 第16章 模块
第16章 模块
# 第16章 模块
本章介绍C++20的新特性——模块(Modules)。模块提供了一种将多个文件中的代码组合成一个逻辑实体(模块、组件)的方式。与类的情况类似,数据封装有助于清晰地定义模块的应用程序编程接口(API)。这样做的一个附带好处是,即使模块代码放在“头文件”中,也能确保其无需多次编译。
本章的撰写得到了丹妮拉·恩格特(Daniela Engert)和亨德里克·尼迈耶(Hendrik Niemeyer)的大力帮助与支持,他们分别在2020年的Meeting C++大会和2021年的ACCU大会上对这一主题进行了精彩的介绍。
# 16.1 使用首个示例说明模块的设计动机
模块使程序员能够为大规模代码定义API。这些代码可能由多个类、多个文件、若干函数以及包括模板在内的各种辅助工具组成。通过使用export关键字,你可以指定哪些内容作为模块的API被导出,该模块封装了提供特定功能的所有代码。这样,我们就能为在多个文件中实现的组件定义一个清晰的API。
让我们看几个简单的示例,在一个文件中声明一个模块,然后在另一个文件中使用这个模块。
# 16.1.1 实现并导出模块
模块API的规范在其主接口(正式名称是主模块接口单元,primary module interface unit)中定义,每个模块仅有一个主接口:
// modules/mod0.cppm
export module Square; // 声明模块Square
int square(int i);
export class Square {
private:
int value;
public:
Square(int i)
: value{square(i)} { }
int getValue() const {
return value;
}
};
export template<typename T>
Square toSquare(const T& x) {
return Square{x};
}
int square(int i) {
return i * i;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
你可能首先注意到的是,该文件使用了一种新的文件扩展名:.cppm。目前,模块文件的扩展名尚未完全确定。我们稍后会讨论编译器对模块文件的处理方式。
主接口的关键入口是使用名称Square声明并导出模块的那一行:
export module Square; // 声明模块Square
注意,这个名称仅用作导入模块的标识符,它不会引入新的作用域或命名空间。模块导出的任何名称仍处于其被导出时所在的作用域中。
模块名称可以包含句点。虽然句点在C++中用于其他类型的标识符时是无效的,但作为模块名称标识符的一部分,句点是有效的,且没有特殊含义。例如:
export module Math.Square; // 声明模块“Math.Square”
除了将模块命名为“MathDotSquare”之外,这与其他命名方式没有什么不同,只是使用句点具有一定的视觉效果。句点可用于表示由组件或项目建立的模块之间的某些逻辑关系,使用它们不会产生语法或形式上的影响。
模块的公共API由使用export关键字显式导出的所有内容定义。在这个例子中,我们导出了类Square和函数模板toSquare<>():
export class Square {
...
};
export template<typename T>
Square toSquare(const T& x) {
...
}
2
3
4
5
6
7
8
其他所有内容都不会被导出,导入该模块的代码不能直接使用(我们稍后会讨论未导出的模块符号如何能被访问但不可见)。因此,没有使用export声明的函数square()不能被导入此模块的代码使用。
该文件看起来像一个头文件,但有以下区别:
- 我们有声明模块的那一行代码。
- 我们有使用
export导出的符号、类型、函数(甚至模板)。 - 定义函数时不需要使用
inline关键字。 - 不需要使用预处理保护(preprocessor guards)。
然而,模块文件不只是一个改进的头文件。模块文件既可以充当头文件,也可以充当源文件,它可以包含声明和定义。此外,在模块文件中,你无需使用inline或预处理保护来指定定义。模块导出的实体在被不同的翻译单元导入时,不会违反“单一定义规则(One Definition Rule)”。
每个模块必须有且仅有一个指定名称的主接口文件。如你所见,模块的名称与模块内的任何符号都不会冲突,它也不会隐式引入命名空间。因此,模块可以与其(主要)命名空间、类或函数同名。在实践中,模块名称通常与导出符号的命名空间相匹配,但这需要你显式实现。
# 16.1.2 编译模块单元
如你所见,一个模块文件既可以包含声明,也可以包含定义。从传统意义上讲,它可以被看作是头文件和源文件的组合。这就意味着你需要对它做两件事:
- 预编译声明(包括所有通用代码),这会将声明转换为特定于编译器的格式。
- 编译定义,这会创建常规的目标文件。
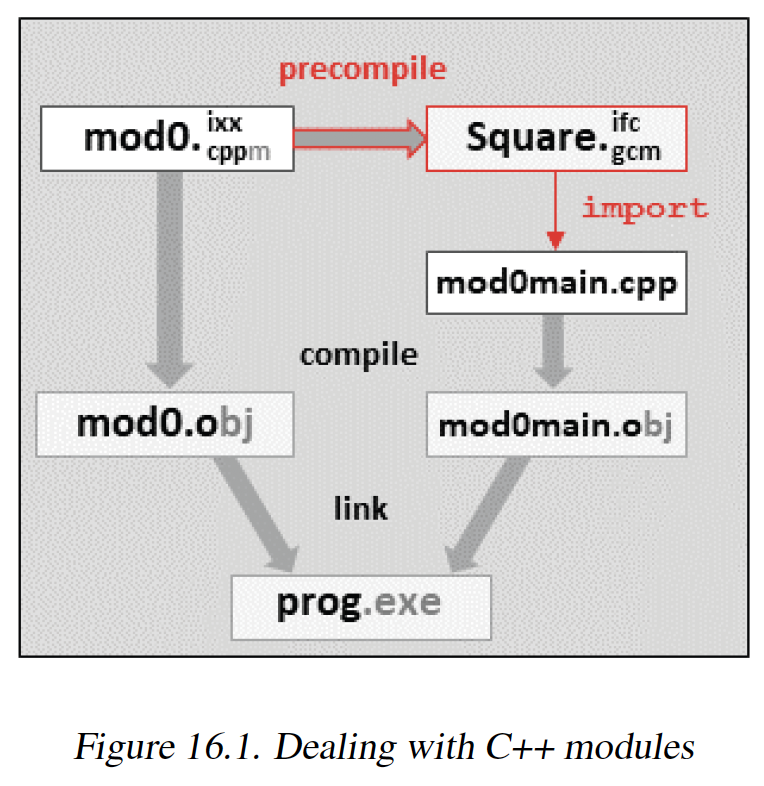
图16.1 处理C++模块
给定上述主模块接口mod0.cppm,我们必须按照图16.1所示的两种方式来处理它:
- 我们必须预编译
mod0.cppm,以创建一个预编译模块文件,该文件包含所有导出的声明,包括预编译的模板定义。它由模块名Square来标识,而不是源文件名。 - 我们必须编译
mod0.cppm,以创建一个目标文件mod0.o或mod0.obj,其中包含所有可以直接编译的定义的汇编代码。
如前所述,源模块文件并没有特定要求的文件扩展名。我在这里使用.cppm。预编译模块文件也没有标准化的后缀,这由编译器来决定。目前默认情况下:
gcc/g++使用.gcm作为预编译文件的扩展名(并将它们放在gcm.cache子目录中)。Visual C++使用.ifc作为预编译文件的扩展名(并将它们放在本地目录中)。我们稍后会详细讨论文件后缀以及处理模块单元的选项。
请注意,成功编译一个导入模块的源文件需要该模块的预编译产物可用。因此,在编译mod0test.cpp之前,你必须先预编译mod0.cppm。如果不遵循正确的顺序,你可能会导入一个不是最新版本的指定模块。因此,循环导入依赖是不被允许的。
与其他编程语言不同,C++并不要求模块有特殊的文件名或位于特殊的目录中。任何C++文件都可以定义一个模块(但只能定义一个),并且模块名与文件的名称或位置没有必然联系。
当然,在某种程度上保持文件名和模块名同步是很有意义的。不过,最终的决定还是取决于你的个人偏好以及你所使用的配置管理和构建系统的限制。
# 16.1.3 导入和使用模块
要在程序中使用模块的代码,你必须按模块名导入该模块。下面是一个简单的程序示例,它仅使用上面定义的Square模块:
// modules/mod0main.cpp
#include <iostream>
import Square; // 导入模块“Square”
int main() {
Square x = toSquare(42);
std::cout << x.getValue() << "\n";
}
2
3
4
5
6
7
8
通过
import Square; // 导入模块“Square”
我们导入了Square模块中所有导出的符号。这意味着我们随后可以使用导出的类Square和函数模板toSquare<>()。
使用模块中未导出的任何符号会导致编译时错误:
import Square; // 导入模块”Square”
square(42) // 错误:square()未导出
2
再次注意,模块不会自动引入一个新的命名空间。我们在导出符号所在的作用域中使用模块导出的符号。如果你希望模块中导出的所有内容都在其自己的命名空间中,可以整体导出命名空间。
# 16.1.4 可触及性与可见性
在使用模块时,会涉及到一个新的区别:可触及性(reachability)与可见性(visibility)。当导出数据时,我们可能无法看到并直接使用模块中的某个名称或符号;尽管我们也许能够间接使用它。
当一个导出的API提供了对未导出类型的访问时,就会出现可触及但不可见的符号。考虑以下示例:
export module ModReach; // 声明模块ModReach
struct Data { // 声明一个未导出的类型
int value;
};
export struct Customer { // 声明一个导出的类型
private:
Data data;
public:
Customer(int i)
: data{i} {}
Data getData() const { // 返回一个未导出的类型
return data;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
当导入这个模块时,类型Data是不可见的,因此不能直接使用:
import ModReach;
...
Data d{11}; // 错误:Data类型未导出
Customer c{42};
const Data& dr = c.getData(); // 错误:Data类型未导出
2
3
4
5
然而,类型Data是可触及的,因此可以间接使用:
import ModReach;
...
Customer c{42};
const auto& dr = c.getData(); // 正确:使用了Data类型
auto d = c.getData(); // 正确:d的类型是Data
std::cout << d.value << "\n"; // 正确:使用了Data类型
2
3
4
5
6
你甚至可以如下声明一个Data类型的对象:
decltype(std::declval<Customer>().getData()) d; // d的类型是未导出的Data
通过使用std::declval<>(),我们假设存在一个Customer类型的对象并调用其getData()函数。因此,我们声明了d的类型为getData()的返回类型Data(如果getData()是针对Customer类型的对象调用的话)。
私有模块片段可用于限制间接导出的类和函数的可触及性。
稍后我们将详细讨论导出符号的可见性和可触及性。
# 16.1.5 模块与命名空间
如前所述,模块的符号会在与导出时相同的作用域中被导入。与其他一些编程语言不同,C++模块不会自动为模块引入命名空间。
因此,你可以采用一种惯例,即将模块中的所有内容都在一个与模块同名的命名空间中导出。有两种方式可以实现:
- 在命名空间内部使用
export指定要导出的组件:
export module Square; // 声明模块“Square”
namespace Square {
int square(int i);
export class Square {
// ...
};
export template<typename T>
Square toSquare(const T& x) {
// ...
}
int square(int i) { // 未导出
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 使用
export声明命名空间,并在其中指定要导出的所有内容:
export module Square; // 声明模块“Square”
int square(int i);
export namespace Square {
class Square {
// ...
};
template<typename T>
Square toSquare(const T& x) {
// ...
}
}
int square(int i) { // 未导出
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在这两种情况下,模块都会导出Square::Square类和Square::toSquare<>()函数(因此,符号的命名空间会被导出,即使没有用export标记)。
现在使用该模块的方式如下:
#include <iostream>
import Square; // 导入模块“Square”
int main() {
Square::Square x = Square::toSquare(42);
std::cout << v.getValue() << '\n';
}
2
3
4
5
6
7
# 16.2 多文件模块
模块的目的是处理分布在多个文件中的大量代码。模块可用于封装由2个、10个甚至100个文件组成的小型、中型和大型组件的代码。这些文件甚至可能由多个程序员和团队提供和维护。
为了展示这种方法的可扩展性及其优势,现在让我们看看如何使用多个文件来定义一个可供其他代码使用/导入的模块。示例的代码量仍然较小,通常情况下你不会将其分散到多个文件中。我们的目标是通过非常简单的示例来展示这些特性。
# 16.2.1 模块单元
一般来说,模块由多个模块单元组成。模块单元是属于某个模块的翻译单元。
所有模块单元都必须以某种方式进行编译。即使它们只包含声明(在传统代码中这些声明会放在头文件中),也需要进行某种预编译。因此,这些文件总是会被转换为特定于平台的内部格式,以避免反复(预)编译相同的代码。
除了主模块接口单元,C++还提供了其他三种单元类型,用于将模块代码拆分到多个文件中:
- 模块实现单元(Module implementation units)允许程序员在各自的文件中实现定义,以便可以单独编译(类似于传统C++中
.cpp文件中的源代码)。 - 内部分区(Internal partitions)允许程序员在单独的文件中提供仅在模块内部可见的声明和定义。
- 接口分区(Interface partitions)甚至允许程序员将导出的模块API拆分到多个文件中。
接下来的部分将通过示例介绍这些额外的模块单元。
# 16.2.2 使用实现单元
第一个多文件实现模块的示例展示了如何拆分定义(如函数实现),避免将它们放在一个文件中。这样做的常见动机是能够单独编译这些定义。
这可以通过使用模块实现(正式名称是模块实现单元)来完成。它们的处理方式类似于单独编译的传统源文件。
让我们来看一个示例。
# 带有全局模块片段的主接口
通常,首先我们需要定义导出内容的主接口:
// modules/mod1/mod1.cppm
module; // 以全局模块片段开始模块单元
#include <string>
#include <vector>
export module Mod1; // 模块声明
struct Order {
int count;
std::string name;
double price;
Order(int c, const std::string& n, double p) : count{c}, name{n}, price{p} {
}
};
export class Customer {
private:
std::string name;
std::vector<Order> orders;
public:
Customer(const std::string& n) : name{n} {
}
void buy(const std::string& ordername, double price) {
orders.push_back(Order{1, ordername, price});
}
void buy(int num, const std::string& ordername, double price) {
orders.push_back(Order{num, ordername, price});
}
double sumPrice() const;
double averagePrice() const;
void print() const;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这次,模块以module;开始,以表明我们有一个模块。这样我们就可以在模块中使用一些预处理命令:
module; // 以全局模块片段开始模块单元
#include <iostream>
#include <string>
#include <vector>
export module Mod1; // 模块声明
// ...
2
3
4
5
6
module;和模块声明之间的区域称为全局模块片段。你可以在其中放置#define和#include等预处理命令。该区域内的任何内容都不会被导出(没有宏、声明或定义)。
在使用模块声明正式开始模块单元之前,不能进行其他操作(当然注释除外):
export module mod1; // 模块声明
此模块中定义的内容有:
- 一个内部数据结构
Order:
struct Order {
// ...
};
2
3
这个数据结构用于订单条目。每个条目保存有关订购物品数量、名称和价格的信息。构造函数确保我们初始化所有成员。
- 一个导出的类
customer:
export class Customer {
// ...
};
2
3
如你所见,定义Customer类需要头文件和内部数据结构Order。然而,由于没有导出它们,导入此模块的代码无法直接使用它们。
对于Customer类,成员函数averagePrice()、sumPrice()和print()仅进行了声明。在这里,我们利用模块实现单元来定义它们。
# 模块实现单元
一个模块可以有任意数量的实现单元。在我们的示例中,提供了两个实现单元:一个用于实现数值运算,另一个用于实现输入/输出操作。
用于数值运算的模块实现单元如下所示:
// modules/mod1/mod1price.cpp
module Mod1; // 模块Mod1的实现单元
double Customer::sumPrice() const {
double sum = 0.0;
for (const Order& od : orders) {
sum += od.count * od.price;
}
return sum;
}
double Customer::averagePrice() const {
if (orders.empty()) {
return 0.0;
}
return sumPrice() / orders.size();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
该文件是一个模块实现单元,因为它以声明开始,表明这是模块Mod1的文件:
module Mod1;
这个声明会导入模块的主接口单元(但不会导入其他内容)。因此,Order和Customer类型的声明是已知的,我们可以直接提供它们成员函数的实现。
请注意,模块实现单元不会导出任何内容。export仅在模块的接口文件(主接口或接口分区)中允许使用,这些文件使用export module声明(请记住,每个模块只允许有一个主接口)。
同样,模块实现单元可以以全局模块片段开始,在用于输入/输出的模块实现单元中可以看到这一点:
// modules/mod1/mod1io.cpp
module; // start module unit with global module fragment
#include <iostream>
#include <format>
module Mod1; // implementation unit of module Mod1
void Customer::print() const {
// 打印名称:
std::cout << name << " :\n";
// 打印订单条目:
for (const auto& od : orders) {
std::cout << std::format("{:3} {:14} {:6.2f} {:6.2f}\n",
od.count, od.name, od.price, od.count * od.price);
}
// 打印总和:
std::cout << std::format("{:25} ------\n", " ");
std::cout << std::format("{:25} {:6.2f}\n", " Sum : ", sumPrice());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在这里,我们使用module;引入模块,以便为实现单元中使用的头文件创建一个全局模块片段。<format>是新格式化库的头文件。
如你所见,模块实现单元使用传统C++翻译单元的文件扩展名(大多数情况下是.cpp)。编译器处理它们的方式与其他非模块C++代码一样。
# 使用模块
使用该模块的代码如下:
// modules/mod1/testmod1.cpp
#include <iostream>
import Mod1;
int main() {
Customer c1{"Kim "};
c1.buy( "table ", 59.90);
c1.buy(4, "chair ", 9.20);
c1.print();
std::cout << " Average : " << c1.averagePrice() << "\n";
}
2
3
4
5
6
7
8
9
10
11
在这里,我们使用主接口中导出的Customer类创建一个客户对象,下了一些订单,打印出客户及其所有订单,并打印出平均订单价格。
该程序的输出如下:
Kim:
1 table 59.90 59.90
4 chair 9.20 36.80
------
Sum: 96.70
Average: 48.35
2
3
4
5
6
注意,在导入该模块的代码中,任何使用Order类型的尝试都会导致编译时错误。还要注意,模块的使用并不依赖于我们有多少个实现单元。实现单元的数量仅在链接器必须使用为它们生成的所有目标文件时才重要。
# 16.2.3 内部分区
在前面的示例中,我们引入了一个仅在模块内部使用的数据结构Order。看起来我们必须在主接口中声明它,以便所有实现单元都能使用它,当然,在大型项目中,这种做法并不可行。
使用内部分区(internal partitions),你可以在单独的文件中声明和定义模块的内部类型和函数。注意,分区也可用于在单独的文件中定义导出接口的部分内容,我们稍后会讨论这一点。
注意,内部分区有时也被称为分区实现单元,这是基于在C++20标准中,它们被正式称为“作为模块分区的模块实现单元”,听起来它们提供了接口分区的实现。但实际上并非如此。它们只是类似于模块的内部头文件,可以同时提供声明和定义。
# 定义内部分区
使用内部分区,我们可以在其自己的模块单元中定义局部类型Order,如下所示:
// modules/mod2/mod2order.cppp
module ;
#include <string>
module Mod2:Order;
struct Order {
int count;
std::string name;
double price;
Order(int c, const std::string& n, double p) : count{c}, name{n}, price{p} {
}
};
2
3
4
5
6
7
8
9
10
11
12
如你所见,一个分区的名称由模块名、冒号和分区名组成:module Mod2:Order;
不支持像Mod2:Order:Main这样的子分区。
你可能会再次注意到,该文件使用了另一种新的文件扩展名:.cppp,在查看其内容后,我们稍后会讨论这个问题。
主接口必须仅通过名称:Order导入这个分区:
// modules/mod2/mod2.cppm
module ;
#include <string>
#include <vector>
export module Mod2;
import :Order;
export class Customer {
private:
std::string name;
std::vector<Order> orders;
public:
Customer(const std::string& n) : name{n} {
}
void buy(const std::string& ordername, double price) {
orders.push_back(Order{1, ordername, price});
}
void buy(int num, const std::string& ordername, double price) {
orders.push_back(Order{num, ordername, price});
}
double sumPrice() const ;
double averagePrice() const ;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
主接口必须导入内部分区,因为它使用了Order类型。通过该导入,该分区在模块的所有单元中都可用。如果主接口不需要Order类型且不导入内部分区,那么所有需要Order类型的模块单元都必须直接导入该内部分区。
再次强调,分区只是模块的内部实现方面。对于代码的使用者来说,代码是在主模块、其实现中还是在内部分区中并不重要。但是,内部分区中的代码不能被导出。
# 16.2.4 接口分区
你还可以将模块的接口拆分为多个文件。在这种情况下,你需要声明接口分区(interface partitions),这些分区本身会导出任何应该被导出的内容。
如果模块提供多个由不同程序员和/或团队维护的接口,接口分区会特别有用。为简单起见,我们仅使用当前示例,通过在单独的文件中定义Customer接口来演示如何使用此功能。
为了仅定义Customer接口,我们可以提供以下文件:
// modules/mod3/mod3customer.cppm
module ;
#include <string>
#include <vector>
export module Mod3:Customer;
import :Order;
export class Customer {
private:
std::string name;
std::vector<Order> orders;
public:
Customer(const std::string& n) : name{n} {
}
void buy(const std::string& ordername, double price) {
orders.push_back(Order{1, ordername, price});
}
void buy(int num, const std::string& ordername, double price) {
orders.push_back(Order{num, ordername, price});
}
double sumPrice() const ;
double averagePrice() const ;
void print() const ;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这个分区或多或少类似于之前的主接口,只有一个区别:
- 作为一个分区,我们在模块名和冒号后声明其名称:
Mod3:Customer
与主接口类似:
- 我们导出这个模块分区:
export module Mod3:Customer;
- 我们使用新的文件扩展名
.cppm,我们稍后会再次讨论这个问题。
主接口仍然是指定模块导出内容的唯一位置。但是,主模块可以将导出委托给接口分区。实现方法是直接将导入的接口分区作为一个整体导出:
// modules/mod3/mod3.cppm
export module Mod3;
export import :Customer;
2
3
通过同时导入和导出接口分区(是的,你必须同时编写这两个关键字),主接口将Customer分区的接口作为自己的接口导出:
export import :Customer; // 导入并导出Customer分区
不允许导入接口分区而不导出它。
再次强调,分区只是模块的内部实现方面。接口和实现是否在分区中提供并不重要。分区不会创建新的作用域。
因此,对于Customer类成员函数的实现,将类的声明移动到分区中并没有什么影响。你可以将Customer类的成员函数作为模块Mod3的一部分来实现:
// modules/mod3/mod3io.cpp
module ;
#include <iostream>
#include <vector>
#include <format>
module Mod3;
import :Order;
void Customer::print() const {
// 打印名称:
std::cout << name << " :\n " ;
// 打印订单条目:
for (const Order& od : orders) {
std::cout << std::format( "{:3} {:14} {:6.2f} {:6.2f}\n " ,
od.count, od.name, od.price, od.count * od.price);
}
// 打印总和:
std::cout << std::format( "{:25} ------\n " , " ");
std::cout << std::format( "{:25} {:6.2f}\n " , " Sum : ", sumPrice());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
然而,这个实现单元有一个不同之处:由于主接口不再导入内部分区:Order,这个模块必须导入它,因为它使用了Order类型。
对于导入该模块的代码来说,代码在内部的分布方式也无关紧要。我们仍然在全局作用域中导出Customer类:
// modules/mod3/testmod3.cpp
#include <iostream> import Mod3;
int main() {
Customer c1{"Kim "};
c1.buy( "table " , 59.90);
c1.buy(4, "chair " , 9.20);
c1 .print();
std::cout << " Average : " << c1 .averagePrice() << ✬\n ✬ ;
}
2
3
4
5
6
7
8
9
# 16.2.5 模块拆分到不同文件的总结
本节中的示例展示了如何处理代码量不断增加的模块,在这种情况下,拆分代码对于“驾驭复杂情况”很有帮助,甚至是必要的:
- 模块实现单元允许项目将定义分散到多个文件中,这样不同的程序员可以维护源代码,并且如果局部内容发生变化,无需重新编译所有代码。
- 内部分区允许项目将模块内部的声明和定义从主接口中分离出来。主接口或仅需要它们的模块单元可以导入这些内容。
- 接口分区允许项目在不同文件中维护导出接口。当导出的API变得庞大,由不同文件(以及不同团队)处理其中的部分内容会有所帮助时,这种做法通常是合理的。
主接口将所有内容整合在一起,并指定哪些内容会被导出给模块的用户(通过直接导出符号或导出导入的接口分区)。
我们拥有的模块单元类型取决于C++源文件中的模块声明(在注释和用于预处理命令的全局模块片段之后):
export module name;:标识主接口。对于每个模块,在一个C++程序中它只能存在一次。module name;:标识仅提供定义(可能会使用局部声明)的实现单元。这类单元的数量不受限制。module name:partname;:标识仅在模块内部使用的声明和定义的内部分区。可以有多个分区,但对于每个partname,只能有一个内部分区文件。export module name:partname;:标识接口分区。可以有多个接口分区,但对于每个partname,只能有一个接口分区文件。
由于不同的模块单元没有标准后缀,工具必须解析C++源文件的开头,以检测它们是否为模块单元以及属于哪种类型的模块单元。注意,模块声明可能出现在注释和全局模块片段之后。有关示例可查看位于http://github.com/josuttis/cppmodules的clmod.py,这是一个Python脚本,展示了相关情况。
# 16.3 模块的实际应用
本节讨论在实际使用模块时的一些其他方面。
# 16.3.1 使用不同编译器处理模块文件
在C++中,文件扩展名没有标准化。在实际应用中,会使用不同的文件扩展名(通常是.cpp和.hpp,也会使用.cc、.cxx、.C、.hh、.hxx、.H,甚至.h)。
我们也没有模块的标准扩展名。更糟糕的是,对于是否有必要(现在)使用新的扩展名,大家还未达成共识。原则上,有两种方法:
- 编译器应将所有类型的模块文件视为普通的C++源文件,并根据其内容确定如何处理它们。采用这种方法时,所有文件仍使用
.cpp扩展名。gcc/g++遵循这一策略。 - 编译器对(部分)模块文件的处理方式不同,因为它们既可以是用于声明的文件(传统的头文件),也可以是包含定义的文件(传统的源文件)。虽然使用不同的后缀无疑会有很大帮助,但编译器甚至可能间接要求使用不同的后缀,以避免对相同的扩展名使用不同的命令行选项。Visual C++采用这种方法。
因此,不同的编译器在实际应用中推荐使用不同的模块文件扩展名(.cppm、.ixx和.cpp),这也是在实际使用模块时仍具有挑战性的原因之一。
我对此思考了一段时间,进行了一些尝试,并与标准委员会的成员讨论了这种情况,但到目前为止,似乎还没有一个令人信服的解决方案。从形式上讲,C++标准并未对源代码的处理方式进行标准化(代码甚至可能不存储在文件中)。这导致即使编写一个简单的、可移植的模块示例也并非易事。
因此,我在此提出一些建议,以便你至少可以在不同平台上尝试使用模块:使用不同的文件扩展名似乎有多个原因:
- 编译器处理不同类型的模块文件需要不同的命令行选项。
- 与头文件类似,你必须向客户和第三方代码提供部分模块文件。
- 不同的模块文件会生成不同的工件(artifacts),你可能需要处理这些工件(例如,在删除生成的工件时)。
就我个人而言,目前对于模块文件的扩展名还没有最终的决定和建议。然而,鉴于当前的情况,我建议如下:
- 对于接口文件(包括主接口和接口分区),使用文件扩展名
.cppm。原因如下:- 这是最具自解释性的文件扩展名(比目前Visual C++推荐的
.ixx好得多)。 - 这是Clang目前所要求的。
- 它可用于gcc。
- 除非使用
.ixx扩展名,否则Visual C++无论如何都需要特殊处理。
- 这是最具自解释性的文件扩展名(比目前Visual C++推荐的
- 对于模块实现文件(但不包括分区实现文件),使用通常的文件扩展名
.cpp。原因如下:- 不会生成特殊的工件。
- 不需要特殊的命令行选项。
- 对于内部分区文件(分区实现文件),使用文件扩展名
.cppp。原因如下:- Visual C++要求对这些文件使用命令行选项
/internalPartition。文件后缀并不重要。因此,你必须使用特殊后缀,以便在不想解析文件内容的构建系统中设置通用规则。 - 它可用于gcc。
- 目前(2021年9月),Clang根本不支持这些文件。
- Visual C++要求对这些文件使用命令行选项
微软对内部分区的处理方式对模块的推广非常不利,我希望他们能尽快解决对特定后缀的需求问题。
因此,你必须按如下方式(预)编译模块文件:
- Visual C++:Visual C++需要特定的命令行扩展,并且倾向于使用与我建议不同的
.ixx文件扩展名。因此:- 按如下方式编译接口文件
file.cppm:
- 按如下方式编译接口文件
cl /TP /interface /c file.cppm
/TP选项指定其后的所有文件都包含C++源代码。或者,你也可以使用/Tpfile.cppm。/interface选项指定其后的所有文件都是接口文件(在同一命令行中同时包含接口文件和非接口文件可能无法正常工作)。
如果你使用.ixx文件扩展名,编译器会自动将该文件识别为接口文件。
- 按如下方式编译内部分区文件file.cppp:
cl /Tp /internalPartition /c file.cppp
/internalPartition选项指定其后的所有文件都是内部分区。请注意,不支持在同一命令行中同时包含内部分区文件和接口文件。没有其他特定后缀可供使用;内部分区始终需要这个选项。
目前,Visual C++推荐不同的文件后缀,并对特定的模块单元要求特定的命令行选项,这使得模块的使用既麻烦又不可移植。为了规避Visual C++的这些限制(至少在通过命令行编译时),我提供了Python脚本clmod.py,你可以在http://github.com/josuttis/cppmodules (opens new window)找到它。我希望微软能修复这些问题,这样就不再需要这个解决方法了。
- gcc/g++:gcc根本不需要任何特殊的文件扩展名或命令行选项。因此,通过使用特殊的文件扩展名,你只需要使用命令行选项
-xc++指定文件包含C++代码即可:- 按如下方式编译接口文件
file.cppm:
- 按如下方式编译接口文件
g++ -xc++ -c file.cppm
- 按如下方式编译内部分区文件`file.cppp`:
g++ -xc++ -c file.cppp
- Clang:Clang目前仅支持接口文件。由于无论如何都需要使用提议的
.cppm扩展名,使用它应该可行。
然而,Clang目前不支持使用内部分区文件。
# 16.3.2 处理头文件
虽然理论上模块可以取代存在各种缺陷的传统头文件,但在实际中这是不可能实现的。会存在为C++(和C)开发的代码和库所使用的头文件,这些头文件并不需要使用模块。尤其因为预编译器的使用使得C++程序的编译和链接更加复杂,这种情况会一直存在。因此,模块应该能够处理传统头文件。
使用传统头文件的基本方法是使用全局模块片段。
- 以
module;开始你的模块。 - 然后,在模块声明之前放置所有必要的预处理命令。在这种情况下:
- 包含的头文件中未使用的所有内容都将被丢弃。
- 使用的所有内容都将获得模块链接,这意味着它仅在整个模块单元内可见,在其他模块单元或模块外部均不可见。
#include之前的#define会生效。例如:
module;
#include <string>
#define NDEBUG
#include <cassert>
export module ModTest;
...
void foo(std::string s) {
assert(s.empty()); // 有效,但不会进行检查
...
}
2
3
4
5
6
7
8
9
10
通过这个全局模块片段,预处理符号NDEBUG和<cassert>中的宏assert()在这个模块单元内被定义。然而,由于NDEBUG的存在,assert()的任何运行时检查都被禁用。NDEBUG和assert()在这个模块的其他单元或导入的模块中均不可见。
在模块声明之后,不再支持#include。其他预处理命令,如#define和#ifdef,仍可使用。
# 头文件的import
未来的目标是让整个C++标准库都能作为模块使用。然而,对于标准C++头文件,已经可以使用import,并且可以在模块中使用。例如:
export module ModTest;
import <chrono>;
2
这条指令是声明并导入一个模块的快捷方式,该模块会导出相应头文件中的所有内容。通过这种导入方式,宏在这个模块内也是可见的(而在其他导入方式中,宏不可见)。
然而,在import之前用#define定义的常量不会传递到导入的头文件中。这样,我们可以保证导入的头文件内容始终一致,以便对头文件进行预编译。
请注意,这个特性仅保证在标准C++头文件上有效。它也不适用于C++采用的标准C头文件:
export module ModTest;
import <chrono>; // 可行
import <cassert>; // 错误(或者至少不可移植)
2
3
平台也可以对其他头文件支持这个特性;但是,使用这个特性的代码是不可移植的。
# 标准模块
C++20只是引入了模块技术,并没有引入任何标准模块(其中一个原因是标准委员会希望通过不同模块重新组织符号,以清理头文件带来的一些历史遗留问题)。
看起来在C++23中会有两个标准模块(见http://wg21.link/p2465 (opens new window)):
std模块将提供C++头文件中std命名空间内的所有内容,包括那些包装C函数的内容(例如std::sort()、std::ranges::sort()、std::fopen()和::operator new)。该模块不提供宏和特性测试宏。如果需要使用这些,你必须自己包含<cassert>或<version>头文件。std.compat模块将提供std模块中的所有内容,以及C头文件中C符号的对应内容(例如::fopen()) 。
请注意,std以及每个以std开头的模块名均被C++标准保留用于其标准模块。
# 16.4 模块详解
本节介绍一些使用模块的额外细节。
# 16.4.1 私有模块片段
在主接口中声明模块时,有时可能需要一个私有模块片段。这使得程序员可以在主接口中进行声明和定义,这些内容对其他任何模块或翻译单元都不可见且无法访问。使用私有模块片段的一种方式是,在导出类或函数声明的同时,禁止导出其定义。
例如,考虑以下主接口:
export module MyMod;
export class C; // 类C被导出
export void print(const C& c); // print()函数被导出
class C { // 提供被导出类的详细信息
private:
int value;
public:
void print() const;
};
void print(const C& c) { // 提供被导出函数的详细信息
c.print();
}
2
3
4
5
6
7
8
9
10
11
12
在这里,我们首先使用export向前声明类C和函数print():
export module MyMod;
export class C; // 类C被导出
export void print(const C& c); // print()函数被导出
2
3
export在一个名称在其命名空间中被引入时只能指定一次。之后也会导出详细信息。因此,任何翻译单元都可以导入这个模块并使用C类型的对象:
import MyMod;
...
C c; // 可行,类C的定义已被导出
print(c); // 可行(编译器可以用函数体替换函数调用)
2
3
4
然而,如果你想在模块内封装定义,使导入代码只能看到声明,同时又希望在主接口中保留定义,那么就必须将定义放在私有模块片段中:
export module MyMod;
export class C; // 声明被导出
export void print(const C& c); // 声明被导出
module :private; // 以下符号甚至不会被隐式导出
class C { // 完整的类不会被导出
private:
int value;
public:
void print() const;
};
void print(const C& c) { // 定义不会被导出
c.print();
}
2
3
4
5
6
7
8
9
10
11
12
13
私有模块片段通过module :private;声明。
它只能出现在主接口中,并且只能出现一次。声明之后,文件的其余部分不再被隐式导出(甚至不会被隐式导出)。之后再使用export导出任何内容都是错误的。
通过将定义移动到私有模块片段中,导入代码无法再使用其中的任何定义。它只能使用类C的向前声明(类C是一个不完全类型)和print()函数。
例如,你不能创建C类型的对象:
import MyMod;
...
C c; // 错误(C仅被声明,未被定义)
print(c); // 可行(编译器可以用函数体替换函数调用)
2
3
4
然而,这些声明对于使用C类型的引用和指针来说已经足够:
import MyMod;
...
void foo(const C& c) { // 可行
print(c); // 可行
}
2
3
4
5
# 16.4.2 模块声明和导出详解
模块单元必须以以下内容之一开头(在初始注释和空白字符之后):
module;export module name;module name;module name:partname;export module name:partname;
如果模块单元以module;开头引入全局模块片段,那么在全局模块片段中的预处理命令之后,必须紧接着上述其他模块声明中的一个。
在模块内部,你可以导出各种有名称的符号:
- 你可以导出有名称的命名空间,这会导出命名空间声明中定义的所有符号。例如:
export namespace MyMod {
... // 命名空间MyMod中被导出的符号
}
namespace MyMod {
... // 命名空间MyMod中未被导出的符号
}
export namespace MyMod {
... // 命名空间MyMod中更多被导出的符号
}
2
3
4
5
6
7
8
9
- 你可以导出类型,这会导出该类型及其所有成员(如果有的话)。例如:
export class MyClass;
export struct MyStruct;
export union MyUnion;
export enum class MyEnum;
export using MyString = std::string;
2
3
4
5
你不必导出类成员或枚举值。如果导出了类型,类成员和枚举类型的值会自动被导出。
- 你可以导出对象。例如:
export std::string progname;
namespace MyStream {
export using std::cout; // 将std::cout导出为MyStream::cout
}
export auto myLambda = [] {};
2
3
4
5
- 你可以导出函数。例如:
export friend std::ostream& operator<< (std::ostream&, const MyType&);
要声明一个要导出的实体,在其首次声明时使用export。之后你可以再次指定它是被导出的,但不允许先不使用export声明实体,然后再使用export进行声明/定义2。
export不允许在未命名命名空间、静态对象以及私有模块片段中使用。
任何导出都不需要使用inline。从形式上讲,模块内的定义始终只存在一份。即使该对象也被另一个模块重新导出,也是如此。
# 16.4.3 伞形模块(Umbrella Modules)
模块可以导出它们导入的所有内容。对于导入的接口分区,甚至必须进行导出。要导出导入的符号,通常可以使用using:
export module MyMod; // 声明模块MyMod
// 整体导出OtherModule中的所有符号:
export import OtherModule;
// 导入LogModule以导出其中部分内容:
import LogModule;
// 将LogModule命名空间中的Logger导出为::Logger:
export using LogModule::Logger;
// 将LogModule命名空间中的Logger导出为LogModule::Logger:
export namespace LogModule {
using LogModule::Logger;
}
// 导出全局符号globalLogger:
export using ::globalLogger;
// 导出全局符号log(例如函数log()):
export using ::log;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2不过,我见过有编译器接受先不使用export声明,之后再使用export定义的情况。
# 16.4.4 模块导入详解
通过import,任何C++源代码文件都可以导入一个模块,以使用其中导出的函数、类型和对象。
import不是一个普通的关键字,它是一个上下文关键字。这意味着你仍然可以使用import作为其他组件的标识符,尽管不建议这么做。它没有被作为普通关键字引入,是因为这可能会破坏太多现有代码。
使用import的翻译单元或模块单元必须在模块预编译之后进行编译。否则,你可能会得到模块未定义的错误,更糟糕的是,你可能会依据模块的旧版本进行编译。因此,循环导入是不可能的。
# 16.4.5 可访问与可见符号详解
让我们进一步了解导出和导入符号的可见性和可访问性的一些细节,并看一个示例。
导入模块时,你也会间接导入导出API所使用的所有类型。如果这些类型没有被显式导出,你可以使用这些类型及其所有成员函数,但不能使用独立函数。
以下模块将getPerson()作为可见符号导出,将Person作为可访问类导出:
[`modules/person1.cppm`]
module;
#include <iostream>
#include <string>
export module ModPerson; // 模块接口
class Person { // 注意:未被导出
std::string name;
public:
Person(std::string n)
: name{std::move(n)} { }
std::string getName() const {
return name;
}
};
std::ostream& operator<< (std::ostream& strm, const Person& p) {
return strm << p.getName();
}
export Person getPerson(std::string s) {
return Person{s};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
导入这个模块会产生以下结果:
#include <iostream>
import ModPerson; // 导入模块ModPerson
...
Person p1{ "Cal "}; // ERROR: Person不可见
Person p2 = getPerson( "Kim "); // ERROR: Person不可见
auto p3 = getPerson( "Tana "); // OK
std::string s1 = p3.getName(); // ERROR (除非<iostream>包含<string>)
auto s2 = p3.getName(); // OK
std::cout << p3 << "\n"; // ERROR: 独立的operator<<未被导出
std::cout << s2 << "\n"; // OK
2
3
4
5
6
7
8
9
10
如果这段代码还包含了字符串的头文件,s1的声明就能编译通过:
#include <iostream>
#include <string>
import ModPerson; // 导入模块ModPerson
...
Person p1{ "Cal "}; // ERROR: Person不可见
Person p2 = getPerson( "Kim "); // ERROR: Person不可见
auto p3 = getPerson( "Tana "); // OK
std::string s1 = p3.getName(); // OK
auto s2 = p3.getName(); // OK
std::cout << p3 << "\n"; // ERROR: 独立的operator<<未被导出
std::cout << s2 << "\n"; // OK
2
3
4
5
6
7
8
9
10
11
如果你在Person类中将operator<<声明为隐藏的友元函数(这是你应该始终做的):
export module ModPerson;
class Person {
...
friend std::ostream& operator<< (std::ostream& strm, const Person& p) {
return strm << p.getName();
}
};
2
3
4
5
6
7
8
成员运算符就变得可访问了:
auto p3 = getPerson( "Tana "); //OK
std::cout << p3 << "\n"; // OK (现在operator<<可访问)
2
再次注意,通过使用私有模块片段,你可以限制间接导出符号的可访问性。
# 未导出符号不会冲突
间接导出的符号不可见但可访问这一特性,使得程序员可以使用不同的模块,这些模块在其导出接口中使用相同的符号名。例如,假设有一个模块定义了一个Person类如下:
export module ModPerson1;
class Person {
...
public:
std::string getName() const {
return name;
}
};
export Person getPerson1(std::string s) {
return Person{s};
}
2
3
4
5
6
7
8
9
10
11
12
13
还有另一个模块也定义了一个不同的Person类:
export module ModPerson2;
class Person {
...
public:
std::string getName() const {
return name;
}
};
export Person getPerson2(std::string s) {
return Person{s};
}
2
3
4
5
6
7
8
9
10
11
12
13
在这种情况下,一个程序可以导入这两个模块而不会有任何冲突,因为唯一可见的符号是第一个模块中的getPerson1()和第二个模块中的getPerson2()。以下代码可以正常工作:
auto p1 = getPerson1( "Tana ");
auto s1 = p1.getName();
auto p2 = getPerson2( "Tana ");
auto s2 = p2.getName();
2
3
4
p1和p2的类型名称相同,但实际上是不同的类型:
std::same_as<decltype(p1), decltype(p2)> // 结果为false
# 16.5 补充说明
在C++中支持模块的想法由来已久。关于这方面的第一篇论文由Daveed Vandevoorde于2004年发表,网址为http://wg21.link/n1736 (opens new window)。
由于该特性的复杂性,通过http://wg21.link/n4592 (opens new window)制定了一个模块技术规范(实验性技术规范,Modules TS)来研究细节。Gabriel Dos Reis是该技术规范内容的主要推动者。
最终将模块合并到C++20标准中的措辞由Richard Smith在http://wg21.link/p1103r3 (opens new window)中制定。之后,许多作者在不同的论文中进行了一些修正和说明。