 14. 并行STL算法
14. 并行STL算法
# 14. 并行STL算法
并发和并行是任何现代编程语言的核心方面。在C++11之前,C++语言没有对线程的标准支持,那时你可以使用第三方库或系统应用程序编程接口(API)。现代C++开始引入越来越多必要的特性:线程、原子操作、锁、std::async和futures。
C++17为我们提供了一种将大多数标准库算法并行化的方法。通过一个强大且简单的抽象层,你可以充分利用机器的更多计算能力。
在本章中,你将学到:
- C++在并行和并发方面的发展方向
- 为什么
std::thread不够用 - 执行策略是什么
- 如何运行并行算法
- 哪些算法已被并行化
- 有哪些新算法
- 并行执行的预期性能
- 并行执行的示例和基准测试
# 引言
看看我们周围的计算机,会发现大多数都是多处理器单元。就连手机都有4核甚至8核。更不用说配备了数百(甚至数千)个小型计算核心的显卡了。
赫伯·萨特(Herb Sutter)在一篇著名文章《免费午餐已结束:软件向并发的根本转变 (opens new window)》中,完美地总结了多核机器的发展趋势。这篇文章发表于2006年。
只要环顾一下就会发现,这一趋势并未放缓。
虽然对于一个简单的应用程序来说,可能无需使用机器的全部计算能力,但有些应用程序确实有这样的需求。比如游戏、快速响应的应用程序、图形处理、视频/音乐编辑、数据处理、金融领域、服务器等许多类型的系统。在CPU上创建线程并并发处理任务是实现这一目标的一种方式。
随着C++11/14的出现,线程终于被纳入标准库。现在你可以创建std::thread实例,而不必仅仅依赖第三方库或系统API。此外,还有通过futures(std::async)进行的异步处理。
多线程是现代C++的一个重要方面。在C++委员会中,有一个单独的小组——“SG1,并发”,致力于为标准带来更多此类特性。
未来还会有什么呢?
- 协程(Coroutines)
- 原子智能指针(Atomic Smart pointers)
- 事务内存(Transactional Memory)
- 屏障(Barriers)
- 任务块(Tasks blocks)
- 并行(Parallelism)
- 计算(Compute)
- 执行器(Executors)
- 异构编程模型支持(Heterogeneous programming models support)
正如你所见,C++的规划是尽可能多地从标准库中直接调用机器的计算能力。
# 不止是线程
如前所述,使用线程并非利用机器计算能力的唯一方式。
如果你的系统CPU有8个核心,那么你可以使用8个线程。假设你能将工作分成不同的块,那么理论上,你处理任务的速度会比单线程快好几倍。
但还有机会让处理速度更快!那么其余的计算能力从何而来呢?来自CPU的向量指令和GPU计算。
第一个要素——向量指令,它允许你在一条指令中计算数组的多个分量,也被称为单指令多数据(SIMD,Single Instruction Multiple Data)。大多数CPU都有128位宽的寄存器,而最新的芯片甚至包含256位或512位宽的寄存器(AVX 256、AVX 512)。
例如,使用AVX-512指令,你可以同时对16个32位的整数值进行操作!
第二个要素是GPU,它可能包含数百个较小的核心。
有一些第三方API允许你访问GPU或进行向量化操作,比如CUDA、OpenCL、OpenGL、英特尔线程构建模块(Intel TBB)、OpenMP等等。甚至你的编译器可能会尝试自动向量化某些代码。不过,我们希望标准库能直接提供这种支持,这样相同的代码就能在多个平台上使用。
C++17朝着这个方向迈进了一步,让我们能够使用更多的计算能力:它为标准库中的算法开启了自动向量化/自动并行化功能。
# 概述
从用户的角度来看,C++17的这个新特性出奇地简单。你有一个新的模板参数,可以传递给大多数标准算法,这个新参数被称为执行策略(execution policy)。
template < class ExecutionPolicy, class RandomIt , ... >
std::algorithm_name(ExecutionPolicy&& policy, RandomIt first, RandomIt last, ...);
2
我们稍后会详细介绍,大致思路是,调用一个算法时,指定它的执行方式,比如是并行执行还是串行执行。
例如:
std::vector<int> v = genLargeVector();
// 使用并行策略对向量进行排序
std::sort(std::execution::par, v.begin(), v.end());
2
3
上述示例将按照第一个参数std::execution::par的指定,并行对向量进行排序。整个实现机制对用户是隐藏的。由STL的实现来选择并行运行任务的最佳方式,通常它们可能会利用线程池。
这个提示——执行策略参数是必要的,因为编译器无法从代码中推断出所有信息。作为代码的编写者,只有你清楚是否存在副作用、可能的竞态条件、死锁,或者并行运行是否没有意义(比如处理的数据量很少的情况)。
C++17的并行特性源自2015年正式发布的技术规范。将并行算法引入C++的整个项目耗时超过五年,从2012年开始,到2017年被纳入标准。详见论文:P0024 - 并行技术规范应标准化 (opens new window)。
# 执行策略
执行策略参数表明算法应如何执行。
我们有以下选项:
| 策略名称 | 描述 |
|---|---|
sequenced_policy | 这是一种执行策略类型,用作唯一类型来区分并行算法的重载,并要求并行算法的执行不进行并行化。 |
parallel_policy | 这是一种执行策略类型,用作唯一类型来区分并行算法的重载,并表明并行算法的执行可以进行并行化。 |
parallel_unsequenced_policy | 这是一种执行策略类型,用作唯一类型来区分并行算法的重载,并表明并行算法的执行可以进行并行化和向量化。 |
我们还有三个与每种执行策略类型对应的全局对象:
std::execution::seqstd::execution::parstd::execution::par_unseq
请注意,执行策略是独特的类型,有各自对应的全局对象。它们既不是枚举类型,也没有相同的基类型。
执行策略的声明和全局对象位于<execution>头文件中。
# 理解执行策略
为了理解不同执行策略之间的差异,让我们尝试构建一个算法运行模式。
考虑一个简单的浮点型(float)向量。在下面的示例中,向量的每个元素都乘以2,然后将结果存储到一个输出容器中:
// std::transform对向量的操作
std::vector<float> vecX = {...}; // 生成
std::vector<float> vecY(vecX.size());
std::transform(
std::execution::seq,
begin(vecX), end(vecX), // 输入范围
begin(vecY), // 输出
[](float x) { return x * 2.0f; }); // 操作
2
3
4
5
6
7
8
下面是上述算法顺序执行的伪代码:
operation
{
load vecX[i] into RegisterX
multiply RegisterX by 2.0f
store RegisterX into vecY[i]
}
2
3
4
5
6
在顺序执行中,我们将访问一个元素(来自vecX),执行一个操作,然后将结果存储到输出(vecY)中。所有元素的执行都在单个线程(调用线程)上进行。
使用并行策略(par policy)时,第i个元素的整个操作将在一个线程上执行。但是可能有多个线程处理容器中的不同元素。例如,如果系统中有8个空闲线程,容器中的8个元素可能会同时进行计算。元素的访问顺序是不确定的。
标准库的实现通常会利用线程池(thread - pool)来执行并行算法。线程池持有一些工作线程(通常与系统核心数量相同),然后调度器会将输入划分为多个块,并将它们分配给工作线程。理论上,在CPU上,你也可以创建与容器中元素数量相同的线程,但由于上下文切换,这样做不会带来良好的性能。另一方面,使用GPU的实现可能会提供数百个较小的“核心”,在这种情况下,调度器的工作方式可能会完全不同。
第三种执行策略par_unseq是并行执行策略的扩展。第i个元素的操作将在单独的线程上执行,但该操作的指令也可能会交错执行并向量化。
例如:
operation
{
load vecX[i...i+3] into RegisterXYZW
multiply RegisterXYZW by 2 // 一次处理4个元素!
store RegisterXYZW into vecY[i...i+3]
}
2
3
4
5
6
上述伪代码使用
RegisterXYZW表示一个宽寄存器,可以存储容器中的4个元素。例如,在SSE(Streaming SIMD Extensions,流式单指令多数据扩展)中,你有128位寄存器,可以处理4个32位值,如4个整数或4个浮点数(或者可以存储8个16位值)。然而,这种向量化甚至可以扩展到更大的寄存器,比如在AVX中,你有256位甚至512位寄存器。选择最佳的向量化方案取决于标准库的实现。
在这种情况下,操作的每条指令都会“复制”并与其他指令交错执行。这样,编译器可以生成一次处理容器中多个元素的指令。
理论上,如果你有8个空闲的系统线程,使用128位SIMD寄存器,并且处理浮点数(32位值),那么我们一次可以计算8×4 = 32个值!
为什么需要顺序策略呢?
大多数时候,你可能对使用并行策略或并行无序策略更感兴趣。但是在调试时,使用
std::execution::seq可能会更方便。这个参数也非常便捷,因为你可以通过模板参数轻松地在不同执行模型之间切换。对于某些算法,顺序策略可能比C++14版本的对应算法性能更好。在“基准测试”部分可以了解更多信息。
# 限制和不安全指令
执行策略的核心是轻松实现标准算法的并行化。然而,你需要注意一些限制。
例如,使用std::par时,如果你想修改共享资源,就需要使用某种同步机制来防止数据竞争和死锁(当你仅想读取共享资源时,就无需进行同步操作):
// 并行操作中的加锁
std::vector<int> vec(1000);
std::iota(vec.begin(), vec.end(), 0);
std::vector<int> output;
std::mutex m;
std::for_each(std::execution::par, vec.begin(), vec.end(),
[&output, &m, &x](int& elem) {
if (elem % 2 == 0) {
std::lock_guard guard(m);
output.push_back(elem);
}
});
2
3
4
5
6
7
8
9
10
11
12
上述代码对输入向量进行筛选,然后将元素放入输出容器中。
如果你忘记使用互斥锁(mutex)(或其他形式的同步机制),那么push_back可能会导致数据竞争,因为多个线程可能会同时尝试向向量中添加新元素。
上面的示例性能也会很差,因为过多的同步点会削弱并行执行的效果。
使用
par执行策略时,尽量少地访问共享资源。
使用par_unseq时,函数调用可能会交错执行,因此禁止使用不安全的向量化代码。例如,使用互斥锁或内存分配可能会导致数据竞争和死锁。
// par_unseq执行中的不安全指令
std::vector<int> vec = GenerateData();
std::mutex m;
int x = 0;
std::for_each(std::execution::par_unseq, vec.begin(), vec.end(),
[&m, &x](int& elem) {
std::lock_guard guard(m);
elem = x;
x++; // 递增一个共享值
});
2
3
4
5
6
7
8
9
10
由于指令可能在一个线程上交错执行,最终可能会出现以下操作顺序:
std::lock_guard guard(m) // 针对第i个元素
std::lock_guard guard(m) // 针对第i+1个元素
...
2
3
如你所见,在单个线程上会发生两次对同一互斥锁的锁定,从而导致死锁!
在使用
par_unseq执行时,不要使用同步和内存分配操作。
# 异常
使用执行策略时,你需要为两种情况做好准备。
- 调度器或实现无法为调用分配资源,此时会抛出
std::bad_alloc异常。 - 用户代码(仿函数)抛出异常,在这种情况下,异常不会被重新抛出,而是调用
std::terminate()。
请参见下面的示例。
// Chapter Parallel Algorithms/par_exceptions.cpp
try {
std::vector<int> v{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
std::for_each(std::execution::par, v.begin(), v.end(),
[](int& i) {
std::cout << i << '\n';
if (i == 5)
throw std::runtime_error("something wrong... !");
});
}
catch (const std::bad_alloc& e) {
std::cout << "Error in execution: " << e.what() << '\n';
}
catch (const std::exception& e) { // will not happen
std::cout << e.what() << '\n';
}
catch (...) {
std::cout << "error!\n";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
如果你运行上述代码,catch块只会处理std::bad_alloc异常。如果你因为某个异常而从lambda表达式中退出,那么会调用std::terminate。异常不会被重新抛出。
当你使用并行算法时,为了更好地处理错误,尽量让你的仿函数(functor)是
noexcept的。
# 算法更新
执行策略参数被添加到了大多数现有算法中。以下是这些算法的新重载列表:
adjacent_difference | inplace_merge | replace_copy |
|---|---|---|
adjacent_find | is_heap | replace_copy_if |
all_of | is_heap_until | replace_if |
any_of | is_partitioned | reverse |
copy | is_sorted | reverse_copy |
copy_if | is_sorted | rotate |
copy_n | is_sorted_until | rotate_copy |
count | lexicographical_compare | search |
count_if | max_element | search_n |
equal | merge | set_difference |
exclusive_scan | min_element | set_intersection |
fill | minmax_element | set_symmetric_difference |
fill_n | mismatch | set_union |
find | move | sort |
find_end | none_of | stable_partition |
find_first_of | nth_element | stable_sort |
find_if | partial_sort | swap_ranges |
find_if_not | partial_sort_copy | transform |
for_each | partition | transform_exclusive_scan |
for_each_n | partition_copy | transform_inclusive_scan |
generate | remove | transform_reduce |
generate_n | remove_copy | uninitialized_copy |
includes | remove_copy_if | uninitialized_copy_n |
inclusive_scan | remove_if | uninitialized_fill |
inner_product | replace unique | uninitialized_fill_n unique_copy |
# 新算法
为了全面支持新的并行执行模式,标准库还配备了一组新算法:
| 算法 | 描述 |
|---|---|
for_each | 与for_each类似,但返回值为void |
for_each_n | 将函数对象应用于序列的前n个元素 |
reduce | 与accumulate类似,但可无序执行以实现并行计算 |
transform_reduce | 使用一元操作对输入元素进行转换,然后无序归约输出结果 |
exclusive_scan | partial_sum的并行版本,在第i个和中排除第i个输入元素,无序执行以实现并行计算 |
inclusive_scan | partial_sum的并行版本,在第i个和中包含第i个输入元素,无序执行以实现并行计算 |
transform_exclusive_scan | 应用仿函数,然后计算排他扫描 |
transform_inclusive_scan | 应用仿函数,然后计算包含扫描 |
新算法分为三组:for_each、reduce,以及scan及其相关变体。
使用reduce和scan时,还能得到像transform_reduce这样的 “融合” 版本。这些组合比使用两个单独步骤的性能要好得多,因为并行执行的设置成本更低,而且减少了一次循环遍历。
新算法还提供了不带执行策略参数的重载版本,这样就可以在标准串行版本中使用它们。
下面将对每组算法进行描述。
# for_each算法
在for_each的串行版本(C++17之前可用的版本)中,该算法会返回一个一元函数。
在并行版本中无法返回这样的对象,因为调用顺序是不确定的。
下面是一个基本示例:
// Chapter Parallel Algortihms/par_basic.cpp
std::vector<int> v(100);
std::iota(v.begin(), v.end(), 0);
std::for_each(std::execution::par, v.begin(), v.end(),
[](int& i) { i += 10; });
std::for_each_n(std::execution::par, v.begin(), v.size()/2,
[](int& i) { i += 10; });
2
3
4
5
6
7
第一个for_each算法将更新向量中的所有元素,而第二个执行操作仅作用于容器的前半部分。
# 理解reduce算法
C++17中另一个核心算法是std::reduce。这个新算法提供了std::accumulate的并行版本。但理解它们之间的区别很重要。
std::accumulate返回一个范围内所有元素的总和(或者是一个二元运算的结果,该运算不一定只是求和)。
std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
auto sum = std::accumulate(v.begin(), v.end(), /*init*/0); // sum是55
2
该算法是顺序执行的,并且执行 “左折叠”,这意味着它会从容器的开头到结尾累加元素。
上述示例可以扩展为以下代码:
sum = init +
v[0] + v[1] + v[2] +
v[3] + v[4] + v[5] +
v[6] + v[7] + v[8] + v[9];
2
3
4
并行版本std::reduce使用树形方法计算最终总和(先对子范围求和,然后合并结果,采用分治策略)。这种方法可以以不确定的顺序调用二元运算/求和。因此,如果二元运算binary_op不满足结合律或交换律,其行为也是不确定的。
下面是一个简化图示,展示对10个元素求和的并行方式:
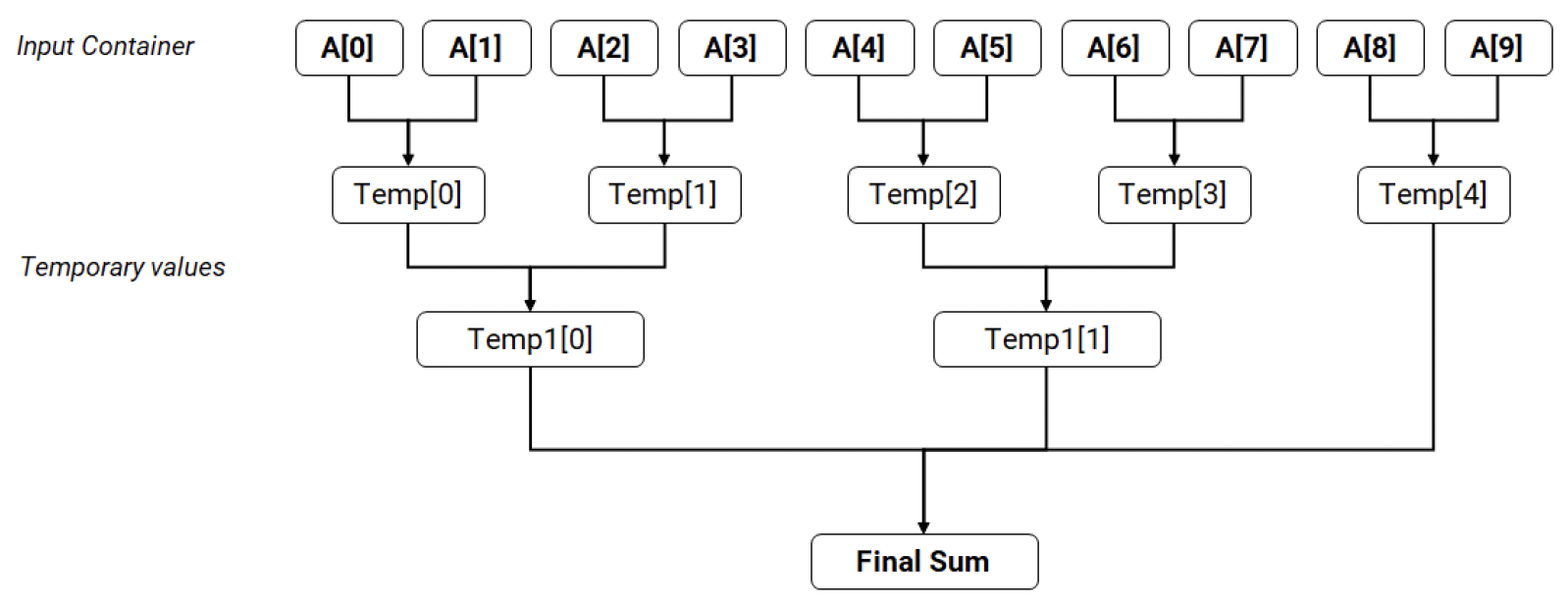 图 14.1 并行求和示例
图 14.1 并行求和示例
上述使用accumulate的示例可以改写为使用reduce:
std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
auto sum = std::reduce(std::execution::par, v.begin(), v.end(), 0);
2
默认情况下,使用std::plus<>{}来计算归约步骤。这里对结合律和交换律运算做一点解释:
对于集合S上的二元运算@,如果对于S中的所有x、y和z,都满足以下等式,则该运算满足结合律:
(x @ y) @ z = x @ (y @ z)
如果满足:x @ y = y @ x,则该运算满足交换律。
例如,对于整数向量求和,accumulate和reduce会得到相同的结果,但对于浮点数或双精度数向量,可能会有细微差异。这是因为浮点数求和运算不满足结合律。
示例:
// #include <limits> - 用于numeric_limits
std::cout.precision(std::numeric_limits<double>::max_digits10);
std::cout << (0.1+0.2)+0.3 << " != " << 0.1+(0.2+0.3) << '\n ';
2
3
输出:
0.60000000000000009 != 0.59999999999999998
另一个示例是运算类型:对于整数,加法plus满足结合律和交换律,但减法minus既不满足结合律也不满足交换律:
1+(2+3) == (1+2)+3 // 加法满足结合律
1+8 == 8+1 // 加法满足交换律
1-(5-4) != (1-5)-4 // 减法不满足结合律
1-7 != 7-1 // 减法不满足交换律
2
3
4
# transform_reduce - 融合算法
为了获得更大的灵活性和性能提升,reduce算法还有一个版本,可以在执行归约之前应用转换操作。
std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
auto sumTransformed = std::transform_reduce(std::execution::par,
v.begin(),
v.end(),
0,
std::plus<int>{},
[](const int& i) { return i * 2; }
);
// sum是110
2
3
4
5
6
7
8
9
上述代码首先执行一元仿函数(将输入值翻倍的lambda表达式),然后将结果归约为单个总和。
融合版本比分别使用std::transform和std::reduce两个算法要快,因为实现过程只需要进行一次并行执行设置。
# scan算法
第三组新算法是scan。它们实现了partial_sum的版本,但执行顺序是无序的。
exclusive_scan在输出的第i个和中不包含第i个元素,而inclusive_scan则包含。
例如,对于数组{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},部分和的计算结果如下:
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 排他部分和 | 0 | 1 | 3 | 6 | 10 | 15 | 21 | 28 | 36 | 45 |
| 包含部分和 | 1 | 3 | 6 | 10 | 15 | 21 | 28 | 36 | 45 | 55 |
与std::reduce类似,操作顺序是无序的,因此为了得到确定的结果,二元运算binary_op必须满足结合律。
scan也有两个融合算法:transform_exclusive_scan和transform_inclusive_scan。这两个算法都会对输入容器执行一元操作,然后对输出计算前缀和。
前缀和在许多应用中都起着重要作用,例如流压缩、计算累加面积表或基数排序。这里有一篇文章详细介绍了这些算法:《GPU Gems 3 - Chapter 39. Parallel Prefix Sum (Scan) with CUDA》 (opens new window)。
# 并行算法的性能
并行算法是一个强大的抽象层。虽然它们相对容易使用,但评估其性能却不那么简单。
首先要注意的是,并行算法通常比串行版本执行更多的工作。这是因为算法需要设置和安排线程子系统来运行任务。
例如,如果对一个包含10万个元素的向量调用std::transform,那么STL实现需要将向量划分为多个块,然后安排每个块进行适当的执行。如有必要,实现过程甚至可能在执行前复制元素。如果系统有10个空闲线程,10万个元素的向量可能会被划分为大小为1万个元素的块,然后每个块由一个线程进行转换。由于并行代码的设置成本和其他限制,整个执行时间不会比串行版本快10倍。
第二个重要因素是同步。如果操作需要在某些共享对象上进行同步,那么并行执行的性能会下降。当执行独立任务时,并行算法的性能最佳。
第三个对执行有重大影响的因素是内存吞吐量。观察普通桌面CPU可以发现,所有核心共享相同的内存总线。因此,如果指令等待从内存中获取数据,那么与串行版本相比,性能提升就不明显,因为所有核心都会在内存访问时进行同步。像std::copy、std::reverse这样的算法在普通PC硬件上甚至可能比它们的串行版本更慢 。当并行任务使用CPU周期进行计算而不是等待内存访问时,性能最佳。
第四点很重要的是,算法的性能在很大程度上依赖于具体实现。它们可能使用不同的技术来实现并行化。更不用说算法可能在不同的设备上执行,比如CPU或GPU。
截至2019年7月,流行的编译器中有两种实现方式:从Visual Studio 2017和GCC 9.1开始支持。
Visual Studio的实现基于Windows的线程池,仅支持在CPU上执行,并且不支持向量化执行策略 。
在GCC 9.1中,并行算法基于流行的英特尔实现 - PSTL(Parallel STL)。英特尔提供了该实现,并更新了许可证,以便代码可以在标准库中复用。在内部,它需要OpenMP 4.0支持,并且应用程序需要链接英特尔线程构建模块(Intel Threading Building Blocks,Intel TBB) 。
另外还有GPU支持。由于GPU有数百个较小的计算核心,算法在GPU上的执行速度可能比在CPU上更快。需要记住的是,在GPU上执行操作之前,通常需要将数据复制到GPU可见的内存中(除非是像集成显卡中的共享内存)。有时数据传输的成本可能会降低整体性能。
如果决定使用并行算法,最好与串行版本进行性能对比测试。有时,特别是对于元素数量较少的情况,并行算法的性能甚至可能更慢。
# 示例
到目前为止,已经看到了并行算法的入门代码示例。本节将介绍一些更复杂场景的示例。
- 会看到一些基准测试,并了解与串行版本相比的性能提升。
- 将讨论如何在同一个并行算法中处理多个容器的示例。
- 还会有一个实现并行版本元素计数的示例。
# 基准测试
最后,来看看新算法的性能。
看一个示例,在每个元素上执行独立任务,使用std::transform。在这个示例中,与串行版本相比的加速效果应该更明显。
// Chapter Parallel Algorithms/par_benchmark.cpp
#include <algorithm>
#include <execution>
#include <iostream>
#include <numeric>
#include <cmath>
#include "simpleperf.h"
int main(int argc, const char* argv[]) {
const size_t vecSize = argc > 1 ? atoi(argv[1]) : 6000000;
std::cout << vecSize << '\n ';
std::vector<double> vec(vecSize, 0.5);
std::vector out(vec);
RunAndMeasure("std::transform seq", [&vec, &out] {
std::transform(std::execution::seq, vec.begin(), vec.end(), out.begin(),
[](double v) {
return std::sin(v)*std::cos(v);
}
);
return out.size();
});
RunAndMeasure("std::transform par", [&vec, &out] {
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(),
[](double v) {
return std::sin(v)*std::cos(v);
}
);
return out.size();
});
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
代码计算sin*cos,并将结果存储在输出向量中。这些三角函数会让CPU忙于执行算术指令,而不是仅仅从内存中获取元素。
该应用程序在两台机器上以三种模式运行:
i7 4720H VS- 表示Windows 10 64位系统,i7 4720H处理器,基础频率2.60 GHz,4核心/8线程,MSVC 2017 15.8版本,发布模式,x86架构。i7 8700 VS- 表示Windows 10 64位系统,i7 8700处理器,基础频率3.2 GHz,6核心/12线程,MSVC 2017 15.8版本,发布模式,x86架构。i7 8700 GCC- 表示NixOS 19.03 64位系统,i7 8700处理器,基础频率3.2 GHz,6核心/12线程,GCC 9.1版本,使用英特尔线程构建模块(Intel TBB)。
RunAndMeasure是一个辅助函数,用于运行一个函数并打印执行时间。返回结果会被后续使用,这样编译器就不会优化掉该变量。
template <typename TFunc>
void RunAndMeasure(const char* title, TFunc func) {
const auto start = std::chrono::steady_clock::now();
ret = func();
const auto end = std::chrono::steady_clock::now();
std::cout << title
<< ": " << std::chrono::duration<double, std::milli>(end - start).count()
<< " ms " << ret << '\n ';
}
2
3
4
5
6
7
8
9
以下是结果(时间单位为毫秒):
| 算法 | 向量大小 | i7 4720H VS | i7 8700 VS | i7 8700 GCC |
|---|---|---|---|---|
std::transform, seq | 1000000 | 10.9347 | 7.51991 | 19.8189 |
std::transform, par | 1000000 | 2.67921 | 1.30245 | 3.14286 |
std::transform, seq | 2000000 | 21.8466 | 15.028 | 37.3226 |
std::transform, par | 2000000 | 5.29644 | 2.34634 | 6.22417 |
std::transform, seq | 3000000 | 32.7403 | 22.1449 | 55.8141 |
std::transform, par | 3000000 | 7.79366 | 3.42295 | 9.34034 |
std::transform, seq | 4000000 | 44.2565 | 30.1643 | 74.2437 |
std::transform, par | 4000000 | 11.7558 | 4.40974 | 12.4206 |
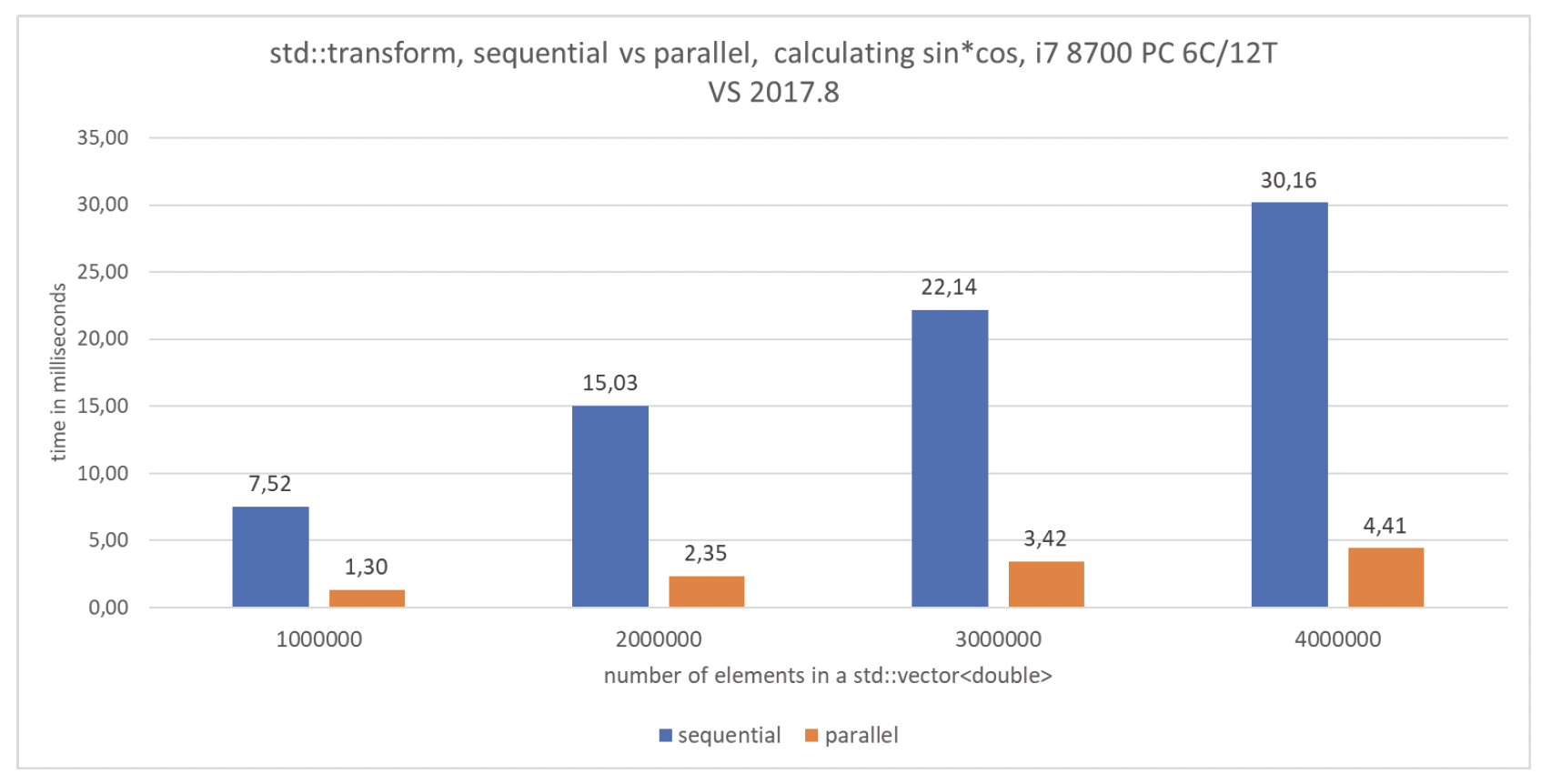
图 14.2 std::transform的基准测试
上述示例可能是并行化的理想情况:我们有一个需要大量指令(三角函数运算)的操作,而且所有任务都是相互独立的。在这种情况下,在一台拥有6个核心和12个线程的机器上,性能提升近7倍!在一台拥有4个核心和8个线程的计算机上,性能提升了4.2倍。
GCC的结果比Visual Studio版本慢得有些出乎意料 。不过,我们也能注意到,在拥有6个核心/12个线程的机器上,并行执行的性能相比串行执行提升了8倍。
同样值得注意的是,当转换指令很简单,比如return v*2.0时,可能看不到性能提升。这是因为所有代码可能都在等待访问全局内存,其性能可能与串行版本相同。
下面是一个计算向量中所有元素总和的基准测试:
// Chapter Parallel Algorithms/par_benchmark.cpp
#include <algorithm>
#include <execution>
#include <iostream>
#include <numeric>
#include "simpleperf.h"
int main(int argc, const char* argv[]) {
const size_t vecSize = argc > 1 ? atoi(argv[1]) : 6000000;
std::cout << vecSize << '\n ';
std::vector<double> vec(vecSize, 0.5);
RunAndMeasure("std::accumulate", [&vec] {
return std::accumulate(vec.begin(), vec.end(), 0.0);
});
RunAndMeasure("std::reduce, seq", [&vec] {
return std::reduce(std::execution::seq,
vec.begin(), vec.end(), 0.0);
});
RunAndMeasure("std::reduce, par", [&vec] {
return std::reduce(std::execution::par,
vec.begin(), vec.end(), 0.0);
});
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
以下是测试结果:
| 算法 | 向量大小 | i7 4720H VS | i7 8700 VS | i7 8700 GCC |
|---|---|---|---|---|
std::accumulate | 10000000 | 10.5814 | 9.62405 | 9.65569 |
std::reduce seq | 10000000 | 6.9556 | 4.58746 | 9.20017 |
std::reduce par | 10000000 | 4.88708 | 3.67831 | 2.45625 |
std::accumulate | 15000000 | 17.8769 | 14.9163 | 14.2885 |
std::reduce seq | 15000000 | 11.5103 | 5.42508 | 13.7725 |
std::reduce par | 15000000 | 9.99877 | 4.5679 | 3.79334 |
std::accumulate | 20000000 | 21.8888 | 19.6507 | 18.8786 |
std::reduce seq | 20000000 | 16.2142 | 6.80581 | 18.4035 |
std::reduce par | 20000000 | 10.8826 | 4.79214 | 5.141 |

图 14.3 std::accumulate与std::reduce的基准测试
在这次测试中,并行版本比标准的std::accumulate快2到4倍!
对比并行版本和accumulate,这次GCC的结果与Visual Studio的结果几乎相同。同样明显的是,当在std::reduce中使用串行模式时,GCC版本会切换为常规的std::accumulate。
还有使用串行策略的其他原因吗?
在Visual Studio中,
std::reduce的串行版本也比std::accumulate快。这可能是因为在std::reduce中操作顺序是不确定的,而std::accumulate是左折叠操作。编译器在优化std::reduce的代码时有更多选择。
# 同时处理多个容器
在使用并行算法时,有时可能需要访问其他容器。例如,可能想要对两个容器执行for_each操作。
主要的方法是获取当前正在处理的元素的索引。然后可以使用该索引访问其他容器(前提是这些容器大小相同)。
有几种实现方式:
- 使用单独的索引容器 -使用拉链迭代器/包装器
下面来看看这些方法:
# 单独的索引容器
// Chapter Parallel Algorithms/par_iterating_multiple.cpp
void Process(int a, int b) { }
std::vector<int> v(100);
std::vector<int> w(100);
std::iota(v.begin(), v.end(), 0);
std::iota(w.begin(), w.end(), 0);
std::vector<size_t> indexes(v.size());
std::iota(indexes.begin(), indexes.end(), 0);
std::for_each(std::execution::par, indexes.begin(), indexes.end(),
[&v, &w](size_t& id) {
Process(v[id], w[id]);
}
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
由于执行顺序未指定,不能使用某个全局变量i来遍历v和w。因此,必须生成一个单独的索引向量,然后用它来访问容器。
# 拉链迭代器(Zip Iterators)
// Chapter Parallel Algorithms/par_iterating_multiple.cpp
void Process(int a, int b) { }
std::vector<int> v(100);
std::vector<int> w(100);
std::iota(v.begin(), v.end(), 0);
std::iota(w.begin(), w.end(), 0);
vec_zipper<int, int> zipped{ v, w };
std::for_each(std::execution::seq, zipped.begin(), zipped.end(),
[](std::pair<int&, int&>& twoElements) {
Process(twoElements.first, twoElements.second);
}
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这是一种更优雅的方法,将两个容器合并成一个序列,然后一次性迭代。该示例使用了自定义的vec_zipper实现,它仅适用于std::vector。可以改进代码,使其更通用,或者使用第三方拉链迭代器(如Boost (opens new window) )。
# 错误的方法
此外,有一个方面必须提及。
根据标准[algorithms.parallel.exec] (opens new window) :
除非另有说明,对于
is_trivially_copy_constructible_v<T>和is_trivially_destructible_v<T>都为真的序列,实现可以对其中的元素(类型为T)进行任意复制。[注意:这意味着用户提供的函数对象不应依赖于此类输入序列中参数的对象标识。对于那些函数对象的参数的对象标识很重要的用户,应考虑使用返回非复制实现对象的包装迭代器,如reference_wrapper<T>或其他等效解决方案。 —— 结束注释]
因此,不能这样写:
// 不要依赖地址
vector<int> vec;
vector<int> other;
vector<int> external;
int* beg = vec.data();
std::transform(std::execution::par,
vec.begin(), vec.end(), other.begin(),
[&beg, &external](const int& elem) {
// 使用指针运算
auto index = &elem - beg;
return elem * externalVec[index];
}
);
2
3
4
5
6
7
8
9
10
11
12
13
14
上面的代码使用指针运算来查找元素的当前索引,然后用该索引访问其他容器。
然而,这种方法基于一个假设,即elem是容器中的原始元素,而不是其副本!由于实现可能会复制元素,这些地址可能完全不相关!这种错误的方法还假设容器在连续的内存块中存储元素。
只有for_each和for_each_n保证在执行过程中不会复制元素[alg.foreach (opens new window)] :
| 实现不能享有[algorithms.parallel.exec]中规定的对输入序列中的元素进行任意复制的自由。 |
|---|
# 元素计数
为了练习一下,我们来构建一个计算容器中元素数量的算法。我们的算法将是另一个标准算法count_if的并行版本。
主要思路是使用transform_reduce,这是一种新的 “融合” 算法。它首先对元素应用某个一元函数,然后执行归约操作。
为了统计满足某个谓词的元素数量,可以先对每个元素进行过滤(转换)。如果元素通过过滤则返回1,否则返回0。然后,在归约步骤中,统计返回1的元素数量。
下面的示意图展示了一个简单情况下的算法:
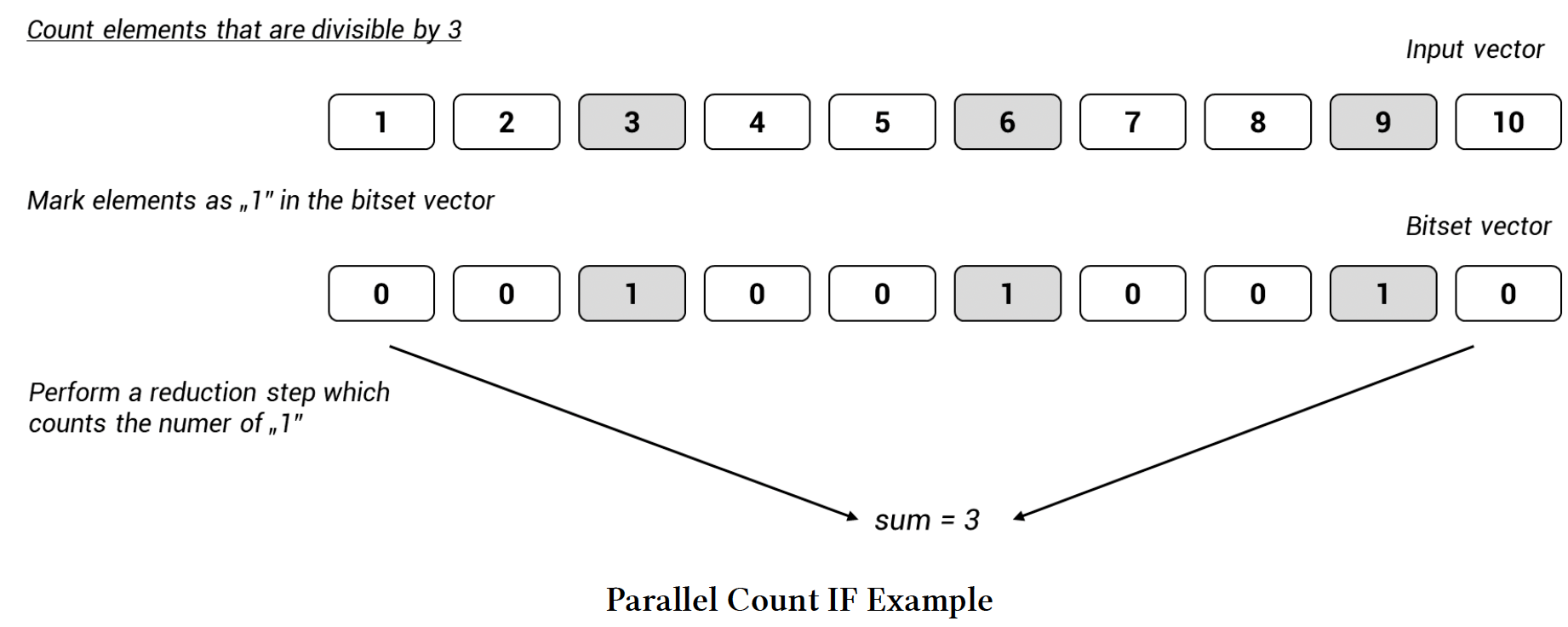 图 14.4 并行 Count IF 示例
图 14.4 并行 Count IF 示例
- 第一步是在
transform_reduce算法中执行转换步骤。对于匹配的元素返回1,否则返回0。 - 然后使用归约步骤计算所有1的总和。有三个值满足条件,所以输出是3。
下面是代码:
// Chapter Parallel Algorithms/par_count_if.cpp
template <typename Policy, typename Iter, typename Func>
std::size_t CountIf(Policy policy, Iter first, Iter last, Func predicate) {
return std::transform_reduce(policy,
first,
last,
std::size_t(0),
std::plus<std::size_t>{},
[&predicate](const Iter::value_type& v) {
return predicate(v)? 1 : 0;
}
);
}
2
3
4
5
6
7
8
9
10
11
12
13
可以在以下测试容器上运行该算法:
// Chapter Parallel Algorithms/par_count_if.cpp
std::vector<int> v(100);
std::iota(v.begin(), v.end(), 0);
auto NumEven = CountIf(std::execution::par, v.begin(), v.end(),
[](int i) { return i % 2 == 0; }
);
std::cout << NumEven << '\n ';
2
3
4
5
6
7
8
统计字符串中的空格数量:
// Chapter Parallel Algorithms/par_count_if.cpp
std::string_view sv = "Hello Programming World";
auto NumSpaces = CountIf(std::execution::seq, sv.begin(), sv.end(),
[](char ch) { return ch ==''; }
);
std::cout << NumSpaces << '\n ';
2
3
4
5
6
7
甚至可以在映射(map)上使用:
// Chapter Parallel Algorithms/par_count_if.cpp
std::map<std::string, int> CityAndPopulation{
{"Cracow", 765000},
{"Warsaw", 1745000},
{"London", 10313307},
{"New York", 18593220},
{"San Diego", 3107034}
};
auto NumCitiesLargerThanMillion = CountIf(std::execution::seq, CityAndPopulation.begin(), CityAndPopulation.end(),
[](const std::pair<const std::string, int>& p) {
return p.second > 1000000;
}
);
std::cout << CitiesLargerThanMillion << '\n ';
2
3
4
5
6
7
8
9
10
11
12
13
14
15
该示例使用了简单的测试数据,为了获得比串行版本更好的性能,数据量需要大幅增加。例如,可以从数据库中加载城市及其人口数据。
# 更多示例
以下是一些其他适合使用并行算法的场景:
- 统计分析 —— 计算一组数据的各种数学属性
- 并行逐行处理CSV记录
- 并行解析文件 —— 每个线程处理一个文件,或者每个线程处理文件的一部分
- 计算累加面积表
- 并行矩阵运算
- 并行点积运算
可以在以下文章中找到更多示例:
- 《C++17并行算法的惊人性能,可能吗?》(The Amazing Performance of C++17 Parallel Algorithms, is it Possible? ) (opens new window)
- 《如何利用英特尔并行STL和C++17并行算法提升性能》(How to Boost Performance with Intel Parallel STL and C++17 Parallel Algorithms ) (opens new window)
- 《C++17并行算法示例》(Examples of Parallel Algorithms From C++17 ) (opens new window)
- 《并行STL和文件系统:文件单词计数示例》(Parallel STL And Filesystem: Files Word Count Example ) (opens new window)
# 章节总结
阅读完本章后,你应该掌握了并行算法的核心知识。我们讨论了执行策略、它们在硬件上的执行方式以及有哪些新算法。
目前,并行算法展现出良好的潜力。只需额外添加一个参数,你就可以轻松地将代码并行化。以前,这需要使用一些第三方库,或者编写自定义的线程池系统。
当然,我们还需要等待更多可用的实现并积累经验。目前,只有Visual Studio和GCC 9.1支持使用并行算法,我们也在期待Clang的标准库能够跟进。在GPU上执行代码尤其令人期待。
同样值得引用TS规范P0024 (opens new window):
| 并行技术规范(Parallelism TS)中的并行算法和执行策略仅仅是一个起点。我们已经预见到了扩展并行技术规范功能的机会,这将增加程序员的灵活性和表达能力。一个完全实现的执行器功能将产生新的、灵活的执行创建方式,包括并行算法的执行。 |
|---|
需要记住的要点:
- 并行STL提供了一组69个算法,这些算法都有针对执行策略参数的重载。
- 执行策略描述了算法的执行方式。
- C++17(
<execution>头文件)中有三种执行策略:std::execution::seq——顺序执行std::execution::par——并行执行std::execution::par_unseq——并行且向量化执行
- 在并行执行策略中,传递给算法的仿函数不能导致死锁和数据竞争。
- 在并行无序执行策略中,仿函数不能调用不安全的向量化指令,如内存分配或任何同步机制。
- 为了处理新的执行模式,还出现了一些新算法,比如
std::reduce、exclusive_scan。它们的执行顺序是无序的,因此操作必须具有结合性,才能生成确定的结果。 - 有“融合”算法:
transform_reduce、transform_exclusive_scan、transform_inclusive_scan,它们将两种算法结合在一起。 - 假设并行执行中没有同步点,并行算法应该比顺序版本更快。不过,它们会执行更多的工作,尤其是在任务的设置和划分方面。
- 实现通常会使用一些线程池在CPU上实现并行算法。
# 编译器支持
截至2019年7月,只有两款编译器/STL实现支持并行算法:Visual Studio(从2017 15.7版本开始)和GCC(从9.1版本开始)。
Visual Studio将par_unseq实现为par,所以你不应期望代码运行时会有任何差异。
GCC的实现使用了修改后的英特尔PSTL,并且依赖OpenMP 4.0和英特尔TBB 2018。如果你想使用并行算法,需要安装并链接-ltbb库。
例如:
g++-9.1 -std=c++17 -Wall -O2 sample.cpp -ltbb
关于构建GCC 9.1和英特尔TBB,你可以查看《Solarian程序员:在Linux和macOS上使用GCC 9.1和英特尔TBB实现C++17 STL并行算法 (opens new window)》这份指南。
总结:
| 特性 | GCC | Clang | MSVC |
|---|---|---|---|
| 并行算法 | 9.1²¹ | 开发中 | VS 2017 15.7²² |
²¹ 参考这里: GCC 9.1 Released and *GCC 9 Release Series — Changes, New Features, and Fixes (opens new window))*
²² 参考这里: MSVC Conforms to the C++ Standard | Visual C++ Team Blog (opens new window)
此外,还有其他一些实现:
- Codeplay——SYCL并行STL (opens new window)
- STE||AR Group——HPX (opens new window)
- 英特尔——并行STL (opens new window),基于OpenMP 4.0和英特尔® TBB。
- 并行STL (opens new window),微软针对技术规范的早期实现。
- n3554,提案实现(由英伟达发起) (opens new window)
- http://github.com/t-lutz/ParallelSTL (opens new window),早期实现