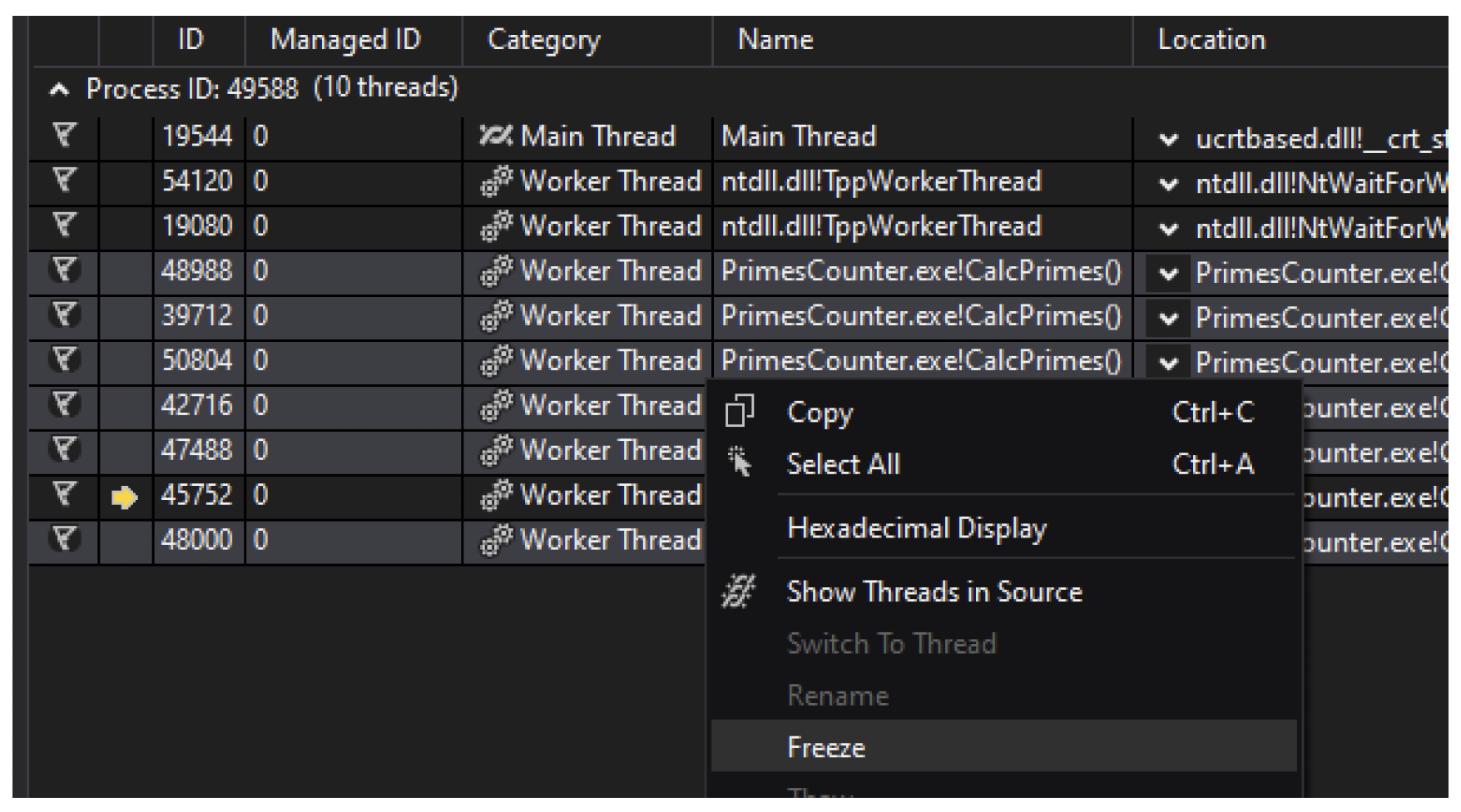 图 10-9:“线程”调试器窗口的上下文菜单选项
图 10-9:“线程”调试器窗口的上下文菜单选项
图 10-9中显示的“在源代码中显示线程”选项,会在断点命中时,在有一个或多个线程所在的源代码位置添加一个线程图标。
断点可以设置条件。其中一个可能的条件是线程 ID 或线程名称,这使你可以仅在感兴趣的特定线程(或多个线程)上中断,如图 10-10 所示。
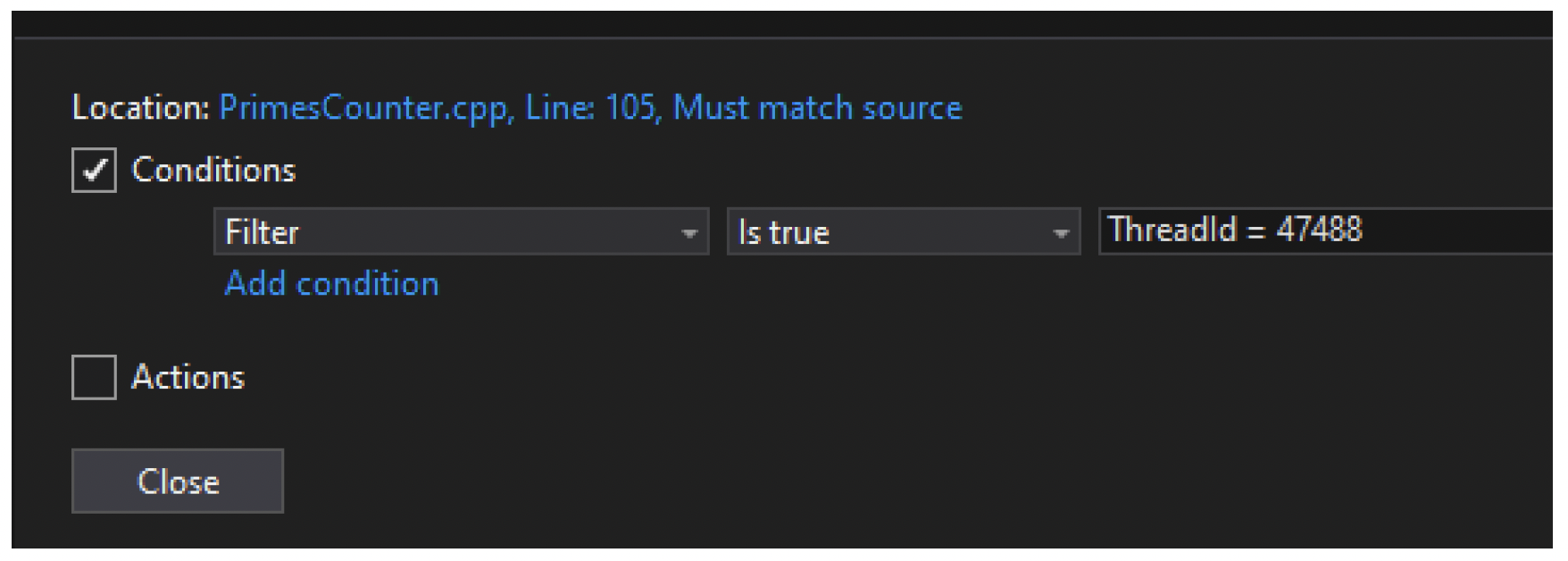 图 10-10:断点线程筛选器
图 10-10:断点线程筛选器
# 并行堆栈
“并行堆栈”窗口(可通过“调试”/“窗口”/“并行堆栈”菜单访问)以图形化方式展示线程是如何从其他线程派生出来的,很好地可视化了进程中正在运行的所有线程,如图 10-11 所示。
 图 10-11:并行堆栈窗口
图 10-11:并行堆栈窗口
# 并行监视
“并行监视”窗口的访问方式与“并行堆栈”窗口类似,它显示了多个运行相同代码的线程所使用的选定变量或表达式,每个线程都有该变量的各自副本,如图 10-12 所示。
 图 10-12:并行监视窗口
图 10-12:并行监视窗口
# 线程名称
第 5 章介绍了线程名称,在 Windows 10 中可以使用 SetThreadDescription 函数设置线程名称。在调试过程中,也可以直接在“线程”窗口中更改线程的名称,这样更便于跟踪特定线程。不过,调试会话结束后,这些名称会被重置,所以最好在代码中对已知线程调用 SetThreadDescription,以便在开始调试时线程名称就已设置好。
# 练习
- 使用
concrt创建一个计算曼德勃罗集(Mandelbrot set)的控制台应用程序。将你的结果与第 5 章的相同练习进行比较。
# 总结
本章介绍了各种与线程相关的主题。在下一章中,我们将不再讨论线程,而是探讨文件和设备的输入/输出操作。