 第13章:内存操作
第13章:内存操作
# 第13章:内存操作
在第12章中,我们探讨了虚拟内存和物理内存的基础知识。在本章中,我们将讨论开发人员可用于管理内存的各种应用程序编程接口(API,Application Programming Interface)。有些API更适合用于大内存分配,而另一些则更适合管理小内存分配。学完本章后,你应该能很好地理解各种API及其功能,从而在涉及内存的工作中选择合适的工具。
本章内容包括:
- 内存API
VirtualAlloc*函数- 保留和提交内存
- 工作集
- 堆
- 其他虚拟函数
- 写入和读取其他进程的内存
- 大页面
- 地址窗口化扩展(Address Windowing Extensions)
- 非统一内存访问(NUMA,Non-Uniform Memory Architecture)
VirtualAlloc2函数
# 内存API
Windows提供了几组用于内存操作的API。图13-1展示了可用的API组及其依赖关系。
 图13-1:Windows用户模式API
图13-1:Windows用户模式API
我们将从最低级别到最高级别来研究这些API。每组API都有其优点和缺点。
# VirtualAlloc*函数
最底层的虚拟API(Virtual API)与内存管理器最为接近,这带来了几个影响:
- 它是功能最强大的API,几乎可以实现对虚拟内存的所有操作。
- 它始终以页为单位进行操作,并且操作的地址必须是页边界。
- 正如我们将在本章中看到的,它被更高级别的API所使用。
用于保留和 / 或提交内存的最基本函数是VirtualAlloc:
LPVOID VirtualAlloc(
_In_opt_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD flAllocationType,
_In_ DWORD flProtect);
2
3
4
5
扩展函数VirtualAllocEx可在不同的进程中进行操作:
LPVOID VirtualAllocEx(
_In_ HANDLE hProcess,
_In_opt_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD flAllocationType,
_In_ DWORD flProtect);
2
3
4
5
6
VirtualAllocEx与VirtualAlloc的区别仅在于多了一个进程句柄参数,该进程句柄必须具有PROCESS_VM_OPERATION访问掩码。
VirtualAlloc(Ex)不能在通用Windows平台(UWP,Universal Windows Platform )进程中调用。Windows 10增加了一个VirtualAlloc的变体VirtualAllocFromApp,可以在UWP进程中调用:
PVOID VirtualAllocFromApp(
_In_opt_ PVOID BaseAddress,
_In_ SIZE_T Size,
_In_ ULONG AllocationType,
_In_ ULONG Protection);
2
3
4
5
为了让UWP进程使用起来更方便,VirtualAlloc被内联定义并调用VirtualAllocFromApp,所以从技术上讲,你可以在UWP进程中调用VirtualAlloc。
Windows 10版本1803中引入了另一个VirtualAlloc的变体VirtualAlloc2,我们将在专门的章节中讨论它。还有一个VirtualAlloc的变体VirtualAllocExNuma,专门用于非统一内存访问(NUMA)架构,我们也会在相应章节进行讨论 。
我们将从描述基本的VirtualAlloc函数开始,其他相关函数都是在此基础上构建的。VirtualAlloc的主要作用是保留和 / 或提交一块内存。
VirtualAlloc的第一个参数是一个可选指针,指定保留 / 提交操作应在何处进行。如果是新的分配,通常传入NULL,这表明内存管理器应寻找某个空闲地址。如果该区域已经被保留,并且需要在该区域内进行提交操作,那么lpAddress则指示提交操作应从何处开始。在任何情况下,地址都会向下舍入到最近的页边界。对于新的保留操作,地址会向下舍入到分配粒度。
在所有Windows架构和版本中,当前的分配粒度是64KB。你可以通过调用
GetSystemInfo动态获取该值。
dwSize是要保留 / 提交的内存块大小。如果lpAddress为NULL,大小会向上舍入到最近的页边界。例如,1KB会被舍入到4KB,50KB会被舍入到52KB。如果lpAddress不为NULL,那么从lpAddress到lpAddress + dwSize范围内的所有页都会被包含在内。
flAllocationType指示要执行的操作类型。最常见的标志是MEM_RESERVE和MEM_COMMIT。使用MEM_RESERVE时,会保留内存区域,但如果lpAddress指定的是一个已被保留的区域,函数将会失败。
MEM_COMMIT用于提交之前保留的区域(或区域的一部分)。这意味着在这种情况下lpAddress不能为NULL。不过,可以通过组合这两个标志来同时保留和提交内存。例如,以下代码保留并提交128KB的内存:
void* p = ::VirtualAlloc(nullptr, 128 << 10, MEM_COMMIT | MEM_RESERVE,
PAGE_READWRITE);
if (!p) {
// 发生了一些错误
}
2
3
4
5
VirtualAlloc的一个漏洞:从技术上讲,你可以仅使用MEM_COMMIT来同时提交和保留内存。严格来说,这是不正确的。它能起作用的原因可以追溯到该API存在的一个漏洞。不幸的是,许多开发人员(不管是否知情)都利用了这个漏洞,所以微软决定不修复它,以免现有代码出现问题。如果要同时保留和提交内存,你应该始终使用这两个标志。
任何已提交的页面都保证会被填充为零。这是出于安全要求,即一个进程永远不能看到属于另一个进程的任何内存,即使该进程已不存在。明确地说,内存总是会被清零。
像malloc这类函数则不是这样,本章后面会说明原因。
保留一个已经被保留的内存区域是错误的。另一方面,提交已经提交过的内存会隐式成功。
VirtualAlloc的最后一个参数是为保留 / 提交的内存设置的页面保护(有关保护标志的更多信息,请参阅第1部分的第12章)。对于已提交的内存,这就是要设置的页面保护。对于保留的内存,它设置的是初始保护(MEMORY_BASIC_INFORMATION中的AllocationProtect成员),不过在后续提交内存时,该保护设置可能会改变。保护标志对保留的内存没有实际影响,因为保留的内存是不可访问的。即便如此,在这种情况下也必须提供一个有效值。
VirtualAlloc的返回值在操作成功时是操作的基地址,否则为NULL。如果lpAddress不为NULL,返回值可能等于也可能不等于lpAddress,这取决于其页对齐或分配粒度对齐情况(如前所述) 。
除了MEM_RESERVE和MEM_COMMIT,VirtualAlloc还有其他可能的标志:
MEM_RESET是一个标志,如果使用它,必须是唯一的标志。它向内存管理器表明该范围内已提交的内存不再需要,因此内存管理器无需将其写入页面文件。已提交的内存不能由映射文件支持,只能由页面文件支持。请注意,这与取消提交内存不同;内存仍然是提交状态,以后还可以使用(见下一个标志)。MEM_RESET_UNDO与MEM_RESET相反,表示再次需要该已提交的内存区域。该范围内的值不一定为零,因为内存管理器可能已经重新使用了映射的物理页,也可能没有。MEM_LARGE_PAGES表示操作应使用大页面而非小页面。我们将在本章后面的 “大页面” 部分讨论这个选项。MEM_PHYSICAL是一个只能与MEM_RESERVE一起指定的标志,用于地址窗口化扩展(AWE,Address Windowing Extensions),本章后面会介绍。MEM_TOP_DOWN是一个建议标志,用于告知内存管理器优先使用高地址而非低地址。MEM_WRITE_WATCH是一个必须与MEM_RESERVE一起指定的标志。该标志指示系统应跟踪对该区域的内存写入操作(当然,是在提交之后)。在 “内存跟踪” 部分将进一步介绍。
# 取消提交/释放内存
VirtualAlloc必须有一个相反的函数,能够取消提交和 / 或释放(与保留相反)一块内存。这就是VirtualFree和VirtualFreeEx的作用:
BOOL VirtualFree(
_in_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD dwFreeType);
2
3
4
BOOL VirtualFreeEx(
_In_ HANDLE hProcess,
_In_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD dwFreeType);
2
3
4
5
VirtualFreeEx是VirtualFree的扩展版本,在由hProcess指定的进程中执行请求的操作,hProcess必须具有PROCESS_VM_OPERATION访问掩码(与VirtualAllocEx一样)。dwFreeType参数仅支持两个标志 ——MEM_DECOMMIT和MEM_RELEASE,必须且只能指定其中一个。
MEM_DECOMMIT用于取消提交从lpAddress到lpAddress + dwSize范围内的页面,将内存区域恢复为保留状态。MEM_RELEASE表示应完全释放该区域。
lpAddress必须是最初保留区域的基地址,并且dwSize必须为零。如果该区域内有任何已提交的内存,会先取消提交,然后再释放整个区域(页面变为空闲状态)。
# 保留和提交内存
当需要进行大内存分配时,使用VirtualAlloc函数来保留和提交内存是个不错的选择,因为该函数以页粒度进行操作。对于小内存分配,使用VirtualAlloc则过于浪费,因为每次新的分配都在新的页面上。对于小内存分配,更好的选择是使用堆函数(本章后面会介绍)。
已提交内存和随机存取存储器(RAM):提交内存并不意味着会立即为该内存分配RAM。提交内存会增加系统的总提交量,这意味着它保证在访问已提交内存时,该内存可用。一旦访问某个页面,系统会将该页面放入RAM中,访问才能顺利进行。如果系统内存不足,将页面放入RAM可能会以牺牲另一个RAM中的页面为代价,该页面会被交换到磁盘上。无论如何,这个过程对应用程序来说是透明的。
假设你想创建一个类似Microsoft Excel的应用程序,其中有一个单元格网格用于输入某种数据。进一步假设你希望用户可以使用一个大网格,比如1024×1024个单元格,并且每个单元格可以存储1KB的数据。在这样的应用程序中,你该如何管理这些单元格呢?
一种方法是使用某种链表或映射实现,其中每个元素是一个1KB的内存块。当用户访问某个单元格时,根据管理的数据结构检索该元素并使用。由于每个单元格大小相同,另一种选择可能是分配一个足够大的内存块,然后通过简单计算来访问特定的单元格。以下是一个示例:
int cellSize = 1 << 10; // 1 KB
int maxx = 1 << 10, maxy = 1 << 10; // 1024 x 1024 个单元格
void* data = malloc(maxx * maxy * cellSize);
// 定位单元格 (x,y) 的地址
void* pCell = (BYTE*)data + (y * maxx + x) * cellSize;
// 对pCell进行访问...
2
3
4
5
6
这种方法可行,并且定位单元格的速度非常快。问题在于,它预先提交了1GB的内存。这很浪费,因为用户不太可能使用所有可用的单元格。此外,如果我们以后决定允许使用更多单元格,已提交的内存必须更大。
我们想要的是一种既能快速定位单元格,又能在使用单元格数据时才进行分配的方法。这就是保留内存并按块提交可以解决问题的地方。我们首先保留1GB的地址空间:
void* data = ::VirtualAlloc(nullptr, maxx * maxy * cellSize,
MEM_RESERVE, PAGE_READWRITE);
2
保留操作的开销非常小,系统的提交大小不会被修改。现在,每当需要访问某个单元格时,我们可以像之前一样计算其在内存块中的地址,然后提交所需的单元格:
// 为单元格 (x, y) 提交页面
void* pCell = (BYTE*)data + (y * maxx + x) * cellSize;
::VirtualAlloc(pCell, cellSize, MEM_COMMIT, PAGE_READWRITE);
// 访问单元格...
2
3
4
代码像之前一样计算单元格的地址,但由于内存最初是保留的,所以该地址处实际上没有数据。以任何方式访问该内存都会导致访问冲突异常。通过使用带有MEM_COMMIT标志的VirtualAlloc,单元格所在的页面被提交,使其变为 “真实” 的内存。现在访问该内存必定会成功。
VirtualAlloc始终按页进行操作,所以上述代码提交的是4个单元格(请记住每个单元格大小为1KB),而不只是一个。使用Virtual*函数时,这是无法避免的。
每当需要使用一个单元格时,都会运行相同的代码,提交该单元格(以及相邻的3个单元格),以便可以访问它们。内存仅用于那些被使用的单元格(以及相邻的单元格,即使它们未被使用)。这种方案使我们能够使用大量潜在的单元格,而不会浪费过多内存。例如,我们可以将最大网格大小增加到2048×2048。唯一的变化是保留的内存量,以保持地址空间的连续性。
这种方法的主要缺点是占用了大量的地址空间。在64位进程中(其地址空间为128TB),这不是问题。但在32位进程中,这可能会失败。例如,使用2048×2048的网格,每个单元格1KB内存,需要4GB的地址空间,这超出了32位进程的能力(即使在设置了LARGEADDRESSAWARE的WOW64环境中也是如此,因为地址空间还必须包含动态链接库(DLL,Dynamic - Link Library )、线程栈等)。地址范围还必须是连续的,即使大小较小,在32位进程中获取这样的地址范围也可能是个问题。
提交已经提交的内存不是问题,但这确实会引发一次系统调用,如果相关的单元格内存已经提交,或许可以避免这次系统调用。该怎么做呢?
一种方法是使用第12章中描述的VirtualQuery函数来查询内存区域,以决定是否提交内存。但这本身就需要一次系统调用,所以实际上比在每次访问前直接提交内存更糟糕。另一种选择是 “盲目” 地访问内存 —— 如果内存已经提交,访问会正常进行;如果没有提交,会引发一个异常,可以捕获该异常并通过提交所需的内存来处理。以下是代码的基本思路:
void DoWork(void* data, int x, int y) {
// 在某个函数中
void* pCell = (BYTE*)data + (y * maxx + x) * cellSize;
__try
// 访问单元格内存
::strcpy((char*)pCell, "some text data");
// 如果执行到这里,一切正常
}
__except(FixMemory(pCell, GetExceptionCode())) {
// 这里无需代码
}
}
int FixMemory(void* p, DWORD code) {
if (code == EXCEPTION_ACCESS_VIOLATION) {
// 我们可以通过提交内存来解决问题
::VirtualAlloc(p, cellSize, MEM_COMMIT, PAGE_READWRITE);
// 告诉CPU重试
return EXCEPTION_CONTINUE_EXECUTION;
}
// 其他异常,到别处寻找处理程序
return EXCEPTION_CONTINUE_SEARCH;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如果在strcpy调用中引发异常,__except表达式会通过使用有问题的地址和异常代码调用FixMemory函数进行求值。该函数的目的是返回三个可能的值之一,指示异常处理机制下一步该怎么做。如果异常代码是访问冲突,那么我们可以采取措施,提交所需的内存,然后返回EXCEPTION_CONTINUE_EXECUTION,指示处理器应重试原始指令。如果是其他异常,我们不处理它,而是返回EXCEPTION_CONTINUE_SEARCH,继续在调用栈中查找处理程序。
另一个可能的返回值是
EXCEPTION_EXECUTE_HANDLER。异常处理的详细内容请参阅第23章。
# 微型Excel应用程序
微型Excel应用程序展示了上述技术。运行该程序会显示图13-2中的对话框。
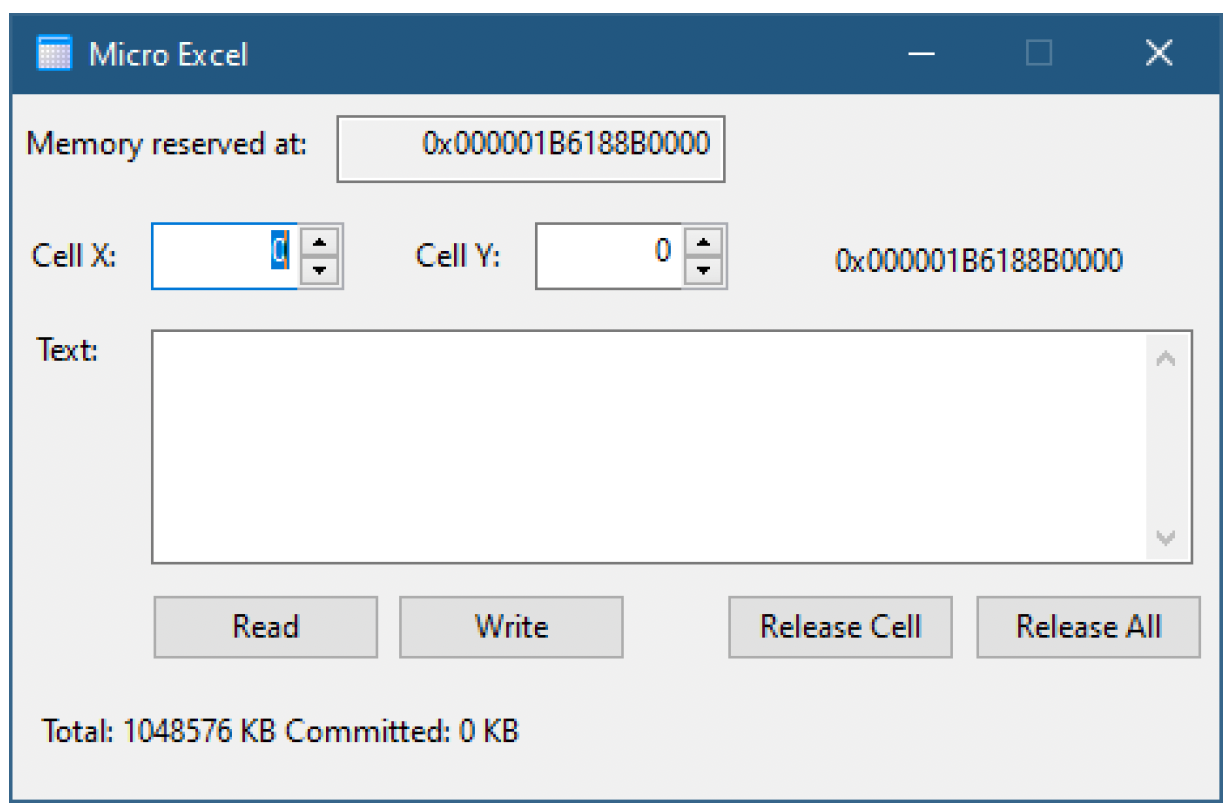
图13-2:微型Excel应用程序
该应用程序保留了一个1GB的内存范围,起始地址显示在顶部。“Cell X”和“Cell Y”编辑框允许在两个方向(0 - 1023)选择单元格。在大编辑框中输入内容并点击“Write”(写入)后,文本会被写入到请求的单元格中。如果内存尚未提交(第一次使用时肯定是这种情况),则通过处理访问冲突异常来提交内存。在向单元格(0,0)添加一个字符串后,应用程序窗口如图13-3所示。

图13-3:有一次内存分配的微型Excel应用程序
底部的文本显示已提交了4KB,这与我们的预期相符,因为一个1KB的单元格需要占用一个页面。如果我们将单元格X设置为1并写入内容,提交的大小会是多少呢?它将保持不变,因为第一个提交的页面覆盖了4个单元格(图13-4)。

图13-4:写入单元格(1,0)
如果向单元格(0,1)写入内容会发生什么呢?试试看并找出答案!你可以使用“Read”(读取)按钮从任何单元格读取内容。如果单元格未提交,则会返回错误。
使用VMMap查看已分配的内存区域很有意思。每次提交一个新页面时,它都会在大的保留区域中“打一个洞”。图13-5显示了应用程序使用的内存区域,其中有几个已提交内存的“洞”。

图13-5:VMMap显示大保留区域内的已提交区域
该应用程序是作为一个标准的基于WTL对话框的应用程序构建的。CMainDlg类包含几个与管理内存相关的数据成员:
class CMainDlg : public CDialogImpl<CMainDlg> {
//...
const int CellSize = 1024, SizeX = 1024, SizeY = 1024;
const size_t TotalSize = CellSize * SizeX * SizeY;
void* m_Address{ nullptr };
};
2
3
4
5
6
各种大小都被声明为常量,但如果这些大小是动态设置的,也不会有太大区别。OnInitDialog调用AllocateRegion来保留初始内存区域:
bool CMainDlg::AllocateRegion() {
m_Address = ::VirtualAlloc(nullptr, TotalSize, MEM_RESERVE, PAGE_READWRITE);
if (!m_Address) {
AtlMessageBox(nullptr , L"Available address space is not large enough",
IDR_MAINFRAME, MB_ICONERROR);
EndDialog(IDCANCEL);
return false;
}
// 更新用户界面
CString addr;
addr.Format(L"0x%p", m_Address);
SetDlgItemText(IDC_ADDRESS, addr);
SetDlgItemText(IDC_CELLADDR, addr);
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
一旦用户点击任何一个按钮,就需要获取单元格的地址。这是通过GetCell完成的:
void* CMainDlg::GetCell(int& x, int& y, bool reportError /* = true */) const {
// 从用户界面获取索引
x = GetDlgItemInt(IDC_CELLX);
y = GetDlgItemInt(IDC_CELLY);
// 检查范围有效性
if (x < 0 || x >= SizeX || y < 0 || y >= SizeY) {
if(reportError)
AtlMessageBox(*this , L"Indices out of range",
IDR_MAINFRAME, MB_ICONEXCLAMATION);
return nullptr ;
}
return (BYTE*)m_Address + CellSize * ((size_t)x + SizeX * y);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
有趣的代码在“Write”按钮的处理程序中。首先,获取单元格地址:
LRESULT CMainDlg::OnWrite(WORD, WORD, HWND, BOOL&) {
int x, y;
auto p = GetCell(x, y);
if (!p)
return 0;
2
3
4
5
接下来,读取编辑框内容并写入内存块。如果发生异常,会调用辅助函数FixMemory:
WCHAR text[512];
GetDlgItemText(IDC_TEXT, text, _countof(text));
try {
::wcscpy_s((WCHAR*)p, CellSize / sizeof(WCHAR), text);
}
except (FixMemory(p, GetExceptionCode())) {
// nothing to do: this code is never reached
}
2
3
4
5
6
7
8
如果确实是访问冲突,FixMemory将尝试纠正错误:
int CMainDlg::FixMemory(void* address, DWORD exceptionCode) {
if (exceptionCode == EXCEPTION_ACCESS_VIOLATION) {
// 提交单元格
::VirtualAlloc(address, CellSize, MEM_COMMIT, PAGE_READWRITE);
// 告诉CPU重试
return EXCEPTION_CONTINUE_EXECUTION;
}
// 其他错误,继续在调用栈中查找处理程序
return EXCEPTION_CONTINUE_SEARCH;
}
2
3
4
5
6
7
8
9
10
11
从技术上讲,如果系统达到最大提交限制,FixMemory中的VirtualAlloc调用可能会失败。在这种情况下,VirtualAlloc返回NULL,并且FixMemory的返回值应该是EXCEPTION_CONTINUE_SEARCH。
“Read”按钮的处理程序类似,不同之处在于如果单元格未提交,则不会尝试提交,而是显示错误:
LRESULT CMainDlg::OnRead(WORD, WORD, HWND, BOOL&) {
int x, y;
auto p = GetCell(x, y);
if (!p)
return 0;
WCHAR text[512];
try {
::wcscpy_s(text, _countof(text), (PCWSTR)p);
SetDlgItemText(IDC_TEXT, text);
}
except (EXCEPTION_EXECUTE_HANDLER) {
AtlMessageBox(nullptr , L"Cell memory is not committed",
IDR_MAINFRAME, MB_ICONWARNING);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
“Release”(释放)和“Release All”(全部释放)按钮分别用于取消提交一个单元格和释放整个内存块:
LRESULT CMainDlg::OnRelease(WORD, WORD, HWND, BOOL&) {
int x, y;
auto p = GetCell(x, y);
if (p) {
::VirtualFree(p, CellSize, MEM_DECOMMIT);
}
return 0;
}
LRESULT CMainDlg::OnReleaseAll(WORD, WORD wID, HWND, BOOL&) {
::VirtualFree(m_Address, 0, MEM_RELEASE);
// 分配一个新的保留区域
AllocateRegion();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
最后,底部显示已提交内存量的输出是通过一个定时器实现的,该定时器使用第12章中的VirtualQuery API遍历整个内存区域并计算已提交内存的大小:
LRESULT CMainDlg::OnTimer(UINT, WPARAM id, LPARAM, BOOL&) {
if (id == 1) {
MEMORY_BASIC_INFORMATION mbi;
auto p = (BYTE*)m_Address;
size_t committed = 0;
while (p < (BYTE*)m_Address + TotalSize) {
::VirtualQuery(p, &mbi, sizeof(mbi));
if (mbi.State == MEM_COMMIT)
committed += mbi.RegionSize;
p += mbi.RegionSize;
}
CString text;
text.Format(L"Total: %llu KB Committed: %llu KB",
TotalSize >> 10, committed >> 10);
SetDlgItemText(IDC_STATS, text);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 工作集(Working Sets)
术语“工作集”表示可在不引发页面错误(page fault)的情况下访问的内存。自然地,一个进程希望其所有已提交的内存都在其工作集中。内存管理器必须平衡一个进程的需求与所有其他进程的需求。长时间未被访问的内存可能会从一个进程的工作集中移除。这并不意味着它会自动被丢弃——内存管理器有复杂的算法,会将曾经属于一个进程工作集的物理页面在随机存取存储器(RAM)中保留的时间比可能需要的时间更长,这样如果相关进程决定访问该内存,它可以立即被错误处理(faulted)到工作集中(这被称为软页面错误,soft page fault)。
内存管理器管理物理内存的具体方式超出了本书的范围。感兴趣的读者可以查阅《Windows Internals, 7th ed. Part 1》一书中的第5章。
一个进程的当前和峰值工作集可以通过调用GetProcessMemoryInfo来获取,该函数在第12章(第1部分)中有描述,为方便起见在此重复:
BOOL GetProcessMemoryInfo(
HANDLE Process,
PPROCESS_MEMORY_COUNTERS ppsmemCounters,
DWORD cb);
2
3
4
PROCESS_MEMORY_COUNTERS的成员WorkingSetSize和PeakWorkingSetSize给出了指定进程的当前和峰值工作集。这个(以及扩展)结构的其他成员提供了其他有用的指标。完整细节请参考第12章。
一个进程有最小和最大工作集。默认情况下,这些限制是软限制,因此如果内存充足,进程可以消耗比其最大工作集更多的随机存取存储器(RAM),如果内存不足,进程可以使用比其最小工作集更少的随机存取存储器(RAM)。你可以使用GetProcessWorkingSetSize查询这些限制:
BOOL GetProcessWorkingSetSize(
_In_ HANDLE hProcess,
_Out_ PSIZE_T lpMinimumWorkingSetSize, // 字节
_Out_ PSIZE_T lpMaximumWorkingSetSize); // 字节
2
3
4
进程句柄必须具有PROCESS_QUERY_INFORMATION或PROCESS_QUERY_LIMITED_INFORMATION访问掩码。默认值是最小50个页面(200KB),最大345个页面(1380KB),但这些限制可以通过调用SetProcessWorkingSetSize来更改:
BOOL SetProcessWorkingSetSize(
_In_ HANDLE hProcess,
_In_ SIZE_T dwMinimumWorkingSetSize, // 字节
_In_ SIZE_T dwMaximumWorkingSetSize); // 字节
2
3
4
进程句柄必须具有PROCESS_SET_QUOTA访问掩码,该操作才有可能成功。如果最小或最大工作集的值高于当前最大工作集,调用者的令牌必须具有SE_INC_WORKING_SET_NAME特权。这通常不是问题,因为所有用户都有这个特权。
最小工作集大小的最小值是20个页面(80KB),最大工作集大小的最小值是13个页面(52KB)。最大工作集大小的最大值比可用内存少512个页面。为任何一个值指定零都是错误的。
一种特殊情况是为两个值都指定(SIZE_T)-1。这会导致系统从进程的工作集中尽可能多地移除页面。使用EmptyWorkingSet函数也可以实现相同的效果:
BOOL WINAPI EmptyWorkingSet(_In_ HANDLE hProcess);
进程句柄必须具有PROCESS_SET_QUOTA访问掩码以及PROCESS_QUERY_INFORMATION或PROCESS_QUERY_LIMITED_INFORMATION。
如前所述,默认情况下最小和最大工作集大小是软限制。这可以通过SetProcessWorkingSetSize的扩展版本SetProcessWorkingSetSizeEx来更改:
BOOL SetProcessWorkingSetSizeEx(
_In_ HANDLE hProcess,
_In_ SIZE_T dwMinimumWorkingSetSize,
_In_ SIZE_T dwMaximumWorkingSetSize,
_In_ DWORD Flags);
2
3
4
5
额外的Flags参数可以是表13-1中列出的值的组合。
表13-1:SetProcessWorkingSetSizeEx的标志
| 标志 | 描述 |
|---|---|
QUOTA_LIMITS_HARDWS_MIN_ENABLE (1) | 最小工作集的硬限制 |
QUOTA_LIMITS_HARDWS_MIN_DISABLE (2) | 最小工作集的软限制 |
QUOTA_LIMITS_HARDWS_MAX_ENABLE (4) | 最大工作集的硬限制 |
QUOTA_LIMITS_HARDWS_MAX_DISABLE (8) | 最大工作集的软限制 |
如果一个进程被配置为使用最大工作集硬限制,该进程可能希望作为其工作集一部分的任何额外已提交内存都会导致其他页面从其工作集中移除,本质上是对自身造成页面错误。为Flags指定零不会更改限制标志,本质上使该调用等同于SetProcessWorkingSetSize。也有用于获取当前限制和标志的相反函数:
BOOL GetProcessWorkingSetSizeEx(
_In_ HANDLE hProcess,
_Out_ PSIZE_T lpMinimumWorkingSetSize,
_Out_ PSIZE_T lpMaximumWorkingSetSize,
_Out_ PDWORD Flags);
2
3
4
5
# 工作集应用程序
工作集(Working Sets)应用程序展示了所有进程的内存相关计数器,如工作集大小、峰值工作集大小、最小值和最大值等等。它基于上一节讨论的应用程序编程接口(API)开发。了解各种进程如何使用内存很有意思,有时也是必要的。
首次启动该应用程序时,许多进程不会显示任何内存计数器。这是因为无法成功打开这些进程的句柄。选择 “视图”/“仅显示可访问进程” 后,显示列表中就只会留下可访问的进程。或者,选择 “文件”/“以管理员身份运行”(或以管理员权限启动应用程序),就可以显示出更多可访问的进程。图13-6展示了可能的显示效果。

图13-6:工作集应用程序
显示内容每秒自动刷新一次。你可以尝试操作某个特定进程,观察其工作集和提交内存使用情况的动态变化。你还可以按任意列进行排序。图13-7展示了峰值工作集使用量最高的进程(至少是可查询到的进程)。

图13-7:按峰值工作集排序的工作集
内存压缩(Memory Compression)进程的峰值工作集最高,这并不奇怪,因为它保存着压缩后的内存,从而节省了物理内存。列表中的下一个是Windows Defender,对于一款反恶意软件软件来说,它消耗的内存太多了。接下来是Visual Studio Code等等。
你可以选择 “进程”/“清空工作集” 菜单项,强制某个进程释放其大部分物理内存使用量(至少在一段时间内)。对于某些进程,这可能会失败,因为并非每个进程都能获取到PROCESS_SET_QUOTA权限。
该应用程序是作为一个标准的Windows模板库(WTL)单文档界面(SDI)构建的,其视图基于列表视图控件。最重要的函数是CView::Refresh,它在初始时以及定时器每秒到期时被调用。每个进程的信息存储在以下结构体中(在view.h中定义为嵌套类型):
struct ProcessInfo {
DWORD Id; // 进程ID
CString ImageName;
SIZE_T MinWorkingSet, MaxWorkingSet;
DWORD WorkingSetFlags;
PROCESS_MEMORY_COUNTERS_EX Counters;
bool CountersAvailable{ false };
};
std::vector<ProcessInfo> m_Items;
2
3
4
5
6
7
8
9
10
Refresh方法的首要任务是开始进程枚举:
void CView::Refresh() {
wil::unique_handle hSnapshot(::CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0));
if (!hSnapshot)
return;
PROCESSENTRY32 pe;
pe.dwSize = sizeof(pe);
// 跳过空闲进程
::Process32First(hSnapshot.get(), &pe);
m_Items.clear();
m_Items.reserve(512);
2
3
4
5
6
7
8
9
10
11
12
这里使用了第3章介绍的Toolhelp函数。对于每个进程,都会填充一个ProcessInfo对象:
while (::Process32Next(hSnapshot.get(), &pe)) {
// 尝试打开进程句柄
wil::unique_handle hProcess(::OpenProcess(PROCESS_QUERY_LIMITED_INFORMATION,
FALSE, pe.th32ProcessID));
if (!hProcess && m_ShowOnlyAccessibleProcesses)
continue;
ProcessInfo pi;
pi.Id = pe.th32ProcessID;
pi.ImageName = pe.szExeFile;
2
3
4
5
6
7
8
9
10
如果无法获取句柄且设置了 “仅显示可访问进程” 选项,则跳过此进程。否则,填充所有进程都必定可用的两个值 —— 进程ID和进程映像名称。
接下来,如果成功打开了合适的句柄,就调用内存API获取信息并存储到ProcessInfo实例中:
if (hProcess) {
::GetProcessMemoryInfo(hProcess.get(), (PROCESS_MEMORY_COUNTERS*)&pi.Counters,
sizeof(pi.Counters));
::GetProcessWorkingSetSizeEx(hProcess.get(), &pi.MinWorkingSet,
&pi.MaxWorkingSet, &pi.WorkingSetFlags);
pi.CountersAvailable = true;
}
2
3
4
5
6
7
如果句柄可用,就将CountersAvailable字段设置为true,表示结构体中的内存信息有效。最后,将该对象添加到向量中,并继续循环处理所有进程:
m_Items.push_back(pi);
}
2
剩下要做的就是对项目进行排序(如有必要)并更新列表视图:
DoSort(GetSortInfo(*this));
SetItemCountEx(static_cast<int>(m_Items.size()),
LVSICF_NOSCROLL | LVSICF_NOINVALIDATEALL);
RedrawItems(GetTopIndex(), GetTopIndex() + GetCountPerPage());
}
2
3
4
5
我不会讨论CView类中的其他函数,因为它们不使用任何与内存相关的API。感兴趣的读者可以浏览完整的源代码。
要清空工作集,可以调用SetProcessWorkingSetSize函数,并将两个值都设为 - 1。也可以调用EmptyWorkingSet函数:
LRESULT CView::OnEmptyWorkingSet(WORD, WORD, HWND, BOOL&) {
auto index = GetSelectedIndex();
ATLASSERT(index >= 0);
const auto& item = m_Items[index];
wil::unique_handle hProcess(::OpenProcess(PROCESS_SET_QUOTA, FALSE, item.Id));
if (!hProcess) {
AtlMessageBox(*this, L"Failed to open process", IDR_MAINFRAME, MB_ICONERROR);
return 0;
}
if (!::SetProcessWorkingSetSize(hProcess.get(), (SIZE_T)-1, (SIZE_T)-1)) {
AtlMessageBox(*this, L"Failed to empty working set",
IDR_MAINFRAME, MB_ICONERROR);
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
添加一个菜单选项来设置最小和 / 或最大工作集大小(也许可以通过一个对话框),同时提供SetProcessWorkingSetSizeEx函数可用的可选标志,并对这些值如何影响正在运行的进程进行一些实验。
# 堆
VirtualAlloc系列函数功能十分强大,因为它们与内存管理器紧密相关。不过,这也存在一个弊端。这些函数仅按页进行分配:如果分配10字节,实际会得到一页内存;再分配10字节,又会得到另一页。对于管理应用程序中常见的小内存分配而言,这种方式太过浪费。而堆的作用就体现在这里。
堆管理器是位于Virtual API之上的一个组件,它能够高效地管理小内存分配。在此情境下,堆是指由堆管理器管理的内存块。每个进程都从一个堆开始,这个堆被称为默认进程堆。可以通过GetProcessHeap函数获取该堆的句柄:
HANDLE GetProcessHeap();
还可以创建更多的堆,这在“其他堆”一节中会有介绍。有了堆句柄后,就可以使用HeapAlloc函数来分配(提交)内存:
LPVOID HeapAlloc(
_In_ HANDLE hHeap,
_In_ DWORD dwFlags,
_In_ SIZE_T dwBytes
);
2
3
4
5
HeapAlloc函数接受堆句柄、可选标志以及请求分配的内存字节数作为参数。标志可以为零,也可以是以下值的组合:
- HEAP_ZERO_MEMORY:指定函数返回的内存块应被清零。否则,该内存块中的原有内容将保持不变。
- HEAP_NO_SERIALIZE:表示函数不应获取堆的锁。这意味着开发者需要自行提供同步机制,或者确保不会对堆进行并发访问。对于默认进程堆,不应指定此值,因为默认堆创建时就启用了同步机制,并且一些API不支持对其进行非同步访问。对于应用程序创建的堆,在使用HeapCreate函数创建堆时(详见后文),可以指定此标志,这样在每次分配时就无需再指定。
- HEAP_GENERATE_EXCEPTIONS:表示函数应通过引发结构化异常处理(SEH)异常(STATUS_NO_MEMORY)来报告失败,而不是返回NULL。如果希望所有堆操作都具有这种行为,可以在使用HeapCreate函数创建堆时指定此标志。下面是一个从默认进程堆分配数据的示例:
struct MyData {
//...
};
MyData* pData = (MyData*)::HeapAlloc(::GetProcessHeap(), 0, sizeof(MyData));
if (pData == nullptr) {
// 处理失败情况
}
2
3
4
5
6
7
8
如果需要在保留现有数据的情况下增加或减少已分配内存块的大小,可以使用HeapReAlloc函数:
LPVOID HeapReAlloc(
_Inout_ HANDLE hHeap,
_In_ DWORD dwFlags,
_Frees_ptr_opt_ LPVOID lpMem,
_In_ SIZE_T dwBytes
);
2
3
4
5
6
lpMem是现有内存地址,dwBytes是新请求的大小。函数返回新内存块的地址,如果新大小小于或等于原大小,或者现有堆块中有足够空间进行调整而无需移动内存块时,返回的地址可能与原地址相同。如果新大小大于原大小且现有堆块无法容纳,则会将内存复制到新位置,并返回新地址。如果不希望进行这种复制操作,HeapReAlloc函数还支持一个额外标志HEAP_REALLOC_IN_PLACE_ONLY,若指定此标志,当新大小无法在现有块中容纳时,重新分配操作将失败 。
一旦不再需要某个分配的内存块,可调用HeapFree函数将其返回给堆:
BOOL HeapFree(
_Inout_ HANDLE hHeap,
_In_ DWORD dwFlags,
_In_ LPVOID lpMem
);
2
3
4
5
HeapFree函数唯一有效的标志是HEAP_NO_SERIALIZE。成功调用HeapFree后,lpMem所指向的地址应被视为无效。在大多数情况下,从该地址仍指向已提交内存的意义上讲,它仍然是有效的,但新的分配可能会重用这个地址。如果在未进行适当分配的情况下访问该内存,不太可能抛出访问冲突异常。这与VirtualFree函数形成对比,VirtualFree函数会解除内存的提交状态,因此对同一页面的任何访问都会引发访问冲突异常。
# 私有堆
堆最初是一块保留的内存区域,其中部分可能已提交。堆可以有固定的最大大小,也可以是可增长的。可增长的堆在进程地址空间允许的范围内可以不断增大。默认进程堆是可增长的,其初始保留和提交大小可以通过链接器设置指定。图13-8展示了Visual Studio中用于设置这些值的项目属性对话框。
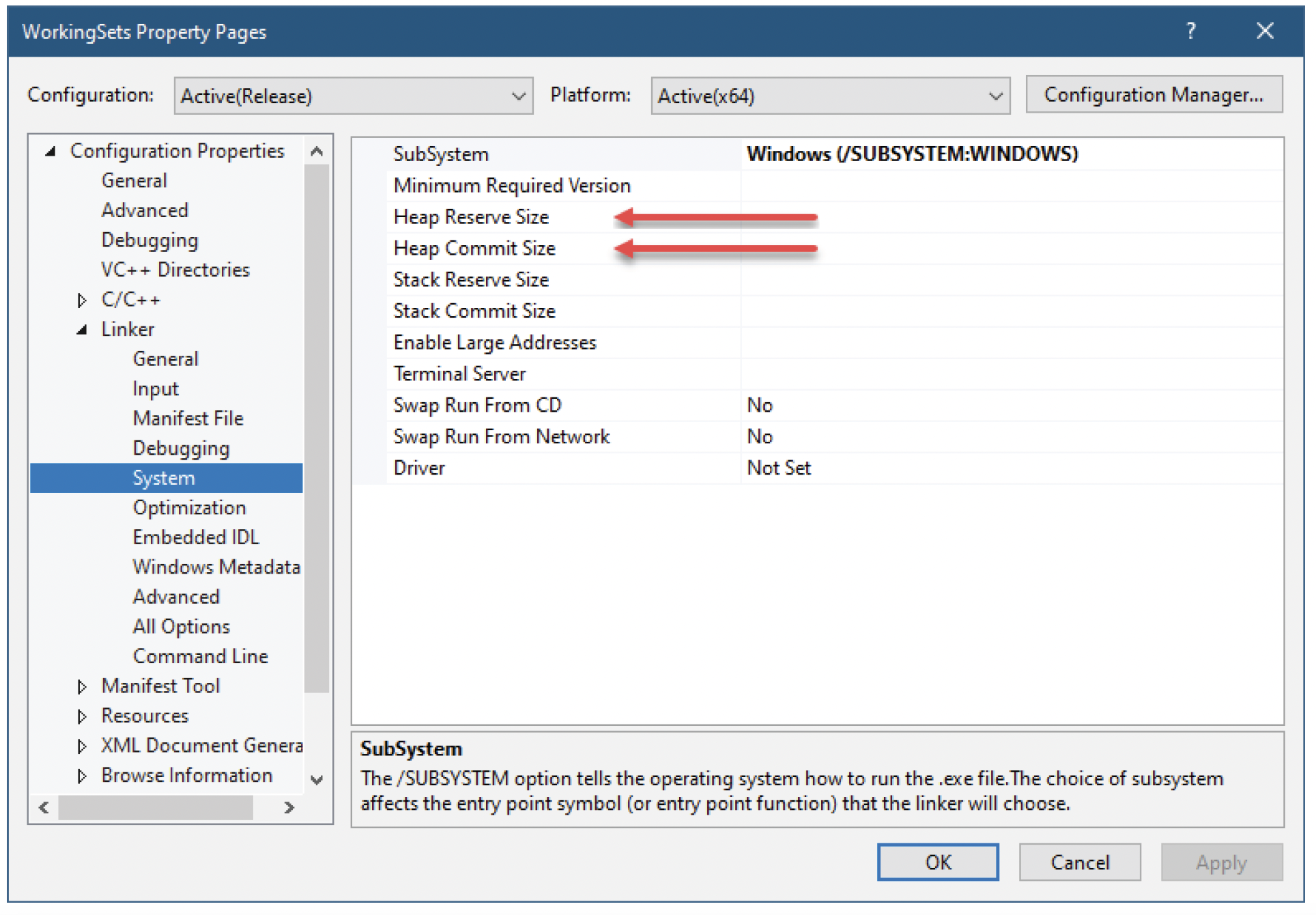
图13-8:堆大小链接器设置
可以使用任何PE查看器工具(如Dumpbin)查看默认进程堆的默认大小。以下是Notepad的示例:
c:\>dumpbin /headers c:\Windows\System32\notepad.exe
Microsoft (R) COFF/PE Dumper Version 14.26.28805.0
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\Windows\System32\notepad.exe
PE signature found
File Type: EXECUTABLE IMAGE
...
OPTIONAL HEADER VALUES
20B magic # (PE32+)
...
100000 size of heap reserve
1000 size of heap commit
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
初始提交为单个页面,初始保留大小为1MB。如果在链接器设置中未指定自定义值,这就是默认设置。
默认进程堆始终存在且无法被销毁。既然它是可增长的,那为什么还要创建额外的堆呢?
一个原因是为了避免内存碎片化。当在同一个堆上进行不同大小的内存分配时,或多或少都会出现碎片化问题。例如,假设应用程序分配了几个16字节大小的结构体。现在假设其中一个结构体被释放,而需要分配一个24字节大小的新结构体。16字节的空闲空间不够,因此堆管理器会在已使用堆区域的末尾分配该块。如果需要一个12字节的结构体,它可以放入16字节的空间中,但此时剩余的4字节空间可能永远不会再被使用。这种碎片化会导致使用的内存比实际需求更多。如果进程持续运行数小时甚至更久,并且有大量的内存分配和释放操作,问题会更加严重。
每次堆分配都会在CPU和内存方面带来一定的管理开销。因此,使用VirtualAlloc函数总是会快一些,并且没有相同的内存开销。
解决这个问题的一种(部分)方法是使用低碎片化堆(LFH),这在“堆类型”一节中会有介绍。另一种方法是创建一个单独的(私有)堆,用于存放特定大小的内存块。如果一个块被释放,恰好会有空间容纳一个相同大小的新块。如果在进程的整个生命周期中,需要频繁分配和释放大量特定大小(通常是特定的结构体/类)的对象,这种方案会很有用。
使用HeapCreate函数创建新堆:
HANDLE HeapCreate(
_In_ DWORD flOptions,
_In_ SIZE_T dwInitialSize,
_In_ SIZE_T dwMaximumSize
);
2
3
4
5
第一个选项参数可以为零,也可以是三个标志的组合,其中两个标志在HeapAlloc函数中已经见过:HEAP_GENERATE_EXCEPTIONS和HEAP_NO_SERIALIZE。如果指定了HEAP_NO_SERIALIZE,堆管理器在执行堆操作时不会持有任何锁。这意味着对堆的任何并发访问都可能导致堆损坏。此选项会使堆管理器运行速度略有提升,但如果有需要,开发者必须自行提供对堆的同步访问机制。设置此标志的一个潜在缺点是,堆无法使用低碎片化堆(LFH)层(后文会介绍)。
最后一个标志HEAP_CREATE_ENABLE_EXECUTE,告知堆管理器以PAGE_EXECUTE_READWRITE权限而不是仅仅PAGE_READWRITE权限来分配内存块。如果要将代码写入堆并执行,例如在即时(JIT)编译场景中,这会很有用。
dwInitialSize参数表示应预先提交的内存量。该值会向上取整到最接近的页面大小。值为零表示一个页面。dwMaximumSize指定堆可以增长到的最大大小。初始提交大小和最大大小之间的内存将被保留。如果指定的最大值为零,则堆是可增长的;否则,这就是堆的最大大小(固定大小堆)。任何试图分配超过堆大小的内存操作都会失败。如果堆是固定大小的,在32位系统中,最大可分配的内存块略小于512KB,在64位进程中略小于1MB。对于如此大的内存分配,无论如何都不应使用堆API,而应使用VirtualAlloc函数 。
函数的返回值是新堆的句柄,可用于其他堆函数,如HeapAlloc和HeapFree。如果函数失败,则返回NULL。
私有堆在某个时刻需要被销毁,这可以通过HeapDestroy函数完成:
BOOL HeapDestroy(_In_ HANDLE hHeap);
HeapDestroy函数会一次性释放整个堆,因此在即将销毁堆时,无需逐个释放每个分配的内存块。这可能是创建私有堆的另一个动机。
一种利用私有堆存储相同大小结构体的方法是,利用C++重写new和delete操作符的能力,这样结构体的任何动态分配或释放操作都在私有堆上进行,而开发者无需操心调用任何特定的API。以下是此类示例类型的头文件:
class MyClass {
public:
void* operator new(size_t);
void operator delete(void*);
void DoWork();
private:
static HANDLE s_hHeap;
static unsigned s_Count;
};
2
3
4
5
6
7
8
9
10
该类包含两个静态成员(对MyClass的所有实例都是公共的)。它们分别保存堆句柄和实例数量,以便在最后一个实例被释放时销毁堆。以下是实现代码:
HANDLE MyClass::s_hHeap = nullptr;
unsigned MyClass::s_Count = 0;
void* MyClass::operator new(size_t size) {
if (InterlockedIncrement(&s_Count) == 1)
s_hHeap = ::HeapCreate(0, 64 << 10, 16 << 20);
return ::HeapAlloc(s_hHeap, 0, size);
}
void MyClass::operator delete(void* p) {
::HeapFree(s_hHeap, 0, p);
if (::InterlockedDecrement(&s_Count) == 0)
::HeapDestroy(s_hHeap);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这里创建的私有堆初始提交大小为64KB,最大大小为16MB(当然,这些只是示例值)。任何使用MyClass类型的客户端都可以使用普通的C++操作:
auto obj = new MyClass;
obj->DoWork();
delete obj;
2
3
客户端无需知道在底层,对象是从私有堆中分配的,而私有堆可以保证无碎片化的使用。
# 堆类型
我们已经了解到,堆可以创建为固定最大大小,也可以是可增长的。为了帮助缓解堆碎片化问题,对于那些创建时没有设置无序列化(未设置HEAP_NO_SERIALIZE标志)的堆,Windows支持低碎片堆(Low Fragmentation Heap,LFH)。LFH试图通过使用特定大小的块来最小化碎片化,这些块更有可能满足分配需求。例如,一个8字节和一个12字节的分配请求都会得到16字节的空间。当这样的分配被释放时,如果新的分配请求大小不超过16字节,那么就更有可能将新的分配放入同一个块中。这意味着LFH可能会为每次分配使用比所需更多的内存,以此来最小化碎片化。
LFH是作为标准堆的一个可选前端层构建的。它在特定条件下会自动激活,一旦激活就无法关闭。也不能强制使用LFH。
在Vista之前的Windows版本确实允许打开和关闭LFH。但开发人员很难知道何时进行这些操作才合适,所以现在堆管理器使用自己的调优逻辑。
你可以使用HeapQueryInformation函数查询堆的类型:
BOOL HeapQueryInformation(
_In_opt_ HANDLE HeapHandle,
_In_ HEAP_INFORMATION_CLASS HeapInformationClass,
_Out_ PVOID HeapInformation,
_In_ SIZE_T HeapInformationLength,
_Out_opt_ PSIZE_T ReturnLength
);
2
3
4
5
6
7
该函数提供了一种通用的方式,基于HEAP_INFORMATION_CLASS枚举来查询一些堆参数,其中有一个值(HeapCompatibilityInformation)是官方有文档说明的。输出缓冲区是一个32位数字,它可以是0(表示没有使用LFH)或2(表示使用了LFH)。下面的示例查询默认进程堆的类型:
ULONG type;
::HeapQueryInformation(::GetProcessHeap(), HeapCompatibilityInformation, &type,
sizeof(type), nullptr);
2
3
Windows 8引入了另一种类型的堆,称为段堆(Segment Heap)。这种堆对块有更好的管理,并采取了额外的安全措施,有助于防止进程中的恶意代码仅仅通过指向堆上某个位置的指针就识别出堆块。所有通用Windows平台(UWP)进程都使用段堆,因为它的内存占用较小,这对在手机或平板电脑等小型设备上运行的UWP进程很有好处。一些系统进程也使用段堆,包括smss.exe、csrss.exe和svchost.exe。
由于兼容性原因,段堆不是默认堆。可以通过在注册表项HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options中创建一个子项(子项名称为可执行文件的名称,包含.exe扩展名但不包含路径,这需要管理员权限),为特定的可执行文件启用段堆。在该子项中,添加一个名为FrontEndHeapDebugOptions的DWORD值,并将其值设置为8。图13-9展示了为Notepad.exe设置此值的情况。下次启动这个可执行文件时,它将默认使用段堆。
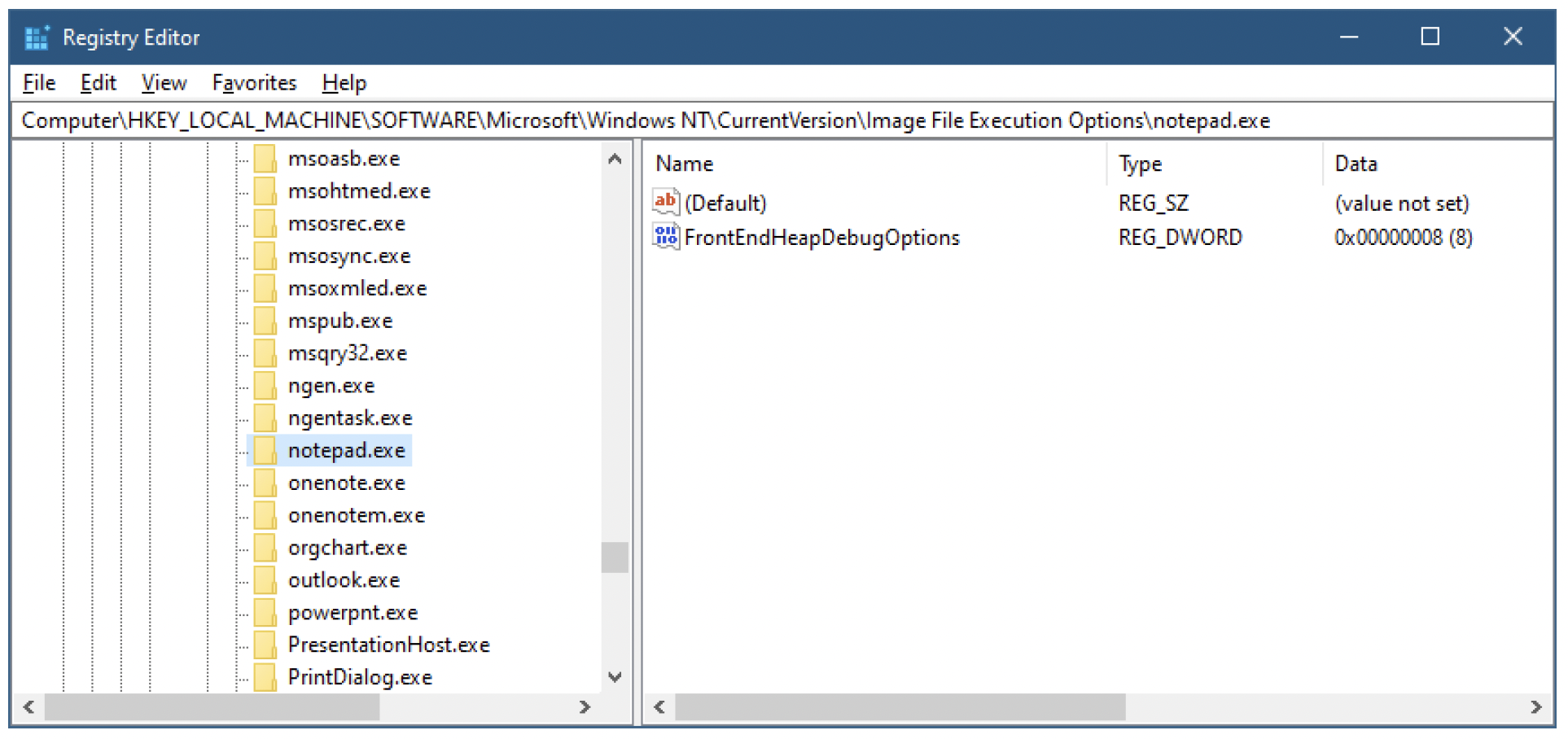
图13-9:为可执行文件启用段堆
有关段堆的更多信息,请查阅《Windows Internals 7th edition Part 1》一书的第5章。
# 堆调试功能
在使用堆API时,一个常见的问题是堆损坏,这通常是由于使用悬空指针访问内存,或者写入的数据超出了分配的大小。在除了最简单的应用程序之外的所有程序中,这些错误都极难追踪。导致这些问题难以解决的主要原因是,通常在错误代码已经不在调用堆栈中时,才检测到堆损坏。有时出现这些情况的其他原因是有人试图在堆上注入恶意代码。在这方面,堆管理器提供了一些帮助。
你可以调用HeapValidate函数,让堆管理器扫描给定堆中的所有分配,并验证它们的完整性:
BOOL HeapValidate(
_In_ HANDLE hHeap,
_In_ DWORD dwFlags,
_In_opt_ LPCVOID lpMem
);
2
3
4
5
该函数唯一有效的标志是前面讨论过的HEAP_NO_SERIALIZE。如果lpMem为NULL,则会扫描整个堆;否则,仅检查提供的内存块的完整性。如果lpMem不为NULL,该指针必须指向一个分配的起始位置(由之前调用HeapAlloc或HeapReAlloc返回)。
如果堆/块有效,HeapValidate返回TRUE,否则返回FALSE。如果有调试器连接到该进程,默认情况下会触发一个异常,使程序中断进入调试器。验证整个堆可能会很耗时,所以这个选项通常仅用于调试目的。
如果lpMem为NULL,对于段堆,HeapValidate总是返回TRUE。
有些错误HeapValidate无法检测到。如果有代码写入超出某个块大小的数据,而这个块恰好是空闲的,或者因为使用了LFH而有额外的内存,HeapValidate就会错过溢出问题。
另一种选择是通过调用HeapSetInformation函数,要求堆管理器在检测到堆损坏时终止进程(而不是继续运行):
BOOL HeapSetInformation(
_In_opt_ HANDLE HeapHandle,
_In_ HEAP_INFORMATION_CLASS HeapInformationClass,
_In_ PVOID HeapInformation,
_In_ SIZE_T HeapInformationLength
);
2
3
4
5
6
这里的HEAP_INFORMATION_CLASS是HeapEnableTerminationOnCorruption。这个选项是针对整个进程的,所以堆句柄会被忽略,可以指定为NULL。HeapInformation和HeapInformationLength应该分别设置为NULL和0。一旦启用,在进程的生命周期内,这个功能就无法禁用。
还有一些其他的堆调试功能,可以通过在前面章节中使用的Image File Execution Options注册表项中的NtGlobalFlags值设置某些标志来实现。通常,这些值是使用工具设置的,比如GFlags(Windows调试工具包的一部分,通常随Windows SDK一起安装),或者我自己开发的GFlagsX工具。图13-10展示了用于Notepad.exe的GFlags。有几个与堆相关的选项,在图13-10中做了标记。有关这些选项的描述,请查阅GFlags工具的文档。
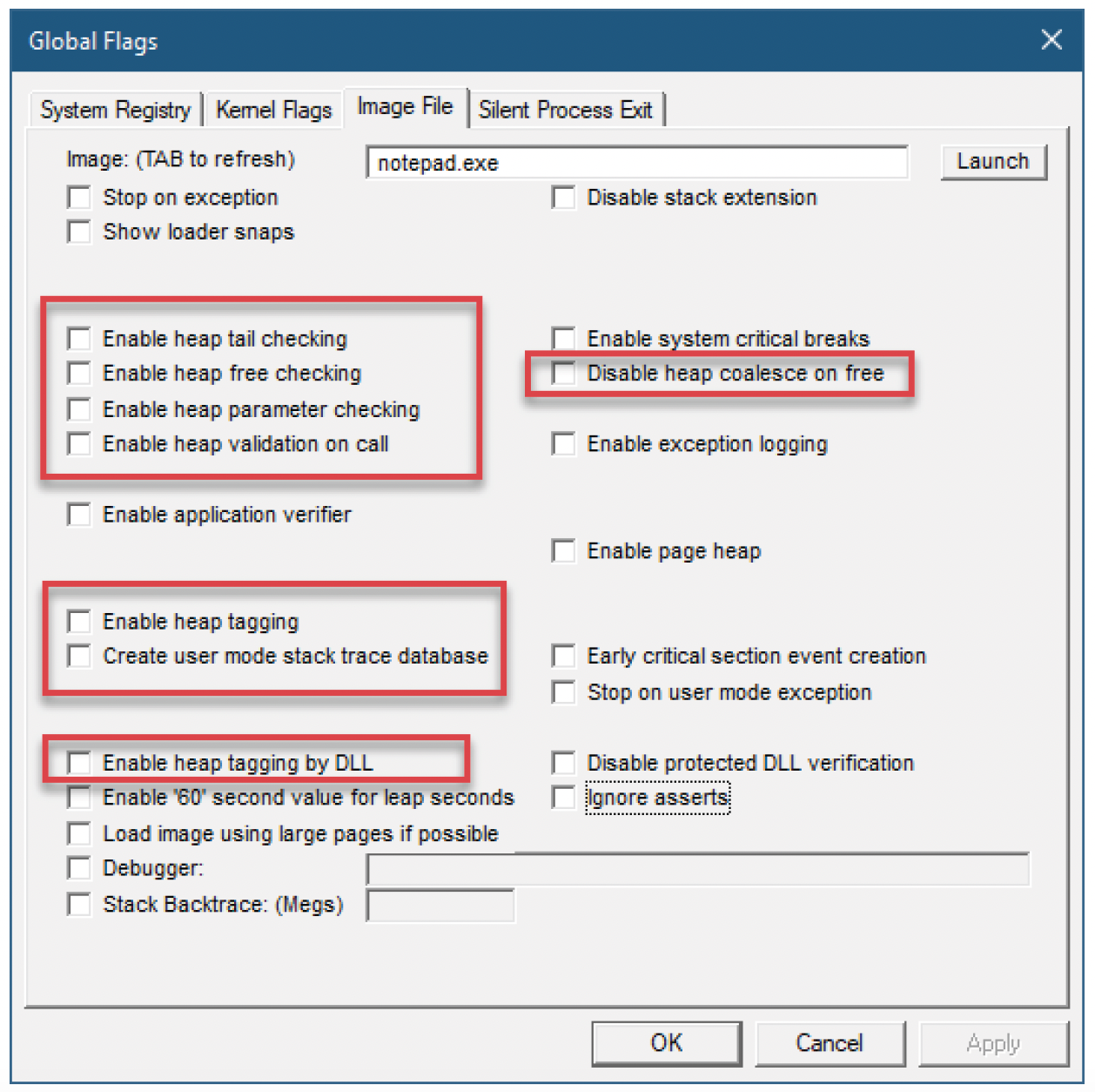
图13-10:GFlags(全局标志工具)与堆相关的选项
使用任何调试选项(除了“禁用释放时的堆合并”)都会减慢所有堆操作的速度,所以最好只在调试或排查与堆相关的问题时使用这些选项。
# C/C++运行时
C/C++内存管理函数(如malloc、calloc、free、C++的new和delete运算符等)的实现依赖于编译器提供的库。由于我们主要使用微软的编译器,所以可以介绍一下Visual C++运行时对这些函数的实现。
C/C++运行时使用堆函数来管理它们的分配。当前的实现使用默认的进程堆。由于CRT(C运行时库)源代码随Visual Studio一起分发,所以可以直接查看其实现。下面是去除了一些宏和指令,简化后的malloc实现(在malloc.cpp中):
extern "C" void* cdecl malloc(size_t const size) {
#ifdef _DEBUG
return _malloc_dbg(size, _NORMAL_BLOCK, nullptr, 0);
#else
return _malloc_base(size);
#endif
}
2
3
4
5
6
7
malloc有两种实现,一种用于调试版本构建,另一种用于发布版本构建。下面是发布版本构建中的代码片段(在malloc_base.cpp文件中):
extern "C" declspec(noinline) void* cdecl _malloc_base(size_t const size) {
// 确保请求的大小不会太大:
_VALIDATE_RETURN_NOEXC(_HEAP_MAXREQ >= size, ENOMEM, nullptr);
// 确保我们请求的分配至少为一个字节:
size_t const actual_size = size == 0 ? 1 : size;
for ( ; ; ) {
void* const block = HeapAlloc(acrt_heap, 0, actual_size);
if (block)
return block;
//...省略代码...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
全局变量__acrt_heap在这个函数中初始化(来自heap_handle.cpp):
extern "C" bool cdecl acrt_initialize_heap() {
acrt_heap = GetProcessHeap();
if (acrt_heap == nullptr)
return false;
return true;
}
2
3
4
5
6
7
这个实现使用默认的进程堆。
# 本地/全局API
以Local和Global为前缀的一组API,如LocalAlloc、GlobalAlloc、LocalFree、LocalLock等,主要是为了与16位Windows兼容而创建的。它们使用起来不太方便,因为分配操作返回的是某种句柄,需要使用LocalLock或GlobalLock函数将其转换为指针。
在一些非常特定的场景中,不幸的是需要使用其中的一些函数。第一种场景与剪贴板操作有关。将某些数据放到剪贴板上需要使用GlobalAlloc返回的HGLOBAL句柄。另一种场景涉及一些API(特别是安全API),其中一些API会分配一些数据并返回给调用者。调用者通常在不再需要这些数据时,必须使用LocalFree函数来释放它们。
简而言之,只有在某些限制条件要求时,才应该使用这些函数。对于所有其他情况,应使用堆API、C/C++ API或虚拟内存(Virtual)API。
# 其他堆函数
前面的章节没有涵盖一些其他的堆函数。本节简要介绍这些函数及其用途。
可以使用HeapSummary函数获取特定堆的汇总信息:
typedef struct _HEAP_SUMMARY {
DWORD cb;
SIZE_T cbAllocated;
SIZE_T cbCommitted;
SIZE_T cbReserved;
SIZE_T cbMaxReserve;
} HEAP_SUMMARY, *PHEAP_SUMMARY;
BOOL HeapSummary(
_In_ HANDLE hHeap,
_In_ DWORD dwFlags,
_Out_ PHEAP_SUMMARY lpSummary
);
2
3
4
5
6
7
8
9
10
11
12
13
在调用HeapSummary之前,需要将cb成员初始化为该结构体的大小。HEAP_SUMMARY的成员如下:
cbAllocated是堆上当前已分配(正在使用)的字节数。cbCommitted是堆上当前已提交的字节数。cbReserved是堆可以增长到的预留内存大小。cbMaxReserve在当前实现中与cbReserved相同。
HeapSize函数用于查询已分配块的大小:
SIZE_T HeapSize(
_In_ HANDLE hHeap,
_In_ DWORD dwFlags,
_In_ LPCVOID lpMem
);
2
3
4
5
唯一有效的标志是HEAP_NO_SERIALIZE。lpMem指针必须是之前由HeapAlloc或HeapReAlloc返回的指针。
创建时没有设置HEAP_NO_SERIALIZE的堆会维护一个临界区(锁),以防止在并发访问时堆损坏。HeapLock和HeapUnlock函数用于获取和释放堆的临界区:
BOOL HeapLock(_In_ HANDLE hHeap);
BOOL HeapUnlock(_In_ HANDLE hHeap);
2
这可以用于加快一些不需要获取锁就能调用的操作。其中一个可用于调试目的的操作是使用HeapWalk遍历堆块:
BOOL HeapWalk(
_In_ HANDLE hHeap,
_Inout_ LPPROCESS_HEAP_ENTRY lpEntry
);
2
3
4
堆枚举是通过编写一个循环来实现的,该循环返回PROCESS_HEAP_ENTRY类型的结构体:
typedef struct _PROCESS_HEAP_ENTRY {
PVOID lpData;
DWORD cbData;
BYTE cbOverhead;
BYTE iRegionIndex;
WORD wFlags;
union {
struct {
HANDLE hMem;
DWORD dwReserved[3];
} Block;
struct {
DWORD dwCommittedSize;
DWORD dwUnCommittedSize;
LPVOID lpFirstBlock;
LPVOID lpLastBlock;
} Region;
} DUMMYUNIONNAME;
} PROCESS_HEAP_ENTRY, *LPPROCESS_HEAP_ENTRY, *PPROCESS_HEAP_ENTRY;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
堆枚举从分配一个PROCESS_HEAP_ENTRY实例并将其lpData设置为NULL开始。每次调用HeapWalk都会返回堆上下一个已分配块的数据。当HeapWalk返回FALSE时,枚举结束。有关各个字段的详细描述,请查阅相关文档。
编写一个堆枚举函数,该函数接受一个堆句柄,并显示各个块及其属性。
使用HeapWalk进行堆枚举仅适用于当前进程。如果希望对其他进程进行堆遍历,ToolHelp提供了一个用于CreateToolhelp32Snapshot的标志(TH32CS_SNAPHEAPLIST),它提供了一种枚举选定进程中的堆(Heap32ListFirst、Heap32ListNext)的方法,并且可以进一步枚举每个堆中的块(Heap32First、Heap32Next)。
在处理堆时,可能会有两个或更多连续的空闲内存块。通常,堆会自动合并这些相邻的空闲块。图13-10中显示的一个全局标志允许禁用此功能(称为“禁用释放时的堆合并”),以节省一些处理时间。在这种情况下,你可以调用HeapCompact函数强制进行合并:
SIZE_T HeapCompact(
_In_ HANDLE hHeap,
_In_ DWORD dwFlags
);
2
3
4
唯一有效的标志是HEAP_NO_SERIALIZE。如果合并功能被禁用,该函数会合并空闲块,并返回堆上可以分配的最大块。
最后,可以使用GetProcessHeaps函数获取当前进程中所有堆的句柄:
DWORD GetProcessHeaps(
_In_ DWORD NumberOfHeaps,
_Out_ PHANDLE ProcessHeaps
);
2
3
4
该函数接受要返回的最大堆句柄数和一个句柄数组。它返回进程中的堆总数。如果堆的总数大于NumberOfHeaps,则并非所有堆句柄都被返回。获取当前进程中堆数量的一种简单方法是使用以下代码片段:
DWORD heapCount = ::GetProcessHeaps(0, nullptr);
# 其他虚拟内存函数
在本节中,我们将介绍除第12章涵盖的VirtualQuery系列函数之外的其他Virtual系列API函数。
# 内存保护
一旦提交了某个内存区域,就可以使用VirtualProtect*系列函数来更改属于同一初始保留区域的一组页面的页面保护属性:
BOOL VirtualProtect(
_In_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD flNewProtect,
_Out_ PDWORD lpflOldProtect
);
BOOL VirtualProtectEx(
_In_ HANDLE hProcess,
_In_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD flNewProtect,
_Out_ PDWORD lpflOldProtect
);
BOOL VirtualProtectFromApp(
_In_ PVOID Address,
_In_ SIZE_T Size,
_In_ ULONG NewProtection,
_Out_ PULONG OldProtection
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
与VirtualAllocEx类似,假设进程句柄具有PROCESS_VM_OPERATION访问掩码,VirtualProtectEx能够在不同的进程上下文中执行此操作。VirtualProtectFromApp是允许从通用Windows平台(UWP)进程调用的变体。与VirtualAlloc一样,如果定义了宏WINAPI_PARTITION_APP(表示调用者来自应用容器),VirtualProtect会通过调用VirtualProtectFromApp来内联实现。
地址范围从lpAddress到lpAddress+dwSize的所有页面的保护属性都会被更改,新的保护属性设置为flNewProtect(有关可能的保护属性列表,请参见第12章)。页面范围之前的保护属性通过lpflOldProtect参数返回(该参数不能为NULL)。如果页面跨度内有多个保护值,则返回第一个。
# 锁定内存
如我们所见,属于进程工作集的已提交内存并不能保证一直留在工作集中,它可能会被换出。在某些情况下,即使某个内存缓冲区长时间未被访问,进程可能仍希望告知内存管理器该缓冲区不应被换出。VirtualLock函数可用于此目的,而VirtualUnlock函数则用于解除锁定:
BOOL VirtualLock(
_In_ LPVOID lpAddress,
_In_ SIZE_T dwSize
);
BOOL VirtualUnlock(
_In_ LPVOID lpAddress,
_In_ SIZE_T dwSize
);
2
3
4
5
6
7
8
9
与任何Virtual系列API一样,这两个函数的地址范围总是向上舍入到最接近的页面边界。进程能够锁定的最大内存大小略小于其最小工作集大小。如果要锁定更大的内存块,应调用SetProcessWorkingSetSize(Ex)来增加最小(可能还有最大)工作集大小。当然,进程应注意不要锁定过多内存,因为这可能会对其他进程和整个系统产生不利影响。
# 内存提示函数
本节介绍的函数并非绝对必要,但可以通过向内存管理器提示应用程序对已提交内存的使用情况,在某些方面提高性能。
OfferVirtualMemory函数在Windows 8.1(和Server 2012 R2)中引入,它向内存管理器表明一段已提交内存不再被使用,因此系统可以丢弃该内存正在使用的物理页面,且系统无需将数据写入页面文件。
typedef enum OFFER_PRIORITY {
VmOfferPriorityVeryLow = 1,
VmOfferPriorityLow,
VmOfferPriorityBelowNormal,
VmOfferPriorityNormal
} OFFER_PRIORITY;
DWORD OfferVirtualMemory(
_Inout_ PVOID VirtualAddress,
_In_ SIZE_T Size,
_In_ OFFER_PRIORITY Priority
);
2
3
4
5
6
7
8
9
10
11
12
虚拟地址必须按页对齐,并且大小必须是页面大小的倍数。
乍一看,简单地解除内存提交(VirtualFree)似乎具有相同的效果。从释放随机存取存储器(RAM)的角度来看,两者相似。但是使用VirtualFree时,应用程序会放弃该地址范围和已提交的内存,因此将来需要重新分配内存,而重新分配可能成功,也可能失败;而且重新分配内存比直接重用已有的已提交内存块速度更慢。
priority参数指定内存区域的重要性。优先级越低,物理内存越早被丢弃的可能性越大。该函数直接返回错误代码(无需调用GetLastError),其中ERROR_SUCCESS(0)表示成功。
一旦应用程序准备再次使用释放的内存,可以使用ReclaimVirtualMemory将其收回:
DWORD ReclaimVirtualMemory(
_In_ void const* VirtualAddress,
_In_ SIZE_T Size
);
2
3
4
收回的内存可能包含也可能不包含其先前的内容。应用程序应假定需要用有意义的数据重新填充该内存。
另一个与OfferVirtualMemory类似的函数是DiscardVirtualMemory:
DWORD DiscardVirtualMemory(
_Inout_ PVOID VirtualAddress,
_In_ SIZE_T Size
);
2
3
4
DiscardVirtualMemory等效于以VmOfferPriorityVeryLow优先级调用OfferVirtualMemory。
本节的最后一个函数是PrefetchVirtualMemory(从Windows 8和Server 2012开始可用):
typedef struct _WIN32_MEMORY_RANGE_ENTRY {
PVOID VirtualAddress;
SIZE_T NumberOfBytes;
} WIN32_MEMORY_RANGE_ENTRY, *PWIN32_MEMORY_RANGE_ENTRY;
BOOL PrefetchVirtualMemory(
_In_ HANDLE hProcess,
_In_ ULONG_PTR NumberOfEntries,
_In_ PWIN32_MEMORY_RANGE_ENTRY VirtualAddresses,
_In_ ULONG Flags
);
2
3
4
5
6
7
8
9
10
11
PrefetchVirtualMemory的目的是让应用程序优化从非连续内存块读取数据时的输入/输出(I/O)使用情况,前提是进程相当确定会使用这些内存块。调用者提供已提交的内存块(使用WIN32_MEMORY_RANGE_ENTRY结构数组),内存管理器使用大缓冲区进行并发I/O操作,比正常访问页面时更快地获取数据。此函数并非必需,只是一种优化手段。
# 读写其他进程的内存
通常情况下,进程之间相互隔离保护,但如果拥有足够权限的句柄,一个进程就可以读取和/或写入另一个进程的地址空间。可以使用以下函数:
BOOL ReadProcessMemory(
_In_ HANDLE hProcess,
_In_ LPCVOID lpBaseAddress,
_Out_ LPVOID lpBuffer,
_In_ SIZE_T nSize,
_Out_opt_ SIZE_T* lpNumberOfBytesRead
);
BOOL WriteProcessMemory(
_In_ HANDLE hProcess,
_In_ LPVOID lpBaseAddress,
_In_ LPCVOID lpBuffer,
_In_ SIZE_T nSize,
_Out_opt_ SIZE_T* lpNumberOfBytesWritten
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ReadProcessMemory需要具有PROCESS_VM_READ访问掩码的句柄,而WriteProcessMemory需要PROCESS_VM_WRITE访问掩码。lpBaseAddress是目标进程中要读取/写入的地址。lpBuffer是用于读取或写入数据的本地缓冲区。nSize是要读取/写入的缓冲区大小。最后,最后一个可选参数返回实际读取或写入的字节数。
即使拥有进程访问掩码,这些函数也可能因不兼容的页面保护属性而失败。例如,WriteProcessMemory无法写入受PAGE_READONLY保护的页面。当然,调用者可以尝试使用VirtualProtectEx更改保护属性。
这些函数的主要使用者是调试器。调试器必须能够从被调试进程读取信息,例如局部变量、线程栈等。类似地,调试器允许用户修改被调试进程中的数据。不过,这些函数还有其他用途。在第15章中,我们将使用WriteProcessMemory的一个示例来帮助将动态链接库(DLL)注入目标进程。
# 大页
Windows支持两种基本页面大小:小页和大页(还有一种超大页,稍后会提及)。表12-1展示了页面大小,所有架构的小页大小均为4KB,除了ARM架构的大页大小为4MB外,其他架构的大页大小均为2MB。VirtualAlloc系列函数支持使用MEM_LARGE_PAGE标志分配大页。使用大页有哪些好处呢?
- 大页在内部性能更好,因为虚拟地址到物理地址的转换不使用页表(仅使用页目录,请参阅《Windows内核原理》一书)。这也使转换后备缓冲器(TLB)CPU缓存的效率更高 —— 单个条目映射2MB,而不是仅4KB。
- 大页始终不可换页(永远不会被换出到磁盘)。然而,大页也有一些缺点:
- 大页不能在进程之间共享。
- 大页分配必须是大页大小的精确倍数。
- 如果物理内存过于碎片化,大页分配可能会失败。
还有另一个重要的注意事项 —— 由于大页始终不可换页,使用大页需要SeLockMemoryPrivilege特权,通常任何用户都没有该特权,包括管理员组。图13-11展示了本地安全策略工具中的特权列表,其中“锁定内存页”特权显示未分配给任何用户或组。
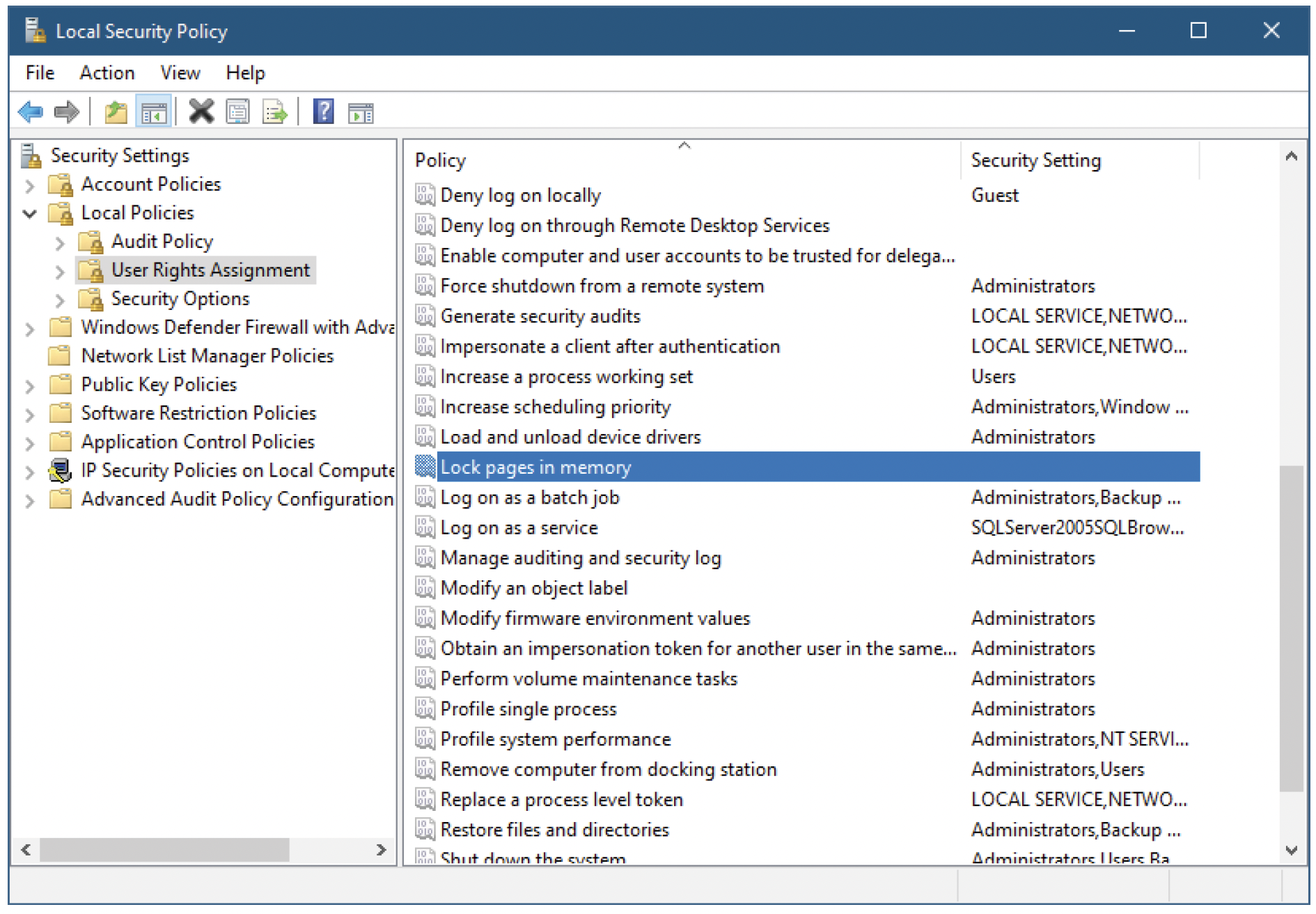 图13-11:本地安全策略特权窗口
图13-11:本地安全策略特权窗口
有两种方法可以获取所需的特权:
- 管理员可以添加用户/组以拥有此特权。下次该用户注销并重新登录时,该特权将成为其访问令牌的一部分。
- 以本地系统帐户运行的服务可以请求其所需的任何特权(服务以及此功能将在第19章中介绍)。
可以使用GetLargePageMinimum查询系统上的大页大小。这一点很重要,因为大页分配必须是大页大小的倍数:
SIZE_T GetLargePageMinimum();
超大页
现代处理器支持第三种页面大小 —— 超大页,大小为1GB。超大页的优点与大页基本相同,并且对TLB缓存的利用更好。
VirtualAlloc没有使用超大页的标志。相反,当进行大页分配时,如果大小至少为1GB,系统会首先尝试查找超大页,然后对剩余部分使用大页。如果无法获取超大页(因为这需要在物理内存中存在连续的1GB块),则会使用大页。
拥有SeLockMemoryPrivilege特权还不够,还必须启用它。这与第3章中用于启用调试特权的函数非常相似(此代码的详细讨论将留到第16章):
bool EnableLockMemoryPrivilege() {
HANDLE hToken;
if (!::OpenProcessToken(::GetCurrentProcess(), TOKEN_ADJUST_PRIVILEGES, &hToken))
return false;
bool result = false;
TOKEN_PRIVILEGES tp;
tp.PrivilegeCount = 1;
tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
if (::LookupPrivilegeValue(nullptr, SE_LOCK_MEMORY_NAME, &tp.Privileges[0].Luid)) {
if (::AdjustTokenPrivileges(hToken, FALSE, &tp, sizeof(tp), nullptr, nullptr))
result = ::GetLastError() == ERROR_SUCCESS;
}
::CloseHandle(hToken);
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
现在,除了使用MEM_LARGE_PAGE标志外,使用大页与使用普通页没有区别:
if (!EnableLockMemoryPrivilege()) {
printf("Failed to enable privilege\n");
return 1;
}
auto largePage = ::GetLargePageMinimum();
// 分配5个大页
auto p = ::VirtualAlloc(nullptr, 5 * largePage, MEM_RESERVE | MEM_COMMIT | MEM_LARGE_PAGES, PAGE_READWRITE);
if (p) {
// 成功 - 使用内存
}
else {
printf("Error: %u\n", ::GetLastError());
}
// 释放内存
::VirtualFree(p, 0, MEM_RELEASE);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 地址窗口化扩展(AWE)
在Windows NT早期,系统最多支持4GB物理内存,这是当时Windows运行的处理器的最大支持容量。从英特尔奔腾Pro开始,32位系统支持超过4GB的物理内存(当时还没有64位)。想要利用超过4GB额外物理内存的应用程序,必须使用一种名为地址窗口化扩展(Address Windowing Extensions,AWE)的特殊API —— 对于超过4GB的任何物理内存,其使用都不是“自动的”。
AWE允许进程直接分配物理页面,然后将它们映射到自己的地址空间。由于分配的物理内存量可能大于32位地址空间所能容纳的量,应用程序可以将一个“窗口”映射到该内存中,使用完内存后取消映射该窗口,并在另一个偏移处映射新窗口。
实际上,这种机制很麻烦,使用频率很低。唯一广为人知的在32位系统上利用AWE获取大内存优势的应用程序是SQL Server。
由于使用AWE意味着应用程序正在分配物理页面,因此与大页一样,需要SeLockMemoryPrivilege特权。
以下是一个使用AWE分配和使用物理页面的示例:
EnableLockMemoryPrivilege();
ULONG_PTR pages = 1000; // 页面数
ULONG_PTR parray[1000]; // 不透明数组(页框号,PFNs)
if (!::AllocateUserPhysicalPages(::GetCurrentProcess(), &pages, parray))
return ::GetLastError();
if (pages < 1000)
printf("Only allocated %zu pages\n", pages);
// 最多访问前200页
auto usePages = min(pages, 200);
// 保留用于映射物理页面的内存区域
void* pWindow = ::VirtualAlloc(nullptr, usePages << 12, MEM_RESERVE | MEM_PHYSICAL, PAGE_READWRITE); // 读写是唯一有效的值
if (!pWindow)
return ::GetLastError();
// 将页面映射到进程地址空间
if (!::MapUserPhysicalPages(pWindow, usePages, parray))
return ::GetLastError();
// 使用内存...
::memset(pWindow, 0xff, usePages << 12);
// 清理
::FreeUserPhysicalPages(::GetCurrentProcess(), &pages, parray);
::VirtualFree(pWindow, 0, MEM_RELEASE);
return 0;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
AWE分配的页面不可换页,并且必须使用PAGE_READWRITE进行保护,不支持其他值。
在64位Windows上运行的32位进程(WOW64)无法使用AWE函数。
如今,AWE很少被使用,因为在64位系统(主流系统)中,无需使用任何特殊API即可访问任意数量的物理内存,尽管正常的内存使用并不能保证内存始终驻留。AWE的复杂性以及它需要
SeLockMemoryPrivilege特权这一事实,使得它几乎没什么用处。
# 非统一内存访问架构(NUMA)
非统一内存访问架构(Non Uniform Memory Architecture,NUMA)系统由一组节点构成,每个节点都包含一组处理器和内存。图13-12展示了这类系统的一个拓扑示例。

图13-12:一个NUMA系统
图13-12展示了一个具有两个NUMA节点的系统示例。每个节点都有一个包含4个核心和8个逻辑处理器的插槽。从任何CPU都能运行任何代码并访问任何节点中的任何内存这个意义上来说,NUMA系统仍然是对称的。然而,从本地节点访问内存要比从其他节点访问内存快得多。
Windows系统能够识别NUMA系统的拓扑结构。正如第6章中讨论的线程调度那样,调度器会充分利用这一信息,尝试将线程调度到其栈位于该节点物理内存中的CPU上。
NUMA系统在服务器中很常见,因为服务器通常有多个插槽。获取NUMA拓扑信息需要调用多个API。系统中的NUMA节点数量可以通过GetNumaHighestNodeNumber函数间接获取:
BOOL GetNumaHighestNodeNumber(_Out_ PULONG HighestNodeNumber);
该函数会返回系统中编号最高的NUMA节点,如果返回0,则意味着该系统不是NUMA系统。在一个双节点系统中,函数返回时*HighestNodeNumber会被设置为1。
对于每个节点,可以使用GetNumaNodeProcessorMaskEx函数获取进程亲和性掩码(连接到某个节点的处理器):
BOOL GetNumaNodeProcessorMaskEx(
_In_ USHORT Node,
_Out_ PGROUP_AFFINITY ProcessorMask);
2
3
也可以使用GetNumaNodeProcessorMask或GetNumaNodeProcessorMaskEx函数来检索连接到特定节点的处理器:
BOOL GetNumaNodeProcessorMask(
_In_ UCHAR Node,
_Out_ PULONGLONG ProcessorMask);
BOOL GetNumaNodeProcessorMaskEx(
_In_ USHORT Node,
_Out_ PGROUP_AFFINITY ProcessorMask );
2
3
4
5
6
7
GetNumaNodeProcessorMask函数适用于处理器数量少于64个的系统(它会返回该节点所属组的进程掩码),而GetNumaNodeProcessorMaskEx函数可以通过返回一个GROUP_AFFINITY结构来处理任意数量的处理器,该结构结合了处理器组和处理器位掩码(有关进程组的更多信息,请参阅第6章):
typedef struct _GROUP_AFFINITY {
KAFFINITY Mask;
WORD Group;
WORD Reserved[3];
} GROUP_AFFINITY, *PGROUP_AFFINITY;
2
3
4
5
可以使用GetNumaAvailableMemoryNodeEx函数获取某个节点中可用的物理内存量。在分配内存并指定特定节点时,这一信息可作为参考:
BOOL GetNumaAvailableMemoryNodeEx(
_In_ USHORT Node,
_Out_ PULONGLONG AvailableBytes);
2
3
以下函数使用上述函数来展示NUMA节点信息:
void NumaInfo() {
ULONG highestNode;
::GetNumaHighestNodeNumber(&highestNode);
printf("NUMA nodes: %u\n", highestNode + 1);
GROUP_AFFINITY group;
for (USHORT node = 0; node <= (USHORT)highestNode; node++) {
::GetNumaNodeProcessorMaskEx(node, &group);
printf("Node %d:\tProcessor Group: %2d, Affinity: 0x%08zX\n",
(int)node, group.Group, group.Mask);
ULONGLONG bytes;
::GetNumaAvailableMemoryNodeEx(node, &bytes);
printf("\tAvailable memory: %llu KB\n", bytes >> 10);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
以下是一个运行示例(2个节点,共8个处理器):
NUMA nodes: 2
Node 0: Processor Group: 0, Affinity: 0x0000000F
Available memory: 3567936 KB
Node 1: Processor Group: 0, Affinity: 0x000000F0
Available memory: 3283832 KB
2
3
4
5
VirtualAlloc函数会让系统决定提交内存的物理内存来源。如果想要选择一个首选的NUMA节点,可以调用VirtualAllocExNuma函数:
LPVOID VirtualAllocExNuma(
_In_ HANDLE hProcess,
_In_opt_ LPVOID lpAddress,
_In_ SIZE_T dwSize,
_In_ DWORD flAllocationType,
_In_ DWORD flProtect,
_In_ DWORD nndPreferred);
2
3
4
5
6
7
该函数与VirtualAllocEx函数相同,但增加了一个首选的NUMA节点编号作为最后一个参数。所指定的NUMA节点仅在初始内存块被保留或保留并提交时有效。对同一内存区域的进一步操作会忽略NUMA节点参数,而且继续使用VirtualAlloc(Ex)函数会更加简便。
以下示例两次使用上述NumaInfo函数,在两次调用之间提交了一些内存(并强制放入随机存取存储器(RAM)):
NumaInfo();
auto p = ::VirtualAllocExNuma(::GetCurrentProcess(), nullptr , 1 << 30, // 1GB
MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE, 1); // node 1
// touch memory
::memset(p, 0xff, 1 << 30);
NumaInfo();
::VirtualFree(p, 0, MEM_RELEASE);
2
3
4
5
6
7
8
以下是一个输出示例:
NUMA nodes: 2
Node 0: Processor Group: 0, Affinity: 0x0000000F
Available memory: 3587332 KB
Node 1: Processor Group: 0, Affinity: 0x000000F0
Available memory: 3287952 KB
NUMA nodes: 2
Node 0: Processor Group: 0, Affinity: 0x0000000F
Available memory: 3584884 KB
Node 1: Processor Group: 0, Affinity: 0x000000F0
Available memory: 2243764 KB
2
3
4
5
6
7
8
9
10
请注意,节点1上的物理内存量有所减少。
在非NUMA系统上测试与NUMA相关的代码存在问题,因为这类系统只有一个节点。解决这一问题的一种方法是使用虚拟化技术,如Hyper-V,来模拟NUMA节点。对于Hyper-V,可以在虚拟机的CPU节点设置中配置NUMA节点(请注意,必须禁用动态内存才能使其生效)。
# VirtualAlloc2函数
VirtualAlloc2函数在Windows 10版本1803(RS4)中引入,它有可能替代其他各种VirtualAlloc函数变体。它整合了这些函数的所有功能,因此通过一次调用就能实现使用不同于当前进程的进程、选择首选的NUMA节点、进行特定的内存对齐、使用地址窗口扩展(AWE)技术以及选择内存分区(这是一个半公开的概念,超出了本书的讨论范围)。其函数原型如下:
PVOID VirtualAlloc2(
_In_opt_ HANDLE Process,
_In_opt_ PVOID BaseAddress,
_In_ SIZE_T Size,
_In_ ULONG AllocationType,
_In_ ULONG PageProtection,
_Inout_ MEM_EXTENDED_PARAMETER* ExtendedParameters,
_In_ ULONG ParameterCount);
2
3
4
5
6
7
8
前5个参数与VirtualAllocEx函数相同。最后两个参数是一个可选的MEM_EXTENDED_PARAMETER结构数组,每个结构都指定了与调用相关的一些额外属性。此类结构的数量由最后一个参数指定。MEM_EXTENDED_PARAMETER结构如下:
typedef struct DECLSPEC_ALIGN(8) MEM_EXTENDED_PARAMETER {
struct {
DWORD64 Type : MEM_EXTENDED_PARAMETER_TYPE_BITS;
DWORD64 Reserved : 64 - MEM_EXTENDED_PARAMETER_TYPE_BITS;
} DUMMYSTRUCTNAME;
union {
DWORD64 ULong64;
PVOID Pointer;
SIZE_T Size;
HANDLE Handle;
DWORD ULong;
} DUMMYUNIONNAME;
} MEM_EXTENDED_PARAMETER, *PMEM_EXTENDED_PARAMETER;
2
3
4
5
6
7
8
9
10
11
12
13
14
这个结构实际上是一个联合体,根据Type成员(它是一个枚举,用于选择联合体内的有效成员),只有一个成员是有效的:
typedef enum MEM_EXTENDED_PARAMETER_TYPE {
MemExtendedParameterInvalidType = 0,
MemExtendedParameterAddressRequirements,
MemExtendedParameterNumaNode,
MemExtendedParameterPartitionHandle,
MemExtendedParameterUserPhysicalHandle,
MemExtendedParameterAttributeFlags,
MemExtendedParameterMax
} MEM_EXTENDED_PARAMETER_TYPE;
2
3
4
5
6
7
8
9
例如,与“NUMA”一节中的示例类似,设置首选NUMA节点可以通过VirtualAlloc2函数这样实现:
MEM_EXTENDED_PARAMETER param = { 0 };
param.Type = MemExtendedParameterNumaNode;
param.ULong = 1; // NUMA node
auto p = ::VirtualAlloc2(::GetCurrentProcess(), // NULL also works for current proce\ ss
nullptr , 1 << 30,
MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE,
¶m, 1);
2
3
4
5
6
7
更多示例请查阅相关文档。
# 总结
在本章中,我们探讨了Windows系统提供的用于分配和管理内存的各种API。内存是计算机系统中的基本资源之一,几乎其他所有资源都以某种方式映射到内存使用上。
在下一章中,我们将深入研究内存映射文件,以及它们将文件映射到内存和在进程间共享内存的功能。