 第2章 Rust概览
第2章 Rust概览
# 第2章 Rust概览
Rust给像本书这样的书籍作者带来了一个挑战:赋予这门语言独特性的,并非某个能在开篇就展示的惊人特性,而是它所有部分协同工作的方式,这些设计都是为了实现上一章提到的目标:安全、高性能的系统编程。这门语言的每个部分,只有在其他部分共同构成的大背景下,才能彰显其最佳价值。
因此,我们没有逐一讲解语言特性,而是准备了几个小型但完整的程序示例,每个示例都在实际情境中介绍了Rust的一些特性:
- 作为热身,我们有一个程序,它对命令行参数进行简单计算,并包含单元测试。这个程序展示了Rust的核心类型,并引入了特性(traits)的概念。
- 接下来,我们构建一个Web服务器。我们将使用第三方库来处理HTTP的细节,并介绍字符串处理、闭包和错误处理。
- 第三个程序绘制一个漂亮的分形图,通过多线程并行计算来提高速度。这个示例包含一个泛型函数,展示了如何处理像素缓冲区之类的内容,以及Rust对并发的支持。
- 最后,我们展示一个强大的命令行工具,它使用正则表达式处理文件。这个程序展示了Rust标准库中处理文件的功能,以及最常用的第三方正则表达式库。
Rust承诺在对性能影响最小的情况下防止未定义行为,这一理念影响着整个语言系统的设计,从向量和字符串等标准数据结构,到Rust程序使用第三方库的方式。本书会详细介绍这一理念的实现细节。但现在,我们想让你知道,Rust是一门强大且易用的语言。
当然,首先你需要在计算机上安装Rust。
# rustup和Cargo
安装Rust的最佳方式是使用rustup。访问https://rustup.rs 并按照那里的说明进行操作。
或者,你也可以访问Rust官方网站,获取适用于Linux、macOS和Windows的预构建安装包。一些操作系统发行版中也包含Rust。我们更推荐使用rustup,因为它是一个管理Rust安装的工具,类似于Ruby的RVM或Node的NVM。例如,当有新版本的Rust发布时,你只需输入rustup update,无需任何点击操作就能完成升级。
无论采用哪种方式,安装完成后,你应该可以在命令行中使用三个新命令:
$ cargo --version
cargo 1.49.0 (d00d64df9 2020-12-05)
$ rustc --version
rustc 1.49.0 (e1884a8e3 2020-12-29)
$ rustdoc --version
rustdoc 1.49.0 (e1884a8e3 2020-12-29)
2
3
4
5
6
这里,$是命令提示符;在Windows系统中,它可能是C:\>或类似的符号。在这段记录中,我们运行了刚刚安装的三个命令,查看它们的版本号。下面依次介绍每个命令:
cargo是Rust的编译管理器、包管理器和通用工具。你可以使用Cargo创建新项目、构建和运行程序,以及管理代码所依赖的外部库。rustc是Rust编译器。通常我们让Cargo为我们调用编译器,但有时直接运行它也很有用。rustdoc是Rust文档工具。如果你在程序源代码的注释中采用合适的格式编写文档,rustdoc可以将它们生成格式良好的HTML文档。和rustc一样,我们通常让Cargo来运行rustdoc。
为了方便使用,Cargo可以为我们创建一个新的Rust包,并合理设置一些标准元数据:
$ cargo new hello
Created binary (application) `hello` package
2
这个命令创建了一个名为hello的新包目录,用于构建命令行可执行程序。查看该包的顶级目录:
$ cd hello
$ ls -la
total 24
drwxrwxr-x. 4 jimb jimb 4096 Sep 22 21:09.
drwx------. 62 jimb jimb 4096 Sep 22 21:09..
drwxrwxr-x. 6 jimb jimb 4096 Sep 22 21:09.git
-rw-rw-r--. 1 jimb jimb 7 Sep 22 21:09.gitignore
-rw-rw-r--. 1 jimb jimb 88 Sep 22 21:09 Cargo.toml
drwxrwxr-x. 2 jimb jimb 4096 Sep 22 21:09 src
2
3
4
5
6
7
8
9
我们可以看到,Cargo创建了一个Cargo.toml文件来保存包的元数据。目前这个文件内容不多:
[package]
name = "hello"
version = "0.1.0"
authors = ["You <you@example.com>"]
edition = "2018"
# 更多键及其定义,请查看
# https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
2
3
4
5
6
7
8
如果我们的程序依赖其他库,可以将这些依赖记录在这个文件中,Cargo会负责为我们下载、构建和更新这些库。我们将在第8章详细介绍Cargo.toml文件。
Cargo为我们的包设置了git版本控制系统,创建了一个.git元数据子目录和一个.gitignore文件。你可以在命令行中给cargo new传递--vcs none参数,让Cargo跳过这一步。src子目录包含实际的Rust代码:
$ cd src
$ ls -l
total 4
-rw-rw-r--. 1 jimb jimb 45 Sep 22 21:09 main.rs
2
3
4
看起来Cargo已经帮我们开始编写程序了。main.rs文件包含以下内容:
fn main() {
println!("Hello, world!");
}
2
3
在Rust中,你甚至不需要自己编写 “Hello, World!” 程序。这就是一个新Rust程序的全部样板代码:两个文件,总共十三行。
我们可以在包内的任何目录中调用cargo run命令来构建并运行我们的程序:
$ cargo run
Compiling hello v0.1.0 (/home/jimb/rust/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.28s
Running `/home/jimb/rust/hello/target/debug/hello`
Hello, world!
2
3
4
5
这里,Cargo调用了Rust编译器rustc,然后运行生成的可执行文件。Cargo将可执行文件放在包顶级目录的target子目录中:
$ ls -l ./target/debug
total 580
drwxrwxr-x. 2 jimb jimb 4096 Sep 22 21:37 build
drwxrwxr-x. 2 jimb jimb 4096 Sep 22 21:37 deps
drwxrwxr-x. 2 jimb jimb 4096 Sep 22 21:37 examples
-rwxrwxr-x. 1 jimb jimb 576632 Sep 22 21:37 hello
-rw-rw-r--. 1 jimb jimb 198 Sep 22 21:37 hello.d
drwxrwxr-x. 2 jimb jimb 68 Sep 22 21:37 incremental
$ ./target/debug/hello
Hello, world!
2
3
4
5
6
7
8
9
10
完成操作后,Cargo可以帮我们清理生成的文件:
$ cargo clean
$ ./target/debug/hello
bash: ./target/debug/hello: No such file or directory
2
3
# Rust函数
Rust的语法有意借鉴了其他语言。如果你熟悉C、C++、Java或JavaScript,那么理解Rust程序的总体结构应该不会太难。下面是一个使用欧几里得算法计算两个整数最大公约数的函数。你可以将这段代码添加到src/main.rs文件的末尾:
fn gcd(mut n: u64, mut m: u64) -> u64 {
assert!(n != 0 && m != 0);
while m != 0 {
if m < n {
let t = m;
m = n;
n = t;
}
m = m % n;
}
n
}
2
3
4
5
6
7
8
9
10
11
12
fn关键字(读作 “fun”)用于定义函数。这里,我们定义了一个名为gcd的函数,它有两个参数n和m,类型都是u64,即无符号64位整数。->符号后面是返回类型:我们的函数返回一个u64值。四个空格的缩进是Rust的标准风格。
Rust的机器整数类型名称反映了它们的大小和符号性:i32是有符号32位整数;u8是无符号8位整数(用于表示 “字节” 值),依此类推。isize和usize类型用于存储与指针大小相同的有符号和无符号整数,在32位平台上是32位,在64位平台上是64位。Rust还有两种浮点类型f32和f64,它们分别是IEEE单精度和双精度浮点类型,类似于C和C++ 中的float和double。
默认情况下,变量一旦初始化,其值就不能更改,但在参数n和m前面加上mut关键字(读作 “mute”,是mutable的缩写),就可以在函数体内对它们进行赋值。在实际应用中,大多数变量不会被重新赋值;在会被重新赋值的变量前加上mut关键字,在阅读代码时是一个有用的提示。
函数体以调用assert!宏开始,用于验证两个参数都不为零。!字符表明这是一个宏调用,而不是函数调用。和C、C++ 中的assert宏一样,Rust的assert!宏会检查其参数是否为真,如果不为真,则会终止程序并输出包含失败检查的源代码位置的提示信息;这种突然终止的情况被称为程序恐慌(panic)。与C和C++ 不同,在C和C++ 中可以跳过断言检查,而Rust无论程序如何编译,总是会检查断言。还有一个debug_assert!宏,在为提高速度而编译程序时,它的断言会被跳过。
我们函数的核心是一个while循环,其中包含一个if语句和一个赋值操作。与C和C++ 不同,Rust不要求在条件表达式周围加上括号,但要求在受条件控制的语句周围加上花括号。
let语句用于声明局部变量,比如我们函数中的t。只要Rust能从变量的使用方式中推断出其类型,我们就不需要显式写出t的类型。在我们的函数中,能用于t的唯一类型是u64,与m和n的类型匹配。Rust只在函数体内进行类型推断:你必须像我们之前那样,写出函数参数和返回值的类型。如果我们想显式写出t的类型,可以这样写:
let t: u64 = m;
Rust有return语句,但gcd函数并不需要它。如果函数体以一个没有紧跟分号的表达式结束,这个表达式的值就是函数的返回值。实际上,任何用花括号括起来的代码块都可以作为一个表达式。例如,下面这个表达式会先打印一条消息,然后返回x.cos()的值:
{
println!("evaluating cos x");
x.cos()
}
2
3
4
在Rust中,通常在函数 “自然结束” 时使用这种形式来确定函数的返回值,只有在函数中间需要提前返回时,才使用return语句。
# 编写和运行单元测试
Rust语言内置了对测试的简单支持。为了测试我们的gcd函数,可以在src/main.rs文件的末尾添加以下代码:
#[test]
fn test_gcd() {
assert_eq!(gcd(14, 15), 1);
assert_eq!(gcd(2 * 3 * 5 * 11 * 17,
3 * 7 * 11 * 13 * 19),
3 * 11);
}
2
3
4
5
6
7
这里我们定义了一个名为test_gcd的函数,它调用gcd函数并检查其返回值是否正确。定义上方的#[test]标记将test_gcd标记为一个测试函数,在正常编译时会被跳过,但如果我们使用cargo test命令运行程序,它会被包含并自动调用。我们可以在整个源代码树中分散地定义测试函数,将它们放在要测试的代码旁边,cargo test会自动收集并运行所有测试函数。
#[test]标记是属性(attribute)的一个示例。属性是一种开放式的系统,用于为函数和其他声明添加额外信息,类似于C++ 和C# 中的属性,或者Java中的注解。它们用于控制编译器警告、代码风格检查、有条件地包含代码(类似于C和C++ 中的#ifdef)、告知Rust如何与其他语言编写的代码交互等等。随着学习的深入,我们会看到更多属性的示例。
在本章开头创建的hello包中添加了gcd和test_gcd的定义后,在包的子目录中的任意位置,我们都可以按如下方式运行测试:
$ cargo test
Compiling hello v0.1.0 (/home/jimb/rust/hello)
Finished test [unoptimized + debuginfo] target(s) in 0.35s
Running /home/jimb/rust/hello/target/debug/deps/hello-2375a82d9e9673d7
running 1 test
test test_gcd ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
2
3
4
5
6
7
# 处理命令行参数
为了让我们的程序能够将一系列数字作为命令行参数,并打印出它们的最大公约数,我们可以将src/main.rs中的main函数替换为以下内容:
use std::str::FromStr;
use std::env;
fn main() {
let mut numbers = Vec::new();
for arg in env::args().skip(1) {
numbers.push(u64::from_str(&arg)
.expect("error parsing argument"));
}
if numbers.len() == 0 {
eprintln!("Usage: gcd NUMBER...");
std::process::exit(1);
}
let mut d = numbers[0];
for m in &numbers[1..] {
d = gcd(d, *m);
}
println!("The greatest common divisor of {:?} is {}",
numbers, d);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这段代码比较长,下面我们逐部分分析:
use std::str::FromStr;
use std::env;
2
第一个use声明将标准库中的FromStr特性引入作用域。特性是一组类型可以实现的方法集合。任何实现了FromStr特性的类型都有一个from_str方法,用于尝试从字符串中解析出该类型的值。u64类型实现了FromStr,我们将调用u64::from_str来解析命令行参数。虽然在程序的其他地方我们从未使用过FromStr这个名字,但为了使用其方法,必须将该特性引入作用域。我们将在第11章详细介绍特性。
第二个use声明引入了std::env模块,该模块提供了几个与执行环境交互的有用函数和类型,包括args函数,通过它我们可以访问程序的命令行参数。
接着看程序的main函数:
fn main() {
我们的main函数不返回值,所以可以省略通常会在参数列表后面的->和返回类型。
let mut numbers = Vec::new();
我们声明了一个可变的局部变量numbers,并将其初始化为一个空向量。Vec是Rust的可增长向量类型,类似于C++的std::vector、Python的列表或JavaScript的数组。尽管向量被设计为可以动态增长和收缩,但我们仍必须将变量标记为mut,这样Rust才允许我们向其末尾添加数字。
numbers的类型是Vec<u64>,即一个u64值的向量,但和之前一样,我们不需要显式写出这个类型。Rust会为我们推断出这个类型,部分原因是我们向向量中添加的是u64值,另外也因为我们将向量的元素传递给了gcd函数,而gcd函数只接受u64值。
for arg in env::args().skip(1) {
这里我们使用for循环来处理命令行参数,将变量arg依次设置为每个参数,并执行循环体。
std::env模块的args函数返回一个迭代器,迭代器是一种按需生成每个参数,并能指示何时结束的对象。迭代器在Rust中无处不在;标准库中还包含其他迭代器,用于生成向量的元素、文件的行、在通信通道上接收的消息,以及几乎任何适合循环遍历的内容。Rust的迭代器非常高效:编译器通常能够将它们转换为与手写循环相同的代码。我们将在第15章展示其工作原理并给出示例。
除了在for循环中使用,迭代器还包含一系列可以直接使用的方法。例如,args返回的迭代器生成的第一个值始终是正在运行的程序的名称。我们想要跳过这个值,所以调用迭代器的skip方法,生成一个新的迭代器,该迭代器会忽略第一个值。
numbers.push(u64::from_str(&arg)
.expect("error parsing argument"));
2
这里我们调用u64::from_str,尝试将命令行参数arg解析为无符号64位整数。u64::from_str不是我们在某个已有的u64值上调用的方法,而是与u64类型相关联的函数,类似于C++或Java中的静态方法。from_str函数不会直接返回一个u64值,而是返回一个Result值,用于指示解析是否成功。Result值有两种变体:
Ok(v):表示解析成功,v是生成的值。Err(e):表示解析失败,e是一个错误值,用于解释失败的原因。
任何可能会失败的函数,如进行输入输出或与操作系统进行其他交互的函数,都可能返回Result类型,其Ok变体携带成功的结果(如传输的字节数、打开的文件等),而Err变体则携带指示错误原因的错误代码。与大多数现代语言不同,Rust没有异常:所有错误都使用Result或panic来处理,第7章会详细介绍。
我们使用Result的expect方法来检查解析是否成功。如果结果是Err(e),expect会打印一条包含e描述的消息,并立即退出程序。然而,如果结果是Ok(v),expect只会返回v本身,这样我们最终就能将其添加到numbers向量的末尾。
if numbers.len() == 0 {
eprintln!("Usage: gcd NUMBER...");
std::process::exit(1);
}
2
3
4
一组空数字不存在最大公约数,所以我们检查向量中是否至少有一个元素,如果没有,则向标准错误输出流写入错误消息并退出程序。我们使用eprintln!宏将错误消息写入标准错误输出流。
let mut d = numbers[0];
for m in &numbers[1..] {
d = gcd(d, *m);
}
2
3
4
这个循环使用d作为运行值,不断更新它,使其始终是到目前为止处理的所有数字的最大公约数。和之前一样,我们必须将d标记为可变的,以便在循环中对其进行赋值。
这个for循环有两个令人疑惑的地方。第一,我们写的是for m in &numbers[1..],这里的&运算符有什么用呢?第二,我们写的是gcd(d, *m),这里*m中的*又是什么意思呢?这两个细节是相互关联的。
到目前为止,我们的代码只处理像整数这样占用固定大小内存块的简单值。但现在我们要遍历一个向量,向量的大小可能是任意的,甚至可能非常大。Rust在处理这类值时非常谨慎:它希望让程序员控制内存消耗,明确每个值的生命周期,同时确保不再需要时能及时释放内存。
所以在遍历向量时,我们要告诉Rust,向量的所有权应该仍属于numbers;我们只是在循环中借用其元素。&numbers[1..]中的&运算符从向量的第二个元素开始借用对向量元素的引用。for循环遍历这些被引用的元素,使m依次借用每个元素。*m中的*运算符解引用m,得到它所指向的值;这就是我们要传递给gcd函数的下一个u64值。最后,由于numbers拥有向量的所有权,当main函数结束,numbers超出作用域时,Rust会自动释放向量所占用的内存。
Rust的所有权和引用规则是Rust内存管理和安全并发的关键;我们将在第4章及其后续的第5章详细讨论这些规则。要熟练掌握Rust,你需要熟悉这些规则,但在这个入门介绍中,你只需要知道&x表示借用对x的引用,而*r表示引用r所指向的值。继续看程序:
println!("The greatest common divisor of {:?} is {}",
numbers, d);
2
遍历完numbers的元素后,程序将结果打印到标准输出流。println!宏接受一个模板字符串,将剩余参数的格式化版本替换模板字符串中出现的{...}形式,并将结果写入标准输出流。
与C和C++不同,C和C++要求main函数在程序成功完成时返回零,出现错误时返回非零退出状态,而Rust假设只要main函数返回,程序就成功完成。只有显式调用expect或std::process::exit等函数,我们才能使程序以错误状态码终止。
cargo run命令允许我们向程序传递参数,这样我们就可以测试命令行参数的处理功能:
$ cargo run 42 56
Compiling hello v0.1.0 (/home/jimb/rust/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.22s
Running `/home/jimb/rust/hello/target/debug/hello 42 56`
The greatest common divisor of [42, 56] is 14
$ cargo run 799459 28823 27347
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `/home/jimb/rust/hello/target/debug/hello 799459 28823 27347`
The greatest common divisor of [799459, 28823, 27347] is 41
$ cargo run 83
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `/home/jimb/rust/hello/target/debug/hello 83`
The greatest common divisor of [83] is 83
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `/home/jimb/rust/hello/target/debug/hello`
Usage: gcd NUMBER...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在本节中,我们使用了Rust标准库中的一些特性。如果你对标准库中还有哪些可用的功能感到好奇,强烈建议你尝试使用Rust的在线文档。它有一个实时搜索功能,方便探索,甚至还包含源代码的链接。在安装Rust时,rustup命令会自动在你的计算机上安装一份标准库文档。你可以在Rust官方网站上查看标准库文档,也可以在浏览器中使用以下命令查看:
$ rustup doc --std
# 搭建Web服务
Rust的优势之一在于,在crates.io网站上有大量免费的库包可供使用。cargo命令让你的代码使用crates.io上的包变得轻而易举:它会下载合适版本的包,进行构建,并根据需求进行更新。Rust的包,无论是库还是可执行文件,都被称为“crate”;Cargo和crates.io的名称都源于这个术语。
为了展示其工作原理,我们将使用actix-web网络框架库、serde序列化库以及它们所依赖的其他各种库,搭建一个简单的Web服务器。如图2 - 1所示,我们的网站将提示用户输入两个数字,并计算它们的最大公约数。
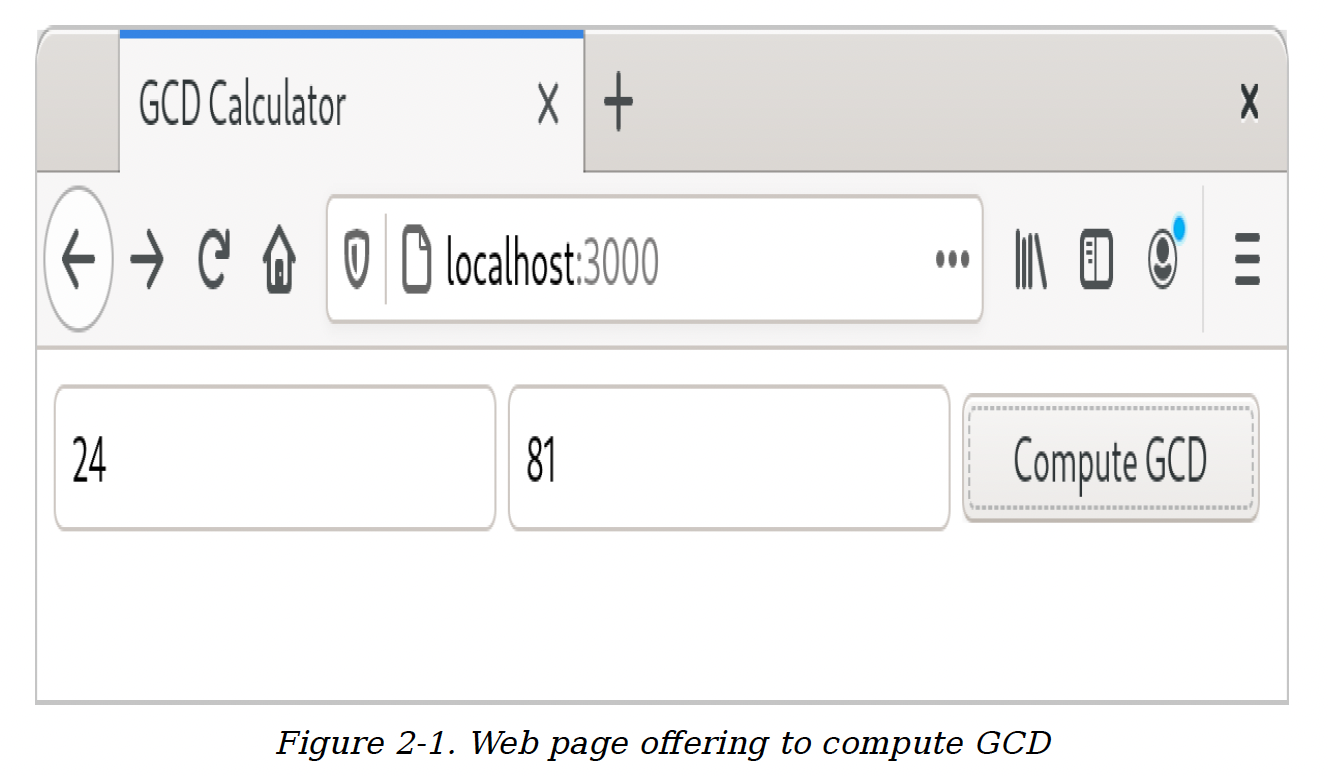 图2 - 1. 用于计算最大公约数的网页
图2 - 1. 用于计算最大公约数的网页
首先,我们让Cargo为我们创建一个名为actix-gcd的新包:
$ cargo new actix-gcd
Created binary (application) `actix-gcd` package
$ cd actix-gcd
2
3
然后,我们编辑新项目的Cargo.toml文件,列出我们想要使用的包;文件内容如下:
[package]
name = "actix-gcd"
version = "0.1.0"
authors = ["You <you@example.com>"]
edition = "2018"
# 更多键及其定义请见
# https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
actix-web = "1.0.8"
serde = { version = "1.0", features = ["derive"] }
2
3
4
5
6
7
8
9
10
11
12
Cargo.toml文件中[dependencies]部分的每一行,都指定了crates.io上的一个crate名称,以及我们想要使用的版本。在这个例子中,我们需要actix-web库的1.0.8版本和serde库的1.0版本。crates.io上很可能有比这里列出的更新的版本,但通过指定我们测试代码时所使用的具体版本,即使这些包发布了新版本,我们也能确保代码仍能编译。我们将在第8章更详细地讨论版本管理。
crate可以有可选功能:这些是并非所有用户都需要的接口或实现部分,但将它们包含在crate中仍有意义。serde库提供了一种非常简洁的方式来处理来自Web表单的数据,但根据serde的文档,只有选择了该crate的derive功能,这个功能才可用,所以我们在Cargo.toml文件中按上述方式进行了指定。
注意,我们只需要列出直接使用的crate;cargo会负责引入这些crate所依赖的其他所有crate。
在第一个版本中,我们让Web服务器保持简单:它只提供一个页面,提示用户输入用于计算的数字。在actix-gcd/src/main.rs中,我们添加以下代码:
use actix_web::{web, App, HttpResponse, HttpServer};
fn main() {
let server = HttpServer::new(|| {
App::new()
.route("/", web::get().to(get_index))
});
println!("Serving on http://localhost:3000...");
server
.bind("127.0.0.1:3000")
.expect("error binding server to address")
.run()
.expect("error running server");
}
fn get_index() -> HttpResponse {
HttpResponse::Ok()
.content_type("text/html")
.body(
r#"
<title>GCD Calculator</title>
<form action="/gcd" method="post">
<input type="text" name="n"/>
<input type="text" name="m"/>
<button type="submit">Compute GCD</button>
</form>
"#,
)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
我们首先通过use声明,让actix-web库中的一些定义更易于使用。当我们编写use actix_web::{...}时,花括号内列出的每个名称都可以在我们的代码中直接使用;这样,每次使用actix_web::HttpResponse时,我们无需完整写出这个名称,而可以简单地用HttpResponse来指代它。(稍后我们会用到serde库。)
main函数很简单:它调用HttpServer::new创建一个服务器,该服务器只响应对/路径的请求;打印一条消息,提醒我们如何连接到该服务器;然后让它在本地机器的TCP端口3000上监听。
我们传递给HttpServer::new的参数是Rust闭包表达式|| { App::new()... }。闭包是一种可以像函数一样被调用的值。这个闭包不接受参数,但如果需要接受参数,参数名会出现在||竖线之间。{... }是闭包的主体。当我们启动服务器时,Actix会启动一个线程池来处理传入的请求。每个线程都会调用这个闭包,以获取一个新的App值副本,该值会告诉线程如何路由和处理请求。
闭包调用App::new创建一个新的空App,然后调用其route方法为/路径添加一条路由。为该路由提供的处理函数web::get().to(get_index),通过调用get_index函数来处理HTTP GET请求。route方法返回调用它的App,此时App已添加了新的路由。由于闭包主体的末尾没有分号,所以App就是闭包的返回值,可供HttpServer线程使用。
get_index函数构建一个HttpResponse值,代表对HTTP GET /请求的响应。HttpResponse::Ok()代表HTTP 200 OK状态,表示请求成功。我们调用它的content_type和body方法来填充响应的详细信息;每个调用都会返回应用了这些修改的HttpResponse。最后,body的返回值作为get_index的返回值。
由于响应文本包含很多双引号,我们使用Rust的“原始字符串”语法来编写:字母r,零个或多个井号(即#字符),一个双引号,然后是字符串内容,最后以另一个双引号和相同数量的井号结束。原始字符串中可以包含任何字符,无需转义,包括双引号;实际上,像\"这样的转义序列在原始字符串中是不被识别的。我们可以通过在双引号周围使用比文本中更多的井号,来确保字符串在我们期望的位置结束。
编写好main.rs后,我们可以使用cargo run命令来完成启动服务器所需的所有操作:获取所需的crate,编译它们,构建我们自己的程序,将所有内容链接在一起并启动:
$ cargo run
Updating crates.io index
Downloading crates...
Downloaded serde v1.0.100
Downloaded actix-web v1.0.8
Downloaded serde_derive v1.0.100
...
Compiling serde_json v1.0.40
Compiling actix-router v0.1.5
Compiling actix-http v0.2.10
Compiling awc v0.2.7
Compiling actix-web v1.0.8
Compiling gcd v0.1.0 (/home/jimb/rust/actix-gcd)
Finished dev [unoptimized + debuginfo] target(s) in 1m 24s
Running `/home/jimb/rust/actix-gcd/target/debug/actix-gcd`
Serving on http://localhost:3000...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
此时,我们可以在浏览器中访问给定的URL,看到前面图2 - 1所示的页面。
遗憾的是,点击“Compute GCD”按钮除了将浏览器导航到一个空白页面外,没有任何其他作用。接下来,我们通过为App添加另一条路由来处理表单的POST请求,修复这个问题。
现在终于要用到我们在Cargo.toml文件中列出的serde库了:它提供了一个便捷的工具,帮助我们处理表单数据。首先,我们需要在src/main.rs文件顶部添加以下use指令:
use serde::Deserialize;
Rust程序员通常会把所有的use声明集中放在文件顶部,但这并非严格要求:只要声明出现在适当的嵌套层级,Rust允许它们以任意顺序出现 。
接下来,我们定义一个Rust结构体类型,用于表示我们期望从表单中获取的值:
#[derive(Deserialize)]
struct GcdParameters {
n: u64,
m: u64,
}
2
3
4
5
这定义了一个名为GcdParameters的新类型,它有两个字段n和m,每个字段都是u64类型 —— 这正是我们的gcd函数所期望的参数类型。
结构体定义上方的注释是一个属性,就像我们之前用于标记测试函数的#[test]属性一样。在类型定义上方放置#[derive(Deserialize)]属性,会告诉serde库在程序编译时检查该类型,并自动生成代码,以便从HTML表单用于POST请求的数据格式中解析出该类型的值。实际上,有了这个属性,你几乎可以从任何结构化数据中解析出GcdParameters值:JSON、YAML、TOML,或者其他多种文本和二进制格式。serde库还提供了一个Serialize属性,用于生成代码,将Rust值以结构化格式输出。
有了这个定义,我们可以很容易地编写处理函数:
fn post_gcd(form: web::Form<GcdParameters>) -> HttpResponse {
if form.n == 0 || form.m == 0 {
return HttpResponse::BadRequest()
.content_type("text/html")
.body("Computing the GCD with zero is boring.");
}
let response =
format!("The greatest common divisor of the numbers {} and {} \
is <b>{}</b>\n ",
form.n, form.m, gcd(form.n, form.m));
HttpResponse::Ok()
.content_type("text/html")
.body(response)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
要使一个函数成为Actix的请求处理函数,其参数类型必须是Actix能够从HTTP请求中提取的类型。我们的post_gcd函数有一个参数form,其类型为web::Form<GcdParameters>。Actix能够从HTTP请求中提取任何web::Form<T>类型的值,前提是且仅当T可以从HTML表单POST数据中反序列化。由于我们在GcdParameters类型定义上添加了#[derive(Deserialize)]属性,Actix可以从表单数据中反序列化它,所以请求处理函数可以期望得到一个web::Form<GcdParameters>类型的参数。这些类型和函数之间的关系都是在编译时确定的;如果你编写的处理函数的参数类型Actix不知道如何处理,Rust编译器会立即提示你错误。
查看post_gcd函数内部,该函数首先检查,如果任何一个参数为零,则返回HTTP 401 BAD REQUEST错误,因为如果参数为零,我们的gcd函数会发生恐慌(panic)。然后,它使用format!宏构建对请求的响应。format!宏与println!宏类似,只是它不会将文本输出到标准输出,而是将其作为字符串返回。获取到响应文本后,post_gcd将其包装在一个HTTP 200 OK响应中,设置其内容类型,然后返回给发送方。
我们还必须将post_gcd注册为表单的处理函数。我们用以下版本替换main函数:
fn main() {
let server = HttpServer::new(|| {
App::new()
.route("/", web::get().to(get_index))
.route("/gcd", web::post().to(post_gcd))
});
println!("Serving on http://localhost:3000...");
server
.bind("127.0.0.1:3000")
.expect("error binding server to address")
.run()
.expect("error running server");
}
2
3
4
5
6
7
8
9
10
11
12
13
这里唯一的变化是,我们添加了另一个对route的调用,将web::post().to(post_gcd)设置为/gcd路径的处理函数。
最后剩下的是我们之前编写的gcd函数,将其添加到actix-gcd/src/main.rs文件中。完成这些后,你可以中断可能正在运行的服务器,重新构建并重启程序:
$ cargo run
Compiling actix-gcd v0.1.0 (/home/jimb/rust/actix-gcd)
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/actix-gcd`
Serving on http://localhost:3000...
2
3
4
5
这次,访问http://localhost:3000,输入一些数字,然后点击“Compute GCD”按钮,你应该能看到实际的计算结果(图2 - 2)。
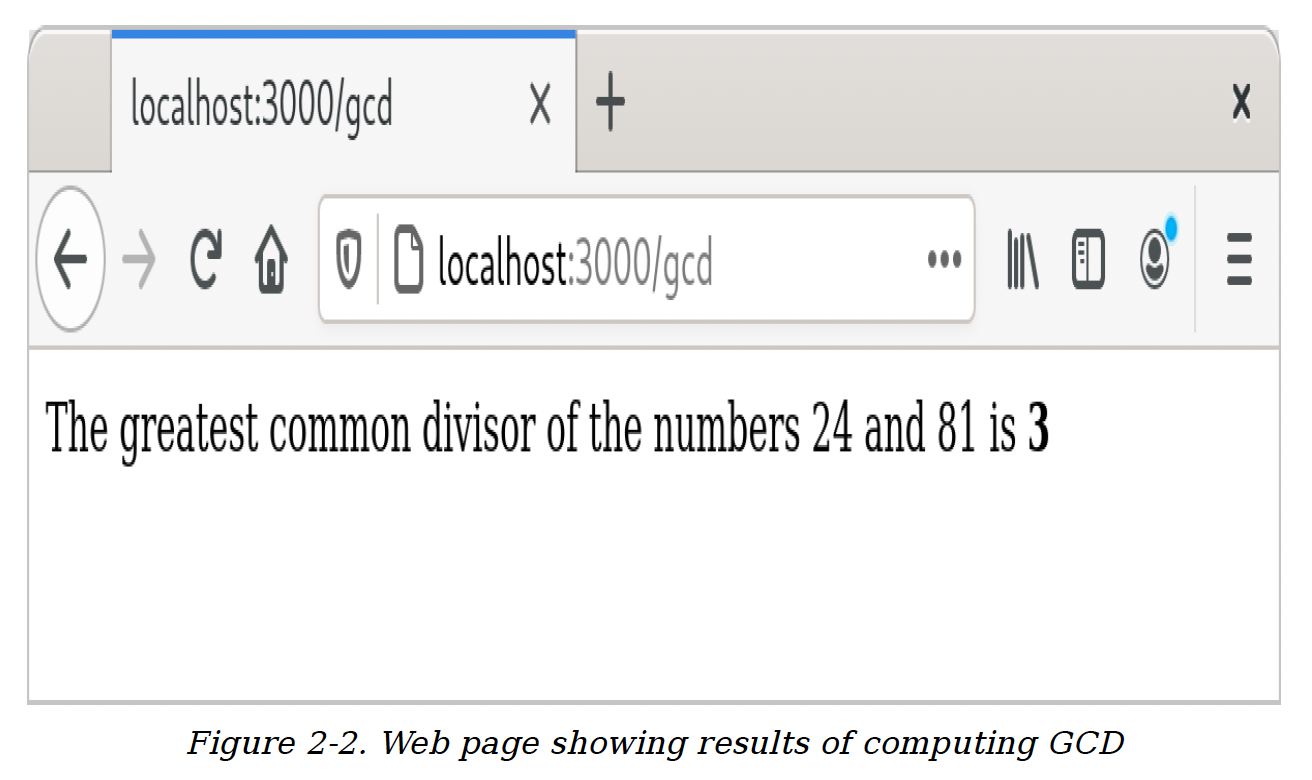 图2 - 2. 显示最大公约数计算结果的网页
图2 - 2. 显示最大公约数计算结果的网页
# 并发编程
Rust的一大优势在于它对并发编程的支持。那些确保Rust程序没有内存错误的规则,同样也能确保线程在共享内存时避免数据竞争。例如:
- 如果你使用互斥锁(mutex)来协调多个线程对共享数据结构的修改,Rust能确保你只有在持有锁的情况下才能访问数据,并且在使用完后自动释放锁。而在C和C++中,互斥锁和它所保护的数据之间的关系仅靠注释来描述。
- 如果你想在多个线程之间共享只读数据,Rust能确保你不会意外修改数据。在C和C++中,类型系统可以提供一定帮助,但也很容易出错。
- 如果你将一个数据结构的所有权从一个线程转移到另一个线程,Rust会确保你确实放弃了对该数据的所有访问。在C和C++中,则需要你自己检查发送线程不会再访问该数据。如果处理不当,其结果可能取决于处理器缓存中的内容以及你最近对内存的写入次数。倒不是我们对此耿耿于怀。
在本节中,我们将带你逐步完成编写第二个多线程程序的过程。
你其实已经编写过第一个多线程程序了:你用来实现最大公约数服务器的Actix网络框架,它使用一个线程池来运行请求处理函数。如果服务器同时收到多个请求,它可能会在多个线程中同时运行get_form和post_gcd函数。这可能有点让人惊讶,因为我们在编写这些函数时肯定没有考虑到并发情况。但Rust保证,无论你的服务器变得多么复杂,这样做都是安全的:如果你的程序能编译通过,就不会存在数据竞争问题。所有的Rust函数都是线程安全的。
本节的程序将绘制曼德布洛特集合(Mandelbrot set),这是一种通过对复数迭代一个简单函数而生成的分形图形。绘制曼德布洛特集合通常被称为“令人尴尬的并行算法”,因为线程之间的通信模式非常简单;我们将在第19章介绍更复杂的模式,但这个任务展示了一些并发编程的要点。
首先,我们创建一个新的Rust项目:
$ cargo new mandelbrot
Created binary (application) `mandelbrot` package
$ cd mandelbrot
2
3
所有代码都将放在mandelbrot/src/main.rs中,并且我们会在mandelbrot/Cargo.toml中添加一些依赖项。
在深入探讨并发的曼德布洛特集合实现之前,我们需要描述一下即将执行的计算过程。
# 曼德布洛特集合的实际原理
阅读代码时,对代码的功能有一个具体的概念会很有帮助,所以让我们先来简单了解一些纯数学知识。我们从一个简单的例子开始,逐步添加复杂的细节,最终得到曼德布洛特集合核心的计算方法。
下面是一个无限循环,使用Rust专门的循环语句loop来编写:
fn square_loop(mut x: f64) {
loop {
x = x * x;
}
}
2
3
4
5
在实际情况中,Rust能识别出x从未被使用,所以可能不会去计算它的值。但目前,假设代码按编写的那样运行。那么x的值会发生什么变化呢?对任何小于1的数进行平方会使其变得更小,趋近于0;对1进行平方结果为1;对大于1的数进行平方会使其变得更大,趋近于无穷大;对负数进行平方会使其变为正数,之后的情况就和前面的某一种相同(见图2 - 3)。
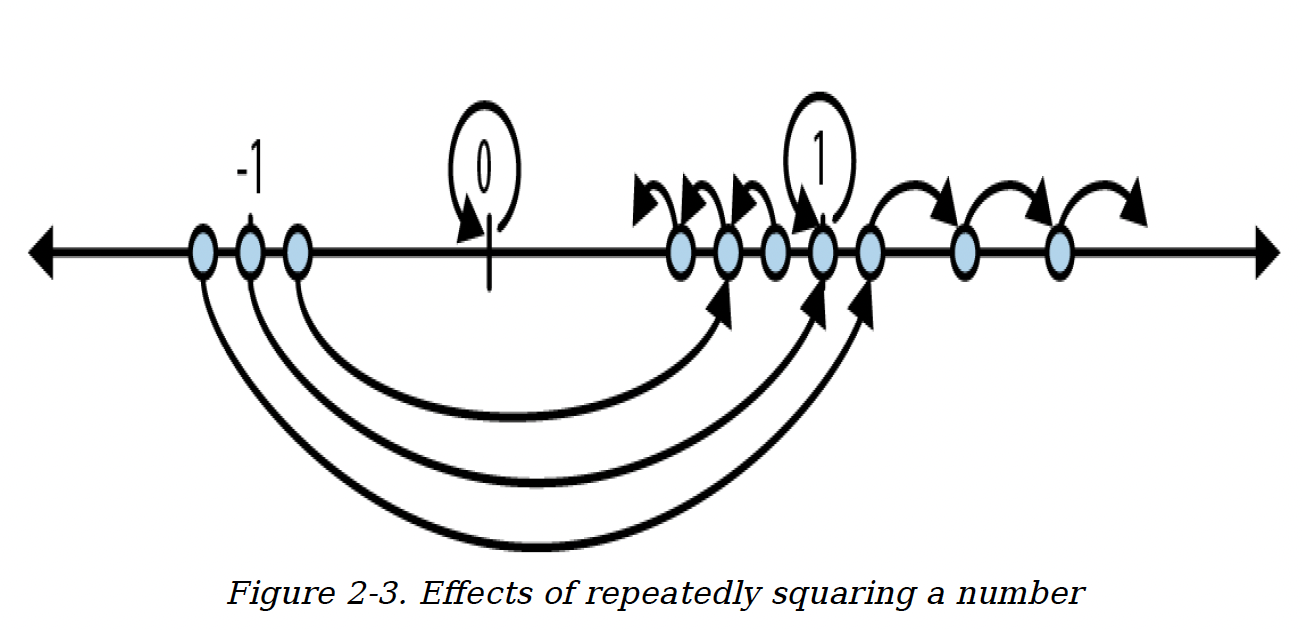 图2 - 3. 反复对一个数进行平方的结果
图2 - 3. 反复对一个数进行平方的结果
所以,根据你传递给square_loop的数值不同,x会保持在0或1,或者趋近于0,又或者趋近于无穷大。
现在考虑一个稍微不同的循环:
fn square_add_loop(c: f64) {
let mut x = 0.;
loop {
x = x * x + c;
}
}
2
3
4
5
6
这次,x从0开始,并且在每次迭代中,我们在对x平方后加上c来改变它的变化过程。这样就不太容易看出x的变化情况了,但通过一些实验可以发现,如果c大于0.25或者小于 - 2.0,那么x最终会变得无穷大;否则,它会在0附近的某个范围内。
接下来的变化是:不再使用f64类型的值,而是考虑使用复数进行相同的循环。crates.io上的num库提供了我们可以使用的复数类型,所以我们必须在程序的Cargo.toml文件的[dependencies]部分添加一行关于num的内容。到目前为止,整个文件内容如下(我们稍后还会添加更多内容):
[package]
name = "mandelbrot"
version = "0.1.0"
authors = ["You <you@example.com>"]
edition = "2018"
# 更多键及其定义请见
# https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
num = "0.4"
2
3
4
5
6
7
8
9
10
11
现在我们可以编写这个循环的倒数第二个版本:
use num::Complex;
fn complex_square_add_loop(c: Complex<f64>) {
let mut z = Complex { re: 0.0, im: 0.0 };
loop {
z = z * z + c;
}
}
2
3
4
5
6
7
8
按照惯例,复数通常用z表示,所以我们重命名了循环变量。表达式Complex { re: 0.0, im: 0.0 }是使用num库的Complex类型表示复数0的方式。Complex是一个Rust结构体类型(或简称struct),定义如下:
struct Complex<T> {
/// 复数的实部
re: T,
/// 复数的虚部
im: T,
}
2
3
4
5
6
上述代码定义了一个名为Complex的结构体,有两个字段re和im。Complex是一个泛型结构体:你可以把类型名后面的<T>理解为“对于任何类型T”。例如,Complex<f64>是一个复数,它的re和im字段都是f64类型的值;Complex<f32>则使用32位浮点数,以此类推。根据这个定义,像Complex { re: 0.24, im: 0.3 }这样的表达式会生成一个Complex值,其re字段初始化为0.24,im字段初始化为0.3。
num库让*、+等算术运算符能够作用于Complex值,所以这个函数的其余部分和前面的版本类似,只是它操作的是复平面上的点,而不仅仅是实数轴上的点。我们将在第12章解释如何让Rust的运算符适用于你自己定义的类型。
最后,我们终于来到了这次纯数学探索的终点。曼德布洛特集合被定义为这样一组复数c:对于这些复数,z不会趋向于无穷大。我们最初的简单平方循环结果很容易预测:任何大于1或小于 - 1的数都会趋向无穷大。在每次迭代中加入+ c后,其行为变得有点难以预测:正如前面所说,c大于0.25或小于 - 2会导致z趋向无穷大。但是将范围扩展到复数后,会产生非常奇异且美丽的图案,这正是我们想要绘制的。
由于复数c有实部c.re和虚部c.im,我们将把它们当作笛卡尔平面上一个点的x和y坐标。如果c属于曼德布洛特集合,就把这个点涂成黑色,否则涂成较浅的颜色。所以对于图像中的每个像素,我们都必须在复平面上对应的点上运行前面的循环,判断它是趋向于无穷大还是会永远围绕原点循环,然后据此给像素上色。
这个无限循环运行起来需要一些时间,但对于没耐心的人有两个技巧。第一,如果我们不打算永远运行这个循环,而只是尝试有限次迭代,结果发现仍然可以得到该集合的一个不错的近似图形。需要迭代多少次取决于我们想要绘制边界的精确程度。第二,已经证明,如果z一旦离开以原点为圆心、半径为2的圆,那么它最终肯定会离原点越来越远,趋向于无穷大。所以下面是我们循环的最终版本,也是程序的核心部分:
use num::Complex;
/// 尝试判断`c`是否属于曼德布洛特集合,最多使用`limit`次迭代来判断。
///
/// 如果`c`不属于该集合,返回`Some(i)`,其中`i`是`c`离开以原点为圆心、半径为2的圆所需要的迭代次数。如果`c`似乎属于该集合(更准确地说,如果我们达到了迭代次数上限,仍无法证明`c`不属于该集合),返回`None`。
fn escape_time(c: Complex<f64>, limit: usize) -> Option<usize> {
let mut z = Complex { re: 0.0, im: 0.0 };
for i in 0..limit {
if z.norm_sqr() > 4.0 {
return Some(i);
}
z = z * z + c;
}
None
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这个函数接受我们要测试是否属于曼德布洛特集合的复数c,以及在放弃并认定c可能属于该集合之前尝试的最大迭代次数limit。
函数的返回值是Option<usize>。Rust标准库对Option类型的定义如下:
enum Option<T> {
None,
Some(T),
}
2
3
4
Option是一个枚举类型,通常简称为enum,因为它的定义列举了该类型的值可能的几种变体:对于任何类型T,Option<T>类型的值要么是Some(v),其中v是T类型的值,要么是None,表示不存在T类型的值。和我们前面讨论的Complex类型一样,Option是一个泛型类型:你可以使用Option<T>来表示任何你想要的T类型的可选值。
在我们的例子中,escape_time返回Option<usize>来表示c是否属于曼德布洛特集合 —— 如果不属于,还会返回我们发现这一点所需要的迭代次数。如果c不属于该集合,escape_time返回Some(i),其中i是z离开半径为2的圆时的迭代次数。否则,c显然属于该集合,escape_time返回None。
for i in 0..limit {
前面的示例展示了for循环遍历命令行参数和向量元素的用法;这个for循环只是遍历从0开始到(但不包括)limit的整数范围。
z.norm_sqr()方法调用返回z到原点距离的平方。为了判断z是否离开了半径为2的圆,我们没有计算平方根,而是直接将距离的平方与4.0进行比较,这样更快。
你可能已经注意到,我们使用///来标记函数定义上面的注释行;Complex结构体成员上面的注释也是以///开头。这些是文档注释;rustdoc工具知道如何解析它们以及它们所描述的代码,并生成在线文档。Rust标准库的文档就是以这种形式编写的。我们将在第8章详细介绍文档注释。
程序的其余部分将关注绘制集合的哪一部分、以什么分辨率绘制,以及如何将工作分配到多个线程以加快计算速度。
# 解析成对的命令行参数
这个程序接受几个命令行参数,用于控制我们要生成的图像的分辨率以及图像展示的曼德勃罗集(Mandelbrot set)的部分区域。由于这些命令行参数都遵循一种常见的形式,下面是一个用于解析它们的函数:
use std::str::FromStr;
/// 将字符串`s`解析为坐标对,比如`"400x600"`或`"1.0,0.5"`。
///
/// 具体来说,`s`的形式应该是<left><sep><right>,其中<sep>是由`separator`参数指定的字符,<left>和<right>都是可以通过`T::from_str`解析的字符串。`separator`必须是ASCII字符。
///
/// 如果`s`格式正确,返回`Some<(x, y)>`。如果解析不正确,返回`None`。
fn parse_pair<T: FromStr>(s: &str, separator: char) -> Option<(T, T)> {
match s.find(separator) {
None => None,
Some(index) => {
match (T::from_str(&s[..index]), T::from_str(&s[index + 1..])) {
(Ok(l), Ok(r)) => Some((l, r)),
_ => None
}
}
}
}
#[test]
fn test_parse_pair() {
assert_eq!(parse_pair::<i32>("", ','), None);
assert_eq!(parse_pair::<i32>("10,", ','), None);
assert_eq!(parse_pair::<i32>(",10", ','), None);
assert_eq!(parse_pair::<i32>("10,20", ','), Some((10, 20)));
assert_eq!(parse_pair::<i32>("10,20xy", ','), None);
assert_eq!(parse_pair::<f64>("0.5x", 'x'), None);
assert_eq!(parse_pair::<f64>("0.5x1.5", 'x'), Some((0.5, 1.5)));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
parse_pair的定义是一个泛型函数:
fn parse_pair<T: FromStr>(s: &str, separator: char) -> Option<(T, T)> {
你可以把<T: FromStr>这个子句读作 “对于任何实现了FromStr特性的类型T……” 。这实际上让我们一次定义了一整个函数族:parse_pair::<i32>是一个解析i32值对的函数,parse_pair::<f64>用于解析浮点值对,依此类推。这与C++中的函数模板非常相似。Rust程序员会把T称为parse_pair的类型参数。当你使用泛型函数时,Rust通常能够为你推断出类型参数,你无需像我们在测试代码中那样写出来。
我们的返回类型是Option<(T, T)>:要么是None,要么是Some((v1, v2)),其中(v1, v2)是一个包含两个T类型值的元组。parse_pair函数没有使用显式的return语句,所以它的返回值是函数体中最后(也是唯一)一个表达式的值:
match s.find(separator) {
None => None,
Some(index) => {
...
}
}
2
3
4
5
6
String类型的find方法在字符串中搜索与separator匹配的字符。如果find返回None,意味着分隔符字符在字符串中不存在,整个match表达式的值就是None,表示解析失败。否则,我们把index当作分隔符在字符串中的位置。
match (T::from_str(&s[..index]), T::from_str(&s[index + 1..])) {
(Ok(l), Ok(r)) => Some((l, r)),
_ => None
}
2
3
4
这里开始展示match表达式的强大之处。match的参数是这个元组表达式:
(T::from_str(&s[..index]), T::from_str(&s[index + 1..]))
&s[..index]和&s[index + 1..]是字符串的切片,分别位于分隔符的前面和后面。类型参数T关联的from_str函数会分别尝试将它们解析为T类型的值,生成一个结果元组。我们对这个结果元组进行匹配:
(Ok(l), Ok(r)) => Some((l, r)),
这个模式只有在元组的两个元素都是Result类型的Ok变体时才会匹配,这表明两次解析都成功了。如果是这样,Some((l, r))就是match表达式的值,也就是函数的返回值。
_ => None
通配符模式_可以匹配任何内容并忽略其值。如果执行到这一步,说明parse_pair解析失败,所以整个表达式的值为None,这也是函数的返回值。
现在有了parse_pair函数,编写一个解析一对浮点坐标并将它们作为Complex<f64>值返回的函数就很容易了:
/// 将用逗号分隔的一对浮点数解析为一个复数。
fn parse_complex(s: &str) -> Option<Complex<f64>> {
match parse_pair(s, ',') {
Some((re, im)) => Some(Complex { re, im }),
None => None
}
}
#[test]
fn test_parse_complex() {
assert_eq!(parse_complex("1.25,-0.0625"),
Some(Complex { re: 1.25, im: -0.0625 }));
assert_eq!(parse_complex(",-0.0625"), None);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
parse_complex函数调用parse_pair,如果坐标解析成功就构建一个Complex值,解析失败则将None返回给调用者。
如果你仔细阅读,可能已经注意到我们使用了一种简写符号来构建Complex值。用同名变量初始化结构体字段是很常见的,所以Rust允许你直接写Complex { re, im },而不必写成Complex { re: re, im: im }。这借鉴了JavaScript和Haskell中的类似表示法。
# 从像素到复数的映射
这个程序需要在两个相关的坐标空间中工作:输出图像中的每个像素都对应复平面上的一个点。这两个空间之间的关系取决于我们要绘制的曼德勃罗集的部分区域,以及由命令行参数确定的图像分辨率。下面的函数用于将图像空间转换为复数空间:
/// 给定输出图像中像素的行和列,返回复平面上对应的点。
///
/// `bounds`是一个包含图像宽度和高度(以像素为单位)的对。
/// `pixel`是一个表示图像中特定像素的(列,行)对。
/// `upper_left`和`lower_right`参数是复平面上指定图像覆盖区域的点。
fn pixel_to_point(bounds: (usize, usize),
pixel: (usize, usize),
upper_left: Complex<f64>,
lower_right: Complex<f64>)
-> Complex<f64> {
let (width, height) = (lower_right.re - upper_left.re,
upper_left.im - lower_right.im);
Complex {
re: upper_left.re + pixel.0 as f64 * width / bounds.0 as f64,
im: upper_left.im - pixel.1 as f64 * height / bounds.1 as f64,
// 为什么这里是减法?因为pixel.1随向下移动而增加,但虚部随向上移动而增加。
}
}
#[test]
fn test_pixel_to_point() {
assert_eq!(pixel_to_point((100, 200), (25, 175),
Complex { re: -1.0, im: 1.0 },
Complex { re: 1.0, im: -1.0 }),
Complex { re: -0.5, im: -0.75 });
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
图2 - 4展示了pixel_to_point执行的计算过程。
pixel_to_point的代码只是进行计算,所以我们不会详细解释。不过,有几点需要指出。这种形式的表达式用于引用元组元素:
pixel.0
这表示引用元组pixel的第一个元素。
pixel.0 as f64
这是Rust的类型转换语法:将pixel.0转换为f64值。与C和C++不同,Rust通常拒绝隐式地在数值类型之间进行转换;你必须显式写出所需的转换。这可能会有点繁琐,但明确指出哪些转换会发生以及何时发生,实际上非常有帮助。隐式整数转换看似无害,但在实际的C和C++代码中,它们一直是导致错误和安全漏洞的常见原因。
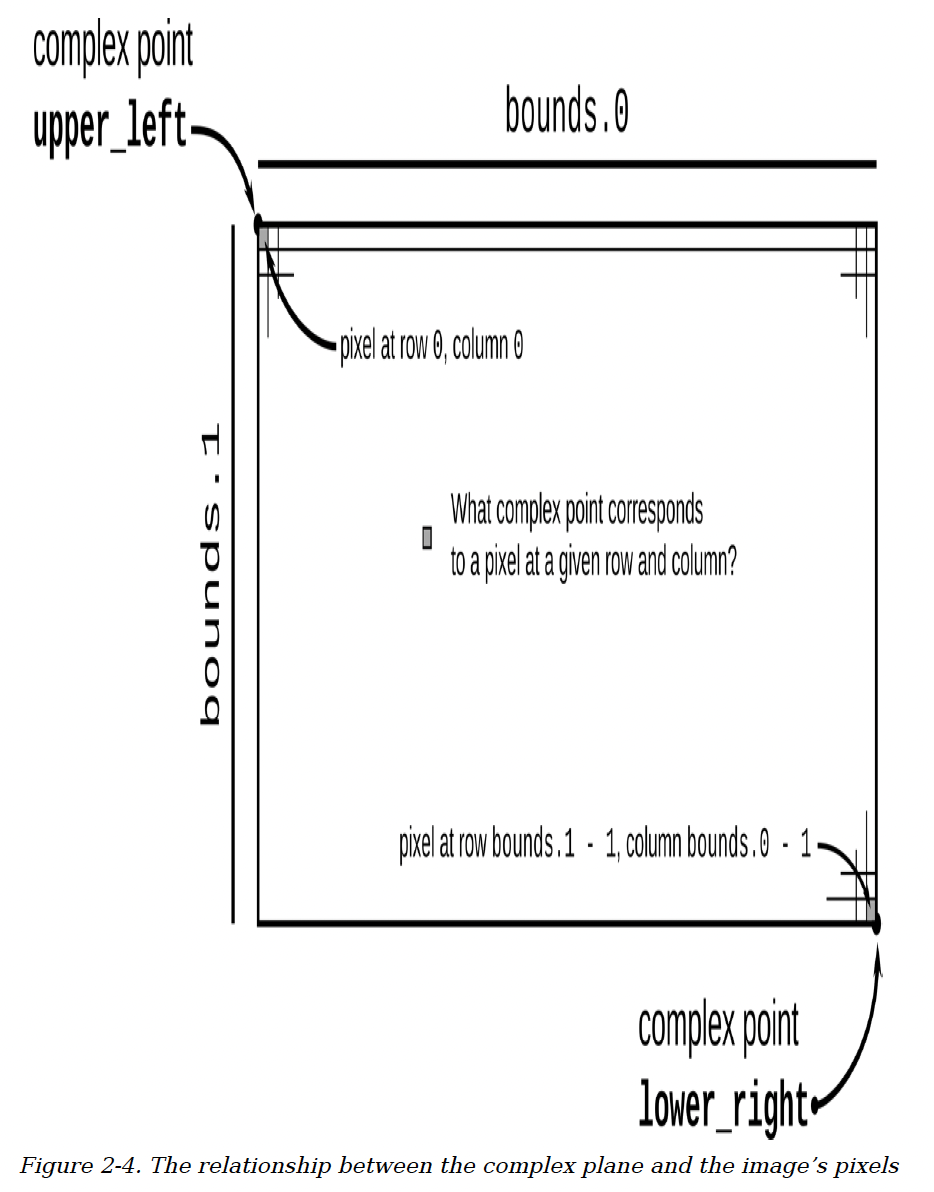 图2 - 4 复平面与图像像素之间的关系
图2 - 4 复平面与图像像素之间的关系
# 绘制集合
为了绘制曼德勃罗集(Mandelbrot set),对于图像中的每个像素,我们只需对复平面上对应的点应用escape_time函数,然后根据结果为像素上色:
/// 将曼德勃罗集的一个矩形区域渲染到像素缓冲区中。
///
/// `bounds`参数给出了缓冲区`pixels`的宽度和高度,该缓冲区每个字节存储一个灰度像素值。`upper_left`和`lower_right`参数指定了复平面上与像素缓冲区左上角和右下角对应的点。
fn render(pixels: &mut [u8],
bounds: (usize, usize),
upper_left: Complex<f64>,
lower_right: Complex<f64>) {
assert!(pixels.len() == bounds.0 * bounds.1);
for row in 0..bounds.1 {
for column in 0..bounds.0 {
let point = pixel_to_point(bounds, (column, row), upper_left, lower_right);
pixels[row * bounds.0 + column] =
match escape_time(point, 255) {
None => 0,
Some(count) => 255 - count as u8
};
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
到这里,这些代码看起来应该很熟悉了。
pixels[row * bounds.0 + column] =
match escape_time(point, 255) {
None => 0,
Some(count) => 255 - count as u8
};
2
3
4
5
如果escape_time表明point属于该集合,render函数会将对应的像素设为黑色(0)。否则,对于那些逃逸出圆所需时间更长的点,render会为其对应的像素分配更暗的颜色。
# 写入图像文件
image库提供了用于读取和写入多种图像格式的函数,以及一些基本的图像操作函数。特别地,它包含一个用于PNG图像文件格式的编码器,本程序使用该编码器来保存计算的最终结果。为了使用image库,在Cargo.toml的[dependencies]部分添加以下一行代码:
image = "0.13.0"
添加完成后,我们可以编写如下代码:
use image::ColorType;
use image::png::PNGEncoder;
use std::fs::File;
/// 将尺寸由`bounds`指定的缓冲区`pixels`写入名为`filename`的文件。
fn write_image(filename: &str, pixels: &[u8], bounds: (usize, usize))
-> Result<(), std::io::Error> {
let output = File::create(filename)?;
let encoder = PNGEncoder::new(output);
encoder.encode(&pixels,
bounds.0 as u32, bounds.1 as u32, ColorType::Gray(8))?;
Ok(())
}
2
3
4
5
6
7
8
9
10
11
12
13
这个函数的操作非常直接:它打开一个文件,并尝试将图像写入其中。我们将pixels中的实际像素数据、bounds中的宽度和高度传递给编码器,最后一个参数用于说明如何解释pixels中的字节:ColorType::Gray(8)表示每个字节是一个8位灰度值。
这都很简单明了。这个函数有趣的地方在于它如何处理出错的情况。如果遇到错误,我们需要将错误报告给调用者。如前所述,在Rust中可能出错的函数应该返回一个Result值,成功时为Ok(s),其中s是成功的值;失败时为Err(e),其中e是错误代码。那么write_image的成功和错误类型是什么呢?
当一切顺利时,write_image函数没有有用的值需要返回;它已经将所有需要的内容写入了文件。所以它的成功类型是单元类型(),之所以这样称呼,是因为它只有一个值,也写作()。单元类型类似于C和C++中的void。
当发生错误时,原因要么是File::create无法创建文件,要么是encoder.encode无法将图像写入文件;I/O操作会返回一个错误代码。File::create的返回类型是Result<std::fs::File, std::io::Error>,而encoder.encode的返回类型是Result<(), std::io::Error>,所以它们的错误类型都是std::io::Error。我们的write_image函数也采用相同的错误类型是合理的。在任何一种情况下,失败都应该导致立即返回,并传递描述错误原因的std::io::Error值。
所以,为了正确处理File::create的结果,我们需要对其返回值进行匹配,如下所示:
let output = match File::create(filename) {
Ok(f) => f,
Err(e) => {
return Err(e);
}
};
2
3
4
5
6
成功时,output为Ok值中包含的File。失败时,将错误传递给我们自己的调用者。
这种match语句在Rust中是一种非常常见的模式,因此语言提供了?操作符作为这种模式的简写。所以,每次尝试可能失败的操作时,你无需显式写出这种逻辑,而是可以使用下面这种等效且更易读的语句:
let output = File::create(filename)?;
如果File::create失败,?操作符会从write_image返回,并传递错误。否则,output保存成功打开的File。
| 注意 在 main函数中尝试使用?操作符是初学者常犯的错误。由于main函数本身不返回值,这样做行不通;你需要使用match语句,或者像unwrap和expect这样的简写方法。还有一种选择是直接将main函数改为返回Result,我们稍后会介绍。 |
|---|
# 一个并发的曼德勃罗程序
现在所有部分都已准备就绪,我们可以展示main函数了,在这个函数中我们将利用并发来提高性能。
首先,为了简单起见,展示一个非并发版本:
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
if args.len() != 5 {
eprintln!("Usage: {} FILE PIXELS UPPERLEFT LOWERRIGHT", args[0]);
eprintln!("Example: {} mandel.png 1000x750 -1.20,0.35 -1,0.20", args[0]);
std::process::exit(1);
}
let bounds = parse_pair(&args[2], 'x')
.expect("error parsing image dimensions");
let upper_left = parse_complex(&args[3])
.expect("error parsing upper left corner point");
let lower_right = parse_complex(&args[4])
.expect("error parsing lower right corner point");
let mut pixels = vec![0; bounds.0 * bounds.1];
render(&mut pixels, bounds, upper_left, lower_right);
write_image(&args[1], &pixels, bounds)
.expect("error writing PNG file");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
将命令行参数收集到一个String类型的向量中后,我们对每个参数进行解析,然后开始计算。
let mut pixels = vec![0; bounds.0 * bounds.1];
宏调用vec![v; n]会创建一个长度为n的向量,其元素初始化为v,所以前面的代码创建了一个长度为bounds.0 * bounds.1的零向量,其中bounds是从命令行解析得到的图像分辨率。我们将这个向量用作一个由单字节灰度像素值组成的矩形数组,如图2 - 5所示。
下一行值得关注的代码是:
render(&mut pixels, bounds, upper_left, lower_right);
这一行调用render函数来实际计算图像。表达式&mut pixels借用了对像素缓冲区的可变引用,这样render函数就可以用计算得到的灰度值填充它,同时pixels仍然是该向量的所有者。其余参数传递了图像的尺寸以及我们选择绘制的复平面矩形区域。
write_image(&args[1], &pixels, bounds)
.expect("error writing PNG file");
2
 图2 - 5 将向量用作像素的矩形数组
图2 - 5 将向量用作像素的矩形数组
最后,我们将像素缓冲区作为PNG文件写入磁盘。在这种情况下,我们传递对缓冲区的共享(不可变)引用,因为write_image无需修改缓冲区的内容。
此时,我们可以以发布模式构建并运行该程序,这种模式会启用许多强大的编译器优化。经过几秒后,它会将一幅精美的图像写入mandel.png文件:
$ cargo build --release
Updating crates.io index
Compiling autocfg v1.0.1
...
Compiling image v0.13.0
Compiling mandelbrot v0.1.0 ($RUSTBOOK/mandelbrot)
Finished release [optimized] target(s) in 25.36s
$ time target/release/mandelbrot mandel.png 4000x3000 -1.20,0.35 -1,0.20
real 0m4.678s
user 0m4.661s
sys 0m0.008s
2
3
4
5
6
7
8
9
10
11
这条命令应该会创建一个名为mandel.png的文件,你可以使用系统的图像查看程序或在网页浏览器中查看它。如果一切顺利,它看起来应该如图2 - 6所示。
 图2 - 6 并行曼德勃罗程序的结果
图2 - 6 并行曼德勃罗程序的结果
在前面的记录中,我们使用了Unix系统的time程序来分析程序的运行时间:在图像的每个像素上运行曼德勃罗计算总共花费了大约5秒。但几乎所有现代计算机都有多个处理器核心,而这个程序只使用了一个核心。如果我们能够将工作分配到计算机提供的所有计算资源上,那么完成图像绘制的速度应该会快得多。
为此,我们将图像划分为多个部分,每个处理器负责一个部分,让每个处理器为分配给它的像素上色。为简单起见,我们将其划分为水平条带,如图2 - 7所示。当所有处理器都完成后,我们就可以将像素写入磁盘。
 图2 - 7 将像素缓冲区划分为条带以进行并行渲染
图2 - 7 将像素缓冲区划分为条带以进行并行渲染
crossbeam库提供了许多有价值的并发工具,包括一个作用域线程工具,正好满足我们这里的需求。要使用它,我们必须在Cargo.toml文件中添加以下一行代码:
crossbeam = "0.8"
然后,我们需要把调用render函数的那一行代码替换为以下内容:
let threads = 8;
let rows_per_band = bounds.1 / threads + 1;
{
let bands: Vec<&mut [u8]> =
pixels.chunks_mut(rows_per_band * bounds.0).collect();
crossbeam::scope(|spawner| {
for (i, band) in bands.into_iter().enumerate() {
let top = rows_per_band * i;
let height = band.len() / bounds.0;
let band_bounds = (bounds.0, height);
let band_upper_left =
pixel_to_point(bounds, (0, top), upper_left, lower_right);
let band_lower_right =
pixel_to_point(bounds, (bounds.0, top + height), upper_left, lower_right);
spawner.spawn(move |_| {
render(band, band_bounds, band_upper_left, band_lower_right);
});
}
}).unwrap();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
像往常一样逐部分分析这段代码:
let threads = 8;
let rows_per_band = bounds.1 / threads + 1;
2
这里我们决定使用8个线程。然后计算每个条带应该包含多少行像素。我们向上取整行数,以确保即使图像高度不是线程数的整数倍,这些条带也能覆盖整个图像。
let bands: Vec<&mut [u8]> =
pixels.chunks_mut(rows_per_band * bounds.0).collect();
2
这里我们将像素缓冲区划分为条带。缓冲区的chunks_mut方法返回一个迭代器,生成缓冲区的可变、不重叠的切片,每个切片包含rows_per_band * bounds.0个像素 —— 换句话说,就是rows_per_band整行的像素。chunks_mut生成的最后一个切片可能包含较少的行数,但每一行包含的像素数相同。最后,迭代器的collect方法构建一个包含这些可变、不重叠切片的向量。
现在我们可以使用crossbeam库了:
crossbeam::scope(|spawner| {
...
}).unwrap();
2
3
参数|spawner| { ... }是一个Rust闭包,它期望接收一个参数spawner。注意,与使用fn声明的函数不同,我们不需要声明闭包参数的类型;Rust会推断它们的类型以及闭包的返回类型。在这种情况下,crossbeam::scope调用这个闭包,并将一个值作为spawner参数传递给闭包,闭包可以使用这个值来创建新线程。crossbeam::scope函数会等待所有这样创建的线程完成执行后才返回自身。这种行为确保了在pixels超出作用域后,这些线程不会再访问其对应的像素部分,也让我们可以确定,当crossbeam::scope返回时,图像计算已经完成。如果一切顺利,crossbeam::scope返回Ok(()),但如果我们创建的任何一个线程发生了恐慌(panic),它就会返回一个Err。我们对这个Result值调用unwrap,这样在发生错误时,我们的程序也会恐慌,用户就能得到错误报告。
for (i, band) in bands.into_iter().enumerate() {
这里我们遍历像素缓冲区的条带。into_iter()迭代器在每次循环时,将一个条带的所有权独占式地交给循环体,确保同一时间只有一个线程可以写入该条带。我们将在第5章详细解释其工作原理。然后,enumerate适配器生成元组,将每个向量元素与其索引配对。
let top = rows_per_band * i;
let height = band.len() / bounds.0;
let band_bounds = (bounds.0, height);
let band_upper_left =
pixel_to_point(bounds, (0, top), upper_left, lower_right);
let band_lower_right =
pixel_to_point(bounds, (bounds.0, top + height), upper_left, lower_right);
2
3
4
5
6
7
根据条带的索引和实际大小(记住最后一个条带可能比其他条带短),我们可以生成render函数所需的那种边界框,但这个边界框只针对缓冲区的这个条带,而不是整个图像。同样,我们重新利用渲染器的pixel_to_point函数,来确定条带的左上角和右下角在复平面上的位置。
spawner.spawn(move |_| {
render(band, band_bounds, band_upper_left, band_lower_right);
});
2
3
最后,我们创建一个线程,运行闭包move |_| { ... }。前面的move关键字表示这个闭包获取它所使用的变量的所有权;特别地,只有这个闭包可以使用可变切片band。参数列表|_|表示这个闭包接受一个参数,但不使用它(这个参数是另一个用于创建嵌套线程的spawner)。
如前所述,crossbeam::scope调用确保在返回之前所有线程都已完成,这意味着现在将图像保存到文件是安全的,这也是我们接下来要做的。
# 运行曼德勃罗集绘图程序
在这个程序中,我们使用了几个外部库:num用于复数运算,image用于写入PNG文件,crossbeam用于作用域线程创建原语。
下面是包含所有这些依赖项的最终Cargo.toml文件:
[package]
name = "mandelbrot"
version = "0.1.0"
authors = ["You <you@example.com>"]
edition = "2018"
[dependencies]
num = "0.4"
image = "0.13"
crossbeam = "0.8"
2
3
4
5
6
7
8
9
10
准备好这些后,我们就可以构建并运行程序:
$ cargo build --release
Updating crates.io index
Compiling crossbeam-queue v0.3.1
Compiling crossbeam v0.8.0
Compiling mandelbrot v0.1.0 ($RUSTBOOK/mandelbrot)
Finished release [optimized] target(s) in #.## secs
$ time target/release/mandelbrot mandel.png 4000x3000 -1.20,0.35 -1,0.20
real 0m1.436s
user 0m4.922s
sys 0m0.011s
2
3
4
5
6
7
8
9
10
这里,我们再次使用time命令来查看程序运行了多长时间;注意,即使我们仍然花费了近5秒的处理器时间,但实际经过的时间只有大约1.5秒。你可以通过注释掉写入图像文件的代码并再次测量,来验证部分时间花在了写入图像文件上。在测试这段代码的笔记本电脑上,并行版本将曼德勃罗集的计算时间缩短了近四倍。我们将在第19章展示如何进一步大幅提升性能。
和之前一样,这个程序会创建一个名为mandel.png的文件。有了这个更快的版本,你可以通过更改命令行参数,更轻松地探索曼德勃罗集。
# 安全特性是隐形的
最终,我们得到的这个并行程序与用其他语言编写的程序并没有太大区别:我们将像素缓冲区的各个部分分配给不同的处理器,让每个处理器分别处理自己负责的部分,当所有处理器都完成后,展示结果。那么Rust对并发的支持有什么特别之处呢?
我们在这里没有展示的是那些我们无法用Rust编写的程序。本章中我们看到的代码能够正确地在多个线程之间划分缓冲区,但对这段代码进行一些小的改动就可能导致错误(从而引入数据竞争);而这些有问题的改动没有一个能通过Rust编译器的静态检查。C或C++编译器会毫无问题地让你去探索那些存在微妙数据竞争的程序;而Rust会提前告诉你哪里可能出错。
在第4章和第5章,我们将描述Rust的内存安全规则。第19章将解释这些规则如何也确保了正确的并发安全性。
# 文件系统和命令行工具
Rust在命令行工具领域占据了重要的一席之地。作为一门现代、安全且快速的系统编程语言,它为程序员提供了一个工具集,让他们能够构建流畅的命令行界面,这些界面可以复制或扩展现有工具的功能。例如,bat命令提供了一个支持语法高亮的cat替代工具,并且内置了对分页工具的支持;hyperfine可以自动对任何可以通过命令或管道运行的程序进行基准测试。
虽然本书不会涉及那么复杂的内容,但Rust让你很容易涉足人性化的命令行应用程序开发领域。在本节中,我们将展示如何构建自己的搜索和替换工具,该工具带有彩色输出和友好的错误消息。
首先,我们创建一个新的Rust项目:
$ cargo new quickreplace
Created binary (application) `quickreplace` package
$ cd quickreplace
2
3
对于我们的程序,我们还需要另外两个库:text-colorize用于在终端中创建彩色输出,regex用于实际的搜索和替换功能。和之前一样,我们将这些库添加到Cargo.toml文件中,告诉cargo我们需要它们:
[package]
name = "quickreplace"
version = "0.1.0"
authors = ["You <you@example.com>"]
edition = "2018"
# 更多键及其定义,请查看
# https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
text-colorize = "1"
regex = "1"
2
3
4
5
6
7
8
9
10
已经达到1.0版本的Rust库,会遵循 “语义化版本控制” 规则:在主版本号1不变的情况下,较新的版本应该始终是其前身的兼容扩展。所以,如果我们使用某个库的1.2版本测试我们的程序,它应该也能在1.3、1.4等版本上正常工作;但2.0版本可能会引入不兼容的更改。当我们在Cargo.toml文件中简单地请求某个库的版本为"1"时,Cargo会使用2.0版本之前的最新可用版本。
# 命令行界面
这个程序的界面非常简单。它接受四个参数:要搜索的字符串(或正则表达式)、用于替换的字符串(或正则表达式)、输入文件名和输出文件名。我们在main.rs文件的开头定义一个包含这些参数的结构体:
#[derive(Debug)]
struct Arguments {
target: String,
replacement: String,
filename: String,
output: String,
}
2
3
4
5
6
7
#[derive(Debug)]属性告诉编译器生成一些额外的代码,这样我们就可以在println!中使用{:?}格式化Arguments结构体。
如果用户输入的参数数量不正确,通常会打印出一个简洁的程序使用说明。我们将通过一个名为print_usage的简单函数来实现这一点,并导入text-colorize库中的所有内容,以便添加一些颜色:
use text_colorize::*;
fn print_usage() {
eprintln!("{} - change occurrences of one string into another",
"quickreplace".green());
eprintln!("Usage: quickreplace <target> <replacement> <INPUT> <OUTPUT>");
}
2
3
4
5
6
7
只需在字符串字面量的末尾添加.green(),就会生成一个包含适当ANSI转义码的字符串,在终端模拟器中会显示为绿色。然后这个字符串会在打印之前插入到消息的其余部分中。
现在我们可以收集并处理程序的参数:
use std::env;
fn parse_args() -> Arguments {
let args: Vec<String> = env::args().skip(1).collect();
if args.len() != 4 {
print_usage();
eprintln!("{} wrong number of arguments: expected 4, got {}",
"Error:".red().bold(), args.len());
std::process::exit(1);
}
Arguments {
target: args[0].clone(),
replacement: args[1].clone(),
filename: args[2].clone(),
output: args[3].clone()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
为了获取用户输入的参数,我们使用与前面示例中相同的args迭代器。.skip(1)会跳过迭代器的第一个值(正在运行的程序的名称),这样结果中就只包含命令行参数。
collect()方法生成一个参数向量。然后我们检查参数数量是否正确,如果不正确,就打印一条消息并以错误代码退出程序。我们再次为消息的部分内容添加颜色,并使用.bold()使文本加粗。如果参数数量正确,我们将它们放入一个Arguments结构体中并返回。
然后我们添加一个main函数,它只调用parse_args并打印输出:
fn main() {
let args = parse_args();
println!("{:?}", args);
}
2
3
4
此时,我们可以运行程序,看到它会输出正确的错误消息:
$ cargo run
Updating crates.io index
Compiling libc v0.2.82
Compiling lazy_static v1.4.0
Compiling memchr v2.3.4
Compiling regex-syntax v0.6.22
Compiling thread_local v1.1.0
Compiling aho-corasick v0.7.15
Compiling atty v0.2.14
Compiling text-colorize v1.0.0
Compiling regex v1.4.3
Compiling quickreplace v0.1.0 (/home/jimb/quickreplace)
Finished dev [unoptimized + debuginfo] target(s) in 6.98s
Running `target/debug/quickreplace`
quickreplace - change occurrences of one string into another
Usage: quickreplace <target> <replacement> <INPUT> <OUTPUT>
Error: wrong number of arguments: expected 4, got 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
如果你给程序提供一些参数,它会打印出Arguments结构体的表示:
$ cargo run "find" "replace" file output
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/quickreplace find replace file output`
Arguments { target: "find", replacement: "replace", filename: "file", output: "output" }
2
3
4
这是一个非常好的开始!参数被正确获取并放入Arguments结构体的正确位置。
# 读取和写入文件
接下来,我们需要某种方式从文件系统中获取数据,以便进行处理,并在处理完成后将其写回。Rust有一套强大的输入输出工具,但标准库的设计者知道读写文件是非常常见的操作,所以他们特意让这变得很容易。我们只需要导入一个模块std::fs,就可以使用read_to_string和write函数:
use std::fs;
std::fs::read_to_string返回一个Result<String, std::io::Error>。如果函数成功,它会返回一个String。如果失败,它会返回一个std::io::Error,这是标准库中用于表示I/O问题的类型。类似地,std::fs::write返回一个Result<(), std::io::Error>:成功时返回空元组(),出错时返回相同的错误详细信息。
fn main() {
let args = parse_args();
let data = match fs::read_to_string(&args.filename) {
Ok(v) => v,
Err(e) => {
eprintln!("{} failed to read from file '{}': {:?}",
"Error:".red().bold(), args.filename, e);
std::process::exit(1);
}
};
match fs::write(&args.output, &data) {
Ok(_) => {},
Err(e) => {
eprintln!("{} failed to write to file '{}': {:?}",
"Error:".red().bold(), args.filename, e);
std::process::exit(1);
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这里,我们使用之前编写的parse_args()函数,并将得到的文件名传递给read_to_string和write函数。对这些函数输出的match语句能够优雅地处理错误,打印出文件名、错误原因,并添加一点颜色以引起用户的注意。
有了这个更新后的main函数,我们可以运行程序,当然会发现新文件和旧文件的内容完全相同:
$ cargo run "find" "replace" Cargo.toml Copy.toml
Compiling quickreplace v0.1.0 (/home/jimb/rust/quickreplace)
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/quickreplace find replace Cargo.toml Copy.toml`
2
3
4
程序确实读取了输入文件Cargo.toml,也确实写入了输出文件Copy.toml,但由于我们还没有编写任何实际进行查找和替换的代码,所以输出内容没有任何变化。我们可以通过运行diff命令轻松检查,该命令不会检测到任何差异:
$ diff Cargo.toml Copy.toml
# 查找和替换
这个程序的最后一步是实现其实际功能:查找和替换。为此,我们将使用regex库,它可以编译和执行正则表达式。它提供了一个名为Regex的结构体,用于表示编译后的正则表达式。Regex有一个replace_all方法,顾名思义:它在字符串中搜索正则表达式的所有匹配项,并用给定的替换字符串替换每个匹配项。我们可以将这个逻辑提取到一个函数中:
use regex::Regex;
fn replace(target: &str, replacement: &str, text: &str) -> Result<String, regex::Error> {
let regex = Regex::new(target)?;
Ok(regex.replace_all(text, replacement).to_string())
}
2
3
4
5
6
注意这个函数的返回类型。和我们之前使用的标准库函数一样,replace返回一个Result,这里的错误类型由regex库提供。
Regex::new用于编译用户提供的正则表达式,如果给定的字符串无效,它可能会失败。和曼德勃罗集程序中一样,我们在Regex::new失败时使用?来短路处理,但在这种情况下,函数返回的是regex库特有的错误类型。一旦正则表达式编译完成,它的replace_all方法会用给定的替换字符串替换text中的所有匹配项。
如果replace_all找到了匹配项,它会返回一个新的String,其中匹配项被替换为我们提供的文本。否则,replace_all会返回指向原始文本的指针,避免不必要的内存分配和复制。然而,在这种情况下,我们始终希望得到一个独立的副本,所以无论哪种情况,我们都使用to_string方法来获取一个String,并将这个字符串包装在Result::Ok中返回,就像其他函数一样。
现在,是时候将这个新函数整合到我们的主代码中了:
fn main() {
let args = parse_args();
let data = match fs::read_to_string(&args.filename) {
Ok(v) => v,
Err(e) => {
eprintln!("{} failed to read from file '{}': {:?}",
"Error:".red().bold(), args.filename, e);
std::process::exit(1);
}
};
let replaced_data = match replace(&args.target,
&args.replacement, &data) {
Ok(v) => v,
Err(e) => {
eprintln!("{} failed to replace text: {:?}",
"Error:".red().bold(), e);
std::process::exit(1);
}
};
match fs::write(&args.output, &replaced_data) {
Ok(v) => v,
Err(e) => {
eprintln!("{} failed to write to file '{}': {:?}",
"Error:".red().bold(), args.filename, e);
std::process::exit(1);
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
有了这最后一步,程序就完成了,你应该可以对它进行测试:
$ echo "Hello, world" > test.txt
$ cargo run "world" "Rust" test.txt test-modified.txt
Compiling quickreplace v0.1.0 (/home/jimb/rust/quickreplace)
Finished dev [unoptimized + debuginfo] target(s) in 0.88s
Running `target/debug/quickreplace world Rust test.txt test-modified.txt`
$ cat test-modified.txt
Hello, Rust
2
3
4
5
6
7
当然,错误处理也已经就位,能够优雅地向用户报告错误:
$ cargo run "[[a-z]" "0" test.txt test-modified.txt
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/quickreplace '[[a-z]' 0 test.txt test-modified.txt`
Error: failed to replace text: Syntax(
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~
regex parse error: [[a-z]
^
error: unclosed character class
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~)~~~~~~~~~~~~~
2
3
4
5
6
7
8
9
10
11
当然,这个简单的示例还缺少许多功能,但基本的部分已经具备。你已经看到了如何读取和写入文件、传递和显示错误,以及为改善终端中的用户体验而对输出进行彩色化处理。
后续章节将探索更多应用开发的高级技术,从数据集合和使用迭代器的函数式编程,到用于实现极高并发效率的异步编程技术。但首先,你需要通过下一章对Rust基本数据类型的扎实学习来打下基础。
批注:
num_cpus库提供了一个函数,可以返回当前系统上可用的CPU数量。