 第9章 结构体
第9章 结构体
# 第9章 结构体
很久以前,当牧羊人想知道两群羊是否同构时,他们会寻找一个明确的同构关系。 ——约翰·C·贝兹(John C. Baez)和詹姆斯·多兰(James Dolan),《范畴化》
Rust中的结构体(structs,有时也称为structures)类似于C和C++中的结构体类型、Python中的类以及JavaScript中的对象。结构体将几种不同类型的值组合成一个单一的值,这样你就可以把它们当作一个单元来处理。有了结构体,你可以读取和修改它的各个组件。并且结构体可以关联一些方法,这些方法用于操作其组件。
Rust有三种结构体类型:具名字段结构体(named-field struct)、元组结构体(tuple-like struct)和类单元结构体(unit-like struct),它们在引用组件的方式上有所不同:具名字段结构体为每个组件赋予一个名称,而元组结构体通过组件出现的顺序来标识它们。类单元结构体根本没有组件;这类结构体并不常见,但比你想象的更有用。
在本章中,我们将详细解释每种结构体类型,并展示它们在内存中的样子。我们还会介绍如何为结构体添加方法,如何定义适用于多种不同组件类型的泛型结构体类型,以及如何让Rust为你的结构体生成常见实用特性(traits)的实现。
# 具名字段结构体
具名字段结构体类型的定义看起来像这样:
/// 一个由八位灰度像素组成的矩形。
struct GrayscaleMap {
pixels: Vec<u8>,
size: (usize, usize)
}
2
3
4
5
这声明了一个名为GrayscaleMap的类型,它有两个字段,分别是pixels和size,类型如定义所示。在Rust中,所有类型(包括结构体)的命名约定是每个单词的首字母大写,比如GrayscaleMap,这种命名约定称为驼峰命名法(CamelCase,也叫帕斯卡命名法PascalCase)。字段和方法名采用小写字母,单词之间用下划线分隔,这称为蛇形命名法(snake_case)。
你可以使用结构体表达式来构造这种类型的值,如下所示:
let width = 1024;
let height = 576;
let image = GrayscaleMap {
pixels: vec![0; width * height],
size: (width, height)
};
2
3
4
5
6
结构体表达式以类型名(GrayscaleMap)开头,列出每个字段的名称和值,并用花括号括起来。还有一种简写方式,当局部变量或参数与字段同名时,可以用它们来填充字段:
fn new_map(size: (usize, usize), pixels: Vec<u8>) -> GrayscaleMap {
assert_eq!(pixels.len(), size.0 * size.1);
GrayscaleMap { pixels, size }
}
2
3
4
结构体表达式GrayscaleMap { pixels, size }是GrayscaleMap { pixels: pixels, size: size }的简写形式。在同一个结构体表达式中,你可以对一些字段使用key: value语法,对其他字段使用简写形式。
要访问结构体的字段,可以使用熟悉的.运算符:
assert_eq!(image.size, (1024, 576));
assert_eq!(image.pixels.len(), 1024 * 576);
2
和所有其他项一样,结构体默认是私有的,只能在声明它的模块及其子模块中可见。你可以在结构体定义前加上pub,使其在模块外部可见。它的每个字段也是如此,默认情况下字段也是私有的:
/// 一个由八位灰度像素组成的矩形。
pub struct GrayscaleMap {
pub pixels: Vec<u8>,
pub size: (usize, usize)
}
2
3
4
5
即使一个结构体被声明为pub,它的字段也可以是私有的:
/// 一个由八位灰度像素组成的矩形。
pub struct GrayscaleMap {
pixels: Vec<u8>,
size: (usize, usize)
}
2
3
4
5
其他模块可以使用这个结构体以及它可能有的任何公共关联函数,但不能通过名称访问私有字段,也不能使用结构体表达式来创建新的GrayscaleMap值。也就是说,创建结构体值需要结构体的所有字段都是可见的。这就是为什么你不能使用结构体表达式来创建新的String或Vec。这些标准类型都是结构体,但它们所有的字段都是私有的。要创建一个String或Vec,你必须使用公共的类型关联函数,比如Vec::new()。
在创建具名字段结构体值时,你可以使用另一个相同类型的结构体来为省略的字段提供值。在结构体表达式中,如果具名字段后面跟着.. EXPR,那么未提及的任何字段将从EXPR获取值,EXPR必须是同一结构体类型的另一个值。假设我们有一个表示游戏中怪物的结构体:
// 在这个游戏中,扫帚是怪物。你会明白的。
struct Broom {
name: String,
height: u32,
health: u32,
position: (f32, f32, f32),
intent: BroomIntent
}
/// `Broom`可能执行的两种不同任务。
#[derive(Copy, Clone)]
enum BroomIntent {
FetchWater,
DumpWater
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
对程序员来说,最好的童话故事是《魔法师的学徒》:一个新手魔法师对一把扫帚施了魔法,让它为自己干活,但完工后却不知道如何让它停下来。用斧头把扫帚砍成两半,只会得到两把大小减半的扫帚,它们仍会像原来那把一样盲目地继续执行任务:
// 按值接收输入的Broom,获取其所有权。
fn chop(b: Broom) -> (Broom, Broom) {
// 大部分从`b`初始化`broom1`,只更改`height`。
// 由于`String`不是`Copy`类型,`broom1`获取`b`的`name`的所有权。
let mut broom1 = Broom { height: b.height / 2, ..b };
// 大部分从`broom1`初始化`broom2`。由于`String`不是`Copy`类型,我们必须显式克隆`name`。
let mut broom2 = Broom { name: broom1.name.clone(), ..broom1 };
// 给每个碎片取一个不同的名字。
broom1.name.push_str(" I");
broom2.name.push_str(" II");
(broom1, broom2)
}
2
3
4
5
6
7
8
9
10
11
12
有了这个定义,我们可以创建一把扫帚,把它砍成两半,看看会得到什么:
let hokey = Broom {
name: "Hokey".to_string(),
height: 60,
health: 100,
position: (100.0, 200.0, 0.0),
intent: BroomIntent::FetchWater
};
let (hokey1, hokey2) = chop(hokey);
assert_eq!(hokey1.name, "Hokey I");
assert_eq!(hokey1.height, 30);
assert_eq!(hokey1.health, 100);
assert_eq!(hokey2.name, "Hokey II");
assert_eq!(hokey1.height, 30);
assert_eq!(hokey2.health, 100);
2
3
4
5
6
7
8
9
10
11
12
13
14
新的hokey1和hokey2扫帚名字做了调整,高度减半,生命值和原来的一样。
# 元组结构体
第二种结构体类型称为元组结构体,因为它类似于元组:
struct Bounds(usize, usize);
你构造这种类型的值的方式和构造元组很相似,只是必须包含结构体名称:
let image_bounds = Bounds(1024, 768);
元组结构体保存的值和元组中的值一样,也称为元素。你可以像访问元组元素一样访问它们:
assert_eq!(image_bounds.0 * image_bounds.1, 786432);
元组结构体的单个元素可以是公共的,也可以不是:
pub struct Bounds(pub usize, pub usize);
表达式Bounds(1024, 768)看起来像函数调用,实际上它就是:定义这个类型时也隐式定义了一个函数:
fn Bounds(elem0: usize, elem1: usize) -> Bounds { ... }
从最基本的层面来看,具名字段结构体和元组结构体非常相似。选择使用哪种结构体取决于可读性、是否存在歧义以及简洁性等问题。如果你经常使用.运算符来获取值的组件,那么通过名称标识字段可以为读者提供更多信息,并且可能更不容易出现拼写错误。如果你通常使用模式匹配来查找元素,那么元组结构体可能更合适。
元组结构体适用于新类型(newtypes),即只有一个组件的结构体,你定义它是为了获得更严格的类型检查。例如,如果你处理的是仅包含ASCII字符的文本,你可以这样定义一个新类型:
struct Ascii(Vec<u8>);
对于你的ASCII字符串使用这种类型,比仅仅传递Vec<u8>缓冲区并在注释中解释它们要好得多。这种新类型有助于Rust捕获错误,比如将其他字节缓冲区传递给期望ASCII文本的函数。我们将在第22章给出一个使用新类型进行高效类型转换的示例。
# 类单元结构体
第三种结构体有点晦涩:它声明了一种没有任何元素的结构体类型:
struct Onesuch;
这种类型的值不占用内存,很像单元类型()。Rust不会在内存中实际存储类单元结构体的值,也不会生成操作它们的代码,因为它仅从类型就能知道关于这个值可能需要的所有信息。但从逻辑上讲,空结构体和其他类型一样,是有值的类型 —— 或者更准确地说,是只有一个值的类型:
let o = Onesuch;
在“字段和元素”一节中学习..范围运算符时,你已经遇到过类单元结构体。像3..5这样的表达式是结构体值Range { start: 3, end: 5 }的简写形式,而表达式..(省略两个端点的范围)是类单元结构体值RangeFull的简写形式。
类单元结构体在处理特性(traits,我们将在第11章介绍)时也很有用。
# 结构体布局
在内存中,具名字段结构体和元组结构体本质上是一样的:它们都是可能包含多种不同类型值的集合,以特定方式在内存中进行布局。例如,在本章前面我们定义了这样一个结构体:
struct GrayscaleMap {
pixels: Vec<u8>,
size: (usize, usize)
}
2
3
4
一个GrayscaleMap值在内存中的布局如图9-1所示。
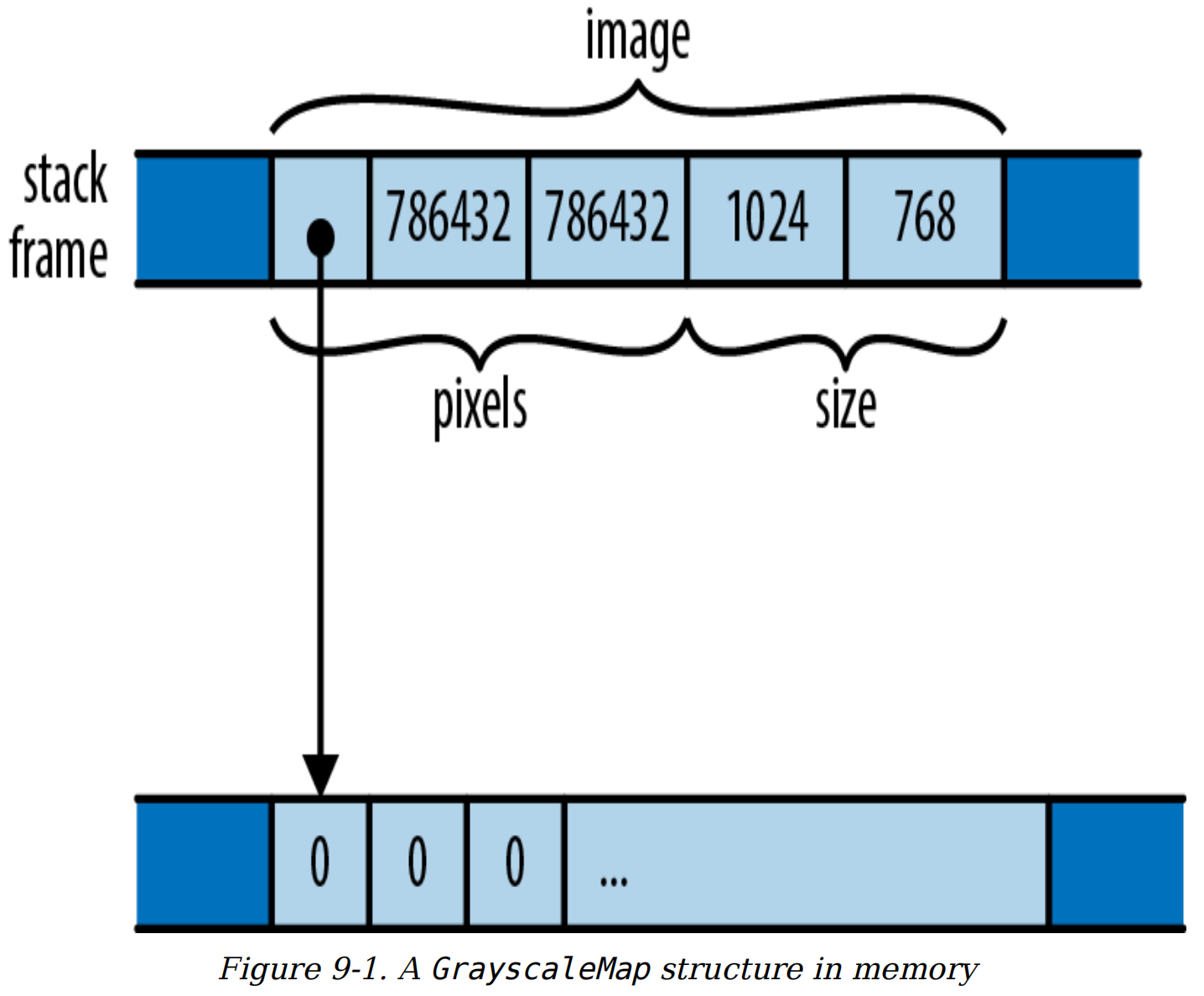 图9-1 内存中的GrayscaleMap结构体
图9-1 内存中的GrayscaleMap结构体
与C和C++不同,Rust并没有对结构体字段或元素在内存中的排列顺序做出具体保证;此图仅展示了一种可能的排列方式。不过,Rust保证会将字段的值直接存储在结构体的内存块中。JavaScript、Python和Java会将pixels和size的值分别存储在各自在堆上分配的内存块中,让GrayscaleMap的字段指向它们,而Rust则将pixels和size直接嵌入到GrayscaleMap值中。只有pixels向量所拥有的在堆上分配的缓冲区仍存储在其自身的内存块中。
你可以使用#[repr(C)]属性,让Rust以与C和C++兼容的方式布局结构体。我们将在第23章详细介绍这一点。
# 使用impl定义方法
在本书中,我们一直在对各种值调用方法。我们使用v.push(e)向向量中添加元素,使用v.len()获取向量的长度,使用r.expect("msg")检查Result值是否存在错误等等。你也可以为自己定义的结构体类型定义方法。
与C++或Java不同,Rust的方法并不出现在结构体定义内部,而是出现在单独的impl块中。impl块就是一组fn定义,其中每个定义都会成为该块顶部所指定结构体类型的一个方法。例如,这里我们定义了一个公共结构体Queue,然后为它定义了两个公共方法push和pop:
pub struct Queue {
/// 一个先进先出的字符队列。
older: Vec<char>, // 较旧的元素,最早的在最后
younger: Vec<char> // 较新的元素,最新的在最后
}
impl Queue {
/// 将一个字符添加到队列的尾部。
pub fn push(&mut self, c: char) {
self.younger.push(c);
}
/// 从队列头部移除一个字符。如果有字符可移除,返回`Some(c)`;如果队列为空,返回`None`。
pub fn pop(&mut self) -> Option<char> {
if self.older.is_empty() {
if self.younger.is_empty() {
return None;
}
// 将younger中的元素移到older中,并按顺序排列
use std::mem::swap;
swap(&mut self.older, &mut self.younger);
self.older.reverse();
}
// 现在可以确定older中有元素。Vec的pop方法已经返回一个Option,所以我们直接使用它。
self.older.pop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在impl块中定义的函数称为关联函数(associated functions),因为它们与特定的类型相关联。与关联函数相对的是自由函数(free function),即不是在impl块中定义的函数。
Rust将调用方法的值作为第一个参数传递给该方法,这个参数必须使用特殊名称self。由于self的类型显然是impl块顶部指定的类型,或者是对该类型的引用,所以Rust允许你省略类型,用self、&self或&mut self作为self: Queue、self: &Queue或self: &mut Queue的简写。如果你愿意,也可以使用完整形式,但几乎所有的Rust代码都使用简写形式,如前面的示例所示。
在我们的示例中,push和pop方法通过self.older和self.younger来引用Queue的字段。与C++和Java不同,在C++和Java中,“this”对象的成员在方法体中可以直接通过未限定的标识符访问,而Rust方法必须显式使用self来引用调用该方法的值,这与Python方法使用self以及JavaScript方法使用this的方式类似。
由于push和pop需要修改Queue,所以它们都接受&mut self。不过,当你调用方法时,无需自己借用可变引用;普通的方法调用语法会隐式处理这一点。有了这些定义后,你可以像这样使用Queue:
let mut q = Queue { older: Vec::new(), younger: Vec::new() };
q.push('0');
q.push('1');
assert_eq!(q.pop(), Some('0'));
q.push('∞');
assert_eq!(q.pop(), Some('1'));
assert_eq!(q.pop(), Some('∞'));
assert_eq!(q.pop(), None);
2
3
4
5
6
7
8
简单地写q.push(...)就会借用q的可变引用,就好像你写了(&mut q).push(...)一样,因为这是push方法对self的要求。
如果一个方法不需要修改self,那么你可以将其定义为接受共享引用。例如:
impl Queue {
pub fn is_empty(&self) -> bool {
self.older.is_empty() && self.younger.is_empty()
}
}
2
3
4
5
同样,方法调用表达式知道应该借用哪种类型的引用:
assert!(q.is_empty());
q.push('☉');
assert!(!q.is_empty());
2
3
或者,如果一个方法想要获取self的所有权,它可以按值接受self:
impl Queue {
pub fn split(self) -> (Vec<char>, Vec<char>) {
(self.older, self.younger)
}
}
2
3
4
5
调用这个split方法的方式与其他方法调用类似:
let mut q = Queue { older: Vec::new(), younger: Vec::new() };
q.push('P');
q.push('D');
assert_eq!(q.pop(), Some('P'));
q.push('X');
let (older, younger) = q.split();
// q现在已未初始化。
assert_eq!(older, vec!['D']);
assert_eq!(younger, vec!['X']);
2
3
4
5
6
7
8
9
但请注意,由于split按值接受self,这会将Queue从q中移出,使q未初始化。由于split的self现在拥有了这个队列,所以它能够将其中的各个向量移出并返回给调用者。
有时,像这样按值接受self,甚至按引用接受self都不够,所以Rust还允许你通过智能指针类型来传递self。
# 将Self作为Box、Rc或Arc传递
方法的self参数也可以是Box<Self>、Rc<Self>或Arc<Self>。这样的方法只能在给定指针类型的值上调用。调用该方法时,会将指针的所有权传递给它。
通常你不需要这样做。一个期望按引用接受self的方法,在对上述任何指针类型的值调用时都能正常工作:
let mut bq = Box::new(Queue::new());
// `Queue::push`期望一个`&mut Queue`,但`bq`是一个`Box<Queue>`。
// 这没问题:Rust会在调用期间从`Box`中借用一个`&mut Queue`。
bq.push('■');
2
3
4
对于方法调用和字段访问,Rust会自动从Box、Rc和Arc等指针类型中借用引用,所以在方法签名中,&self和&mut self几乎总是合适的选择,偶尔也会用到self。
但是,如果方法的目的涉及管理指针的所有权呢?假设我们有一个类似这样的节点树,是某种极度简化的XML:
use std::rc::Rc;
struct Node {
tag: String,
children: Vec<Rc<Node>>
}
impl Node {
fn new(tag: &str) -> Node {
Node {
tag: tag.to_string(),
children: vec![],
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
每个节点都有一个标签,用于指示它是哪种类型的节点,还有一个子节点向量,通过引用计数指针来持有这些子节点,以便实现共享并使它们的生命周期更灵活。
通常,标记节点会有一个方法用于将子节点追加到自己的列表中,但现在,我们反过来,为Node定义一个方法,用于将自身追加到其他Node的子节点列表中。我们可能会这样写:
impl Node {
fn append_to(self, parent: &mut Node) {
parent.children.push(Rc::new(self));
}
}
2
3
4
5
但这样不太令人满意。这个方法调用Rc::new来分配一个新的堆内存位置,并将self移动到其中,但如果调用者已经有一个Rc<Node>,那么所有这些操作都是不必要的:我们应该只是增加引用计数,然后将指针推到向量中。使用Rc的目的不就是为了实现共享吗?
相反,我们可以这样写:
impl Node {
fn append_to(self: Rc<Self>, parent: &mut Node) {
parent.children.push(self);
}
}
2
3
4
5
如果调用者手头有一个Rc<Node>,它可以直接调用append_to,按值传递Rc:
let shared_node = Rc::new(Node::new("first"));
shared_node.append_to(&mut parent);
2
这将shared_node的所有权传递给了方法:不会调整引用计数,当然也不会进行新的内存分配。
如果调用者需要保留指向该节点的指针以供后续使用,那么它可以先克隆Rc:
shared_node.clone().append_to(&mut parent);
克隆Rc只会增加其引用计数:仍然不会进行堆内存分配或复制。但当调用返回时,shared_node和parent的子节点向量都指向同一个Node。
最后,如果调用者实际上完全拥有这个Node,那么它必须在传递之前自己创建Rc:
let owned = Node::new("owned directly");
Rc::new(owned).append_to(&mut parent);
2
将Rc<Self>放入append_to方法的签名中,能让调用者清楚Node的要求。这样,调用者就可以根据自身需求尽量减少内存分配和引用计数操作:
- 如果它可以传递
Rc的所有权,那么直接传递指针即可。 - 如果它需要保留
Rc的所有权,那么只需增加引用计数。 - 只有当它自己拥有
Node时,才必须调用Rc::new来分配堆内存空间,并将Node移动到其中。由于parent会坚持通过Rc<Node>指针来引用其子节点,所以这最终是必要的操作。
同样,对于大多数方法来说,&self、&mut self和self(按值)就足够了。但是,如果一个方法的目的是影响值的所有权,那么为self使用其他指针类型可能是正确的选择。
# 类型关联函数
为某个类型定义的impl块还可以定义根本不把self作为参数的函数。这些仍然是关联函数,因为它们在impl块中,但它们不是方法,因为它们不接受self参数。为了将它们与方法区分开来,我们称它们为类型关联函数。
它们通常用于提供构造函数,如下所示:
impl Queue {
pub fn new() -> Queue {
Queue { older: Vec::new(), younger: Vec::new() }
}
}
2
3
4
5
要使用这个函数,我们通过Queue::new来调用它:即类型名、双冒号,然后是函数名。现在我们的示例代码变得更简洁了:
let mut q = Queue::new();
q.push('*');
...
2
3
在Rust中,构造函数通常命名为new;我们已经见过Vec::new、Box::new、HashMap::new等。但new这个名字并没有什么特殊之处。它不是关键字,而且类型通常还有其他用作构造函数的关联函数,比如Vec::with_capacity。
虽然可以为单个类型编写多个独立的impl块,但它们都必须位于定义该类型的同一个包中。不过,Rust允许你为其他类型添加自己的方法;我们将在第11章解释如何实现。
如果你习惯了C++或Java,可能会觉得把类型的方法与其定义分开有点不寻常,但这样做有几个好处:
- 始终很容易找到类型的数据成员。在大型C++类定义中,你可能需要浏览数百行成员函数定义,才能确定没有遗漏类的数据成员;而在Rust中,它们都集中在一处。
- 虽然可以想象将方法融入具名字段结构体的语法中,但对于元组结构体和类单元结构体来说,这样做并不简洁。将方法提取到
impl块中,为这三种结构体提供了统一的语法。实际上,Rust使用相同的语法为根本不是结构体的类型(比如枚举类型和像i32这样的基本类型)定义方法。(任何类型都可以有方法,这也是Rust不太常用“对象”这个术语,而更倾向于把所有东西都称为“值”的原因之一。) - 相同的
impl语法也可以很好地用于实现特性(traits),我们将在第11章介绍。
# 关联常量
Rust在其类型系统中采用了C#和Java等语言的另一个特性,即与类型相关联的值,而不是与该类型的特定实例相关联。在Rust中,这些被称为关联常量(associated consts)。
顾名思义,关联常量是常量值。它们通常用于指定类型的常用值。例如,你可以定义一个用于线性代数的二维向量,并为其定义一个关联的单位向量:
pub struct Vector2 {
x: f32,
y: f32,
}
impl Vector2 {
const ZERO: Vector2 = Vector2 { x: 0.0, y: 0.0 };
const UNIT: Vector2 = Vector2 { x: 1.0, y: 0.0 };
}
2
3
4
5
6
7
8
9
这些值与类型本身相关联,你可以在不引用Vector2的其他实例的情况下使用它们。与关联函数很相似,通过指定它们所关联的类型,然后跟上它们的名称来访问:
let scaled = Vector2::UNIT.scaled_by(2.0);
关联常量也不必与它所关联的类型相同;我们可以利用这个特性为类型添加ID或名称。例如,如果有几个类似于Vector2的类型,需要写入文件并在之后加载到内存中,那么可以使用关联常量来添加名称或数字ID,这些ID可以写在数据旁边以标识其类型:
impl Vector2 {
const NAME: &'static str = "Vector2";
const ID: u32 = 18;
}
2
3
4
# 泛型结构体
我们之前对Queue的定义并不令人满意:它被写成用于存储字符,但它的结构和方法实际上与字符并没有什么特定的关联。如果我们要定义另一个存储String值的结构体,除了将char替换为String之外,代码可能完全相同。这将是浪费时间。
幸运的是,Rust结构体可以是泛型的,这意味着它们的定义是一个模板,你可以在其中插入任何你喜欢的类型。例如,下面是一个可以存储任何类型值的Queue定义:
struct Queue<T> {
older: Vec<T>,
younger: Vec<T>
}
2
3
4
你可以将Queue<T>中的<T>理解为“对于任何元素类型T……”。所以这个定义的意思是,“对于任何类型T,Queue<T>是两个类型为Vec<T>的字段”。例如,在Queue<String>中,T是String,所以older和younger的类型是Vec<String>。在Queue<char>中,T是char,我们得到的结构体与我们最初定义的特定于字符的结构体相同。实际上,Vec本身就是一个泛型结构体,就是以这种方式定义的。
在泛型结构体定义中,尖括号中使用的类型名称称为类型参数(type parameters)。泛型结构体的impl块看起来像这样:
impl<T> Queue<T> {
pub fn new() -> Queue<T> {
Queue { older: Vec::new(), younger: Vec::new() }
}
pub fn push(&mut self, t: T) {
self.younger.push(t);
}
pub fn is_empty(&self) -> bool {
self.older.is_empty() && self.younger.is_empty()
}
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
你可以将impl<T> Queue<T>这一行理解为“对于任何类型T,这里有一些Queue<T>可用的关联函数”。然后,你可以在关联函数定义中使用类型参数T作为类型。
这种语法可能看起来有点冗余,但impl<T>明确表明这个impl块涵盖任何类型T,这将它与为特定类型的Queue编写的impl块区分开来,比如下面这个:
impl Queue<f64> {
fn sum(&self) -> f64 {
...
}
}
2
3
4
5
这个impl块头部的意思是,“这里有一些专门为Queue<f64>定义的关联函数”。这为Queue<f64>提供了一个sum方法,其他类型的Queue没有这个方法。
在前面的代码中,我们使用了Rust对self参数的简写;如果到处都写出Queue<T>会很冗长,也会分散注意力。另一种简写方式是,每个impl块(无论是否是泛型的)都定义了一个特殊的类型参数Self(注意是驼峰命名法),它表示我们正在为其添加方法的类型。在前面的代码中,Self就是Queue<T>,所以我们可以进一步简化Queue::new的定义:
pub fn new() -> Self {
Queue { older: Vec::new(), younger: Vec::new() }
}
2
3
你可能已经注意到,在new函数的主体中,我们在构造表达式中不需要写出类型参数;只写Queue { ... }就足够了。这是Rust的类型推断在起作用:因为对于这个函数的返回值只有一种类型是合适的,即Queue<T>,所以Rust会为我们提供这个参数。
不过,在函数签名和类型定义中,你总是需要提供类型参数。Rust不会推断这些类型;相反,它会使用这些显式类型作为在函数体中推断类型的基础。
Self也可以这样使用;我们也可以写成Self { ... }。选择哪种方式取决于你觉得哪种更容易理解。
对于关联函数调用,你可以使用::<>(涡轮鱼)符号显式提供类型参数:
let mut q = Queue::<char>::new();
但在实际使用中,通常你可以让Rust为你推断类型:
let mut q = Queue::new();
let mut r = Queue::new();
q.push("CAD"); // 显然是一个Queue<&'static str>
r.push(0.74); // 显然是一个Queue<f64>
q.push("BTC"); // 2019年6月比特币兑美元汇率
r.push(13764.0); // Rust未能检测到非理性繁荣
2
3
4
5
6
7
8
实际上,这正是我们在本书中一直对另一个泛型结构体类型Vec所做的事情。
并非只有结构体可以是泛型的。枚举也可以使用非常相似的语法接受类型参数。我们将在“枚举”一节中详细介绍。
# 带有生命周期参数的结构体
正如我们在“包含引用的结构体”中讨论的,如果一个结构体类型包含引用,你必须指定这些引用的生命周期。例如,下面是一个可能用于保存某个切片中最大和最小元素引用的结构体:
struct Extrema<'elt> {
greatest: &'elt i32,
least: &'elt i32
}
2
3
4
之前,我们让你把struct Queue<T>这样的声明理解为,给定任何特定类型T,你都可以创建一个存储该类型的Queue<T>。类似地,你可以把struct Extrema<'elt>理解为,给定任何特定的生命周期'elt,你都可以创建一个包含具有该生命周期引用的Extrema<'elt>。
下面是一个扫描切片并返回一个Extrema值的函数,该值的字段引用切片中的元素:
fn find_extrema<'s>(slice: &'s [i32]) -> Extrema<'s> {
let mut greatest = &slice[0];
let mut least = &slice[0];
for i in 1..slice.len() {
if slice[i] < *least {
least = &slice[i];
}
if slice[i] > *greatest {
greatest = &slice[i];
}
}
Extrema { greatest, least }
}
2
3
4
5
6
7
8
9
10
11
12
13
这里,由于find_extrema借用了slice的元素,而slice的生命周期是's,所以我们返回的Extrema结构体也将's用作其引用的生命周期。Rust总是会为调用推断生命周期参数,所以对find_extrema的调用不必提及它们:
let a = [0, -3, 0, 15, 48];
let e = find_extrema(&a);
assert_eq!(*e.least, -3);
assert_eq!(*e.greatest, 48);
2
3
4
因为返回类型通常与参数使用相同的生命周期,所以当有一个明显的候选生命周期时,Rust允许我们省略生命周期。我们也可以这样写find_extrema的签名,意思不变:
fn find_extrema(slice: &[i32]) -> Extrema {
...
}
2
3
诚然,我们可能会认为是Extrema<'static>,但这非常不常见。Rust为常见情况提供了一种简写方式。
# 为结构体类型派生常见特性
结构体很容易编写:
struct Point {
x: f64,
y: f64
}
2
3
4
然而,如果你开始使用这个Point类型,很快就会发现有点麻烦。按照目前的定义,Point不可复制(copyable)也不可克隆(cloneable)。你不能使用println!("{:?}", point);打印它,而且它不支持==和!=运算符。
在Rust中,这些特性都有名称 —— Copy、Clone、Debug和PartialEq。它们被称为特性(traits)。在第11章,我们将展示如何为自己的结构体手动实现特性。但对于这些标准特性以及其他一些特性,如果不需要某种自定义行为,你无需手动实现它们。Rust可以自动、准确地为你实现这些特性。只需在结构体上添加一个#[derive]属性:
#[derive(Copy, Clone, Debug, PartialEq)]
struct Point {
x: f64,
y: f64
}
2
3
4
5
只要结构体的每个字段都实现了某个特性,Rust就可以为该结构体自动实现这些特性。我们可以让Rust为Point派生PartialEq,因为它的两个字段都是f64类型,而f64已经实现了PartialEq。
Rust还可以派生PartialOrd,这将为比较运算符<、>、<=和>=提供支持。我们这里没有这样做,因为比较两个点来判断一个是否“小于”另一个实际上是一件很奇怪的事情。点并没有一种常规的顺序。所以我们选择不为Point值支持这些运算符。像这样的情况是Rust让我们编写#[derive]属性,而不是自动派生它能派生的每个特性的原因之一。另一个原因是,实现一个特性自动成为结构体的公共特性,所以可复制性、可克隆性等都是结构体公共API的一部分,应该慎重选择。
我们将在第13章详细描述Rust的标准特性,并解释哪些特性可以通过#[derive]派生。
# 内部可变性
可变性就像其他任何事物一样:过度使用会引发问题,但有时你确实只需要一点。例如,假设你的蜘蛛机器人控制系统有一个核心结构体SpiderRobot,它包含设置和输入/输出句柄。机器人启动时进行设置,这些值从不改变:
pub struct SpiderRobot {
species: String,
web_enabled: bool,
leg_devices: [fd::FileDesc; 8],
...
}
2
3
4
5
6
机器人的每个主要系统都由不同的结构体处理,并且每个结构体都有一个指向SpiderRobot的指针:
use std::rc::Rc;
pub struct SpiderSenses {
robot: Rc<SpiderRobot>, // <- 指向设置和I/O的指针
eyes: [Camera; 32],
motion: Accelerometer,
...
}
2
3
4
5
6
7
8
用于织网、捕食、毒液流量控制等的结构体也都有一个Rc<SpiderRobot>智能指针。回想一下,Rc代表引用计数,Rc盒子中的值总是共享的,因此总是不可变的。
现在假设你想给SpiderRobot结构体添加一些日志功能,使用标准的File类型。这里有个问题:File必须是可变的。所有用于写入它的方法都需要可变引用。
这种情况相当常见。我们需要的是在一个不可变的值(SpiderRobot结构体)内部有一些可变的数据(一个File)。这被称为内部可变性(interior mutability)。Rust提供了几种实现方式;在本节中,我们将讨论两种最直接的类型:std::cell模块中的Cell<T>和RefCell<T>。
Cell<T>是一个结构体,它包含一个类型为T的私有值。Cell唯一特殊的地方在于,即使你没有对Cell本身的可变访问权限,也可以获取和设置其字段:
Cell::new(value):创建一个新的Cell,将给定的值移动到其中。cell.get():返回cell中值的副本。cell.set(value):将给定的值存储在cell中,丢弃之前存储的值。这个方法将self作为不可变引用:fn set(&self, value: T)// 注意:不是&mut self
当然,对于名为set的方法来说,这很不寻常。到现在,Rust让我们习惯了这样的认知:如果想要修改数据,就需要可变访问权限。但同样地,这个不寻常的细节正是Cell的全部意义所在。它们只是一种安全地打破不可变性规则的方式 —— 仅此而已。
Cell还有一些其他方法,你可以在文档中查看。
如果你要给SpiderRobot添加一个简单的计数器,Cell会很有用。你可以这样写:
use std::cell::Cell;
pub struct SpiderRobot {
...
hardware_error_count: Cell<u32>,
...
}
2
3
4
5
6
7
然后,即使SpiderRobot的不可变方法也可以使用.get()和.set()方法访问那个u32:
impl SpiderRobot {
/// 将错误计数增加1。
pub fn add_hardware_error(&self) {
let n = self.hardware_error_count.get();
self.hardware_error_count.set(n + 1);
}
/// 如果报告过任何硬件错误,则返回true。
pub fn has_hardware_errors(&self) -> bool {
self.hardware_error_count.get() > 0
}
}
2
3
4
5
6
7
8
9
10
11
12
这很简单,但它并没有解决我们的日志记录问题。Cell不允许你对共享值调用可变方法。.get()方法返回cell中值的副本,所以只有当T实现了Copy特性时它才有效。对于日志记录,我们需要一个可变的File,而File是不可复制的。
在这种情况下,正确的工具是RefCell。和Cell<T>一样,RefCell<T>是一个泛型类型,它包含一个类型为T的值。与Cell不同,RefCell支持借用其T值的引用:
RefCell::new(value):创建一个新的RefCell,将value移动到其中。ref_cell.borrow():返回一个Ref<T>,本质上就是对存储在ref_cell中的值的共享引用。如果该值已经被可变借用,这个方法会触发panic;详细信息见下文。ref_cell.borrow_mut():返回一个RefMut<T>,本质上是对ref_cell中值的可变引用。如果该值已经被借用,这个方法会触发panic;详细信息见下文。ref_cell.try_borrow(),ref_cell.try_borrow_mut():工作方式与borrow()和borrow_mut()类似,但返回一个Result。如果值已经被可变借用,它们不会触发panic,而是返回一个Err值。
同样,RefCell还有一些其他方法,你可以在文档中找到。
这两个借用方法只有在你试图违反Rust中可变引用是独占引用这条规则时才会触发panic。例如,下面这段代码会触发panic:
use std::cell::RefCell;
let ref_cell: RefCell<String> =
RefCell::new("hello".to_string());
let r = ref_cell.borrow(); // 正常,返回一个Ref<String>
let count = r.len(); // 正常,返回 "hello".len()
assert_eq!(count, 5);
let mut w = ref_cell.borrow_mut(); // panic:已经被借用
w.push_str(" world");
2
3
4
5
6
7
8
9
10
11
为了避免触发panic,你可以将这两个借用操作放在不同的代码块中。这样,在尝试借用w之前,r会被丢弃。
这和普通引用的工作方式很相似。唯一的区别在于,通常当你借用一个变量的引用时,Rust会在编译时检查以确保你安全地使用引用。如果检查失败,你会得到一个编译错误。RefCell使用运行时检查来执行相同的规则。所以,如果你违反了规则,就会触发panic(或者对于try_borrow和try_borrow_mut,会得到一个Err)。
现在我们可以在SpiderRobot类型中使用RefCell了:
pub struct SpiderRobot {
...
log_file: RefCell<File>,
...
}
impl SpiderRobot {
/// 向日志文件写入一行内容。
pub fn log(&self, message: &str) {
let mut file = self.log_file.borrow_mut();
// `writeln!`和`println!`类似,但会将输出发送到给定的文件。
writeln!(file, "{}", message).unwrap();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
变量file的类型是RefMut<File>。它可以像对File的可变引用一样使用。关于文件写入的详细信息,见第18章。
Cell使用起来很简单。必须调用.get()和.set() 或者.borrow()和.borrow_mut(),这有点麻烦,但这就是我们为打破规则所付出的代价。另一个缺点不太明显但更严重:Cell以及任何包含它们的类型都不是线程安全的。因此,Rust不允许多个线程同时访问它们。我们将在第19章讨论 “Mutex<T>”、“原子操作(Atomics)” 和 “全局变量” 时,介绍线程安全的内部可变性实现方式。
无论一个结构体是具名字段的还是元组结构体,它都是其他值的聚合:如果我有一个SpiderSenses结构体,那么我有一个指向共享的SpiderRobot结构体的Rc指针,我有眼睛,还有一个加速度计等等。所以结构体的本质是 “和” 这个概念:我有一个X和一个Y。但是,如果有一种类型是围绕 “或” 这个概念构建的呢?也就是说,当你有一个这种类型的值时,你要么有一个X,要么有一个Y?事实证明,这种类型非常有用,在Rust中随处可见,它们是下一章的主题。