 20. 如何实现CSV读取器的并行化
20. 如何实现CSV读取器的并行化
# 20. 如何实现CSV读取器的并行化
在“并行算法”章节中,我们学习了如何通过在多个线程上自动运行代码来提高速度,该章节展示了一些小型示例和基准测试。了解更广泛的应用场景以及它们如何从并行化中获益同样很有意义,这也正是我们接下来要探讨的内容。
在后续内容中,你将看到如何构建一个处理CSV文件的工具,将文件中的行解析为销售记录,然后对数据进行计算。你会发现,为选定的算法添加并行执行功能非常简单,而且整个应用程序的性能都能得到提升。最后,我们将讨论在这个过程中遇到的问题以及未来可能的改进方向。
在本章中,你将学习:
- 如何构建一个加载CSV文件的应用程序
- 如何高效使用并行算法
- 如何使用
std::filesystem库收集所需文件 - 如何使用其他C++17库特性,如
std::optional、转换函数std::from_chars和string_view
# 引言和需求
假设你正在处理一些销售数据,其中一项任务是计算某些产品的订单总和。你的购物系统比较基础,没有使用数据库,而是用CSV文件存储订单数据,每个产品对应一个文件。
以图书销售为例:
| 日期 | 优惠券代码 | 价格 | 折扣 | 数量 |
|---|---|---|---|---|
| 5-12-2018 | 10.0 | 0 | 2 | |
| 5-12-2018 | 10.0 | 0 | 1 | |
| 6-12-2018 | Santa | 10.0 | 0.25 | 1 |
| 7-12-2018 | 10.0 | 0 | 1 |
每一行展示了某一天的图书销售情况。例如,12月5日有三笔销售,每本售价10美元,其中一人购买了两本。12月6日有一笔使用优惠券的交易。
数据编码在一个CSV文件中:sales/book.csv
5-12-2018;;10.0;0;2;
5-12-2018;;10.0;0;1;
6-12-2018;Santa;10.0;0.25;1;
7-12-2018;;10.0;0;1;
2
3
4
应用程序需要读取这些数据并计算总和,在上述例子中:
sum = 10*2+10*1+ // 12月5日
10*(1-0.25)*1 + // 12月6日,使用25%折扣优惠券
10*1; // 12月7日
2
3
对于上述销售数据,最终总和为47.5美元。
我们要构建的应用程序的需求如下:
- 应用程序加载给定文件夹中的所有CSV文件,文件夹路径从命令行的第一个参数读取。
- 文件可能包含数千条记录,但数据量在内存可容纳范围内,无需额外支持超大文件。
- 应用程序可选择从命令行的第二个和第三个参数读取开始日期和结束日期。
- 每个CSV行的结构如下:日期;优惠券代码;单价;数量;折扣。
- 应用程序计算给定日期范围内的所有订单总和,并将结果输出到标准输出。
我们将首先实现串行版本,然后尝试将其并行化。
# 串行版本
第一步,我们将介绍应用程序的串行版本,这有助于你理解系统的核心部分以及该工具的工作原理。
代码较长,无法在一页内完整展示,你可以查看CSV Chapter/csv_reader.cpp文件。
接下来的部分,我们将探讨应用程序的核心部分。
# 主函数
从main()函数开始:
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
int main(int argc, const char** argv) {
if (argc <= 1)
return 1;
try {
const auto paths = CollectPaths(argv[1]);
if (paths.empty()) {
std::cout << "No files to process...\n ";
return 0;
}
const auto startDate = argc > 2 ? Date(argv[2]) : Date();
const auto endDate = argc > 3 ? Date(argv[3]) : Date();
const auto results = CalcResults(paths, startDate, endDate);
ShowResults(startDate, endDate, results);
}
catch (const std::filesystem::filesystem_error& err) {
std::cerr << "filesystem error! " << err.what() << '\n ';
}
catch (const std::runtime_error& err) {
std::cerr << "runtime error! " << err.what() << '\n ';
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
确认命令行有足够参数后,进入主处理流程:
- 第6行:在
CollectPaths()函数中收集所有要处理的文件。 - 第16行:在
CalcResults()函数中,将文件中的数据转换为记录数据并计算结果。 - 第18行:在
ShowResults()函数中,将结果输出展示。
整个应用程序依赖异常处理机制。
使用std::filesystem库中的directory_iterator收集文件路径:
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
bool IsCSVFile(const fs::path &p) {
return fs::is_regular_file(p) && p.extension() == CSV_EXTENSION;
}
[[nodiscard]] std::vector<fs::path> CollectPaths(const fs::path& startPath) {
std::vector<fs::path> paths;
fs::directory_iterator dirpos{ startPath };
std::copy_if(fs::begin(dirpos), fs::end(dirpos), std::back_inserter(paths),
IsCSVFile);
return paths;
}
2
3
4
5
6
7
8
9
10
11
12
和其他文件系统示例一样,命名空间fs是std::filesystem的别名。
借助directory_iterator,我们可以轻松遍历给定目录。通过copy_if,可以筛选掉不需要的文件,仅选择CSV文件。注意,获取路径元素并检查文件属性是多么容易。
回到main()函数,我们检查是否有文件需要处理(第8行)。
然后,在第13行和14行,解析可选的日期:startDate和endDate分别从argv[2]和argv[3]读取。
日期存储在辅助类Date中,该类支持从“日-月-年”或“年-月-日”的简单格式字符串进行转换,并且支持日期比较,这有助于检查某个订单是否在选定的日期范围内。
现在,所有计算和输出操作都包含在以下代码行中:
const auto results = CalcResults(paths, startDate, endDate);
ShowResults(results, startDate, endDate);
2
CalcResults()函数实现了应用程序的核心需求:
- 将文件中的数据转换为要处理的记录列表。
- 计算给定日期范围内的记录总和。
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
struct Result {
std::string mFilename;
double mSum{ 0.0 };
};
[[nodiscard]] std::vector<Result>
CalcResults(const std::vector<fs::path>& paths, Date startDate, Date endDate) {
std::vector<Result> results;
for (const auto& p : paths) {
const auto records = LoadRecords(p);
const auto totalValue = CalcTotalOrder(records, startDate, endDate);
results.push_back({ p.string(), totalValue });
}
return results;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这段代码从每个CSV文件加载记录,然后计算这些记录的总和,结果(以及文件名)存储在输出向量中。
现在,我们来看看LoadRecords和CalcTotalOrder这两个关键方法的代码实现。
# 将行转换为记录
LoadRecords函数以文件名作为参数,将文件内容读取到std::string中,然后进行转换:
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
[[nodiscard]] std::vector<OrderRecord> LoadRecords(const fs::path& filename) {
const auto content = GetFileContents(filename);
const auto lines = SplitLines(content);
return LinesToRecords(lines);
}
2
3
4
5
6
我们假设文件足够小,可以完全加载到内存中,因此无需分块处理。
核心任务是将一个长字符串拆分为多行,然后将它们转换为记录集合。
查看代码可以发现,content是std::string类型,而lines是std::string_view类型的向量。使用视图是为了优化性能。在处理文件内容(视图)的各个部分时,我们保证持有整个文件内容的大字符串。这样可以提高性能,因为无需复制字符串数据。
最终,将字符转换为OrderRecord表示形式。
# OrderRecord类
用于计算结果的主要类是OrderRecord,它直接表示CSV文件中的一行数据。
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
class OrderRecord {
public:
// 构造函数...
double CalcRecordPrice() const noexcept;
bool CheckDate(const Date& start, const Date& end) const noexcept;
private:
Date mDate;
std::string mCouponCode;
double mUnitPrice{ 0.0 };
double mDiscount{ 0.0 }; // 0... 1.0
unsigned int mQuantity{ 0 };
};
2
3
4
5
6
7
8
9
10
11
12
13
# 转换过程
有了行数据后,我们可以逐个将它们转换为对象:
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
[[nodiscard]] std::vector<OrderRecord>
LinesToRecords(const std::vector<std::string_view>& lines) {
std::vector<OrderRecord> outRecords;
std::transform(lines.begin(), lines.end(),
std::back_inserter(outRecords), LineToRecord);
return outRecords;
}
2
3
4
5
6
7
8
9
上述代码只是一个转换操作,它使用LineToRecord函数完成主要工作:
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
[[nodiscard]] OrderRecord LineToRecord(std::string_view sv) {
const auto cols = SplitString(sv, CSV_DELIM);
if (cols.size() == static_cast<size_t>(OrderRecord::ENUM_LENGTH)) {
const auto unitPrice = TryConvert<double>(cols[OrderRecord::UNIT_PRICE]);
const auto discount = TryConvert<double>(cols[OrderRecord::DISCOUNT]);
const auto quantity = TryConvert<unsigned int>(cols[OrderRecord::QUANTITY]);
if (unitPrice && discount && quantity) {
return { Date(cols[OrderRecord::DATE]),
std::string(cols[OrderRecord::COUPON]),
*unitPrice,
*discount,
*quantity };
}
}
throw std::runtime_error("Cannot convert Record from " + std::string(sv));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
首先,将行拆分为列,然后处理每一列。如果所有元素都能成功转换,就可以构建一个记录。
对于元素的转换,我们使用了一个基于std::from_chars的小工具:
// 文档中未提及csv_reader.cpp具体位置,仅按原文保留
template <typename T>
[[nodiscard]] std::optional<T> TryConvert(std::string_view sv) noexcept {
T value{ };
const auto last = sv.data() + sv.size();
const auto res = std::from_chars(sv.data(), last, value);
if (res.ec == std::errc{} && res.ptr == last)
return value;
return std::nullopt;
}
2
3
4
5
6
7
8
9
10
11
TryConvert使用std::from_chars,如果没有错误则返回转换后的值。要确保所有字符都被解析,还需检查res.ptr == last。否则,对于像“123xxx”这样的输入,转换可能会返回成功。
# 计算
当所有记录都可用时,我们可以计算它们的总和:
CSV Chapter/csv_reader.cpp - CalcTotalOrder()
[[nodiscard]] double CalcTotalOrder(const std::vector<OrderRecord>& records,
const Date& startDate, const Date& endDate) {
return std::accumulate(std::begin(records), std::end(records), 0.0,
[&startDate, &endDate](double val, const OrderRecord& rec) {
if (rec.CheckDate(startDate, endDate))
return val + rec.CalcRecordPrice();
else
return val;
});
}
2
3
4
5
6
7
8
9
10
11
这段代码遍历所有记录的向量,若记录的日期在startDate和endDate之间,则计算其价格,然后使用std::accumulate对这些价格进行求和。
# 设计改进
该应用程序目前仅计算订单的总和,但我们可以考虑添加其他功能,例如计算最小值、最大值、平均订单金额以及其他统计信息。
当前代码采用了一种简单的方法,将文件加载到字符串中,然后创建一个临时的行向量。我们还可以通过使用行迭代器来改进这一点,行迭代器可以处理大字符串,并在迭代时逐行返回。
另一个改进思路与错误处理有关。例如,我们可以改进转换步骤,记录成功处理的记录数量,而不是抛出异常。
# 运行代码
应用程序已准备好进行编译,我们可以使用引言中展示的示例数据来运行它。
CSVReader.exe sales/
这将读取单个文件sales/book.csv,并对所有记录进行求和(因为未指定日期):
.\CalcOrdersSerial.exe.\sales\
Name Of File | Total Orders Value
sales\book.csv | 47.50
CalcResults: 3.13 ms
CalcTotalOrder: 0.01 ms
Parsing Strings: 0.01 ms
2
3
4
5
6
完整版本的代码还包含计时测量,所以你可以看到整个操作大约耗时3毫秒。文件处理耗时最长,计算和解析几乎是瞬间完成的。
在接下来的部分,你将看到一些可以应用并行算法的简单步骤。
# 使用并行算法
之前,代码是顺序执行的,我们可以用以下图表来说明:

图 20.1 顺序执行的CSV读取器
我们逐个打开文件、处理文件、进行计算,然后处理下一个文件,所有这些操作都在单个线程上进行。
然而,有几个地方我们可以考虑使用并行算法:
- 每个文件可以单独处理的地方
- 文件的每一行可以独立转换为记录数据的地方
- 计算过程可以通过并行执行得到优化的地方
如果我们关注第二和第三个选项,可以采用以下执行模型:
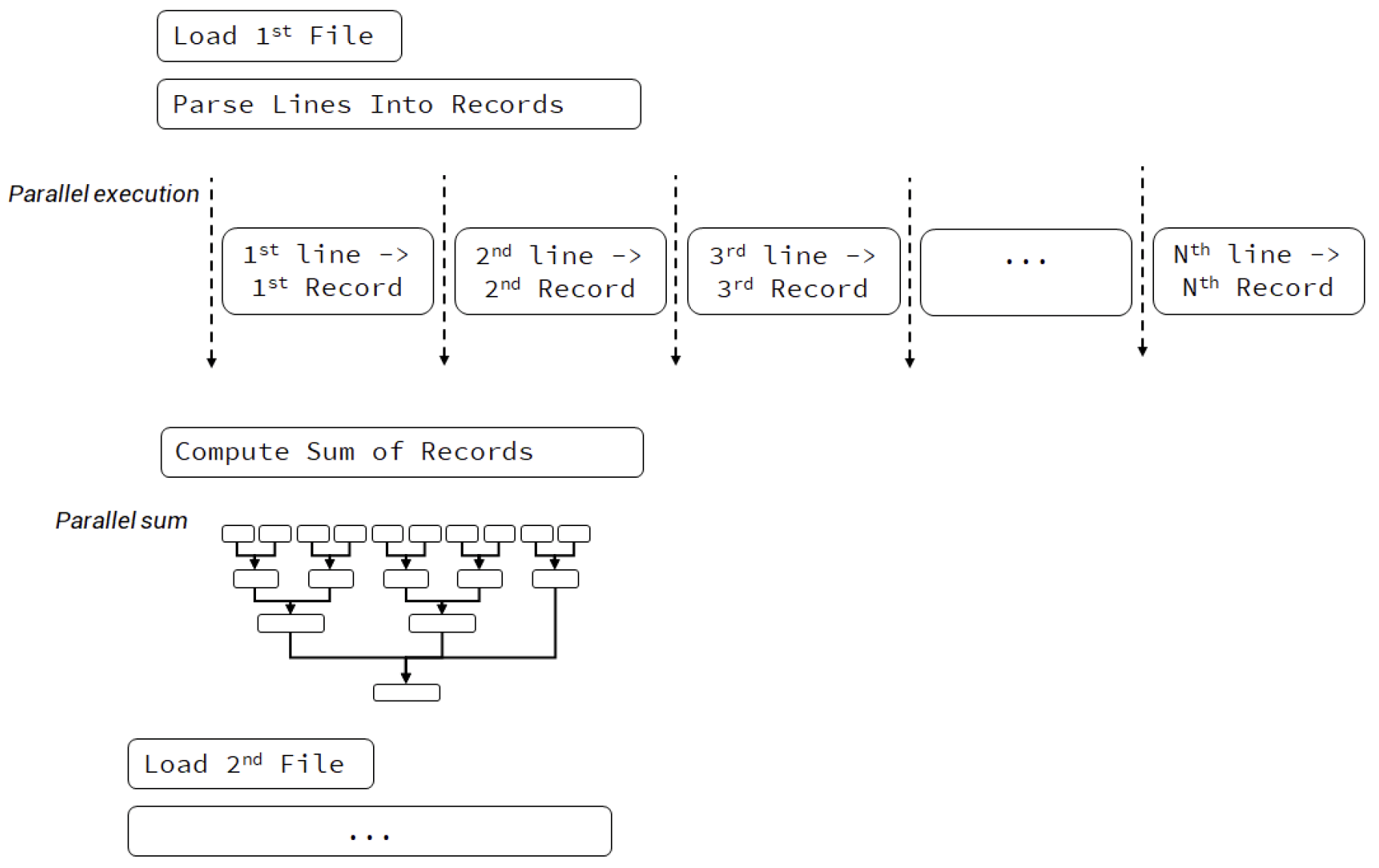
图 20.2 并行执行的CSV读取器
上图显示,我们仍然逐个处理文件,但在解析字符串和进行计算时使用了并行执行。
在进行转换时,要记住我们的代码不会重新抛出异常,只会调用std::terminate。
截至2019年7月,只有MSVC编译器(自Visual Studio 2017起)和GCC(自9.1起)支持标准库中的并行执行。示例的并行版本在Clang上无法运行。可以使用像英特尔并行STL(Intel Parallel STL)或HPX这样的第三方库。
# 数据大小和指令数量很重要
如何通过并行算法获得最佳性能呢?你需要具备两点:
- 大量要处理的数据
- 让CPU保持忙碌的指令
同时,我们必须记住一条规则:
一般来说,并行算法会执行更多工作,因为它们引入了管理并行执行框架的额外开销,以及将任务拆分成更小批次的开销。
首先,我们必须考虑操作的数据大小。如果只有几个文件,每个文件只有几十条记录,那么并行执行可能不会带来任何好处。但如果有大量文件,每个文件有数百行记录,那么并行执行的潜力就会增加。
其次是指令数量。CPU核心需要进行计算,而不是仅仅等待内存。如果算法受限于内存,那么并行执行可能不会比顺序执行更快。在我们的例子中,解析字符串的任务似乎很适合并行处理,代码在字符串上执行搜索和数值转换操作,这让CPU保持忙碌。
# 并行数据转换
如前所述,我们可以在数据转换的地方添加并行执行。我们有大量的行需要解析,并且每次解析都是独立的。
CSV Chapter/csv_reader.cpp - LinesToRecord()
[[nodiscard]] std::vector<OrderRecord>
LinesToRecords(const std::vector<std::string_view>& lines) {
std::vector<OrderRecord> outRecords(lines.size());
std::transform(std::execution::par, std::begin(lines), std::end(lines),
std::begin(outRecords), LineToRecord);
return outRecords;
}
2
3
4
5
6
7
8
相较于顺序版本,需要做两处修改:
- 我们需要预先分配向量空间
- 我们必须将
std::execution::par(或par_unseq)作为第一个参数传递
顺序代码也使用了std::transform,那为什么不能直接传递执行策略参数呢?
我们甚至可以编译这段代码…… 但你应该会看到类似这样的错误:
Parallel algorithms require forward iterators or stronger.
原因很简单:std::back_inserter虽然很方便,但它不是前向迭代器。它将元素插入向量中,这会导致向量被多个线程修改(重新分配)。所有的插入操作都必须由某个临界区进行保护,因此整体性能可能会很差。
由于需要预先分配向量空间,我们必须考虑两点:
- 我们需要为向量中的对象进行默认构造,当对象相对较小且创建速度很快时,这可能不是什么大问题。
- 另一方面,向量只需分配一次,无需像使用
std::back_inserter时那样进行增长(复制、重新分配)操作。
# 并行计算
另一个可以利用并行算法的地方是CalcTotalOrder()函数。我们可以使用std::transform_reduce来替代std::accumulate。
正如在“并行算法”一章中提到的,浮点求和操作不具有结合性。不过,在我们的例子中,结果的精度应该足够稳定,能保留两位小数。如果你需要更高的精度和数值稳定性,可能使用其他方法会更好。
CSV Chapter/csv_reader.cpp - CalcTotalOrder()
double CalcTotalOrder(const std::vector<OrderRecord>& records,
const Date& startDate, const Date& endDate) {
return std::transform_reduce(std::execution::par,
std::begin(records), std::end(records), 0.0,
std::plus<>(),
[&startDate, &endDate](const OrderRecord& rec) {
if (rec.CheckDate(startDate, endDate))
return rec.CalcRecordPrice();
return 0.0;
});
}
2
3
4
5
6
7
8
9
10
11
12
我们使用std::transform_reduce的转换步骤来“提取”要相加的值。我们不能轻易使用std::reduce,因为这需要编写一个适用于两个OrderRecord对象的归约操作。
# 测试
我们可以在一组文件上运行这两个版本的代码,比较这些更改是否提高了性能。该应用程序在一台6核/12线程的PC(i7 8700)上进行了测试,配备快速固态硬盘,运行Windows 10系统。
由于我们的应用程序会访问文件,因此很难进行精确的基准测试,因为文件很容易被缓存到文件系统缓存中。在大规模运行应用程序之前,会使用一个名为“Use SysInternal’s RAMMap app (opens new window)”的工具来清除缓存中的文件。此外,硬盘硬件缓存更难在不重启系统的情况下释放。
# 中等大小文件(10个文件,每个文件1000行)
我们从10个文件开始,每个文件1000行。文件不在操作系统缓存中:
| 步骤 | 顺序执行(毫秒) | 并行执行(毫秒) |
|---|---|---|
| 所有步骤 | 74.05 | 68.391 |
CalcTotalOrder | 0.02 | 0.22 |
| 解析字符串 | 7.85 | 2.82 |
文件在系统缓存中的情况:
| 步骤 | 顺序执行(毫秒) | 并行执行(毫秒) |
|---|---|---|
| 所有步骤 | 8.59 | 4.01 |
CalcTotalOrder | 0.02 | 0.23 |
| 解析字符串 | 7.74 | 2.73 |
前两个数字(74毫秒和68毫秒)来自读取未缓存的文件,而接下来的两次运行未清除系统缓存,这样你可以观察到系统缓存带来的加速效果。
并行版本仍然顺序读取文件,所以我们只获得了几毫秒的性能提升。解析字符串(将行拆分并转换为记录)的速度现在几乎提高了3倍。但求和计算并没有变得更好,因为单线程版本似乎能更高效地处理求和操作。
# 大文件集(10个文件,每个文件10000行)
更大的输入数据会怎样呢?未缓存文件:
| 步骤 | 顺序执行(毫秒) | 并行执行(毫秒) |
|---|---|---|
| 所有步骤 | 239.96 | 178.32 |
CalcTotalOrder | 0.2 | 0.74 |
| 解析字符串 | 70.46 | 15.39 |
缓存文件:
| 步骤 | 顺序执行(毫秒) | 并行执行(毫秒) |
|---|---|---|
| 所有步骤 | 72.43 | 18.51 |
CalcTotalOrder | 0.33 | 0.67 |
| 解析字符串 | 70.46 | 15.56 |
处理的数据越多,结果越好。加载未缓存文件的开销在处理记录所需的时间面前逐渐变得不那么明显。在处理10000行数据的情况下,我们还可以看到解析字符串的步骤快了3.5倍,然而计算速度仍然较慢。
# 最大文件集(10个文件,每个文件100000行)
让我们用最大的文件再做一次测试:未缓存文件:
| 步骤 | 顺序执行(毫秒) | 并行执行(毫秒) |
|---|---|---|
| 所有步骤 | 757.07 | 206.85 |
CalcTotalOrder | 3.03 | 2.47 |
| 解析字符串 | 699.54 | 143.31 |
缓存文件:
| 步骤 | 顺序执行(毫秒) | 并行执行(毫秒) |
|---|---|---|
| 所有步骤 | 729.94 | 162.49 |
CalcTotalOrder | 3.05 | 2.16 |
| 解析字符串 | 707.34 | 141.28 |
在处理大文件(每个文件约2MB)的情况下,并行版本明显更优。
# 总结与讨论
本章的主要目的是展示使用并行算法是多么容易。最终代码位于两个文件中:顺序版本在Chapter CSV Reader/csv_reader.cpp,并行版本在Chapter CSV Reader/csv_reader_par.cpp。
在大多数情况下,要添加并行执行,我们需要确保任务之间无需同步,并且尽可能提供前向迭代器。这就是为什么在进行转换时,有时我们需要预先分配std::vector(或其他兼容的容器),而不是使用std::back_inserter。另一个例子是,我们不能并行遍历目录,因为std::filesystem::directory_iterator不是前向迭代器。
接下来是选择合适的并行算法。在这个例子中,我们在计算时用std::transform_reduce替代了std::accumulate。在进行字符串解析时,无需更改std::transform,只需使用额外的执行策略参数即可。
我们的应用程序并行版本的性能比顺序版本略好。以下是一些思考:
- 并行执行需要独立的任务。如果任务相互依赖,性能可能会低于顺序版本!这是因为额外的同步步骤。
- 任务不能受限于内存,否则CPU会等待内存。例如,字符串解析代码在并行处理时表现更好,因为它有许多指令要执行,如字符串搜索和字符串转换。
- 需要处理大量数据才能看到性能提升。在我们的例子中,每个文件需要包含数千行数据,才能比顺序版本有性能提升。
- 求和计算的性能提升不明显,对于较小的输入数据,性能甚至更差。这是因为
std::reduce算法需要额外的归约步骤,并且我们的计算比较简单。如果代码中包含更多统计计算,可能会提高性能。 - 顺序版本的代码很直接,有一些地方可以进一步提高性能。例如,可以减少额外的复制操作和临时向量。在顺序版本中使用顺序执行的
std::transform_reduce可能比std::accumulate更快。你可以考虑先优化顺序版本,再将其并行化。 - 如果你依赖异常,可能需要为
std::terminate实现一个处理程序,因为使用执行策略调用的代码不会重新抛出异常。
综上所述,我们可以得出以下总结:
并行算法可以为应用程序带来额外的速度提升,但必须明智地使用。它们引入了并行执行框架的额外开销,拥有大量独立且适合并行化的任务至关重要。一如既往,测量不同版本之间的性能,才能有信心选择最终的实现方案。
还有其他改进项目的方法吗?让我们在接下来的内容中看看其他一些可能性。
# 额外修改和选项
并行版本的代码跳过了一个选项:并行访问文件。到目前为止,我们逐个读取文件,但是从不同线程读取不同文件会怎样呢?
下面的图表说明了这个选项:
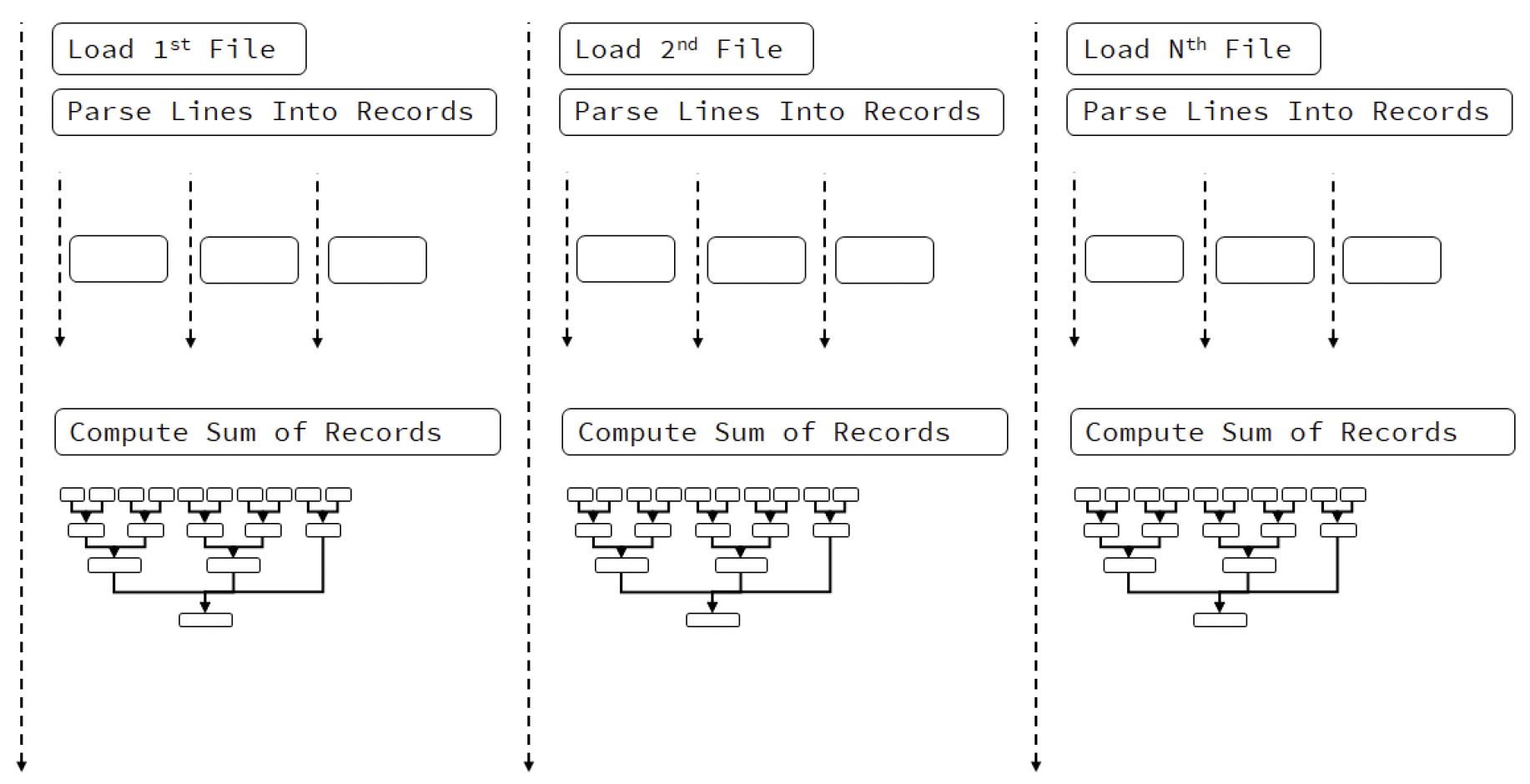
图 20.3 并行执行的CSV读取器,在不同线程中读取文件
上图所示的情况有点复杂。如果假设操作系统无法处理多个文件访问,那么线程会等待文件。但一旦文件可用,处理过程就可以并行进行。
如果你想尝试这种技术,可以在CalcResults()函数中将std::execution::seq替换为std::execution::par,这将允许编译器并行运行LoadRecords()和CalcTotalOrder()函数。
你的系统能够从不同线程访问文件吗?
一般来说,答案可能很复杂,因为这取决于许多因素:硬件、系统以及计算成本等。例如,在配备快速固态硬盘的机器上,系统可以处理多个文件读取操作,而在机械硬盘上,性能可能会较慢。现代硬盘还使用原生命令队列(Native Command Queues),所以即使从多个线程进行访问,发送到硬盘的命令也会是串行的,并且会被重新排列以实现更优化的方式。由于这个主题超出了本书的范围,我们将实验留给读者。