 第11章:文件和设备输入输出
第11章:文件和设备输入输出
# 第11章:文件和设备输入/输出
在前面的章节中,我们以多种方式使用线程来执行受CPU限制的任务。然而,并非所有操作都与CPU相关。有些操作需要与文件或其他设备进行通信,这类操作通常被称为输入/输出(I/O)操作。在I/O操作完成之前,它们并不占用CPU资源,操作完成后,线程代码会利用I/O操作的结果继续进行处理。
在本章中,我们将探讨同步和异步I/O操作,并研究线程如何高效地获取I/O结果以继续处理。
本章内容包括:
- I/O系统
- CreateFile函数
- 同步I/O
- 异步I/O
- I/O完成端口
- I/O取消
- 设备
- 管道和邮槽
- 事务性NTFS
- 文件搜索和枚举
- NTFS流
# I/O系统
I/O系统的主要作用是对物理设备和逻辑设备的访问进行抽象。访问任何文件系统中的文件,与访问串口、USB摄像头或打印机的方式都应有所不同。I/O系统由多个组件构成,部分组件处于用户模式,而大部分组件处于内核模式。图11-1展示了其中最重要的部分。
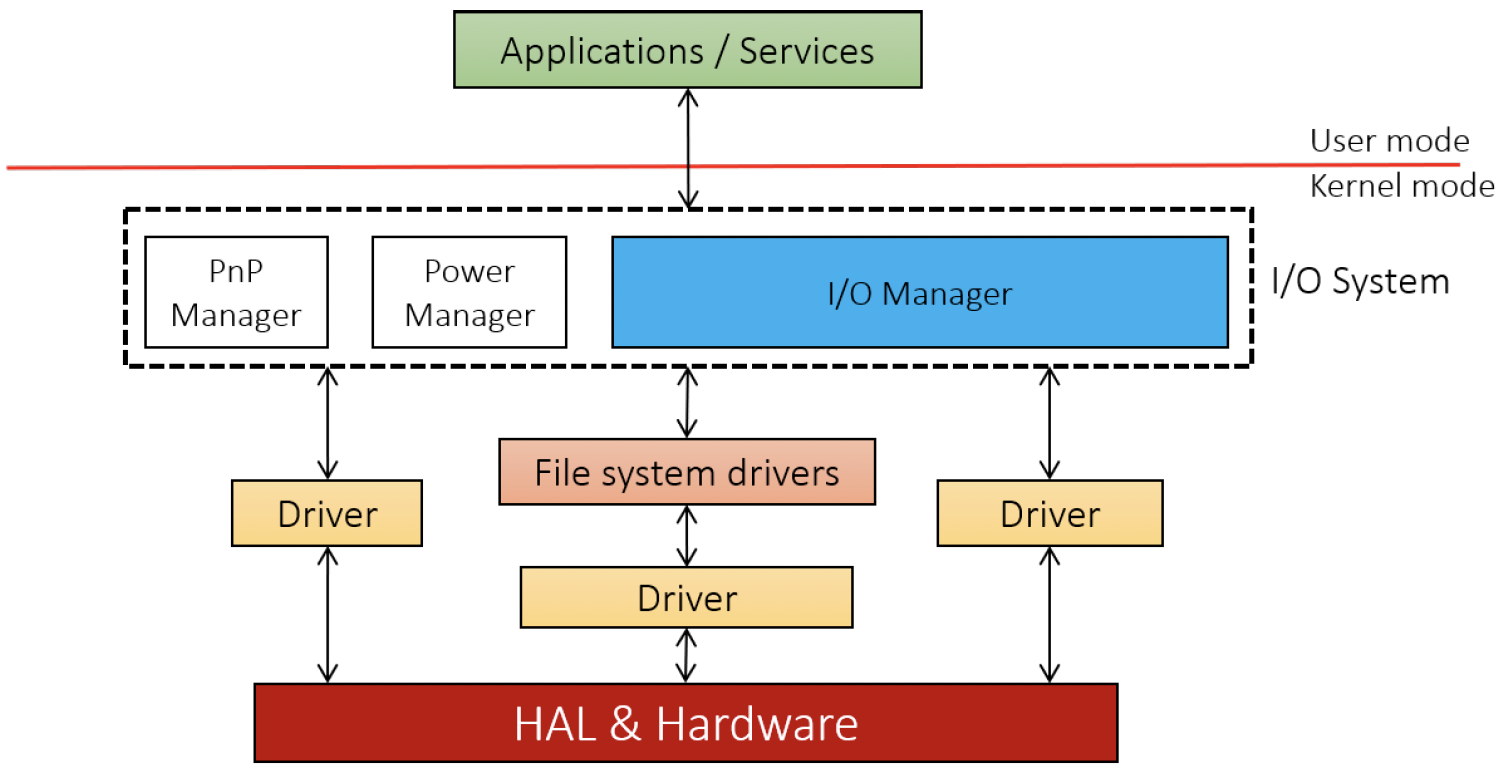 图11-1:I/O系统的重要组成部分
图11-1:I/O系统的重要组成部分
用户模式进程通过各种Windows API调用I/O系统,本章将对这些API进行研究。在内核层面,所有文件和设备操作均由I/O管理器发起。像读取或写入这样的请求,会通过创建一个名为I/O请求包(I/O Request Packet,IRP)的内核结构来处理,填充请求的详细信息后,再将其传递给相应的设备驱动程序。对于实际文件,该请求会被传递到文件系统驱动程序,比如NTFS。如图11-2所示,这个过程与普通系统调用在本质上并无差异。
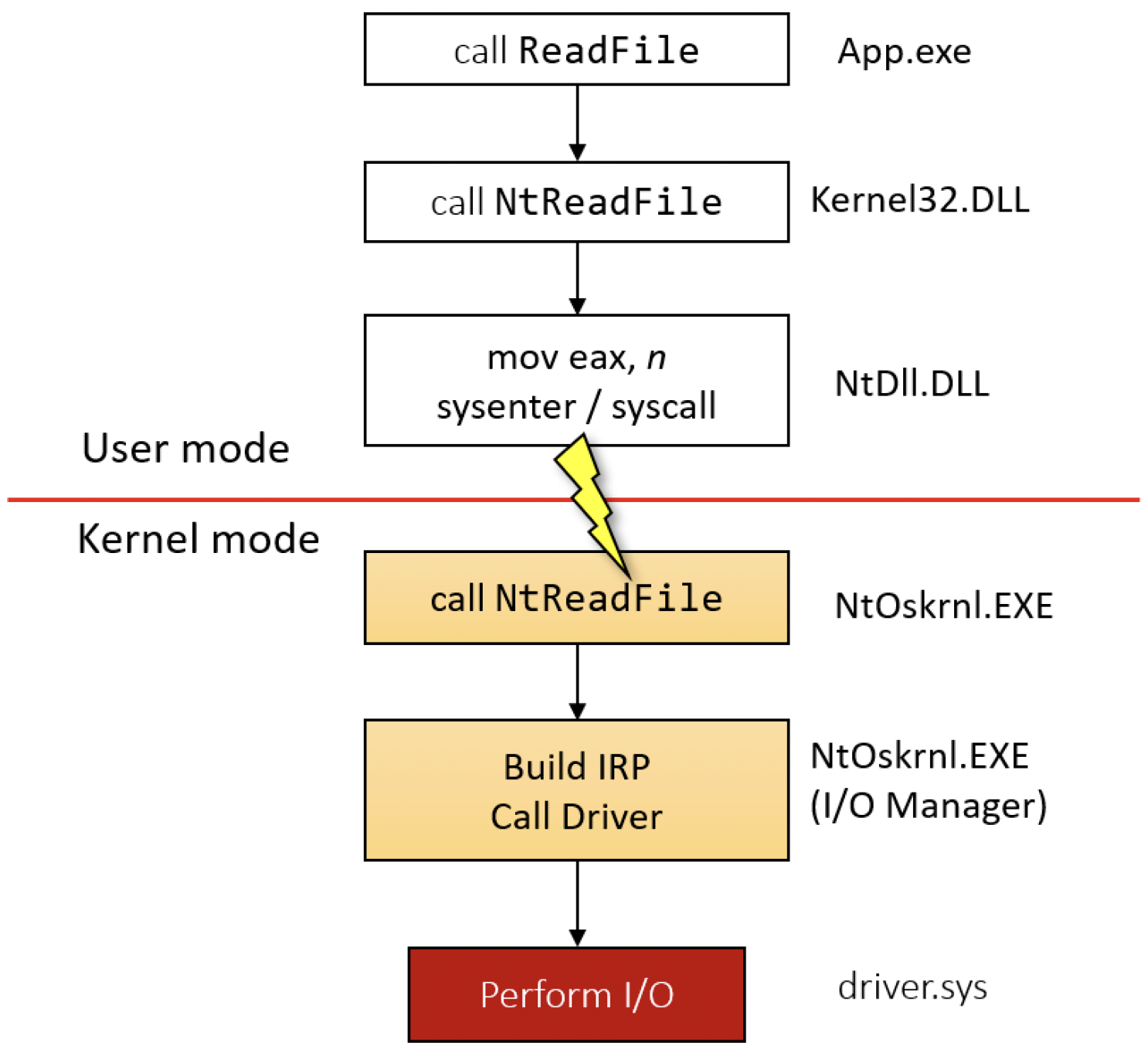 图11-2:读取I/O操作的调用流程
图11-2:读取I/O操作的调用流程
就内核而言,I/O操作始终是异步的。这意味着驱动程序应启动操作并尽快返回,以便调用线程能够重新获得控制权。不过,原始调用者可以选择进行同步调用。在这种情况下,I/O管理器会代表调用者等待,直到操作完成。从客户端的角度来看,这种灵活性非常实用。
# CreateFile函数
CreateFile函数是进入I/O操作领域的入口。函数名本身可能会让人产生误解。CreateFile中的“File”一词是“File Object”(文件对象)的简称,文件对象是内核用于表示与设备连接的抽象概念,无论该设备是否为文件系统中的文件。CreateFile的函数原型如下:
HANDLE CreateFile(
_In_ LPCTSTR lpFileName,
_In_ DWORD dwDesiredAccess,
_In_ DWORD dwShareMode,
_In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes,
_In_ DWORD dwCreationDisposition,
_In_ DWORD dwFlagsAndAttributes,
_In_opt_ HANDLE hTemplateFile
);
2
3
4
5
6
7
8
9
Windows 8和Server 2012添加了一个类似的函数CreateFile2,其定义如下:
typedef struct _CREATEFILE2_EXTENDED_PARAMETERS {
DWORD dwSize;
DWORD dwFileAttributes;
DWORD dwFileFlags;
DWORD dwSecurityQosFlags;
LPSECURITY_ATTRIBUTES lpSecurityAttributes;
HANDLE hTemplateFile;
} CREATEFILE2_EXTENDED_PARAMETERS, *PCREATEFILE2_EXTENDED_PARAMETERS;
HANDLE CreateFile2(
_In_ LPCWSTR lpFileName,
_In_ DWORD dwDesiredAccess,
_In_ DWORD dwShareMode,
_In_ DWORD dwCreationDisposition,
_In_opt_ PCREATEFILE2_EXTENDED_PARAMETERS pCreateExParams
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CreateFile2与CreateFile非常相似,但它既可以在UWP应用程序中使用,也能在桌面应用程序中使用。而CreateFile不能从UWP应用程序中调用。需要注意的是,CreateFile2仅支持Unicode,而CreateFile有常见的CreateFileA和CreateFileW两种变体。CreateFile2还支持一个新标志(FILE_FLAG_OPEN_REQUIRING_OPLOCK),这是CreateFile所不具备的。
| 机会锁(Opportunistic locks,Oplocks)超出了本章的讨论范围。 |
|---|
lpFileName参数指定要创建或打开的文件或设备名称。正如该参数名所示,它不一定是传统意义上的“文件名”。它是指向执行体对象管理器命名空间的符号链接,并附带一些解析规则。表11-1展示了一些常见的文件名模式,其中部分模式将在后续段落中进一步阐述。
表11-1:CreateFile常见的文件名参数
| 文件名格式 | 示例 | 描述 |
|---|---|---|
| x:\dir1\dir2\file | c:\mydir\myfile.txt | 文件系统中文件/目录的完整路径 |
| ..\dir1\file | ..\mydir\myfile.txt | 相对于文件/目录系统的路径(..表示父目录) |
| dir1\dir2\file | mydir1\mydir2\myfile.txt | 相对于当前目录的文件/目录路径 |
| file | myfile.txt | 当前目录文件系统中的文件 |
| \server\share\dir1\dir2\file | \myserver\myshare\mydir\myfile.txt | 另一台机器共享中的文件/目录 |
| \server\pipe\pipename | \myserver\pipe\mypipe | 命名管道客户端 |
| \server\mailslot\mailslotname | \myserver\mailslot\mymailslot | 邮槽客户端 |
| \.*devicename* | .\kobjexp | 设备符号链接名称 |
| builtin | com1 | 旧的DOS名称会被视为符号链接,而非当前目录中的文件 |
“符号链接”是CreateFile中文件名的基本取值。即使像“c:”这样看似十分“基础”的内容,实际上也是一个符号链接。若要查看这些符号链接,我们可以使用第2章中简要介绍过的Sysinternals的WinObj工具,或者我自己开发的对象资源管理器(Object Explorer)工具。图11-3展示了选中Global??对象目录的WinObj界面。图11-4展示了对象资源管理器中相同的目录(选择“对象”/“对象管理器命名空间”以打开该视图)。选中的目录就是符号链接目录。
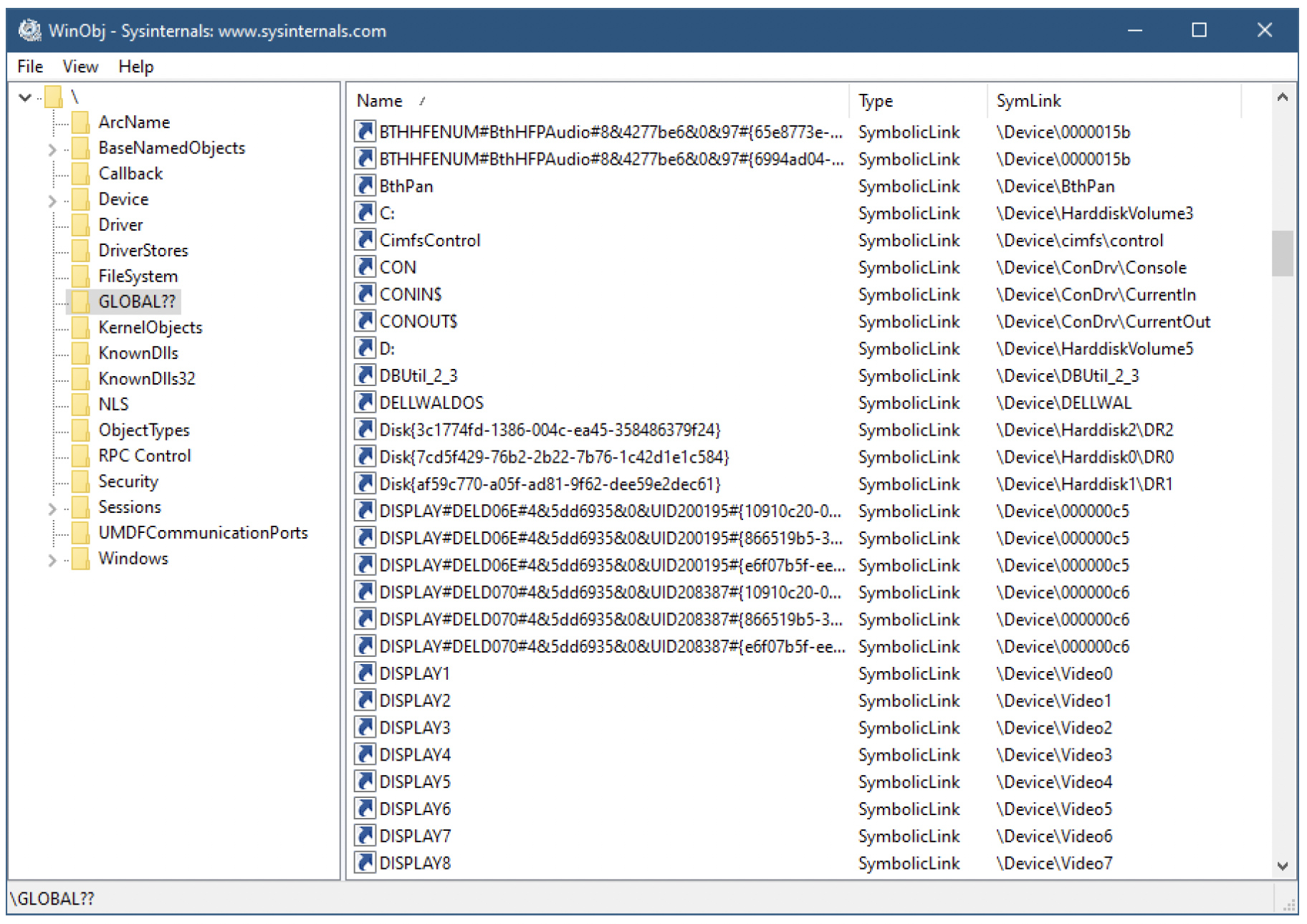 图11-3:WinObj中的符号链接
图11-3:WinObj中的符号链接
 图11-4:对象资源管理器中的符号链接
图11-4:对象资源管理器中的符号链接
列表中的每个名称都是一个符号链接(symbolic link),它是使用前缀“\.\”调用CreateFile函数的候选对象。有些符号链接不需要这个前缀,比如“C:”。请注意,“C:”实际上就是一个符号链接,它指向类似“Device\HarddiskVolume3”的对象,在设备对象管理器目录下可以找到该对象。
有些符号链接看起来很规整,比如“C:”“PhysicalDrive0”“PIPE”等,而其他的则像是一堆带有全局唯一标识符(GUID)的数字组合。这些链接大多用于硬件设备。本章后面的“与设备通信”小节会提供更多详细信息。
接下来,在讨论可以使用该函数访问的一些常见“文件”之前,我们将研究CreateFile函数的其余参数。
dwDesiredAccess参数用于指定访问文件对象所需的访问掩码。在大多数情况下,你会使用一个或多个通用访问权限:GENERIC_READ(用于从文件/设备读取数据)、GENERIC_WRITE(用于向文件/设备写入数据),或者两者都用(GENERIC_READ | GENERIC_WRITE)。如果你只是要访问非常基本的信息,比如文件的时间戳或大小,也可以指定为零。你还可以使用与正在访问的文件或设备相关的更精细的访问掩码。例如,FILE_READ_DATA是用于文件的特定访问掩码,用于请求读取文件内容。然而,读取文件属性需要另一个访问掩码——FILE_READ_ATTRIBUTES。GENERIC_READ作为一个通用访问掩码,会映射到特定的访问掩码,对于文件来说,这些特定访问掩码包括FILE_READ_DATA和FILE_READ_ATTRIBUTES。
无论是否显式指定,SYNCHRONIZE和FILE_READ_ATTRIBUTES访问掩码总是会被请求。
| 有关访问掩码和通用映射的更多信息,请参阅第16章(“安全性”)。 |
|---|
dwShareMode参数指定文件/设备应采用的共享模式打开。这主要用于文件系统中的文件或目录。如果文件/目录未打开,调用方会指定她允许其他CreateFile调用如何共享该对象。例如,如果初始调用方允许以只读方式共享,后续调用方就不能以GENERIC_WRITE访问权限打开该对象。如果在另一个CreateFile调用针对同一对象进入时,文件/目录已经打开,则共享模式将被忽略。表11-2列出了可能的共享模式。
表11-2:CreateFile的共享模式
| 共享模式 | 描述 |
|---|---|
| 0 | 对象以独占访问方式打开。其他CreateFile调用都无法成功。 |
FILE_SHARE_READ | 允许后续调用方以GENERIC_READ访问权限打开对象。 |
FILE_SHARE_WRITE | 允许后续调用方以GENERIC_WRITE访问权限打开对象。 |
FILE_SHARE_DELETE | 允许后续调用方以DELETE访问权限打开对象。当所有句柄都关闭时,文件将被删除。 |
| 上述模式的组合 | 组合每个标志的含义 |
下一个参数lpSecurityAttributes是第2章讨论过的标准SECURITY_ATTRRIBUTES。
dwCreationDisposition参数指定如何创建或打开文件系统对象(文件和目录)。对于其他设备,该标志应始终设置为OPEN_EXISTING。可能的值及其含义在表11-3中进行了描述。
表11-3:CreateFile的创建方式
| 值 | 文件存在时 | 文件不存在时 |
|---|---|---|
CREATE_NEW (1) | CreateFile失败 | 创建一个新文件 |
CREATE_ALWAYS (2) | 覆盖现有文件 | 创建一个新文件 |
OPEN_EXISTING (3) | 打开文件 | CreateFile失败 |
OPEN_ALWAYS (4) | 打开文件(不覆盖) | 创建文件 |
TRUNCATE_EXISTING (5) | 打开文件并将其截断为零大小 | CreateFile失败 |
dwFlagsAndAttributes参数允许设置三个不同的标志/值,这些值可以通过普通的按位或(OR)运算符进行组合:
- 各种影响文件对象创建后要执行的操作的标志(表11-4)
- 如果在文件系统中创建新文件,则为结果文件的文件属性(表11-5)
- 如果还存在
SECURITY_SQOS_PRESENT标志,则为命名管道客户端的服务质量标志。命名管道将在第18章(第2部分)中讨论。
表11-4:dwFlagsAndAttributes的标准标志
标志(FILE_FLAG_*) | 描述 |
|---|---|
WRITE_THROUGH | 强制任何写入操作将数据刷新到磁盘(并写入缓存) |
NO_BUFFERING | 强制操作直接写入磁盘(不使用缓存) |
SEQUENTAIL_SCAN | 向文件系统提示对该文件的典型操作是顺序读取,这可能对性能有积极影响 |
RANDOM_ACCESS | 向文件系统提示预期会对文件进行随机访问 |
DELETE_ON_CLOSE | 指示当文件的最后一个句柄关闭时应删除该文件 |
OVERLAPPED | 打开文件/设备以进行异步操作(请参阅本章后面的内容) |
BACKUP_SEMANTICS | 打开目录句柄而非文件句柄所需的标志。该标志允许具有备份或还原权限的调用方打开任何文件,而不管文件的安全设置如何 |
POSIX_SEMANTICS | 请求文件名查找区分大小写。在Windows的最新版本中,这个标志似乎未被遵循 |
OPEN_REPARSE_POINT | 忽略重解析点(如果有的话)的正常处理,并以正常访问方式打开文件(重解析点超出了本章的范围) |
OPEN_NO_RECALL | 向文件系统提示远程文件不一定会读取到本地存储 |
SESSION_AWARE (Windows 8+) | 以会话感知方式打开设备。这允许会话0打开以访问具有会话感知功能的设备。此标志还需要一个注册表项来启用此检查。必须在HKLM\System\CurrentControlSet\SessionManager\I/O System中将值IoEnableSessionZeroAccessCheck设置为1 |
表11-5:dwFlagsAndAttributes的文件属性
文件属性(FILE_ATTRIBUTE_*) | 描述 |
|---|---|
NORMAL或无 | 普通文件(如果使用,必须不包含以下任何属性) |
HIDDEN | 文件被隐藏 |
ARCHIVE | 文件应存档。它实际上没有效果,但执行文件备份的应用程序将其用作标记 |
ENCRYPTED | 文件内容被加密 |
READONLY | 文件为只读,不能以写入访问权限打开 |
SYSTEM | 文件是系统文件,仅供操作系统(OS)和系统组件使用 |
OFFLINE | 文件的实际存储位置在其他地方。此标志不应随意设置 |
TEMPORARY | 向文件系统和缓存管理器提示该文件用于临时存储。系统会尽量避免将文件数据写入存储,因为预计该文件很快会被删除。与FILE_FLAG_DELETE_ON_CLOSE结合使用效果很好 |
NOT_CONTENT_INDEXED | 文件不会被索引服务索引 |
定义的属性列表比表11-5中显示的更长,但这些额外的属性不能使用CreateFile设置,必须使用不同的应用程序编程接口(API,具体取决于相关问题中的属性)进行设置,本章后面会对此进行描述。
对于文件,谨慎使用与缓存相关的标志(FILE_FLAG_WRITE_THROUGH、FILE_FLAG_NO_BUFFERING、FILE_FLAG_SEQUENTAIL_SCAN、FILE_FLAG_RANDOM_ACCESS)可以提高性能。然而,对于FILE_FLAG_NO_BUFFERING,要使其正常工作有一些要求:
- 读/写访问大小必须是卷扇区大小的倍数。这个大小可以通过调用
GetDiskFreeSpace函数来获取。 - 读/写操作中使用的缓冲区必须在物理扇区大小边界上对齐。对于这类缓冲区,建议使用
VirtualAlloc函数进行分配,因为它总是按页(4KB)对齐(有关VirtualAlloc的更多信息,请参阅第13章),或者使用C运行时的_aligned_malloc函数。物理扇区大小可能与GetDiskFreeSpace提供的逻辑扇区大小不同。要获取物理扇区大小,需要使用IOCTL_STORAGE_QUERY_PROPERTY控制代码对卷进行DeviceIoControl调用(有关DeviceIoControl的更多信息,请参阅本章后面的内容)。
如果使用缓存(通常情况),可以调用FlushFileBuffers函数强制将数据刷新到文件:
BOOL FlushFileBuffers(_In_ HANDLE hFile);
CreateFile函数的最后一个参数hTemplateFile是一个可选的文件句柄,如果正在创建新文件,则从该句柄复制属性。如果指定了该参数,句柄必须具有GENERIC_READ访问掩码。如果打开现有文件,则会忽略此参数。
CreateFile函数返回创建的文件对象的句柄,如果失败则返回INVALID_HANDLE_VALUE(它是少数几个失败时不返回NULL的创建函数之一)。和往常一样,可以通过GetLastError函数获取更多错误信息。
在以下各节中,我们将研究文件和设备操作的各个方面,并详细阐述本节中描述的一些标志。
# 使用符号链接
如我们所见,CreateFile函数在内部通过解析符号链接来工作。这些链接可以使用QueryDosDevice函数进行查询:
DWORD QueryDosDevice(
_In_opt_ LPCTSTR lpDeviceName,
_Out_ LPTSTR lpTargetPath,
_In_ DWORD ucchMax
);
2
3
4
5
该函数有两种工作模式:如果lpDeviceName不为NULL,函数会查找符号链接并将其目标(如果有)返回到lpTargetPath中。如果lpDeviceName为NULL,它会在lpTargetPath中返回所有符号链接,这些符号链接用'\0'分隔,因此如果需要,可以通过对每个符号链接调用QueryDosDevice函数来进行迭代。在这种情况下,最后一个条目会有一个额外的'\0'来表示列表的结束。该函数返回写入目标缓冲区的字符数,如果函数失败则返回零。如果函数因目标缓冲区太小而失败,GetLastError函数会返回ERROR_INSUFFICIENT_BUFFER。
symlinks应用程序允许使用QueryDosDevice函数查询符号链接。如果没有传入参数,该应用程序会转储所有符号链接及其目标。如果提供了一个参数,该应用程序只会转储名称中包含所提供字符串的那些符号链接。
第一步是分配一个足够大的缓冲区来读取所有符号链接。这是必要的,因为应用程序需要要么转储所有符号链接,要么在其中搜索匹配项。无论哪种方式,都需要读取所有符号链接:
#include <memory>
#include <string>
#include <set>
using namespace std;
int wmain(int argc, wchar_t* argv[]) {
auto size = 1 << 14;
unique_ptr<WCHAR[]> buffer;
for ( ; ; ) {
buffer = make_unique<WCHAR[]>(size);
if (0 == ::QueryDosDevice(nullptr, buffer.get(), size)) {
if (::GetLastError() == ERROR_INSUFFICIENT_BUFFER) {
size *= 2;
continue ;
}
else {
printf("Error: %d\n", ::GetLastError());
return 1;
}
}
else
break ;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
构建一个循环,使用std::make_unique<>分配一个字符数组,然后使用NULL的lpDeviceName调用QueryDosDevice函数以获取所有符号链接。如果缓冲区太小,则将大小加倍并再次尝试。
一旦成功,必须对返回的列表进行迭代,对与提供的命令行参数匹配的每个符号链接(或者对所有符号链接)再次调用QueryDosDevice函数。该应用程序使用std::set(它将元素插入到按元素排序的二叉搜索树中)和一个自定义比较器来对结果按符号链接进行排序,这样比较就不区分大小写(这不是std::wstring的默认行为):
if (argc > 1) {
// convert argument to lowercase
::_wcslwr_s(argv[1], ::wcslen(argv[1]) + 1);
}
auto filter = argc > 1 ? argv[1] : nullptr;
// simplify stored type
using LinkPair = pair<wstring, wstring>;
struct LessNoCase {
bool operator()(const LinkPair& p1, const LinkPair& p2) const {
return ::_wcsicmp(p1.first.c_str(), p2.first.c_str()) < 0;
}
};
// sorted by LessNoCase
set<LinkPair, LessNoCase> links;
WCHAR target[512];
for (auto p = buffer.get(); *p; ) {
wstring name(p);
auto locase(name);
::_wcslwr_s((wchar_t*)locase.data(), locase.size() + 1);
if (filter == nullptr || locase.find(filter) != wstring::npos) {
::QueryDosDevice(name.c_str(), target, _countof(target));
// add pair to results
links.insert({ name, target });
}
// move to next item
p += name.size() + 1;
}
// print results
for (auto& link : links) {
printf("%ws = %ws\n", link.first.c_str(), link.second.c_str());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
以下是一些常见符号链接(symbolic link)的运行示例:
C:\>symlinks.exe c:
C: = \Device\HarddiskVolume3
c:\> symlinks.exe pipe
PIPE = \Device\NamedPipe
c:\>symlinks.exe nul
NUL = \Device\Null
c:\>symlinks con
CimfsControl = \Device\cimfs\control
CON = \Device\ConDrv\Console
CONIN$ = \Device\ConDrv\CurrentIn
CONOUT$ = \Device\ConDrv\CurrentOut
...
PartmgrControl = \Device\PartmgrControl
PciControl = \Device\PciControl
...
UVMLiteController = \Device\UVMLiteController0x1
VolMgrControl = \Device\VolMgrControl
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
与QueryDosDevice功能相反的函数也存在,它允许定义新的符号链接:
BOOL DefineDosDevice(
_In_ DWORD dwFlags,
_In_ LPCTSTR lpDeviceName,
_In_opt_ LPCTSTR lpTargetPath);
2
3
4
lpDeviceName是符号链接的名称,lpTargetPath是链接的目标。例如,进行以下调用会设置一个新的逻辑驱动器,使其指向现有目录:
::DefineDosDevice(0, L"s:", L"c:\\Windows\\System32");
这与Windows内置工具subst.exe的效果相同:
c:>subst s: c:\windows\system32
在进行上述调用之一后,你可以打开文件资源管理器(Explorer),看到新的驱动器像其他任何驱动器一样出现。
然而,回到WinObj或对象资源管理器(Object Explorer),新的符号链接不会出现在全局??对象管理器目录中;这一操作的权限过大。相反,它是与调用进程的令牌相关联的登录会话的一部分。图11-5展示了此类符号链接的存储位置。
| 如果调用者在本地系统(LocalSystem)账户下运行,则该映射会影响全局命名空间。 |
|---|
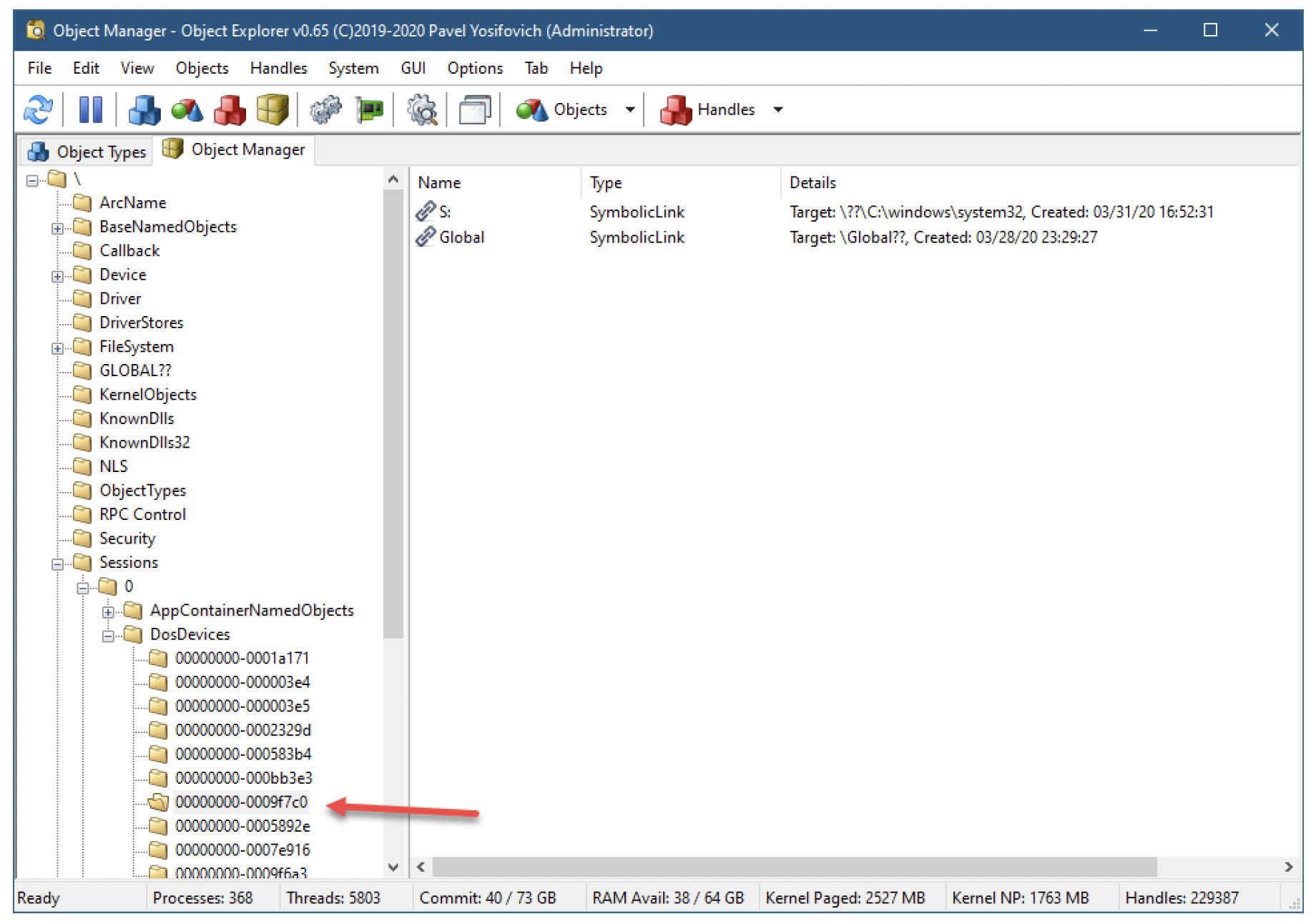
图11-5:使用DefineDosDevice创建的符号链接
图11-5中箭头指向的目录名称是登录会话ID。第16章“安全性”将对此进行进一步讨论。
DefineDosDevice的dwFlags参数可以为零,也可以是表11-6中所示值的组合。
表11-6:DefineDosDevice的标志
| 标志 | 描述 |
|---|---|
DDD_NO_BROADCAST_SYSTEM | 防止该函数广播WM_SETTINGSCHANGE消息。此消息通常用于让文件资源管理器(Explorer)等应用程序更新其状态 |
DDD_RAW_TARGET_PATH | 目标路径被解释为本机路径(类似于\Device\Harddiskvolume3\MyDir),而非Win32路径(c:\MyDir) |
DDD_REMOVE_DEFINITION | 删除符号链接映射。通常将lpTargetPath设置为NULL以删除lpDeviceName中提供的名称。否则,会查找目标名称以进行删除 |
DDD_EXACT_MATCH_ON_REMOVE | 仅在使用前一个标志时有效。对目标路径执行精确匹配(而非部分匹配) |
# 路径长度
传统上,CreateFile函数的文件名长度限制为MAX_PATH个字符,定义为260个字符。使用该函数的Unicode版本(CreateFileW)时,通过在路径前加上\?\(例如\\?\c:\MyDir\MyFile.txt),路径长度可扩展到约32767个字符。路径中的每个部分限制为255个字符。
请记住,在C/C++字符串中,每个反斜杠都必须用另一个反斜杠进行转义。因此,“c:\temp”必须写为“c:\temp”。C++ 11提供了另一种方法,即使用字符串字面量特性。在引号前的字符串前加上R,然后将路径用括号括起来即可。例如:R"(c:\temp\file.txt)",对于Unicode字符串则为LR"(c:\temp\file.txt)"。在(之前可以出现一个可选的分隔符序列,并且在)之后必须相同,但对于路径来说,这种情况很少需要。
使用\\?\扩展路径也适用于通用命名约定(UNC,Universal Naming Convention)路径,此时前缀变为\\?\UNC\。
Windows 10版本1607和Windows Server 2016添加了一项新功能,可突破这些路径长度限制。这是一个可选功能,需要进行两项设置:
- 必须将
HKLM\System\CurrentControlSet\Control\FileSystem下名为LongPathsEnabled的全局注册表值设置为1(DWORD值)。进程首次调用I/O函数时,会读取此值并在进程的生命周期内进行缓存。这意味着对此值的任何更改仅对新进程有效。如果更改此值并重新启动系统,则所有进程都将确保看到新值。 - 特定的可执行文件必须在其清单中包含
longPathAware元素,并将其设置为true。清单XML文件中的完整部分如下:
<application xmlns="urn:schemas-microsoft-com:asm.v3">
<windowsSettings xmlns:ws2="http://schemas.microsoft.com/SMI/2016/WindowsSettings">
<ws2:longPathAware>true</ws2:longPathAware>
</windowsSettings>
</application>
2
3
4
5
注册表是一项计算机范围的设置,因此需要管理员权限才能更改。
Windows API中大多数处理路径的函数都可以处理可能非常长的路径。
使用长路径时要小心,因为大多数内置应用程序的清单中都没有此设置。例如,文件资源管理器(Windows Explorer)就没有。对于非常长的路径,文件资源管理器将无法处理。
# 目录
如果在dwFlagsAndAttribute参数中指定FILE_FLAG_BACKUP_SEMANTICS标志,CreateFile函数可以打开现有目录的句柄。若要创建目录,则需要使用单独的函数:
BOOL CreateDirectory(
_In_ LPCTSTR lpPathName,
_In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes);
BOOL CreateDirectoryEx(
_In_ LPCTSTR lpTemplateDirectory,
_In_ LPCTSTR lpNewDirectory,
_In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes);
2
3
4
5
6
7
8
CreateDirectory的lpPathName参数和CreateDirectoryExW的lpNewDirectory参数指定新目录的路径(可以是完整路径或相对路径,但在调用之前,路径中除新目录之外的所有组件都必须存在)。可以提供一个可选的SECURITY_ATTRIBUTES指针,为新目录设置安全描述符(有关更多信息,请参阅第16章)。最后,CreateDirectoryEx的lpTemplateDirectory参数允许指定一个现有目录,新目录的某些属性(如压缩和加密设置)将从该目录复制。
# 文件
打开文件句柄后,可以查询有关该文件的一些基本信息。其中最常见的可能是文件大小:
DWORD GetFileSize(
_In_ HANDLE hFile,
_Out_opt_ LPDWORD lpFileSizeHigh);
BOOL GetFileSizeEx(
_In_ HANDLE hFile,
_Out_ PLARGE_INTEGER lpFileSize);
2
3
4
5
6
7
文件大小为64位,这意味着Windows可以处理极大的文件。实际上,最大文件大小比理论上的2的64次方(16 EB)字节要受限得多,并且取决于实际磁盘大小、文件系统以及一些属性,例如文件是否被压缩或为稀疏文件(本章后面将讨论)。尽管如此,大于32位大小(4 GB)的文件相当常见,除非有充分理由不这么做,否则代码通常应考虑到这种大小的文件。
GetFileSize函数将文件大小的低32位作为返回值,如果指定了lpFileSizeHigh参数,则将高32位值存储在该参数中。如果lpFileSizeHigh为NULL,则不返回高32位值。发生错误时,该函数返回INVALID_FILE_SIZE,定义为0xffffffff。
GetFileSizeEx函数更简单,它将文件大小存储在LARGE_INTEGER结构中,我们之前见过这个结构。该函数返回常规的布尔值,用于指示操作成功或失败。
上述两个函数返回的文件大小是逻辑文件大小,可能与物理文件大小不同。例如,如果文件被压缩或为稀疏文件,其在磁盘上的实际大小可能会更小。对于此类文件,可以使用专门的函数来查询其在磁盘上的实际大小:
DWORD GetCompressedFileSize(
_In_ LPCTSTR lpFileName,
_Out_opt_ LPDWORD lpFileSizeHigh);
2
3
GetCompressedFileSize函数接受文件名而非句柄,并以与GetFileSize相同的格式返回请求的大小。
关于文件的另一项基本信息与它的创建时间、修改时间和访问时间有关。GetFileTime函数用于检索这些值:
BOOL GetFileTime(
_In_ HANDLE hFile,
_Out_opt_ LPFILETIME lpCreationTime,
_Out_opt_ LPFILETIME lpLastAccessTime,
_Out_opt_ LPFILETIME lpLastWriteTime);
2
3
4
5
返回的时间以自1601年1月1日起的100纳秒为单位。对于任何不需要的时间,可以提供NULL指针,以表明调用者对该特定结果不感兴趣。
可以使用GetFileAttributes或GetFileAttributesEx函数检索文件属性:
DWORD GetFileAttributes(_In_ LPCTSTR lpFileName);
BOOL GetFileAttributesEx(
_In_ LPCTSTR lpFileName,
_In_ GET_FILEEX_INFO_LEVELS fInfoLevelId,
_Out_ LPVOID lpFileInformation);
2
3
4
5
6
GetFileAttributes函数接受文件名并返回其属性。这些属性包括表11-5中的属性,还可能包括在CreateFile调用中无法合法设置的其他属性。这些额外的值列在表11-7中。
表11-7:更多文件属性
| 文件属性 | 描述 |
|---|---|
DIRECTORY或无 | 表示是目录(而非文件) |
REPARSE_POINT | 文件具有关联的重解析点 |
COMPRESSED | 文件被压缩 |
SPARSE_FILE | 文件是稀疏文件 |
INTEGRITY_STREAM(Windows 8+) | 目录或数据流配置了完整性(仅ReFS文件系统)* |
NO_SCRUB_DATA(Windows 8+) | 数据流不应被数据完整性扫描程序读取(仅ReFS文件系统和存储空间)* |
* 对
FILE_ATTRIBUTE_INTEGRITY_STREAM和FILE_ATTRIBUTE_NO_SCRUB_DATA属性的详细讨论超出了本书的范围。
GetFileAttributesEx函数目前仅接受一个值为GetFileExInfoStandard的“级别”,并返回一个WIN32_FILE_ATTRIBUTE_DATA结构,定义如下:
typedef struct _WIN32_FILE_ATTRIBUTE_DATA {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
} WIN32_FILE_ATTRIBUTE_DATA, *LPWIN32_FILE_ATTRIBUTE_DATA;
2
3
4
5
6
7
8
除了前面讨论的文件属性外,该函数还返回文件的创建时间、上次访问时间、上次写入时间和大小。
若要获取文件的更多信息,可以调用GetFileInformationByHandle函数:
BOOL GetFileInformationByHandle(
_In_ HANDLE hFile,
_Out_ LPBY_HANDLE_FILE_INFORMATION lpFileInformation);
2
3
该函数接受文件句柄而非文件路径,并返回WIN32_FILE_ATTRIBUTE_DATA的超集BY_HANDLE_FILE_INFORMATION:
typedef struct _BY_HANDLE_FILE_INFORMATION {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD dwVolumeSerialNumber;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD nNumberOfLinks;
DWORD nFileIndexHigh;
DWORD nFileIndexLow;
} BY_HANDLE_FILE_INFORMATION, *PBY_HANDLE_FILE_INFORMATION;
2
3
4
5
6
7
8
9
10
11
12
该函数返回多条信息,其中一些也是WIN32_FILE_ATTRIBUTE_DATA的一部分。额外的信息包括卷序列号、文件的链接数(如果在NTFS文件系统上存在硬链接,则链接数可能大于1)以及文件的索引(64位,以两个32位数字提供)。时间以自1601年1月1日起的100纳秒为单位。文件索引在特定卷上是唯一的。这意味着将文件索引与卷编号相结合,可以在特定计算机上标识一个文件。这可用于比较两个文件句柄,以判断它们是否指向同一个文件。
如果只对文件的属性感兴趣,
GetFileInformationByHandle函数比GetFileAttributes或GetFileAttributesEx函数更快,因为它使用已打开的句柄。其他函数需要打开文件、获取信息并关闭文件。如果有文件句柄,始终优先使用句柄,而不是文件路径。
若要获取关于文件的更多信息,可以调用GetFileInformationByHandleEx函数:
BOOL GetFileInformationByHandleEx(
_In_ HANDLE hFile,
_In_ FILE_INFO_BY_HANDLE_CLASS FileInformationClass,
_Out_ LPVOID lpFileInformation,
_In_ DWORD dwBufferSize
);
2
3
4
5
6
该函数能够检索到相当多的信息,所请求的信息由FILE_INFO_BY_HANDLE_CLASS枚举提供:
typedef enum _FILE_INFO_BY_HANDLE_CLASS {
FileBasicInfo,
FileStandardInfo,
FileNameInfo,
FileRenameInfo,
FileDispositionInfo,
FileAllocationInfo,
FileEndOfFileInfo,
FileStreamInfo,
FileCompressionInfo,
FileAttributeTagInfo,
FileIdBothDirectoryInfo,
FileIdBothDirectoryRestartInfo,
FileIoPriorityHintInfo,
FileRemoteProtocolInfo,
FileFullDirectoryInfo,
FileFullDirectoryRestartInfo,
#if (_WIN32_WINNT >= _WIN32_WINNT_WIN8)
FileStorageInfo,
FileAlignmentInfo,
FileIdInfo,
FileIdExtdDirectoryInfo,
FileIdExtdDirectoryRestartInfo,
#endif
#if (_WIN32_WINNT >= _WIN32_WINNT_WIN10_RS1)
FileDispositionInfoEx, FileRenameInfoEx,
#endif
#if (NTDDI_VERSION >= NTDDI_WIN10_19H1)
FileCaseSensitiveInfo, FileNormalizedNameInfo,
#endif
MaximumFileInfoByHandleClass
} FILE_INFO_BY_HANDLE_CLASS, *PFILE_INFO_BY_HANDLE_CLASS;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
这是一个很长的枚举列表。条件编译部分展示了哪些值是在Windows 8/Server 2012及更高版本、Windows 10版本1607和Server 2016,以及Windows 10版本1903中添加的。
对于每个枚举值,文档中都描述了与之相关的结构。
# 设置文件信息
GetFileAttributes函数有一个用于设置文件属性的互补函数:
BOOL SetFileAttributes(
_In_ LPCTSTR lpFileName,
_In_ DWORD dwFileAttributes);
2
3
这些函数能够设置的属性包括:FILE_ATTRIBUTE_ARCHIVE、FILE_ATTRIBUTE_HIDDEN、FILE_ATTRIBUTE_NORMAL、FILE_ATTRIBUTE_NOT_CONTENT_INDEXED、FILE_ATTRIBUTE_OFFLINE、FILE_ATTRIBUTE_READONLY、FILE_ATTRIBUTE_SYSTEM和FILE_ATTRIBUTE_TEMPORARY。
通过其他API可以更改的其他属性包括:
FILE_ATTRIBUTE_COMPRESSED- 使用FSCTL_SET_COMPRESSION控制代码调用DeviceIoControl函数(本章稍后会详细介绍DeviceIoControl函数)。FILE_ATTRIBUTE_ENCRYPTED- 如果文件创建时未设置此属性,可以调用EncryptFile函数对文件当前内容进行加密,并设置该属性。FILE_ATTRIBUTE_REPARSE_POINT- 使用FSCTL_SET_REPARSE_POINT控制代码调用DeviceIoControl函数,将文件与重解析点(reparse point)关联起来。FILE_ATTRIBUTE_SPARSE_FILE- 使用FSCTL_SET_SPARSE控制代码调用DeviceIoControl函数,将文件转换为稀疏文件(sparse file)。稀疏文件预计大部分内容为零,这样可以节省磁盘空间。
更改与文件相关的时间需要调用SetFileTime函数:
BOOL SetFileTime(
_In_ HANDLE hFile,
_In_opt_ CONST FILETIME* lpCreationTime,
_In_opt_ CONST FILETIME* lpLastAccessTime,
_In_opt_ CONST FILETIME* lpLastWriteTime);
2
3
4
5
文件句柄必须具有FILE_WRITE_ATTRIBUTES权限才能进行这些更改。调用者可以为不想更改的值指定NULL。
若要为文件设置其他信息,可以使用GetFileInformationByHandleEx函数的互补函数:
BOOL SetFileInformationByHandle(
_In_ HANDLE hFile,
_In_ FILE_INFO_BY_HANDLE_CLASS FileInformationClass,
_In_reads_bytes_(dwBufferSize) LPVOID lpFileInformation,
_In_ DWORD dwBufferSize);
2
3
4
5
FileInformationClass参数与传递给GetFileInformationByHandleEx函数的枚举类型相同。不过,只有一小部分信息类可用于设置数据,包括:FileBasicInfo、FileRenameInfo、FileDispositionInfo、FileAllocationInfo、FileEndOfFileInfo和FileIoPriorityHintInfo 。
# 同步I/O
调用CreateFile函数时,如果在dwFlagsAndAttributes参数中未指定FILE_FLAG_OVERLAPPED,则创建的文件对象仅用于同步I/O。这是最容易使用的方式,所以我们先来探讨同步I/O。
执行I/O操作的主要函数是ReadFile和WriteFile,它们可用于任何文件对象(不一定指向文件系统中的文件):
BOOL ReadFile(
_In_ HANDLE hFile,
_Out_ LPVOID lpBuffer,
_In_ DWORD nNumberOfBytesToRead,
_Out_opt_ LPDWORD lpNumberOfBytesRead,
_Inout_opt_ LPOVERLAPPED lpOverlapped);
BOOL WriteFile(
_In_ HANDLE hFile,
_In_ LPCVOID lpBuffer,
_In_ DWORD nNumberOfBytesToWrite,
_Out_opt_ LPDWORD lpNumberOfBytesWritten,
_Inout_opt_ LPOVERLAPPED lpOverlapped);
2
3
4
5
6
7
8
9
10
11
12
13
这些函数适用于同步和异步I/O。lpBuffer是读取数据(WriteFile)的源缓冲区或写入数据(ReadFile)的目标缓冲区。对于ReadFile函数,nNumberOfBytesToRead指定要读取到缓冲区中的字节数;对于WriteFile函数,nNumberOfBytesToWrite指定要写入的字节数。
实际读取/写入的字节数会返回在lpNumberOfBytesRead(读取时)或lpNumberOfBytesWritten(写入时)中。这个值可能小于请求的字节数,甚至可能为零。请注意,在同步I/O中,不能为这些参数传递NULL,否则函数在尝试解引用空指针时会引发访问冲突。
最后一个参数lpOverlapped,在异步操作中必须为非NULL,但在同步I/O中应该为NULL。
这些函数是同步的,这意味着调用线程会被阻塞(进入等待状态),直到操作完成且数据传输完毕。如果函数执行失败,会返回FALSE,可以通过GetLastError函数获取具体的错误信息。
以下示例展示了如何创建一个新文件并向其中写入一些数据:
HANDLE hFile = ::CreateFile(LR"(c:\temp\mydata.txt)",
GENERIC_WRITE, // 访问权限
0, // 共享模式(独占)
nullptr, // 安全属性
CREATE_NEW, // 创建方式
0, // 标志和属性
nullptr); // 模板文件
if (hFile != INVALID_HANDLE_VALUE) {
char text[] = "Hello from Windows!";
DWORD bytes;
::WriteFile(hFile, text, ::strlen(text), &bytes, nullptr);
::CloseHandle(hFile);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
下一个示例展示了如何读取文件中的所有字节:
HANDLE hFile = ::CreateFile(LR"(c:\temp\mydata.txt)",
GENERIC_READ, // 访问权限
FILE_SHARE_READ, // 共享模式
nullptr, // 安全属性
OPEN_EXISTING, // 创建方式
0, // 标志和属性
nullptr); // 模板文件
if (hFile != INVALID_HANDLE_VALUE) {
// 假设文件大小小于4GB
DWORD size = ::GetFileSize(hFile, nullptr);
auto buffer = std::make_unique<char[]>(size + 1);
DWORD bytes;
if (::ReadFile(hFile, buffer.get(), size, &bytes, nullptr)) {
// 假设数据为ASCII文本
buffer[bytes] = '\0'; // 添加字符串结束符
printf("%s\n", buffer.get());
}
::CloseHandle(hFile);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
每个为同步访问而打开的文件对象都维护一个内部文件指针,每次I/O操作后该指针会自动向前移动。例如,打开一个文件并执行一次读取10字节的操作,操作完成后文件指针会向前移动10字节。如果再执行一次读取10字节的操作,将读取第10到19字节的数据,文件指针会移动到文件中的第20个位置。
对于顺序读写操作,这种方式非常方便。但在某些情况下,你可能希望向前或向后跳转,并从不同的位置进行读写操作。这可以通过以下函数之一来实现:
DWORD SetFilePointer(
_In_ HANDLE hFile,
_In_ LONG lDistanceToMove,
_Inout_opt_ PLONG lpDistanceToMoveHigh,
_In_ DWORD dwMoveMethod);
BOOL SetFilePointerEx(
_In_ HANDLE hFile,
_In_ LARGE_INTEGER liDistanceToMove,
_Out_opt_ PLARGE_INTEGER lpNewFilePointer,
_In_ DWORD dwMoveMethod);
2
3
4
5
6
7
8
9
10
11
这些函数将内部文件指针移动到所需的位置。SetFilePointerEx函数更易于使用,因为它允许在liDistanceToMove参数中提供完整的64位偏移量。SetFilePointer函数在lDistanceToMove中接受偏移量的低32位,并在lpDistanceToMoveHigh(可选)中接受高32位。这两个函数都试图返回先前的文件指针:SetFilePointerEx函数在lpNewFilePointer中返回,SetFilePointer函数在返回值(低32位)和lpDistanceToMoveHigh(如果不为NULL,则为高32位)中返回。
不过,要移动的偏移量不一定是从文件开头计算的偏移量。最后一个参数dwMoveMethod指定了如何解释提供的偏移量:
FILE_BEGIN(0) - 从文件开头开始计算FILE_CURRENT(1) - 从当前文件位置开始计算FILE_END(2) - 从文件末尾开始计算
通过指定零偏移量和FILE_CURRENT移动方式,可以查询当前文件指针而不移动它。通过指定零偏移量和FILE_END移动方式,可以将文件指针移动到文件末尾。
对同一文件打开的多个文件对象是相互独立的,包括它们的文件指针在内,任何方面都不会同步。每个文件对象都有自己的文件指针,它们之间不会相互影响。
调用SetFilePointer(Ex)函数时,如果偏移量超出文件当前大小,文件会被扩展到该大小。相反,通过先将文件指针设置为所需大小,然后调用SetEndOfFile函数,可以对文件进行截断操作:
BOOL SetEndOfFile(_In_ HANDLE hFile);
# 异步I/O
如本章开头所述,Windows I/O系统本质上是异步的。一旦设备驱动程序向其控制的硬件(如磁盘驱动器)发出请求,驱动程序无需等待操作完成。相反,它会将请求标记为“挂起”,然后返回给调用者。此时,线程可以自由地执行其他操作,而I/O操作则在后台进行。
一段时间后,硬件设备完成I/O操作。设备会发出硬件中断,这会导致运行驱动程序提供的回调函数,从而完成挂起的请求。
使用同步I/O简单便捷,在许多情况下已经足够。然而,如果要处理大量请求,为每个发起I/O操作的请求创建一个线程并等待其完成是低效的,这种方式的扩展性不佳。异步I/O提供了解决方案,线程发起一个请求后,无需等待即可返回处理下一个请求,以此类推,因为I/O操作可以在CPU执行其他代码的同时并发进行。这种简单模型中唯一的难点在于,线程如何得知I/O操作已完成。正如我们很快会看到的,Windows提供了一些技术来解决这个问题。
请求异步操作必须从最初的CreateFile函数调用开始(顺便说一句,CreateFile函数本身始终是同步的)。必须在dwFlagsAndAttributes参数中指定FILE_FLAG_OVERLAPPED标志,这样才能以异步模式打开文件/设备。
以异步模式打开文件会带来一个结果,即不再有文件指针。这意味着每个操作都必须以某种方式提供从文件开头开始的偏移量,以便执行操作(文件大小不是问题,因为它是读写调用的一部分)。这是OVERLAPPED结构的任务之一,该结构必须作为最后一个参数传递给ReadFile和WriteFile函数:
typedef struct _OVERLAPPED {
ULONG_PTR Internal;
ULONG_PTR InternalHigh;
union {
struct {
DWORD Offset;
DWORD OffsetHigh;
};
PVOID Pointer;
};
HANDLE hEvent;
} OVERLAPPED, *LPOVERLAPPED;
2
3
4
5
6
7
8
9
10
11
12
这个结构包含三个不同的信息部分:
Internal和InternalHigh是有特定用途的字段,由I/O管理器使用,不应被写入,不过下面会介绍它们的用法。Offset和OffsetHigh是要设置的偏移量,用于指示操作在文件中的起始位置。如果需要64位偏移量,联合体中的Pointer成员是这些字段的替代选择,使用起来会更方便一些。hEvent是一个内核事件对象的句柄,如果不为NULL,当操作完成时,I/O管理器会发出信号通知该事件。
从技术上讲,Internal字段存储I/O操作的错误代码。对于正在进行的异步操作,它存储STATUS_PENDING,这在内核中等同于STILL_ACTIVE(0x103)。实际上,Windows定义了一个宏HasOverlappedIoCompleted,正是利用了这一特性。其定义如下:
#define HasOverlappedIoCompleted(lpOverlapped) \
(((DWORD)(lpOverlapped)->Internal) != STATUS_PENDING)
2
InternalHigh成员在操作完成后存储传输的字节数。
在异步操作中,ReadFile或WriteFile函数通常会返回FALSE,因为操作尚未完成,才刚刚开始。在某些情况下,底层设备驱动程序可能会决定同步执行操作,这种情况下函数会返回TRUE。对于针对文件系统文件的ReadFile和WriteFile函数,这种情况很少发生。
如果函数返回FALSE,那么调用GetLastError会返回ERROR_IO_PENDING,这意味着一切按计划进行——操作正在进行中,线程可以继续执行其他操作。如果返回其他错误,那么这就是真正的错误——操作尚未开始。
ReadFile和WriteFile函数都有一个返回字节数的参数,在同步操作的情况下,该参数返回传输的字节数。但在异步操作中,这没有意义,因为操作尚未完成。虽然可以提供一个DWORD类型的地址并忽略结果,但为避免混淆,最好将该参数指定为NULL。
根据上述信息,下面的代码示例以异步方式打开一个文件,执行读取操作,在操作进行时进行一些其他处理,然后等待操作完成:
HANDLE hFile = ::CreateFile(LR"(c:\temp\mydata.txt)", GENERIC_READ,
FILE_SHARE_READ, nullptr, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, nullptr);
if (hFile != INVALID_HANDLE_VALUE) {
// 初始化OVERLAPPED
OVERLAPPED ov = { 0 }; // 偏移量为零
ov.hEvent = ::CreateEvent(nullptr, TRUE, FALSE, nullptr);
BYTE buffer[1 << 12]; // 4KB
BOOL ok = ::ReadFile(hFile, buffer, sizeof(buffer), nullptr, &ov);
if (!ok) {
if (::GetLastError() != ERROR_IO_PENDING) {
// 发生了一些真正的错误...
return;
}
else {
// 做一些其他工作...
// 等待操作完成
::WaitForSingleObject(ov.hEvent, INFINITE);
::CloseHandle(ov.hEvent);
}
}
// 处理结果...
::CloseHandle(hFile);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
关于上述代码,有几点需要注意:
OVERLAPPED实例在I/O操作进行期间必须一直存在。在上述代码中,它是在栈上分配的,调用线程会等待操作完成,因此可以保证该实例一直存在。在更复杂的情况下,可能需要动态分配。- 虽然原始调用者会等待事件,但这不是必须的;任何线程都可以等待该事件,包括线程池线程(如第9章所示)。
操作完成后,如何知道传输了多少字节呢?我们无法从最初的ReadFile/WriteFile调用中获取这个信息。我们可以从OVERLAPPED结构的InternalHigh成员中获取,但有一个专门的函数用于获取此信息:
BOOL GetOverlappedResult(
_In_ HANDLE hFile,
_In_ LPOVERLAPPED lpOverlapped,
_Out_ LPDWORD lpNumberOfBytesTransferred,
_In_ BOOL bWait);
2
3
4
5
GetOverlappedResult接受文件句柄和特定操作的OVERLAPPED结构(可以从同一个文件句柄发起多个操作,每个操作都有不同的OVERLAPPED实例)。lpNumberOfBytesTransferred返回实际传输的字节数。
最后一个参数bWait指定在报告结果之前是否等待操作完成(TRUE)。如果操作已经完成,那么这个参数无关紧要。如果操作仍在进行且bWait为TRUE,调用线程会等待直到操作完成,函数返回TRUE。如果bWait为FALSE且操作仍在进行,函数返回FALSE,并且GetLastError返回ERRO_IO_INCOMPLETE。
一个扩展函数GetOverlappedResultEx在等待操作完成时提供了更大的灵活性:
BOOL GetOverlappedResultEx(
_In_ HANDLE hFile,
_In_ LPOVERLAPPED lpOverlapped,
_Out_ LPDWORD lpNumberOfBytesTransferred,
_In_ DWORD dwMilliseconds,
_In_ BOOL bAlertable);
2
3
4
5
6
该函数允许设置等待的超时时间(dwMilliseconds),还可以在可提醒状态下等待(bAlertable)(有关可提醒状态的更多信息,请参见第7章)。
Windows提供了几种处理异步I/O完成的方法。我们刚刚看到了其中一种,即使用事件对象。表11-8总结了可用的选项。
表11-8:异步完成处理选项
| 机制 | 备注 |
|---|---|
| 等待文件句柄 | 易于使用,但仅限于单个操作 |
等待OVERLAPPED结构中的事件 | 易于使用。任何线程都可以等待该事件 |
使用带有回调的ReadFileEx和WriteFileEx | 回调作为异步过程调用(APC)排队到调用线程,这意味着只有该线程可以处理结果 |
| I/O完成端口 | 不像其他方法那么简单,但灵活且功能强大 |
表11-8中的第一个选项表明文件句柄是一个可等待对象,当异步操作完成时会变为已通知状态。如果一次只进行一个这样的请求,这种方法效果很好。如果有多个请求在进行,当第一个请求完成时文件句柄会变为已通知状态,但无法保证是哪个请求完成了。
一般来说,I/O操作可能会无序完成,因为如何调度实际请求是驱动程序的权限。你绝不应依赖I/O操作完成的某种顺序。
由于等待文件句柄并不理想,你可以告诉系统无需对其进行通知:
BOOL SetFileCompletionNotificationModes(
_In_ HANDLE FileHandle,
_In_ UCHAR Flags);
2
3
其中一个标志是FILE_SKIP_SET_EVENT_ON_HANDLE,这个标志用于告诉I/O管理器跳过对文件对象的通知。
使用OVERLAPPED结构中的事件对象的第二种方法效果很好,前提是每个操作都与自己的事件相关联。任何线程都可以等待该事件,包括线程池线程。
# ReadFileEx和WriteFileEx
响应已完成的I/O操作的第三种方法是使用ReadFile或WriteFile的扩展版本:
BOOL ReadFileEx(
_In_ HANDLE hFile,
_Out_ LPVOID lpBuffer,
_In_ DWORD nNumberOfBytesToRead,
_Inout_ LPOVERLAPPED lpOverlapped,
_In_ LPOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine);
BOOL WriteFileEx(
_In_ HANDLE hFile,
_In_ LPCVOID lpBuffer,
_In_ DWORD nNumberOfBytesToWrite,
_Inout_ LPOVERLAPPED lpOverlapped,
_In_ LPOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine);
2
3
4
5
6
7
8
9
10
11
12
13
这些函数与它们的非Ex版本相同,除了多了一个参数,该参数是一个函数指针,其原型必须如下:
typedef VOID (WINAPI *LPOVERLAPPED_COMPLETION_ROUTINE)(
_In_ DWORD dwErrorCode,
_In_ DWORD dwNumberOfBytesTransfered,
_Inout_ LPOVERLAPPED lpOverlapped);
2
3
4
从表面上看,这种机制近乎完美:当异步I/O操作完成时会调用回调函数。不幸的是,回调函数被封装在一个异步过程调用(Asynchronous Procedure Call,APC)中,并排队到调用ReadFileEx或WriteFileEx的原始线程。这意味着只有这个特定的线程可以通过进入可提醒状态(至少偶尔进入)来调用回调函数。有关APC和可提醒状态的更多信息,请参见第8章。
回调函数一旦被调用,会提供操作的错误代码(如果一切正常,则为ERROR_SUCCESS)、传输的字节数以及指向原始OVERLAPPED结构的指针。最后这一点非常方便,因为如果该结构是动态分配的(很有可能),代码可以在回调函数中释放该结构——此时I/O管理器不会再访问该结构。
# 手动排队的APC
一般来说,有另一个与APC相关的函数值得介绍。它能够将一个APC排队到目标线程:
DWORD QueueUserAPC(
_In_ PAPCFUNC pfnAPC,
_In_ HANDLE hThread,
_In_ ULONG_PTR dwData);
2
3
4
该函数将一个APC排队到由hThread参数表示的目标线程,目标线程必须具有THREAD_SET_CONTEXT访问掩码。pfnAPC是一个函数指针,其原型必须如下:
typedef VOID (WINAPI *PAPCFUNC)(_In_ ULONG_PTR Parameter);
dwData是通过Parameter参数传递给APC函数的值。
这仍然是一个APC,因此如果要执行APC回调,目标线程必须进入可提醒状态。这意味着将APC排队到任意线程是有问题的;调用者应该事先知道目标线程在不久的将来可能会处于可提醒状态。否则,这些APC会排队,直到达到某个限制,但永远不会被执行。
QueueUserAPC的一个简单用途是实现一个由特定线程服务的简单队列,而无需创建和管理任何数据结构。运行工作项的线程需要一直处于可提醒状态,除非收到退出指令:
DWORD WorkThread(PVOID param) {
// 假设传入一个事件句柄来发出线程退出信号
HANDLE hEvent = (HANDLE)param;
for ( ; ; ) {
if(::WaitForSingleObjectEx(hEvent, INFINITE, TRUE) == WAIT_OBJECT_0)
break;
// 如果等待结束且事件未设置,这意味着有一个或多个APC执行了。继续等待更多的APC或退出信号
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
该线程由以下代码创建:
HANDLE hEvent = ::CreateEvent(nullptr, TRUE, FALSE, nullptr);
HANDLE hThread = ::CreateThread(nullptr, 0, WorkThread, (PVOID)hEvent, 0, nullptr);
2
此时,可以使用QueueUserAPC来排队一个工作项:::QueueUserAPC(hThread, SomeFunction, SomeData);
最后,当需要终止线程时,只需设置事件,并可选择等待线程退出,也许还可以完成仍在队列中的APC:
::SetEvent(hEvent);
::WaitForSingleObject(hEvent, INFINITE);
2
# I/O完成端口
I/O完成端口值得单独用一个主要部分来介绍,因为它们不仅对处理异步I/O很有用。我们在第4章讨论作业时简要提到过它们——一个作业可以与一个I/O完成端口相关联,以接收与该作业相关的通知。在本节中,我们将重点介绍I/O完成端口在处理I/O完成方面的用途。
一个I/O完成端口与一个或多个文件对象相关联。它封装了一个请求队列,以及一个线程列表,这些线程可以在请求完成后处理它们。每当一个异步操作完成时,等待在完成端口上的一个线程应该被唤醒并处理该完成事件,可能会启动下一个请求。
第一步是创建一个I/O完成端口对象,并将其与一个或多个文件句柄相关联。这是CreateIoCompletionPort函数的任务:
HANDLE CreateIoCompletionPort(
_In_ HANDLE FileHandle,
_In_opt_ HANDLE ExistingCompletionPort,
_In_ ULONG_PTR CompletionKey,
_In_ DWORD NumberOfConcurrentThreads);
2
3
4
5
该函数可以执行两种不同的操作,也可能将两者结合起来。它可以执行以下任何操作:
- 创建一个与任何文件对象都不相关联的I/O完成端口。
- 将一个现有的完成端口与一个文件对象相关联。
- 在一次调用中结合上述两种操作。
该函数是创建内核对象的函数中唯一一个不接受SECURITY_ATTRIBUTES结构的函数。这是因为完成端口始终属于创建它的进程。从技术上讲,将这样的句柄复制到另一个进程是成功的,但新句柄无法使用。
创建一个新的与任何文件都不相关联的完成端口只需要最后一个参数,如下所示:
HANDLE hNewCP = ::CreateIoCompletionPort(INVALID_HANDLE_VALUE, nullptr, 0,
NumberOfConcurrentThreads);
2
并发线程数表示可以通过这个I/O完成端口处理I/O完成事件的最大线程数。指定为零会将数量设置为系统上逻辑处理器的数量。稍后我们将看到这个参数的效果。
一旦创建了一个I/O完成端口对象,就可以将其与一个或多个文件对象(句柄)相关联。对于每个文件句柄,都要指定一个完成键,这是由应用程序定义的。文件对象必须是以FILE_FLAG_OVERLAPPED标志打开的。下面是一个将文件对象添加到完成端口的示例:
const int Key = 1;
HANDLE hFile = ::CreateFile(..., FILE_FLAG_OVERLAPPED, ...);
HANDLE hOldCP = ::CreateIoCompletionPort(hFile, hNewCP, Key, 0);
assert(hOldCP == hNewCP);
2
3
4
在这种情况下,实际上不需要捕获返回的句柄,因为现有的完成端口句柄已作为第二个参数指定。上面的断言只是为了更清楚地说明。
请记住,“文件”不一定是文件系统中的文件。例如,它可以是管道、套接字或设备。
上述代码可以对其他文件对象重复执行,所有这些文件对象都与完成端口相关联。图11-6展示了一个I/O完成端口的简单示意图。我们稍后将了解绑定线程是什么以及这一切是如何工作的。
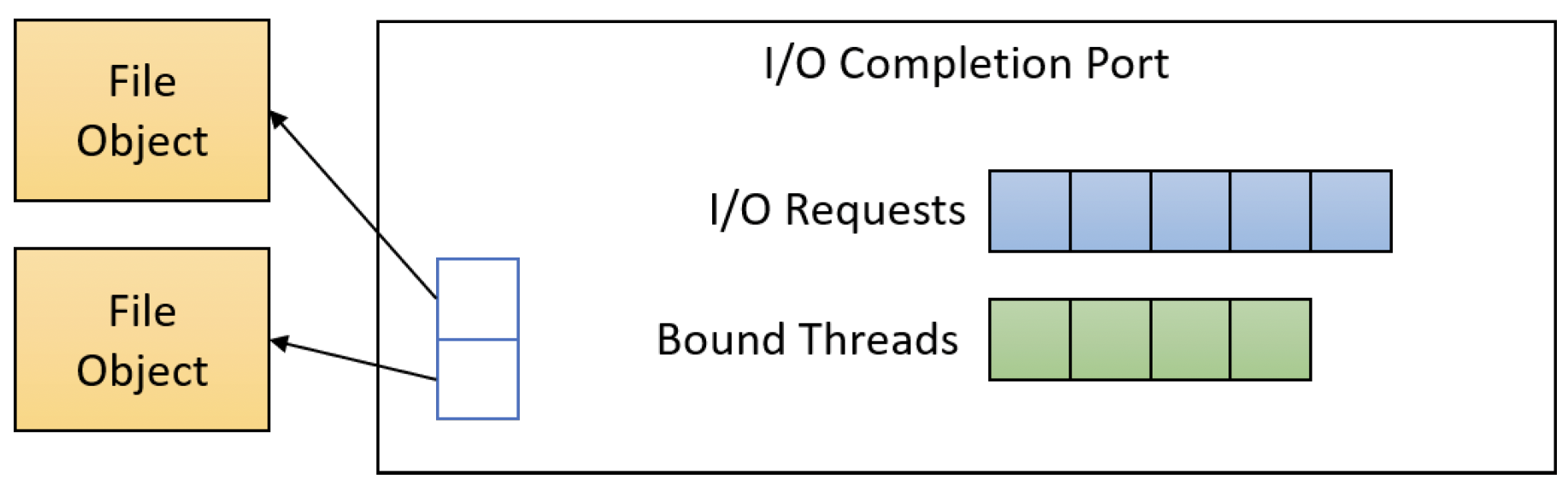
图11-6:I/O完成端口组件
I/O完成端口的目的是允许工作线程处理已完成的I/O操作,这里的“工作线程”可以指任何绑定到完成端口的线程。当一个线程调用GetQueuedCompletionStatus时,它就会绑定到完成端口:
BOOL GetQueuedCompletionStatus(
_In_ HANDLE CompletionPort,
_Out_ LPDWORD lpNumberOfBytesTransferred,
_Out_ PULONG_PTR lpCompletionKey,
_Out_ LPOVERLAPPED* lpOverlapped,
_In_ DWORD dwMilliseconds);
2
3
4
5
6
该调用会使线程进入等待状态,直到与完成端口相关联的某个文件对象发起的异步I/O操作完成,或者超时。通常,dwMilliseconds设置为INFINITE,这意味着在线程在I/O操作完成之前无事可做。如果唤醒线程的操作成功完成,GetQueuedCompletionStatus返回TRUE,并且输出参数会填充传输的字节数、最初与文件句柄相关联的完成键以及用于请求的OVERLAPPED结构指针。
如果发生错误,返回值为FALSE,并且GetLastError返回错误代码。如果超时时间不是无限的,返回值仍然是FALSE,但GetLastError返回WAIT_TIMEOUT,并且OVERLAPPED指针设置为NULL。
任意数量的线程都可以调用GetQueuedCompletionStatus等待完成的数据包到达。I/O完成端口不会允许超过在端口创建时指定的最大线程数同时成功调用该函数。但是,如果一个线程的GetQueuedCompletionStatus调用成功,并且该线程在处理完成操作时由于某种原因(如SuspendThread、WaitForSingleObject等)进入等待状态,完成端口将允许另一个线程的GetQueuedCompletionStatus调用结束等待。这意味着处理完成数据包的线程数有时可能会高于最初指定的最大值。然而,只有最大数量的线程会处于“可运行”状态——即不处于等待状态。
一旦一个线程第一次调用GetQueuedCompletionStatus,它就会绑定到完成端口,直到线程退出、完成端口关闭,或者该线程在另一个完成端口上调用GetQueuedCompletionStatus。
如果多个线程等待完成数据包,获取下一个数据包的线程是最后一个执行的线程,即它是一个后进先出(Last In First Out,LIFO)队列(从技术上讲是一个栈)。在完成操作的速率相对较低的情况下,这是有益的,它允许同一个线程或少数几个线程进行处理。这可能减少上下文切换,并且肯定能更好地利用CPU缓存。
线程还可以通过GetQueuedCompletionStatus的扩展版本请求出队多个I/O完成结果:
BOOL GetQueuedCompletionStatusEx(
_In_ HANDLE CompletionPort,
_Out_ LPOVERLAPPED_ENTRY lpCompletionPortEntries,
_In_ ULONG ulCount,
_Out_ PULONG ulNumEntriesRemoved,
_In_ DWORD dwMilliseconds,
_In_ BOOL fAlertable
);
2
3
4
5
6
7
8
该函数会填充一个OVERLAPPED_ENTRY结构数组,最多填充ulCount个。每个这样的结构如下所示:
typedef struct _OVERLAPPED_ENTRY {
ULONG_PTR lpCompletionKey;
LPOVERLAPPED lpOverlapped;
ULONG_PTR Internal;
DWORD dwNumberOfBytesTransferred;
} OVERLAPPED_ENTRY, *LPOVERLAPPED_ENTRY;
2
3
4
5
6
该结构包含了GetQueuedCompletionStatus为单个完成项提供的三个输出参数。Internal成员就是如其名所示,不应被修改。回到GetQueuedCompletionStatusEx——实际返回的项数由ulNumEntriesRemoved参数提供。此外,如果需要,该函数允许等待处于可提醒状态(alertable state)。
通过调用PostQueuedCompletionStatus,可以手动向I/O完成端口(I/O completion port)发送一个完成数据包,这使得这些对象更具通用性,而不仅仅与I/O相关。作业对象(job object)的通知正是这样工作的。
BOOL PostQueuedCompletionStatus(
_In_ HANDLE CompletionPort,
_In_ DWORD dwNumberOfBytesTransferred,
_In_ ULONG_PTR dwCompletionKey,
_In_opt_ LPOVERLAPPED lpOverlapped
);
2
3
4
5
6
除了完成端口外,该函数还接受三个参数,这些参数稍后会被GetQueuedCompletionStatus(Ex)提取。通常,完成键(completion key)用于区分通知的类型。此外,对于非I/O操作,OVERLAPPED结构意义不大,因此在这种情况下通常传入NULL。
# 批量复制应用程序
批量复制(BuldCopy)应用程序的主窗口如图11-7所示,它展示了如何将各个部分组合起来,创建一个可以异步复制多个文件的应用程序,并且每个文件都可以自定义复制到选定的目标位置。
 图11-7:批量复制应用程序的初始窗口
图11-7:批量复制应用程序的初始窗口
可以使用“添加文件…”按钮添加源文件(允许多选)。然后使用“设置目标目录…”按钮为复制操作选择目标位置(适用于所有或部分源文件)。图11-8展示了添加三个源文件的示例。
 图11-8:批量复制中添加的文件
图11-8:批量复制中添加的文件
此时“开始复制!”按钮变为可用状态,点击该按钮即可执行复制操作。对话框底部的进度条会显示复制进度(图11-9)。
 图11-9:批量复制中的复制操作进行中
图11-9:批量复制中的复制操作进行中
当所有复制操作完成后,应用程序会显示一个“全部完成!”的消息框。
“添加目录…”按钮用于添加目录,但该应用程序未实现对目录中文件的复制操作,这部分内容留给读者作为练习。
复制文件远比单纯地从一个文件读取数据并写入另一个文件复杂得多。实际上,还需要复制更多元素,例如安全描述符(security descriptor)和NTFS流(NTFS streams,本章后面会介绍NTFS流相关内容)。
将文件添加到列表视图(list view)的过程并不特别复杂,除了需要获取每个文件的大小。以下是完整的消息处理程序:
LRESULT CMainDlg::OnAddFiles(WORD, WORD wID, HWND, BOOL&) {
CMultiFileDialog dlg(nullptr , nullptr ,
OFN_FILEMUSTEXIST | OFN_ALLOWMULTISELECT,
L"所有文件 (*.*)\0*.*\0", *this);
dlg.ResizeFilenameBuffer(1 << 16);
if (dlg.DoModal() == IDOK) {
CString path;
int errors = 0;
dlg.GetFirstPathName(path);
do {
wil::unique_handle hFile(::CreateFile(path, 0, FILE_SHARE_READ, nul\
lptr,
OPEN_EXISTING, 0, nullptr));
if (!hFile) { errors++; continue ; }
LARGE_INTEGER size;
::GetFileSizeEx(hFile.get(), &size);
int n = m_List.AddItem(m_List.GetItemCount(), 0, path, 0);
m_List.SetItemText(n, 1, FormatSize(size.QuadPart));
m_List.SetItemData(n, (DWORD_PTR)Type::File);
} while (dlg.GetNextPathName(path));
m_List.EnsureVisible(m_List.GetItemCount() - 1, FALSE);
UpdateButtons();
if (errors > 0)
AtlMessageBox(*this , L"部分文件无法打开",
IDR_MAINFRAME, MB_ICONEXCLAMATION);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
首先,创建一个多文件打开对话框并显示给用户。使用GetFileSizeEx打开每个文件以获取其大小。注意,这里提供的访问掩码为零,因为如前所述,始终会请求SYNCHRONIZE和FILE_READ_ATTRIBUTES,而这些属性中包含文件大小信息。然后,将文件及其大小(通过一个小辅助函数FormatSize进行格式化)添加到列表视图中。
从Windows API的角度来看,设置目标路径并没有什么特别之处,因为这完全与用户界面(UI)相关。真正的工作是从点击“开始复制!”按钮后开始的。
每对源文件/目标文件,以及它们的文件句柄(handle)都存储在一个辅助结构中,该结构定义如下:
struct FileData {
CString Src;
CString Dst;
wil::unique_handle hDst, hSrc;
};
2
3
4
5
为了在处理I/O操作时保持句柄有效,这些结构存储在对话框类的一个成员中(在MainDlg.h中):
std::vector<FileData> m_Data;
“开始复制”按钮的处理程序首先要做的是构建这个向量,但此时还不打开文件:
LRESULT CMainDlg::OnGo(WORD, WORD wID, HWND, BOOL&) {
// transfer list data to vector
m_Data.clear();
int count = m_List.GetItemCount();
m_Data.reserve(count);
for (int i = 0; i < count; i++) {
if (m_List.GetItemData(i) != (DWORD_PTR)Type::File) {
// folders not yet implemented
continue ;
}
FileData data;
m_List.GetItemText(i, 0, data.Src);
m_List.GetItemText(i, 2, data.Dst);
m_Data.push_back(std::move(data));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这段代码从列表视图中提取文件名,并填充FileData结构,然后将它们添加到向量中。
用户界面线程不应绑定到任何I/O完成端口,因为这会导致在该线程等待完成数据包时,用户界面无响应。因此,需要创建一个新线程来处理I/O完成端口。以下是OnGo函数的其余部分:
// create a worker thread
auto hThread = ::CreateThread(nullptr , 0, [](auto param) {
return ((CMainDlg*)param)->WorkerThread();
}, this , 0, nullptr);
// error handling ommitted
::CloseHandle(hThread);
// update UI state
m_Progress.SetPos(0);
m_Running = true;
UpdateButtons();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
实际的工作由WorkerThread函数完成。它的首要任务是创建一个新的I/O完成端口,此时该端口不与任何文件句柄关联:
DWORD CMainDlg::WorkerThread() {
wil::unique_handle hCP(::CreateIoCompletionPort(
INVALID_HANDLE_VALUE, nullptr , 0, 0));
ATLASSERT(hCP);
if (!hCP) {
PostMessage(WM_ERROR, ::GetLastError());
return 0;
}
2
3
4
5
6
7
8
后续的各种读写操作将按块进行,这里设置为64KB(你也可以尝试其他块大小)。
const int chunkSize = 1 << 16; // 64 KB
I/O操作的架构如图11-10所示。
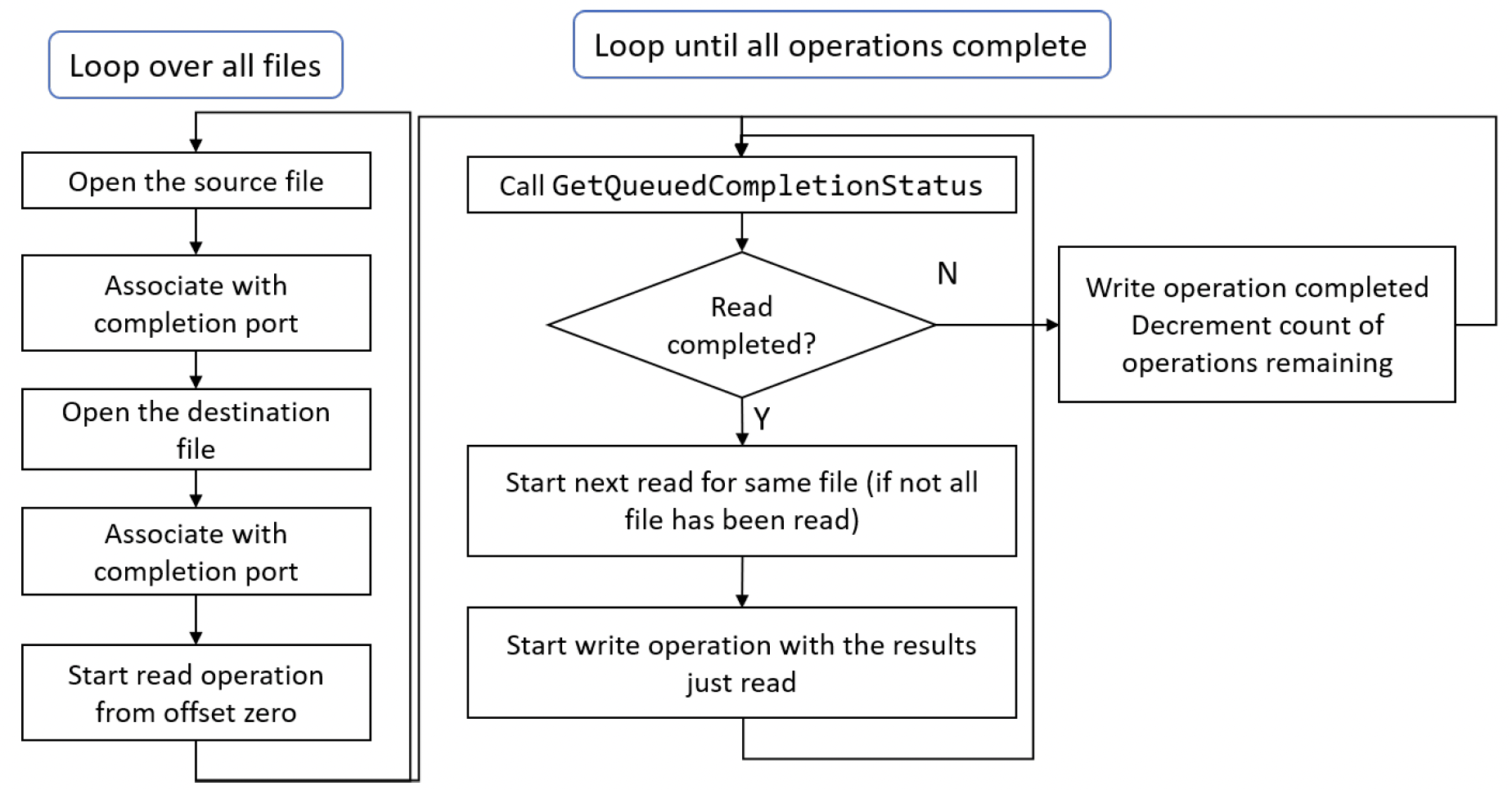 图11-10:处理I/O操作
图11-10:处理I/O操作
首先,遍历所有文件对,打开每个源文件和目标文件。对于源文件,查询其大小:
LONGLONG count = 0;
for (auto& data : m_Data) {
// open source file for async I/O
wil::unique_handle hSrc(::CreateFile(data.Src, GENERIC_READ, FILE_SHARE_READ,
nullptr, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, nullptr));
if (!hSrc) {
PostMessage(WM_ERROR, ::GetLastError());
continue ;
}
// get file size
LARGE_INTEGER size;
::GetFileSizeEx(hSrc.get(), &size);
2
3
4
5
6
7
8
9
10
11
12
13
目标文件可能存在,也可能不存在。我们需要打开或创建它,然后设置其最终大小:
// create the target file and set final size
CString filename = data.Src.Mid(data.Src.ReverseFind(L'\\'));
wil::unique_handle hDst(::CreateFile(data.Dst + filename, GENERIC_WRITE, 0,
nullptr, OPEN_ALWAYS, FILE_FLAG_OVERLAPPED, nullptr));
if (!hDst) {
PostMessage(WM_ERROR, ::GetLastError());
continue ;
}
::SetFilePointerEx(hDst.get(), size, nullptr, FILE_BEGIN);
::SetEndOfFile(hDst.get());
2
3
4
5
6
7
8
9
10
11
将文件扩展到其最终大小非常重要,因为文件扩展操作始终是同步进行的,所以最好一次性完成。
现在可以将两个文件都关联到完成端口,并将句柄保存到FileData结构中:
ATLVERIFY(hCP.get() == ::CreateIoCompletionPort(hSrc.get(), hCP.get(),
(ULONG_PTR)Key::Read, 0));
ATLVERIFY(hCP.get() == ::CreateIoCompletionPort(hDst.get(), hCP.get(),
(ULONG_PTR)Key::Write, 0));
data.hSrc = std::move(hSrc);
data.hDst = std::move(hDst);
2
3
4
5
6
7
这里使用了一个简单的枚举(enum)来区分源文件的完成键(Key::Read)和目标文件的完成键(Key::Write),因为我们需要知道每个操作是读操作还是写操作,这是传递该信息的一种简单方法,因为每个文件仅用于读或写操作。
ATLVERIFY类似于assert,但在发布版本(Release build)和调试版本(Debug)中都会被编译。使用assert或ATLASSERT会导致编译后的二进制文件中移除整个指令。这些断言只是验证向现有完成端口添加操作是否返回相同的句柄。
现在是时候为源文件发起第一次读取请求了。我们需要为每个操作提供一些上下文信息。一种技巧是从OVERLAPPED派生一个类,并添加所需的任何上下文信息。每次成功调用GetQueuedCompletionStatus后,该指针都可用,然后我们可以将其转换为完整的类型。以下是派生的数据结构(在MainDlg.h中定义):
struct IOData : OVERLAPPED {
HANDLE hSrc, hDst;
std::unique_ptr<BYTE[]> Buffer;
ULONGLONG Size;
};
2
3
4
5
我们需要源文件和目标文件的句柄、用于读写的缓冲区以及文件大小。这将使我们能够判断文件是否已全部读取。
有了这个结构体,我们就可以构建第一个读取操作:
auto io = new IOData;
io->Size = size.QuadPart;
io->Buffer = std::make_unique<BYTE[]>(chunkSize);
io->hSrc = data.hSrc.get();
io->hDst = data.hDst.get();
::ZeroMemory(io, sizeof(OVERLAPPED));
auto ok = ::ReadFile(io->hSrc, io->Buffer.get(), chunkSize, nullptr, io);
ATLASSERT(!ok && ::GetLastError() == ERROR_IO_PENDING);
count += (size.QuadPart + chunkSize - 1) / chunkSize;
2
3
4
5
6
7
8
9
该结构体是动态分配的,因为它必须在操作完成后才释放。在这个特定的应用程序中,我们本可以静态创建这些数据结构,因为所有操作都在单个函数中完成,但我选择使用动态分配,以展示如果应用程序的架构不同,这种模式是必要的。结构体中OVERLAPPED部分的偏移量被清零(文件起始位置),分配了缓冲区,文件大小被复制过来,然后使用ReadFile函数和结构体指针开始操作。
最后,局部变量count会根据读取(和写入)整个文件所需的块数进行更新。这将有助于确定所有操作何时完成。
此时,根据文件数量,会有多个读取操作正在进行。现在是时候等待输入/输出(I/O)完成通知并做出相应反应了:
PostMessage(WM_PROGRESS_START, count); // 更新用户界面
while (count > 0) {
DWORD transferred;
ULONG_PTR key;
OVERLAPPED* ov;
BOOL ok = ::GetQueuedCompletionStatus(hCP.get(), &transferred, &key, &ov, INFINITE);
if (!ok) {
PostMessage(WM_ERROR, ::GetLastError());
count--;
delete ov;
continue ;
}
2
3
4
5
6
7
8
9
10
11
12
一旦GetQueuedCompletionStatus成功返回,我们就需要检查已完成的数据包:
// 获取实际的数据对象
auto io = static_cast<IOData*>(ov);
if (key == (DWORD_PTR)Key::Read) {
// 检查是否需要再次读取
ULARGE_INTEGER offset = { io->Offset, io->OffsetHigh };
offset.QuadPart += chunkSize;
if (offset.QuadPart < io->Size) {
auto newio = new IOData;
newio->Size = io->Size;
newio->Buffer = std::make_unique<BYTE[]>(chunkSize);
newio->hSrc = io->hSrc;
newio->hDst = io->hDst;
::ZeroMemory(newio, sizeof(OVERLAPPED));
newio->Offset = offset.LowPart;
newio->OffsetHigh = offset.HighPart;
auto ok = ::ReadFile(newio->hSrc, newio->Buffer.get(), chunkSize, nullptr, newio);
auto error = ::GetLastError();
ATLASSERT(!ok && error == ERROR_IO_PENDING);
}
// 读取完成,开始向目标文件的相同偏移位置写入数据
// 偏移量相同,只是文件不同
io->Internal = io->InternalHigh = 0;
ok = ::WriteFile(io->hDst, io->Buffer.get(), transferred, nullptr, ov);
auto error = ::GetLastError();
ATLASSERT(!ok && error == ERROR_IO_PENDING);
}
else {
// 写入操作完成
count--;
delete io;
PostMessage(WM_PROGRESS);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
如果读取操作完成,我们检查是否需要再次读取,如果需要,就分配一个新的IOData对象,并使用文件中的下一个数据块进行适当填充。由于读取操作已完成,就会启动一个写入操作,将返回的缓冲区写入目标文件。
如果完成的是写入操作,我们就减少剩余操作的计数,释放IOData对象,并向用户界面发送一个更新消息。这个循环会一直持续,直到所有I/O操作完成。
最后,可以更新用户界面,清空所有文件数据的向量(关闭所有文件的句柄),线程可以正常退出,同时也关闭I/O完成端口。
目前,读取操作构建了两次:第一次读取和后续所有读取。使用
PostQueuedCompletionStatus发布一个自定义通知,以便初始读取的构建方式与后续读取相同。
添加一个选项来限制正在进行的并发I/O操作的数量。目前,这个数量是基于文件数量的,而文件数量可能非常大。
# 使用线程池进行I/O完成操作
在第9章中,我们已经了解了线程池的使用方法和优势。我们忽略的一组函数与I/O操作相关。现在是时候填补这个空白了。在批量复制应用程序中,我们创建了一个专用线程,该线程调用GetQueuedCompletionStatus并处理I/O完成操作。线程池也提供了这项服务,所以无需显式创建线程,并且可以利用线程池的扩展功能,让多个线程来处理完成操作。要开始使用,调用CreateThreadpoolIo在后台创建一个完成端口,并将其与文件句柄关联:
PTP_IO CreateThreadpoolIo(
_In_ HANDLE hFile,
_In_ PTP_WIN32_IO_CALLBACK pfnio,
_Inout_opt_ PVOID pv,
_In_opt_ PTP_CALLBACK_ENVIRON pcbe);
2
3
4
5
hFile是要与内部I/O完成端口关联的文件句柄(已为异步I/O打开)。pfnio是一个回调函数,每当内部对GetQueuedCompletionStatus的调用返回时,线程池线程就会调用该函数。pv参数是一个应用程序定义的值,会原封不动地传递给回调函数。最后,pcbe是一个可选的回调环境,在第9章中有介绍。该函数返回一个指向I/O线程池对象的不透明指针。
回调函数必须具有以下原型:
typedef VOID (WINAPI *PTP_WIN32_IO_CALLBACK)(
_Inout_ PTP_CALLBACK_INSTANCE Instance,
_Inout_opt_ PVOID Context,
_Inout_opt_ PVOID Overlapped,
_In_ ULONG IoResult,
_In_ ULONG_PTR NumberOfBytesTransferred,
_Inout_ PTP_IO Io);
2
3
4
5
6
7
该函数提供了与其他线程池回调函数一样的标准实例值(Instance参数),以及传递给CreateThreadpoolIo的上下文。接下来的三个参数与I/O操作相关:OVERLAPPED指针、结果代码(如果一切正常则为ERROR_SUCCESS)和传输的字节数。最后一个参数是从CreateThreadpoolIo返回的I/O线程池对象。我们很快就会看到,它在这里很有用。
为了启动线程池完成操作的基础架构,必须在每次异步操作之前调用StartThreadpoolIo:
VOID StartThreadpoolIo(_Inout_ PTP_IO pio);
如果ReadFile或WriteFile调用返回错误(返回值为FALSE且GetLastError不是ERROR_IO_PENDING),则必须使用CancelThreadpoolIo取消线程池I/O操作:
VOID CancelThreadpoolIo(_Inout_ PTP_IO pio);
与我们遇到的其他线程池应用程序编程接口(API)类似,线程可以等待和/或取消挂起的I/O操作:
VOID WaitForThreadpoolIoCallbacks(
_Inout_ PTP_IO pio,
_In_ BOOL fCancelPendingCallbacks
);
2
3
4
最后,需要关闭线程池I/O对象:
VOID CloseThreadpoolIo(_Inout_ PTP_IO pio);
# 批量复制2应用程序
BulkCopy2项目在功能上与BulkCopy项目相同,但它使用线程池来响应I/O完成操作。在本节中,我们将查看为使其正常工作而进行的代码更改。
首先,由于我们使用线程池,因此无需创建专用线程 —— 这正是线程池的作用。响应“开始”按钮点击的OnGO函数会调用一个名为StartCopy的函数来启动复制操作。它首先遍历所有文件对,打开文件,并设置目标文件的最终大小:
void CMainDlg::StartCopy() {
m_OperationCount = 0;
for (auto& data : m_Data) {
// 为异步I/O打开源文件
wil::unique_handle hSrc(::CreateFile(data.Src, GENERIC_READ, FILE_SHARE_READ, nullptr, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, nullptr));
if (!hSrc) {
PostMessage(WM_ERROR, ::GetLastError());
continue ;
}
// 获取文件大小
LARGE_INTEGER size;
::GetFileSizeEx(hSrc.get(), &size);
// 创建目标文件并设置最终大小
CString filename = data.Src.Mid(data.Src.ReverseFind(L'\\'));
wil::unique_handle hDst(::CreateFile(data.Dst + filename, GENERIC_WRITE, 0, nullptr, OPEN_ALWAYS, FILE_FLAG_OVERLAPPED, nullptr));
if (!hDst) {
PostMessage(WM_ERROR, ::GetLastError());
continue ;
}
::SetFilePointerEx(hDst.get(), size, nullptr, FILE_BEGIN);
::SetEndOfFile(hDst.get());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
我们没有显式创建I/O完成端口。相反,我们使用线程池创建两个线程池I/O对象,并将它们与两个文件关联。FileData结构体已扩展,用于存储这些句柄:
struct FileData {
CString Src;
CString Dst;
wil::unique_handle hDst, hSrc;
wil::unique_threadpool_io tpSrc, tpDst;
};
2
3
4
5
6
注意使用了wil::unique_threadpool_io,当对象超出作用域时,它会调用CloseThreadpoolIo。
继续在StartCopy函数中,我们创建线程池I/O对象:
data.tpDst.reset(::CreateThreadpoolIo(hDst.get(), WriteCallback, this , nullptr));
data.tpSrc.reset(::CreateThreadpoolIo(hSrc.get(), ReadCallback, data.tpDst.get(), nullptr));
2
对于写入操作,this作为上下文参数传递。对于读取操作,传递写入I/O池对象。在实现读取和写入回调函数时,我们将看到为什么需要这样做。此循环中的最后一项工作是启动第一个读取操作,这与批量复制应用程序非常相似,只是增加了对StartThreadpoolIo的调用,以启动线程池I/O机制:
data.hSrc = std::move(hSrc);
data.hDst = std::move(hDst);
// 启动第一个读取操作
auto io = new IOData;
io->Size = size.QuadPart;
io->Buffer = std::make_unique<BYTE[]>(chunkSize);
io->hSrc = data.hSrc.get();
io->hDst = data.hDst.get();
::ZeroMemory(io, sizeof(OVERLAPPED));
::StartThreadpoolIo(data.tpSrc.get());
auto ok = ::ReadFile(io->hSrc, io->Buffer.get(), chunkSize, nullptr, io);
ATLASSERT(!ok && ::GetLastError() == ERROR_IO_PENDING);
::InterlockedAdd64(&m_OperationCount, (size.QuadPart + chunkSize - 1) / chunkSize);
}
PostMessage(WM_PROGRESS_START, (WPARAM)m_OperationCount);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
StartCopy运行速度很快,它会为所有文件启动读取操作,然后返回以处理用户界面(UI)消息。其余的工作由在CreateThreadpoolIo中注册的两个静态回调函数完成。以下是读取回调函数:
void CMainDlg::ReadCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context,
PVOID Overlapped, ULONG IoResult, ULONG_PTR Transferred, PTP_IO Io) {
if (IoResult == ERROR_SUCCESS) {
auto io = static_cast<IOData*>(Overlapped);
ULARGE_INTEGER offset = { io->Offset, io->OffsetHigh };
offset.QuadPart += chunkSize;
if (offset.QuadPart < io->Size) {
auto newio = new IOData;
newio->Size = io->Size;
newio->Buffer = std::make_unique<BYTE[]>(chunkSize);
newio->hSrc = io->hSrc;
newio->hDst = io->hDst;
::ZeroMemory(newio, sizeof(OVERLAPPED));
newio->Offset = offset.LowPart;
newio->OffsetHigh = offset.HighPart;
::StartThreadpoolIo(Io);
auto ok = ::ReadFile(newio->hSrc, newio->Buffer.get(), chunkSize,
nullptr, newio);
auto error = ::GetLastError();
ATLASSERT(!ok && error == ERROR_IO_PENDING);
}
// 读取完成,启动向目标文件中相同偏移位置的写入操作
io->Internal = io->InternalHigh = 0;
auto writeIo = (PTP_IO)Context;
::StartThreadpoolIo(writeIo);
auto ok = ::WriteFile(io->hDst, io->Buffer.get(),
(ULONG)Transferred, nullptr, io);
auto error = ::GetLastError();
ATLASSERT(!ok && error == ERROR_IO_PENDING);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
这段代码与原始应用程序中处理读取完成的代码非常相似。在发起新请求之前,调用StartThreadpoolIo是必需的,这就说明了为什么最后一个参数(PTP_IO)很有用。由于结束读取操作需要启动写入操作,传入的上下文是目标的PTP_IO对象,这样就可以调用正确的StartThreadpoolIo进行写入操作。或者,也可以很容易地将线程池I/O对象放在IOData结构中。
写入回调函数更简单,它只需要(以线程安全的方式)更新操作计数,并释放已完成的操作:
void CMainDlg::WriteCallback(PTP_CALLBACK_INSTANCE Instance, PVOID Context,
PVOID Overlapped, ULONG IoResult, ULONG_PTR Transferred, PTP_IO Io) {
if (IoResult == ERROR_SUCCESS) {
auto pThis = static_cast<CMainDlg*>(Context);
pThis->PostMessage(WM_PROGRESS);
auto io = static_cast<IOData*>(Overlapped);
delete io;
if (0 == InterlockedDecrement64(&pThis->m_OperationCount)) {
pThis->PostMessage(WM_DONE);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# I/O取消操作
一旦I/O操作开始,如何取消它呢?在这方面,Windows API提供了一些选项。
I/O取消操作的一个明显需求与异步操作有关。为此,有两个函数:
BOOL CancelIo(_In_ HANDLE hFile);
BOOL CancelIoEx(
_In_ HANDLE hFile,
_In_opt_ LPOVERLAPPED lpOverlapped);
2
3
4
CancelIo试图取消调用线程通过提供的文件句柄发起的所有异步操作。如果需要更细粒度的控制,可以使用CancelIoEx并传入一个特定的OVERLAPPED结构,该结构代表要取消的操作。
无论如何,取消I/O操作并不能保证成功。取消操作本身是由负责该操作的设备驱动程序实现的。有些驱动程序(特别是针对某些设备的驱动程序)根本不支持取消操作。即使驱动程序支持取消操作,也可能无法对每个操作都进行取消。例如,如果某个操作当前正在由硬件处理,那么可能就来不及取消了。你应该将取消API视为请求取消操作,不保证一定能成功。
I/O操作在以下场景中也会被取消:
- 当文件句柄关闭时,所有挂起的I/O操作都会被取消(除非文件句柄与完成端口相关联)。
- 当线程退出时,该线程发出的所有挂起的I/O操作都会被取消,除了对与I/O完成端口相关联的文件句柄发出的请求。
如果I/O操作成功取消,GetLastError的返回值(或线程池回调提供的错误结果)是ERROR_OPERATION_ABORTED。
那么同步操作呢?显然,发起请求的线程无法取消它,因为该线程正在等待I/O操作完成。不过,另一个线程可以使用CancelSynchronousIo尝试取消操作:
BOOL CancelSynchronousIo(_In_ HANDLE hThread);
线程句柄必须具有PROCESS_TERMINATE访问掩码。如前所述,取消操作并不保证成功。如果操作被取消,原始线程的等待将完成,操作返回FALSE,并且GetLastError返回ERROR_OPERATION_ABORTED 。
# 设备
使用设备(即非文件系统文件)与使用文件系统文件本质上没有区别。ReadFile和WriteFile函数适用于任何设备,包括异步操作,尽管并非所有设备都支持读写操作。对于设备,还有另一个用于执行I/O操作的函数——DeviceIoControl:
BOOL DeviceIoControl(
_In_ HANDLE hDevice,
_In_ DWORD dwIoControlCode,
_In_ LPVOID lpInBuffer,
_In_ DWORD nInBufferSize,
_Out_ LPVOID lpOutBuffer,
_In_ DWORD nOutBufferSize,
_Out_opt_ LPDWORD lpBytesReturned,
_Inout_opt_ LPOVERLAPPED lpOverlapped);
2
3
4
5
6
7
8
9
DeviceIoControl是一个通用函数,它允许通过一个控制代码(dwIoControlCode)发送请求,并可选择提供两个缓冲区,一个指定为“输入”缓冲区,另一个指定为“输出”缓冲区。该函数返回写入输出缓冲区的字节数(如果有的话,存储在lpBytesReturned中),并且如果请求要异步执行,则接受一个可选的OVERLAPPED结构。
例如,考虑稀疏文件的概念。稀疏文件应该大部分内容是零,因此文件系统可以用比正常存储所有字节更少的空间来存储它。压缩也可以提供类似的效果,但这些格式并不相同。要将文件转换为稀疏文件,需要使用FSCTL_SET_SPARSE I/O控制代码调用DeviceIoControl。此控制代码的文档说明了输入和输出缓冲区应该包含什么内容。对于FSCTL_SET_SPARSE,输入缓冲区应该指向以下结构:
typedef struct _FILE_SET_SPARSE_BUFFER {
BOOLEAN SetSparse;
} FILE_SET_SPARSE_BUFFER;
2
3
这是一个非常简单的结构,用于指示是否启用稀疏文件功能。此操作没有输出缓冲区。将文件设置为稀疏文件可以这样做:
FILE_SET_SPARSE_BUFFER buffer;
buffer.SetSparse = TRUE;
DWORD bytes;
::DeviceIoControl(hFile, FSCTL_SET_SPARSE, &buffer, sizeof(buffer),
nullptr, 0, &bytes, nullptr);
2
3
4
5
一旦文件变为稀疏文件,必须使用另一个控制代码FSCTL_SET_ZERO_DATA显式写入零,如下所示:
FILE_ZERO_DATA_INFORMATION buffer;
buffer.FileOffset.QuadPart = 100;
buffer.BeyondFinalZero.QuadPart = 1 << 20;
::DeviceIoControl(hFile, FSCTL_SET_ZERO_DATA, &buffer, sizeof(buffer),
nullptr, 0, &bytes, nullptr);
2
3
4
5
对于各种类型的设备,还有许多其他标准控制代码,更多信息请查看文档。
CreateFile适用于任何符号链接,如图11-3和图11-4中所示的那些。例如,有一些名为“PhysicalDrive0”的符号链接,可能还有其他的,这是一种直接打开驱动器扇区的方式,而无需通过文件系统的视角来查看。
DumpDrive应用程序从所需的扇区开始显示磁盘的原始字节。主函数首先解析命令行参数:
int main(int argc, const char* argv[]) {
if (argc < 4) {
printf("Usage: DumpDrive <index> <offset in sectors> <size in sectors>\n");
return 0;
}
WCHAR path[] = L"\\\\.\\PhysicalDriveX";
path[::wcslen(path) - 1] = argv[1][0];
auto offset = atoll(argv[2]) * 512;
auto size = atol(argv[3]) * 512;
2
3
4
5
6
7
8
9
10
偏移量和大小必须是扇区大小的倍数。否则,后续的ReadFile调用将因ERROR_INVALID_PARAMETER而失败。上面的代码假设每个扇区为512字节。最好不要做这样的假设,而是通过编程方式获取实际大小。本节末尾的练习将为你指明正确的方向。
接下来,我们需要打开驱动器,将文件指针移动到所需的偏移位置并执行读取操作:
HANDLE hDevice = ::CreateFile(path, GENERIC_READ, FILE_SHARE_READ
| FILE_SHARE_WRITE, nullptr, OPEN_EXISTING, 0, nullptr);
if (hDevice == INVALID_HANDLE_VALUE)
return Error("Failed to open Physical drive");
LARGE_INTEGER fp;
fp.QuadPart = offset;
if (!::SetFilePointerEx(hDevice, fp, nullptr, FILE_BEGIN))
return Error("Failed in SetFilePointerEx");
auto buffer = std::make_unique<BYTE[]>(size);
DWORD bytes;
if (!::ReadFile(hDevice, buffer.get(), size, &bytes, nullptr))
return Error("Failed to read data");
DisplayData(offset, buffer.get(), bytes);
::CloseHandle(hDevice);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
我们处理的是设备而不是文件系统文件这一事实并没有改变我们编写代码的基本方式。CreateFile的路径才是关键。DisplayData是一个简单的函数,用于将十六进制字节输出到控制台:
void DisplayData(long long offset, const BYTE* buffer, DWORD bytes) {
const int bytesPerLine = 16;
for (DWORD i = 0; i < bytes; i += bytesPerLine) {
printf("%16X: ", offset + i);
for (int b = 0; b < bytesPerLine; b++) {
printf("%02X ", buffer[i + b]);
}
printf("\n");
}
}
2
3
4
5
6
7
8
9
10
11
以下是在我的物理驱动器1上运行的一个截断示例:
c:\>DumpDrive 1 0 2
0: 33 C0 8E D0 BC 00 7C FB 50 07 50 1F FC BE 1B 7C
10: BF 1B 06 50 57 B9 E5 01 F3 A4 CB BD BE 07 B1 04
20: 38 6E 00 7C 09 75 13 83 C5 10 E2 F4 CD 18 8B F5
30: 83 C6 10 49 74 19 38 2C 74 F6 A0 B5 07 B4 07 8B
40: F0 AC 3C 00 74 FC BB 07 00 B4 0E CD 10 EB F2 88
50: 4E 10 E8 46 00 73 2A FE 46 10 80 7E 04 0B 74 0B
60: 80 7E 04 0C 74 05 A0 B6 07 75 D2 80 46 02 06 83
70: 46 08 06 83 56 0A 00 E8 21 00 73 05 A0 B6 07 EB
...
120: 32 E4 8A 56 00 CD 13 EB D6 61 F9 C3 49 6E 76 61
130: 6C 69 64 20 70 61 72 74 69 74 69 6F 6E 20 74 61
140: 62 6C 65 00 45 72 72 6F 72 20 6C 6F 61 64 69 6E
150: 67 20 6F 70 65 72 61 74 69 6F 6E 20 73 79 73 74
...
3E0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
3F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
添加代码以动态确定扇区的大小。使用IOCTL_DISK_GET_DRIVE_GEOMETRY控制代码查询磁盘的几何信息。
符号链接的其他用途是用于“软件驱动程序”,这些驱动程序不管理任何硬件,但需要执行在用户模式下无法完成的操作。一个典型的例子是Process Explorer(进程资源管理器)的驱动程序,它必须公开一个符号链接,以便Process Explorer本身(驱动程序的客户端)可以打开设备句柄并对其调用DeviceIoControl,根据驱动程序建立并为Process Explorer所知的通信协议请求各种服务。
如果你至少以管理员权限运行一次Process Explorer,使用诸如WinObj或ObjectExplorer之类的工具,你会找到名为“ProcExp152”的符号链接。这意味着Process Explorer使用如下代码打开其设备句柄:
HANDLE hDevice = ::CreateFile(L"\\\\.\\ProcExp152", GENERIC_READ | GENERIC_WRITE, 0, nullptr,
OPEN_EXISTING, 0, nullptr);
2
然后在需要时调用DeviceIoControl。
我自己的工具ObjectExplorer也使用内核驱动程序,其符号链接名为“KObjExp”。我使用类似的CreateFile调用来与我的设备驱动程序进行通信。
另一组有趣的符号链接看起来像是毫无意义的字符串,不太可能是人为选择的;实际上,这些是由内核生成的(至少)用于确保唯一性。这些看起来很奇怪的符号链接用于硬件设备名称。例如,如果你想访问连接到计算机的摄像头,你会怎么做呢?并没有名为“Camera1”或类似名称的符号链接,因为这种字符串存在一些局限性:
- 如果有两个或更多摄像头怎么办?
- 设备可以拔出后再重新插入——数字编号会以某种方式保留吗?
- 英语有什么特别之处吗——为什么是“Camera”这个词?每个驱动程序都可以想出自己的名称。
- 如果名称可以是任意内容,如何枚举摄像头设备呢?
- 有些设备可能有多种“功能”。例如,打印机设备也可能是扫描仪。
一些DOS时代的经典名称仍然保留以保持兼容性,如PRN、LPT、COM、NUL等。
在幕后,设备公开设备接口,你可以将其视为与软件接口类似。每个接口代表某种功能。例如,打印机设备可以“实现”打印接口和扫描接口。有了这些接口,你就可以搜索“打印机”或“扫描仪”。
设备接口由GUID(全局唯一标识符,Globally Unique Identifier)表示,许多接口由微软定义,可以在文档中找到。这意味着我们需要使用一个API来定位设备,该API返回的部分信息是设备的符号链接,我们可以直接将其作为参数传递给CreateFile。
EnumDevices应用程序展示了一个如何基于设备接口枚举设备并定位设备符号链接的示例。该应用程序的核心是EnumDevices函数,它接受一个请求的设备接口的GUID(全局唯一标识符,Globally Unique Identifier),并执行枚举操作。每个设备信息通过以下结构体返回:
struct DeviceInfo {
std::wstring SymbolicLink;
std::wstring FriendlyName;
};
2
3
4
设备枚举从使用SetupDiGetClassDevs构建设备信息集(infoset)开始:
std::vector<DeviceInfo> EnumDevices(const GUID& guid) {
std::vector<DeviceInfo> devices;
auto hInfoSet = ::SetupDiGetClassDevs(&guid, nullptr , nullptr ,
DIGCF_PRESENT | DIGCF_INTERFACEDEVICE);
if (hInfoSet == INVALID_HANDLE_VALUE)
return devices;
2
3
4
5
6
7
“SetupDi”是“Setup Device Interface”的缩写。关于SetupDi系列API(应用程序编程接口,Application Programming Interface)的详细讨论超出了本书的范围。
SetupDiGetClassDevs的第一个参数是设备GUID,这要求最后一个标志参数包含DIGCF_INTERFACEDEVICE。指定的另一个标志(DIGCF_PRESENT)表示只应枚举已连接的设备。
一旦创建了信息集,就可以使用几个枚举函数对其进行枚举,在这种情况下,我们需要的是SetupDiEnumDeviceInterfaces。如果它返回FALSE,则意味着没有更多设备(或者发生了其他错误):
devices.reserve(4);
SP_INTERFACE_DEVICE_DATA data = { sizeof(data) };
SP_DEVINFO_DATA ddata = { sizeof(ddata) };
BYTE buffer[1 << 12];
for (DWORD i = 0; ; i++) {
if (!::SetupDiEnumDeviceInterfaces(hInfoSet, nullptr , &guid, i, &data))
break ;
2
3
4
5
6
7
枚举返回一个SP_INTERFACE_DEVICE_DATA结构体,可用于查询符号链接:
if (::SetupDiGetDeviceInterfaceDetail(hInfoSet, &data, details,
sizeof(buffer), nullptr , &ddata)) {
DeviceInfo info;
info.SymbolicLink = details->DevicePath;
2
3
4
最后,我们可以获取设备的“友好名称”,并将设备添加到向量中:
if(::SetupDiGetDeviceRegistryProperty(hInfoSet, &ddata,
SPDRP_DEVICEDESC, nullptr , buffer, sizeof(buffer), nullptr))
info.FriendlyName = (WCHAR*)buffer;
devices.push_back(std::move(info));
}
}
::SetupDiDestroyDeviceInfoList(hInfoSet);
return devices;
}
2
3
4
5
6
7
8
9
10
11
DisplayDevices函数接受一组DeviceInfo实例,显示这些信息,并尝试使用CreateFile打开一个句柄:
void DisplayDevices(const std::vector<DeviceInfo>& devices, const char* name) {
printf("%s\n%s\n", name, std::string(::strlen(name), '-').c_str());
for (auto& di : devices) {
printf("Symbolic link: %ws\n", di.SymbolicLink.c_str());
printf(" Name: %ws\n", di.FriendlyName.c_str());
auto hDevice = ::CreateFile(di.SymbolicLink.c_str(), GENERIC_READ,
FILE_SHARE_READ | FILE_SHARE_WRITE,
nullptr, OPEN_EXISTING, 0, nullptr);
if (hDevice == INVALID_HANDLE_VALUE)
printf(" Failed to open device (%d)\n", ::GetLastError());
else {
printf(" Device opened successfully!\n");
::CloseHandle(hDevice);
}
}
printf("\n");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
主函数使用各种头文件中的一些GUID来枚举某些类型的设备:
#define INITGUID
#include <Wiaintfc .h>
#include <Ntddvdeo .h>
#include <devpkey.h>
#include <Ntddkbd .h>
int main() {
auto devices = EnumDevices(GUID_DEVINTERFACE_IMAGE);
DisplayDevices(devices, "Image");
// now in one stroke
DisplayDevices(EnumDevices(GUID_DEVINTERFACE_MONITOR), "Monitor");
DisplayDevices(EnumDevices(GUID_DEVINTERFACE_DISPLAY_ADAPTER),
"Display Adapter");
DisplayDevices(EnumDevices(GUID_DEVINTERFACE_DISK), "Disk");
DisplayDevices(EnumDevices(GUID_DEVINTERFACE_KEYBOARD), "keyboard");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
以下是在我的机器上运行的一个示例(已截断):
...
Monitor
-------
Symbolic link: \\?\display#deld06e#4&5dd6935&0&uid200195#{e6f07b5f-ee97-4a90-b0\
76-33f57bf4eaa7}
Name: Generic PnP Monitor
Device opened successfully!
Symbolic link: \\?\display#deld070#4&5dd6935&0&uid208387#{e6f07b5f-ee97-4a90-b0\
76-33f57bf4eaa7}
Name: Generic PnP Monitor
Device opened successfully!
Display Adapter
Symbolic link: \\?\pci#ven_8086&dev_3e9b&subsys_09261028&rev_02#3&11583659&0&10\
#{5b45201d-f2f2-4f3b-85bb-30ff1f953599}
Name: Intel(R) UHD Graphics 630
Failed to open device (5)
Symbolic link: \\?\pci#ven_10de&dev_1f36&subsys_09261028&rev_a1#4&13a74b11&0&00\
08#{5b45201d-f2f2-4f3b-85bb-30ff1f953599}
Name: NVIDIA Quadro RTX 3000
Failed to open device (5)
Symbolic link: \\?\root#basicdisplay#0000#{5b45201d-f2f2-4f3b-85bb-30ff1f953599}
Name: Microsoft Basic Display Driver
Failed to open device (5)
Disk
----
Symbolic link: \\?\scsi#disk&ven_nvme&prod_pm981a_nvme_sams#4&9bd8d03&0&020000#\
{53f56307-b6bf-11d0-94f2-00a0c91efb8b}
Name: Disk drive
Device opened successfully!
Symbolic link: \\?\usbstor#disk&ven_wd&prod_elements_10b8&rev_1012#575836314134\
344e39393230&0#{53f56307-b6bf-11d0-94f2-00a0c91efb8b}
Name: Disk drive
Device opened successfully!
keyboard
--------
Symbolic link: \\?\hid#vid_1532&pid_021e&mi_01&col01#9&5ed78c5&0&0000#{884b96c3\
-56ef-11d1-bc8c-00a0c91405dd}
Name: Razer Ornata Chroma
Failed to open device (5)
Symbolic link: \\?\hid#vid_044e&pid_1212&col01&col02#7&1551398c&0&0001#{884b96c\
3-56ef-11d1-bc8c-00a0c91405dd}
Name: HID Keyboard Device
Failed to open device (5)
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
前缀“\?\”与“\.\”相同。
# 管道和邮槽
本节值得提及两种类型的设备——管道(Pipes)和邮槽(Mailslots)。管道是一种单向或双向(也称为半双工和全双工)的通信机制,可跨进程以及跨网络中的计算机工作。邮槽是一种单向通信机制,可在本地或通过网络工作。
你可以使用对象资源管理器(Object Explorer)查看现有的管道和邮槽。从“对象”菜单中选择“管道...”或“邮槽...”。在一个典型的系统上有很多打开的管道(图11-11)。
 图11-11:系统上的管道(对象资源管理器)
图11-11:系统上的管道(对象资源管理器)
表11-1展示了一个与命名管道和邮槽相关的路径示例。CreateFile函数由命名管道/邮槽客户端使用。对于服务器端点,则需要使用其他函数。
# 管道
管道有两种变体——匿名管道和命名管道。匿名管道是一种简单的单向通信机制,仅限于本地计算机。匿名管道对通过CreatePipe创建:
BOOL CreatePipe(
_Out_ PHANDLE hReadPipe,
_Out_ PHANDLE hWritePipe,
_In_opt_ LPSECURITY_ATTRIBUTES lpPipeAttributes,
_In_ DWORD nSize);
2
3
4
5
CreatePipe为管道的两端创建句柄。使用匿名管道的一个经典示例是将输入和/或输出重定向到另一个进程。这允许一个进程将数据提供给另一个进程,而另一个进程对此一无所知,也并不关心,它只是使用标准句柄进行输入/输出。
SimpleRedirect应用程序展示了一个将输出句柄重定向到上一节的EnumDevices应用程序的示例。EnumDevices的输出不会输出到其控制台,而是会输出到SimpleRedirect进程。
该应用程序窗口是一个带有大编辑框的简单对话框(图11-12)。点击“创建并重定向”会创建管道、启动EnumDevices进程并执行重定向。结果是该进程写入的文本(图11-13)。
 图11-12:启动时的Simple Redirect
图11-12:启动时的Simple Redirect
 图11-13:Simple Redirect中重定向的文本
图11-13:Simple Redirect中重定向的文本
基本思路是创建一个匿名管道,并将其写入端共享给EnumDevices进程。这样,EnumDevices进程写入的任何内容,都可以通过管道的读取端读取。为了使其正常工作,管道的写入端必须连接到EnumDevices进程的标准输出,这样任何标准输出调用(例如printf)都可以通过管道获取。这种安排如图11-14所示。
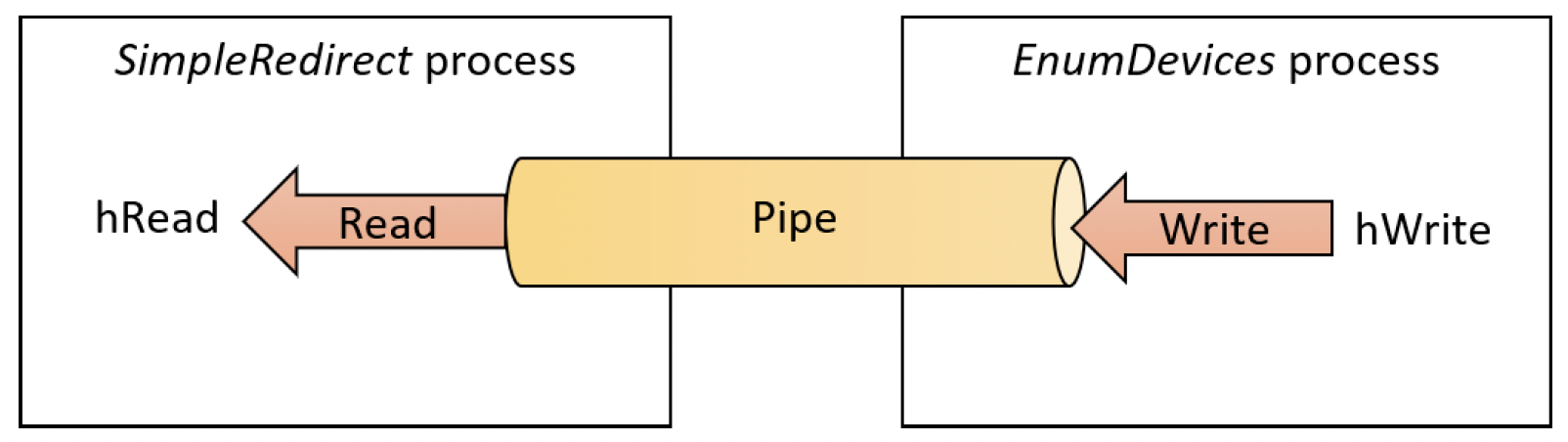 图11-14:带重定向的匿名管道
图11-14:带重定向的匿名管道
关键在于将写入句柄传递给新进程,这通过进程句柄继承来完成,如第3章所述。
CMainDlg::OnRedirect函数负责创建管道并使用它。首先,它创建管道:
LRESULT CMainDlg::OnRedirect(WORD, WORD wID, HWND, BOOL&) {
wil::unique_handle hRead, hWrite;
if (!::CreatePipe(hRead.addressof(), hWrite.addressof(), nullptr, 0))
return Error(L"Failed to create pipe");
2
3
4
5
接下来,需要将写入句柄与新进程(尚未创建)共享,因此必须使其可继承:
::SetHandleInformation(hWrite.get(), HANDLE_FLAG_INHERIT, HANDLE_FLAG_INHERIT);
现在,可以通过调用CreateOtherProcess辅助函数(稍后讨论)来创建EnumDevices进程。然后,不再需要本地写入句柄,因此可以关闭它:
if (!CreateOtherProcess(hWrite.get()))
return Error(L"Failed to create process");
// 本地写入句柄不再需要
hWrite.reset();
2
3
4
5
剩下要做的就是从管道的读取端读取数据并使用这些数据:
char buffer[1 << 12] = { 0 };
DWORD bytes;
CEdit edit(GetDlgItem(IDC_TEXT));
ATLASSERT(edit);
while (::ReadFile(hRead.get(), buffer, sizeof(buffer), &bytes, nullptr) && bytes > 0) {
CString text;
edit.GetWindowText(text);
text += CString(buffer);
edit.SetWindowText(text);
::memset(buffer, 0, sizeof(buffer));
}
2
3
4
5
6
7
8
9
10
11
这是一个普通的ReadFile调用,只要另一端有数据写入管道,就会重复执行。
为了使这个功能正常工作,需要使用句柄继承和适当的标志来创建新进程,以便将继承的句柄用作标准输出:
bool CMainDlg::CreateOtherProcess(HANDLE hOutput) {
PROCESS_INFORMATION pi;
STARTUPINFO si = { sizeof(si) };
si.hStdOutput = hOutput;
si.dwFlags = STARTF_USESTDHANDLES;
WCHAR path[MAX_PATH];
::GetModuleFileName(nullptr, path, _countof(path));
*::wcsrchr(path, L'\\') = L'\0';
::wcscat_s(path, L"\\EnumDevices.exe");
BOOL created = ::CreateProcess(nullptr, path, nullptr, nullptr, TRUE,
CREATE_NO_WINDOW, nullptr, nullptr, &si, &pi);
if (created) {
::CloseHandle(pi.hProcess);
::CloseHandle(pi.hThread);
}
return created;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
STARTUPINFO结构通过将hStdOutput成员设置为写入句柄的值来初始化。这之所以可行,是因为继承的句柄在新进程中具有相同的值。STARTF_USESTDHANDLES标志确保新进程自动获取标准句柄。
为了定位EnumDevices可执行文件,代码假定它与当前可执行文件位于同一目录中。第一个参数为NULL的GetModuleFileName函数会返回当前进程的完整可执行文件路径。然后,将文件名部分替换为“EnumDevices”。
最后,调用CreateProcess函数时将句柄继承标志设置为TRUE(第五个参数)。返回的句柄会被正确关闭,因为实际上并不需要它们。添加CREATE_NO_WINDOW标志是一个不错的做法,可以防止新进程弹出控制台窗口。
命名管道(Named pipes)和邮件槽(mailslots)将在单独的章节(第二部分)中讨论。
# 事务性NTFS
Windows执行体有一个名为内核事务管理器(Kernel Transaction Manager,KTM)的组件,它为文件(和注册表)操作使用事务提供支持。对于文件操作,它有时也被称为事务性NTFS(Transactional NTFS,TxF)。事务是一组遵循所谓ACID属性的操作:
- 原子性(Atomicity):事务中的所有操作要么全部成功,要么全部失败。
- 一致性(Consistency):文件系统始终处于一致状态。
- 隔离性(Isolation):多个正在进行的事务不会相互影响。
- 持久性(Durability):系统故障不应导致事务违反上述属性。
多年来,微软的文档一直在警告开发人员不要依赖KTM,而是寻找其他机制来获得类似的结果。该警告表明,文件和注册表操作的事务支持可能会在未来的Windows版本中被移除。原因是什么呢?我猜测是因为使用这个强大功能的开发人员并不多。无论如何,这一情况尚未发生,而且在我看来,文档中列出的替代方案并不能真正取代KTM。
本节将简要介绍TxF。要开始事务操作,可以调用CreateTransaction来创建一个新事务:
HANDLE CreateTransaction (
_In_opt_ LPSECURITY_ATTRIBUTES lpTransactionAttributes,
_In_opt_ LPGUID UOW, // 必须为NULL
_In_opt_ DWORD CreateOptions,
_In_opt_ DWORD IsolationLevel, // 必须为0
_In_opt_ DWORD IsolationFlags, // 必须为0
_In_opt_ DWORD Timeout,
_In_opt_ LPTSTR Description);
2
3
4
5
6
7
8
事务API有自己的#include(<ktmw32.h>)和导入库(ktmw32.lib)。
该函数有一些未使用的参数。lpTransactionAttributes是标准的SECURITY_ATTRIBUTES结构。CreateOptions可以为零或TRANSACTION_DO_NOT_PROMOTE,以防止将事务提升为分布式事务。如果提供的Timeout不为零或INFINITE,则事务将在指定的毫秒数过去后中止。否则,事务没有超时限制。最后一个参数是一个可选的、供人阅读的字符串,用于描述事务。
该函数返回新事务的句柄,如果失败,则返回INVALID_HANDLE_VALUE。
有了事务句柄后,一些与文件相关的函数可以接受事务句柄,例如CreateFileTransacted:
HANDLE CreateFileTransacted(
_In_ LPCTSTR lpFileName,
_In_ DWORD dwDesiredAccess,
_In_ DWORD dwShareMode,
_In_opt_ LPSECURITY_ATTRIBUTES lpSecurityAttributes,
_In_ DWORD dwCreationDisposition,
_In_ DWORD dwFlagsAndAttributes,
_In_opt_ HANDLE hTemplateFile,
_In_ HANDLE hTransaction,
_In_opt_ PUSHORT pusMiniVersion,
_Reserved_ PVOID lpExtendedParameter); // NULL
2
3
4
5
6
7
8
9
10
11
该函数是CreateFile的扩展版本。文件名必须引用本地文件,否则函数将失败,并且GetLastError返回ERROR_TRANSACTIONS_UNSUPPORTED_REMOTE。hTransaction是从CreateTransaction获得的事务句柄。
如果文件仅以读取访问方式打开,则pusMiniVersion参数应为NULL。如果以写入访问方式打开,则它指示在事务期间文件应向客户端呈现何种视图(在txfw32.h中定义):
TXFS_MINIVERSION_COMMITTED_VIEW:基于上次提交的视图。TXFS_MINIVERSION_DIRTY_VIEW:事务正在修改时的脏视图。TXFS_MINIVERSION_DEFAULT_VIEW:对于不修改文件的事务,为已提交视图;否则为脏视图。- 也可以使用
FSCTL_TXFS_CREATE_MINIVERSIONI/O控制代码创建自定义的小版本视图(查看文档)。
CreateFileTransacted返回的句柄可以传递给普通的I/O访问函数,例如ReadFile和WriteFile。这意味着,一旦以事务方式创建了文件对象,对该文件的所有其他操作都保持完全相同。
与CreateFileTransacted类似,还有其他函数可以作为事务的一部分工作:CopyFileTransacted、CreateHardLinkTransacted、DeleteFileTransacted、CreateDirectoryTransacted等等。
一旦所有操作都成功完成,就可以使用CommitTransaction提交事务:
BOOL CommitTransaction(_In_ HANDLE TransactionHandle);
如果事务中的各种操作出现问题,可以请求回滚所有操作:
BOOL RollbackTransaction(_In_ HANDLE TransactionHandle);
事务句柄通常使用CloseHandle关闭。
事务的内核对象类型是TmTx。
每个事务都有一个ID,可以使用GetTransactionId获取:
BOOL GetTransactionId (
_In_ HANDLE TransactionHandle,
_Out_ LPGUID TransactionId);
2
3
返回的GUID可用于使用OpenTransaction打开现有事务的句柄:
HANDLE OpenTransaction (
_In_ DWORD dwDesiredAccess,
_In_ LPGUID TransactionId);
2
3
事务在底层是通过通用日志文件系统(Common Log FileSystem,CLFS)日志记录功能实现的。
# 文件搜索和枚举
有时需要搜索或枚举文件和目录。幸运的是,文件管理API提供了几个函数来完成这项工作。要开始枚举/搜索,可以调用FindFirstFile或FindFirstFileEx:
HANDLE FindFirstFileW(
_In_ LPCTSTR lpFileName,
_Out_ LPWIN32_FIND_DATA lpFindFileData);
HANDLE FindFirstFileEx(
_In_ LPCTSTR lpFileName,
_In_ FINDEX_INFO_LEVELS fInfoLevelId,
_Out_ LPVOID lpFindFileData,
_In_ FINDEX_SEARCH_OPS fSearchOp,
_Reserved_ LPVOID lpSearchFilter,
_In_ DWORD dwAdditionalFlags);
2
3
4
5
6
7
8
9
10
11
这两个函数都接受一个文件名来开始搜索。这个文件名可以是任何路径规范,并且可以包含通配符。例如c:\temp\*.png和c:\mydir\file??.txt。
每个结果都通过定义如下的WIN32_FIND_DATA结构返回:
typedef struct _WIN32_FIND_DATA {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD dwReserved0;
DWORD dwReserved1;
_Field_z TCHAR cFileName[MAX_PATH];
_Field_z TCHAR cAlternateFileName[14];
} WIN32_FIND_DATA, *PWIN32_FIND_DATA, *LPWIN32_FIND_DATA;
2
3
4
5
6
7
8
9
10
11
12
该结构给出了文件的基本属性。
扩展函数有一个fInfoLevelId参数,用于指示返回哪些信息。使用FindExInfoStandard与非扩展函数等效。另一个可选值FindExInfoBasic不会返回短文件名(在cAlternateFileName中),这会加快搜索操作,并且由于很少(如果有的话)需要短文件名,所以推荐使用该值。
fSearchOp参数唯一有用的值是FindExSearchLimitToDirectories,它表示仅查找目录。并非所有文件系统都支持这个提示,所以不要依赖它。
扩展函数的最后一个参数dwAdditionalFlags为搜索提供了更多自定义选项:
FIND_FIRST_EX_CASE_SENSITIVE- 搜索区分大小写。FIND_FIRST_EX_LARGE_FETCH- 使用更大的缓冲区进行搜索,这可以提高性能,但会消耗更多内存。FIND_FIRST_EX_ON_DISK_ENTRIES_ONLY- 跳过非驻留文件(例如像OneDrive这类服务中常见的虚拟化文件)。
这些函数返回一个搜索句柄,如果发生错误,则返回INVALID_HANDLE_VALUE。
如果句柄有效,就可以获取第一个搜索匹配项。要查找下一个匹配项,可以调用FindNextFile函数:
BOOL FindNextFile(
_In_ HANDLE hFindFile,
_Out_ LPWIN32_FIND_DATA lpFindFileData);
2
3
该函数返回下一个匹配项,如果没有匹配项,则返回FALSE。
当搜索完成后,调用FindClose函数关闭搜索句柄:
BOOL FindClose(_Inout_ HANDLE hFindFile);
# NTFS数据流
NTFS文件系统支持文件流(file streams),本质上就是文件中的文件。通常情况下,我们使用默认的数据流,但也可以创建和使用其他数据流。这些数据流在正常视图中基本是隐藏的,不会出现在像Windows资源管理器这样的标准工具中。
一个常见的例子是,从网络上下载某些类型的文件时,在资源管理器中选择“属性”,会出现类似图11-15的内容。
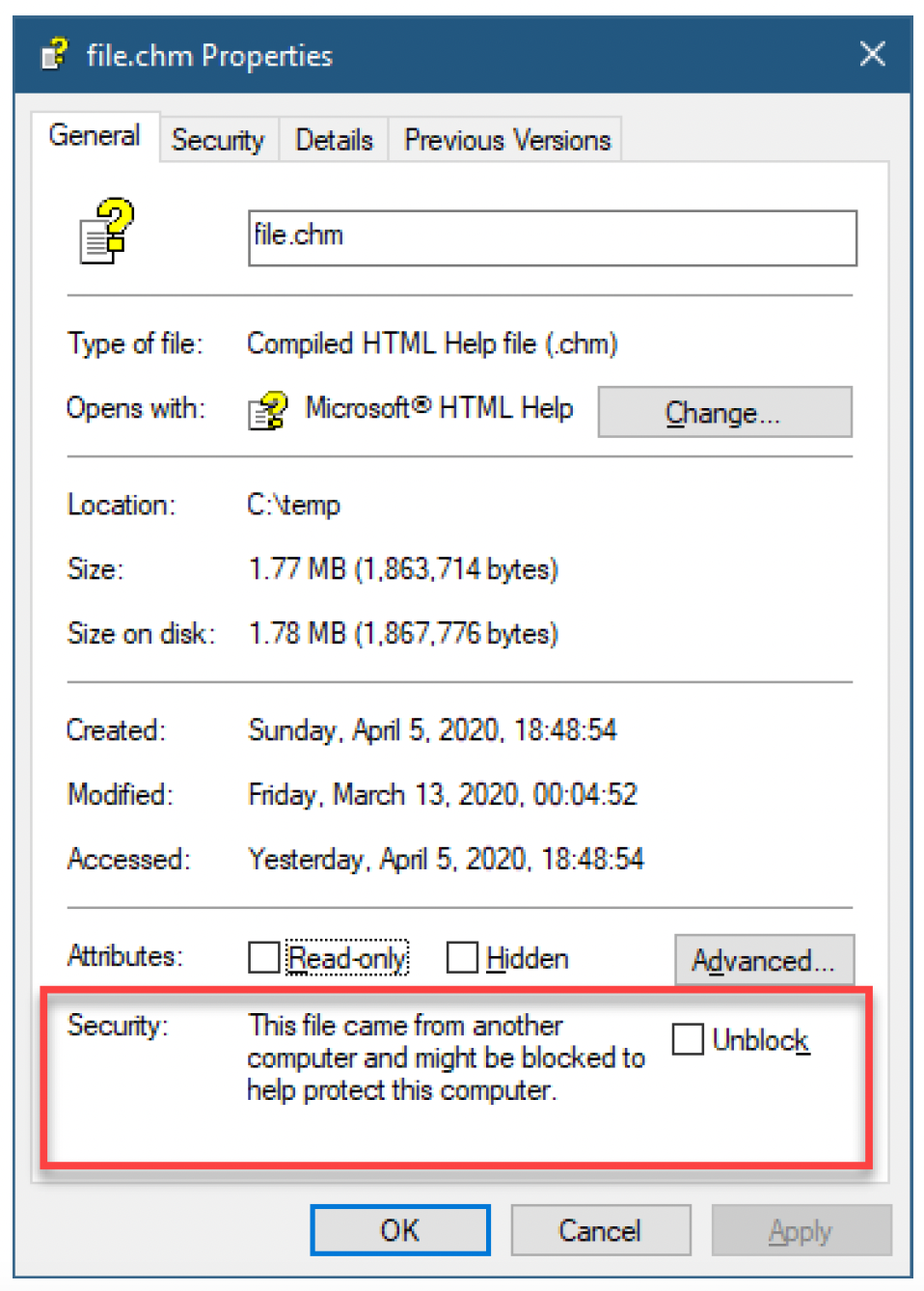 图11-15:一个“被阻止”文件的属性
图11-15:一个“被阻止”文件的属性
资源管理器是如何“知道”这个文件来自另一台计算机的呢?秘密就在于文件内部的一个NTFS数据流。Sysinternals的streams命令行工具可以识别这类数据流。下面是图11-15中文件的输出结果:
C:\>streams -nobanner file.chm
C:\file.chm:
:Zone.Identifier:$DATA 26
2
3
在这个文件中有一个隐藏的NTFS数据流,名为“Zone.Identifier”,长度为26字节。streams工具不会显示NTFS数据流的内容,但我的工具“NTFS Streams”可以(图11-16)。
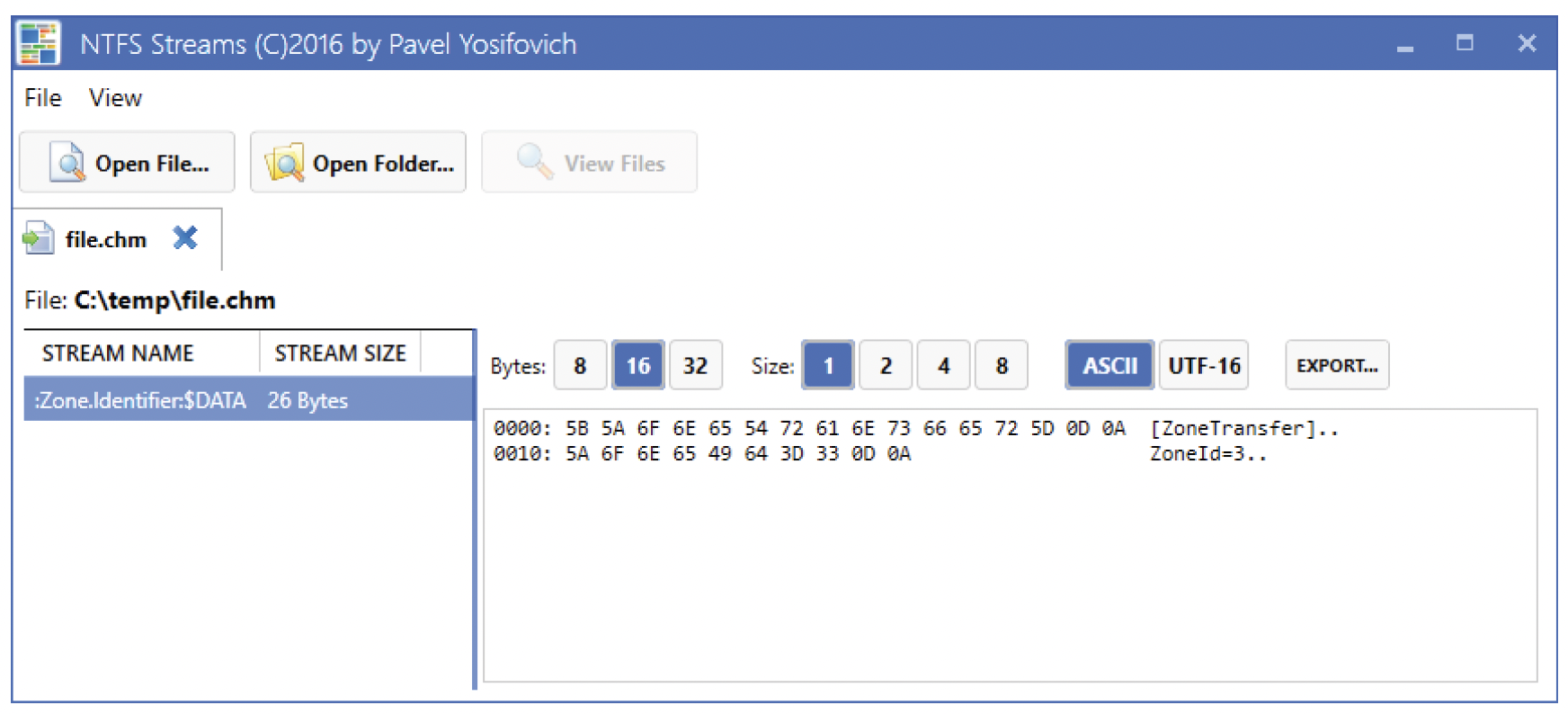 图11-16:NTFS Streams中的流内容
图11-16:NTFS Streams中的流内容
你可以在我的GitHub仓库(https://github.com/zodiacon/AllTools 或 https://github.com/zodiacon/NtfsStreams )中找到“NTFS Streams”。
Windows应用程序HTML帮助(hh.exe)会查找这个数据流,如果找到,就不会解析HTML内容。
图11-15中的“解除阻止”复选框会删除这个数据流,从而使HTML帮助正常工作。
我们如何创建这样的隐藏数据流呢?可以使用普通的CreateFile函数,在文件名后加上冒号和数据流的名称。下面是一个示例:
HANDLE hFile = ::CreateFile(L"c:\\temp\\myfile.txt:mystream", GENERIC_WRITE, 0,
nullptr, CREATE_NEW, 0, nullptr);
char text[] = "Hello from a hidden stream!";
DWORD bytes;
::WriteFile(hFile, text, ::strlen(text), &bytes, nullptr);
::CloseHandle(hFile);
2
3
4
5
6
下面是与这个新文件的一些交互操作:
C:\temp>dir myfile.txt
Volume in drive C is OS
Volume Serial Number is 9010-6C18
Directory of C:\temp
06-Apr-20 12:11 0 myfile.txt
1 File(s) 0 bytes
0 Dir(s) 904,581,414,912 bytes free
C:\temp>streams -nobanner myfile.txt
C:\temp\myfile.txt:
:mystream:$DATA 27
2
3
4
5
6
7
8
9
10
11
12
13
这个文件显示大小为零!显然并非如此,因为里面有一个可以任意长度的隐藏数据流。“NTFS Streams”会显示这个数据流的内容。
“$DATA”后缀是默认数据流的重解析点。可以创建自定义重解析点,文件系统筛选驱动程序会以特殊方式处理它们。但这超出了本书的范围。
你可能想知道streams和“NTFS Streams”是如何工作的。有两个函数可以枚举文件中的数据流,与上一节的搜索函数非常相似:
HANDLE WINAPI FindFirstStream(
_In_ LPCTSTR lpFileName,
_In_ STREAM_INFO_LEVELS InfoLevel,
_Out_ LPVOID lpFindStreamData,
_Reserved_ DWORD dwFlags);
2
3
4
5
BOOL FindNextStreamW(
_In_ HANDLE hFindStream,
_Out_ LPVOID lpFindStreamData);
2
3
这些函数可以枚举文件中的所有数据流。lpFindStreamData参数中返回的每个值实际上是以下结构:
typedef struct _WIN32_FIND_STREAM_DATA {
LARGE_INTEGER StreamSize;
WCHAR cStreamName[MAX_PATH + 36];
} WIN32_FIND_STREAM_DATA, *PWIN32_FIND_STREAM_DATA;
2
3
4
该结构提供了数据流的大小和名称。
编写一个与streams功能相同的工具。
# 总结
本章主要介绍了输入/输出操作。我们学习了如何同步和异步地处理文件和设备。本章没有涵盖更多与文件相关的API,你可以在文档中找到更多相关信息。本章未讨论的功能示例包括文件操作(复制、移动等)、文件链接(软链接和硬链接)、文件锁定以及文件加密和解密。
在下一章中,我们将探索一个任何应用程序或操作系统都不可或缺的新领域——内存管理。