 12. 搜索器与字符串匹配
12. 搜索器与字符串匹配
# 12. 搜索器与字符串匹配
C++14中的std::search提供了一种通用的方式,用于在给定范围内搜索某个模式。该算法不仅可用于字符容器,还可用于包含自定义类型的容器。遗憾的是,这种技术存在一定局限性,因为其性能通常较慢 —— 它使用朴素匹配算法,时间复杂度为模式长度乘以文本长度。在C++17中,std::search有了新的重载版本,引入了像Boyer Moore变体这样强大的新算法,这些算法在平均情况下具有线性时间复杂度。
在本章中,你将学到:
- 如何通过模式预处理优化朴素搜索算法。
- 如何使用
std::search在范围内高效搜索模式。 - 如何将
std::search用于自定义类型。
# 字符串匹配算法概述
字符串匹配是指在一段文本中查找一个或所有出现的某个字符串(“模式”)。这些字符串由一组有限的字符构成,这组字符被称为 “字母表”。
有许多算法可以解决这个问题,以下是维基百科 (opens new window)列出的部分算法:
| 算法 | 预处理 | 匹配 | 空间复杂度 |
|---|---|---|---|
| 朴素字符串搜索 | 无 | O(nm) | 无 |
| Rabin - Karp | O(m) | 平均O(n + m),最坏O((n−m)m) | O(1) |
| Knuth - Morris - Pratt | O(m) | O(n) | O(m) |
| Boyer - Moore | O(m + k) | 最佳O(n/m),最坏O(mn) | O(k) |
| Boyer - Moore - Horspool | O(m + k) | 最佳O(n/m),最坏O(mn) | O(k) |
m - 模式的长度 n - 文本的长度 k - 字母表的大小
朴素算法会尝试在文本的每个位置匹配模式:
模式 = Hello
文本 = SuperHelloWorld
SuperHelloWorld
1. Hello <- XX
2. Hello <- XX
3. Hello <- XX
4. Hello <- XX
5. Hello <- XX
6. Hello <- OK!
2
3
4
5
6
7
8
9
10
在上面的例子中,我们在“SuperHelloWorld”中查找“Hello”。可以看到,朴素算法会尝试每个位置,直到在第6次迭代时找到“Hello”。
朴素算法与其他算法的主要区别在于,更快的算法会利用关于输入模式的额外信息。这样,它们可以跳过许多不必要的比较。
为了获取这些信息,它们通常会在预处理阶段为模式构建一些查找表。查找表的大小通常与模式的长度和字母表的大小相关。
在上述例子中,我们可以跳过大部分迭代。比如当我们在第一个位置尝试匹配“Hello”时,发现最后一个字母'o'和'r'不匹配。实际上,由于'r'根本不在我们的模式中,我们可以直接往后移动5步。
模式 = Hello
文本 = SuperHelloWorld
SuperHelloWorld
1. Hello <- XX,
2. Hello <- OK
2
3
4
5
6
我们只用了2次迭代就找到了匹配项!这个例子中使用的规则来自Boyer Moore算法,称为“坏字符规则”。
在C++中,字符串匹配是通过std::search实现的,它用于在一个范围(文本)内查找另一个范围(模式):
template < class ForwardIt1 , class ForwardIt2 >
ForwardIt1 search( ForwardIt1 first, ForwardIt1 last,
ForwardIt2 s_first, ForwardIt2 s_last );
2
3
在C++17之前,你无法控制std::search内部使用的算法。std::search的时间复杂度被指定为O(mn),所以它通常采用朴素算法。现在,在C++17中,你有了更多选择。
确切地说,还有string::find,它专门用于字符序列。这个方法可能有不同的实现,并且你无法控制其内部使用的算法。在示例部分,你将看到一些性能实验,这些实验还会将std::search的新算法与string::find进行比较。
# C++17中的新算法
C++17以两种方式更新了std::search算法:
- 现在你可以使用执行策略(execution policy)以并行方式运行算法的默认版本。
- 你可以提供一个搜索器(Searcher)对象来处理搜索过程。
在C++17中,我们有三种搜索器:
default_searcher:与C++17之前的版本相同,通常采用朴素算法。适用于前向迭代器(Forward Iterators)。boyer_moore_searcher:使用Boyer Moore算法的完整版本,包含两个规则:坏字符规则和好后缀规则。适用于随机访问迭代器(Random Access Iterators)。boyer_moore_horspool_searcher:Boyer - Moore算法的简化版本,仅使用坏字符规则,但平均复杂度仍然较好。适用于随机访问迭代器。
带搜索器的std::search不能与执行策略一起使用。
# 使用搜索器
std::search函数对搜索器使用以下重载版本:
template <class ForwardIterator , class Searcher>
ForwardIterator search(ForwardIterator first, ForwardIterator last, const Searcher& searcher );
2
例如:
string testString = "Hello Super World";
string needle = "Super";
const auto it = search(begin(testString), end(testString),
boyer_moore_searcher(begin(needle), end(needle));
if (it == cend(testString))
cout << "The string " << needle << " not found\n";
2
3
4
5
6
7
每个搜索器通过构造函数初始化其状态。构造函数需要存储模式范围,并执行预处理阶段。然后std::search调用它们的operator()(iter TextFirst, iter TextLast)方法在文本范围内进行搜索 。
由于搜索器是一个对象,你可以在应用程序中传递它。如果你想在多个文本对象中搜索相同的模式,这会很有用,因为这样预处理阶段只需执行一次。
# 示例
# 性能实验
这个示例构建了一个性能测试,用于测试在较大文本中查找模式的几种方法。
测试的工作方式如下:
- 应用程序加载一个文本文件(可通过命令行参数配置),例如一本图书的片段(如一个500KB的文本文件)。
- 整个文件内容存储在一个字符串中,这个字符串将作为我们进行查找操作的“文本”。
- 选择一个模式,从输入文本中选取N个字母。这样可以确保能找到该模式。字符串的位置可以在文本的开头、中间或结尾。
- 基准测试使用多种算法,每个搜索操作运行ITER次 。
你可以在Chapter Searchers/searchers_benchmark.cpp中找到这个示例。示例基准测试如下:
std::string::find版本:
RunAndMeasure("string::find", [&]() {
for (size_t i = 0; i < ITERS; ++i) {
std::size_t found = testString.find(needle);
if (found == std::string::npos) {
std::cout << "The string " << needle << " not found\n";
}
}
});
2
3
4
5
6
7
8
boyer_moore_horspool版本:
RunAndMeasure("boyer_moore_horspool_searcher", [&]() {
for (size_t i = 0; i < ITERS; ++i) {
auto it = std::search(testString.begin(), testString.end(),
std::boyer_moore_horspool_searcher(needle.begin(), needle.end()));
if (it == testString.end()) {
std::cout << "The string " << needle << " not found\n";
}
}
});
2
3
4
5
6
7
8
9
10
RunAndMeasure是一个函数,它接受一个可调用对象(例如lambda表达式)并执行,测量执行时间并打印结果。
由于输入字符串是从文件加载的,编译器无法进行优化,不会将代码优化掉。
以下是在Win 10 64位系统、i7 8700、3.20 GHz基础频率、6核/12线程(不过应用程序在单线程上运行)的环境下运行应用程序的部分结果。
字符串大小为547412字节(来自一个500KB的文本文件),我们运行基准测试1000次。
| 算法 | GCC 8.2 | Clang 7.0 | Visual Studio(x64发布版) |
|---|---|---|---|
string::find | 579.48 | 367.90 | 380.78 |
default searcher | 391.99 | 552.02 | 604.33 |
boyer_moore_searcher | 37.89(初始化时间3.98) | 32.73(初始化时间3.02) | 34.71(初始化时间3.52) |
boyer_moore_horspool_searcher | 30.943(初始化时间0) | 28.72(初始化时间0.5) | 31.70(初始化时间0.69) |
在输入字符串中间搜索1000个字母时,这两种新算法都比默认搜索器和string::find更快。boyer_moore比boyer_moore_horspool花费更多时间进行初始化(它创建两个查找表,而不是一个,所以会占用更多空间并需要更多预处理时间)。结果还表明,boyer_moore通常比boyer_moore_horspool花费更长时间预处理输入模式。而且在我们的测试中,第二种算法更快。总体而言,新算法的性能比默认版本快10到15倍。
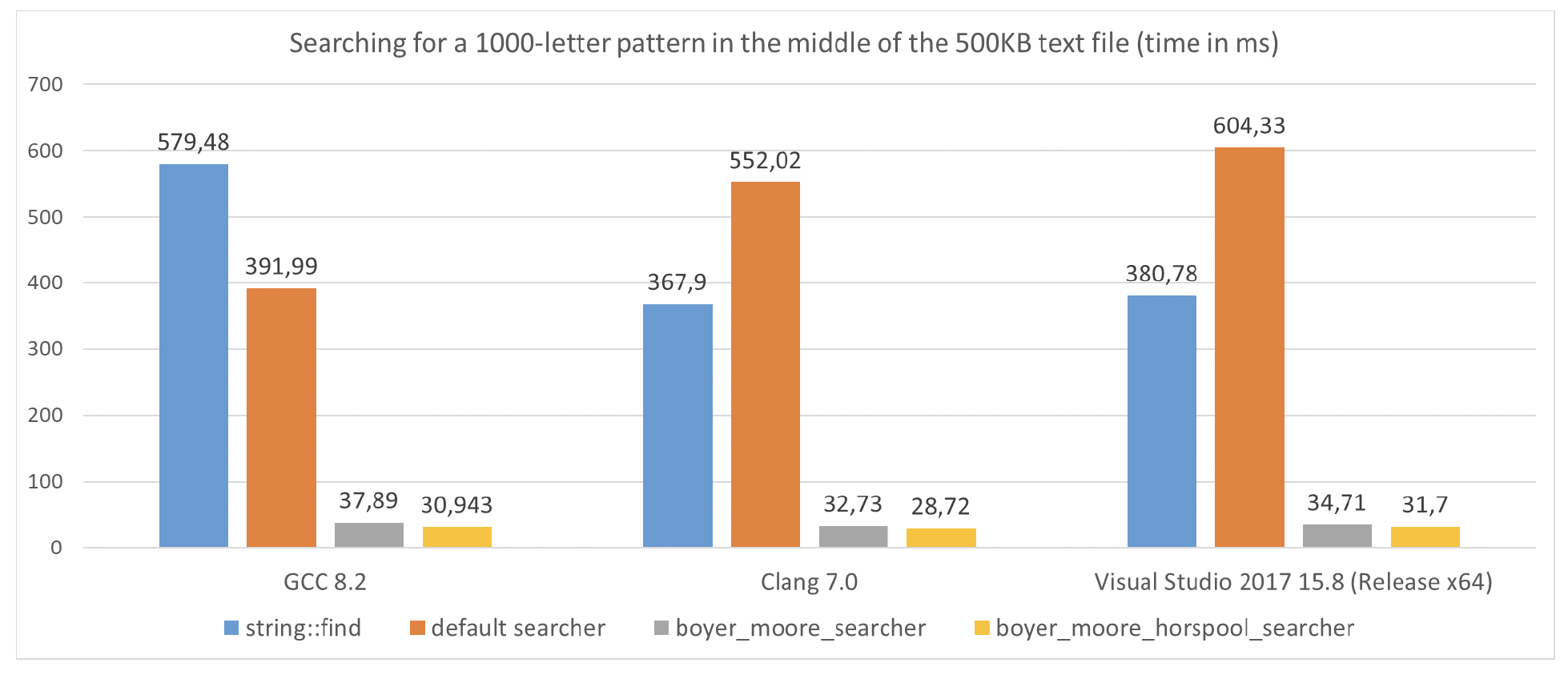
图 12.2 在500KB文本文件中间搜索1000个字母的模式
以下是另一次运行的结果,这次我们使用相同的输入字符串(来自一个500KB的文本文件),执行1000次迭代,但模式只有48个字母,是位于文件末尾的一个句子(只出现一次)。
| 算法 | GCC 8.2 | Clang 7.0 | Visual Studio(x64发布版) |
|---|---|---|---|
string::find | 164.58 | 39.63 | 40.28 |
default searcher | 102.75 | 332.98 | 396.11 |
boyer_moore_searcher | 115.69(初始化时间0.96) | 95.56(初始化时间0.45) | 101.73(初始化时间0.49) |
boyer_moore_horspool_searcher | 100.74(初始化时间0) | 97.48(初始化时间0.21) | 105.44(初始化时间0.23) |
在这次测试中,Visual Studio和Clang中的Boyer - Moore算法比string::find慢2.5倍。然而,在GCC上,string::find的表现更差,boyer_moore_horspool是最快的。

图 12.2 在500KB文本文件末尾搜索48个字母的文本(时间,单位:毫秒)
你可以运行这些实验,看看你的STL实现的性能如何。有很多方法可以配置基准测试,你可以测试文本中不同位置(开头、中间、结尾)的情况,或者检查某些字符串模式。
# DNA匹配
为了展示std::search的广泛用途,让我们来看一个简单的DNA匹配示例。这个示例将匹配自定义类型,而不是普通字符。
例如,我们想要在DNA序列“CTGATGTTAAGTCAACGCTGC”中搜索“GCTGC”是否存在。
该应用程序使用了一个简单的核苷酸数据结构:在Chapter Searchers/dna_demo.cpp文件中:
struct Nucleotide {
enum class Type : uint8_t {
A = 0,
C = 1,
G = 2,
T = 3
};
Type mType;
friend bool operator==(Nucleotide a, Nucleotide b) noexcept {
return a.mType == b.mType;
}
static char ToChar(Nucleotide t);
static Nucleotide FromChar(char ch);
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
还有两个转换静态方法:在Chapter Searchers/dna_demo.cpp文件中:
char Nucleotide::ToChar(Nucleotide t) {
switch (t.mType) {
case Nucleotide::Type::A: return 'A';
case Nucleotide::Type::C: return 'C';
case Nucleotide::Type::G: return 'G';
case Nucleotide::Type::T: return 'T';
}
return 0;
}
Nucleotide Nucleotide::FromChar(char ch) {
return Nucleotide{ static_cast<Nucleotide::Type>((ch >> 1) & 0x03) };
}
2
3
4
5
6
7
8
9
10
11
12
13
以及两个处理整个字符串的函数:在Chapter Searchers/dna_demo.cpp文件中:
std::vector<Nucleotide> FromString(const std::string& s) {
std::vector<Nucleotide> out;
out.reserve(s.length());
std::transform(std::cbegin(s), std::cend(s),
std::back_inserter(out), Nucleotide::FromChar);
return out;
}
std::string ToString(const std::vector<Nucleotide>& vec) {
std::stringstream ss;
std::ostream_iterator<char> out_it(ss);
std::transform(std::cbegin(vec), std::cend(vec), out_it, Nucleotide::ToChar);
return ss.str();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这个示例使用了boyer_moore_horspool_searcher,它需要哈希支持。所以我们必须如下定义:在Chapter Searchers/dna_demo.cpp文件中:
namespace std {
template <> struct hash<Nucleotide> {
size_t operator()(Nucleotide n) const noexcept {
return std::hash<Nucleotide::Type>{}(n.mType);
}
};
}
2
3
4
5
6
7
std::hash支持枚举类型,所以我们只需要从整个类进行 “重定向”。然后是测试代码:在Chapter Searchers/dna_demo.cpp文件中:
const std::vector<Nucleotide> dna = FromString("CTGATGTTAAGTCAACGCTGC");
std::cout << ToString(dna) << '\n';
const std::vector<Nucleotide> s = FromString("GCTGC");
std::cout << ToString(s) << '\n';
std::boyer_moore_horspool_searcher searcher(std::cbegin(s), std::cend(s));
const auto it = std::search(std::cbegin(dna), std::cend(dna), searcher);
if (it == std::cend(dna)) {
std::cout << "The pattern " << ToString(s) << " not found\n";
} else {
std::cout << "DNA matched at position: " << std::distance(std::cbegin(dna), it) << '\n';
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到,这个示例构建了一个自定义类型Nucleotide的向量。为了满足搜索器的要求,自定义类型需要支持std::hash接口,并且定义operator==。
Nucleotide类型有点浪费空间,因为我们用整整一个字节来存储四种选项(C、T、G、A)。其实我们可以只用2位来存储,不过实现起来会更复杂。另一种选择是表示核苷酸三联体(密码子)。每个密码子可以用6位表示,这样我们就能更有效地利用整个字节。
# 总结
在本章中,你学习了可以传递给std::search算法的搜索器。它们让你能够在字符串匹配中使用更高级的算法,如Boyer - Moore和Boyer - Moore - Horspool算法,这些算法比朴素算法的复杂度更低。
带搜索器的std::search是一种通用算法,适用于大多数提供随机访问迭代器的容器。如果你处理的是字符串和字符,也可以将其与std::string::find进行比较,std::string::find通常是针对字符处理进行专门优化的(具体取决于实现!)。
额外信息
相关变更提案在:N3905 (opens new window) 。
# 编译器支持情况
| 特性 | GCC | Clang | MSVC |
|---|---|---|---|
| 搜索器 | 7.1 | 3.9 | VS 2017 15.3 |