 3. 语言澄清(Language Clarification)
3. 语言澄清(Language Clarification)
# 3. 语言澄清(Language Clarification)
C++是一门具有挑战性的语言,想要完全掌握并非易事,其中一些部分可能会让程序员感到困惑。导致理解不清晰的原因之一可能是实现过程或编译器具有过多的自由裁量权。例如,语言中的某些部分描述得较为模糊,以便进行更激进的优化。此外,由于需要与C语言兼容,也会带来一些其他的理解困难。C++17对语言中一些最常见的 “漏洞” 进行了修正。
在本章中,你将了解到:
- 求值顺序是什么,为什么它可能会产生意想不到的结果;
- 语言中关于复制省略的保证;
- 作为类型系统一部分的异常规范;
- (过度)对齐数据的内存分配。
# 更严格的表达式求值顺序
在C++17之前,语言并没有规定函数参数的求值顺序。
就是这么回事。
例如,这就是为什么在C++14中,make_unique 不仅仅是语法糖,它还能保证内存安全:
考虑以下示例:
foo(unique_ptr<T>(new T), otherFunction()); // 第一种情况,使用显式的new
foo(make_unique<T>(), otherFunction()); // 第二种情况
2
对于第一种情况,在C++14中,我们只知道new T 肯定会在unique_ptr 构造之前发生,但仅此而已。例如,可能会先调用new T,然后调用otherFunction(),最后调用unique_ptr 的构造函数。
在这种求值顺序下,当otherFunction() 抛出异常时,new T 会产生内存泄漏(因为此时unique_ptr 还未创建)。
当你像第二种情况那样使用make_unique 时,就不会出现泄漏问题,因为你将内存分配和unique_ptr 的创建封装在了一次调用中。
C++17解决了第一种情况中出现的问题。现在,函数参数的求值顺序变得 “切实可行” 且可预测。在我们的示例中,编译器不允许在unique_ptr<T>(new T) 表达式完全求值之前调用otherFunction()。
# 变更内容
在表达式f(a, b, c); 中:
a、b、c 的求值顺序仍然未指定,但任何一个参数都必须在开始计算下一个参数之前完全求值。对于像这样的复杂表达式,这一点尤为关键:
f(a(x), b, c(y));
如果编译器选择先计算a(x),那么在处理b、c(y) 或y 之前,它必须先计算x。
这一保证解决了make_unique 与unique_ptr<T>(new T()) 的问题。给定的函数参数必须在其他参数求值之前完全求值。
考虑以下情况:
Chapter Clarification/chain_order.cpp
#include <iostream>
class Query {
public:
Query& addInt(int i) {
std::cout << "addInt: " << i << '\n ';
return *this;
}
Query& addFloat(float f) {
std::cout << "addFloat: " << f << '\n ';
return *this;
}
};
float computeFloat() {
std::cout << "computing float... \n ";
return 10.1f;
}
float computeInt() {
std::cout << "computing int... \n ";
return 8;
}
int main() {
Query q;
q.addFloat(computeFloat()).addInt(computeInt());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
你可能期望在使用C++14时,computeInt() 在addFloat 之后执行。但遗憾的是,情况可能并非如此。例如,这是GCC 4.7.3的输出结果:
computing int...
computing float...
addFloat: 10.1
addInt: 8
2
3
4
函数链式调用已经规定是从左到右执行(因此addInt() 在addFloat() 之后执行),但内部表达式的求值顺序可能不同。确切地说:
这些表达式的求值顺序是不确定的。
在C++17中,当函数链式调用包含内部表达式时,它将按预期工作,即从左到右求值:在表达式a(expA).b(expB).c(expC) 中,expA 会在调用b() 之前求值。
使用符合C++17标准的编译器编译前面的示例,会得到以下结果:
computing float... addFloat: 10.1
computing int... addInt: 8
2
这一变更的另一个结果是,在使用运算符重载时,求值顺序由相应的内置运算符的顺序决定。
例如:
std::cout << a() << b() << c();
上述代码包含运算符重载,展开后为以下函数表示法:
operator<<(operator<<(operator<<(std::cout, a()), b()), c());
在C++17之前,a()、b() 和c() 可以按任意顺序求值。现在,在C++17中,会先求值a(),然后是b(),最后是c()。
在论文P0145R3 (opens new window)中描述了更多规则:
| 以下表达式按a、b的顺序求值: 1. a.b2. a->b3. a->*b4. a(b1, b2, b3)(b1、b2、b3 的求值顺序任意)5. b @= a(@ 表示任意运算符)6. a[b]7. a << b8. a >> b |
|---|
如果你不确定代码的求值方式,最好将其简化,并拆分成几个清晰的语句。你可以在《C++核心准则》中找到一些指导,例如ES.44 (opens new window) 和ES.44 (opens new window)。
# 额外信息
该变更在P0145R3 (opens new window) 中被提出。
# 保证复制省略
复制省略(Copy Elision)是一种常见的优化手段,它可以避免创建不必要的临时对象。例如:
// Clarification/copy_elision.cpp
#include <iostream>
struct Test {
Test() { std::cout << "Test::Test\n"; }
Test(const Test&) { std::cout << "Test(const Test&)\n"; }
Test(Test&&) { std::cout << "Test(Test&&)\n"; }
~Test() { std::cout << "~Test\n"; }
};
Test Create() {
return Test();
}
int main() {
auto n = Create();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在上述调用中,你可能会认为会使用一个临时副本,来存储Create的返回值。在C++14中,大多数编译器都能识别出这个临时对象很容易被优化,它们可以直接从Create()的调用中创建n。所以你可能会看到以下输出:
Test::Test // 创建n
~Test // main结束时销毁n
2
复制省略优化的基本形式被称为返回值优化(Return Value Optimisation,RVO)。
作为一个实验,在GCC中你可以添加编译器标志-fno-elide-constructors并使用-std=c++14(或更早的语言标准)。在这种情况下,你会看到不同的输出:
// 编译命令为 "g++ CopyElision.cpp -std=c++14 -fno-elide-constructors"
Test::Test
Test(Test&&)
~Test
Test(Test&&)
~Test
~Test
2
3
4
5
6
7
在这种情况下,编译器为了将返回值传递给n,额外进行了两次复制操作。
编译器甚至更智能,在返回命名对象时,它们也可以进行省略操作,这被称为命名返回值优化(Named Return Value Optimisation,NRVO):
Test Create() {
Test t;
// 一些初始化't'的指令...
return t;
}
auto n = Create(); // 临时对象通常会被省略
2
3
4
5
6
目前,标准允许在以下情况下进行省略:
- 当一个临时对象用于初始化另一个对象时(包括函数返回的对象,或由
throw表达式创建的异常对象)。 - 当一个即将超出作用域的变量被返回或抛出时。
- 当按值捕获异常时。
然而,是否进行省略取决于编译器或实现。在实际应用中,所有构造函数的定义都是必需的。
在C++17中,我们有了明确的规则来确定何时必须进行省略操作,因此构造函数可能会被完全省略。实际上,编译器不是省略复制操作,而是推迟对象的“具体化”。
这为什么有用呢?
- 允许返回不可移动/不可复制的对象,因为现在我们可以跳过复制/移动构造函数。
- 提高代码的可移植性,因为每个符合标准的编译器都支持相同的规则。
- 支持“按值返回”模式,而不是使用输出参数。
- 提高性能。
下面是一个基于P0135R0的不可移动/不可复制类型的示例:
// Clarification/copy_elision_non_moveable.cpp
struct NonMoveable {
NonMoveable(int x) : v(x) {}
NonMoveable(const NonMoveable&) = delete;
NonMoveable(NonMoveable&&) = delete;
std::array<int, 1024> arr;
int v;
};
NonMoveable make(int val) {
if (val > 0)
return NonMoveable(val);
return NonMoveable(-val);
}
int main() {
auto largeNonMoveableObj = make(90); // 构造对象
return largeNonMoveableObj.v;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上述代码在C++14下无法编译,因为它缺少复制和移动构造函数。但在C++17中,构造函数不是必需的,因为largeNonMovableObj对象将在原地构造。
请注意,你也可以在一个函数中使用多个return语句,复制省略仍然会起作用。
此外,需要记住的是,在C++17中,复制省略仅适用于未命名的临时对象,并且命名返回值优化(NRVO)不是强制的。
为了理解C++标准中强制复制省略/推迟临时对象具体化是如何定义的,我们必须了解值类别,下一节将对此进行介绍。
# 更新的值类别
在C++98/03中,我们有两种基本的表达式类别:
- 左值(lvalue):可以出现在赋值操作符左边的表达式。
- 右值(rvalue):只能出现在赋值操作符右边的表达式。
C++11由于引入了移动语义,扩展了这个分类,增加了另外三个类别:
- 将亡值(xvalue):即将过期的左值。
- 纯右值(prvalue):纯粹的右值、将亡值、临时对象或子对象,或者是与对象无关的值。
- 泛左值(glvalue):广义的左值,即左值或将亡值。
例如:
std::string str;
str; // 左值
42; // 纯右值
str + "10" // 纯右值
std::move(str); // 将亡值
2
3
4
5
下面的图表展示了这些类别之间的关系:
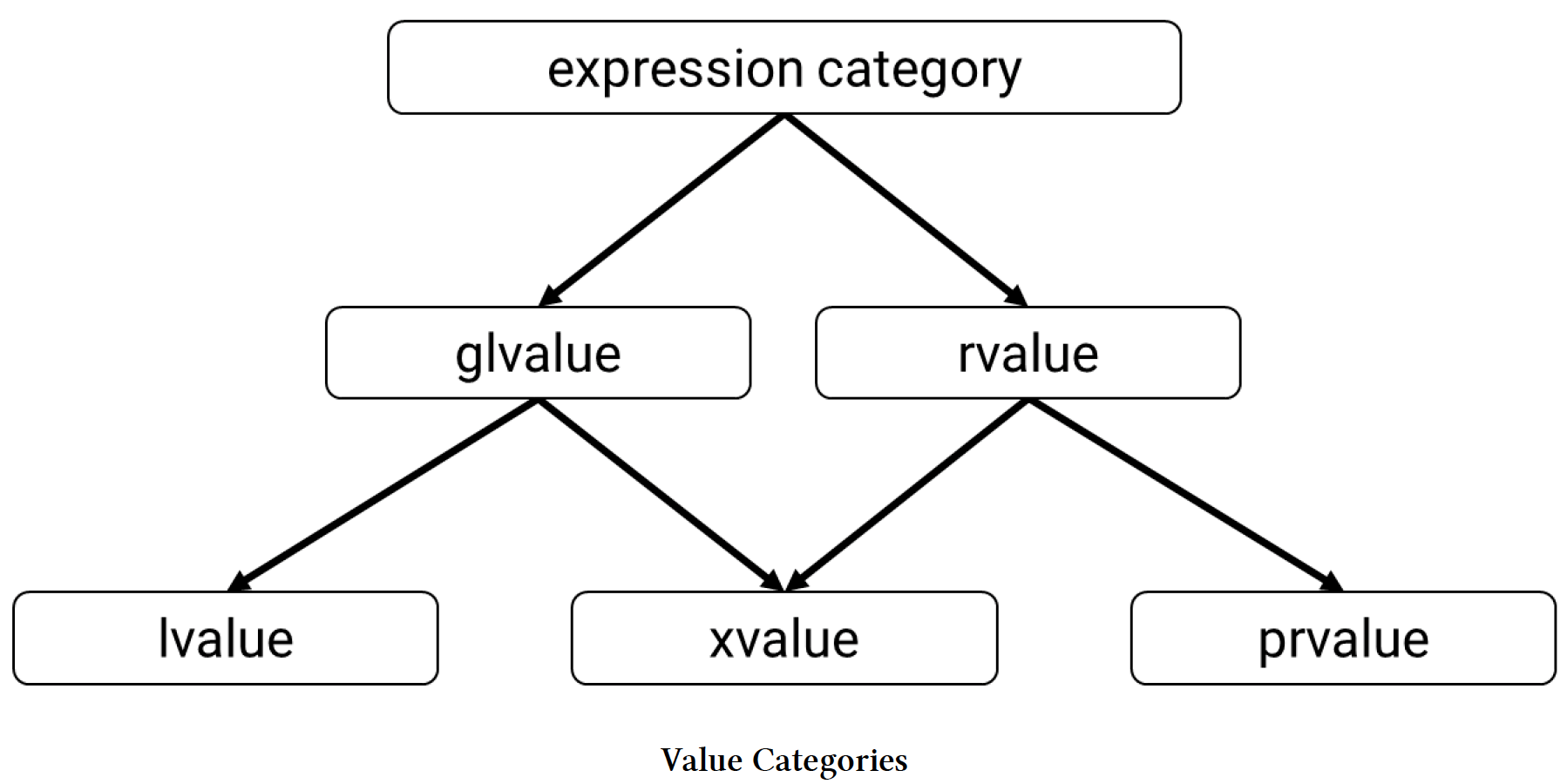 图3.1 值类别
图3.1 值类别
有三个核心类别(以下是通俗的“定义”):
- 左值:具有标识,我们可以获取其地址的表达式。
- 将亡值:“即将过期的左值”,我们可以从中移动数据、可以重用的对象。通常,其生命周期很快结束。
- 纯右值:纯粹的右值,没有名称,我们无法获取其地址,我们可以从这样的表达式中移动数据。
为了支持复制省略,提案作者提供了泛左值和纯右值的更新定义。根据标准 (opens new window):
| 泛左值(glvalue) - 泛左值是这样一种表达式,其求值计算出一个对象、位域或函数的位置。 纯右值(prvalue) - 纯右值是这样一种表达式,其求值会初始化一个对象、位域或操作符的操作数,具体由其出现的上下文指定。 |
|---|
例如:
class X { int a; };
X{10} // 这个表达式是纯右值
X x; // x是左值
x.a // 它是左值(位置)
2
3
4
简而言之:纯右值执行初始化,泛左值描述位置。C++17标准规定,当有一个纯右值初始化某个泛左值时,无需创建临时对象,我们可以推迟其具体化。
在C++17中,复制省略/推迟临时对象具体化发生在以下情况:
- 用纯右值初始化对象时:
Type t = T()。 - 函数调用中,函数返回纯右值时,就像我们的示例一样。
# 额外信息
该变更在P0135R0 (opens new window)(论证)和P0135R1 (opens new window)(措辞)中被提出。
# 过对齐数据的动态内存分配
嵌入式环境、内核、驱动程序、游戏开发等领域可能会对内存分配有非默认对齐的要求。满足这些要求可能会提升性能,或者满足某些硬件接口的需求。
例如,要使用单指令多数据(SIMD(单指令多数据(Single Instruction, Multiple Data),例如SSE2、AVX,详见https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions))指令进行几何数据处理时,对于存储三维坐标的结构体,可能需要16字节或32字节的对齐:
struct alignas(32) Vec3d { // alignas自C++11起可用
double x, y, z;
};
auto pVectors = new Vec3d[1000];
2
3
4
5
Vec3d 结构体包含 double 类型的成员,通常情况下,其天然对齐方式应为8字节。现在,借助 alignas 关键字,我们将对齐方式改为32字节。这种方式能让编译器把对象放入像AVX(256位宽寄存器)这样的SIMD寄存器中。
遗憾的是,在C++11/14中,无法保证 new[] 操作后内存的对齐情况。通常,必须使用 std::aligned_alloc() 或微软Visual C++(MSVC)的 _aligned_malloc() 这样的函数,才能确保对齐得以维持。但这并不理想,因为它与智能指针配合使用时不太方便,而且会让代码中的内存管理操作暴露无遗。
C++17通过为 new() 和 delete() 引入带有 align_val_t 参数的新内存分配函数重载,填补了这一漏洞。以下是示例函数签名(详见https://en.cppreference.com/w/cpp/memory/new/operator_new上的全部22个 new() 重载函数):
void* operator new(size_t , align_val_t);
void operator delete(void*, size_t , align_val_t);
2
标准还定义了 STDCPP_DEFAULT_NEW_ALIGNMENT 宏,用于指定动态内存分配的默认对齐方式。在常见平台上,Clang、GNU编译器集合(GCC)和MSVC将其指定为16字节。
现在,在C++17中,当进行如下分配时:
auto pVectors = new Vec3d[1000];
Vec3d 的对齐方式大于 STDCPP_DEFAULT_NEW_ALIGNMENT,因此编译器会选择带有 align_val_t 参数的重载函数。
在Clang和GCC中,可以使用 fnew-alignment 开关来控制默认对齐方式(详见Clang的文档 (opens new window))。MSVC编译器提供了 /Zc:alignedNew 标志 (opens new window),用于开启或关闭该功能。
我们也可以提供自定义实现,如下所示:
// Chapter Clarification/aligned_new.cpp
void* operator new(std::size_t size, std::align_val_t align) {
#if defined(_WIN32) || defined( CYGWIN )
auto ptr = _aligned_malloc(size, static_cast<std::size_t>(align));
#else
auto ptr = std::aligned_alloc(static_cast<std::size_t>(align), size);
#endif
if ( !ptr) throw std::bad_alloc{};
std::cout << "new: " << size << ", align: "
<< static_cast<std::size_t>(align) << ", ptr: " << ptr << '\n ';
return ptr;
}
void operator delete(void* ptr, std::size_t size, std::align_val_t algn) noexcept {
std::cout << "delete: " << size << ", align: "
<< static_cast<std::size_t>(algn) << ", ptr : " << ptr << '\n ';
#if defined(_WIN32) || defined( CYGWIN )
_aligned_free(ptr);
#else
std::free(ptr);
#endif
}
void operator delete(void* ptr, std::align_val_t algn) noexcept {
...
} // hidden
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这段代码在Windows版本中使用 _aligned_malloc() 和 _aligned_free()(这适用于MSVC、 MinGW、Windows 版本Clang 、 Cygwin) 。这是因为Windows平台对过对齐数据采用了不同的分配机制,所以 std::free() 无法正确释放内存。在其他符合C11标准的平台上,可以尝试使用 std::aligned_alloc(),因为自C++17起,标准是基于C11规范的。在这种情况下,free() 可以释放对齐的内存。
这项新功能能够显著优化代码,现在无需编写自定义分配器或智能指针的自定义删除器,就可以在标准容器中存储对齐的对象。
例如:
// Chapter Clarification/aligned_new.cpp
std::vector<Vec3d> vec;
vec.push_back({});
vec.push_back({});
vec.push_back({});
assert(reinterpret_cast<uintptr_t>(vec.data()) % alignof(Vec3d) == 0);
2
3
4
5
6
执行时,我们替换后的分配函数可能会记录如下输出:
new: 32, align: 32, ptr: 000001F866625960
new: 64, align: 32, ptr: 000001F866625680
delete: 32, align: 32, ptr : 000001F866625960
new: 96, align: 32, ptr: 000001F866623EA0
delete: 64, align: 32, ptr : 000001F866625680
delete: 96, align: 32, ptr : 000001F866623EA0
2
3
4
5
6
该示例先为单个元素分配内存,然后删除它,接着两次增大向量的大小,以便为全部三个元素腾出空间。最后,我们检查指针的对齐情况,确保其为32字节对齐。
你可以在《New new() - The C++17’s Alignment Parameter for Operator new() (opens new window)》 中了解更多关于这项新功能的实验内容。这篇博客文章还展示了在使用定位 new 请求非标准对齐时的潜在风险。
# 额外信息
这项更改是在P0035 (opens new window) 中提出的。
# 类型系统中的异常规范
函数的异常规范过去不属于函数类型的一部分,但现在它成为了函数类型的一部分。现在可以有两个函数重载:一个使用 noexcept,另一个不使用。如下所示:
// Chapter Clarification/func_except_type.cpp
using TNoexceptVoidFunc = void (*)() noexcept;
void SimpleNoexceptCall(TNoexceptVoidFunc f) {
f();
}
using TVoidFunc = void (*)();
void SimpleCall(TVoidFunc f) {
f();
}
void fNoexcept() noexcept {
}
void fRegular() {
}
int main() {
SimpleNoexceptCall(fNoexcept);
//SimpleNoexceptCall(fRegular); // 无法转换
SimpleCall(fNoexcept); // 转换为普通函数
SimpleCall(fRegular);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
指向 noexcept 函数的指针可以转换为指向普通函数的指针(这对指向成员函数的指针同样适用)。但反过来则不行(从普通函数指针转换为标记了 noexcept 的函数指针)。
添加这项功能的原因之一,是为了有机会更好地优化代码。如果编译器能确定一个函数不会抛出异常,那么它就能生成更快的代码。
此外,正如上一章关于语言修正的内容所述,在C++17中,异常规范得到了清理。实际上,只能使用noexcept 说明符 (opens new window)来声明一个函数不会抛出异常。
# 额外信息
这项更改是在P0012R1 (opens new window)中提出的。
# 编译器支持
| 特性 | GCC | Clang | MSVC |
|---|---|---|---|
| 更严格的表达式求值顺序 | 7.0 | 4.0 | VS 2017 |
| 保证的复制省略 | 7.0 | 4.0 | VS 2017 15.6 |
| 过对齐数据的动态内存分配 | 7.0 | 4.0 | VS 2017 15.5 |
| 异常规范成为类型系统的一部分 | 7.0 | 4.0 | VS 2017 15.5 |