 第3章 基本类型
第3章 基本类型
# 第3章 基本类型
世界上的书籍种类繁多,这很合理,因为人也多种多样,每个人都想读点不一样的东西。
—— 雷蒙尼·斯尼奇(Lemony Snicket)
在很大程度上,Rust语言是围绕其类型进行设计的。它对高性能代码的支持源于让开发者选择最适合具体情况的数据表示方式,在简单性和成本之间找到恰当的平衡。Rust的内存和线程安全保证也依赖于其类型系统的健全性,而Rust的灵活性则源于其泛型类型和特性(traits)。
本章将介绍Rust用于表示值的基本类型。这些源代码级别的类型在机器层面有具体的对应类型,其成本和性能都是可预测的。虽然Rust不能保证它表示数据的方式与你要求的完全一致,但只有在确实能改进的情况下,它才会与你的要求有所不同。
与像JavaScript或Python这样的动态类型语言相比,Rust需要你在前期做更多规划。你必须明确写出函数参数、返回值、结构体字段以及其他一些结构的类型。
不过,Rust的两个特性让这比你想象的要轻松:
- 基于你明确写出的类型,Rust的类型推断会为你推断出大部分其余类型。在实际应用中,对于给定的变量或表达式,通常只有一种类型是合适的;在这种情况下,Rust允许你省略类型。例如,你可以像这样写出函数中的每个类型:
fn build_vector() -> Vec<i16> {
let mut v: Vec<i16> = Vec::<i16>::new();
v.push(10i16);
v.push(20i16);
v
}
2
3
4
5
6
但这样写既杂乱又重复。根据函数的返回类型,很明显v必须是Vec<i16>,即一个16位有符号整数的向量;其他类型都不合适。由此可以推断,向量的每个元素都必须是i16。这正是Rust的类型推断所采用的推理方式,所以你可以这样写:
fn build_vector() -> Vec<i16> {
let mut v = Vec::new();
v.push(10);
v.push(20);
v
}
2
3
4
5
6
这两个定义完全等效,Rust无论采用哪种方式都会生成相同的机器代码。类型推断在保留了动态类型语言易读性的同时,仍然能在编译时捕获类型错误。
- 函数可以是泛型的:单个函数可以处理多种不同类型的值。
在Python和JavaScript中,所有函数天生都能这样工作:一个函数可以对任何具有该函数所需属性和方法的值进行操作(这就是常说的 “鸭子类型”:如果它走起路来像鸭子,叫起来也像鸭子,那它就是鸭子)。但正是这种灵活性使得这些语言很难尽早检测出类型错误;测试通常是发现这类错误的唯一方法。Rust的泛型函数在为语言提供一定程度灵活性的同时,仍然能在编译时捕获所有类型错误。
尽管泛型函数很灵活,但它们与非泛型函数一样高效。例如,为每个整数类型编写一个特定的求和函数,与编写一个处理所有整数的泛型函数相比,并没有内在的性能优势。我们将在第11章详细讨论泛型函数。
本章的其余部分将自下而上地介绍Rust的类型,从整数和浮点数等简单的数值类型开始,然后介绍存储更多数据的类型:装箱(boxes)、元组、数组和字符串。
以下是你在Rust中会看到的各类类型的总结。表3 - 1展示了Rust的基本类型、标准库中一些非常常见的类型以及一些用户定义类型的示例。
表3 - 1 Rust中的类型示例
| 类型 | 描述 | 值 |
|---|---|---|
i8、i16、i32、i64、i128u8、u16、u32、u64、u128 | 指定宽度的有符号和无符号整数 | 42,-5i8,0x400u16,0o100i16,20_922_789_888_000u64,b'*'(u8字节字面量) |
isize、usize | 与机器地址大小相同(32位或64位)的有符号和无符号整数 | 137,-0b0101_0010isize,0xffff_fc00usize |
f32、f64 | IEEE单精度和双精度浮点数 | 1.61803,3.14f32,6.0221e23f64 |
bool | 布尔类型 | true,false |
char | 32位宽的Unicode字符 | '*','\n','字','\x7f','\u{CA0}' |
(char, u8, i32) | 元组:允许混合类型 | ('%', 0x7f, -1) |
() | “单元”(空元组) | () |
struct S { x: f32, y: f32 } | 带命名字段的结构体 | S { x: 120.0, y: 209.0 } |
struct T (i32, char); | 类似元组的结构体 | T(120, 'X') |
struct E; | 类似单元的结构体;没有字段 | E |
enum Attend { OnTime, Late(u32) } | 枚举,代数数据类型 | Attend::Late(5),Attend::OnTime |
Box<Attend> | 装箱:指向堆中值的拥有所有权的指针 | Box::new(Late(15)) |
&i32,&mut i32 | 共享和可变引用:非拥有所有权的指针,其生命周期不能超过所指向的对象 | &s.y,&mut v |
String | 动态大小的UTF - 8字符串 | "ラーメン : rame n".to_string() |
&str | 对str的引用:指向UTF - 8文本的非拥有所有权的指针 | "そば : soba",&s[0..12] |
[f64; 4],[u8; 256] | 数组,固定长度;元素类型相同 | [1.0, 0.0, 0.0, 1.0],[b'; 256] |
Vec<f64> | 向量,可变长度;元素类型相同 | vec![0.367, 2.718, 7.389] |
&[u8],&mut [u8] | 对切片的引用:对数组或向量一部分的引用,由指针和长度组成 | &v[10..20],&mut a[..] |
Option<&str> | 可选值:要么是None(不存在),要么是Some(v)(存在,值为v) | Some("Dr."),None |
Result<u64, Error> | 可能失败的操作的结果:要么是成功值Ok(v),要么是错误Err(e) | Ok(4096),Err(Error::last_os_error()) |
&dyn Any,&mut dyn Read | 特性对象:对实现了一组给定方法的任何值的引用 | value as &dyn Any,&mut file as &mut dyn Read |
fn(&str) -> bool | 函数指针 | str::is_empty |
| (闭包类型没有书面形式) | 闭包 | |a, b| { a*a + b*b } |
除了以下类型,本章将涵盖上述的大部分类型:
- 我们将在第9章专门介绍结构体类型。
- 我们将在第10章专门介绍枚举类型。
- 我们将在第11章介绍特性对象。
- 我们在这里介绍
String和&str的基本要点,但会在第17章提供更详细的内容。 - 我们将在第14章介绍函数和闭包类型。
# 固定宽度的数值类型
Rust类型系统的基础是一组固定宽度的数值类型,这些类型与几乎所有现代处理器直接在硬件中实现的类型相匹配。
固定宽度的数值类型可能会发生溢出或精度损失,但它们适用于大多数应用场景,并且比任意精度整数和精确有理数等表示方式快数千倍。如果你需要这些数值表示方式,num库提供了支持。
Rust数值类型的名称遵循一定的规律,明确指出了它们的位宽和所使用的表示方式(表3 - 2)。 表3 - 2 Rust数值类型
| 大小(位) | 无符号整数 | 有符号整数 | 浮点数 |
|---|---|---|---|
| 8 | u8 | i8 | - |
| 16 | u16 | i16 | - |
| 32 | u32 | i32 | f32 |
| 64 | u64 | i64 | f64 |
| 128 | u128 | i128 | - |
| 机器字长 | usize | isize | - |
这里,机器字长是指代码运行所在机器的地址大小,为32位或64位。
# 整数类型
Rust的无符号整数类型利用其全部范围来表示正数和零(表3-3)。 表3-3 Rust无符号整数类型
| 类型 | 范围 |
|---|---|
u8 | 0到$2^8 - 1$(0到255) |
u16 | 0到$2^{16} - 1$(0到65,535) |
u32 | 0到$2^{32} - 1$(0到4,294,967,295) |
u64 | 0到$2^{64} - 1$(0到18,446,744,073,709,551,615,即18 quintillion) |
u128 | 0到$2^{128} - 1$(0到约$3.4×10^{38}$) |
usize | 0到$2^{32} - 1$ 或$2^{64} - 1$ |
Rust的有符号整数类型采用补码表示法,使用与相应无符号类型相同的位模式来表示一定范围的正数和负数(表3-4)。 表3-4 Rust有符号整数类型
| 类型 | 范围 |
|---|---|
i8 | $-2^7$到$2^7 - 1$(-128到127) |
i16 | $-2^{15}$到$2^{15} - 1$(-32,768到32,767) |
i32 | $-2^{31}$到$2^{31} - 1$(-2,147,483,648到2,147,483,647) |
i64 | $-2^{63}$到$2^{63} - 1$(-9,223,372,036,854,775,808到9,223,372,036,854,775,807) |
i128 | $-2^{127}$到$2^{127} - 1$(约 -$1.7×10^{38}$到 +$1.7×10^{38}$) |
isize | $-2^{31}$到$2^{31} - 1$ 或$-2^{63}$到$2^{63} - 1$ |
Rust使用u8类型表示字节值。例如,从二进制文件或套接字读取数据会得到一个u8值的流。
与C和C++不同,Rust将字符与数值类型区分开来:char不是u8,也不是u32(尽管它是32位长)。我们将在“字符”部分描述Rust的char类型。
usize和isize类型类似于C和C++中的size_t和ptrdiff_t。它们的精度与目标机器的地址空间大小相匹配:在32位架构上是32位长,在64位架构上是64位长。Rust要求数组索引必须是usize值。表示数组、向量大小或某些数据结构中元素数量的值通常也使用usize类型。
Rust中的整数字面量可以带有后缀来表明其类型:42u8是一个u8值,1729isize是一个isize值。如果一个整数字面量没有类型后缀,Rust会推迟确定其类型,直到它以某种方式被使用,从而确定其类型:比如存储在特定类型的变量中、传递给期望特定类型的函数、与另一个特定类型的值进行比较等等。最终,如果有多种类型都可行,并且i32是其中一种可能,Rust会默认将其类型确定为i32。否则,Rust会将这种不明确性报告为错误。
前缀0x、0o和0b分别表示十六进制、八进制和二进制字面量。
为了使长数字更易读,你可以在数字中插入下划线。例如,你可以将最大的u32值写为4_294_967_295。下划线的具体位置并不重要,所以你可以将十六进制或二进制数字按四位一组进行分隔,如0xffff_ffff,也可以将类型后缀与数字分开,如127_u8。表3-5展示了一些整数字面量的示例。
表3-5 整数字面量示例
| 字面量 | 类型 | 十进制值 |
|---|---|---|
116i8 | i8 | 116 |
0xcafeu32 | u32 | 51966 |
0b0010_1010 | 推断 | 42 |
0o106 | 推断 | 70 |
虽然数值类型和char类型是不同的,但Rust提供了字节字面量,这是用于u8值的类似字符的字面量:b'X'表示字符X的ASCII码,是一个u8值。例如,由于字符A的ASCII码是65,所以字面量b'A'和65u8完全等效。字节字面量中只能出现ASCII字符。
有一些字符不能直接放在单引号后面,因为这可能会导致语法歧义或难以阅读。表3-6中的字符只能使用由反斜杠引入的替代表示法来书写 。 表3-6 需要替代表示法的字符
| 字符 | 字节字面量 | 数值等效 |
|---|---|---|
单引号 ' | b'\'' | 39u8 |
反斜杠 \ | b'\\' | 92u8 |
| 换行符 | b'\n' | 10u8 |
| 回车符 | b'\r' | 13u8 |
| 制表符 | b'\t' | 9u8 |
对于难以书写或阅读的字符,你可以用十六进制写出它们的代码。形式为b'\xHH'的字节字面量,其中HH是任意两位十六进制数,表示值为HH的字节。例如,你可以将ASCII“转义”控制字符的字节字面量写为b'\x1b',因为“转义”的ASCII码是27,即十六进制的1B。由于字节字面量只是u8值的另一种表示法,所以要考虑简单的数值字面量是否更易读:只有当你想强调该值表示一个ASCII码时,使用b'\x1b'而不是直接使用27才有意义。
你可以使用as运算符在不同整数类型之间进行转换。我们将在“类型转换”中解释转换的工作原理,以下是一些示例:
assert_eq!(10_i8 as u16, 10_u16); // 在范围内
assert_eq!(2525_u16 as i16, 2525_i16); // 在范围内
assert_eq!(-1_i16 as i32, -1_i32); // 符号扩展
assert_eq!(65535_u16 as i32, 65535_i32); // 零扩展
// 超出目标类型范围的转换会产生与原值对2^N取模等效的值,
// 其中N是目标类型的位数。这有时被称为“截断”。
assert_eq!(1000_i16 as u8, 232_u8);
assert_eq!(65535_u32 as i16, -1_i16);
assert_eq!(-1_i8 as u8, 255_u8);
assert_eq!(255_u8 as i8, -1_i8);
2
3
4
5
6
7
8
9
10
标准库为整数提供了一些操作方法。例如:
assert_eq!(2_u16.pow(4), 16); // 求幂
assert_eq!((-4_i32).abs(), 4); // 求绝对值
assert_eq!(0b101101_u8.count_ones(), 4); // 统计二进制表示中1的个数
2
3
你可以在在线文档中找到这些方法。不过要注意,文档中对于类型本身有单独的页面(在“i32(基本类型)”下),对于专门针对该类型的模块也有单独页面(搜索“std::i32”)。
在实际代码中,你通常不需要像我们这里这样写出类型后缀,因为上下文会确定类型。然而,当上下文无法确定类型时,错误信息可能会让人感到意外。例如,下面的代码无法编译:
println!("{}", (-4).abs());
Rust会报错:
error: can't call method `abs` on ambiguous numeric type `{integer}`
这可能有点令人困惑:所有有符号整数类型都有abs方法,那问题出在哪里呢?由于技术原因,Rust在调用类型的方法之前,需要确切知道一个值的具体整数类型。只有在所有方法调用都解析完成后,如果类型仍然不明确,才会应用默认的i32类型,所以在这里默认类型无法提供帮助。解决方法是明确指定你想要的类型,可以使用后缀或特定类型的函数:
println!("{}", (-4_i32).abs());
println!("{}", i32::abs(-4));
2
注意,方法调用的优先级高于一元前缀运算符,所以在对取负的值应用方法时要小心。在第一条语句中,如果没有(-4_i32)周围的括号,-4_i32.abs()会先对正值4应用abs方法,得到正值4,然后再取负,结果为 -4。
# 带检查、环绕、饱和及溢出的算术运算
在调试版本中,当整数算术运算发生溢出时,Rust会引发恐慌(panic)。在发布版本中,运算会进行环绕处理:它产生的值等同于数学上正确的结果对该类型取值范围取模后的结果。(在这两种情况下,溢出都不会像在C和C++中那样导致未定义行为。)
例如,以下代码在调试版本中会引发恐慌:
let mut i = 1;
loop {
i *= 10; // 恐慌:尝试进行乘法运算时发生溢出(但仅在调试版本中!)
}
2
3
4
在发布版本中,这个乘法运算会环绕为一个负数,并且循环会无限运行下去。
当默认行为无法满足需求时,整数类型提供了一些方法,让你可以明确指定所需的行为。例如,以下代码在任何构建版本中都会引发恐慌:
let mut i: i32 = 1;
loop {
// 恐慌:乘法运算溢出(在任何构建版本中)
i = i.checked_mul(10).expect("multiplication overflowed");
}
2
3
4
5
这些整数算术方法大致分为四类:
- 带检查的运算:返回结果的
Option类型:如果数学上正确的结果可以表示为该类型的值,则返回Some(v);否则返回None。例如:
// 10和20相加的结果可以用u8表示
assert_eq!(10_u8.checked_add(20), Some(30));
// 遗憾的是,100和200相加的结果无法用u8表示
assert_eq!(100_u8.checked_add(200), None);
// 进行加法运算;如果溢出则引发恐慌
let sum = x.checked_add(y).unwrap();
// 奇怪的是,有符号除法在一种特定情况下也会溢出
// 有符号n位类型可以表示 -2ⁿ⁻¹,但不能表示2ⁿ⁻¹
assert_eq!((-128_i8).checked_div(-1), None);
2
3
4
5
6
7
8
9
- 环绕运算:返回的值等同于数学上正确的结果对该类型取值范围取模后的结果:
// 第一个乘积可以用u16表示;第二个则不能,所以我们得到250000对2¹⁶取模的结果
assert_eq!(100_u16.wrapping_mul(200), 20000);
assert_eq!(500_u16.wrapping_mul(500), 53392);
// 有符号类型的运算可能会环绕为负数
assert_eq!(500_i16.wrapping_mul(500), -12144);
// 在位运算移位操作中,移位距离会被环绕,使其落在值的大小范围内
// 所以对16位类型进行17位的移位操作,实际相当于移位1位
assert_eq!(5_i16.wrapping_shl(17), 10);
2
3
4
5
6
7
8
如前所述,这就是普通算术运算符在发布版本中的行为。这些方法的优点是在所有构建版本中行为一致。
- 饱和运算:返回最接近数学上正确结果的可表示值。换句话说,结果会被“限制”在该类型能表示的最大值和最小值范围内:
assert_eq!(32760_i16.saturating_add(10), 32767);
assert_eq!((-32760_i16).saturating_sub(10), -32768);
2
不存在饱和除法、取余或位运算移位方法。
- 溢出运算:返回一个元组
(result, overflowed),其中result是函数环绕版本的返回值,overflowed是一个布尔值,用于指示是否发生了溢出:
assert_eq!(255_u8.overflowing_sub(2), (253, false));
assert_eq!(255_u8.overflowing_add(2), (1, true));
2
overflowing_shl和overflowing_shr与上述模式略有不同:只有当移位距离大于或等于类型本身的位数时,overflowed才会返回true。实际应用的移位操作是请求的移位对类型的位数取模后的结果:
// 对u16类型来说,17位的移位太大了,17对16取模的结果是1
assert_eq!(5_u16.overflowing_shl(17), (10, true));
2
在checked_、wrapping_、saturating_或overflowing_前缀之后的操作名称如表3-7所示。
表3-7 操作名称
| 运算 | 名称后缀 | 示例 |
|---|---|---|
| 加法 | add | 100_i8.checked_add(27) == Some(127) |
| 减法 | sub | 10_u8.checked_sub(11) == None |
| 乘法 | mul | 128_u8.saturating_mul(3) == 255 |
| 除法 | div | 64_u16.wrapping_div(8) == 8 |
| 取余 | rem | (-32768_i16).wrapping_rem(-1) == 0 |
| 取反 | neg | (-128_i8).checked_neg() == None |
| 绝对值 | abs | (-32768_i16).wrapping_abs() == -32768 |
| 求幂 | pow | 3_u8.checked_pow(4) == Some(81) |
| 按位左移 | shl | 10_u32.wrapping_shl(34) == 40 |
| 按位右移 | shr | 40_u64.wrapping_shr(66) == 10 |
# 浮点类型
Rust提供了IEEE单精度和双精度浮点类型。这些类型包括正无穷和负无穷、不同的正零和负零值,以及一个非数字值(表3 - 8)。 表3 - 8 IEEE单精度和双精度浮点类型
| 类型 | 精度 | 范围 |
|---|---|---|
f32 | IEEE单精度(至少6位十进制数字) | 大致为–3.4×10³⁸到+3.4×10³⁸ |
f64 | IEEE双精度(至少15位十进制数字) | 大致为–1.8×10³⁰⁸到+1.8×10³⁰⁸ |
Rust的f32和f64分别对应C和C++(在支持IEEE浮点标准的实现中)以及Java(始终使用IEEE浮点标准)中的float和double类型。
浮点数字面量的一般形式如图3 - 1所示。
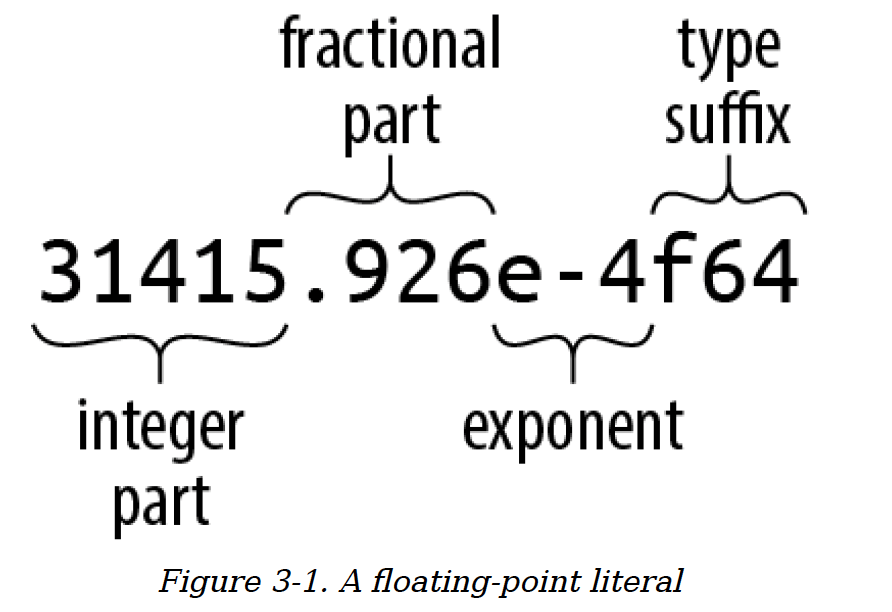 图3 - 1 浮点数字面量
图3 - 1 浮点数字面量
浮点数字面量中,整数部分之后的每一部分都是可选的,但小数部分、指数部分或类型后缀中至少要有一个存在,以便与整数字面量区分开来。小数部分可以只有一个小数点,所以5.是一个有效的浮点常量。
如果一个浮点数字面量没有类型后缀,Rust会像处理整数字面量一样,检查上下文以确定该值的使用方式。如果最终发现两种浮点类型都适用,它会默认选择f64。
在类型推断方面,Rust将整数字面量和浮点数字面量视为不同的类别:它永远不会为整数字面量推断出浮点类型,反之亦然。表3 - 9展示了一些浮点数字面量的示例。
表3 - 9 浮点数字面量示例
| 字面量 | 类型 | 数学值 |
|---|---|---|
-1.5625 | 推断得出 | −(19⁄16) |
2. | 推断得出 | 2 |
0.25 | 推断得出 | ¼ |
1e4 | 推断得出 | 10,000 |
40f32 | f32 | 40 |
9.109_383_56e-31f64 | f64 | 大致为9.10938356×10⁻³¹ |
f32和f64类型有与IEEE标准要求的特殊值相关的常量,如INFINITY(无穷大)、NEG_INFINITY(负无穷大)、NAN(非数字值),以及MIN和MAX(最大和最小的有限值):
assert!((-1. / f32::INFINITY).is_sign_negative());
assert_eq!(-f32::MIN, f32::MAX);
2
f32和f64类型提供了完整的数学计算方法;例如,2f64.sqrt()是2的双精度平方根。一些示例如下:
assert_eq!(5f32.sqrt() * 5f32.sqrt(), 5.); // 按照IEEE标准,结果恰好为5.0
assert_eq!((-1.01f64).floor(), -2.0);
2
同样,方法调用的优先级高于前缀运算符,所以在对负值进行方法调用时,一定要正确添加括号。
std::f32::consts和std::f64::consts模块提供了各种常用的数学常量,如E、PI和根号2。
在查阅文档时,要记住既有类型本身的页面,名为“f32(基本类型)”和“f64(基本类型)”,也有每个类型对应的模块页面,即std::f32和std::f64。
与整数一样,在实际代码中,你通常不需要写出浮点数字面量的类型后缀,但如果需要写,在字面量或函数上加上类型就可以:
println!("{}", (2.0_f64).sqrt());
println!("{}", f64::sqrt(2.0));
2
与C和C++不同,Rust几乎不会进行隐式数值转换。如果一个函数期望一个f64类型的参数,传入一个i32值作为参数会报错。实际上,即使每个i16值也都是i32值,Rust也不会将i16值隐式转换为i32值。但是你始终可以使用as运算符进行显式转换:i as f64或x as i32。
缺少隐式转换有时会使Rust表达式比类似的C或C++代码更冗长。然而,隐式整数转换一直以来都容易引发错误和安全漏洞,尤其是当相关整数表示内存中某个事物的大小时,可能会出现意外的溢出情况。以我们的经验来看,在Rust中写出数值转换的过程让我们注意到了一些原本可能会忽略的问题。
我们将在“类型转换”中详细解释转换的具体行为。
# bool类型
Rust的布尔类型bool,和其他语言中的布尔类型一样,有两个值:true和false。像==和<这样的比较运算符会产生bool类型的结果:2 < 5的值为true。
许多语言在需要布尔值的上下文中对使用其他类型的值比较宽松:C和C++会隐式地将字符、整数、浮点数和指针转换为布尔值,所以它们可以直接用作if或while语句中的条件。Python允许在布尔上下文中使用字符串、列表、字典甚至集合,只要这些值不为空,就将它们视为true。然而,Rust非常严格:像if和while这样的控制结构,以及短路逻辑运算符&&和||,都要求它们的条件是bool表达式。你必须写成if x != 0 { ... },而不能简单地写成if x { ... }。
Rust的as运算符可以将bool值转换为整数类型:
assert_eq!(false as i32, 0);
assert_eq!(true as i32, 1);
2
然而,as运算符不能反向转换,即从数值类型转换为bool类型。相反,你必须写出像x != 0这样的显式比较表达式。
虽然一个bool值只需要一位来表示,但在内存中Rust为一个bool值分配一个完整的字节,这样你就可以创建指向它的指针。
# 字符类型
Rust的字符类型char表示单个Unicode字符,是一个32位的值。
Rust在表示单个字符时使用char类型,但在表示字符串和文本流时使用UTF - 8编码。所以,String类型将其文本表示为一个UTF - 8字节序列,而不是字符数组。
字符字面量是用单引号括起来的字符,比如'8'或'!'。你可以使用完整的Unicode字符集:'錆'就是一个字符字面量,代表日语中“锈”的意思。
和字节字面量一样,有几个字符需要使用反斜杠转义(表3 - 10)。 表3 - 10 需要反斜杠转义的字符
| 字符 | Rust字符字面量 |
|---|---|
单引号,' | '\'' |
反斜杠,\ | '\\' |
| 换行符 | '\n' |
| 回车符 | '\r' |
| 制表符 | '\t' |
如果你愿意,也可以用十六进制写出字符的Unicode码点:
- 如果字符的码点在U + 0000到U + 007F范围内(也就是说,它来自ASCII字符集),那么你可以将字符写为
'\xHH',其中HH是一个两位十六进制数。例如,字符字面量'*'和'\x2A'是等效的,因为字符*的码点是42,即十六进制的2A。 - 你可以将任何Unicode字符写为
'\u{HHHHHH}',其中HHHHHH是一个最多六位的十六进制数,并且和往常一样允许使用下划线进行分组。例如,字符字面量'\u{CA0}'代表字符“ಠ”,这是在Unicode表情“ಠ_ಠ”中使用的卡纳达语字符。同样的字面量也可以简单地写成'ಠ'。
一个char总是持有一个在0x0000到0xD7FF或0xE000到0x10FFFF范围内的Unicode码点。char永远不会是代理对的一半(即码点在0xD800到0xDFFF范围内),也不会是Unicode编码空间之外的值(即大于0x10FFFF)。Rust使用类型系统和动态检查来确保char值始终在允许的范围内。
Rust从不隐式地在char和其他任何类型之间进行转换。你可以使用as转换运算符将char转换为整数类型;对于小于32位的类型,字符值的高位会被截断:
assert_eq!('*' as i32, 42);
assert_eq!('ಠ' as u16, 0xca0);
assert_eq!('ಠ' as i8, -0x60); // U+0CA0截断为八位有符号数
2
3
反过来,as运算符只能将u8类型转换为char:Rust希望as运算符仅执行简单且不会出错的转换,但除了u8之外的每个整数类型都包含不被允许作为Unicode码点的值,所以那些转换需要运行时检查。相反,标准库函数std::char::from_u32接受任何u32值并返回一个Option<char>:如果u32不是一个允许的Unicode码点,那么from_u32返回None;否则,它返回Some(c),其中c是结果char。
标准库为字符提供了一些有用的方法,你可以在在线文档的“char(基本类型)”和“std::char”模块下查找。例如:
assert_eq!('*'.is_alphabetic(), false);
assert_eq!('β'.is_alphabetic(), true);
assert_eq!('8'.to_digit(10), Some(8));
assert_eq!('ಠ'.len_utf8(), 3);
assert_eq!(std::char::from_digit(2, 10), Some('2'));
2
3
4
5
自然地,单个孤立的字符不如字符串和文本流有趣。我们将在“字符串类型”中介绍Rust的标准String类型和一般的文本处理。
# 元组
元组是由一对、三个、四个、五个等(因此有二元组、三元组…… 即n元组)不同类型的值组成的。你可以将元组写成一个由逗号分隔、括号包围的元素序列。例如,("Brazil", 1985)是一个元组,它的第一个元素是一个静态分配的字符串,第二个元素是一个整数;它的类型是(&str, i32)。给定一个元组值t,你可以通过t.0、t.1等方式访问它的元素。
在一定程度上,元组类似于数组:这两种类型都表示有序的值序列。许多编程语言会混淆或合并这两个概念,但在Rust中,它们是完全不同的。一方面,元组的每个元素可以有不同的类型,而数组的元素必须是相同的类型。此外,元组只允许使用常量作为索引,比如t.4。你不能写成t.i或t[i]来获取第i个元素。
Rust代码经常使用元组类型从函数中返回多个值。例如,字符串切片上的split_at方法,它将一个字符串分成两部分并返回这两部分,其声明如下:
fn split_at(&self, mid: usize) -> (&str, &str);
返回类型(&str, &str)是一个包含两个字符串切片的元组。你可以使用模式匹配语法将返回值的每个元素分配给不同的变量:
let text = "I see the eigenvalue in thine eye";
let (head, tail) = text.split_at(21);
assert_eq!(head, "I see the eigenvalue ");
assert_eq!(tail, "in thine eye");
2
3
4
这比等效的代码更易读:
let text = "I see the eigenvalue in thine eye";
let temp = text.split_at(21);
let head = temp.0;
let tail = temp.1;
assert_eq!(head, "I see the eigenvalue ");
assert_eq!(tail, "in thine eye");
2
3
4
5
6
你还会看到元组被用作一种简单的结构体类型。例如,在第2章的曼德勃罗集程序中,我们需要将图像的宽度和高度传递给绘制图像和将图像写入磁盘的函数。我们可以声明一个包含宽度和高度成员的结构体,但对于这么明显的东西,这样的表示法太繁琐了,所以我们直接使用了元组:
/// 将尺寸由`bounds`指定的缓冲区`pixels`写入名为`filename`的文件。
fn write_image(filename: &str, pixels: &[u8], bounds: (usize, usize))
-> Result<(), std::io::Error> {
...
}
2
3
4
5
bounds参数的类型是(usize, usize),即一个包含两个usize值的元组。诚然,我们也可以分别写出宽度和高度参数,生成的机器代码在这两种情况下大致相同。这是一个清晰度的问题。我们将尺寸视为一个值,而不是两个值,使用元组可以让我们表达出自己的意图。
另一种常用的元组类型是零元组()。传统上它被称为单元类型,因为它只有一个值,也写作()。在没有有意义的值需要传递,但上下文仍然需要某种类型的情况下,Rust会使用单元类型。
例如,一个不返回值的函数的返回类型是()。标准库中的std::mem::swap函数没有有意义的返回值;它只是交换两个参数的值。std::mem::swap的声明如下:
fn swap<T>(x: &mut T, y: &mut T);
<T>表示swap是泛型函数:你可以将它用于指向任何类型T的值的引用。但这个签名完全省略了swap的返回类型,这是返回单元类型的简写方式:
fn swap<T>(x: &mut T, y: &mut T) -> ();
类似地,我们之前提到的write_image示例的返回类型是Result<(), std::io::Error>,这意味着如果出现错误,该函数返回一个std::io::Error值,但在成功时不返回值。
如果你愿意,你可以在元组的最后一个元素后加上逗号:(&str, i32,)和(&str, i32)这两种类型是等效的,("Brazil", 1985,)和("Brazil", 1985)这两个表达式也是等效的。在Rust中,只要使用逗号的地方,都始终允许额外的尾随逗号:函数参数、数组、结构体和枚举定义等等。
这对人类读者来说可能看起来很奇怪,但当在列表末尾添加和删除条目时,它可以使差异(diff)更易于阅读。
为了保持一致性,甚至存在包含单个值的元组。字面量("lonely hearts",)是一个包含单个字符串的元组;它的类型是(&str,)。这里,值后面的逗号是必要的,用于将单元素元组与简单的括号表达式区分开来。
# 指针类型
Rust有几种表示内存地址的类型。这是Rust与大多数具有垃圾回收机制的语言的一个很大区别。在Java中,如果类Rectangle包含一个字段Vector2D upperLeft;,那么upperLeft是对另一个单独创建的Vector2D对象的引用。在Java中,对象永远不会在物理上包含其他对象。
Rust则不同。这门语言旨在尽量减少内存分配。默认情况下,值是嵌套存储的。值((0, 0), (1440, 900))被存储为四个相邻的整数。如果你将它存储在一个局部变量中,你就有了一个占用四个整数宽度的局部变量。没有任何内容在堆上分配。
这对内存效率来说非常好,但结果是,当Rust程序需要值指向其他值时,它必须显式使用指针类型。好消息是,在安全的Rust中使用的指针类型受到限制,以消除未定义行为,所以在Rust中正确使用指针比在C++中容易得多。
我们在这里将讨论三种指针类型:引用、装箱和不安全指针。
# 引用
类型为&String(读作“ref String”)的值是对String值的引用,&i32是对i32的引用,依此类推。
将引用看作Rust的基本指针类型是最容易理解的。在运行时,对i32的引用是一个机器字,保存着i32的地址,该i32可能在栈上或堆上。表达式&x生成对x的引用;用Rust的术语来说,我们说它借用了对x的引用。给定一个引用r,表达式*r引用r指向的值。这些与C和C++中的&和*运算符非常相似。和C指针一样,引用在超出作用域时不会自动释放任何资源。
然而,与C指针不同,Rust引用永远不会是null:在安全的Rust中,根本无法生成null引用。而且与C不同,Rust会跟踪值的所有权和生命周期,所以像悬空指针、双重释放和指针无效等错误在编译时就会被排除。
Rust引用有两种类型:
&T:一种不可变的、共享的引用。你可以同时有多个对给定值的共享引用,但它们是只读的:禁止修改它们指向的值,这与C中的const T*类似。&mut T:一种可变的、独占的引用。你可以读取和修改它指向的值,就像C中的T*一样。但是只要这个引用存在,你就不能有对该值的任何其他类型的引用。实际上,访问该值的唯一方式就是通过这个可变引用。
Rust利用共享引用和可变引用之间的这种二分法来强制执行“单写多读”规则:要么你可以读写一个值,要么这个值可以被任意数量的读者共享,但绝不能同时进行。这种通过编译时检查来实施的分离,是Rust安全保证的核心。第5章将解释Rust中安全使用引用的规则。
# 装箱
在堆上分配值的最简单方法是使用Box::new:
let t = (12, "eggs");
let b = Box::new(t); // 在堆上分配一个元组
2
t的类型是(i32, &str),所以b的类型是Box<(i32, &str)>。对Box::new的调用会在堆上分配足够的内存来容纳这个元组。当b超出作用域时,除非b被移动(例如通过返回它),否则内存会立即被释放。移动操作在Rust处理堆分配值的方式中至关重要;我们将在第4章详细解释这一切。
# 裸指针
Rust还有裸指针类型*mut T和*const T。裸指针真的和C++中的指针很像。使用裸指针是不安全的,因为Rust不会跟踪它指向的内容。例如,裸指针可能是null,或者它们可能指向已经释放的内存,或者现在包含不同类型值的内存。C++中所有经典的指针错误在Rust中使用裸指针时都可能出现。
然而,你只能在unsafe块内解引用裸指针。unsafe块是Rust用于启用高级语言特性的机制,这些特性的安全性由你自己负责。如果你的代码没有unsafe块(或者如果有,写得正确),那么我们在本书中强调的安全保证仍然成立。详细内容请参见第22章。
# 数组、向量和切片
Rust有三种类型用于在内存中表示值的序列:
- 类型
[T; N]表示包含N个T类型值的数组。数组的大小是在编译时确定的常量,并且是类型的一部分;你不能向数组追加新元素或缩小数组大小。 - 类型
Vec<T>,称为T的向量,是一个动态分配、可增长的T类型值的序列。向量的元素存储在堆上,所以你可以随意调整向量的大小:向其添加新元素、将其他向量追加到它后面、删除元素等等。 - 类型
&[T]和&mut [T],分别称为T的共享切片和可变切片,是对属于其他某个值(如数组或向量)的一系列元素的引用。你可以把切片看作是指向其第一个元素的指针,再加上从该点开始可以访问的元素数量。可变切片&mut [T]允许你读取和修改元素,但不能共享;共享切片&[T]允许你在多个读取者之间共享访问,但不允许修改元素。
对于这三种类型中的任何一种值v,表达式v.len()会返回v中的元素数量,v[i]引用v的第i个元素。第一个元素是v[0],最后一个元素是v[v.len() - 1]。Rust会检查i是否始终在这个范围内;如果不在,表达式会引发程序恐慌(panic)。v的长度可能为零,在这种情况下,任何对其进行索引的尝试都会引发恐慌。i必须是usize类型的值;你不能使用其他任何整数类型作为索引。
# 数组
有几种方式可以表示数组值。最简单的方法是在方括号内写入一系列值:
let lazy_caterer: [u32; 6] = [1, 2, 4, 7, 11, 16];
let taxonomy = ["Animalia", "Arthropoda", "Insecta"];
assert_eq!(lazy_caterer[3], 7);
assert_eq!(taxonomy.len(), 3);
2
3
4
对于用某个值填充的长数组这种常见情况,你可以写成[V; N],其中V是每个元素应有的值,N是长度。例如,[true; 10000]是一个包含10000个bool元素的数组,所有元素都设置为true:
let mut sieve = [true; 10000];
for i in 2..100 {
if sieve[i] {
let mut j = i * i;
while j < 10000 {
sieve[j] = false;
j += i;
}
}
}
assert!(sieve[211]);
assert!(!sieve[9876]);
2
3
4
5
6
7
8
9
10
11
12
你会看到这种语法用于固定大小的缓冲区:[0u8; 1024]可以是一个1KB的缓冲区,用零填充。Rust没有表示未初始化数组的符号(一般来说,Rust确保代码永远无法访问任何未初始化的值)。
数组的长度是其类型的一部分,并且在编译时固定。如果n是一个变量,你不能写成[true; n]来得到一个包含n个元素的数组。当你需要一个在运行时长度可变的数组(通常你会有这种需求)时,应该使用向量。
你可能希望在数组上看到的有用方法(如遍历元素、搜索、排序、填充、过滤等),实际上都是在切片上提供的方法,而不是数组本身的方法。但是,Rust在查找方法时会隐式地将对数组的引用转换为切片,所以你可以直接在数组上调用任何切片方法:
let mut chaos = [3, 5, 4, 1, 2];
chaos.sort();
assert_eq!(chaos, [1, 2, 3, 4, 5]);
2
3
这里,sort方法实际上是在切片上定义的,但由于它通过引用获取操作数,Rust会隐式地生成一个指向整个数组的&mut [i32]切片,并将其传递给sort方法进行操作。实际上,我们前面提到的len方法也是切片的方法。我们将在“切片”部分更详细地介绍切片。
# 向量
向量Vec<T>是一个在堆上分配的、可调整大小的T类型元素的数组。
有几种创建向量的方式。最简单的是使用vec!宏,它提供了一种看起来很像数组字面量的向量语法:
let mut primes = vec![2, 3, 5, 7];
assert_eq!(primes.iter().product::<i32>(), 210);
2
但当然,这是一个向量,不是数组,所以我们可以动态地向它添加元素:
primes.push(11);
primes.push(13);
assert_eq!(primes.iter().product::<i32>(), 30030);
2
3
你还可以通过重复给定的值一定次数来构建向量,同样使用模仿数组字面量的语法:
fn new_pixel_buffer(rows: usize, cols: usize) -> Vec<u8> {
vec![0; rows * cols]
}
2
3
vec!宏相当于调用Vec::new创建一个新的空向量,然后将元素逐个添加到其中,这是另一种习惯用法:
let mut pal = Vec::new();
pal.push("step");
pal.push("on");
pal.push("no");
pal.push("pets");
assert_eq!(pal, vec!["step", "on", "no", "pets"]);
2
3
4
5
6
另一种方式是从迭代器生成的值构建向量:
let v: Vec<i32> = (0..5).collect();
assert_eq!(v, [0, 1, 2, 3, 4]);
2
在使用collect时,你通常需要指定类型(就像我们这里做的一样),因为它可以构建多种不同类型的集合,而不仅仅是向量。通过指定v的类型,我们明确了想要的集合类型。
和数组一样,你可以在向量上使用切片方法:
// 一个回文序列!
let mut palindrome = vec!["a man", "a plan", "a canal", "panama"];
palindrome.reverse();
// 合理但有点无趣:
assert_eq!(palindrome, vec!["panama", "a canal", "a plan", "a man"]);
2
3
4
5
这里,reverse方法实际上是在切片上定义的,但调用时会隐式地从向量借用一个&mut [&str]切片,并在该切片上调用reverse。
Vec是Rust中一个非常重要的类型,几乎在任何需要动态大小列表的地方都会用到它,所以有许多其他方法可以用于构建新向量或扩展现有向量。我们将在第16章介绍它们。
Vec<T>由三个值组成:一个指向堆上为元素分配的缓冲区的指针(由Vec<T>创建并拥有该缓冲区)、该缓冲区能够存储的元素数量,以及它当前实际包含的元素数量(即它的长度)。当缓冲区达到其容量时,向向量中再添加一个元素需要分配一个更大的缓冲区,将现有内容复制到新缓冲区中,更新向量的指针和容量以描述新缓冲区,最后释放旧缓冲区。
如果你提前知道向量需要的元素数量,你可以调用Vec::with_capacity而不是Vec::new来创建一个从一开始就有足够大的缓冲区来容纳所有元素的向量;然后,你可以逐个添加元素,而不会导致任何重新分配。vec!宏就使用了类似的技巧,因为它知道最终向量会有多少个元素。请注意,这只是确定向量的初始大小;如果你超过了估计的数量,向量会像往常一样扩大其存储空间。
许多库函数会尽量使用Vec::with_capacity而不是Vec::new。例如,在前面的collect示例中,迭代器0..5提前知道它会生成五个值,collect函数利用这一点预先分配返回向量的正确容量。我们将在第15章了解其工作原理。
就像向量的len方法返回它当前包含的元素数量一样,它的capacity方法返回在不重新分配的情况下它能够容纳的元素数量:
let mut v = Vec::with_capacity(2);
assert_eq!(v.len(), 0);
assert_eq!(v.capacity(), 2);
v.push(1);
v.push(2);
assert_eq!(v.len(), 2);
assert_eq!(v.capacity(), 2);
v.push(3);
assert_eq!(v.len(), 3);
// 通常会打印“capacity is now 4”:
println!("capacity is now {}", v.capacity());
2
3
4
5
6
7
8
9
10
11
最后打印的容量不一定正好是4,但它至少会是3,因为向量中存储了三个值。
你可以在向量中的任意位置插入和删除元素,不过这些操作会将受影响位置之后的所有元素向前或向后移动,所以如果向量很长,这些操作可能会比较慢:
let mut v = vec![10, 20, 30, 40, 50];
// 将索引为3的元素设为35
v.insert(3, 35);
assert_eq!(v, [10, 20, 30, 35, 40, 50]);
// 删除索引为1的元素
v.remove(1);
assert_eq!(v, [10, 30, 35, 40, 50]);
2
3
4
5
6
7
你可以使用pop方法删除并返回向量的最后一个元素。更准确地说,从Vec<T>中弹出一个值会返回一个Option<T>:如果向量已经为空,则返回None;如果其最后一个元素是v,则返回Some(v):
let mut v = vec!["Snow Puff", "Glass Gem"];
assert_eq!(v.pop(), Some("Glass Gem"));
assert_eq!(v.pop(), Some("Snow Puff"));
assert_eq!(v.pop(), None);
2
3
4
你可以使用for循环遍历向量:
// 将命令行参数收集为一个String类型的向量
let languages: Vec<String> = std::env::args().skip(1).collect();
for l in languages {
println!("{}: {}", l,
if l.len() % 2 == 0 {
"functional"
} else {
"imperative"
});
}
2
3
4
5
6
7
8
9
10
用一系列编程语言名称运行这个程序会很有意思:
$ cargo run Lisp Scheme C C++ Fortran
Compiling proglangs v0.1.0 (/home/jimb/rust/proglangs)
Finished dev [unoptimized + debuginfo] target(s) in 0.36s
Running `target/debug/proglangs Lisp Scheme C C++ Fortran`
Lisp: functional
Scheme: functional
C: imperative
C++: imperative
Fortran: imperative
$
2
3
4
5
6
7
8
9
10
最后,这是对“函数式语言”这个术语的一个令人满意的定义。
尽管Vec起着基础性的作用,但它是Rust中定义的普通类型,并非语言内置的。我们将在第22章介绍实现这类类型所需的技术。
# 切片
切片,写作[T](不指定长度),是数组或向量的一部分。由于切片的长度可以是任意的,所以切片不能直接存储在变量中或作为函数参数传递。切片总是通过引用传递。
对切片的引用是一个胖指针(fat pointer):一个双字值,由指向切片第一个元素的指针和切片中的元素数量组成。
假设你运行以下代码:
let v: Vec<f64> = vec![0.0, 0.707, 1.0, 0.707];
let a: [f64; 4] = [0.0, -0.707, -1.0, -0.707];
let sv: &[f64] = &v;
let sa: &[f64] = &a;
2
3
4
在最后两行中,Rust会自动将&Vec<f64>引用和&[f64; 4]引用转换为直接指向数据的切片引用。
最后,内存状态如图3 - 2所示。
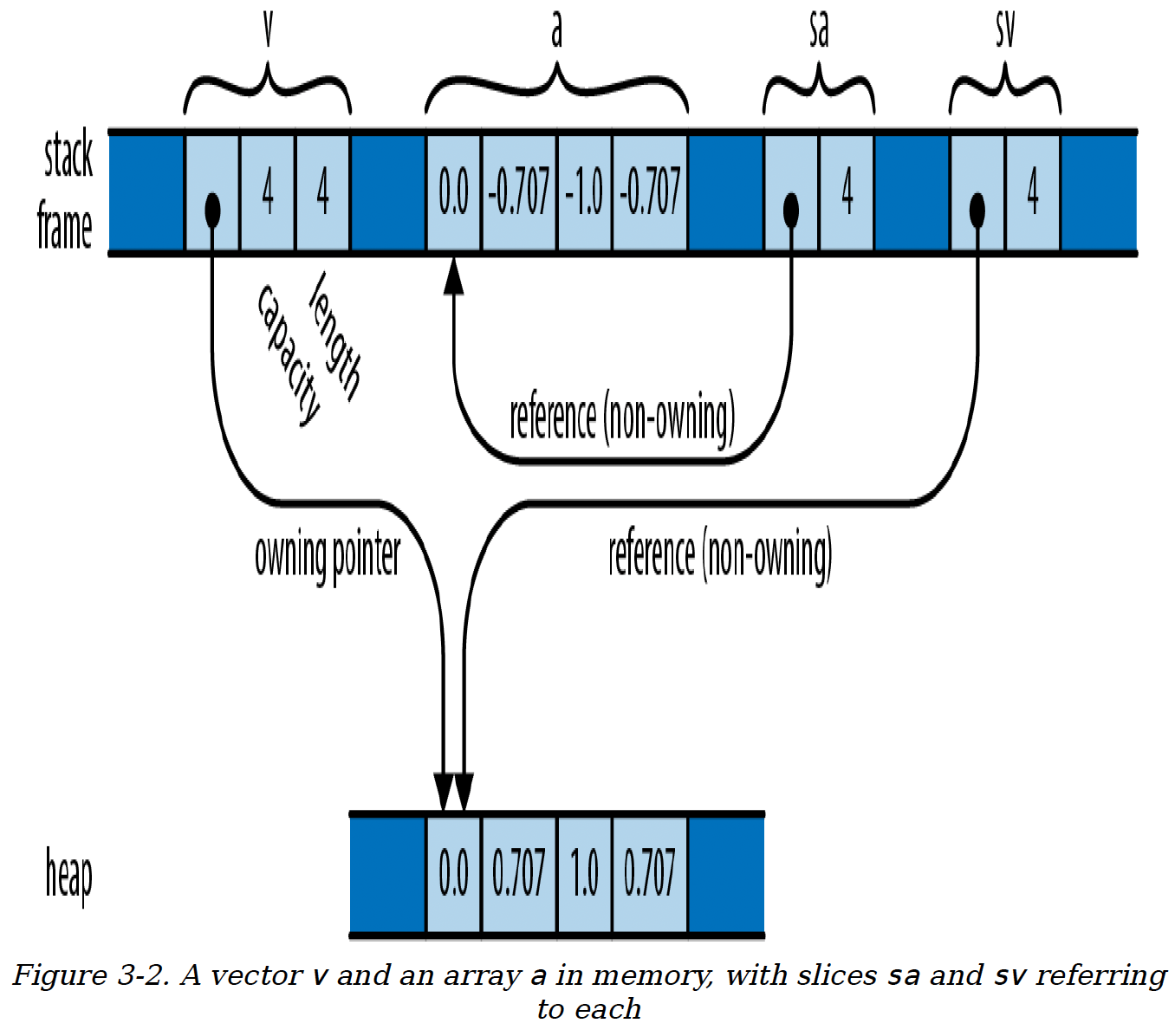 图3 - 2 内存中的向量v和数组a,以及分别指向它们的切片sa和sv
图3 - 2 内存中的向量v和数组a,以及分别指向它们的切片sa和sv
普通引用是指向单个值的非拥有所有权的指针,而对切片的引用是指向内存中一系列连续值的非拥有所有权的指针。这使得切片引用成为编写对数组或向量都能进行操作的函数的理想选择。例如,下面是一个逐行打印数字切片的函数:
fn print(n: &[f64]) {
for elt in n {
println!("{}", elt);
}
}
print(&a); // 对数组有效
print(&v); // 对向量有效
2
3
4
5
6
7
因为这个函数接受一个切片引用作为参数,所以你可以像上面展示的那样,将它应用于向量或数组。实际上,许多你可能认为属于向量或数组的方法,其实是在切片类型[T]上定义的方法:例如,sort和reverse方法,它们用于对元素序列进行原地排序或反转,实际上是切片类型的方法。
你可以通过使用范围索引来获取对数组、向量或现有切片的一部分的引用:
print(&v[0..2]); // 打印v的前两个元素
print(&a[2..]); // 打印从a[2]开始的a的元素
print(&sv[1..3]); // 打印v[1]和v[2]
2
3
和普通的数组访问一样,Rust会检查索引是否有效。尝试借用超出数据末尾的切片会导致程序恐慌。
由于切片几乎总是通过引用出现,我们通常将&[T]或&str这样的类型简称为“切片”,用更简短的名称来表示这个更常见的概念。
# 字符串类型
熟悉C++的程序员会记得,C++中有两种字符串类型。字符串字面量的指针类型是const char *。标准库还提供了一个类std::string,用于在运行时动态创建字符串。
Rust有类似的设计。在本节中,我们将展示编写字符串字面量的所有方式,然后介绍Rust的两种字符串类型。我们将在第17章提供关于字符串和文本处理的更多详细信息。
# 字符串字面量
字符串字面量用双引号括起来。它们使用与字符字面量相同的反斜杠转义序列:
let speech = "\"Ouch!\" said the well.\n ";
在字符串字面量中,与字符字面量不同,单引号不需要用反斜杠转义,而双引号需要。
字符串可以跨多行:
println!("In the room the women come and go,
Singing of Mount Abora");
2
该字符串字面量中的换行符会包含在字符串中,因此也会出现在输出中。第二行开头的空格也是如此。
如果字符串的一行以反斜杠结尾,那么换行符和下一行开头的空白字符将被忽略:
println!("It was a bright, cold day in April, and \
there were four of us—\
more or less.");
2
3
这会打印出一行文本。字符串中“and”和“there”之间只有一个空格,因为程序中反斜杠前面有一个空格,而破折号和“more”之间没有空格。
在某些情况下,在字符串中每个反斜杠都需要转义会很麻烦(经典的例子是正则表达式和Windows路径)。对于这些情况,Rust提供了原始字符串。原始字符串用小写字母r标记。原始字符串中的所有反斜杠和空白字符都会按字面意思包含在字符串中。不会识别任何转义序列:
let default_win_install_path = r"C:\Program Files\Gorillas";
let pattern = Regex::new(r"\d+(\.\d+)*");
2
你不能简单地在原始字符串中通过在双引号前加反斜杠来包含双引号 —— 记住,我们说过原始字符串中不识别任何转义序列。不过,也有解决办法。原始字符串的开头和结尾可以用井号(#)标记:
println!(r###"
This raw string started with 'r###"'.
Therefore it does not end until we reach a quote mark ( '"')
followed immediately by three pound signs ( '###'):
"###);
2
3
4
5
你可以根据需要添加任意数量的井号,以明确原始字符串的结束位置。
# 字节字符串
带有前缀b的字符串字面量是字节字符串。这样的字符串是u8值(即字节)的切片,而不是Unicode文本:
let method = b"GET";
assert_eq!(method, &[b'G', b'E', b'T']);
2
method的类型是&[u8; 3]:它是一个指向包含三个字节的数组的引用。它没有我们接下来要讨论的任何字符串方法。它和字符串最相似的地方就是书写语法。
字节字符串可以使用我们介绍过的所有其他字符串语法:它们可以跨多行、使用转义序列,还可以用反斜杠连接行。原始字节字符串以br"开头。
字节字符串不能包含任意的Unicode字符,只能使用ASCII字符和\xHH转义序列。
# 内存中的字符串
Rust中的字符串是Unicode字符序列,但它们在内存中并不是以char数组的形式存储的。相反,它们使用UTF - 8可变宽度编码进行存储。字符串中的每个ASCII字符占用一个字节,其他字符则占用多个字节。
图3 - 3展示了由以下代码创建的String和&str值:
let noodles = "noodles".to_string();
let oodles = &noodles[1..];
let poodles = "O_O";
2
3
String有一个可调整大小的缓冲区,用于存储UTF - 8文本。该缓冲区在堆上分配,所以它可以根据需要或请求调整缓冲区大小。在这个例子中,noodles是一个String,它拥有一个8字节的缓冲区,其中7个字节被使用。你可以把String看作是一个保证包含格式良好的UTF - 8的Vec<u8>;实际上,String就是这样实现的。
&str(读作“stir”或“string slice”)是对由其他对象拥有的一段UTF - 8文本的引用:它“借用”了这段文本。在这个例子中,oodles是一个&str,指向noodles所包含文本的最后6个字节,所以它表示的文本是“oodles”。和其他切片引用一样,&str是一个胖指针,既包含实际数据的地址,也包含其长度。你可以把&str看作是一个保证包含格式良好的UTF - 8的&[u8]。
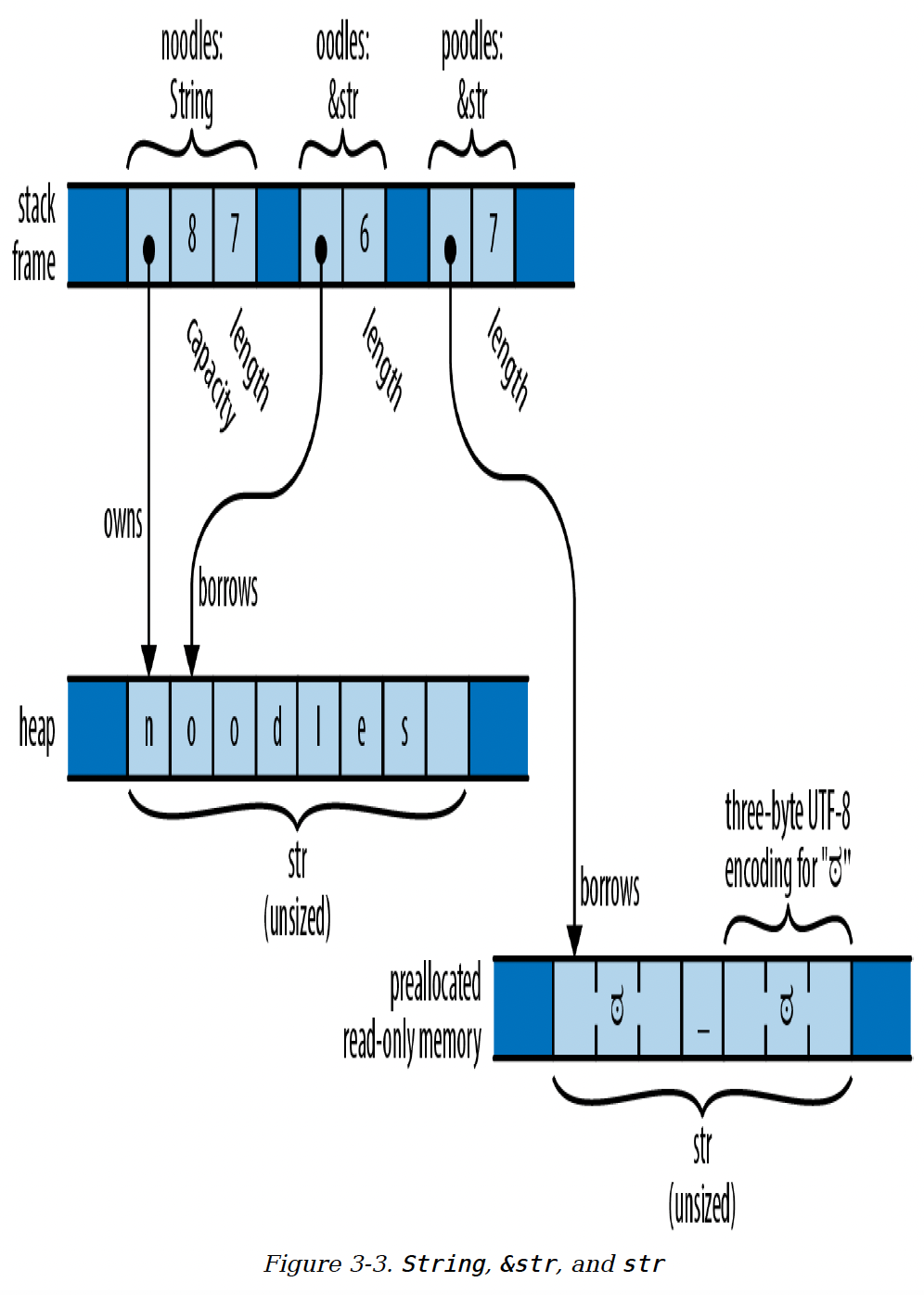
图3 - 3 String、&str和str
字符串字面量是一个&str,它指向预先分配的文本,这些文本通常与程序的机器代码一起存储在只读内存中。在前面的例子中,poodles是一个字符串字面量,指向7个字节的内容,这些内容在程序开始执行时创建,直到程序退出才会消失。
String或&str的.len()方法返回其长度。这里的长度是以字节为单位测量的,而不是字符:
assert_eq!("O_O".len(), 7);
assert_eq!("O_O".chars().count(), 3);
2
无法修改&str:
let mut s = "hello";
s[0] = 'c'; // 错误: `&str` 不可修改,还有其他原因
s.push('\n'); // 错误: 在`&str`引用上未找到名为`push`的方法
2
3
要在运行时创建新字符串,请使用String。
&mut str类型确实存在,但它不是很有用,因为几乎任何对UTF - 8的操作都可能改变其总字节长度,而切片不能重新分配其引用的对象。实际上,&mut str上仅有的可用操作是make_ascii_uppercase和make_ascii_lowercase,它们会原地修改文本,并且根据定义,只影响单字节字符。
# String
&str很像&[T]:是指向某些数据的胖指针。String类似于Vec<T>,如表3 - 11所示。
表3 - 11 Vec<T>和String的比较
| 特性 | Vec<T> | String |
|---|---|---|
| 自动释放缓冲区 | 是 | 是 |
| 可增长 | 是 | 是 |
::new()和::with_capacity()类型关联函数 | 是 | 是 |
.reserve()和.capacity()方法 | 是 | 是 |
.push()和.pop()方法 | 是 | 是 |
范围语法v[start..stop] | 是,返回&[T] | 是,返回&str |
| 自动转换 | &Vec<T>转换为&[T] | &String转换为&str |
| 继承方法 | 来自&[T] | 来自&str |
和Vec一样,每个String都有自己在堆上分配的缓冲区,不会与其他String共享。当一个String变量超出作用域时,除非该String被移动,否则其缓冲区会自动释放。
有几种创建String的方式:
.to_string()方法将&str转换为String。这会复制字符串:
let error_message = "too many pets".to_string();
.to_owned()方法也有同样的作用,你可能会看到它以相同的方式被使用。它也适用于其他一些类型,我们将在第13章讨论。
format!()宏的工作方式与println!()类似,不同之处在于它返回一个新的String,而不是将文本写入标准输出,并且它不会自动在末尾添加换行符:
assert_eq!(format!("{}°{:02}′{:02}″N", 24, 5, 23), "24°05′23″N".to_string());
- 字符串数组、切片和向量有两个方法,
.concat()和.join(sep),用于从多个字符串中形成一个新的String:
let bits = vec!["veni", "vidi", "vici"];
assert_eq!(bits.concat(), "venividivici");
assert_eq!(bits.join(", "), "veni, vidi, vici");
2
3
有时会面临选择使用哪种类型的问题:&str还是String。第5章将详细讨论这个问题。目前只需指出,&str可以引用任何字符串的任何切片,无论它是字符串字面量(存储在可执行文件中)还是String(在运行时分配和释放)。这意味着当允许调用者传递任意一种字符串时,&str更适合作为函数参数。
# 使用字符串
字符串支持==和!=运算符。如果两个字符串包含相同顺序的相同字符(无论它们是否指向内存中的相同位置),则它们相等:
assert!("ONE".to_lowercase() == "one");
字符串还支持比较运算符<、<=、>和>=,以及许多有用的方法和函数,你可以在在线文档的“str(基本类型)”或“std::str”模块中找到(或者直接翻到第17章)。以下是一些示例:
assert!("peanut".contains("nut"));
assert_eq!("O_O".replace("O", "■"), "■_■");
assert_eq!(" clean\n ".trim(), "clean");
for word in "veni, vidi, vici".split(", ") {
assert!(word.starts_with("v"));
}
2
3
4
5
6
请记住,由于Unicode的特性,简单的逐字符比较并不总是能给出预期的结果。例如,Rust字符串"th\u{e9}"和"the\u{301}"都是法语单词“thé”(茶)的有效Unicode表示。Unicode规定它们在显示和处理时应该是相同的,但Rust将它们视为两个完全不同的字符串。类似地,Rust的排序运算符(如<)使用基于字符码点值的简单字典序。这种排序只是在某些情况下与用户语言和文化中用于文本的排序相似。我们将在第17章更详细地讨论这些问题。
# 其他类似字符串的类型
Rust保证字符串是有效的UTF - 8。但有时程序确实需要处理无效的Unicode字符串。这种情况通常发生在Rust程序必须与其他不强制执行此类规则的系统进行交互时。例如,在大多数操作系统中,很容易创建一个文件名不是有效Unicode的文件。当Rust程序遇到这种文件名时应该怎么做呢?
Rust的解决方案是针对这些情况提供一些类似字符串的类型:
- 对于Unicode文本,坚持使用
String和&str。 - 处理文件名时,使用
std::path::PathBuf和&Path。 - 处理完全不是UTF - 8编码的二进制数据时,使用
Vec<u8>和&[u8]。 - 处理操作系统提供的原生形式的环境变量名和命令行参数时,使用
OsString和&OsStr。 - 与使用以空字符结尾的字符串的C库进行交互时,使用
std::ffi::CString和&CStr。
# 类型别名
type关键字的用法类似于C++中的typedef,用于为现有类型声明一个新名称:
type Bytes = Vec<u8>;
我们这里声明的Bytes类型是这种特定Vec的简写:
fn decode(data: &Bytes) {
...
}
2
3
# 超越基础
类型是Rust的核心部分。在本书中,我们将继续讨论类型并介绍新的类型。特别是,Rust的用户定义类型赋予了这门语言很多特色,因为方法就是在这些类型中定义的。有三种用户定义类型,我们将在接下来的三章中分别介绍:第9章介绍结构体,第10章介绍枚举,第11章介绍特性。
函数和闭包有它们自己的类型,将在第14章介绍。本书也会介绍构成标准库的各种类型。例如,第16章介绍标准集合类型。
不过,所有这些都要等一等。在继续之前,是时候探讨一下Rust安全规则核心的那些概念了。